Unit - 2
Structured Query Language (SQL)
In order to describe the values that a column can hold, SQL Datatype is used.
Each column is needed in the database table to have a name and data type.
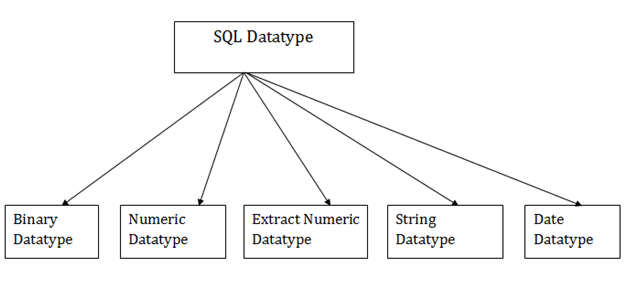
Fig 1: SQL data types
- Binary data types
Three kinds of binary data types are given below:
Data type | Description |
Binary | It has a fixed byte length of 8000. It includes binary data of fixed-length. |
Varbinary | It has a fixed byte length of 8000. It includes binary data of variable-length. |
Image | It has a maximum of 2,147,483,647 bytes in length. It includes binary data of variable-length. |
2. Numeric data types
The subtypes are given below:
Data type | From | To | Description |
Float | -1.79E + 308 | 1.79E + 308 | Used to specify a floating-point value |
Real | -3.40e + 38 | 3.40E + 38 | Specifies a single precision floating point number |
3. Extract numeric data types
The subtypes are given below:
Data types | Description |
Int | Used to specify an integer value. |
Smallint | Used to specify small integer value |
Bit | Number of bits to store. |
Decimal | Numeric value that can have a decimal number |
Numeric | Used to specify a numeric value |
4. Character String data types
Data types | Description |
Char | It contains Fixed-length (max - 8000 character) |
Varchar | It contains variable-length (max - 8000 character) |
Text | It contains variable-length (max - 2,147,483,647 character) |
5. Date and Time data types
Data types | Description |
Date | Used to store the year, month, and days value. |
Time | Used to store the hour, minute, and second values. |
Timestamp | Stores the year, month, day, hour, minute, and the second value. |
Constraints are rules that can be applied to a table's data type. That is, we may use constraints to limit the type of data that can be recorded in a specific column in a table.
Constraints set restrictions on how much and what kind of data can be inserted, modified, and deleted from a table. Constraints are used to ensure data integrity during an update, removal, or insert into a table.
Primary key
The primary key is a field that uniquely identifies each table row. If a column in a table is designated as a primary key, it cannot include NULL values, and all rows must have unique values for this field. To put it another way, this is a combination of NOT NULL and UNIQUE constraints.
The ROLL NO field is marked as primary key in the example below, which means it cannot contain duplicate or null entries.
CREATE TABLE STUDENT(
ROLL_NO INT NOT NULL,
STU_NAME VARCHAR (35) NOT NULL UNIQUE,
STU_AGE INT NOT NULL,
STU_ADDRESS VARCHAR (35) UNIQUE,
PRIMARY KEY (ROLL_NO)
);
Foreign key
A foreign key differs from a super key, candidate key, or primary key in that it is used to join two tables or link them together.
A foreign key is a secondary key that connects two tables via the primary key. It signifies that one table's columns point to the other table's primary key attribute. It also means that any attribute set as a primary key attribute will serve as a foreign key attribute in another table. A foreign key, on the other hand, has nothing to do with the primary key.
A Foreign Key column establishes a connection between two tables. Foreign keys are used to guarantee data integrity while also allowing navigation between two different instances of the same entity. It functions as a cross-reference between two tables since it refers to another table's main key.
Example
DeptCode | DeptName |
1 | Computer |
2 | Science |
3 | English |
TeacherID | Fname | Lname |
T007 | Sara | Choubey |
T019 | David | Chopda |
T004 | Raj | Sharma |
We have two tables in this key in dbms example, teach and department in a school. There is, however, no way to see which searches are used in which departments.
We may construct a relationship between the two tables in this table by adding the foreign key in DeptCode to the Teacher name.
TeacherID | DeptCode | Fname | Lname |
T007 | 1 | Sara | Choubey |
T019 | 2 | David | Chopda |
T004 | 3 | Raj | Sharma |
This concept is also known as Referential Integrity.
Null
The NOT NULL constraint ensures that no NULL values are stored in a column. When we don't specify a value for a field when inserting a record into a table, the column defaults to NULL. We can ensure that a certain column(s) cannot have NULL values by specifying a NULL constraint.
Example:
CREATE TABLE STUDENT(
ROLL_NO INT NOT NULL,
STU_NAME VARCHAR (35) NOT NULL,
STU_AGE INT NOT NULL,
STU_ADDRESS VARCHAR (235),
PRIMARY KEY (ROLL_NO)
);
Check
This constraint is used to specify a table's range of values for a certain column. When this constraint is applied to a column, it assures that the value of the specified column must be inside the provided range.
CREATE TABLE STUDENT(
ROLL_NO INT NOT NULL CHECK(ROLL_NO >1000) ,
STU_NAME VARCHAR (35) NOT NULL,
STU_AGE INT NOT NULL,
EXAM_FEE INT DEFAULT 10000,
STU_ADDRESS VARCHAR (35) ,
PRIMARY KEY (ROLL_NO)
);
The check constraint on the ROLL NO column of the STUDENT database was set in the preceding example. The value of the ROLL NO field must now be bigger than 1000.
Default
When no value is provided when inserting a record into a table, the DEFAULT constraint assigns a default value to the field.
Example
The following SQL, for example, creates a new table called CUSTOMERS and adds five fields to it. The SALARY column is set to 5000.00 by default in this situation, so if the INSERT INTO statement does not supply a value for this column, it will be set to 5000.00 by default.
CREATE TABLE CUSTOMERS(
ID INT NOT NULL,
NAME VARCHAR (20) NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR (25) ,
SALARY DECIMAL (18, 2) DEFAULT 5000.00,
PRIMARY KEY (ID)
);
If the CUSTOMERS table has already been established, you'll need to perform a query similar to the one shown in the code block below to add a DEFAULT constraint to the SALARY column.
ALTER TABLE CUSTOMERS
MODIFY SALARY DECIMAL (18, 2) DEFAULT 5000.00;
Drop Default Constraint
Use the SQL statement below to remove a DEFAULT constraint.
ALTER TABLE CUSTOMERS
ALTER COLUMN SALARY DROP DEFAULT;
Key takeaway
- Constraints are rules that can be applied to a table's data type. That is, we may use constraints to limit the type of data that can be recorded in a specific column in a table.
- The primary key is a field that uniquely identifies each table row.
- A foreign key is a table field that uniquely identifies each row of a different table.
Select
The SELECT statement is used in the database to select / retrieve data from a table. The most frequently used statement is the SQL Pick Statement.
The SELECT Statement question retrieves data from the table as a whole or from some particular columns.
We need to write SELECT statement queries in SQL if we want to retrieve any data from a table.
We retrieve the data by columns in SELECT Statement wise.
Syntax
The SQL SELECT Syntax categorizes into two sections, first we get complete table data from all columns, second we get some unique columns from a table.
SELECT all Columns data from a table
SELECT * FROM table_name;
* = indicate the retrieve all the columns from a table.
Table_name = is the name of table from which the data is retrieved.
SELECT some columns data from a table
SELECT Col1, Col2, Col3 FROM table_name
Col1, Col2, Col3 = is the column name from which data is retrieved.
Table_name = is the name of table from which the data is retrieved.
A SELECT command has number of clauses:
- WHERE clause: Any output row from the FROM stage applies a criterion, further reducing the number of rows.
- GROUP BY clause: Class sets of rows with values balanced by columns in a group.
- HAVING clause: Criteria for each group of rows are added. Criteria can only be extended to columns within a category that have constant values (those in the grouping columns or aggregate functions applied across the group).
- ORDER BY clause: The rows returned from the SELECT stage are sorted as desired. Supports sorting, ascending or descending on multiple columns in a specified order. The output columns will be similar and have the same name as the columns returned from the SELECT point.
- INTO clause: Logically, the INTO clause is last used in processing.
Key takeaway:
The SELECT statement is used in the database to select / retrieve data from a table. We retrieve the data by columns in SELECT Statement wise.
The SELECT Statement question retrieves data from the table as a whole or from some particular columns.
Where
When collecting data from a single table or merging many tables, the SQL WHERE clause is used to set a condition. Only a specific value from the table is returned if the stated condition is met. To filter the records and retrieve only the ones you need, use the WHERE clause.
The WHERE clause is utilized not just in the SELECT statement, but also in the UPDATE, DELETE, and other statements.
Syntax
The SELECT statement with the WHERE clause has the following basic syntax.
SELECT column1, column2, columnN
FROM table_name
WHERE [condition]
You can use comparison or logical operators like >, =, LIKE, NOT, etc. to describe a condition.
Example
Consider the following records in the CUSTOMERS table:
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
| 7 | Muffy | 24 | Indore | 10000.00 |
+----+----------+-----+-----------+----------+
The following code retrieves the ID, Name, and Salary fields from the CUSTOMERS database, where the salary is larger than 2000 dollars.
SQL> SELECT ID, NAME, SALARY
FROM CUSTOMERS
WHERE SALARY > 2000;
This would result in the following:
+----+----------+----------+
| ID | NAME | SALARY |
+----+----------+----------+
| 4 | Chaitali | 6500.00 |
| 5 | Hardik | 8500.00 |
| 6 | Komal | 4500.00 |
| 7 | Muffy | 10000.00 |
+----+----------+----------+
The following query, for example, would retrieve the ID, Name, and Salary fields for a client named Hardik from the CUSTOMERS table.
It's vital to remember that all strings should be enclosed in single quotes ("). Numeric values, on the other hand, should be presented without any quotation marks, like in the example above.
SQL> SELECT ID, NAME, SALARY
FROM CUSTOMERS
WHERE NAME = 'Hardik';
This would result in the following:
+----+----------+----------+
| ID | NAME | SALARY |
+----+----------+----------+
| 5 | Hardik | 8500.00 |
+----+----------+----------+
Group by
What is the SQL Group by Clause?
The GROUP BY clause is a SQL command that is used to group rows that have the same values. The GROUP BY clause is used in the SELECT statement. Optionally it is used in conjunction with aggregate functions to produce summary reports from the database.
That's what it does, summarizing data from the database.
The queries that contain the GROUP BY clause are called grouped queries and only return a single row for every grouped item.
SQL GROUP BY Syntax
Now that we know what the SQL GROUP BY clause is, let's look at the syntax for a basic group by query.
SELECT statements... GROUP BY column_name1[,column_name2,...] [HAVING condition];
HERE
● "SELECT statements..." is the standard SQL SELECT command query.
● "GROUP BYcolumn_name1" is the clause that performs the grouping based on column_name1.
● "[,column_name2,...]" is optional; represents other column names when the grouping is done on more than one column.
● "[HAVING condition]" is optional; it is used to restrict the rows affected by the GROUP BY clause. It is similar to the WHERE clause.
Grouping using a Single Column
In order to help understand the effect of SQL Group By clause, let's execute a simple query that returns all the gender entries from the member’s table.
SELECT gender FROM members;
Gender |
Female |
Female |
Male |
Female |
Male |
Male |
Male |
Male |
Male |
Suppose we want to get the unique values for genders. We can use a following query -
SELECT gender FROM members GROUP BY gender;
Executing the above script in MYSQL workbench against the Myflixdb gives us the following results.
Gender |
Female |
Male |
Note only two results have been returned. This is because we only have two gender types Male and Female. The GROUP BY clause in SQL grouped all the "Male" members together and returned only a single row for it. It did the same with the "Female" members.
Grouping using multiple columns
Suppose that we want to get a list of movie category_id and corresponding years in which they were released.
Let's observe the output of this simple query
SELECT category_id,year_released FROM movies;
Category_id | Year_released |
1 | 2011 |
2 | 2008 |
NULL | 2008 |
NULL | 2010 |
8 | 2007 |
6 | 2007 |
6 | 2007 |
8 | 2005 |
NULL | 2012 |
7 | 1920 |
8 | NULL |
8 | 1920 |
The above result has many duplicates.
Let's execute the same query using group by in SQL -
SELECT category_id,year_released FROM movies GROUP BY category_id,year_released;
Executing the above script in MySQL workbench against the myflixdb gives us the following results shown below.
Category_id | Year_released |
NULL | 2008 |
NULL | 2010 |
NULL | 2012 |
1 | 2011 |
2 | 2008 |
6 | 2007 |
7 | 1920 |
8 | 1920 |
8 | 2005 |
8 | 2007 |
The GROUP BY clause operates on both the category id and year released to identify unique rows in our above example.
If the category id is the same but the year released is different, then a row is treated as a unique one. If the category id and the year released is the same for more than one row, then it's considered a duplicate and only one row is shown.
Order by
The SQL ORDER BY clause is used to sort data by one or more columns in ascending or descending order. By default, some databases sort query results in ascending order.
Syntax
The ORDER BY clause's basic grammar is as follows:
SELECT column-list
FROM table_name
[WHERE condition]
[ORDER BY column1, column2, .. ColumnN] [ASC | DESC];
In the ORDER BY clause, you can utilize more than one column. Make sure that whichever column you're using to sort is included in the column-list.
Example
Consider the following records in the CUSTOMERS table:
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
| 7 | Muffy | 24 | Indore | 10000.00 |
+----+----------+-----+-----------+----------+
The following code block shows an example of sorting the results by NAME and SALARY in ascending order.
SQL> SELECT * FROM CUSTOMERS
ORDER BY NAME, SALARY;
This would result in the following:
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
| 7 | Muffy | 24 | Indore | 10000.00 |
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
+----+----------+-----+-----------+----------+
An operator is a reserved word or character that is used in the WHERE clause of a SQL statement to perform operations like comparisons and arithmetic operations. These Operators are used to define conditions in SQL statements and to function as conjunctions for multiple conditions in a single statement.
● Arithmetic operators
● Comparison operators
● Logical operators
● Operators used to negate conditions
Logical
Assume that 'variable a' and 'variable b' exist. In this case, 'a' has 20 and 'b' has 10.
Sr.No | Operator & Description |
1 | ALL When a value is compared to all of the values in another value set, the ALL operator is used. |
2 | AND The AND operator allows multiple conditions to occur in the WHERE clause of a SQL statement. |
3 | ANY The ANY operator compares a value to any valid value in the list according to the condition. |
4 | BETWEEN The BETWEEN operator is used to find values that are between the minimum and maximum values in a set of values. |
5 | EXISTS The EXISTS operator is used to look for a row in a given table that meets a certain set of criteria. |
6 | IN When a value is compared to a list of literal values that have been defined, the IN operator is used. |
7 | LIKE The LIKE operator compares a value to other values that are identical using wildcard operators. |
8 | NOT The NOT operator flips the definition of the logical operator it's used with. For example, NOT EXISTS, NOT BETWEEN, NOT IN, and so on. It's a negation operator. |
9 | OR The OR operator is used in the WHERE clause of a SQL statement to combine several conditions. |
10 | IS NULL When a value is compared to a NULL value, the NULL operator is used. |
11 | UNIQUE The UNIQUE operator looks for uniqueness in every row of a table (no duplicates). |
Relational
When two expressions or values are compared, a Boolean result is returned. The table below lists all of the relational operations that PL/SQL supports. Assume variable A contains 10 and variable B contains 20, then
Operator | Description | Example |
= | Checks whether the values of two operands are equal, and if they are, the condition is true. | (A = B) is not true. |
!= <> ~= | Checks whether the values of two operands are equivalent; if they aren't, the condition is true.
| (A != B) is true. |
> | If the left operand's value is greater than the right operand's value, the condition becomes true. | (A > B) is not true. |
< | If the value of the left operand is less than the value of the right operand, the condition is satisfied. | (A < B) is true. |
>= | If the left operand's value is larger than or equal to the right operand's value, the condition becomes true. | (A >= B) is not true. |
<= | If the left operand's value is less than or equal to the right operand's value, then the condition is true. | (A <= B) is true |
Special - In
IN operator
The IN operator allows you to specify two or more expressions to use in a query search. If the value of the corresponding column equals one of the phrases indicated by the IN predicate, the condition is true.
Syntax:
SELECT column_name(s)
FROM table_name
WHERE column_name IN (list_of_values);
Between
The BETWEEN operator gives a range that sets the qualifying values' bottom and upper bounds. This operator combines the and and operators. A range of values larger than or equal to 5000 and less than or equal to 20000 has been chosen as the data. Numeric, text, and date data types can all be used with the Between operator.
Syntax:
SELECT column_name(s)
FROM table_name
WHERE column_name BETWEEN value1 AND value2;
Like
LIKE is a comparison operator that compares column values to a pattern. Regular characters must match the characters supplied in the character string exactly during pattern matching. Any character or date data type can be used in the column. Wildcard characters are characters that can be used anywhere in the pattern. I utilized four different forms of wildcards:
- Percent sign (%): It is used to represent or search any string of zero or more characters.
- Underscore (_): It is used to represent or search a single character.
- Bracket ([]): It is used to represent or search any single character within the specified range.
- Caret (^): It is used to represent or search any single character not within the specified range.
Syntax:
SELECT *
FROM users
WHERE first_name LIKE ‘%Bob%’;
Key takeaway
An operator is a reserved word or character that is used in the WHERE clause of a SQL statement to perform operations like comparisons and arithmetic operations.
A Subquery is a query within another SQL query and embedded within the WHERE clause.
Important Rule:
● A subquery can be placed in a number of SQL clauses like WHERE clause, FROM clause, HAVING clause.
● You can use Subquery with SELECT, UPDATE, INSERT, DELETE statements along with the operators like =, <, >, >=, <=, IN, BETWEEN, etc.
● A subquery is a query within another query. The outer query is known as the main query, and the inner query is known as a subquery.
● Subqueries are on the right side of the comparison operator.
● A subquery is enclosed in parentheses.
● In the Subquery, ORDER BY command cannot be used. But GROUP BY command can be used to perform the same function as ORDER BY command.
1. Subqueries with the Select Statement
SQL subqueries are most frequently used with the Select statement.
Syntax
- SELECT column_name
- FROM table_name
- WHERE column_name expression operator
- ( SELECT column_name from table_name WHERE ... );
Example
Consider the EMPLOYEE table have the following records:
ID | NAME | AGE | ADDRESS | SALARY |
1 | John | 20 | US | 2000.00 |
2 | Stephan | 26 | Dubai | 1500.00 |
3 | David | 27 | Bangkok | 2000.00 |
4 | Alina | 29 | UK | 6500.00 |
5 | Kathrin | 34 | Bangalore | 8500.00 |
6 | Harry | 42 | China | 4500.00 |
7 | Jackson | 25 | Mizoram | 10000.00 |
The subquery with a SELECT statement will be:
- SELECT *
- FROM EMPLOYEE
- WHERE ID IN (SELECT ID
- FROM EMPLOYEE
- WHERE SALARY > 4500);
This would produce the following result:
ID | NAME | AGE | ADDRESS | SALARY |
4 | Alina | 29 | UK | 6500.00 |
5 | Kathrin | 34 | Bangalore | 8500.00 |
7 | Jackson | 25 | Mizoram | 10000.00 |
2. Subqueries with the INSERT Statement
● SQL subquery can also be used with the Insert statement. In the insert statement, data returned from the subquery is used to insert into another table.
● In the subquery, the selected data can be modified with any of the character and date functions.
Syntax:
- INSERT INTO table_name (column1, column2, column3....)
- SELECT *
- FROM table_name
- WHERE VALUE OPERATOR
Example
Consider a table EMPLOYEE_BKP with similar as EMPLOYEE.
Now use the following syntax to copy the complete EMPLOYEE table into the EMPLOYEE_BKP table.
- INSERT INTO EMPLOYEE_BKP
- SELECT * FROM EMPLOYEE
- WHERE ID IN (SELECT ID
- FROM EMPLOYEE);
3. Subqueries with the UPDATE Statement
The subquery of SQL can be used in conjunction with the Update statement. When a subquery is used with the Update statement, then either single or multiple columns in a table can be updated.
Syntax
- UPDATE table
- SET column_name = new_value
- WHERE VALUE OPERATOR
- (SELECT COLUMN_NAME
- FROM TABLE_NAME
- WHERE condition);
Example
Let's assume we have an EMPLOYEE_BKP table available which is backup of EMPLOYEE table. The given example updates the SALARY by .25 times in the EMPLOYEE table for all employee whose AGE is greater than or equal to 29.
- UPDATE EMPLOYEE
- SET SALARY = SALARY * 0.25
- WHERE AGE IN (SELECT AGE FROM CUSTOMERS_BKP
- WHERE AGE >= 29);
This would impact three rows, and finally, the EMPLOYEE table would have the following records.
ID | NAME | AGE | ADDRESS | SALARY |
1 | John | 20 | US | 2000.00 |
2 | Stephan | 26 | Dubai | 1500.00 |
3 | David | 27 | Bangkok | 2000.00 |
4 | Alina | 29 | UK | 1625.00 |
5 | Kathrin | 34 | Bangalore | 2125.00 |
6 | Harry | 42 | China | 1125.00 |
7 | Jackson | 25 | Mizoram | 10000.00 |
4. Subqueries with the DELETE Statement
The subquery of SQL can be used in conjunction with the Delete statement just like any other statements mentioned above.
Syntax
- DELETE FROM TABLE_NAME
- WHERE VALUE OPERATOR
- (SELECT COLUMN_NAME
- FROM TABLE_NAME
- WHERE condition);
Example
Let's assume we have an EMPLOYEE_BKP table available which is backup of EMPLOYEE table. The given example deletes the records from the EMPLOYEE table for all EMPLOYEE whose AGE is greater than or equal to 29.
- DELETE FROM EMPLOYEE
- WHERE AGE IN (SELECT AGE FROM EMPLOYEE_BKP
- WHERE AGE >= 29 );
This would impact three rows, and finally, the EMPLOYEE table would have the following records.
ID | NAME | AGE | ADDRESS | SALARY |
1 | John | 20 | US | 2000.00 |
2 | Stephan | 26 | Dubai | 1500.00 |
3 | David | 27 | Bangkok | 2000.00 |
7 | Jackson | 25 | Mizoram | 10000.00 |
Key takeaway
A Subquery is a query within another SQL query and embedded within the WHERE clause.
Important Rule:
● A subquery can be placed in a number of SQL clauses like WHERE clause, FROM clause, HAVING clause.
● You can use Subquery with SELECT, UPDATE, INSERT, DELETE statements along with the operators like =, <, >, >=, <=, IN, BETWEEN, etc.
● A subquery is a query within another query. The outer query is known as the main query, and the inner query is known as a subquery.
● Subqueries are on the right side of the comparison operator.
● A subquery is enclosed in parentheses.
● In the Subquery, ORDER BY command cannot be used. But GROUP BY command can be used to perform the same function as ORDER BY command.
A subquery can be rebuilt as a JOIN in many circumstances, but not all.
Rewriting Subqueries as JOINS
The DISTINCT keyword can be used to rewrite a subquery that uses IN, for example:
SELECT * FROM table1 WHERE col1 IN (SELECT col1 FROM table2);
Can be rephrased as:
SELECT DISTINCT table1.* FROM table1, table2 WHERE table1.col1=table2.col1;
You can also rewrite NOT IN or NOT EXISTS queries. These two queries, for example, yield the same result:
SELECT * FROM table1 WHERE col1 NOT IN (SELECT col1 FROM table2);
SELECT * FROM table1 WHERE NOT EXISTS (SELECT col1 FROM table2 WHERE table1.col1=table2.col1);
Both of which can be rewritten as:
SELECT table1.* FROM table1 LEFT JOIN table2 ON table1.id=table2.id WHERE table2.id IS NULL;
Sometimes, subqueries that can be rebuilt as an LEFT JOIN are more efficient.
Using Subqueries instead of JOINS
However, there are some situations when subqueries are preferable to joins:
● When you need duplicates but not bogus ones. Assume Table 1 has three rows numbered 1,1,2 and Table 2 contains two rows numbered 1,2,2. Only this subquery-based SELECT statement will give you the correct result (1,1,2) if you need to list the rows in Table 1 that are also in Table 2:
SELECT Table_1.column_1
FROM Table_1
WHERE Table_1.column_1 IN
(SELECT Table_2.column_1
FROM Table_2);
This SQL statement is incorrect:
SELECT Table_1.column_1
FROM Table_1,Table_2
WHERE Table_1.column_1 = Table_2.column_1;
Because the output will be 1,1,2,2 — and 2 duplication is a mistake This SQL query will also fail:
SELECT DISTINCT Table_1.column_1
FROM Table_1,Table_2
WHERE Table_1.column_1 = Table_2.column_1;
Since the outcome is 1,2 — thus removing the repeated 1 is also an error.
● When the statement before the query is not a query. The SQL command:
UPDATE Table_1 SET column_1 = (SELECT column_1 FROM Table_2);
Cannot be expressed using a join unless some uncommon SQL3 features are employed.
● When the join is complete, an expression is used. The SQL command:SELECT * FROM Table_1
WHERE column_1 + 5 =
(SELECT MAX(column_1) FROM Table_2);
It's difficult to convey with a join. In fact, this SQL query is the only thing that comes to mind:
SELECT Table_1.*
FROM Table_1,
(SELECT MAX(column_1) AS max_column_1 FROM Table_2) AS Table_2
WHERE Table_1.column_1 + 5 = Table_2.max_column_1;
Nothing is gained from the change because it still involves a parenthesized query.
Subqueries can be nested inside each other. SQL allows you to stack queries within each other. A subquery is a SELECT statement that returns intermediate results and is nested within another SELECT statement. The innermost subquery is executed first, followed by the following level.
You may recall that joins allow you to filter queries. Rather than filtering in the WHERE clause, it's customary to connect a subquery that hits the same table as the outer query.
SELECT *
FROM tutorial.sf_crime_incidents_2014_01 incidents
JOIN ( SELECT date
FROM tutorial.sf_crime_incidents_2014_01
ORDER BY date
LIMIT 5
) sub
ON incidents.date = sub.date
When paired with aggregations, this can be extremely useful. When you join, the subquery output requirements are less severe than when you employ the WHERE clause. Your inner query, for example, can return numerous results. The following query sorts all of the results by the number of events recorded in a single day. It accomplishes this by collecting the total number of incidences per day in the inner query, then sorting the outer query using those values:
SELECT incidents.*,
sub.incidents AS incidents_that_day
FROM tutorial.sf_crime_incidents_2014_01 incidents
JOIN ( SELECT date,
COUNT(incidnt_num) AS incidents
FROM tutorial.sf_crime_incidents_2014_01
GROUP BY 1
) sub
ON incidents.date = sub.date
ORDER BY sub.incidents DESC, time
Subqueries can help you improve the performance of your queries significantly. Let's go over the Crunchbase Data again. Consider how you'd like to compile all of the companies that receive funding and those that are bought each month. If you wanted to, you could accomplish it without subqueries, but don't run it because it will take minutes to return:
SELECT COALESCE(acquisitions.acquired_month, investments.funded_month) AS month,
COUNT(DISTINCT acquisitions.company_permalink) AS companies_acquired,
COUNT(DISTINCT investments.company_permalink) AS investments
FROM tutorial.crunchbase_acquisitions acquisitions
FULL JOIN tutorial.crunchbase_investments investments
ON acquisitions.acquired_month = investments.funded_month
GROUP BY 1
Note that you must join on date fields to execute this effectively, which results in a big "data explosion." Essentially, you're linking every row in a given month from one table to every month in a given row on the other table, resulting in an enormous number of rows returned. COUNT(DISTINCT) must be used instead of COUNT to acquire accurate counts due to the multiplicative impact. This is what you'll see below:
7,414 rows are returned with the following query:
SELECT COUNT(*) FROM tutorial.crunchbase_acquisitions
There are 83,893 rows in the following query:
SELECT COUNT(*) FROM tutorial.crunchbase_investments
The query below returns 6,237,396 rows:
SELECT COUNT(*)
FROM tutorial.crunchbase_acquisitions acquisitions
FULL JOIN tutorial.crunchbase_investments investments
ON acquisitions.acquired_month = investments.funded_month
If you want to learn more about cartesian products, you can do some additional study. It's also worth noting that the FULL JOIN and COUNT operations above are rather quick—the it's COUNT(DISTINCT) that takes the longest. More on this in the query optimization lesson.
Of course, you could solve this much faster by aggregating the two tables individually, then merging them together to conduct the counts across much smaller datasets:
SELECT COALESCE(acquisitions.month, investments.month) AS month,
acquisitions.companies_acquired,
investments.companies_rec_investment
FROM (
SELECT acquired_month AS month,
COUNT(DISTINCT company_permalink) AS companies_acquired
FROM tutorial.crunchbase_acquisitions
GROUP BY 1
) acquisitions
FULL JOIN (
SELECT funded_month AS month,
COUNT(DISTINCT company_permalink) AS companies_rec_investment
FROM tutorial.crunchbase_investments
GROUP BY 1
)investments
ON acquisitions.month = investments.month
ORDER BY 1 DESC
Just in case one table had observations in a month that the other table didn't, we utilized a FULL JOIN above. When the acquisitions subquery didn't have any month entries, we utilised COALESCE to display them (presumably no acquisitions occurred in those months). To better understand how these elements work, we strongly advise you to re-run the query without them. You can also run each subquery separately to gain a better grasp of how they work.
Key takeaway
Subqueries can be nested inside each other. SQL allows you to stack queries within each other. A subquery is a SELECT statement that returns intermediate results and is nested within another SELECT statement.
To get data from various tables, SQL JOINS are needed. When two or more tables are listed in a SQL statement, a SQL JOIN is done.
Equi Join
EQUI JOIN creates a JOIN between two tables for equality or matching column(s) values. EQUI JOIN also creates a JOIN by using ON and then providing the names of the columns and their corresponding tables to check equality using the equal sign (=).
Syntax:
SELECT column_list
FROM table1, table2....
WHERE table1.column_name =
Table2.column_name;
Example –
SELECT student.name, student.id, record.class, record.city
FROM student, record
WHERE student.city = record.city;
Or
Syntax :
SELECT column_list
FROM table1
JOIN table2
[ON (join_condition)]
Example –
SELECT student.name, student.id, record.class, record.city
FROM student
JOIN record
ON student.city = record.city;
Table name — Student
Id | Name | Class | City |
3 | Hina | 3 | Delhi |
4 | Megha | 2 | Delhi |
6 | Gouri | 2 | Delhi |
Table name — Record
Id | Class | City |
9 | 3 | Delhi |
10 | 2 | Delhi |
12 | 2 | Delhi |
Output after Equi join
Name | Id | Class | City |
Hina | 3 | 3 | Delhi |
Megha | 4 | 3 | Delhi |
Gouri | 6 | 3 | Delhi |
Hina | 3 | 2 | Delhi |
Megha | 4 | 2 | Delhi |
Gouri | 6 | 2 | Delhi |
Hina | 3 | 2 | Delhi |
Megha | 4 | 2 | Delhi |
Gouri | 6 | 2 | Delhi |
Simple Join
As long as the condition is met, the INNER JOIN keyword selects all rows from both tables. This keyword will generate a result-set by combining all rows from both tables that satisfy the requirement, i.e. the common field's value will be the same.
Syntax
SELECT columns
FROM table1
INNER JOIN table2
ON table1.column = table2.column;
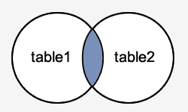
Fig 2: Inner join
Outer Join
LEFT OUTER JOIN
This join retrieves all rows from the table on the left side of the join, as well as matching rows from the table on the right. The result-set will include null for the rows for which there is no matching row on the right side. LEFT OUTER JOIN is another name for LEFT JOIN.
Syntax
SELECT columns
FROM table1
LEFT [OUTER] JOIN table2
ON table1.column = table2.column;
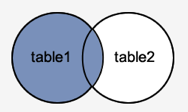
Fig 3: Left outer join
RIGHT OUTER JOIN
The RIGHT JOIN function is analogous to the LEFT JOIN function. This join retrieves all rows from the table on the right side of the join, as well as matching rows from the table on the left. The result-set will include null for the rows for which there is no matching row on the left side. RIGHT OUTER JOIN is another name for RIGHT JOIN.
Syntax
SELECT columns
FROM table1
RIGHT [OUTER] JOIN table2
ON table1.column = table2.column;
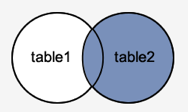
Fig 4: Right outer join
FULL OUTER JOIN
The result-set of FULL JOIN is created by combining the results of both LEFT JOIN and RIGHT JOIN. All of the rows from both tables will be included in the result-set. The result-set will contain NULL values for the rows for which there is no match.
Syntax
SELECT columns
FROM table1
FULL [OUTER] JOIN table2
ON table1.column = table2.column;
Fig 5: Full outer join
Self Join
A self-join is a join that connects the table to itself. It's usually utilised when the entities have a hierarchical relationship (for example, employee-manager) or when you want to compare rows within the same table. The inner join or left outer join syntax is used. Within a query, table aliases are used to give the same table multiple names.
Syntax:
SELECT <columns>
FROM <table> AS <alias1>
JOIN <table> AS <alias2>
ON <alias1>.<columnA> = <alias2>.<columnB>
Example
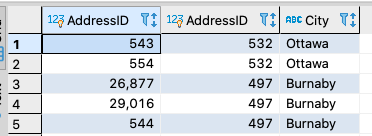
Use the following query to get addresses in the same city:
SELECT a1.AddressID, a2.AddressID, a1.City
FROM Person.Address a1
JOIN Person.Address a2
ON a1.AddressID > a2.AddressID
WHERE a1.City = a2.City
In SQL, a view is a virtual table based on the SQL statement result-set.
A view, much like a real table, includes rows and columns. Fields in a database view are fields from one or more individual database tables.
You can add SQL, WHERE, and JOIN statements to a view and show the details as if the data came from a single table.
Create a view
Syntax
CREATE VIEW view_name AS
SELECT column1, column2, ...
FROM table_name
WHERE condition;
Up-to-date data still displays a view! Any time a user queries a view, the database engine recreates the data, using the view's SQL statement.
Create a view example
A view showing all customers from India is provided by the following SQL.
CREATE VIEW [India Customers] AS
SELECT CustomerName, ContactName
FROM Customers
WHERE Country = 'India';
Updating a view
With the Build OR REPLACE VIEW command, the view can be changed.
Create or replace view syntax
CREATE OR REPLACE VIEW view_name AS
SELECT column1, column2, ...
FROM table_name
WHERE condition;
For the "City" view, the following SQL adds the "India Customers" column:
CREATE OR REPLACE VIEW [India Customers] AS
SELECT CustomerName, ContactName, City
FROM Customers
WHERE Country = 'India';
Dropping a view
With the DROP VIEW instruction, a view is removed.
Drop view syntax
DROP VIEW view_name;
"The following SQL drops the view of "India Customers":
DROP VIEW [India Customers];
Indexes
● Special lookup tables are indexes. It is used to very easily extract data from the database.
● To speed up select queries and where clauses are used, an Index is used. But it displays the data input with statements for insertion and update. Without affecting the data, indexes can be generated or dropped.
● An index is much like an index on the back of a book in a database.
For example, when you refer to all the pages in a book that addresses a certain subject, you must first refer to an index that lists all the subjects alphabetically, and then refer to one or more particular page numbers.
● Create index statement
It is used on a table to construct an index. It allows value to be duplicated
Syntax
CREATE INDEX index_name
ON table_name (column1, column2, ...);
Example
CREATE INDEX idx_name
ON Persons (LastName, FirstName);
● Unique index statement
It is used on a table to construct a specific index. Duplicate value does not make it.
Syntax
CREATE UNIQUE INDEX index_name
ON table_name (column1, column2, ...);
Example
CREATE UNIQUE INDEX websites_idx
ON websites (site_name);
● Drop index statement
It is used to delete a table's index.
Syntax
DROP INDEX index_name;
Example
DROP INDEX websites_idx;
Key takeaway:
- It is used to very easily extract data from the database.
- To speed up select queries and where clauses are used, an Index is used.
Indexing is a technique for data structure that helps you to access information from a database file quickly. An Index is a small table of two columns only. The first column consists of a copy of a table's primary or candidate key. The second column includes a series of pointers to hold the disc block address where that particular key value is located.
Indexing is a way of maximizing a database's output by minimizing the amount of disc access needed when processing a question. It is a technique for data structure that is used to find and access the data in a database easily.
Using a few database columns, indexes are established.
- The first column is the Search key, which includes a copy of the table's primary or candidate key. In order for the corresponding data to be accessed easily, these values are stored in sorted order.
- The second column is the Data Reference or Pointer, which includes a series of pointers that hold the disc block address where you can find the particular key value.
Indexing has different attributes:
- Access Types: This refers to the access type, such as value-based quest, access to the range, etc.
- Access Time: This refers to the time taken to locate a single element of data or a collection of elements.
- Insertion Time: It relates to the time it takes to find a suitable space and insert new data.
- Deletion Time: It takes time to find and delete an object and to update the layout of the index.
- Space Overhead: It refers to the extra space that the index takes.
Types of indexes
Fig 6: Types of database
- Primary index
The Primary Index is an ordered file with two fields and a fixed length scale. The first field is the same as the primary key, and the second field is pointed to that particular block of information. In the primary index, the relationship between the entries in the index table is always one-to-one.
Main DBMS indexing is also further split into two forms:
● Dense
● Sparse
Dense index
In a dense index, for each search key valued in the database, a record is generated. This helps you to search more easily, however more space is required to store index records. Method records include the value of the search key in this index and point to the actual record on the disc.
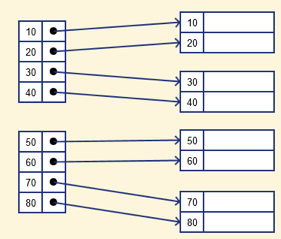
Fig 7: Dense index
Sparse index
It is an index record that only exists in the file for some of the values. The Sparse Index helps you solve the problems of DBMS Dense Indexing. A number of index columns store the same data block address in this form of indexing technique, and the block address will be fetched when data needs to be retrieved.
However, for only those search-key values, sparse Index stores index records. It requires less space, less overhead maintenance for insertion, and deletions, but compared to the dense index for locating records, it is slower.
The database index below is an example of the Sparse Index
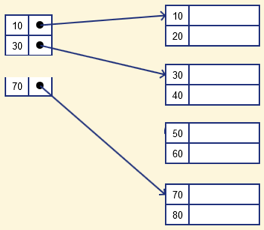
Fig 8: Sparse index
2. Clustering index
The records themselves are stored in the index in a clustered index, and not the pointers. On non-primary key columns, the Index is often generated, which may not be unique for each record.
You can group two or more columns in such a situation to get unique values and create an index called the Clustered Index. This helps you locate the record faster as well.
Example:
Suppose a business has many staff in each department. Suppose we use a clustering index, where all employees within a single cluster who belong to the same Dept ID are considered, and index pointers point to the entire cluster. Dept Id is a non-unique key here.
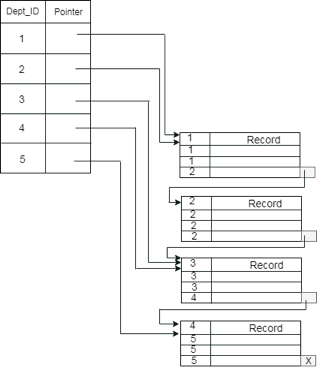
Fig 9: Example of cluster index
3. Secondary index
In DBMS, a secondary index can be created by a field that has a specific value for each record and should be a candidate key. It is also known as an index for non-clustering.
To reduce the mapping size of the first level, this two-level database indexing technique is used. A wide range of numbers is chosen for the first level because of this; the mapping size still remains small.
In secondary indexing, another degree of indexing is added to reduce the mapping scale. The huge range for the columns is initially chosen in this process, so that the mapping scale of the first level becomes small. Each range is then further split into smaller ranges.
The first level mapping is stored in the primary memory, so that the fetching of addresses is easier. In the secondary memory, the second level mapping and actual data are stored (hard disk).
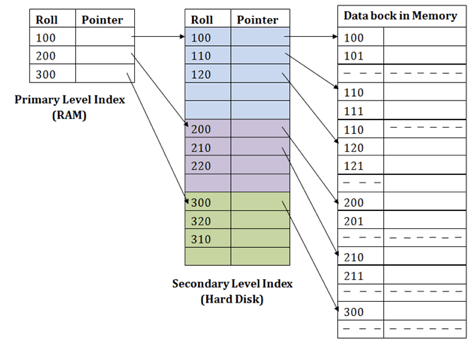
Fig 10: Secondary index
Let’s understand this by an example:
- If you want to find the record of roll 111 in the diagram, the first level index will look for the highest entry that is smaller than or equal to 111. At this amount, he'll get 100.
- Then again, it does max (111) <= 111 at the second index stage and gets 110. It now goes to the data block using the address 110, and starts looking for each record until it gets 111.
- This is how this approach is used to conduct a search. Often, adding, modifying or removing is performed the same way.
Key takeaway:
● Data can be stored in sorted order or may not be stored.
● The Primary Index is an ordered file with two fields and a fixed length scale.
● For this category, records which have similar characteristics are grouped and indexes are established in cluster index.
● In secondary indexing, another degree of indexing is added to reduce the mapping scale.
The sequence generator generates a series of integers in a specific order. The sequence generator comes in handy when you need to create unique sequential ID numbers.
Individual sequence numbers that were generated and utilized in a transaction that was subsequently rolled back can be skipped.
For numeric columns in database tables, a sequence generates a serial list of unique numbers. Sequences make application programming easier by producing unique integer values for each row of a single table or several tables automatically.
Assume that two users are putting new employee entries into the EMP database at the same time. Neither user has to wait for the other to enter the next available employee number when utilizing a sequence to generate unique employee numbers for the EMPNO column. The sequence creates the correct values for each user automatically.
Tables are unrelated to sequence numbers, so the same sequence can be used for one or multiple tables. A sequence can be accessed by several people to generate actual sequence numbers once it is created.
A sequence is a set of integers, such as 1, 2, 3, and so on, that are generated and supported by some database systems in order to produce unique values on demand.
- A sequence is a schema-bound user-defined object that generates a list of numeric values.
- Many databases employ sequences because many applications need that each row in a table include a unique value, and sequences give an easy way to do so.
- The sequence of numeric numbers is generated at defined intervals in ascending or descending order, and it can be adjusted to resume when max value is exceeded.
Syntax
CREATE SEQUENCE sequence_name
START WITH initial_value
INCREMENT BY increment_value
MINVALUE minimum value
MAXVALUE maximum value
CYCLE|NOCYCLE ;
Sequence_name: Name of the sequence.
Initial_value: starting value from where the sequence starts.
Initial_value should be greater than or equal
To minimum value and less than equal to maximum value.
Increment_value: Value by which sequence will increment itself.
Increment_value can be positive or negative.
Minimum_value: Minimum value of the sequence.
Maximum_value: Maximum value of the sequence.
Cycle: When sequence reaches its set_limit
It starts from the beginning.
Nocycle: An exception will be thrown
If the sequence exceeds its max_value.
Example
Make a table called students, with the columns id and name.
CREATE TABLE students
(
ID number(10),
NAME char(20)
);
Insert values into the table now.
INSERT into students VALUES(sequence_1.nextval,'Ramesh');
INSERT into students VALUES(sequence_1.nextval,'Suresh');
Where sequence_1.nextval will insert id’s in id column in a sequence as defined in sequence_1.
Output
______________________
| ID | NAME |
------------------------
| 1 | Ramesh |
| 2 | Suresh |
----------------------
Key takeaway
The sequence generator generates a series of integers in a specific order. The sequence generator comes in handy when you need to create unique sequential ID numbers.
References:
- Database system concept- Korth Silberschatz.
- SQL - PL/SQL by Ivan Bayross BPB Publications.
- Structure query language-By Osborne
- Learning MySQL by O’reilly




