UNIT 6
Standard Template Library (STL)
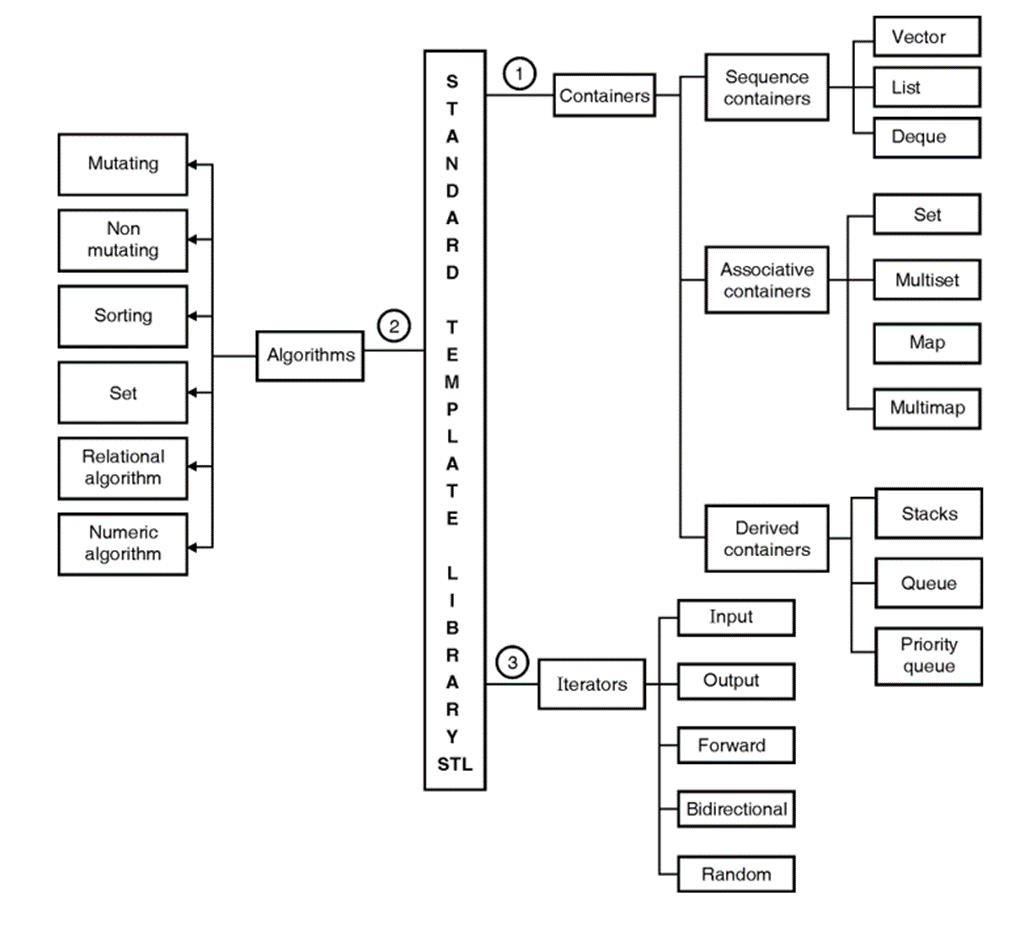
Fig: Standard Template Library (STL)
Components of STL
1. Containers 2. Algorithms 3. Iterators
Components of STL
1. Containers 2. Algorithms 3. Iterators
Containers- Sequence container and associative containers, container adapters
Containers can be broadly categorized into 3 types :
1. Sequence containers
They store the elements in linear fashion and hence all the elements are accessed sequentially.
They are of three types :
(a) Vector :
Container template class for vector
(b) List
(c) Deque
2. Associative containers
(a) Set
(b) Multiset
(c) Map
(d) Multimap
Duplicate keys are permitted.
3. Derived Containers
(a) Stacks
Container template class for vector and stack
1. push : Inserts element
2. pop : Deletes element
3. size : Returns size of stack
4. empty : test if stack is empty
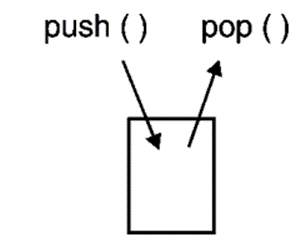
Fig.
(b) queue

Fig.
(c) Priority Queue
(a) Vector :
Container template class for vector
6. size() : Returns the number of elements in a vector.
7. swap() : Exchanges the elements of two vectors.
8. data() : returns the pointer to first element of vector.
9. insert() : insert element at specified position.
10. erase() : Deletes element from specified position.
(b) List
Pseudo-code for MinMax Algorithm:
Initial call:
Minimax(node, 3, true)
Working of Min-Max Algorithm:
Step-1: In the first step, the algorithm generates the entire game-tree and apply the utility function to get the utility values for the terminal states. In the below tree diagram, let's take A is the initial state of the tree. Suppose maximizer takes first turn which has worst-case initial value =- infinity, and minimizer will take next turn which has worst-case initial value = +infinity.
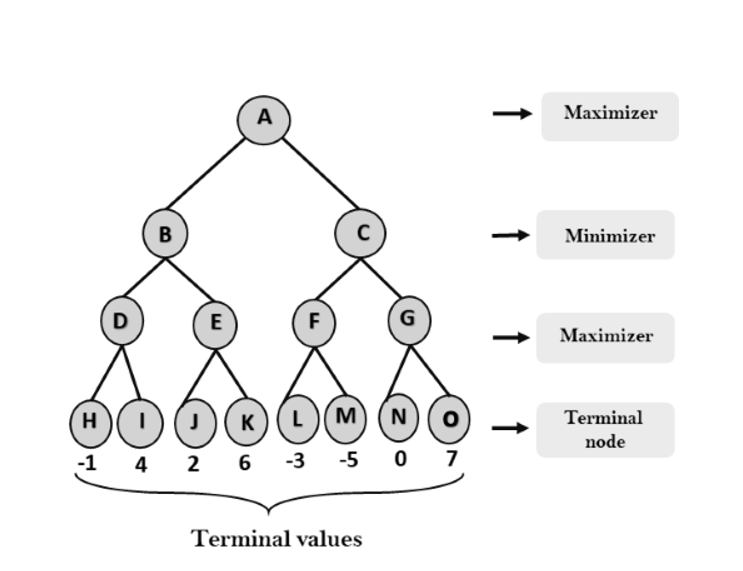
Step 2: Now, first we find the utilities value for the Maximizer, its initial value is -∞, so we will compare each value in terminal state with initial value of Maximizer and determines the higher nodes values. It will find the maximum among the all.
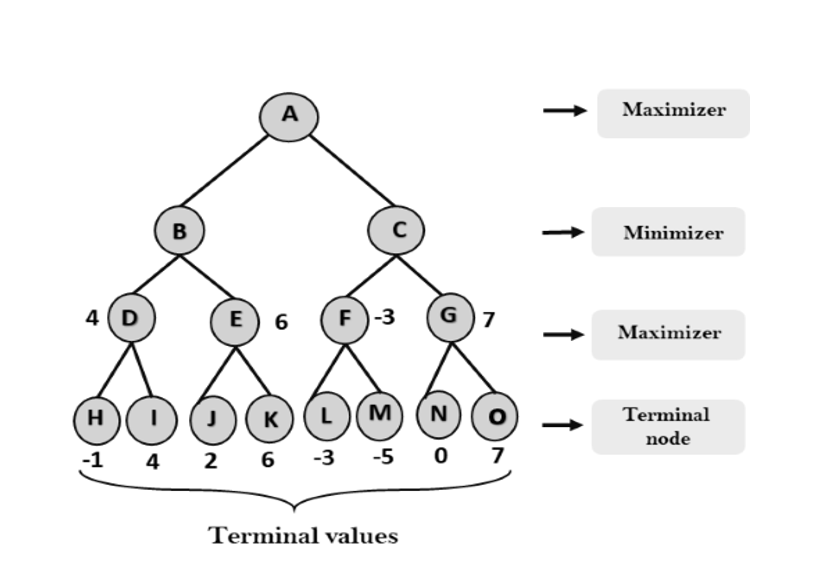
Step 3: In the next step, it's a turn for minimizer, so it will compare all nodes value with +∞, and will find the 3rd layer node values.
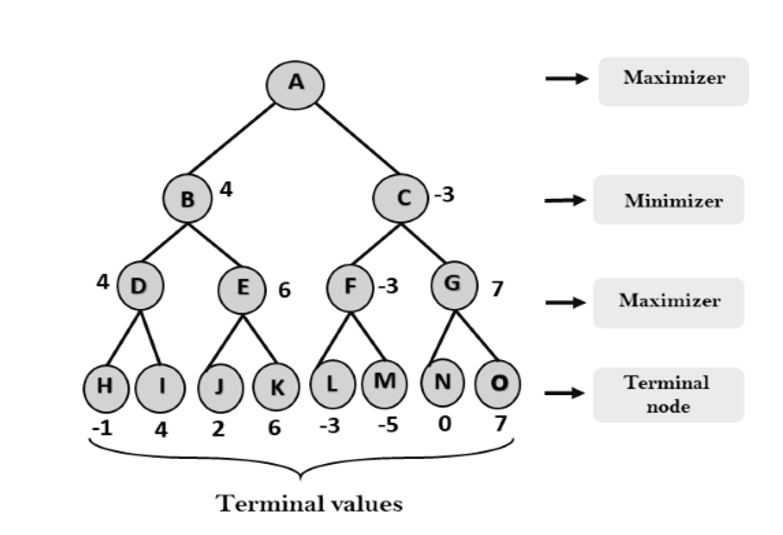
Step 3: Now it's a turn for Maximizer, and it will again choose the maximum of all nodes value and find the maximum value for the root node. In this game tree, there are only 4 layers, hence we reach immediately to the root node, but in real games, there will be more than 4 layers.
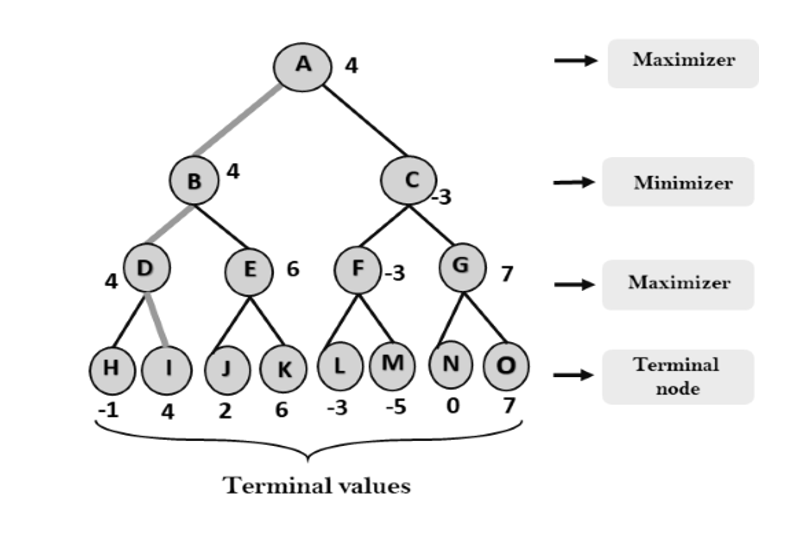
That was the complete workflow of the minimax two player game.
Properties of Mini-Max algorithm:
Introduction to set
Sets are part of the C++ STL (Standard Template Library). Sets are the associative containers that stores sorted key, in which each key is unique and it can be inserted or deleted but cannot be altered.
Syntax
Parameter
T: Type of element stored in the container set.
Compare: A comparison class that takes two arguments of the same type bool and returns a value. This argument is optional and the binary predicate less<T>, is the default value.
Alloc: Type of the allocator object which is used to define the storage allocation model.
Member Functions
Below is the list of all member functions of set:
Constructor/Destructor
Functions | Description |
(constructor) | Construct set |
(destructor) | Set destructor |
operator= | Copy elements of the set to another set. |
Iterators
Functions | Description |
Begin | Returns an iterator pointing to the first element in the set. |
Cbegin | Returns a const iterator pointing to the first element in the set. |
End | Returns an iterator pointing to the past-end. |
Cend | Returns a constant iterator pointing to the past-end. |
Rbegin | Returns a reverse iterator pointing to the end. |
Rend | Returns a reverse iterator pointing to the beginning. |
Crbegin | Returns a constant reverse iterator pointing to the end. |
Crend | Returns a constant reverse iterator pointing to the beginning. |
Capacity
Functions | Description |
Empty | Returns true if set is empty. |
Size | Returns the number of elements in the set. |
max_size | Returns the maximum size of the set. |
Modifiers
Functions | Description |
Insert | Insert element in the set. |
Erase | Erase elements from the set. |
Swap | Exchange the content of the set. |
Clear | Delete all the elements of the set. |
emplace | Construct and insert the new elements into the set. |
emplace_hint | Construct and insert new elements into the set by hint. |
Observers
Functions | Description |
key_comp | Return a copy of key comparison object. |
value_comp | Return a copy of value comparison object. |
Operations
Functions | Description |
Find | Search for an element with given key. |
count | Gets the number of elements matching with given key. |
lower_bound | Returns an iterator to lower bound. |
upper_bound | Returns an iterator to upper bound. |
equal_range | Returns the range of elements matches with given key. |
Allocator
Functions | Description |
get_allocator | Returns an allocator object that is used to construct the set. |
Non-Member Overloaded Functions
Functions | Description |
operator== | Checks whether the two sets are equal or not. |
operator!= | Checks whether the two sets are equal or not. |
operator< | Checks whether the first set is less than other or not. |
operator<= | Checks whether the first set is less than or equal to other or not. |
operator> | Checks whether the first set is greater than other or not. |
operator>= | Checks whether the first set is greater than equal to other or not. |
swap() | Exchanges the element of two sets. |
Heap Sort is based on the binary heap data structure. In the binary heap the child nodes of a parent node are smaller than or equal to it in the case of a max heap, and the child nodes of a parent node are greater than or equal to it in the case of a min heap.
An example that explains all the steps in Heap Sort is as follows.
The original array with 10 elements before sorting is −
20 | 7 | 1 | 54 | 10 | 15 | 90 | 23 | 77 | 25 |
This array is built into a binary max heap using max-heapify. This max heap represented as an array is given as follows.
90 | 77 | 20 | 54 | 25 | 15 | 1 | 23 | 7 | 10 |
The root element of the max heap is extracted and placed at the end of the array. Then max heapify is called to convert the rest of the elements into a max heap. This is done until finally the sorted array is obtained which is given as follows −
1 | 7 | 10 | 15 | 20 | 23 | 25 | 54 | 77 | 90 |
The program to sort an array of 10 elements using the heap sort algorithm is given as follows.
Example
#include<iostream>
using namespace std;
void heapify(int arr[], int n, int i) {
int temp;
int largest = i;
int l = 2 * i + 1;
int r = 2 * i + 2;
if (l < n && arr[l] > arr[largest])
largest = l;
if (r < n && arr[r] > arr[largest])
largest = r;
if (largest != i) {
temp = arr[i];
arr[i] = arr[largest];
arr[largest] = temp;
heapify(arr, n, largest);
}
}
void heapSort(int arr[], int n) {
int temp;
for (int i = n / 2 - 1; i >= 0; i--)
heapify(arr, n, i);
for (int i = n - 1; i >= 0; i--) {
temp = arr[0];
arr[0] = arr[i];
arr[i] = temp;
heapify(arr, i, 0);
}
}
int main() {
int arr[] = { 20, 7, 1, 54, 10, 15, 90, 23, 77, 25};
int n = 10;
i nt i;
cout<<"Given array is: "<<endl;
for (i = 0; i *lt; n; i++)
cout<<arr[i]<<" ";
cout<<endl;
heapSort(arr, n);
printf("\nSorted array is: \n");
for (i = 0; i < n; ++i)
cout<<arr[i]<<" ";
}
Output
Given array is:
20 7 1 54 10 15 90 23 77 25
Sorted array is:
1 7 10 15 20 23 25 54 77 90
In the above program, the function heapify() is used to convert the elements into a heap. This function is a recursive function and it creates a max heap starting from the element it is called on i.e. i in this case. The code snippet demonstrating this is given as follows.
void heapify(int arr[], int n, int i) {
int temp;
int largest = i;
int l = 2 * i + 1;
int r = 2 * i + 2;
if (l < n && arr[l] > arr[largest])
largest = l;
if (r < n && arr[r] > arr[largest])
largest = r;
if (largest != i) {
temp = arr[i];
arr[i] = arr[largest];
arr[largest] = temp;
heapify(arr, n, largest);
}
}
The function heapSort() of sorts the array elements using heap sort. It starts from the non-leaf nodes and calls the heapify() on each of them. This converts the array into a binary max heap. This is shown as follows −
for (int i = n / 2 - 1; i >= 0; i--)
heapify(arr, n, i);
After this, the function heapSort() takes the root element in each iteration of the for loop and puts it at the end of the array. Then heapify() is called to make sure the rest of the elements are a max heap. Eventually, all the elements are taken out of the max heap using this method and a sorted array is obtained. This is shown as follows.
for (int i = n - 1; i >= 0; i--) {
temp = arr[0];
arr[0] = arr[i];
arr[i] = temp;
heapify(arr, i, 0);
}
In the function main(), first the array is displayed. Then, the function heapSort() is called to sort the array. This is given by the following code snippet.
cout<<"Given array is: "<<endl;
for (i = 0; i < n; i++)
cout<<arr[i]<<" ";
cout<<endl;
heapSort(arr, n);
Finally, the sorted array is displayed. This is shown below.
printf("\nSorted array is: \n");
for (i = 0; i < n; ++i)
cout<<arr[i]<<" ";
1. Input : It performs single pass input operation.
2. Output : It performs single pass output operation.
3. Forward : It performs single pass input/output operation but only in forward direction.
4. Bidirectional : It performs single pass input/output operation in forward and backward direction.
5. Random : It performs single pass input/output operation in forward and backward direction. It has ability to jump to any random arbitrary location.
Object Oriented Programming (OOP) is a software design pattern that allows you to think about problems in terms of objects and their interactions. OOP is typically done with classes or with prototypes. Most languages that implement OOP (e.g., Java, C++, Ruby, Python) use class-based inheritance. JavaScript implements OOP via Prototypal inheritance. In this article, I’m going to show you how to use both approaches for OOP in JavaScript, discuss the advantages and disadvantages of the two approaches of OOP and introduce an alternative for OOP for designing more modular and scalable applications.
Primer: What is an Object?
OOP is concerned with composing objects that manages simple tasks to create complex computer programs. An object consists of private mutable states and functions (called methods) that operate on these mutable states. Objects have a notion of self and reused behavior inherited from a blueprint (classical inheritance) or other objects (prototypal inheritance).
Inheritance is the ability to say that these objects are just like that other set of objects except for these changes. The goal of inheritance is to speed up development by promoting code reuse.
Classical Inheritance
In classical OOP, classes are blueprints for objects. Objects are created or instantiated from classes. There’s a constructor that is used to create an instance of the class with custom properties.
Consider the following example:
class Person {
constructor(firstName, lastName) {
this.firstName = firstName
this.lastName = lastName
}
getFullName() {
return this.firstName + ‘ ‘ + this.lastName
}
}
The class keyword from ES6 is used to create the Person class with properties stored in this called firstName and lastName, which are set in the constructor and accessed in the getFullName method.
We instantiate an object called person from the Person class with the new key word as follows:
let person = new Person(‘Dan’, ‘Abramov’)
person.getFullName() //> “Dan Abramov”// We can use an accessor function or access directly
person.firstName //> “Dan”
person.lastName //> “Abramov”
Objects created using the new keyword are mutable. In other words, changes to a class affect all objects created from that class and all derived classes which extends from the class.
To extend a class, we can create another class. Let’s extend the Person class to make a User. A User is a Person with an email and a password.
class User extends Person {
constructor(firstName, lastName, email, password) {
super(firstName, lastName)
this.email = email
this.password = password
}
getEmail() {
return this.email
}
getPassword() {
return this.password
}
}
In the code above, we created a User class which extends the capability of the Person class by adding email and password properties and accessor functions. In the App function below, a user object is instantiated from the User class:
function App() {
let user = new User('Dan',
'Abramov',
' dan@abramov.com ',
'iLuvES6')
user.getFullName() //> "Dan Abramov"
user.getEmail() //> “dan@abramov.com”
user.getPassword() //> “iLuvES6” user.firstName //> “Dan”
user.lastName //> “Abramov”
user.email //> “dan@abramov.com”
user.password //> “iLuvES6”
}
That seems to work just fine but there’s a big design flaw with using the classical inheritance approach: How the heck do the users of the User class (e.g., App) know User comes with firstName and lastName and there’s a function called getFullName that can be used? Looking at the code for User class does not tell us anything about the data or methods from its super class. We have to dig into the documentation or trace code through the class hierarchy.
The problem with inheritance is that the descendants have too much access to the implementation details of every base class in the hierarchy, and vice versa. When the requirements change, refactoring a class hierarchy is so hard that it turns into a WTF sandwich with traces of outdated requirements.
Classical inheritance is based on establishing relationships through dependencies. The base class (or super class) sets the baseline for the derived classes. Classical inheritance is OK for small and simple applications that don’t often change and has no more than one level of inheritance (keeping our inheritance trees shallow to avoid The Fragile Base Classproblem) or wildly different use cases. Class-based inheritance can become unmaintainable as the class hierarchy expands.
Eric Elliot described how classical inheritance can potentially lead to project failure, and in the worst cases, company failures:
Get enough clients using new, and you can’t back out of the constructor implementation even if you want to, because code you don’t own will break if you try.
When many derived classes with wildly different use cases are created from the same base class, any seemingly benign change to the base class could cause the derived classes to malfunction. At the cost of increased complexity to your code and the entire software creation process, you could try to mitigate side effects by creating a dependency injection container to provide an uniform service instantiation interface by abstracting the instantiation details. Is there a better way?
Prototypal Inheritance
Prototypal inheritance does not use classes at all. Instead, objects are created from other objects. We start with a generalized object we called a prototype. We can use the prototype to create other objects by cloning it or extend it with custom features.
typeof Person //> “function”
typeof User //> “function”
ES6 classes are actually syntactic sugar of JavaScript’s existing prototypal inheritance. Under the hood, creating a class with a new keyword creates a function object with code from the constructor.
JavaScript is fundamentally a prototype-oriented language.
The simple types of JavaScript are numbers, strings, booleans (true and false), null, and undefined. All other values are objects. Numbers, strings, and booleans are object-like in that they have methods, but they are immutable. Objects in JavaScript are mutable keyed collections. In JavaScript, arrays are objects, functions are objects, regular expressions are objects, and, of course, objects are objects. ~ JavaScript: The Good Parts by Douglas Crockford (creator of JSON)
Let’s look at one of these objects that JavaScript gives us for free out-of-the-box: the Array.
Array instances inherit from Array.prototype which includes many methods which are categorized as accessors (do not modify the original array), mutators (modifies the original array), and iterators (applies the function passed in as an argument onto every element in the array to create a new array).
Accessors
Mutators:
Mutator functions modify the original array. splice gives you the same sub-array as slice but you want to maintain the original array, slice is a better choice.
Iterators:
map and forEach are similar in that they are doing something to everything to the array but the key difference is map returns an array while forEach is like a void function and returns nothing. Good functional software design practices say we should always write functions that has no side effects, i.e., don’t use void functions. forEach doesn’t do anything to the original array so map is a better choice if you want to do any data transformation. One potential use case of forEach is printing to console for debugging:
let arr = [1,2,3]
arr.forEach(e => console.log(e))
arr //> [1,2,3]
Suppose we want to extend the Array prototype by introducing a new method called partition, which divides the array into two arrays based on a predicate. For example [1,2,3,4,5] becomes [[1,2,3], [4,5]] if the predicate is “less than or equal to 3”. Let’s write some code to add partition to the Array prototype:
Array.prototype.partition = function(pred) {
let passed = []
let failed = []
for(let i=0; i<this.length; i++) {
if (pred(this[i])) {
passed.push(this[i])
} else {
failed.push(this[i])
}
}
return [ passed, failed ]
}
Now we can use partition on any array:
[1,2,3,4,5].partition(e => e <=3)
//> [[1, 2, 3], [4, 5]]
[1,2,3,4,5] is called a literal. The literal is one way to create an object. We can also use factory functions or Object.create to create the same array:
// Literal
[1,2,3,4,5]// Factory Function
Array(1,2,3,4,5)// Object.create
let arr = Object.create(Array.prototype)
arr.push(1)
arr.push(2)
arr.push(3)
arr.push(4)
arr.push(5)
A factory function is any function that takes a few arguments and returns a new object composed of those arguments. In JavaScript, any function can return an object. When it does so without the new keyword, it’s a factory function. Factory functions have always been attractive in JavaScript because they offer the ability to easily produce object instances without diving into the complexities of classes and the new keyword.
In the code above, we created an object called arr using Object.create and pushed 5 elements into the array. arr comes with all the functions inherited from the Array prototype such as map, pop, slice, and even partition that we just created for the Array prototype. Let’s add some more functionality to the arr object:
arr.hello = () => “hello”
Pop Quiz! What’s going to be returned when we run the following code?
arr.partition(e => e < 3) // #1arr.hello() // #2let foo = [1,2,3]
foo.hello() // #3Array.prototype.bye = () => “bye”
arr.bye() // #4
foo.bye() // #5
Answers
Now we understand the fundamental of prototype, let’s go back to the previous example and create Person and User using prototypal inheritance:
function Person(firstName, lastName) {
this.firstName = firstName
this.lastName = lastName
}
Person.prototype.getFullName = function () {
return this.firstName + ‘ ‘ + this.lastName
}
Now we can use the Person prototype like so:
let person = new Person(‘Dan’, ‘Abramov’)
person.getFullName() //> Dan Abramov
person is an object. Doing a console.log(person gives us the following:
Person {
firstName: “Dan”,
lastName: “Abramov”,
__proto__: {
getFullName: f
constructor: f Person(firstName, lastName)
},
__proto__: Object
}
For our User, we just need to extend the Person class:
function User(firstName, lastName, email, password) {
// call super constructor:
Person.call(this, firstName, lastName) this.email = email
this.password = password
}User.prototype = Object.create(Person.prototype);User.prototype.setEmail = function(email) {
this.email = email
}User.prototype.getEmail = function() {
return this.email
}user.setEmail(‘dan@abramov.com’)
user is an object. Doing a console.log(user) gives us the following:
User {
firstName: “Dan”,
lastName: “Abramov”,
email: “dan@abramov.com”,
password: “iLuvES6”,
__proto__: Person {
getEmail: f ()
setEmail: f (email)
__proto__: {
getFullName: f,
constructor: f Person(firstName, lastName)
__proto__: Object
}
}
}
What if we want to customize the getFullName function for User? How is the following code going to affect person and user?
User.prototype.getFullName = function () {
return 'User Name: ' +
this.firstName + ' ' +
this.lastName
}user.getFullName() //> “User Name: Dan Abramov”
person.getFullName() //> “Dan Abramov”
As we expect, person is not be affected at all.
How about decorating the Person object by adding a gender attribute and corresponding getter and setter functions?
Person.prototype.setGender = function (gender) {
this.gender = gender
}
Person.prototype.getGender = function () {
return this.gender
}person.setGender(‘male’)
person.getGender() //> maleuser.getGender() //> returns undefined … but is a function
user.setGender(‘male’)
user.getGender() //> male
Both person and user are affected because User is prototyped from Person so if Person changes, User changes too.
The decorator pattern from prototypal inheritance is not so different from the classical inheritance.
Classes vs Prototypes
Instead of creating a class hierarchy, consider creating several factory functions. They may call each other in chain, tweaking the behavior of each other. You may also teach the “base” factory function to accept a “strategy” object modulating the behavior, and have the other factory functions provide it.
A Third way: No OOP
The three cornerstones of OOP — Inheritance, Encapsulation, and Polymorphism — are powerful programming tools/concepts but have their shortcomings:
Inheritance
Inheritance promotes code reuse but you are often forced to take more than what you want.
Joe Armstrong (creator of Erlang) puts it best:
The problem with object-oriented languages is they’ve got all this implicit environment that they carry around with them. You wanted a banana but what you got was a gorilla holding the banana and the entire jungle.
So what if there’s more than what we ask for? Can’t we just ignore the stuff we don’t need? Only if it’s that simple. When we need classes that depend on other classes, which depend on other classes, we’re going to have to deal with dependency hell, which really slows down the build and debugging processes. Additionally, applications that carry a long chain of dependencies are not very portable.
There’s of course the fragile base class problem as mentioned above. It’s unrealistic to expect everything to fall neatly into placewhen we create mappings between real-world objects and their classes. Inheritance is not forgiving when you need to refactor your code, especially the base class. Also, inheritance weakens encapsulation, the next cornerstone of OOP:
The problem is that if you inherit an implementation from a superclass and then change that implementation, the change from the superclass ripples through the class hierarchy. This rippling effect potentially affects all the subclasses.
Encapsulation
Encapsulation keeps every object’s internal state variables safe from the outside. The ideal case is that your program would consist of “islands of objects” each with their own states passing messages back and forth. This sounds like a good idea in theory if you are building a perfectly distributed system but in practice, designing a program consisting of perfectly self-contained objects is hard and limiting.
Lots of real world applications require solving difficult problems with many moving parts. When you take an OOP approach to design your application, you’re going to run into conundrums like how do you divide up the functionalities of your overall applications between different objects and how to manage interactions and data sharing between different objects. This article has some interesting points about the design challenges OOP applications:
When we consider the needed functionality of our code, many behaviors are inherently cross-cutting concerns and so don’t really belong to any particular data type. Yet these behaviors have to live somewhere, so we end up concocting nonsense doer classes to contain them…And these nonsense entities have a habit of begetting more nonsense entities: when I have umpteen Manager objects, I then need a ManagerManager.
It’s true. I’ve seen “ManagerManager classes” in production software that wasn’t originally designed to be this way has grown in complexity over the years.
As we will see next when I introduce function composition (the alternative to OOP), we have something much simpler than objects that encapsulates its private variables and performs a specific task — it’s called functions!
But before we go there, we need to talk about the last cornerstone of OOP:
Polymorphism
Polymorphism let’s us specify behavior regardless of data type. In OOP, this means designing a class or prototype that can be adapted by objects that need to work with different kinds of data. The objects that use the polymorphic class/prototype needs to define type-specific behavior to make it work. Let’s see an example.
Suppose to want to create a general (polymorphic) object that takes some data and a status flag as parameters. If the status says the data is valid (i.e., status === true), a function can be applied onto the data and the result, along with the status flag, will be returned. If the status flags the data as invalid, then the function will not be applied onto the data and the data, along with the invalid status flag, will be returned.
Let’s start with creating a polymorphic prototype object called Maybe:
function Maybe({data, status}) {
this.data = data
this.status = status
}
Maybe is a wrapper for data. To wrap the data in Maybe, we provide an additional field called status that indicates if the data is valid or not.
We can make Maybe a prototype with a function called apply, which takes a function and applies it on the data only if the status of the data indicates that it is valid.
Maybe.prototype.apply = function (f) {
if(this.status) {
return new Maybe({data: f(this.data), status: this.status})
}
return new Maybe({data: this.data, status: this.status})
}
We can add another function to the Maybe prototype which gets the data or returns a message if there’s an error with the data.
Maybe.prototype.getOrElse = function (msg) {
if(this.status) return this.data
return msg
}
Now we create two objects from the Maybe prototype called Number:
function Number(data) {
let status = (typeof data === 'number')
Maybe.call(this, {data, status})
}
Number.prototype = Object.create(Maybe.prototype)
and String:
function String(data) {
let status = (typeof data === ‘string’)
Maybe.call(this, {data, status})
}
String.prototype = Object.create(Maybe.prototype)
Let’s see our objects in action. We create a function called increment that’s only defined for numbers and another function called split that’s only defined for strings:
const increment = num => num + 1
const split = str => str.split('')
Because JavaScript is not type safe, it won’t prevent you from incrementing a string or splitting a number. You will see a runtime error when you uses an undefined method on a data type. For example, suppose we try the following:
let foop = 12
foop.split('')
That’s going to give you a type error when you run the code.
However, if we used our Number and String objects to wrap the numbers and strings before operating on them, we can prevent these run time errors:
let numValid = new Number(12)
let numInvalid = new Number(“foo”)
let strValid = new String(“hello world”)
let strInvalid = new String(-1)let a = numValid.apply(increment).getOrElse('TypeError!')
let b = numInvalid.apply(increment).getOrElse('TypeError Oh no!')
let c = strValid.apply(split).getOrElse('TypeError!')
let d = strInvalid.apply(split).getOrElse('TypeError :(')
What will the following print out?
console.log({a, b, c, d})
Since we designed our Maybe prototype to only apply the function onto the data if the data is the right type, this will be logged to console:
{
a: 13,
b: ‘TypeError Oh no!’,
c: [ 'h', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd' ],
d: ‘TypeError :(‘
}
What we just did is a type of a monad (albeit I didn’t implement Maybe to follow all the monad laws). The Maybe monad is a wrapper that’s used when a value can be absent or some validation can fail and you don’t care about the exact cause. Typically this can occur during data retrieval and validation. Maybe handles failure in validation or failure in applying a function similar to the try-catch you’ve likely seen before. In Maybe, we are handling the failure in type validation by printing to a string, but we can easily revise the getOrElse function to call another function which handles the validation error.
Some programming languages like Haskell come with a built-in monad type, but in JavaScript, you have to roll your own. ES6 introduced Promise, which is a monad for dealing with latency. Sometimes you need data that could take a while to retrieve. Promise lets you write code that appears synchronous while delaying operation on the data until the data becomes available. Using Promise is a cleaner way of asynchronous programming than using callback functions, which could lead to a phenomenon called the callback hell.
Composition
As alluded to earlier, there’s something much simpler than class/prototypes which can be easily reused, encapsulates internal states, performs a given operation on any type of data, and be polymorphic — it’s called functional composition.
JavaScript easily lets us bundle related functions and data together in an object:
const Person = {
firstName: 'firstName',
lastName: 'lastName',
getFullName: function() {
return ${this.firstName} ${this.lastName}
}
}
Then we can use the Person object directly like this:
let person = Object.create(Person)person.getFullName() //> “firstName lastName”// Assign internal state variables
person.firstName = 'Dan'
person.lastName = 'Abramov'// Access internal state variables
person.getFullName() //> “Dan Abramov”
Let’s make a User object by cloning the Person object, then augmenting it with additional data and functions:
const User = Object.create(Person)
User.email = ''
User.password = ''
User.getEmail = function() {
return this.email
}
Then we can create an instance of user using Object.create
let user = Object.create(User)
user.firstName = 'Dan'
user.lastName = 'Abramov'
user.email = 'dan@abramov.com'
user.password = 'iLuvES6'
A gotcha here is use Object.create whenever you want to copy. Objects in JavaScript are mutable so when you straight out assigning to create a new object and you mutate the second object, it will change the original object!
Except for numbers, strings, and boolean, everything in JavaScript is an object.
// Wrong
const arr = [1,2,3]
const arr2 = arr
arr2.pop()
arr //> [1,2]
In the above example, I used const to show that it doesn’t protect you from mutating objects. Objects are defined by their reference so while const prevents you from reassigning arr, it doesn’t make the object “constant”.
Object.create makes sure we are copying an object instead of passing its reference around.
Like Lego pieces, we can create copies of the same objects and tweak them, compose them, and pass them onto other objects to augment the capability of other objects.
For example, we define a Customer object with data and functions. When our User converts, we want to add the Customer stuff to our user instance.
const Customer = {
plan: 'trial'
}
Customer.setPremium = function() {
this.plan = 'premium'
}
Now we can augment user object with an Customer methods and fields.
User.customer = Customer
user.customer.setPremium()
After running the above two lines of codes, this becomes our user object:
{
firstName: 'Dan',
lastName: 'Abramov',
email: 'dan@abramov.com',
password: 'iLuvES6',
customer: { plan: 'premium', setPremium: [Function] }
}
When we want to supply a object with some additional capability, higher order objects cover every use case.
Classical inheritance creates is-a relationships with restrictive taxonomies, all of which are eventually wrong for new use-cases. But it turns out, we usually employ inheritance for has-a, uses-a, or can-do relationships.
References:
1. Herbert Schildt, ―C++ The complete reference‖, Eighth Edition, McGraw Hill Professional, 2011, ISBN:978-00-72226805
2. Matt Weisfeld, ―The Object-Oriented Thought Process, Third Edition Pearson ISBN-13:075- 2063330166
3. Cox Brad, Andrew J. Novobilski, ―Object –Oriented Programming: An EvolutionaryApproach‖, Second Edition, Addison–Wesley, ISBN:13:978-020-1548341
4. Deitel, “C++ How to Program”, 4th Edition, Pearson Education, ISBN:81-297-0276-2




