UNIT 1
Fundamentals of Object Oriented Programming
Procedure Oriented Programming
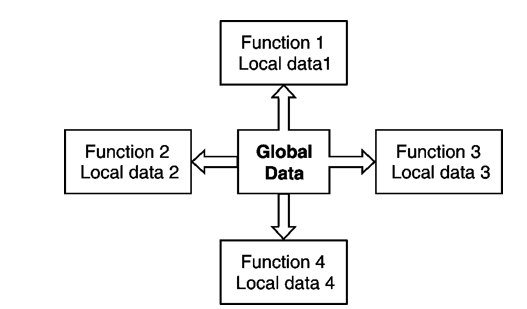
It employs top down approach.
Fig.: Structure of procedure oriented programming
Modular oriented programming
Generic oriented programming
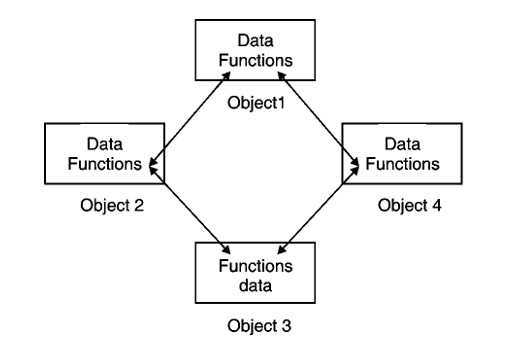
It employs bottom up approach.
Fig.: Structure of Object Oriented Programming
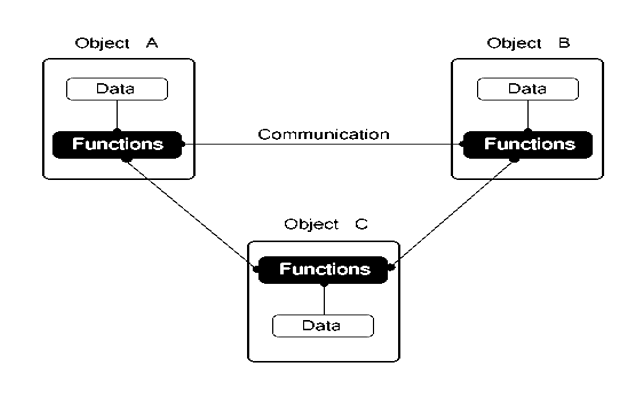
Some of the striking features of object-oriented programming are
Namespaces
Consider a situation, when we have two persons with the same name, Zara, in the same class. Whenever we need to differentiate them definitely we would have to use some additional information along with their name, like either the area, if they live in different area or their mother’s or father’s name, etc.
Same situation can arise in your C++ applications. For example, you might be writing some code that has a function called xyz() and there is another library available which is also having same function xyz(). Now the compiler has no way of knowing which version of xyz() function you are referring to within your code.
A namespace is designed to overcome this difficulty and is used as additional information to differentiate similar functions, classes, variables etc. with the same name available in different libraries. Using namespace, you can define the context in which names are defined. In essence, a namespace defines a scope.
Defining a Namespace
A namespace definition begins with the keyword namespace followed by the namespace name as follows −
namespace namespace_name {
// code declarations
}
To call the namespace-enabled version of either function or variable, prepend (::) the namespace name as follows −
name::code; // code could be variable or function.
Let us see how namespace scope the entities including variable and functions −
#include <iostream>
using namespace std;
// first name space
namespace first_space {
void func() {
cout << "Inside first_space" << endl;
}
}
// second name space
namespace second_space {
void func() {
cout << "Inside second_space" << endl;
}
}
int main () {
// Calls function from first name space.
first_space::func();
// Calls function from second name space.
second_space::func();
return 0;
}
If we compile and run above code, this would produce the following result −
Inside first_space
Inside second_space
The using directive
You can also avoid prepending of namespaces with the using namespace directive. This directive tells the compiler that the subsequent code is making use of names in the specified namespace. The namespace is thus implied for the following code −
#include <iostream>
using namespace std;
// first name space
namespace first_space {
void func() {
cout << "Inside first_space" << endl;
}
}
// second name space
namespace second_space {
void func() {
cout << "Inside second_space" << endl;
}
}
using namespace first_space;
int main () {
// This calls function from first name space.
func();
return 0;
}
If we compile and run above code, this would produce the following result −
Inside first_space
The ‘using’ directive can also be used to refer to a particular item within a namespace. For example, if the only part of the std namespace that you intend to use is cout, you can refer to it as follows −
using std::cout;
Subsequent code can refer to cout without prepending the namespace, but other items in the std namespace will still need to be explicit as follows –
#include <iostream>
using std::cout;
int main () {
cout << "std::endl is used with std!" << std::endl;
return 0;
}
If we compile and run above code, this would produce the following result −
std::endl is used with std!
Names introduced in a using directive obey normal scope rules. The name is visible from the point of the using directive to the end of the scope in which the directive is found. Entities with the same name defined in an outer scope are hidden.
Discontiguous Namespaces
A namespace can be defined in several parts and so a namespace is made up of the sum of its separately defined parts. The separate parts of a namespace can be spread over multiple files.
So, if one part of the namespace requires a name defined in another file, that name must still be declared. Writing a following namespace definition either defines a new namespace or adds new elements to an existing one −
namespace namespace_name {
// code declarations
}
Nested Namespaces
Namespaces can be nested where you can define one namespace inside another name space as follows −
namespace namespace_name1 {
// code declarations
namespace namespace_name2 {
// code declarations
}
}
You can access members of nested namespace by using resolution operators as follows −
// to access members of namespace_name2
using namespace namespace_name1::namespace_name2;
// to access members of namespace:name1
using namespace namespace_name1;
In the above statements if you are using namespace_name1, then it will make elements of namespace_name2 available in the scope as follows −
#include <iostream>
using namespace std;
// first name space
namespace first_space {
void func() {
cout << "Inside first_space" << endl;
}
// second name space
namespace second_space {
void func() {
cout << "Inside second_space" << endl;
}
}
}
using namespace first_space::second_space;
int main () {
// This calls function from second name space.
func();
return 0;
}
If we compile and run above code, this would produce the following result −
Inside second_space
Objects
// creates object b1 of class Book
b1 |
Data Members: name pages price |
Member functions: Accept() Display() |
b1 |
| b2 |
Data Members : name pages price |
| Data Members : name pages price |
Member functions: Accept() Display() |
| Member functions : Accept() Display() |
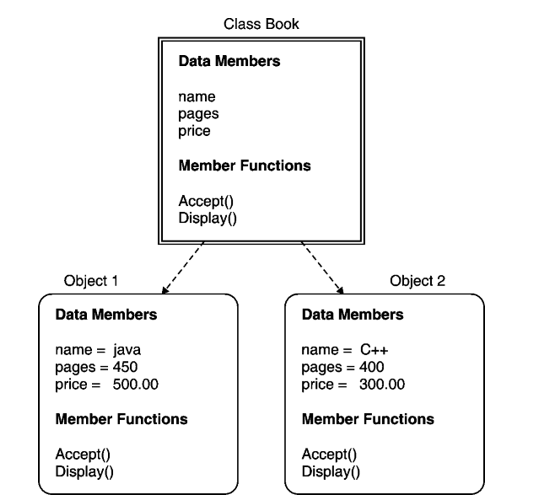
Though they will posses same class attributes, the values of these attributes will be different. It is shown in Fig.
Fig.: Classes and objects
Write a program to accept and display details of book.
Solution :
#include<iostream> //Step 1 Header file
using namespace std ;
class Book //Step 2 Declares class Book
{
char name[10]; //Declares data members name, pages and price.
int pages; These data members are private.
float price;
public: //Starts public section of class book
void accept() //Step 3 Defines function “accept”
{ //Entering the details of book
cout<<“Enter name of book”;
cin>>name;
cout<<“Enter pages of book”;
cin>>pages;
cout<<“Enter price of book”;
cin>>price;
} //End of accept function definition
void display() //Step 4 Defines function display
{ // Displays all the details of book
cout<<“Name of book is :”<<name;
cout<<“No. of Pages in book are :”<<pages;
cout<<“Price of book is:”<<price;
} // End of display function
}; //Step 5 End of class
int main() //Step 6 Start of main() function
{
Book b1,b2; //Step 7 Creates objects b1,b2
b1.accept(); //Step 8 Calls accept function for b1
b2.accept(); // Calls accept function for b2
b1.display(); //Step 9 Calls display function for b1
b2.display(); //Calls display function for b2
return 0;
} // End of main
Explanation
Step 1 : Every C++ program starts with header file “iostream.h” as it contains declarations of input and output streams in program.
#include<iostream>
using namespace std ;
Step 2 : Class “Book” is declared and defined. It consists of data members name, pages and price. Access specifier is not mentioned for these members so they are considered as private.
class Book //Declares class Book
{
char name[10]; //Declares data members name, pages and price. These int pages; data members are private.
float price;
Step 3: Accept function accepts all the details of book. It shows new features cout, <<, cin, >>.
cout
Standard predefined object that represents standard output stream in C++.
<<: Insertion or output operator
It sends data to standard output object cout.
cout<< name<<“ ”<< pages<<“ ”<< price; // Separating output by space
cout<<name<<“,”<< pages<<“,”<< price; // Separating output by comma
cin
Standard predefined object that represents standard input stream in C++.
>>:Extraction or input operator
It reads data and stores to its right hand variable.
void accept() //Defines function “accept”
{ //Entering the details of book
cout<<“Enter name of book”;
cin>>name;
cout<<“Enter pages of book”;
cin>>pages;
cout<<“Enter price of book”;
cin>>price;
} //End of accept function definition
Step 4: Defines display function.
It displays all the details of book.
void display() // Defines function display
{ // Displays all the details of book
cout<<“Name of book is :”<<name;
cout<<“No. of Pages in book are :”<<pages;
cout<<“Price of book is:”<<price;
} // End of display function
Step 5: It indicates end of class definition.
}; // End of class
Step 6: In C++ main is always written outside class.
int main() // Start of main() function
Step7: Two objects of class book b1 and b2 are created.
Book b1,b2; // Creates objects b1,b2
Step 8: In main() every function is called with object and dot operator.
Syntax for function call from main()
objectname.functionname(arguments);
eg. obj1.accept();
Using b1.accept() we are accepting data for object b1.
Similarly b2.accept will accept data for object b2.
b1.accept(); //Calls accept function for b1
b2.accept(); // Calls accept function for b2
Step 9: b1.display() will print details of book b1.
Similarly b2.display() prints details of book b2.
b1.display(); // Calls display function for b1
b2.display(); //Calls display function for b2
Step 10: End of main indicates end of program.
} // End of main
Classes
Introduction to Class
class Book
Structure of a class
Class |
Data Members |
Member functions |
Structure of a “Book” class
Book |
Data Members name pages price |
Member functions Accept() Display() |
Structure of class declaration
class class_name
{
Access specifier:
Data Members;
Access specifier:
Member Functions;
};
We will discuss new terms in above declaration.
Class
Access Specifier
It specifies if class members are accessible to external functions (functions of other classes).
C++ provides three access specifiers :
1. private
2. public
3. protected
Data members
Data _type Variable_name;
e.g. int roll_no;
float price;
string name;
Methods
Functions declared or defined within a class are known as member functions of that class. Member functions are also called as methods.
Table: Let us create a class Book
Class Definition | Explanation | |
class Book
| Class “Book” is created | |
{ | Start of class definition | |
char name[10]; | Declares data member “name” of the type char. | Here access specifier is not mentioned so all these data members are private as default access specifier is private. |
int pages; | Declares data member “page” of the type int | |
float price; | Declares data member “price” of the type float | |
public: | Starts public section of a class | |
void accept(); | Declares member function accept | |
void display(); | Declares member function display | |
}; | End of class definition | |
Messages
Programming languages like Smalltalk and Objective-C are considered more flexible than C++ because they support dynamic message passing. C++ does not support dynamic message passing; it only supports static message passing: when a method of an object is invoked, the target object must have the invoked method; otherwise, the compiler outputs an error.
Although the way C++ does message passing is much faster than the way Smalltalk or Objective-C does it, sometimes the flexibility of Smalltalk or Objective-C is required. This little article shows how it is possible to achieve dynamic message passing in C++ with minimum code.
Example
The supplied header contains an implementation of dynamic message passing. In order to add dynamic message passing capabilities to an object, the following things must be done:
Here is an example:
Hide Copy Code
//the dynamic-message-passing header
#include "dmp.hpp"
//the message signature
std::string my_message(int a, double b) { return ""; }
//a class that accepts messages dynamically
class test : public dmp::object {
public:
test() {
add_message(&::my_message, &test::my_message);
}
std::string my_message(int a, double b);
};
int main() {
test t;
std::string s = t.invoke(&::my_message, 10, 3.14);
}
How it Works
Each object contains a shared ptr to a map. The map's key is the pointer to the signature of the message. The map's value is a pointer to an internal message structure which holds a pointer to the method to invoke.
When a method is invoked, the appropriate message structure is retrieved from the map, and the method of the object stored in the message structure is invoked, using this as the target object.
The map used internally is unordered, for efficiency reasons.
The message map of objects is shared between objects for efficiency reasons as well. When a message map is modified, it is duplicated if it is not unique, i.e., the copy-on-write pattern is applied.
The code is thread safe only when the message maps are not modified while used for look-up by different threads. If a message map is modified, then no thread must send messages to an object at the same time.
The code uses the boost library because of:
Data encapsulation
Data abstraction and information hiding
Inheritance
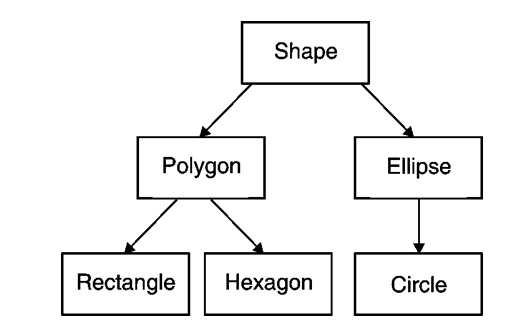
Fig. : Inheritance
Polymorphism
Fig. 3.1.4.
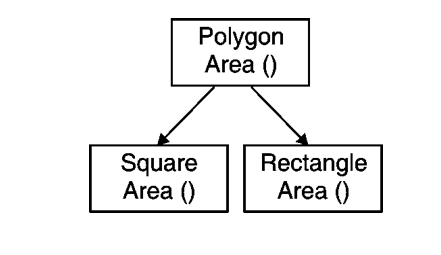
Fig. : Polymorphism
The major purpose of C++ programming is to introduce the concept of object orientation to the C programming language.
Object Oriented Programming is a paradigm that provides many concepts such as inheritance, data binding, polymorphism etc.
The programming paradigm where everything is represented as an object is known as truly object-oriented programming language. Smalltalk is considered as the first truly object-oriented programming language.
OOPs (Object Oriented Programming System)
Object means a real word entity such as pen, chair, table etc. Object-Oriented Programming is a methodology or paradigm to design a program using classes and objects. It simplifies the software development and maintenance by providing some concepts:
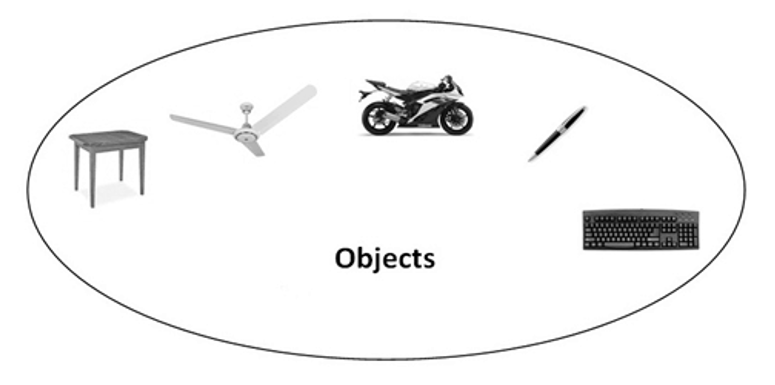
Object
Any entity that has state and behaviour is known as an object. For example: chair, pen, table, keyboard, bike etc. It can be physical and logical.
Class
Collection of objects is called class. It is a logical entity.
Inheritance
When one object acquires all the properties and behaviours of parent object i.e. known as inheritance. It provides code reusability. It is used to achieve runtime polymorphism.
Polymorphism
When one task is performed by different ways i.e. known as polymorphism. For example: to convince the customer differently, to draw something e.g. shape or rectangle etc.
In C++, we use Function overloading and Function overriding to achieve polymorphism.
Abstraction
Hiding internal details and showing functionality is known as abstraction. For example: phone call, we don't know the internal processing.
In C++, we use abstract class and interface to achieve abstraction.
Encapsulation
Binding (or wrapping) code and data together into a single unit is known as encapsulation. For example: capsule, it is wrapped with different medicines.
Advantage of OOPs over Procedure-oriented programming language
When we consider a C++ program, it can be defined as a collection of objects that communicate via invoking each other's methods. Let us now briefly look into what a class, object, methods, and instant variables mean.
C++ Program Structure
Let us look at a simple code that would print the words Hello World.
#include <iostream>
using namespace std;
// main() is where program execution begins.
int main() {
cout << "Hello World"; // prints Hello World
return 0;
}
Let us look at the various parts of the above program −
Compile and Execute C++ Program
Let's look at how to save the file, compile and run the program. Please follow the steps given below −
$ g++ hello.cpp
$ ./a.out
Hello World
Make sure that g++ is in your path and that you are running it in the directory containing file hello.cpp.
You can compile C/C++ programs using makefile.
Semicolons and Blocks in C++
In C++, the semicolon is a statement terminator. That is, each individual statement must be ended with a semicolon. It indicates the end of one logical entity.
For example, following are three different statements −
x = y;
y = y + 1;
add(x, y);
A block is a set of logically connected statements that are surrounded by opening and closing braces. For example −
{
cout << "Hello World"; // prints Hello World
return 0;
}
C++ does not recognize the end of the line as a terminator. For this reason, it does not matter where you put a statement in a line. For example −
x = y;
y = y + 1;
add(x, y);
is the same as
x = y; y = y + 1; add(x, y);
C++ Identifiers
A C++ identifier is a name used to identify a variable, function, class, module, or any other user-defined item. An identifier starts with a letter A to Z or a to z or an underscore (_) followed by zero or more letters, underscores, and digits (0 to 9).
C++ does not allow punctuation characters such as @, $, and % within identifiers. C++ is a case-sensitive programming language. Thus, Manpower and manpower are two different identifiers in C++.
Here are some examples of acceptable identifiers −
mohd zara abc move_name a_123
myname50 _temp j a23b9 retVal
C++ Keywords
The following list shows the reserved words in C++. These reserved words may not be used as constant or variable or any other identifier names.
asm | Else | new | this |
auto | Enum | operator | throw |
bool | explicit | private | true |
break | export | protected | try |
case | extern | public | typedef |
catch | False | register | typeid |
char | Float | reinterpret_cast | typename |
class | For | return | union |
const | friend | short | unsigned |
const_cast | Goto | signed | using |
continue | If | sizeof | virtual |
default | inline | static | void |
delete | Int | static_cast | volatile |
do | Long | struct | wchar_t |
double | mutable | switch | while |
dynamic_cast | namespace | template |
|
Trigraphs
A few characters have an alternative representation, called a trigraph sequence. A trigraph is a three-character sequence that represents a single character and the sequence always starts with two question marks.
Trigraphs are expanded anywhere they appear, including within string literals and character literals, in comments, and in preprocessor directives.
Following are most frequently used trigraph sequences −
Trigraph | Replacement |
??= | # |
??/ | \ |
??' | ^ |
??( | [ |
??) | ] |
??! | | |
??< | { |
??> | } |
??- | ~ |
All the compilers do not support trigraphs and they are not advised to be used because of their confusing nature.
Whitespace in C++
A line containing only whitespace, possibly with a comment, is known as a blank line, and C++ compiler totally ignores it.
Whitespace is the term used in C++ to describe blanks, tabs, newline characters and comments. Whitespace separates one part of a statement from another and enables the compiler to identify where one element in a statement, such as int, ends and the next element begins.
Statement 1
int age;
In the above statement there must be at least one whitespace character (usually a space) between int and age for the compiler to be able to distinguish them.
Statement 2
fruit = apples + oranges; // Get the total fruit
In the above statement 2, no whitespace characters are necessary between fruit and =, or between = and apples, although you are free to include some if you wish for readability purpose.
In C++, data types are declarations for variables. This determines the type and size of data associated with variables.
For example,
int age = 13;
Here, age is a variable of type int. Meaning, the variable can only store integers of either 2 or 4 bytes.
C++ Fundamental Data Types
The table below shows the fundamental data types, their meaning, and their sizes (in bytes):
Data Type Meaning Size (in Bytes)
int Integer 2 or 4
float Floating-point 4
double Double Floating-point 8
char Character 1
wchar_t Wide Character 2
bool Boolean 1
void Empty 0
1. int
The int keyword is used to indicate integers.
Its size is usually 4 bytes. Meaning, it can store values from -2147483648 to 214748647.
For example,
int salary = 85000;
2. float and double
float and double are used to store floating-point numbers (decimals and exponentials).
The size of float is 4 bytes and the size of double is 8 bytes. Hence, double has two times the precision of float. To learn more, visit C++ float and double.
For example,
float area = 64.74;
double volume = 134.64534;
As mentioned above, these two data types are also used for exponentials. For example,
double distance = 45E12 // 45E12 is equal to 45*10^12
3. char
Keyword char is used for characters.
Its size is 1 byte.
Characters in C++ are enclosed inside single quotes ' '.
For example,
char test = 'h';
Note: In C++, an integer value is stored in a char variable rather than the character itself. To learn more, visit C++ characters.
4. wchar_t
Wide character wchar_t is similar to the char data type, except its size is 2 bytes instead of 1.
It is used to represent characters that require more memory to represent them than a single char.
For example,
wchar_t test = L'ם' // storing Hebrew character;
C++ Structs
In C++, classes and structs are blueprints that are used to create the instance of a class. Structs are used for lightweight objects such as Rectangle, color, Point, etc.
Unlike class, structs in C++ are value type than reference type. It is useful if you have data that is not intended to be modified after creation of struct.
C++ Structure is a collection of different data types. It is similar to the class that holds different types of data.
The Syntax Of Structure
In the above declaration, a structure is declared by preceding the struct keyword followed by the identifier(structure name). Inside the curly braces, we can declare the member variables of different types. Consider the following situation:
In the above case, Student is a structure contains three variables name, id, and age. When the structure is declared, no memory is allocated. When the variable of a structure is created, then the memory is allocated. Let's understand this scenario.
How to create the instance of Structure?
Structure variable can be defined as:
Student s;
Here, s is a structure variable of type Student. When the structure variable is created, the memory will be allocated. Student structure contains one char variable and two integer variable. Therefore, the memory for one char variable is 1 byte and two ints will be 2*4 = 8. The total memory occupied by the s variable is 9 byte.
How to access the variable of Structure:
The variable of the structure can be accessed by simply using the instance of the structure followed by the dot (.) operator and then the field of the structure.
For example:
In the above statement, we are accessing the id field of the structure Student by using the dot(.) operator and assigns the value 4 to the id field.
C++ Struct Example
Let's see a simple example of struct Rectangle which has two data members width and height.
Output:
Area of Rectangle is: 40
C++ Struct Example: Using Constructor and Method
Let's see another example of struct where we are using the constructor to initialize data and method to calculate the area of rectangle.
Output:
Area of Rectangle is: 24
Structure v/s Class
Structure | Class |
If access specifier is not declared explicitly, then by default access specifier will be public. | If access specifier is not declared explicitly, then by default access specifier will be private. |
Syntax of Structure: | Syntax of Class: |
The instance of the structure is known as "Structure variable". | The instance of the class is known as "Object of the class". |
C++ Enumeration
Enum in C++ is a data type that contains fixed set of constants.
It can be used for days of the week (SUNDAY, MONDAY, TUESDAY, WEDNESDAY, THURSDAY, FRIDAY and SATURDAY) , directions (NORTH, SOUTH, EAST and WEST) etc. The C++ enum constants are static and final implicitly.
C++ Enums can be thought of as classes that have fixed set of constants.
Points to remember for C++ Enum
C++ Enumeration Example
Let's see the simple example of enum data type used in C++ program.
Output:
Day: 5
Decision making statements like if-else
A program is consists of set of instructions. These instructions are not always written in linear sequence. Program is designed to make decisions and to execute set of instructions number of times. Control Structure satisfies these requirements.
Decision Making Statements.
Decision making statements consists of two or more conditions specified to execute statement so that any condition becomes true or false another condition executes.
The if-else statement
The if else statement consists of if followed by else. Condition specified in if becomes true then statement in if block executes. When condition mentioned in if becomes false then statements in else execute.
Structure of the if – else.

e.g.

Nested if-else
The Nested if- else consist of multiple if-else statements in another if – else. In this specified conditions are executed from top. While executing nested if else, when condition becomes true statement related with it gets execute and rest conditions are bypassed. When all the conditions become false last else statement gets execute.
Structure of the nested if – else:

eg.


Here output is 5. When i=5 condition will match it will give is 5 output if not then last output will be i is not present.
Goto
The goto
The goto is an unconditional jump type of statement. The goto is used to jump between programs from one point to another. The goto can be used to jump out of the nested loop.
Structure of the goto:

While executing program goto provides the information to goto instruction defined as a label. This label is initialized with goto statement before.
e.g.

When the compiler will come to goto label then control will goto label defined before the loop and output will be 1 2 3 4 5.
Break
The break
The break statement is used to terminate the execution where number of iterations is not unknown. It is used in loop to terminate the loop and then control goes to the first statement of the loop. The break statement is also in switch case.
Structure of the break:
e.g.


When the compiler will reach to break it will come out and print the output. Output will be x=1,x=9,x=8,x=7,x=6,break.
Continue
The continue
The continue statement work like break statement but it is opposite of break. The Continue statement continues with execution of program by jumping from current code instruction to the next.
Structure of the break:

e.g.

Output is 1 2 3 4 5.
Switch case
The switch statement is a branch selection statement. The switch statement consists of multiple cases and each case has number of statement. When the condition gets satisfied the statements associated with that case execute. The break statement is used inside switch loop to terminate the execution.
Structure of the switch statement:

e.g.


Outout is “world”.
Loop statement like for loop
Loop Statements
The for loop
The for loop executes repeatedly until the condition specified in for loop is satisfied. When the condition becomes false it resumes with statement written in for loop.
Structure of the for loop:

Initialization is the assignment to the variable which controls the loop. Condition is an expression, specifies the execution of loop. Increment/ decrement operator changes the variable as the loop executes.
e.g.

Output is 1 2 3 4 5.
Nested for loop
The Nested for loop.
Nested for loop is for within for loop.
Structure of the nested for loop:

While Loop
The while loop consists of a condition with set of statements. The Execution of the while loop is done until the condition mentioned in while is true. When the condition becomes false the control comes out of loop.
Structure of the while loop:

e.g.

X is initialized to 1. The loop will execute till x<=6.
Output will be 1 2 3 4 5 6 7 8 9 10.
Do – while loop
The do – while loop consist of consist of condition mentioned at the bottom with while. The do – while executes till condition is true. As the condition is mentioned at bottom do – while loop is executed at least once.
Structure of the do – while:

e.g.

Output is: 1 2 3 4 5 6 7 8 9 10.
Arrays

int arr[] = { 10, 20, 30, 40 } |

Strings
The string is actually a one-dimensional array of characters which is terminated by a null character '\0'. Thus a null-terminated string contains the characters that comprise the string followed by a null.
The following declaration and initialization create a string consisting of the word "Hello". To hold the null character at the end of the array, the size of the character array containing the string is one more than the number of characters in the word "Hello."
char greeting[6] = {'H', 'e', 'l', 'l', 'o', '\0'};
Following is the memory presentation of above defined string in C/C++ −
String Presentation in C/C++
The C++ compiler automatically places the '\0' at the end of the string when it initializes the array.
Example:
#include <iostream>
using namespace std;
int main () {
char greeting[6] = {'H', 'e', 'l', 'l', 'o', '\0'};
cout << "Greeting message: ";
cout << greeting << endl;
return 0;
}
When the above code is compiled and executed, it produces the following result −
Greeting message: Hello
C++ supports a wide range of functions that manipulate null-terminated strings −
Sr.No Function & Purpose
1 strcpy(s1, s2); Copies string s2 into string s1.
2 strcat(s1, s2); Concatenates string s2 onto the end of string s1.
3 strlen(s1); Returns the length of string s1.
4 strcmp(s1, s2); Returns 0 if s1 and s2 are the same;
less than 0 if s1<s2; greater than 0 if s1>s2.
5 strchr(s1, ch);Returns a pointer to the first occurrence of character ch in string s1.
6 strstr(s1, s2); Returns a pointer to the first occurrence of string s2 in string s1.
Example:
#include <iostream>
#include <cstring>
using namespace std;
int main () {
char str1[10] = "Hello";
char str2[10] = "World";
char str3[10];
int len ;
// copy str1 into str3
strcpy( str3, str1);
cout << "strcpy( str3, str1) : " << str3 << endl;
// concatenates str1 and str2
strcat( str1, str2);
cout << "strcat( str1, str2): " << str1 << endl;
// total lenghth of str1 after concatenation
len = strlen(str1);
cout << "strlen(str1) : " << len << endl;
return 0;
}
When the above code is compiled and executed, it produces result something as follows −
strcpy( str3, str1) : Hello
strcat( str1, str2): HelloWorld
strlen(str1) : 10
The main purpose of C++ programming is to add object orientation to the C programming language and classes are the central feature of C++ that supports object-oriented programming and are often called user-defined types.
A class is used to specify the form of an object and it combines data representation and methods for manipulating that data into one neat package. The data and functions within a class are called members of the class.
C++ Class Definitions
When you define a class, you define a blueprint for a data type. This doesn't actually define any data, but it does define what the class name means, that is, what an object of the class will consist of and what operations can be performed on such an object.
A class definition starts with the keyword class followed by the class name; and the class body, enclosed by a pair of curly braces. A class definition must be followed either by a semicolon or a list of declarations. For example, we defined the Box data type using the keyword class as follows −
class Box {
public:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
};
The keyword public determines the access attributes of the members of the class that follows it. A public member can be accessed from outside the class anywhere within the scope of the class object. You can also specify the members of a class as private or protected which we will discuss in a sub-section.
Define C++ Objects
A class provides the blueprints for objects, so basically an object is created from a class. We declare objects of a class with exactly the same sort of declaration that we declare variables of basic types. Following statements declare two objects of class Box −
Box Box1; // Declare Box1 of type Box
Box Box2; // Declare Box2 of type Box
Both of the objects Box1 and Box2 will have their own copy of data members.
Accessing the Data Members
The public data members of objects of a class can be accessed using the direct member access operator (.). Let us try the following example to make the things clear −
#include <iostream>
using namespace std;
class Box {
public:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
};
int main() {
Box Box1; // Declare Box1 of type Box
Box Box2; // Declare Box2 of type Box
double volume = 0.0; // Store the volume of a box here
// box 1 specification
Box1.height = 5.0;
Box1.length = 6.0;
Box1.breadth = 7.0;
// box 2 specification
Box2.height = 10.0;
Box2.length = 12.0;
Box2.breadth = 13.0;
// volume of box 1
volume = Box1.height * Box1.length * Box1.breadth;
cout << "Volume of Box1 : " << volume <<endl;
// volume of box 2
volume = Box2.height * Box2.length * Box2.breadth;
cout << "Volume of Box2 : " << volume <<endl;
return 0;
}
When the above code is compiled and executed, it produces the following result −
Volume of Box1 : 210
Volume of Box2 : 1560
It is important to note that private and protected members can not be accessed directly using direct member access operator (.). We will learn how private and protected members can be accessed.
Classes and Objects in Detail
So far, you have got very basic idea about C++ Classes and Objects. There are further interesting concepts related to C++ Classes and Objects which we will discuss in various sub-sections listed below −
Sr.No | Concept & Description |
1 | Class Member Functions A member function of a class is a function that has its definition or its prototype within the class definition like any other variable. |
2 | Class Access Modifiers A class member can be defined as public, private or protected. By default members would be assumed as private. |
3 | Constructor & Destructor A class constructor is a special function in a class that is called when a new object of the class is created. A destructor is also a special function which is called when created object is deleted. |
4 | Copy Constructor The copy constructor is a constructor which creates an object by initializing it with an object of the same class, which has been created previously. |
5 | Friend Functions A friend function is permitted full access to private and protected members of a class. |
6 | Inline Functions With an inline function, the compiler tries to expand the code in the body of the function in place of a call to the function. |
7 | this Pointer Every object has a special pointer this which points to the object itself. |
8 | Pointer to C++ Classes A pointer to a class is done exactly the same way a pointer to a structure is. In fact a class is really just a structure with functions in it. |
9 | Static Members of a Class Both data members and function members of a class can be declared as static. |
In C++ program if we implement class with private and public members then it is an example of data abstraction.
Data Abstraction can be achieved in two ways:
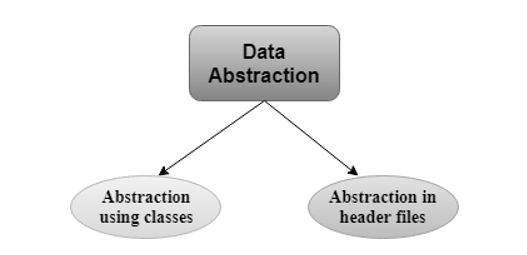
Abstraction using classes: An abstraction can be achieved using classes. A class is used to group all the data members and member functions into a single unit by using the access specifiers. A class has the responsibility to determine which data member is to be visible outside and which is not.
Abstraction in header files: An another type of abstraction is header file. For example, pow() function available is used to calculate the power of a number without actually knowing which algorithm function uses to calculate the power. Thus, we can say that header files hides all the implementation details from the user.
Access Specifiers Implement Abstraction:
Let's see a simple example of abstraction in header files.
// program to calculate the power of a number.
Output:
Cube of n is : 64
In the above example, pow() function is used to calculate 4 raised to the power 3. The pow() function is present in the math.h header file in which all the implementation details of the pow() function is hidden.
Let's see a simple example of data abstraction using classes.
Output:
Enter two numbers:
3
6
Sum of two number is: 9
In the above example, abstraction is achieved using classes. A class 'Sum' contains the private members x, y and z are only accessible by the member functions of the class.
Advantages of Abstraction:
C++ supports three access specifiers as follows :
1. private
class Example
{
int x; // x is private.
public:
void accept()
{
cin>>x;
cout<<x;
}
};
Variable x is accessible to accept() function as it is member function of the same class.
However if we try to access ‘x’ from outside the class it will throw error.
int main()
{
Example Obj;
Obj.x=10; // error as x is private
:
:
}
2. public
class Example
{
int x;
public:
int y; //y is public
void accept() // accept() is public
{
:
:
}
};
int main()
{
Example obj;
Obj.y=10; // OK as obj is public
:
:
}
3. protected
Members declared under protected section can be accessed from within the class and from derived class. It is used only in inheritance.
This article discusses three related problems in the design of C++ classes and surveys five of the solutions to them found in the literature. These problems and solutions are considered together because they relate to separating the design choices that are manifested in the interface from those that are made in implementing the class. The problems are:
These have led developers to seek ways to separate interface from implementation and practice has seen all of the following idioms used and documented. We will be evaluating them to see how they compare as solutions to the above problems:
In order to illustrate the problems and solutions we are going to use a telephone address book (with very limited functionality) as an example. For comparison purposes we have implemented this as a naïve implementation (see first sidebar) which does not attempt to address any of the stated problems. We have also refactored this example to use each of the idioms - the header files are reproduced in the corresponding sidebars. (The full implementation and sample client code for all versions of the example are available with the online version of this article [WEB05].)
Problem 1: Reducing Implementation Detail Exposed to the User
Client code makes use of an object via its public interface, without any recourse to implementation details. Since the authors of client code have to use an object through its public interface that interface is all they need to understand. This public interface typically comprises member function declarations.
Naïve Implementation
// naive.h - implementation hiding example.
#ifndef INCLUDED_NAIVE_H
#define INCLUDED_NAIVE_H
#include <string>
#include <utility>
#include <map>
namespace naive {
/** Telephone list. Example of implementing a
* telephone list using a naive implementation.
*/
class telephone_list {
public:
/** Create a telephone list.
* @param name The name of the list.
*/
telephone_list(const std::string& name);
/** Get the list's name.
* @return the list's name.
*/
std::string get_name() const;
/** Get a person's phone number.
* @param person Person's name (exact match)
* @return pair of success flag and (if success)
* number.
*/
std::pair<bool, std::string>
get_number(const std::string& person) const;
/** Add an entry. If an entry already exists for
* this person it is overwritten.
* @param name The person's name
* @param number The person's number
*/
telephone_list&
add_entry(const std::string& name,
const std::string& number);
private:
typedef std::map<std::string, std::string> dictionary_t;
std::string name;
dictionary_t dictionary;
telephone_list(const telephone_list& rhs);
telephone_list& operator=(const telephone_list& rhs);
};
} // namespace naive
#endif
C++ allows developers to separate the implementation code for member functions from the class definition, but there is no comparable support for separating the member data that implements an object's state (or, for that matter, for separating the declarations of private member functions). Consequently the implementation detail exposed in a class's definition is still there as background noise, providing users with an added distraction. The definition of a class is typically encumbered with implementation "noise" that is of no interest to the user and is inaccessible to the client code written by that user: the naïve implementation shows this with MyDict, myName and dict.
Problem 2: Reducing Physical Coupling
The purpose of defining a class in a header file is for the definition of that class to be included in any translation units that define the client code for that class. If classes are designed in a naïve manner this leads to compilation dependencies upon details of the implementation that are not only inaccessible to the client code but also (in most cases) do not affect it in any way.
These compilation dependencies are undesirable for two reasons:
In a medium to large system the effect of these compilation dependencies can multiply to an extent that causes excessive and problematic build times.
Problem 3: Allowing Customised Implementations
Library code frequently defines points of customisation for user code to exploit. One of the ways to do this is to specify an interface as a class and allow the user code to supply objects that conform to this interface.
Such a library is typically compiled before the user code is written. In this case the library contains the "client code" and for this to have compilation dependencies on the implementation would be problematic.
Clearly, the naïve implementation makes no provision for alternative implementations.
We present the best known idioms for implementation hiding along with some comments in italics.
Each of these idioms can have advantages and these need to be understood when choosing between them.
A private "representation" class is written that embodies the same functionality and interface as the naïve class - however, unlike the naïve version, this is defined and implemented entirely within the implementation file. The public interface of the class published in the header is unchanged, but the private implementation details are reduced to a single member variable that points to an instance of the "representation" class, each of its member functions forwards to the corresponding function of the "representation" class.
The term "Cheshire Cat" (see [Murray1993]) is an old one, coined by John Carollan over a decade ago. Sadly it seems to have disappeared from use in contemporary C++ literature. It appears described as a special case of the Bridge pattern in "Design Patterns" [GOF95], but the name "Cheshire Cat" is not mentioned. Herb Sutter (in [Sut00]) discusses it under the name "Pimpl idiom", but considers it only from the perspective if its use in reducing physical dependencies. It has also been called "Compilation Firewall".
Cheshire Cat requires "boilerplate" code in the form of forwarding functions (see "Cheshire Cat Implementation" sidebar below) that are tedious to write and (if the compiler fails to optimise them away) can introduce a slight performance hit. It also requires care with the copy semantics (although it is possible to factor this out into a smart pointer - see Griffiths99). As the relationship between the public and implementation classes is not explicit it can cause maintenance issues.
Cheshire Cat
// cheshire_cat.h Cheshire Cat -
// implementation hiding example
#ifndef INCLUDED_CHESHIRE_CAT_H
#define INCLUDED_CHESHIRE_CAT_H
#include <string>
#include <utility>
namespace cheshire_cat {
class telephone_list {
public:
telephone_list(const std::string& name);
~telephone_list();
std::string get_name() const;
std::pair<bool, std::string>
get_number(const std::string& person) const;
telephone_list&
add_entry(const std::string& name,
const std::string& number);
private:
class telephone_list_implementation;
telephone_list_implementation* rep;
telephone_list(const telephone_list& rhs);
telephone_list& operator=(
const telephone_list& rhs);
};
} // namespace cheshire_cat
#endif
One or more areas of the class functionality are factored out from the naïve implementation into separate helper classes. The class published in the header holds a pointer to each of these classes and delegates responsibility for the corresponding functionality by forwarding the corresponding operations. This is similar to Cheshire Cat, except that some implementation may remain exposed (like myName in the example) and there may be more than one helper class. (The helper classes may be defined and implemented in the implementation file - as in the sample code - or placed in a header file and made available for use by other code.)
Delegation is attractive where there is a distinct area of functionality that can be factored out or shared with another class. In maintenance and performance terms it is similar to Cheshire Cat.
Delegation
// delegation.h - Delegation implementation hiding
// example.
#ifndef INCLUDED_DELEGATION_H
#define INCLUDED_DELEGATION_H
#include <string>
#include <utility>
namespace delegation {
class telephone_list {
public:
telephone_list(const std::string& name);
~telephone_list();
std::string get_name() const;
std::pair<bool, std::string>
get_number(const std::string& person) const;
telephone_list&
add_entry(const std::string& name,
const std::string& number);
private:
std::string name;
class dictionary;
dictionary* lookup;
telephone_list(const telephone_list& rhs);
telephone_list& operator=(
const telephone_list& rhs);
};
} // namespace delegation
#endif
As with Cheshire Cat a private "representation" class is written which implements the same functionality and interface as the naïve class but is defined and implemented entirely within the implementation file. The variations from Cheshire Cat are:
Frankly Envelope/Letter confuses us - we don't see what advantage it gives over Cheshire Cat. (Maybe it is just a misguided attempt to represent the correspondence of interface and implementation functions explicitly?) But please read Coplien and make up your own mind! In performance terms each client call initiates two function calls dispatched via the v-table - so it is the slowest of the idioms. (However it is rare that the overhead of a virtual function call is significant.)
Envelope/Letter
// envelope_letter.h - Envelope/Letter
// implementation hiding example.
#ifndef INCLUDED_ENVELOPE_LETTER_H
#define INCLUDED_ENVELOPE_LETTER_H
#include <string>
#include <utility>
namespace envelope_letter {
class telephone_list {
public:
telephone_list(const std::string& name);
virtual ~telephone_list();
virtual std::string get_name() const;
virtual std::pair<bool, std::string>
get_number(const std::string& person) const;
virtual telephone_list&
add_entry(const std::string& name,
const std::string& number);
protected:
telephone_list();
private:
telephone_list* rep;
telephone_list(const telephone_list& rhs);
telephone_list& operator=(
const telephone_list& rhs);
};
} // namespace envelope_letter
#endif
All member data is removed from the naïve class and all member functions are made pure virtual. In the implementation file a derived class is defined that implements these member functions. The derived class is not used directly by client code, which sees only a pointer to the public class.
Conceptually the Interface Class idiom is the simplest of those we consider. However, it may be necessary to provide an additional component and interface in order to create instances. Interface Classes, being abstract, can not be instantiated by the client. If a derived "implementation" class implements the pure virtual member functions of the Interface Class, then the client can create instances of that class. (But making the implementation class publicly visible re-introduces noise.) Alternatively, if the implementation class is provided with the Interface Class and (presumably) buried in an implementation file, then provision of an additional instantiation mechanism - e.g. a factory function - is necessary. This is shown as a static create function in the corresponding sidebar.
As objects are dynamically allocated and accessed via pointers this solution requires the client code to manage the object lifetime. This is not a handicap where the domain understanding implies objects are to be managed by a smart pointer (or handle) but it may be significant in some cases.
Note: Interfaces may play an additional role in design to that addressed in this article - they may be used to delineate each of several roles supported by a concrete type. This allows for client code that depend only on (the interface to) the relevant role.
Interface Class
// interface_class.h - Interface Class
// implementation hiding example.
#ifndef INCLUDED_INTERFACE_CLASS_H
#define INCLUDED_INTERFACE_CLASS_H
#include <string>
#include <utility>
namespace interface_class {
class telephone_list {
public:
static telephone_list*
create(const std::string& name);
virtual ~telephone_list() {}
virtual std::string get_name() const = 0;
virtual std::pair<bool, std::string>
get_number(const std::string& person) const = 0;
virtual telephone_list&
add_entry(const std::string& name,
const std::string& number) = 0;
protected:
telephone_list() {}
telephone_list(const telephone_list& rhs) {}
private:
telephone_list& operator=(
const telephone_list& rhs);
};
} // namespace interface_class
#endif
All member data is removed from the naïve class, the public interface becomes non-virtual forwarding functions that delegate to corresponding private pure virtual functions. As with Interface Class the implementation file defines a derived class that implements these member functions. The derived class is not used directly by client code, which sees only a pointer to the public class.
We had thought Non-Virtual Public Interface an idea that had been tried and discarded as introducing unjustified complexity. While the standard library uses this idiom in the iostreams design we've yet to see an implementation of the library that exploits the additional flexibility (in implementing the public functions) it offers over Interface Class. Further, there are some costs to providing this flexibility:
Non-Virtual Public Interface
// non_virtual_public_interface.h - Non-Virtual
// Public Interface implementation hiding example
#ifndef INCLUDED_NONVIRTUAL_PUBLIC_INTERFACE_H
#define INCLUDED_NONVIRTUAL_PUBLIC_INTERFACE_H
#include <string>
#include <utility>
namespace non_virtual_public_interface {
class telephone_list {
public:
static telephone_list* create(
const std::string& name);
virtual ~telephone_list() {}
std::string get_name() const
{ return do_get_name(); }
std::pair<bool, std::string>
get_number(const std::string& person) const
{ return do_get_number(person); }
virtual telephone_list&
add_entry(const std::string& name,
const std::string& number)
{ return do_add_entry(name, number); }
protected:
telephone_list() {}
telephone_list(const telephone_list& rhs) {}
private:
telephone_list& operator=(
const telephone_list& rhs);
virtual std::string do_get_name() const = 0;
virtual std::pair<bool, std::string>
do_get_number(const std::string& person) const = 0;
virtual telephone_list&
do_add_entry(const std::string& name,
const std::string& number) = 0;
};
} // namespace non_virtual_public_interface
#endif
Problem 1: Reducing Implementation Detail Exposed to the User
All the idioms considered address this problem reasonably successfully. The only implementation detail any of these idioms expose is the mechanism by which they support the separation:
Delegation is in a way the odd one out, because it does not by nature conceal all the implementation detail. This point is illustrated in our example implementation where the std::string member myName is visible in the definition of TelephoneList. Delegation reduces the implementation noise exposed to clients, but - unless all functionality is delegated to one (or more) other classes - it leaves the class still vulnerable to the problems suffered by the naïve implementation.
Cheshire Cat Implementation
// MCheshireCat.cpp - implementation hiding example.
#include "cheshire_cat.h"
#include <map>
namespace cheshire_cat {
// Declare the implementation class
class telephone_list::telephone_list_implementation {
public:
telephone_list_implementation(
const std::string& name);
~telephone_list_implementation();
std::string get_name() const;
std::pair<bool, std::string>
get_number(const std::string& person) const;
void add_entry(const std::string& name,
const std::string& number);
private:
typedef std::map<std::string, std::string>
dictionary_t;
std::string name;
dictionary_t dictionary;
};
// Implement the stubs for the wrapper class
telephone_list::telephone_list(
const std::string& name)
: rep(new telephone_list_implementation(name)) {}
telephone_list::~telephone_list() { delete rep; }
std::string telephone_list::get_name() const {
return rep->get_name();
}
std::pair<bool, std::string> telephone_list::
get_number(const std::string& person) const {
return rep->get_number(person);
}
telephone_list& telephone_list::add_entry(
const std::string& name,
const std::string& number) {
rep->add_entry(name, number);
return *this;
}
// Implement the implementation class
telephone_list::telephone_list_implementation::
telephone_list_implementation(
const std::string& name)
: name(name) {}
telephone_list::telephone_list_implementation::
~telephone_list_implementation() {}
std::string telephone_list::
telephone_list_implementation::get_name() const {
return name;
}
std::pair<bool, std::string>
telephone_list::telephone_list_implementation::
get_number(const std::string& person) const {
dictionary_t::const_iterator i
= dictionary.find(person);
return(i != dictionary.end()) ?
std::make_pair(true, (*i).second) :
std::make_pair(true, std::string());
}
void telephone_list::telephone_list_implementation::
add_entry(const std::string& name,
const std::string& number) {
dictionary[name] = number;
}
} // namespace cheshire_cat
Problem 2: Reducing Physical Coupling
When the principal concern is reducing compile time dependencies the size (including indirect inclusions) of the header is more significant than that of the implementation file. However, in most cases, there is very little difference between the header files required by the different idioms - in our example they all have the same includes and the file lengths are as follows:
$ wc *.h | sort
62 163 1580 cheshire_cat.h
62 184 1677 interface_class.h
65 162 1535 naive.h
66 163 1554 delegation.h
66 164 1605 envelope_letter.h
94 285 2688 non_virtual_public_interface.h
The lack of variation is not surprising: all of the examples have eliminated the <map> header file and the only substantial difference is that Non-Virtual Public Interface declares twice as many functions (having both public and private versions of each).
Problem 3: Allowing Customised Implementations
It should be noted that only Interface Class and Non-Virtual Public Interface allow user implementation - the other idioms do not publish an implementation interface.
When our principal concern is that of simplifying the task of implementing the class then the size of the implementation file is most significant:
$ wc interface_class.cpp /
non_virtual_public_interface.cpp
85 147 2013 interface_class.cpp
89 151 2186 non_virtual_public_interface.cpp
There is no substantial difference in implementation cost between these approaches as they contain almost identical code.
Interface Class Implementation
// MAbstractBaseClass.cpp - implementation hiding
// example.
#include "interface_class.h"
#include <map>
// Declare the implementation class
namespace {
class telephone_list_implementation
: public interface_class::telephone_list {
public:
telephone_list_implementation(const std::string& name);
virtual ~telephone_list_implementation();
private:
virtual std::string get_name() const;
virtual std::pair<bool, std::string>
get_number(const std::string& person) const;
virtual interface_class::telephone_list&
add_entry(const std::string& name,
const std::string& number);
typedef std::map<std::string, std::string>
dictionary_t;
std::string name;
dictionary_t dictionary;
};
} // anonymous namespace
// Implement the stubs for the base class
namespace interface_class {
telephone_list* telephone_list::create(
const std::string& name) {
return new telephone_list_implementation(name);
}
} // namespace interface_class
// Implement the implementation class
namespace {
telephone_list_implementation::
telephone_list_implementation(const std::string& name)
: name(name) {}
telephone_list_implementation::
~telephone_list_implementation() {}
std::string telephone_list_implementation::get_name() const
{ return name; }
std::pair<bool, std::string>
telephone_list_implementation::
get_number(const std::string& person) const {
std::pair<bool, std::string> rc(false,
std::string());
dictionary_t::const_iterator i
= dictionary.find(person);
return(i != dictionary.end()) ?
std::make_pair(true, (*i).second) :
std::make_pair(true, std::string());
}
interface_class::telephone_list&
telephone_list_implementation::
add_entry(const std::string& name, const std::string& number) {
dictionary[name] = number;
return *this;
}
} // anonymous namespace
In scenarios where customisation of implementation needs to be supported the choice is between Interface Class and Non-Virtual Public Interface. In this case we would prefer the simplicity of Interface Class (unless we have a need for the public functions to do more work than forwarding - which leads us into the territory of TEMPLATE METHOD).
Sometimes we wish to develop "value based" classes - these can, for example, be used directly with the standard library containers. Only three of the idioms (Cheshire Cat, Envelope/Letter and Delegation) permit this style of class. (Using value-based classes implies that the identity of class instances is transparent - and that may not be appropriate). Of these options, Cheshire Cat is most often the appropriate choice - although Delegation may be appropriate if it allows common functionality to be factored out.
There are many occasions where user customisation of implementation is not required, and the identity of instances of the class is important. In these circumstances it is reasonable to expect client code to manage object lifetime explicitly (e.g. by using a smart pointer). Both Interface Class and Cheshire Cat are reasonable choices here. Interface Class is simpler, but where a strong separation of interface and implementation is required Cheshire Cat may be preferred.
Function
 Functions are used to increase readability of the code. Size of program can be reducing by using functions. By using function, programmer can divide complex tasks into smaller manageable tasks and test them independently before using them together.
Functions are used to increase readability of the code. Size of program can be reducing by using functions. By using function, programmer can divide complex tasks into smaller manageable tasks and test them independently before using them together.
Function prototype
return-type function-name(data-type 1 arg 1, data-type 2 arg2, …..,data type n arg n);
argument list
int add(int x,int y,int z);
int add(int ,int ,int );//valid
int add(int x,int y ,z );//invalid
int add(int x, float y, double z);
Accessing function and utility function
Access functions can read or display data. Another common use for access functions is to test the truth or falsity of conditions such functions are often called predicate functions. An example of a predicate function would be an is Empty function for any container class a class capable of holding many objects such as a linked list, a stack or a queue. A program might test is Empty before attempting to read another item from the container object. An is Full predicate function might test a container-class object to determine whether it has no additional room. Useful predicate functions for our Time class might be is AM and is PM.
The program of Figs. 9.59.7 demonstrates the notion of a utility function (also called a helper function). A utility function is not part of a class's public interface; rather, it is a private member function that supports the operation of the class's public member functions. Utility functions are not intended to be used by clients of a class (but can be used by friends of a class, as we will see in Chapter 10).
1 // Fig.: SalesPerson.h 2 // SalesPerson class definition. 3 // Member functions defined in SalesPerson.cpp. 4 #ifndef SALESP_H 5 #define SALESP_H 6 7 class SalesPerson 8 { 9 public: 10 SalesPerson(); // constructor 11 void getSalesFromUser(); // input sales from keyboard 12 void setSales( int, double ); // set sales for a specific month 13 void printAnnualSales(); // summarize and print sales 14 private: 15 double totalAnnualSales(); // prototype for utility function 16 double sales[ 12 ]; // 12 monthly sales figures 17 }; // end class SalesPerson 18 19 #endif
|
Class SalesPerson (Fig. 9.5) declares an array of 12 monthly sales figures (line 16) and the prototypes for the class's constructor and member functions that manipulate the array.
In Fig. 9.6, the SalesPerson constructor (lines 1519) initializes array sales to zero. The public member function setSales (lines 3643) sets the sales figure for one month in array sales. The public member function printAnnualSales (lines 4651) prints the total sales for the last 12 months. The private utility function totalAnnualSales (lines 5462) totals the 12 monthly sales figures for the benefit of printAnnualSales. Member function printAnnualSales edits the sales figures into monetary format.
1 // Fig: SalesPerson.cpp 2 // Member functions for class SalesPerson. 3 #include <iostream> 4 using std::cout; 5 using std::cin; 6 using std::endl; 7 using std::fixed; 8 9 #include <iomanip> 10 using std::setprecision; 11 12 #include "SalesPerson.h" // include SalesPerson class definition 13 14 // initialize elements of array sales to 0.0 15 SalesPerson::SalesPerson() 16 { 17 for ( int i = 0; i < 12; i++ ) 18 sales[ i ] = 0.0; 19 } // end SalesPerson constructor 20 21 // get 12 sales figures from the user at the keyboard 22 void SalesPerson::getSalesFromUser() 23 { 24 double salesFigure; 25 26 for ( int i = 1; i <= 12; i++ ) 27 { 28 cout << "Enter sales amount for month " << i << ": "; 29 cin >> salesFigure; 30 setSales( i, salesFigure ); 31 } // end for 32 } // end function getSalesFromUser 33 34 // set one of the 12 monthly sales figures; function subtracts 35 // one from month value for proper subscript in sales array 36 void SalesPerson::setSales( int month, double amount ) 37 { 38 // test for valid month and amount values 39 if ( month >= 1 && month <= 12 && amount > 0 ) 40 sales[ month - 1 ] = amount; // adjust for subscripts 0-11 41 else // invalid month or amount value 42 cout << "Invalid month or sales figure" << endl; 43 } // end function setSales 44 45 // print total annual sales (with the help of utility function) 46 void SalesPerson::printAnnualSales() 47 { 48 cout << setprecision( 2 ) << fixed 49 << "\nThe total annual sales are: $" 50 << totalAnnualSales() << endl; // call utility function 51 } // end function printAnnualSales 52 53 // private utility function to total annual sales 54 double SalesPerson::totalAnnualSales() 55 { 56 double total = 0.0; // initialize total 57 58 for ( int i = 0; i < 12; i++ ) // summarize sales results 59 total += sales[ i ]; // add month i sales to total 60 61 return total; 62 } // end function totalAnnualSales
|
In Fig. , notice that the application's main function includes only a simple sequence of member-function callsthere are no control statements. The logic of manipulating the sales array is completely encapsulated in class SalesPerson's member functions.
1 // Fig.: fig09_07.cpp 2 // Demonstrating a utility function. 3 // Compile this program with SalesPerson.cpp 4 5 // include SalesPerson class definition from SalesPerson.h 6 #include "SalesPerson.h" 7 8 int main() 9 { 10 SalesPerson s; // create SalesPerson object s 11 12 s.getSalesFromUser(); // note simple sequential code; 13 s.printAnnualSales(); // no control statements in main 14 return 0; 15 } // end main
|
class example
{
int x,y;
public:
example() //constructor, same name as that of class
{
}
void display()
{
:
}
};
class example
{
int x,y;
public:
example() //constructor initializing data members of class
{
x=10;
y=20;
}
void display()
{
:
}
};
It is always declared under public section.
class example
{
private:
int x,y;
example() // error, constructor declared under private section
{
x=10;
y=20;
}
:
:
};
class example
{
int x, y;
public:
void example() // error, constructor does not have return type
{
x=10;
y=20;
}
:
:
};
class example
{
int x, y;
public:
example() // constructor
{
x=10;
y=20;
}
void display()
{
cout<<x<<y;
}
};
int main()
{
example obj; //invokes constructor and initialize data
member x and y to 10 and 20 respectively.
obj.display();
return 0 ;
}
class example
{
int x, y;
public:
example(); // constructor declared
:
:
};
example::example(); // constructor defined outside class
{
x=10;
y=20;
}
 Types of constructors with syntax
Types of constructors with syntax
1. Default /Non parameterized Constructor
2. Parameterized Constructor
3. Copy Constructor
1. Default /Non parameterized Constructor
class Volume
{
int x;
public:
Volume () // default constructor
{
x=10;
}
void display()
{
cout<<x*x*x;
}
};
void main()
{
Volume Obj; //invokes default constructor
Obj.display();
}
2. Parameterized Constructor
A constructor that receives parameters is parameterized constructor.
class Volume {
int x;
public:
Volume ( int a) // parameterized constructor
{
x=a;
}
void display()
{
cout<<x*x*x;
}
};
int main()
{
Volume obj(10); //invokes parameterized constructor
and pass argument 10 to it.
obj.display();
return 0 ;
}
3. Copy Constructor
Copy constructor initializes an object using values of another object passed to it as a parameter.
class Volume
{
int x;
public:
Volume ( int & P) // copy constructor
{
x=P.x; //copies value
}
void display()
{
cout<<x*x*x;
}
};
int main()
{
Volume obj1; //invokes default constructor
Volume obj2(obj1); //calls copy constructor
obj2.display();
return 0 ;
}
Destructor
class example
{
public:
~example();//destructor
};
A good understanding of how dynamic memory really works in C++ is essential to becoming a good C++ programmer. Memory in your C++ program is divided into two parts −
Many times, you are not aware in advance how much memory you will need to store particular information in a defined variable and the size of required memory can be determined at run time.
You can allocate memory at run time within the heap for the variable of a given type using a special operator in C++ which returns the address of the space allocated. This operator is called new operator.
If you are not in need of dynamically allocated memory anymore, you can use delete operator, which de-allocates memory that was previously allocated by new operator.
new and delete Operators
There is following generic syntax to use new operator to allocate memory dynamically for any data-type.
new data-type;
Here, data-type could be any built-in data type including an array or any user defined data types include class or structure. Let us start with built-in data types. For example we can define a pointer to type double and then request that the memory be allocated at execution time. We can do this using the new operator with the following statements −
double* pvalue = NULL; // Pointer initialized with null
pvalue = new double; // Request memory for the variable
The memory may not have been allocated successfully, if the free store had been used up. So it is good practice to check if new operator is returning NULL pointer and take appropriate action as below −
double* pvalue = NULL;
if( !(pvalue = new double )) {
cout << "Error: out of memory." <<endl;
exit(1);
}
The malloc() function from C, still exists in C++, but it is recommended to avoid using malloc() function. The main advantage of new over malloc() is that new doesn't just allocate memory, it constructs objects which is prime purpose of C++.
At any point, when you feel a variable that has been dynamically allocated is not anymore required, you can free up the memory that it occupies in the free store with the ‘delete’ operator as follows −
delete pvalue; // Release memory pointed to by pvalue
Let us put above concepts and form the following example to show how ‘new’ and ‘delete’ work −
#include <iostream>
using namespace std;
int main () {
double* pvalue = NULL; // Pointer initialized with null
pvalue = new double; // Request memory for the variable
*pvalue = 29494.99; // Store value at allocated address
cout << "Value of pvalue : " << *pvalue << endl;
delete pvalue; // free up the memory.
return 0;
}
If we compile and run above code, this would produce the following result −
Value of pvalue : 29495
Dynamic Memory Allocation for Arrays
Consider you want to allocate memory for an array of characters, i.e., string of 20 characters. Using the same syntax what we have used above we can allocate memory dynamically as shown below.
char* pvalue = NULL; // Pointer initialized with null
pvalue = new char[20]; // Request memory for the variable
To remove the array that we have just created the statement would look like this −
delete [] pvalue; // Delete array pointed to by pvalue
Following the similar generic syntax of new operator, you can allocate for a multi-dimensional array as follows −
double** pvalue = NULL; // Pointer initialized with null
pvalue = new double [3][4]; // Allocate memory for a 3x4 array
However, the syntax to release the memory for multi-dimensional array will still remain same as above −
delete [] pvalue; // Delete array pointed to by pvalue
Dynamic Memory Allocation for Objects
Objects are no different from simple data types. For example, consider the following code where we are going to use an array of objects to clarify the concept −
#include <iostream>
using namespace std;
class Box {
public:
Box() {
cout << "Constructor called!" <<endl;
}
~Box() {
cout << "Destructor called!" <<endl;
}
};
int main() {
Box* myBoxArray = new Box[4];
delete [] myBoxArray; // Delete array
return 0;
}
If you were to allocate an array of four Box objects, the Simple constructor would be called four times and similarly while deleting these objects, destructor will also be called same number of times.
If we compile and run above code, this would produce the following result −
Constructor called!
Constructor called!
Constructor called!
Constructor called!
Destructor called!
Destructor called!
Destructor called!
Destructor called!
Variable and functions
Static Variables
Static variables in a Function: When a variable is declared as static, space for it gets allocated for the lifetime of the program. Even if the function is called multiple times, space for the static variable is allocated only once and the value of variable in the previous call gets carried through the next function call. This is useful for implementing in C/C++ or any other application where previous state of function needs to be stored.
// C++ program to demonstrate // the use of static Static // variables in a Function #include <iostream> #include <string> using namespace std;
void demo() { // static variable static int count = 0; cout << count << " ";
// value is updated and // will be carried to next // function calls count++; }
int main() { for (int i=0; i<5; i++) demo(); return 0; } |
Output:
0 1 2 3 4
You can see in the above program that the variable count is declared as static. So, its value is carried through the function calls. The variable count is not getting initialized for every time the function is called.
Static variables in a class: As the variables declared as static are initialized only once as they are allocated space in separate static storage so, the static variables in a class are shared by the objects. There can not be multiple copies of same static variables for different objects. Also because of this reason static variables can not be initialized using constructors.
// C++ program to demonstrate static // variables inside a class
#include<iostream> using namespace std;
class GfG { public: static int i;
GfG() { // Do nothing }; };
int main() { GfG obj1; GfG obj2; obj1.i =2; obj2.i = 3;
// prints value of i cout << obj1.i<<" "<<obj2.i; } |
You can see in the above program that we have tried to create multiple copies of the static variable i for multiple objects. But this didn’t happen. So, a static variable inside a class should be initialized explicitly by the user using the class name and scope resolution operator outside the class as shown below:
// C++ program to demonstrate static // variables inside a class
#include<iostream> using namespace std;
class GfG { public: static int i;
GfG() { // Do nothing }; };
int GfG::i = 1;
int main() { GfG obj; // prints value of i cout << obj.i; } |
Output:
1
Static Members of Class
Consider the below program where the object is non-static.
// CPP program to illustrate // when not using static keyword #include<iostream> using namespace std;
class GfG { int i; public: GfG() { i = 0; cout << "Inside Constructor\n"; } ~GfG() { cout << "Inside Destructor\n"; } };
int main() { int x = 0; if (x==0) { GfG obj; } cout << "End of main\n"; } |
Output:
Inside Constructor
Inside Destructor
End of main
In the above program the object is declared inside the if block as non-static. So, the scope of variable is inside the if block only. So when the object is created the constructor is invoked and soon as the control of if block gets over the destructor is invoked as the scope of object is inside the if block only where it is declared.
Let us now see the change in output if we declare the object as static.
// CPP program to illustrate // class objects as static #include<iostream> using namespace std;
class GfG { int i = 0;
public: GfG() { i = 0; cout << "Inside Constructor\n"; }
~GfG() { cout << "Inside Destructor\n"; } };
int main() { int x = 0; if (x==0) { static GfG obj; } cout << "End of main\n"; } |
Output:
Inside Constructor
End of main
Inside Destructor
You can clearly see the change in output. Now the destructor is invoked after the end of main. This happened because the scope of static object is through out the life time of program.
Static member functions are allowed to access only the static data members or other static member functions, they can not access the non-static data members or member functions of the class.
// C++ program to demonstrate static // member function in a class #include<iostream> using namespace std;
class GfG { public:
// static member function static void printMsg() { cout<<"Welcome to GfG!"; } };
// main function int main() { // invoking a static member function GfG::printMsg(); } |
Output:
Welcome to GfG!
Inline function
inline return-type function-name(argument list)
{
Function body
}
Example
inline int add(int x,int y, int z)
{
return(x*y*z);
}
add(10,20,25);
will be expanded by its function definition.
- Function definition is large.
- Function is recursive
- Function return values
Write a C++ program to illustrate inline functions.
Solution :
# include<iostream>
using namespace std ;
inline void data(int x) // Step 1 Defines function data as inline
{
return (x%2==0)?cout<<“Even\n”:cout<<“Odd”; // Step 2
}
void main()
{
data(10); // Step 3 Calling inline function
data(5); // Step 4
}
Explanation
Step 1 : Function data is declared as inline with one argument.
It finds if a number is even or odd.
inline void data(int x) | //Defines function data as inline |
Step 2 : Conditional operator is used to check if number is even or odd.
return (x%2==0)?cout<<“Even\n”:cout<<“Odd”; |
Step 3 : Pass parameter 10 to data function. Here data function is expanded to its corresponding code instead of passing control to function definition. It gives output as even number.
data(10); |
Step 4 : Pass parameter 5 to data function. It gives output as odd number.
Data(5); |
Output
Even
Odd
Friend function
A friend function of a class is defined outside that class' scope but it has the right to access all private and protected members of the class. Even though the prototypes for friend functions appear in the class definition, friends are not member functions.
A friend can be a function, function template, or member function, or a class or class template, in which case the entire class and all of its members are friends.
To declare a function as a friend of a class, precede the function prototype in the class definition with keyword friend as follows −
class Box {
double width;
public:
double length;
friend void printWidth( Box box );
void setWidth( double wid );
};
To declare all member functions of class ClassTwo as friends of class ClassOne, place a following declaration in the definition of class ClassOne −
friend class ClassTwo;
Consider the following program −
#include <iostream>
using namespace std;
class Box {
double width;
public:
friend void printWidth( Box box );
void setWidth( double wid );
};
// Member function definition
void Box::setWidth( double wid ) {
width = wid;
}
// Note: printWidth() is not a member function of any class.
void printWidth( Box box ) {
/* Because printWidth() is a friend of Box, it can
directly access any member of this class */
cout << "Width of box : " << box.width <<endl;
}
// Main function for the program
int main() {
Box box;
// set box width without member function
box.setWidth(10.0);
// Use friend function to print the wdith.
printWidth( box );
return 0;
}
When the above code is compiled and executed, it produces the following result −
Width of box : 10
References:
1. Herbert Schildt, ―C++ The complete reference‖, Eighth Edition, McGraw Hill Professional, 2011, ISBN:978-00-72226805
2. Matt Weisfeld, ―The Object-Oriented Thought Process, Third Edition Pearson ISBN-13:075- 2063330166
3. Cox Brad, Andrew J. Novobilski, ―Object –Oriented Programming: An EvolutionaryApproach‖, Second Edition, Addison–Wesley, ISBN:13:978-020-1548341
4. Deitel, “C++ How to Program”, 4th Edition, Pearson Education, ISBN:81-297-0276-2




