Unit -2
Object and object relational databases
The term object-oriented abbreviated by OO. Today Object Oriented concepts are applied within the areas like databases, software engineering, knowledge bases, AI, and computer systems. OOPLs have their roots within the SIMULA language, which was proposed within the late 1960s.
In SIMULA, the concept of a class groups together the interior arrangement of an object during a class declaration. Subsequently, researchers proposed the concept of abstract data type, which hides the interior data structures and specifies all possible external operations which will be applied to an object, resulting in the concept of encapsulation.
An object has two components: state (value) and behavior (operations). Hence, it's somewhat almost like a program variable during a programing language, except that it'll typically have a posh arrangement also as specific operations defined by the programmer.
Objects in an OOPL exist only during program execution and are hence called transient objects. An Object Oriented database extend the existence of objects in order that they're stored permanently, and the objects persist beyond program termination and may be retrieved later and shared by other programs.
One goal of OO databases is to take care of an immediate correspondence between real-world and database objects in order that objects don't lose their integrity and identity and may easily be identified and operated upon.
Another feature of OO databases is that objects may have an object structure of arbitrary complexity so as to contain all of the required information that describes the thing.
The internal structure of an object in OOPLs includes the specification of instance variables, which hold the values that outline the interior state of the thing. Hence, an instance variable is analogous to the concept of an attribute, except that instance variables could also be encapsulated within the thing and thus aren't necessarily visible to external users.
2.1.1 Object Identity
An OO database system provides a singular identity to every independent object stored within the database. This unique identity is usually implemented via a singular, system-generated object identifier, or OID. The worth of an OID isn't visible to the external user, but it's used internally by the system to spot each object uniquely and to make and manage inter-object references.
The main property required of an OID is that it's immutable; that’s, the OID value of a specific object shouldn't change. This maintain the identity of the real-world object being represented. Hence, an OO database system must have some mechanism for generating OIDs and preserving the immutability property. It’s also desirable that every OID be used only once; that’s, albeit an object is far away from the database, its OID shouldn't be assigned to a different object.
These two properties imply that the OID shouldn't depend upon any attribute values of the thing, since the worth of an attribute could also be changed or corrected. It’s also generally considered inappropriate to base the OID on the physical address of the thing in storage, since the physical address can change after a physical reorganization of the database.
However, some systems do use the physical address as OID to extend the efficiency of object retrieval. If the physical address of the thing changes, an indirect pointer are often placed at the previous address, which provides the new physical location of the thing. It’s more common to use long integers as OIDs then to use some sort of hash table to map the OID value to the physical address of the thing.
Some early OO data models required that everythingfrom an easy value to a posh object be represented as an object; hence, every basic value, like an integer, string, or Boolean value, has an OID. This enables two basic values to possess different OIDs, which may be useful in some cases. Forinstance, the integer value 50 are often used sometimes to mean a weight in kilograms and at other times to mean the age of an individual.
2.1.2 Object Structure
In OO databases, the state (current value) of a posh object could also be constructed from other objects by using certain type constructors. One formal way of representing such objects is to look at each object as a triple (i, c, v), where i may be a unique object identifier (the OID), c may be a type constructor, and v is that the object state. The info model will typically include several type constructors.
The three most elementary constructors are atom, tuple, and set. Other constructors contains list, bag, and array. The atom constructor is employed to represent all basic atomic values, like integers, real numbers, character strings, Booleans, and the other basic data types that the system supports directly.
The object state v of an object (i, c, v) is interpreted supported the constructor c. If c = atom, the state (value) v is an atomic value from the domain of basic values supported by the system. If c = set, the state v may be a set of object identifiers, which are the OIDs for a group of objects that are typically of an equivalent type. If c = tuple, the state v may be a tuple of the shape, where each is an attribute name an OID.
If c = list, the worth v is an ordered list of OIDs of objects of an equivalent type. An inventory is analogous to a group except that the OIDs during a list are ordered, and hence we will ask the primary, second, or object during a list. For c = array, the state of the thing may be a single-dimensional array of object identifiers.
The main difference between array and list is that an inventory can have an arbitrary number of elements whereas an array typically features a maximum size. The difference between set and bag is that each one elements during a set must be distinct whereas a bag can have duplicate elements.
EXAMPLE 1:
A Complex Object
We now represent some objects from the electronic database shown as following, using the preceding model, where an object is defined by a triple (OID, type constructor, state) and therefore the available type constructors are atom, set, and tuple. We use i1, i2,i3,….to stand for unique system-generated object identifiers. Consider the subsequent objects:
O1 =(i1, atom, 'Houston')
O2=(i2, atom, 'Bellaire')
O3 =(i3 , atom, 'Sugarland')
O4=(i4,atom,5)
O5=(i5,atom,’Research’)
O6=(i6,atom,’1998-5-22’)
O7=(i7,set,{i1,i2,i3})
EXAMPLE 2:
Identical Versus Equal Objects
A example can described the difference between the two definitions for comparing object states for equality. Consider the following objects
O1= (i1, tuple, <a1:i4 , a2:i6 >)
O2=(i2, tuple, <a1 :i5, a2:i6 >)
O3= (i3 , tuple, <a1:i4 , a2:i6 >)
O4 = (i4, atom, 10)
O5= (i5, atom, 10)
O6 =(i6 , atom, 20)
The objects O1 and O2 have equal states, since their states at the atomic level are an equivalent but the values are reached through distinct objects O4 and O5. However, the states of objects O1 and O3 are identical, albeit the objects themselves aren't because they need distinct OIDs. Similarly, although the states of O4 and O5 are identical, the particular objects O4 and O5 are equal but not identical, because they need distinct OIDs.
2.1.3 Type Constructors
An object definition language (ODL) that comes with the preceding type constructors are often wont to define the thing types for a specific database application. the sort constructors are often wont to define the info structures for an OO database schema. We use the keywords tuple, set, and list for the sort constructors, and therefore the available standard data types for atomic types.

Figure 2.1.3(I)specifying the thing types Employee, Date, and Department using type constructors.
Attributes that ask other objects such as dept of Employee or projects of Department are basically references to other objects and hence serve to represent relationships among the thing types. For instance, the attribute dept of Employee is of type Department, and hence is employed to ask a selected Department object.
The value of such an attribute would be an OID for a selected Department object. A binary relationship are often represented in one direction, or it can have an inverse reference. The latter representation makes it easy to traverse the connection in both directions. for instance , the attribute employees of Department has as its value a group of references (that is, a group of OIDs) to things of type Employee; these are the workers who work for the department. The inverse is that the reference attribute dept of Employee.
2.1.4 Encapsulation of Operations, Methods, and Persistence
The concept of encapsulation is one among the most characteristics of OO languages and systems. it's also associated with the concepts of abstract data types and knowledge hiding in programming languages. In traditional database models and systems, this idea wasn't applied, since it's customary to form the structure of database objects visible to users and external programs.
In these traditional models, variety of ordinary database operations are applicable to things of all kinds. For instance, within the relational model, the operations for choosing, inserting, deleting, and modifying tuples are generic and should be applied to any relation within the database. The relation and its attributes are visible to users and to external programs that access the relation by using these operations.
Specifying Object Behavior via Class Operations
The concepts of data hiding and encapsulation are often applied to database objects. The most idea is to define the behavior of a kind of object supported the operations which will be externally applied to things of that type. The interior structure of the thing is hidden, and therefore the object is accessible only through variety of predefined operations.
Some operations could also be wont to create or destroy objects; other operations may update the thing state; et al. could also be wont to retrieve parts of the thing state or to use some calculations. Still other operations may perform a mixture of retrieval, calculation, and update. Generally, the implementation of an operation are often laid out in a general-purpose programing language that gives flexibility and power in defining the operations.
The external users of the thing are only made conscious of the interface of the thing type, which defines the name and arguments of every operation. The implementation is hidden from the external users; it includes the definition of the interior data structures of the thing and therefore the implementation of the operations that access these structures.
In OO terminology, the interface a part of each operation is named the signature, and therefore the operation implementation is named a way. Typically, a way is invoked by sending a message to the thing to execute the corresponding method. Notice that, as a part of executing a way, a subsequent message to a different object could also be sent, and this mechanism could also be wont to return values from the objects to the external environment or to other objects.

Figure 2.1.4(I) Adding operations to the definitions of Employee and Department.
For database applications, the need that each one objects be completely encapsulated is just too stringent. a method of relaxing this requirement is to divide the structure of an object into visible and hidden attributes. Visible attributes could also be directly accessed for reading by external operators, or by a high-level command language. The hidden attributes of an object are completely encapsulated and may be accessed only through predefined operations. Most OODBMSs employ high-level query languages for accessing visible attributes.
Specifying Object Persistence via Naming and Reach ability
An OODBMS is usually closely including an OOPL. The OOPL is employed to specify the tactic implementations also as other application code. An object is usually created by some executing application, by invoking the thing constructor operation. Not all objects are meant to be stored permanently within the database. Transient objects exist within the executing program and disappear once the program terminates. Persistent objects are stored within the database and persist after program termination. The standard mechanisms for creating an object persistent are naming and reach ability.
The naming mechanism involves giving an object a singular persistent name through which it are often retrieved by this and other programs. All such names given to things must be unique within a specific database. Hence, the named persistent objects are used as entry points to the database through which users and applications can start their database access.
Obviously, it's not practical to offer names to all or any objects during a large database that has thousands of objects, so most objects are made persistent by using the second mechanism, called reach ability. The reach ability mechanism works by making the thing reachable from some persistent object. An object B is claimed to be reachable from an object A if a sequence of references within the object graph lead from object A to object B.

Figure 2.1.4(II) Creating persistent objects by naming and reach ability.
If we first create a named persistent object N, whose state is a set or list of objects of some class C, we will make objects of C persistent by adding them to the set or list, and thus making them reachable from N. Therefore N defines a persistent collection of objects of class C. For instance, we will define a class Department Set whose objects are of type set (Department). Suppose that an object of type Department Set is made, and suppose that it is named All Departments and thus made persistent.
Any Department object which is added to the set of All Departments by using the add_dept operation becomes persistent by virtue of its reachable from All Departments. The All Departments object is usually called the extent of the class Department, because it will hold all persistent objects of type Department. The ODMG ODL standard gives the schema designer the choice of naming an extent as a part of class definition.
The difference between traditional database models and OO databases during this respect. In traditional database models, like the relational model or the EER model, all objects are consider as persistent. Therefore when an entity type or class like EMPLOYEE is defined within the EER model, it represents both the type declaration for EMPLOYEE and a persistent set of all EMPLOYEE objects.
In the object oriented a class declaration of EMPLOYEE specifies only the type and operations for a class of objects. The user need to separately define a persistent object of type set(EMPLOYEE) or list(EMPLOYEE) whose value is the collection of references to all persistent EMPLOYEE objects, if this is desired. In fact, it is possible to define multiple persistent collections for the same class definition, if desired. This allows transient and persistent objects to follow the equivalent type and class declarations of the ODL and the OOPL.
2.1.5 Type Hierarchies and Inheritance
Another characteristic of OO database systems is it allow type hierarchies and inheritance. Type hierarchies in databases imply a constraint on the extents related to the types in the hierarchy. We use a different OO model in a model in which attributes and operations are treated uniformly since both attributes and operations can be inherited.
Type Hierarchies and Inheritance
In all database applications, there are numerous objects of the same type or class. Therefore OO databases need to provide an ability for classifying objects based on their type. But in OO databases, a further requirement is that the system permit the definition of new types depends on other predefined types, leading to a type (or class) hierarchy.
A type is defined by assigning it a type name and then defining a number of attributes and operations for the type. In some cases, the attributes and operations are collectively called functions, since attributes resemble functions with zero arguments. A function name is used to refer to the value of an attribute or to refer to the resulting value of an operation.
A type in its simplest form will be defined by giving it a type name and then listing the names of its visible functions. When specifying a type we use the following format, which does not specify arguments of functions, to simplify the discussion:
TYPE_NAME: function, function, . . . , function
For example, a type that shows the characteristics of a PERSON can be defined as follows:
PERSON: Name, Address, Birth date, Age, SSN
In the PERSON type, the Name, Address, SSN, and Birthdate functions are implemented as stored attributes and the Age function can be implemented as a method that calculates the Age from the value of the Birthdate attribute and the current date.
The concept of subtype is useful when the designer or user must create a new type which is similar but not identical to an already defined type. The subtype then inherits all the functions of the predefined type, which we call the supertype. For example consider that we want to define two new types EMPLOYEE and STUDENT as follows:
EMPLOYEE: Name, Address, Birth date, Age, SSN, Salary, HireDate, Seniority
STUDENT: Name, Address, Birth date, Age, SSN, Major, GPA
Since both STUDENT and EMPLOYEE contain all the functions defined for PERSON with some additional functions of their own, we will declare them to be subtypes of PERSON. Each will inherit the previously defined functions of PERSON namely, Name, Address, Birth date, Age, and SSN. For STUDENT, it’s only necessary to define the new (local) functions Major and GPA, which not inherited.
Presumably, Major are often defined as a stored attribute, whereas GPA could be also implemented as a way that calculates the student’s grade mark average by accessing the Grade values that are internally stored (hidden) within every STUDENT object as private attributes. For EMPLOYEE, the Salary and Hire Date functions are stored attributes, and Seniority could also be a way that calculates Seniority from the worth of Hire Date.
The idea of defining a kind contains defining all of its functions and implementing them as attributes or methods. When a subtype is defined, it can then inherit all of those functions and their implementations. Only functions that are specific or local to the subtype, and hence aren't implemented within the supertype, got to be defined and implemented. Therefore, we will declare EMPLOYEE and STUDENT as follows:
EMPLOYEE subtype-of PERSON: Salary, HireDate, Seniority
STUDENT subtype-of PERSON: Major, GPA
In general, a subtype includes all of the functions that are defined for its supertype plus some additional functions that are specific only to the subtype. Hence, it's possible to get a type hierarchy to point out the supertype/subtype relationships among all the kinds declared within the system.
As another example, consider a kind that describes objects in geometry, which can be defined as follows:
GEOMETRY_OBJECT: Shape, Area, Reference Point
For the GEOMETRY_OBJECT type, Shape is implemented as an attribute and Area is a method that is applied to calculate the area. Consider that we want to define a number of subtypes for the GEOMETRY_OBJECT type, as follows:
RECTANGLE subtype-of GEOMETRY_OBJECT: Width, Height
TRIANGLE subtype-of GEOMETRY_OBJECT: Side1, Side2, Angle
CIRCLE subtype-of GEOMETRY_OBJECT: Radius
Notice that the Area operation cloud be also implemented by a special method for every subtype, since the procedure for area calculation is different for rectangles, triangles, and circles. Similarly, the attribute Reference Point may have a special meaning for every subtype; it might be the center point for RECTANGLE and CIRCLE objects, and therefore the vertex point between the two given sides for a TRIANGLE object. Some OO database systems allow the renaming of inherited functions in several subtypes to reflect the meaning more closely.
An alternative way of declaring these three subtypes is to specify the value of the Shape attribute as a condition that has got to satisfied for objects of every subtype:
RECTANGLE subtype-of GEOMETRY_OBJECT (Shape=‘rectangle’): Width, Height
TRIANGLE subtype-of GEOMETRY_OBJECT (Shape=‘triangle’): Side1, Side2, Angle
CIRCLE subtype-of GEOMETRY_OBJECT (Shape=‘circle’): Radius
Here, only GEOMETRY_OBJECT objects whose Shape=‘rectangle’ are of the subtype RECTANGLE, and same for the other two subtypes. In this all functions of the GEOMETRY_OBJECT supertype are inherited by each of the three subtypes, but the value of the Shape attribute is restricted to a specific value for each.
Constraints on Extents Corresponding to a Type Hierarchy
In most OO databases, the collection of objects in an extent has the equivalent type or class. However, this is often not a necessary condition. For instance SMALLTALK, a so-called typeless OO language, allows a set of objects to contain objects of various types.
This can even be the case when other non-object-oriented typeless languages, like LISP, are extended with OO concepts. However, most object oriented databases support types, we will assume that extents are collections of objects of the equivalent type.
It is common in database applications that every type or subtype will have an extent associated with it holds the set of all persistent objects of that type or subtype. In this case, the constraint is that every object in an extent that corresponds to a subtype must also be a member of the extent that corresponds to its supertype.
Some object oriented database systems have a predefined system type whose extent contains all the objects within the system. Classification then proceeds by assigning objects into additional subtypes that are meaningful to the application, creating a type hierarchy or class hierarchy for the system. All extents for system and user-defined classes are subsets of the extent related to the class OBJECT, directly or indirectly. In the ODMG model, the user may or may not specify an extent for each class (type), depending on the application.
In most object orientd systems, a distinction is made between persistent and transient objects and collections. A persistent collection is a collection of objects that is stored fixed in the database and can be accessed and shared by several programs. A transient collection exists temporarily during the execution of a program but is not kept when the program terminates.
For example, a transient collection could be also created during a program to carry the result of a query that selects some objects from a persistent collection and copies these objects into the transient collection. The transient collection has the identical type of objects because the persistent collection. The program manipulate the objects in the transient collection, and once the program terminates, the transient collection ceases to exist. Generally, numerous collections transient or persistent may contain objects of the equivalent type.
The type constructors allow the state of one object to be a set of objects. Therefore collection objects whose types are based on the set constructor can define a number of collections one like each object. The set-valued objects are members of another collection. This support for multilevel classification schemes, where an object in one collection has as its state a collection of objects of a different class.
The ODMG 2.0 model distinguishes between type inheritance called interface inheritance and denoted by the ":" symbol extent inheritance constraint denoted by the keyword EXTEND.
A principal motivation used to the development of object oriented systems to represent complex objects. There are two types of complex objects: structured and unstructured. A structured complex object is built with help of components and is defined by applying the available type constructor’s recursively at multiple levels. An unstructured complex object is a data type that need a large amount of storage, like a data type that represents an image or a large textual object.
Unstructured Complex Objects and Type Extensibility
An unstructured complex object is provided by a DBMS permits the storage and retrieval of large objects that are required by the database application. Consider example of objects are bitmap images and long text strings; they are called as binary large objects, or BLOBs in short. These objects are unstructured because the DBMS does not know what their structure is only the application that uses them can interpret their meaning.
For example, the application have functions to display an picture or to search for a few keywords during a long text string. The objects are considered complex because they have a large area of storage which isn’t part of the standard data types provided by DBMSs. Because the object size is big, a DBMS retrieve a part of the object and provide the application program before the entire object is retrieved. The DBMS use buffering and caching techniques to prefetch part of the object before the application program must access them.
The DBMS software does not have the capability to directly process selection conditions and other operations depends on values of these objects, unless the application provides the code to do the comparison operations required for the selection. In an OODBMS, this can be accomplished by defining a new abstract data type for the uninterpreted objects and by providing the methods for selecting, comparing, and displaying these objects.
For example, suppose objects that are two-dimensional bitmap images and the application required to select from a collection of such objects only those that include a certain pattern. In this case, the user need to provide the pattern recognition program as a method on objects of the bitmap type. The OODBMS then retrieves an object from the database and runs the method for pattern recognition on it to determine whether the object includes the specified pattern.
Because an OODBMS allows users to make new types, and since a kind includes both structure and operations, we will view an OODBMS as having an extensible type system. We will create libraries of latest types by defining their structure and operations, including complex types. Applications can then use or modify these types, within the latter case by creating subtypes of the kinds provided within the libraries.
However, the DBMS internals must provide the underlying storage and retrieval capabilities for objects that need large amounts of storage in order that the operations could also be applied efficiently. Many OODBMSs provide for the storage and retrieval of huge unstructured objects like character strings or bit strings, which may be passed "as is" to the application program for interpretation. Recently, relational and extended relational DBMSs have also been ready to provide such capabilities.
Structured Complex Objects
A structured complex object differs from an unstructured complex object therein the object’s structure is defined by repeated application of the sort constructors provided by the OODBMS. Hence, the thing structure is defined and known to the OODBMS. As an example, consider the DEPARTMENT object shown in above Figure. At the primary level, the thing features a tuple structure with six attributes: DNAME, DNUMBER, MGR, LOCATIONS, EMPLOYEES, and PROJECTS.
Therefore two of these attribute like DNAME and DNUMBER contains a basic values; the other four contains complex values and therefore build the second level of the complex object structure. One of these four (MGR) has a tuple structure, and the other three (LOCATIONS, EMPLOYEES, PROJECTS) have set structures.
At the third level, for a MGR tuple value contains one basic attribute (MANAGERSTARTDATE) and one attribute (MANAGER) which refers to an employee object, which features a tuple structure. For a LOCATIONS set, we've a group of basic values, except for both the workers and therefore the PROJECTS sets, we've sets of tuple-structured objects.
There are two sorts of reference semantics available during a complex object and its components at every level. the primary type, says as ownership semantics, applies when the sub-objects of a posh object are encapsulated within the complex object and are considered as a part of the complex object. The second type, called reference semantics, applies when the components of the complex object are themselves independent objects but are often referenced from the complex object.
For example consider the DNAME, DNUMBER, MGR, and LOCATIONS attributes to be owned by a DEPARTMENT, whereas EMPLOYEES and PROJECTS are references because they reference independent objects. The first type is also referred to as the is-part-of or is-component-of relationship; and the second type is called the is-associated-with relationship and it describes an equal association between two independent objects.
The is-part-of relationship for constructing complex objects has the property that the component objects are encapsulated within the complex object and are considered a part of the internal object state. They have not have object identifiers and may only be accessed by methods of that object. They’re deleted if the thing itself is deleted. On the opposite hand, a complex object whose components are referenced is taken into account to contain independent objects which will have their own identity and methods.
When a complex object must access its referenced components, it must do so by invoking the acceptable methods of the components, since they're not encapsulated within the complex object. Hence, reference semantics represents relationships among independent objects. Additionally, a referenced component object could also be referenced by quite one complex object and hence isn't automatically deleted when the complex object is deleted.
An OODBMS should provide storage options for clustering the component objects of a complex object together on secondary storage so as to extend the efficiency of operations that access the complex object. In many cases, the thing structure is stored on disk pages in an uninterpreted fashion.
When a disk page that has an object is retrieved into memory, the OODBMS can build up the structured complex object from the knowledge on the disk pages, which can ask additional disk pages that has got to be retrieved. this is often referred to as complex object assembly.
Other Objected-Oriented Concepts
Polymorphism (Operator Overloading)
Another characteristic of OO systems is that they supply for polymorphism of operations, which is additionally sometimes mentioned as operator overloading. this idea allows an equivalent operator name or symbol to be sure to two or more different implementations of the operator, counting on the type of objects to which the operator is applied.
A simple example from programming languages can illustrate this idea . In some languages, the operator symbol "+" can mean various things when applied to operands (objects) of various types. If the operands of "+" are of type integer, the operation invoked is integer addition. If the operands of "+" are of type floating point, the operation invoked is floating point addition. If the operands of "+" are of type set, the operation invoked is about union. The compiler can determine which operation to execute supported the kinds of operands supplied.
In OO databases, an identical situation may occur. Suppose that we declare GEOMETRY_OBJECT and its subtypes as follows:
GEOMETRY_OBJECT: Shape, Area, ReferencePoint
RECTANGLE subtype-of GEOMETRY_OBJECT (Shape=‘rectangle’): Width, Height
TRIANGLE subtype-of GEOMETRY_OBJECT (Shape=‘triangle’): Side1, Side2, Angle
CIRCLE subtype-of GEOMETRY_OBJECT (Shape=‘circle’): Radius
Here, the function Area is said for all objects of type GEOMETRY_OBJECT. However, the implementation of the method for Area may differ for every subtype of GEOMETRY_OBJECT. One possibility is to possess a general implementation for calculating the area of a generalized GEOMETRY_OBJECT then to rewrite more efficient algorithms to calculate the areas of specific sorts of geometric objects, like a circle, a rectangle, a triangle, and so on.
In this case, the area function is overloaded by different implementations. The OODBMS must now select the acceptable method for the area function supported the type of geometric object to which it's applied. In strongly typed systems, this will be done at compile time, since the object types must be known.
This is termed early (or static) binding. However, in systems with weak typing or no typing (such as SMALLTALK and LISP), the sort of the object to which a function is applied might not be known until run-time. During this case, the function must check the type of object at run-time then invoke the acceptable method. this is often mentioned as late (or dynamic) binding.
The ODMG object model is that the data model upon which the thing definition language (ODL) and object query language (OQL) are based. In fact, this object model provides the data types, type constructors, and other concepts which will be utilized within the ODL to specify object database schemas. Hence, it's meant to supply a standard data model for object-oriented databases, even as the SQL report describes a standard data model for relational databases.
Objects and Literals
Objects and literals are the basic building blocks of the object model. the most difference between the two is that an object has both an object identifier and a state (or current value), whereas a literal has only a worth but no object identifier. In either case, the value can have a complex structure. the thing state can change over time by modifying the thing value. A literal is essentially a continuing value, possibly having a complex structure, that doesn't change.
An object is described by four characteristics: (1) identifier, (2) name, (3) lifetime, and (4) structure. the object identifier may be a unique system-wide identifier (or Object_Id). Every object must have an object identifier. additionally to the Object_Id, some objects may optionally tend a unique name within a specific database—this name are often wont to ask the object during a program, and therefore the system should be ready to locate the object as long as name.
Obviously, not all individual objects will have unique names. Typically, a couple of objects, mainly people who hold collections of objects of a specific object type such as extents will have a name. These names are used as entry points to the database; that’s, by locating these objects by their unique name, the user can then locate other objects that are referenced from these objects. Other important objects within the application can also have unique names. All such names within a specific database must be unique. The lifetime of an object specifies whether it's a persistent object or transient object.
Finally, the structure of an object specifies how the object is made by using the sort constructors. The structure specifies whether an object is atomic or a set object. The term atomic object is different than the way we defined the atom constructor and it's quite different from an atomic literal. Within the ODMG model, an atomic object is any object that's not a set, so this also covers structured objects created using the struct constructor. First, we define the concept of a literal.
In the object model, a literal may be a value that doesn't have an object identifier. However, the value may have a simple or complex structure. There are three types of literals: (1) atomic, (2) collection, and (3) structured.
Atomic literals correspond to the values of basic data types and are predefined. the essential data types of the object model include long, short, and unsigned integer numbers, regular and double character strings (String), and enumeration types (Enum), among others.
Structured literals correspond roughly to values that are constructed using the tuple constructor. They include Date, Interval, Time, and Timestamp as built-in structures, also as any additional user-defined type structures as required by each application. User-defined structures are created using the Struct keyword in ODL, as within the C and C++ programming languages.
Collection literals specify a value that's a set of objects or values but the gathering itself doesn't have an Object_Id. The collections within the object model are Set, Bag, List, and Array, where t is that the type of objects or values within the collection. Another collection type is Dictionary, which may be a collection of associations where each k may be a key related to a value v; this will be used to create an index on a set of values.
Built-in Interfaces for Collection Objects
Any collection object inherits the basic Collection interface shown in figure, which shows the operations for all collection objects. Given a collection object o, the o.cardinality() operation returns the number of elements in the collection. The operation o.is_empty() returns true if the collection o is empty, and false if not empty. The operations o.insert_element(e) and o.remove_element(e) used to insert or remove element e from the collection o.
Finally, the operation o.contains_element(e) returns true if the collection o includes element e, and returns false otherwise. The operation i = o.create_iterator() creates an iterator object i for the collection object o, which can be iterate over every element within the collection. The i.reset() operation sets the iterator at the primary element during a collection , and i.next_position() sets the iterator to the next element. The i.get_element() retrieves the current element, which is that the element at which the iterator is currently positioned.
The ODMG object model uses exceptions for reporting errors or particular conditions. The ElementNotFound exception within the collection interface would be raised by the o.remove_element(e) operation if e isn't a component within the collection o. The NoMoreElements exception within the iterator interface would be raised by the i.next_position() operation if the iterator is currently positioned at the last element within the collection, and hence no more elements exist for the iterator to point to.
Collection objects are further specialized into Set, List, Bag, Array, and Dictionary, which inherit the operations of the collection interface. a bunch object type are often wont to create objects such the worth of object o could also be a set whose elements are of type t. The Set interface includes the additional operation p = o.create_union(s), which returns a new object p of type Set that's the union of the 2 sets o and s. Other operations almost like create_union are create_intersection(s) and create_difference(s).
Operations for set comparison include the o.is_subset_of(s) operation, which returns true if the set object o may be a subset of another set object s, and returns false otherwise. Similar operation are is_proper_subset_of(s), is_superset_of(s), and is_proper_superset_of(s). The Bag object type allows duplicate elements within the collection and also inherits the collection interface.
There are three operations like create_union(b), create_intersection(b), and create_difference(b) which all return a new object of type Bag. for instance , p = o.create_union(b) returns a Bag object p that's the union of o and b (keeping duplicates). The o.occurrences_of(e) operation returns the number of duplicate occurrences of element e in bag o.
A List object type inherits the collection operations and may be wont to create collections where the order of the weather is vital. The value of every such object o is an ordered list whose elements are of type t.
The Array object type also inherits the collection operations. it's almost like a list except that an array features a fixed number of elements. The perticular operations for an Array object o are o.replace_element_at(i,e), which change the array element at position i with element e; e = o.remove_element_at(i), which retrieves the ith element and replaces it with a null value; and e = o.retrieve_element_at(i), which retrieves the ith element of the array. Any of those operations can raise the exception InvalidIndex if i is bigger than the array’s size. The operation o.resize(n) changes the number of array elements to n.
The last type of collection objects are of type Dictionary. this enables the creation of a set of association pairs , where all k (key) values are unique. this enables for associative retrieval of a specific pair given its key value.
If o may be a collection object of type Dictionary, then o.bind(k,v) binds value v to the key k as an association within the collection, whereas o.unbind(k) removes the association with key k from o, and v = o.lookup(k) returns the value v related to key k in o. The latter two operations can raise the exception KeyNotFound. Finally, o.contains_key(k) returns true if key k exists in o, and returns false –otherwise.
Atomic (User-Defined) Objects
In last we described the built-in collection kinds of the object model. Now discuss how object types for atomic objects are often constructed. These are specified using the keyword class in ODL. Within the object model, any user-defined object that's not a set object is named an atomic object.
For example, during a UNIVERSITY database application, the user specify an object type (class) for Student objects. of these objects are going to be structured objects; for instance , a Student object have a posh structure, with many attributes, relationships, and operations, but it's still considered atomic because it's not a set . Such a user-defined atomic object type is defined a category by describing its properties and operations.
The properties define the state of the object and are further distinguished into attributes and relationships. During this subsection, we describe on the three sorts of components—attributes, relationships, and operation during which a user-defined object type for atomic (structured) objects can include. We show our discussion with the 2 classes Employee and Department shown in Figure.

Figure 2.3(I) The attributes, relationships, and operations in a class definition.
An attribute may be a property that describes some aspect of an object. Attributes have values, which are typically literals having a simple or complex structure that are stored within the object. However, attribute values also can be Object_Ids of other objects. Attribute values can even be specified via methods that are wont to calculate the attribute value. The attributes for Employee are name, ssn, birthdate, sex, and age, and people for Department are dname, dnumber, mgr, locations, and projs.
A relationship isa property that specifies that two objects within the database are related together. Within the object model of ODMG, only binary relationships are explicitly represented, and every binary relationship is represented by a pair of inverse references specified via the keyword relationship. One relationship exists that relates each Employee to the Department during which he or she works the works for relationship of Employee.
In addition to attributes and relationships, the designer can include operations in object type (class) specifications. Each object type can have variety of operation signatures, which specify the operation name, its argument types, and its returned value, if applicable. Operation names are unique within each object type, but they will be overloaded by having an equivalent operation name appear in distinct object types.
Interfaces, Classes, and Inheritance
In the ODMG 2.0 object model, two concepts exist for specifying object types: interfaces and classes. Additionally, two sorts of inheritance relationships exist. During this section, we discuss the differences and similarities among these concepts. Following the ODMG 2.0 terminology, we use the word behavior to see operations, and state to refer to properties.
An interface may be a specification of the abstract behavior of an object type, which specifies the operation signatures. Although an interface may have state properties as a part of its specifications, these can't be inherited from the interface, as we shall see. An interface is also no instantiable that's , one cannot create objects that correspond to an interface definition.
A class may be a specification of both the abstract behavior and abstract state of an object type, and is instantiable that's , one can create individual object instances like a class definition. Because interfaces are non-instantiable, they're mainly wont to specify abstract operations which will be inherited by classes or by other interfaces.
This is called behavior inheritance and is specified by the ":" symbol. Hence, within the ODMG 2.0 object model, behavior inheritance requires the supertype to be an interface, whereas the subtype might be either a class or another interface.
Another inheritance relationship, called EXTENDS and specified by the extends keyword, is employed to inherit both state and behavior strictly among classes. In an EXTENDS inheritance, both the supertype and therefore the subtype must be classes.
Multiple inheritance via EXTENDS isn't permitted. However, multiple inheritance is allowed for behavior inheritance via ":". Hence, an interface may inherit behavior from several other interfaces. a class can also inherit behavior from several interfaces via ":", additionally to inheriting behavior and state from at the most one other class via EXTENDS.
Extents, Keys, and Factory Objects
In the ODMG 2.0 object model, the database designer can declare an extent for any object type that's defined via a class declaration. The extent is given a name, and it'll contain all persistent objects of that class. Hence, the extent behaves as a group object that holds all persistent objects of the class. In Figure the employee and Department classes have extents called all_employees and all_departments, respectively.
This is almost like creating two objects one among type Set and therefore the second of type Set and making them persistent by naming them all_employees and all_departments. Extents also are wont to automatically enforce the set/subset relationship between the extents of a supertype and its subtype.
If two classes A and B have extents all_A and all_B, and class B may be a subtype of class A (that is, class B EXTENDS class A), then the collection of objects in all_B must be a subset of these in all_A at any point in time. This constraint is automatically enforced by the database system.
A class with an extent can have one or more keys. A key consists of 1 or more properties whose values are constrained to be unique for every object within the extent. the employee class has the ssn attribute as key, and the Department class has two unique keys: dname and dnumber . For a composite key that is made of several properties, the properties that form the key are contained in parentheses. For example, if a class Vehicle with an extent all_vehicles has a key make a combination of two attributes state and license_number, they placed in parentheses as (state, license_number) in the key declaration.
2.4.1 The Object Definition Language
The ODL is designed to support the semantic constructs of the ODMG 2.0 object model and is independent of any particular programming language. Its main use is to create object specifications like a classes and interfaces.
Hence, ODL is not a full programming language. A user can specify a database schema in ODL independently of any programming language, then use the specific language is to specify how ODL constructs can be mapped to constructs in specific programming languages like C++, SMALLTALK, and JAVA.
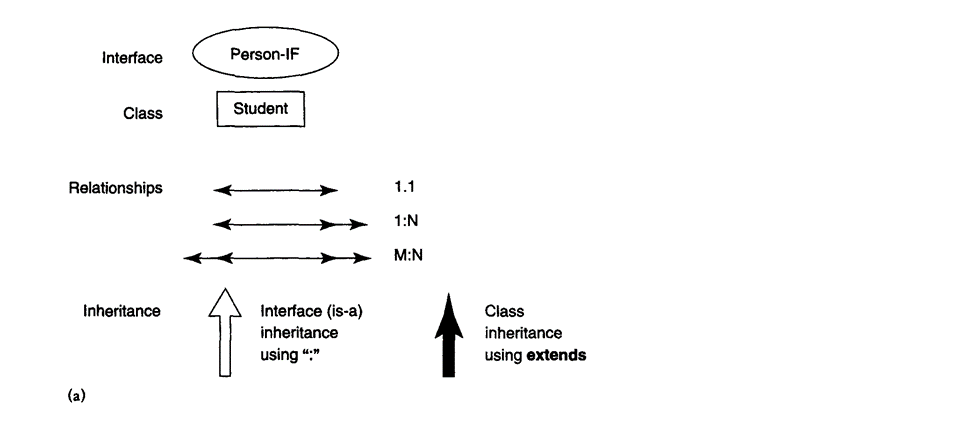
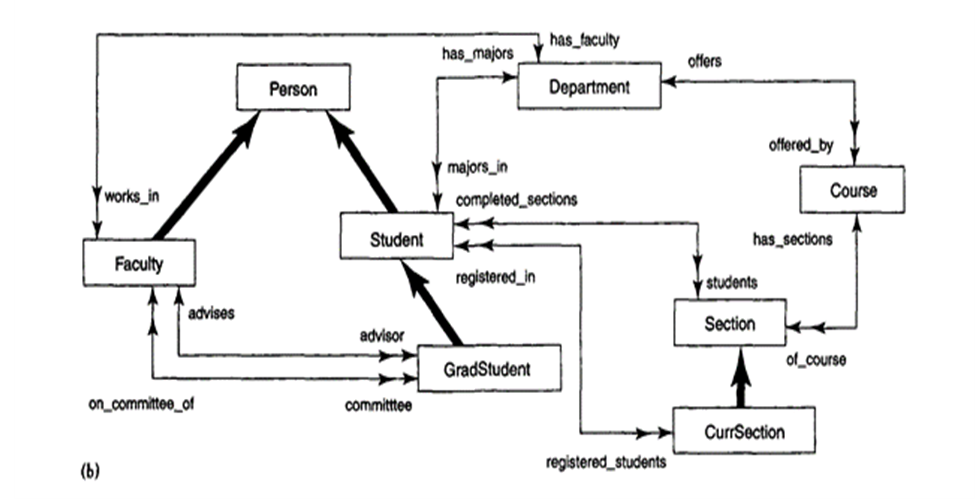
Figure 2.4.1
(I)An example of a database schema. (a) Graphical notation for representing mas. (b) A graphical object database schema for part of the UNIVERSITY database.
The graphical notation for Figure (b) is described in Figure (a) and can be considered as a variation of EER diagrams with the added concept of interface inheritance but without several EER concepts, such as categories and attributes of relationships.
Figure shows one possible set of ODL class definitions for the UNIVERSITY database. In general, there may be several possible mappings from an object schema diagram (or EER schema diagram) into ODL classes.
EER schema diagram) into ODL classes.
Figure 2/4/1(II) Possible ODL schema for the UNIVERSITY database
Entity types are mapped into ODL classes, and inheritance is performed using EXTENDS. There is no direct way to map categories or to do multiple inheritance. In Figure the classes Person, Faculty, Student, and GradStudent have the extents persons, faculty, students, and grad_students, respectively. Both Faculty and Student EXTENDS Person, and GradStudent EXTENDS Student.
The collection of students is constrained to be a subset of the collection of persons at any point in time. Same as the group of grad_students will be a subset of students. At the same time, individual Student and Faculty objects will inherit the properties and operations of Person, and individual GradStudent objects will inherit those of Student.
Multiple inheritance of interfaces by a class is allowed, as multiple inheritance of interfaces by another interface. Therefore with the EXTENDS inheritance, multiple inheritance is not permitted. So a class can inherit through EXTENDS from at most one class.
2.4.2 The Object Query Language
The object query language (OQL) is the query language proposed for the ODMG object model. It’s designed to closely with the programming languages that an ODMG binding is defined, like C++, SMALLTALK, and JAVA. OQL query is embedded into one among above programming languages can return objects that match the sort system of that language.
In addition, the implementations of class operations in an ODMG schema also have their code written in these programming languages. The OQL syntax for queries is same as to the syntax of the relational standard query language SQL, with extra features for ODMG concepts, like object identity, complex objects, operations, inheritance, polymorphism, and relationships.
Simple OQL Queries, Database Entry Points, and Iterator Variables
The basic OQL syntax is a select . . . from . . . where . . . structure, as for SQL. For example, the query to retrieve the names of all departments in the college of ‘Engineering’ was written as follows:
Q0: select d.dname from d in departments where d.college=’Engineering’;
In general, an entry point to the database is need for every query, which can be any named persistent object. For several queries, the entry point is that the name of the extent of a class. Recall that the extent name is taken into account to be the name of a persistent object whose type may be a group of objects from the class.
The use of an extent name departments in Q0 as an entry point referred a persistent collection of objects. Whenever a set is referenced in an OQL query is always define an iterator variable d in Q0 that ranges over each object within the collection. In many cases, as in Q0, the query will select certain objects from the collection, supported the conditions per the where-clause.
In Q0, only persistent objects d within the collection of departments that satisfy the condition d.college = ‘Engineering’ are selected for the query result. for every selected object d, the value of d.dname is retrieved within the query result. Hence, the kind of the result for Q0 is bag, because the type of every dname value is string. Generally, the results of a query would be of type bag for select . . . from . . . and of type set for select distinct . . . from . . ., as in SQL (adding the keyword distinct eliminates duplicates).
Using the example in Q0, there are three syntactic options for specifying iterator variables:
d in departments
departments d
departments as d
We will use the primary construct in our examples.
The named objects used as database entry points for OQL queries aren't limited to the names of extents. Any named persistent object, it refers to an atomic object or to a collection object can be used as a database entry point.
Query Results and Path Expressions
The result of a query can in general be of any type that can be expressed in the ODMG object model. A query does not have to follow the select . . . from . . . where . . . structure; in the simplest case, any persistent name on its own is a query, whose result is a reference to that persistent object. For example, the query
Q1: departments;
Returns a regard to the collection of all persistent department objects, whose type is about. Similarly, suppose we had given a persistent name csdepartment to one department object (the computer science department); then, the query:
Q1a: csdepartment;
Returns a regard to that individual object of type Department. Once an entry point is specified, the concept of a path expression are often used to specify a path to related attributes and objects. A path expression typically starts at a persistent object name, or at the iterator variable that ranges over individual objects during a collection.
This name are going to be followed by zero or more relationship names or attribute names connected using the dot notation. Forinstance, referring to the UNIVERSITY database the subsequent are samples of path expressions, which also are valid queries in OQL:
Q2: csdepartment.chair;
Q2a: csdepartment.chair.rank;
Q2b: csdepartment.has_faculty;
The first expression Q2 returns an object of type Faculty, because that's the type of the attribute chair of the Department class. this may be a regard to the faculty object that's associated with the department object whose persistent name is csdepartment via the attribute chair; that's , a regard to the faculty object who is chairperson of the computer science department.
The second expression Q2a is analogous, except that it returns the rank of this Faculty object instead of the thing reference; hence, the type returned by Q2a is string, which is that the data type for the rank attribute of the faculty class.
Path expressions Q2 and Q2a return single values, because the attributes chair (of Department) and rank (of Faculty) are both single-valued and that they are applied to one object. The third expression Q2b is different; it returns an object of type set even when applied to one object, because that's the type of the relationship has_faculty of the Department class.
The collection returned will include references to all or any Faculty objects that are associated with the department object whose persistent name is csdepartment via the relationship has faculty; that's , references to all or any Faculty objects who are working within the computer science department. Now, to return the ranks of computer science faculty, we cannot write
Q3’: csdepartment.has_faculty.rank;
This is because it's not clear whether the object returned would be of type set or bag. Due to this type of ambiguity problem, OQL doesn't allow expressions like Q3’. Rather, one must use an iterator variable over these collections, as in Q3a or Q3b below:
Q3a: select f.rank from f in csdepartment.has_faculty;
Q3b: select distinct f.rank from f in csdepartment.has_faculty;
Here, Q3a returns bag that means duplicate rank values appear within the result, whereas Q3b returns set. Both Q3a and Q3b illustrate how an iterator variable are often defined within the from-clause to range over a restricted collection specified in the query.
The variable f in Q3a and Q3b ranges over the weather of the collection csdepartment.has_faculty, which is of type set, and includes only those faculty that are members of the computer science department.
In general, an OQL query can return a result with a complex structure specified in the query itself by utilizing the struct keyword. Consider the subsequent two examples:
Q4: csdepartment.chair.advises;
Q4a: select struct (name:struct(last_name: s.name.lname, first_name: s.name.fname), degrees:(select struct (deg: d.degree, yr: d.year, college: d.college) from d in s.degrees) from s in csdepartment.chair.advises;
Here, Q4 is simple, returning an object of type set as its result; this is often the collection of graduate students that are advised by the chair of the computer science department. Now, suppose that a query is required to retrieve the last and first names of those graduate students, plus the list of previous degrees of every . T
his are often written as in Q4a, where the variable s ranges over the collection of graduate students advised by the chairperson, and therefore the variable d ranges over the degrees of every such student s. the type of the results of Q4a may be a collection of (first-level) structs where each struct has two components: name and degrees. The name component may be a further struct made from last_name and first_name, each being a single string. The degrees component is defined by an embedded query and is itself a set of further structs, each with three string components: deg, yr, and college.
2.4.3 Object Relational and Extended Relational Database Systems
We discussed how of these data models are thoroughly developed in terms of the subsequent features:
• Modeling constructs for developing schemas for database applications.
• Constraints facilities for expressing certain sorts of relationships and constraints on the data as determined by application semantics.
• Operations and language facilities to control the database.
Out of those three models, the ER model has been primarily employed just in case tools that are used for database and software design, whereas the opposite two models are used because the basis for commercial DBMSs. This chapter discusses the emerging class of commercial DBMSs that are called object-relational or enhanced relational systems, and a few of the conceptual foundations for these systems.
These systems which are often called object-relational DBMSs (ORDBMSs) emerged as a way of enhancing the capabilities of relational DBMSs (RDBMSs) with a number of the features that appeared in object DBMSs (ODBMSs).
Evolution and Current Trends of Database Technology
1) The Evolution of Database Systems Technology
In the commercial world today, there are several families of DBMS products available. Two of the foremost dominant ones are RDBMS and ODBMS, which subscribe the relational and therefore the object data models respectively. Two other major sorts of DBMS products hierarchical and network are now being mentioned as legacy DBMSs; these are supported the hierarchical and therefore the network data models, both of which were introduced within the mid-1960s.
The hierarchical family primarily has one dominant product IMS of IBM, whereas the network family includes a large number of DBMSs, like IDS II (Honeywell), IDMS (Computer Associates), IMAGE (Hewlett Packard), VAX-DBMS (Digital), and TOTAL/SUPRA (Cincom), to name a couple of .
As database technology evolves, the legacy DBMSs are going to be gradually replaced by newer offerings. Within the interim, we must face the main problem of interoperability the interoperation of variety of databases belonging to all or any of the disparate families of DBMSs also on legacy file management systems. an entire series of latest systems and tools to deal with this problem are emerging also . Outlined standards like ODMG and CORBA, which are bringing interoperability and portability to applications involving databases from different models and systems.
2) The Current Drivers of Database Systems Technology
The main forces behind the event of extended ORDBMSs stem from the lack of the legacy DBMSs and therefore the basic relational data model also because the earlier RDBMSs to satisfy the challenges of latest applications.
These are primarily in areas that involve a spread of types of data for instance, text in computer-aided desktop publishing; images in satellite imaging or weather forecasting; complex nonconventional data in engineering designs, within the biological genome information, and in architectural drawings; time series data in history of stock exchange transactions or sales histories; and spatial and geographic data in maps, air/water pollution data, and traffic data.
Hence there's a transparent need to design databases which will develop, manipulate, and maintain the complex objects arising from such applications. Furthermore, it's becoming necessary to handle digitized information that represents audio and video data streams requiring the storage of BLOBs (binary large objects) in DBMSs.
The popularity of the relational model is helped by a really robust infrastructure in terms of the commercial DBMSs that are designed to support it. However, the essential relational model and earlier versions of its SQL language proved inadequate to satisfy the above challenges. Legacy data models just like the network data model have a facility to model relationships explicitly, but they suffer from an important use of pointers within the implementation and haven't any concepts like object identity, inheritance, encapsulation, or the support for multiple data types and complex objects.
The hierarchical model fits well with some present hierarchies in nature and in organizations, but it's too limited and rigid in terms of built-in hierarchical paths within the data. Hence, a trend was began to combine the simplest features of the thing data model and languages into the relational data model in order that it are often extended to affect the challenging applications of today.
In most we highlight the features of two representative DBMSs that exemplify the ORDBMS approach: Informix Universal Server and Oracle 8. We then discuss features of the SQL3 language subsequent version of the SQL standard—which extends SQL2 by incorporating object database and other features like extended data types.
We conclude by briefly discussing the nested relational model, which has its origin during a series of research proposals and prototype implementations; this provides a way of embedding hierarchically structured complex objects within the relational framework.
The Informix Universal Server
The Informix Universal Server is an ORDBMS that combines relational and object database technologies from two previously existing products: Informix and Illustra. The latter system originated from the POSTGRES DBMS, which was a search project at the University of California at Berkeley that was commercialized because the Montage DBMS and went through the name Miro before being named Illustra. Illustra was then acquired by Informix, integrated into its RDBMS, and introduced because the Informix Universal Server an ORDBMS.
To see why ORDBMSs emerged, we start by that specialize in a method of classifying DBMS applications consistent with two dimensions or axes: (1) complexity of data the X-dimension and (2) complexity of querying the Y-dimension. We will arrange these axes into an easy 0-1 space having four quadrants:
Quadrant 1 (X = 0, Y = 0): Simple data, simple querying
Quadrant 2 (X = 0, Y = 1): Simple data, complex querying
Quadrant 3 (X = 1, Y = 0): Complex data, simple querying
Quadrant 4 (X = 1, Y = 1): Complex data, complex querying
Traditional RDBMSs belong to Quadrant 2. Although they support complex unplanned queries and updates, they will deal only with simple data which will be modeled as a group of rows during a table. Many object databases (ODBMSs) fall in Quadrant 3, since they consider managing complex data but have somewhat limited querying capabilities supported navigation.
In order to move into the fourth quadrant to support both complex data and querying, RDBMSs are incorporating more complex data objects while ODBMSs are incorporating more complex querying. The Informix Universal Server belongs to Quadrant 4 because it's extended its basic relational model by incorporating a variety of features that make it object-relational.
Other current ORDBMSs that evolved from RDBMSs include Oracle 8 from Oracle Corporation, Universal DB (UDB) from IBM, Odapter by Hewlett Packard (HP) (which extends Oracle’s DBMS), and Open ODB from HP.
The more successful products seem to be people who maintain the choice of working as an RDBMS while introducing the extra functionality. Another system, UniSQL from UniSQL Inc., was developed from scratch as an ORDBMS product. Our intent here isn't to supply a comparative analysis of those products but only to offer a summary of two representative systems.
How Informix Universal Server Extends the Relational Data Model
The extensions to the relational data model provided by Illustrate and incorporated into Informix Universal Server fall under the subsequent categories:
• Support for extra or extensible data types.
• Support for user-defined routines (procedures or functions).
• Implicit notion of inheritance.
Support for indexing extensions.
• Data Blades Application Programming Interface (API).
1) Extensible Data Types
The architecture of Informix Universal Server comprises the essential DBMS plus variety of data Blade modules. The thought is to treat the DBMS as a razor into which a selected blade is inserted for the support of a specific data type. Variety of data types are provided, including two-dimensional geometric objects, images, statistic, text, and sites.
When Informix announced the Universal Server, 29 Data Blades were already available. It’s also possible for an application to make its own types, thus making the data type notion fully extendible. Additionally to the built-in types, Informix Universal Server provides the user with the subsequent four constructs to declare additional types:
1. Opaque type.
2. Distinct type.
3. Row type.
4. Collection type.
When creating a kind supported one among the primary three options, the user has got to provide functions and routines for manipulation and conversion, including built-in, aggregate, and operator functions also as any additional user-defined functions and routines. the details of those four types are presented within the following sections.
Opaque Type
The opaque type has its representation hidden, so it's used for encapsulating a kind . The user has got to provide casting functions to convert an opaque object between its hidden representation within the server (database) and its visible representation as seen by the client. The user functions send/receive are needed to convert to/from the server representation from/to the client representation.
Similarly, import/export functions are wont to convert to/from an external representation for bulk copy from/to the internal representation. Several other functions could also be defined for processing the opaque types, including assign(), destroy(), and compare().
The specification of an opaque type includes its name, internal length if fixed, maximum internal length if it's variable length, alignment, also as whether or not it's hashable. If we write
CREATE OPAQUE TYPE fixed_opaque_udt (INTERNALLENGTH = 8, ALIGNMENT = 4, CANNOTHASH);
CREATE OPAQUE TYPE var_opaque_udt (INTERNALLENGTH = variable, MAXLEN=1024, ALIGNMENT = 8);
then the first statement creates a fixed-length user-defined opaque type, named fixed_opaque_udt, and the second statement creates a variable length one, named var_opaque_udt. Both represented in an implementation with internal parameters that are not visible to the client.
Distinct Type
The distinct data type is used to increase an existing type through inheritance. The newly defined type inherits the functions/routines of its base type, if they're not overridden. for example, the statement
CREATE DISTINCT TYPE hiring_date AS DATE;
creates a new user-defined type, hiring_date, which can be used as any other built-in type.
Row Type
The row type, which represents a composite attribute, is analogous to a struct type within the C programing language. it's a composite type that contains one or more fields. Row type is additionally used to support inheritance by using the keyword UNDER, but the type system supports single inheritance only. By creating tables whose tuples are of a specific row type, it's possible to treat a relation as a part of an object-oriented schema and establish inheritance relationships among the relations. Within the following row type declarations, employee_t and student_t inherit person_t:
CREATE ROW TYPE person_t(name VARCHAR(60), social_security NUMERIC(9), birth_date DATE);
CREATE ROW TYPE employee_t(salary NUMERIC(10,2), hired_on hiring_date) UNDER person_t;
CREATE ROW TYPE student_t(gpa NUMERIC(4,2), address VARCHAR(200)) UNDER person_t;
Collection Type
Informix Universal Server collections include lists, sets, and multisets (bags) of built-in types also as user-defined types. A set are often the type of either a field during a row type or a column during a table. The weather of a group collection cannot contain duplicate values, and haven't any specific order. The list may contain duplicate elements, and order is critical. Finally, the multiset may include duplicates and has no specific order. Consider the following example:
CREATE TABLE employee (name VARCHAR(50) NOT NULL, commission MULTISET (MONEY));
Here, the employee table contains the commission column, which is of type multiset.
2) Support for User-Defined Routines
Informix Universal Server supports user-defined functions and routines to control the user defined types. The implementation of those functions are often in either Stored Procedure Language (SPL), or within the C or JAVA programming languages. User-defined functions enable the user to define operator functions like plus( ), minus( ), times( ), divide( ), positive( ), and negate( ), built-in functions like cos( ) and sin( ), aggregate functions like sum( ) and avg( ), and user-defined routines.
This enables Informix Universal Server to handle user-defined types as a built-in type whenever the specified functions are defined. the following example specifies an equal function to match two objects of the fixed_opaque_udt type declared earlier:
CREATE FUNCTION equal (arg1 fixed_opaque_udt, arg2 fixed_opaque_udt) RETURNING BOOLEAN;
EXTERNAL NAME "/usr/lib/informix/libopaque.so (fixed_opaque_udt_equal)" LANGUAGE C;
END FUNCTION;
Informix Universal Server also supports cast a function that converts objects from a source type to a target type. There are two sorts of user-defined casts: (1) implicit and (2) explicit. Implicit casts are invoked automatically, whereas explicit casts are invoked only the cast operator is specified explicitly by using "::" or CAST AS. If the source and target types have an equivalent internal structure, no user-defined functions are needed.
Consider the subsequent example to illustrate explicit casting, where the employee table features a col1 column of type var_opaque_udt and a col2 column of type fixed_opaque_udt.
SELECT col1 FROM employee WHERE fixed_opaque_udt::col1 = col2;
In order to compare col1 with col2, the cast operator is applied to col1 to convert it from var_opaque_udt to fixed_opaque_udt.
3) Support for Inheritance
Inheritance is used at two levels in Informix Universal Server: (1) data inheritance and (2) function inheritance.
Data Inheritance
To create subtypes under existing row types, we use the UNDER keyword. Consider the following example:
CREATE ROW TYPE employee_type ( ename VARCHAR(25), ssn CHAR(9), salary INT);
CREATE ROW TYPE engineer_type ( degree VARCHAR(10), license VARCHAR(20))UNDER employee_type;
CREATE ROW TYPE engr_mgr_type ( manager_start_date VARCHAR(10), dept_managed VARCHAR(20)) UNDER engineer_type;
The above statements create an employee_type and a subtype called engineer_type, which represents employees who are engineers and hence inherits all attributes of employees and has additional properties of degree and license.
Another type called engr_mgr_type may be a subtype under engineer_type, and hence inherits from engineer_type and implicitly from employee_type also . Informix Universal Server doesn't support multiple inheritance. we will now create tables called employee, engineer, and engr_mgr supported these row types.
Note that storage options for storing type hierarchies in tables vary. Informix Universal Server provides the choice to store instances in several combinations—for example, one instance (record) at each level or one instance that consolidates all levels these correspond to the mapping options.
The inherited attributes are either represented repeatedly within the tables at lower levels or are represented with a regard to the object of the supertype. The processing of SQL commands is appropriately modified supported the type hierarchy. for instance , the query
SELECT * FROM employee WHERE salary > 100000;
Returns the employee information from all tables where every selected employee is shown. Therefore the scope of the employee table extends to all tuples under employee. As a default, queries on the supertable return columns from the supertable also those from the subtables that inherit from that supertable. In contrast, the query
SELECT * FROM ONLY (employee) WHERE salary > 100000;
Returns instances from only the employee table because of the keyword ONLY.
It is possible to query a supertable using a correlation variable therefore the result consist of not only supertable_type columns of the subtables but also subtype-specific columns of the subtables. Such a query returns rows of different sizes; the result is called a jagged row result. Retrieving all information about an employee from all levels in a "jagged form" is accomplished by
SELECT e FROM employee e;
For every employee, based on whether he or she is an engineer or some other subtype(s), it return additional sets of attributes from the perticular subtype tables.
Views defined on supertables cannot be updated because placement of inserted rows is ambiguous.
Function Inheritance
The data is inherited in tables along a type hierarchy, functions are also inherited in an ORDBMS. For example, a function overpaid is defined on employee_type to select those employees making a higher salary than Bill Brown as follows:
CREATE FUNCTION overpaid (employee_type) RETURNS BOOLEAN AS RETURN $1.salary > (SELECT salary FROM employee WHERE ename = ‘Bill Brown’);
CREATE FUNCTION overpaid (engr_mgr_type) RETURNS BOOLEAN AS RETURN $1.salary > (SELECT salary FROM employee WHERE ename = ‘Jack Jones’);
Uses the second definition of overpaid, which overrides the first. This is called operation (or function) overloading. The overpaid and other functions can also be treated as virtual attributes; hence overpaid may be referenced as employee.overpaid or engr_mgr.overpaid in a query.
4) Support for Indexing Extensions
Informix Universal Server supports indexing on user-defined routines on a single table or a table hierarchy. For example,
CREATE INDEX empl_city ON employee (city (address));
Creates an index on the table employee using the value of the city function.
To support user-defined indexes, Informix Universal Server supports operator classes, which also support user-defined data types in the generic B-tree as well as other secondary access methods such as R-trees.
5) Support for External Data Source
Informix Universal Server supports external data sources that are mapped to a table within the database called the virtual table interface. This interface enables the user to define operations which will be used as proxies for the other operations, which are needed to access and manipulate the row or rows related to the underlying data source.
These operations include open, close, fetch, insert, and delete. Informix Universal Server also supports a group of functions that permits calling SQL statements within a user-defined routine without the overhead of browsing a client interface.
6) Support for Data Blades Application Programming Interface
The Data Blades Application Programming Interface (API) of Informix Universal Server provides new data types and functions for specific sorts of applications. we'll review the extensible data types for two-dimensional operations, the info types associated with image storage and management, the time series data type, and a couple of features of the text data type.
The strength of ORDBMSs to affect the new unconventional applications is essentially attributed to those special data types and therefore the tailored functionality that they supply.
Two-Dimensional Data Types
For a two-dimensional application, the relevant data types would include the following:
• A point defined by (X, Y) coordinates.
• A line defined by its two end points.
• A polygon defined by an ordered list of n points that form its vertices.
• A path defined by a sequence (ordered list) of points.
• A circle defined by its center point and radius.
Given the above as data types, a function like distance could also be defined between two points, some extent and a line, a line and a circle, and so on, by implementing the acceptable mathematical expressions for distance during a programming language . Similarly, a Boolean cross function which returns true or false depending on whether two geometric objects intersect are often defined between a line and a polygon, a path and a polygon, a line and a circle, and so on.
Other relevant Boolean functions for GIS applications would be overlap (polygon, polygon), contains (polygon, polygon), contains (point, polygon), and so on. Note that the concept of overloading (operation polymorphism) applies when an equivalent function name is used with different argument types.
Image Data Types
Images are stored during a kind of standard formats like TIFF, GIF, JPEG, photoCD, GROUP 4, and FAX so one may define a data type for every of those formats and use appropriate library functions to input images from other media or to render images for display. Alternately, IMAGE are often considered a single data type with an outsized number of options for storage of data.
The latter option would allow a column during a table to be of type IMAGE and yet accept images during a kind of different formats. The subsequent are some possible functions (operations) on images:
rotate (image, angle) returns image.
crop (image, polygon) returns image.
enhance (image) returns image.
The crop function extracts the portion of an image that intersects with a polygon. The enhance function improves the standard of an image by performing contrast enhancement. Multiple images could also be supplied as parameters to the subsequent functions:
common (image1, image2) returns image.
union (image1, image2) returns image.
similarity (image1, image2) returns number.
The similarity function typically takes into account the distance between two vectors with components that describe the content of the 2 images. The VIR Data Blade in Informix Universal Server are often wont to accomplish a search on images by content supported the above similarity measure.
Time Series Data Type
Informix Universal Server supports a time series data type that creates the handling of your time series data far more simplified than storing it in multiple tables. for example, consider storing the closing stock price on the ny stock market for quite 3,000 stocks for every workday when the market is open. Such a table are often defined as follows:
CREATE TABLE stockprices ( company-name VARCHAR(30), symbol VARCHAR(5), prices TIME_SERIES OF FLOAT);
Regarding the stock price data for all 3,000 companies over a whole period of, say, several years, just one relation is adequate because of the time series data type for the prices attribute. Without this data type, each company would wish one table. for instance , a table for the coca_cola company could also be declared as follows:
CREATE TABLE coca_cola ( recording_date DATE, price FLOAT);
In this table, there would be approximately 260 tuples per annum one for every business day. The time series data type takes under consideration the calendar, beginning , recording interval (for example, daily, weekly, monthly), and so on. Functions like extracting a subset of the time series , summarizing at a coarser granularity , and constructing moving averages are appropriate.
A query on the stockprices table that provides the moving average for 30 days starting at June 1, 1999 for the coca_cola stock can use the MOVING-AVG function as follows:
SELECT MOVING-AVG(prices, 30, ‘1999-06-01’) FROM stockprices WHERE symbol = "KO";
The same query in SQL on the table coca_cola would be far more complicated to write down and would access numerous tuples, whereas the above query on the stockprices table deals with one row within the table like this company. it's claimed that using the time series data type provides an order of magnitude performance gain in processing such queries.
Text Data Type
The text DataBlade supports storage, search, and retrieval for text objects. It defines one data type called doc, whose instances are stored as large objects that belong to the built-in data type large-text. We’ll briefly discuss a couple of important features of this data type.
The underlying storage for large-text is that the same as that for the large-object data type. References to one large object are recorded within the ‘refcount’ system table, which stores information like number of rows referring to the large object, its OID, its storage manager, its last modification time, and its archive storage manager.
Automatic conversion between large-text and text data types enables any functions with text arguments to be applied to large-text objects. Thus concatenation of large-text objects as strings as well as extraction of substrings from a large-text object are possible.
The Text DataBlade parameters include format for which the default is ASCII, with other possibilities such as postscript, dvipostscript, nroff, troff, and text. A Text Conversion DataBlade, which is separate from the Text DataBlade, is needed to convert documents among the various formats. An External File parameter instructs the internal representation of doc to store a pointer to an external file rather than copying it to a large object.
For manipulation of doc objects, functions such as the following are used:
Import_doc (doc, text) returns doc.
Export_doc (doc, text) returns text.
Assign (doc) returns doc.
Destroy (doc) returns void.
The Assign and Destroy functions already exist for the built-in large-object and large-text data types, but they must be redefined by the user for objects of type doc. The following statement creates a table called legaldocuments, where each row has a title of the document in one column and the document itself as the other column:
CREATE TABLE legaldocuments( title TEXT, document DOC);
To insert a new row into this table of a document called ‘lease.contract,’ the following statement can be used:
INSERT INTO legaldocuments (title, document) VALUES (‘lease.contract’, ‘format {troff}:/user/local/ documents/lease’);
The second value in the values clause is the path name specifying the file location of this document; the format specification signifies that it is a troff document. To search the text, an index must be created, as in the following statement:
CREATE INDEX legalindex ON legaldocuments USING dtree(document text_ops);
In the above, text_ops is an op-class (operator class) applicable to an access structure called a dtree index, which is a special index structure for documents. When a document of the doc data type is inserted into a table, the text is parsed into individual words.
The Text DataBlade is case insensitive; hence, Housenumber, HouseNumber, or housenumber are all considered the same word. Words are stemmed according to the WORDNET thesaurus. For example, houses or housing would be stemmed to house, quickly to quick, and talked to talk. A stopword file is kept, which contains insignificant words such as articles or prepositions that are ignored in the searches. Examples of stopwords include is, not, a, the, but, for, and, if, and so on.
Informix Universal Server provides two sets of routines the contains routines and text-string functions to enable applications to determine which documents contain a certain word or words and which documents are similar. When these functions are used in a search condition, the data is returned in descending order of how well the condition matches the documents, with the best match showing first.
There is WeightContains(index to use, tuple-id of the document, input string) function and a similar WeightContainsWords function that returns a precision number between 0 and 1 indicating the closeness of the match between the input string or input words and the specific document for that tuple-id. To illustrate the use of these functions, consider the following query: Find the titles of legal documents that contain the top ten terms in the document titled ‘lease contract’, which can be specified as follows:
SELECT d.title FROM legaldocuments d, legaldocuments l WHERE contains (d.doc, AndTerms (TopNTerms(l,document,10))) AND l.title = ‘lease.contract’ AND d.title <> ‘lease.contract’;
This query illustrates how SQL can be enhanced with these data type specific functions to yield a very powerful capability of handing text-related functions. In this query, variable d refers to the entire legal corpus whereas l refers to the specific document whose title is ‘lease.contract’. TopNTerms extracts the top ten terms from the ‘lease.contract’ document (l); AndTerms combines these terms into a list; and contains compares the terms in that list with the stemwords in every other document (d) in the table legaldocuments.
1) Representing Multivalued Attributes Using VARRAY
Some attributes of an object/entity could be multivalued. In the relational model, the multivalued attributes would have to be handled by forming a new table. If ten attributes of a large table were multivalued, we would have eleven tables generated from a single table after normalization.
To get the data back, the developer would have to do ten joins across these tables. This does not happen in an object model since all the attributes of an object including multivalued ones are encapsulated within the object. Oracle 8 achieves this by using a varying length array (VARRAY) data type, which has the following properties:
1. COUNT: Current number of elements.
2. LIMIT: Maximum number of elements the VARRAY can contain. This is user defined.
Consider the example of a customer VARRAY entity with attributes name and phone_numbers, where phone_numbers is multivalued. First, we need to define an object type representing a phone_number as follows:
CREATE TYPE phone_num_type AS OBJECT (phone_number CHAR(10));
Then we define a VARRAY whose elements would be objects of type phone_num_type:
CREATE TYPE phone_list_type as VARRAY (5) OF phone_num_type;
Now we can create the customer_type data type as an object with attributes customer_name and phone_numbers:
CREATE TYPE customer_type AS OBJECT (customer_name VARCHAR(20), phone_numbers phone_list_type);
CREATE TYPE phone_num_type AS OBJECT (phone_number CHAR(10), description CHAR(30));
We next redefine phone_list_type as a table of phone_number_type as follows:
CREATE TYPE phone_list_type AS TABLE OF phone_number_type;
We can then create the type customer_type and the customer table as before. The only difference is that phone_list_type is now a nested table instead of a VARRAY. Both structures have similar functions with a few differences.
Nested tables do not have an upper bound on the number of items whereas VARRAYs do have a limit. Individual items can be retrieved from the nested tables, but this is not possible with VARRAYs. Additional indexes can also be built on nested tables for faster data access.
Object Views
Object views are often wont to build virtual objects from relational data, thereby enabling programmers to evolve existing schemas to support objects. this enables relational and object applications to coexist on an equivalent database. In our example, allow us to say that we had modeled our customer database employing a relational model, but management decided to try to to all future applications within the object model. Moving over to the thing view of an equivalent existing relational data would thus facilitate the transition.
2) Managing Large Objects and Other Storage Features
Oracle store extremely large objects like video, audio, and text documents. New data types are introduced for this reason. These include the following:
• BLOB (binary large object).
• CLOB (character large object).
• BFILE (binary file stored outside the database).
• NCLOB (fixed-width multibyte CLOB).
All of the above except for BFILE, which is stored outside the database, are stored inside the database along with other data. Only the directory name for a BFILE is stored in the database.
Index Only Tables
Standard Oracle 7.X involves keeping indexes as a B+-tree that contains pointers to data blocks. this provides good performance in most situations. However, both the index and therefore the data block must be accessed to read the info . Moreover, key values are stored twice within the table and within the index increasing the storage costs.
Oracle 8 supports both the standard indexing scheme and also index only tables, where the data records and index are kept together during a B-tree structure. this enables faster data retrieval and requires less space for storing for small-to medium-sized files where the record size isn't overlarge .
Partitioned Tables and Indexes
Large tables and indexes are often broken down into smaller partitions. The table now becomes a logical structure and therefore the partitions become the particular physical structures that hold the info. This provides the subsequent advantages:
• Continued data availability within the event of partial failures of some partitions.
• Scalable performance allowing substantial growth in data volumes.
• Overall performance improvement in query and transaction processing.
An Overview of SQL3
1) The SQL3 Standard and Its Components
The SQL3 standard includes the subsequent parts :
• SQL/Framework, SQL/Foundation, SQL/Bindings, SQL/Object.
• New parts addressing temporal, transaction aspects of SQL.
• SQL/CLI (Call Level Interface).
• SQL/PSM (Persistent Stored Modules).
SQL/Foundation deals with new data types, new predicates, relational operations, cursors, rules and triggers, user-defined types, transaction capabilities, and stored routines. SQL/CLI (Call Level Interface) provides rules that allow execution of application code without providing source code and avoids the requirement for preprocessing.
It provides a new type of language binding and is analogous to dynamic SQL in SQL-92. supported Microsoft ODBC (Open Database Connectivity) and SQL Access Group’s standard, it contains about 50 routines for tasks like connection to the SQL server, allocating and deallocating resources, obtaining diagnostic and implementation information, and controlling termination of transactions.
SQL/PSM (Persistent Stored Modules) specifies facilities for partitioning an application between a client and a server. The goal is to boost performance by minimizing network traffic. SQL/Bindings includes Embedded SQL and Direct Invocation as in SQL-92. Embedded SQL has been enhanced to incorporate additional exception declarations.
SQL/Temporal deals with historical data, time series data, and other temporal extensions, and it's being proposed by the TSQL2 committee. SQL/Transaction specification formalizes the XA interface to be used by SQL implementors.
2) Some New Operations and Features in SQL3
New kinds of operations are added to SQL3. These include SIMILAR, which allows the utilization of regular expressions to match character strings. Boolean values are extended with UNKNOWN when a comparison yields neither true nor false because some values could also be null. a major new operation is linear recursion for specifying recursive queries.
To illustrate this, suppose we've a table called PART_TABLE(Part1, Part2), which contains a tuple whenever part p1 contains part p2 as a component. a query to produce the bill of materials for a few part p1 (that is, all component parts needed to produce p1) is written as a recursive query as follows:
WITH RECURSIVE BILL_MATERIAL (Part1, Part2) AS (SELECT Part1, Part2 FROM PART_TABLE WHERE Part1 = ‘p1’ UNION ALL SELECT PART_TABLE(Part1), PART_TABLE(Part2) FROM BILL_MATERIAL, PART_TABLE
WHERE PART_TABLE.Part1 = BILL_MATERIAL(Part2)) SELECT * FROM BILL_MATERIAL ORDER BY Part1, Part2;
3) Object-Relational Support in SQL3
The SQL/Object specification extends SQL-92 to incorporate object-oriented capabilities. New data types include Boolean, character, and binary large objects (LOBs), and enormous object locators.
SQL3 proposes LOB manipulation within the DBMS without having to use external files. Certain operators don't apply to LOB-valued attributes—for example, arithmetic comparisons, group by, and order by. On the opposite hand, retrieval of partial value, LIKE comparison, concatenation, substring, position, and length are operations which will be applied to LOBs.
Objects in SQL3
Under SQL/Foundation and SQL/Object Specification, SQL allows user-defined data types, type constructors, collection types, user-defined functions and procedures, support for large objects, and triggers. Objects in SQL3 are of two types:
• Row or tuple types whose instances are tuples in tables.
• Abstract Data Types (shortened as ADT or value ADT), which are any general types used as components of tuples.
A row type may be defined using the syntax
CREATE ROW TYPE row_type_name (<component declarations>);
An example is
CREATE ROW TYPE Emp_row_type ( name VARCHAR (35), age INTEGER );
CREATE ROW TYPE Comp_row_type ( compname VARCHAR (20), location VARCHAR (20) );
A table can then be created based on the row type declaration as follows:
CREATE TABLE Employee OF TYPE Emp_row_type;
CREATE TABLE Company OF TYPE Comp_row_type;
A component attribute of one tuple may be a reference to a tuple of another relation. Thus we can define
CREATE ROW TYPE Employment_row_type ( employee REF (Emp_row_type), company REF (Comp_row_type) );
CREATE TABLE Employment OF TYPE Employment_row_type;
SQL3 uses a double dot notation to build path expressions that refer to the components of tuples. For example, the query below retrieves employees working in New York from the Employment table.
SELECT Employment..employee..name FROM Employment WHERE Employment..company..location = ‘New York’;
In SQL3, â is used for dereferencing and has the same meaning assigned to it in C. Thus if r is a reference to a tuple and a is a component attribute in that tuple, râa is the value of attribute a in that tuple. Object identifiers can be explicitly declared and accessed. For example, the definition of Emp_row_type may be changed as follows:
CREATE ROW TYPE Emp_row_type ( name CHAR (35), age INTEGER, emp_id REF (Emp_row_type) );
In the above example, the emp_id values may be system generated by using
CREATE TABLE Employee OF TYPE Emp_row_type VALUES FOR emp_id ARE SYSTEM GENERATED;
If several relations of the same row type exist, SQL3 provides a mechanism by which a reference attribute may be made to point to a specific table of that type by using
SCOPE FOR <attribute>IS <relation>
Although the row types discussed above provide the functionality of objects and eventually allow construction of complex object types by combining row types, they do not provide for encapsulation which is an essential feature of object modeling. Encapsulation is provided through abstract data types in SQL3.
Abstract Data Types in SQL3
In SQL3 a construct almost like class definition is provided whereby the user can create a named user-defined type with its own behavioral specification and internal structure; it's referred to as an Abstract Data Type (ADT). The overall form of an ADT specification is:
CREATE TYPE <type-name> ( list of component attributes with individual types declaration of EQUAL and LESS THAN functions declaration of other functions (methods) );
SQL3 provides certain built-in functions for ADTs. For an ADT called Type_T, the constructor function Type_T() returns a new object of that type. In the new ADT object, every attribute is initialized to its default value. An observer function A is implicitly created for each attribute A to read its value. Hence, A(X) returns the value of attribute A of Type_T if X is of type Type_T.
A mutator function for updating an attribute sets the value of the attribute to a new value. SQL3 allows these functions to be blocked from public use; an EXECUTE privilege is needed to have access to these functions.
An ADT has a number of user-defined functions associated with it. The syntax is
FUNCTION <name> (<argument_list>) RETURNS <type>;
Two types of functions can be defined: internal SQL3 and external. Internal functions are written in the extended (computationally complete) version of SQL. External functions are written in a host language, with only their signature (interface) appearing in the ADT definition. The form of an external function definition is
DECLARE EXTERNAL <function_name><signature>LANGUAGE <language_name>;
Many ORBDMSs have taken the approach of defining a set of ADTs and associated functions for specific application domains, and packaging them together. For example, the Data Blades in Informix Universal Server and the cartridges in Oracle can be considered as such packages or libraries of ADTs for specific application domains.
ADTs are often used because the types for attributes in SQL3 and therefore the parameter types during a function or procedure, and as a source type during a distinct type. Type Equivalence is defined in SQL3 at two levels. Two types are name equivalent if and as long as they need an equivalent name. Two types are structurally equivalent if and as long as they need an equivalent number of components and therefore the components are pairwise type equivalent. Under SQL-92, the definition of UNION-compatibility among two tables is predicated on the tables being structurally equivalent. Operations on columns, however, are supported name equivalence. Thus the operation
UPDATE table_t SET c1 = c2 WHERE <condition>
would be acceptable if the types of c1 and c2 are name equivalent (or are implicitly convertible). Attributes and functions in ADTs are divided into three categories:
• PUBLIC (visible at the ADT interface).
• PRIVATE (not visible at the ADT interface).
• PROTECTED (visible only to subtypes).
It is also possible to define virtual attributes as part of ADTs, which are computed and updated using functions. SQL3 has rules for dealing with inheritance, overloading, and resolution of functions. They can be summarized as follows:
Inheritance
• All attributes are inherited.
• The order of supertypes in the UNDER clause to find the inheritance hierarchy.
• An instance of a subtype is used in every context in which a supertype instance is used.
Overloading
• A subtype can redefine any function which is defined in its supertype, with the restriction that the signature be the same.
Resolution of Functions
• When a function is named , the simplest match is chosen supported the kinds of all arguments.
• For dynamic linking, the runtime sorts of parameters is taken into account .
SQL3 supports constructors for collection types, which may be used for creating nested structures for complex objects. List, set, and multiset are supported as built-in type constructors.
Arguments for these type constructors are often the other type, including row types, ADTs, and other collection types. Instances of those types are often treated as tables for query purposes. Collections are often unnested by correlating derived tables in SQL3. for instance , to return the weather of the set hobbies for employee Smith , we first define an attribute within the table employee as follows:
hobbies SET (VARCHAR(20))
We can then write THE (SELECT e.hobbies FROM employee e WHERE e.name = "John Smith")
Another facility in SQL3 is the supertable/subtable facility, which is not equivalent to super and subtypes and no substitutability is assumed. However, a subtable inherits every column from its supertable; every row of a subtable corresponds to one and only one row in the supertable; every row in the supertable corresponds to at most one row in a subtable. INSERT, DELETE, and UPDATE operations are appropriately propagated. For example, consider the real_estate_info table defined as follows:
CREATE TABLE real_estate_info ( property real_estate, owner CHAR(25), price MONEY, );
The following subtables can be defined:
CREATE TABLE american_real_estate UNDER real_estate_info;
CREATE TABLE georgia_real_estate UNDER american_real_estate;
CREATE TABLE atlanta_real_estate UNDER georgia_real_estate;
We have given an summary of the proposed facilities in SQL3. At this point , both the SQL/Foundations and SQL/Object specification have reached the third step of the standardization process called the Committee Draft status. it's evident that the facilities that make SQL3 object-oriented closely follow what has been implemented in commercial ORDBMSs.
The next two steps of standardization are called Draft International Standard and International Standard, respectively. SQL/MM is being proposed as a separate standard for multimedia database management with multiple parts: framework, full text, spatial, general purpose facilities, and still image. It’s being pursued by a separate committee. We already saw the utilization of the two-dimensional data types and therefore the image and text Datablades in Informix Universal Server that have considered issues relevant to the present standard.
Reference book




