Unit 5
Templates, Namespaces and Exception handling
Templates are the foundation of generic programming, which involves writing code in a way that is independent of any particular type.
A template is a blueprint or formula for creating a generic class or a function. The library containers like iterators and algorithms are examples of generic programming and have been developed using template concept.
There is a single definition of each container, such as vector, but we can define many different kinds of vectors for example, vector <int> or vector <string>.
You can use templates to define functions as well as classes, let us see how they work −
Function Template
The general form of a template function definition is shown here −
Template <class type> ret-type func-name(parameter list) {
// body of function
}
Here, type is a placeholder name for a data type used by the function. This name can be used within the function definition.
The following is the example of a function template that returns the maximum of two values −
#include <iostream>
#include <string>
Using namespace std;
Template <typename T>
Inline T const& Max (T const& a, T const& b) {
Return a < b ? b:a;
}
Int main () {
Int i = 39;
Int j = 20;
Cout << "Max(i, j): " << Max(i, j) << endl;
Double f1 = 13.5;
Double f2 = 20.7;
Cout << "Max(f1, f2): " << Max(f1, f2) << endl;
String s1 = "Hello";
String s2 = "World";
Cout << "Max(s1, s2): " << Max(s1, s2) << endl;
Return 0;
}
If we compile and run above code, this would produce the following result −
Max(i, j): 39
Max(f1, f2): 20.7
Max(s1, s2): World
Class Template
Just as we can define function templates, we can also define class templates. The general form of a generic class declaration is shown here −
Template <class type> class class-name {
.
.
.
}
Here, type is the placeholder type name, which will be specified when a class is instantiated. You can define more than one generic data type by using a comma-separated list.
Following is the example to define class Stack<> and implement generic methods to push and pop the elements from the stack −
#include <iostream>
#include <vector>
#include <cstdlib>
#include <string>
#include <stdexcept>
Using namespace std;
Template <class T>
Class Stack {
Private:
Vector<T> elems; // elements
Public:
Void push(T const&); // push element
Void pop(); // pop element
T top() const; // return top element
Bool empty() const { // return true if empty.
Return elems.empty();
}
};
Template <class T>
Void Stack<T>::push (T const& elem) {
// append copy of passed element
Elems.push_back(elem);
}
Template <class T>
Void Stack<T>::pop () {
If (elems.empty()) {
Throw out_of_range("Stack<>::pop(): empty stack");
}
// remove last element
Elems.pop_back();
}
Template <class T>
T Stack<T>::top () const {
If (elems.empty()) {
Throw out_of_range("Stack<>::top(): empty stack");
}
// return copy of last element
Return elems.back();
}
Int main() {
Try {
Stack<int> intStack; // stack of ints
Stack<string> stringStack; // stack of strings
// manipulate int stack
IntStack.push(7);
Cout << intStack.top() <<endl;
// manipulate string stack
StringStack.push("hello");
Cout << stringStack.top() << std::endl;
StringStack.pop();
StringStack.pop();
} catch (exception const& ex) {
Cerr << "Exception: " << ex.what() <<endl;
Return -1;
}
}
If we compile and run above code, this would produce the following result −
7
Hello
Exception: Stack<>::pop(): empty stack
KEY TAKEAWAY
Templates are the foundation of generic programming, which involves writing code in a way that is independent of any particular type.
A template is a blueprint or formula for creating a generic class or a function. The library containers like iterators and algorithms are examples of generic programming and have been developed using template concept.
There is a single definition of each container, such as vector, but we can define many different kinds of vectors for example, vector <int> or vector <string>.
Overloaded functions
In C++, two different functions can have the same name if their parameters are different; either because they have a different number of parameters, or because any of their parameters are of a different type. For example:
1 | // overloading functions #include <iostream> Using namespace std;
Int operate (int a, int b) { Return (a*b); }
Double operate (double a, double b) { Return (a/b); }
Int main () { Int x=5,y=2; Double n=5.0,m=2.0; Cout << operate (x,y) << '\n'; Cout << operate (n,m) << '\n'; Return 0; } |
|
|
In this example, there are two functions called operate, but one of them has two parameters of type int, while the other has them of type double. The compiler knows which one to call in each case by examining the types passed as arguments when the function is called. If it is called with two int arguments, it calls to the function that has two int parameters, and if it is called with two doubles, it calls the one with two doubles.
In this example, both functions have quite different behaviors, the int version multiplies its arguments, while the double version divides them. This is generally not a good idea. Two functions with the same name are generally expected to have -at least- a similar behavior, but this example demonstrates that is entirely possible for them not to. Two overloaded functions (i.e., two functions with the same name) have entirely different definitions; they are, for all purposes, different functions, that only happen to have the same name.
Note that a function cannot be overloaded only by its return type. At least one of its parameters must have a different type.
Function templates
Overloaded functions may have the same definition. For example:
1 | // overloaded functions #include <iostream> Using namespace std;
Int sum (int a, int b) { Return a+b; }
Double sum (double a, double b) { Return a+b; }
Int main () { Cout << sum (10,20) << '\n'; Cout << sum (1.0,1.5) << '\n'; Return 0; } |
|
|
Here, sum is overloaded with different parameter types, but with the exact same body.
The function sum could be overloaded for a lot of types, and it could make sense for all of them to have the same body. For cases such as this, C++ has the ability to define functions with generic types, known as function templates. Defining a function template follows the same syntax as a regular function, except that it is preceded by the template keyword and a series of template parameters enclosed in angle-brackets <>:
template <template-parameters> function-declaration
The template parameters are a series of parameters separated by commas. These parameters can be generic template types by specifying either the class or typename keyword followed by an identifier. This identifier can then be used in the function declaration as if it was a regular type. For example, a generic sum function could be defined as:
1 | Template <class SomeType> SomeType sum (SomeType a, SomeType b) { Return a+b; } |
|
It makes no difference whether the generic type is specified with keyword class or keyword typename in the template argument list (they are 100% synonyms in template declarations).
In the code above, declaring SomeType (a generic type within the template parameters enclosed in angle-brackets) allows SomeType to be used anywhere in the function definition, just as any other type; it can be used as the type for parameters, as return type, or to declare new variables of this type. In all cases, it represents a generic type that will be determined on the moment the template is instantiated.
Instantiating a template is applying the template to create a function using particular types or values for its template parameters. This is done by calling the function template, with the same syntax as calling a regular function, but specifying the template arguments enclosed in angle brackets:
name <template-arguments> (function-arguments)
For example, the sum function template defined above can be called with:
| x = sum<int>(10,20); |
|
The function sum<int> is just one of the possible instantiations of function template sum. In this case, by using int as template argument in the call, the compiler automatically instantiates a version of sum where each occurrence of SomeType is replaced by int, as if it was defined as:
1 | Int sum (int a, int b) { Return a+b; } |
|
Let's see an actual example:
1 | // function template #include <iostream> Using namespace std;
Template <class T> T sum (T a, T b) { T result; Result = a + b; Return result; }
Int main () { Int i=5, j=6, k; Double f=2.0, g=0.5, h; k=sum<int>(i,j); h=sum<double>(f,g); Cout << k << '\n'; Cout << h << '\n'; Return 0; } |
|
|
In this case, we have used T as the template parameter name, instead of SomeType. It makes no difference, and T is actually a quite common template parameter name for generic types.
In the example above, we used the function template sum twice. The first time with arguments of type int, and the second one with arguments of type double. The compiler has instantiated and then called each time the appropriate version of the function.
Note also how T is also used to declare a local variable of that (generic) type within sum:
| T result; |
|
Therefore, result will be a variable of the same type as the parameters a and b, and as the type returned by the function.
In this specific case where the generic type T is used as a parameter for sum, the compiler is even able to deduce the data type automatically without having to explicitly specify it within angle brackets. Therefore, instead of explicitly specifying the template arguments with:
1 | k = sum<int> (i,j); h = sum<double> (f,g); |
|
It is possible to instead simply write:
1 | k = sum (i,j); h = sum (f,g); |
|
without the type enclosed in angle brackets. Naturally, for that, the type shall be unambiguous. If sum is called with arguments of different types, the compiler may not be able to deduce the type of T automatically.
Templates are a powerful and versatile feature. They can have multiple template parameters, and the function can still use regular non-templated types. For example:
1 | // function templates #include <iostream> Using namespace std;
Template <class T, class U> Bool are_equal (T a, U b) { Return (a==b); }
Int main () { If (are_equal(10,10.0)) Cout << "x and y are equal\n"; Else Cout << "x and y are not equal\n"; Return 0; } | x and y are equal |
|
Note that this example uses automatic template parameter deduction in the call to are_equal:
| Are_equal(10,10.0) |
|
Is equivalent to:
| Are_equal<int,double>(10,10.0) |
|
There is no ambiguity possible because numerical literals are always of a specific type: Unless otherwise specified with a suffix, integer literals always produce values of type int, and floating-point literals always produce values of type double. Therefore 10 has always type int and 10.0 has always type double.
Non-type template arguments
The template parameters can not only include types introduced by class or typename, but can also include expressions of a particular type:
1 | // template arguments #include <iostream> Using namespace std;
Template <class T, int N> T fixed_multiply (T val) { Return val * N; }
Int main() { Std::cout << fixed_multiply<int,2>(10) << '\n'; Std::cout << fixed_multiply<int,3>(10) << '\n'; } |
|
|
The second argument of the fixed_multiply function template is of type int. It just looks like a regular function parameter, and can actually be used just like one.
But there exists a major difference: the value of template parameters is determined on compile-time to generate a different instantiation of the function fixed_multiply, and thus the value of that argument is never passed during runtime: The two calls to fixed_multiply in main essentially call two versions of the function: one that always multiplies by two, and one that always multiplies by three. For that same reason, the second template argument needs to be a constant expression (it cannot be passed a variable).
KEY TAKEAWAY
In C++, two different functions can have the same name if their parameters are different; either because they have a different number of parameters, or because any of their parameters are of a different type.
The function sum could be overloaded for a lot of types, and it could make sense for all of them to have the same body. For cases such as this, C++ has the ability to define functions with generic types, known as function templates. Defining a function template follows the same syntax as a regular function, except that it is preceded by the template keyword and a series of template parameters enclosed in angle-brackets <>:
Consider a situation, when we have two persons with the same name, Zara, in the same class. Whenever we need to differentiate them definitely we would have to use some additional information along with their name, like either the area, if they live in different area or their mother’s or father’s name, etc.
Same situation can arise in your C++ applications. For example, you might be writing some code that has a function called xyz() and there is another library available which is also having same function xyz(). Now the compiler has no way of knowing which version of xyz() function you are referring to within your code.
A namespace is designed to overcome this difficulty and is used as additional information to differentiate similar functions, classes, variables etc. with the same name available in different libraries. Using namespace, you can define the context in which names are defined. In essence, a namespace defines a scope.
Defining a Namespace
A namespace definition begins with the keyword namespace followed by the namespace name as follows −
Namespace namespace_name {
// code declarations
}
To call the namespace-enabled version of either function or variable, prepend (::) the namespace name as follows −
Name::code; // code could be variable or function.
Let us see how namespace scope the entities including variable and functions −
#include <iostream>
Using namespace std;
// first name space
Namespace first_space {
Void func() {
Cout << "Inside first_space" << endl;
}
}
// second name space
Namespace second_space {
Void func() {
Cout << "Inside second_space" << endl;
}
}
Int main () {
// Calls function from first name space.
First_space::func();
// Calls function from second name space.
Second_space::func();
Return 0;
}
If we compile and run above code, this would produce the following result −
Inside first_space
Inside second_space
The using directive
You can also avoid prepending of namespaces with the using namespace directive. This directive tells the compiler that the subsequent code is making use of names in the specified namespace. The namespace is thus implied for the following code −
#include <iostream>
Using namespace std;
// first name space
Namespace first_space {
Void func() {
Cout << "Inside first_space" << endl;
}
}
// second name space
Namespace second_space {
Void func() {
Cout << "Inside second_space" << endl;
}
}
Using namespace first_space;
Int main () {
// This calls function from first name space.
Func();
Return 0;
}
If we compile and run above code, this would produce the following result −
Inside first_space
The ‘using’ directive can also be used to refer to a particular item within a namespace. For example, if the only part of the std namespace that you intend to use is cout, you can refer to it as follows −
Using std::cout;
Subsequent code can refer to cout without prepending the namespace, but other items in the std namespace will still need to be explicit as follows −
#include <iostream>
Using std::cout;
Int main () {
Cout << "std::endl is used with std!" << std::endl;
Return 0;
}
If we compile and run above code, this would produce the following result −
Std::endl is used with std!
Names introduced in a using directive obey normal scope rules. The name is visible from the point of the using directive to the end of the scope in which the directive is found. Entities with the same name defined in an outer scope are hidden.
Discontiguous Namespaces
A namespace can be defined in several parts and so a namespace is made up of the sum of its separately defined parts. The separate parts of a namespace can be spread over multiple files.
So, if one part of the namespace requires a name defined in another file, that name must still be declared. Writing a following namespace definition either defines a new namespace or adds new elements to an existing one −
Namespace namespace_name {
// code declarations
}
Nested Namespaces
Namespaces can be nested where you can define one namespace inside another name space as follows −
Namespace namespace_name1 {
// code declarations
Namespace namespace_name2 {
// code declarations
}
}
You can access members of nested namespace by using resolution operators as follows −
// to access members of namespace_name2
Using namespace namespace_name1::namespace_name2;
// to access members of namespace:name1
Using namespace namespace_name1;
In the above statements if you are using namespace_name1, then it will make elements of namespace_name2 available in the scope as follows −
#include <iostream>
Using namespace std;
// first name space
Namespace first_space {
Void func() {
Cout << "Inside first_space" << endl;
}
// second name space
Namespace second_space {
Void func() {
Cout << "Inside second_space" << endl;
}
}
}
Using namespace first_space::second_space;
Int main () {
// This calls function from second name space.
Func();
Return 0;
}
If we compile and run above code, this would produce the following result −
Inside second_space
KEY TAKEAWAY
A namespace is designed to overcome this difficulty and is used as additional information to differentiate similar functions, classes, variables etc. with the same name available in different libraries. Using namespace, you can define the context in which names are defined. In essence, a namespace defines a scope.
An exception is a problem that arises during the execution of a program. A C++ exception is a response to an exceptional circumstance that arises while a program is running, such as an attempt to divide by zero.
Exceptions provide a way to transfer control from one part of a program to another. C++ exception handling is built upon three keywords: try, catch, and throw.
- Throw − A program throws an exception when a problem shows up. This is done using a throw keyword.
- Catch − A program catches an exception with an exception handler at the place in a program where you want to handle the problem. The catch keyword indicates the catching of an exception.
- Try − A try block identifies a block of code for which particular exceptions will be activated. It's followed by one or more catch blocks.
Assuming a block will raise an exception, a method catches an exception using a combination of the try and catch keywords. A try/catch block is placed around the code that might generate an exception. Code within a try/catch block is referred to as protected code, and the syntax for using try/catch as follows −
Try {
// protected code
} catch( ExceptionName e1 ) {
// catch block
} catch( ExceptionName e2 ) {
// catch block
} catch( ExceptionName eN ) {
// catch block
}
You can list down multiple catch statements to catch different type of exceptions in case your try block raises more than one exception in different situations.
Throwing Exceptions
Exceptions can be thrown anywhere within a code block using throw statement. The operand of the throw statement determines a type for the exception and can be any expression and the type of the result of the expression determines the type of exception thrown.
Following is an example of throwing an exception when dividing by zero condition occurs −
Double division(int a, int b) {
If( b == 0 ) {
Throw "Division by zero condition!";
}
Return (a/b);
}
Catching Exceptions
The catch block following the try block catches any exception. You can specify what type of exception you want to catch and this is determined by the exception declaration that appears in parentheses following the keyword catch.
Try {
// protected code
} catch( ExceptionName e ) {
// code to handle ExceptionName exception
}
Above code will catch an exception of ExceptionName type. If you want to specify that a catch block should handle any type of exception that is thrown in a try block, you must put an ellipsis, ..., between the parentheses enclosing the exception declaration as follows −
Try {
// protected code
} catch(...) {
// code to handle any exception
}
The following is an example, which throws a division by zero exception and we catch it in catch block.
#include <iostream>
Using namespace std;
Double division(int a, int b) {
If( b == 0 ) {
Throw "Division by zero condition!";
}
Return (a/b);
}
Int main () {
Int x = 50;
Int y = 0;
Double z = 0;
Try {
z = division(x, y);
Cout << z << endl;
} catch (const char* msg) {
Cerr << msg << endl;
}
Return 0;
}
Because we are raising an exception of type const char*, so while catching this exception, we have to use const char* in catch block. If we compile and run above code, this would produce the following result −
Division by zero condition!
C++ Standard Exceptions
C++ provides a list of standard exceptions defined in <exception> which we can use in our programs. These are arranged in a parent-child class hierarchy shown below −
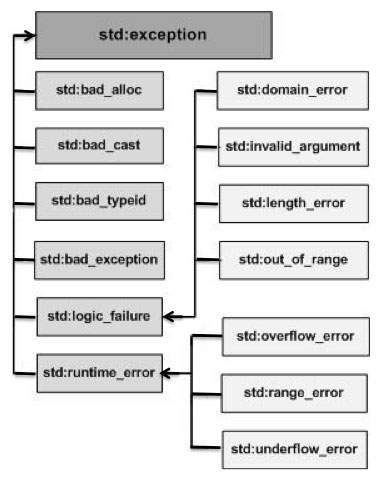
Here is the small description of each exception mentioned in the above hierarchy −
Sr.No | Exception & Description |
1 | Std::exception An exception and parent class of all the standard C++ exceptions. |
2 | Std::bad_alloc This can be thrown by new. |
3 | Std::bad_cast This can be thrown by dynamic_cast. |
4 | Std::bad_exception This is useful device to handle unexpected exceptions in a C++ program. |
5 | Std::bad_typeid This can be thrown by typeid. |
6 | Std::logic_error An exception that theoretically can be detected by reading the code. |
7 | Std::domain_error This is an exception thrown when a mathematically invalid domain is used. |
8 | Std::invalid_argument This is thrown due to invalid arguments. |
9 | Std::length_error This is thrown when a too big std::string is created. |
10 | Std::out_of_range This can be thrown by the 'at' method, for example a std::vector and std::bitset<>::operator[](). |
11 | Std::runtime_error An exception that theoretically cannot be detected by reading the code. |
12 | Std::overflow_error This is thrown if a mathematical overflow occurs. |
13 | Std::range_error This is occurred when you try to store a value which is out of range. |
14 | Std::underflow_error This is thrown if a mathematical underflow occurs. |
Define New Exceptions
You can define your own exceptions by inheriting and overriding exception class functionality. Following is the example, which shows how you can use std::exception class to implement your own exception in standard way −
#include <iostream>
#include <exception>
Using namespace std;
Struct MyException : public exception {
Const char * what () const throw () {
Return "C++ Exception";
}
};
Int main() {
Try {
Throw MyException();
} catch(MyException& e) {
Std::cout << "MyException caught" << std::endl;
Std::cout << e.what() << std::endl;
} catch(std::exception& e) {
//Other errors
}
}
This would produce the following result −
MyException caught
C++ Exception
Here, what() is a public method provided by exception class and it has been overridden by all the child exception classes. This returns the cause of an exception.
KEY TAKEAWAY
An exception is a problem that arises during the execution of a program. A C++ exception is a response to an exceptional circumstance that arises while a program is running, such as an attempt to divide by zero.
Exceptions provide a way to transfer control from one part of a program to another. C++ exception handling is built upon three keywords: try, catch, and throw.
Exception specifications are a C++ language feature that indicate the programmer's intent about the exception types that can be propagated by a function. You can specify that a function may or may not exit by an exception by using an exception specification. The compiler can use this information to optimize calls to the function, and to terminate the program if an unexpected exception escapes the function.
Prior to C++17 there were two kinds of exception specification. The noexcept specification was new in C++11. It specifies whether the set of potential exceptions that can escape the function is empty. The dynamic exception specification, or throw(optional_type_list) specification, was deprecated in C++11 and removed in C++17, except for throw(), which is an alias for noexcept(true). This exception specification was designed to provide summary information about what exceptions can be thrown out of a function, but in practice it was found to be problematic. The one dynamic exception specification that did prove to be somewhat useful was the unconditional throw() specification. For example, the function declaration:
C++
Void MyFunction(int i) throw();
Tells the compiler that the function does not throw any exceptions. However, in /std:c++14 mode this could lead to undefined behavior if the function does throw an exception. Therefore we recommend using the noexcept operator instead of the one above:
C++
Void MyFunction(int i) noexcept;
The following table summarizes the Microsoft C++ implementation of exception specifications:
Table 1 | |
Exception specification | Meaning |
Noexcept | The function does not throw an exception. In /std:c++14 mode (which is the default), noexcept and noexcept(true) are equivalent. When an exception is thrown from a function that is declared noexcept or noexcept(true), std::terminate is invoked. When an exception is thrown from a function declared as throw() in /std:c++14 mode, the result is undefined behavior. No specific function is invoked. This is a divergence from the C++14 standard, which required the compiler to invoke std::unexpected. |
Noexcept(false) | The function can throw an exception of any type. |
Throw(type) | (C++14 and earlier) The function can throw an exception of type type. The compiler accepts the syntax, but interprets it as noexcept(false). In /std:c++17 mode the compiler issues warning C5040. |
If exception handling is used in an application, there must be a function in the call stack that handles thrown exceptions before they exit the outer scope of a function marked noexcept, noexcept(true), or throw(). If any functions called between the one that throws an exception and the one that handles the exception are specified as noexcept, noexcept(true) (or throw() in /std:c++17 mode), the program is terminated when the noexcept function propagates the exception.
Explicit exception specifications are not allowed on C functions. A C function is assumed not to throw exceptions under /EHsc, and may throw structured exceptions under /EHs, /EHa, or /EHac.
The following table summarizes whether a C++ function may potentially throw under various compiler exception handling options:
Table 2 | ||||
Function | /EHsc | /EHs | /EHa | /EHac |
C++ function with no exception specification | Yes | Yes | Yes | Yes |
C++ function with noexcept, noexcept(true), or throw() exception specification | No | No | Yes | Yes |
C++ function with noexcept(false), throw(...), or throw(type) exception specification | Yes | Yes | Yes | Yes |
Example
C++
// exception_specification.cpp
// compile with: /EHs
#include <stdio.h>
Void handler() {
Printf_s("in handler\n");
}
Void f1(void) throw(int) {
Printf_s("About to throw 1\n");
If (1)
Throw 1;
}
Void f5(void) throw() {
Try {
f1();
}
Catch(...) {
Handler();
}
}
// invalid, doesn't handle the int exception thrown from f1()
// void f3(void) throw() {
// f1();
// }
Void __declspec(nothrow) f2(void) {
Try {
f1();
}
Catch(int) {
Handler();
}
}
// only valid if compiled without /EHc
// /EHc means assume extern "C" functions don't throw exceptions
Extern "C" void f4(void);
Void f4(void) {
f1();
}
Int main() {
f2();
Try {
f4();
}
Catch(...) {
Printf_s("Caught exception from f4\n");
}
f5();
}
Output
About to throw 1
In handler
About to throw 1
Caught exception from f4
About to throw 1
In handler
KEY TAKEAWAY
Exception specifications are a C++ language feature that indicate the programmer's intent about the exception types that can be propagated by a function. You can specify that a function may or may not exit by an exception by using an exception specification. The compiler can use this information to optimize calls to the function, and to terminate the program if an unexpected exception escapes the function.
An exception is a situation, which occured by the runtime error. In other words, an exception is a runtime error. An exception may result in loss of data or an abnormal execution of program.
Exception handling is a mechanism that allows you to take appropriate action to avoid runtime errors.
C++ provides three keywords to support exception handling.
- Try : The try block contain statements which may generate exceptions.
- Throw : When an exception occur in try block, it is thrown to the catch block using throw keyword.
- Catch :The catch block defines the action to be taken, when an exception occur.
The general form of try-catch block in c++.

Example of simple try-throw-catch
#include<iostream.h>
#include<conio.h>
Void main()
{
Int n1,n2,result;
Cout<<"\nEnter 1st number : ";
Cin>>n1;
Cout<<"\nEnter 2nd number : ";
Cin>>n2;
Try
{
If(n2==0)
Throw n2; //Statement 1
Else
{
Result = n1 / n2;
Cout<<"\nThe result is : "<<result;
}
}
Catch(int x)
{
Cout<<"\nCan't divide by : "<<x;
}
Cout<<"\nEnd of program.";
}
Output :
Enter 1st number : 45
Enter 2nd number : 0
Can't divide by : 0
End of program
The catch block contain the code to handle exception. The catch block is similar to function definition.
Catch(data-type arg)
{
- - - - - - - - - -
- - - - - - - - - -
- - - - - - - - - -
};
Data-type specifies the type of exception that catch block will handle, Catch block will recieve value, send by throw keyword in try block.
Multiple Catch Statements
A single try statement can have multiple catch statements. Execution of particular catch block depends on the type of exception thrown by the throw keyword. If throw keyword send exception of integer type, catch block with integer parameter will get execute.
Example of multiple catch blocks
#include<iostream.h>
#include<conio.h>
Void main()
{
Int a=2;
Try
{
If(a==1)
Throw a; //throwing integer exception
Else if(a==2)
Throw 'A'; //throwing character exception
Else if(a==3)
Throw 4.5; //throwing float exception
}
Catch(int a)
{
Cout<<"\nInteger exception caught.";
}
Catch(char ch)
{
Cout<<"\nCharacter exception caught.";
}
Catch(double d)
{
Cout<<"\nDouble exception caught.";
}
Cout<<"\nEnd of program.";
}
Output :
Character exception caught.
End of program.
Catch All Exceptions
The above example will caught only three types of exceptions that are integer, character and double. If an exception occur of long type, no catch block will get execute and abnormal program termination will occur. To avoid this, We can use the catch statement with three dots as parameter (...) so that it can handle all types of exceptions.
Example to catch all exceptions
#include<iostream.h>
#include<conio.h>
Void main()
{
Int a=1;
Try
{
If(a==1)
Throw a; //throwing integer exception
Else if(a==2)
Throw 'A'; //throwing character exception
Else if(a==3)
Throw 4.5; //throwing float exception
}
Catch(...)
{
Cout<<"\nException occur.";
}
Cout<<"\nEnd of program.";
}
Output :
Exception occur.
End of program.
Rethrowing Exceptions
Rethrowing exception is possible, where we have an inner and outer try-catch statements (Nested try-catch). An exception to be thrown from inner catch block to outer catch block is called rethrowing exception.
Syntax of rethrowing exceptions
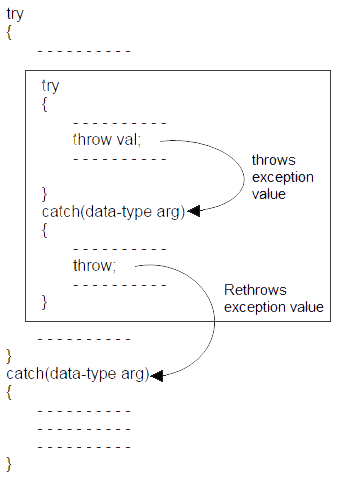
Example of rethrowing exceptions
#include<iostream.h>
#include<conio.h>
Void main()
{
Int a=1;
Try
{
Try
{
Throw a;
}
Catch(int x)
{
Cout<<"\nException in inner try-catch block.";
Throw x;
}
}
Catch(int n)
{
Cout<<"\nException in outer try-catch block.";
}
Cout<<"\nEnd of program.";
}
Output :
Exception in inner try-catch block.
Exception in outer try-catch block.
End of program.
Restricting Exceptions
We can restrict the type of exception to be thrown, from a function to its calling statement, by adding throw keyword to a function definition.
Example of restricting exceptions
#include<iostream.h>
#include<conio.h>
Void Demo() throw(int ,double)
{
Int a=2;
If(a==1)
Throw a; //throwing integer exception
Else if(a==2)
Throw 'A'; //throwing character exception
Else if(a==3)
Throw 4.5; //throwing float exception
}
Void main()
{
Try
{
Demo();
}
Catch(int n)
{
Cout<<"\nException caught.";
}
Cout<<"\nEnd of program.";
}
The above program will abort because we have restricted the Demo() function to throw only integer and double type exceptions and Demo() is throwing character type exception.
KEY TAKEAWAY
An exception is a situation, which occured by the runtime error. In other words, an exception is a runtime error. An exception may result in loss of data or an abnormal execution of program.
Exception handling is a mechanism that allows you to take appropriate action to avoid runtime errors.
C++ provides three keywords to support exception handling.
- Try : The try block contain statements which may generate exceptions.
- Throw : When an exception occur in try block, it is thrown to the catch block using throw keyword.
- Catch :The catch block defines the action to be taken, when an exception occur.
So far, we have been using the iostream standard library, which provides cin and cout methods for reading from standard input and writing to standard output respectively.
This tutorial will teach you how to read and write from a file. This requires another standard C++ library called fstream, which defines three new data types −
Sr.No | Data Type & Description |
1 | Ofstream This data type represents the output file stream and is used to create files and to write information to files. |
2 | Ifstream This data type represents the input file stream and is used to read information from files. |
3 | Fstream This data type represents the file stream generally, and has the capabilities of both ofstream and ifstream which means it can create files, write information to files, and read information from files. |
To perform file processing in C++, header files <iostream> and <fstream> must be included in your C++ source file.
Opening a File
A file must be opened before you can read from it or write to it. Either ofstream or fstream object may be used to open a file for writing. And ifstream object is used to open a file for reading purpose only.
Following is the standard syntax for open() function, which is a member of fstream, ifstream, and ofstream objects.
Void open(const char *filename, ios::openmode mode);
Here, the first argument specifies the name and location of the file to be opened and the second argument of the open() member function defines the mode in which the file should be opened.
Sr.No | Mode Flag & Description |
1 | Ios::app Append mode. All output to that file to be appended to the end. |
2 | Ios::ate Open a file for output and move the read/write control to the end of the file. |
3 | Ios::in Open a file for reading. |
4 | Ios::out Open a file for writing. |
5 | Ios::trunc If the file already exists, its contents will be truncated before opening the file. |
You can combine two or more of these values by ORing them together. For example if you want to open a file in write mode and want to truncate it in case that already exists, following will be the syntax −
Ofstream outfile;
Outfile.open("file.dat", ios::out | ios::trunc );
Similar way, you can open a file for reading and writing purpose as follows −
Fstream afile;
Afile.open("file.dat", ios::out | ios::in );
Closing a File
When a C++ program terminates it automatically flushes all the streams, release all the allocated memory and close all the opened files. But it is always a good practice that a programmer should close all the opened files before program termination.
Following is the standard syntax for close() function, which is a member of fstream, ifstream, and ofstream objects.
Void close();
Writing to a File
While doing C++ programming, you write information to a file from your program using the stream insertion operator (<<) just as you use that operator to output information to the screen. The only difference is that you use an ofstream or fstream object instead of the cout object.
Reading from a File
You read information from a file into your program using the stream extraction operator (>>) just as you use that operator to input information from the keyboard. The only difference is that you use an ifstream or fstream object instead of the cin object.
Read and Write Example
Following is the C++ program which opens a file in reading and writing mode. After writing information entered by the user to a file named afile.dat, the program reads information from the file and outputs it onto the screen −
#include <fstream>
#include <iostream>
Using namespace std;
Int main () {
Char data[100];
// open a file in write mode.
Ofstream outfile;
Outfile.open("afile.dat");
Cout << "Writing to the file" << endl;
Cout << "Enter your name: ";
Cin.getline(data, 100);
// write inputted data into the file.
Outfile << data << endl;
Cout << "Enter your age: ";
Cin >> data;
Cin.ignore();
// again write inputted data into the file.
Outfile << data << endl;
// close the opened file.
Outfile.close();
// open a file in read mode.
Ifstream infile;
Infile.open("afile.dat");
Cout << "Reading from the file" << endl;
Infile >> data;
// write the data at the screen.
Cout << data << endl;
// again read the data from the file and display it.
Infile >> data;
Cout << data << endl;
// close the opened file.
Infile.close();
Return 0;
}
When the above code is compiled and executed, it produces the following sample input and output −
$./a.out
Writing to the file
Enter your name: Zara
Enter your age: 9
Reading from the file
Zara
9
Above examples make use of additional functions from cin object, like getline() function to read the line from outside and ignore() function to ignore the extra characters left by previous read statement.
File Position Pointers
Both istream and ostream provide member functions for repositioning the file-position pointer. These member functions are seekg ("seek get") for istream and seekp ("seek put") for ostream.
The argument to seekg and seekp normally is a long integer. A second argument can be specified to indicate the seek direction. The seek direction can be ios::beg (the default) for positioning relative to the beginning of a stream, ios::cur for positioning relative to the current position in a stream or ios::end for positioning relative to the end of a stream.
The file-position pointer is an integer value that specifies the location in the file as a number of bytes from the file's starting location. Some examples of positioning the "get" file-position pointer are −
// position to the nth byte of fileObject (assumes ios::beg)
FileObject.seekg( n );
// position n bytes forward in fileObject
FileObject.seekg( n, ios::cur );
// position n bytes back from end of fileObject
FileObject.seekg( n, ios::end );
// position at end of fileObject
FileObject.seekg( 0, ios::end );
KEY TAKEAWAY
We have been using the iostream standard library, which provides cin and cout methods for reading from standard input and writing to standard output respectively.
This tutorial will teach you how to read and write from a file. This requires another standard C++ library called fstream, which defines three new data types −
Sr.No | Data Type & Description |
1 | Ofstream This data type represents the output file stream and is used to create files and to write information to files. |
2 | Ifstream This data type represents the input file stream and is used to read information from files. |
3 | Fstream This data type represents the file stream generally, and has the capabilities of both ofstream and ifstream which means it can create files, write information to files, and read information from files. |
To perform file processing in C++, header files <iostream> and <fstream> must be included in your C++ source file.
Unformatted data
- The printed data with default setting by the I/O function of the language is known as unformatted data.
- It is the basic form of input/output and transfers the internal binary representation of the data directly between memory and the file.
- For example, in cin statement it asks for a number while executing. If the user enters a decimal number, the entered number is displayed using cout statement. There is no need to apply any external setting, by default the I/O function represents the number in decimal format.
Formatted data
- If the user needs to display a number in hexadecimal format, the data is represented with the manipulators are known as formatted data.
- It converts the internal binary representation of the data to ASCII characters which are written to the output file.
- It reads characters from the input file and coverts them to internal form.
- For example, cout<<hex<<13; converts decimal 13 to hexadecimal d. Formatting is a representation of data with different settings (like number format, field width, decimal points etc.) as per the requirement of the user.
Input/Output Streams
- The iostream standard library provides cin and cout object.
- Input stream uses cin object for reading the data from standard input and Output stream uses cout object for displaying the data on the screen or writing to standard output.
- The cin and cout are pre-defined streams for input and output data.
Syntax:
cin>>variable_name;
cout<<variable_name; - The cin object uses extraction operator (>>) before a variable name while the cout object uses insertion operator (<<) before a variable name.
- The cin object is used to read the data through the input device like keyboard etc. while the cout object is used to perform console write operation.
Example: Program demonstrating cin and cout statements
#include<iostream>
using namespace std;
int main()
{
char sname[15];
cout<<"Enter Employee Name : "<<endl;
cin>>sname;
cout<<"Employee Name is : "<<sname;
return 0;
}
Output:
Enter Employee Name : Prajakta
Employee Name is : Prajakta
In the above example, cout<<"Employee Name is : "<<sname displays the contents of character array sname (student name). The cout statement is like printf statement as used in C language.
The cin statement cin>>sname reads the string through keyboard and stores in the array sname[15]. The cin statement is like scanf statement as used in C language. The endl is a manipulator that breaks a line.
Typecasting
Typecasting is a conversion of data in one basic type to another by applying external use of data type keywords.
Example: Program for Typecasting and displaying the converted values
#include<iostream>
using namespace std;
int main()
{
int i = 69;
float f = 4.5;
char c = 'D';
cout<<"Before Typecasting"<<endl;
cout<<"---------------------------------------------"<<endl;
cout<<"i = "<<i<<endl;
cout<<"f = "<<f<<endl;
cout<<"c = "<<c<<endl<<endl;
cout<<"After Typecasting"<<endl;
cout<<"--------------------------------------------"<<endl;
cout<<"Integer(int) in Character(char) Format : "<<(char)i<<endl;
cout<<"Float(float) in Integer(int) Format : "<<(int)f<<endl;
cout<<"Character(char) in Integer(int) Format : "<<(int)c<<endl;
return 0;
}
Output:
Before Typecasting
---------------------------------------------
i = 69
f = 4.5
c = D
After Typecasting
--------------------------------------------
Integer(int) in Character(char) Format : E
Float(float) in Integer(int) Format : 4
Character(char) in Integer(int) Format : 68
In the above example, the variables of integer(int), float(float) and character(char) are declared and initialized i = 69, f = 4.5, c = 'D'.
In first cout statement, integer value converted into character according to ASCII character set and the character E is displayed.
In second cout statement, float value is converted into integer format. The displayed value is 4 not 4.5, because while performing typecasting from float to integer, it removes decimal part of float value and considers only integer part.
In third cout statement, character converted into integer. The value of 'D' is 69, printed as an integer. The integer format converts character into integer.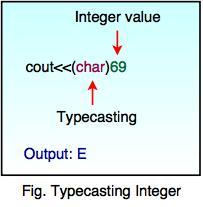
In the above diagram, 69 is an integer value and it is converted into character E by using typecasting format (char).
What are C++ Manipulators (endl, setw, setprecision, setf)?
Stream Manipulators are functions specifically designed to be used in conjunction with the insertion (<<) and extraction (>>) operators on stream objects, for example −
Std::cout << std::setw(10);
They are still regular functions and can also be called as any other function using a stream object as an argument, for example −
Boolalpha (cout);
Manipulators are used to changing formatting parameters on streams and to insert or extract certain special characters.
Following are some of the most widely used C++ manipulators −
Endl
This manipulator has the same functionality as ‘\n’(newline character). But this also flushes the output stream.
Example
#include<iostream>
Int main() {
Std::cout << "Hello" << std::endl << "World!";
}
Output
Hello
World!
Showpoint/noshowpoint
This manipulator controls whether decimal point is always included in the floating-point representation.
Example
#include <iostream>
Int main() {
Std::cout << "1.0 with showpoint: " << std::showpoint << 1.0 << '\n'
<< "1.0 with noshowpoint: " << std::noshowpoint << 1.0 << '\n';
}
Output
1.0 with showpoint: 1.00000
1.0 with noshowpoint: 1
Setprecision
This manipulator changes floating-point precision. When used in an expression out << setprecision(n) or in >> setprecision(n), sets the precision parameter of the stream out or into exactly n.
Example
#include <iostream>
#include <iomanip>
Int main() {
Const long double pi = 3.141592653589793239;
Std::cout << "default precision (6): " << pi << '\n'
<< "std::setprecision(10): " << std::setprecision(10) << pi << '\n';
}
Output
Default precision (6): 3.14159
Std::setprecision(10): 3.141592654
Setw
This manipulator changes the width of the next input/output field. When used in an expression out << setw(n) or in >> setw(n), sets the width parameter of the stream out or in to exactly n.
Example
#include <iostream>
#include <iomanip>
Int main() {
Std::cout << "no setw:" << 42 << '\n'
<< "setw(6):" << std::setw(6) << 42 << '\n'
<< "setw(6), several elements: " << 89 << std::setw(6) << 12 << 34 << '\n';
}
Output
No setw:42
Setw(6): 42
Setw(6), several elements: 89 1234
KEY TAKEAWAY
Unformatted data
- The printed data with default setting by the I/O function of the language is known as unformatted data.
- It is the basic form of input/output and transfers the internal binary representation of the data directly between memory and the file.
- For example, in cin statement it asks for a number while executing. If the user enters a decimal number, the entered number is displayed using cout statement. There is no need to apply any external setting, by default the I/O function represents the number in decimal format.
Formatted data
- If the user needs to display a number in hexadecimal format, the data is represented with the manipulators are known as formatted data.
- It converts the internal binary representation of the data to ASCII characters which are written to the output file.
- It reads characters from the input file and coverts them to internal form.
- For example, cout<<hex<<13; converts decimal 13 to hexadecimal d. Formatting is a representation of data with different settings (like number format, field width, decimal points etc.) as per the requirement of the user.
References:
1. E Balagurusamy, “Programming with C++”, Tata McGraw Hill, 3rd Edition.
2. Herbert Schildt, “The Complete Reference C++”, 4th Edition.
3. Robert Lafore, “Object Oriented Programming in C++”, Sams Publishing, 4th Edition.
4. Matt Weisfeld, “The Object-Oriented Thought Process”, Pearson Education.




