Unit - 6
Distributed Databases
A distributed database is a database that is not restricted to a single system and is dispersed across numerous places, such as multiple computers or a network of computers. A distributed database system is made up of multiple sites with no physical components in common. This may be necessary if a database needs to be viewed by a large number of people all over the world. It must be administered in such a way that it appears to users as a single database.
A distributed database system (DDBS) is a database that does not have all of its storage devices connected to the same CPU. It might be stored on numerous computers in the same physical place, or it could be spread throughout a network of connected computers. Simply said, it is a logically centralized yet physically dispersed database system. It's a database system and a computer network all rolled into one. Despite the fact that this is a major issue in database architecture, one of the most serious challenges in today's database systems is storage and query in distributed database systems.
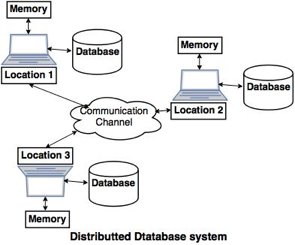
Fig 1: Distributed database
A centralized software system that manages a distributed database as if it were all kept in a single location is known as a distributed database management system (DDBMS).
Features
● It's used to create, retrieve, update, and destroy databases that are distributed.
● It synchronizes the database on a regular basis and provides access mechanisms, making the distribution transparent to the users.
● It ensures that data modified on any site is updated across the board.
● It's utilized in applications where a lot of data is processed and accessible by a lot of people at the same time.
● It's made to work with a variety of database platforms.
● It protects the databases' confidentiality and data integrity.
Key takeaway
- A distributed database system is made up of multiple sites with no physical components in common.
- A distributed database system (DDBS) is a database that does not have all of its storage devices connected to the same CPU.
The following factors support switching to a DDBMS:
● Distributed Nature of Organizational Units - In today's world, most businesses are separated into many parts that are physically dispersed across the globe. Each unit necessitates its own collection of local information. As a result, the organization's whole database is scattered.
● Need for Sharing of Data - Various organizational units must frequently communicate with one another and share data and resources. This necessitates the usage of shared databases or replicated databases that are synchronized.
● Support for Both OLTP and OLAP - Online Transaction Processing (OLTP) and Online Analytical Processing (OLAP) are two systems that operate together to process data. By providing synchronized data, distributed database systems enhance both of these processes.
● Database Recovery - Data replication over several sites is one of the most used DDBMS approaches. If a database on any site is corrupted, data replication automatically aids in data recovery. While the broken site is being rebuilt, users can access data from other sites. As a result, database failure may become almost imperceptible to users.
● Support for Multiple Application Software - The majority of businesses employ a range of application software, each with its own database support. DDBMSs provide standardized capability for sharing data across platforms.
The advantages of distributed databases versus centralized databases are as follows.
● Modular Development − In centralized database systems, if the system needs to be expanded to additional locations or units, the activity necessitates significant effort and disruption of current operations. In distributed databases, on the other hand, the process is merely moving new computers and local data to the new site and then connecting them to the distributed system, with no interruption in present operations.
● More Reliable − When a database fails, the entire centralized database system comes to a halt. When a component fails in a distributed system, however, the system may continue to function but at a lower level of performance.
● Better Response − If data is delivered efficiently, user requests can be fulfilled from local data, resulting in a speedier response. In centralized systems, on the other hand, all inquiries must transit through the central computer for processing, lengthening the response time.
● Lower Communication Cost − When data is stored locally where it is most frequently utilized in distributed database systems, communication costs for data manipulation can be reduced. In centralized systems, this is not possible.
As illustrated in the diagram, distributed databases can be divided into homogeneous and heterogeneous distributed database settings, each with its own set of sub-divisions.
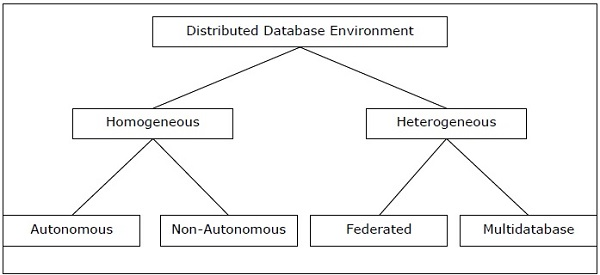
Fig 2: Types of distributed database
1. Homogeneous Database:
All the different sites store databases identically in a homogeneous database. For all locations, the operating system, database management system and the data systems used are all the same. They're easy to handle, therefore.
Example: Remember that we use Oracle-9i for DBMS to have three departments. If any improvements in one department were made, the other department will also be modified.
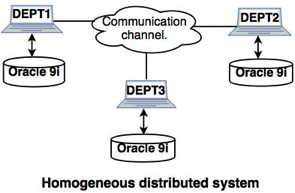
Fig 3: Homogeneous distributed system
Types of Homogenous Distributed Database
A homogeneous distributed database can be divided into two forms.
● Autonomous - Each database is self-contained and self-contained. A controlling program integrates them and uses message passing to share data updates.
● Non - Autonomous - Data is dispersed throughout the homogenous nodes, and data changes are coordinated across the sites by a central or master DBMS.
2. Heterogeneous Database:
Different sites may use various schemes and applications in a heterogeneous distributed database that can lead to query processing and transaction problems. A unique site may also be totally unaware of the other pages. A separate operating system, a distinct database programme, may be used by different computers. For the database, they can also use various data models. Therefore, for different sites to interact, translations are needed.
Example: In the following diagram, ODBC and JDBC are used to render different DBMS applications available to each other.
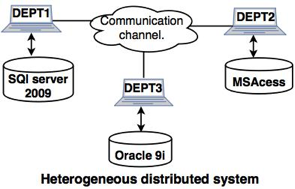
Fig 4: Heterogeneous distributed system
Types of Heterogeneous Distributed Database
● Federated − The heterogeneous database systems are self-contained in nature but can be linked together to form a single database system.
● Un-federated − The databases are accessible through a central coordinating module in database systems.
Key takeaway:
All the different sites store databases identically in a homogeneous database. For all locations, the operating system, database management system and the data systems used are all the same.
Different sites may use various schemes and applications in a heterogeneous distributed database that can lead to query processing and transaction problems.
The following are some of the most common architectural models:
Client - server Architecture
In a client-server architecture, a network is made up of a number of clients and a few servers. One of the servers receives a query from a client. The first accessible server solves the problem and responds. Because of the centralized server system, a client-server architecture is straightforward to develop and execute.
The functionality is divided into servers and clients in this two-level design. Data management, query processing, optimization, and transaction management are the main server functions. User interface is one of the most important client tasks. They do, however, have some capabilities, such as consistency checking and transaction management.
There are two distinct client-server architectures.
● Single Server Multiple Client
● Multiple Server Multiple Client
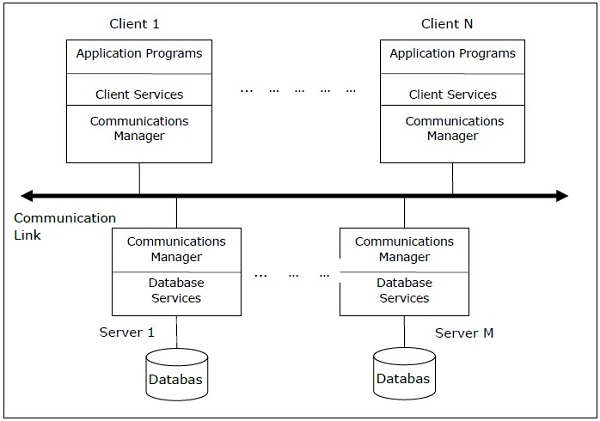
Fig 5: Client - server architecture
Collaborating server architecture
● A collaborative server architecture is one that allows a single query to be executed across numerous servers.
● The result is delivered to the client after the server breaks down a single query into many tiny requests.
● A set of database servers makes up a collaborative server architecture. Each server has the ability to execute current transactions across databases.
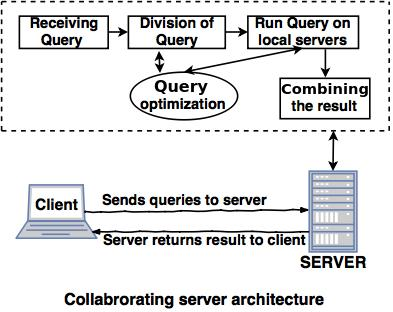
Fig 6: Collaborating server architecture
Middleware architecture
● Middleware designs are built so that a single query can be processed on numerous servers.
● Only one server is required for this system, and it must be capable of coordinating requests and transactions from numerous servers.
● Local servers are used in middleware architecture to handle local queries and transactions.
● This type of software is known as middleware, and it is used to execute queries and transactions across one or more separate database servers.
We'll look at the approaches that make it easier to embrace the designs. The tactics are separated into two categories: replication and fragmentation. In most circumstances, though, a combination of the two is used.
- Replication
The complete relation is stored redundantly at two or more sites in this manner. It is a fully redundant database if the entire database is available at all sites. As a result, in replication, systems keep duplicates of data.
This is useful since it increases data availability across several places. Query queries can now be executed in parallel as well.
It does, however, have some downsides. Data must be updated on a regular basis. Any modification made at one site must be recorded at every site where that relationship is saved, or else inconsistency would result. This is a significant amount of overhead. Concurrent access must now be checked across multiple sites, making concurrency control much more difficult.
Advantages of replication
● Reliability - In the event that one of the sites fails, the database system continues to function because a copy is available at another location (s).
● Quicker response - Short query processing and, as a result, quick response time are ensured by the availability of local copies of data.
● Reduction in network load - Due to the availability of local copies of data, query processing can be done with less network usage, especially during peak hours. Data updates can be completed during non-peak hours.
Types
A database can be either fully replicated, partially replicated or unreplicated.
● Full replication - Multiple copies of each database fragment are stored at different locations. Due to the amount of overhead put on the system, fully replicated databases may be impracticable.
● Partial replication - Multiple copies of some database fragments are stored at various locations. Most DDBMS are capable of handling this form of replication.
● No replication - Each database fragment is stored at a single location. There is no duplicate.
2. Fragmentation
The relations are broken (i.e., divided into smaller portions) with this manner, and each of the fragments is kept in multiple locations as needed. It must be ensured that the fragments can be utilized to recreate the original relationship (i.e., that no data is lost).
Fragmentation is useful since it avoids the creation of duplicate data, and consistency is not an issue.
Advantages of fragmentation
● The database system's efficiency is improved since data is stored near to the point of use.
● Because data is available locally, local query optimization techniques are sufficient for most queries.
● The database system's security and privacy can be maintained because irrelevant data is not available at the sites.
Types
Relationships can be fragmented in the following ways:
Horizontal fragmentation – Splitting by rows –Each tuple is assigned to at least one fragment once the relation is broken into groups of tuples.
Vertical fragmentation – Splitting by columns – The relation's schema is broken into smaller schemas. To ensure a lossless join, each fragment must have a common candidate key.
Mixed fragmentation (Hybrid) - This is a two-step process of fragmentation. Horizontal fragmentation is performed first to obtain the required rows, followed by vertical fragmentation to divide the attributes among the rows.
3. Data Allocation
The process of determining where to store data is known as data allocation. It also necessitates a determination of which data should be stored where. Data can be allocated centrally, partitioned, or replicated.
● Centralised - The complete database is kept on a single server. There is no dispersion.
● Partitioned - The database is partitioned into multiple fragments, each of which is stored at a different location.
● Replicated - Several locations maintain copies of one or more database fragments.
Key takeaway
- A distributed database is a database that is not restricted to a single system and is dispersed across numerous places, such as multiple computers or a network of computers.
- A distributed database system is made up of multiple sites with no physical components in common.
Distributed Data Store refers to a computer network in which data is replicated across multiple nodes and stored on multiple nodes. It can refer to either a distributed database or a computer network in which users store information on a number of peer network nodes. Distributed databases are non-relational databases that allow for rapid data access over a large number of nodes.
Some distributed databases allow for sophisticated querying, while others are restricted to key-value store semantics. On the other side, peer network nodes allow users to reciprocate by allowing other users to use their computer as a storage node as well. Depending on the network's design, information may or may not be visible to other users. Some peer-to-peer networks lack distributed data stores, which means that a user's data is only accessible while their node is connected to the network.
When complex tasks are involved, distributed data storage becomes even more important. This is due to the fact that complicated tasks necessitate complex networks and take a long time to operate and implement. The goal of distributed data storage is to avoid focusing all of your resources on a single job. Rather, it evenly distributes resources across all channels. The distributed data storage approach has proven to be more powerful and resourceful than stand-alone systems based on previous observations.
A typical gaming system network is the best illustration of a distributed data store. A central set of servers serves as the game's backbone, with the rest of the workstations doing additional tasks.
There is no procedure that can't be run using a distributed database system because of its advantages. The distributed data storage system can include any type of device, from a simple cell phone to smartwatches. This demonstrates the enormous potential and scope of cloud distributed database services, as well as the opportunity for the development of more powerful distributed data stores.
A distributed transaction is a set of data operations that spans two or more data repositories (especially databases). It is typically coordinated across separate nodes connected by a network, but may also span multiple databases on a single server.
There are two possible outcomes: 1) all operations successfully complete, or 2) none of the operations are performed at all due to a failure somewhere in the system. In the latter case, if some work was completed prior to the failure, that work will be reversed to ensure no net work was done. This operation adheres to the “ACID” (atomicity, consistency, isolation, and durability) database principles, which ensure data integrity. ACID is most frequently associated with single-database-server transactions, whereas distributed transactions extend that guarantee to several databases.
A distributed transaction is a type of operation known as a "two-phase commit" (2PC). The XA protocol, which is one implementation of a two-phase commit process, is used in "XA transactions."
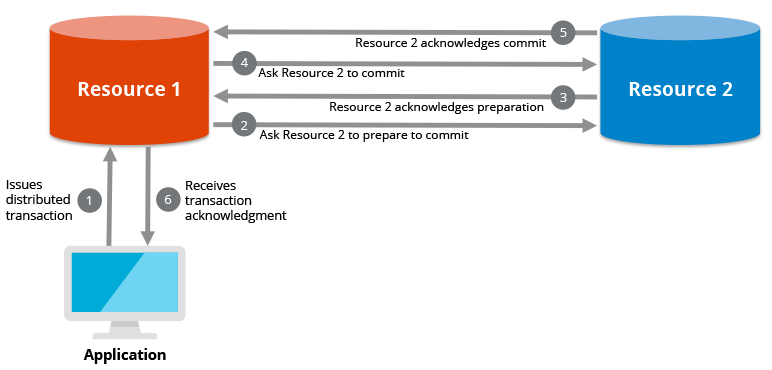
Fig 7: A distributed transaction spans multiple databases and guarantees data integrity
Distributed transaction work
The processing requirements for distributed transactions are the same as for regular database transactions, but they must be managed across multiple resources, making them more difficult to implement for database developers. The multiple resources add more points of failure, such as the distinct software systems that run the resources (e.g., the database software), the extra hardware servers, and network issues. As a result, distributed transactions are vulnerable to failures, necessitating the implementation of safeguards to maintain data integrity.
Transaction managers organize the resources in order for a distributed transaction to take place (either multiple databases or multiple nodes of a single database). The transaction manager can be one of the data repositories that will be changed as part of the transaction, or it can be a completely different resource responsible just for coordination. The transaction manager determines whether a successful transaction should be committed or a failed transaction should be rolled back, with the latter leaving the database unchanged.
An application first sends a request to the transaction management for a distributed transaction. The transaction manager then branches to each resource, each of which will have its own "resource manager" to aid in distributed transaction participation. To protect against incomplete updates that may occur when a failure occurs, distributed transactions are frequently done in two phases. The first phase, known as the "prepare-to-commit" phase, entails acknowledging an intention to commit. After all resources have acknowledged, the transaction is finished by asking them to run a final commit.
Failure modes
A distributed system can experience the same kinds of problems as a centralized one (for example, software errors, hardware errors, or disk crashes). In a distributed context, however, there are additional sorts of failure with which we must contend.
The most common types of failure are:
● Failure of a site
● Loss of messages
● Failure of a communication link
● Network partition
In a distributed system, message loss or corruption is always a possibility. To handle such failures, the system employs transmission-control protocols like TCP/IP. Information on similar protocols may be found in most networking textbooks.
Messages from one site to the other must, however, be routed through a series of communication links if two sites A and B are not directly connected. Messages that would have been transmitted through a communication link must be diverted if the link fails. In rare situations, another route through the network can be found, allowing the messages to reach their intended destination. In other circumstances, a failure may result in the loss of connectivity between some sites. A system has been partitioned if it has been divided into two (or more) subsystems, known as partitions, that are not connected.
Key takeaway:
A distributed transaction is a set of data operations that spans two or more data repositories (especially databases).
It is typically coordinated across separate nodes connected by a network, but may also span multiple databases on a single server.
A distributed system can experience the same kinds of problems as a centralized one. In a distributed context, however, there are additional sorts of failure with which we must contend.
In a local database system, the transaction manager just needs to inform the recovery manager of the decision to commit a transaction. In a distributed system, however, the transaction manager should communicate and uniformly enforce the decision to commit to all servers in the various sites where the transaction is being conducted. When each site's processing is complete, it enters the partially committed transaction state and waits for all other transactions to enter this state. It begins to commit when it receives the message that all of the sites are ready. Either all sites commit or none of them commit in a distributed system.
The various distributed commit protocols are as follows:
● One-phase commit
● Two-phase commit
● Three-phase commit
One phase commit
The simplest commit technique is distributed one-phase commit. Consider a scenario in which the transaction is carried out on a master site and a number of slave sites. The stages involved in a distributed commit are as follows:
● Each slave sends a "DONE" notification to the controlling site once it has completed its transaction locally.
● The slaves wait for the controlling site to send a "Commit" or "Abort" message. This period of waiting is referred to as the "window of vulnerability."
● The controlling site decides whether to commit or abort when each slave sends a "DONE" message. The commit point is what it's called. The message is then sent to all of the slaves.
● A slave either commits or aborts after receiving this message, and then sends an acknowledgement message to the controlling site.
Two phase commit
The vulnerability of one-phase commit protocols is reduced by distributed two-phase commits. The steps performed in the two phases are as follows −
Phase 1: Prepare Phase
● Each slave sends a "DONE" notification to the controlling site once it has completed its transaction locally. When all slaves have sent a "DONE" message to the controlling site, it sends a "Prepare" message to the slaves.
● The slaves vote on whether they still want to commit or not. If a slave wants to commit, it sends a “Ready” message.
● A slave who refuses to commit sends the message "Not Ready." When the slave has conflicting concurrent transactions or there is a timeout, this can happen.
Phase 2: Commit/Abort Phase
After all of the slaves have sent "Ready" messages to the controlling site,
● The slaves receive a "Global Commit" message from the controlling site.
● The slaves complete the transaction and send the controlling site a "Commit ACK" message.
● The transaction is considered committed when the controlling site receives "Commit ACK" messages from all slaves.
After any slave sends the first "Not Ready" notification to the controlling site,
● The slaves receive a "Global Abort" notification from the controlling site.
● The slaves abort the transaction and send the controlling site a "Abort ACK" message.
● The transaction is considered aborted when the controlling site receives "Abort ACK" messages from all slaves.
Three phase commit
The following are the steps in a distributed three-phase commit:
Phase 1: Prepare Phase
The methods are identical to those for a distributed two-phase commit.
Phase 2: Prepare to Commit Phase
The controlling site broadcasts the phrase "Enter Prepared State."
In response, the slave sites vote "OK."
Phase 3: Commit / Abort Phase
The methods are identical to those for a two-phase commit, with the exception that no “Commit ACK”/ “Abort ACK” message is necessary.
Key takeaway:
In a distributed system, however, the transaction manager should communicate and uniformly enforce the decision to commit to all servers in the various sites where the transaction is being conducted.
It begins to commit when it receives the message that all of the sites are ready. Either all sites commit or none of them commit in a distributed system.
In this section, we'll look at how the concepts mentioned above are implemented in a distributed database system.
Distributed Two phase Locking Algorithm
The underlying principle of distributed two-phase locking is identical to that of traditional two-phase locking. In a distributed system, however, there are locations that are designated as lock managers. Lock acquisition requests from transaction monitors are managed by a lock manager. To ensure that lock managers at different sites work together, at least one site is given the authority to view all transactions and detect lock conflicts.
There are three types of distributed two-phase locking approaches, depending on the number of locations that can identify lock conflicts.
● Centralized two-phase locking - One site is designated as the central lock manager in this method. The central lock manager's location is known by all sites in the environment, and it is used to obtain locks during transactions.
● Primary copy two-phase locking - A number of locations are designated as lock control centers in this strategy. Each of these locations is responsible for a specific set of locks. All of the sites are aware of which lock control center is in charge of whatever data table/fragment item's lock.
● Distributed two-phase locking - There are several lock managers in this technique, each of which controls locks on data items stored at its local site. The lock manager's position is determined by data dissemination and replication.
Distributed Timestamp Concurrency Control
The physical clock reading determines the timestamp of any transaction in a centralized system. However, because local physical/logical clock readings are not globally unique, they cannot be used as global timestamps in a distributed system. A timestamp is made up of the site ID and the clock reading for that site.
Each site has a scheduler that keeps a separate queue for each transaction manager in order to apply timestamp ordering techniques. A transaction manager sends a lock request to the site's scheduler during the transaction. The scheduler assigns the request to the appropriate queue in order of increasing timestamp. Requests are processed from the front of the queues in the order of their timestamps, i.e., the oldest first.
Conflict Graphs
Creating conflict graphs is another option. Transaction classes have been defined for this purpose. The read set and write set are two sets of data elements in a transaction class. If the transaction's read set is a subset of the class's read set and the transaction's write set is a subset of the class's write set, the transaction belongs to that class. Each transaction issues read requests for the data items in its read set during the read phase. Each transaction issues its own write requests during the write phase.
For the classes that active transactions belong to, a conflict graph is produced. There are vertical, horizontal, and diagonal edges in this. A vertical edge connects two nodes of a class and indicates class conflicts. A horizontal edge joins two nodes from different classes and indicates a write-write conflict between them. A diagonal edge joins two nodes from different classes, indicating a write-read or read-write conflict between them.
The conflict graphs are examined to see if two transactions from the same class or from two distinct classes can be executed simultaneously.
Key takeaway
In a distributed system, however, there are locations that are designated as lock managers. Lock acquisition requests from transaction monitors are managed by a lock manager.
The conflict graphs are examined to see if two transactions from the same class or from two distinct classes can be executed simultaneously.
References:
- C.J. Date, A. Kannan, S. Swamynathan “An introduction to Database Systems”, Pearson, 8th Edition.
- Martin Gruber, “Understanding SQL”, Sybex Publications.
- Ivan Bayross, “SQL- PL/SQL”, BPB Publications, 4th Edition.
- S.K. Singh, “Database Systems: Concepts, Design and Application”, Pearson, Education, 2nd Edition.




