Unit - 1
Planning the Computer Program
A computer is a tremendously powerful and adaptable equipment that can execute a wide range of activities, yet it lacks intelligence and thinking ability.
Many jobs are carried out by the computer exactly how it is instructed. This sets the onus on the user to provide accurate and specific instructions to the computer so that it can complete the essential task correctly. A faulty or confusing command can be dangerous at times.
The computer cannot solve the problem on its own; instead, the computer requires step-by-step instructions. In truth, it is not the computer's job to solve problems.
The programmer is responsible for expressing the answer to the problem in terms of simple procedures that the computer can comprehend and perform.
Problem-solving is a step-by-step process of examining information about a situation and coming up with effective responses.
To solve a problem using a computer, one must go through a series of stages or phases.
Steps to Solve a Problem With the Computer
Here, we attempt to comprehend the situation in its entirety. Before moving on to the next stage or step, we must be certain of the problem's objectives.
Step 1: Understanding the Problem:
We look at several ways to address the problem and evaluate each of these solutions after completely comprehending the problem to be solved.
Step 2: Analyzing the Problem:
The goal is to find an appropriate solution to the problem at hand. This stage concludes with a general review of the actions that must be performed in order to address the given problem.
Step 3: Developing the solution:
The overview of the sequence of activities that emerged from the analysis stage is expanded here to create a detailed step-by-step solution to the problem at hand.
Step 4: Coding and Implementation:
The conversion of the detailed sequence of operations into a language that the computer can understand is the final stage of problem-solving. Each step is then transformed to the appropriate instruction or instructions in the computer language for the implantation.
A set of explicit and unambiguous instructions defined in a programming language serves as the vehicle for a computer solution to a problem. A programme is a sequence of instructions that solves a problem using C programming.
A programme is also a set of instructions written in a programming language. As a result, an algorithm refers to a problem solution that is independent of any programming language.
Once we have the software, we must usually provide it with input or data to receive the computer solution to a problem. The programme then manipulates this data in accordance with its instructions. Finally, it generates an output that represents the problem's computer solution.
Issue solving is an acquired ability, and there are no universal ways to problem solving. Essentially, one must investigate all conceivable solutions one by one until the appropriate path to a solution is discovered.
Problem Solving Steps
Problem solving is a creative process that involves systematisation and automation. There are a variety of steps that can be performed to improve one's problem-solving abilities.
In order to solve an issue, a problem-solving technique follows a set of procedures. Let's have a look at each stage one by one:
- Problem Definition Phase:
Only after a thorough understanding of the problem is it possible to achieve success in solving it. That is, we can't expect to fix an issue we don't comprehend. As a result, comprehending the problem is the first step toward its resolution.
We must highlight what must be done rather than how it must be done throughout the problem definition phase. That is, we aim to extract the issue statement's precisely defined set of tasks.
Inexperienced problem solvers frequently rush through the issue-solving process, only to discover that they are either tackling the wrong problem, solving the wrong problem, or solving only one problem.
2. Getting Started on a Problem:
A issue can be solved in a variety of ways, and there may be multiple solutions. As a result, determining which option would be more fruitful is challenging. C programming is used to solve problems.
Even though the problem has been defined, you may not know where to begin tackling it. Such a barrier can develop when you become preoccupied with the details of the implementation before you have fully comprehended or worked out a solution.
The best advise is to avoid getting caught up in the details. These can be added later once the problem's complexities are known.
3. Use of Specific Examples:
We can employ heuristics, or the rule of thumb, to get started on a problem. This technique allows us to begin by identifying a specific problem that we want to address and attempting to figure out the mechanism that will allow us to tackle that problem.
Because the relationship between the mechanism and the problem is more clearly defined, it is usually much easier to work out the details of a solution to a specific problem.
This method of focusing on a specific problem can provide us with the necessary groundwork to begin solving the larger problem.
4. Similarities Among Problems:
Consider a specific example as one approach to get started. Another option is to apply previous experience to current issues. As a result, it's critical to look for parallels between the current challenge and previous problems that we've handled.
The more experience one has, the more tools and strategies one can apply to the problem at hand. However, it might occasionally prevent us from finding a desirable or superior solution to the situation.
The capacity to view a situation from various perspectives is an important talent to strive to cultivate in problem-solving.
One must be able to turn a problem inside out, sideways, backwards, forwards, and so on in metaphorical terms. It should be possible to get started on any problem once this skill has been mastered.
5. Working Backwards from the Solution:
In some circumstances, we can assume we already know the answer to the problem and then proceed backwards to the beginning. Even a wild guess at the solution to the problem might be enough to get us started on it.
By writing down the many steps and explorations done, we can standardise the studies and avoid duplication of work.
Another activity that aids in the development of problem-solving skills is to intentionally look back on how we went about identifying the solution after we have solved an issue.
Key takeaway
Problem-solving is a step-by-step process of examining information about a situation and coming up with effective responses.
A problem, also known as an issue, is any situation that comes unexpectedly or hinders anything from happening. When dealing with computer issues, you must first identify the root of the problem before attempting to resolve it.
"It is an action to recognise the problem, comprehend the problem, and comprehend any limitations that may be the solution's limitations."
A computer is a highly capable and flexible machine that can do a wide range of activities, yet it lacks intelligence and the ability to reason. A computer has no intelligence. Many jobs are completed exactly as instructed by a computer. It is the user's obligation to properly and accurately instruct the computer so that the system can perform properly.
Incorrect or ambiguous advice might be disastrous at times. The user must have a clear idea of how to address the problem in order to correctly educate the computer.
Part of this is that he should be able to devise a mechanism for solving it in a sequential manner. Instructing the computer to solve the problem becomes reasonably simple after the problem has been adequately defined and a solution has been devised.
As a result, before attempting to develop a computer programme to address a problem, consider the following. Problems must be meticulously established or defined.
Key takeaway
A problem, also known as an issue, is any situation that comes unexpectedly or hinders anything from happening. When dealing with computer issues, you must first identify the root of the problem before attempting to resolve it.
Problem analysis entails breaking down problems into its constituent parts so that they can be easily understood. Create an ALGORITHM of the problem to do so.
We look for different approaches to solving the problem and evaluate each one once we've figured out how to do it. The goal is to find the most effective solution to the issue at hand.
Identifying the overarching problem and determining the sources and effects of that problem constitutes problem analysis. This study will make sure that the "root causes" of the problem, not simply the symptoms, are recognised and addressed in the project design.
Purpose
The problem analysis technique is used to look at all of the issues and elements that prevent an organisation from reaching its goals. The goal of problem analysis is to distill these limits down to their essential issues, allowing them to be understood and resolved at the source.
Example
The goal of problem analysis is to determine cause and effect. Determining what is cause and what is consequence can be challenging. A problem that appears to be a human error may instead be a hidden human error caused by a poorly designed user interface, system, or process.
Algorithms
An algorithm is the finite set of English statements which are designed to accomplish the specific task. Study of any algorithm is based on the following four criteria:
1. Design of algorithm: This is the first step in the creation of an algorithm. Design of algorithm includes the problem statement which tell user about the area for which algorithm is required. After problem statement next important thing required is the information about available and required resources. The last thing required in design of algorithm phase is information about the expected output.
2. Validation of algorithm: Once an algorithm is designed , it is necessary to validate it for several possible input and make sure that algorithm is providing correct output for every input. This process is known as algorithm validation. The purpose of the validation is to assure us that this algorithm will work correctly independently of the issues concerning the programming language it will eventually be written in.
3. Analysis of algorithm: Analysis of algorithms is also called as performance analysis. This phase refers to the task of determining how much computing time and storage an algorithm requires. The efficiency is measured in best case, worst case and average case analysis.
4. Testing of algorithm: This phase is about to testing of a program which coded as per the algorithm. Testing of such program consists of two phases:
● Debugging: It is the process of executing programs on sample data sets to determine whether faulty results occur or not and if occur, to correct them.
● Profiling: Profiling or performance measurement is the process of executing a correct program on data sets and measuring the time and space it takes to compute the result
Characteristics of an algorithm
● Input: Algorithm must accept zero or more inputs.
● Output: Algorithm must provide at least one quantity.
● Definiteness: Algorithm must consist of clear and unambiguous instruction.
● Finiteness: Algorithm must contain finite set of instruction and algorithm will terminates after a finite number of steps.
● Effectiveness: Every instruction in algorithm must be very basic and effective.
Uses of algorithm
● Algorithm provide independent layout of the program.
● It is easy to develop the program in any desired language with help of layout.
● Algorithm representation is very easy to understand.
● To design algorithm there is no need of expertise in programming language.
There are three ways to represent an algorithm. Consider the following algorithm of addition of two numbers
Step 1 : Start
Step 2 : Read a number, say x and y
Step 3 : Add x and y
Step 4 : Display Addition
Step 5 : Stop
- Flowcharts: A flow chart is a diagrammatic / pictorial representation of an algorithm. It is the simplest way of representing an algorithm. Initially an algorithm is represented in the form of flowchart and then flowchart is given to the programmer to express it in some programming language. Logical error detection is very easy in flowchart as it shows the flow of operations in diagrammatic form. Once the flowchart is ready it is very easy to write a program in terms of statements of a programming language. Following are the symbols used in designing the flowcharts.
- Pseudo code: Pseudo code is the combination of English statements with programming methodology. In pseudo code, there is no restriction of following the syntax of the programming language. Pseudo codes cannot be compiled. It is just a previous step of developing a code for a given algorithm.
- Program: In this way of representation, a complete algorithm is represented using some programming language by following the complete syntax of the programming language.
Flow chart
Flowchart is a diagrammatic representation of the sequence of logical steps of a program. Flowcharts use simple geometric shapes to depict processes and arrows to show relationships and process/data flow.
Flowchart Symbols
Here is a chart for some of the common symbols used in drawing flowcharts.
Symbol | Symbol Name | Purpose |
 | Start/Stop | Used at the beginning and end of the algorithm to show start and end of the program. |
 | Process | Indicates processes like mathematical operations. |
 | Input/ Output | Used for denoting program inputs and outputs. |
 | Decision | Stands for decision statements in a program, where answer is usually Yes or No. |
 | Arrow | Shows relationships between different shapes. |
 | On-page Connector | Connects two or more parts of a flowchart, which are on the same page. |
 | Off-page Connector | Connects two parts of a flowchart which are spread over different pages. |
Guidelines for Developing Flowcharts
These are some points to keep in mind while developing a flowchart −
● Flowchart can have only one start and one stop symbol
● On-page connectors are referenced using numbers
● Off-page connectors are referenced using alphabets
● General flow of processes is top to bottom or left to right
● Arrows should not cross each other
Example Flowcharts
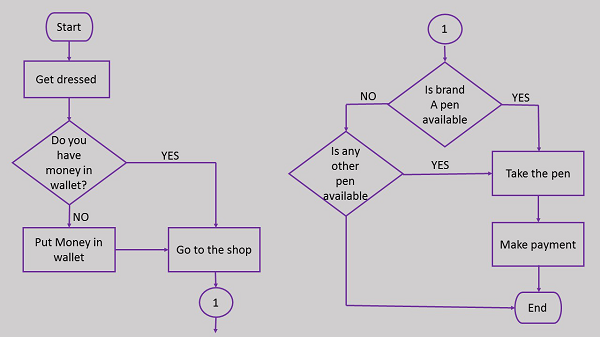
Here is the flowchart for going to the market to purchase a pen.
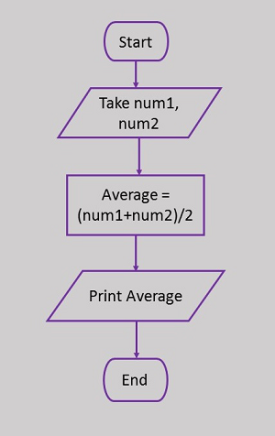
Here is a flowchart to calculate the average of two numbers.
Key takeaway
An algorithm is the finite set of English statements which are designed to accomplish the specific task.
Flowcharts use simple geometric shapes to depict processes and arrows to show relationships and process/data flow.
Debugging is the process by which a developer (who may or may not be the author of the code he is trying to debug) attempts to update a portion of previously written code using various tools accessible to him in order to eliminate an error that was not discovered during compile (or syntax checking) time (in other words that has surfaced at the run time subject to certain conditions).
Different types of debugging
Debugging can be accomplished in a variety of methods. But, before we go over them, it's important to recognise that any debugging process is made up of two core tasks. First, look at the values of various variables at various phases of the programme execution, and then look at how the control flows (Are we approaching the "if" block?). Is it ever reached the "break" statement inside the "while" loop?
● Print statements
While running the code, you use "print" (or "printf" or "echo" or whatever the equivalent is) to output certain values. This is probably the simplest approach to begin debugging. It is also the most inconvenient and time-consuming method. It's inconvenient since we can simply leave all (or portion of) those print statements in the code once we're done, resulting in messy code (and in some very rare occasions, breaking it in production.). It takes time since we have to write all of the print statements before monitoring them while the programme is running.
● Using logging
This method is text-based, similar to printing, but with a lot more features. We may actually transmit structured messages from our software to log management platforms and then utilise those tools to run various searches across the corpus of text to get the necessary information, rather than using "stdout" as the output mechanism (as with printing). It is an extremely efficient method. And for any genuine production software, logging is a must. However, it has its own limitations. We still have to write all of our log statements by hand (and remove them later if they aren't needed), and we can't peer behind the hood of programme execution in most circumstances.
● Interactive (Symbolic) debugger
If you've ever used a programme like "gdb," (or “ipdb” or “pydb” or “lldb” or anything like that) you'll understand what I'm talking about. For the rest, there are tools on your development machines that give you full interactive access to the programme at runtime and allow you to investigate extremely low level (and high level) issues on a running piece of code. The benefit of this method of debugging is that it requires no additional work on your behalf to begin debugging the code. You simply start the debugger and point it to the executable, and there you have it! You're in the middle of a running programme, but you have complete control over its investigation (and, if necessary, change) in real time.
Steps for Debugging in C
- Make a file named fib.c.
#include <stdio.h>
Int main()
{
int i;
int numTerms = 10;
int t1 = 0, t2 = 1;
int nextTerm;
printf("Fibonacci Series: ");
for (i = 1; i <= numTerms; ++i)
{
printf("%d, ", t1);
nextTerm = t1 + t2;
t1 = t2;
t2 = nextTerm;
}
return 0;
}
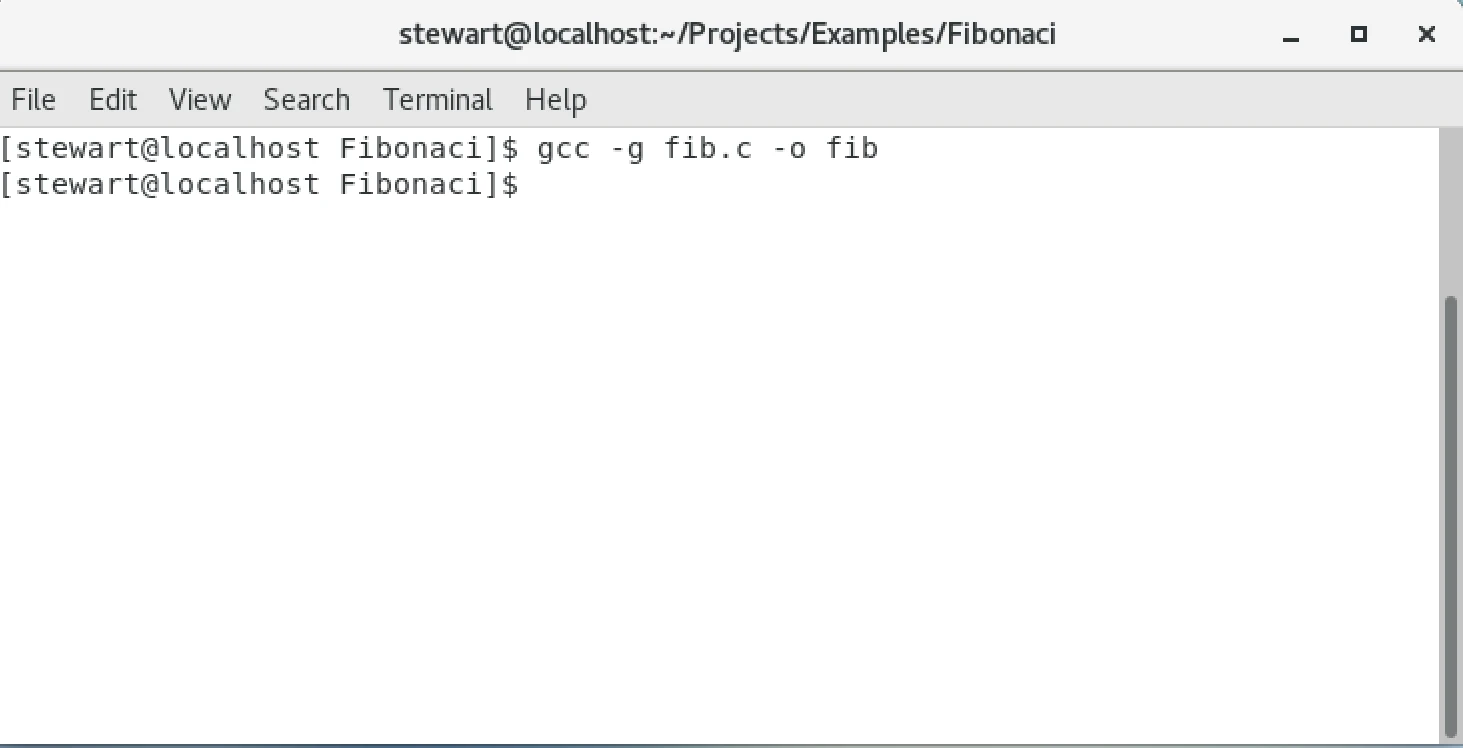
2. Use the gcc compiler and the -g flag to enable debug symbols when compiling the fib.c file.
3. Debug the fib application with TotalView.
4. By clicking on the line number, you can set a breakpoint at line 12.
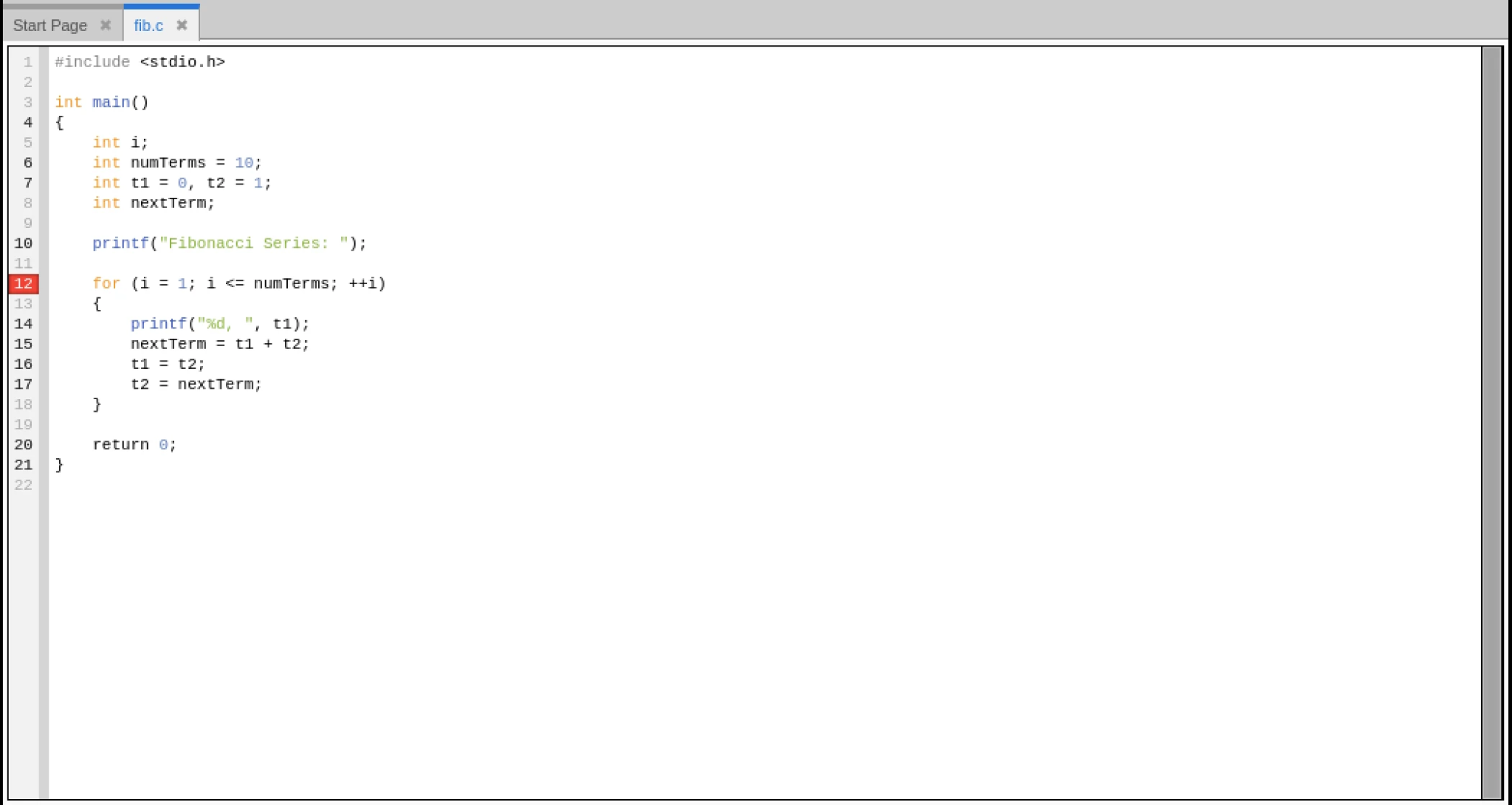
5. Press the Green GO button to begin debugging. TotalView executes the programme until it reaches the line 12 breakpoint, at which point it quits.
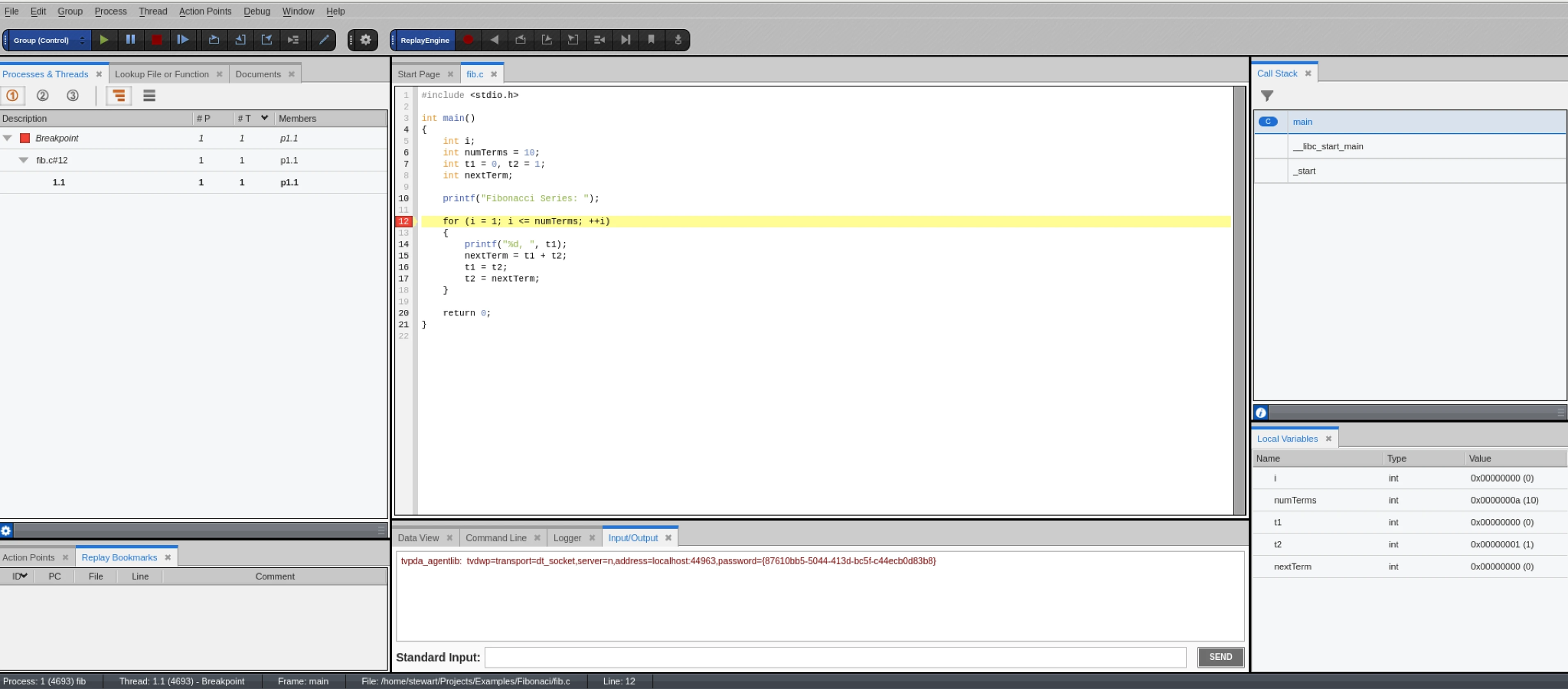
6. Step through the loop with the Next button, watching the values of the variables in the Local Variables box change.
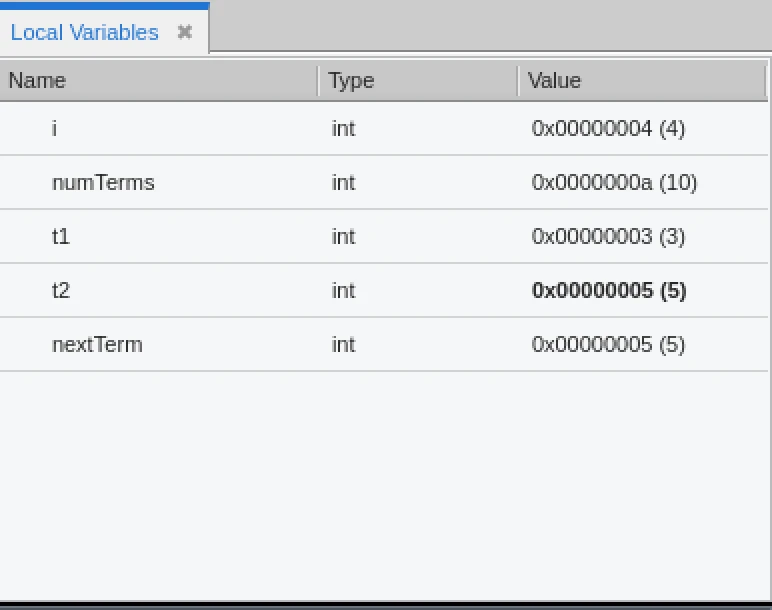
7. TotalView is a unique function that allows you to record the execution of your programme so that you may look back in time.
By pressing the Red Record button on the Replay Engine toolbar, you can enable reverse debugging and then go backward and forward through the code.
Key takeaway
Debugging can be accomplished in a variety of methods. But, before we go over them, it's important to recognise that any debugging process is made up of two core tasks.
Error is an illegal operation performed by the user which results in abnormal working of the program.
Programming errors often remain undetected until the program is compiled or executed. Some of the errors inhibit the program from getting compiled or executed. Thus errors should be removed before compiling and executing.
The most common errors can be broadly classified as follows.
Type of errors

- Syntax errors: Errors that occur when you violate the rules of writing C/C++ syntax are known as syntax errors. This compiler error indicates something that must be fixed before the code can be compiled. All these errors are detected by compiler and thus are known as compile-time errors.
Most frequent syntax errors are:
- Missing Parenthesis (})
- Printing the value of variable without declaring it
- Missing semicolon like this:
// C program to illustrate
// syntax error
#include<stdio.h>
Void main()
{
Int x = 10;
Int y = 15;
Printf("%d", (x, y)) // semicolon missed
}
Error:
Error: expected ';' before '}' token
Syntax of a basic construct is written wrong. For example: while loop
// C program to illustrate
// syntax error
#include<stdio.h>
Int main(void)
{
// while() cannot contain "." as an argument.
While(.)
{
Printf("hello");
}
Return 0;
}
Error:
Error: expected expression before '.' token
While(.)
In the given example, the syntax of while loop is incorrect. This causes a syntax error.
2. Run-time Errors: Errors which occur during program execution(run-time) after successful compilation are called run-time errors. One of the most common run-time error is division by zero also known as Division error. These types of error are hard to find as the compiler doesn’t point to the line at which the error occurs.
For more understanding run the example given below.
// C program to illustrate
// run-time error
#include<stdio.h>
Void main()
{
Int n = 9, div = 0;
// wrong logic
// number is divided by 0,
// so this program abnormally terminates
Div = n/0;
Printf("resut = %d", div);
}
Error:
Warning: division by zero [-Wdiv-by-zero]
Div = n/0;
In the given example, there is Division by zero error. This is an example of run-time error i.e errors occurring while running the program.
3. Linker Errors: These error occurs when after compilation we link the different object files with main’s object using Ctrl+F9 key(RUN). These are errors generated when the executable of the program cannot be generated. This may be due to wrong function prototyping, incorrect header files. One of the most common linker error is writing Main() instead of main().
// C program to illustrate
// linker error
#include<stdio.h>
Void Main() // Here Main() should be main()
{
Int a = 10;
Printf("%d", a);
}
Error:
(.text+0x20): undefined reference to main'
4. Logical Errors: On compilation and execution of a program, desired output is not obtained when certain input values are given. These types of errors which provide incorrect output but appears to be error free are called logical errors. These are one of the most common errors done by beginners of programming.
These errors solely depend on the logical thinking of the programmer and are easy to detect if we follow the line of execution and determine why the program takes that path of execution.
// C program to illustrate
// logical error
Int main()
{
Int i = 0;
// logical error : a semicolon after loop
For(i = 0; i < 3; i++);
{
Printf("loop ");
Continue;
}
Getchar();
Return 0;
}
No output
5. Semantic errors: This error occurs when the statements written in the program are not meaningful to the compiler.
// C program to illustrate
// semantic error
Void main()
{
Int a, b, c;
a + b = c; //semantic error
}
Error
Error: lvalue required as left operand of assignment
a + b = c; //semantic error
Key takeaway
Error is an illegal operation performed by the user which results in abnormal working of the program.
A programme or software document is any written text, graphics, or video that describes a software or programme to its users. A user can be anyone, from a programmer to a system analyst to an end user. Multiple documents for different users may be developed at various phases of development. Software documentation is, in reality, an important part of the overall software development process.
Because multiple teams produce separate modules of the product in modular programming, documentation becomes even more critical. Good and detailed documentation will make it easier for anyone other than the development team to comprehend a module.
These are some guidelines for document creation.
● Documentation should be written from the reader's perspective.
● The document should be clear.
● There should not be any repeats.
● Industry norms must be followed.
● Always keep your documents up to date.
● Any outdated document should be phased out after it has been properly documented.
Advantages of Documentation
Providing software documentation has a number of advantages.
● Keeps track of all components of a programme or software.
● Maintenance is less difficult.
● Other than the developer, all parts of software can be understood by programmers.
● Enhances the software's overall quality.
● Assists with user education.
● If people leave the system abruptly, it ensures knowledge decentralisation, reducing costs and effort.
Example Documents
Many different types of papers can be related with software. Among the most significant are:
● User manual - It contains instructions and processes for end users to use the software's many functionalities.
● Operational manual - It identifies and summarises all of the operations in progress, as well as their interrelationships.
● Design Document - It provides an overview of the software as well as detailed descriptions of design features. It contains information such as data flow diagrams, entity relationship diagrams, and so on.
● Requirements Document - It includes a list of all the system's needs as well as an appraisal of their viability. It could include user stories, real-life incidents, and so forth.
● Technical Documentation − It is a record of actual programming elements such as algorithms, flowcharts, programme codes, functional modules, and so on.
● Testing Document − It keeps track of the test plan, test cases, validation and verification plans, and test outcomes, among other things. One component of software development that necessitates extensive documentation is testing.
● List of Known Bugs − Every piece of software has defects or faults that can't be fixed because they were discovered too late, are innocuous, or require more effort and time than is required. These bugs are documented with the programme documentation so that they can be fixed later. If the problem is triggered, they also assist users, implementers, and maintenance personnel.
Key takeaway
A programme or software document is any written text, graphics, or video that describes a software or programme to its users. A user can be anyone, from a programmer to a system analyst to an end user.
Basics of Linux Operating System (Ubuntu)
The Linux Kernel provides the foundation for a community of open-source Unix-like operating systems. Linus Torvalds initially released it on September 17, 1991. It is a free and open-source operating system, with the source code available for business or non-commercial use under the GNU General Public License.
Linux began as a personal computer operating system, but it has now expanded to include servers, mainframe computers, supercomputers, and other equipment. Linux is now found in embedded systems such as routers, automation controls, televisions, digital video recorders, video game consoles, smartwatches, and other devices. Android (operating system), which is built on the Linux kernel and runs on smartphones and tablets, is Linux's biggest success. Linux has the greatest installed base of any general-purpose operating system thanks to Android. A Linux distribution is a collection of Linux packages.
Linux Distribution
Linux distribution is an operating system that consists of a collection of software based on the Linux kernel, or distribution, which includes the Linux kernel as well as supporting libraries and software. You can also receive a Linux-based operating system by downloading one of the Linux distributions, which are available for various devices such as embedded devices, personal computers, and so on. There are over 600 Linux distributions available, with the following being some of the most popular:
● MX Linux
● Manjaro
● Linux Mint
● elementary
● Ubuntu
● Debian
● Solus
● Fedora
● openSUSE
● Deepin
Ubuntu
Ubuntu is an operating system based on Linux. Computers, cellphones, and network servers are all supported. Canonical Ltd, based in the United Kingdom, created the system. All of the principles utilised to create the Ubuntu software are based on Open Source software development principles.
Features of Ubuntu
The following are some of Ubuntu's most notable features.
● Ubuntu's desktop edition works with all of the standard Windows programmes, such as Firefox, Chrome, and VLC.
● It works with the LibreOffice office suite.
● Thunderbird, an email client included into Ubuntu, allows users to access email services such as Exchange, Gmail, and Hotmail.
● Users may browse and edit images using a variety of free programmes.
● There are other video management applications that allow users to exchange videos.
● With Ubuntu's clever searching feature, finding content is simple.
● The finest aspect is that it is a free operating system with a large open source community behind it.
Features
Ubuntu has a number of features:
● Ubuntu Desktop
● Ubuntu Server
● Kubuntu
● Linux Mint
● Ubuntu Desktop
Ubuntu is a desktop operating system designed for everyday use. The Ubuntu operating system includes pre-installed software that assists users with a variety of common tasks. The Ubuntu desktop operating system has a number of features, including multimedia, email, and browsing.
● Ubuntu Server
The Ubuntu server operating system is mostly used to host database and web server applications. This operating system also supports Azure and AWS, among other cloud services.
● Kubuntu
The Unity programme powers the Ubuntu operating system's user interface. The Kubuntu interface, on the other hand, is based on the KDE Plasma desktop. The KDE Plasma desktop gives Ubuntu a look and feel. The Kubuntu operating system has the same software availability and features as the Ubuntu operating system.
● Linux Mint
The Ubuntu-based Linux Mint operating system is likewise based on Ubuntu. The Linux Mint operating system comes with a number of pre-installed multimedia and photo applications. The Linux Mint operating system is based entirely on open-source software.
Advantages of the Ubuntu Operating System
The Ubuntu operating system has a number of advantages:
● Ubuntu is Free
● Ubuntu can be Easily Customized
● Virtual Desktops
● Better Option for Development
● Ubuntu is more Secure
● Free Apps
‘C’ programming language
What is C programming?
C is a general-purpose programming language that is extremely popular, simple and flexible. It is machine-independent, structured programming language which is used extensively in various applications.
C was the basic language to write everything from operating systems (Windows and many others) to complex programs like the Oracle database, Git, Python interpreter and more.
It is said that 'C' is a god's programming language. One can say, C is a base for the programming. If you know 'C,' you can easily grasp the knowledge of the other programming languages that uses the concept of 'C'
It is essential to have a background in computer memory mechanisms because it is an important aspect when dealing with the C programming language.
History of C language
The base or father of programming languages is 'ALGOL.' It was first introduced in 1960. 'ALGOL' was used on a large basis in European countries. 'ALGOL' introduced the concept of structured programming to the developer community. In 1967, a new computer programming language was announced called as 'BCPL' which stands for Basic Combined Programming Language. BCPL was designed and developed by Martin Richards, especially for writing system software.
This was the era of programming languages. Just after three years, in 1970 a new programming language called 'B' was introduced by Ken Thompson that contained multiple features of 'BCPL.' This programming language was created using UNIX operating system at AT & T and Bell Laboratories. Both the 'BCPL' and 'B' were system programming languages.
In 1972, a great computer scientist Dennis Ritchie created a new programming language called 'C' at the Bell Laboratories. It was created from 'ALGOL', 'BCPL' and 'B' programming languages. 'C' programming language contains all the features of these languages and many more additional concepts that make it unique from other languages.
'C' is a powerful programming language which is strongly associated with the UNIX operating system. Even most of the UNIX operating system is coded in 'C'. Initially 'C' programming was limited to the UNIX operating system, but as it started spreading around the world, it became commercial, and many compilers were released for cross-platform systems. Today 'C' runs under a variety of operating systems and hardware platforms. As it started evolving many different versions of the language were released.
At times it became difficult for the developers to keep up with the latest version as the systems were running under the older versions. To assure that 'C' language will remain standard, American National Standards Institute (ANSI) defined a commercial standard for 'C' language in 1989. Later, it was approved by the International Standards Organization (ISO) in 1990. 'C' programming language is also called as 'ANSI C'.

History of C
Languages such as C++/Java are developed from 'C'. These languages are widely used in various technologies. Thus, 'C' forms a base for many other languages that are currently in use.
Where is C used? Key Applications
- 'C' language is widely used in embedded systems.
- It is used for developing system applications.
- It is widely used for developing desktop applications.
- Most of the applications by Adobe are developed using 'C' programming language.
- It is used for developing browsers and their extensions. Google's Chromium is built using 'C' programming language.
- It is used to develop databases. MySQL is the most popular database software which is built using 'C'.
- It is used in developing an operating system. Operating systems such as Apple's OS X, Microsoft's Windows, and Symbian are developed using 'C' language. It is used for developing desktop as well as mobile phone's operating system.
- It is used for compiler production.
- It is widely used in IOT applications.
Why learn 'C'?
As we studied earlier, 'C' is a base language for many programming languages. So, learning 'C' as the main language will play an important role while studying other programming languages. It shares the same concepts such as data types, operators, control statements and many more. 'C' can be used widely in various applications. It is a simple language and provides faster execution. There are many jobs available for a 'C' developer in the current market.
'C' is a structured programming language in which program is divided into various modules. Each module can be written separately and together it forms a single 'C' program. This structure makes it easy for testing, maintaining and debugging processes.
'C' contains 32 keywords, various data types and a set of powerful built-in functions that make programming very efficient.
Another feature of 'C' programming is that it can extend itself. A 'C' program contains various functions which are part of a library. We can add our features and functions to the library. We can access and use these functions anytime we want in our program. This feature makes it simple while working with complex programming.
Various compilers are available in the market that can be used for executing programs written in this language.
It is a highly portable language which means programs written in 'C' language can run on other machines. This feature is essential if we wish to use or execute the code on another computer.
How 'C' Works?
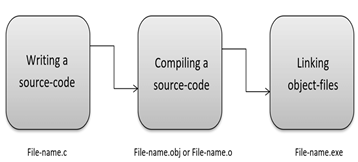
C is a compiled language. A compiler is a special tool that compiles the program and converts it into the object file which is machine readable. After the compilation process, the linker will combine different object files and creates a single executable file to run the program. The following diagram shows the execution of a 'C' program
Nowadays, various compilers are available online, and you can use any of those compilers. The functionality will never differ and most of the compilers will provide the features required to execute both 'C' and 'C++' programs.
Following is the list of popular compilers available online:
● Clang compiler
● MinGW compiler (Minimalist GNU for Windows)
● Portable 'C' compiler
● Turbo C
Advantages of C language
● Reliability: C language allows low level access to data and commands and maintains the syntax of a high level language. These qualities make it a useful language for both systems programming and general purpose programs.
● Flexibility: C is a powerful and flexible language which provides fast program execution.
● Modularity: C language provides features like Functions, Structures, Unions and Built-in Library functions which support code reusability.
● Efficiency and Effectiveness: The programs of C language are less complex and do not require any special programming language platform other than compiler. C language plays vital role in hardware programming
Key takeaway
'C' was developed by Dennis Ritchie in 1972. It is a robust language. It is a low programming level language close to machine language. It is widely used in the software development field. It is a procedure and structure oriented language. It is highly portable.
GNU Compiler Collection (GCC) is a GNU Project optimising compiler that supports a wide range of programming languages, hardware architectures, and operating systems. GCC is distributed as free software by the Free Software Foundation (FSF) under the GNU General Public License (GNU GPL). GCC is an important part of the GNU toolchain and the standard compiler for most GNU and Linux kernel projects. GCC is one of the largest free programmes in existence, with around 15 million lines of code in 2019. It has served as both a tool and an example in the development of free software.
History of GCC
Richard Stallman, the founder of the GNU Project, is the original author of the GNU C Compiler (GCC).
The GNU Project began in 1984 with the goal of creating a free Unix-like operating system to encourage freedom and collaboration among computer users and programmers. Every Unix-like operating system requires a C compiler, and the GNU Project had to create one from scratch because there were no free compilers available at the time. Individuals and businesses contributed to the Free Software Foundation, a non-profit organisation established to support the GNU Project's efforts.
GCC was released for the first time in 1987. Being the first portable ANSI C optimising compiler released as free software, this was a notable milestone. Since then, GCC has grown into one of the most significant tools for free software development.
In 1992, the 2.0 series of the compiler was released, which included the ability to compile C++. To increase optimization and C++ support, an experimental branch of the compiler (EGCS) was built in 1997. Following this work, EGCS was accepted as the new main-line for GCC development, and these capabilities were made generally available in GCC 3.0 in 2001.
GCC has been extended to support a variety of other languages throughout time, including Fortran, ADA, Java, and Objective-C. The "GNU Compiler Collection" is now referred to by the moniker GCC. The GCC Steering Committee, which is made up of representatives from GCC user communities in industry, research, and academia, oversees its development.
Features of GCC
To begin with, GCC is a portable compiler that runs on the majority of modern systems and can provide output for a variety of CPUs. It supports microcontrollers, DSPs, and 64-bit CPUs in addition to the processors used in personal computers.
GCC isn't just a native compiler; it can also cross-compile any programme, resulting in executable files for systems other than GCC's own. This makes it possible to compile software for embedded systems that lack the ability to execute a compiler. GCC is written in C with a heavy emphasis on portability, and it can compile itself, making it simple to adapt to new systems.
For parsing different languages, GCC includes numerous language frontends. Any architecture may compile or cross-compile programmes written in each language. An ADA programme, for example, can be compiled for a microcontroller, whereas a C programme can be compiled for a supercomputer.
GCC's modular design allows for the addition of new languages and architectures. When you add a new language front-end to GCC, you can use it on any architecture as long as you have the requisite run-time facilities (such as libraries). Adding support for a new architecture does the same thing, making it available to all languages.
Last but not least, GCC is free software, distributed under the GNU General Public License (GNU GPL). As with all GNU software, you have complete freedom to use and modify GCC. You can either add support for a new type of CPU, a new language, or a new feature yourself or hire someone to do it for you. If an issue is critical to your job, you can hire someone to fix it.
You also have the option of sharing any GCC improvements you create. You can also use enhancements to GCC made by others as a result of this flexibility. GCC's numerous features demonstrate how this flexibility to collaborate benefits you and everyone else who uses GCC.
GCC Versions
The various GCC versions are:
GCC version 1 (1987): Initial version that support C.
GCC version 2 (1992): supports C++.
GCC version 3 (2001): incorporating ECGS (Experimental GNU Compiler System), with improve optimization.
GCC version 4 (2005)
GCC version 5 (2015)
GCC Version 6 (2016)
GCC Version 7 (2017)
Simple program
Hello World is the most well-known C sample programme. The source code for our version of the application is as follows:
#include <stdio.h>
Int
Main (void)
{
printf ("Hello, world!\n");
return 0;
}
We'll assume the source code is saved in a file named 'hello.c.' Use the following command to build the file 'hello.c' using gcc:
$ gcc -Wall hello.c -o hello
This converts the source code in 'hello.c' to machine code, which is then stored in the 'hello' executable file. The -o option specifies the output file for the machine code. The last argument on the command line is normally this option. The output is written to a default file called 'a.out' if it is not specified.
A file with the same name as the executable file will be rewritten if it already exists in the current directory.
The option -Wall enables all of the most often used compiler warnings; it is strongly suggested that you use this option at all times. When programming in C, compiler warnings are a critical tool for spotting errors.
Key takeaway
GCC is distributed as free software by the Free Software Foundation (FSF) under the GNU General Public License (GNU GPL). GCC is an important part of the GNU toolchain and the standard compiler for most GNU and Linux kernel projects.
A data type specifies the type of data that a variable can store such as integer, floating, character, etc.
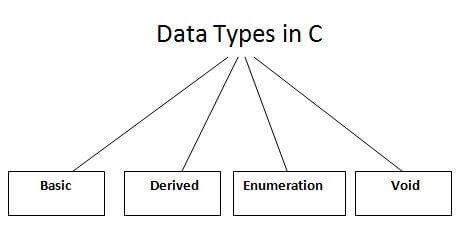
There are the following data types in C language.
Types | Data Types |
Basic Data Type | Int, char, float, double |
Derived Data Type | Array, pointer, structure, union |
Enumeration Data Type | Enum |
Void Data Type | Void |
Basic Data Types
The basic data types are integer-based and floating-point based. C language supports both signed and unsigned literals.
The memory size of the basic data types may change according to 32 or 64-bit operating system.
Let's see the basic data types. Its size is given according to 32-bit architecture.
Data Types | Memory Size | Range |
Char | 1 byte | −128 to 127 |
Signed char | 1 byte | −128 to 127 |
Unsigned char | 1 byte | 0 to 255 |
Short | 2 byte | −32,768 to 32,767 |
Signed short | 2 byte | −32,768 to 32,767 |
Unsigned short | 2 byte | 0 to 65,535 |
Int | 2 byte | −32,768 to 32,767 |
Signed int | 2 byte | −32,768 to 32,767 |
Unsigned int | 2 byte | 0 to 65,535 |
Short int | 2 byte | −32,768 to 32,767 |
Signed short int | 2 byte | −32,768 to 32,767 |
Unsigned short int | 2 byte | 0 to 65,535 |
Long int | 4 byte | -2,147,483,648 to 2,147,483,647 |
Signed long int | 4 byte | -2,147,483,648 to 2,147,483,647 |
Unsigned long int | 4 byte | 0 to 4,294,967,295 |
Float | 4 byte |
|
Double | 8 byte |
|
Long double | 10 byte |
|
Key takeaway
A data type specifies the type of data that a variable can store such as integer, floating, character, etc.
A variable is nothing but a name given to a storage area that our programs can manipulate. Each variable in C has a specific type, which determines the size and layout of the variable's memory; the range of values that can be stored within that memory; and the set of operations that can be applied to the variable.
The name of a variable can be composed of letters, digits, and the underscore character. It must begin with either a letter or an underscore. Upper and lowercase letters are distinct because C is case-sensitive. Based on the basic types explained in the previous chapter, there will be the following basic variable types −
Sr.No. | Type & Description |
1 | Char Typically a single octet(one byte). It is an integer type. |
2 | Int The most natural size of integer for the machine. |
3 | Float A single-precision floating point value. |
4 | Double A double-precision floating point value. |
5 | Void Represents the absence of type. |
C programming language also allows to define various other types of variables, which we will cover in subsequent chapters like Enumeration, Pointer, Array, Structure, Union, etc. For this chapter, let us study only basic variable types.
Variable Definition in C
A variable definition tells the compiler where and how much storage to create for the variable. A variable definition specifies a data type and contains a list of one or more variables of that type as follows −
Type variable_list;
Here, type must be a valid C data type including char, w_char, int, float, double, bool, or any user-defined object; and variable_list may consist of one or more identifier names separated by commas. Some valid declarations are shown here −
Int i, j, k;
Char c, ch;
Float f, salary;
Double d;
The line int i, j, k; declares and defines the variables i, j, and k; which instruct the compiler to create variables named i, j and k of type int.
Variables can be initialized (assigned an initial value) in their declaration. The initializer consists of an equal sign followed by a constant expression as follows −
Type variable_name = value;
Some examples are −
Extern int d = 3, f = 5; // declaration of d and f.
Int d = 3, f = 5; // definition and initializing d and f.
Byte z = 22; // definition and initializes z.
Char x = 'x'; // the variable x has the value 'x'.
For definition without an initializer: variables with static storage duration are implicitly initialized with NULL (all bytes have the value 0); the initial value of all other variables are undefined.
Variable Declaration in C
A variable declaration provides assurance to the compiler that there exists a variable with the given type and name so that the compiler can proceed for further compilation without requiring the complete detail about the variable. A variable definition has its meaning at the time of compilation only, the compiler needs actual variable definition at the time of linking the program.
A variable declaration is useful when you are using multiple files and you define your variable in one of the files which will be available at the time of linking of the program. You will use the keyword extern to declare a variable at any place. Though you can declare a variable multiple times in your C program, it can be defined only once in a file, a function, or a block of code.
Example
Try the following example, where variables have been declared at the top, but they have been defined and initialized inside the main function −
#include <stdio.h>
// Variable declaration:
Extern int a, b;
Extern int c;
Extern float f;
Int main () {
/* variable definition: */
Int a, b;
Int c;
Float f;
/* actual initialization */
a = 10;
b = 20;
c = a + b;
Printf("value of c : %d \n", c);
f = 70.0/3.0;
Printf("value of f : %f \n", f);
Return 0;
}
When the above code is compiled and executed, it produces the following result −
Value of c : 30
Value of f : 23.333334
The same concept applies on function declaration where you provide a function name at the time of its declaration and its actual definition can be given anywhere else. For example −
// function declaration
Int func();
Int main() {
// function call
Int i = func();
}
// function definition
Int func() {
Return 0;
}
Key takeaway
A variable is nothing but a name given to a storage area that our programs can manipulate. Each variable in C has a specific type, which determines the size and layout of the variable's memory; the range of values that can be stored within that memory; and the set of operations that can be applied to the variable.
There are some library functions which are available for transferring the information between the computer and the standard input and output devices.
These functions are related to the symbolic constants and are available in the header file.
Some of the input and output functions are as follows:
i) printf
This function is used for displaying the output on the screen i.e the data is moved from the computer memory to the output device.
Syntax:
Printf(“format string”, arg1, arg2, …..);
In the above syntax, 'format string' will contain the information that is formatted. They are the general characters which will be displayed as they are
arg1, arg2 are the output data items.
Example: Demonstrating the printf function
Printf(“Enter a value:”);
● Printf will generally examine from left to right of the string.
● The characters are displayed on the screen in the manner they are encountered until it comes across % or \.
● Once it comes across the conversion specifiers it will take the first argument and print it in the format given.
Ii) scanf
Scanf is used when we enter data by using an input device.
Syntax:
Scanf (“format string”, &arg1, &arg2, …..);
The number of items which are successful are returned.
Format string consists of the conversion specifier. Arguments can be variables or array name and represent the address of the variable. Each variable must be preceded by an ampersand (&). Array names should never begin with an ampersand.
Example: Demonstrating scanf
Int avg;
Float per;
Char grade;
Scanf(“%d %f %c”,&avg, &per, &grade):
● Scanf works totally opposite to printf. The input is read, interpret using the conversion specifier and stores it in the given variable.
● The conversion specifier for scanf is the same as printf.
● Scanf reads the characters from the input as long as the characters match or it will terminate. The order of the characters that are entered are not important.
● It requires an enter key in order to accept an input.
Iii) getch
This function is used to input a single character. The character is read instantly and it does not require an enter key to be pressed. The character type is returned but it does not echo on the screen.
Syntax:
Int getch(void);
Ch=getch();
where,
Ch - assigned the character that is returned by getch.
Iv) putch
This function is a counterpart of getch. Which means that it will display a single character on the screen. The character that is displayed is returned.
Syntax:
Int putch(int);
Putch(ch);
Where,
Ch - the character that is to be printed.
v) getche
This function is used to input a single character. The main difference between getch and getche is that getche displays the (echoes) the character that we type on the screen.
Syntax:
Int getch(void);
Ch=getche();
Vi) getchar
This function is used to input a single character. The enter key is pressed which is followed by the character that is typed. The character that is entered is echoed.
Syntax:
Ch=getchar;
Vii) putchar
This function is the other side of getchar. A single character is displayed on the screen.
Syntax:
Putchar(ch);
Viii) gets and puts
They help in transferring the strings between the computer and the standard input-output devices. Only single arguments are accepted. The arguments must be such that it represents a string. It may include white space characters. If gets is used enter key has to be pressed for ending the string. The gets and puts function are used to offer simple alternatives of scanf and printf for reading and displaying.
Example:
#include <stdio.h>
Void main()
{
Char line[30];
Gets (line);
Puts (line);
}
Key takeaway
There are some library functions which are available for transferring the information between the computer and the standard input and output devices.
C Library Functions
Library functions are the inbuilt function in C that are grouped and placed at a common place called the library. Such functions are used to perform some specific operations. For example, printf is a library function used to print on the console. The library functions are created by the designers of compilers. All C standard library functions are defined inside the different header files saved with the extension.h.
We need to include these header files in our program to make use of the library functions defined in such header files. For example, To use the library functions such as printf/scanf we need to include stdio.h in our program which is a header file that contains all the library functions regarding standard input/output.
The list of mostly used header files is given in the following table.
SN | Header file | Description |
1 | Stdio.h | This is a standard input/output header file. It contains all the library functions regarding standard input/output. |
2 | Conio.h | This is a console input/output header file. |
3 | String.h | It contains all string related library functions like gets(), puts(),etc. |
4 | Stdlib.h | This header file contains all the general library functions like malloc(), calloc(), exit(), etc. |
5 | Math.h | This header file contains all the math operations related functions like sqrt(), pow(), etc. |
6 | Time.h | This header file contains all the time-related functions. |
7 | Ctype.h | This header file contains all character handling functions. |
8 | Stdarg.h | Variable argument functions are defined in this header file. |
9 | Signal.h | All the signal handling functions are defined in this header file. |
10 | Setjmp.h | This file contains all the jump functions. |
11 | Locale.h | This file contains locale functions. |
12 | Errno.h | This file contains error handling functions. |
13 | Assert.h | This file contains diagnostics functions. |
Key takeaway
Library functions are the inbuilt function in C that are grouped and placed at a common place called the library. Such functions are used to perform some specific operations.
The two main aspects of C programming are algorithm and procedure.
Algorithm
The execution flow of a programme is defined by algorithms. It is a step-by-step procedure that provides a solution to the problem. The following is a typical logical assortment:
- Sequence
- Selection
- Iteration
- Case type statement
In C, "sequence statements" are essential, while "if then else" statements and case type statements like "switch statements" are used to make decisions. "while," "do-while," and "for" statements are iteration statements.
Pseudocodes
Pseudocodes are a slang term for an informal method of writing algorithms. It employs English-like terminology to represent algorithm steps. Before any novice grammar student begins coding and algorithm development, it is always advised that he or she completes the following: Write the pseudo code first because it helps you understand how the algorithm works. The following is a simple example of pseudocode:
If patient temperature is greater than 98 degree
Print “high fever”
Else
print “no fever”
Procedure
A procedure is a collection of code statements that describe an algorithm. A procedure is made up of assertions contained by a pair of {}. Some procedures added value to the programme construct called functions.
Program
A programme is a collection of explicit instructions written in a programming language. We need to offer some input data to the programme to get output once we have a programme as a solution to the problem.
The components above structure are:
A header file is a file with extension .h which contains C function declarations and macro definitions to be shared between several source files.
Some of C Header files:
- Stddef.h – Defines several useful types and macros.
- Stdint.h – Defines exact width integer types.
- Stdio.h – Defines core input and output functions
- Stdlib.h – Defines numeric conversion functions, pseudo-random network generator, memory allocation
- String.h – Defines string handling functions
- Math.h – Defines common mathematical functions
Main Method Declaration: The next part of a C program is to declare the main() function. The syntax to declare the main function is:
Syntax to Declare the main method:
Int main()
{}
Variable Declaration: The next part of any C program is the variable declaration. It refers to the variables that are to be used in the function. Please note that in the C program, no variable can be used without being declared. Also in a C program, the variables are to be declared before any operation in the function.
Example:
Int main()
{
Int a;
.
.
Body: The body of a function in the C program, refers to the operations that are performed in the functions. It can be anything like manipulations, searching, sorting, printing, etc.
Example:
int main()
{
Int a;
Printf("%d", a);
.
.
Return Statement: The last part of any C program is the return statement. The return statement refers to the returning of the values from a function. This return statement and return value depend upon the return type of the function.
For example, if the return type is void, then there will be no return statement. In any other case, there will be a return statement and the return value will be of the type of the specified return type.
Example:
Int main()
{
Int a;
Printf("%d", a);
Return 0;
}
Writing first program:
Following is first program in C
#include <stdio.h>
Int main(void)
Printf("GeeksQuiz");
Return 0;
}
Let us analyze the program line by line.
Line 1: [ #include <stdio.h> ] In a C program, all lines that start with # are processed by a preprocessor which is a program invoked by the compiler.
In a very basic term, the preprocessor takes a C program and produces another C program. The produced program has no lines starting with #, all such lines are processed by the preprocessor.
In the above example, the preprocessor copies the preprocessed code of stdio.h to our file. The .h files are called header files in C. These header files generally contain declarations of functions. We need stdio.h for the function printf() used in the program.
Line 2 [ int main(void)] There must be a starting point from where execution of compiled C program begins. In C, the execution typically begins with the first line of main(). The void written in brackets indicates that the main doesn’t take any parameter.
Main() can be written to take parameters also. The int was written before main indicates return type of main().
The value returned by main indicates the status of program termination.
Line 3 and 6: [ { and } ] In C language, a pair of curly brackets define scope and are mainly used in functions and control statements like if, else, loops. All functions must start and end with curly brackets.
Line 4 printf() is a standard library function to print something on standard output. The semicolon at the end of printf indicates line termination. In C, a semicolon is always used to indicate end of a statement.
Line 5 [ return 0; ] The return statement returns the value from main(). The returned value may be used by an operating system to know the termination status of your program. The value 0 typically means successful termination.
How to execute the above program:
In order to execute the above program, we need to have a compiler to compile and run our programs.
The abbreviation Vim stands for Vi IMproved. Bram Moolenaar created this free and open source text editor. It was first launched in 1991 for UNIX variations, with the primary purpose of improving the Vi editor, which was first released in 1976.
Vim is a clone of the Vi editor. It's a command-centric editor, just like Vi. One of the benefits of learning Vim is that it is portable. Vim is installed by default on any UNIX variation, including Linux, Mac, HP-UX, AIX, and many others. Vim has never had a graphical user interface, but there is now a separate installer called gVim that does.
Why Vim was Created
Vim is based on Bill Joy's original Vi editor, which he invented in 1976. Vi was falling behind in the 1990s, and there was a so-called editor war between Vi and Emacs. As a result, Bram added a slew of missing features that the Emacs community used to argue that Emacs was superior to Vi/Vim.
Features of Vim
Some of Vim's key features are discussed here.
● It has a small memory footprint.
● It's all about commands. With a few commands, you can do sophisticated text-related tasks.
● It is very configurable and stores its settings in a simple text file.
● There are numerous Vim plug-ins available. These plug-ins can greatly increase the usefulness of the system.
● Multiple windows are supported. This function allows you to split your screen into numerous windows.
● Multiple buffers are supported in the same way as multiple windows are.
● It has several tabs, allowing you to work on multiple files.
● It has recording capabilities, allowing you to record and play Vim commands repeatedly.
Vim modes
Vim has a variety of modes. This section goes over some of the key modes that will be used on a daily basis.
Command mode
This is Vim's default mode when it starts up. In this mode, we can type editor commands. In this mode, we can utilise a number of commands such as copy, paste, remove, replace, and many more.
Insert mode
This mode allows you to type or edit text. Press the I key to switch from default command to insert mode. The current mode will be displayed in the editor's bottom left corner.
Once we're in insert mode, we can type whatever we want. This is depicted in the graphic below.
To return to command mode from this mode, press the Escape key.
Command line mode
This mode is also where commands are entered. In this mode, commands begin with a colon (:). In the previous section, for example, the quit command was input in this manner. This mode can be accessed from either command or insert mode.
● Simply type colon to go from command mode to this mode.
● Press Escape and type colon to move from insert mode to this mode.
Visual mode
We may visually choose text and run commands on selected areas in this manner.
● Type v to switch from command to visual mode.
● To transition from any other mode to visual mode, press Escape to return to command mode, then type v to enter visual mode.
Visual mode is shown in the lower left corner of the image below.
Key takeaway
Vim is a clone of the Vi editor. It's a command-centric editor, just like Vi. One of the benefits of learning Vim is that it is portable. Vim is installed by default on any UNIX variation, including Linux, Mac, HP-UX, AIX, and many others.
Hello World Example
A C program basically consists of the following parts −
● Preprocessor Commands
● Functions
● Variables
● Statements & Expressions
● Comments
Let us look at a simple code that would print the words "Hello World" −
#include <stdio.h>
Int main() {
/* my first program in C */
Printf("Hello, World! \n");
Return 0;
}
Let us take a look at the various parts of the above program −
● The first line of the program #include <stdio.h> is a preprocessor command, which tells a C compiler to include stdio.h file before going to actual compilation.
● The next line int main() is the main function where the program execution begins.
● The next line /*...*/ will be ignored by the compiler and it has been put to add additional comments in the program. So such lines are called comments in the program.
● The next line printf(...) is another function available in C which causes the message "Hello, World!" to be displayed on the screen.
● The next line return 0; terminates the main() function and returns the value 0.
Compile and Execute C Program
Let us see how to save the source code in a file, and how to compile and run it. Following are the simple steps −
● Open a text editor and add the above-mentioned code.
● Save the file as hello.c
● Open a command prompt and go to the directory where you have saved the file.
● Type gcc hello.c and press enter to compile your code.
● If there are no errors in your code, the command prompt will take you to the next line and would generate a.out executable file.
● Now, type a.out to execute your program.
● You will see the output "Hello World" printed on the screen.
$ gcc hello.c
$ ./a.out
Hello, World!
Make sure the gcc compiler is in your path and that you are running it in the directory containing the source file hello.c.
The compilation is a process of converting the source code into object code. It is done with the help of the compiler. The compiler checks the source code for the syntactical or structural errors, and if the source code is error-free, then it generates the object code.
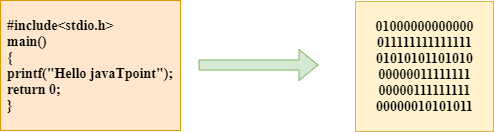
The c compilation process converts the source code taken as input into the object code or machine code. The compilation process can be divided into four steps, i.e., Pre-processing, Compiling, Assembling, and Linking.
The preprocessor takes the source code as an input, and it removes all the comments from the source code. The preprocessor takes the preprocessor directive and interprets it. For example, if <stdio.h>, the directive is available in the program, then the preprocessor interprets the directive and replace this directive with the content of the 'stdio.h' file.
The following are the phases through which our program passes before being transformed into an executable form:
● Preprocessor
● Compiler
● Assembler
● Linker
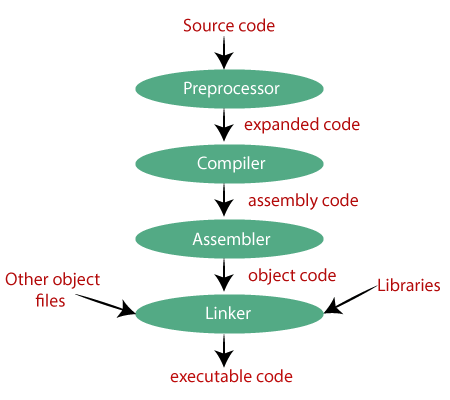
Preprocessor
The source code is the code which is written in a text editor and the source code file is given an extension ".c". This source code is first passed to the preprocessor, and then the preprocessor expands this code. After expanding the code, the expanded code is passed to the compiler.
Compiler
The code which is expanded by the preprocessor is passed to the compiler. The compiler converts this code into assembly code. Or we can say that the C compiler converts the pre-processed code into assembly code.
Assembler
The assembly code is converted into object code by using an assembler. The name of the object file generated by the assembler is the same as the source file. The extension of the object file in DOS is '.obj,' and in UNIX, the extension is 'o'. If the name of the source file is 'hello.c', then the name of the object file would be 'hello.obj'.
Linker
Mainly, all the programs written in C use library functions. These library functions are pre-compiled, and the object code of these library files is stored with '.lib' (or '.a') extension. The main working of the linker is to combine the object code of library files with the object code of our program. Sometimes the situation arises when our program refers to the functions defined in other files; then linker plays a very important role in this. It links the object code of these files to our program.
Therefore, we conclude that the job of the linker is to link the object code of our program with the object code of the library files and other files. The output of the linker is the executable file. The name of the executable file is the same as the source file but differs only in their extensions. In DOS, the extension of the executable file is '.exe', and in UNIX, the executable file can be named as 'a.out'. For example, if we are using printf() function in a program, then the linker adds its associated code in an output file.
Let's understand through an example.
Hello.c
- #include <stdio.h>
- Int main()
- {
- Printf("Hello javaTpoint");
- Return 0;
- }
Now, we will create a flow diagram of the above program:
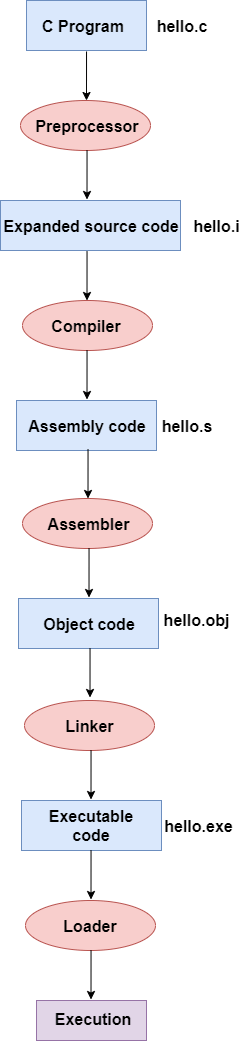
In the above flow diagram, the following steps are taken to execute a program:
● Firstly, the input file, i.e., hello.c, is passed to the preprocessor, and the preprocessor converts the source code into expanded source code. The extension of the expanded source code would be hello.i.
● The expanded source code is passed to the compiler, and the compiler converts this expanded source code into assembly code. The extension of the assembly code would be hello.s.
● This assembly code is then sent to the assembler, which converts the assembly code into object code.
● After the creation of an object code, the linker creates the executable file. The loader will then load the executable file for the execution.
Format specifiers in console formatted I/O functions
Some of the most commonly used format specifiers used in console formatted input/output functions are displayed in the table below -
Format Specifiers | Description |
%hi |
|
%hu |
|
%d |
|
%u |
|
%ld |
|
%lu |
|
%c |
|
%c |
|
%f |
|
%lf |
|
%Lf |
|
%s |
|
Optional specifiers within a format specifier
We could specify two more optional specifiers within each format specifier, such as integer value and a sign.
An integer value specifies the number of columns used on the screen for printing a value i.e. width. This integer value may or may not have a minus sign before it.
● A (-)minus sign before the integer value means left justification of the value to be printed on the screen and integer value following the minus sign is the number of blanks on its right.
● No minus sign before the integer value means right justification of the value to be printed on the screen and integer value specifies the number of blanks on its left.
The escape sequence, as the name suggests, is a scenario in which a character changes from its typical shape and signifies something other than its usual meaning. An escape sequence usually starts with a backslash " and then a character or characters. Any character followed by a " is interpreted by the c compiler as an escape sequence. Escape sequences are used to format the output text, however they are rarely visible on the screen. Each escape sequence has a predetermined purpose.
List of Escape Sequences in C
Escape Sequence | Meaning |
\a | Alarm or Beep |
\b | Backspace |
\f | Form Feed |
\n | New Line |
\r | Carriage Return |
\t | Tab (Horizontal) |
\v | Vertical Tab |
\\ | Backslash |
\' | Single Quote |
\" | Double Quote |
\? | Question Mark |
\nnn | Octal number |
\xhh | Hexadecimal number |
\0 | Null |
\a (Audible bell)
This is the escape sequence that generates a bell sound to indicate the program's completion. 013 is its ASCII value. The ASCII code for it is 007.
\b (BackSpace)
This is the backspace escape sequence. A word that comes before the letter b will be eliminated. The ASCII code for it is 008.
\f (Form Feed)
For a form feed, this escape sequence is used. 012 is its ASCII value.
\n (New Line)
It's used to start a new line and position the pointer on it. Words after the 'n' will be moved to a new line. The ASCII code for it is 010.
\r (Carriage Return)
This is the escape sequence that will place the cursor at the start of the line. 013 is its ASCII value.
\t (Horizontal Tab)
This is the horizontal tab's escape sequence. After 't,' words will be squeezed onto the same line, leaving some spaces. The ASCII code for it is 009.
\v (Vertical Tab)
This is where the vertical tab is printed. 011 is its ASCII value.
\\ (Back Slash)
The backslash is printed using this escape sequence (\). 092 is its ASCII value.
\’ (Printing single quotation)
The single quotation mark is printed using this escape sequence. 039 is its ASCII value.
\” (printing double quotation)
The single quotation mark is printed using this escape sequence. 034 is its ASCII value.
\? (Question Mark Sequence)
The question symbol (?) is printed using this escape sequence. 063 is its ASCII value.
\nnn (Print octal value)
This is used to print the equivalent octal value character.
\xhh(Print Hexadecimal value)
The hexadecimal value is printed using this sequence.
\0 (Null Value)
This is where a null value is printed. It has the ASCII code 000. The statement following 0 will be skipped.
Example
#include<stdio.h>
Int main(){
int number=50;
printf("You\nare\nlearning\n\'c\' language\n\"Do you know C language\"");
Return 0;
}
Output
You
Are
Learning
'c' language
"Do you know C language"
Key takeaway
The escape sequence, as the name suggests, is a scenario in which a character changes from its typical shape and signifies something other than its usual meaning.
Control structure is an important concept in high level programming languages. Control structures are the instruction or the group of instructions in the programming language which are responsible to determine the sequence of other instructions in the program.
Control structure is used for the reusability of the code. Control structure is useful when the program demands to repeatedly execute blocks of code for a specific number of times or till a certain condition is satisfied. Control structures can control the flow of execution of a program based on some conditions. Following are the advantages of using control structures in C language.
- Increases the reusability of the code
- Reduces complexity, improves clarity, and facilitates debugging and modifying
- Easy to define in flowcharts
- Increases programmer productivity.
- Control statements are also useful in the indentation of the program.
There are two types of control statements
Conditional Branching: In conditional branching decision point is based on the run time logic. Conditional branching makes use of both selection logic and iteration logic. In conditional branching flow of a program is transferred when the specified condition is satisfied.
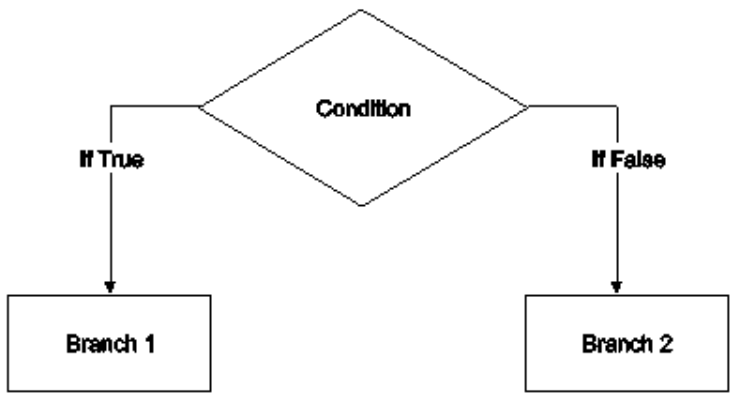
Fig: Flowchart for conditional branching
Unconditional Branching: In Unconditional branching flow of a program is transferred to a particular location without concerning the condition. Unconditional branching makes use of sequential logic. In unconditional branching flow of the program is transferred as per the instruction.
Conditional Branching
In conditional branching change in sequence of statement execution depends upon the specified condition. Conditional statements allow programmers to check a condition and execute certain parts of code depending on the result of conditional expression. Conditional expression must be resulted in Boolean value. In C language, there are two forms of conditional statements:
1. If-----else statement: It is used to select one option between two alternatives
2. Switch statement: It is used to select one option between multiple alternative
If Statements
This statement permits the programmer to allocate conditions on the execution of a statement. If the evaluated condition is found to be true, the single statement following the "if" is executed. If the condition is found to be false, the following statement is skipped.
Syntax of the if statement is as follows
If(condition)
{
Statement1;
Statement2;
}
In the above syntax, “if” is the keyword and condition in parentheses must evaluate to true or false. If the condition is satisfied (true) then the compiler will execute statement1 and then statement2. If the condition is not satisfied (false) then the compiler will skip statement1 and directly execute statement2.
If-------else statement;
This statement permits the programmer to execute a statement out of the two statements. If the evaluated condition is found to be true, the single statement following the "if" is executed and the statement following else is skipped. If the condition is found to be false, statement following the "if" is skipped and statement following else is executed.
In this statement “if” part is compulsory whereas “else” is the optional part. For every “if” statement there may be or may not be an “else” statement but for every “else” statement there must be an “if” part otherwise the compiler will give a “Misplaced else” error.
Flowchart of if statement in C

Let's see a simple example of C language if statement.
- #include<stdio.h>
- Int main(){
- Int number=0;
- Printf("Enter a number:");
- Scanf("%d",&number);
- If(number%2==0){
- Printf("%d is even number",number);
- }
- Return 0;
- }
Output
Enter a number:4
4 is even number
Enter a number:5
Program to find the largest number of the three.
- #include <stdio.h>
- Int main()
- {
- Int a, b, c;
- Printf("Enter three numbers?");
- Scanf("%d %d %d",&a,&b,&c);
- If(a>b && a>c)
- {
- Printf("%d is largest",a);
- }
- If(b>a && b > c)
- {
- Printf("%d is largest",b);
- }
- If(c>a && c>b)
- {
- Printf("%d is largest",c);
- }
- If(a == b && a == c)
- {
- Printf("All are equal");
- }
- }
Output
Enter three numbers?
12 23 34
34 is largest
If-else Statement
The if-else statement is used to perform two operations for a single condition. The if-else statement is an extension to the if statement using which, we can perform two different operations, i.e., one is for the correctness of that condition, and the other is for the incorrectness of the condition. Here, we must notice that if and else block cannot be executed simultaneously. Using if-else statement is always preferable since it always invokes an otherwise case with every if condition. The syntax of the if-else statement is given below.
- If(expression){
- //code to be executed if condition is true
- }else{
- //code to be executed if condition is false
- }
Flowchart of the if-else statement in C
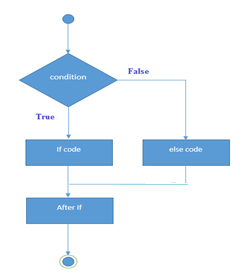
Let's see the simple example to check whether a number is even or odd using if-else statement in C language.
- #include<stdio.h>
- Int main(){
- Int number=0;
- Printf("enter a number:");
- Scanf("%d",&number);
- If(number%2==0){
- Printf("%d is even number",number);
- }
- Else{
- Printf("%d is odd number",number);
- }
- Return 0;
- }
Output
Enter a number:4
4 is even number
Enter a number:5
5 is odd number
Program to check whether a person is eligible to vote or not.
- #include <stdio.h>
- Int main()
- {
- Int age;
- Printf("Enter your age?");
- Scanf("%d",&age);
- If(age>=18)
- {
- Printf("You are eligible to vote...");
- }
- Else
- {
- Printf("Sorry ... you can't vote");
- }
- }
Output
Enter your age?18
You are eligible to vote...
Enter your age?13
Sorry ... You can't vote
Nested if----else statements:
Nested “if-----else” statements are used when a programmer wants to check multiple conditions. Nested “if---else” contains several “if---else” statements, out of which only one statement is executed. Number of “if----else” statements is equal to the number of conditions to be checked. Following is the syntax for nested “if---else” statements for three conditions
If (condition1)
Statement1;
Else if (condition2)
Statement2;
Else if (condition3)
Statement3;
Else
Statement4;
In the above syntax, the compiler first checks condition1, if it tries then it will execute statement1 and skip all the remaining statements. If condition1 is false then compiler directly checks condition2, if it is true then compiler execute statement2 and skip all the remaining statements. If condition2 is also false then compiler directly checks condition3, if it is true then compiler execute statement3 otherwise it will execute statement 4.
Note:
If the test expression is evaluated to true,
- Statements inside the body of if are executed.
- Statements inside the body of else are skipped from execution.
If the test expression is evaluated to false,
- Statements inside the body of else are executed
- Statements inside the body of if are skipped from execution.
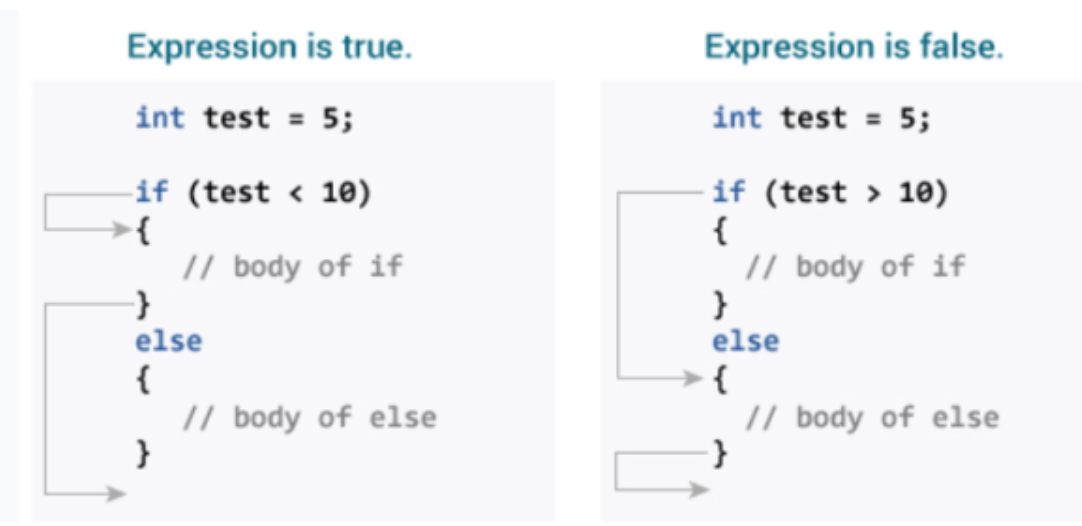
Flowchart of else-if ladder statement in C

The example of an if-else-if statement in C language is given below.
- #include<stdio.h>
- Int main(){
- Int number=0;
- Printf("enter a number:");
- Scanf("%d",&number);
- If(number==10){
- Printf("number is equals to 10");
- }
- Else if(number==50){
- Printf("number is equal to 50");
- }
- Else if(number==100){
- Printf("number is equal to 100");
- }
- Else{
- Printf("number is not equal to 10, 50 or 100");
- }
- Return 0;
- }
Output
Enter a number:4
Number is not equal to 10, 50 or 100
Enter a number:50
Number is equal to 50
Program to calculate the grade of the student according to the specified marks.
- #include <stdio.h>
- Int main()
- {
- Int marks;
- Printf("Enter your marks?");
- Scanf("%d",&marks);
- If(marks > 85 && marks <= 100)
- {
- Printf("Congrats ! you scored grade A ...");
- }
- Else if (marks > 60 && marks <= 85)
- {
- Printf("You scored grade B + ...");
- }
- Else if (marks > 40 && marks <= 60)
- {
- Printf("You scored grade B ...");
- }
- Else if (marks > 30 && marks <= 40)
- {
- Printf("You scored grade C ...");
- }
- Else
- {
- Printf("Sorry you are fail ...");
- }
- }
Output
Enter your marks?10
Sorry you have failed ...
Enter your marks?40
You scored grade C ...
Enter your marks?90
Congrats! you scored grade A ...
// Check whether an integer is odd or even
#include <stdio.h>
Int main() {
Int number;
Printf("Enter an integer: ");
Scanf("%d", &number);
// True if the remainder is 0
If (number%2 == 0) {
Printf("%d is an even integer.",number);
}
Else {
Printf("%d is an odd integer.",number);
}
Return 0;
}
Program to relate two integers using =, > or < symbol
#include <stdio.h>
Int main() {
Int number1, number2;
Printf("Enter two integers: ");
Scanf("%d %d", &number1, &number2);
//checks if the two integers are equal.
If(number1 == number2) {
Printf("Result: %d = %d",number1,number2);
}
//checks if number1 is greater than number2.
Else if (number1 > number2) {
Printf("Result: %d > %d", number1, number2);
}
//checks if both test expressions are false
Else {
Printf("Result: %d < %d",number1, number2);
}
Return 0;
}
Switch Statement
The switch statement in C is an alternate to if-else-if ladder statement which allows us to execute multiple operations for the different possible values of a single variable called switch variable. Here, we can define various statements in the multiple cases for the different values of a single variable.
The syntax of switch statement is given below:
- Switch(expression){
- Case value1:
- //code to be executed;
- Break; //optional
- Case value2:
- //code to be executed;
- Break; //optional
- ......
- Default:
- Code to be executed if all cases are not matched;
- }
Rules for switch statement in C language
1) The switch expression must be of an integer or character type.
2) The case value must be an integer or character constant.
3) The case value can be used only inside the switch statement.
4) The break statement in switch case is not must. It is optional. If there is no break statement found in the case, all the cases will be executed present after the matched case. It is known as fall through the state of C switch statement.
Let's try to understand it by the examples. We are assuming that there are following variables.
- Int x,y,z;
- Char a,b;
- Float f;
Valid Switch | Invalid Switch | Valid Case | Invalid Case |
Switch(x) | Switch(f) | Case 3; | Case 2.5; |
Switch(x>y) | Switch(x+2.5) | Case 'a'; | Case x; |
Switch(a+b-2) |
| Case 1+2; | Case x+2; |
Switch(func(x,y)) |
| Case 'x'>'y'; | Case 1,2,3; |
Flowchart of switch statement in C
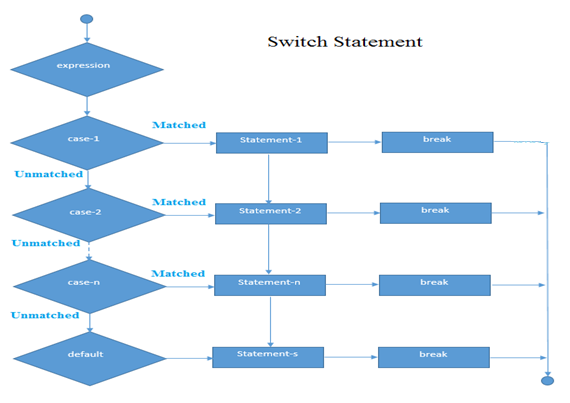
Functioning of switch case statement
First, the integer expression specified in the switch statement is evaluated. This value is then matched one by one with the constant values given in the different cases. If a match is found, then all the statements specified in that case are executed along with the all the cases present after that case including the default statement. No two cases can have similar values.
If the matched case contains a break statement, then all the cases present after that will be skipped, and the control comes out of the switch. Otherwise, all the cases following the matched case will be executed.
Let's see a simple example of c language switch statement.
- #include<stdio.h>
- Int main(){
- Int number=0;
- Printf("enter a number:");
- Scanf("%d",&number);
- Switch(number){
- Case 10:
- Printf("number is equals to 10");
- Break;
- Case 50:
- Printf("number is equal to 50");
- Break;
- Case 100:
- Printf("number is equal to 100");
- Break;
- Default:
- Printf("number is not equal to 10, 50 or 100");
- }
- Return 0;
- }
Output
Enter a number:4
Number is not equal to 10, 50 or 100
Enter a number:50
Number is equal to 50
Switch case example 2
- #include <stdio.h>
- Int main()
- {
- Int x = 10, y = 5;
- Switch(x>y && x+y>0)
- {
- Case 1:
- Printf("hi");
- Break;
- Case 0:
- Printf("bye");
- Break;
- Default:
- Printf(" Hello bye ");
- }
- }
Output
Hi
Example:
Program to spell user entered single digit number in English is as follows
#include<stdio.h>
#include<conio.h>
Void main()
{
Int n;
Clrscr();
Printf(“Enter a number”);
Scanf(“%d”, &n);
Switch(n)
{
Case 0: printf(“\n Zero”);
Break;
Case 1: printf(“\n One”);
Break;
Case 2: printf(“\n Two”);
Break;
Case 3: printf(“\n Three”);
Break;
Case 4: printf(“\n Four”);
Break;
Case 5: printf(“\n Five”);
Break;
Case 6: printf(“\n Six”);
Break;
Case 7: printf(“\n Seven”);
Break;
Case 8: printf(“\n Eight”);
Break;
Case 9: printf(“\n Nine”);
Break;
Default : printf(“Given number is not single digit number”);
Break;
}
Getch();
}
Output
Enter a number
5
Five
C Switch statement is fall-through
In C language, the switch statement is fall through; it means if you don't use a break statement in the switch case, all the cases after the matching case will be executed.
Let's try to understand the fall through state of switch statement by the example given below.
- #include<stdio.h>
- Int main(){
- Int number=0;
- Printf("enter a number:");
- Scanf("%d",&number);
- Switch(number){
- Case 10:
- Printf("number is equal to 10\n");
- Case 50:
- Printf("number is equal to 50\n");
- Case 100:
- Printf("number is equal to 100\n");
- Default:
- Printf("number is not equal to 10, 50 or 100");
- }
- Return 0;
- }
Output
Enter a number:10
Number is equal to 10
Number is equal to 50
Number is equal to 100
Number is not equal to 10, 50 or 100
Nested switch case statement
We can use as many switch statement as we want inside a switch statement. Such type of statements is called nested switch case statements. Consider the following example.
- #include <stdio.h>
- Int main () {
- Int i = 10;
- Int j = 20;
- Switch(i) {
- Case 10:
- Printf("the value of i evaluated in outer switch: %d\n",i);
- Case 20:
- Switch(j) {
- Case 20:
- Printf("The value of j evaluated in nested switch: %d\n",j);
- }
- }
- Printf("Exact value of i is : %d\n", i );
- Printf("Exact value of j is : %d\n", j );
- Return 0;
- }
Output
The value of i evaluated in outer switch: 10
The value of j evaluated in nested switch: 20
Exact value of i is: 10
Exact value of j is: 20
References:
1. The C Programming Language - By Brian W Kernighan and Dennis Ritchie
2. C programming in an open source paradigm:– By R. K. Kamat, K . S. Oza, S.R. Patil
3. The GNU C Programming Tutorial ‐By Mark Burgess
4. Let us C- By Yashwant Kanetkar




