Unit -3
Basics of SQL
DDL
In reality, the DDL or Data Description Language consists of SQL commands that can be used to define the schema for the database. It basically deals with database schema definitions and is used to construct and change the configuration of database objects in the database.
Some of the commands that fall under DDL are as follows:
● CREATE
● ALTER
● DROP
● TRUNCATE
CREATE
It is used in the database for the development of a new table
Syntax
CREATE TABLE TABLE_NAME (COLUMN_NAME DATATYPES[,....]);
Example
CREATE TABLE STUDENT(Name VARCHAR2(20), Address VARCHAR2(100), DOB DATE);
ALTER
It is used to modify the database structure. This move may be either to change the characteristics of an existing attribute or to add a new attribute, likely.
Syntax
In order to add a new column to the table:
ALTER TABLE table_name ADD column_name COLUMN-definition;
To change the current table column:
ALTER TABLE MODIFY(COLUMN DEFINITION....);
Example
ALTER TABLE STU_DETAILS ADD(ADDRESS VARCHAR2(20));
ALTER TABLE STU_DETAILS MODIFY (NAME VARCHAR2(20));
DML (Data Manipulation Language)
DML queries are used to manipulate the data stored in table. Data Manipulation Language commands are used to insert, retrieve and modify the data contained within it.
S . No | Command & description |
1. | SELECT Retrieves certain records from one or more tables. Syntax SELECT * FROM tablename.
OR
SELECT columnname,columnname,….. FROM tablename ; |
2. | INSERT Creates a record in tables.
Example 1: Inserting a single row of data into a table Syntax INSERT INTO table_name [(columnname,columnname)] VALUES (expression,expression); To add a new employee to the personal_info table Example INSERT INTO customer values(1,’Ram’,’Pune’,3333444488)
Example 2 : Inserting data into a table from another table Syntax INSERT INTO tablename SELECT columnname,columnname FROM tablename
|
3. | UPDATE Modifies record stored in table. The UPDATE command can be used to modify information contained within a table.
Syntax
UPDATE customer SET cust_Address=’mumbai’ where cust_id=1; |
4. | DELETE Deletes records stored in table. The DELETE command can be used to delete information contained within a table.
Syntax
DELETE FROM tablename WHERE search condition The DELETE command with a WHERE clause can be used to remove his record from The customer table: Example
DELETE FROM customer WHERE cust_id=12; The following command deletes all the rows from the table Example DELETE FROM customer; |
DCL (Data Control Language)
GRANT and REVOKE are commands in the DCL (Data Control Language) that can be used to grant "rights and permissions." The database system's parameters are controlled by other permissions.
DCL commands include the following:
- Grant
- Revoke
Grant
This command is used to grant a user database access capabilities.
Syntax
GRANT SELECT, UPDATE ON MY_TABLE TO SOME_USER, ANOTHER_USER;
Example
GRANT SELECT ON Users TO'Tom'@'localhost;
Revoke
It's a good idea to back up the user's permissions.
Syntax
REVOKE privilege_nameON object_nameFROM {user_name |PUBLIC |role_name}
Example
REVOKE SELECT, UPDATE ON student FROM Btech, Mtech;
Key takeaway
- DDL queries are used to define and manipulate the structure of tables.
- These commands will primarily be used by database administrators during the setup and removal phases of a database project.
- DML queries are used to manipulate the data stored in table.
- DML commands are used to insert, retrieve and modify the data contained within it.
Constraints are rules that can be applied to a table's data type. That is, we may use constraints to limit the type of data that can be recorded in a specific column in a table.
Constraints set restrictions on how much and what kind of data can be inserted, modified, and deleted from a table. Constraints are used to ensure data integrity during an update, removal, or insert into a table.
Primary key
The primary key is a field that uniquely identifies each table row. If a column in a table is designated as a primary key, it cannot include NULL values, and all rows must have unique values for this field. To put it another way, this is a combination of NOT NULL and UNIQUE constraints.
The ROLL NO field is marked as primary key in the example below, which means it cannot contain duplicate or null entries.
CREATE TABLE STUDENT(
ROLL_NO INT NOT NULL,
STU_NAME VARCHAR (35) NOT NULL UNIQUE,
STU_AGE INT NOT NULL,
STU_ADDRESS VARCHAR (35) UNIQUE,
PRIMARY KEY (ROLL_NO)
);
Foriegn key
The columns of a table that point to the primary key of another table are known as foreign keys. They serve as a table-to-table cross-reference.
A foreign key is a table field that uniquely identifies each row of a different table. That is, this field refers to a table's main key. This usually results in a connection between the tables.
Consider the following two tables:
Orders
O_ID ORDER_NO C_ID
1 2253 3
2 3325 3
3 4521 2
4 8532 1
Customers
C_ID NAME ADDRESS
1 RAMESH DELHI
2 SURESH NOIDA
3 DHARMESH GURGAON
The field C_ID in the Orders table is clearly the main key in the Customers table, i.e. it uniquely identifies each row in the Customers dataset. As a result, the Orders table has a Foreign Key.
Syntax
CREATE TABLE Orders
(
O_ID int NOT NULL,
ORDER_NO int NOT NULL,
C_ID int,
PRIMARY KEY (O_ID),
FOREIGN KEY (C_ID) REFERENCES Customers(C_ID)
)
Unique key
UNIQUE constraint forces the values of a column or set of columns to be unique. If a column has a unique constraint, it signifies that no two values in the table can be the same.
CREATE TABLE STUDENT(
ROLL_NO INT NOT NULL,
STU_NAME VARCHAR (35) NOT NULL UNIQUE,
STU_AGE INT NOT NULL,
STU_ADDRESS VARCHAR (35) UNIQUE,
PRIMARY KEY (ROLL_NO)
);
Not null
The NOT NULL constraint ensures that no NULL values are stored in a column. When we don't specify a value for a field when inserting a record into a table, the column defaults to NULL. We can ensure that a certain column(s) cannot have NULL values by specifying a NULL constraint.
Example
CREATE TABLE STUDENT(
ROLL_NO INT NOT NULL,
STU_NAME VARCHAR (35) NOT NULL,
STU_AGE INT NOT NULL,
STU_ADDRESS VARCHAR (235),
PRIMARY KEY (ROLL_NO)
);
Check
This constraint is used to specify a table's range of values for a certain column. When this constraint is applied to a column, it assures that the value of the specified column must be inside the provided range.
CREATE TABLE STUDENT(
ROLL_NO INT NOT NULL CHECK(ROLL_NO >1000) ,
STU_NAME VARCHAR (35) NOT NULL,
STU_AGE INT NOT NULL,
EXAM_FEE INT DEFAULT 10000,
STU_ADDRESS VARCHAR (35) ,
PRIMARY KEY (ROLL_NO)
);
The check constraint on the ROLL NO column of the STUDENT database was set in the preceding example. The value of the ROLL NO field must now be bigger than 1000.
IN operator
The IN operator allows you to specify two or more expressions to use in a query search. If the value of the corresponding column equals one of the phrases indicated by the IN predicate, the condition is true.
Key takeaway
- Constraints are rules that can be applied to a table's data type. That is, we may use constraints to limit the type of data that can be recorded in a specific column in a table.
- The primary key is a field that uniquely identifies each table row.
- A foreign key is a table field that uniquely identifies each row of a different table.
- UNIQUE constraint forces the values of a column or set of columns to be unique.
- The NOT NULL constraint ensures that no NULL values are stored in a column.
These functions are used to perform operations on the column's values and return a single value.
● AVG()
● COUNT()
● FIRST()
● LAST()
● MAX()
● MIN()
● SUM()
AVG() -
After calculating from values in a numeric column, it returns the average value.
Syntax
SELECT AVG(column_name) FROM table_name;
Queries -
- Calculating students' average grades.
SELECT AVG(MARKS) AS AvgMarks FROM Students;
Output
AvgMarks
80
2. Calculating the average student age.
SELECT AVG(AGE) AS AvgAge FROM Students;
Output
AvgAge
19.4
COUNT() -
It's used to count how many rows a SELECT command returns. It isn't compatible with MS ACCESS.
Syntax
SELECT COUNT(column_name) FROM table_name;
Queries
- The total number of students is calculated.
SELECT COUNT(*) AS NumStudents FROM Students;
Output:
NumStudents
5
2. Counting the number of students who are of a specific age.
SELECT COUNT(DISTINCT AGE) AS NumStudents FROM Students;
Output
NumStudents
4
FIRST() -
The FIRST() function returns the selected column's first value.
Syntax
SELECT FIRST(column_name) FROM table_name;
Queries
- Taking the first student's marks from the Students table.
SELECT FIRST(MARKS) AS MarksFirst FROM Students;
Output:
MarksFirst
90
2. The first student's age is retrieved from the Students table.
SELECT FIRST(AGE) AS AgeFirst FROM Students;
Output:
AgeFirst
19
LAST() -
The LAST() function returns the chosen column's last value. It can only be used in MS ACCESS.
Syntax
SELECT LAST(column_name) FROM table_name;
Queries
- Taking the final student's grades from the Students table.
SELECT LAST(MARKS) AS MarksLast FROM Students;
Output:
MarksLast
82
2. Obtaining the age of the most recent student from the Students table.
SELECT LAST(AGE) AS AgeLast FROM Students;
Output:
AgeLast
18
MAX() -
The MAX() method returns the selected column's maximum value.
Syntax
SELECT MAX(column_name) FROM table_name;
Queries
- Obtaining the highest possible grade among students from the Students table.
SELECT MAX(MARKS) AS MaxMarks FROM Students;
Output:
MaxMarks
95
2. The maximum age among students is retrieved from the Students table.
SELECT MAX(AGE) AS MaxAge FROM Students;
Output:
MaxAge
21
MIN() -
The MIN() method returns the selected column's minimal value.
Syntax
SELECT MIN(column_name) FROM table_name;
Queries
- Obtaining the lowest possible grade among students from the Students table.
SELECT MIN(MARKS) AS MinMarks FROM Students;
Output:
MinMarks
50
2. Obtaining the student's minimum age from the Students table.
SELECT MIN(AGE) AS MinAge FROM Students;
Output:
MinAge
18
SUM() -
SUM() returns the total of all the values in the chosen column.
Syntax
SELECT SUM(column_name) FROM table_name;
Queries
- Obtaining the overall score of all students from the Students table.
SELECT SUM(MARKS) AS TotalMarks FROM Students;
Output:
TotalMarks
400
2. Obtaining the total age of all students from the Students table.
SELECT SUM(AGE) AS TotalAge FROM Students;
Output:
TotalAge
97
In order to describe the values that a column can hold, SQL Datatype is used.
Each column is needed in the database table to have a name and data type.
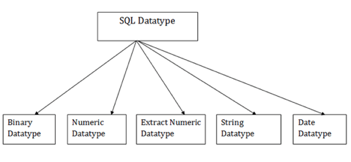
Fig 1: SQL data types
- Numeric data types
The subtypes are given below:
Data type | From | To | Description |
Float | -1.79E + 308 | 1.79E + 308 | Used to specify a floating-point value |
Real | -3.40e + 38 | 3.40E + 38 | Specifies a single precision floating point number |
2. Character String data types
Data types | Description |
Char | It contains Fixed-length (max - 8000 character) |
Varchar | It contains variable-length (max - 8000 character) |
Text | It contains variable-length (max - 2,147,483,647 character) |
3. Date and Time data types
Data types | Description |
Date | Used to store the year, month, and days value. |
Time | Used to store the hour, minute, and second values. |
Timestamp | Stores the year, month, day, hour, minute, and the second value. |
Mysql> create database set1;
Query OK, 1 row affected (0.00 sec)
Mysql> use set1;
Database changed
CREATING FIRST TABLE:
Mysql> create table A (x int (2), y varchar(2));
Query OK, 0 rows affected (0.19 sec)
Mysql> select * from A;
+------+------+
| x | y |
+------+------+
| 1 | a |
| 2 | b |
| 3 | c |
| 4 | d |
+------+------+
4 rows in set (0.00 sec)
CREATING SECOND TABLE:
Mysql> create table B (x int (2), y varchar(2));
Query OK, 0 rows affected (0.22 sec)
Mysql> select * from B;
+------+------+
| x | y |
+------+------+
| 1 | a |
| 3 | c |
+------+------+
2 rows in set (0.00 sec)
● INTERSECTION OPERATOR:
Mysql> select A.x,A.y from A join B using (x,y);
+------+------+
| x | y |
+------+------+
| 1 | a |
| 3 | c |
+------+------+
Mysql> select * from A where (x,y) in (select * from B);
+------+------+
| x | y |
+------+------+
| 1 | a |
| 3 | c |
+------+------+
2 rows in set (0.00 sec)
● UNION OPERATOR:
Mysql> select * from A union (select * from B);
+------+------+
| x | y |
+------+------+
| 1 | a |
| 2 | b |
| 3 | c |
| 4 | d |
+------+------+
4 rows in set (0.00 sec)
Mysql> select * from A union all(select * from B);
+------+------+
| x | y |
+------+------+
| 1 | a |
| 2 | b |
| 3 | c |
| 4 | d |
| 1 | a |
| 3 | c |
+------+------+
6 rows in set (0.00 sec)
● DIFFERENCE OPERATOR:
Mysql> select * from A where not exists (select * from B where A.x =B.x and A.y=B.y);
+------+------+
| x | y |
+------+------+
| 2 | b |
| 4 | d |
+------+------+
2 rows in set (0.11 sec)
● Symmetric Difference Operator:
Mysql> (select * from A where not exists (select * from B where A.x =B.x and A.y=B.y))
Union( select * from B where not exists (select * from A where A.x =B.x and A.y=B.y));
+------+------+
| x | y |
+------+------+
| 2 | b |
| 4 | d |
+------+------+
A subquery, also known as an inner query or nested query, is a query that is placed within another SQL query's WHERE clause.
A subquery is used to return data that will be utilized as a condition in the main query to further limit the data that may be retrieved.
Subqueries can be used with SELECT, INSERT, UPDATE, and DELETE statements, as well as operators such as =, >, >=, =, IN, BETWEEN, and so on.
Subqueries must adhere to a set of guidelines.
● Parentheses must be used to surround subqueries.
● Unless many columns are in the main query for the subquery to compare its selected columns, a subquery can only have one column in the SELECT clause.
● An ORDER BY command cannot be used in a subquery, although it can be used in the main query. In a subquery, the GROUP BY command can accomplish the same function as the ORDER BY command.
● Multiple value operators, such as the IN operator, can only be used with subqueries that return more than one row.
● There can't be any references to values that evaluate to a BLOB, ARRAY, CLOB, or NCLOB in the SELECT list.
● A set function cannot immediately enclose a subquery.
● A subquery cannot be used with the BETWEEN operator. Within the subquery, however, the BETWEEN operator can be utilized.
Subqueries are most frequently used with the SELECT statement, however you can use them within a INSERT, UPDATE, or DELETE statement as well, or inside another subquery.
● Subqueries with the SELECT Statement
The following statement will return the details of only those customers whose order value in the orders table is more than 5000 dollar. Also note that we’ve used the
Keyword DISTINCT in our subquery to eliminate the duplicate cust_id values from the
Result set.
1. SELECT * FROM customers WHERE cust_id IN (SELECT DISTINCT cust_id
FROM orders WHERE order_value > 5000);
● Subqueries with the INSERT Statement
Subqueries can also be used with INSERT statements. Here’s an example:
INSERT INTO premium_customers
SELECT * FROM customers
WHERE cust_id IN (SELECT DISTINCT cust_id FROM orders
WHERE order_value > 5000);
The above statement will insert the records of premium customers into a table
Called premium_customers, by using the data returned from subquery. Here the premium customers are the customers who have placed orders worth more than 5000 dollar.
● Subqueries with the UPDATE Statement
You can also use the subqueries in conjunction with the UPDATE statement to update the single or multiple columns in a table, as follow:
UPDATE orders
SET order_value = order_value + 10
WHERE cust_id IN (SELECT cust_id FROM customers
WHERE postal_code = 75016);
The above statement will update the order value in the orders table for those customers who live in the area whose postal code is 75016, by increasing the current order value by 10 dollar.
Key takeaway:
- A subquery, also known as an inner query or nested query, is a query that is placed within another SQL query's WHERE clause.
- A subquery can be used anywhere that expression is used and must be closed in parentheses.
To organize identical data into groups, the SQL GROUP BY clause is used in conjunction with the SELECT command. In a SELECT statement, the GROUP BY clause comes after the WHERE clause and before the ORDER BY clause.
Syntax
The following code block illustrates the basic syntax of a GROUP BY clause. The GROUP BY clause must come after the WHERE clause's conditions and, if one is used, before the ORDER BY clause.
SELECT column1, column2
FROM table_name
WHERE [ conditions ]
GROUP BY column1, column2
ORDER BY column1, column2
Example
Consider the following records in the CUSTOMERS table:
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
| 7 | Muffy | 24 | Indore | 10000.00 |
+----+----------+-----+-----------+----------+
The GROUP BY query might be as follows if you want to know the total amount of each customer's salary.
SQL> SELECT NAME, SUM(SALARY) FROM CUSTOMERS
GROUP BY NAME;
This would result in the following:
+----------+-------------+
| NAME | SUM(SALARY) |
+----------+-------------+
| Chaitali | 6500.00 |
| Hardik | 8500.00 |
| kaushik | 2000.00 |
| Khilan | 1500.00 |
| Komal | 4500.00 |
| Muffy | 10000.00 |
| Ramesh | 2000.00 |
+----------+-------------+
Having
You can use the HAVING Clause to establish conditions that limit which group results appear in the results.
The WHERE clause applies conditions to the columns that have been chosen, but the HAVING clause applies conditions to the groups that have been generated by the GROUP BY clause.
Syntax
The HAVING Clause is shown in the following code block in a query.
SELECT
FROM
WHERE
GROUP BY
HAVING
ORDER BY
In a query, the HAVING clause must come after the GROUP BY clause and, if used, before the ORDER BY clause. The syntax of the SELECT statement, including the HAVING clause, is shown in the following code block.
SELECT column1, column2
FROM table1, table2
WHERE [ conditions ]
GROUP BY column1, column2
HAVING [ conditions ]
ORDER BY column1, column2
Example
Consider the following records in the CUSTOMERS table:
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
| 7 | Muffy | 24 | Indore | 10000.00 |
+----+----------+-----+-----------+----------+
The following is an example of a record for a similar age count that is more than or equal to two.
SQL > SELECT ID, NAME, AGE, ADDRESS, SALARY
FROM CUSTOMERS
GROUP BY age
HAVING COUNT(age) >= 2;
This would result in the following:
+----+--------+-----+---------+---------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+--------+-----+---------+---------+
| 2 | Khilan | 25 | Delhi | 1500.00 |
+----+--------+-----+---------+---------+
Order by
The SQL ORDER BY clause is used to sort data by one or more columns in ascending or descending order. By default, some databases sort query results in ascending order.
Syntax
The ORDER BY clause's basic grammar is as follows:
SELECT column-list
FROM table_name
[WHERE condition]
[ORDER BY column1, column2, .. ColumnN] [ASC | DESC];
In the ORDER BY clause, you can utilize more than one column. Make sure that whichever column you're using to sort is included in the column-list.
Example
Consider the following records in the CUSTOMERS table:
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
| 7 | Muffy | 24 | Indore | 10000.00 |
+----+----------+-----+-----------+----------+
The following code block shows an example of sorting the results by NAME and SALARY in ascending order.
SQL> SELECT * FROM CUSTOMERS
ORDER BY NAME, SALARY;
This would result in the following:
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
| 7 | Muffy | 24 | Indore | 10000.00 |
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
+----+----------+-----+-----------+----------+
Key takeaway
- To organize identical data into groups, the SQL GROUP BY clause is used in conjunction with the SELECT command.
- You can use the HAVING Clause to establish conditions that limit which group results appear in the results.
- The SQL ORDER BY clause is used to sort data by one or more columns in ascending or descending order.
To get data from various tables, SQL JOINS are needed. When two or more tables are listed in a SQL statement, a SQL JOIN is done.
SQL joins can be divided into four categories:
● SQL INNER JOIN (sometimes called simple join)
● SQL LEFT OUTER JOIN (sometimes called LEFT JOIN)
● SQL RIGHT OUTER JOIN (sometimes called RIGHT JOIN)
● SQL FULL OUTER JOIN (sometimes called FULL JOIN)
INNER JOIN
As long as the condition is met, the INNER JOIN keyword selects all rows from both tables. This keyword will generate a result-set by combining all rows from both tables that satisfy the requirement, i.e. the common field's value will be the same.
Syntax
SELECT columns
FROM table1
INNER JOIN table2
ON table1.column = table2.column;
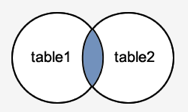
Fig 2: Inner join
LEFT OUTER JOIN
This join retrieves all rows from the table on the left side of the join, as well as matching rows from the table on the right. The result-set will include null for the rows for which there is no matching row on the right side. LEFT OUTER JOIN is another name for LEFT JOIN.
Syntax
SELECT columns
FROM table1
LEFT [OUTER] JOIN table2
ON table1.column = table2.column;

Fig 3: Left outer join
RIGHT OUTER JOIN
The RIGHT JOIN function is analogous to the LEFT JOIN function. This join retrieves all rows from the table on the right side of the join, as well as matching rows from the table on the left. The result-set will include null for the rows for which there is no matching row on the left side. RIGHT OUTER JOIN is another name for RIGHT JOIN.
Syntax
SELECT columns
FROM table1
RIGHT [OUTER] JOIN table2
ON table1.column = table2.column;
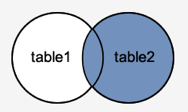
Fig 4: Right outer join
FULL OUTER JOIN
The result-set of FULL JOIN is created by combining the results of both LEFT JOIN and RIGHT JOIN. All of the rows from both tables will be included in the result-set. The result-set will contain NULL values for the rows for which there is no match.
Syntax
SELECT columns
FROM table1
FULL [OUTER] JOIN table2
ON table1.column = table2.column;
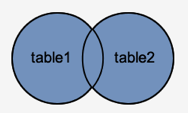
Fig 5: Full outer join
Exists function
The exists function takes a subquery as an input and returns true if the subquery produces one or more rows, false otherwise.
The EXISTS operator operates on a subquery and returns either TRUE or FALSE as a Boolean value.
● If the subquery produces at least one row, it returns TRUE.
● If the subquery returns no rows, it returns FALSE.
ANY and ALL operator
Comparison operators are always used in conjunction with the operators ANY and ALL.
ANY operator
Both operators have the same general syntax: column operator[ ANY | ALL ] query.
A comparison operator is represented by Operator.
If the result of an inner query has at least one row that meets the comparison, the any operator evaluates to true.
ALL operator
If the assessment of a table column in an inner query returns all values of the column, the ALL Operator evaluates to true.
Key takeaway
- To get data from various tables, SQL JOINS are needed. When two or more tables are listed in a SQL statement, a SQL JOIN is done.
- As long as the condition is met, the INNER JOIN keyword selects all rows from both tables.
- The result-set of FULL JOIN is created by combining the results of both LEFT JOIN and RIGHT JOIN.
In SQL, a view is a virtual table based on the SQL statement result-set.
A view, much like a real table, includes rows and columns. Fields in a database view are fields from one or more individual database tables.
You can add SQL, WHERE, and JOIN statements to a view and show the details as if the data came from a single table.
Create a view
Syntax
CREATE VIEW view_name AS
SELECT column1, column2, ...
FROM table_name
WHERE condition;
Up-to-date data still displays a view! Any time a user queries a view, the database engine recreates the data, using the view's SQL statement.
Create a view example
A view showing all customers from India is provided by the following SQL.
CREATE VIEW [India Customers] AS
SELECT CustomerName, ContactName
FROM Customers
WHERE Country = 'India';
Updating a view
With the Build OR REPLACE VIEW command, the view can be changed.
Create or replace view syntax
CREATE OR REPLACE VIEW view_name AS
SELECT column1, column2, ...
FROM table_name
WHERE condition;
For the "City" view, the following SQL adds the "India Customers" column:
CREATE OR REPLACE VIEW [India Customers] AS
SELECT CustomerName, ContactName, City
FROM Customers
WHERE Country = 'India';
Dropping a view
With the DROP VIEW instruction, a view is removed.
Drop view syntax
DROP VIEW view_name;
"The following SQL drops the view of "India Customers":
DROP VIEW [India Customers];
Indexes
● Special lookup tables are indexes. It is used to very easily extract data from the database.
● To speed up select queries and where clauses are used, an Index is used. But it displays the data input with statements for insertion and update. Without affecting the data, indexes can be generated or dropped.
● An index is much like an index on the back of a book in a database.
For example, when you refer to all the pages in a book that addresses a certain subject, you must first refer to an index that lists all the subjects alphabetically, and then refer to one or more particular page numbers.
● Create index statement
It is used on a table to construct an index. It allows value to be duplicated
Syntax
CREATE INDEX index_name
ON table_name (column1, column2, ...);
Example
CREATE INDEX idx_name
ON Persons (LastName, FirstName);
● Unique index statement
It is used on a table to construct a specific index. Duplicate value does not make it.
Syntax
CREATE UNIQUE INDEX index_name
ON table_name (column1, column2, ...);
Example
CREATE UNIQUE INDEX websites_idx
ON websites (site_name);
● Drop index statement
It is used to delete a table's index.
Syntax
DROP INDEX index_name;
Example
DROP INDEX websites_idx;
Key takeaway:
- It is used to very easily extract data from the database.
- To speed up select queries and where clauses are used, an Index is used.
TCL commands, or transaction control language, deal with database transactions.
Commit
All transactions are saved to the database with this command.
The COMMIT command is used to save any transaction into the database permanently.
When we use a DML command like INSERT, UPDATE, or DELETE, the changes we make are temporary and can be rolled back until the current session is closed.
To avoid this, we use the COMMIT command to permanently indicate the modifications.
Syntax
COMMIT;
Example
DELETE FROM Students
WHERE RollNo =25;
COMMIT;
Rollback
You can use the rollback command to undo transactions that haven't yet been stored to the database.
This command returns the database to the state it was in when it was last committed. It can also be used in conjunction with the SAVEPOINT command to go to a specific savepoint in a running transaction.
If we used the UPDATE command to make changes to the database that we later realized were unnecessary, we can use the ROLLBACK command to undo those changes if they were not committed using the COMMIT command.
Syntax
ROLLBACK;
Example
DELETE FROM Students
WHERE RollNo =25;
Key takeaway:
The COMMIT command is used to save any transaction into the database permanently.
You can use the rollback command to undo transactions that haven't yet been stored to the database.
Oracle produces a memory space called the context area when a SQL statement is processed. The context region is shown by a cursor. It includes all of the data required to process the statement. Cursor in PL/SQL is in charge of the context area. A cursor keeps track of the rows of data accessed by a select statement.
A cursor is a software that fetches and processes each row returned by a SQL statement one by one. Cursors come in two varieties:
● Implicit Cursors
● Explicit Cursors
Implicit cursors
When a SQL statement is executed and there is no explicit cursor for the statement, Oracle automatically creates implicit cursors. Programmers have no control over implicit cursors or the data they contain.
When a DML statement (INSERT, UPDATE, or DELETE) is issued, it is accompanied by an implicit cursor. The cursor holds the data that needs to be inserted for INSERT operations. The cursor identifies the rows that will be affected by UPDATE and DELETE actions.
The most recent implicit cursor is known as the SQL cursor in PL/SQL, and it always has attributes like %FOUND, % ISOPEN, %NOTFOUND, and %ROWCOUNT. For use with the FORALL statement, the SQL cursor has two additional attributes: %BULK ROWCOUNT and % BULK EXCEPTIONS. The most commonly used properties are described in the table below.
Attribute | Description |
%FOUND | If DML actions like INSERT, DELETE, and UPDATE change at least one row or more rows, or if a SELECT INTO statement returned one or more rows, the return value is TRUE. Otherwise, FALSE is returned. |
%NOTFOUND | If DML statements like INSERT, DELETE, and UPDATE have no effect on any rows, or if a SELECT INTO statement returns no rows, it returns TRUE. Otherwise, FALSE is returned. It's the polar opposite of % FOUND. |
%ISOPEN | Because the SQL cursor is automatically closed after processing its related SQL statements, it always returns FALSE for implicit cursors.
|
%ROWCOUNT | It calculates the number of rows affected by DML statements such as INSERT, DELETE, and UPDATE, as well as the number of rows returned by a SELECT INTO command. |
Example
Create a customers table with the following records:
ID | NAME | AGE | ADDRESS | SALARY |
1 | Ramesh | 23 | Allahabad | 20000 |
2 | Suresh | 22 | Kanpur | 22000 |
3 | Mahesh | 24 | Ghaziabad | 24000 |
4 | Chandan | 25 | Noida | 26000 |
5 | Alex | 21 | Paris | 28000 |
6 | Sunita | 20 | Delhi | 30000 |
To update the table and boost each customer's salary by 5000, run the following software. The number of rows affected is determined using the SQL % ROWCOUNT attribute:
Create procedure:
DECLARE
Total_rows number(2);
BEGIN
UPDATE customers
SET salary = salary + 5000;
IF sql%notfound THEN
Dbms_output.put_line('no customers updated');
ELSIF sql%found THEN
Total_rows := sql%rowcount;
Dbms_output.put_line( total_rows || ' customers updated ');
END IF;
END;
/
Output:
6 customers updated
PL/SQL procedure successfully completed.
If you look at the records in the customer table now, you'll notice that the rows have been changed.
Select * from customers;
ID | NAME | AGE | ADDRESS | SALARY |
1 | Ramesh | 23 | Allahabad | 25000 |
2 | Suresh | 22 | Kanpur | 27000 |
3 | Mahesh | 24 | Ghaziabad | 29000 |
4 | Chandan | 25 | Noida | 31000 |
5 | Alex | 21 | Paris | 33000 |
6 | Sunita | 20 | Delhi | 35000 |
Explicit cursors
Explicit cursors are cursors that have been programmed to give the user more control over the context area. In the PL/SQL Block's declaration section, an explicit cursor should be defined. It's based on a SELECT statement that returns multiple rows.
Creating an explicit cursor has the following syntax.
CURSOR cursor_name IS select_statement;
The steps for working with an explicit cursor are as follows:
● Declaring the cursor for memory initialization.
● Opening the cursor for allocating the memory.
● Fetching the cursor for retrieving the data.
● Closing the cursor to release the allocated memory.
Declaring the cursors
Declaring the cursor gives it a name and the SELECT statement that goes with it. For instance,
CURSOR c_customers IS
SELECT id, name, address FROM customers;
Opening the cursors
The cursor's memory is allocated when it is opened, and it is ready to receive the rows produced by the SQL statement. For instance, let's open the above-mentioned cursor as follows:
OPEN c_customers;
Fetching the cursors
The cursor is retrieved by accessing one row at a time. For instance, we can get rows from the above-opened cursor by doing the following:
FETCH c_customers INTO c_id, c_name, c_addr;
Closing the cursors
The allocated memory is released when the cursor is closed. For example, the above-opened cursor will be closed as follows:
CLOSE c_customers;
Example
Programmers define explicit cursors to have additional control over the context area. It's defined in the PL/SQL block's declaration section. It's based on a SELECT statement that returns multiple rows.
Let's look at an example of how to use explicit cursor. In this example, we'll use the CUSTOMERS table, which has already been established.
Create a customers table with the following records:
ID | NAME | AGE | ADDRESS | SALARY |
1 | Ramesh | 23 | Allahabad | 20000 |
2 | Suresh | 22 | Kanpur | 22000 |
3 | Mahesh | 24 | Ghaziabad | 24000 |
4 | Chandan | 25 | Noida | 26000 |
5 | Alex | 21 | Paris | 28000 |
6 | Sunita | 20 | Delhi | 30000 |
Create procedure:
To get the customer's name and address, run the following software.
DECLARE
c_id customers.id%type;
c_name customers.name%type;
c_addr customers.address%type;
CURSOR c_customers is
SELECT id, name, address FROM customers;
BEGIN
OPEN c_customers;
LOOP
FETCH c_customers into c_id, c_name, c_addr;
EXIT WHEN c_customers%notfound;
Dbms_output.put_line(c_id || ' ' || c_name || ' ' || c_addr);
END LOOP;
CLOSE c_customers;
END;
/
Output
1 Ramesh Allahabad
2 Suresh Kanpur
3 Mahesh Ghaziabad
4 Chandan Noida
5 Alex Paris
6 Sunita Delhi
PL/SQL procedure successfully completed.
Key takeaway
Cursor in PL/SQL is in charge of the context area. A cursor keeps track of the rows of data accessed by a select statement.
When a SQL statement is executed and there is no explicit cursor for the statement, Oracle automatically creates implicit cursors.
In PL/SQL, a Procedure is a subprogram unit made up of a collection of PL/SQL statements that can be invoked by name. Each procedure in PL/SQL has its own distinct name that can be used to refer to and invoke it. The Oracle database stores this subprogram unit as a database object.
A subprogram is nothing more than a process that must be manually constructed according to the requirements. They will be saved as database objects once they have been generated.
In PL/SQL, the following are the features of the Procedure subprogram unit:
● Procedures are individual software blocks that can be saved in a database.
● To execute the PL/SQL statements, call these PL/SQL procedures by referring to their names.
● In PL/SQL, it's mostly used to run a process.
● It can be defined and nested inside other blocks or packages, or it can have nested blocks.
● It consists of three parts: declaration (optional), execution, and exception handling (optional).
● The values can be supplied into or retrieved from an Oracle process using parameters.
● The calling statement should include these parameters.
● In SQL, a procedure can have a RETURN statement to return control to the caller block, but the RETURN statement cannot return any values.
● SELECT statements cannot directly invoke procedures. They can be accessed via the EXEC keyword or from another block.
Syntax
CREATE OR REPLACE PROCEDURE
<procedure_name>
(
<parameterl IN/OUT <datatype>
..
.
)
[ IS | AS ]
<declaration_part>
BEGIN
<execution part>
EXCEPTION
<exception handling part>
END;
● Construct PROCEDURE tells the compiler to create a new Oracle procedure. The keyword 'OR REPLACE' tells the compiler to replace any existing procedures with this one.
● The name of the procedure should be unique.
● When a stored procedure in Oracle is nested inside other blocks, the keyword 'IS' will be used. 'AS' will be used if the procedure is solo. Both have the same meaning aside from the coding standard.
Key takeaway
In PL/SQL, a Procedure is a subprogram unit made up of a collection of PL/SQL statements that can be invoked by name. Each procedure in PL/SQL has its own distinct name that can be used to refer to and invoke it.
Functions is a PL/SQL subprogram that runs on its own. Functions, like PL/SQL procedures, have a unique name by which they can be identified. These are saved as database objects in PL/SQL.
Some of the qualities of functions are listed below.
● Functions are a type of standalone block that is mostly used to do calculations.
● The value is returned using the RETURN keyword, and the datatype is defined at the time of creation.
● Return is required in functions since they must either return a value or raise an exception.
● Functions that do not require DML statements can be called directly from SELECT queries, whereas functions that require DML operations can only be invoked from other PL/SQL blocks.
● It can be defined and nested inside other blocks or packages, or it can have nested blocks.
● It consists of three parts: declaration (optional), execution, and exception handling (optional).
● The parameters can be used to pass values into the function or to retrieve values from the process.
● The calling statement should include these parameters.
● In addition to utilizing RETURN, a PLSQL function can return the value using OUT parameters.
● Because it always returns the value, it is always used in conjunction with the assignment operator to populate the variables in the calling statement.
Syntax
CREATE OR REPLACE FUNCTION
<procedure_name>
(
<parameterl IN/OUT <datatype>
)
RETURN <datatype>
[ IS | AS ]
<declaration_part>
BEGIN
<execution part>
EXCEPTION
<exception handling part>
END;
● The command CREATE FUNCTION tells the compiler to construct a new function. The keyword 'OR REPLACE' tells the compiler to replace any existing functions with the new one.
● The name of the function should be unique.
● It's important to mention the RETURN datatype.
● When the method is nested inside other blocks, the keyword 'IS' will be utilized. 'AS' will be used if the procedure is solo. Both have the same meaning aside from the coding standard.
Key takeaway:
Functions is a PL/SQL subprogram that runs on its own.
Functions, like PL/SQL procedures, have a unique name by which they can be identified.
These are saved as database objects in PL/SQL.
When a defined event occurs, the Oracle engine immediately calls the trigger. Triggers are stored in databases and are called repeatedly when certain conditions are met.
Triggers are stored programs that are executed or fired automatically when a certain event happens.
Triggers can be written to respond to any of the events listed below.
● A database manipulation (DML) statement (DELETE, INSERT, or UPDATE).
● A database definition (DDL) statement (CREATE, ALTER, or DROP).
● A database operation (SERVERERROR, LOGON, LOGOFF, STARTUP, or SHUTDOWN).
Triggers can be set on the table, view, schema, or database connected with the event.
Advantages
The following are some of the benefits of Triggers:
Trigger automatically creates some derived column values.
Referential integrity is enforced.
Information on table access is logged and stored in an event log.
Auditing.
Tables are replicated in a synchronous manner.
Putting in place security authorizations.
Preventing transactions that aren't valid.
Creating a trigger
Syntax for creating trigger:
CREATE [OR REPLACE ] TRIGGER trigger_name
{BEFORE | AFTER | INSTEAD OF }
{INSERT [OR] | UPDATE [OR] | DELETE}
[OF col_name]
ON table_name
[REFERENCING OLD AS o NEW AS n]
[FOR EACH ROW]
WHEN (condition)
DECLARE
Declaration-statements
BEGIN
Executable-statements
EXCEPTION
Exception-handling-statements
END;
Where,
CREATE [OR REPLACE] TRIGGER trigger_name: With the trigger name, it creates or replaces an existing trigger.
{BEFORE | AFTER | INSTEAD OF} : This determines when the trigger will be activated.
The INSTEAD OF clause is used to make a view trigger.
{INSERT [OR] | UPDATE [OR] | DELETE}: The DML operation is specified here.
[OF col_name]: This is the name of the column that will be modified.
[ON table_name]: The name of the table linked with the trigger is specified here.
[REFERENCING OLD AS o NEW AS n]: This allows you to refer to new and old values for INSERT, UPDATE, and DELETE DML statements.
[FOR EACH ROW]: This is a row-level trigger, which means it will be executed for each row that is affected. Otherwise, the trigger, which is known as a table level trigger, will only activate once when the SQL query is executed.
WHEN (condition): This provides a condition for rows for which the trigger would fire. This clause is valid only for row level triggers.
Example
We'll begin by looking at the CUSTOMERS table -
Select * from customers;
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
+----+----------+-----+-----------+----------+
The following application sets a row-level trigger for the customers table that fires when the CUSTOMERS table is INSERTED, UPDATED, or DELETED. This trigger will show the difference in salary between the old and new values.
CREATE OR REPLACE TRIGGER display_salary_changes
BEFORE DELETE OR INSERT OR UPDATE ON customers
FOR EACH ROW
WHEN (NEW.ID > 0)
DECLARE
Sal_diff number;
BEGIN
Sal_diff := :NEW.salary - :OLD.salary;
Dbms_output.put_line('Old salary: ' || :OLD.salary);
Dbms_output.put_line('New salary: ' || :NEW.salary);
Dbms_output.put_line('Salary difference: ' || sal_diff);
END;
/
When the preceding code is run at the SQL prompt, the following is the result:
Trigger created.
The following considerations must be made in this case:
● For table-level triggers, OLD and NEW references are not available; however, record-level triggers can use them.
● If you want to query the table within the same trigger, use the AFTER keyword, because triggers can only query or alter the table after the original modifications have been implemented and the table has returned to a consistent state.
● The above trigger will fire before every DELETE, INSERT, or UPDATE action on the table, but you may create your trigger to fire before a single or many operations, such as BEFORE DELETE, which will fire whenever a record is deleted on the table using the DELETE operation.
Triggering a Trigger
Let's use the CUSTOMERS table to conduct some DML operations. Here's an example of an INSERT statement that will add a new record to the table:
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (7, 'Kriti', 22, 'HP', 7500.00 );
When a record in the CUSTOMERS database is generated, the above create trigger, display salary changes, is triggered, and the following result is displayed:
Old salary:
New salary: 7500
Salary difference:
Because this is a new record, the previous salary is unavailable, hence the result above is nil. Let's do another DML transaction on the CUSTOMERS table now. The UPDATE statement will update a table record that already exists.
UPDATE customers
SET salary = salary + 500
WHERE id = 2;
When a record in the CUSTOMERS database is updated, the aforementioned create trigger, display salary changes, is triggered, and the following result is displayed:
Old salary: 1500
New salary: 2000
Salary difference: 500
References:
- C.J. Date, A. Kannan, S. Swamynathan “An introduction to Database Systems”, Pearson, 8th Edition.
- Martin Gruber, “Understanding SQL”, Sybex Publications.
- Ivan Bayross, “SQL- PL/SQL”, BPB Publications, 4th Edition.
- S.K. Singh, “Database Systems: Concepts, Design and Application”, Pearson, Education, 2nd Edition.




