Unit - 3
Java Servlets and XML
A Servlet is an instance of a class that implements the javax.servlet.Servlet interface in its most basic form. Most Servlets, on the other hand, extend one of the standard implementations, particularly javax.servlet.GenericServlet and javax.servlet.http.HttpServlet. Only HTTP Servlets that extend the javax.servlet.http.HttpServlet class will be discussed in this lesson.
The packages javax.servlet (the fundamental Servlet framework) and javax.servlet.http are used by Servlets to leverage Java standard extension classes (extensions of the Servlet framework for Servlets that answer HTTP requests). Servlets provide a way to construct sophisticated server extensions in a server and operating system independent manner because they are built in the highly portable Java language and follow a standard framework.
HTTP Servlets are commonly used for the following purposes:
Data from an HTML form is processed and/or saved.
Providing dynamic content to the client, such as the results of a database query.
Managing state information on top of stateless HTTP, for example, for an online shopping cart system that manages several concurrent customers' shopping carts and maps every request to the correct customer.
The position of Servlets in a Web Application is depicted in the diagram below.
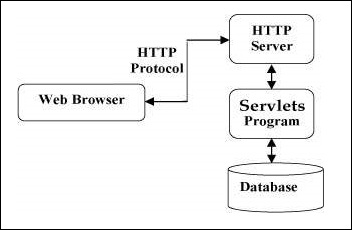
Fig 1: Architecture
A “hello world” servlet
The HttpServlet class is widely used to create the servlet because it provides
Methods to handle http requests such as doGet(), doPost, doHead() etc.Following is the sample source code of a servlet example to show Hello World message:
(a) By extending HttpServlet class:
Import java.io.*;
Import javax. Servlet. *;
Import javax. Servlet .http. *;
Public class Demo extends HttpServlet
{
Private String message;
Public void init() throws ServletException
{
∕∕ Do required initialization
Message = ’’Hello World”;
}
Public void doGet(HttpServletRequest request, HttpServletResponse response) throws
ServletException, IOException
{
∕∕ Set response content type
Response. SetContentType(“text∕htmΓ);
PrintWriter out = response.getWriter();
Out.println(”<hl>;” + message + ”</hl>”);
}
Public void destroyO
{
∕∕ do nothing.
}
(b) By Implementing the Servlet Interface : import java.io.*;
Import javax. Servlet. *;
Public class Demo implements Servlet
{
ServletConfιgconfιg=null;
Public void Init(ServletConfigconfig)
{
This. Confιg=confιg;
System.out.println( π Initialization of init method”); }
Public void service(ServletRequestreq,ServletResponse response) throws
IOException,ServletException
{
Response.setContentType( π text∕htmΓ);
PrintWriter out=response.getWriter();
Out.print( π <html><body> π );
Out.print( π<b>Hello World<;∕b> π );
Out.print( π <∕body><∕html> π );
}
Public void destroy()
{
System.out.println(“Εxecution of servlet is stopped”);
}
PublicServletConfιggetServletConfιg()
{
Retumconfιg;
}
}
1. Compile the ServletfcFor compiling the Servlet, jar file is required to be loaded. Different Servers provide different jar files. You can load jar files either by using set classpath or paste the jar file in JRE/lib/extfolder.Keep java file in any folder and after compiling the java file, paste the class file of servlet in WEB-INF/classes directory.
2. Create a Deployment Descriptor: The “web.xml” is called web application deployment descriptor. It provides the configuration options for that particular web application, such as defining the mapping between URL and servlet class. A web user invokes a servlet, which is kept in the web server, by issuing a specific URL from the browser. In this example, configure the following request URL to activate the “Demo”: http://hostname:port/Demo/hello
The next Servlet we'll create provides an HTML form-based user interface to a mailing list. A user should be able to subscribe to a mailing list by typing their email address into a text field and pressing a button, or unsubscribe by pressing another button.
Data management and client interaction are the two main components of the Servlet.
Client interaction
Two of the standard HttpServlet methods, doGet and doPost, manage client interaction.
The doGet function responds to GET requests by sending an HTML page that includes a list of presently subscribed addresses as well as a form for subscribing or unsubscribing to an address:
Protected void doGet(HttpServletRequest req, HttpServletResponse res)
Throws ServletException, IOException
{
Res.setContentType("text/html"); res.setHeader("pragma", "no-cache"); PrintWriter out = res.getWriter();
Out.print("<HTML><HEAD><TITLE>List
Manager</TITLE></HEAD>");
Out.print("<BODY><H3>Members:</H3><UL>");
For(int i=0; i<addresses.size(); i++) out.print("<LI>" + addresses.elementAt(i));
Out.print("</UL><HR><FORM METHOD=POST>");
Out.print("Enter your email address: <INPUT TYPE=TEXT NAME=email><BR>"); out.print("<INPUT TYPE=SUBMIT NAME=action VALUE=subscribe>"); out.print("<INPUT TYPE=SUBMIT NAME=action VALUE=unsubscribe>"); out.print("</FORM></BODY></HTML>"); out.close();
}
Key takeaway
A user should be able to subscribe to a mailing list by typing their email address into a text field and pressing a button, or unsubscribe by pressing another button.
The entire process from conception to destruction can be defined as a servlet life cycle. The paths that a servlet takes are as follows.
● The init() method is used to initialise the servlet.
● To process a client's request, the servlet uses the service() method.
● The destroy() method is used to terminate the servlet.
● Finally, the trash collector of the JVM collects the servlet.
The init() Method
Only one call to the init method is made. It is only called once, when the servlet is built, and it is not called again for any subsequent user requests. As a result, it's used for one-time initializations, similar to how applets' init method is utilised.
The servlet is generally formed when a user visits a URL that corresponds to the servlet, but you can also have the servlet loaded when the server starts up.
When a user requests a servlet, a single instance of that servlet is produced, with each user request spawning a new thread that is passed to doGet or doPost as needed. The init() method merely produces or loads data that will be used by the servlet throughout its lifetime.
This is how the init method is defined:
Public void init() throws ServletException {
// Initialization code...
}
The service() Method
The main technique for performing the operation is the service() method. The service() function is called by the servlet container (i.e. web server) to handle requests from clients (browsers) and to write the prepared response back to the client.
When a request for a servlet is received, the server creates a new thread and calls service. The service() function validates the HTTP request type (GET, POST, PUT, DELETE, and so on) and then calls the relevant doGet, doPost, doPut, doDelete, and so on methods.
This method's signature is as follows:
Public void service(ServletRequest request, ServletResponse response)
Throws ServletException, IOException {
}
The container calls the service () method, which in turn calls the doGet, doPost, doPut, doDelete, and other methods as needed. So you have nothing to do with the service() function, but depending on the type of request you receive from the client, you override either doGet() or doPost().
In each service request, the doGet() and doPost() procedures are the most commonly utilised methods. The signature of these two approaches is as follows.
The doGet() Method
A GET request is generated by a standard URL request or an HTML form with no METHOD provided, and it should be handled by the doGet() method.
Public void doGet(HttpServletRequest request, HttpServletResponse response)
Throws ServletException, IOException {
// Servlet code
}
The doPost() Method
A POST request is generated by an HTML form with POST as the METHOD, and it should be handled by the doPost() method.
Public void doPost(HttpServletRequest request, HttpServletResponse response)
Throws ServletException, IOException {
// Servlet code
}
The destroy() Method
At the end of a servlet's life cycle, the destroy() method is only called once. This method allows your servlet to conduct cleanup tasks such as closing database connections, halting background threads, writing cookie lists or hit counts to disc, and so on.
The servlet object is designated for trash collection when the destroy() method is called. This is how the destruct method is defined:
Public void destroy() {
// Finalization code...
}
Parameter data
Reading Parameters
Here's a simple example that reads the values of the parameters param1, param2, and param3 and displays them in a bulleted list. Although you must define response settings (content type, status line, and other HTTP headings) before beginning to generate the content, you are not obliged to read the request parameters at any specific point.
Front End to ShowParameters
This HTML form sends a variety of arguments to this servlet. To get the HTML, right-click on the source code link. To test it out online, left-click on the link. It sends the data using POST (as should all forms with PASSWORD inputs), highlighting the need of servlets having both a doGet and a doPost method. However, a version using GET can be downloaded or tried out on-line for demonstration purposes.
PostForm.html
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN"> <HTML>
<HEAD>
<TITLE>A Sample FORM using POST</TITLE> </HEAD>
<BODY BGCOLOR="#FDF5E6">
<H1 ALIGN="CENTER">A Sample FORM using POST</H1>
<FORM ACTION="/servlet/hall.ShowParameters"
METHOD="POST">
Item Number:
<INPUT TYPE="TEXT"
NAME="itemNum"><BR> Quantity:
<INPUT TYPE="TEXT"
NAME="quantity"><BR> Price Each:
<INPUT TYPE="TEXT" NAME="price"
VALUE="$"><BR> <HR>
First Name:
<INPUT TYPE="TEXT"
NAME="firstName"><BR> Last Name:
<INPUT TYPE="TEXT"
NAME="lastName"><BR> Middle Initial:
<INPUT TYPE="TEXT"
NAME="initial"><BR> Shipping Address:
<TEXTAREA NAME="address" ROWS=3
COLS=40></TEXTAREA><BR> Credit Card:<BR>
<INPUT TYPE="RADIO"
NAME="cardType"
VALUE="Visa">Visa<B
R>
<INPUT TYPE="RADIO" NAME="cardType"
VALUE="Master Card">Master
Card<BR> <INPUT TYPE="RADIO" NAME="cardType"
VALUE="Amex">American
Express<BR> <INPUT TYPE="RADIO"
NAME="cardType"
VALUE="Discover">Discover<BR
> <INPUT TYPE="RADIO" NAME="cardType"
VALUE="Java SmartCard">Java
SmartCard<BR> Credit Card Number:
Key takeaway
The entire process from conception to destruction can be defined as a servlet life cycle.
Session Tracking
A Servlet can associate a request with a user using Session Tracking. A session can span several stateless
HYPERLINK "http://www.novocode.com/doc/servlet-essentials/appendix.html#a d HTTP" HTTP requests and connections. There are two ways to keep sessions going:
1. By utilising cookies. A cookie is a string that is delivered to a client to start a session (in this example, the session ID). If the client wants to keep the session going, it sends the Cookie back with each subsequent request. This is the most typical method for tracking sessions.
2. Using URL rewriting. All links and redirections made by a Servlet must be encoded in order to include the session ID. Because the session cannot be preserved by requesting a well-known URL or picking a URL that was formed in a different (or no) session, this is a less elegant option (both for Servlet implementors and users). It also prohibits the creation of static pages. All HTML pages delivered within a session must be dynamically generated.
Our next Servlet is in charge of maintaining a virtual shopping cart. HTML forms allow users to add numerous things to their shopping cart. The contents of each user's shopping cart are saved on the server, and each user has his own shopping cart, which is automatically picked every time he makes a request to the Servlet.
● Cookies are the mostly used technology for session tracking. A cookie is a small text file that contains small amount of information about a user visiting your site and is stored on the site visitor’s computer by their web browser.
● In Cookie, data comes in name value pair, sent by the server to the web browser.
● Browser saves it in its space in the client computer. Whenever the browser sends a request to that server it sends the cookie along with it.
● Then the server can identify the client using the cookie. A web server can assign a unique session ID as a cookie to each web client and for subsequent requests from the client they can be recognized using the received cookie. By default, each request is considered as a new request.
● In cookies technique, you can add cookie with response from the servlet. So cookie is stored in the cache of the browser.
● After that if request is sent by the user, cookie is added with request by default. Thus, we identify the user as the old user. See the following fig. 5.4 which shows this scenario:
● Adds the specified cookie to the response.
Following steps are required for creating a new cookie:
1. Create a new Cookie Object
- Cookie cookie = new Cookie (name, value);
2. Set any cookie attributes
- Cookie.SetMaxAge (40);
3. Add your cookie to the response object:
- Response.addCookie (cookie)
Session tracking is easy to implement and maintain using the cookies. Cookies can be deleted or disabled by the client. In such case, the browser will not save the cookie at the client computer and Cookies are sent from the server to the client via “Set-Cookie” headers.
∕∕ CookieQ
Cookie cookie = new Cookie (String name, String value);
For example,
Cookie cookie = new Cookie("ID n , ”1234”);
Syntax:
Setcookie(name,value,expire,path,domain,secure)
Description of all parameters mentioned in setcookie() method is given in following table.
Parameter | Description |
Name | Specifies the name of the cookie |
Value | Specifies the value of the cookie |
Expire | Specifies when the cookie expires. If this parameter is not set, the cookie will expire at the end of the session. This field is optional |
Path | Specifies the server path of the cookie. If set to the cookie will be available within the entire domain. The default value is the current directory that the cookie is being set in. This field is optional. |
Domain | Specifies the domain name of the cookie. This field is optional. |
Secure | Specifies whether or not the cookie should only be transmitted over a secure HTTPS connection. TRUE value indicates that the cookie will only be set if a secure connection exists. Default is FALSE. This field is optional.
|
Cookie cookie = new
Cookie(“ID”, ”123”);
Response.addCookie(cookie);
URL rewriting
- URL rewriting is a better way to maintain sessions and it works even when browsers don’t support cookies. You can append some extra data on the end of each URL that identifies the session.
- It means in URL rewriting, you can append a token or identifier to the URL of the next Servlet or the next resource. We can send parameter name-value pairs using the following syntax:
- Url7name 1 =value 1 &name2=value2&??
- A name and a value is separated by using an equal (=)sign, a parameter name-value pair is separated from another parameter by using the ampersand(&) sign.
- When the user clicks the hyperlink, the parameter name-value pairs will be passed to the server.
- The getParameter() method is used to get the parameter value at the server side. It will always work whether cookie is disabled or not. In URL rewriting extra form submission is not required on each page.
- The limitation of URL rewriting is that you would have to generate every URL dynamically to assign a session ID, even in case of a simple static HTML page. URL rewriting will work only with links.
Example
You can maintain the state of the user by using the following field. In the following example, appending the name of the user in the query string and accessing the value from the query string in another page is shown. This scenario is also shown in the figure.
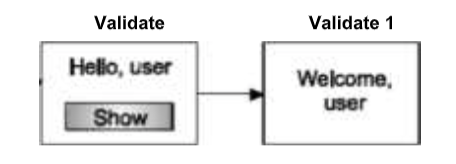
Fig 2: Example of URL rewriting
Home.html
<form method=”post” action-’validate”>
Name:<input type=”text” name=”username” ∕><br>
Password:<input type=”text” name- , pwd”><br∕>
<inputtype=”submit” value=”Show”>
<∕form>
DemolJava
Import java.io.*;
Import javax. Servlet. *;
Import javax.servlet.http.*;
Public class Demol extends HttpServlet {
Public void doGet(HttpServletRequest request, HttpServletResponse response) { try{
Response.setContentType( π text∕htmΓ , );
PrintWriter out = response.getWriter();
String n=request.getParameter(“username”);
Out.print( , ’Hello ”+n);
//append the username in the query string
Out.print( π <a href=validate 1 ?uname=”+n+”’>Show</a>”);
Out.close();
}catch(Exception e){System.out.println(e);}
}
}
Key takeaway
Cookies are the mostly used technology for session tracking. A cookie is a small text file that contains small amount of information about a user visiting your site and is stored on the site visitor’s computer by their web browser.
In Cookie, data comes in name value pair, sent by the server to the web browser.
URL rewriting is a better way to maintain sessions and it works even when browsers don’t support cookies. You can append some extra data on the end of each URL that identifies the session.
Servlets are responsible for the following major tasks:
● Take a look at the data that the clients have supplied you (browsers). This could be in the form of an HTML form on a Web page, an applet, or a custom HTTP client programme.
● Examine the data sent by clients in their implicit HTTP requests (browsers). This contains cookies, media kinds, and compression algorithms supported by the browser, among other things.
● Process the facts and come up with a solution. Talking to a database, conducting an RMI or CORBA call, contacting a Web service, or computing the response directly may all be required in this procedure.
● Send the customers the specific data (i.e., the document) (browsers). Text (HTML or XML), binary (GIF graphics), Excel, and other formats are all options for sending this document.
● Send the clients the implicit HTTP response (browsers). This includes informing browsers or other clients about the type of document being delivered (e.g., HTML), as well as setting cookies and caching parameters and other responsibilities.
Data storage
The ability to preserve state, export content, and integrate data from other files and services on the system is a vital component of many programmes.
Well-deployed technologies
The Web Storage specification provides two basic techniques for simple data storage: localStorage and sessionStorage, which can store data permanently or for a single browser session.
The Indexed Database API (IndexedDB) describes a database of values and hierarchical objects that integrates seamlessly with JavaScript and can be accessed and updated very quickly - a third edition of the specification is in the works.
The Web Cryptography API, developed by the Web Cryptography Working Group, delivers strong cryptography primitives to Web applications and can be connected to pre-provisioned keys through the WebCrypto Key Discovery API.
The HTML5 download element offers a straightforward way to initiate a file download (rather than a page navigation), with the option of specifying a user-friendly filename.
Types
There are two forms of web storage, each with its own set of capabilities and lifespan.
Local Storage: Windows is used by Local Storages. Every page has access to the localStorage object, which saves data. However, data is retained even after the browser is closed and reopened (Stores data with no Expiration).
Session Storage: Windows is used for Session Storage. The sessionStorage object holds data for a single session and is lost when the window or browser tab is closed.
Servlet concurrency
A multithreaded Java servlet container or web server can handle numerous requests to the same servlet at the same time. As a result, when writing a servlet, we must take concurrency into account.
Only one Servlet instance is created, and for each new request, the Servlet Container creates a new thread to execute the servlet's doGet() or doPost() methods.
Servlets are not thread safe by default, and it is the job of the servlet developer to ensure that they are.
Threads
A thread is a small process that has its own call stack and can access data shared by other threads in the same process (shares heap memory). Every thread has its own cache of memory.
When we say a programme is multithreaded, we're referring to the fact that the same instance of an object might spawn numerous threads that process the same piece of code. This means that the same memory block can handle several sequential control flows. Multiple threads are executing a single instance of a programme, which means they are sharing instance variables and may be attempting to read and write them.
Take a look at a simple Java sample.
Public class Counter
{
Int counter=10;
Public void doSomething()
{
System.out.println(“Inital Counter = ” + counter);
Counter ++;
System.out.println(“Post Increment Counter = ” + counter);
}
}
To perform the doSomething() method, we now run two threads, Thread1 and Thread2. It's therefore possible that
● Thread 1 reads the value of the counter, which is 10 in this case.
● The initial counter is set to 10 and the counter is incremented.
● Before Thread1 actually advances the counter, another Thread1 increments the counter, bringing the counter value to 11.
● Thread1's counter currently has a value of 10, which is stale.
Because instance variables are shared by all threads executing in the same instance, this scenario is conceivable in multithreaded environments like servlets.
It is the database's logical framework for storing data. A schema, like a database, is a collection of tables containing rows and fields for which a distinct query can be made. In MySQL, schema refers to a template. They provide the size, kind, and grouping of data.
Database objects like views, tables, and privileges are included in the schemas. Data types, functions, and operators are all part of a schema. They're used in business analysis to figure out what features to look for and how to incorporate them into new data sets using relational databases and information schemas.
MySQL uses schemas to define the database structure by combining rows and values from the same table with the appropriate data types. They employ indexes to search the entire table for relevant rows. Because solid logical and physical design is the cornerstone for running high-performance queries, it is vital to develop schemas for specific queries.
The schema objects, which contain a trigger, check constraint, and foreign key, play an important role in schemas. Databases, tables, schema objects owners, and mapping MySQL to other databases are all covered by schema migrations.
Creation
The process of creating a schema is similar to that of creating a database.
Create a schema name;
The following command will display a list of available schemas:
My SQL Show schemas;
MySQL Database Table:
MySQL desc table name;
Another query to see the schema of a table in a database:
Mysql use database name; (to work in the database)
MySQL uses schema table name;
Names (table & column names)
In MySQL, you can get the names of all tables by using the "display" keyword or queryING INFORMATION SCHEMA.
To acquire all table names for a database in SQL Server, you can use either sys.tables or INFORMATION_SCHEMA.
Mysql> SELECT table_name FROM information_schema.tables WHERE table_type = 'base table' AND table_schema='test';
+------------+
| TABLE_NAME |
+------------+
| department |
| employee |
| role |
| user |
+------------+
4 rows in set (0.00 sec)
Mysql> SHOW tables;
+----------------+
| Tables_in_test |
+----------------+
| department |
| employee |
Column name
SHOW [EXTENDED] [FULL] {COLUMNS | FIELDS}
{FROM | IN} tbl_name
[{FROM | IN} db_name]
[LIKE 'pattern' | WHERE expr]
SHOW COLUMNS is a command that displays information about the columns in a table. It can also be used to generate views. SHOW COLUMNS only shows information for columns for which you have permission.
Mysql> SHOW COLUMNS FROM City;
+-------------+----------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------------+----------+------+-----+---------+----------------+
| ID | int(11) | NO | PRI | NULL | auto_increment |
| Name | char(35) | NO | | | |
| CountryCode | char(3) | NO | MUL | | |
| District | char(20) | NO | | | |
| Population | int(11) | NO | | 0 | |
+-------------+----------+------+-----+---------+----------------+
Tbl name is an alternative to tbl name. The syntax for db name is db name. Tbl name. These two statements are interchangeable:
SHOW COLUMNS FROM mytable FROM mydb;
SHOW COLUMNS FROM mydb.mytable;
The optional EXTENDED keyword causes the output to contain information about MySQL's internal secret columns, which aren't visible to users.
The FULL keyword adds the column collation and comments, as well as the privileges you have for each column, to the output.
Java servlets
● Generally, Dynamic websites were often created with CGI (Common Gateway Interface). But when you use CGI for today’s needs it has some limitations. So a better solution was needed and it is Servlet.
● Servlet Definition: Servlets are protocol- and platform-independent server side technology, which is written in Java & dynamically extend Java-enabled servers.
● They have become more and more popular as they benefit from all the advantages of the Java programming language in particular architecture and platform independence and the ability to build robust and secure applications.
● A servlet is a java class that extends an application hosted on a web server. It handles the HTTP request-response process. It is a running Java program under a web server taking a ‘request’ object as an input and responding back by a ’response’ object. Typically a web browser will send the request in HTTP format. The Servlet container will convert that into a request object. Similarly the response object - populated by the Servlet is converted into an HTTP response by the Servlet container. This mechanism makes the browser - web server interaction very easy.
● A Servlet provides a component base architecture for web development, using the Java Platform.
● A servlet is like an applet, but it works on the server side.
● Java Servlets are programs that run on a Web server or Application server and act as an intermediate layer between a requests coming from a Web browser or client.
● Java Servlet is a consistent mechanism for extending the functionality of a web server. They are precompiled Java programs that are executed on the server side.
● By using Servlets, you can collect input from users through different web pages, retrieve records from a database or another source, and create web pages dynamically.
● A servlet is a Java object which resides within a servlet engine. A servlet engine is usually contained within a web server.
● Servlets respond to HTTP requests. Servlets may return data of any type but they often return HTML. Servlets can be passed parameters through the HTTP request.
● Java Servlets/JSP are part of the Sun’s J2EE Enterprise Architecture.
● ServletAPI is Standard Java Extension API and available as add-on package.
● Servlet is the foundation for Java Server Pages (JSP).
● Java Servlets are more efficient, easier to use, more powerful, more portable, and cheaper than traditional CGI.
● Client of the servlet can be any of the following:
○ Browser
○ Applet
○ JavaApplication
Key takeaway
It is the database's logical framework for storing data. A schema, like a database, is a collection of tables containing rows and fields for which a distinct query can be made. In MySQL, schema refers to a template. They provide the size, kind, and grouping of data.
A basic unit of XML information, an XML document is a well-organized collection of components and associated markup. An XML document can hold a wide range of information. For instance, a number database, a number expressing chemical structure, or a mathematical equation.
Document example
The following is an example of a simple document.
<?xml version = "1.0"?>
<contact-info>
<name>Tanmay Patil</name>
<company>TutorialsPoint</company>
<phone>(011) 123-4567</phone>
</contact-info>
The parts of an XML document are depicted in the diagram below.

Document Prolog section
The Document Prolog appears before the root element at the top of the document. This section provides the following information:
● XML declaration
● Document type declaration
Document Elements Section
The building components of XML are Document Elements. These sections divide the document into a hierarchy of sections, each with its own function. A document can be divided into sections so that they can be presented differently or used by a search engine. Containers with a mix of text and other elements can be used as elements.
"Well Formed" XML is XML with correct syntax. "Valid" XML is XML that has been validated against a DTD.
The following is the right XML syntax for a "Well Formed" XML document:
- A root element is required in XML documents.
- A closing tag is required for XML items.
- The case of XML tags is important.
- XML elements must be nested correctly.
- The value of an XML attribute must be quoted.
Example for XML Document
<?xml version="1.0" encoding="ISO-8859-1"?> <note>
<to>Tove</to>
<from>Jani</from>
<heading>Reminder</heading> <body>Don't forget me! </body> </note>
Xml document begins with XML declaration statement: <? xml version="1.0" encoding="ISO-8859-1"?>. The document's root element is described in the following line: note>. All other elements are "parented" by this element. The following four lines explain the root's four child elements: to, from, heading, and body. Finally, the last line defines the root element's end: /note>.
Key takeaway
A basic unit of XML information, an XML document is a well-organized collection of components and associated markup. An XML document can hold a wide range of information. For instance, a number database, a number expressing chemical structure, or a mathematical equation.
Details that prepare an XML processor to parse the XML document are contained in the XML declaration. It's optional, however it must exist in the first line of the XML document if it's used.
Syntax
The XML declaration is shown in the following syntax.
<?xml
Version = "version_number"
Encoding = "encoding_declaration"
Standalone = "standalone_status"
?>
Within a quotation, each parameter has a parameter name, an equals sign (=), and a parameter value. The following table delves deeper into the above syntax.
Parameter | Parameter_value | Parameter_description |
Version | 1.0 | The version of the XML standard that was used. |
Encoding | UTF-8, UTF-16, ISO-10646-UCS-2, ISO-10646-UCS-4, ISO-8859-1 to ISO-8859-9, ISO-2022-JP, Shift_JIS, EUC-JP | It specifies the document's character encoding. The default encoding is UTF-8. |
Standalone | Yes or no | It tells the parser whether the document's content is based on data from an external source, such as an external document type definition (DTD). The value is set to no by default. When set to yes, the processor understands that no external declarations are necessary to parse the page. |
It's a list of element and attribute names that are linked to an XML vocabulary. Using XML Namespaces, you may avoid element name conflicts.
XML document 1
<table>
<tr>
<td>Apples</td>
<td>Bananas</td>
</tr>
</table>
XML document2
<table>
<name> Coffee Table</name> <width>80</width> <length>120</length> </table>
There would be a name problem if these XML parts were combined. Both have a table> element, but the content and semantics of the elements are different. Such a name is incongruent.
Using a name prefix, such as the one given below, it is simple to avoid XML:
<h:table>
<h:tr>
<h:td>Apples</h:td>
<h:td>Bananas</h:td>
</h:tr>
</h:table>
<f:table>
<f:name>African Coffee Table</f:name> <f:width>80</f:width> <f:length>120</f:length>
</f:table>
A namespace for the prefix must be defined when utilising prefixes in XML. The xmlns attribute in an element's start tag defines the namespace. The following is the syntax for a namespace declaration.
Xmlns:prefix="URI"
For example,
<h:table xmlns:h="http://www.w3.org/table"> <h:tr>
<h:td>Apples</h:td>
<h:td>Bananas</h:td>
</h:tr>
</h:table>
<f:table xmlns:f="http://www.w3.org/furniture"> <f:name>African Coffee Table</f:name> <f:width>80</f:width> <f:length>120</f:length>
Default namespace
Xmlns:http://www.w3.org/1999/xhtml is the default xml namespace uri for document elements.
RSS
Rich Site Summary (RSS) is an acronym for Rich Site Summary.
RSS is a web content delivery format that is updated on a regular basis. Many news sites and other online publishers make their information available as an RSS Feed to anyone who wants it.
You can syndicate your site's information via RSS.
RSS stands for "Really Simple Syndication," which is a simple way to share and read headlines and material.
It is feasible to disseminate current web material from a single website to thousands of other websites all over the world using RSS.
RSS offers you quick access to news and updates. RSS was created to display just certain types of data.
To distribute your information via RSS, you'll need to create a single file that contains all of your content.
This file will be stored on your server in order for other websites to be able to see your channel. You can just change your file to update your channel.
Users will have to check your site daily for new updates if you don't use RSS. For many people, this may be very time consuming. Because RSS data is tiny and fast, they can check your site faster using an RSS aggregator (a site or programme that receives and sorts RSS feeds). Loading
RSS is beneficial for frequently updated websites, such as:
1. News sites - Provides a list of news stories with titles, dates, and descriptions.
2. Businesses - Provides information about new products and services.
3. Calendars - This type of calendar keeps track of forthcoming events and crucial dates.
4. Site changes - Lists pages that have changed or have been added to the site.
RSS files can be updated automatically.
RSS enables you customised views of various websites.
XML is used to create RSS feeds.
It is feasible to disseminate current web material from a single website to thousands of other websites all over the world using RSS.
RSS offers you quick access to news and updates. RSS was created to display just certain types of data.
To distribute your information via RSS, you'll need to create a single file that contains all of your content.
This file will be stored on your server in order for other websites to be able to see your channel. You can just change your file to update your channel.
Users will have to check your site daily for new updates if you don't use RSS. For many people, this may be very time consuming. Because RSS data is tiny and fast, they can check your site faster using an RSS aggregator (a site or programme that receives and sorts RSS feeds). Loading
RSS is beneficial for frequently updated websites, such as:
1. News sites - Provides a list of news stories with titles, dates, and descriptions.
2. Businesses - Provides information about new products and services.
3. Calendars - This type of calendar keeps track of forthcoming events and crucial dates.
4. Site changes - Lists pages that have changed or have been added to the site.
Creating an RSS File
The first thing you'll need to do is figure out what file you're working with. Place the following code at the top of your text file to accomplish this.
<?xml version="1.0"?> <rss version="0.91">
The next step is to design your channel header. You're starting a new channel when you use the "channel" tag.
<channel>
<title>Web-Source.net Syndication</title> <link>http://www.web-source.net</link>
<description>Web Development article syndication feeds!</description> <language>en-us</language>
The "title" tag specifies your channel's name. A link to your website will be included in the "link" tag. The "description" tag defines your channel, while the "language" tag shows that you're writing in English from the United States.
<item>
<title> Creating A Customized Marquee </title> <link>http://www.example.com/tips.htm</link> <description>
Learn how to create a customized marquee for your web </description>
</item>
Finally, add the following tags to your channel to close it down:
</channel>
</rss>
Save your new RSS file as a.rss file and upload it to your server. You're now ready to share your content with the world.
Key takeaway
It's a list of element and attribute names that are linked to an XML vocabulary. Using XML Namespaces, you may avoid element name conflicts.
Document Object Model is an acronym for Document Object Model. It establishes a protocol for document access and manipulation. The Document Object Model (DOM) is an HTML and XML document programming API. It specifies the logical structure of documents as well as how they are accessed and modified.
One of the main goals of the Document Object Model as a W3C specification is to provide a basic programming interface that can be used in a broad range of environments and applications. Any programming language can use the Document Object Model.
The XML Document Object Model (DOM) specifies a standard for accessing and manipulating XML data.
What does XML DOM
For an XML text, the XML DOM creates a tree-structure view.
The DOM tree provides access to all components.
We may change or remove their content, as well as add new elements. Nodes are the elements, as well as their content (text and attributes).
Properties of DOM
These are some typical DOM properties:
● x.nodeName - the name of x
● x.nodeValue - the value of x
● x.parentNode - the parent node of x
● x.childNodes - the child nodes of x
● x.attributes - the attributes nodes of x
DOM Methods
● x.getElementsByTagName(name) - get all elements with a specified tag name
● x.appendChild(node) - insert a child node to x
● x.removeChild(node) - remove a child node from x
Key takeaway
Document Object Model is an acronym for Document Object Model. It establishes a protocol for document access and manipulation. The Document Object Model (DOM) is an HTML and XML document programming API. It specifies the logical structure of documents as well as how they are accessed and modified.
Various transformation strategies can be used to transform, or convert, an XML document into another format. You can convert one XML document to another XML document, which could be a subset of the original by filtering particular information, or to a completely different data format, such as HTML, eXtensible HyperText Markup Language (XHTML), Wireless Markup Language (WML), CSV, and so on.
Why would you wish to change the format of our well-formatted XML document? We can read and interpret the data in its current state. Although you took the time to study XML and can now understand it as a technically aware individual, most people would prefer their data to be presented in a user-friendly format.
The eXtensible Stylesheet Language for Transformations (XSLT) standard is one of the most widely used ways for converting XML to another format. The interface required to convert XML data is provided by an XSLT processor. The XML parser, which is required for the XSLT processor to interpret and interact with XML, is one of the processor's components. When you consider it, the XSLT processor needs to parse the document in order to extract the information included in the XML before it can format the contents. To accomplish the transformation, the processor requires an XSLT stylesheet. An XSLT stylesheet is an XML document that has embedded rules for performing transformations. To transform a page, an XSLT processor uses XPath and the rules in the XSLT stylesheet. It uses XPath to search through the XML data and find the desired elements.
The transformation of XML to HTML is one of the most prevalent (and easily demonstrated) transformations in use today. While the data is transferred and processed as a well-formatted XML document, the XML document must be translated into HTML before it can be displayed in the browser with any formatting.
Key takeaway
Various transformation strategies can be used to transform, or convert, an XML document into another format. You can convert one XML document to another XML document, which could be a subset of the original by filtering particular information, or to a completely different data format, such as HTML, eXtensible HyperText Markup Language (XHTML), Wireless Markup Language (WML), CSV, and so on.
XML is a medium for storing and transporting data that is independent of software and hardware.
The eXtensible Markup Language (XML) stands for eXtensible Markup Language.
XML, like HTML, is a markup language that was created to store and transport data. It was also created to be self-descriptive.
Document Type Definition (DTD) is an acronym for Document Type Definition. It specifies the legal components of an XML document. It's used to specify the structure of a document using a list of legal elements and attributes.
Its main function is to describe an XML document's structure. It includes a set of legal elements that are used to describe the framework.
Checking validation
You must verify the validation before continuing with the XML DTD. If an XML document contains the correct syntax, it is said to be "well-formed."
A legitimate and well-formed XML document is one that has been checked against a DTD.
Description of DTD
<!DOCTYPE employee: It specifies that the document's root variable is employee.
<!ELEMENT employee: The employee element is described as having three elements: "firstname, lastname, and email."
<!ELEMENT firstname: It specifies that the firstname element is of type #PCDATA. (a data form that can be parsed).
<!ELEMENT lastname: It specifies that the lastname element is of type #PCDATA. (a data form that can be parsed).
<!ELEMENT email: It specifies that the email element is of type #PCDATA. (a data form that can be parsed).
Syntax
Basic syntax of a DTD is as follows:
<!DOCTYPE element DTD identifier
[
Declaration1
Declaration2
........
]>
Internal DTD
If elements are declared inside the XML files, the DTD is referred to as an internal DTD. The standalone attribute in the XML declaration must be set to yes to refer to it as internal DTD. This means that the declaration is self-contained and does not depend on a third-party source.
Syntax
The syntax of the internal DTD is as follows.
<!DOCTYPE root-element [element-declarations]>
Element-declarations is where you declare the elements, where root-element is the name of the root element.
External DTD
The elements of an external DTD are declared outside of the XML format. The device attributes, which can be either a legal.dtd file or a valid URL, are used to access them. The standalone attribute in the XML declaration must be set to no to refer to it as an external DTD. This means that the declaration contains data from a third-party source.
Syntax
The syntax of the internal DTD is as follows.
<!DOCTYPE root-element SYSTEM "file-name">
Where file-name is the name of the.dtd file.
Types
You may use device identifiers or public identifiers to refer to an external DTD.
System Identifiers
You may define the location of an external file containing DTD declarations using a device identifier. The following is the syntax:
<!DOCTYPE name SYSTEM "address.dtd" [...]>
As you can see, it includes the keyword SYSTEM as well as a URI reference to the document's location.
Public Identifiers
The following is a list of public identifiers that can be used to find DTD resources:
<!DOCTYPE name PUBLIC "-//Beginning XML//DTD Address Example//EN">
As you can see, it starts with the keyword PUBLIC and then moves on to a more specific identifier. An entry in a catalog is identified by a public identifier. Public identifiers may be in any format, however Formal Public Identifiers, or FPIs, are a popular choice.
Elements
The building pieces of an XML document are known as XML elements. Elements can be used to hold text, elements, attributes, media objects, or a combination of these.
An ELEMENT declaration is used to declare a DTD element. When a DTD parser validates an XML file, the parser looks for the root element first, then the child elements.
Syntax
This is the general form of all DTD element declarations.
<!ELEMENT elementname (content)>
● The ELEMENT declaration informs the parser that an element is about to be defined.
● The element name (also known as the generic identifier) that you are defining is elementname.
● The content specifies what type of content (if any) can be placed within the element.
Element Content Types
Content of elements declaration in a DTD can be categorized as below −
● Empty content
● Element content
● Mixed content
● Any content
Attributes
DTD Attributes provide additional information about an element or, more accurately, specify an element's property. A name-value pair is always the format of an XML attribute. An element can have as many distinct qualities as it wants.
In many respects, attribute declarations are identical to element declarations, with the exception that instead of defining allowed content for elements, you define a list of allowable attributes for each. ATTLIST declaration is the name for these lists.
Syntax
The following is the basic syntax for declaring DTD attributes:
<!ATTLIST element-name attribute-name attribute-type attribute-value>
In the preceding syntax,
● The DTD attributes begin with the requirement that the attributes be defined.
● The name of the element to which the attribute applies is specified by element-name.
● The name of the attribute that is included with the element-name is specified by attribute-name.
● The type of attributes is defined by attribute-type.
● attribute-value accepts a fixed value that must be defined by the attributes.
Example
The following is a simple DTD attribute declaration example.
<?xml version = "1.0"?>
<!DOCTYPE address [
<!ELEMENT address ( name )>
<!ELEMENT name ( #PCDATA )>
<!ATTLIST name id CDATA #REQUIRED>
]>
<address>
<name id = "123">Tanmay Patil</name>
</address>
Rule of Attributes declarations
● All attributes used in an XML document must be declared using an Attribute-List Declaration in the Document Type Definition (DTD).
● Only start or empty tags can have attributes.
● ATTLIST must be written in capital letters.
● Within the attribute list for a given element, no duplicate attribute names will be allowed.
Attribute Types
You can indicate how the processor should treat the data in the value when declaring attributes. Attribute types can be divided into three categories.
● String type
● Tokenized types
● Enumerated types
Key takeaway
- Document Type Definition (DTD) is an acronym for Document Type Definition.
- It specifies the legal components of an XML document.
- It's used to specify the structure of a document using a list of legal elements and attributes.
- If elements are declared inside the XML files, the DTD is referred to as an internal DTD.
Key takeaway
Document Type Definition (DTD) is an acronym for Document Type Definition. It specifies the legal components of an XML document. It's used to specify the structure of a document using a list of legal elements and attributes.
AJAX (Asynchronous JavaScript and XML) is an acronym for Asynchronous JavaScript and XML. AJAX is a new technique for using XML, HTML, CSS, and Java Script to create better, quicker, and more interactive web applications.
● For dynamic content display, Ajax uses XHTML for content, CSS for appearance, and Document Object Model and JavaScript.
● Asynchronous requests are used by traditional web applications to send and receive data to and from the server. It means that once you submit a form, you will be redirected to a new page with updated information from the server.
● When you submit a form using AJAX, JavaScript sends a request to the server, interprets the response, and updates the current screen. In the truest sense, the user would have no idea that anything was sent to the server at all.
● Although XML is typically used to receive server data, any format, including plain text, can be utilised.
● AJAX is a web browser technology that is not dependent on the web server.
● While the client software seeks information from the server in the background, the user can continue to utilise the application.
● User interaction that is intuitive and natural. It is not necessary to click; mouse movement is sufficient as an event trigger.
● Data-driven rather than page-driven.
Uses
Gmail, Facebook, Twitter, Google Maps, and YouTube are just a few examples of web apps that use ajax technology.
Key takeaway
AJAX (Asynchronous JavaScript and XML) is an acronym for Asynchronous JavaScript and XML. AJAX is a new technique for using XML, HTML, CSS, and Java Script to create better, quicker, and more interactive web applications.
Asynchronous and synchronous requests are the two types of requests. Synchronous requests are those that occur in a sequential order, i.e., if one process is running and another wants to run at the same time, it will not be allowed, implying that only one process will run at a time. This is bad since most of the time the CPU is idle in this type of procedure, such as during I/O operations, which are orders of magnitude slower than the CPU processing the instructions. As a result, asynchronous calls are used to fully use the CPU and other resources. Visit this website for further information. Why is the term javascript used here?
The requests are actually made with the help of javascript functions. The term XML is now used to describe the XMLHttpRequest object.
As a result of the previous explanation, Ajax enables asynchronous web page updates by exchanging small quantities of data with the server behind the scenes. Now we'll talk about the most crucial element and how to put it into action. Only be aware of the XMLHttpRequest object while implementing Ajax. Now, let's look at what it is. It's a behind-the-scenes object for exchanging data with the server. Remember the OOP paradigm, which states that objects communicate by calling methods (or in general sense message passing). The similar argument might be made in this scenario. Typically, this object is created and used to call the methods, resulting in successful communication. The XMLHttpRequest object is supported by all current browsers.
Keep in mind that AJAX is neither a programming language or a single technology. AJAX, as previously said, is a set of web development approaches. The system is made up of the following components:
● The main language is HTML/XHTML, while the presentation is CSS.
● The Document Object Model (DOM) is used to show dynamic data and interact with it.
● For data interchange, XML is used, and for data transformation, XSLT is used. Because JSON is more similar in form to JavaScript, many developers have begun to use it instead.
● For asynchronous communication, use the XMLHttpRequest object.
● Finally, the JavaScript programming language is used to connect all of these technologies.
To properly comprehend it, you may need some technical knowledge. However, the general technique for using AJAX is pretty straightforward. For a more detailed comparison, see the graphic and table below.
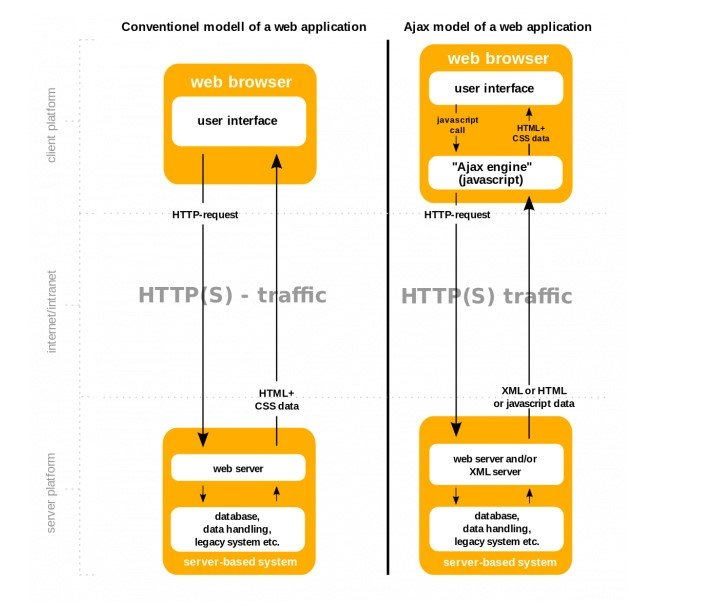
Fig 3: Detailed comparison
Key takeaway
Asynchronous and synchronous requests are the two types of requests. Synchronous requests are those that occur in a sequential order, i.e., if one process is running and another wants to run at the same time, it will not be allowed, implying that only one process will run at a time.
How to quickly build a blogging website using only HTML, CSS, and JS. There is no other library like it. We'll also store/retrieve blog data using Firebase firestore.
This is an excellent project for full-stack development practise. When I first started learning web development, I was always thinking about how I could create my own blogging website. And today, I am proud of the fact that I attempted to create a blogging site. Our website is incredibly user-friendly and includes features such as
● Dynamic Blog pages.
● Have a dedicated editor for blogs.
● You can add/make as many blogs you want.
● You can add Headings, paragraphs, and Images to the blog post.
● Have read more blogs section also.
The Dynamic Websites – Server-side Programming topic is a collection of modules that demonstrate how to build dynamic websites, or websites that respond to HTTP requests with customised information. The modules include a general introduction to server-side programming as well as detailed beginner-level guidance on how to develop basic apps using the Django (Python) and Express (Node.js/JavaScript) web frameworks.
To dynamically display data as needed, most big websites employ server-side technologies. Consider how many things are accessible on Amazon and how many postings have been made on Facebook, for example. Because it would be inefficient to display all of these on separate static pages, such sites instead display static templates (built using HTML, CSS, and JavaScript) and then dynamically update the data displayed inside those templates as needed, such as when you want to view a different Amazon product.
Learning about server-side development is highly recommended in today's web development industry.
Pathway to study
Because dynamic websites perform a lot of very similar operations (retrieving data from a database and displaying it in a page, validating user-entered data and saving it in a database, checking user permissions and logging users in, etc.) and are built using web frameworks that make these and other common web server operations easy, getting started with server-side programming is usually easier than getting started with client-side programming.
Basic programming concepts (or knowledge of a specific programming language) are helpful but not required. Similarly, while client-side coding experience is not essential, having a rudimentary understanding will help you collaborate more effectively with the engineers building your client-side web "front end."
Modules
The following modules are included in this topic. Start with the first module, then move on to one of the following modules, which demonstrate how to use two popular server-side languages with appropriate web frameworks.
Server-side website programming first steps
This module answers questions like "what is server-side website programming?" "how does it differ from client-side website programming?" and "why is it useful?" in a technology-neutral manner. This session also covers some of the most common server-side web frameworks and how to choose the right one for your site. Finally, a primer on web server security is presented.
Django Web Framework (Python)
Django is a server-side web framework built in Python that is very popular and has a lot of features. The module discusses why Django is such a great web server framework, how to set up a development environment, and how to use it to accomplish typical tasks.
Express Web Framework (Node.js/JavaScript)
Express is a popular web framework that is written in JavaScript and runs on the node.js platform. The module walks you through some of the framework's most important features, as well as how to set up your development environment and execute standard web development and deployment chores.
References:
- Jeffrey C.Jackson, "Web Technologies: A Computer Science Perspective", Second Edition, Pearson Education, 2007, ISBN 978-0131856035
- Marty Hall, Larry Brown, “Core Web Programming", Second Edition, Pearson Education, 2001, ISBN 978-0130897930.




