Unit - 4
Operating System (OS)
This article delves into the evolution of operating systems since 1950. We'll go over six major operating system types that have been reviewed during the last 70 years.
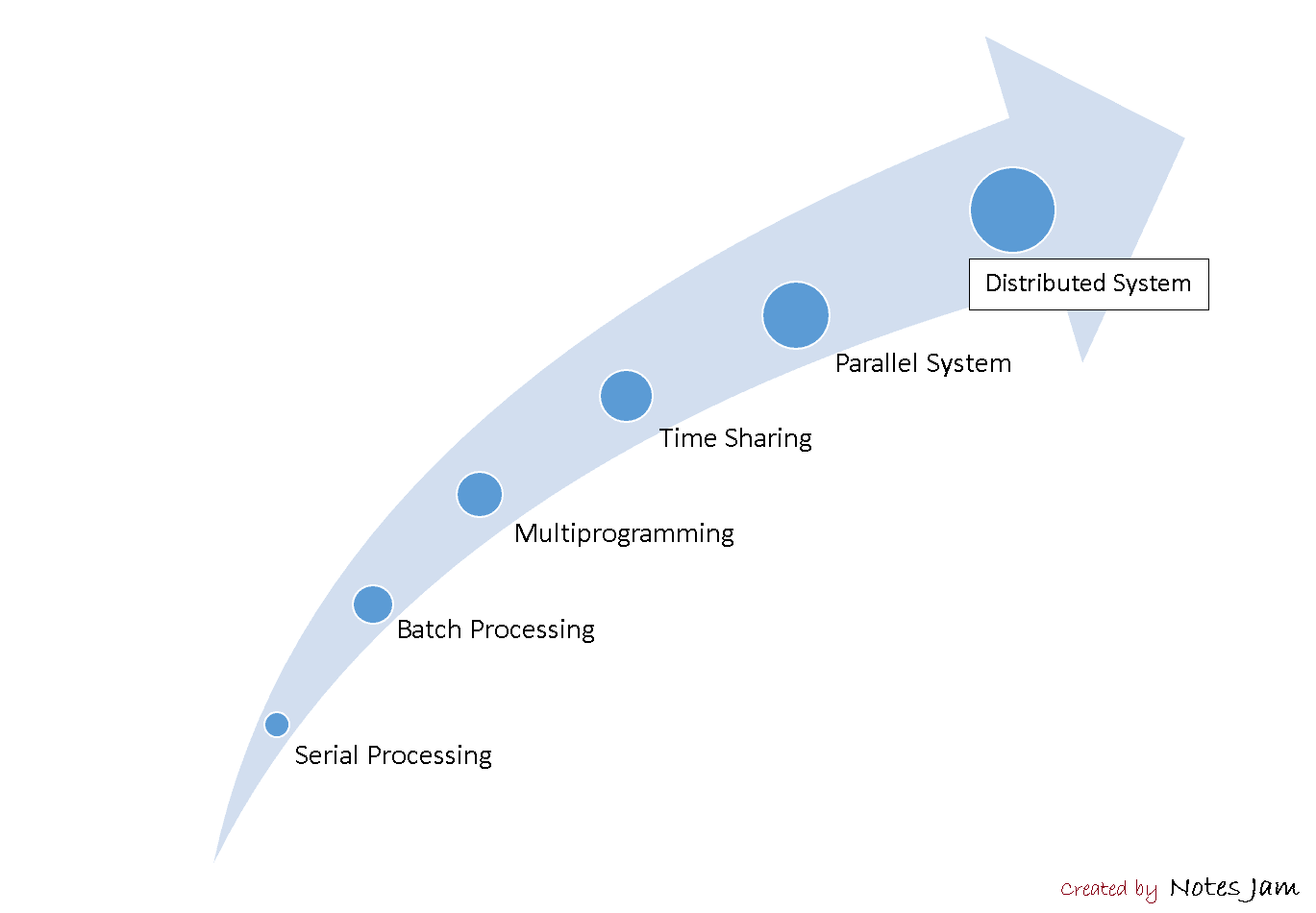
Fig 1: Evolution of OS
Serial processing
The operating system's history dates back to 1950. There was no operating system in 1950, therefore programmers interacted directly with the hardware. The following serial steps are required if a programmer wishes to run a program on specific days.
● The program or punched card should be typed in.
● Use a card reader to convert the punched card.
● If there are any errors, submit to the computing machine, and the lights will indicate the error.
● To determine the source of an error, the programmer inspected the registers and main memory.
● Print the results on the printers.
● Then the programmer ready for the next program.
Batch processing
● This kind of operating system does not collaborate with the computer legitimately. There is an administrator which takes comparable jobs having same prerequisite and gathering them into batches.
● In this kind of system, there is no direct connection among user and the computer.
● The client needs to present work (composed on cards or tape) to a computer administrator.
● At that point computer administrator puts a batch of a several jobs on an input device.
● Jobs are batched together by sort of language and necessity.
● At that point an exceptional program, the monitor, deals with the execution of each program in the batch.
● The monitor is consistently in the primary memory and accessible for execution.
Advantages of Batch Operating System:
● It is exceptionally hard to estimate or realize the time required by any job to finish. Processors of the batch systems realize to what extent the job would be when it is in line.
● Various users can share the batch systems
● The inert time for batch system is extremely less
● It is easy to oversee huge work more than once in batch systems
Disadvantages of Batch Operating System:
● The computer administrators should have complete information with batch systems
● Batch systems are difficult to debug
● It is at some point expense
● Different jobs should sit tight for an obscure time if any jobs fail
Multiprogramming
● This sort of OS is utilized to execute more than one job at the same time by a single processor.
● It builds CPU by sorting out jobs with the goal that the CPU consistently has one job to execute.
● The idea of multiprogramming is depicted as pursues:
● Every one of the job that enter the system are kept in the job pool (in a disk). The operating system stacks a lot of jobs from job pool into main memory and starts to execute.
● During execution, the job may need to wait for some tasks, for example, an I/O operation, to finish. In a multiprogramming system, the operating system basically changes to another activity and executes. At the point when that job needs to wait, the CPU is changed to another job, etc.
● At the point when the first job completes the process of waiting and it recovers the CPU.
● For whatever length of time that in any event one job needs to execute, the CPU is never idle.
● Multiprogramming operating systems utilize the component of job scheduling and CPU scheduling.
Time sharing
● Time-sharing systems are not accessible in 1960s.
● Time-sharing or performing multiple tasks is a legitimate expansion of multiprogramming. That is processors time is shared among numerous users at the same time is called time-sharing.
● The primary contrast between Multiprogrammed Batch Systems and Time-Sharing Systems is, in Multiprogrammed batch systems its goal is expand processor use, while in Time-Sharing Systems its goal is minimize response time.
● Numerous jobs are executed by the CPU by switching between them, however the switches happen in such a less time, so that the user can gets a prompt response.
● For instance, in a transaction processing, processor execute every user program in a short burst or quantum of calculation.
● That is if n users are available, every user can get time quantum.
● At the point when the user presents the instruction, the response time is seconds all things considered.
● Operating system utilizes CPU scheduling and multiprogramming to give every user a little part of a time.
● Computer systems that were structured essentially as batch systems have been altered to time-sharing systems.
● For instance, IBM's OS/360.
● As the name itself recommends, in a time-sharing system or performing various tasks system, different jobs can be executed on a system simultaneously by sharing the CPU time among them.
● It is viewed as a logical expansion of multiprogramming on the grounds that the two does synchronous execution yet vary in their prime aims.
● The fundamental goal of time-sharing systems is to limit reaction time yet not boosting the processor use (which is the target of multiprogramming systems).
● The time-sharing systems were created to give an intuitive utilization of the computer system.
● A time-shared system utilizes CPU planning and multiprogramming to give every user a little segment of a period shared computer.
● It enables numerous users to share the computer resources all the while. As the system switches quickly from one user to the next, a brief timeframe opening is given to every user for their executions.
● The time-sharing operating system guarantees that every one of the assignments get the chance to get to the CPU individually and for a fixed little interval of time. This interval is known as the time quantum.
● E.g.: Unix Systems
Parallel system
● Parallel Processing Systems are intended to accelerate the execution of programs by isolating the program into numerous pieces and processing those fragments simultaneously.
● Such systems are multiprocessor systems called as tightly coupled systems.
● Parallel systems manage the synchronous utilization of numerous computer resources that can incorporate a single computer with various processors, various computers associated by a network to frame a parallel processing cluster or a blend of both.
● Parallel systems are more hard to program than computers with a single processor in light of the fact that the engineering of parallel computers fluctuates appropriately and the procedures of numerous CPUs must be composed and synchronized.
● A few models for interfacing processors and memory modules exist, and every topology requires an alternate programming model.
● The three models that are most regularly utilized in structuring parallel computers incorporate synchronous processors each with its very own memory, asynchronous processors each with its own memory and asynchronous processors with a typical, shared memory.
● Parallel operating systems are essentially worried about dealing with the resources of parallel machines.
● This task faces numerous difficulties: application software engineers request all the performance possible, numerous equipment configurations exist and change all around quickly, yet the operating system should progressively be good with the standard adaptations utilized in computers.
● Today, new applications emerge and request faster computers. Business applications are the most utilized on parallel computers.
● A computer that runs such an application; ought to have the option to process enormous amount of data in modern ways. These applications incorporate designs, virtual reality, and decision support, parallel databases, medical diagnosis, etc.
● We can say with almost certainly that business applications will characterize future parallel computers design however scientific applications will stay significant users of parallel processing innovation.
Distributed system
The processors in a distributed operating system cannot share memory or a clock; instead, each CPU has its own local memory. The processors connect with one another via a variety of channels, including high-speed buses. "Loosely Coupled" systems are what these systems are called.
Advantages
● It is possible to share resources from one site to another if a number of sites are connected by high-speed communication lines, for example, s1 and s2. Some communication lines link them together. The site s1 has a printer, however there is no print on the site. The system can then be changed without having to switch from s2 to s1. As a result, resource sharing in a distributed operating system is possible.
● In distributed systems, a large computer is partitioned into a number of sub-partitions that run concurrently.
● We can use alternative systems/resources in other sites if a resource or system fails in one site owing to technological issues. As a result, the distributed system's reliability will improve.
Key takeaway
Time-sharing or performing multiple tasks is a legitimate expansion of multiprogramming. That is processors time is shared among numerous users at the same time is called time-sharing.
Parallel Processing Systems are intended to accelerate the execution of programs by isolating the program into numerous pieces and processing those fragments simultaneously.
Users and programs both benefit from the services provided by an operating system.
● It provides a platform for programs to run in.
● It gives users the ability to run programs in a more convenient way.
The following are some of the most common services offered by an operating system:
● Program execution
● I/O operations
● File System manipulation
● Communication
● Error Detection
● Resource Allocation
● Protection
Program execution
Operating systems handle a wide range of tasks, from user programs to system programs such as the printer spooler, name servers, and file servers, among others. Each of these actions is broken down into a series of steps.
The entire execution context is included in a process (code to execute, data to manipulate, registers, OS resources in use). The key activities of an operating system in terms of program management are as follows:
● Loads a program into memory.
● Executes the program.
● Handles program's execution.
● Provides a mechanism for process synchronization.
● Provides a mechanism for process communication.
● Provides a mechanism for deadlock handling.
I/O operation
I/O subsystems are made up of I/O devices and the software that controls them. Users are shielded from the quirks of certain hardware devices by drivers.
The communication between the user and the device drivers is managed by the operating system.
● A read or write operation with any file or specialized I/O device is referred to as an I/O operation.
● When needed, the operating system grants access to the required I/O device.
File system manipulation
A file is a container for a group of connected data. For long-term storage, computers can store files on disk (secondary storage). Magnetic tape, magnetic disk, and optical disk drives such as CD and DVD are examples of storage media. Speed, capacity, data transfer rate, and data access mechanisms are all unique to each of these medium.
A file system is usually divided into directories to make it easier to navigate and use. Files and other directions may be found in these directories. The key activities of an operating system in terms of file management are listed below.
● A file must be read or written by the program.
● The operating system grants the software permission to operate on a file.
● Permissions range from read-only to read-write to denied.
● The operating system provides a user interface for creating and deleting files.
● The operating system provides a user interface for creating and deleting folders.
Communication
The operating system oversees communications between all processes in distributed systems, which are a collection of processors that do not share memory, peripheral devices, or a clock. Through the network's communication channels, multiple processes can communicate with one another.
The operating system is in charge of routing and connection techniques, as well as contention and security issues. The following are the key communication-related activities of an operating system:
● Data must frequently be transmitted between two operations.
● Both operations can run on the same computer or on separate systems, but they are linked via a computer network.
● Communication may be implemented by two methods, either by Shared Memory or by Message Passing.
Error handling
Errors can happen at any time and in any place. An error can happen in the CPU, I/O devices, or memory hardware. The key activities of an operating system in terms of error management are as follows:
● The operating system is continually looking for problems.
● The operating system takes the necessary steps to ensure accurate and consistent computing.
Resource management
Resources such as main memory, CPU cycles, and file storage must be allotted to each user or job in a multi-user or multi-tasking system. The key activities of an operating system in terms of resource management are listed below.
● Schedulers are used by the OS to manage a variety of resources.
● CPU scheduling techniques are used to maximize CPU utilization.
Protection
When using a computer system with several users and multiple processes running at the same time, the different processes must be secured from each other's actions.
A mechanism or a method for controlling the access of programs, processes, or users to the resources defined by a computer system is referred to as protection. The primary activities of an operating system in terms of security are listed below.
● All access to system resources is regulated by the operating system.
● External I/O devices are protected by the OS from unauthorized access attempts.
● Passwords are used by the OS to provide authentication functionality for each user.
Key takeaway
Operating systems handle a wide range of tasks, from user programs to system programs such as the printer spooler, name servers, and file servers, among others.
I/O subsystems are made up of I/O devices and the software that controls them.
A file is a container for a group of connected data. For long-term storage, computers can store files on disk (secondary storage).
Errors can happen at any time and in any place. An error can happen in the CPU, I/O devices, or memory hardware.
In an operating system software plays out every one of the following functions:
- Process management: Process management causes the os to create and delete processes. It likewise gives mechanisms for synchronization and communication among processes.
- Memory management: Memory management module plays out the role of assignment and de-allotment of memory space to programs needing the resources.
- File management: It deals with all the file-related tasks, for example, storage organization, recovery, naming, sharing, and protection of files.
- Device management: Device management keeps track of all the devices. This module is in charge of the task also known as the i/o controller. It additionally plays out the undertaking of designation and de-distribution of the devices.
- I/o system management: One of the primary objects of any os is to conceal the identity of that hardware device from the user.
- Secondary-storage management: Systems have a few degrees of storage which incorporates primary storage, secondary storage, and cache storage. Instructions and data must be put away in primary storage or cache so a running program can reference them.
- Security: Security module ensures the data and information of a computer system against malware danger and authorized access.
- Command interpretation: This module is interpreting directions given by the acting system and assigns resources to process those directions.
- Networking: A distributed system is a collection of processors that don't share a memory, hardware devices, or a clock. The processors speak with each other through the network.
- Job accounting: Keeping track of time and resources utilized by different jobs and users.
- Communication management: Manage the coordination and task of compilers, interpreters, and other software resources of the different users of the computer systems.
Key takeaway
- An operating system (os) is system software that manages computer equipment and software resources and gives normal services to computer programs.
- An operating system is software with the accompanying highlights −
● An operating system is a program that goes about as an interface between the software and the computer hardware.
● It is a coordinated set of particular programs used to manage the overall resources and operations of the computer.
● It is specific programming that controls and monitors the execution of every single other program that resides in the computer, including application programs and other system software.
A process is basically a program in execution. The execution of a process must progress in a sequential fashion.
A process is defined as an entity which represents the basic unit of work to be implemented in the system.
To put it in simple terms, we write our computer programs in a text file and when we execute this program, it becomes a process which performs all the tasks mentioned in the program.
When a program is loaded into the memory and it becomes a process, it can be divided into four sections ─ stack, heap, text and data. The following image shows a simplified layout of a process inside main memory −
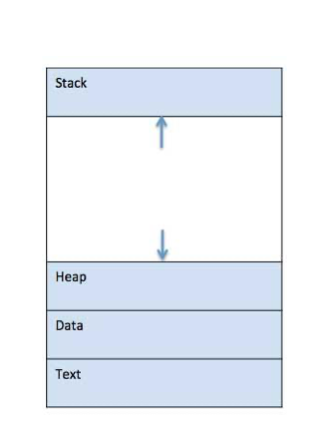
Fig 2: A simplified layout of a process inside main memory
S.N. | Component & Description |
1 | Stack The process Stack contains the temporary data such as method/function parameters, return address and local variables. |
2 | Heap This is dynamically allocated memory to a process during its run time. |
3 | Text This includes the current activity represented by the value of Program Counter and the contents of the processor's registers. |
4 | Data This section contains the global and static variables. |
Process states
When a process executes, it passes through different states. These stages may differ in different operating systems, and the names of these states are also not standardized.
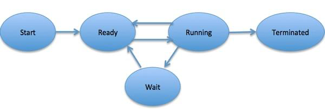
Fig 3: Process state
In general, a process can have one of the following five states at a time.
S.N. | State & Description |
1 | Start This is the initial state when a process is first started/created. |
2 | Ready The process is waiting to be assigned to a processor. Ready processes are waiting to have the processor allocated to them by the operating system so that they can run. Process may come into this state after Start state or while running it by but interrupted by the scheduler to assign CPU to some other process. |
3 | Running Once the process has been assigned to a processor by the OS scheduler, the process state is set to running and the processor executes its instructions. |
4 | Waiting Process moves into the waiting state if it needs to wait for a resource, such as waiting for user input, or waiting for a file to become available. |
5 | Terminated or Exit Once the process finishes its execution, or it is terminated by the operating system, it is moved to the terminated state where it waits to be removed from main memory. |
A Process Control Block is a data structure maintained by the Operating System for every process. The PCB is identified by an integer process ID (PID). A PCB keeps all the information needed to keep track of a process as listed below in the table −
S.N. | Information & Description |
1 | Process State The current state of the process i.e., whether it is ready, running, waiting, or whatever. |
2 | Process privileges This is required to allow/disallow access to system resources. |
3 | Process ID Unique identification for each of the process in the operating system. |
4 | Pointer A pointer to parent process. |
5 | Program Counter Program Counter is a pointer to the address of the next instruction to be executed for this process. |
6 | CPU registers Various CPU registers where process need to be stored for execution for running state. |
7 | CPU Scheduling Information Process priority and other scheduling information which is required to schedule the process. |
8 | Memory management information This includes the information of page table, memory limits, Segment table depending on memory used by the operating system. |
9 | Accounting information This includes the amount of CPU used for process execution, time limits, execution ID etc. |
10 | IO status information This includes a list of I/O devices allocated to the process. |
The architecture of a PCB is completely dependent on Operating System and may contain different information in different operating systems. Here is a simplified diagram of a PCB −

Fig 4: PCB
Key takeaway
A process is basically a program in execution. The execution of a process must progress in a sequential fashion.
A process is defined as an entity which represents the basic unit of work to be implemented in the system.
To put it in simple terms, we write our computer programs in a text file and when we execute this program, it becomes a process which performs all the tasks mentioned in the program.
There is a way of thread execution within the method of any software. With the exception of this, there may be quite one thread within a method. Threading is usually cited as a light-weight method.
The process may be reduced into such a big amount of threads. For instance, in an exceedingly large browser, several tabs may be viewed as threads. MS Word uses several threads - data format text from one thread, process input from another thread, etc.
Types of Threads
In the software, there square measures 2 sorts of threads.
- Kernel level thread.
- User-level thread.
User-level thread
The software doesn't acknowledge the user-level thread. User threads may be simply enforced and it's enforced by the user. If a user performs a user-level thread obstruction operation, the complete method is blocked. The kernel level thread doesn't have an unskilled person regarding the user level thread. The kernel-level thread manages user-level threads as if they're single-threaded processes? Examples: Java thread, POSIX threads, etc.
Advantages of User-level threads
- The user threads may be simply enforced than the kernel thread.
- User-level threads may be applied to such sorts of in operation systems that don't support threads at the kernel-level.
- It's quicker and economical.
- Context switch time is shorter than the kernel-level threads.
- It doesn't need modifications of the software.
- User-level threads illustration is extremely easy. The register, PC, stack, and mini thread management blocks square measure hold on within the address house of the user-level method.
- It's easy to form, switch, and synchronize threads while not the intervention of the method.
Disadvantages of User-level threads
- User-level threads lack coordination between the thread and therefore the kernel.
- If a thread causes a page fault, the whole method is blocked.
Kernel level thread
The kernel thread acknowledges the software. There square measure a thread management block and method management block within the system for every thread and method within the kernel-level thread. The kernel-level thread is enforced by the software. The kernel is aware of regarding all the threads and manages them. The kernel-level thread offers a supervisor call instruction to form and manage the threads from user-space. The implementation of kernel threads is troublesome than the user thread. Context switch time is longer within the kernel thread. If a kernel thread performs an obstruction operation, the Banky thread execution will continue. Example: Window Solaris.
Advantages of Kernel-level threads
- Kernel can schedule many threads from the same process on numerous processes at the same time.
- If a process's main thread is stalled, the Kernel can schedule another process's main thread.
- Kernel routines can be multithreaded as well.
Disadvantages of Kernel-level threads
- Kernel threads are more difficult to establish and maintain than user threads.
- A mode switch to the Kernel is required to transfer control from one thread to another within the same process.
Benefits of Threads
● Enhanced outturn of the system: once the method is split into several threads, and every thread is treated as employment, the quantity of jobs worn out the unit time will increase. That's why the outturn of the system additionally will increase.
● Effective Utilization of digital computer system: after you have quite one thread in one method, you'll be able to schedule quite one thread in additional than one processor.
● Faster context switch: The context shift amount between threads is a smaller amount than the method context shift. The method context switch suggests that additional overhead for the hardware.
● Responsiveness: once the method is split into many threads, and once a thread completes its execution, that method may be suffered as before long as doable.
● Communication: Multiple-thread communication is easy as a result of the threads share an equivalent address house, whereas in method, we have a tendency to adopt simply some exclusive communication methods for communication between 2 processes.
● Resource sharing: Resources may be shared between all threads at intervals a method, like code, data, and files. Note: The stack and register can't be shared between threads. There square measure a stack and register for every thread.
Thread life cycle
Appearing on your screen may be a thread state diagram. Let's take a more in-depth explore the various states showing on the diagram.
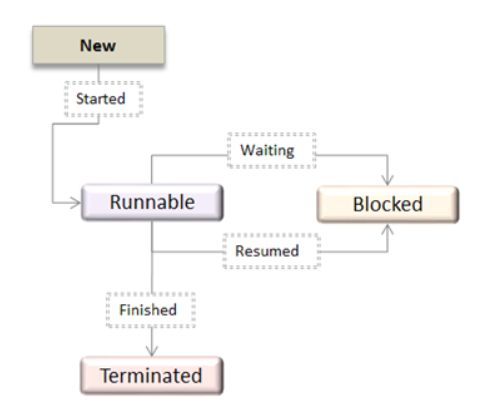
Fig 5: OS Thread State Diagram
A thread is within the new state once it's been created. It does not take any hardware resources till it's really running. Now, the method is taking on hardware resources as a result of it's able to run. However, it's in an exceedingly runnable state as a result of it might be looking forward to another thread to run and then it's to attend for its flip.
A thread that isn't allowed to continue remains in an exceedingly blocked state. Parenthetically that a thread is looking forward to input/output (I/O), however it ne'er gets those resources, therefore it'll stay in an exceedingly blocked state. The great news is that a blocked thread will not use hardware resources. The thread is not stopped forever. For instance, if you permit emergency vehicles to pass, it doesn't mean that you just square measure forever barred from your final destination. Similarly, those threads (emergency vehicles) that have the next priority square measure processed prior to you. If a thread becomes blocked, another thread moves to the front of the road. However, this is often accomplished is roofed within the next section regarding programming and context shift.
Finally, a thread is terminated if it finishes a task with success or abnormally. At this time, no hardware resources square measure used.
Key takeaway
There is a way of thread execution within the method of any software. With the exception of this, there may be quite one thread within a method. Threading is usually cited as a light-weight method.
A thread that isn't allowed to continue remains in an exceedingly blocked state.
Some operating system provides a combined user level thread and Kernel level thread facility. Solaris is a good example of this combined approach. In a combined system, multiple threads within the same application can run in parallel on multiple processors and a blocking system call need not block the entire process.
Multithreading models are three types
● Many to many relationship
● Many to one relationship
● One to one relationship
Many to Many Model
The many-to-many model multiplexes any number of user threads onto an equal or smaller number of kernel threads.
The following diagram shows the many-to-many threading model where 6 user level threads are multiplexing with 6 kernel level threads. In this model, developers can create as many user threads as necessary and the corresponding Kernel threads can run in parallel on a multiprocessor machine. This model provides the best accuracy on concurrency and when a thread performs a blocking system call, the kernel can schedule another thread for execution.
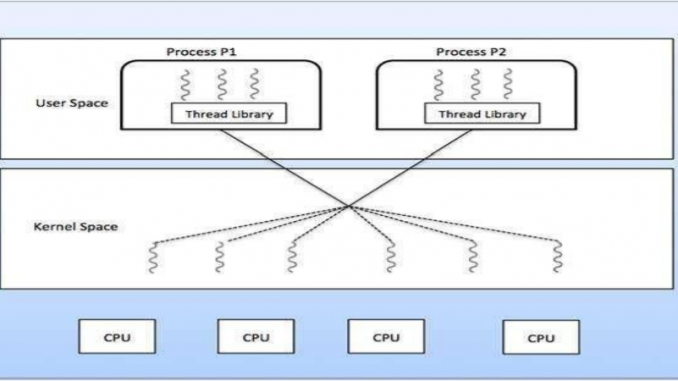
Fig 6: The best accuracy on concurrency
Many to One Model
Many-to-one model maps many user level threads to one Kernel-level thread. Thread management is done in user space by the thread library. When thread makes a blocking system call, the entire process will be blocked. Only one thread can access the Kernel at a time, so multiple threads are unable to run in parallel on multiprocessors.
If the user-level thread libraries are implemented in the operating system in such a way that the system does not support them, then the Kernel threads use the many-to-one relationship modes.
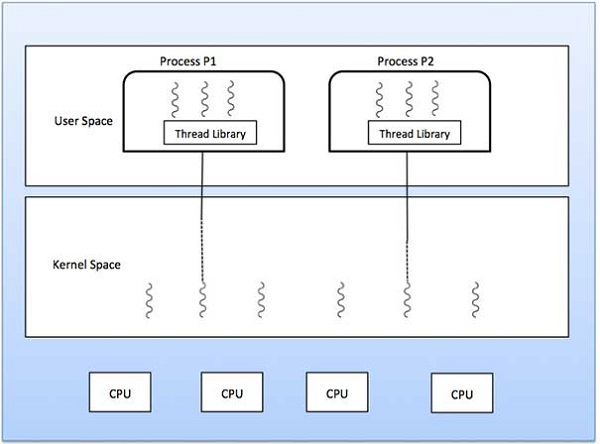
Fig 7: Many to one model
One to One Model
There is one-to-one relationship of user-level thread to the kernel-level thread. This model provides more concurrency than the many-to-one model. It also allows another thread to run when a thread makes a blocking system call. It supports multiple threads to execute in parallel on microprocessors.
Disadvantage of this model is that creating user thread requires the corresponding Kernel thread. OS/2, windows NT and windows 2000 use one to one relationship model.
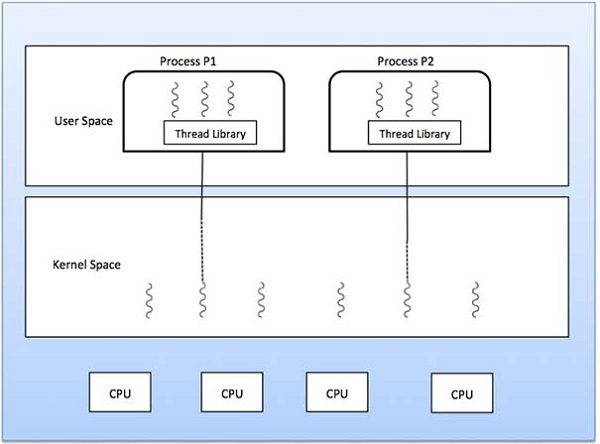
Fig 8: One to one model
Key takeaway
In a combined system, multiple threads within the same application can run in parallel on multiple processors and a blocking system call need not block the entire process.
The many-to-many model multiplexes any number of user threads onto an equal or smaller number of kernel threads.
Many-to-one model maps many user level threads to one Kernel-level thread. Thread management is done in user space by the thread library.
There is one-to-one relationship of user-level thread to the kernel-level thread.
The interface between a process and an operating system is provided by system calls. In general, system calls are available as assembly language instructions. They are also included in the manuals used by the assembly level programmers. System calls are usually made when a process in user mode requires access to a resource. Then it requests the kernel to provide the resource via a system call.
A figure representing the execution of the system call is given as follows −
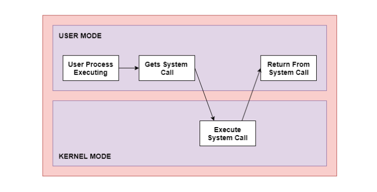
Fig 9: The execution of the system call
As can be seen from this diagram, the processes execute normally in the user mode until a system call interrupts this. Then the system call is executed on a priority basis in the kernel mode. After the execution of the system call, the control returns to the user mode and execution of user processes can be resumed.
In general, system calls are required in the following situations −
● If a file system requires the creation or deletion of files. Reading and writing from files also require a system call.
● Creation and management of new processes.
● Network connections also require system calls. This includes sending and receiving packets.
● Access to a hardware device such as a printer, scanner etc. requires a system call.
Types of System Calls
There are mainly five types of system calls. These are explained in detail as follows −
Process Control
These system calls deal with processes such as process creation, process termination etc.
File Management
These system calls are responsible for file manipulation such as creating a file, reading a file, writing into a file etc.
Device Management
These system calls are responsible for device manipulation such as reading from device buffers, writing into device buffers etc.
Information Maintenance
These system calls handle information and its transfer between the operating system and the user program.
Communication
These system calls are useful for interprocess communication. They also deal with creating and deleting a communication connection.
Some of the examples of all the above types of system calls in Windows and Unix are given as follows −
Types of System Calls | Windows | Linux |
Process Control | CreateProcess() ExitProcess() WaitForSingleObject() | Fork() Exit() Wait() |
File Management | CreateFile() ReadFile() WriteFile() CloseHandle() | Open() Read() Write() Close() |
Device Management | SetConsoleMode() ReadConsole() WriteConsole() | Ioctl() Read() Write() |
Information Maintenance | GetCurrentProcessID() SetTimer() Sleep() | Getpid() Alarm() Sleep() |
Communication | CreatePipe() CreateFileMapping() MapViewOfFile() | Pipe() Shmget() Mmap() |
There are many different system calls as shown above. Details of some of those system calls are as follows −
Open ()
The open () system call is used to provide access to a file in a file system. This system call allocates resources to the file and provides a handle that the process uses to refer to the file. A file can be opened by multiple processes at the same time or be restricted to one process. It all depends on the file organization and file system.
Read ()
The read () system call is used to access data from a file that is stored in the file system. The file to read can be identified by its file descriptor and it should be opened using open () before it can be read. In general, the read () system calls take three arguments i.e., the file descriptor, buffer which stores read data and number of bytes to be read from the file.
Write ()
The write () system calls write the data from a user buffer into a device such as a file. This system call is one of the ways to output data from a program. In general, the write system calls take three arguments i.e., file descriptor, pointer to the buffer where data is stored and number of bytes to write from the buffer.
Close ()
The close () system call is used to terminate access to a file system. Using this system call means that the file is no longer required by the program and so the buffers are flushed, the file metadata is updated and the file resources are de-allocated.
Key takeaway
The interface between a process and an operating system is provided by system calls. In general, system calls are available as assembly language instructions. They are also included in the manuals used by the assembly level programmers. System calls are usually made when a process in user mode requires access to a resource. Then it requests the kernel to provide the resource via a system call.
The goal of processor scheduling is to assign operations to the processor or processors in a way that achieves system goals including reaction time, throughput, and processor efficiency over time. This scheduling activity is divided into three functions in many systems: long-, medium-, and short-term scheduling. These functions are performed on different time scales, as indicated by their names.
When a new process is created, long-term scheduling is done.
The switching function includes medium-term scheduling.
The actual decision of which ready procedure to perform next is known as short-term scheduling.
Multiprogramming, as we all know, is a technique for increasing the efficiency of a microprocessor. When a process is blocked while waiting for an I/O event, another process may be scheduled to run in its place. Currently, the issue of scheduling is at hand, determining which process should be run by the processor, as there may be multiple processes ready to be scheduled.
Criteria
Short-term scheduling work can be done using a variety of algorithms. We must know how capable they are. To evaluate the performance of the algorithms, various criteria are required.
The following are the main factors for processor scheduling:
● Turnaround time is the time it takes for a process to be completed after it is submitted. In a batch operating system, this is an appropriate measure for a process.
● The Response time between submitting a request and receiving a response is known as response time.
● The rate at which procedures are performed is known as throughput. The scheduling policy should aim to maximize throughput in order to complete more tasks.
● The percentage of time the processor is busy is known as processor utilization. This is a critical criteria in a shared system, but it is less important in single-user systems and real-time systems.
● Fairness considers if certain processes are starved. In most systems, fairness should be enforced.
These criteria can be divided into two categories: user-centric and system-centric. The former concentrates on the features that are visible and relevant to users. In an interactive system, for example, a user always wants a response as soon as possible. Response time can be used to gauge this. Some criteria, such as throughout, are system-oriented, focused on effective and efficient processor utilization.
There are two types of user-centric criteria: user-centric and system-centric. The former focuses on features that are visible to users and are meaningful to them. In an interactive system, a user, for example, expects a response as quickly as possible. This can be measured using response time. Some criteria, such as those used throughout, are system-oriented, focusing on the most effective and efficient use of processors.
The above criteria are obviously interrelated and cannot be optimized at the same time. Providing good reaction time, for example, may necessitate a scheduling algorithm that switches between processes often, increasing the system's overhead and lowering throughput.
Preemptive
● In preemptive mode, as of now running process might be interrupted and moved to the ready state by the operating system.
● When another process arrives or when an interrupt happens, preemptive algorithms may bring more prominent overhead than non-preemptive form however preemptive method may give better support.
● It is reuired to expand CPU usage and throughput, and to limit turnaround time, waiting time and response time.
● In this sort of Scheduling, the tasks are generally allocated with needs or priorities.
● Here it is important to run a specific task that has a higher need before another task despite the fact that it is running.
● Subsequently, the running task is interrupted for quite a while and continued later when the needed task has completed its execution.
Non- preemptive
● Under non-preemptive scheduling, when the CPU has been assigned to a process, the process keeps the CPU until it wishes either by terminating or by changing to the waiting state.
● This scheduling technique is utilized by the Microsoft Windows 3.1 and by the Apple Macintosh operating systems.
● It is the main technique that can be utilized on certain hardware stages, since it doesn't require the exceptional hardware (for model: a timer) required for preemptive scheduling.
● In non-preemptive mode, once if a process goes into running state, it keeps on executing until it ends or terminates itself to wait for Input/Output event or by requesting some operating system service.
Long Term Scheduler
It is also called a job scheduler. A long-term scheduler determines which programs are admitted to the system for processing. It selects processes from the queue and loads them into memory for execution. Process loads into the memory for CPU scheduling.
The primary objective of the job scheduler is to provide a balanced mix of jobs, such as I/O bound and processor bound. It also controls the degree of multiprogramming. If the degree of multiprogramming is stable, then the average rate of process creation must be equal to the average departure rate of processes leaving the system.
On some systems, the long-term scheduler may not be available or minimal. Time-sharing operating systems have no long-term scheduler. When a process changes the state from new to ready, then there is use of long-term scheduler.
Short Term Scheduler
It is also called as CPU scheduler. Its main objective is to increase system performance in accordance with the chosen set of criteria. It is the change of ready state to running state of the process. CPU scheduler selects a process among the processes that are ready to execute and allocates CPU to one of them.
Short-term schedulers, also known as dispatchers, make the decision of which process to execute next. Short-term schedulers are faster than long-term schedulers.
Medium Term Scheduler
Medium-term scheduling is a part of swapping. It removes the processes from the memory. It reduces the degree of multiprogramming. The medium-term scheduler is in-charge of handling the swapped out-processes.
A running process may become suspended if it makes an I/O request. A suspended process cannot make any progress towards completion. In this condition, to remove the process from memory and make space for other processes, the suspended process is moved to the secondary storage. This process is called swapping, and the process is said to be swapped out or rolled out. Swapping may be necessary to improve the process mix.
Comparison among Scheduler
S.N. | Long-Term Scheduler | Short-Term Scheduler | Medium-Term Scheduler |
1 | It is a job scheduler | It is a CPU scheduler | It is a process swapping scheduler. |
2 | Speed is lesser than short term scheduler | Speed is fastest among other two | Speed is in between both short- and long-term scheduler. |
3 | It controls the degree of multiprogramming | It provides lesser control over degree of multiprogramming | It reduces the degree of multiprogramming. |
4 | It is almost absent or minimal in time sharing system | It is also minimal in time sharing system | It is a part of Time-sharing systems. |
5 | It selects processes from pool and loads them into memory for execution | It selects those processes which are ready to execute | It can re-introduce the process into memory and execution can be continued. |
Key takeaway
In preemptive mode, as of now running process might be interrupted and moved to the ready state by the operating system.
Under non-preemptive scheduling, when the CPU has been assigned to a process, the process keeps the CPU until it wishes either by terminating or by changing to the waiting state.
A long-term scheduler determines which programs are admitted to the system for processing.
Short-term schedulers, also known as dispatchers, make the decision of which process to execute next.
The medium-term scheduler is in-charge of handling the swapped out-processes.
FCFS
● It is the simplest scheduling algorithm among all the scheduling algorithm.
● It is a non-preemptive scheduling.
● In this scheduling algorithm CPU is assigned to those process whose request comes first.
● It follows the concept of first in first out.
● When the CPU is executing the current running process, it places the oldest process in the ready queue to execute next.
● The average waiting time for this algorithm i.e., FCFS is quite long.
● Example-
Process | Burst Time (in ms) |
P1 | 20 |
P2 | 5 |
P3 | 3 |
Gantt chart for the above process according to FCFS algorithm is
P1 | P2 | P3 |
0 20 25 28
Average waiting time = (0 + 20 + 25) / 3 = 15ms
Average Turnaround time = (20 + 25 + 28) / 3 = 24.33 ms
Note- Waiting is time at which process starts its execution in Gantt chart.
And turnaround time = waiting time + burst time
SJF
● This algorithm partners with each process the length of the following CPU burst.
● Shortest-job first scheduling is additionally called as shortest process next (SPN).
● The process with the most limited expected processing time is chosen for execution, among the accessible processes in the ready queue.
● SJF can be either non-preemptive or preemptive algorithm.
● A non-preemptive SJF will allow the currently running process to finish its execution first weather a newly created process is of shorter CPU burst time.
● A preemptive SJF is known as Shortest Remaining Job First (SRJF).
● Example-
Process | Burst Time (in ms) |
P1 | 3 |
P2 | 6 |
P3 | 4 |
P4 | 2 |
According to SJF algorithm the sequence of process execution will be P4, P1, P3 and P2.
P4 | P3 | P3 | P2 |
0 2 5 9 15
Average waiting time = (0 + 2 + 5 + 9) / 4 = 4 ms
Average turnaround time = (2 + 5 + 9 + 15) / 4 = 7.75 ms
RR
● This scheduling algorithm is for a time-sharing system.
● Same as FCFS algorithm with preemption added here so as to switch between processes.
● Here a small unit of time is used which is known as time quantum or time slice.
● The value of time quantum is generally between 1 to 100 ms.
● To design this algorithm a read queue is treated as a circular queue.
● The CPU scheduler pick one process from the ready queue and execute it for a particular time quantum and as soon as time quantum is finish CPU will switch the current process with the next process in the ready queue.
● In this manner CPU scheduler goes around the read queue till all the processes will finish its execution.
● Example-
Process | Burst Time (in ms) | Time Quantum = 2 ms |
P1 | 3 | |
P2 | 6 | |
P3 | 4 | |
P4 | 2 |
According to RR scheduling, the sequence of process execution will be as shown below in the Gantt chart:
P1 | P2 | P3 | P4 | P1 | P2 | P3 | P2 |
0 2 4 6 8 9 11 13 15
Average waiting time = (6 + 9 + 9 + 6) / 4 = 7.5 ms
Average turnaround time = (9 + 15 + 13 + 8) / 4 = 11.25 ms
Priority
A process is assigned a priority in many systems, and the scheduler will always prefer a higher priority process over a lower priority process. The improved process queue model with priority consideration is depicted in Figure.
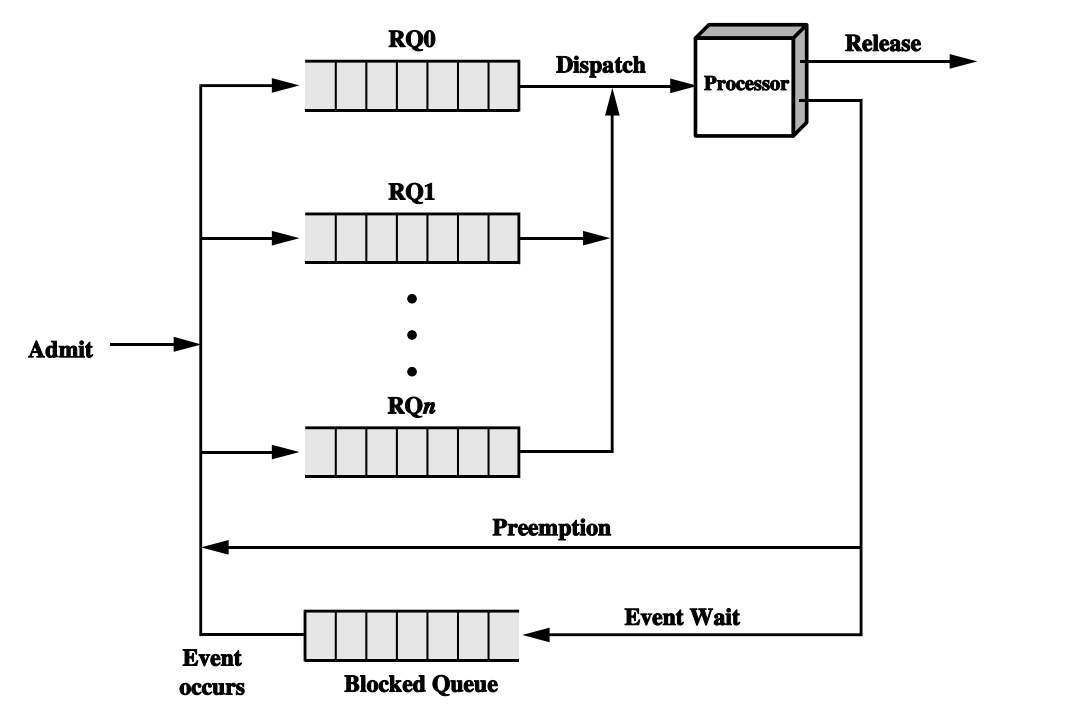
Fig 10: Priority queue
The new paradigm divides the READY queue into multiple distinct queues, each with its own priority. The dispatcher always executes the process with the highest priority in the queue, and if the queue is empty, the process with the lowest priority next to it, and so on.
However, a challenge that such a system must deal with is that a low-priority activity may be starved. If there are constantly procedures of higher priority waiting to be scheduled, that process will be overlooked. The priority of processes can be dynamically altered to solve this problem. For example, a process that has been waiting for a longer period of time is given a higher priority, such that any process, regardless of priority, will eventually get dispatched.
Key takeaway
Shortest-job first scheduling is additionally called as shortest process next (SPN).
SJF can be either non-preemptive or preemptive algorithm.
A process is assigned a priority in many systems, and the scheduler will always prefer a higher priority process over a lower priority process.
An Operating System (OS) is software that manages and controls the main computer hardware, the hardware peripherals and software resources, thus also the users. It also works as an interface between the computer user, including programmers, and the computer hardware by providing a platform and support for applications. On a specific OS platform, applications software such as word processors, spreadsheets, databases, and other dedicated apps that businesses require run.
Standard services for process implementation, such as storage, deadlock, scheduling, and other processes, are provided by operating systems. It also comes with a programming environment that allows users to build and run programs in a much more convenient and efficient manner. Every computer system, including desktops, laptops, tablets, supercomputers, mobile devices, and video gaming consoles, uses an operating system. In today's ICT environment, there are many different types of operating systems. Apple Inc. Created and owns the Mac operating system, Microsoft Inc. Owns Windows, Community owns Linux, and Google Inc. Owns Android.
Over time, many Operating Systems have arisen, each with its own set of features and functions. Users' decisions regarding which operating system to install on their computers are guided by their understanding of each OS's functionalities. As a result, a comparison of different operating systems is unavoidable. As a result, a comparative analysis is required to provide an overview of the similarities and differences across various types of operating systems in order to convey and map the OS's characteristics to various user services.
Comparative Analysis of Windows, Linux, Android, and IOS
The emphasis here is on conducting a comparative analysis of the operating systems Windows, Linux, Android, and iOS. Computer Architecture Supported, Target System Type, File System Supported, User Friendly for Lay Users, Integrated Firewall, Security Threats, Shell Terminal, Kernel Type, Reliability, and Compatibility are some of the issues to be concerned about. The merits and disadvantages of each operating system were also listed. Table shows a comparison of operating systems based on their characteristics and functionalities.
| Windows | Linux | Android | IOS |
Manufacturer | Microsoft Inc. | Linux is developed as open source OS under the GNU project by the Originator, Linus Torvalds and many others.
| Open source OS designed & developed by Android Inc. Google is now the current owner | Apple Inc. Closed, with components that are source openly
|
Development and Distribution | Developed and distributed by Microsoft. | Linux is Open Sourced and distributed by various vendors. | OHA (Open Handset Alliance) | Apple Inc. Developed and distribute
|
File System Supported | NTFS, FAT & exFAT with ISO 9660; UDF, 3rd Party driver that supports file system | Ext2, and ext3, ReiserFS, and HFS ext2, ext3, ex4, ReiserFS, FAT, ISO 9660, UDF, NFS, and others.
| Ext4 | HFS+, FTP |
Compatibility | Can coexist on local networks with Windows, BSD, Macs, and other Unix-like systems. More compatible. | Linux has few programs and games like Windows. But is more compatible and scalable than Unix | Better than iOS | Compatibility is fair |
Reliability | Great | Great | Could be unstable | More than Android |
User Friendly for Lay Users | Very User Friendly | Depends on Distribution. More friendlier to users than unix | Very User Friendly | Very User Friendly |
Linux operating system
UNIX is a well-known operating system that is frequently utilized in minicomputers and mainframe computers. The popularity of UNIX has grown dramatically in recent years as a result of one of its most popular descendants, the Linux operating system.
Linux is one of the most widely used UNIX operating systems. It is an open source operating system in the sense that its source code is freely available. Linux was created with UNIX compatibility in mind. Its capabilities are very comparable to those of UNIX. Because Linux has a graphical user interface (GUI), instead of inputting instructions to complete user operations, users can log in graphically to meet their needs.
Linux also includes the ability to use the command line to manage essential system needs. Initially, Linux developers focused on networking and services, with office applications being the final hurdle to overcome. Apart from desktop operating systems, Linux is a good alternative for workstations since it has a simple user interface and MS compatible office software such as word processors, spreadsheets, and presentations. As a result, Linux has entered the desktop market.
On the server side, Linux is known for being a robust and trustworthy platform, with firms such as Amazon, the US Postal Service, the German Army, and others using it to provide database and trade services. Firewalls, proxy servers, and web servers all run on Linux. Every UNIX system administrator who appreciates a comfy management station can find a Linux box within reach.
Objectives
You will be able to, after completing this unit:
● Understand the basic features of the Linux Operating System
● Determine the features of the Linux operating system.
● Learn about the history of the Linux operating system.
● Learn about Linux's process management and how it compares to other operating systems.
● Understand how Linux handles memory management.
● Understand File management in Linux.
● Understand the security features of Linux.
Process management in Linux
The kernel creates the illusion of multitasking. By switching between various jobs operating on the system, the CPU is capable of conducting the activities in parallel. The context change is carried out in parallel and at regular intervals. Because of the short intervals, the user is unable to notice the task change. A Linux process can be thought of as a running software instance. Simply opening a text editor on your Linux system will start a text editor process.
The kernel is responsible for a number of activities related to process management.
Until all of the procedures are complete, they should work independently of one another wished to engage in conversation Linux is a multiuser operating system. Even if numerous processes are running at the same time, an issue that occurs in one program will not affect another. All of these parallel-running applications/programs will be unable to access the memory content of the other application/program. This feature protects the application's data from being accessed by other users.
All the processes of the system will fairly utilize CPU time and share in between multiple applications. The priority of the applications is allocated, and the order in which they are executed is determined. The kernel determines the amount of execution time allotted to each process (time quantum) and when context switching between processes should occur. This raises the question of which process is the next in line. Platforms are not used to make decisions about time slot allocation or context switching.
The kernel will ensure that the execution environment of a process brought back is exactly the same as when it last withdrew CPU resources while context switching. The contents of the processor registers and the virtual address space structure, for example, must be similar.
The latter task is highly reliant on the processor type. The scheduler policy, which is distinct from the task switching mechanism used to move between processes, determines how CPU time is allocated.
Process priorities
Not every step is equally important. There are several criticality classes to meet different demands, in addition to process priority. Processes can be divided into two categories: real-time and non-real-time.
Hard real-time processes and delicate real-time or soft real-time processes are the two categories of real-time processes. Hard real-time processes have stringent time constraints that must be met in order for specific tasks to be completed. If an aircraft's flight control commands are handled by computer, they must be forwarded as soon as feasible — and within a certain time frame. The main feature of hard real-time operations is that they must be completed within a certain amount of time. It's important to note that this does not indicate that the time frame is particularly brief. Instead, the system must ensure that a set time limit is never exceeded, even in the face of improbable or undesirable circumstances.
In soft real-time systems, achieving deadlines is not required for every activity all of the time, but the process must be completed and the product delivered. Even soft real-time systems cannot miss the deadline for each task or process, which must meet or miss the deadline based on the priority. If the system consistently misses the deadline, the system's performance will deteriorate, and users will be unable to use it. Personal computers, audio and video systems, and other soft real-time systems are good examples. A compose activity to a CD is an example of a delicate real-time procedure. Since information is retained in contact with the medium in a nonstop stream, it should be obtained by the CDauthorata specified rate.
Hard real-time processing is not supported in Linux, at least not in the vanilla kernel. This capability is available in modified versions such as RTLinux, Xenomai, and RATI. In these implementations, the Linux kernel runs as a distinct ‘‘process," handling less important applications while real-time work is done outside the kernel. Only if no real-time important activities are done may the kernel run. Guaranteed response times are difficult to obtain because Linux is optimized for throughput and strives to handle typical scenarios as quickly as feasible.
Process hierarchy
The process ID is a unique positive integer that identifies each process. The first process's 30 pid is 1, and each succeeding process gets a new, unique pid.
Processes in Linux follow a rigid hierarchy known as the process tree. The initial process, known as the init process, is usually the init program, which is the root of the process tree. The fork() system call is used to start new processes. The calling process is duplicated when you use this system call. The original process is referred to as the parent, while the new process is referred to as the kid. Except for the first, every process has a parent. The kernel will reparent the child to the init process if a parent process expires before its child.
When a process finishes, it is not removed from the system right away. Instead, the kernel keeps parts of the process in memory so that the process's parent can check on its status after it has terminated. This inquiry is known as waiting on the terminated process. Once the parent process has waited on its terminated child, the child is fully destroyed. A process that has terminated, but has not yet been waited upon, is called a zombie. The init process routinely waits on all of its children, ensuring that re-parented processes do not remain zombies forever.
Linux Process States
Processes are born, share resources with their parents for a period of time, obtain their own copy of resources when they are ready to make changes, cycle through various states based on their priority, and then die. The various states of Linux processes are listed below.
● RUNNING - This state indicates whether the process is currently running or is waiting to run.
● INTERRUPTIBLE - This state indicates that the process is waiting to be interrupted because it is in sleep mode and is awaiting some action to wake it up. The action could be a hardware interrupt, a signal, or something else entirely.
● UN-INTERRUPTIBLE - It is just like the INTERRUPTIBLE state, the only difference being that a process in this state cannot be waken up by delivering a signal.
● STOPPED - This state indicates that the process has come to a halt. If a signal such as SIGSTOP, SIGTTIN, or other is sent to the process, this can happen.
● TRACED - This state indicates that the process is under investigation. This state is entered whenever the process is stopped by a debugger (to assist the user in debugging the code).
● ZOMBIE - This state indicates that the process has been terminated but is still present in the kernel process table because the process's parent has not yet fetched the process's termination status. To get the termination status, Parent employs the wait() family of methods.
● DEAD - This state indicates that the process has ended and that the entry in the process table has been removed. This state is achieved when the parent successfully fetches the termination status as explained in ZOMBIE state.
References:
- Dhamdhere D., "Systems Programming and Operating Systems", McGraw Hill, ISBN 0 - 07 - 463579 – 4
- Leland Beck, “System Software: An Introduction to Systems Programming”, Pearson
- John R. Levine, Tony Mason, Doug Brown, “Lex & Yacc”, 1st Edition, O’REILLY,
ISBN 81-7366-062-X
4. https://www.tutorialspoint.com/operating_system/os_services.html
5. http://www.sci.brooklyn.cuny.edu/~jniu/teaching/csc33200/files/1201-UniprocessorScheduling.pdf




