Unit -1
Parallel and Distributed Databases
The architecture of a database system is depending on multiple factors such as number of PC’s, web servers, database servers and other components.
The modern databases are implemented to run on a single physical machine supporting multitasking like centralized database systems. An enterprise-scale application which is runs on a centralized database system today may have from tens to thousands of users and database sizes ranging from megabytes to hundreds of gigabytes.
1.1.1 Centralized Systems
The Centralized System is run on single computer system without interact with other computer systems. It is also known as General-purpose computer system in which one to a few CPUs and a number of device controllers that are connected through a common bus that provides access to shared memory.
The centralized system can be categorized in two ways in which computers are used as single-user systems and as multiuser systems.
In Single-user system it has desk-top unit, single user, only one CPU and one or two hard disks and the OS may support only one user. For e.g. personal computer.
In Multi-user system more disks, more memory, multiple CPUs, and a multi-user OS. This type of system contains a large number of users who are connected to the system through terminals. Often called server systems.
Database systems designed for single-user systems that not provide many ofthe facilities that a multiuser database provides. They support verysimple concurrency control schemes, since highly concurrent access to the databaseis very unlikely. Provisions for crash recovery in such systems may also be either verybasic or even absent in some cases.Such systems may not support SQL and may instead provide an API for data access.Such database systems are called as embedded databases.
The multiuser database systems support the full transactional features. Such databases are usually designed as servers, which service requests received from application programs; the requests could be in the form of SQL queries, or they could be requests for retrieving, storing, or updating data specified using an API.

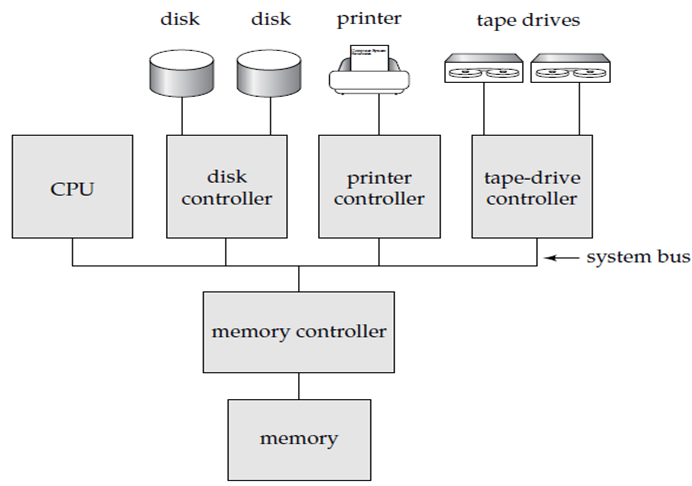
Figure 1.1.1 (I) A centralized computer system.
1.1.2 Client–Server Systems
As personal computers became faster, more powerful, and cheaper, therefore move away from the centralized system architecture. Personal computers supplanted terminals connected to centralized systems.
Personal computers assumed the user-interface functionality that used to be handled directly by the centralized systems. A centralized systems today act as server systems that satisfy requests generated by client systems.
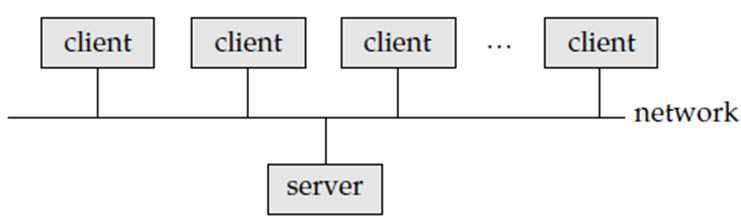
Figure 1.1.2(I) shows the general structure of a client–server system.
In the Client-server system Database functions can be divided into two parts as Front end and back end.
The front end of a database system contains tools such as forms, report writers, and graphical user interface facilities.
The back end is used to manage access structures of database, query evaluation and optimization, concurrency control, and recovery. In this Communication takes place between the front end and the back end through SQL or with the help of application programs.
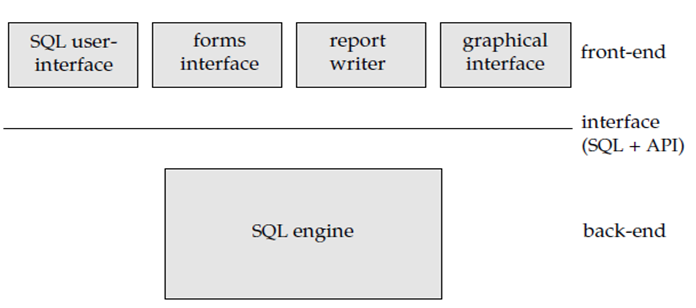
Figure 1.1.2 (II) Front-end and back-end functionality.
Standards like ODBC and JDBC are developed to interface clients with servers. Any client that uses the ODBC or JDBC interfaces are connect to any server which provides the interface.
There are certain application programs, such as spreadsheets and statistical-analysis packages, use the client–server interface directly to access data from a back-end server.
Advantages of replacing mainframes with networks of workstations or personal computers connected to back-end server machines:
1. Provides the better functionality for the cost.
2. It supports flexibility for locating resources and increasing the facilities.
3. Easy to maintain.
4. It has Better user interface.
Server systems is divided into two servers named as transaction servers and data servers.Transaction servers is widely used in relational database systems, and the data servers are used in object-oriented database systems.
A. Transaction servers
Transaction server systems are known as query-server systems. These servers provide interface to the clients which can send requests to perform an action and in response they execute some action and send back results to the client.
The client computer sends the transactions to the server systems then these transactions are executed, and results are sent back to clients that are in charge of displaying the data. Requests are sent with the help of SQL, and communicated to the server through a remote procedure call that is RPC mechanism. In that transactional RPC allows many RPC calls to form a transaction.
Open Database Connectivity (ODBC) is a C language application program interface standard from Microsoft for connecting to a server, sending SQL requests, and receiving results. JDBC standard is similar to ODBC, for Java.
Transaction Server Process Structure
A transaction server is collection of multiple processes which accessing data from shared memory. Following are the processes which are present in transaction server process structure.
Server processes
Server processes receive user queries that means transactions, execute these transactions and send the results back to the client. The queries may be submitted to the server processes from a user interface, or from a user process running embedded SQL, or through JDBC, ODBC, or similar protocols.
Some database systems use a separate process for each user session, and a few uses a single database process for all user sessions, but with multiple threads so that multiple queries can execute concurrently. Many database systems use hybrid architecture, with multiple processes, each one running multiple threads.
Database writer process
There are multiple processes that output modified buffer blocks back to disk on a continuous basis.
Lock manager process
This process performs lock manager functionality, which contains lock grant, lock release, and deadlock detection.
Log writer process
This process outputs log records from the log record buffer to stable storage.
Server processes can add log records to the log record buffer in shared memory, and if a log force is needed then they request the log writer process to output log records.
Checkpoint process
This process is used for periodic checkpoints.
Process monitor process
This process handles other processes, and if any of the process fails then it takes recovery actions for the process like aborting any transaction being executed by the failed process, and then restarting the process.
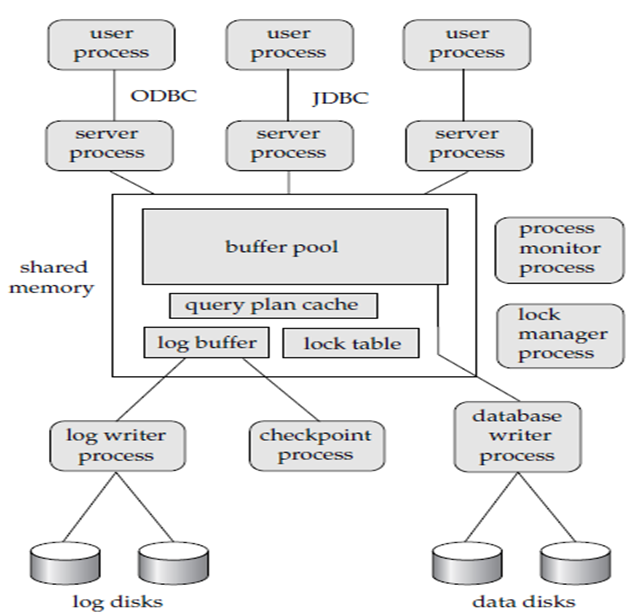
Figure 1.2 (I) shows shared memory and process structure.
The shared memory consists of all shared data, such as:
Buffer pool
Lock table
Log buffer
Cached query plans
All database processes are used to access the data in shared memory. To perform these operations no two processes are accessing the same data structure at the same time therefore the databases systems implement mutual exclusion with the help of Operating system semaphores ar Atomic instructions like test-and-set.
To avoid overhead of inter process communication for lock request/grant, every database process operates directly on the lock table instead of sending requests to lock manager, process lock manager process still used for deadlock detection
B. Data servers
Data-server systems support clients to interact with the servers by sending requests to read or update data, in units like files or pages. For example, file servers provide a file-system interface then clients perform operations as create, update, read, and delete files.
Data servers for database systems provides more functionality. They support units of data like pages, tuples, or objects which are small than a file.
They provide indexing facilities for data, and provide transaction facilities therefore the data is not left in an inconsistent state when a client machine or process fails.
Issues occurs in such architecture
Page shipping versus item shipping
The unit of communication for data can be of coarse granularity, like a page, or fine granularity like a tuple.
Page shipping is considered as a form of prefetching if multiple items reside on a page, therefore all the items in the page are shipped when a process are ready to access a single item in the page.
Locking
Locks are granted by the server for the data items that it ships to the client machines.
A disadvantage of page shipping is that client machines might be granted locks of too coarse a granularity a lock on a page implicitly locks all items contained in the page. Even if the client is not accessing some items in the page, it has acquired locks on all pre-fetched items. Other client machines that require locks on same items may be blocked unnecessarily.
Data caching
Data that are shipped to a client in a transaction is cached at the client side, even after that the transaction completes, if there is required amount of storage space is available.
Successive transactions at the same client may be able to make use of the cached data. However, cache coherency is an issue: Even if a transaction finds cached data, it must make sure that those data are up to date, since they may have been updated by a different client after they were cached.
The message is still be exchanged with the server to check validity of the data, and to acquire a lock on the data.
Lock caching
Locks are absorbed by client system even in between transactions. The transactions can acquire cached locks locally, without contacting server. Server calls back locks from clients when it receives conflicting lock request. Client returns lock once no local transaction is using it same as de-escalation, but across transactions.
Parallel systems boost processing and I/O speeds by using multiple CPUs and disks in parallel. The driving force behind parallel database systems is the demands of applications that have to query extremely large databases or that have to process an extremely large number of transactions per second that is thousands of transactions per second. Centralized and client–server database systems are not powerful enough to handle this application.
In parallel processing, many operations are performed at the same time as opposed to serial processing, in which the computational steps are performed sequentially. A coarse-grain parallel device contains a small number of powerful processors. In a massively parallel or fine-grain parallel machine uses a greater number of smaller processors.
Most high-end machines provide some degree of course-grain parallelism in that two or four processor machines are common. Massively parallel computers differentiated from the coarse-grain parallel machines by the more degree of parallelism that they support. Parallel computers with a greater number of CPUs and disks which are available commercially.
There are two important measures of performance in database system: (1) throughput that means the number of tasks that can be completed in a particular time interval, and (2) response time says that the amount of time it takes to complete a single task from the time it is submitted. A system which processes a greater number of small transactions that improve throughput with the help of processing many transactions in parallel. A system that processes large transactions improve the response time and throughput by performing subtasks of each and every transaction in parallel.
Speedup and Scale up
Two important issues present in parallelism are speedup and scaleup. Running a given task in minimum time by increasing the degree of parallelism is called speedup Handling the big tasks by increasing the degree of parallelism is known scaleup. Consider a database application running on a parallel system with some number of processors and disks. When we increase the size of the system by increasing the number of processors, disks, and other components of the system. The aim is to process the task in time inversely proportional to the number of processors and disks are allocated. Consider the execution time of a task on the larger machine is TL, and the execution time of the same task on the small machine is TS.
The speedup is occurred because of parallelism is defined as TS/TL. The parallel system demonstrates linear speedup if the speedup is N when the larger system has N times the resources such as CPU, disk of the smaller system. If the speedup is less than N, the system defines sublinear speedup. Following figure represents linear and sublinear speedup.
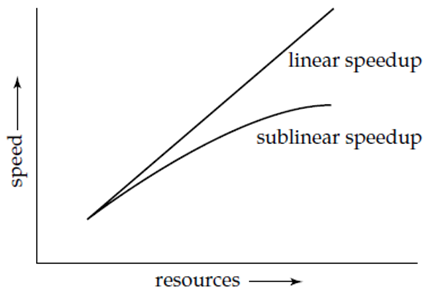
Figure 1.3 (I) Speedup with increasing the resources.
Scaleup related to the ability to process larger tasks in the same amount of time by providing a greater number of resources. Consider Q be a task, and QN is a task which is N times larger than Q. Suppose the execution time of task Q on a given machine MS is TS, and the execution time of task QN on a parallel machine ML is N times larger than MS, is TL.
The scaleup is defined as TS/TL. The parallel system ML is used for linear scaleup on task Q if TL = TS. If TL > TS, the system is said to be a sublinear scaleup. There are two types of scaleup in parallel database systems, based on how the size of the task is measured:
In batch scaleup, the size of the database increases, and the tasks are big jobs whose runtime is based on the size of the database.
In transaction scaleup, the rate at which transactions are submitted to the database increases and the size of the database increases proportionally to the transaction rate. This type of scaleup is relevant in transaction processing systems where the transactions are small updates. Consider the example, a deposit or withdrawal from an account and transaction rates grow as more accounts are created.
The goal of parallelism in database systems is to confirm that the database system can continue to perform at an acceptable speed, even as the size of the database and the number of transactions increases. Increasing the capacity of the system by increasing the parallelism provides a path for growth for an enterprise which replacing a centralized system by a faster machine.
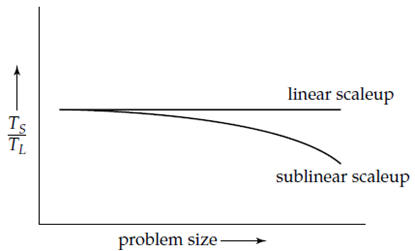
Figure 1.3(II) Scaleup with increasing problem size and resources.
More number of factors work against efficient parallel operation and effect on speedup and scaleup also.
Startup costs
There is a startup cost related with initiating a single process. In a parallel operation contains thousands of processes, the startup time overshadow the actual processing time which effect on speedup adversely.
Interference
The processes executing in a parallel system access shared resources, a slowdown is occurring from the interference of each new process as it competes with existing processes for commonly used resources like system bus, shared disks, or locks. Both speedup and scale up are affected by this parts.
Skew. By dividing a single task into a number of parallel steps, we reduce the size of the average step. The service time for the single slowest step calculated the service time for the task as a whole. It is difficult to divide a task into exactly equal-sized parts, and the method that the sizes are distributed is skewed.
Interconnection Networks
Parallel systems is a set of components like processors, memory, and disks which communicate with each other through an interconnection network. Following figure shows three types of interconnection networks:
Bus
All the system devices can send and receive data from a single communication bus. This type of interconnection is shown in Figure a. The bus is an Ethernet or a parallel interconnect. Bus architectures work properly for minimum numbers of processors.
Mesh
The components are considered as nodes in a grid, and every component connects to all its adjacent components in the grid. In a two-dimensional mesh every node connects to four adjacent nodes, while in a three-dimensional mesh every node connects to six adjacent nodes. Figure b shows a two-dimensional mesh. Nodes that are not directly connected are communicate with each other by routing messages via a sequence of intermediate nodes that are directly connected to one another.
Hypercube
In this the components are numbered in binary, and connected to another if the binary representations of their numbers differ in exactly one bit. Therefore, every n component is connected to log(n) other components. Figure c shows a hypercube with 8 nodes. In a hypercube interconnection, a message from a component can reach any other component by going through at most log(n) links.
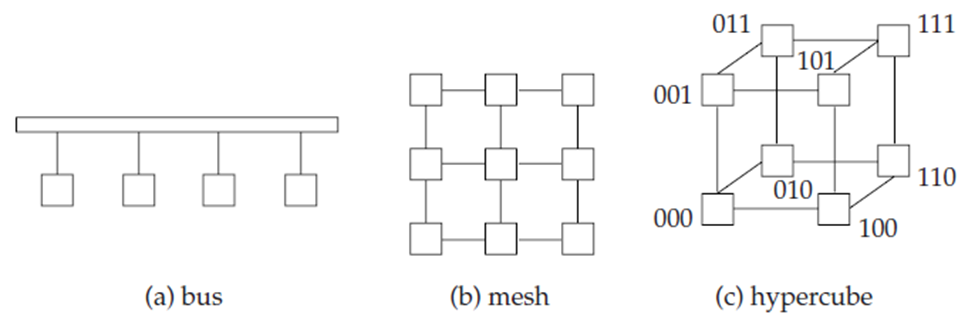
Figure 1.3(III) Interconnection networks.
Parallel Database Architectures
There are many architectural models for parallel machine. Figure shows different architectures in which M represents memory, P represents a processor, and disks are shown as cylinders.
Shared memory
All the processors share a common memory shown in Figure a.
Shared disk
All the processors share a common set of disks shown in Figure b. Shared-disk systems are also called as clusters.
Shared nothing
The processors do not share common memory or common disk shown in Figure c.
Hierarchical
This model is a hybrid of the preceding three architectures shown in Figure d.
Techniques are used to increase the speed of transaction processing on data-server systems is data and lock caching and lock de-escalation. It is also used in shared-disk parallel databases and in shared-nothing parallel databases. They are very important for efficient transaction processing in such systems.
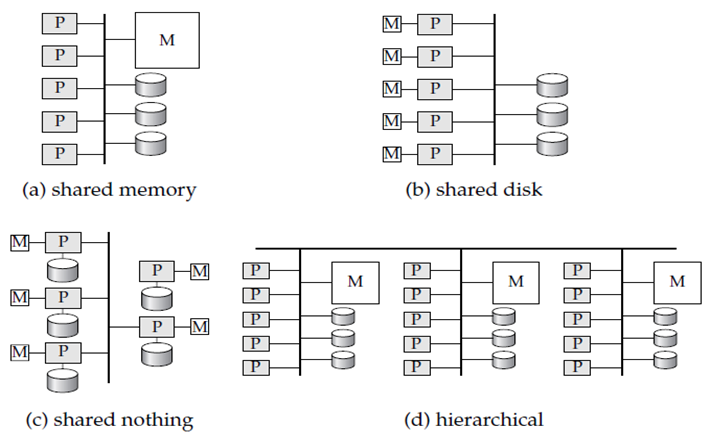
Figure 1.3 (IV) shows Parallel database architectures.
Shared Memory
In a shared-memory architecture, the processors and disks have access to a common memory through a bus or an interconnection network. The advantage of shared memory is extremely efficient communication between processors data in shared memory can be accessed by any processor without changing the software.
A processor sends messages to other processors faster by using memory writes than by sending a message via a communication mechanism. The drawbacks of shared-memory machines are that the architecture is not scalable more than 32 or 64 processors.
Adding multiple processors does not help after a point, since the processors will spend more time for waiting their turn on the bus to access memory. Shared-memory architectures consist of large memory caches at every processor therefore referencing of the shared memory is avoided when it possible. Therefore at least some of the data will not be in the cache, and accesses will go to the shared memory.
Shared Disk
In the shared-disk model all processors access multiple disks directly with help of an interconnection network, but the processors keep a private memory. There are two benefits of this architecture compare with a shared-memory architecture. One is that every processor has its own memory and the memory bus is not a bottleneck. Second, it supports a cheap way to provide a degree of fault tolerance that means If a processor fails, the other processors can take over its tasks and the database is resident on disks that are accessible from all processors. The shared-disk architecture is used in many applications.
The main problem with a shared-disk system is scalability. Compared to shared-memory systems, shared-disk systems can scale to a larger number of processors, but communication with processors is slower.
Shared Nothing
In shared-nothing system every node consists of a processor, memory, and one or more disks. The processors at one node communicate with another processor at another node by a high-speed interconnection network.
Since local disk references are serviced by local disks at each processor, the shared-nothing model minimize the disadvantage of requiring all I/O to go through a single interconnection network; only queries, accesses to nonlocal disks, and result relations pass through the network.
The interconnection networks for shared-nothing systems are designed to be scalable, so their transmission capacity increases as a greater number of nodes are added. Shared-nothing architectures are more scalable and also support a large number of processors.
The drawbacks of shared-nothing systems are the costs of communication and of non-local disk access, which is higher compare with shared-memory or shared-disk architecture since sending data contains a software interaction at both ends. The Grace and the Gamma research prototypes also used shared-nothing architectures.
Hierarchical
The hierarchical architecture combines the properties of shared-memory, shared disk, and shared-nothing architectures. At the top level is shared nothing architecture in this the system contains nodes connected by an interconnection network, and do not share disks or memory with others. Every node of the system is a shared-memory system with a few processors.
Every node is a shared-disk system share a set of disks is a shared-memory system. Therefore, a system is built as a hierarchy, with help of shared-memory architecture, processors at the base, and a shared nothing architecture at the top and shared-disk architecture in the middle.
Figure d shows a hierarchical architecture with shared-memory nodes connected with each other in a shared-nothing architecture. Commercial parallel database systems today run on several of these architectures.
In a distributed database system, the database is stored on multiple computers. The computers in a distributed system communicate with each other with help of various communication media like high-speed networks or telephone lines.
The computers in a distributed system may change in size and function, ranging from workstations up to mainframe systems.
The computers in a distributed system considered as a number of different names like sites or nodes, depending on the area in which they are mentioned.
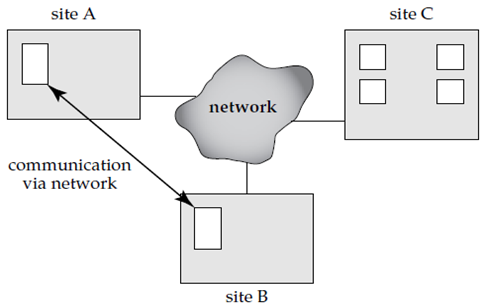
Figure 1.4(I) A distributed system.
The important differences between shared-nothing parallel databases and distributed databases is that distributed databases are geographically separated, separately administered, and with slower interconnection.
Another difference is that we differentiate system between local and global transactions. A local transaction accesses data only from sites where the transaction was initiated. A global transaction accesses data in a site different from the one at which the transaction was initiated, or accesses data in several different sites.
There are multiple reasons for developing distributed database systems with sharing of data, autonomy, and availability.
Sharing data
The major advantage of using a distributed database system is the provision of an environment where users at one site able to access the data present at other sites.
Autonomy
The primary advantage of sharing data by means of data distribution is that each site is able to retain a degree of control over data that are stored locally. The possibility of local autonomy is a major advantage of distributed databases.
Availability
If one site fails in a distributed system, the remaining sites may be able to continue operating.
In particular, if data items are replicated in several sites, a transaction need a particular data item may find that item in any of several sites. The failure of a site does not affect the shutdown of the system.
Disadvantage
Added complexities need a proper coordination among sites.
Software development cost.
Greater potential for bugs.
Increased processing overhead.
Implementation Issues for Distributed Databases
Atomicity of transactions is important issue in distributed database system. If a transaction runs across two sites, unless the system designers are careful, it may commit at one site and abort at another and maintain an inconsistent state.
In transaction commit protocols these situations cannot arise. The two-phase commit protocol (2PC) is the mostly used in these protocols.
Concurrency control is also issue in a distributed database. Transaction can access data items from multiple sites, transaction managers at multiple sites need to coordinate to implement concurrency control.
Locking can be performed locally at the sites consist of accessed data items, but there is a possibility of deadlock taking part in transactions originating at multiple sites. Therefore, deadlock detection required to be carried out across multiple sites.
Another disadvantage of distributed database system is the added complexity need to make proper coordination between the sites. This increased complexity has multiple forms such as:
Software-development cost
It is more difficult to implement a distributed database system therefore it is more costly.
Greater potential for bugs
The sites which contains the distributed system operate in parallel, it is harder to achieve the correctness of algorithms also operation during failures of part of the system, and recovery from failures.
Increased processing overhead
The interchange of messages and the additional computation need to achieve inter site coordination are a form of overhead that doesn’t arise in centralized systems.
In Database System Architecture parallelism is used to provide speedup, in which queries are executed faster because more resources like processors and disks, are provided. Parallelism provides scale up in which increasing workloads is handled without increased response time, through an increase in the degree of parallelism.
It has the different architectures for parallel database systems such as shared-memory, shared-disk, shared-nothing, and hierarchical architectures. In shared-memory architectures, all processors share a common memory and disks; in shared-disk architectures, processors have independent memories, but share disks; in shared-nothing architectures, processors not share memory nor disks; and hierarchical architectures have nodes that share neither memory nor disks with each other, but internally every node has a shared-memory or a shared-disk architecture.
1.5.1 I/O Parallelism
I/O parallelism minimizes the time needed to retrieve relations from disk by partitioning the relations on multiple disks. The common form of data partitioning in a parallel database is horizontal partitioning. In horizontal partitioning, the tuples in relation are divided into multiple disks, so that every tuple based on one disk.
Partitioning Techniques
There are three types of data-partitioning techniques. Consider there are n disks, D0, D1, . . ., Dn−1, across which the data are to be partitioned.
Round-robin
This technique scans the relation in any order and sends the ith tuple to disk number Di mod n. The round-robin method provides an even distribution of tuples across disks; that is every disk has the same number of tuples as the others.
Hash partitioning
This de-clustering technique designates one or more attributes from the given relation’s schema as the partitioning attributes. A hash function is selected whose range is {0, 1, . . ., n − 1}. Each tuple of the original relation is hashed on the partitioning attributes. If the hash function returns i, then the tuple is added in disk Di.
Range partitioning
This technique divides contiguous attribute-value ranges to every disk. It selects a partitioning attribute, A, as a partitioning vector. The relation is partitioned is as follows. Consider [v0, v1, . . ., vn − 2] denotes partitioning vector, such as if i < j, then vi < vj. Consider a tuple t such that t [A] = x. If x < v0, then t goes on disk D0. If x ≥ vn−2, then t goes on disk Dn−1. If vi ≤ x < vi+1, then t goes on disk Di+1.
Comparison of Partitioning Techniques
Once a relation is partitioned in multiple disks then we can retrieve it in parallel, using all the disks. Same as when a relation is being partitioned, it can be written to multiple disks in parallel. Therefore, the transfer rates for reading or writing an entire relation is faster with I/O parallelism than without it. However, reading a whole relation, or scanning a relation, is only one part of access to data. Access to data can be distributed as follows:
Scanning the entire relation
Locating a tuple associatively these queries are called as point queries, seek tuples that have a specified value for a specific attribute
Placing all tuples for which the value of a given attribute is between a particular range like 15000 < salary < 25000 these queries are known as range queries.
The multiple partitioning techniques support these types of access at different levels of efficiency:
Round-robin
The scheme is used for applications that wish to read the entire relation sequentially for each query. In this both point queries and range queries are complicated to process, since each of the n disks must be used for the search.
Hash partitioning
This method is suitable for point queries based on the partitioning attribute. For example, if a relation is partitioned on the telephone number then result of the query “Find the record of the employee with telephone-number = 555-4433” by applying the partitioning hash function to 555-4433 and then searching that disk.
Hash partitioning is useful for sequential scans of the entire relation. If the hash function is a good randomizing function, and the partitioning attributes form a key of the relation, then the number of tuples in each of the disks is approximately the same. The time taken to scan the relation is approximately 1/n of the time is need to scan the relation in a single disk system.
Range partitioning
This method is used for point and range queries on the partitioning attribute. For point queries, we can use the partitioning vector to locate the disk where the tuple are presents. For range queries, we consult the partitioning vector to find the range of disks on which the tuples may reside. In both cases, the search narrows to those same disks that may have any tuples of interest.
An advantage is that, if there are only a few tuples in the queried range, then the query is sent to one disk, as opposed to all the disks. Therefore, other disks are used to answer other queries, range partitioning results in higher throughput while maintaining good response time.
Handling of Skew
When a relation is partitioned by a technique other than round-robin, there may be a skew occurs in the distribution of tuples, with a high percentage of tuples placed in some partitions and some tuples in other partitions. The different ways that skew is present are:
Attribute-value skew
Partition skew
Attribute-value
Skew is used when some values appear in the partitioning attributes of many tuples. All the tuples with the same value for the partitioning attribute end up in the same partition and skew is present.
Partition skew
Isused when there may be load imbalance in the partitioning, even there is no attribute skew.
Attribute-value skew can result in skewed partitioning instead of whether range partitioning or hash partitioning is used. If the partition vector is not selected carefully then range partitioning may result in partition skew. Partition skew is less likely with hash partitioning, if a good hash function is selected.
A balanced range-partitioning vector made with the help of sorting: The relation is first sorted on the partitioning attributes. The relation is then scanned in sorted order. After every 1/n of the relation has been read, the value of the partitioning attribute of the next tuple is added to the partition vector. In this n denotes the number of partitions to be constructed. In case there are a greater number of tuples with the same value for the partitioning attribute, the technique can result in skew. The main drawback of this method is the extra I/O overhead occurred in doing the initial sort.
The I/O overhead for constructing balanced range-partition vectors can be overcome by constructing and storing a frequency table, or histogram, of the attribute values for each attribute of each relation.
Flowing figure shows an example of a histogram for an integer-valued attribute with values in the range in 1 to 25. A histogram takes only a little space, so histograms on multiple different attributes can be stored in the system catalog. It is simple to construct a balanced range-partitioning function given a histogram on the partitioning attributes. If the histogram is not stored then it can be computed by sampling the relation, using only tuples from a randomly selected subset of the disk blocks of the relation.
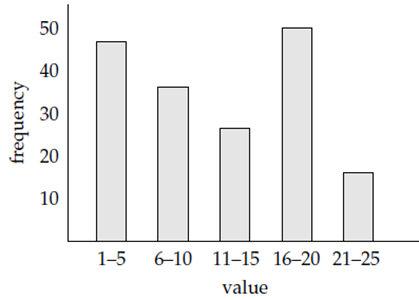
Figure 1.5.1 (I) Example of histogram.
Another technique is used to overcome the effect of skew with help of range partitioning, is to use virtual processors. In the virtual processor we consider there are several times as multiple virtual processors as the number of real processors.
1.5.2 Inter query Parallelism
In inter query parallelism multiple queries or transactions execute in parallel with one another. Transaction throughput is increased by this form of parallelism. Therefore, the response times of every transactions are no faster than they would be if the transactions were run in isolation. The main use of interquery parallelism is to scaleup a transaction-processing system to support a larger number of transactions per second.
Interquery parallelism is the easiest form of parallelism to support in a database system particularly in a shared-memory parallel system. Database systems designed for single-processor systems can be used with no changes on a shared-memory parallel architecture even sequential database systems support concurrent processing. Transactions are operated in a time-shared concurrent manner on a sequential machine operate in parallel in the shared-memory parallel architecture.
Interquery parallelism is more complicated in a shared-disk or shared nothing architecture. Processors perform some tasks like locking and logging, in a coordinated fashion, and that requires that they pass messages to each other. A parallel database system ensure that two processors do not update the same data independently at the same time.
When a processor accesses or updates data then database system must ensure that the processor has the latest version of the data in its buffer pool. The problem is occurred in this version is called as the cache-coherency problem.
Many protocols present to guarantee cache coherency and cache-coherency protocols are integrated with concurrency-control protocols so that their overhead is reduced. One protocol is used for a shared-disk system is
Before any read or write access to a page, a transaction locks the page in shared or exclusive mode. Immediately after the transaction obtains either a shared or exclusive lock on a page, it also reads the most recent copy of the page from the shared disk.
Before a transaction releases an exclusive lock on a page, it removes the page to the shared disk after that it releases the lock.
This protocol is used when a transaction sets a shared or exclusive lock on a page then gets the correct copy of the page. More complex protocols avoid the repeated reading and writing to disk needed by the preceding protocol. These protocols do not write pages to disk when exclusive locks are released. When a shared or exclusive lock is obtained and if the most recent version of a page is in the buffer pool of some processor then the page is obtained from there.
The protocols are designed to handle concurrent requests. The shared disk protocols can be extended to shared-nothing architectures by this method: Each page has a home processor Pi, and is stored on disk Di. When other processors want to read or write the page then they send requests to the home processor Pi of the page and they cannot directly communicate with the disk.
Intra query Parallelism
Intra query parallelism is used for the execution of a single query in parallel on multiple processors and disks. Using intra query parallelism is important for speeding up long-running queries. Inter query parallelism does not help in this task and each query is run sequentially.
Suppose the relation is partitioned in multiple disks by range partitioning on some attribute, and the sort is requested on the partitioning attribute. The sort operation is applying by sorting each partition in parallel, then concatenating the sorted partitions to get the final sorted relation.
We can parallelize a query by parallelizing individual operations. There is another source of parallelism in evaluating a query: The operator tree for a query can contain many operations. We can parallelize the evaluation of the operator tree by evaluating in parallel some of the operations that do not depend on each other. The two operations can be executed in parallel on separate processors, one generates output that is consumed by the other.
The execution of a single query is parallelized in two different ways:
Intraoperation parallelism
In this we can speed up processing of a query by parallelizing the execution of every operation, such as sort, select, project, and join.
Interoperation parallelism
We can speed up processing of a query by executing in parallel the different operations in a query expression.
The number of operations in a typical query is small, compared to the number of tuples processed by each operation, the first form of parallelism can scale better with increasing parallelism. Therefore, with the relatively small number of processors in parallel systems today, both forms of parallelism are important.
1.5.3 Intra operation Parallelism
Relational operations work on relations consist of large sets of tuples; we can parallelize the operations by executing them in parallel on different subsets of the relations. Then the number of tuples in a relation can be large and the degree of parallelism is potentially enormous. Therefore, intra operation parallelism is natural in a database system.
Parallel Sort
Consider that we need to sort a relation that is present on n disks D0, D1, . . ., Dn−1. If the relation is range partitioned on the attributes on which it is sorted, we can sort each partition individually, and combine the results to get the full sorted relation. In that the tuples are partitioned on n disks, the time required for reading the entire relation is reduced by the parallel access.
If the relation is partitioned in any other way, we can sort it in one of two ways:
We can range partition it on the sort attributes, and then sort each partition separately.
We can use a parallel version of the external sort–merge algorithm.
Range-Partitioning Sort
Range-partitioning sort is performed in two steps: first is the range partitioning the relation, then sorting every partition separately. When we sort by range partitioning the relation, it is not necessary to range-partition the relation on the same set of processors or disks as those on which that relation is stored. Consider that we select processors P0, P1, . . ., Pm in that m < n to sort the relation. There are two steps present in this operation:
Redistribute the tuples in the relation with the help of a range-partition technique, so that all tuples that present in i’th range are sent to processor Pi, which stores the relation not permanently on disk Di. To perform range partitioning, in parallel every processor reads the tuples from its disk and sends the tuples to their destination processor. Each processor P0, P1, . . ., Pm accept tuples to its partition, and stores them locally. This step needs disk I/O and communication overhead.
Every processor sorts its partition of the relation locally, without interaction with the other processors. Each processor executes the same operation namely, sorting on a different data set. The final merge operation is complicated, because the range partitioning in the first phase ensures that, for 1 ≤ i < j ≤ m, the key values in processor Pi are all less than the key values in Pj.
Parallel External Sort–Merge
Parallel external sort–merge is an alternative to the range partitioning. Consider that a relation has already partitioned among disks D0, D1, . . ., Dn−1. Then parallel external sort–merge works in following ways:
Every processor Pi locally sorts the data on disk Di.
The system merges the sorted runs on each processor to get the final sorted output.
The merging of the sorted runs in 2 steps and parallelized by following sequence of actions:
The system range-partitions the sorted partitions at each processor Pi through the processors P0, P1, . . ., Pm−1. It sends the tuples in sorted order therefore each processor receives the tuples in sorted streams.
Each processor Pi performs a merge on the streams to get a single sorted run.
The system concatenates the sorted runs on processors P0, P1, . . ., Pm−1 to get the final result.
Parallel Join
The join operation needs the system test pairs of tuples to find whether they satisfy the join condition; if they do then the system adds the pair to the join output. Parallel join algorithms ready to divide the pairs to be tested over multiple processors. Each processor then computes part of the join locally. Then, the system gathers the results from each processor to produce the final result.
Partitioned Join
Consider that we are using n processors, and that the relations to be joined are r and s. Partitioned join works like the system partitions the relations r and s each into n partitions represented as r0, r1, . . ., rn−1 and s0, s1, . . ., sn−1. The system sends partitions ri and si to processor Pi, where their join is computed locally.
The partitioned join technique works properly only if the join is an equi-join and if we partition r and s by the same partitioning function on their join attributes. The idea of partitioning is same as that behind the partitioning step of hash–join. In a partitioned join there are two different ways of partitioning r and s:
Range partitioning on the join attributes
Hash partitioning on the join attributes
Following figure shows the partitioning in a partitioned parallel join.
Once the relations are partitioned then we can use any join technique locally at each processor Pi to make the join of ri and si. For example, hash–join, merge–join, or nested-loop join is used then we use partitioning to make a parallelize any join technique.
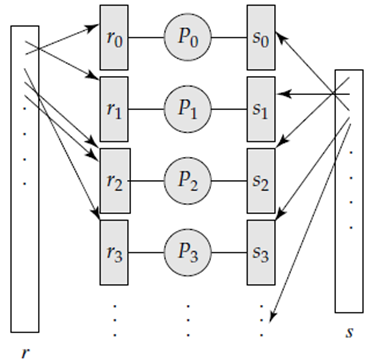
Figure 1.5.3 (I) Partitioned parallel join.
If one or both relations r and s are already partitioned then the work required for partitioning is minimize. If the relations are not partitioned, or are partitioned on attributes other than the join attributes, then the tuples need to be re-partitioned. Every processor Pi reads in the tuples on disk Di used for each tuple t the partition j to which t belongs, and sends tuple t to processor Pj. Processor Pj stores the tuples on disk Dj.
We can use the join algorithm used at each processor to reduce I/O by buffering some of the tuples to memory, instead of writing them to disk. Skew shows a special problem when range partitioning is used, since a partition vector divide one relation of the join into equal-sized partitions may split the other relations into partitions in different size.
Fragment-and-Replicate Join
Partitioning is not applicable to all types of joins. If the join condition is a not equality like r ⋈r. a<s.b s then all tuples in r join with some tuple in s. Therefore, there may be no easy way of partitioning r and s so that tuples in partition ri join with only tuples in partition si.
We can parallelize these joins by using a technique called fragment and replicate. Consider a special case of fragment and replicate asymmetric fragment-and replicate join which works as follows.
The system partitions one of the relations say, r. Any partitioning technique can be used on r containing round-robin partitioning.
The system replicates the other relation, s over all the processors.
Processor Pi locally perform the join of ri with all of s, using any join technique.
The asymmetric fragment-and-replicate technique shown in Figure a. If r is already stored by partitioning, there is not required to partition it further in step 1. Only there is need to replicate s across all processors. The general case of fragment and replicate join appears in Figure b it works as the system partitions relation r into n partitions, r0, r1, . . ., rn−1, and partitions s into m partitions, s0, s1, . . ., sm−1. As before, any partitioning technique is used on r and on s.
The values of m and n do not require to be equal, but they selected so that there are at least m* n processors. Asymmetric fragment and replicate are a special case of general fragment and replicate, where m = 1. Fragment and replicate minimize the sizes of the relations at each processor, compared with asymmetric fragment and replicate.
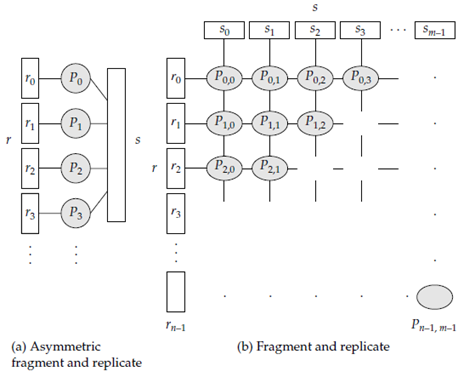
Figure 1.5.3 (II) shows fragment-and-replicate schemes.
Consider processors are P0, 0, P0, 1, . . ., P0, m−1, P1,0, . . ., Pn−1, m−1. Processor Pi, jperforms the join of ri with sj. Each processor must get the tuples in the partitions it works on. To do this the system replicates ri to processors Pi,0, Pi,1, . . .,Pi, m−1, and replicates si to processors P0, i, P1, i, . . ., Pn−1, i. Any join technique is used at each processor Pi, j. Fragment and replicate works with any join condition and every tuple in r can be tested with every tuple in s. Therefore, it can be used where partitioning cannot be.
Partitioned Parallel Hash–Join
Consider that n processors, P0, P1, . . ., Pn−1, and two relations r and s, such that the relations r and s are partitioned across several disks.
Choose a hash function h1 which accept the join attribute value for each tuple in r and s and maps the tuple to 1 of the n processors. Suppose ri represents the tuples of relation r that are mapped to processor Pi. Same as si denote the tuples of relation s that are mapped to processor Pi. Each processor Pi reads the tuples of s that are on its disk Di, and sends each tuple to the actual processor on the premise of hash function h1.
The destination processor Pi get the tuples of si, then it partitions with help of another hash function, h2, which the processor uses to compute the hash–join locally. The partitioning at this level is same as within the partitioning phase of the sequential hash–join algorithm. Every processor Pi executes this step independently from the opposite processors.
Once the tuples of s have been distributed, the system redistributes the larger relation r across the m processors by the hash function h1. Because it receives each tuple, the destination processor repartitions it by the function h2 same like probe relation is partitioned within the sequential hash–join algorithm.
Every processor Pi executes the build and probe phases of the hash–join algorithm on the local partitions like ri and si of r and s relation for a partition of the end output of the hash–join.
The hash–join at each processor isn’t depends on other processors, and receiving the tuples of ri and si is same as reading them from disk. Therefore, any of the optimizations of the hash–join described in Query Processing be applied to the parallel case. We will use the hybrid hash–join algorithm to cache some of the incoming tuples in memory, and avoid the price of writing them and of reading they back in.
Parallel Nested-Loop Join
To show the utilization of fragment-and-replicate–based parallelization, consider the case where the relation s is smaller than relation r. Suppose that relation r is stored by partitioning and also the attribute on which it is partitioned does not consider. Suppose there is an index on a join attribute of relation r at each of the partitions of relation r.
Using the asymmetric fragment and replicate, with help of relation s is replicated and also use the existing partitioning of relation r. Every processor Pj partition of relation s is stored reads the tuples of relation s stored in Dj, and replicates the tuples to other processor Pi. At the top relation s is replicated at all sites that store tuples of relation r.
Every processor Pi performs an indexed nested-loop join of relation s with the ith partition of relation r. We are able to overlap the indexed nested-loop join with the distribution of tuples of relation s, to beat the price of writing the tuples of relation s to disk, and of reading them again. Therefore, the replication of relation s must be synchronized with the join so there is sufficient space within the in-memory buffers at each processor Pi to carry the tuples of relation s that received but not utilize the join.
Other Relational Operations
The evaluation of other relational operations also can also be parallelized:
Selection
Let the selection be σθ(r). Consider first case within which θ is in form ai = v, where ai is an attribute and v are a value. If the relation r is divided on ai, the selection proceeds at a single processor. If θ is of the form l ≤ ai ≤ u that is, θ is a range selection and the relation has been range partitioned on ai, then the selection proceeds at each processor whose partition overlaps with the specified range of values. In all other cases, the selection proceeds in parallel at all the processors.
Duplicate elimination
Duplicates can be removed with help of sorting. In that the parallel sort techniques are used to minimizes duplicates as soon as they appear during sorting. We also parallelize duplicate overcome by partitioning the tuple and overcome the duplicates locally at every processor.
Projection
Projection without duplicate elimination is performed as tuples are read in the form of disk in parallel.
Aggregation
Consider an aggregation operation. We can parallelize the operation by partitioning the relation on the grouping attributes, and then computing the aggregate values locally at each processor. Either hash partitioning or range partitioning can be used.
We can minimize the cost of transferring tuples in partitioning by partly computing aggregate values before partitioning, at least for used aggregate functions. Consider an aggregation operation on a relation r, using the sum aggregate function on attribute B, with grouping on attribute A.
The system performs the operation at every processor Pi on those r tuples stored on disk Di. This computation results in tuples with partial sums at each processor in that there is one tuple at Pi for each value for attribute A present in r tuples stored on Di. The system partitions the result of the local aggregation on the grouping attribute A, and performs the aggregation again at every processor Pi to induce the result at end.
Cost of Parallel Evaluation of Operations
Parallelism is achieved by partitioning the I/O on multiple disks, and partitioning the CPU work among several processors. If such distribution is achieved with none overhead, and if there is no skew in the splitting of work, a parallel operation using n processors will take 1/n times because the same operation on one processor.
The time cost of parallel processing is 1/n of the time cost of sequential processing of the operation. Consider account for the following costs:
Startup costs for performing the operation at multiple processors
Skew in the splitting of work among the processors, with some processors getting a larger number of tuples than others
Contention for resources like memory, disk, and the communication network resulting in delays
Cost of assembling the final result by transferring partial results from each processor
The time taken by a parallel operation is calculated as Tpart + Tasm +max (T0, T1, . . ., Tn−1) where Tpart is the time for partitioning the relations, Tasm is the time required for assembling the results and Ti the time taken for the operation at processor Pi. Consider that the tuples are distributed without any skew, the number of tuples sent to each processor is calculated as 1/n of the total number of tuples. The cost Ti of the operations at each processor Pi is calculated by the techniques in Query Processing.
Interoperation Parallelism
There are two types of interoperation parallelism such as pipelined parallelism, and independent parallelism.
A. Pipelined Parallelism
Pipelining is an important source of economy of computation for database query processing. In pipelining, the output tuples of one operation, A, are consumed by a second operation, B before the first operation has produced the entire set of tuples in its output. The benefit of pipelined execution in a sequential evaluation is that we can carry out a sequence of operations without writing any of the intermediate results to disk.
Pipelines is a base of parallelism in the same way that instruction pipelines are a source of parallelism in hardware design also. It is possible to run operations A and B at same time on multiple processors, so that B consumes tuples in parallel and A producing them. This process of parallelism is called pipelined parallelism.
Consider a join of four relations:
r1 ⋈ r2 ⋈ r3 ⋈ r4
Pipeline allows the three joins to be performed in parallel. Suppose processor P1 is assigned the computation of temp1 ← r1 ⋈ r2, and P2 is assigned the computation of r3 ⋈ temp1. As P1 computes tuples in r1 ⋈ r2, it makes these tuples available to processor P2.
Therefore, P2 is available to some of the tuples in r1 ⋈ r2 before P1 has finished its computation. P2 use tuples are available to start computation of temp1 ⋈ r3, even before r1 ⋈ r2 is fully computed by P1. Same as P2 computes tuples in (r1 ⋈ r2) ⋈ r3, it provides these tuples to P3, which computes the join of these tuples with r4.
Pipelined parallelism is used with a minimum number of processors, but does not scale up as needed. First pipeline chains do not have sufficient length to provide a high degree of parallelism. Second, it is not possible to pipeline relational operators which not produce output until all inputs are accessed like set-difference operation. Third, only marginal speedup is used for the frequent cases in this one operator’s execution cost is higher than others.
B. Independent Parallelism
Operations in a query expression is not depend on one another and executed in parallel. This form of parallelism is known as independent parallelism. Suppose join r1 ⋈ r2 ⋈ r3 ⋈ r4. We can compute temp1 ← r1 ⋈ r2 in parallel with temp2 ← r3 ⋈ r4. When these two computations complete, we compute temp1 ⋈ temp2.
To obtain parallelism need to pipeline the tuples in temp1 and temp2 into the computation of temp1 ⋈ temp2, which is itself performed by a pipelined join. Independent parallelism is also not providing a high degree of parallelism, and is less useful in a highly parallel system, it is useful with a lower degree of parallelism.
Query Optimization
Query optimizers used in large measure for the success of relational technology. Query optimizers for parallel query evaluation are not less complicated than query optimizers for sequential query evaluation. First, the cost models are more complicated, since partitioning costs have to be accounted for, and issues like skew and resource contention is considered. How to parallelize a query is a main issue. Consider that we have somehow selected an expression to be used for evaluating the query.
To evaluate an operator tree in a parallel system, we need make the following decisions:
How to parallelize each operation, and how many processors to use for it
What operations to pipeline in multiple processors, what operations to execute independently in parallel, and what operations to execute sequentially, one after the other
These decisions perform the task of scheduling the execution tree. Determining the resources like processors, disks, and memory that should be allocated to each operation in the tree is another aspect of the optimization problem. For movement it may appear to use the maximum amount of parallelism but it is a best idea not to execute some operations in parallel.
Operations computational needs are minimum than the communication overhead should be clustered with one of their neighbors. One concern is that long pipelines do not lend itself to good resource utilization. Unless the operations are coarse grained, the final operation of the pipeline may wait for a long time to get inputs, while holding precious resources like memory. Therefore, long pipelines is avoided.
Optimizing parallel queries by is highly expensive than optimizing sequential queries. Therefore, we adopt heuristic approaches to minimize the number of parallel execution plans that we consider. There are two popular heuristics are present.
The first heuristic is to consider only evaluation plans that parallelize every operation across all processors, and that do not use any pipelining. This concept is used in the Teradata DBC series machines. Finding the best execution plan is like doing query optimization in a sequential system. The main differences are that in how the partitioning is performed and what cost-estimation formula is used. The second heuristic is to select the most efficient sequential evaluation plan, and then to parallelize the operations in that evaluation plan. The Volcano parallel database popularized a model of parallelization called the exchange-operator model.
This model uses existing implementations of operations, operating on local copies of data, coupled with an exchange operation in that moves data around between different processors. Exchange of operators is introduced into an evaluation plan to convert into a parallel evaluation plan.
Another dimension of optimization is the design of physical-storage organization to increase the speed of queries. The optimal physical organization is changeable for several queries. The database administrator needs to select a physical organization that present to be good for the expected mix of database queries. Therefore, the area of parallel query optimization is complex and it is also used for active research.
1.5.4 Design of Parallel Systems
Large-scale parallel database systems are used for storing large volumes of data, and for processing decision-support queries on those data, these topics are the very important in a parallel database system. Parallel loading of data from external sources is an important need, if we handle large volumes of incoming data.
A large parallel database system addresses following types of availability issues:
Resilience to failure of some processors or disks
Online reorganization of data and schema changes
With help of large number of processors and disks, the probability that at least one processor or disk will malfunction is larger than in a single-processor system with one disk. A poorly designed parallel system will stop functioning if any component is fails. Consider that the probability of failure of a single processor or disk is minimum then the probability of failure of the system goes high linearly with the number of processors and disks.
If a single processor or disk would fail in every 5 years, a system with 100 processors would have a failure every 18 days. Therefore, large-scale parallel database systems like Compaq Himalaya, Teradata, and Informix XPS, are designed to operate even if a processor or disk fails. Data are replicated across at least two processors. If a processor fails, the data that it stored can still be accessed from the other processors. The system keeps track of failed processors and distributes the work between functioning processors.
Requests for data stored at the failed site are automatically routed to the backup sites that store a replica of the data. If all the data of a processor A are replicated at a single processor B, B will have to handle all the requests to A as well as those to itself, and that will result in B becoming a bottleneck. Therefore, the replicas of the data of a processor are partitioned with respect to multiple other processors.
When working is based on large volumes of data, simple operations like creating indices, and changes to schema like inserting a column to a relation, required long time. Therefore, it is unacceptable for the database system to be unavailable while these operations are in progress. Many parallel database systems, such as the Compaq Himalaya systems support such operations to be performed online until the system is executing other transactions.
Consider, for instance, online index construction. A system which supports this feature allows insertions, deletions, and updates on a relation even as an index is being built on the relation. The index-building operation therefore cannot lock the whole relation in shared mode. Instead, the process keeps track of updates that occur while it is active, and incorporates the changes into the index being constructed
In parallel systems processors are tightly coupled and used a single database system therefore a distributed database system is a loosely coupled site which does not share physical components. Therefore, the database systems which are run on every site have a substantial degree of mutual independence.
Each site takes a part in the execution of transactions that access data at one site, or multiple sites. The main difference between centralized and distributed database systems is that the data presented in one single location and several locations. This distribution of data is the cause of several difficulties in transaction processing and query processing.
Distributed databases system is classified as homogeneous or heterogeneous.
Homogeneous and Heterogeneous Databases
In a homogeneous distributed database, all sites have unique database management system software in which databases are known to one another, and ready to processing users requests. In these type of databases local sites grabs a portion of their autonomy in terms of their right to change method or database management system software.
That software work with other sites for interchanging data related to transactions, to make transaction processing possible over the multiple sites. This type of database with multiple sites use different schemas, and multiple database management system software. The sites may not be aware of one another, and they provide only limited facilities for cooperation in transaction processing. The differences in schemas are a big problem for query processing and the divergence in software is a hindrance for processing transactions that access many sites.
1.6.1 Distributed Data Storage
Consider a relation r which is stored in the database. There are two methods to storing this relation in the distributed database:
Replication
The system maintains multiple identical replicas of the relation, and stores each replica at a different site. The alternative to replication is to store only one copy of relation r.
Fragmentation
The system partitions the relation into multiple fragments, and stores every fragment at a different site.
Fragmentation and replication are mix that A relation is partitioned into multiple fragments and there may be multiple replicas of each fragment.
Data Replication
If relation r is replicated, a copy of relation r is stored on multiple sites. In some cases we have full replication, in which a copy is stored in every site in the system. There are a many advantages and disadvantages to replication.
Availability
If one of the sites consist of relation r fails, then the relation r is found in another site. Therefore, the system can continue to process queries involving r, despite the failure of one site.
Increased parallelism
In this majority of accesses to the relation r result in only the reading of the relation, then multiple sites can process queries containing r in parallel. The more replicas of r there are, the greater the chance to find needed data in the site where the transaction is executing. Therefore, data replication reduce the movement of data between sites.
Increased overhead on update
The system must consider that all replicas of a relation r are consistent; otherwise, erroneous computations may result. Whenever r is updated, the update must be propagated to all sites containing replicas. The result is increased overhead. For example, in a banking system the account information is replicated in many sites, it is need to ensure that the balance in a particular account agrees in all sites.
Replication boost the performance of read operations and increases the availability of data which is related to read-only operations. Therefore, update transactions produce greater overhead. Controlling concurrent updates with the help of multiple transactions to replicated data is more complex than in centralized systems. We can simplify the management of replicas of relation r by selecting one of them as the primary copy of r. Consider the example of banking in which account is related with the site in that account is opened. Same as in an airline reservation system, a flight is related with the site at which the flight originates.
Data Fragmentation
If relation r is fragmented, r is divided into many fragments like r1, r2, . . ., rn. These fragments contain sufficient information to allow reconstruction of the original relation r. There are two different technique for fragmenting a relation: horizontal fragmentation and vertical fragmentation. Horizontal fragmentation divides the relation with related to every tuple of r to multiple fragments. Vertical fragmentation divides the relation by decomposing the scheme R of relation r. Consider account schema
Account-schema = (account-number, branch-name, balance)
In horizontal fragmentation the relation r is divided into a number of subsets, r1, r2, . . ., rn. Each tuple of relation r is from at least one of the fragments, so that the original relation can be reconstructed, if needed. The account relation can be divided into multiple different fragments, each consists of tuples of accounts belonging to a particular branch.
If the banking system has only two branches Hillside and Valleyview then there are two different fragments:
account1 = σbranch-name = “Hillside” (account)
account2 = σbranch-name = “Valleyview” (account)
Horizontal fragmentation is used to maintain the tuples at the sites where they are used to reduce data transfer. A horizontal fragment is defined as a selection on the global relation r. In that we use a predicate Pi to construct fragment ri:
ri = σPi (r)
We reconstruct the relation r by taking the union of all fragments like
r =r1 ∪ r2 ∪···∪ rn
In example, the fragments are disjoint. By changing the selection predicates used to construct the fragments, we can have a particular tuple of r present in more than one of the ri. The vertical fragmentation is the same as decomposition. Vertical fragmentation of r(R) contains the definition of multiple subsets of attributes R1, R2, . . ., Rn of the schema R so that
R=R1 ∪ R2 ∪···∪ Rn
Each fragment ri of r is defined by
ri = ΠRi (r)
The fragmentation should be done like we can reconstruct relation r from the fragments by taking the natural join
r=r1 ⋈ r2 ⋈ r3 ⋈···⋈ rn
In vertical fragmentation, consider the example of company database with a relation employee-data it stores data of employee like empid, name, designation, salary etc. For security this relation is divided into a relation empprivate data contains empid and salary, and another relation emppublic-data consist of attributes empid, name, and designation. These are stored at multiple sites for security purpose.
The two types of fragmentation which are used with a single schema; for instance, the fragments achieved by horizontally fragmenting a relation which is afterword’s partitioned vertically. Fragments are also be replicated.
Transparency
The user of a distributed database system not need to know either where the data are physically located or how the data can be accessed at the specific local site.
This characteristic, called data transparency, can take several forms:
Fragmentation transparency
Users are not required to know how a relation has been fragmented.
Replication transparency
Users view each data object as logically unique. The distributed system replicate object to enhance system performance or data availability. Users do not need to worry about what data objects have been replicated, or where replicas are placed.
Location transparency
Users are not need to aware about the physical location of the data. The distributed database system should be able to find any data as long as the data identifier is supplied by the user transaction.
Data items like relations, fragments, and replicas required unique names. This property is very easy to apply in a centralized database. In a distributed database need to take care of two sites do not use the same name for unique data items.
One solution to this problem is to need all names to be registered in a central name server. The name server helps to make that the same name not used for different data items. Sometimes we use the name server to locate a data item, given the name of the item. This technique has two disadvantages.
First drawback is name server’s performance is bottleneck when data items are located by their names, resulting in poor performance. Second, if the name server crashes, it is not possible for any site in the distributed system to continue to run.
The solution is that each site prefixes its own site identifier to any name that it generates. This says no two sites generate the same name. Therefore, no central control is required. This solution fails to achieve location transparency, since site identifiers are attached to names. The account relation is referred to as site17.account, or account@site17. Many database systems use the internet address of a site to identify it.
To reduce this problem, the database system can create a set of alternative names or aliases for data items. A user refers to data items by simple names that are translated by the system to complete names. The mapping of aliases to the real names can be stored at each site. With help of aliases, the user is unknown of the physical location of a data item. Therefore, the user will be unaffected if the database administrator decides to transfer a data item from one site to another.
Users not need to refer to a specific replica of a data item. Instead, the system should identify which replica to reference on a read request, and update all replicas on a write request. There is no need to maintaining a catalog table, which the system uses to find out all replicas for the data item.
1.6.2 Distributed Transactions
Access to the various data items in a distributed system is possible with help of transactions, which need to preserve the ACID properties. There are two types of transaction. The local transactions are those that access and update data in only one local database; the global transactions are those that access and update data multiple local databases.
Consider the ACID properties of the local transactions used for global transactions, this task is most complicated because multiple sites may be participating in execution. The failure of one of these sites, or the failure of a communication link connecting these sites, may result in erroneous computations.
System Structure
Every site required its own local transaction manager which perform the ACID properties of those transactions that execute at that site. The several transaction managers cooperate to execute global transactions. To understanding implementation, consider an abstract model of a transaction system, in that each site contains two subsystems:
The transaction manager manages the execution of transactions that access data stored in a local site. Such transaction can be either a local transaction or part of a global transaction.
The transaction coordinator coordinates the execution of the several transactions initiated at that site.
The overall system architecture shown in following Figure.
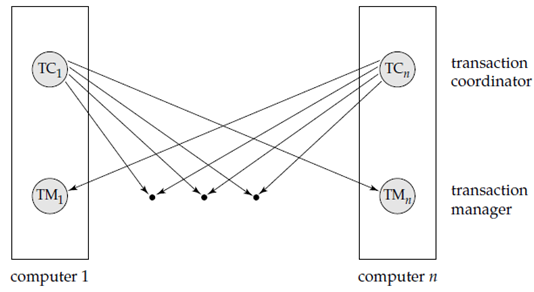
Figure 1.6.2(I) shows system architecture.
The structure of a transaction manager is same as to the structure of a centralized system. Every transaction manager is responsible for
Maintaining a log record for recovery purposes
Participating in particular concurrency-control scheme to coordinate the concurrent execution of the transactions executing at that site. There is need to modify both the recovery and concurrency schemes to perform the distribution of transactions.
The transaction coordinator subsystem is not needed in the centralized environment and a transaction use data at only a single site. A transaction coordinator is responsible for coordinating the execution of all the transactions initiated at that site. For all these transactions, the coordinator is responsible for
Starting the execution of the transaction
Breaking the transaction into a number of sub transactions and distributing these into the particular sites for execution
Managing the termination of the transaction, because of this the transaction is committed at all sites or aborted all sites
System Failure Modes
In distributed system same types of failure occur that a centralized system does same as software errors, hardware errors, or disk crashes. There are additional types of failure with which we need to handle in a distributed environment. The basic types of failure are
Failure of a site
Loss of messages
Failure of a communication link
Network partition
The loss of messages is always a presented in a distributed system. The system uses transmission-control protocols, like TCP/IP, to handle these types of errors.
If two sites A and B are not directly connected, messages from one to the other must be routed through a sequence of communication links. If a communication link fails then the data transmitted over the link need to rout again. In some cases, it is possible to find another route via the network, so that the messages reach to their destination. In other cases, a failure may result in there being no connection between some pairs of sites. A system is partitioned if it has been divided into two subsystems, called partitions that lack any connection between them.
1.6.3 Commit Protocols
To achieve atomicity, all the sites in which a transaction T executed need to agree on the final outcome of the execution. T need to be committed at all sites, or it must abort at all sites. To achieve this the transaction coordinator of T must execute a commit protocol.
Most widely used and simplest commit protocols is the two-phase commit protocol (2PC). The three-phase commit protocol (3PC) minimize some disadvantages of the 2PC protocol but adds to complexity and overhead.
A. Two-Phase Commit
Consider a transaction T initiated at site Si and the Ci is a transaction coordinator.
The Commit Protocol
When transaction T completes its execution then all the sites at which T has executed inform Ci that T has completed and Ci starts the 2PC protocol.
Phase1. Ci adds the record<prepare T> to the log, and forces the log onto stable storage. It then sends a prepare T information to all sites where T executed. On receiving these messages, the transaction manager at that site identify whether it is ready to commit its portion of T. If the answer is no then it adds a record <no T> to the log, and then responds by sending an abort T message to Ci. If the answer is yes, it adds a record <ready T> to the log, and forces the log onto stable storage. The transaction manager replies with a ready transaction T message to Ci.
Phase2. When Ci receives responses to perform T message from all the sites, or when already specified interval of time has elapsed then the prepare T message is sent out, Ci can identify whether the transaction T is committed or aborted. Transaction T can be committed if Ci received a ready T message from all the participating sites. Otherwise, transaction T must be aborted. Depending on the verdict a record <commit T> or a record<abort T> is added to the log and the log is forced onto stable storage.
The coordinator sends either a commit T or an abort T message to all participating sites. When a site receives a message after that it records the message in the log record.
A site at which T executed can unconditionally abort T at any time before it sends the message ready T to the coordinator. When the message is sent, the transaction in the ready state at the site. The ready T message is, in effect follow the coordinator’s order to commit T or to abort T. To make such a promise, the required data must first be stored in stable storage. Otherwise, if the site crashes after sending ready T. The locks acquired by the transaction need continue to be held until the transaction completes.
Handling of Failures
The 2PC protocol performed in different ways to several types of failures:
Failure of a participating site
If the coordinator Ci finds that a site has failed, it perform following actions such as If it fails before responding with a ready T message to Ci then the coordinator assume that it responded with an abort T message. If the site fails after the coordinator has received the ready T message from the site, the coordinator executes the remaining commit protocol in the normal way, ignoring the failure of the site.
When a participating site Sk recovers from a failure, it needs to manage its log to search the fate of these transactions which are in the middle of execution when the failure occurred. Consider T is a transaction. We study each of the possible cases:
The log contains a <commit T> record. During this case, the site executes redo(T).
The log contains an<abort T>record. During this case, the site executes undo(T).
The log contains a <ready T> record. In which the site need to consult Ci to find out the fate of T. If Ci is up, it notifies Sk regarding whether T committed or aborted. In the former case, it executes redo(T).
If Ci is down, Sk need to find the fate of T from other sites. It performed by sending a query status T message to all the sites in the system. On receiving these messages, a site must consult its log to identify whether T has executed there, and if T has, whether T committed or aborted. It then notifies Sk about this outcome.
If no site has the actual information, then Sk neither abort nor commit T. The choice concerning T is postponed until Sk can obtain the needed information. Thus, Sk must periodically resend the query status message to the other sites. It continues to until a site which contains the needed information recovers.
The log contains no control records like abort, commit, ready related with T.
Therefore, the Sk failed before responding to the prepare T message from Ci. Since the failure of Sk precludes the sending of such a response, by our algorithm Ci need to abort T. Hence, Sk must execute undo (T).
Failure of the coordinator
If the coordinator fails in middle of the execution of the commit protocol for transaction T, then the participating sites need decide the fate of T. In some cases, the participating sites cannot decide whether to commit or abort T, and thus these sites need to wait for the recovery of the failed coordinator.
If an active site contains a <commit T> record in its log, then T must be committed.
If an active site contains an <abort T> record in its log, then T must be aborted.
If some active site does not contain a <ready T> record in its log, then the failed coordinator Ci cannot have decided to commit T, because a site that does not have a <ready T> record in its log cannot have sent a ready T message to Ci. However, the coordinator may have decided to abort T, but not to commit T. Rather than wait for Ci to recover, it is preferable to abort T.
If none of the preceding cases holds, then all active sites must have a <ready T> record in their logs, but no additional control records (such as <abort T> or <commit T>). Since the coordinator has failed, it's impossible to work out whether a choice has been made, and if one has, what that call is, until the coordinator recovers. Thus, the active sites must await Ci to recover. Since the fate of T remains unsure, T may still hold system resources.
Network partition
When a network partitions, two possibilities exist:
The coordinator and all its participants remain in one partition. Case, the failure has no effect on the commit protocol.
The coordinator and its participants belong partitions. From of the sites in the partitions, it appears that the sites in other partitions have failed. Sites that partition containing the coordinator simply execute the protocol to failure of the coordinator.
The coordinator sites that are same partition coordinator follow commit protocol, assuming that the sites other partitions have failed. Thus, disadvantage of the 2PC protocol is that coordinator failure may blocking, where either to commit or to abort T may be postponed until Ci recovers.
Recovery and Concurrency Control
Recovery and Concurrency Control When a failed site restarts, perform recovery by using, the recovery algorithm. To deal with distributed commit protocols, the recovery procedure must treat in-doubt transactions specially; in-doubt transactions are transactions for which a <ready T> log record is found, but neither a <commit T> log record nor an <abort T> log record is found.
The recovering site need to determine the commit–abort status of such transactions by contacting other sites. If recovery is completed as just described, however, normal transaction processing at the location cannot begin until all in-doubt transactions are committed or rolled back.
Finding the status of in-doubt transactions are often slow, since multiple sites may need to be contacted. Further, if the coordinator has failed, and no other site has information about the commit–abort status of an incomplete transaction, recovery potentially could become blocked if 2PC is employed.
As a result, the location performing restart recovery may remain unusable for an extended period. To bypass this problem, recovery algorithms typically provide support for noting lock information within the log. Instead of writing a <ready T> log record, the algorithm writes a <ready T, L> log record, where L is a list of all write locks held by the transaction T when the log record is written. At recovery time, after performing local recovery actions, for every in-doubt transaction T, all the write locks noted in the <ready T, L> log record are reacquired.
After lock reacquisition is complete for all in-doubt transactions, transaction processing can start at the location, even before the commit–abort status of the in-doubt transactions is decided.
The commit or rollback of in-doubt transactions proceeds concurrently with the execution of latest transactions. Thus, site recovery is quicker, and never gets blocked. Note that new transactions that have a lock conflict with any write locks held by in-doubt transactions are going to be unable to form progress until the conflicting in-doubt transactions are committed or rolled back.
B. Three-Phase Commit
The three-phase commit (3PC) protocol is an extension of the two-phase commit protocol that avoids the blocking problem under certain assumptions. Especially, it's assumed that no network partition occurs, and less than k sites fail, where k is a few predetermined numbers.
Under these assumptions, the protocol avoids blocking by introducing an additional third phase where multiple sites are involved within the decision to commit. Rather than directly noting the commit decision in its persistent storage, the coordinator first ensures that a minimum of k other sites know that it intended to commit the transaction. If the coordinator fails, the remaining sites first select a replacement coordinator.
This new coordinator checks the status of the protocol from the remaining sites; if the coordinator had decided to commit, a minimum of one among the opposite k sites that it informed are going to be up and can make sure that the commit decision is respected. The new coordinator restarts the third phase of the protocol if some site knew that the old coordinator intended to commit the transaction.
Otherwise the new coordinator aborts the transaction. While the 3PC protocol has the desirable property of not blocking unless k sites fail, it's the disadvantage that a partitioning of the network will appear to be an equivalent as quite k sites failing, which might cause blocking.
The protocol also has got to be carefully implemented to make sure that network partitioning doesn't end in inconsistencies, where a transaction is committed in one partition, and aborted in another. Due to its overhead, the 3PC protocol isn't widely used.
Alternative Models of Transaction Processing
For many applications, the blocking problem of two-phase commit isn't acceptable. The matter here is that the notion of one transaction that works across multiple sites. to know persistent messaging consider how one might transfer funds between two different banks, each with its own computer.
One approach is to possess a transaction span the 2 sites, and use two-phase plan to ensure atomicity. However, the transaction may need to update the entire bank balance, and blocking could have a significant impact on all other transactions at each bank, since most transactions at the bank would update the entire bank balance.
In contrast, consider how fund transfer by a check occurs. The bank first deducts the quantity of the check from the available balance and prints out a check. The check is then physically transferred to the opposite bank where it's deposited. After verifying the check, the bank increases the local balance by the quantity of the check.
The check constitutes a message sent between the 2 banks. in order that funds aren't lost or incorrectly increased, the check must not be lost, and must not be duplicated and deposited quite once. When the bank computers are connected by a network, persistent messages provide an equivalent service because the check.
Persistent messages are messages that are guaranteed to be delivered to the recipient exactly once, regardless of failures, if the transaction sending the message commits, and are guaranteed to not be delivered if the transaction aborts. Database recovery techniques are wont to implement persistent messaging on top of the traditional network channels, as we'll see shortly. In contrast, regular messages could also be lost or may even be delivered multiple times in some situations.
Error handling is more complicated with persistent messaging than with two phase commits. As an example, if the account where the check is to be deposited has been closed, the check must be sent back to the originating account and credited back there. Both sites must therefore be given error handling code, alongside code to handle the persistent messages.
In contrast, with two-phase commit, the error would be detected by the transaction, which might then never deduct the quantity within the first place. the kinds of exception conditions which will arise depend upon the appliance, so it's impossible for the database system to handle exceptions automatically.
The appliance programs that send and receive persistent messages must include code to handle exception conditions and convey the system back to a uniform state. As an example, it's not acceptable to only lose the cash being transferred if the receiving account has been closed; the cash must be credited back to the originating account, and if that's impossible for a few reasons, humans must be alerted to resolve things manually.
There are many applications where the advantage of eliminating blocking is well worth the extra effort to implement systems that use persistent messages. In fact, few organizations would comply with support two-phase commit for transactions originating outside the organization, since failures could end in blocking of access to local data. Persistent messaging therefore plays a crucial role in completing transactions that cross organizational boundaries.
Workflows provide a general model of transaction processing involving multiple sites and possibly human processing of certain steps. as an example, when a bank receives anapplication, there are many steps it must take, including contacting external credit-checking agencies, before approving or rejecting anapplication.
Persistent messaging is often implemented on top of an unreliable messaging infrastructure, which can lose messages or deliver them multiple times, by these protocols:
Sending site protocol: When a transaction got to send a persistent message, it writes a record containing the message during a special relation messages to- send, rather than directly sending out the message. The message is additionally given a singular message identifier.
A message delivery process monitors the relation, and when a replacement message is found, it sends the message to its destination. The standard database concurrency control mechanisms make sure that the system process reads the message only after the transaction that wrote the message commits; if the transaction aborts, the standard recovery mechanism would delete the message from the relation.
The message delivery process deletes a message from the relation only after it receives an acknowledgment from the destination site. If it receives no acknowledgment from the destination site, after a while it sends the message again. It repeats this until an acknowledgment is received. Just in case of permanent failures, the system will decide, after some period of your time that the message is undelivered. Exception handling code provided by the appliance is then invoked to affect the failure.
Writing the message to a relation and processing it only after the transaction commits ensures that the message is going to be delivered if and as long as the transaction commits. Repeatedly sending it guarantees it'll be delivered albeit there are system or network failures.
Receiving site protocol: When a site receives a persistent message, it runs a transaction that adds the message to a special received-messages relation, provided it's not already present within the relation. After the transaction commits, or if the message was already present within the relation, the receiving site sends an acknowledgment back to the sending site.
1.6.4 Concurrency Control in Distributed Databases
We show here how a number of the concurrency-control schemes are often modified in order that they will be utilized in a distributed environment. We assume that every site participates within the execution of a commit protocol to make sure global transaction atomicity.
The protocols we describe during this section require updates to be done on all replicas of a knowledge item. If any site containing a reproduction of a knowledge item has failed, updates to the info item can't be processed. We describe protocols which will continue transaction processing in sites or links have failed, thereby providing high availability.
Locking Protocols
The various locking protocols introduced in concurrency-control are utilized in a distributed environment. The sole change that must be incorporated is within the way the lock manager deals with replicated data. We present several possible schemes that are applicable to an environment where data are often replicated in several sites. As in concurrency-control we shall assume the existence of the shared and exclusive lock modes.
1. Single Lock-Manager Approach
In the single lock-manager approach, the system maintains one lock manager that resides during a single chosen site say Si. All lock and unlock requests used at site Si. When a transaction must lock a knowledge item, it sends a lock request to Si. The lock manager determines whether the lock is often granted immediately.
If the lock is often granted, the lock manager sends a message thereto effect to the location at which the lock request was initiated. Otherwise, the request is delayed until it is often granted, at which era a message is shipped to the location at which the lock request was initiated. The transaction can read the info item from anybody of the sites at which a reproduction of the info item resides. Within the case of a write, all the sites where a reproduction of the info item resides must be involved within the writing.
The scheme has these advantages:
• Simple implementation. This scheme requires two messages for handling lock requests, and one message for handling unlock requests.
• Simple deadlock handling. Since all lock and unlock requests are made at one site, the deadlock-handling algorithms discussed in concurrency control are often applied on to this environment.
The disadvantages of the scheme are:
• Bottleneck. The location Si becomes a bottleneck, since all requests must be processed there.
• Vulnerability. If the location Si fails, the concurrency controller is lost. Either processing must stop, or a recovery scheme must be used in order that a backup site can take over lock management from Si.
2. Distributed Lock Manager
A compromise between the benefits and drawbacks are often achieved through the distributed lock-manager approach, during which the lock-manager function is distributed over several sites. Each site maintains an area lock manager whose function is to administer the lock and unlock requests for those data items that are stored therein site.
When a transaction wishes to lock data item Q, which isn't replicated and resides at site Si, a message is shipped to the lock manager at site Si requesting a lock. If data item Q is locked in an incompatible mode, then the request is delayed until it is often granted. Once it's determined that the lock request is often granted, the lock manager sends a message back to the initiator indicating that it's granted the lock request.
There are several other ways of handling replication of knowledge items. The distributed lock manager scheme has the advantage of straightforward implementation, and reduces the degree to which the coordinator may be a bottleneck. it's a fairly low overhead, requiring two message transfers for handling lock requests, and one message transfer for handling unlock requests. However, deadlock handling is more complex, since the lock and unlock requests are not any longer made at one site:
There could also be inter site deadlocks even when there's no deadlock within one site. The deadlock-handling algorithms discussed in must be modified, to detect global deadlocks.
3. Primary Copy
When a system uses data replication, we will choose one among the replicas because the primary copy. Thus, for every data item Q, the first copy of Q must reside in just one site, which we call the first site of when a transaction must lock a knowledge item Q, it requests a lock at the first site of Q. As before, the response to the request is delayed until it are often granted.
Thus, the first copy enables concurrency control for replicated data to be handled like that for un-replicated data. This similarity allows for an easy implementation. However, if the first site of Q fails, Q is inaccessible, albeit other sites containing a reproduction could also be accessible.
4. Majority Protocol
The majority protocol works this way: If data item Q is replicated in n different sites, then a lock-request message must be sent to quite one-half of the n sites during which Q is stored. Each lock manager finds out whether the lock are granted immediately.
As before, the response is delayed until the request are often granted. The transaction doesn't operate Q until it's successfully obtained a lock on a majority of the replicas of Q. This scheme deals with replicated data during a decentralized manner, thus avoiding the drawbacks of central control. However, it suffers from these disadvantages,
Implementation
The bulk protocol is more complicated to implement than are the previous schemes. It requires 2(n/2 + 1) messages for handling lock requests, and (n/2 + 1) messages for handling unlock requests.
Deadlock handling
Additionally, to the matter of worldwide deadlocks thanks to the utilization of a distributed lock-manager approach, it's possible for a deadlock to occur albeit just one data item is being locked. As an illustration, consider a system with four sites and full replication. Suppose that transactions T1 and T2 want to lock data item Q in exclusive mode.
Transaction T1 may achieve locking Q at sites S1 and S3 and the transaction T2 may acquire locking Q at sites S2 and S4. Each then must wait to accumulate the third lock; hence, a deadlock has occurred. Luckily, we will avoid such deadlocks with relative ease, by requiring all sites to request locks on the replicas of a knowledge item within the same predetermined order.
5. Biased Protocol
The biased protocol is another approach to handling replication. The difference from the bulk protocol is that requests for shared locks are given more favorable treatment than requests for exclusive locks.
Shared locks
When a transaction must lock data item Q, it simply requests a lock on Q from the lock manager at one site that contains a reproduction of Q.
Exclusive locks
When a transaction needs to lock data item Q, it requests a lock on Q from the lock manager in the least sites that contain a reproduction of Q. As earlier the response to the request is delayed until it is often granted. The biased scheme has the advantage of imposing less overhead on read operations than does the bulk protocol.
This savings is particularly significant in common cases during which the frequency of read is far greater than the frequency of write. However, the extra overhead on writes may be a disadvantage. Furthermore, the biased protocol shares the bulk protocol’s drawback of complexity in handling deadlock.
6. Quorum Consensus Protocol
The quorum consensus protocol is a next version of the majority protocol. The quorum consensus protocol assigns each site a non-negative weight. It assigns read and write operations on an item x two integers, called read quorum Qr and write quorum Qw, that must satisfy the following condition, where S is the total weight of all sites at which x resides:
Qr + Qw > S and 2 * Qw > S
To execute a read operation required replicas must be read that their total weight is ≥ Qr. To execute a write operation, enough replicas must be written so that their total weight is ≥ Qw. The benefit of the quorum consensus approach is that it can permit the cost of either reads or writes to be selectively reduced by appropriately defining the read and write quorums.
For instance, with a little read quorum, reads got to read fewer replicas, but the write quorum are going to be higher, hence writes can succeed as long as correspondingly more replicas are available. Also, if higher weights are given to some sites, fewer sites got to be accessed for acquiring locks. In fact, by setting weights and quorums appropriately, the quorum consensus protocol can simulate the bulk protocol and therefore the biased protocols.
Time stamping
The idea using the time stamping scheme that every transaction is given a unique timestamp that the system uses choose the serialization order. Our first task, then, in generalizing the centralized scheme to a distributed scheme is to develop a scheme for generating unique timestamps. Then, the varied protocols can operate on to the non-replicated environment.
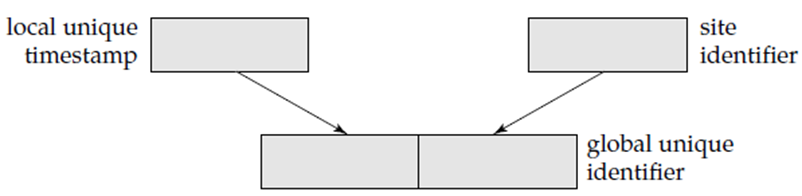
Figure Generation of unique timestamps.
There are two primary methods for produce unique timestamps, one centralized and other distributed. In the centralized scheme, a single site distributes the timestamps. The site can use a logical counter or its own local clock for this purpose. In the distributed system every site generates a unique local timestamp by using either a logical counter or the local clock.
There is a drag if one site generates local timestamps at a rate faster than that of the opposite sites. In such a case, the fast site’s logical counter is going to be larger than that of other sites. Therefore, all timestamps generated by the fast site are going to be larger than those generated by other sites. What we'd like a mechanism to identify that local timestamps are generated fairly across the system. We define within each site Si a logical clock (LCi), which generates the unique local timestamp.
The logical clock can be implemented as a counter that is incremented after a new local timestamp is generated. To ensure that the various logical clocks are synchronized, we require that a site Si advance its logical clock whenever a transaction Ti with timestamp<x, y> visits that site and x is greater than the current value of LCi.
If the system clock is employed to get timestamps, then timestamps are going to be assigned fairly, as long as no site features a system clock that runs fast or slow. Since clocks might not be perfectly accurate, a way almost like that for logical clocks must be wont to make sure that no clock gets far before or behind another clock.
Replication with Weak Degrees of Consistency
Many commercial databases today support replication, which may take one among several forms. With master–slave replication, the database allows updates at a primary site, and automatically propagates updates to replicas at other sites. Transactions may read the replicas at other sites, but aren't permitted to update them. a crucial feature of such replication is that transactions don't obtain locks at remote sites.
To ensure that transactions running at the replica sites see a uniform view of the database, the replica should reflect a transaction consistent snapshot of the info at the primary; that's , the replica should reflect all updates of transactions up to some transaction within the serialization order, and will not reflect any updates of later transactions within the serialization order.
The database could also be configured to propagate updates immediately after they occur at the first, or to propagate updates only periodically. Master–slave replication is especially useful for distributing information, as an example from a headquarters to branch offices of a corporation. Another use for this type of replication is in creating a replica of the database to run large queries, in order that queries don't interfere with transactions. Updates should be propagated periodically nightly, for instance in order that update propagation doesn't interfere with query processing.
The Oracle database system supports snapshot refresh, which may be done either by re-computing the snapshot or by incrementally updating it. Oracle supports automatic refresh, either continuously or at periodic intervals. With multi master replication updates are permitted at any replica of a knowledge item, and are automatically propagated to all or any replicas. This model is that the basic model won’t to manage replicas in distributed databases. Transactions update the local copy and therefore the system updates other replicas transparently.
Many database systems use the biased protocol, where writes need to lock and update all replicas and skim s lock and read anybody replica, as their currency-control technique. Many database systems provide an alternate sort of updating: They update at one site, with lazy propagation of updates to other sites, rather than immediately applying updates to all or any replicas as a part of the transaction performing the update.
Schemes supported lazy propagation allow transaction processing to proceed albeit a site is disconnected from the network, thus improving availability, but, unfortunately, do so at the value of consistency. One among two approaches is typically followed when lazy propagation is used:
• Updates at replicas are translated into updates at a primary site, which are then propagated lazily to all or any replicas. This approach ensures that updates to an item are ordered serially, although serializability problems can occur, since transactions may read an old value of another data item and use it to perform an update.
• Updates are performed at any replica and propagated to all or any other replicas. This approach can cause even more problems, since an equivalent data item could also be updated concurrently at multiple sites.
Some conflicts thanks to the shortage of distributed concurrency control are often detected when updates are propagated to other sites, but resolving the conflict involves rolling back committed transactions, and sturdiness of committed transactions is therefore not guaranteed. Further, human intervention could also be required to affect conflicts.
Deadlock Handling
The deadlock-prevention and deadlock-detection algorithms in Concurrency Control is used in a distributed system which provides modifications are made. For example, we will use the tree protocol by defining a worldwide tree among the system data items.
Similarly, the timestamp-ordering approach might be directly applied to a distributed environment. Deadlock prevention may end in unnecessary waiting and rollback. Furthermore, certain deadlock-prevention techniques may require more sites to be involved within the execution of a transaction than would rather be the case.
If we allow deadlocks to occur and believe deadlock detection, the most problem during a distributed system is deciding the way to maintain the wait-for graph. Common techniques for handling this issue require that every site keep an area wait-for graph. The nodes of the graph correspond to all or any the transactions that are currently either holding or requesting any of the things local thereto site.
For example, Figure shows a system containing two sites, each maintaining its local wait-for graph. Note that transactions T2 and T3 appear in both graphs, indicating that the transactions have requested items at both sites.
These local wait-for graphs are constructed within the usual manner for local transactions and data items. When a transaction Ti on site S1 needs a resource in site S2, it sends an invitation message to site S2. If the resource is held by transaction Tj , the system inserts a foothold Ti → Tj within the local wait-for graph of site S2.
Clearly, if any local wait-for graph features a cycle, deadlock has occurred. On the opposite hand, the very fact that there is not any t any cycles in any of the local wait-for graphs doesn't mean that there are no deadlocks. Forinstance, this problem, we consider the local wait-for graphs of Figure. Each wait-for graph is a cyclic; nevertheless, a deadlock exists within the system because the union of the local wait-for graphs contains a cycle. This graph appears in Figure.
Figure Local wait-for graphs.
Figure Global wait-for graph.
In the centralized deadlock detection approach, the system constructs and maintains a global wait-for graph in a single site: the deadlock-detection coordinator. There is communication delay in the system need to distinguish between two types of wait-for graphs. The real graph shows the real but unknown state of the system at any instance in time. The constructed graph is an approximation generated by the controller during the execution of the controller’s algorithm. The global wait-for graph can be reconstructed or updated under following conditions:
• Whenever a new edge is added in or removed from one of the local wait-for graphs.
• Periodically, when a number of changes have occurred in a local wait-for graph.
• When the coordinator required to invoke the cycle-detection algorithm.
When the coordinator invokes the deadlock-detection algorithm, it searches its global graph. If it finds a cycle, it selects a victim to be rolled back. The coordinator needs to notify all the sites that a particular transaction has been selected as victim. The sites, in turn, roll back the victim transaction. This scheme may produce unnecessary rollbacks if:
• False cycles present in the global wait-for graph. As shown in figure, consider a snapshot of the system represented by the local wait-for graphs of Figure. Suppose that T2 releases the resource that it is holding in site S1, resulting in the deletion of the edge T1 → T2 in S1.
Transaction T2 requests a resource held by T3 at site S2, resulting in the addition of the edge T2 → T3 in S2. If the insert T2 → T3 message from S2 arrives before the remove T1 → T2 message from S1, the coordinator may discover the false cycle T1 → T2 → T3 after the insert Deadlock recovery may be initiated therefore no deadlock has occurred.
1.6.5 Distributed Query Processing
The need for distributed query processing originally arose when organizations needed to execute queries across multiple databases that were often geographically distributed. However, today the same need arises because organizations have data stored in multiple different databases and data storage systems, and they need to execute queries that access multiples of these databases and data storage systems.
Data Integration from Multiple Data Sources
Different parts of an enterprise may use different databases, either because of a legacy of how they were automated, or because of mergers of companies. Migrating an entire organization to a common system may be an expensive and time-consuming operation.
An alternative is to keep data in individual databases, but to provide users with a logical view of integrated data. The local database systems may employ different logical models, different data-definition and data-manipulation languages, and may differ in their concurrency-control and transaction-management mechanisms.
Some of the sources of data may not be full-fledged database systems but may instead be data storage systems, or even just files in a file system. Yet another possibility is that the data source may be on the cloud and accessed as a web service. Queries may need access to data stored across multiple databases and data sources.
Manipulation of information located in multiple databases and other data sources requires an additional software layer on top of existing database systems. This layer creates the illusion of logical database integration without requiring physical database integration and is sometimes called a federated database system.
Database integration can be done in several different ways:
•The federated database approach creates a common schema, called a global schema, for data from all the databases/data sources; each database has its own local schema. The task of creating a unified global schema from multiple local schemas is referred to as schema integration.
Users can issue queries against the global schema. A query on a global schema must be translated into queries on the local schemas at each of the sites where the query has to be executed. The query results have to be translated back into the global schema and combined to get the final result.
In general, updates to the common schema also need to be mapped to updates to the individual databases; systems that support a common schema and queries, but not updates, against the schema are sometimes referred to as mediator systems.
• The data virtualization approach allows applications to access data from multiple databases/data sources, but it does not try to enforce a common schema. Users have to be aware of the different schemas used in different databases, but they do not need to worry about which data are stored on which database system, or about how to combine information from multiple databases.
• The external data approach allows database administrators to provide schema information about data that are stored in other databases, along with other information, such as connection and authorization information needed to access the data. Data stored in external sources that can be accessed from a database are referred to as external data. Foreign tablesare views defined in a database whose actual data are stored in an external data source.
Such tables can be read as well as updated, depending on what operations the external data source supports. Updates on foreign tables, if supported, must be translated into updates on the external data source.
Unlike the earlier-mentioned approaches, the goal here is not to create a full-fledged distributed database, but merely to facilitate access to data from other data sources. The SQL Management of External Data (SQL MED) component of the SQL standard defines standards for accessing external data sources from a database.
Schema and Data Integration
The first task in providing a unified view of data lies in creating a unified conceptual schema, a task that is referred to as schema integration. Each local system provides its own conceptual schema. The database system must integrate these separate schemas into one common schema. Schema integration is a complicated task, mainly because of the semantic heterogeneity. The same attribute names may appear in different local databases but with different meanings.
Schema integration requires the creation of a global schema, which provides a unified view of data in different databases. Schema integration also requires a way to define how data are mapped from the local schema representation at each database, to the global schema. This step can be done by defining views at each site which, transform data from the local schema to the global schema. Data in the global schema is then treated as the union of the global views at the individual site. This approach is called the global-as-view (GAV) approach.
Consider an example with two sites which store student information in two different ways:
• Site s1 which uses the relation student1 (ID, name, dept name), and the relation studentCreds (ID, tot cred).
• Site s2 which uses the relation student2 (ID, name, tot cred), and the relation studentDept (ID, dept name).
Let the global schema chosen be student (ID, name, dept name, tot cred).
Then, the global schema view at site s1 would be defined as the view: create view student s1(ID, name, dept name, tot cred) asselect ID, name, dept name, tot credfrom student1, studentCredswhere student1.ID= studentCreds.ID;
While the global schema view at site s2 would be defined as the view:
create view student s2(ID, name, dept name, tot cred) as select ID, name, dept name, tot cred from student2, studentDept where student2.ID= studentDept.ID;
Finally, the global schema student would be defined as the union of student s1 and student s2.
Query Processing Across Multiple Data Sources
A naive way to execute a query that accesses data from multiple data sources is to fetch all required data to one database, which then executes the query. But suppose, for example, that the query has a selection condition that is satisfied by only one or a few records out of a large relation.
If the data source allows the selection to be performed at the data source, it makes no sense to retrieve the entire relation; instead, the selectionoperation should be performed at the data source, while other operations, if any, maybe performed at the database where the query was issued.
In general, different data sources may support different query capabilities. For example, if the source is a data storage system, it may support selections on key attributes only. Web data sources may restrict which fields selections are allowed on and may additionally require that selections be present on certain fields.
On the other hand, if the source is a database that supports SQL, operations such as join or aggregation could be performed at the source and only the result brought over to the database that issues the query. In general, queries may divide and performed partly at the data source and partly at the site issuing the query.
The cost of processing a query that accesses several data sources is depends on the local execution costs and also on the data transfer cost. If the network has a low bandwidth wide-area network then attention is on minimizing data transfer.
Join Locations and Join Ordering
Consider the following relational-algebra expression:
r1 ⋈r2 ⋈r3
Consider that r1 is stored at site S1, r2 at S2, and r3 at S3. Let SI denote the site at which the query was issued. The system needs to produce the result at site SI. Among the possible strategies for processing this query are these:
• Ship copies of all three relations to site SI.
• Ship a copy of the r1 relation to site S2, and compute temp1 = r1 ⋈r2 at S2. Ship temp1 from S2 to S3, and compute temp2 = temp1 ⋈r3 at S3. Ship the result temp2 to SI.
• Devise strategies similar to the previous one, with the roles of S1, S2, and S3 exchanged.
There are several other possible strategies.
No one strategy is always the best one. Considering the multiple factors that must the volume of data being shipped, the cost of transmitting a block of data between a pair of sites, and the relative speed of processing at each site. Consider the first strategy.
Suppose indices present at S2 and S3 are useful for computing the join. If we ship all three relations to SI, we would need to either re-create these indices at SI or use a different, possibly more expensive, join strategy. Re-creation of indices entails extra processing overhead and extra disk accesses. There are many variants of the second strategy, which process joins in different orders.
The cost of each of the strategies depends on the sizes of the intermediate results, the network transmission costs, and the costs of processing at each node. The query optimizer needs to choose the best strategy, based on cost estimates.
Semijoin Strategy
Suppose that we want to evaluate the expression r1 ⋈r2, where r1 and r2 are stored at sites S1 and S2, respectively. Consider the schemas of r1 and r2 be R1 and R2. Suppose required the result at S1. If there are many tuples of r2 that do not join with any tuple of r1, then shipping r2 to S1 entails shipping tuples that fail to contribute to the result. We want to remove such tuples before shipping data to S1, particularly if network costs are high.
A possible strategy to accomplish all this is:
1. Compute temp1 ←ΠR1 ∩R2 (r1) at S1.
2. Ship temp1 from S1 to S2.
3. Compute temp2 ←r2 ⋈temp1 at S2.
4. Ship temp2 from S2 to S1.
5. Compute r1 ⋈temp2 at S1.The resulting relation is the same as r1 ⋈r2.
Before considering the efficiency of this strategy, let us verify that the strategy computes the correct answer. In step 3, temp2 has the result of
r2 ⋈ΠR1 ∩R2(r1).
In step 5, we compute: r1 ⋈r2 ⋈ΠR1 ∩R2(r1)
Since join is associative and commutative, we can rewrite this expression as:
(r1 ⋈ΠR1 ∩R2(r1)) ⋈r2
Since r1 ⋈Π(R1 ∩R2) (r1) = r1, the expression is, indeed, equal to r1 ⋈r2, the expression we are trying to evaluate.
This strategy is called a semijoin strategy, after the semijoin operator of the relational algebra. The natural semijoin of r1 with r2, denoted r1 ⋉r2, is defined as:
r1 ⋉r2 ≝ΠR1 (r1 ⋈r2)
Thus, r1 ⋉r2 selects those tuples of relation r1 that contributed to r1 ⋈r2. In step 3, temp2 = r2 ⋉r1. The semijoin operation is easily extended to theta-joins. The theta semijoin of r1 with r2, denoted r1 ⋉θr2, is defined as:
r1 ⋉θr2 ≝ΠR1 (r1 ⋈θr2)
For joins of several relations, the semijoin strategy can be extended to a series of semijoin steps. It is the job of the query optimizer to choose the best strategy based on cost estimates.
This strategy is particularly advantageous when relatively few tuples of r2 contribute to the join. This situation is likely to occur if r1 is the result of a relational-algebra expression involving selection. In such a case, temp2, that is, r2⋉r1, may have significantly fewer tuples than r2. The cost savings of the strategy result from having to ship only r2 ⋉r1, rather than all of r2, to S1.
Distributed Query Optimization
Several extensions need to be made to existing query optimization techniques in order to optimize distributed query plans.
The first extension is to record the location of data as a physical property of the data; recall that optimizers already deal with other physical properties such as the sort order of results. Just as the sort operation is used to create different sort orders, an exchange operation is used to transfer data between different sites.
The second extension is to track where an operator is executed; optimizers already consider different algorithms, such as hash join or merge join, for a given logical operator, in this case, the join operator. The optimizer is extended to additionally consider alternative sites for execution of each algorithm. Note that to execute an operator at a given site, its inputs must satisfy the physical property of being located at that site.
The third extension is to consider semijoin operations to reduce data transfer costs. Semijoin operations can be introduced as logical transformation rules; however, if done naively, the search space increases greatly, making this approach infeasible.
Optimization cost are often reduced by restricting, as a heuristic, semijoin to be applied only on database tables, and never on intermediate join results. A fourth extension is to use schema information to limit the set of nodes at which a question must be executed. Recall from Section 22.9.2 that the local-as-view approach are often wont to specify that a relation is partitioned during a particular way.
In the example we saw there, site s3 contains all student tuples with dept name being Comp. Sci., while s4 contains all the other student tuples. Suppose a query has a selection “dept name='Comp. Sci.'” on student; then, the optimizer should recognize that there is no need to involve site s4 when executing this query.
Distributed Directory Systems
A directory is a listing of information about some class of objects such as persons. Directories can be used to find information about a specific object, or in the reverse direction to find objects that meet a certain requirement. Several directory access protocols are developed to supply a uniform way of accessing data during a directory.
A very widely used distributed directory system is that the internet name Service (DNS) system, which provides a uniform thanks to map domain names (such as db-book.com or www.cs.yale.edu, to the IP addresses of the machines. The Lightweight Directory Access Protocol (LDAP) is another very widely used protocol designed for storing organizational data.
Data stored in directories can be represented in the relational model, stored in a relational database, and accessed through standard protocols such as JDBC or ODBC.
The question then is, why come up with a specialized protocol for accessing directory information? There are several reasons.
• First, directory access protocols are simplified protocols that cater to a limited type of access to data. They evolved in parallel with the database access protocol standards.
• Second, directory systems were designed to support a hierarchical naming system for objects, similar to file system directory names. Such a naming system is important in many applications. For example, all computers whose names end in yale.edu belong to Yale, while those whose names end in iitb.ac.in belong to IIT Bombay. Within the yale.edu domain, there are subdomains such as cs.yale.edu, which corresponds to the CS department in Yale, and math.yale.edu which corresponds to the Math department at Yale.
• Third, and most important from a distributed systems perspective, the data in a distributed directory system are stored and controlled in a distributed, hierarchical, manner.
Reference book
Reference link




