Unit 3
Searching and Sorting
1. Linear /Sequential search
Linear search is the simplest searching algorithm that searches for an element in a list in sequential order. We start at one end and check every element until the desired element is not found.
Algorithm
Linear Search (Array A, Value x)
Step 1: Set i to 1
Step 2: if i> n then go to step 7
Step 3: if A[i] = x, then go to step 6
Step 4: Set i to i + 1
Step 5: Go to Step 2
Step 6: Print Element x Found at index i and go to step 8
Step 7: Print element not found
Step 8: Exit
Array to be search for
2 | 4 | 0 | 1 | 9 |
K=1
2 | 4 | 0 | 1 | 9 |
K≠2
2 | 4 | 0 | 1 | 9 |
K≠4
2 | 4 | 0 | 1 | 9 |
K≠0
2. If x==k then return index
2 | 4 | 0 | 1 | 9 |
K=1
3. Else return ; element not found
E.g. Input: arr[] = {10, 20, 180, 30, 60, 50, 110, 100, 70}, x = 180
10 | 20 | 180 | 30 | 60 | 50 | 110 | 100 | 70 |
index 0 1 2 3 4 5 6 7 8
Output: 180 is present at index 2
Input: arr[] = {10, 20, 180, 30, 60, 50, 110, 100, 70}, x = 90
10 | 20 | 180 | 30 | 60 | 50 | 110 | 100 | 70 |
index 0 1 2 3 4 5 6 7 8
Output: element not found
Algorithm
Function Binary search(a, value, left ,right)
Return not found
Return mid
Return binarysearch(a,value,left,mid-1)
Return binarysearch(a,value,mid+1,right)
1. The array in which searching is to be performed is
3 | 4 | 5 | 6 | 7 | 8 | 9 |
Element to find x=4
2. Set two pointers low and high at the lowest and the highest positions respectively
3 | 4 | 5 | 6 | 7 | 8 | 9 |
Low high
3. Find the middle element mid=arr(low+high)/2= 6
3 | 4 | 5 | 6 | 7 | 8 | 9 |
Mid
4.If x == mid, then return mid. Else, compare the element to be searched with m.
5. If x > mid, compare x with the middle element of the elements on the right side of mid. This is done by setting low to low = mid + 1.
6. Else, compare x with the middle element of the elements on the left side of mid. This is done by setting high to high = mid - 1.
3 | 4 | 5 | 6 | 7 | 8 | 9 |
Low high
7. Repeat steps 3 to 6 until low meets high.
3 | 4 | 5 |
Low mid high
8 if x==mid return
3 | 4 | 5 |
X=mid
Binary search complexities
Time Complexities
Space Complexity
Fibonacci Search is a comparison-based technique that uses Fibonacci numbers to search an element in a sorted array.
Similarities with Binary Search:
Differences with Binary Search:
Algorithm
Below is that the complete algorithm
- Compare x with the last element of the range covered by fibMm2
- If x matches, return index
- Else if x is a smaller amount than the element, move the three Fibonacci variables two Fibonacci down, indicating elimination of roughly rear two-third of the remaining array.
- Else x is bigger than the element, move the three Fibonacci variables one Fibonacci down. Reset offset to index. Together these indicate elimination of roughly front one-third of the remaining array.
Time complexity for Fibonacci search
The worst case will occur once we have our target within the larger (2/3) fraction of the array, as we proceed to seek out it. In other words, we are eliminating the smaller (1/3) fraction of the array whenever. We call once for n, then for(2/3) n, then for (4/9) n and henceforth.
Time complexity=O(log n)
Characteristics of Indexed Sequential Search:
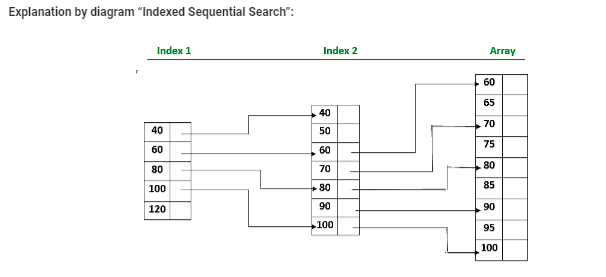
Time complexity of indexed sequential search
Space complexity O(1)
There are two different categories in sorting:
Internal sorting:
External sorting:
General Sort Order
For any column, sorting is performed in the following order:
Sort Order for StringsSince all values are valid for String data type, this sort order represents the most common representation for sort order.
a) Numeric values (low value to high value)
b) Whitespace
c) Special characters
d) Alphabetical
Sort Order for Integers and Decimals
For Integers and Decimals, sorting happens in the following order:
- Numeric values (low value to high value)
Stability
Efficiency
Number of passes
Number of passes in an algorithm is basically the count of iterations that will take to get the desired output
searchList([3, 37, 45, 57, 93, 120], 45)
The algorithm starts off by initializing the variable index to 1. It then begins to loop.
Iteration #1:
Iteration #2:
Iteration #3:
Operation | No of times |
Initialize index to 1 | 1 |
Check if the index is bigger than LENGTH(numbers) | 3 |
Check if numbers[index] equals targetNumber | 3 |
Return index | 1 |
Increment index by 1 | 2 |
That's a complete of 10 operations to seek out the target number at the index of three. Notice the connection to the amount 3? The loop repeated 3 times, and every time, it executed 3 operations.
1. Bubble sort
Bubble sort is an algorithm that compares the adjacent elements and swaps their positions if they are not in the intended order. The order can be ascending or descending
Algorithm
- for i<- 1 to indexOfLastUnsortedElement-1
- if leftElement>rightElement
- swap leftElement and rightElement

2. The same process goes on for the remaining iterations. After each iteration, the largest element among the unsorted elements is placed at the end. In each iteration, the comparison takes place up to the last unsorted element.
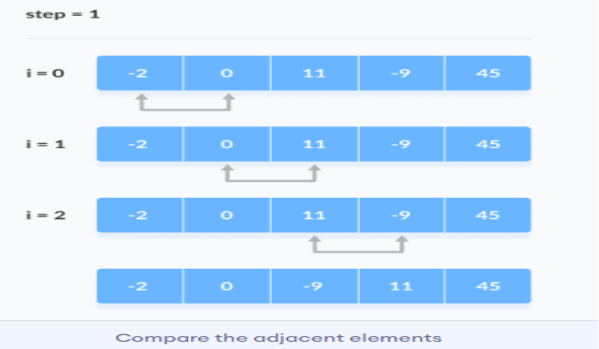
3. The same process goes on for the remaining iterations. After each iteration, the largest element among the unsorted elements is placed at the end. In each iteration, the comparison takes place up to the last unsorted element.
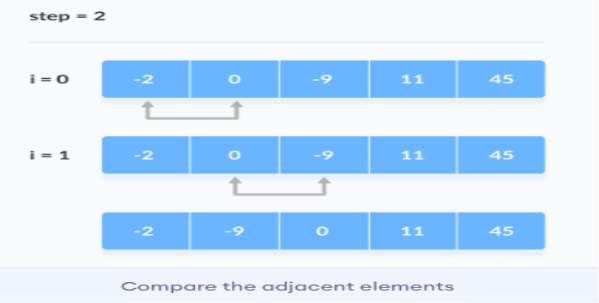
The array is sorted when all the unsorted elements are placed at their correct positions.
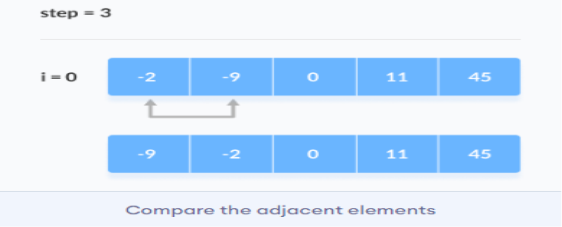
Time Complexities:
Space Complexity:
Bubble Sort Applications
2. Insertion sort
Algorithm
insertionSort(array)
1. The first element in the array is assumed to be sorted. Take the second element and store it separately in key.
Array

Compare key with the first element. If the first element is greater than key, then key is placed in front of the first element.
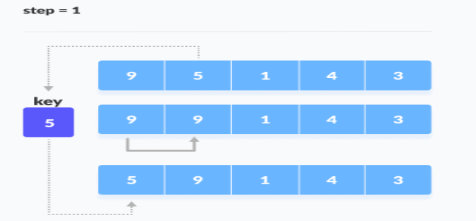
If the first element is greater than key, then key is placed in front of the first element
2. Now, the first two elements are sorted.Take the third element and compare it with the elements on the left of it. Placed it just behind the element smaller than it. If there is no element smaller than it, then place it at the beginning of the array.
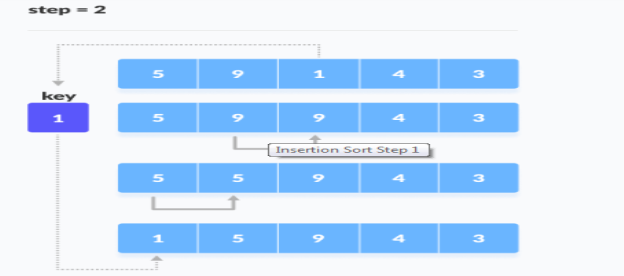
Place 1 at the beginning
3. Similarly, place every unsorted element at its correct position.
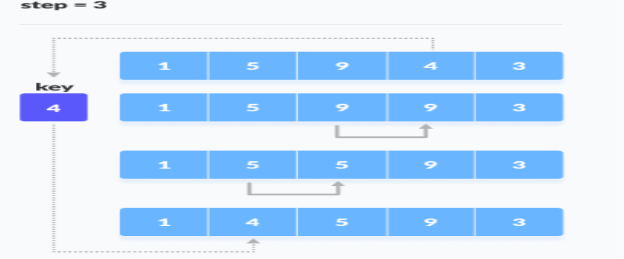
Place 4 behind 1
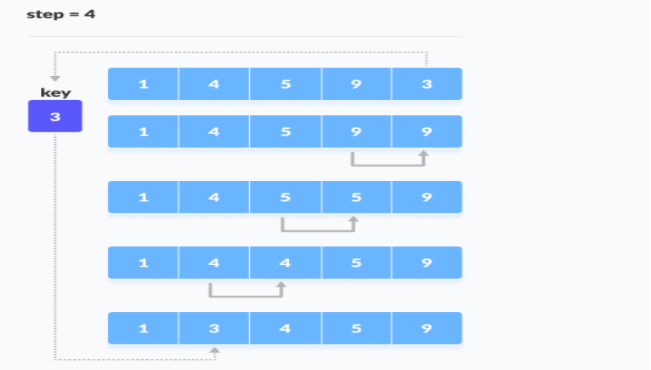
Place 3 behind 1 and the array is sorted
3. Selection sort
Implementation
Algorithm

First element as minimum
2. Compare minimum with the second element. If the second element is smaller than minimum, assign the second element as minimum.
Compare minimum with the third element. Again, if the third element is smaller, then assign minimum to the third element otherwise do nothing. The process goes on until the last element.
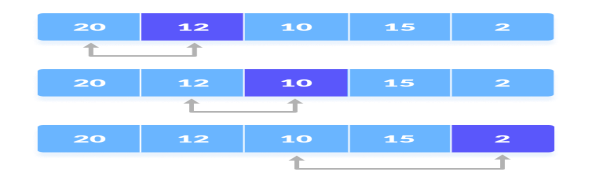 Compare minimum with the remaining elements
Compare minimum with the remaining elements
3. After each iteration, minimum is placed in the front of the unsorted list.
Swap the first with minimum
4. For each iteration, indexing starts from the first unsorted element. Step 1 to 3 are repeated until all the elements are placed at their correct positions.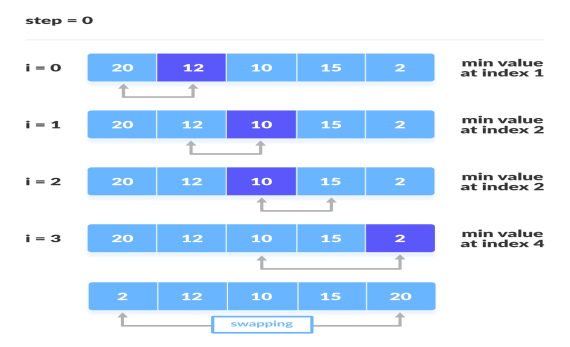
The first iteration
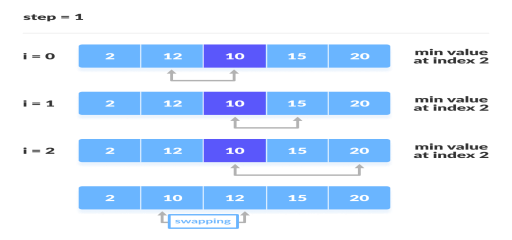
The second iteration
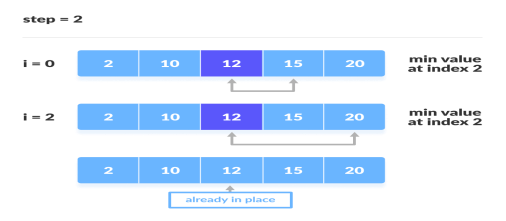
The third iteration
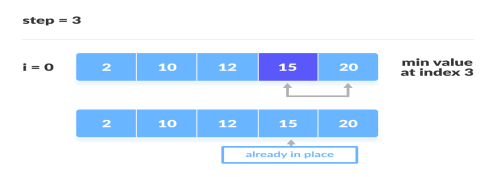
The fourth iteration
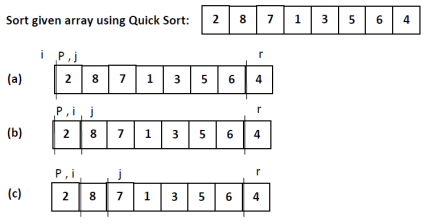
4. Quick sort
Algorithm
- if (leftmostIndex<rightmostIndex)
- pivotIndex<- partition(array,leftmostIndex, rightmostIndex)
- quickSort(array, leftmostIndex, pivotIndex)
- quickSort(array, pivotIndex + 1, rightmostIndex)
- set rightmostIndex as pivotIndex
- storeIndex<- leftmostIndex – 1
- for i<- leftmostIndex + 1 to rightmostIndex
- if element[i] <pivotElement
- swap element[i] and element[storeIndex]
- storeIndex++
- swap pivotElement and element[storeIndex+1]
- return storeIndex + 1
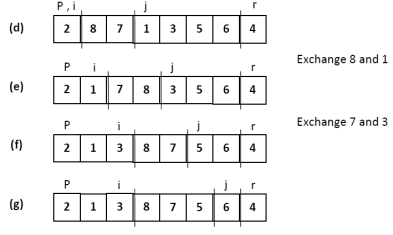
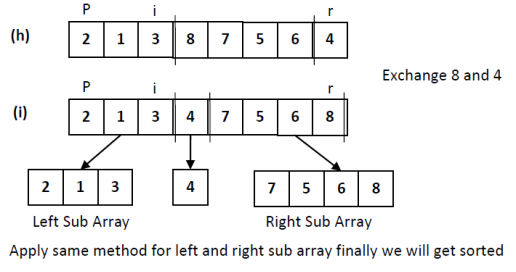
Quick sort
- Divide: Partition T[i..j] Into two sub arrays T[i..l-1] and T[l+1… j] such each element of T[i..l-1] isless than or adequate to T[l], which is, in turn, but or adequate to each element of T[l+1… j]. Compute theindex l as a part of this partitioning procedure
- Conquer: Sort the 2 sub arrays T[i..l-1] and T[l+1… j] by recursive calls to quicksort.
- Combine: Since the sub arrays are sorted in situ, no work is required to combing them: the whole arrayT[i..j], is now sorted.
5. Shell sort
Algorithm
- for interval i<- size/2n down to 1
- for each interval "i" in array
- sort all the elements at interval "
1. Suppose, we need to sort the following array.
Initial array

2. We are using the shell's original sequence (N/2, N/4, ...1) as intervals in our algorithm
In the first loop, if the array size is N = 8 then, the elements lying at the interval of N/2 = 4 are compared and swapped if they are not in order.
The 0th element is compared with the 4th element.
If the 0th element is greater than the 4th one then, the 4th element is first stored in temp variable and the 0th element (ie. greater element) is stored in the 4th position and the element stored in temp is stored in the 0th position.
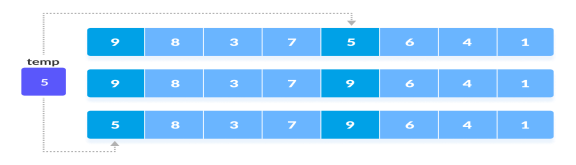
Rearrange the elements at n/2 interval
This process goes on for all the remaining elements.
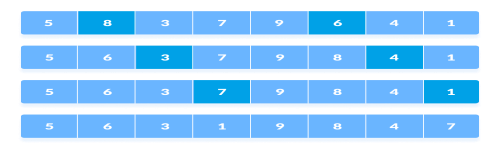
Rearrange all the elements at n/2 interval
3. In the second loop, an interval of N/4 = 8/4 = 2 is taken and again the elements lying at these intervals are sorted
Rearrange the elements at n/4 interval
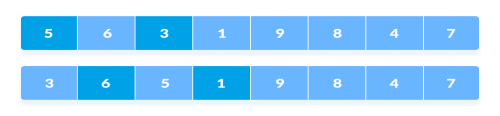
All the elements in the array lying at the current interval are compared. The elements at 4th and 2nd position are compared. The elements at 2nd and 0th position are also compared. All the elements in the array lying at the current interval are compared.
4. The same process goes on for remaining elements.

Rearrange all the elements at n/4 interval
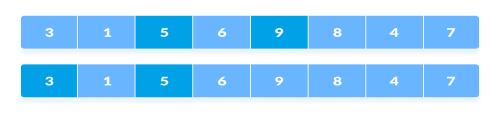
5. Finally, when the interval is N/8 = 8/8 =1 then the array elements lying at the interval of 1 are sorted. The array is now completely sorted.

Rearrange the elements at n/8 interval
1. Radix Sort
Algorithm
- d <- maximum number of digits in the largest element
- create d buckets of size 0-9
- for i<- 0 to d
- sort the elements according to ith place digits using countingSort
- max <- find largest element among dth place elements
- initialize count array with all zero
- for j <- 0 to size
- find the total count of each unique digit in dth place of elements and
- store the count at jth index in count array
- for i<- 1 to max
- find the cumulative sum and store it in count array itself
- for j <- size down to 1
- restore the elements to array
- decrease count of each element restored by 1
input array=[576, 494, 194,296,278,176, 954}
input
576 49[4] 9[5]4 [1]76 176
494 19[4] 5[7]6 [1]94 194
194 95[4] 1[7]6 [2]78 278
296 → 57[6] → 2[7]8 → [2]96→ 296
278 29[6] 4[9]4 [4]94 494
176 17[6] 1[9]4 [5]76 576
954 27[8] 2[9]6 [9]54 954
2. Counting Sort
Algorithm
COUNTING-SORT(A,B,K)

2. Initialize an array of length max+1 with all elements 0. This array is used for storing the count of the elements in the array.

3. Store the count of each element at their respective index in count array.
For example: if the count of element 3 is 2 then, 2 is stored in the 3rd position of count array. If element "5" is not present in the array, then 0 is stored in 5th position.

4. Store cumulative sum of the elements of the count array. It helps in placing the elements into the correct index of the sorted array.

5. Find the index of each element of the original array in the count array. This gives the cumulative count. Place the element at the index calculated as shown in figure below.
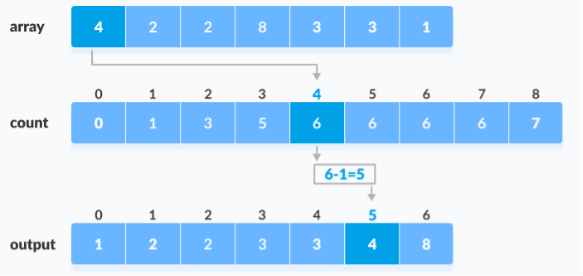
6. After placing each element at its correct position, decrease its count by on
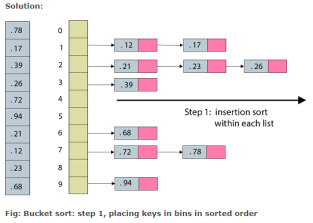
3. Bucket Sort
Algorithm
- create N buckets each of which can hold a range of values
- for all the buckets
- initialize each bucket with 0 values
- for all the buckets
- put elements into buckets matching the range
- for all the buckets
- sort elements in each bucket
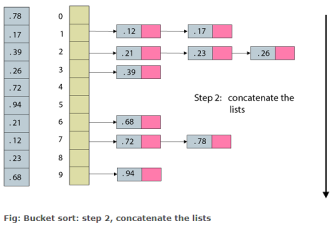
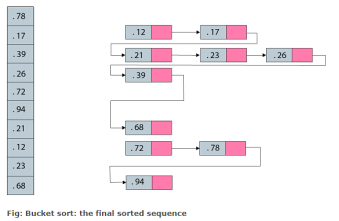
- gather elements from each bucket
bucket sort
arrayA = (0.78, 0.17, 0.39, 0.26, 0.72, 0.94, 0.21, 0.12, 0.23, 068)
S no. | Sorting algorithm | Time complexity | Space complexity | ||
Best case | Average case | Worst case | |||
1 | Bubble sort | O(n) | O(n^2) | O(n^2) | O(1) |
2 | Selection sort | O(n^2) | O(n^2) | O(n^2) | O(1) |
3 | Insertion sort | O(n) | O(n^2) | O(n^2) | O(1) |
4 | Quick sort | O(n log n) | O(n log n) | O(n^2) | O(n) |
5 | Merge sort | O(n log n) | O(n log n) | O(n log n) | O(n) |
6 | Heap sort | O(n log n) | O(n log n) | O(n log n) | O(1) |
7 | Radix sort | O (nk) | O(nk) | O(nk) | O(n+k) |
8 | Counting sort | O (n+k) | O(n+k) | O(n+k) | O(k) |
9 | Bucket sort | O (n+k) | O(n+k) | O(n^2) | O(n) |




