File is a collection of records related to each other. The file size is limited by the size of memory and storage medium.
There are two important features of file:
1. File Activity
2. File Volatility
File activity specifies percent of actual records which proceed in a single run.
File volatility addresses the properties of record changes. It helps to increase the efficiency of disk design than tape.
File Organization
File organization ensures that records are available for processing. It is used to determine an efficient file organization for each base relation.
For example, if we want to retrieve employee records in alphabetical order of name. Sorting the file by employee name is a good file organization. However, if we want to retrieve all employees whose marks are in a certain range, a file is ordered by employee name would not be a good file organization.
There are three types of organizing the file:
1. Sequential access file organization
2. Direct access file organization
3. Indexed sequential access file organization
1. Sequential access file organization
Advantages of sequential file
Disadvantages of sequential file
2. Direct access file organization
Advantages of direct access file organization
Disadvantages of direct access file organization
3. Indexed sequential access file organization
Advantages of Indexed sequential access file organization
Disadvantages of Indexed sequential access file organization
Key takeaway
File Organization
File organization ensures that records are available for processing. It is used to determine an efficient file organization for each base relation.
For example, if we want to retrieve employee records in alphabetical order of name. Sorting the file by employee name is a good file organization. However, if we want to retrieve all employees whose marks are in a certain range, a file is ordered by employee name would not be a good file organization.
It is one of the simple methods of file organization. Here each file/records are stored one after the other in a sequential manner. This can be achieved in two ways:

Inserting a new record:
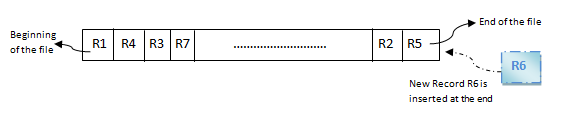
In the diagram above, R1, R2, R3 etc are the records. They contain all the attribute of a row. i.e.; when we say student record, it will have his id, name, address, course, DOB etc. Similarly R1, R2, R3 etc can be considered as one full set of attributes.

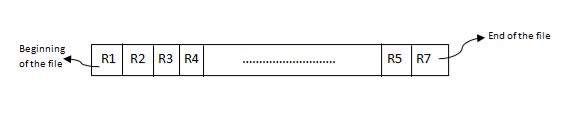
Inserting a new record:
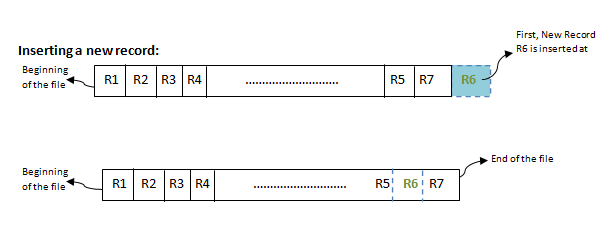
Advantages of Sequential File Organization
Disadvantages of Sequential File Organization
Key takeaway
It is one of the simple methods of file organization. Here each file/records are stored one after the other in a sequential manner. This can be achieved in two ways:
When a file is used, information is read and accessed into computer memory and there are several ways to access this information of the file. Some systems provide only one access method for files. Other systems, such as those of IBM, support many access methods, and choosing the right one for a particular application is a major design problem.
There are three ways to access a file into a computer system: Sequential-Access, Direct Access, Index sequential Method.
It is the simplest access method. Information in the file is processed in order, one record after the other. This mode of access is by far the most common; for example, editor and compiler usually access the file in this fashion.
Read and write make up the bulk of the operation on a file. A read operation -read next- read the next position of the file and automatically advance a file pointer, which keeps track I/O location. Similarly, for the writewrite next append to the end of the file and advance to the newly written material.
Key points:
2. Direct Access –
Another method is direct access method also known as relative access method. A filed-length logical record that allows the program to read and write record rapidly. in no particular order. The direct access is based on the disk model of a file since disk allows random access to any file block. For direct access, the file is viewed as a numbered sequence of block or record. Thus, we may read block 14 then block 59 and then we can write block 17. There is no restriction on the order of reading and writing for a direct access file.
A block number provided by the user to the operating system is normally a relative block number; the first relative block of the file is 0 and then 1 and so on.
3. Index sequential method –
It is the other method of accessing a file which is built on the top of the sequential access method. These methods construct an index for the file. The index, like an index in the back of a book, contains the pointer to the various blocks. To find a record in the file, we first search the index and then by the help of pointer we access the file directly.
Key points:
Key takeaway
When a file is used, information is read and accessed into computer memory and there are several ways to access this information of the file. Some systems provide only one access method for files. Other systems, such as those of IBM, support many access methods, and choosing the right one for a particular application is a major design problem.
ISAM method is an advanced sequential file organization. In this method, records are stored in the file using the primary key. An index value is generated for each primary key and mapped with the record. This index contains the address of the record in the file.
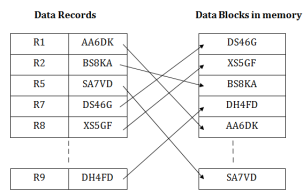
If any record has to be retrieved based on its index value, then the address of the data block is fetched and the record is retrieved from the memory.
Key takeaway
ISAM method is an advanced sequential file organization. In this method, records are stored in the file using the primary key. An index value is generated for each primary key and mapped with the record. This index contains the address of the record in the file.
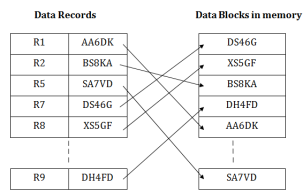
If any record has to be retrieved based on its index value, then the address of the data block is fetched and the record is retrieved from the memory.
File organization
1. Sequential Organization
Interpreting disk memory as sequential memory
- It is easy to implement;
- It provides fast access to the next record using lexicographic order.
- It is difficult to update - inserting a new record may require moving a large proportion of the file;
- Random access is extremely slow.
2. Random File organization
Direct addressing: in direct addressing with equi-size records, available disk space is divided out into nodes large enough to hold a record. Numeric value of primary key is used to determine the node into which a particular record is to be stored.
Directory lookup: the index is not direct access type but is a dense index maintained using a structure suitable for index operations. Retrieving a record involves searching the index for the record address and then accessing the record itself. The storage management scheme will depend on whether fixed size or variable size nodes are being used. It requires more accesses for retrieval and update, since index searching will generally require more than one access. In both direct addressing and directory lookup, some provision must be made to handle collisions.
Hashing: the available file space is divided into buckets and slots. Some space may have to be set aside for an overflow area in case chaining is being used to handle overflows. When variable size records are present, the no. of slots per bucket will be only rough indicator of no. of records a bucket can hold. The actual no. will vary dynamically with the size of records in a particular bucket. Random organization on the primary key using any of the above three techniques overcomes the difficulties of sequential organizations. Insertion, deletions become easy. But batch processing of queries becomes inefficient as records are not maintained in order of primary key. Handling range queries becomes very inefficient except in case of directory lookup.
3. Linked organization
4. Inverted files
5. Cellular partitions
Key takeaway
References:
1. Horowitz, Sahani, Dinesh Mehata, ―Fundamentals of Data Structures in C++‖, Galgotia Publisher, ISBN: 8175152788, 9788175152786.
2. M Folk, B Zoellick, G. Riccardi, ―File Structures‖, Pearson Education, ISBN:81-7758-37-5
3. Peter Brass, ―Advanced Data Structures‖, Cambridge University Press, ISBN: 978-1-107- 43982-5
4. A. Aho, J. Hopcroft, J. Ulman, ―Data Structures and Algorithms‖, Pearson Education, 1998, ISBN-0-201-43578-0.
5. Michael J Folk, ―File Structures an Object-Oriented Approach with C++‖, Pearson Education, ISBN: 81-7758-373-5.
6. Sartaj Sahani, ―Data Structures, Algorithms and Applications in C++‖, Second Edition, University Press, ISBN:81-7371522 X.
7. G A V Pai, ―Data Structures and Algorithms‖, The McGraw-Hill Companies, ISBN - 9780070667266.
8. Goodrich, Tamassia, Goldwasser, ―Data Structures and Algorithms in Java‖, Wiley Publication, ISBN: 9788126551903




