Unit I
INTRODUCTION
Modern computers are unit equipped with powerful hardware facilities driven by intensive code packages. To assess progressive computing, we tend to initial review historical milestones within the development of computers. Then we tend to take a circuit of the crucial hardware and code parts designed into fashionable laptop systems. We tend to then examine the evolutional relations in milestone subject area development. Basic hardware and code factors area unit known in analyzing the performance of computers.
1.1.1 Computer Development Milestones
Computers have older 2 major stages of development: mechanical and
Electronic. Before I945, computers were created with mechanical or mechanical device pans. The earliest mechanical laptop is derived back to 5110 before Christ within the sort of the abacus employed in China. The abacus is operated by hand to perform decimal arithmetic with carry propagation digit by digit.
Blaise Pascal designed a mechanical adder/subtractor in France in 1642. Charles Babbage designed a distinction engine in European country for polynomial analysis in 1822. Konrad Zuse designed the primary binary mechanical laptop in Germany in 1941.
Howard Aiken projected the terribly initial mechanicaldevice decimal laptop, that was designed because the Harvard Mark I by IBM in 1944. Each Zuse and Aiken’s machines were designed for general purpose computations.
Obviously, the actual fact that computing and communication were administrated with moving mechanical elements greatly restricted the computing speed and reliability' of mechanical computers. Fashionable computers were marked by the introduction of electronic parts. The moving elements in mechanical computers were replaced by high-mobility electrons in electronic computers. Data transmission by mechanical gears or levers was replaced by electrical signals traveling virtually at the speed of sunshine.
Computer Generation: Over the past many decades, electronic computers have older roughly 5 generations of development. Table l.l provides s outline of the 5 generations of information processing system development. Every of the primary 3 generations lasted regarding ten years. The fourth generation coated a time span of fifteen years. The fifth generation these days has processors and memory devices with over l billion transistors on one chip. The division of generations is marked primarily by major changes in hardware and code technologies. The entries in Table 1.1 indicate the new hardware and code options introduced with every generation. Most options introduced in earlier generations are passed to later generations.
Table 1.1 Five Generations of Electronic Computers
Generation | Technology and Architecture | Software and Applications | Representative System |
First (1945-54) | Vacuum tubes and relay memories, CPU driven by PC and accumulator, Fined-point arithmetic. | Machine assembly languages, single user, no subroutine linkage, programmed I/O using CPU | ENIAC, Princeton IAS, IBM 701. |
Second (1955-64) | Discrete transistors and core memory, floating point arithmetic, I/O processors, multiplexed memory access | HLL used with compilers, subroutine libraries, batch -processing monitor. | IBM 7090, CDC 1604, Univac LARC. |
Third (1965-74) | Integrated circuits (SS1/- MSI), microprogramming, pipelining, cache, and look ahead processors | Multiprogramming and time sharing OS, multiuser applications. | IBM 360/370, CDC 6600 TI-ASC PDP-8. |
Fourth (1975-90) | LSI/VLSI and semiconductor memory, multiprocessors, vector supercomputers, multicomputer. | Multiprocessor OS, languages, compilers, and environments for parallel processing. | VAX 9000 CDC X-MP IBM 3090 BBN TC 2000. |
Fifth (1991-Present) | Advanced VLSI processors, memory, and switches, high-density packaging, scalable architectures. | Superscalar processors, systems on a chip, massively parallel processing, grand challenge applications, heterogeneous processing. | Convex C3800 Super-node 1000 nCUBE/2 Intel Paragon
|
Progress in Hardware: As way as hardware technology worries, the primary generation (I945 I954} used vacuumed tubes and relay recollections interconnected by insulated wires. The second-generation (1955-1964) was marked by the utilization of distinct transistors, diodes, and magnetic primary solid solution cores, interconnected by written circuits.
The third generation (1965-1974) began to use integrated circuits (ICs) for each logic and memory in small-scale or medium-scale integration (SSI or MSI) and multilayered written circuits. The fourth-generation (l974-1991) used large-scale or very-large integration (LSI or VLSI). Semiconductor memory replaced core memory as computers moved from the third to the fourth generation. The fifth-generation (l99I-present) is highlighted by the utilization of high-density and high-speed processor and memory chips supported advanced VLSI technology. For instance, 64-bit rate vary processors square measure currently on the market on one chip with over one billion transistors.
The First Generation
From the subject and software package points of read, initial generation computers were designed with one central process unit (CPU) that performed serial fixed-point arithmetic employing a program counter, branch directions, ANd an accumulator. The central processing unit should be concerned all told operation and I/O operations. Machine or assembly languages were used.
Representative systems embody the ENIAC (Electronic Numerical measuring device and Calculator) designed at the Moore faculty of the University of Pennsylvania in 1950; the IAS (Institute for Advanced Studies) laptop supported a style projected by John John von Neumann, Arthur Burks, and jazzman Goldstine at Princeton in 1946; and therefore the IBM until, the primary electronic stored-program business laptop designed by IBM in l953. Software package linkage wasn't enforced in early computers.
The Second Generation
Index registers, floating-point arithmetic, multiplexed memory, and I/O processors were introduced with second-generation computers. High-Level Languages (HLL), like FORTRAN, Algol, and COBOL, were introduced together with compilers, software package libraries, and execution monitors. Register transfer language was developed by Irving Reed (1957) for the systematic style of digital computers. Representative systems embody the IBM 7030 (the Stretch computer) that includes instruction look ahead and error-correcting recollections inbuilt 1962, the Univac LARC (Livermore Atomic analysis Computer) inbuilt 1959, and therefore the agency 1604 in-built the Sixties.
Third Generation
The third generation was represented by the IBM 360/370 series, the CDC 6600/7600 series, Texas Instruments ASC and Digital Equipment’s PDP-8 Series from the mid-1960s to the mid-1970s.
Micro-programmed control became popular with this generation. Pipelining and cache memory were introduced to the close up the speed gap between the CPU and main memory. The idea of multiprogramming was implemented to interleave CPU and I/O activities across multiple user programs. This led to the development of time sharing operating system using virtual memory with greater sharing or multiplexing of resources.
Fourth Generation
Parallel computers in various architectures appeared in the fourth generations of computers using shared or distributed memory or optional vector hardware. Multiprocessor OS, special languages, and compilers were developed for parallelism. Software tools and environments were created for parallel processing or distributed computing.
Representative system include the VAX 9000, Cray X-MP, IBM/3090 VF, BBN TC-2000, etc. During these 15 years, the technology of parallel processing gradually became mature and entered the production mainstream.
Fifth Generation
These systems emphasize superscalar processor, clusters computers, and massively parallel processing. Scalable and latency tolerant architectures are being adopted in MPP systems using advanced VLSI technologies, high- density packaging, and optical technologies.
Fifth-generations computers achieved Teraflops performance by the mid-1990s, and have now crossed the range. Heterogeneous processing is emerging to solve large-scaled problems using a networks of heterogeneous computers. Early fifth-generations MPP systems were represented by several projects at Fujitsu, Cray Research, Thinking Machine Corporation, and Intel.
Flynn’s Classification
Flynn’s classification distinguishes multi- processor computer architectures per 2 free dimensions of Instruction stream and data stream. Associate in instruction stream is the sequence of directions dead by machine. And an information stream may be a sequence of information together with input, partial or temporary results utilized by instruction stream. Every of those dimensions will have just one of 2 do-able states: Single or Multiple. Flynn’s classification depends on the excellence between the performances of management unit and therefore the processing unit instead of its operational and structural interconnect ions. Following square measure the four class of Flynn classification and characteristic feature of every of them.
a) Single Instruction Stream, Single Data Stream (SISD):
• They also are referred to as scalar processor i.e., one instruction at a time and every instruction have just one set of operands.
• Single instruction: just one instruction stream is being acted on by the mainframe throughout clock cycle.
• Single data: just one data stream is being employed as input throughout any clock cycle.
• Deterministic execution.
• This is that the oldest and till recently, the foremost prevailing variety of computers.
• Examples: most PCs, single mainframe workstations, and mainframes.
b) Single Instruction Stream, Multiple Data Stream (SIMD) processors:
• A sort of parallel computers.
• Single instruction: All process units execute identical instruction issued by the management unit at any given clock cycle.
• Multiple Data: every process unit will treat a special data part. The processor is connected to shared memory or interconnection network providing multiple knowledge to the process unit.
• This type of machine typically has an instruct ion dispatcher, a very high- bandwidth internal network, and a very large array of very small-capacity instruction units.
• Thus single instruction is dead by totally different process units on different sets of information.
• Best suited to specialised issues characterised by a high degree of regularity, like image processing and vector computation.
• Synchronous and settled execution
b) Multiple Instruction Stream, Single Data Stream (MISD):
• A single knowledge stream is feed into multiple process units.
• Each process unit operates on the information severally via freelance instruction streams. one data stream is forwarded to a special process unit that is connected to the various management unit and executes instruction given thereto by the management unit to that it's connected.
• This design is additionally called linear arrays for pipelined execution of specific directions.
• Few actual samples of this category of parallel computers have ever existed. One is that the experimental Carnegie-Mellon Comp computers (1971).
d) Multiple Instruction Stream, Multiple Data Stream (MIMD)
• Every Processor may be executing a different instruct ion stream
• Multiple Data: each processor is also operating with a special knowledge stream. Multiple knowledge stream is provided by shared memory.
• Can be classified as loosely coupled or tightly coupled counting on the sharing of information and control.
• Execution may be synchronous or asynchronous, settled, or non- settled.
• Examples: most current supercomputers, networked parallel computers “grids" and multi-processor.
Two classes of parallel computers are mentioned below particularly shared memory or unshared distributed memory.
• Shared memory parallel computers vary wide, however usually have in common the ability for all processors to access all memory as global address space.
• Multiple processor s will operate severally however share identical memory resources.
• Changes in memory location stricken by one processor are visible to all alternative processors.
• Shared memory machines may be divided into 2 main categories based mostly upon memory access times:
UMA, NUMA, and COMA.
Uniform Memory Access (UMA):
• Most unremarkably delineated these days by symmetric multiprocessors (SM P) machines.
• Identical processors.
• Equal access and access times to memory.
• Sometimes referred to as CC-UM A - Cache Coherent UMA. Cache coherent suggests that if one processor updates a location in shared memory, all the opposite processors understand the update. Cache coherency is accomplished at the hardware level.
Non-Uniform Memory Access (NUMA):
• Often created by physically linking 2 or additional SMPS
• One SMP will directly access the memory of another SMP
• Not all processors have equal interval to any or all memory
• Memory access across a link is slower
If cache coherency is maintained, then might also be referred to as CC-NUM A - Cache Coherent NUMA
The COMA model (Cache Only Memory Access): The COM A model could be a special case of NUM A machine within which the distributed main memory is regenerated to caches. All caches global address area and there's no memory hierarchy at every processor node.
Advantages:
• Global address area provides a easy programming perspective to memory
• Data sharing between tasks is each quick and uniform because of the proximity of memory to CPUs
Disadvantages:
• Primary disadvantage is that the lack of measurability between memory and CPUs. Adding additional CPUs will geometrically increase traffic on the shared memory-CPU path, and for cache-coherent systems, geometrically increase traffic related to cache/ memory management.
• Programmer responsibility for synchronization constructs that guarantee "correct" access of global memory.
• Expense: it becomes progressively tough and high-priced to style and manufacture shared memory machines with ever-increasing numbers of processors.
2. Distributed Memory
Advantages:
• Memory is ascendible with variety of processors. Increase the amount of processors and therefore the size of memory will increase proportionately.
• Each processor will speedily access its own memory while not interference and while not the overhead incurred with making an attempt to take care of cache coherency.
• Cost-effectiveness: will use goods, ready-made processors, and networking.
Disadvantages:
A vector quantity contains an ordered set of n components, wherever n is termed the length of the vector. Every component in a very vector could be a scalar amount, which can be a number, an integer, a logical worth, or a personality.
A vector processor consists of a scalar processor and a vector unit, that may be thought of as a severally practical unit capable of economical vector operations.
Vector mainframe computer: Vector computers have the hardware to perform vector operations expeditiously. Operands cannot be used directly from memory however rather area unit loaded into registers and area unit return in registers when the operation. Vector hardware has the special ability to overlap or pipeline quantity process. Vector practical unit s pipelined, absolutely divided every stage of the pipeline performs a step of the operate on completely different operand(s) once the pipeline is full; a replacement result's created every clock amount (cp)
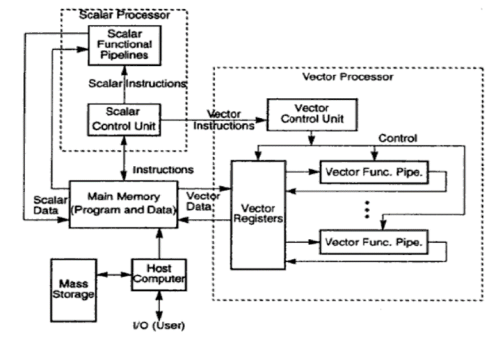
Figure: Architecture of Vector Supercomputer
SIMD Computers
The Synchronous parallel architectures coordinate coinciding operations in lockstep through global clocks, central control units, or vector unit controllers. An asynchronous array of parallel processors is termed an array processor. These processors are composed of identical process components (PES) below the direction of a control unit (CU) This control unit may be a computer with high-speed registers, native memory, and an arithmetic logic unit. An array processor is essentially one instruction and multiple data (SIMD) computers. There are n data streams; one per processor, thus completely different knowledge are often utilized in every process
The figure below show a typical SIMD or array processes
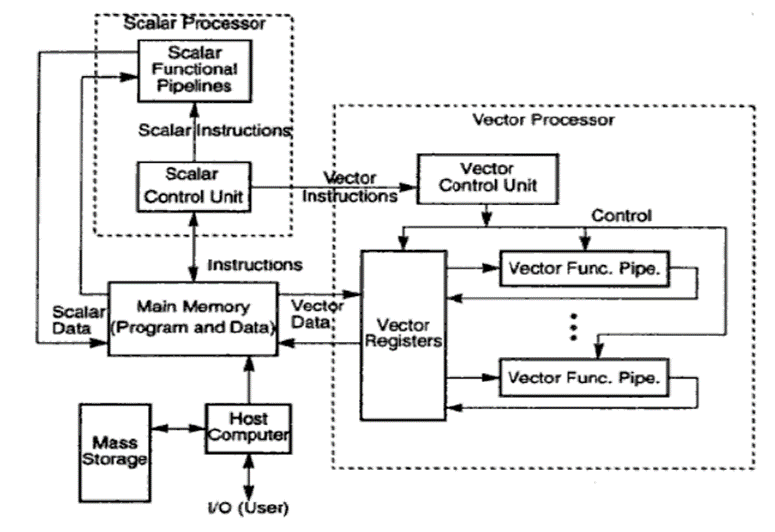
These processors encompass variety of memory modules which will be either global or dedicated to every processor. Therefore the most memory is that the combination of the memory modules. These process components and memory units communicate with one another through an interconnection network. SIM D processors are specially designed for playacting vector computations. SIM D has 2 basic fine arts organizations
a. Array processor using random access memory.
b. Associative processors using content available memory.
All n identical processors operate below the management of one instruction stream issued by a central processing unit. The favoured samples of this kind of SIMD configuration are ILLIAC IV, CM2, M P1.
Every PEI is actually an arithmetic logic unit (ALU) with hooked up operating registers and native memory PEM I for the storage of distributed data. The CU conjointly has its own main memory for the storage of the program. The perform of CU is to decipher the directions and confirm wherever the decoded instruction ought to be. The letter performs a similar perform (same instruction) synchronously in an exceedingly lockstep below command of
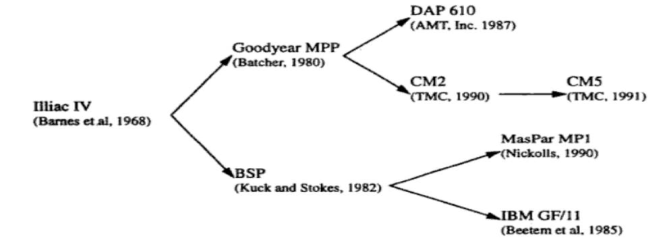
The evolution of parallel computers I spread along the following tracks −
In multiple processor track, it is assumed that different threads execute concurrently on different processors and communicate through shared memory (multiprocessor track) or message passing (multicomputer track) system.

In multiple data track, it is assumed that the same code is executed on the massive amount of data. It is done by executing same instructions on a sequence of data elements (vector track) or through the execution of same sequence of instructions on a similar set of data (SIMD track).
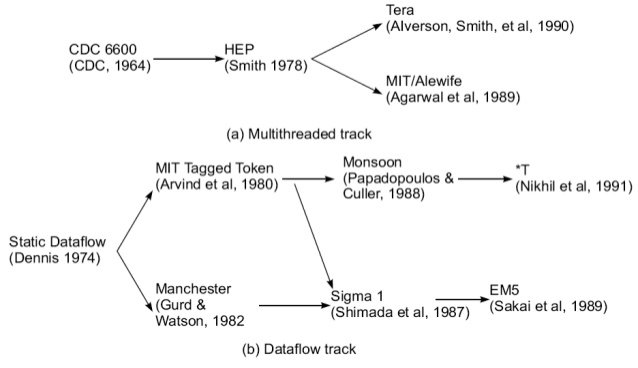
In multiple threads track, it is assumed that the interleaved execution of various threads on the same processor to hide synchronization delays among threads executing on different processors. Thread interleaving can be coarse (multithreaded track) or fine (dataflow track).
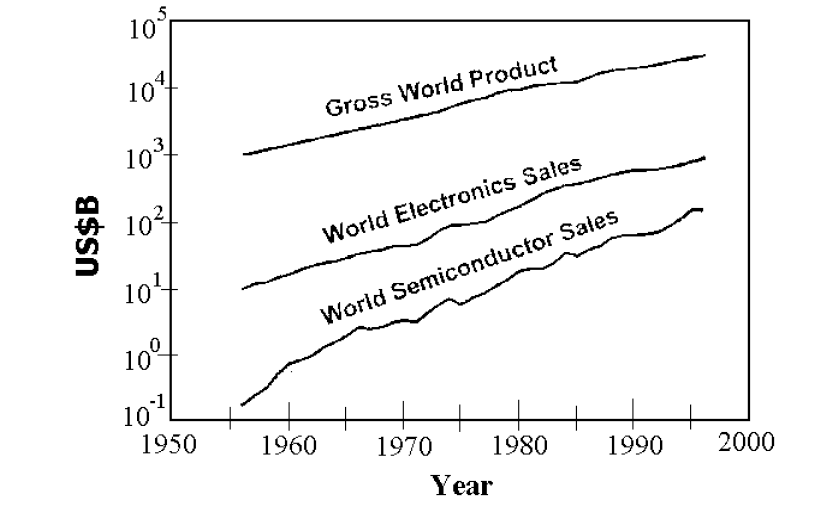
Semiconductors have become increasingly more important part of world
Economy

Silicon CMOS has become the pervasive technology
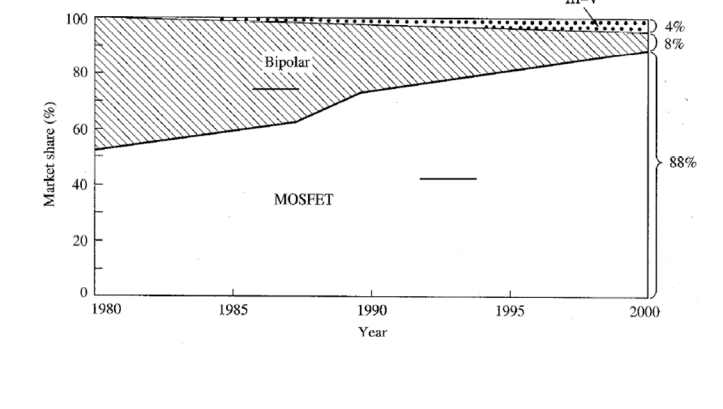
Future projections for silicon technology taken from the SIA ITRS 1999
– Price = what I sell the part for
– Cost = what it costs me
Reference Books:




