UNIT 5
Exception Handling & Templates
Types of Exceptions
1. std:: exception
It is parent class of all exceptions.
2. std::range_error
It occurs when we try to store a value out of range.
3. std::underflow_error
It occurs when arithmetic underflow occurs.
4. std::overflow_error
It occurs when arithmetic overflow occurs.
5. std::invalid_argument
It occurs due to invalid arguments.
An exception is a problem that arises during the execution of a program. A C++ exception is a response to an exceptional circumstance that arises while a program is running, such as an attempt to divide by zero.
Exceptions provide a way to transfer control from one part of a program to another. C++ exception handling is built upon three keywords: try, catch, and throw.
Assuming a block will raise an exception, a method catches an exception using a combination of the try and catch keywords. A try/catch block is placed around the code that might generate an exception. Code within a try/catch block is referred to as protected code, and the syntax for using try/catch as follows −
try {
// protected code
} catch( ExceptionName e1 ) {
// catch block
} catch( ExceptionName e2 ) {
// catch block
} catch( ExceptionName eN ) {
// catch block
}
You can list down multiple catch statements to catch different type of exceptions in case your try block raises more than one exception in different situations.
Throwing Exceptions
Exceptions can be thrown anywhere within a code block using throw statement. The operand of the throw statement determines a type for the exception and can be any expression and the type of the result of the expression determines the type of exception thrown.
Following is an example of throwing an exception when dividing by zero condition occurs −
double division(int a, int b) {
if( b == 0 ) {
throw "Division by zero condition!";
}
return (a/b);
}
Catching Exceptions
The catch block following the try block catches any exception. You can specify what type of exception you want to catch and this is determined by the exception declaration that appears in parentheses following the keyword catch.
try {
// protected code
} catch( ExceptionName e ) {
// code to handle ExceptionName exception
}
Above code will catch an exception of ExceptionName type. If you want to specify that a catch block should handle any type of exception that is thrown in a try block, you must put an ellipsis, ..., between the parentheses enclosing the exception declaration as follows −
try {
// protected code
} catch(...) {
// code to handle any exception
}
The following is an example, which throws a division by zero exception and we catch it in catch block.
#include <iostream>
using namespace std;
double division(int a, int b) {
if( b == 0 ) {
throw "Division by zero condition!";
}
return (a/b);
}
int main () {
int x = 50;
int y = 0;
double z = 0;
try {
z = division(x, y);
cout << z << endl;
} catch (const char* msg) {
cerr << msg << endl;
}
return 0;
}
Because we are raising an exception of type const char*, so while catching this exception, we have to use const char* in catch block. If we compile and run above code, this would produce the following result −
Division by zero condition!
C++ Standard Exceptions
C++ provides a list of standard exceptions defined in <exception> which we can use in our programs. These are arranged in a parent-child class hierarchy shown below −
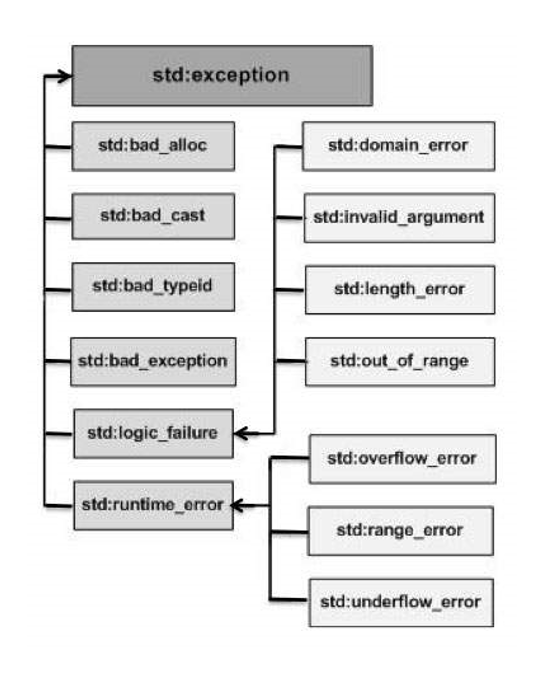
Here is the small description of each exception mentioned in the above hierarchy −
Sr.No | Exception & Description |
1 | std::exception An exception and parent class of all the standard C++ exceptions. |
2 | std::bad_alloc This can be thrown by new. |
3 | std::bad_cast This can be thrown by dynamic_cast. |
4 | std::bad_exception This is useful device to handle unexpected exceptions in a C++ program. |
5 | std::bad_typeid This can be thrown by typeid. |
6 | std::logic_error An exception that theoretically can be detected by reading the code. |
7 | std::domain_error This is an exception thrown when a mathematically invalid domain is used. |
8 | std::invalid_argument This is thrown due to invalid arguments. |
9 | std::length_error This is thrown when a too big std::string is created. |
10 | std::out_of_range This can be thrown by the 'at' method, for example a std::vector and std::bitset<>::operator[](). |
11 | std::runtime_error An exception that theoretically cannot be detected by reading the code. |
12 | std::overflow_error This is thrown if a mathematical overflow occurs. |
13 | std::range_error This is occurred when you try to store a value which is out of range. |
14 | std::underflow_error This is thrown if a mathematical underflow occurs. |
Define New Exceptions
You can define your own exceptions by inheriting and overriding exception class functionality. Following is the example, which shows how you can use std::exception class to implement your own exception in standard way −
#include <iostream>
#include <exception>
using namespace std;
struct MyException : public exception {
const char * what () const throw () {
return "C++ Exception";
}
};
int main() {
try {
throw MyException();
} catch(MyException& e) {
std::cout << "MyException caught" << std::endl;
std::cout << e.what() << std::endl;
} catch(std::exception& e) {
//Other errors
}
}
This would produce the following result −
MyException caught
C++ Exception
Here, what() is a public method provided by exception class and it has been overridden by all the child exception classes. This returns the cause of an exception.
Division by zero is an undefined entity in mathematics, and we need to handle it properly while programming so that it doesn’t return at error at the user end.
Using the runtime_error class
Example
#include <iostream>
#include <stdexcept>
using namespace std;
//handling divide by zero
float Division(float num, float den){
if (den == 0) {
throw runtime_error("Math error: Attempted to divide by Zero\n");
}
return (num / den);
}
int main(){
float numerator, denominator, result;
numerator = 12.5;
denominator = 0;
try {
result = Division(numerator, denominator);
cout << "The quotient is " << result << endl;
}
catch (runtime_error& e) {
cout << "Exception occurred" << endl << e.what();
}
}
Output
Exception occurred
Math error: Attempted to divide by Zero
Using user defined exception handling
Example
#include <iostream>
#include <stdexcept>
using namespace std;
//user defined class for handling exception
class Exception : public runtime_error {
public:
Exception()
: runtime_error("Math error: Attempted to divide by Zero\n") {
}
};
float Division(float num, float den){
if (den == 0)
throw Exception();
return (num / den);
}
int main(){
float numerator, denominator, result;
numerator = 12.5;
denominator = 0;
//trying block calls the Division function
try {
result = Division(numerator, denominator);
cout << "The quotient is " << result << endl;
}
catch (Exception& e) {
cout << "Exception occurred" << endl << e.what();
}
}
Output
Exception occurred
Math error: Attempted to divide by Zero
Using stack unwinding
Example
#include <iostream>
#include <stdexcept>
using namespace std;
//defining function to handle exception
float CheckDenominator(float den){
if (den == 0) {
throw runtime_error("Math error: Attempted to divide by zero\n");
}
else
return den;
}
float Division(float num, float den){
return (num / CheckDenominator(den));
}
int main(){
float numerator, denominator, result;
numerator = 12.5;
denominator = 0;
try {
result = Division(numerator, denominator);
cout << "The quotient is " << result << endl;
}
catch (runtime_error& e) {
cout << "Exception occurred" << endl << e.what();
}
}
Output
Exception occurred
Math error: Attempted to divide by zero
An exception is a situation, which occured by the runtime error. In other words, an exception is a runtime error. An exception may result in loss of data or an abnormal execution of program.
Exception handling is a mechanism that allows you to take appropriate action to avoid runtime errors.
C++ provides three keywords to support exception handling.
The general form of try-catch block in c++.
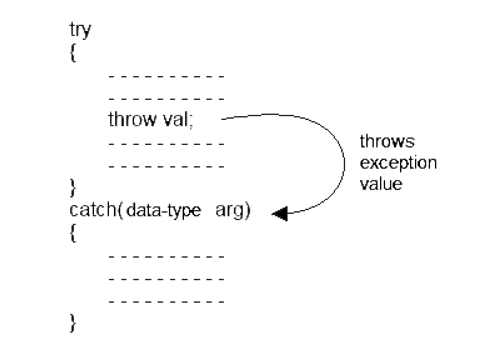
Example of simple try-throw-catch
#include<iostream.h>
#include<conio.h>
void main()
{
int n1,n2,result;
cout<<"\nEnter 1st number : ";
cin>>n1;
cout<<"\nEnter 2nd number : ";
cin>>n2;
try
{
if(n2==0)
throw n2; //Statement 1
else
{
result = n1 / n2;
cout<<"\nThe result is : "<<result;
}
}
catch(int x)
{
cout<<"\nCan't divide by : "<<x;
}
cout<<"\nEnd of program.";
}
Output :
Enter 1st number : 45
Enter 2nd number : 0
Can't divide by : 0
End of program
The catch block contain the code to handle exception. The catch block is similar to function definition.
catch(data-type arg)
{
- - - - - - - - - -
- - - - - - - - - -
- - - - - - - - - -
};
Data-type specifies the type of exception that catch block will handle, Catch block will recieve value, send by throw keyword in try block.
Multiple Catch Statements
A single try statement can have multiple catch statements. Execution of particular catch block depends on the type of exception thrown by the throw keyword. If throw keyword send exception of integer type, catch block with integer parameter will get execute.
Example of multiple catch blocks
#include<iostream.h>
#include<conio.h>
void main()
{
int a=2;
try
{
if(a==1)
throw a; //throwing integer exception
else if(a==2)
throw 'A'; //throwing character exception
else if(a==3)
throw 4.5; //throwing float exception
}
catch(int a)
{
cout<<"\nInteger exception caught.";
}
catch(char ch)
{
cout<<"\nCharacter exception caught.";
}
catch(double d)
{
cout<<"\nDouble exception caught.";
}
cout<<"\nEnd of program.";
}
Output :
Character exception caught.
End of program.
Catch All Exceptions
The above example will caught only three types of exceptions that are integer, character and double. If an exception occur of long type, no catch block will get execute and abnormal program termination will occur. To avoid this, We can use the catch statement with three dots as parameter (...) so that it can handle all types of exceptions.
Example to catch all exceptions
#include<iostream.h>
#include<conio.h>
void main()
{
int a=1;
try
{
if(a==1)
throw a; //throwing integer exception
else if(a==2)
throw 'A'; //throwing character exception
else if(a==3)
throw 4.5; //throwing float exception
}
catch(...)
{
cout<<"\nException occur.";
}
cout<<"\nEnd of program.";
}
Output :
Exception occur.
End of program.
Rethrowing Exceptions
Rethrowing exception is possible, where we have an inner and outer try-catch statements (Nested try-catch). An exception to be thrown from inner catch block to outer catch block is called rethrowing exception.
Syntax of rethrowing exceptions
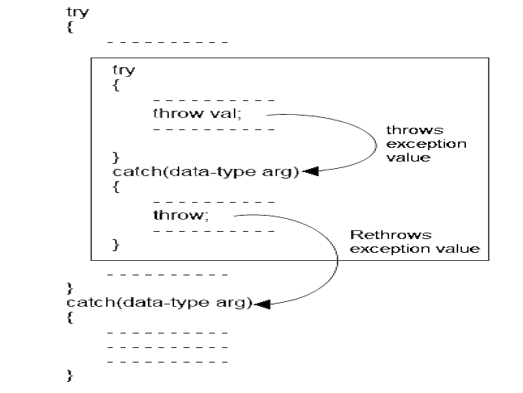
Example of rethrowing exceptions
#include<iostream.h>
#include<conio.h>
void main()
{
int a=1;
try
{
try
{
throw a;
}
catch(int x)
{
cout<<"\nException in inner try-catch block.";
throw x;
}
}
catch(int n)
{
cout<<"\nException in outer try-catch block.";
}
cout<<"\nEnd of program.";
}
Output :
Exception in inner try-catch block.
Exception in outer try-catch block.
End of program.
Restricting Exceptions
We can restrict the type of exception to be thrown, from a function to its calling statement, by adding throw keyword to a function definition.
Example of restricting exceptions
#include<iostream.h>
#include<conio.h>
void Demo() throw(int ,double)
{
int a=2;
if(a==1)
throw a; //throwing integer exception
else if(a==2)
throw 'A'; //throwing character exception
else if(a==3)
throw 4.5; //throwing float exception
}
void main()
{
try
{
Demo();
}
catch(int n)
{
cout<<"\nException caught.";
}
cout<<"\nEnd of program.";
}
The above program will abort because we have restricted the Demo() function to throw only integer and double type exceptions and Demo() is throwing character type exception.
Rethrowing exception is possible, where we have an inner and outer try-catch statements (Nested try-catch). An exception to be thrown from inner catch block to outer catch block is called rethrowing exception.
Syntax of rethrowing exceptions
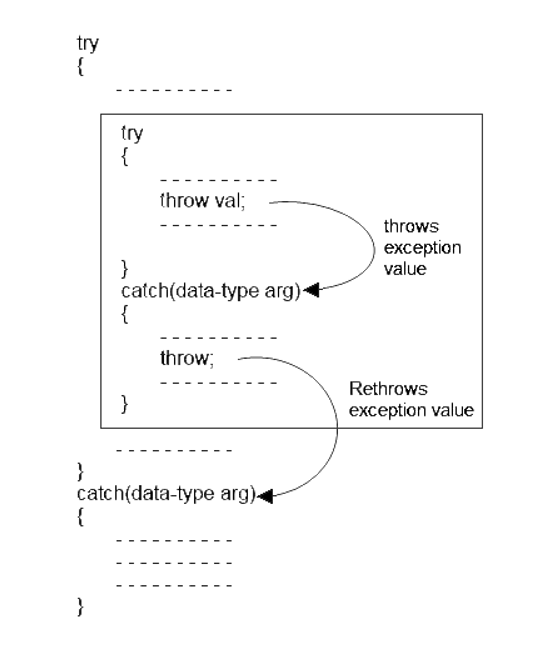
A C++ program to rethrow an exception. Program is as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | #include <iostream> using namespace std; int main() { try { int a, b; cout<<"Enter two integer values: "; cin>>a>>b; try { if(b == 0) { throw b; } else { cout<<(a/b); } } catch(...) { throw; //rethrowing the exception } } catch(int) { cout<<"Second value cannot be zero"; } return 0; } |
Input and output for the above program are as follows:
1 2 | Enter two integer values: 10 0 Second value cannot be zero |
Syntax
| |||||||||
throw( ) | (1) | (deprecated in C++11)(removed in C++20) |
|
|
|
|
|
|
|
| |||||||||
throw(typeid, typeid, ...) | (2) | (deprecated in C++11)(removed in C++17) |
|
|
|
|
|
|
|
| |||||||||
1) Non-throwing dynamic exception specification | (until C++17) |
1) Same as noexcept(true), | (since C++17) |
2) Explicit dynamic exception specification
This specification may appear only on lambda-declarator or on a function declarator that is the top-level (until C++17) declarator of a function, variable, or non-static data member, whose type is a function type, a pointer to function type, a reference to function type, a pointer to member function type. It may appear on the declarator of a parameter or on the declarator of a return type.
void f() throw(int); // OK: function declaration
void (*pf)() throw (int); // OK: pointer to function declaration
void g(void pfa() throw(int)); // OK: pointer to function parameter declaration
typedef int (*pf)() throw(int); // Error: typedef declaration
Explanation
If a function is declared with type T listed in its exception specification, the function may throw exceptions of that type or a type derived from it.
Incomplete types, pointers or references to incomplete types other than cv void*, and rvalue reference types are not allowed in the exception specification. Array and function types, if used, are adjusted to corresponding pointer types. parameter packs are allowed (since C++11).
If the function throws an exception of the type not listed in its exception specification, the function std::unexpected is called. The default function calls std::terminate, but it may be replaced by a user-provided function (via std::set_unexpected) which may call std::terminate or throw an exception. If the exception thrown from std::unexpected is accepted by the exception specification, stack unwinding continues as usual. If it isn't, but std::bad_exception is allowed by the exception specification, std::bad_exception is thrown. Otherwise, std::terminate is called.
Potential exceptions
Each function f, pointer to function pf, and pointer to member function pmf has a set of potential exceptions, which consists of types that might be thrown. Set of all types indicates that any exception may be thrown. This set is defined as follows:
Note: for implicitly-declared special member functions (constructors, assignment operators, and destructors) and for the inheriting constructors (since C++11), the set of potential exceptions is a combination of the sets of the potential exceptions of everything they would call: constructors/assignment operators/destructors of non-variant non-static data members, direct bases, and, where appropriate, virtual bases (including default argument expressions, as always)
Each expression e has a set of potential exceptions. The set is empty if e is a core constant expression, otherwise, it is the union of the sets of potential exceptions of all immediate subexpressions of e (including default argument expressions), combined with another set that depends on the form of e, as follows:
- if the declaration of g uses a dynamic exception specification, the set of potential exceptions of g is added to the set;
- (since C++11) if the declaration of g uses noexcept(true), the set is empty;
- otherwise, the set is the set of all types.
void f() throw(int); // f()'s set is "int"
void g(); // g()'s set is the set of all types
struct A { A(); }; // "new A"'s set is the set of all types
struct B { B() noexcept; }; // "B()"'s set is empty
struct D() { D() throw (double); }; // new D's set is the set of all types
All implicitly-declared member functions and inheriting constructors (since C++11)have exception specifications, selected as follows:
struct A {
A(int = (A(5), 0)) noexcept;
A(const A&) throw();
A(A&&) throw();
~A() throw(X);
};
struct B {
B() throw();
B(const B&) = default; // exception specification is "noexcept(true)"
B(B&&, int = (throw Y(), 0)) noexcept;
~B() throw(Y);
};
int n = 7;
struct D : public A, public B {
int * p = new (std:: nothrow ) int[n];
// D has the following implicitly-declared members:
// D::D() throw(X, std::bad_array_new_length);
// D::D(const D&) noexcept(true);
// D::D(D&&) throw(Y);
// D::~D() throw(X, Y);
};
Example
Run this code
#include <iostream>
#include <exception>
#include <cstdlib>
static_assert(__cplusplus < 201700,
"ISO C++17 does not allow dynamic exception specifications.");
class X {};
class Y {};
class Z : public X {};
class W {};
void f() throw(X, Y)
{
int n = 0;
if (n) throw X(); // OK
if (n) throw Z(); // also OK
throw W(); // will call std::unexpected()
}
int main() {
std::set_unexpected ([]{
std::cout<< "That was unexpected!" <<std::endl; // flush needed
std::abort ();
});
f();
}
Output:
That was unexpected!
The new exception can be defined by overriding and inheriting exception class functionality.
C++ user-defined exception example
Let's see the simple example of user-defined exception in which std::exception class is used to define the exception.
Output:
Enter the two numbers :
10
2
x / y = 5
Output:
Enter the two numbers :
10
0
Attempted to divide by zero!
-->
Note: In above example what() is a public method provided by the exception class. It is used to return the cause of an exception.
Whenever an exception arises in C++, it is handled as per the behavior defined using the try-catch block. However, there is often the case when an exception is thrown but isn’t caught because the exception handling subsystem fails to find a matching catch block for that particular exception. In that case, the following set of actions takes place:
The terminate() and unexpected() simply call other functions to actually handle an error. As explained above, terminate calls abort(), and unexpected() calls terminate(). Thus, both functions halt the program execution when an exception handling error occurs. However, you can change the way termination occurs.
To change the terminate handler, the function used is set_terminate(terminate_handler newhandler), which is defined in the header <exception>.
The following program demonstrates how to set a custom termination handler:
// CPP program to set a new termination handler // for uncaught exceptions. #include <exception> #include <iostream> using namespace std;
// definition of custom termination function void myhandler() { cout << "Inside new terminate handler\n"; abort(); }
int main() { // set new terminate handler set_terminate(myhandler); try { cout << "Inside try block\n"; throw 100; } catch (char a) // won't catch an int exception { cout << "Inside catch block\n"; } return 0; } |
Output:
Inside try block
Inside new terminate handler
When an exception is thrown and control passes to a catch block following a try block, destructors are called for all automatic objects constructed since the beginning of the try block directly associated with that catch block. If an exception is thrown during construction of an object consisting of subobjects or array elements, destructors are only called for those subobjects or array elements successfully constructed before the exception was thrown. A destructor for a local static object will only be called if the object was successfully constructed.
If a destructor detects an exception and issues a throw , the exception can be caught if the caller of the destructor was contained within a try block and an appropriate catch is coded.
If an exception is thrown by a function called from an inner try block, but caught by an outer try block (because the inner try block did not have an appropriate handler), all objects constructed within both the outer and all inner try blocks are destroyed. If the thrown object has a destructor , the destructor is not called until the exception is caught and handled.
Because a throw expression throws an object and a catch statement can catch an object, the object thrown enables error-related information to be transferred from the point at which an exception is detected to the exception's handler. If you throw an object with a constructor, you can construct an object that contains information relevant to the catch expression. The catch block can then access information provided by the thrown object.
Exception handling can be used in conjunction with constructors and destructors to provide resource management that ensures that all locked resources are unlocked when an exception is thrown.
#include <iostream> using namespace std;
class Test { public: Test() { cout << "Constructing an object of Test " << endl; } ~Test() { cout << "Destructing an object of Test " << endl; } };
int main() { try { Test t1; throw 10; } catch(int i) { cout << "Caught " << i << endl; } } |
Output:
Constructing an object of Test
Destructing an object of Test
Caught 10
When an exception is thrown, destructors of the objects (whose scope ends with the try block) is automatically called before the catch block gets exectuted. That is why the above program prints “Destructing an object of Test” before “Caught 10”.
What happens when an exception is thrown from a constructor? Consider the following program.
#include <iostream> using namespace std;
class Test1 { public: Test1() { cout << "Constructing an Object of Test1" << endl; } ~Test1() { cout << "Destructing an Object of Test1" << endl; } };
class Test2 { public: // Following constructor throws an integer exception Test2() { cout << "Constructing an Object of Test2" << endl; throw 20; } ~Test2() { cout << "Destructing an Object of Test2" << endl; } };
int main() { try { Test1 t1; // Constructed and destructed Test2 t2; // Partially constructed Test1 t3; // t3 is not constructed as this statement never gets executed } catch(int i) { cout << "Caught " << i << endl; } } |
Output:
Constructing an Object of Test1
Constructing an Object of Test2
Destructing an Object of Test1
Caught 20
Destructors are only called for the completely constructed objects. When constructor of an object throws an exception, destructor for that object is not called.
As an excecise, predict the output of following program.
#include <iostream> using namespace std;
class Test { static int count; int id; public: Test() { count++; id = count; cout << "Constructing object number " << id << endl; if(id == 4) throw 4; } ~Test() { cout << "Destructing object number " << id << endl; } };
int Test::count = 0;
int main() { try { Test array[5]; } catch(int i) { cout << "Caught " << i << endl; } } |
Exceptions and member functions
Up to this point in the tutorial, you’ve only seen exceptions used in non-member functions. However, exceptions are equally useful in member functions, and even moreso in overloaded operators. Consider the following overloaded [] operator as part of a simple integer array class:
1 2 3 4 | int& IntArray::operator[](const int index) { return m_data[index]; } |
Although this function will work great as long as index is a valid array index, this function is sorely lacking in some good error checking. We could add an assert statement to ensure the index is valid:
1 2 3 4 5 | int& IntArray::operator[](const int index) { assert (index >= 0 && index < getLength()); return m_data[index]; } |
Now if the user passes in an invalid index, the program will cause an assertion error. While this is useful to indicate to the user that something went wrong, sometimes the better course of action is to fail silently and let the caller know something went wrong so they can deal with it as appropriate.
Unfortunately, because overloaded operators have specific requirements as to the number and type of parameter(s) they can take and return, there is no flexibility for passing back error codes or boolean values to the caller. However, since exceptions do not change the signature of a function, they can be put to great use here. Here’s an example:
1 2 3 4 5 6 7 | int& IntArray::operator[](const int index) { if (index < 0 || index >= getLength()) throw index;
return m_data[index]; } |
Now, if the user passes in an invalid index, operator[] will throw an int exception.
When constructors fail
Constructors are another area of classes in which exceptions can be very useful. If a constructor must fail for some reason (e.g. the user passed in invalid input), simply throw an exception to indicate the object failed to create. In such a case, the object’s construction is aborted, and all class members (which have already been created and initialized prior to the body of the constructor executing) are destructed as per usual. However, the class’s destructor is never called (because the object never finished construction).
Because the destructor never executes, you can not rely on said destructor to clean up any resources that have already been allocated. Any such cleanup can happen in the constructor prior to throwing the exception in the first place. However, even better, because the members of the class are destructed as per usual, if you do the resource allocations in the members themselves, then those members can clean up after themselves when they are destructed.
Here’s an example:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 | #include <iostream>
class Member { public: Member() { std::cerr << "Member allocated some resources\n"; }
~Member() { std::cerr << "Member cleaned up\n"; } };
class A { private: int m_x; Member m_member;
public: A(int x) : m_x{x} { if (x <= 0) throw 1; } ~A() { std::cerr << "~A\n"; // should not be called } };
int main() { try { A a{0}; } catch (int) { std::cerr << "Oops\n"; }
return 0; } |
This prints:
Member allocated some resources
Member cleaned up
Oops
In the above program, when class A throws an exception, all of the members of A are destructed. This gives m_member an opportunity to clean up any resources that were allocated.
Exception classes
One of the major problems with using basic data types (such as int) as exception types is that they are inherently vague. An even bigger problem is disambiguation of what an exception means when there are multiple statements or function calls within a try block.
1 2 3 4 5 6 7 8 9 10 | // Using the IntArray overloaded operator[] above
try { int *value{ new int{ array[index1] + array[index2]} }; } catch (int value) { // What are we catching here? } |
In this example, if we were to catch an int exception, what does that really tell us? Was one of the array indexes out of bounds? Did operator+ cause integer overflow? Did operator new fail because it ran out of memory? Unfortunately, in this case, there’s just no easy way to disambiguate. While we can throw const char* exceptions to solve the problem of identifying WHAT went wrong, this still does not provide us the ability to handle exceptions from various sources differently.
One way to solve this problem is to use exception classes. An exception class is just a normal class that is designed specifically to be thrown as an exception. Let’s design a simple exception class to be used with our IntArray class:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | #include <string>
class ArrayException { private: std::string m_error;
public: ArrayException(std::string error) : m_error{error} { }
const char* getError() const { return m_error.c_str(); } }; |
Here’s a full program using this class:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 | #include <iostream> #include <string>
class ArrayException { private: std::string m_error;
public: ArrayException(std::string error) : m_error(error) { }
const char* getError() const { return m_error.c_str(); } };
class IntArray { private:
int m_data[3]; // assume array is length 3 for simplicity public: IntArray() {} int getLength() const { return 3; }
int& operator[](const int index) { if (index < 0 || index >= getLength()) throw ArrayException("Invalid index");
return m_data[index]; }
};
int main() { IntArray array;
try { int value{ array[5] }; } catch (const ArrayException &exception) { std::cerr << "An array exception occurred (" << exception.getError() << ")\n"; } } |
Using such a class, we can have the exception return a description of the problem that occurred, which provides context for what went wrong. And since ArrayException is its own unique type, we can specifically catch exceptions thrown by the array class and treat them differently from other exceptions if we wish.
Note that exception handlers should catch class exception objects by reference instead of by value. This prevents the compiler from making a copy of the exception, which can be expensive when the exception is a class object, and prevents object slicing when dealing with derived exception classes (which we’ll talk about in a moment). Catching exceptions by pointer should generally be avoided unless you have a specific reason to do so.
Exceptions and inheritance
Since it’s possible to throw classes as exceptions, and classes can be derived from other classes, we need to consider what happens when we use inherited classes as exceptions. As it turns out, exception handlers will not only match classes of a specific type, they’ll also match classes derived from that specific type as well! Consider the following example:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | class Base { public: Base() {} };
class Derived: public Base { public: Derived() {} };
int main() { try { throw Derived(); } catch (const Base &base) { std::cerr << "caught Base"; } catch (const Derived &derived) { std::cerr << "caught Derived"; }
return 0; } |
In the above example we throw an exception of type Derived. However, the output of this program is:
caught Base
What happened?
First, as mentioned above, derived classes will be caught by handlers for the base type. Because Derived is derived from Base, Derived is-a Base (they have an is-a relationship). Second, when C++ is attempting to find a handler for a raised exception, it does so sequentially. Consequently, the first thing C++ does is check whether the exception handler for Base matches the Derived exception. Because Derived is-a Base, the answer is yes, and it executes the catch block for type Base! The catch block for Derived is never even tested in this case.
In order to make this example work as expected, we need to flip the order of the catch blocks:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | class Base { public: Base() {} };
class Derived: public Base { public: Derived() {} };
int main() { try { throw Derived(); } catch (const Derived &derived) { std::cerr << "caught Derived"; } catch (const Base &base) { std::cerr << "caught Base"; }
return 0; } |
This way, the Derived handler will get first shot at catching objects of type Derived (before the handler for Base can). Objects of type Base will not match the Derived handler (Derived is-a Base, but Base is not a Derived), and thus will “fall through” to the Base handler.
Rule: Handlers for derived exception classes should be listed before those for base classes.
The ability to use a handler to catch exceptions of derived types using a handler for the base class turns out to be exceedingly useful.
std::exception
Many of the classes and operators in the standard library throw exception classes on failure. For example, operator new can throw std::bad_alloc if it is unable to allocate enough memory. A failed dynamic_cast will throw std::bad_cast. And so on. As of C++17, there are 25 different exception classes that can be thrown, with more being added in each subsequent language standard.
The good news is that all of these exception classes are derived from a single class called std::exception. std::exception is a small interface class designed to serve as a base class to any exception thrown by the C++ standard library.
Much of the time, when an exception is thrown by the standard library, we won’t care whether it’s a bad allocation, a bad cast, or something else. We just care that something catastrophic went wrong and now our program is exploding. Thanks to std::exception, we can set up an exception handler to catch exceptions of type std::exception, and we’ll end up catching std::exception and all (21+) of the derived exceptions together in one place. Easy!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | #include <iostream> #include <exception> // for std::exception #include <string> // for this example
int main() { try { // Your code using standard library goes here // We'll trigger one of these exceptions intentionally for the sake of example std::string s; s.resize(-1); // will trigger a std::length_error } // This handler will catch std::exception and all the derived exceptions too catch (const std::exception &exception) { std::cerr << "Standard exception: " << exception.what() << '\n'; }
return 0; } |
The above program prints:
Standard exception: string too long
The above example should be pretty straightforward. The one thing worth noting is that std::exception has a virtual member function named what() that returns a C-style string description of the exception. Most derived classes override the what() function to change the message. Note that this string is meant to be used for descriptive text only -- do not use it for comparisons, as it is not guaranteed to be the same across compilers.
Sometimes we’ll want to handle a specific type of exception differently. In this case, we can add a handler for that specific type, and let all the others “fall through” to the base handler. Consider:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | Try { // code using standard library goes here } // This handler will catch std::length_error (and any exceptions derived from it) here catch (const std::length_error &exception) { std::cerr << "You ran out of memory!" << '\n'; } // This handler will catch std::exception (and any exception derived from it) that fall // through here catch (const std::exception &exception) { std::cerr << "Standard exception: " << exception.what() << '\n'; } |
In this example, exceptions of type std::length_error will be caught by the first handler and handled there. Exceptions of type std::exception and all of the other derived classes will be caught by the second handler.
Such inheritance hierarchies allow us to use specific handlers to target specific derived exception classes, or to use base class handlers to catch the whole hierarchy of exceptions. This allows us a fine degree of control over what kind of exceptions we want to handle while ensuring we don’t have to do too much work to catch “everything else” in a hierarchy.
Using the standard exceptions directly
Nothing throws a std::exception directly, and neither should you. However, you should feel free to throw the other standard exception classes in the standard library if they adequately represent your needs. std::runtime_error (included as part of the stdexcept header) is a popular choice, because it has a generic name, and its constructor takes a customizable message:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | #include <iostream> #include <stdexcept>
int main() { try { throw std::runtime_error("Bad things happened"); } // This handler will catch std::exception and all the derived exceptions too catch (const std::exception &exception) { std::cerr << "Standard exception: " << exception.what() << '\n'; }
return 0; } |
This prints:
Standard exception: Bad things happened
Deriving your own classes from std::exception
You can, of course, derive your own classes from std::exception, and override the virtual what() const member function. Here’s the same program as above, with ArrayException derived from std::exception:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 | #include <iostream> #include <string> #include <exception> // for std::exception
class ArrayException: public std::exception { private: std::string m_error;
public: ArrayException(std::string error) : m_error{error} { }
// return the std::string as a const C-style string // const char* what() const { return m_error.c_str(); } // pre-C++11 version const char* what() const noexcept { return m_error.c_str(); } // C++11 version };
class IntArray { private:
int m_data[3]; // assume array is length 3 for simplicity public: IntArray() {} int getLength() const { return 3; }
int& operator[](const int index) { if (index < 0 || index >= getLength()) throw ArrayException("Invalid index");
return m_data[index]; }
};
int main() { IntArray array;
try { int value{ array[5] }; } catch (const ArrayException &exception) // derived catch blocks go first { std::cerr << "An array exception occurred (" << exception.what() << ")\n"; } catch (const std::exception &exception) { std::cerr << "Some other std::exception occurred (" << exception.what() << ")\n"; } } |
In C++11, virtual function what() was updated to have specifier noexcept (which means the function promises not to throw exceptions itself). Therefore, in C++11 and beyond, our override should also have specifier noexcept.
It’s up to you whether you want create your own standalone exception classes, use the standard exception classes, or derive your own exception classes from std::exception. All are valid approaches depending on your aims.
Implementation of generic programming in C++
1. Function Templates
2. Class Templates
template <class Ttype> return-type function-name(parameter list)
{
//body of function
}
Or
template <class Ttype>
return-type function-name(parameter list)
{
//body of function
}
Where Ttype -> data type used by the function.
Program
Write a C++ program for a function template that returns the maximum of two values.
Solution :
#include<iostream.h> template <class T> void max1(T x,T y) { if(x>y) cout<<x<< “is greater”; else cout<<y<<”is greater”; } int main() { cout<<"\nInteger"<<max1(3,7); cout<<"\nFloat"<<max1(44.66,22.13); cout<<"\nCharacter "<<max1('t','p'); return 0; } |
// Step 1
//Here, condition is checked
//Step 2 Integers are passed. //Step 3 float are passed. // Step 4 Characters are passed. |
Explanation
Step 1 : Function template for finding maximum of two numbers is written where T represents generic data type. T will be replaced by specific data type depending upon type of parameter passed to function ‘max1’.
void max1 (Tx, Ty)
Step 2 : When we pass integer value to the function, ‘T’ will act as integer type. Thus it finds maximum of two integers.
cout<<"\nInteger"<<max1(3,7);
Step 3 : When we pass float value to the function, ‘T’ will act as float type. Thus it finds maximum of two floats.
cout<<"\nFloat "<<max1(44.66,22.13);
Step 4 : When we passed character value to the function, ‘T’ will act as character type. Thus it finds maximum of two characters.
cout<<"\nCharacter "<<max1('t','p');
Thus Single function is working for all three datatypes.
Output
Integer : 7
Float : 44.66
Character : t
Program
Write a C++ program to swap two numbers using concept of function template.
Solution :
#include<iostream> using namespace std; template <class T> void swapnums(T &x,T &y) { T temp; temp=x x=y; y=temp; } int main() { swapnums (10, 11); swapnums (10.5, 11.5); swapnums (‘A’, ‘D’); return 0; } |
//Function template for swapping
|
Program
Write a program in C++ for bubble sort using function template.
Solution :
#include<iostream> using namespace std; template <class T> void bubblesort(T A[], int n) { for(int i=0;i<=n-1;i++) for(int j=n-1;i<j;j--) if(A[j]<A[j-1]) { swap (A[j], A[j-1]) } template <class X> void swap(X &p, X &q) { X temp=p; p=q; q=temp; }
int main() { int array[5]; cout<<“Enter elements of array”; for(int i=0;i<5;i++) { cin>>a[i]; } bubblesort(array,5); cout<<“Sorted array”; for(int i=0;i<5;i++) { cout<<array[i]<<“”; return 0; } |
//template function for bubble sort
// calls template function for swap
// template function for swap
//accept array elements for sorting
//calls template function for sorting |
Output
Enter elements of array
25 15 30 10 50
Sorted array 10 15 25 30 50
Program
Write a program to display integer value, float value, character and string by using single function.
Solution :
#include<iostream>
using namespace std;
#include<conio.h>
template <class T>
void display(T x)
{
cout<<x<<"\n";
}
int main()
{
display(20);
display(44.3);
display('A');
display("welcome");
return0;
}
Output
20
44.3
A
welcome
Overloading Template Function
#include<iostream>
using namespace std;
//Template function
 template <class T>
template <class T>
void display(T x)
{
cout<<"\n Inside template function : x : "<<x; //Take any type of data (like int,
} float, string etc.)
//Normal function
 void display(int x)
void display(int x)
{
cout<<"\n Inside normal function : x : "<<x; //Take only integer type.
} //This function overrides template function
int main()
{
display(21.45); //calls template function
display(45); //calls normal function
display("Object oriented"); // calls template function
return 0;
}
Output
Inside template function : x :21.45
Inside normal function : x : 45
Inside template function : x : Object Oriented
Class Templates
Syntax
template<class T>
class class_name
{
-------------
class members
-------------
};
Program
Consider class Demo, where we want to find average of three numbers(numbers can be integer or float).
Solution :
#include<iostream>
using namespace std;
template <class T>
class Demo--------------------------------//Step 1
{
private:
T n1,n2,n3;
public:
Demo(T x, T y, T z)
{
n1=x;
n2=y;
n3=z;
}
void avg()---------------------//Step 2
{
cout<<" "<<(n1+n2+n3)/3;
}
};
int main()
{
Demo<int>s1(10,20,30);--------------------- -//Step 3
Demo<float>s2(50.5,40.5,30.5); -------------//Step 4
cout<<"\n Average = "; ------------------------//Step 5
s1.avg();
cout<<"\n Average = ";
s2.avg();
return 0;
}
Explanation
Steps
Step 1 : ‘Demo’ is a template class that defines function ‘avg’.
Class Demo
Step 2 : ‘avg’ function calculates average of three numbers.
void avg()
{
cout<<" "<<(n1+n2+n3)/3;
}
Step 3 : It creates object s1 that stores integer type variables.
Demo<int>s1(10,20,30);
Step 4 : It creates object s2 that stores float type variables.
Demo<float>s2(50.5,40.5,30.5);
Step 5 : Calculates average of three integer numbers.
cout<<"\n Average = ";
s1.avg();
Step 6 : Calculates average of three float numbers.
cout<<"\n Average = ";
s2.avg();
Output
Average = 20
Average = 40.5
Syntax
template<class T>
class class_name
{
-------------
class members
-------------
};
Program
Consider class Demo, where we want to find average of three numbers(numbers can be integer or float).
Solution :
#include<iostream>
using namespace std;
template <class T>
class Demo--------------------------------//Step 1
{
private:
T n1,n2,n3;
public:
Demo(T x, T y, T z)
{
n1=x;
n2=y;
n3=z;
}
void avg()---------------------//Step 2
{
cout<<" "<<(n1+n2+n3)/3;
}
};
int main()
{
Demo<int>s1(10,20,30);--------------------- -//Step 3
Demo<float>s2(50.5,40.5,30.5); -------------//Step 4
cout<<"\n Average = "; ------------------------//Step 5
s1.avg();
cout<<"\n Average = ";
s2.avg();
return 0;
}
Explanation
Steps
Step 1 : ‘Demo’ is a template class that defines function ‘avg’.
Class Demo
Step 2 : ‘avg’ function calculates average of three numbers.
void avg()
{
cout<<" "<<(n1+n2+n3)/3;
}
Step 3 : It creates object s1 that stores integer type variables.
Demo<int>s1(10,20,30);
Step 4 : It creates object s2 that stores float type variables.
Demo<float>s2(50.5,40.5,30.5);
Step 5 : Calculates average of three integer numbers.
cout<<"\n Average = ";
s1.avg();
Step 6 : Calculates average of three float numbers.
cout<<"\n Average = ";
s2.avg();
Output
Average = 20
Average = 40.5
Non-type parameters
A template non-type parameter is a special type of parameter that does not substitute for a type, but is instead replaced by a value. A non-type parameter can be any of the following:
In the following example, we create a non-dynamic (static) array class that uses both a type parameter and a non-type parameter. The type parameter controls the data type of the static array, and the non-type parameter controls how large the static array is.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 | #include <iostream>
template <class T, int size> // size is the non-type parameter class StaticArray { private: // The non-type parameter controls the size of the array T m_array[size];
public: T* getArray(); T& operator[](int index) { return m_array[index]; } };
// Showing how a function for a class with a non-type parameter is defined outside of the class template <class T, int size> T* StaticArray<T, size>::getArray() { return m_array; }
int main() { // declare an integer array with room for 12 integers StaticArray<int, 12> intArray;
// Fill it up in order, then print it backwards for (int count=0; count < 12; ++count) intArray[count] = count;
for (int count=11; count >= 0; --count) std::cout << intArray[count] << " "; std::cout << '\n';
// declare a double buffer with room for 4 doubles StaticArray<double, 4> doubleArray;
for (int count=0; count < 4; ++count) doubleArray[count] = 4.4 + 0.1*count;
for (int count=0; count < 4; ++count) std::cout << doubleArray[count] << ' ';
return 0; } |
This code produces the following:
11 10 9 8 7 6 5 4 3 2 1 0
4.4 4.5 4.6 4.7
One noteworthy thing about the above example is that we do not have to dynamically allocate the m_array member variable! This is because for any given instance of the StaticArray class, size is actually constant. For example, if you instantiate a StaticArray<int, 12>, the compiler replaces size with 12. Thus m_array is of type int[12], which can be allocated statically.
This functionality is used by the standard library class std::array. When you allocate a std::array<int, 5>, the int is a type parameter, and the 5 is a non-type parameter!
Introduction
When writing C++, there are a couple common situations where you may want to create a friend function, such as implementing operator<<. These are straightforward to write for non-template classes, but templates throw a real wrench in the works here. In C++, there are a few different ways to set up template classes with friend functions. Each behaves in a subtly different way, which causes all sorts of confusion when trying to finish your homework the night before it's due. We will examine the possible approaches to this, but first...
Some terminology
Approach #1
1 template<class T>
2 class A
3 {
4 public:
5 A(T a = 0): m_a(a) {}
6
7 template<class U>
8 friend A<U> foo(A<U>& a);
9
10 private:
11 T m_a;
12 };
13
14 template<class T>
15 A<T> foo(A<T>& a)
16 {
17 return a;
18 }
This approach is the most permissive approach to declaring a templated friend function of a templated class. This will work for all cases where you want to explicitly pass an instance of class A to foo().
However, there is one unapparent side effect of this approach: All template instantiations of A are friends with all template instantiations of foo(). So, for example, A<int> is friends with foo<int> but also foo<double>. To see why this is a Bad Thing, consider the following perfectly valid C++:
19 A<double> secret_pie(3.14);
20
21 struct dummy {};
22 template<>
23 A<dummy> foo<dummy>(A<dummy>& d)
24 {
25 cout << "Hacked! " << secret_pie.m_a << endl;
26 return d;
27 }
In an ideal world, line 25 should not work, since it is in a function that by all rights should know nothing about A<double>! To prevent this potential programmer error, we must take a different approach to generate more antisocial friend functions.
Approach #2
1 template<class T>
2 class A;
3
4 template<class T>
5 A<T> foo(A<T>& a);
6
7 template<class T>
8 class A
9 {
10 public:
11 A(T a = 0): m_a(a) {}
12
13 friend A foo<T>(A& a);
14
15 private:
16 T m_a;
17 };
18
19 template<class T>
20 A<T> foo(A<T>& a)
21 {
22 return a;
23 }
This approach is a bit more ugly, but it fixes the issue with approach #1. Here, foo() is declared as a template function using a declared (but not yet defined) templated class A. Then, when we define A, we make each template instantiation of A friends with the corresponding template instantiation of foo(). (In case you're wondering why on line 13 A is used with no <T> after it: inside class definitions, C++ assumes that any reference to that class is templated, so adding the <T> is redundant.)
This may seem like a minor difference from approach #1, but in this case A<int> is friends with foo<int>, but foo<double> is not a friend of A<int> since the type in their template parameters do not match.
In general, this is how template friend functions are done in best practices. They are explicit in the type of objects they will take as parameters and do not allow different template instantiations to be friends.
However, in certain edge cases, such as numeric type objects, these friend functions have an undesirable side effect: since they are template functions, the parameters passed to them must be explicitly associated with the expected parameter types for template argument deduction to succeed. To illustrate,
1 template<class T>
2 class A;
3
4 template<class T>
5 A<T> foo(A<T>& a);
6
7 template<class T>
8 class A
9 {
10 public:
11 A(T a = 0): m_a(a) {}
12
13 friend A foo<T>(A& a);
14
15 private:
16 T m_a;
17 };
18
19 template<class T>
20 A<T> foo(A<T>& a)
21 {
22 return a;
23 }
24
25 int main()
26 {
27 A<int> a(5);
28 int i = 4;
29
30 foo(a); // Succeeds
31 foo(i); // Cannot deduce template parameters
32
33 return 0;
34 }
On line 31, despite there being an implicit conversion from int to A<int>, that conversion is not made. This is because C++ never considers implicit conversions for template parameter deduction on non-member template functions. For the most part, this is not a problem because it prevents certain amounts of ambiguity when dealing with calling template functions, but in the case where we are working with numeric type classes, we do want the implicit conversion to occur.
Approach #3
As we saw in approach #2, C++ won't implicitly convert types for template function parameters, even if such a conversion exists. But in the case where we are working with numeric types, we want that conversion to occur. So, how can we achieve this? Well, C++ will perform implicit type conversion on non-templated non-member functions. What if we were to create some non-template friend function that was automatically created for each template instantiation of some class? As it turns out, that is possible:
1 template<class T>
2 class A
3 {
4 public:
5 A(T a = 0): m_a(a) {}
6
7 friend A operator+(const A& lhs, const A& rhs)
8 {
9 return lhs.m_a + rhs.m_a;
10 }
11
12 private:
13 T m_a;
14 };
15
16 int main()
17 {
18 A<int> a(5);
19 A<int> b(7);
20 int i = 4;
21
22 a + b; // Succeeds
23 i + a; // Also succeeds
24 return 0;
25 }
Here, operator+ is a friend function, but is not templated. Instead, it is a function that is automatically created for each template instantiation of A when that template is instantiated. The generic definition must be inlined in the class definition because operator+ doesn't exist outside the class definition of A until a template instantiation of A is generated, which happens during the compilation process.
As an aside, it is possible to write specific definitions of operator+ outside of A, but no generic definition can be written because operator+ is not a template function:
1 template<class T>
2 class A
3 {
4 public:
5 A(T a = 0): m_a(a) {}
6
7 friend A operator+(const A& lhs, const A& rhs);
8
9 private:
10 T m_a;
11 };
12
13 inline A<int> operator+(const A<int>& lhs, const A<int>& rhs)
14 {
15 return lhs.m_a + rhs.m_a;
16 }
17
18 int main()
19 {
20 A<int> a(5);
21 A<int> b(7);
22 int i = 4;
23
24 a + b; // Succeeds
25 i + a; // Also succeeds
26 return 0;
27 }
However, this code won't compile without warnings in GCC, and is uninteresting anyway because we don't want to write specific implementations of operator+ for each template instantiation of A (otherwise, why bother with templates to begin with?). The warning itself indicates that this is possible, but not usually what you want to do.
Now, you may be wondering why I switched my example function defnition. As it turns out, this sort of non-template friend function is unusual since the function is neither in the global scope nor a member of class A. This means that our function doesn't live in the "standard" places you'd expect it to; neither ::operator+ nor A<int>::operator+ exist. Fortunately, C++ has a feature called ADL, or Argument Dependent Lookup, that can search through functions that aren't in the current scope, but exist in a class or namespace that is suggested by the type of the arguments handed to the function call:
1 template<class T>
2 class A
3 {
4 public:
5 A(T a = 0): m_a(a) {}
6
7 friend A operator+(const A& lhs, const A& rhs)
8 {
9 return lhs.m_a + rhs.m_a;
10 }
11
12 friend A foo(const A& a)
13 {
14 return a;
15 }
16
17 private:
18 T m_a;
19 };
20
21 int main()
22 {
23 A<int> a(5);
24 A<int> b(7);
25 int i = 4;
26
27 a + b; // Succeeds
28 i + a; // Also succeeds
29
30 foo(a); // Succeeds
31 foo(i); // Fails: foo not declared in this scope
32 foo(A<int>(i)); // Succeeds
33 return 0;
34 }
Here, line 28 succeeds because of ADL: even though operator+ is not in the current scope, C++ can see that the second argument to operator+ is of type A<int> and therefore will attempt to implicitly convert i to A<int> because operator+ is not a template function and thus follows standard implicit conversion rules for non-template non-member functions. Since C++ does have a way to convert an int to a A<int>, the call succeeds.
However, the call on line 31 fails because foo() is not in the current scope, and no parameter passed to foo() hints that C++ needs to use ADL to consider functions not in the current scope.
Line 32 succeeds because the parameter to foo() is explicitly of type A<int>, and thus C++ uses ADL to look up foo().
This issue with ADL not always looking up a function when it exists is reason to not use this approach with most classes and instead explicitly convert arguments to the correct types when calling a templated friend function. And, if you're already explicitly converting types, you may as well use approach #2 and lose all the complexity of approach #3.
But, in the case where you require implicit type conversions on friend functions of template classes and can guarantee that ADL will succeed in your function calls, approach #3 will work, and in the worst case it is no more difficult to use than approach #2.
Conclusion
C++ has three approaches for implementing friend functions of template classes. The first approach, making each template instantiation of a function friends with each template instantiation of a class, has some unfortunate consequences for object-oriented encapsulation best practices. The second approach explicitly creates both a template class and a template function and makes each instantiation of the class friends with the corresponding instantiation of the function. This approach is generally what people want when they think of making a template function friends with a template class. Unfortunately, however, template functions do not perform implicit conversions on parameters passed to them. The third approach solves this problem by relying on C++'s template instantiation mechanism to generate a non-template friend function associated with each instantiation of a template class. However, calling this function depends on ADL to find that function, so compiler errors may be odd ("function not declared in this scope" rather than "cannot convert argument").
Of course, you should ask yourself whether you need a friend function to begin with! For example, if you implement operator+= as a member function, you can write a templated operator+ function that just calls your public operator+= function and thus does not need to be a friend function in the first place. (However, be aware that this will not perform implicit conversions; you must use approach #3 if you want those.)
Overall, if you need implicit conversions from other types to instances of a template class, you should take approach #3. Otherwise, consider whether you can implement your non-member function by calling public member functions of the template class; if you can, you don't need a friend function at all. If you cannot, then take approach #2.
Problem
You want to build a program that uses exported templates, meaning that it declares templates in headers with the export keyword and places template implementations in .cpp files.
Solution
First, compile the .cpp files containing the template implementations into object files, passing the compiler the command-line options necessary to enable exported templates. Next, compile and link the .cpp files that use the exported templates, passing the compiler and linker the command-line options necessary to enable exported templates as well as the options to specify the directories that contain the template implementations.
The options for enabling exported templates are given in Table 1-39. The options for specifying the location of template implementations are given in Table 1-40. If your toolset does not appear in this table, it likely does not support exported templates.
Table 1-39. Options to enable exported templates
Toolset | Script |
Comeau (Unix) | —export, -A or —strict |
Comeau (Windows) | —export or —A |
Intel (Linux) | -export or -strict-ansi[22] |
[22] Versions of the Intel compiler for Linux prior to 9.0 used the option -strict_ansi. | |
Table 1-40. Option to specify the location of template implementations
Toolset | Script |
Comeau | —template_directory=<path> |
Intel (Linux) | -export_dir<path> |
For example, suppose you want to compile the program displayed in Example 1-27. It consists of three files:
Example 1-27. A simple program using exported templates
plus.hpp:
#ifndef PLUS_HPP_INCLUDED
#define PLUS_HPP_INCLUDED
export template<typename T>
T plus(const T& lhs, const T& rhs);
#endif // #ifndef PLUS_HPP_INCLUDED
plus.cpp:
#include "plus.hpp"
template<typename T>
T plus(const T& lhs, const T& rhs)
{
return rhs + lhs;
}
test.cpp:
#include <iostream>
#include "plus.hpp"
int main()
{
std::cout << "2 + 2 = " << plus(2, 2) << "\n";
}
To compile plus.cpp to an object file plus.obj using Comeau on Unix, change to the directory containing plus.cpp, plus.cpp, and test.cpp, and enter the following command:
$ como -c --export plus.cpp
This command also generates a file plus.et describing the template implementations contained in plus.cpp.
Tip
For fun, open the file plus.et in a text editor.
Next, compile test.cpp to an object file test.obj, as follows:
$ como -c --export test.cpp
Finally, link the executable test.exe:
$ como --export -o test test.obj
The last two commands could also have been combined:
$ como --export -o test test.cpp
You can now run test.exe:
$ ./test
2 + 2 = 4
Alternatively, suppose that the files plus.hpp and plus.cpp are in a directory named plus, while test.cpp is in a sibling directory test. To compile and link test.cpp, change to the directory test and enter:
$ como --export --template_directory=../plus -I../plus -o test
test.cpp
Discussion
C++ supports two models for supplying the definitions of function templates and static data members of class templates: the inclusion model and the separation model. The inclusion model is familiar to all programmers who regularly use C++ templates, but often seems unnatural to programmer accustomed to writing nontemplated code. Under the inclusion model, the definition of a function template—or of a static data member of a class template—must be included by each source file that uses it. By contrast, for nontemplated functions and data it is sufficient for a source file simply to include a declaration; the definition can be placed in a separate .cpp file.
The separation model is closer to the traditional manner of organizing C++ source code. Templates declared with the export keyword do not need to have their definitions included by source files that use them; instead, the definitions can be placed in separate .cpp files. The parallel with traditional source code organization is not exact, though, because even though code that uses an exported template does not need to include its definition, it still depends on the definition in some subtle ways.
The separation model offers several potential benefits:
Reduced compilation times
Compilation time may improve with the separation model because a template’s definition needs to be scanned less frequently and because the separation modules reduce dependencies between modules.
Reduced symbolic “pollution”
Names of functions, classes, and data used in a template’s implementation file can be completely hidden from code that uses the template, reducing the possibility of accidental name clashes. In addition, the author of a template implementation can worry less about accidental clashes with names from the source files that use the template.
The ability to ship precompiled template implementations
In theory, under the separation mode, a vendor could ship template implementations that have been precompiled into a binary format somewhere between C++ source code and ordinary object files.
All three potential advantages of the separation model are controversial. First, while some users have reported reduced compile times, the separation model can also lead to longer compile times in some cases. At the moment, there is insufficient data to make a definitive judgment. Second, while the separation model does reduce some forms of symbolic pollution, the language rules necessary to support the separation model, particularly the notion of two-phase lookup , have complicated the way templated code is written—even when using the inclusion model—and have had some unintended consequences. Third, all existing implementations of the separation model are based on the EDG frontend, and EDG has not yet provided any means to compile source files containing exported template implementations into binary files that can be shipped in lieu of the source.
References:
1. Herbert Schildt, ―C++ The complete reference‖, Eighth Edition, McGraw Hill Professional, 2011, ISBN:978-00-72226805
2. Matt Weisfeld, ―The Object-Oriented Thought Process, Third Edition Pearson ISBN-13:075- 2063330166
3. Cox Brad, Andrew J. Novobilski, ―Object –Oriented Programming: An EvolutionaryApproach‖, Second Edition, Addison–Wesley, ISBN:13:978-020-1548341
4. Deitel, “C++ How to Program”, 4th Edition, Pearson Education, ISBN:81-297-0276-2




