Unit 3
Estimation and Scheduling
Estimation for Software Projects
Project Planning is an organized and integrated management process, which focuses on activities required for the successful completion of the project. Planning is undertaken and completed even before any development activity starts.
Estimating the subsequent attributes of the project
● Project Size: What’s going to be the size of the project?
● Cost: How much is it going to cost to develop the software?
● Duration: How long will it take to develop the complete project?
● Effort: What proportion of effort would be required to develop a project?
The effectiveness of the following relies on the accuracy of those estimations.
● Planning force and alternative resources
● Workers organization and staffing plans
● Risk identification, analysis, and designing
● Miscellaneous activities such as configuration, quality assurance plan, management, etc.
Project preparation for software is a task that is carried out before software development begins. It is there for the development of software but does not involve any specific operation linked to software production in any direction; rather, it is a collection of multiple processes that encourage software production.
Precise estimation of multiple measures is a must for successful management. Managers can plan and monitor the project more efficiently and effectively with accurate estimates.
Estimating the project could include the following:
● Size of software
● Software quality
● Hardware
● Additional software or tools, licenses, etc.
● Skilled personnel with task-specific skills
● Travel involved
● Communication
● Training and support
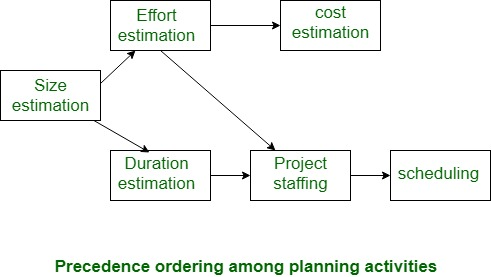
Fig 1: planning activity
Key takeaway :
- Even before any construction operation begins, project design is performed and finished.
- Project Planning is an organized and integrated management process, which focuses on activities required for the successful completion of the project.
The spectrum of applications determines -
- The functions and features that are to be given to end-users.
- The input and output data from the machine.
- Content that is given to users as a result of the program being used.
- Performance, constraints, interfaces, and system-bound reliability.
Scopes can be described by two methods -
- After consultation with all stakeholders, a narrative description of the software scope is developed.
- End users build a set of use cases.
-
Two questions are asked after the scope has been established
- Can we develop applications to comply with this range?
- Is the project practicable?
Too frequently, software developers hurry through these issues.
They are then mired in a project that has been doomed from the beginning.
Feasibility is discussed until the scope is resolved.
Four dimensions of software viability—
- Technology: Technically, is the project feasible? Is it just the state of the art? Can vulnerabilities be minimized to a degree that suits the needs of the application?
- Finance: Is it financially achievable? Can production be done at an expense that can be afforded by the software enterprise, its customer, or the market?
- Time: Can the time-to-market of the project beat the competition?
- Resources: Does the software organization have the resources available to do the project successfully?
Key takeaway :
- After consultation with all stakeholders, a narrative description of the software scope is developed.
- Before the scope is resolved, feasibility is explored.
For that project, all elements used to create a software product can be considered as a resource. This could include human resources, efficient tools, and libraries of software.
Resources are available in small amounts and remain as a pool of assets in the company. The lack of resources hampers project progress and it can lag behind the timetable. Ultimately, allocating more capital raises construction costs. Therefore, the assessment and allocation of sufficient resources for the project is important.
Management of resources requires -
Key takeaway :
- Resources are available in small amounts and remain as a pool of assets in the company.
Software products are costly therefore a software project manager always looks for ways for cutting development costs. A feasible way to reduce development costs is to reuse parts from pre-developed software. Reuse also leads to a higher quality of the developed products.
In software development following items can be reused effectively-
Many organizations use a promising approach i.e. Introduction of a building block approach. For this, the reusable components need to be identified. The most critical issue to reuse effort is to identify reusable components. This issue is prominently handed in by the Domain analysis approach.
● Domain Analysis: Its main aim is to identify the reusable components for a problem domain. A reuse domain is technically a related set of application areas. In this, a body of information is considered to be a problem domain for reuse. A reuse domain is a shared understanding of some community characterized by concepts, techniques, and terminologies that show some relationship. Some examples of domains are accounting, banking, business, manufacturing, automation, etc.
The construction of reusable components is called domain engineering.
The development of problem-oriented language is the ultimate result of domain analysis. Problem-oriented languages are also known as application generators. These application generators after development form application development standards. Following are the stages in which a domain develops -
Stage 1 - No reusable components are available. All software is written from scratch.
Stage 2 - The only experience from similar projects is used in development i.e. there is only knowledge reuse.
Stage 3 - At this point, the domain is ready for the result. Standard solutions to standard problems are available i.e. there is both knowledge and component reuse.
Stage 4 - At this stage, the domain has been fully explored. Programs are now written using a domain-specific language (application generator).
● Component Classification: To develop effective indexing and storing, components need to be properly classified. In general hardware components are classified using a multilevel hierarchy. The higher the level, the more ambiguous it becomes.
According to Prieto-Diaz’s classification scheme, each component is best described using some different characteristics or facets. E.g. object can be classified using the action it performs, objects they change and data structures they used, etc.
● Searching: The repository contains 1000’s reuse items. A popular search technique is the one that provides a web interface to the repository. In this, one would search an item using an automated search using keywords and then from these results would do browsing. This search locates products that appear to fulfill some of the specified requirements.
● Repository maintenance: It involves the entrance of new items, retiring items that are not necessary, and hanging the search attributes to improve the searching apart from this, links of several items may also need to be modified. As technology is advancing, reusable components also do not fully address the requirements on the other hand it is hampering reuse opportunities. Also, negative experience tends to eliminate the trust in the entire reuse system.
● Reuse without modification: It is much more usable than the classical program libraries. In this one can directly plug in the parts in the previous program parts and develop his application. This is supported by compilers through application generators.
Key takeaway :
- the reusable components need to be identified.
- The most critical issue to reuse effort is to identify reusable components.
Environmental services are combined with software and hardware.
Hardware offers a forum that supports the resources needed to manufacture goods for the job.
Access to the hardware elements is required by the software team. A hardware element is defined by the software project planner.
A software framework that supports the development, repair, and improvement of software, as well as the management and control of such operations. The central database and a range of software resources are included in a typical framework. For the lifespan of the project, the central database serves as a repository for all knowledge relevant to a project. The software tools provide support for the different tasks that must be conducted on the project, both technological and managerial.
The project manager may use two commonly accepted methods to estimate the mentioned factors.
The software is believed by this approach to be a product of different compositions.
Before it is possible to make an approximation and apply decomposition techniques, the planner must
- Understand the complexity of the program to be designed.
- Generate an approximation of the size of the program.
Either of the two strategies is then used
- Problem-based estimation
Based on either code source lines or estimates of feature points.
- Process-based estimation
Based on the effort needed to achieve each assignment.
Two major models exist -
Line of code (LOC): The calculation is conducted on behalf of the number of codes in the software product line.
Functions points (FP): Estimation is performed on behalf of the number of software product feature points.
3.7.1 Software Sizing
● Function point sizing
- Create estimates of the features of the information domain.
● Standard component sizing
- Estimate the number of occurrences of each aspect of the norm.
- The delivered LOC size per standard component is calculated using historical project data.
● Change sizing
- Used while improvements to current software are being made.
- Estimate the number and form of improvements that need to be completed.
- Reuse, inserting code, modifying code, and removing code are forms of modifications.
- To measure each form of change and the size of the change, an effort ratio is then used.
3.7.2 Problem-Based Estimation
Start with a restricted declaration of the scope. Decompose the program into problem functions that can be independently calculated for each one. For each function, compute a LOC or FP value. By adding the LOC or FP values to the base productivity metrics (e.g. LOC/person-month or FP/person-month) to extract cost or effort estimates. Merge for the whole project.
LOC and FP estimation are different estimation methods, but both have some characteristics in common. The project manager starts with a restricted software scope statement and tries to decompose software into problem functions that can be independently calculated from this statement. LOC or FP (the estimation variable) is then estimated for each function.
However, it is important to remember that productivity metrics for an enterprise are often greatly distributed, rendering the use of a single baseline productivity metric suspicious. Averages of LOC/pm or FP/pm can usually be determined by the project domain. That is, projects should be grouped according to the size of the team, the area of application, difficulty, and other related parameters.
In the degree of detail needed for decomposition and the goal of the partitioning, the LOC and FP estimation techniques differ. Decomposition is completely necessary when LOC is used as the estimation variable and is always taken to significant levels of detail.
It is then possible to compute a three-point or predicted value. The expected value can be calculated as a weighted average of the positive (sopt), most likely (sm), and pessimistic (spess) estimates for the estimation variable (size), S.
For instance,
S = (sopt + 4sm + spess)/6
3.7.3 Process-Based Estimation
The most popular way of estimating a project is to base the estimation on the method that will be used. That is, the method is broken down into a relatively small set of tasks and it calculates the effort needed to accomplish each task.
Process-based estimation starts, like problem-based techniques, with a delineation of software functions obtained from the scope of the project. For each function, a sequence of software process operations must be performed.
Functions and related activities of the software process can be described as part of a table.
When problem functions and process activities are melded, the planner calculates the effort needed to execute each software process operation for each software function (e.g., person-months). These data constitute the table's core matrix.
The calculated effort for each process operation is then compared to average labour rates (i.e., cost/unit effort). For each job, it’s possible that the labour rate would differ. In general, senior employees heavily involved in early operations are more expensive than junior employees involved in later design projects, code creation, and early testing.
Key takeaway :
- In decomposition technique
- Understand the complexity of the program to be designed.
- Generate an approximation of the size of the program.
- Decompose the program into problem functions that can be independently calculated for each one.
- LOC and FP estimation are different estimation methods, but both have some characteristics in common.
- Process-based estimation starts, like problem-based techniques, with a delineation of software functions obtained from the scope of the project
Method Lines of Code (LOC) tests software and the mechanism by which it is produced. Until a software estimation is made, it is critical and appropriate to understand and estimate the size of the software scope.
Lines of Code (LOC) is a direct approach method which, by decomposition and partitioning, involves a higher degree of detail. In comparison, Feature Points (FP) is an indirect approach method where it focuses on the domain characteristics instead of focusing on the function.
Using the following formula, an estimated value is then computed.
Where,
● EV - estimation variable.
● Sopt - optimistic estimate.
● Sm - most likely estimate.
● Spess - pessimistic estimate.
It is known that there is a very small chance that the effects of the actual size will fall beyond the value of optimism or pessimism.
Contemporary LOC or FP data are applied after the estimated value for the estimation variable has been determined, and personal months, costs, etc. are measured using the following formula.
Productivity = KLOC / Person-month
Quality = Defects / KLOC
Cost = $ / LOC
Documentation = pages of documentation / KLOC
Where,
KLOC - no. of lines of code (in thousands).
Person-month – time (in months) taken by developers to finish the product.
Defects - Total Number of errors discovered
- Lines of Code (LOC) is a direct approach method which, by decomposition and partitioning, involves a higher degree of detail.
- Lines of Code (LOC) tests software and the mechanism by which it is produced.
A Function Point (FP) is a measurement unit that expresses the amount of business functionality that a customer is provided with by an information system (as a product). Software size tests FPs. They are commonly accepted for practical sizing as an industry standard.
A combination of software features is based on a
● External input and output
● User interactions
● External interface
● Files used by the system
Each of these is correlated with one weight. By multiplying each raw count by weight and summing all values, the FP count is computed. The FP count is changed by the project's complexity.
FPs can be used to estimate a given LOC based on the average number of LOCs per FP.
- LOC = AVC * number of function point
- (AVC - language-dependent factor)
Key takeaway :
- FPs are highly subjective. They depend on an estimator for that.
Object point is an alternative measure similar to feature points when the same language is used for growth. OP's are not the same as classes of objects.
A weighted calculation of the number of OPs in a program is
● The number of different displays that will be shown.
● The number of reports that the device generates.
As they are simply concerned with displays, reports, and 3GL modules, OPs are easier to estimate from a specification than feature points.
Consequently, they may be evaluated at an early stage in the production process. At this point, estimating the number of lines of code in a system is very difficult.
You probably thought there should be a simple way to measure the total size of a project from all the effort that went into writing the use cases if you dealt with use cases. The relationship between use cases and code is evident in that complicated use cases normally take longer than simple use cases to code. Fortunately, there is an approach to calculating and preparing case points for use.
Use case points to calculate the size of an application, close in definition to feature points. Once we know the estimated size of an application, if we also know (or can estimate) the rate of progress of the team, we can derive an anticipated timeline for the project.
The number of case points for use in a project depends on the following:
● The number and sophistication of the system's use cases
● The number and sophistication of participants in the system
● Different non-functional specifications (such as portability, performance,
Maintenance) which are not written as use cases
● The atmosphere in which the project will be built (such as the language, enthusiasm of the team, etc.)
The fundamental formula for translating all of this into a single metric, use case points, is that we will "weigh" the complexity of the use cases and actors and then change their collective weight to reflect the effect of non-functional and environmental factors.
The need for all use cases to be written at about the same level is central to the use of use case points.
Five levels for use cases are identified: very high overview, summary, user goal, subfunction, and too low. The very high overview and summary usage cases of Cockburn are useful for establishing the framework under which cases of lower-level use work.
There are two checks to assess if a customer objective use case is written at the correct level: First, the more frequently the target is reached by the user, the more value the organization receives;
Second, within a single session, the use case is usually completed and the user can go on to some other task after the objective is achieved.
- Use case points to calculate the size of an application, close in definition to feature points.
- The need for all use cases to be written at about the same level is central to the use of use case points.
A Use-Case is a set of associated user-system interactions that allow the user to accomplish a task.
Use-Cases are a way of capturing a system's practical demands. The device operator is referred to as an 'Actor'. Use-Cases are in text type, fundamentally.
Use-Case Points (UCP) is a technique of software estimation used to calculate the scale of the software using use cases. UCP's definition is similar to FPs.
The sum of UCPs in a project is dependent on the following −
● The number and complexity of instances of use in the scheme.
● The number and complexity of the scheme's performers
Estimating with UCPs allows all use cases to be written with a target and to provide the same amount of information at about the same stage.
Therefore, the project team should ensure that they have written their use cases with specified priorities and at a comprehensive level before estimating. In a single session, the use case is typically completed and the user can go on to some other task after the objective is achieved.
Reconciliation is an autonomous cost estimate that can be compared by the end-user against the cost estimate of the contractor, reducing budget shortfalls, and fixing identified deficiencies. Reconciliations will help ensure that variations are acceptable and fairly anticipated between the two figures. The advantages of the project are various.
The project scope is carefully checked to ensure that the estimation of the contractor is complete and that any elements that might be hard to measure are discussed and thoroughly vetted. Furthermore, the amounts and unit prices of both figures are compared and confirmed, typically resulting in a more refined estimate that can produce considerable project savings.
The Job Breakdown Framework (WBS) usually organizes a reconciliation and includes all facets of project documentation. Typically, the method focuses on particular adjustments in scope, forecast basis, and plan and risks and includes specifically specifying the discrepancies between the two estimates and the reason for those differences.
- Reconciliation is an autonomous cost estimate that can be compared by the end-user.
- The Job Breakdown Framework usually organizes a reconciliation and includes all facets of project documentation.
To make predictions, this technique uses empirically derived formulas. These formulas are based on LOC or FPs
Putnam model: Lawrence H. Putnam, which is based on Norden's frequency distribution, developed this model (Rayleigh curve). The Putnam model maps time and efforts with the software size needed.
Cocomo model: COCOMO stands for the Barry W. Boehm-developed Positive Cost Model. The software product is broken down into three software categories: organic, semi-detached, and embedded
Empirical Estimation Techniques are based on the data taken from the previous project and some based on guesses and assumptions. There are two popular empirical estimation techniques. They are:
● Expert Judgment Technique
The most widely used cost estimation technique is Expert judgment. Inherently it’s a top-down estimation technique. Expert judgment relies on the experience, background, and business sense of one or more key people in the organization.
Groups of experts sometimes prepare a consensus estimate (collective estimate); this tends to minimize individual oversights and lack of familiarity with particular projects and neutralizes personal biases and the desire to win the contract through an overly optimistic estimate as seen in individual judgment style.
The major disadvantage of group estimation is the effect that interpersonal group dynamics may have on individuals in the group. Group members may not be candid enough due to political considerations. The presence of authority figures in the group or the dominance of an overly assertive group member.
● Delphi Cost Estimation Technique
This technique was developed to gain expert consensus without introducing the adverse side effects of group meetings. The Delphi can be adapted to software cost estimation in the following manners:
A coordinator provides each estimator with the system definition document and a form for recording the cost estimation.
Estimators study the definition and complete their estimates anonymously. They may ask questions to the coordinator, but they do not discuss their estimates with one another.
The coordinator prepares and distributes a summary of the estimator’s responses to any unusual rationales noted by the estimators.
Estimators complete another estimate again anonymously, using the result from the previous estimate. Estimators whose estimates differ sharply from the group may be asked, anonymously, to justify their estimates.
The process is iterated for as many rounds as required. No group discussion is allowed during the entire process.
Key takeaway :
- Expert judgment is a top-down estimation technique.
- Expert judgment relies on the experience, background, and business sense of one or more key people in the organization.
- The Delphi method is rather an old but successful method of forecasting.
- The premise of the Delphi technique is that the assimilation of ideas from an organized group contributes to a positive outcome.
The updated version of the original COCOMO (Constructive Cost Model) is COCOMO-II, which was produced at the University of Southern California. It is the model that helps us, when planning a new software development activity, to estimate the cost, effort, and schedule.
It is composed of three sub-models:
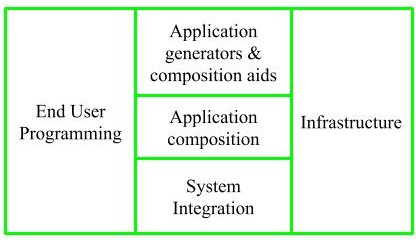
Fig 2: sub-model
Under this sub-model, application generators are used. By using these program generators, the end-user writes the code.
Example – Spreadsheets, report generator, etc.
2. Intermediate sector
This category would create essentially prepackaged user programming capabilities. There will be several reusable components in their brand. Typical companies operating in this industry are Microsoft, Lotus, Oracle, IBM, Borland, Novell.
This group is too diversified and pre-packaged solutions must be addressed. It includes Interface, databases, domain-specific components such as packages for control of financial, medical, or industrial processes.
Large scale and highly embedded systems are discussed in this category.
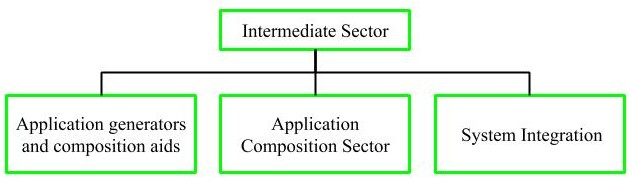
Fig 3: types of intermediate sector
3. Infrastructure sector
This class provides software development infrastructure such as the Operating System, Database Management System, User Interface Management System, Networking System, etc.
Stages of COCOMO II model
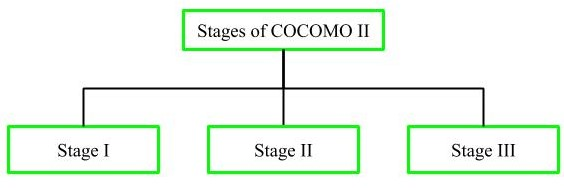
Fig 4: stages of COCOMO II
It supports the prototyping calculation. It uses the Model of Application Composition Estimation for this. For the prototyping stage of the application generator and device integration, this model is used.
II. Stage II
It encourages calculation at the early design stage of the project when we know little about it. It uses the Early Design Estimation Model for this. This model is used for application generators, infrastructure, and system integration in the early design stage
III. Stage III
In a project's post-architecture level, it supports estimation. It uses the Model of Post Architecture Estimation for this. This model is used after the completion of the comprehensive application generator, infrastructure, and system integration architecture.
- The revised edition of the original Cocomo is COCOMO-II
- This model measures the time and effort of production taken as the sum of the
All the different subsystems' figures.
- COCOMO II contributes to spiral model creation and integrates a variety of sub-models that produce a complete estimate.
In the Requirement Traceability Matrix or RTM, we set up a process to record the relations between the client's suggested user specifications and the system being designed. In short, it is a high-level document that maps and traces user specifications with test cases to ensure that appropriate testing levels are accomplished with every requirement.
The method for evaluating all test cases specified for each requirement is called Traceability. Traceability helps us to assess which specifications have produced the most defects during the phase of testing.
Full test coverage is and should be the focus of every research interaction. It means, by coverage, that we need to test anything that needs to be tested. 100 percent test coverage should be the goal of every research project.
Requirements the Traceability Matrix offers a way to ensure that the coverage element is tested. It helps to define coverage gaps by providing a snapshot. In short, it can also be referred to as metrics that specify for each requirement the number of test cases run, passed, failed or blocked, etc.
Types of Traceability Matrix
Forward Traceability:
Requirements for test cases of 'Forward Traceability'. It guarantees that the project is moving according to the desired path and that every condition is thoroughly tested.
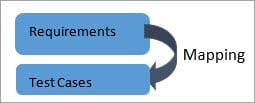
Fig. 5: Forward Traceability Matrix
Backward Traceability:
With the 'Backward Traceability' criteria, the test cases are mapped. Its primary objective is to ensure that the new product being produced is on the right track. It also helps to decide that no additional undefined features are implemented and the project's scope is therefore affected.
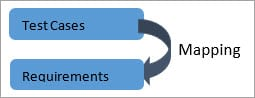
Fig. 6: Backward Traceability Matrix
(Forward + Backward): A Strong Traceability matrix contains references to criteria from test cases and vice versa (requirements to test cases). This is referred to as Traceability 'Bi-Directional.'
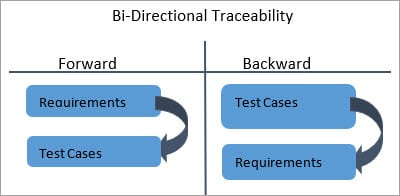
Fig. 7: Bi-directional Traceability Matrix
Key takeaway :
- The method for evaluating all test cases specified for each requirement is called Traceability.
- Traceability helps us to assess which specifications have produced the most defects during the phase of testing.
- Requirements the Traceability Matrix offers a way to ensure that the coverage element is tested.
- It helps to define coverage gaps by providing a snapshot.
A schedule in the time table of your project consists of sequenced tasks and goals that need to be delivered within a given period.
Project schedule essentially means a process that is used to communicate and understand that tasks are important and must be completed or carried out and which organizational resources are provided or allocated to these tasks and in what period framework is expected to be performed.
Successful scheduling of tasks leads to project performance, decreased costs, and improved customer satisfaction. In project management, scheduling means listing tasks, deliverables, and objectives that are delivered within a project. It includes more notes than your weekly planner's average notes. The Gantt chart is the most prevalent and significant form of the project schedule.
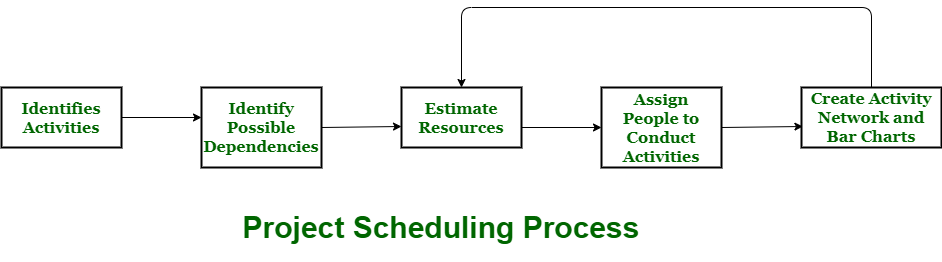
Fig 8: project scheduling process
Process:
The planner has to measure project time and money when preparing the project.
All project activities must be structured in a consistent sequence, meaning that activities should be arranged for easy comprehension in a logical and well-organized manner. Initial project predictions should be made optimistically, which suggests that when all good things occur and no risks or complications occur, estimates can be made.
During the project schedule, the overall work is divided or split into different minor activities or tasks.
Then, the Project Manager will determine the time needed to complete each operation or mission. For efficient efficiency, even such operations are carried out and carried out in parallel. The project manager should realize that not every step of the project is problem-free.
Advantages of project scheduling:
In our project management, there are many benefits offered by the project schedule:
● It ensures that everyone stays on the same page as far as duties, dependencies, and deadlines are completed.
● It helps to recognize problems early on and issues such as resource shortage or unavailability.
● It also helps to establish relationships and process monitoring.
● It offers efficient control of budgets and risk reduction.
- A schedule in the time table of your project consists of sequenced tasks
- The goal of scheduling is that it needs to be delivered within a given period.
- During the project schedule, the overall work is divided or split into different minor activities or tasks.
There were already a variety of different process models mentioned. For software creation, these models offer distinct paradigms. The process model is populated by a collection of tasks that enable a software team to identify, create, and eventually support computer software, irrespective of whether a software team prefers a linear sequential paradigm, an iterative paradigm, an evolutionary paradigm, a concurrent paradigm, or some permutation.
For all projects, no particular set of tasks is suitable. For a small, relatively simple software product, the collection of tasks that would be ideal for a big, complex system would likely be viewed as overkill. Therefore, a list of task sets, each designed to meet the needs of various types of projects, should be established by an efficient software process.
A task set is a list of assignments, milestones, and deliverables of software engineering work that must be completed to complete a specific project. To achieve high software quality, the task set to be chosen must provide enough discipline. But it must not, at the same time, overwhelm the project team with excessive work.
Task sets are meant to handle various types of tasks and various degrees of rigour. While the creation of a detailed taxonomy of software project styles is difficult, most software companies are faced with the following projects:
● Projects for design creation that are launched to investigate some new business concept or some new technology application.
● Projects for new application creation that are conducted as a result of a particular customer order.
● Projects to upgrade applications that arise when current software undergoes significant adjustments to the end-purpose, user's output, or interfaces that are observable.
● Maintenance projects for applications that correct, adapt, or expand current software in ways that may not be instantly evident to the end-user.
● Reengineering projects that are performed to completely or partially restore an existing (legacy) structure.
- For all projects, no particular set of tasks is suitable
- A task set is a list of assignments, milestones, and deliverables of software engineering work that must be completed to complete a specific project
Plan management scheduling is the listing within a project of tasks, deliverables, and milestones. The scheduled start and finish date, duration, and resources allocated to each operation are often usually included in a schedule. A crucial component of efficient time management is effective project scheduling.
In reality, when people discuss the processes for creating a timetable, they typically refer to the first six-time management processes:
References:
2. Roger Pressman, ―Software Engineering: A Practitioner’s Approach‖, McGraw Hill, ISBN 0–07–337597–7
3. Tom Halt, ―Handbook of Software Engineering‖, Clanye International ISBN-10: 1632402939




