Unit - 3
Big Data Analytics Life Cycle
Big data refers to a large amount of data, as the name implies. Big Data refers to a data set that is both huge in volume and complicated. Traditional data processing software cannot handle Big Data because of its vast volume and increasing complexity. Big Data simply refers to datasets that contain a vast amount of unstructured and structured data.
Companies can use Big Data Analytics to address issues they are encountering in their business and efficiently fix these problems. Companies aim to find patterns in this sea of data and extract insights from it so that it may be used to solve the problem(s) at hand.
Despite the fact that businesses have been gathering massive amounts of data for decades, the term "Big Data" only became popular in the early to mid-2000s.
Corporations acknowledged the vast amount of data produced on a daily basis and the need of successfully utilising it.
Big Data is a massive collection of data that continues to grow dramatically over time. It is a data set that is so huge and complicated that no typical data management technologies can effectively store or process it. Big data is similar to regular data, but it is much larger.
Key takeaway
Big data refers to a large amount of data, as the name implies. Big Data refers to a data set that is both huge in volume and complicated. Traditional data processing software cannot handle Big Data because of its vast volume and increasing complexity. Big Data simply refers to datasets that contain a vast amount of unstructured and structured data.
Big data is mostly derived from three sources: social data, machine data, and transactional data. Furthermore, businesses must distinguish between data generated internally, that is, data that resides behind a company's firewall, and data generated outside that must be imported into a system.
It's also vital to consider if the data is unstructured or structured. Because unstructured data lacks a pre-defined data model, it necessitates additional resources to comprehend.
The three primary sources of Big Data
Social data
Likes, Tweets & Retweets, Comments, Video Uploads, and general media are all sources of social data on the world's most popular social media platforms. This type of data may be quite useful in marketing analytics because it provides essential insights into consumer behaviour and sentiment. Another good source of social data is the public web, and tools like Google Trends can help enhance the volume of big data.
Machine data
Machine data includes information generated by industrial machinery, sensors put in machinery, and even web logs that track user behaviour. As the internet of things becomes more prevalent and develops over the world, this type of data is predicted to grow rapidly. In the not-too-distant future, sensors such as medical gadgets, smart metres, road cameras, satellites, games, and the quickly expanding Internet Of Things will give high velocity, value, volume, and variety of data.
Transactional data
Transactional data is derived from all online and offline transactions that occur on a daily basis. Invoices, payment orders, storage records, and delivery receipts are all considered transactional data, but data on its own is nearly worthless, and most businesses struggle to make sense of the data they generate and how to use it effectively.
Other sources
Media as a Big data source
The most common source of big data is the media, which offers significant insights into consumer preferences and evolving trends. It is the quickest way for businesses to acquire an in-depth overview of their target audience, establish patterns and conclusions, and improve their decision-making because it is self-broadcast and overcomes all physical and demographical borders. Social media and interactive platforms such as Google, Facebook, Twitter, YouTube, and Instagram, as well as generic media such as photographs, videos, audios, and podcasts, provide quantitative and qualitative insights on all aspects of user involvement.
Cloud as a big data source
Companies have migrated their data to the cloud to get ahead of traditional data sources. Cloud storage handles both organised and unstructured data and gives real-time data and on-demand insights to businesses. Cloud computing's key feature is its scalability and adaptability. Cloud allows for an efficient and cost-effective data source because huge data may be stored and accessed on public or private clouds via networks and computers.
Database as a big data sources
Businesses nowadays prefer to collect relevant big data by combining old and digital databases. This connection paves the door for a hybrid data model while requiring minimal capital and IT infrastructure. Additionally, these databases are used for a variety of business intelligence reasons. These databases can then be used to extract information that can be used to boost business earnings. MS Access, DB2, Oracle, SQL, and Amazon Simple are just a few examples of popular databases.
Extracting and interpreting data from a large number of big data sources is a time-consuming and difficult task. These issues can be avoided if companies take into account all of the important aspects of big data, assess relevant data sources, and deploy them in a way that is well aligned with their objectives.
Key takeaway
Big data is mostly derived from three sources: social data, machine data, and transactional data. Furthermore, businesses must distinguish between data generated internally, that is, data that resides behind a company's firewall, and data generated outside that must be imported into a system.
For Big Data challenges and data science projects, the data analytic lifecycle was created. To depict a genuine project, the cycle is iterative. Step-by-step approach is needed to organise the actions and processes involved with gathering, processing, analysing, and repurposing data to address the particular requirements for doing Big Data analysis.
The Data Analytics Lifecycle is a six-stage cyclic process that illustrates how data is created, collected, processed, implemented, and analysed for various goals.
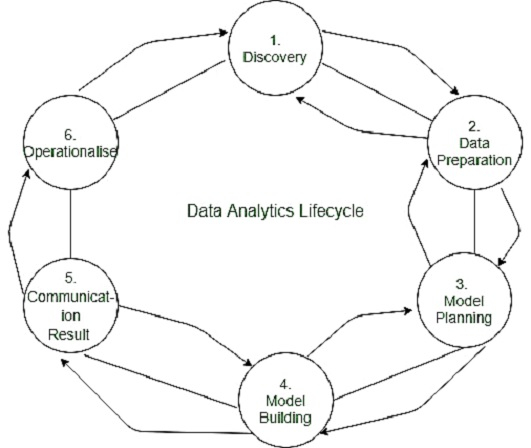
Fig 1: Data analytics life cycle
This is the first step in defining your project's goals and determining how to complete the data analytics lifecycle. Begin by identifying your business area and ensuring that you have sufficient resources (time, technology, data, and people) to meet your objectives.
The most difficult aspect of this step is gathering enough data. You'll need to create an analysis plan, which will take some time and effort.
Accumulate resources
To begin, you must examine the models you wish to create. Then figure out how much domain knowledge you'll need to complete those models.
The next step is to determine whether you have the necessary skills and resources to complete your projects.
Frame the issue
Meeting your client's expectations is the most likely source of problems. As a result, you must identify the project's challenges and explain them to your clients. This is referred to as "framing." You must write a problem statement that explains the current situation as well as potential future issues. You must also identify the project's goal, as well as the project's success and failure criteria.
Formulate initial hypothesis
After you've gathered all of the client's needs, you'll need to construct early hypotheses based on the data you've gathered.
Before moving on to the model building process, the data preparation and processing phase involves gathering, processing, and conditioning data.
Identify data sources
You must identify numerous data sources and assess how much and what type of data you can get in a given amount of time. Evaluate the data structures, investigate their attributes, and gather all of the necessary tools.
Collection of data
There are three ways to collect data:
● Data collection: You can obtain data from a variety of other sources.
● Data Entry: You can use digital technology or manual entry to prepare data points.
● Signal reception: Data from digital devices, such as IoT devices and control systems, can be accumulated.
This is the stage in which you must assess the quality of the data and select a model that is appropriate for your project.
Loading Data in Analytics Sandbox
A data lake design includes an analytics sandbox that allows you to store and handle enormous amounts of data. It can handle a wide range of data types, including big data, transactional data, social media data, web data, and so on. It's a setting that lets your analysts schedule and process data assets using the data tools of their choosing. The adaptability of the analytics sandbox is its best feature. Analysts can process data in real time and obtain critical information in a short amount of time.
There are three ways to load data into the sandbox:
● ETL - Before loading the data into the sandbox, the ETL Team professionals ensure that it complies with the business standards.
● ELT - Data is fed into the sandbox and then transformed according to business standards.
● ETLT - ETL and ELT are both part of ETLT, which consists of two levels of data transformation.
Unnecessary characteristics or null values may be present in the data you've collected. It could take a form that is too difficult to predict. This is where data exploration can assist you in uncovering hidden data trends.
Steps involved in data exploration:
● Data identification
● Univariate Analysis
● Multivariate Analysis
● Filling Null values
● Feature engineering
Regression approaches, decision trees, neural networks, and other techniques are frequently used by data analysts for model planning. Rand PL/R, WEKA, Octave, Statista, and MATLAB are some of the most commonly used tools for model preparation and execution.
The process of deploying the proposed model in a real-time environment is known as model building. It enables analysts to get in-depth analytical knowledge to help them consolidate their decision-making process. This is a time-consuming procedure because you must constantly add new features as requested by your clients.
Here, your goal is to predict corporate decisions, customise market strategies, and develop custom-tailored customer interests. This is accomplished by incorporating the model into your current production domain.
In certain circumstances, a single model perfectly matches with the business objectives/data, while in others, multiple attempts are required. As you begin to explore the data, you'll need to run certain algorithms and compare the results to your goals. In some circumstances, you may need to run multiple variants of a model at the same time until you get the required results.
This is the stage in which you must present the results of your data analysis to your clients. It necessitates a number of sophisticated processes in which you must deliver information to them in a clear and concise manner. Your clients don't have enough time to figure out which information is crucial. As a result, you must perform flawlessly in order to capture your clients' attention.
Check the data accuracy
Is the information provided by the data accurate? If not, you'll need to execute some more operations to fix the problem. You must make certain that the data you process is consistent. This will assist you in constructing a persuasive case while describing your findings.
Highlight important findings
Each piece of information, on the other hand, plays a critical function in the development of a successful project. Some data, on the other hand, has more potent information that can genuinely benefit your readers. Try to organise data into different essential points while describing your findings.
Determine the most appropriate communication format
The way you present your findings says a lot about who you are as a professional. We advise you to use visual presentations and animations because they help you express information much more quickly. However, there are instances when you need to go back to basics. Your clients, for example, may be required to carry the findings in a physical manner. They may also be required to collect and exchange certain information.
Your data analytics life cycle is practically complete once you generate a full report that includes your major results, papers, and briefings. Before providing the final reports to your stakeholders, you must assess the success of your analysis.
You must migrate the sandbox data and execute it in a live environment during this procedure. Then you must keep a tight eye on the results to ensure they are in line with your expectations. You can finish the report if the findings are precisely aligned with your goal. Otherwise, you'll have to go back and make some modifications in your data analytics lifecycle.
EMC's Global Innovation Network and Analytics (GINA) team is a group of senior technologists located in centres of excellence (COEs) around the world. This team's charter is to engage employees across global COEs to drive innovation, research, and university partnerships. In 2012, a newly hired director wanted to improve these activities and provide a mechanism to track and analyse the related information. In addition, this team wanted to create more robust mechanisms for capturing the results of its informal conversations with other thought leaders within EMC, in academia, or in other organizations, which could later be mined for insights.
The GINA team thought its approach would provide a means to share ideas globally and increase knowledge sharing among GINA members who may be separated geographically. It planned to create a data repository containing both structured and unstructured data to accomplish three main goals.
● Store formal and casual information.
● Track research from worldwide technologists.
● Dig the information for examples and bits of knowledge to work in the group's activities and technique.
The GINA contextual analysis gives an illustration of how a group applied the Data Analytics Life cycle to examine advancement information at EMC. Development is regularly a troublesome idea to quantify, and this group needed to search for ways of utilizing progressed scientific techniques to recognize key trend-setters inside the PC.
Phase 1: Discovery
In the GINA project's discovery phase, the crew commenced figuring out statistics sources. Although GINA turned into a collection of technologists professional in lots of specific elements of engineering, it had a few statistics and thoughts approximately what it desired to discover however lacked formal crew that would carry out those analytics. After consulting with various experts which include Tom Davenport, a referred to professional in analytics at Babson College, and Peter Gloor, a professional in collective intelligence and author of CoIN (CollaborativeInnovation Networks) at MIT, the crew determined to crowdsource the paintings through seeking volunteers inside EMC. Here is a listing of the way the numerous roles at the operating crew had been fulfilled.
● Vice President from the Office of the CTO, Business User, Project Sponsor, and Project Manager.
● IT representatives are Business Intelligence Analysts.
● IT representatives: Data Engineer and Database Administrator (DBA).
● Data Scientist: Distinguished Engineer who also created the GINA case study's social graphs.
The project sponsor's strategy was to use social media and blogging [26]to speed up the collecting of innovation and research data around the world and to encourage teams of "volunteer" data scientists in different parts of the world. He needed to be resourceful in locating people who were both capable and ready to offer their time to work on intriguing problems because he didn't have a formal team. Data scientists are often enthusiastic about their work, and the project sponsor was able to capitalise on this enthusiasm to complete difficult tasks in an innovative manner.
The project's data was divided into two categories. The first category, known as the Innovation Roadmap, represented five years of idea entries from EMC's internal innovation challenges (formerly called the InnovationShowcase). The Innovation Roadmap is a structured, organic innovation process in which people from all around the world submit ideas, which are then examined and judged. The finest concepts are chosen for future development. As a result, the data contains a mixture of organised and unstructured content, such as concept numbers, submission dates, and inventor names.
The second set of data included minutes and notes from throughout the world that represented innovation and research activity. There was also a mix of structured and unstructured data here. Dates, names, and geographic places were among the structured data attributes.
The unstructured documents comprised "who, what, when, and where" information that represented rich data regarding the company's knowledge growth and transfer. This type of data is frequently kept in business silos with little or no visibility across different research teams. The GINA team came up with the following ten primary IHs:
● IH1: Corporate strategic directions can be matched to innovation activity in different geographic regions.
● IH2: When global knowledge transfer occurs as part of the idea delivery process, the time it takes to provide ideas lowers.
● IH3: Innovators who engage in global knowledge transfer produce ideas faster than those who do not.
● IH4: An concept can be analysed and reviewed to see whether it has a chance of being funded.
● IH5: For a given topic, knowledge discovery and growth may be measured and compared across geographic locations.
● IH6: Research-specific boundary spanners in disparate regions can be identified through knowledge transfer activities.
● IH7: Geographical regions can be related to strategic company themes.
● IH8: Having frequent knowledge growth and transfer events shortens the time it takes to turn an idea into a company asset.
● IH9: When knowledge expansion and transmission did not (or did not) result in a corporate asset, lineage maps can indicate it.
● IH10: Emerging research ideas can be categorised and related to specific innovators, boundary spanners, and assets.
Phase 2: Data preparations
The team collaborated with its IT department to create a new analytics sandbox where the data could be stored and experimented with. The data scientists and engineers began to discover that certain data needed conditioning and standardisation throughout the data exploration activity. Furthermore, the team discovered that some missing datasets were necessary for testing several of the analytic hypotheses.
As the team looked over the data, it quickly understood that if it didn't have excellent quality data or couldn't access it, it wouldn't be able to complete the rest of the lifecycle process. As a result, it was critical to figure out what level of data quality and cleanliness was appropriate for the project at hand. The team observed that many of the names of the researchers and people interacting with the institutions in the GINA datastore were misspelt or had leading and trailing spaces. Small flaws in the data, such as these, have to be rectified in this phase to allow for better data analysis and aggregation in the following phases.
Phase 3: Model Planning
In the GINA project, it appeared that social network analysis techniques might be used to look at the networks of EMC inventors for a large portion of the dataset. Due to a lack of evidence in other circumstances, it was difficult to come up with adequate strategies to test theories. In one case (IH9), the team decided to start a longitudinal study to track data points about persons producing new intellectual property over time. The team could use this information to test the following two ideas in the future:
● IH8: Having frequent knowledge expansion and transfer events reduces the time it takes to turn an idea into a company asset.
● IH9: When knowledge expansion and transmission did not (or did not) result in a corporate asset, lineage maps can indicate it.
Phase 4: Model Building
Several analytic methodologies were used by the GINA team in Phase 4. The data scientist worked on textual descriptions of the Innovation Roadmap ideas using Natural Language Processing (NLP) tools. He also used R and RStudio to conduct social network analysis, and then used R's ggplot2 tool to create social graphs and visualisations of the network of innovation communications.
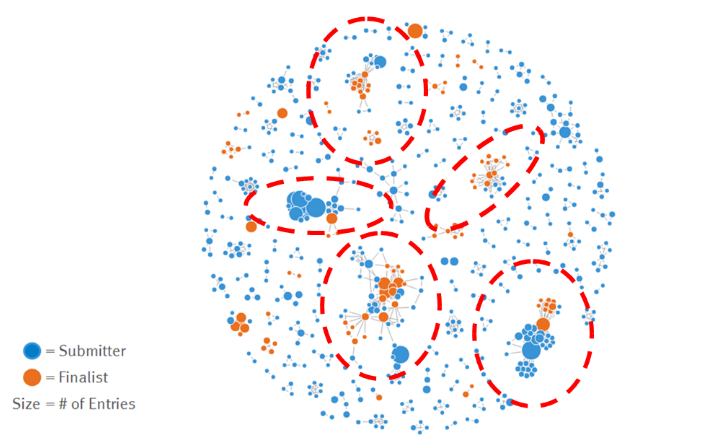
Fig: Social graph visualization of idea submitters and finalists
Depicts GINA's social networks, which depict the relationships between idea submitters. Each hue indicates a different country's innovator.
Phase 5: Communicate Results
In Phase 5, the team devised a number of methods for sifting through the analysis' results and identifying the most important and relevant discoveries. This study was deemed a success in terms of discovering boundary-breakers and unsung innovators.
As a result, the CTO office initiated longitudinal studies to start gathering data and track innovation outcomes over extended periods of time. The GINA project encouraged knowledge sharing among innovators and researchers from many departments both inside and outside the organisation. GINA also allowed EMC to develop new intellectual property, which led to new research topics and chances to form partnerships with universities to conduct cooperative academic research in the disciplines of DataScience and Big Data.
Furthermore, the project was completed on a shoestring budget by relying on a volunteer staff of highly experienced and renowned engineers and data scientists.
One of the project's significant findings was that Cork, Ireland, had a disproportionately high density of inventors. Every year, EMC holds an innovation contest in which workers can submit ideas for new products or services that would add value to the firm. In 2011, 15 percent of the finalists and 15 percent of the winners were from Ireland, according to the data.
Phase 6: Operationalize
Analyzing a sandbox of notes, minutes, and presentations from EMC's innovation initiatives offered valuable insights on the company's innovation culture. The following are some of the project's key findings:
● In the future, the CTO office and GINA will require more data, as well as a marketing campaign to persuade people to share their innovation/research activities with the rest of the world.
● Because some of the data is sensitive, the team must think about data security and privacy issues, such as who may run the models and see the results.
References:
- David Dietrich, Barry Hiller, “Data Science and Big Data Analytics”, EMC education services, Wiley publication, 2012, ISBN0-07-120413-X
- EMC Education Services, “Data Science and Big Data Analytics- Discovering, analyzing Visualizing and Presenting Data”
- Trent Hauk, “Scikit-learn Cookbook”, Packt Publishing, ISBN: 9781787286382




