UNIT 3
Polymorphism
The term "Polymorphism" is the combination of "poly" + "morphs" which means many forms. It is a greek word. In object-oriented programming, we use 3 main concepts: inheritance, encapsulation, and polymorphism.
Real Life Example Of Polymorphism
Let's consider a real-life example of polymorphism. A lady behaves like a teacher in a classroom, mother or daughter in a home and customer in a market. Here, a single person is behaving differently according to the situations.
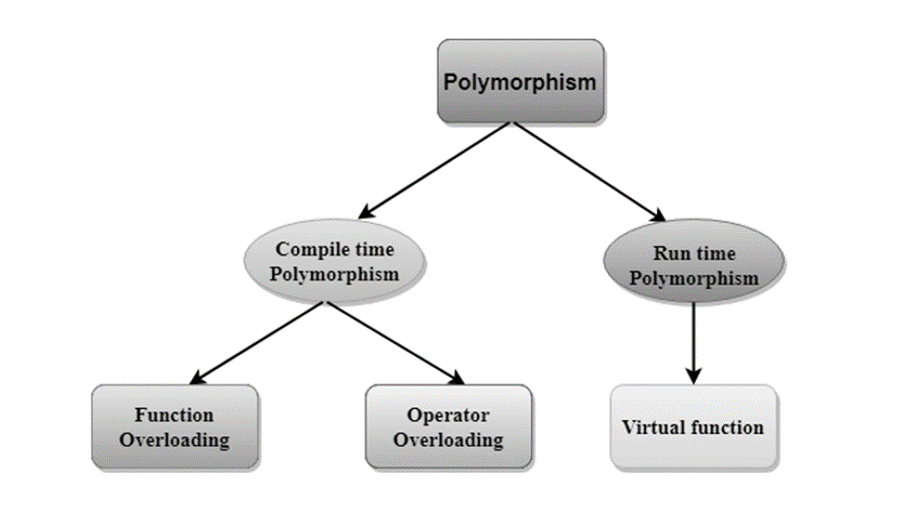
There are two types of polymorphism in C++:
In the above case, the prototype of display() function is the same in both the base and derived class. Therefore, the static binding cannot be applied. It would be great if the appropriate function is selected at the run time. This is known as run time polymorphism.
Differences b/w compile time and run time polymorphism.
Compile time polymorphism | Run time polymorphism |
The function to be invoked is known at the compile time. | The function to be invoked is known at the run time. |
It is also known as overloading, early binding and static binding. | It is also known as overriding, Dynamic binding and late binding. |
Overloading is a compile time polymorphism where more than one method is having the same name but with the different number of parameters or the type of the parameters. | Overriding is a run time polymorphism where more than one method is having the same name, number of parameters and the type of the parameters. |
It is achieved by function overloading and operator overloading. | It is achieved by virtual functions and pointers. |
It provides fast execution as it is known at the compile time. | It provides slow execution as it is known at the run time. |
It is less flexible as mainly all the things execute at the compile time. | It is more flexible as all the things execute at the run time. |
C++ Runtime Polymorphism Example
Let's see a simple example of run time polymorphism in C++.
// an example without the virtual keyword.
Output:
Eating bread...
C++ Run time Polymorphism Example: By using two derived class
Let's see another example of run time polymorphism in C++ where we are having two derived classes.
// an example with virtual keyword.
Output:
drawing...
drawing rectangle...
drawing circle...
Runtime Polymorphism with Data Members
Runtime Polymorphism can be achieved by data members in C++. Let's see an example where we are accessing the field by reference variable which refers to the instance of derived class.
Output:
Black
In this section we will see what is early binding and what is late binding in C++. The binding means the process of converting identifiers into addresses. For each variables and functions this binding is done. For functions it is matching the call with the right function definition by the compiler. The binding is done either at compile time or at runtime.
Early Binding
This is compile time polymorphism. Here it directly associates an address to the function call. For function overloading it is an example of early binding.
Example
#include<iostream>
using namespace std;
class Base {
public:
void display() {
cout<<" In Base class" <<endl;
}
};
class Derived: public Base {
public:
void display() {
cout<<"In Derived class" << endl;
}
};
int main(void) {
Base *base_pointer = new Derived;
base_pointer->display();
return 0;
}
Output
In Base class
Late Binding
This is run time polymorphism. In this type of binding the compiler adds code that identifies the object type at runtime then matches the call with the right function definition. This is achieved by using virtual function.
Example
#include<iostream>
using namespace std;
class Base {
public:
virtual void display() {
cout<<"In Base class" << endl;
}
};
class Derived: public Base {
public:
void display() {
cout<<"In Derived class" <<endl;
}
};
int main() {
Base *base_pointer = new Derived;
base_pointer->display();
return 0;
}
Output
In Derived class
The word polymorphism means having many forms. Typically, polymorphism occurs when there is a hierarchy of classes and they are related by inheritance.
C++ polymorphism means that a call to a member function will cause a different function to be executed depending on the type of object that invokes the function.
Consider the following example where a base class has been derived by other two classes −
#include <iostream>
using namespace std;
class Shape {
protected:
int width, height;
public:
Shape( int a = 0, int b = 0){
width = a;
height = b;
}
int area() {
cout << "Parent class area :" <<endl;
return 0;
}
};
class Rectangle: public Shape {
public:
Rectangle( int a = 0, int b = 0):Shape(a, b) { }
int area () {
cout << "Rectangle class area :" <<endl;
return (width * height);
}
};
class Triangle: public Shape {
public:
Triangle( int a = 0, int b = 0):Shape(a, b) { }
int area () {
cout << "Triangle class area :" <<endl;
return (width * height / 2);
}
};
// Main function for the program
int main() {
Shape *shape;
Rectangle rec(10,7);
Triangle tri(10,5);
// store the address of Rectangle
shape = &rec;
// call rectangle area.
shape->area();
// store the address of Triangle
shape = &tri;
// call triangle area.
shape->area();
return 0;
}
When the above code is compiled and executed, it produces the following result −
Parent class area :
Parent class area :
The reason for the incorrect output is that the call of the function area() is being set once by the compiler as the version defined in the base class. This is called static resolution of the function call, or static linkage - the function call is fixed before the program is executed. This is also sometimes called early binding because the area() function is set during the compilation of the program.
But now, let's make a slight modification in our program and precede the declaration of area() in the Shape class with the keyword virtual so that it looks like this −
class Shape {
protected:
int width, height;
public:
Shape( int a = 0, int b = 0) {
width = a;
height = b;
}
virtual int area() {
cout << "Parent class area :" <<endl;
return 0;
}
};
After this slight modification, when the previous example code is compiled and executed, it produces the following result −
Rectangle class area
Triangle class area
This time, the compiler looks at the contents of the pointer instead of it's type. Hence, since addresses of objects of tri and rec classes are stored in *shape the respective area() function is called.
As you can see, each of the child classes has a separate implementation for the function area(). This is how polymorphism is generally used. You have different classes with a function of the same name, and even the same parameters, but with different implementations.
Virtual Function
A virtual function is a function in a base class that is declared using the keyword virtual. Defining in a base class a virtual function, with another version in a derived class, signals to the compiler that we don't want static linkage for this function.
What we do want is the selection of the function to be called at any given point in the program to be based on the kind of object for which it is called. This sort of operation is referred to as dynamic linkage, or late binding.
Pure Virtual Functions
It is possible that you want to include a virtual function in a base class so that it may be redefined in a derived class to suit the objects of that class, but that there is no meaningful definition you could give for the function in the base class.
We can change the virtual function area() in the base class to the following −
class Shape {
protected:
int width, height;
public:
Shape(int a = 0, int b = 0) {
width = a;
height = b;
}
// pure virtual function
virtual int area() = 0;
};
The = 0 tells the compiler that the function has no body and above virtual function will be called pure virtual function.
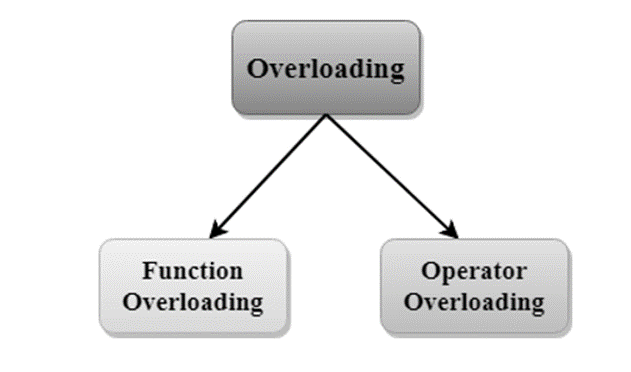
If we create two or more members having the same name but different in number or type of parameter, it is known as C++ overloading. In C++, we can overload:
It is because these members have parameters only.
Types of overloading in C++ are:
C++ Function Overloading
Function Overloading is defined as the process of having two or more function with the same name, but different in parameters is known as function overloading in C++. In function overloading, the function is redefined by using either different types of arguments or a different number of arguments. It is only through these differences compiler can differentiate between the functions.
The advantage of Function overloading is that it increases the readability of the program because you don't need to use different names for the same action.
C++ Function Overloading Example
Let's see the simple example of function overloading where we are changing number of arguments of add() method.
// program of function overloading when number of arguments vary.
Output:
30
55
Let's see the simple example when the type of the arguments vary.
// Program of function overloading with different types of arguments.
Output:
r1 is : 42
r2 is : 0.6
Function Overloading and Ambiguity
When the compiler is unable to decide which function is to be invoked among the overloaded function, this situation is known as function overloading.
When the compiler shows the ambiguity error, the compiler does not run the program.
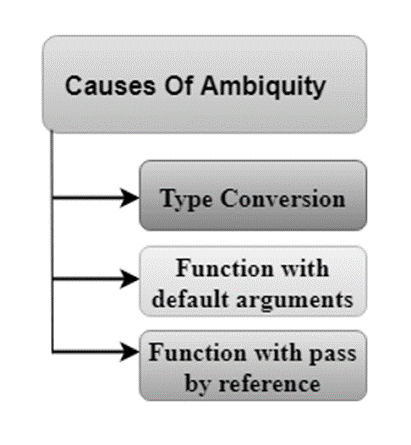
Causes of Function Overloading:
Let's see a simple example.
The above example shows an error "call of overloaded 'fun(double)' is ambiguous". The fun(10) will call the first function. The fun(1.2) calls the second function according to our prediction. But, this does not refer to any function as in C++, all the floating point constants are treated as double not as a float. If we replace float to double, the program works. Therefore, this is a type conversion from float to double.
Let's see a simple example.
The above example shows an error "call of overloaded 'fun(int)' is ambiguous". The fun(int a, int b=9) can be called in two ways: first is by calling the function with one argument, i.e., fun(12) and another way is calling the function with two arguments, i.e., fun(4,5). The fun(int i) function is invoked with one argument. Therefore, the compiler could not be able to select among fun(int i) and fun(int a,int b=9).
Let's see a simple example.
The above example shows an error "call of overloaded 'fun(int&)' is ambiguous". The first function takes one integer argument and the second function takes a reference parameter as an argument. In this case, the compiler does not know which function is needed by the user as there is no syntactical difference between the fun(int) and fun(int &).
C++ Operators Overloading
Operator overloading is a compile-time polymorphism in which the operator is overloaded to provide the special meaning to the user-defined data type. Operator overloading is used to overload or redefines most of the operators available in C++. It is used to perform the operation on the user-defined data type. For example, C++ provides the ability to add the variables of the user-defined data type that is applied to the built-in data types.
The advantage of Operators overloading is to perform different operations on the same operand.
Operator that cannot be overloaded are as follows:
Syntax of Operator Overloading
Where the return type is the type of value returned by the function.
class_name is the name of the class.
operator op is an operator function where op is the operator being overloaded, and the operator is the keyword.
Rules for Operator Overloading
C++ Operators Overloading Example
Let's see the simple example of operator overloading in C++. In this example, void operator ++ () operator function is defined (inside Test class).
// program to overload the unary operator ++.
Output:
The Count is: 10
Let's see a simple example of overloading the binary operators.
// program to overload the binary operators.
Output:
The result of the addition of two objects is : 9
Introduction and Need of Operator Overloading
Operator Function
1. Member operator function
2. Non Member operator function
Overloading using Member Operator Function
Syntax of an operator function
return-type operator OP(argument list);
Where OP -> operator to be overloaded.
Type of Operator | No. of Arguments |
Unary | 0 |
Binary | 1 |
return-type class-name :: operator OP(argument list)
{
Operations that overloaded operator performs
}
Rules of Operator Overloading
Operators which cannot be overloaded
All C++ operators can be overloaded except following
Operators which cannot be overloaded by using Friend Function
Following operators cannot be overloaded using friends
Rules for operator overloading
Member operator function takes no parameter for unary operator and is implicitly passed through “this” pointer.
Program
Write a program in C++ to overload unary minus(-).
Solution :
#include<iostream> using namespace std ; class Example { int x,y,z; public:
Example(int p,int q,int r) { x=p; y=q; z=r; } void display() { cout<<x<<” ”<<y<<” ”<<z; } void operator-() { x=-x; y=-y; z=-z; } }; int main() { Example obj (10,-20,30); cout<<”Original numbers are” obj.display(); - obj; obj.display(); return 0; } |
//Defines class Example
//Parameterized constructor
// Step 1 Operator function to overload minus
// Step 2 Invokes operator function
cout<<”Numbers after applying unary minus” |
Explanation
void operator-() { x=-x; y=-y; z=-z; } | //Operator function to overload minus
|
- obj; cout<<”Numbers after applying unary minus” | //Invokes operator function |
Output
Original numbers are
10 -20 30
Numbers after applying unary minus
-10 20 -30
Program
Write a C++ program to overload binary +, - .
#include<iostream> using namespace std ; class Example { int a,b; public: Example(int p, int q) { a=p; b=q; } void display() { cout<<a<<” ”<<b<<endl; } Example operator+(Example X); Example operator-(Example X); }; Example Example::operator+(Example X) { Example E; E.a= a+X.a; E.b= b+X.b; return E } Example Example:: operator-(Example X) { Example F; F.a= a-X.a; F.b= b-X.b; return F } int main() { Example obj1(10,20); Example obj2(5,5); Example obj3(0,0); cout<<”Addition is” obj3= obj1+ obj2; obj3.display(); cout<<”Subtraction is” obj3= obj1- obj2; obj3.display(); return 0 ; } |
// Step 1 overloads + // Step 1 overloads -
// Step 2 Defines operator function to overload +
//Defines operator function to overload -
// Step 3 //Invokes overloaded binary +
// Step4 //Invokes overloaded binary -
|
Explanation
Return type of an object is always a class so it is declared as follows
Example operator+(Example X); Example operator-(Example X); | //overloads + //overloads - |
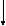
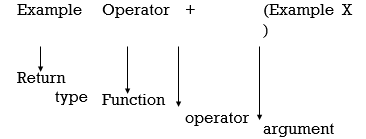
 Example Operator + (Example X )
Example Operator + (Example X )
Return type operator to be overloaded
Function
Argument list
Example Example:: operator+(Example X) { Example E; E.a= a+X.a; E.b= b+X.b; return E; } Example Example:: operator-(Example X) { Example F; F.a= a-X.a; F.b= b-X.b; return F;
} | //Defines operator function to overload +
//Defines operator function to overload -
|
step 3.
O3= O1+ O2;
| //Invokes overloaded binary + |
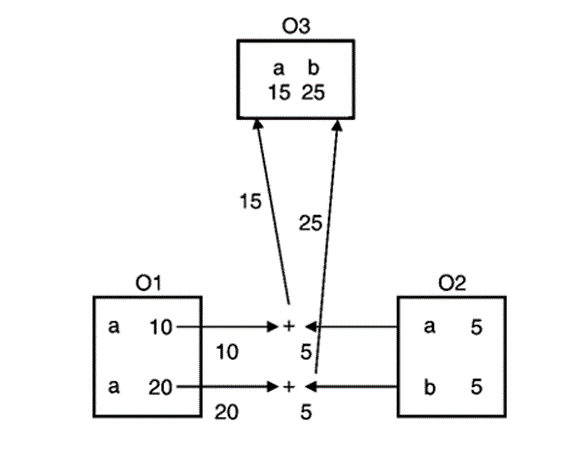
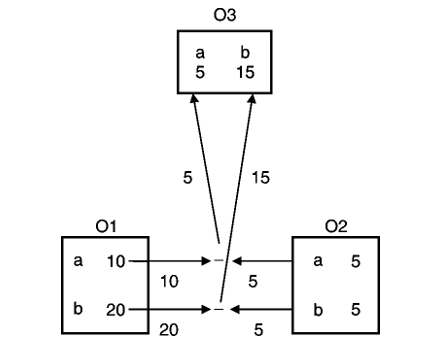
Operator function for subtraction is activated when two objects are subtracted using -. See step 4.
O3= O1- O2; | //Invokes overloaded binary - |
Thus the output will be :
Output
cout<<”Addition is”
a 15 b 25
cout<<”Subtraction is”
a 5 b 15
Program
Write C++ program to demonstrate use of binary (“+”) operator overloading to add two complex numbers using member function.
#include<iostream> using namespace std ; class Demo { int real,imag; public: Demo(int p, int q) { real=p; imag=q; } void display() { cout<<real<<” +j”<<imag<<endl; } Demo operator+(Demo X); }; Demo Demo::operator+(Demo X) { Demo D; D.real=real+X.real; D.imag=imag+D.imag; return D } int main() { Demo obj1(10,20); Demo obj2(5,5); Demo obj3(0,0); cout<<”Addition is” obj3= obj1+ obj2; obj3.display(); return 0 ; } |
//……1overloads +
//.2 Defines operator function to overload +
//Defines operator function to overload -
//…..3 //Invokes overloaded binary +
|
Data conversion in C++ includes conversions between basic types and user-defined types, and conversions between different user-defined types.
The assignments between types, whether they are basic types or user-defined types, are handled by the compiler with no effort on our part, provided that the same data type is used on both sides of the equal sign.
The different possible data conversion situtaions are:
1. Conversion between basic and user defined
a) Conversion from basic to user defined data type
b) Conversion from user-defined data type to basic data type
2. Conversion between user defined data types
a) Conversion in destination object
b) Conversion in source object
Lets look at each of them.
1. Conversion between basic and user defined
(a) Conversion from basic to user defined data type
Conversion from basic to user defined type is done by using the constructor function with one argument of basic type as follows.
Syntax:
class class_name {
private:
//….
public:
class_name ( data_type) {
// conversion code
}
};
Here is program that illustrates this conversion.
//example
//conversion from basic type to object
#include<iostream>
using namespace std;
class celsius
{
private:
float temper;
public:
celsius()
{
temper=0;
} celsius(float ftmp)
{
temper=(ftmp-32)* 5/9;
}
void showtemper()
{
cout<<"Temperature in Celsius: "<<temper;
}
};
int main()
{
celsius cel; //cel is user defined
float fer; //fer is basic type
cout<<"\nEnter temperature in Fahrenheit measurement: ";
cin>>fer;
cel=fer; //convert from basic to user-defined; //eqvt to cel = celsius(fer);
cel.showtemper();
return 0;
}
The output of the program is:
Enter temperature in Fahrenheit measurement: -40
Temperature in Celsius: -40
(b) Conversion from user-defined type to basic data type
Conversion from user-defined type of basic data type is done by overloading the cast operator of basic type as a member function.
Operator function is defined as an overloaded basic data type which takes no arguments.
Return type of operator is not specified because the cast operator function itself specifies the return type.
Syntax:
class class_name {
...
public:
operator data_type() {
//Conversion code
}
};
Here is example program to illustrate conversion from user-defined type of basic data type.
//conversion from user to basic type
#include<iostream>
using namespace std;
class celsius
{
private:
float temper;
public:
celsius()
{
temper=0;
}
operator float()
{
float fer;
fer=temper *9/5 + 32;
return (fer);
}
void gettemper()
{
cout<<"\n Enter Temperature in Celsius:";
cin>>temper;
}
};
int main()
{
celsius cel; //cel is user defined
float fer; //fer is basic type
cel.gettemper();
fer=cel; //convert from user-defined to basic;
//eqvt to fer= float(cel);
cout<<"\nTemperature in Fahrenheit measurement: "<<fer;
}
The output of the program is:
Enter Temperature in Celsius: -40
Temperature in Fahrenheit measurement: -40
1. Conversion between basic and user defined
(a) Conversion in Destination Object
This conversion is exactly like conversion of basic to user defined data type i.e. one argument constructor is used.
Conversion routine is defined as a one argument constructor in destination class and takes the argument of the source class type.
Eg.
classA objA;
classB objB;
objA=objB;
Here, objB is the source of the class classB and objA is the destination object of class classA.
For this expression to work, the conversion routine should exist in classA (destination class type) as a one argument constructor as
//source object class
class classB
{
//body of classB
}
//destination object class
class classA
{
private:
//….
public:
classA (classB objB) //object of source class
{
//code for conversion
//from classB
//to classA
}
};
(b) Conversion in source object
This conversion is exactly like conversion of user-defined type to basic type i.e. overloading the cast operator is used.
Eg.
classA objA;
classB objB;
objA=objB;
Here, objB is the source of the class classB and objA is the destination object of class classA. Conversion routine is specified as conversion (cast) operator overloading for the type of destination class.
Syntax:
//destination object class
class classA
{
//body of classA
}
//source object class
class classB
{
private:
//….
public:
operator classA () //cast operator destination types
{
//code for conversion from classB
//to classA
}
};
Here is an example program.
//example
//conversion from user defined to user defined
//conversion routine in source class
#include<iostream>
#include<cmath>
using namespace std;
class Cartesian
{
private:
float xco, yco;
public:
Cartesian()
{
xco=0;
yco=0;
}
Cartesian(float x, float y)
{
xco=x;
yco=y;
}
void display()
{
cout<<"("<<xco<<","<<yco<<")";
}
};
class Polar
{
private:
float radius, angle;
public:
Polar()
{
radius=0;
angle =0;
}
Polar(float rad, float ang)
{
radius =rad;
angle=ang;
}
operator Cartesian()
{
float x=static_cast<int>(radius * cos(angle));
float y=static_cast<int>(radius * sin(angle));
return Cartesian(x,y);
}
void display()
{
cout<<"("<<radius<<","<<angle<<")";
}
};
int main()
{
Polar pol(10.0, 0.78);
Cartesian cart;
cart=pol;
cout<<"\nGiven Polar: ";
pol.display();
cout<<"\nEquivalent cartesian: ";
cart.display();
return 0;
}
The output of the program is:
Give Polar : (10.0, 0.78)
Equivalent cartesian: (7,7)
int a= 100;
long b;
b=a;
int x;
float y= 2.15;
x=y;
Here y is copied to x. As float is copied to int, its value is truncated.
Explicit type conversions are performed between incompatible types in following three cases:
A. Basic type to class type
B. Class type to basic type
C. One class type to another class type
A. Basic type to class type
class Demo
{
int months;
int days;
public:
Demo(int x) // constructor
{
months=x/30;
days=x%30;
}
…
…
};
//Here months and days are data members of class Demo. Constructor is used to
convert int type to class type.
//Now consider following statements in main function
void main()
{
Demo D; // object is created
int y=75;
D= y; // int to class type
….
}
D=y
invokes constructor and performs conversion written in constructor. After conversion months object D will contain value 2 and days member will contain value 15.
D=y coverts basic type (int) to class type.
B. Class type to basic type
operator typename( )
{
…
… ( function statements )
…
}
This function converts a class type data to typename.
Program Write a C++ Program to convert class data type to basic data type.
class Demo
{
int x;
double y; // Step 1
public:
Demo() // constructor
{
x=10;
y=2.15
}
operator int() // Step 2
{
return (x);
}
operator double() // Step3
{
return (y);
}
};
void main()
{
Demo D;
int i;
float j;
i=D; // Step 4 operator int() is executed
j=D; //Step 5 operator double() is executed
cout<<”Value of i is ”<<i<<endl;
cout<<”Value of j is ”<<j;
}
Explanation
i=D
invokes “operator int()” as we are assigning object(class type) to int(i is integer)type. See step 4.
j=D
invokes “operator double()” as we are assigning object(class type) to double
(j is double) type. See step 5.
Value of i is 10
Value of j is 2.15
- It has no return type
- It has no arguments
- It is a class member
C. One class type to another class type
O1= O2;
Where O1 is an object of class Demo 1 and O2 is an object of class Demo 2. Here we are converting an object of class Demo 2 to an object of class Demo1, So Demo 1 is destination class and Demo 2 is source class.
 1. Single Argument Constructor
1. Single Argument Constructor
2. Conversion Function
1. Conversion using SingleArgument Constructor
2. Conversion usingConversion Function
What is a pitfall?
C++ code that
Example:
if (-0.5 <= x <= 0.5) return 0;
Pitfall:
if (-0.5 <= x <= 0.5) return 0;
This expression does not test the mathematical condition
-1.5 <= x <= 1.5
Instead, it first computes -0.5 <= x, which is 0 or 1, and then compares the result with 0.5.
Moral: Even though C++ now has a bool type, Booleans are still freely convertible to int.
Since bool->int is allowed as a conversion, the compiler cannot check the validity of expressions. In contrast, the Java compiler would flag this statement as an error.
Constructor pitfalls
Example:
int main()
{ string a("Hello");
string b();
string c = string("World");
// ...
return 0;
}
Pitfall:
string b();
This expression does not construct an object b of type string. Instead, it is the prototype for a function b with no arguments and return type string.
Moral: Remember to omit the ( ) when invoking the default constructor.
The C feature of declaring a function in a local scope is worthless since it lies about the true scope. Most programmers place all prototypes in header files. But even a worthless feature that you never use can haunt you.
Example:
template<typename T>
class Array
{
public:
Array(int size);
T& operator[](int);
Array<T>& operator=(const Array<T>&);
// ...
};
int main()
{ Array<double> a(10);
a[0] = 0; a[1] = 1; a[2] = 4;
a[3] = 9; a[4] = 16;
a[5] = 25; a = 36; a[7] = 49;
a[8] = 64; a[9] = 81;
// ...
return 0;
}
Pitfall:
a = 36;
Surprisingly, it compiles:
a = Array<double>(36);
a is replaced with a new array of 36 numbers.
Moral: Constructors with one argument serve double duty as type conversions.
Avoid constructors with a single integer argument! Use the explicit keyword if you can't avoid them.
Example:
template<typename T>
class Array
{
public:
explicit Array(int size);
// ...
private:
T* _data;
int _size;
};
template<typename T>
Array<T>::Array(int size)
: _size(size),
_data(new T(size))
{}
int main()
{ Array<double> a(10);
a[1] = 64; // program crashes
// ...
}
Pitfall:
template<typename T>
Array<T>::Array(int size)
: _size(size),
_data(new T(size)) // should have been new T[size]
{}
Why did it compile?
new T(size)
returns a T* pointer to a single element of type T, constructed from the integer size.
new T[size]
returns a T* pointer to an array of size objects of type T, constructed with the default constructor.
Moral: Array/pointer duality is dumb, but unfortunately pervasive in C and C++.
The Java compiler would catch this--Java, like most programming languages, supports genuine array types.
Example:
template<typename T>
class Array
{
public:
explicit Array(int size);
// ...
private:
T* _data;
int _capacity;
int _size;
};
template<typename T>
Array<T>::Array(int size)
: _size(size),
_capacity(_size + 10),
_data(new T[_capacity])
{}
int main()
{ Array<int> a(100);
. . .
// program starts acting flaky
}
Pitfall:
Array<T>::Array(int size)
: _size(size),
_capacity(size + 10),
_data(new T[_capacity])
{}
Initialization follows the member declaration order, not the initializer order!
Array<T>::Array(int size)
: _data(new T[_capacity])
_capacity(_size + 10),
_size(size),
Tip: Do not use data members in initializer expressions.
Array<T>::Array(int size)
: _data(new T[size + 10])
_capacity(size + 10),
_size(size),
Example:
class Point
{
public:
Point(double x = 0, double y = 0);
// ...
private:
double _x, _y;
};
int main()
{ double a, r, x, y;
// ...
Point p = (x + r * cos(a), y + r * sin(a));
// ...
return 0;
}
Pitfall:
Point p = (x + r * cos(a), y + r * sin(a));
This should be either
Point p(x + r * cos(a), y + r * sin(a));
or
Point p = Point(x + r * cos(a), y + r * sin(a));
The expression
(x + r * cos(a), y + r * sin(a))
has a legal meaning. The comma operator discards x + r * cos(a) and evaluates y + r * sin(a). The
Point(double x = 0, double y = 0)
constructor makes a Point(y + r * sin(a), 0).
Moral: Default arguments can lead to unintended calls. In our case, the construction Point(double) is not reasonable, but the construction Point() is. Only use defaults if all resulting call patterns are meaningful.
Example:
class Shape
{
public:
Shape();
private:
virtual void reset();
Color _color;
};
class Point : public Shape
{
public:
// ...
private:
double _x, _y;
};
void Shape::reset() { _color = BLACK; }
void Point::reset()
{ Shape::reset();
_x = 0; _y = 0;
}
Shape::Shape() { reset(); }
There is no Point constructor--we use the virtual function in the Shape constructor.
Pitfall:
Shape::Shape() { reset(); }
Point p;
When constructing Point, the Shape::reset(), not the Point::reset() virtual function is called. Why?
Explanation: Virtual functions do not work in constructors.
The Shape subobject is constructed before thePoint object. Inside the Shape constructor, the partially constructed object is still a Shape.
Example:
class Shape // an abstract class
{
public:
Shape();
private:
void init();
virtual void reset() = 0;
Color _color;
};
Shape::Shape() { init(); }
void Shape::init() { reset(); }
class Point : public Shape // a concrete derived class
{
public:
virtual void reset();
// ...
private:
double _x, _y;
};
void Point::reset() { _x = _y = 0; }
Pitfall:
int main()
{ Point p; // program crashes
return 0;
}
Explanation: You cannot create an instance of an abstract class (a class with a pure, = 0, virtual function).
Shape s; // compile-time error; Shape is abstract
That's a good thing: if you could, what would happen if you called
s.reset(); // reset not defined for shapes
But...I lied. You can create instances of abstract classes.
When constructing a concrete derived, for a fleeting moment, the base class exists. If you invoke a pure virtual function before the derived class constructor has executed, the program terminates.
Destructor pitfalls
Example:
class Employee
{
public:
Employee(string name);
virtual void print() const;
private:
string _name;
};
class Manager : public Employee
{
public:
Manager(string name, string dept);
virtual void print() const;
private:
string _dept;
};
int main()
{ Employee* staff[10];
staff[0] = new Employee("Harry Hacker");
staff[1] = new Manager("Joe Smith", "Sales");
// ...
for (int i = 0; i < 10; i++)
staff[i]->print();
for (int i = 0; i < 10; i++)
delete staff[i];
return 0;
}
Where is the memory leak?
Pitfall:
delete staff[i];
destroys all objects with ~Employee(). The _dept strings of the Manager objects are never destroyed.
Moral: A class from which you derive must have a virtual destructor.
Example:
class Employee
{
public:
Employee(string name);
virtual void print() const;
virtual ~Employee(); // <-----
private:
string _name;
};
class Employee
{
public:
Employee(string name);
private:
string _name;
};
class Manager
{
public:
Manager(string name, string sname);
~Manager();
private:
Employee* _secretary;
}
Manager::Manager(string name, string sname)
: Employee(name),
_secretary(new Employee(sname))
{}
Manager::~Manager() { delete _secretary; }
What is wrong with the Manager class?
Pitfall:
int main()
{ Manager m1 = Manager("Sally Smith",
"Joe Barnes");
Manager m2 = m1;
// ...
}
The destructors of both m1 and m2 will delete the same Employee object.
Moral: A class with a destructor needs a copy constructor
Manager::Manager(const Manager&)
and an assignment operator
Manager& Manager::operator=(const Manager&).
The Big 3: It's not just a good idea--it's the law (Marshall Cline)
Inheritance pitfalls
Example:
class Employee
{
public:
Employee(string name, string dept);
virtual void print() const;
string dept() const;
private:
string _name;
string _dept;
};
class Manager : public Employee
{
public:
Manager(string name, string dept);
virtual void print() const;
private:
// ...
};
void Employee::print() const
{ cout << _name << endl;
}
void Manager::print() const
{ print(); // print base class
cout << dept() << endl;
}
Pitfall:
void Manager::print() const
{ print(); // print base class
cout << dept() << endl;
}
Despite what the comment says, print() selects the print operation of the Manager class. In contrast, dept() selects the operation of the Employee class sinceManager does not redefine it.
Moral: When calling a base class operation in a derived class operation of the same name, use scope resolution:
void Manager::print() const
{ Employee::print(); // print base class
cout << dept() << endl;
}
Example:
void Manager::print() const
{ Employee:print(); // print base class
cout << dept() << endl;
}
Pitfall:
Employee:print();
It should be
Employee::print();
But why does it compile? Employee: is a goto label!
Moral:Even language features that you never use can bite you!
Example:
class Employee
{
public:
void raise_salary(double by_percent);
// ...
};
class Manager : public Employee
{
public:
// ...
};
void make_them_happy(Employee* e, int ne)
{ for (int i = 0; i < ne; i++)
e[i].raise_salary(0.10);
}
int main()
{ Employee e[20];
Manager m[5];
m[0] = Manager("Joe Bush", "Sales");
// ...
make_them_happy(e, 20);
make_them_happy(m + 1, 4); // let's skip Joe
return 0;
}
Pitfall:
void make_them_happy(Employee* e, int ne);
Manager m[5];
make_them_happy(m + 1, 4);
Why does it compile?
The type of m + 1 is Manager*. Because of inheritance, a Manager* is convertible to an Employee* base class pointer. make_them_happy receives an Employee*. Everyone is happy.
What is the problem?
The array computation e[i] computes an offset of i*sizeof(Employee).
Moral: Pointers are overused in C++. Here we see two interpretations of an Employee* e.
These two interpretations are incompatible. Mixing them leads to runtime errors. However, the intention of the programmer is hidden to the compiler since both ideas are expressed by the same construct--a pointer.
Example:
class Employee
{
public:
Employee(char name[]);
Employee(const Employee& b);
~Employee();
Employee& operator=(const Employee& b);
. . .
private:
char* _name;
string _dept;
};
class Manager : public Employee
{
public:
Manager(char name[], char dept[]);
Manager(const Manager& b);
~Manager();
Manager& operator=(const Manager& b);
. . .
private:
char* _dept;
};
Manager::Manager(const Manager& b)
: _dept(new char[strlen(b._dept) + 1])
{ strcpy(b._dept, _dept);
}
Manager::~Manager()
{ delete[] _dept;
}
Manager& Manager::operator=(const Manager& b)
{ if (this == &b) return *this;
delete[] _dept;
_dept = new char[strlen(b._dept) + 1];
strcpy(b._dept, _dept);
return *this;
}
Pitfall:
Manager& Manager::operator=(const Manager& b)
{ if (this == &b) return *this;
delete[] _dept;
_dept = new char[strlen(b._dept) + 1];
strcpy(b._dept, _dept);
return *this;
}
Constructors and destructors automatically call the base constructors and destructors. But operator= does not automatically invoke the operator= of the base class.
Moral: When redefining operator= in a derived class, explicitly call operator= of the base class:
Manager& Manager::operator=(const Manager& b)
{ if (this == &b) return *this;
Employee::operator=(b);
delete[] _dept;
_dept = new char[strlen(b._dept) + 1];
strcpy(b._dept, _dept);
return *this;
}
Stream pitfalls
Example:
list<int> a;
while (!cin.eof())
{ int x;
cin >> x;
if (!cin.eof()) a.push_back(x);
}
Pitfall:
while (!cin.eof())
{ // ...
}
This may be an infinite loop. If the stream state turns to fail, the end of file will never be reached.
The stream state will be set to fail if a non-digit is encountered when trying to read an integer.
Moral: eof() is only useful in combination with fail(), to find out whether EOF was the cause for failure
Example:
while (cin.good())
{ int x;
cin >> x;
if (cin.good()) a.push_back(x);
}
Pitfall:
cin >> x; // <--- may succeed and then encounter EOF
if (cin.good()) a.push_back(x);
This code may miss the last element in the input file, if it is directly followed by EOF.
Remedy: Use fail():
while (!cin.fail())
{ int x;
cin >> x;
if (!cin.fail()) a.push_back(x);
}
The type conversion basic_ios ----> void* is identical to !fail():
while (cin)
{ int x;
cin >> x;
if (cin) a.push_back(x);
}
Moral: There are four stream test functions: good(), bad(), eof(), and fail(). (Note that bad() does not mean !good().) Only one of them is useful: fail().
Overloading pitfalls
Example:
class Complex
{
public:
Complex(double = 0, double = 0);
Complex operator+(Complex b) const;
Complex operator-(Complex b) const;
Complex operator*(Complex b) const;
Complex operator/(Complex b) const;
Complex operator^(Complex b) const;
// ...
private:
double _re, _im;
};
int main()
{ Complex i(0, 1);
cout << i^2 + 1; // i*i is -1
return 0;
}
Why won't it print (0,0)?
Pitfall:
cout << i^2 + 1;
Using the C/C++ operator precedence rules, we can add parentheses:
cout << (i ^ (2 + 1));
The ^ operator is weaker than + (but stronger than <<).
Moral: You cannot change the operator precedence when overloading operators. Do not overload an operator if its precedence is not intuitive for the problem domain.
The precedence of ^ is fine for XOR but not for raising to a power.
Example: The stream classes support a type conversion basic_ios ----> void* for testing if a stream is happy:
while (cin)
{ int x;
cin >> x;
// ...
}
Why convert to void*? A conversion to bool would seem to make more sense.
template<typename C, typename T = char_traits<C> >
class basic_ios
{
public:
// ...
operator bool() const
{ if (fail()) return false;
else return true;
}
private:
// ...
};
Pitfall:
while (cin)
{ int x;
cin << x;
// ...
}
Note the typo--it should be cin >> x.
But cin << x has an unintended meaning:cin.operator bool(), converted to an int and shifted by x bits.
Moral: Use conversion to void*, not conversion to int or bool, to implement objects yielding truth values. Unlike int or bool, void* have no legal operations other than == comparison.
Example: An array class with a [] operator that grows the array on demand
class Array
{
public:
Array();
~Array();
Array(const Array&);
Array& operator=(const Array&);
int& operator[](int);
private:
int _n; // current number of elements
int* _a; // points to heap array
};
int& Array::operator[](int i)
{ if (i > _n)
{ int* p = new int[i];
for (int k = 0; k < _n; k++)
p[k] = _a[k];
for (; k < i; k++) p[k] = 0;
delete[] _a;
_a = p;
_n = i;
}
return _a[i];
}
int main()
{ Array a;
for (int s = 1; s <= 100; s++)
a[s] = s * s;
return 0;
}
Pitfall:
void swap(int& x, int& y)
{ int temp = x;
x = y;
y = temp;
}
int main()
{ Array a;
a[3] = 9;
swap(a[3], a[4]);
return 0;
}
The swap function gets references to a[3], then to a[4], but the second computation moves the array and invalidates the first reference! a[4] is swapped with a wild reference.
Moral: You cannot simultaneously relocate a memory block and export a reference to it.
Either make [] not grow the array, or use a data structure in which elements never move (i.e. a sequence of chunks, such as in std::deque).
Exception pitfalls
Example:
void read_stuff(const char filename[])
{ FILE* fp = fopen(filename, "r");
do_reading(fp);
fclose(fp);
}
Why is that an "exception pitfall"? There aren't any exceptions in the code!
Pitfall:
FILE* fp = fopen(filename, "r");
do_reading(fp);
fclose(fp); // <-- may never get here
If do_reading throws an exception, or calls a function that throws an exception, it never comes back! fp is never closed.
Moral: Exception handling drastically alters control flow. You cannot take it for granted that a function ever returns.
Remedy 1: (popular but dumb)
void read_stuff(const char filename[])
{ FILE* fp = fopen(filename, "r");
try
do_reading(fp);
catch(...)
{ fclose(fp);
throw;
}
fclose(fp);
}
Remedy 2: (smart)
void read_stuff(const char filename[])
{ fstream fp(filename, ios_base::in);
do_reading(fp);
}
Even if do_reading throws an exception, fp is closed by the ifstream destructor.
Moral: In code with exception handling (i.e. all C++ code starting in 1994), relinquish resources only in destructors!
Example:
double find_salary_increase(auto_ptr<Employee>);
void do_stuff(const char name[])
{ auto_ptr<Employee> pe = new Employee(name);
// can't use
// Employee* pe = new Employee(name)
// that's not not exception safe
double rate = find_salary_increase(pe);
pe->raise_salary(rate);
}
Pitfall:
find_salary_increase(pe);
invokes the copy constructor of auto_ptr<Employee> which transfers ownership to the copy.
Only one auto_ptr can own a heap object. The owning auto_ptr calls the destructor when it goes out of scope.
Remedy: Don't copy an auto_ptr into a function.
double find_salary_increase(Employee*);
void do_stuff(const char name[])
{ Employee* pe = new Employee(name);
auto_ptr<Employee> ape = pe; // use only for destruction
double rate = find_salary_increase(pe);
pe->raise_salary(rate);
}
Container pitfalls
Example: A set of pointers
set<Employee*> staff;
vector<string> names;
for (int i = 0; i < names.size(); i++)
staff.insert(new Employee(names[i]);
Pitfall: Ordered containers (set, map, multiset, multimap) use < for comparison. It is assumed that < is a total ordering.
In a set of pointers
set<Employee*> staff;
the pointers are compared with <.
Given two arbitrary Employee* pointers p and q, is p < q defined? Only if they point to the same array.
In a segmented memory model, only offsets are compared. Ex. p == 0x740A0004 and q == 0x7C1B0004 compare identical.
Remedy: (risky) Only write code for a flat memory space where pointer word size == integer word size and comparison happens to be a total ordering.
Remedy: (tedious) Supply an ordering:
bool employee_ptr_less(const Employee* a, const Employee* b)
{ return a->salary() < b->salary();
}
set<Employee*, bool (*)(const Employee*, const Employee*)>
staff(employee_ptr_less);
Example: Runaway iterators
list<int> a, b;
// ...
list<int>::iterator p
= find(a.begin(), b.end(), 100);
if (p != a.end()) b.push_back(*p);
Pitfall:
find(a.begin(), b.end(), 100); // oops, should have been a.end()
To see why this code crashes dramatically, look at the implementation of find:
template<typename I, typename T>
I find(I from, I to, const T& target)
{ while (from != to && *from != target)
++from;
return from;
}
When from reaches a.end(), *from and ++from are undefined.
Moral: Iterators don't know their state. There is no reason why a list<int> iterator couldn't know its state, but STL was built with the objective to make iterators no more powerful than pointers into a C array. Benefit: You can call the standard algorithms with C arrays:
int a[30];
int* p = find(a, a + 30, 100);
Drawback: Programming with iterators is pointer-oriented, not object-oriented.
Example: Muddled iterators
list<int> a;
list<int> b;
list<int>::iterator p = a.begin();
a.insert(50);
b.insert(100);
b.erase(p);
cout << a.length() << endl; // length is 1
cout << b.length() << endl; // length is 0
Pitfall: In
b.erase(p);
the iterator p pointed inside a! The behavior is undefined, but the standard STL implementation does the following:
Moral: Iterators don't know their owner.
The mutable storage class specifier in C++ (or use of mutable keyword in C++)
auto, register, static and extern are the storage class specifiers in C. typedef is also considered as a storage class specifier in C. C++ also supports all these storage class specifiers. In addition to this C++, adds one important storage class specifier whose name is mutable.
What is the need of mutable?
Sometimes there is requirement to modify one or more data members of class / struct through const function even though you don’t want the function to update other members of class / struct. This task can be easily performed by using mutable keyword. Consider this example where use of mutable can be useful. Suppose you go to hotel and you give the order to waiter to bring some food dish. After giving order, you suddenly decide to change the order of food. Assume that hotel provides facility to change the ordered food and again take the order of new food within 10 minutes after giving the 1st order. After 10 minutes order can’t be cancelled and old order can’t be replaced by new order. See the following code for details.
#include <iostream> #include <string.h> using std::cout; using std::endl;
class Customer { char name[25]; mutable char placedorder[50]; int tableno; mutable int bill; public: Customer(char* s, char* m, int a, int p) { strcpy(name, s); strcpy(placedorder, m); tableno = a; bill = p; } void changePlacedOrder(char* p) const { strcpy(placedorder, p); } void changeBill(int s) const { bill = s; } void display() const { cout << "Customer name is: " << name << endl; cout << "Food ordered by customer is: " << placedorder << endl; cout << "table no is: " << tableno << endl; cout << "Total payable amount: " << bill << endl; } };
int main() { const Customer c1("Pravasi Meet", "Ice Cream", 3, 100); c1.display(); c1.changePlacedOrder("GulabJammuns"); c1.changeBill(150); c1.display(); return 0; } |
Output:
Customer name is: Pravasi Meet
Food ordered by customer is: Ice Cream
table no is: 3
Total payable amount: 100
Customer name is: Pravasi Meet
Food ordered by customer is: GulabJammuns
table no is: 3
Total payable amount: 150
Closely observe the output of above program. The values of placedorder and bill data members are changed from const function because they are declared as mutable.
The keyword mutable is mainly used to allow a particular data member of const object to be modified. When we declare a function as const, the this pointer passed to function becomes const. Adding mutable to a variable allows a const pointer to change members.
mutable is particularly useful if most of the members should be constant but a few need to be updateable. Data members declared as mutable can be modified even though they are the part of object declared as const. You cannot use the mutable specifier with names declared as static or const, or reference.
As an exercise predict the output of following two programs.
// PROGRAM 1 #include <iostream> using std::cout;
class Test { public: int x; mutable int y; Test() { x = 4; y = 10; } }; int main() { const Test t1; t1.y = 20; cout << t1.y; return 0; } |
// PROGRAM 2 #include <iostream> using std::cout;
class Test { public: int x; mutable int y; Test() { x = 4; y = 10; } }; int main() { const Test t1; t1.x = 8; cout << t1.x; return 0; }
Use of explicit keyword in C++ Last Updated: 28-09-2018 Predict the output of following C++ program.
Output: The program compiles fine and produces following output. Same As discussed in this GFact, in C++, if a class has a constructor which can be called with a single argument, then this constructor becomes conversion constructor because such a constructor allows conversion of the single argument to the class being constructed.
Output: Compiler Error no match for 'operator==' in 'com1 == 3.0e+0' We can still typecast the double values to Complex, but now we have to explicitly typecast it. For example, the following program works fine.
Output: The program compiles fine and produces following output. Same
|
F1→ void accept(int x);
F2→ void accept(float y);
F3→ void accept(int x, int y);
Here accept function is overloaded.
int add(int x, int y);
float add(int x, int y);
Here add functions have different return types but they have same argument list. So they are not overloaded functions.
Thus return type does not play any role in function overloading.
Table : Function prototypes and required function calls
Sr. No. | Function Protoypes | Function calls |
1. | void accept(int x); | accept(10); |
2. | void accept(float y); | accept(1.5); |
3. | void accept(int x, int y); | accept(10,20); |
Program
Write a C++ program to calculate the area of circle, rectangle and triangle using function overloading.
Solution :
#include<iostream>
using namespace std ;
#include<conio.h>
#define pi 3.14
class Sample //Defines class Sample
{
public:
void area(int x) // 1.Calculates area of circle
{
int y= pi*x*x;
cout<<“Area of circle is ”<<y;
}
void area(int a, int b) // 2.Calculates area of rectangle
{
int c= a*b;
cout<<“Area of rectangle is”<<c;
}
void area(float p,float q) // 3.Calculates area of triangle
{
int s= 0.5*p*q;
cout<<“area of triangle is”<<s;
}
};
int main()
{
 Sample obj ;
Sample obj ;
obj.area(10); // Step 4 Function call for area for circle
obj.area(10,20); // Function call for area for rectangle
obj.area(1.5,2.5); // Function call for area for triangle
return0 ;
}
Explanation
This program calculates area for circle, rectangle and triangle. For this we are overloading “area” function.
Step 1 : Here x denotes radius of circle. This version of “area” calculates area of circle and hence radius is passed as parameter.
void area(int x) { int y= pi*x*x; cout<<“Area of circle is”<<y; } |
//Calculates area of circle
|
Step 2 : Here a and b denote length and breadth of rectangle. This version of “area” calculates area of rectangle and hence length and breadth are passed as parameters.
void area(int a,int b) { int c= a*b; cout<<“Area of rectangle is”<<c; } |
//Calculates area of Rectangle |
Step 3 : Here p and q denote base and height of triangle. This version of “area” calculates area of triangle and hence base and height are passed as parameters.
void area(float p,float q) { int s= 0.5*p*q; cout<<“area of triangle is”<<s; } |
//Calculates area of triangle |
Step 4 : It denotes function calls for different versions of area depending upon type of geometrical figure.
int main() { Sample obj; obj.area(10); obj.area(10,20); obj.area(1.5,2.5); return0; } |
//Function call for area for circle //Function call for area for rectangle //Function call for area for triangle |
One of the key features of class inheritance is that a pointer to a derived class is type-compatible with a pointer to its base class. Polymorphism is the art of taking advantage of this simple but powerful and versatile feature.
The example about the rectangle and triangle classes can be rewritten using pointers taking this feature into account:
1 | // pointers to base class #include <iostream> using namespace std;
class Polygon { protected: int width, height; public: void set_values (int a, int b) { width=a; height=b; } };
class Rectangle: public Polygon { public: int area() { return width*height; } };
class Triangle: public Polygon { public: int area() { return width*height/2; } };
int main () { Rectangle rect; Triangle trgl; Polygon * ppoly1 = ▭ Polygon * ppoly2 = &trgl; ppoly1->set_values (4,5); ppoly2->set_values (4,5); cout << rect.area() << '\n'; cout << trgl.area() << '\n'; return 0; } |
|
|
Function main declares two pointers to Polygon (named ppoly1 and ppoly2). These are assigned the addresses of rect and trgl, respectively, which are objects of type Rectangle and Triangle. Such assignments are valid, since both Rectangle and Triangle are classes derived from Polygon.
Dereferencing ppoly1 and ppoly2 (with *ppoly1 and *ppoly2) is valid and allows us to access the members of their pointed objects. For example, the following two statements would be equivalent in the previous example:
1 | ppoly1->set_values (4,5); rect.set_values (4,5); |
|
But because the type of ppoly1 and ppoly2 is pointer to Polygon (and not pointer to Rectangle nor pointer to Triangle), only the members inherited from Polygon can be accessed, and not those of the derived classes Rectangle and Triangle. That is why the program above accesses the area members of both objects using rect and trgl directly, instead of the pointers; the pointers to the base class cannot access the area members.
Member area could have been accessed with the pointers to Polygon if area were a member of Polygon instead of a member of its derived classes, but the problem is that Rectangle and Triangle implement different versions of area, therefore there is not a single common version that could be implemented in the base class.
Virtual members
A virtual member is a member function that can be redefined in a derived class, while preserving its calling properties through references. The syntax for a function to become virtual is to precede its declaration with the virtual keyword:
1 | // virtual members #include <iostream> using namespace std;
class Polygon { protected: int width, height; public: void set_values (int a, int b) { width=a; height=b; } virtual int area () { return 0; } };
class Rectangle: public Polygon { public: int area () { return width * height; } };
class Triangle: public Polygon { public: int area () { return (width * height / 2); } };
int main () { Rectangle rect; Triangle trgl; Polygon poly; Polygon * ppoly1 = ▭ Polygon * ppoly2 = &trgl; Polygon * ppoly3 = &poly; ppoly1->set_values (4,5); ppoly2->set_values (4,5); ppoly3->set_values (4,5); cout << ppoly1->area() << '\n'; cout << ppoly2->area() << '\n'; cout << ppoly3->area() << '\n'; return 0; } |
|
|
In this example, all three classes (Polygon, Rectangle and Triangle) have the same members: width, height, and functions set_values and area.
The member function area has been declared as virtual in the base class because it is later redefined in each of the derived classes. Non-virtual members can also be redefined in derived classes, but non-virtual members of derived classes cannot be accessed through a reference of the base class: i.e., if virtual is removed from the declaration of area in the example above, all three calls to area would return zero, because in all cases, the version of the base class would have been called instead.
Therefore, essentially, what the virtual keyword does is to allow a member of a derived class with the same name as one in the base class to be appropriately called from a pointer, and more precisely when the type of the pointer is a pointer to the base class that is pointing to an object of the derived class, as in the above example.
A class that declares or inherits a virtual function is called a polymorphic class.
Note that despite of the virtuality of one of its members, Polygon was a regular class, of which even an object was instantiated (poly), with its own definition of member area that always returns 0.
Abstract base classes
Abstract base classes are something very similar to the Polygon class in the previous example. They are classes that can only be used as base classes, and thus are allowed to have virtual member functions without definition (known as pure virtual functions). The syntax is to replace their definition by =0 (an equal sign and a zero):
An abstract base Polygon class could look like this:
1 | // abstract class CPolygon class Polygon { protected: int width, height; public: void set_values (int a, int b) { width=a; height=b; } virtual int area () =0; }; |
|
Notice that area has no definition; this has been replaced by =0, which makes it a pure virtual function. Classes that contain at least one pure virtual function are known as abstract base classes.
Abstract base classes cannot be used to instantiate objects. Therefore, this last abstract base class version of Polygon could not be used to declare objects like:
| Polygon mypolygon; // not working if Polygon is abstract base class |
|
But an abstract base class is not totally useless. It can be used to create pointers to it, and take advantage of all its polymorphic abilities. For example, the following pointer declarations would be valid:
1 | Polygon * ppoly1; Polygon * ppoly2; |
|
And can actually be dereferenced when pointing to objects of derived (non-abstract) classes. Here is the entire example:
1 | // abstract base class #include <iostream> using namespace std;
class Polygon { protected: int width, height; public: void set_values (int a, int b) { width=a; height=b; } virtual int area (void) =0; };
class Rectangle: public Polygon { public: int area (void) { return (width * height); } };
class Triangle: public Polygon { public: int area (void) { return (width * height / 2); } };
int main () { Rectangle rect; Triangle trgl; Polygon * ppoly1 = ▭ Polygon * ppoly2 = &trgl; ppoly1->set_values (4,5); ppoly2->set_values (4,5); cout << ppoly1->area() << '\n'; cout << ppoly2->area() << '\n'; return 0; } |
|
|
In this example, objects of different but related types are referred to using a unique type of pointer (Polygon*) and the proper member function is called every time, just because they are virtual. This can be really useful in some circumstances. For example, it is even possible for a member of the abstract base class Polygon to use the special pointer this to access the proper virtual members, even though Polygon itself has no implementation for this function:
1 | // pure virtual members can be called // from the abstract base class #include <iostream> using namespace std;
class Polygon { protected: int width, height; public: void set_values (int a, int b) { width=a; height=b; } virtual int area() =0; void printarea() { cout << this->area() << '\n'; } };
class Rectangle: public Polygon { public: int area (void) { return (width * height); } };
class Triangle: public Polygon { public: int area (void) { return (width * height / 2); } };
int main () { Rectangle rect; Triangle trgl; Polygon * ppoly1 = ▭ Polygon * ppoly2 = &trgl; ppoly1->set_values (4,5); ppoly2->set_values (4,5); ppoly1->printarea(); ppoly2->printarea(); return 0; } |
|
|
Virtual members and abstract classes grant C++ polymorphic characteristics, most useful for object-oriented projects. Of course, the examples above are very simple use cases, but these features can be applied to arrays of objects or dynamically allocated objects.
Here is an example that combines some of the features in the latest chapters, such as dynamic memory, constructor initializers and polymorphism:
1 | // dynamic allocation and polymorphism #include <iostream> using namespace std;
class Polygon { protected: int width, height; public: Polygon (int a, int b) : width(a), height(b) {} virtual int area (void) =0; void printarea() { cout << this->area() << '\n'; } };
class Rectangle: public Polygon { public: Rectangle(int a,int b) : Polygon(a,b) {} int area() { return width*height; } };
class Triangle: public Polygon { public: Triangle(int a,int b) : Polygon(a,b) {} int area() { return width*height/2; } };
int main () { Polygon * ppoly1 = new Rectangle (4,5); Polygon * ppoly2 = new Triangle (4,5); ppoly1->printarea(); ppoly2->printarea(); delete ppoly1; delete ppoly2; return 0; } |
|
|
Notice that the ppoly pointers:
1 | Polygon * ppoly1 = new Rectangle (4,5); Polygon * ppoly2 = new Triangle (4,5); |
|
are declared being of type "pointer to Polygon", but the objects allocated have been declared having the derived class type directly (Rectangle and Triangle).
Late binding or Dynamic linkage
In late binding function call is resolved during runtime. Therefore compiler determines the type of object at runtime, and then binds the function call.
Rules of Virtual Function
Output:
Value of x is : 5
In the above example, * a is the base class pointer. The pointer can only access the base class members but not the members of the derived class. Although C++ permits the base pointer to point to any object derived from the base class, it cannot directly access the members of the derived class. Therefore, there is a need for virtual function which allows the base pointer to access the members of the derived class.
C++ virtual function Example
Let's see the simple example of C++ virtual function used to invoked the derived class in a program.
Output:
Derived Class is invoked
Pure Virtual Function
Pure virtual function can be defined as:
Let's see a simple example:
Output:
Derived class is derived from the base class.
In the above example, the base class contains the pure virtual function. Therefore, the base class is an abstract base class. We cannot create the object of the base class.
So far, all of the virtual functions we have written have a body (a definition). However, C++ allows you to create a special kind of virtual function called a pure virtual function (or abstract function) that has no body at all! A pure virtual function simply acts as a placeholder that is meant to be redefined by derived classes.
To create a pure virtual function, rather than define a body for the function, we simply assign the function the value 0.
1 2 3 4 5 6 7 8 9 10 11 | class Base { public: const char* sayHi() const { return "Hi"; } // a normal non-virtual function
virtual const char* getName() const { return "Base"; } // a normal virtual function
virtual int getValue() const = 0; // a pure virtual function
int doSomething() = 0; // Compile error: can not set non-virtual functions to 0 }; |
When we add a pure virtual function to our class, we are effectively saying, “it is up to the derived classes to implement this function”.
Using a pure virtual function has two main consequences: First, any class with one or more pure virtual functions becomes an abstract base class, which means that it can not be instantiated! Consider what would happen if we could create an instance of Base:
1 2 3 4 5 6 7 | int main() { Base base; // We can't instantiate an abstract base class, but for the sake of example, pretend this was allowed base.getValue(); // what would this do?
return 0; } |
Because there’s no definition for getValue(), what would base.getValue() resolve to?
Second, any derived class must define a body for this function, or that derived class will be considered an abstract base class as well.
A pure virtual function example
Let’s take a look at an example of a pure virtual function in action. In a previous lesson, we wrote a simple Animal base class and derived a Cat and a Dog class from it. Here’s the code as we left it:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 | #include <string> #include <utility>
class Animal { protected: std::string m_name;
// We're making this constructor protected because // we don't want people creating Animal objects directly, // but we still want derived classes to be able to use it. Animal(const std::string& name) : m_name{ name } { }
public: std::string getName() const { return m_name; } virtual const char* speak() const { return "???"; }
virtual ~Animal() = default; };
class Cat: public Animal { public: Cat(const std::string& name) : Animal{ name } { }
const char* speak() const override { return "Meow"; } };
class Dog: public Animal { public: Dog(const std::string& name) : Animal{ name } { }
const char* speak() const override { return "Woof"; } }; |
We’ve prevented people from allocating objects of type Animal by making the constructor protected. However, there are two problems with this:
1) The constructor is still accessible from within derived classes, making it possible to instantiate an Animal object.
2) It is still possible to create derived classes that do not redefine function speak().
For example:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | #include <iostream> #include <string>
class Cow : public Animal { public: Cow(const std::string& name) : Animal{ name } { }
// We forgot to redefine speak };
int main() { Cow cow{"Betsy"}; std::cout << cow.getName() << " says " << cow.speak() << '\n';
return 0; } |
This will print:
Betsy says ???
What happened? We forgot to redefine function speak(), so cow.Speak() resolved to Animal.speak(), which isn’t what we wanted.
A better solution to this problem is to use a pure virtual function:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | #include <string>
class Animal // This Animal is an abstract base class { protected: std::string m_name;
public: Animal(const std::string& name) : m_name{ name } { }
const std::string& getName() const { return m_name; } virtual const char* speak() = 0; // note that speak is now a pure virtual function
virtual ~Animal() = default; }; |
There are a couple of things to note here. First, speak() is now a pure virtual function. This means Animal is now an abstract base class, and can not be instantiated. Consequently, we do not need to make the constructor protected any longer (though it doesn’t hurt). Second, because our Cow class was derived from Animal, but we did not define Cow::speak(), Cow is also an abstract base class. Now when we try to compile this code:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | #include <iostream>
class Cow: public Animal { public: Cow(const std::string& name) : Animal{ name } { }
// We forgot to redefine speak };
int main() { Cow cow{ "Betsy" }; std::cout << cow.getName() << " says " << cow.speak() << '\n';
return 0; } |
The compiler will give us a warning because Cow is an abstract base class and we can not create instances of abstract base classes:
C:\Test.cpp(141) : error C2259: 'Cow' : cannot instantiate abstract class due to following members:
C:Test.cpp(128) : see declaration of 'Cow'
C:\Test.cpp(141) : warning C4259: 'const char *__thiscall Animal::speak(void)' : pure virtual function was not defined
This tells us that we will only be able to instantiate Cow if Cow provides a body for speak().
Let’s go ahead and do that:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | #include <iostream> #include <string>
class Cow: public Animal { public: Cow(const std::string& name) : Animal(name) { }
const char* speak() const override { return "Moo"; } };
int main() { Cow cow{ "Betsy" }; std::cout << cow.getName() << " says " << cow.speak() << '\n';
return 0; } |
Now this program will compile and print:
Betsy says Moo
A pure virtual function is useful when we have a function that we want to put in the base class, but only the derived classes know what it should return. A pure virtual function makes it so the base class can not be instantiated, and the derived classes are forced to define these functions before they can be instantiated. This helps ensure the derived classes do not forget to redefine functions that the base class was expecting them to.
Pure virtual functions with bodies
It turns out that we can define pure virtual functions that have bodies:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | #include <string>
class Animal // This Animal is an abstract base class { protected: std::string m_name;
public: Animal(const std::string& name) : m_name{ name } { }
std::string getName() { return m_name; } virtual const char* speak() = 0; // The = 0 means this function is pure virtual
virtual ~Animal() = default; };
const char* Animal::speak() // even though it has a body { return "buzz"; } |
In this case, speak() is still considered a pure virtual function (even though it has been given a body, because of the “= 0”) and Animal is still considered an abstract base class (and thus can’t be instantiated). Any class that inherits from Animal needs to provide its own definition for speak() or it will also be considered an abstract base class.
When providing a body for a pure virtual function, the body must be provided separately (not inline).
For Visual Studio users
Visual Studio mistakenly allows pure virtual function declarations to be definitions, for example
1 2 3 4 5 | // wrong! virtual const char* speak() = 0 { return "buzz"; } |
This is wrong and cannot be disabled.
This paradigm can be useful when you want your base class to provide a default implementation for a function, but still force any derived classes to provide their own implementation. However, if the derived class is happy with the default implementation provided by the base class, it can simply call the base class implementation directly. For example:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | #include <string> #include <iostream>
class Animal // This Animal is an abstract base class { protected: std::string m_name;
public: Animal(const std::string& name) : m_name(name) { }
const std::string& getName() const { return m_name; } virtual const char* speak() const = 0; // note that speak is a pure virtual function
virtual ~Animal() = default; };
const char* Animal::speak() { return "buzz"; // some default implementation }
class Dragonfly: public Animal {
public: Dragonfly(const std::string& name) : Animal{name} { }
const char* speak() const override// this class is no longer abstract because we defined this function { return Animal::speak(); // use Animal's default implementation } };
int main() { Dragonfly dfly{"Sally"}; std::cout << dfly.getName() << " says " << dfly.speak() << '\n';
return 0; } |
The above code prints:
Sally says buzz
This capability isn’t used very commonly.
Virtual Table
To implement virtual functions, C++ uses a special form of late binding known as the virtual table. The virtual table is a lookup table of functions used to resolve function calls in a dynamic/late binding manner. The virtual table sometimes goes by other names, such as “vtable”, “virtual function table”, “virtual method table”, or “dispatch table”.
Because knowing how the virtual table works is not necessary to use virtual functions, this section can be considered optional reading.
The virtual table is actually quite simple, though it’s a little complex to describe in words. First, every class that uses virtual functions (or is derived from a class that uses virtual functions) is given its own virtual table. This table is simply a static array that the compiler sets up at compile time. A virtual table contains one entry for each virtual function that can be called by objects of the class. Each entry in this table is simply a function pointer that points to the most-derived function accessible by that class.
Second, the compiler also adds a hidden pointer to the base class, which we will call *__vptr. *__vptr is set (automatically) when a class instance is created so that it points to the virtual table for that class. Unlike the *this pointer, which is actually a function parameter used by the compiler to resolve self-references, *__vptr is a real pointer. Consequently, it makes each class object allocated bigger by the size of one pointer. It also means that *__vptr is inherited by derived classes, which is important.
By now, you’re probably confused as to how these things all fit together, so let’s take a look at a simple example:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | class Base { public: virtual void function1() {}; virtual void function2() {}; };
class D1: public Base { public: virtual void function1() {}; };
class D2: public Base { public: virtual void function2() {}; }; |
Because there are 3 classes here, the compiler will set up 3 virtual tables: one for Base, one for D1, and one for D2.
The compiler also adds a hidden pointer to the most base class that uses virtual functions. Although the compiler does this automatically, we’ll put it in the next example just to show where it’s added:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | class Base { public: FunctionPointer *__vptr; virtual void function1() {}; virtual void function2() {}; };
class D1: public Base { public: virtual void function1() {}; };
class D2: public Base { public: virtual void function2() {}; }; |
When a class object is created, *__vptr is set to point to the virtual table for that class. For example, when an object of type Base is created, *__vptr is set to point to the virtual table for Base. When objects of type D1 or D2 are constructed, *__vptr is set to point to the virtual table for D1 or D2 respectively.
Now, let’s talk about how these virtual tables are filled out. Because there are only two virtual functions here, each virtual table will have two entries (one for function1() and one for function2()). Remember that when these virtual tables are filled out, each entry is filled out with the most-derived function an object of that class type can call.
The virtual table for Base objects is simple. An object of type Base can only access the members of Base. Base has no access to D1 or D2 functions. Consequently, the entry for function1 points to Base::function1() and the entry for function2 points to Base::function2().
The virtual table for D1 is slightly more complex. An object of type D1 can access members of both D1 and Base. However, D1 has overridden function1(), making D1::function1() more derived than Base::function1(). Consequently, the entry for function1 points to D1::function1(). D1 hasn’t overridden function2(), so the entry for function2 will point to Base::function2().
The virtual table for D2 is similar to D1, except the entry for function1 points to Base::function1(), and the entry for function2 points to D2::function2().
Here’s a picture of this graphically:
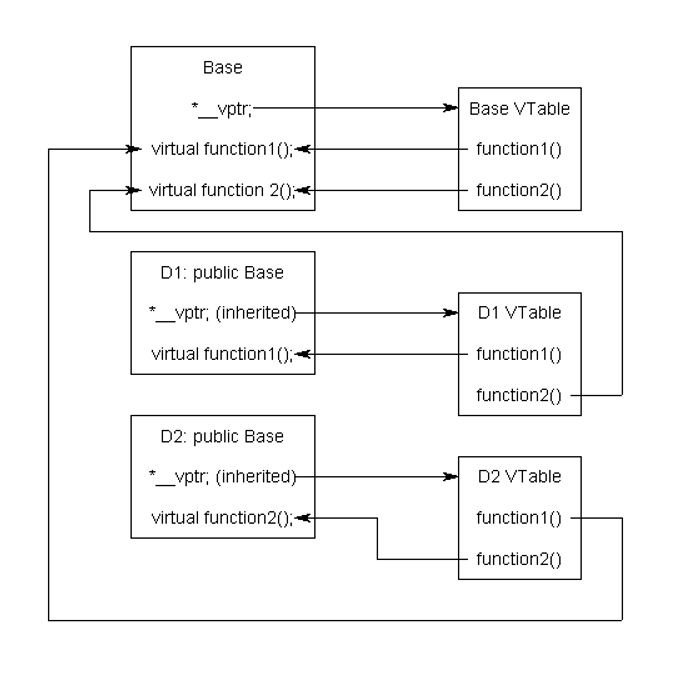
Although this diagram is kind of crazy looking, it’s really quite simple: the *__vptr in each class points to the virtual table for that class. The entries in the virtual table point to the most-derived version of the function objects of that class are allowed to call.
So consider what happens when we create an object of type D1:
1 2 3 4 | int main() { D1 d1; } |
Because d1 is a D1 object, d1 has its *__vptr set to the D1 virtual table.
Now, let’s set a base pointer to D1:
1 2 3 4 5 6 7 | int main() { D1 d1; Base *dPtr = &d1;
return 0; } |
Note that because dPtr is a base pointer, it only points to the Base portion of d1. However, also note that *__vptr is in the Base portion of the class, so dPtr has access to this pointer. Finally, note that dPtr->__vptr points to the D1 virtual table! Consequently, even though dPtr is of type Base, it still has access to D1’s virtual table (through __vptr).
So what happens when we try to call dPtr->function1()?
1 2 3 4 5 6 7 8 | int main() { D1 d1; Base *dPtr = &d1; dPtr->function1();
return 0; } |
First, the program recognizes that function1() is a virtual function. Second, the program uses dPtr->__vptr to get to D1’s virtual table. Third, it looks up which version of function1() to call in D1’s virtual table. This has been set to D1::function1(). Therefore, dPtr->function1() resolves to D1::function1()!
Now, you might be saying, “But what if dPtr really pointed to a Base object instead of a D1 object. Would it still call D1::function1()?”. The answer is no.
1 2 3 4 5 6 7 8 | int main() { Base b; Base *bPtr = &b; bPtr->function1();
return 0; } |
In this case, when b is created, __vptr points to Base’s virtual table, not D1’s virtual table. Consequently, bPtr->__vptr will also be pointing to Base’s virtual table. Base’s virtual table entry for function1() points to Base::function1(). Thus, bPtr->function1() resolves to Base::function1(), which is the most-derived version of function1() that a Base object should be able to call.
By using these tables, the compiler and program are able to ensure function calls resolve to the appropriate virtual function, even if you’re only using a pointer or reference to a base class!
Calling a virtual function is slower than calling a non-virtual function for a couple of reasons: First, we have to use the *__vptr to get to the appropriate virtual table. Second, we have to index the virtual table to find the correct function to call. Only then can we call the function. As a result, we have to do 3 operations to find the function to call, as opposed to 2 operations for a normal indirect function call, or one operation for a direct function call. However, with modern computers, this added time is usually fairly insignificant.
Also as a reminder, any class that uses virtual functions has a *__vptr, and thus each object of that class will be bigger by one pointer. Virtual functions are powerful, but they do have a performance cost.
Although C++ provides a default destructor for your classes if you do not provide one yourself, it is sometimes the case that you will want to provide your own destructor (particularly if the class needs to deallocate memory). You should always make your destructors virtual if you’re dealing with inheritance. Consider the following example:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | #include <iostream> class Base { public: ~Base() // note: not virtual { std::cout << "Calling ~Base()\n"; } };
class Derived: public Base { private: int* m_array;
public: Derived(int length) : m_array{ new int[length] } { }
~Derived() // note: not virtual (your compiler may warn you about this) { std::cout << "Calling ~Derived()\n"; delete[] m_array; } };
int main() { Derived *derived { new Derived(5) }; Base *base { derived };
delete base;
return 0; } |
Note: If you compile the above example, your compiler may warn you about the non-virtual destructor (which is intentional for this example). You may need to disable the compiler flag that treats warnings as errors to proceed.
Because base is a Base pointer, when base is deleted, the program looks to see if the Base destructor is virtual. It’s not, so it assumes it only needs to call the Base destructor. We can see this in the fact that the above example prints:
Calling ~Base()
However, we really want the delete function to call Derived’s destructor (which will call Base’s destructor in turn), otherwise m_array will not be deleted. We do this by making Base’s destructor virtual:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | #include <iostream> class Base { public: virtual ~Base() // note: virtual { std::cout << "Calling ~Base()\n"; } };
class Derived: public Base { private: int* m_array;
public: Derived(int length) : m_array{ new int[length] } { }
virtual ~Derived() // note: virtual { std::cout << "Calling ~Derived()\n"; delete[] m_array; } };
int main() { Derived *derived { new Derived(5) }; Base *base { derived };
delete base;
return 0; } |
Now this program produces the following result:
Calling ~Derived()
Calling ~Base()
Rule: Whenever you are dealing with inheritance, you should make any explicit destructors virtual.
As with normal virtual member functions, if a base class function is virtual, all derived overrides will be considered virtual regardless of whether they are specified as such. It is not necessary to create an empty derived class destructor just to mark it as virtual.
Abstract class is a base class; all the concrete classes can inherit abstract class.
Characteristic of Abstract class.

References:
1. Herbert Schildt, ―C++ The complete reference‖, Eighth Edition, McGraw Hill Professional, 2011, ISBN:978-00-72226805
2. Matt Weisfeld, ―The Object-Oriented Thought Process, Third Edition Pearson ISBN-13:075- 2063330166
3. Cox Brad, Andrew J. Novobilski, ―Object –Oriented Programming: An EvolutionaryApproach‖, Second Edition, Addison–Wesley, ISBN:13:978-020-1548341
4. Deitel, “C++ How to Program”, 4th Edition, Pearson Education, ISBN:81-297-0276-2




