Unit - 5
Databases on the Web and Semi-structured data
Need of xml
XML may be a Platform Independent and Language Independent. Therefore the most advantage of xml is that you simply can use it to require data from a program like Microsoft SQL, convert it into XML then share that XML with other programs and platforms. You’ll communicate between two platforms which are generally very difficult.
XML truly powerful becauseit’s international acceptance. Multiple organizations use XML interfaces for databases, programming, office application, mobile phones and other areas because of its platform independent feature.
Features and Advantages of XML
XML is mostlyused in the time of web development. It’s also used to simplify data storage and data sharing.
The main features or advantages of XML are given below.
1) XML separates data from HTML
If you would like to display dynamic data in your HTML document, it'll take more of work to edit the HTML whenever the data changes.
With XML, data are often stored in separate XML files. This manner you'll concentrate on using HTML/CSS for display and layout, and make certain that changes within the underlying data won't require any changes to the HTML.
With some lines of JavaScript code, you'll read an external XML file and update the data content of your website.
2) XML simplifies data sharing
In the world, computer systems and databases contain data in incompatible formats.
XML data is stored in plain text format. This provides a software and hardware independent way of storing data.
This makes it much easier to form data which can be shared by different applications.
3) XML simplifies data transport
One of the foremost time-consuming challenges for developers is to exchange data between incompatible systems over the web.
Exchanging data as XML overcome this complexity and the data is read by different incompatible applications.
4) XML simplifies Platform change
Upgrading to new systems (hardware or software platforms), is usually time consuming. Large amounts of information must be converted and incompatible data is usually lost.
XML data is stored in text format. Therefore it provides easy way to expand or upgrade to new operating systems, new applications, or new browsers, without losing data.
5) XML increases data availability
Multiple applications access your data in HTML pages and from XML data sources also.
Using XML, your data is offered to some forms of "reading machines" as handheld computers, voice machines, and news feeds which are available for blind people.
6) Create new internet languages using XML
Multiple new Internet languages are created with XML.Following are some examples:
XML Example
XML documents create a hierarchical data structure seems like a tree so it's referred to as XML Tree that starts at "the root" and branches to "the leaves".
Example of XML: Books
books.xml
<bookstore>
<bookcategory="COOKING">
<titlelang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book category="CHILDREN">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category="WEB">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
</bookstore>
The root element within the example is<bookstore>. All elements within the document are contained within it. The element has 4 children: <title>, < author><year> and <price>.
To understand XML first understand its roots as a document markup language. The term markup refers to anything during a document that's not intended to be a part of the printed output. Forinstance, a writer creating text which will eventually be typeset during a magazine might want to form notes about how the typesetting should be done. It is important to type these notes during a way in order that they might be different from the actual content, and a note like “do not break this paragraph” doesn't end up printed within the magazine.
In electronic document processing, a markup language have a proper description of what a part of the document is content, what part is markup, and what the markup means.
Just as database systems evolved from physical file processing to supply a separate logical view, markup languages evolved from specifying instructions for a way to print parts of the document to specify the function of the content.
For the family of markup languages like HTML, SGML, and XML the markup takes the form of tags enclosed in angle-brackets<>.Tags are apply in pairs, with<tag> and <tag>delimiting the start and therefore the end of the portion of the document to which the tag refers. Forinstance, the title of a document could be marked up as follows.
<title>Database System Concepts</title>
Unlike HTML, XML doesn't prescribe the set of tags allowed, and therefore the set could also be specialized as required. This feature is that the key to XML’s major role in data representation and exchange, whereas HTML is used primarily for document formatting. Forinstance, in our running banking application, account and customer information are often represented as a part of an XML document as in Figure. Observe the use of tags like account and account-number. These tags provide context for every value and permit the semantics of the value to be identified.
Compared to storage of information during a database, the XML representation is inefficient, therefore tag names are repeated throughout the document. However, in spite of this disadvantage, an XML representation has significant advantages when it's used to exchange data, for instance, as a part of a message:
• First, the presence of the tags makes the message self-documenting therefore a schema need not be consulted to know the meaning of the text.
• Second, the format of the document isn't rigid. Forinstance, if some sender adds additional information, like a tag last-accessed noting the last date on which an account was accessed, the recipient of the XML data ignore the tag. The ability to recognize and ignore unexpected tags allows the format of the data to evolve over time, without invalidating existing applications.
• Finally, since the XML format is widely accepted, a large type of tools are available to help in its processing, including browser software and database tools.
SQL is the dominant language for querying relational data, XML is becoming the dominant format for data exchange.
<bank>
<account>
<account-number> A-101 </account-number>
<branch-name> Downtown </branch-name>
<balance> 500 </balance>
</account>
<account>
<account-number> A-102 </account-number>
<branch-name> Perryridge </branch-name>
<balance> 400 </balance>
</account>
<account>
<account-number> A-201 </account-number>
<branch-name> Brighton </branch-name>
<balance> 900 </balance>
</account>
<customer>
<customer-name> Johnson </customer-name>
<customer-street> Alma </customer-street>
<customer-city> Palo Alto </customer-city>
</customer>
<customer>
<customer-name> Hayes </customer-name>
<customer-street> Main </customer-street>
<customer-city> Harrison </customer-city>
</customer>
<depositor>
<account-number> A-101 </account-number>
<customer-name> Johnson </customer-name>
</depositor>
<depositor>
<account-number> A-201 </account-number>
<customer-name> Johnson </customer-name>
</depositor>
<depositor>
<account-number> A-102 </account-number>
<customer-name> Hayes </customer-name>
</depositor>
</bank>
Figure 5.1(I) XML representation of bank information.
The fundamental construct in an XML document is the element. An element is a pair of matching start-tag and end-tags, and all the text that appears between them. XML documents must have a single root element that encompasses all other elements in the document. In the example in Figure the <bank> element forms the root element. Further, elements in an XML document must nest properly. For instance,
<account> . . . <balance> . . . </balance> . . . </account>
is properly nested, whereas
<account> . . . <balance> . . . </account> . . . </balance>
is not properly nested. While proper nesting is an intuitive property, we may define it more formally. Text is said to appear within the context of an element if it appears between the start-tag and end-tag of that element. Tags are properly nested if every start-tag features a unique matching end-tag that's within the context of an equivalent parent element.
The text could also be mixed with the sub elements of an element, as in Figure like several other features of XML, this freedom makes more sense during a document processing context than during a data-processing context, and isn't particularly useful for representing more structured data like database content in XML.
The ability to nest elements within other elements provides an alternate way to represent information. Figure shows a representation of the bank information from Figure, but with account elements nested within customer elements. The nested representation makes it easy to search out all accounts of a customer, although it might store account elements redundantly if they're owned by multiple customers.
Nested representations are widely used in XML data interchange applications to avoid joins. As an example, a shipping application would store the complete address of sender and receiver redundantly on a shipping document related to each shipment, whereas a normalized representation may require a join of shipping records with a company-address reference to get address information.
Additionally to elements, XML specifies the notion of an attribute. as an example , the sort of an account can represented as an attribute, as in Figure The attributes of a component appear as name=value pairs before the closing “>” of a tag. Attributes are strings, and don't contain markup. Therefore attributes can appear only once during a given tag, unlike sub elements, which can be repeated.
. . .
<account>
This account is seldom used any more.
<account-number> A-102 </account-number>
<branch-name> Perryridge </branch-name>
<balance> 400 </balance>
</account>
. . .
Figure 5.2(I) Mixture of text with subelements.
<bank-1>
<customer>
<customer-name> Johnson </customer-name>
<customer-street> Alma </customer-street>
<customer-city> Palo Alto </customer-city>
<account>
<account-number> A-101 </account-number>
<branch-name> Downtown </branch-name>
<balance> 500 </balance>
</account>
<account>
<account-number> A-201 </account-number>
<branch-name> Brighton </branch-name>
<balance> 900 </balance>
</account>
</customer>
<customer>
<customer-name> Hayes </customer-name>
<customer-street> Main </customer-street>
<customer-city> Harrison </customer-city>
<account>
<account-number> A-102 </account-number>
<branch-name> Perryridge </branch-name>
<balance> 400 </balance>
</account>
</customer>
</bank-1>
Figure 5.2(II) Nested XML representation of bank information.
In a document construction context, the distinction between sub element and attribute is vital an attribute is implicitly text that doesn't appear within the printed or displayed document. However, in database and data exchange applications of XML, this distinction is a smaller amount relevant, and therefore the choice of representing data as an attribute or a sub element is usually arbitrary.
An element of the form<element></element>, which contains no sub elements or text, are often abbreviated as<element/>; abbreviated elements may, however, contain attributes. Since XML documents are designed to be exchanged between applications, a namespace mechanism has been introduced to permit organizations to specify globally unique names to be used as element tags in documents. The thought of a namespace is to prepend each tag or attribute with a universal resource identifier. Thus, for instance, if First Bank wanted to make sure that XML documents
. . .
<account acct-type= “checking”>
<account-number> A-102 </account-number>
<branch-name> Perryridge </branch-name>
<balance> 400 </balance>
</account>
. . .
Figure 5.2(III) Use of attributes.
It created wouldn't duplicate tags used by any business partner’s XML documents, it can prepend a unique identifier with a colon to every tag name. The bank may use a web URL like a unique identifier. Using long unique identifiers in every tag would be rather inconvenient, therefore the namespace standard provides how to define an abbreviation for identifiers.
In Figure, the root element (bank) contains attribute xmlns:FB, which declares that FB is defined as abbreviation for the URL given as above. The abbreviation can then be used in various element tags, as illustrated within the figure. A document can have quite one namespace, declared as a part of the root element. Different elements can then be related to different namespaces.
A default namespace are often defined, by using the attribute xmlns rather than xmlns:FB within the root element. Elements without a particular namespace prefix would then belong to the default namespace. Sometimes we'd like to store values containing tags without having the tags interpreted as XML tags. In order that we will do so, XML allows this construct:
<![CDATA[<account>···</account>]]>
Because it is enclosed within CDATA, the text <account> is treated as normal text data, not as a tag. The term CDATA stands for character data.
<bank xmlns:FB=“http://www.FirstBank.com”>
. . .
<FB:branch>
<FB:branchname> Downtown </FB:branchname>
<FB:branchcity> Brooklyn </FB:branchcity>
</FB:branch>
. . .
</bank>
Figure 5.2(IV)unique tag names through the use of namespaces.
Databases have schemas, which are used to constrain what information are often stored within the database and to constrain the data styles of the stored information. In contrast, by default, XML documents are often created without any associated schema: an element may then have any sub element or attribute. While such freedom may be acceptable given the self-describing nature of the data format, it's not useful when XML documents need to processed automatically as a part of an application, or when large amounts of related data are to be formatted in XML.
We define the document-oriented schema mechanism included as a part of the XML standard, the Document Type Definition, also because the more recently defined XMLSchema.
Document Type Definition
The document type definition (DTD) is an optional a part of an XML document. Thepurpose of a DTD is like schema: to constrain and typeof the information present within the document. However, the DTD doesn't actually constrain types within the sense of basic types like integer or string. Instead, it only constrains the looks of sub elements and attributes within an element. The DTD is primarily a listing of rules for what pattern of subelements present within an element. Figure shows a part of an example DTD for a bank information document in thatthe XML document conforms to the present DTD.
Each declaration is within the sort of a regular expression for the sub elements of an element. Thus, within the DTD a bank element consists of 1 or more account, customer, or depositor elements; the | operator specifies “or” while the + operator specifies “one or more.” The * operator is used to specify “zero or more,” while the? Operator is used to specify an optional element that's 0 or 1.
<!DOCTYPE bank [
<!ELEMENT bank ( (account—customer—depositor)+)>
<!ELEMENT account ( account-number branch-name balance )>
<!ELEMENT customer ( customer-name customer-street customer-city )>
<!ELEMENT depositor ( customer-name account-number )>
<!ELEMENT account-number ( #PCDATA )>
<!ELEMENT branch-name ( #PCDATA )>
<!ELEMENT balance( #PCDATA )>
<!ELEMENT customer-name( #PCDATA )>
<!ELEMENT customer-street( #PCDATA )>
<!ELEMENT customer-city( #PCDATA )>
] >
Figure 5.3(I)Example of a DTD
The account element has sub elements likeaccount-number, branchname and balance. Similarly, customer and depositor have the attributes in their schema defined as sub elements. Finally, the elements account-number, branch-name, balance, customer-name, customer- street, and customer-city are all declared as type of #PCDATA.
The keyword #PCDATA shows text data; it derives name from “parsed character data.” Two other special type declarations are empty, which represents the element has no contents, which says that there's no constraint on the sub elements of the element; that's , any elements, even those not mentioned within the DTD, can occur as sub elements of the element. The absence of a declaration for an element is like explicitly declaring the type as any.
The allowable attributes for every element declared within the DTD. Unlike sub elements, no order is imposed on attributes. Attributes may specified to be of type CDATA, ID, IDREF, or IDREFS; the type CDATA simply says that the attribute contains character data, while the other three are not simple. As an example, the following line from a DTD specifies that element account has an attribute of type acct-type, with default value checking.
<!ATTLIST account acct-type CDATA “checking” >
Attributes must have a kind declaration and a default declaration. The default declaration can contains a default value for the attribute or #REQUIRED, meaning that a value must be specified for the attribute in each element, or #IMPLIED, that means no default value has been provided. If an attribute features a default value, for each element that doesn't specify a value for the attribute, the default value is filled in automatically when the XML document is read An attribute of type ID provides a unique identifier for the element; a value present in an ID attribute of an element must not occur in the other element within the same document. At the most one attribute of an element is permitted to be of type ID.
<!DOCTYPE bank-2 [
<!ELEMENT account ( branch, balance )>
<!ATTLIST account
account-number ID #REQUIRED
owners IDREFS #REQUIRED >
<!ELEMENT customer ( customer-name, customer-street, customer-city )>
<!ATTLIST customer
customer-id ID #REQUIRED
accounts IDREFS #REQUIRED >
··· declarations for branch, balance, customer-name,
customer-street and customer-city ···
] >
Figure 5.3(II) DTD with ID and IDREF attribute types
An attribute of type IDREF may be a respect to an element; the attribute contain a value that appears within the ID attribute of some element within the document. The type IDREFS allows a listing of references, separated by spaces. Figure shows an example DTD during which customer account relationships are represented by ID and IDREFS attributes, rather than depositor records.
The account elements use account-number as their identifier attribute; to do so, account-number has been made an attribute of account rather than a sub element. The customer elements have a new identifier attribute called customer-id. Additionally, each customer element contains an attribute accounts, of type IDREFS, which may be a list of identifiers of accounts that are owned by the customer. Each account element has an attribute owners, of type IDREFS, which may be a list of owners of the account.
We use a special set of accounts and customers from earlier example, so for example the IDREFS feature better. The ID and IDREF attributes serve a similar role as reference in object-oriented and object-relational databases, supports the development of complex data relationships.
<bank-2>
<account account-number=“A-401” owners=“C100 C102”>
<branch-name> Downtown </branch-name>
<balance> 500 </balance>
</account>
<account account-number=“A-402” owners=“C102 C101”>
<branch-name> Perryridge </branch-name>
<balance> 900 </balance>
</account>
<customer customer-id=“C100” accounts=“A-401”>
<customer-name>Joe</customer-name>
<customer-street> Monroe </customer-street>
<customer-city> Madison </customer-city>
</customer>
<customer customer-id=“C101” accounts=“A-402”>
<customer-name>Lisa</customer-name>
<customer-street> Mountain </customer-street>
<customer-city> Murray Hill </customer-city>
</customer>
<customer customer-id=“C102” accounts=“A-401 A-402”>
<customer-name>Mary</customer-name>
<customer-street> Erin </customer-street>
<customer-city> Newark </customer-city>
</customer>
</bank-2>
Figure 5.3(III) XML data with ID and IDREF attributes.
Document type definitions are strongly connected to the document formatting heritage of XML. Due to this, they're unsuitable in some ways for serving because the type structure of XML for processing applications. Nevertheless, a tremendous number of data exchange formats are being defined in terms of DTDs, since they were a part of the initial standard. Here are a number of the restrictions of DTDs as a schema mechanism.
• Individual text elements and attributes can't be further typed. As an example, the element balance can't be constrained to be a positive number. The lack of such constraints is problematic for data processing and exchange applications, which must then contain code to verify the kinds of elements and attributes.
• It is difficult to use the DTD mechanism to specify unordered sets of sub elements. Order is seldom important for data exchange. While the combination of alternation (the | operation) and therefore the * operation as in Figure permits the specification of unordered collections of tags, it's far more difficult to specify that every tag may only appear once.
• There may be a lack of typing in IDs and IDREFs. Thus, there's no way to specify the type of element to which an IDREF or IDREFS attribute should refer. As a result, the DTD in Figure doesn't prevent the “owners” attribute of an account element from pertaining to other accounts, although this makes no sense.
XML Schema
An effort many of those DTD deficiencies resulted during a more sophisticated schema language, XMLSchema. We describe here an example of XMLSchema, and list some areas during which it improves DTDs, without giving full details of XMLSchema’s syntax.
Figure shows how the DTD in Figure are often represented by XMLSchema. The first element is that the root element bank, whose type is declared later. The instance then defines the kinds of elements account, customer, and depositor. Observe the use of types xsd:string and xsd:decimal to constrain the kinds of data elements. Finally the instance defines the type BankType as containing zero or more occurrences of every of account, customer and depositor.
The default for both minimum and maximum occurrences is 1, so these need to be explicitly specified to permit zero or more accounts, deposits, and customers. Among the advantages that XMLSchema offers over DTDs are these:
• It allows user-defined types to be created.
• It allows the text that appears in elements to be constrained to specific types, like numeric types in specific formats or maybe more complicated types like lists or union.
<xsd:schema xmlns:xsd=“http://www.w3.org/2001/XMLSchema”>
<xsd:element name=“bank” type=“BankType” />
<xsd:element name=“account”>
<xsd:complexType>
<xsd:sequence>
<xsd:element name=“account-number” type=“xsd:string”/>
<xsd:element name=“branch-name” type=“xsd:string”/>
<xsd:element name=“balance” type=“xsd:decimal”/>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
<xsd:element name=“customer”>
<xsd:element name=“customer-number” type=“xsd:string”/>
<xsd:element name=“customer-street” type=“xsd:string”/>
<xsd:element name=“customer-city” type=“xsd:string”/>
</xsd:element>
<xsd:element name=“depositor”>
<xsd:complexType>
<xsd:sequence>
<xsd:element name=“customer-name” type=“xsd:string”/>
<xsd:element name=“account-number” type=“xsd:string”/>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
<xsd:complexType name=“BankType”>
<xsd:sequence>
<xsd:element ref=“account” minOccurs=“0” maxOccurs=“unbounded”/>
<xsd:element ref=“customer” minOccurs=“0” maxOccurs=“unbounded”/>
<xsd:element ref=“depositor” minOccurs=“0” maxOccurs=“unbounded”/>
</xsd:sequence>
</xsd:complexType>
</xsd:schema>
XMLSchema version of DTD
• It allows types to be restricted to make specialized types, as an example by specifying minimum and maximum values.
• It allows complex types to be extended by using a type of inheritance.
• It may be a superset of DTDs.
• It allows uniqueness and foreign key constraints.
• It is integrated with namespaces to permit different parts of a document to conform to different schema.
• It is itself specified by XML syntax, as Figure shows.
However, the price paid for these features is that XMLSchema is significantly more complicated than DTDs.
Given the increasing number of applications that use XML to exchange, mediate, and store data, tools for effective management of XML data are getting more important. Especially, tools for querying and transformation of XML data are need to extract information from large bodies of XML data, and to convert data between different representations that is schemas in XML. Even as the output of a relational query may be a relation, the output of an XML query are often an XML document. As a result, querying and transformation are often combined into one tool.
Several languages provide increasing degrees of querying and transformation capabilities:
• XPath is a language for path expressions, and is really a building block for the remaining two query languages.
• XSLT was designed as a transformation language, as a part of the XSL style sheet system, which is used to regulate the formatting of XML data into HTML or other print or display languages. Although designed for formatting, XSLT can generate XML as output, and may represent many interesting queries. Therefore it's currently the most widely available language for manipulating XML data.
• XQuery has been proposed as a typical for querying of XML data. XQuery combines features from many of the proposals for querying XML as the language Quilt.
Tree Model of XML
A tree model of XML data is used altogether these languages. An XML document is modeled as a tree, with nodes like elements and attributes. Element nodes can have children nodes, which may be sub elements or attributes of the element. Correspondingly, each node, aside from the root element, features a parent node, which is an element. The order of elements and attributes within the XML document is modeled by the ordering of children of nodes of the tree. The terms parent, child, ancestor, descendant, and siblings are interpreted within the tree model of XML data.
The text content of an element are often modeled as a text node child of the element. Elements containing text broken up by intervening sub elements can have multiple text node children. as an example , an element containing “this may be a<bold> wonderful</bold> book” would have a sub element child like the element bold and two text node children like “this is a” and “book”. Since such structures aren't commonly utilized in database data, we shall assume that elements don't contain both text and sub elements.
XPath
XPath addresses parts of an XML document by means of path expressions. The language are often viewed as an extension of the easy path expressions in object-oriented and object-relational databases. A path expression in XPath may be a sequence of location steps separated by “/”. The results of a path expression may be a set of values. As an example, on the document in Figure, the XPath expression /bank-2/customer/name would return these elements:
<name>Joe</name>
<name>Lisa</name>
<name>Mary</name>
The expression /bank-2/customer/name/text() would return an equivalent names, but without the enclosing tags. like a directory hierarchy, the initial ’/’ indicates the root of the document. Path expressions are evaluated from left to right. As a path expression is evaluated, the results of the path at any point consists of a group of nodes from the document.
When an element name, like customer, appears before subsequent ’/’, it refers to all or any elements of the required name that are children of elements within the current element set. Since multiple children can have an equivalent name, the number of nodes within the node set can increase or decrease with each step. Attribute values can also be accessed, using the “@” symbol. as an example , /bank-2/account/@account-number returns a group of all values of account-number attributes of account elements.
XPath supports a number of other features:
We can test the existence of a subelement by listing it without any comparison operation; for example, if we removed just “> 400” from the above, the expression return account numbers of all accounts that have a balance subelement, instead of its value.
• XPath provides several functions which will be used as a part of predicates, including testing the position of the present node within the sibling order and counting the amount of nodes matched. for instance , the path expression /bank-2/account/[customer/count()> 2] returns accounts with more than 2 customers. Boolean connectives and and or are often used in predicates, while the function not (. . .) are often used for negation.
• The function id(“foo”) returns the node (if any) with an attribute of type ID and value “foo”. The function id can even be applied on sets of references, or maybe strings containing multiple references separated by blanks, like IDREFS. as an example , the path /bank-2/account/id (@owner) returns all customers mentioned from the owner’s attribute of account elements.
• The | operator allows expression results to be unioned. for instance , if the DTD of bank-2 also contained elements for loans, with attribute borrower of type IDREFS identifying loan borrower, the expression/bank-2/account/id(@owner) | /bank-2/loan/id(@borrower) gives customers with either accounts or loans. Therefore the | operator can't be nested inside other operators.
• An XPath expression can skip multiple levels of nodes by using “//”. As an example, the expression /bank-2//name finds any name element anywhere under the /bank-2 element, no matter the element during which it's contained. This example show the ability to search out required data without full knowledge of the schema.
• Each step within the path needn't select from the children of the nodes within the current node set. In fact, this is often only one of several directions along which a step within the path may proceed, like parents, siblings, ancestors and descendants. We omit details, but note that “//”, described above, may be a short form for specifying “all descendants,” while “...” specifies the parent.
XSLT
A style sheet may be a representation of formatting options for a document, usually stored outside the document itself, in order that formatting is separate from content. Forinstance, a style sheet for HTML might specify the font to be used on all headers, and thus replace more number of font declarations within the HTML page.
The XML Stylesheet Language (XSL) was designed for generating HTML from XML, and is a logical extension of HTML style sheets. The language includes a general-purpose transformation mechanism, called XSL Transformations (XSLT), which may be used to transform one XML document into another XML document, or to other formats like HTML.1 XSLT transformations are quite powerful, and actually XSLT can even act as a query language.
<xsl:template match=“/bank-2/customer”>
<customer>
<xsl:value-of select=“customer-name”/>
</customer>
</xsl:template>
<xsl:template match=“.”/>
Figure 5.4(I)shows using XSLT to wrap results in new XML elements.
XSLT transformations are represented as a series of recursive rules, called templates. Templates support the selection of nodes in an XML tree by an XPath expression. Therefore, templates generate new XML content, in order that selection and content generation are often mixed in natural and powerful ways. While XSLT are used as a query language, its syntax and semantics are not same as SQL.
A simple template for XSLT consists of a match part and a select part. Consider this XSLT code:
<xsl:template match=“/bank-2/customer”>
<xsl:value-of select=“customer-name”/>
</xsl:template>
<xsl:template match=“.”/>
The xsl:template match statement contains an XPath expression that selects one or more nodes. The first template matches customer elements which occur as children of the bank-2 root element. The xsl:value-of statement enclosed in the match statement outputs values from the nodes in the result of the XPath expression. The first template outputs the value of the customer-name subelement.
The second template matches all nodes. This is required because the default behavior of XSLT on subtrees of the input document not match any template is to copy the subtrees to the output document.XSLT copies any tag which is not in the xsl namespace unchanged to the output. Following example shows how to use this feature to form every customer name as a subelement of a “<customer>” element, by adding the xsl:value-of statement among<customer> and </customer>.
<xsl:template match=“/bank”>
<customers>
<xsl:apply-templates/>
</customers>
</xsl:template>
<xsl:template match=“/customer”>
<customer>
<xsl:value-of select=“customer-name”/>
</customer>
</xsl:template>
<xsl:template match=“.”/>
Figure 5.4(II)Applying rules recursively.
Structural recursion may be a main a part of XSLT. Recall that elements and subelements naturally form a tree structure. the fundamental idea of structural recursion is: When a template matches an element within the tree structure, XSLT use structural recursion to use template rules recursively on subtrees, rather than just outputting a value. It applies rules recursively by the xsl:apply-templates directive, which present in other templates.
For example, the results of previous query is placed in a <customers> element with the help of a rule using xsl:apply-templates. The new rule matches the outer “bank” tag, and constructs a result document by applying all other templates to the subtrees in the bank element, but wrapping the results in the given <customers></customers> element.
Without recursion performed by the <xsl:apply-templates/> clause, the template output <customers></customers>, and then apply the other templates on the subelements. The structural recursion is very difficult to formwell-formed XML documents, therefore XML documents need a single top-level element with all other elements in the document.
XSLT supports a feature called keys, which allows lookup of elements by using values of subelements or attributes; the goals are same as id() function in XPath, but allows attributes other than the ID attributes to be used. Keys are defined by an xsl:key directive contains three parts, for example:
<xsl:key name=“acctno” match=“account” use=“account-number”/>
The name attribute is employed to define different keys. The match attribute represents which nodes the key applies to. Finally, the use attribute define the expression to be used because the value of the key. Therein the expression needn't be unique to an element; because more than one element have an equivalent expression value. Within the example, the key named acctno define that the account-number subelement of account should be used as a key for that account.
Keys are often utilized in templates as a part of any pattern via the key function. This function takes the name of the key and a value, and returns the set of nodes that match that value. Therefore, the XML node for account “A-401” referenced as key (“acctno”, “A-401”).
<xsl:key name=“acctno” match=“account”use=“account-number”/>
<xsl:key name=“custno” match=“customer” use=“customer-name”/>
<xsl:template match=“depositor”>
<cust-acct>
<xsl:value-of select=key(“custno”, “customer-name”)/>
<xsl:value-of select=key(“acctno”, “account-number”)/>
</cust-acct>
</xsl:template>
<xsl:template match=“.”/>
Figure 5.4(III) Joins in XSLT.
With the assistance of keys we will implement some forms of joins. The code within the figure are often applied to XML data within the format, the key function joins the depositor elements with matching customer and account elements. The results of the query consists of pairs of customer and account elements enclosed within cust-acct elements. XSLT allows nodes to be sorted. A simple example shows how xsl:sort would be used in our style sheet to return customer elements sorted by name:
<xsl:template match=“/bank”>
<xsl:apply-templates select=“customer”>
<xsl:sort select=“customer-name”/>
</xsl:apply-templates>
</xsl:template>
<xsl:template match=“customer”>
<customer>
<xsl:value-of select=“customer-name”/>
<xsl:value-of select=“customer-street”/>
<xsl:value-of select=“customer-city”/>
</customer>
</xsl:template>
<xsl:template match=“.”/>
In above example the xsl:apply-template includes a select attribute, which constrains it to be applied only on customer subelements. The xsl:sort directive within the xsl:apply-template element causes nodes to be sorted before they're defined by subsequent set of templates. Options exist to allow sorting on multiple subelements/attributes, by numeric value, and in descending order.
XQuery
The World Wide Web Consortium (W3C) is developing XQuery which may be a query language for XML. The XQuery language derives from an XML query language called Quilt and most of the XQuery features we outline here are a part of Quilt. Quilt itself contains features from earlier languages like XPath, XML query languages, XQL and XML-QL.
Same as XSLT, XQuery doesn’t represent queries in XML. rather than the they present as SQL queries, and are organized into “FLWR” (called “flower”) expressions with four sections: for, let, where, and return. The for section gives a series of variables that range over the results of XPath expressions.
When multiple variables are specified, the results with the cartesian product of the possible values the variables can take, making the for clause same to the from clause of an SQL query. The let clause allows complicated expressions to be assigned to variable names for simplicity of representation. The where section, just like the SQL where clause, performs additional tests on the joined tuples from the for section.
Finally, the return section supports the development of leads to XML. an easy FLWR expression which returns the account numbers for checking accounts is depends on the XML document of Figure, which uses ID and IDREFS:
for $x in /bank-2/account
let $acctno := $x/@account-number
where $x/balance > 400
return <account-number> $acctno </account-number>
In above query the let clause isn't essential, and therefore the variable $acctno within the return clause are often replaced with $x/@account-number. The for clause uses XPath expressions, selections occur within the XPath expression. Thus, a same query may have just for and return clauses:
for $x in /bank-2/account[balance > 400] return <account-number> $x/@account-number </account-number>
Therefore the let clause simplifies complex queries. Path expressions in XQuery return a multiset, with repeated nodes. The function distinct applied on a multiset, returns a group with no duplication. The distinct function utilized in a for clause. XQuery also provides aggregate functions like sum and count which may be applied on collections of sets and multisets.
While XQuery not provide a group by construct, aggregate queries are often written by using nested FLWR constructs in place of grouping. The variables assigned by let clauses could also be set or multiset valued, if the path expression on the right-hand side returns a group or multiset value.
Joins are defined in XQuery same as they're in SQL. The join of depositor, account and customer elements in Figure, during which XSLT , are often written in XQuery this way:
for $b in /bank/account,
$c in /bank/customer,
$d in /bank/depositor
where $a/account-number = $d/account-number
and $c/customer-name = $d/customer-name
return <cust-acct> $c $a </cust-acct>
The same query can be expressed with the selections define as XPath selections:
for $a in /bank/account,
$c in /bank/customer,
$d in /bank/depositor[account-number = $a/account-number
and customer-name = $c/customer-name]
return <cust-acct> $c $a</cust-acct>
XQuery FLWR expressions are often nested within the return clause, to get element nesting which isn't appear within the source document. This feature is same as nested subqueries within the from clause of SQL .For example the XML structure with account elements nested within customer elements, are often generated from the structure in Figure with the assistance of following query:
<bank-1>
for $c in /bank/customer
return
<customer>
$c/*
for $d in /bank/depositor[customer-name = $c/customer-name],
$a in /bank/account[account-number=$d/account-number]
return $a
</customer>
</bank-1>
The query also represents the syntax $c/*, refers to all the children of the node, which is bound to the variable $c. In same way $c/text() gives the text content of an element, without the tags.
Path expressions in XQuery are depends on path expressions in XPath, but XQuery provides some extensions. One of the useful syntax extensions is the operator ->, which is used to dereference IDREFs same the function id(). The operator were applied on a value of type IDREFS to get a set of elements. It is used, for example, to find all the accounts related with a customer, with the ID/IDREFS representation of bank information.
Results can be sorted in XQuery if a sortby clause is added at the end of any expression; the clause defines how the instances of that expression should be sorted. For example, this query outputs all customer elements sorted by the name sub element:
for $c in /bank/customer,
return <customer> $c/* </customer> sortby(name)
To sort in descending order, we can use sortby(name descending).
Sorting performed at multiple levels of nesting. For example, we can get a nested representation of bank information sorted in customer name order, with accounts of every customer sorted by account number, as follows.
<bank-1>
for $c in /bank/customer
return
<customer>
$c/*
for $d in /bank/depositor[customer-name = $c/customer-name],
$a in /bank/account[account-number=$d/account-number]
return <account> $a/* </account> sortby(account-number)
</customer> sortby(customer-name)
</bank-1>
XQuery provides a many built-in functions, and supports user-defined functions. For example, the built-in function document returns the root of a named document; the root then used in a path expression to access the contents of the document. Users can define functions as shown by this function, which returns a list of all balances of a customer with a specified name:
function balances(xsd:string $c) returns list(xsd:numeric) {
for $d in /bank/depositor[customer-name = $c],
$a in /bank/account[account-number=$d/account-number]
return $a/balance
}
XQuery uses the type system of XMLSchema. XQuery provides functions to convert between types. For example, number(x) converts a string to a number. XQuery provides a several other features, like if-then-else clauses, t is used within return clauses, and existential and universal quantification, which can be used in predicates in where clauses. For example, existential quantification was expressed using some $e in path satisfies P where path is a path expression, and P is a predicate which can use $e. Universal quantification can be expressed by using every in place of some.
The Application Program Interface
With the wide acceptance of XML as a data representation and exchange format, software tools are available for manipulation of XML data. There are two standard models for programmatic implementation of XML, each available for use with a many popular programming languages.
One of the standard APIs for manipulating XML is the document object model (DOM), that treats XML content as a tree, with every element represented by a node, called a DOMNode. Programs can access parts of the document in a navigational fashion, starting with the root. DOM libraries are available for most common programming languages and are available in Web browsers, and used to manipulate the document displayed to the user.
The Node interface provides methods like getParentNode(), getFirstChild(), and getNextSibling(), to navigate the DOM tree, starting with the root node. Subelements of an element are accessed by name getElementsByTagName(name), which returns a list of all child elements with a tag name; individual members of the list is accessed by the method item(i), which returns the ith element in the list. Attribute values of an element can be accessed by name, using the method getAttribute( name).
The text value of an element is modeled as a Text node, which may be a child of the element node; a component node with no subelements has just one child node. the method getData() on the Text node returns the text contents. DOM provides a several functions for updating the document by adding and deleting attribute and element children of a node, setting node values, and lots of more.
Many details are needed for writing an actual DOM program. DOM are often used to access XML data stored in databases, and an XML database are often built using DOM as its primary interface for accessing and modifying data. However, the DOM interface doesn't support any kind of declarative querying.
The second programming interface is the Simple API for XML (SAX) is an event model, designed to provide a common interface between parsers and applications. This API is built on the notion of event handlers, which consists of user-specified functions related with parsing events. Parsing events related to the recognition of parts of a document; for example, an event is generated when the start-tag is found for an element, and another event is generated when the end-tag is found. The part of a document are always occurred in order from start to finish. SAX is not appropriate for database applications.
Many applications need storage of XML data. One method to store XML data is to store it as documents in a file system and second method is to build a special-purpose database to store XML data. Another way is to convert the XML data to a relational representation and store it in a relational database.
A. Non-relational Data Stores
There are multiple ways for storing XML data in non-relational data-storage systems:
• Store in flat files. XML is primarily a file format, a natural storage method is simply a flat file. This approach has multiple drawbacks of using file systems as the basis for database applications. In particular, it lacks data isolation, atomicity, concurrent access, and security. Therefore the more availability of XML tools work on file data makes it easy to access and query XML data stored in files. This storage format can be sufficient for some applications.
• Create an XML database. XML databases are databases that use XML as the basic data model. Early XML databases implemented the Document Object Model on a C++ based object-oriented database. This allows object-oriented database infrastructure to be used again, while providing a standard XML interface. The addition of XQuery or other XML query languages provides declarative querying. Other implementations have built the entire XML storage and querying infrastructure on top of a storage manager that provides transactional support.
Although several databases designed specifically to store XML data have been built, building a full-featured database system from ground up is a very complex task. Such a database must support not only XML data storage and querying but also other database features such as transactions, security, support for data access from clients, and a variety of administration facilities. It makes sense to instead use an existing database system to provide these facilities and implement XML data storage and querying either on top of the relational abstraction, or as a layer parallel to the relational abstraction.
Relational Databases
Relational databases are mostly used in existing applications, there are many benefit for storing XML data in relational databases therefore the data can be accessed from existing applications.
Converting XML data to relational form is straightforward if the data were generated from a relational schema in the first place, and XML was used as a data exchange format for relational data. There are many applications where the XML data is not generated from a relational schema, and translating the data to relational form for storage may not be straightforward. In particular, nested elements and elements that recur complicate storage of XML data in relational format. Several alternative approaches are available:
1. Store as string.
A simple way to store XML data during a relational database is to store each child element of the top-level element as a string during a separate tuple within the database. as an example , the XML data in Figure might be stored as a group of tuples during a relation elements (data), with the attribute data of every tuple storing one XML element (account, customer, or depositor) in string form.
While the above representation is simple to use, the database system doesn't know the schema of the stored elements. As a result, it's impossible to query the data directly. In fact, it's not even possible to implement simple selections like finding all account elements, or finding the account element with account number A-401, without scanning all tuples of the relation and examining the contents of the string stored within the tuple.
A partial solution to the present problem is to store different types of elements in several relations, and also store the values of some critical elements as attributes of the reference to enable indexing. as an example , in our example, the relations would be account-elements, customer-elements, and depositor-elements, each with an attribute data. Every relation consist of more attributes to store the values ofsub elements, like account-number or customer-name.
2. Tree Representation
Arbitrary XML data are modeled as a tree and stored using a relation same like nodes (id, parent id, type, label, value) every element and attribute within the XML data is given a unique identifier. A tuple inserted within the nodes relation for each element and attribute with its identifier (id), the identifier of its parent node (parent id), the kind of the node (attribute or element), the name of the (element or attribute), and therefore the text value of the element or attribute.
This representation has the advantage that every one XML information are often represented directly in relational form, and much of XML queries are often translated into relational queries and executed inside the database system. However, it is the disadvantage that each element gets broken up into many pieces, and a large number of joins are required to reassemble subelements into an element.
3. Map to Relations
In this approach, XML elements whose schema is known are mapped to relations and attributes. Elements whose schema is not known are stored as strings or a tree. A relation is made for every element type whose schema is understood and whose type may be a complex type. The basic element of the document are often ignored during this step if it doesn't have any attributes. The attributes in the relation is represented as follows:
• All attributes of those elements are stored as string-valued attributes of the relation.
• If a subelement of the element may be a simple type, an attribute is added to the relation to represent the subelement. The type of the relation attribute defaults to a string value, but if the subelement had an XML Schema type, a corresponding SQL type could also be used.
• Otherwise, a relation is made like the subelement. Further:
◦ An identifier attribute is added to the relations representing the element. The identifier attribute is added one time even if an element has many subelements.
◦ An attribute parent_id is added to the relation representing the subelement, storing the identifier of its parent element.
◦ If ordering is to be preserved, an attribute position is added to the relation representing the subelement. For instance , if we apply the above procedure to the schema like the data then we get the following relations:
department(id, dept_name, building, budget)
course(parent_id, course_id, dept_name, title, credits)
Variants of this approach are possible. Forinstance, the relations like subelements which will occur at the most once are often “flattened” into the parent relation by moving all their attributes into the parent relation. The bibliographical notes provide references to different approaches to represent XML data as relations.
4. Publishing and Shredding XML Data
When XML is used to exchange data among the business applications then the data frequently originates in relational databases. Data in relational databases must be published, that is, converted to XML form, for export to other applications. Incoming data must be shredded, that is, converted back from XML to normalized relation form and stored during a relational database.
While application code can perform the publishing and shredding operations, the operations are so common that the conversions should be done automatically, without writing application code, where possible. Database vendors have spent more of effort to XML-enable their database products.
An XML-enabled database supports an automatic mechanism for publishing relational data as XML. The mapping used for publishing data could also be simple or complex. a simple relation to XML mapping might create an XML element for each row of a table, and make each column therein row a subelement of the XML element.
A more complicated mapping would allow nested structures to be created. Extensions of SQL with nested queries within the select clause are developed to allow easy creation of nested XML output. Mappings even have to be defined to shred XML data into a relational representation. For XML data created from a relational representation, the mapping need to shred the data is a straightforward inverse of the mapping used to publish the information.
5. Native Storage within a Relational Database.
Some relational databases support native storage of XML. Such systems store XML data as strings or in additional efficient binary representations, without converting the information to relational form. A new data type xml is define to represent XML data, andthe CLOB and BLOB data types provide the underlying storage mechanism. XML query languages like XPath and XQuery are supported to query XML data. A relation with an attribute of type xml are often used to store a set of XML documents; every document is stored as a value of type xml during a separate tuple.
Special-purpose indices are formed to index the XML data. Many database systems provide native support for XML data. they provide an xml data type and permit XQuery queries to be embedded within SQL queries. An XQuery query are often executed on one XML document and may be embedded within an SQL query to allow it to execute on each of a set of documents, with each document stored during a separate tuple.
<university>
<department>
<row>
<dept_name>Comp. Sci. </dept_name>
<building>Taylor </building>
<budget>100000 </budget>
</row>
<row>
<dept_name>Biology </dept_name>
<building>Watson </building>
<budget>90000 </budget>
</row>
</department>
<course>
<row>
<course_id>CS-101 </course_id>
<title>Intro. to Computer Science </title>
<dept_name>Comp. Sci </dept_name>
<credits>4 </credits>
</row>
<row>
<course_id>BIO-301 </course_id>
<title>Genetics </title>
<dept_name>Biology </dept_name>
<credits>4 </credits>
</row>
<course>
</university>
Figure 5.5(I)SQL/XML representation of university information.
SQL/XML
While XML is used widely for data interchange, structured data remains widely stored in relational databases. there's often a requirement to convert relational data to XML representation. The SQL/XML standard, developed to satisfy this need, defines a typical extension of SQL, allowing the creation of nested XML output. the standard has several parts, including a standard way of mapping SQL types to XML Schema types, and a typical thanks to map relational schemas to XML schemas, also as SQL query language extensions.
For example, the SQL/XML representation of the department relation consist of XML schema with element department, with each tuple mapped to an XML element row, and relation attribute mapped to an XML element of an equivalent name.
An entire SQL schema, with multiple relations, also can be mapped to XML during a similar fashion. SQL/XML adds several operators and aggregate operations to SQL to allow the development of XML output directly from the extended SQL. The xmlelement function are often used to create XML elements, while xmlattributes are often used to create attributes, as illustrated by the subsequent query.
select xmlelement (name “course”,
xmlattributes (course_id as course_id, dept_name as dept_name),
xmlelement (name “title”, title),
xmlelement (name “credits”, credits))
from course
The above query creates an XML element for each course, with the course identifier and department name represented as attributes, and title and credits as subelements.
The xmlattributes operator creates the XML attribute name using the SQL attribute name, which was changed using clause as shown. The xmlforest operator make easy the construction of XML structures. Its syntax and behavior are same to those of xmlattributes, except that it creates a collection of subelements and a list of attributes. It takes multiple arguments, creating an element for each argument, with the attribute’s SQL name used as the XML element name.
The xmlconcat operator can be used to concatenate elements created by subexpressions into a forest. When the SQL value used to construct an attribute is null, the attribute is omitted. Null values are omitted when the body of an element is constructed. SQL/XML also provides aggregate function xmlagg that creates a collection of XML elements from the set of values on which it is applied.
The following query creates an element for every department with a course, containing as subelements all the courses in that department. Since the query has a clause group by dept_name, the aggregate function is applied on all courses in each department, creating a sequence of course_id elements.
select xmlelement (name “department”, dept_name,
xmlagg (xmlforest(course_id)
order by course_id))
from course
group by dept_name
SQL/XML allows the sequence created by xmlagg to be ordered shown in the above query.
There are several applications of XML for storing and communicating (exchanging) data and for accessing Web services (information resources).
1. Storing Data with Complex Structure
Many applications need to store data that are structured, but aren't easily modeled as relations. As an example, user preferences that has to be stored by an application like a browser. There are usually an outsized number of fields, like home page, security settings, language settings, and display settings that has to be recorded. a number of the fields are multivalued, for example, a list of trusted sites, or even ordered lists, for example, a list of bookmarks.
Applications traditionally used some variety of textual representation to store such data. Today, a majority of such applications choose to store such configuration information in XML format. The ad hoc textual representations used earlier require effort to design and effort to make parsers which will read the file and convert the data into a form that a program can use.
The XML representation avoids both these steps. XML-based representations are now widely used for storing documents, spreadsheet data and other data that are a part of office application packages. The Open Document Format (ODF), supported by the Open Office software suite also as other office suites, and therefore the Office Open XML format, supported by the Microsoft Office suite, are document representation standards supported XML.
They are the 2 most generally used formats for editable document representation. XML is additionally used to represent data with complex structure that has to be exchanged between different parts of an application. for instance , a database system may represent a question execution plan by using XML. this enables one a part of the system to get the query execution plan and another part to display it, without employing a shared data structure. for instance , the data could also be generated at a server system and sent to a client system where the data are displayed.
2. Standardized Data Exchange Formats
XML-based standards for representation of data are developed for a range of specialized applications, starting from business applications like banking and shipping to scientific applications like chemistry and biology . Some examples:
• The chemical industry needs information about chemicals, like their molecular structure, and a range of important properties, like boiling and melting points, calorific values, and solubility in various solvents. ChemML may be a standard for representing such information.
• In shipping, carriers of goods and customs and tax officials need shipment records containing detailed information about the products being shipped, from whom and to where they were sent, to whom and to where they're being shipped, the price of the products, and so on.
• a web marketplace during which business can purchase and sell goods a so-called business-to-business (B2B) market needs information like product catalogs, including detailed product descriptions and price information, product inventories, quotes for a proposed sale, and buy orders.
Forinstance, the RosettaNet standards for e-business applications define XML schemas and semantics for representing data also as standards for message exchange. Using normalized relational schemas to model such complex data requirements would end in a large number of relations that don't correspond on to the objects that are being modeled. The relations would often have large numbers of attributes; explicit representation of attribute/element names beside values in XML helps avoid confusion between attributes.
Nested element representations help reduce the number of relations that has to be represented, also because the number of joins required to get required information, at the possible cost of redundancy. for example, in our university example, listing departments with course elements nested within department elements.
3. Web Services
Applications often require data from outside of the organization, or from another department within the same organization that uses a special database. In many such situations, the outside organization or department isn't willing to permit direct access to its database using SQL, but is willing to supply limited types of information through predefined interfaces.
When the information is to be used directly by a person's , organizations provide Web-based forms, where users can input values and obtain back desired information in HTML form. However, there are many applications where such information must be accessed by software programs, instead of by end users. Providing the results of a query in XML form may be a clear requirement. Additionally, it is sensible to specify the input values to the query also in XML format. In effect, the provider of the knowledge defines procedures whose input and output are both in XML format.
The HTTP protocol is used to communicate the input and output information, since it's widely used and may go through firewalls that institutions use to stay out unwanted traffic from the net. the simple Object Access Protocol (SOAP) defines a standard for invoking procedures, using XML for representing the procedure input and output. SOAP defines a standard XML schema for representing the name of the procedure, and result status indicators like failure/error indicators. The procedure parameters and results are application-dependent XML data embedded within the SOAP XML headers.
Today much of the present electronic data lies outside of database management system: it lies in structured documents like HTML and SGML, nonstandard data formats, legacy systems, etc. The structure of this “non-relational" data is usually irregular, often unknown ahead, and even when it's known, it's going to change often and unexpectedly (e.g. data on the Web).
Research on semi structured data has aimed toward extending database management techniques to data with irregular, unknown, or often changing structure. Most of the research has focused on the logical data model and on query languages for semi structured data. Several query languages are proposed: e.g. Lorel , UnQL, MSL, StruQL .
Data Model
OEM
The OEM model (Object Exchange Model) is that the actual model for semistructured data and was originally introduced for the Tsimmis data integration project. We follow here the presentation in Lore. OEM may be a graph-based, self-describing object instance model. Data is represented by a set of objects . Each object are often atomic or complex. the worth of an atomic object is of some base type (integer, string, image, sound, etc). the value of a posh object may be a set of (attribute, object) pairs. The graph features a root , i.e. a distinguished object with all other objects are accessible from it. Figure shows an example of some OEM bibliography data, and its textual representation is given in Figure.
{author: "Abiteboul",
author: "Hull",
author: "Vianu",
title: "Foundations of Databases",
publisher: "Addison Wesley" }
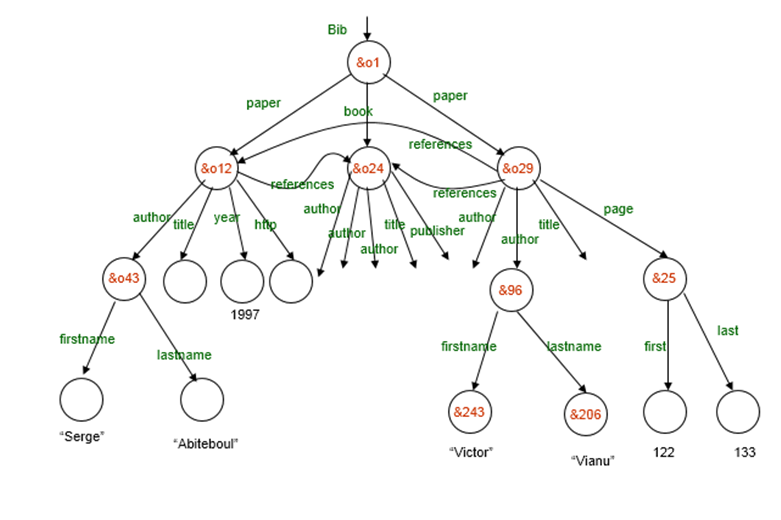
Figure 1: OEM Data
Bib: &o1 { paper: &o12 { … },
book: &o24 { … },
paper: &o29
{ author: &o52 “Abiteboul”,
author: &o96 { firstname: &243 “Victor”,
lastname: &o206 “Vianu”},
title: &o93 “Regular path queries with constraints”,
references: &o12,
references: &o24,
pages: &o25 { first: &o64 122, last: &o92 133}
}
}
Figure 5.7(I) Syntax of Semistructured Data
Comparison to the Relational and OO Models
A relation may be a set of records. Sets are OEM objects where all attributes are an equivalent, and records are objects where all attributes are distinct. Relational data are often easily represented in OEM. On the opposite hand OEM allows more flexibility within the data, like, for instance , missing attributes in records, multiple occurrences of an equivalent attribute, heterogeneous sets, and attributes with differing types in several objects, etc.
Object Equality
Like in object-oriented languages, there are two operators for testing object equality: shallow equality returns true if both are an equivalent object, and deep equality returns true if the graphs accessible from both objects are isomorphic.
XML creates new challenges for semistructured data, derived both from the mismatches and from XML's predicted applications. for a few of those challenges, inspiration are often found within the techniques developed for processing tagged text, and SGML especially , that there exists an in depth literature. While a number of these techniques are definitely of interest, many are limited given their restricted view of the text as a parse tree, and are ill fitted to some of XML's applications.
1. Order
Order was considered a side issue in semistructured data, but it becomes a central problem for XML. Models for text databases having order, but their query languages are limited. For the query language, this creates two problems: such as
• How can we inquire the order within the input?
• How can we order the query's output?
For the primary problem, XML-QL has index variables which may , at a minimum, test the order of sub-objects. for instance consider the query “find all papers published by Abiteboul and Vianu where Vianu is that the first author":
where [Bib.paper] <title> $T</title>
<author>[$i] Vianu</>
<author>Abiteboul</>
$i<$j
</>
Construct <result> $</>
Here $i and $j are index variables and are bound to numbers (0, 1, 2, . . . ) like the positions of the 2 author sub-objects. (They aren't necessarily 0 and 1, because, e.g. title, or year could occur earlier.) The query selects only those titles that Vianu occurs before Abiteboul. within the case of a mixed model, if some paper node is unordered, we may safely assume that $i, $j aren't bound, i.e. that paper won't contribute to the result. Index variables are limited to single edges. it's not clear the way to handle order within the case of more complex path expressions.
For the second problem, one can order the query's output with an ordered-by clause, like in SQL. Consider the following query in Lorel extended with an ordered-by clause:
select X.title from
Bib.paper X
where X.author.lastname = "Vianu"
ordered-by X.year
This lists paper titles so as of their year of publication. Papers without a year aren't listed. just in case of ties the order within the input file is preserved. we might wish to extend this last rule to queries without ordered-by, and say that therein case one just preserves the order within the input. But we'd like to be more precise here. for instance consider the subsequent query:
select Y.author.lastname
from Bib.book X,
X.references Y, Y.references Z
where X.publisher = "Addison-Wesley"
ordered-by Z.year
What does it mean for this query to “preserve the order within the input" ? we propose a possible answer, which is supposed for instance the difficulties instead of be a particular answer. Start by introducing variables altogether path expressions in select, where, and ordered-by:
select N
from Bib.book X,
X.reference Y, Y.reference Z,
Y.author.lastname N, Z.year U
where X.publisher = "Addison-Wesley"
ordered-by U
Fix a complete order on the nodes within the input database. This order depends on the info only and may be recomputed and stored with the info . It might be the order given by the text representation of the info , or, when no text representation is out there , it might be obtained by a depth-first or breadth-first graph traversal. Use this order to sort lexicographically all bindings of the variables (U, X, Y, Z, N): note the order during which the variables are listed. Finally project on the variable N.
Finally, we only mention that, within the context of query languages with declarative updates, one also must worry about having the ability to insert new objects at specific places in lists.
2. XML Data Translation
Different organizations may choose different DTD's to structure semantically related data (e.g. two purchase-order catalogs may organize data about shoes differently); so as to be exchanged, data must be converted. Inside one organization a DTD may evolve over time, and old data must be converted into the new structure. These are only two examples illustrating the necessity for data translation. Translation of XML data raises two problems:
• Given two DTD's D1; D2 and a query Q, make sure all XML data instances of type D1 will indeed be translated into instances which of type D2.
• Given two DTD's how can we automate, or semiautomatic the translation process?
The first problem may be a type inference problem, and has not been addressed thus far in semi structured data.
3. Type checking
As mentioned before type checking is very important in data translation. during a broader sense it are often used to assist the user in query formulation. Given the DTD in Fig., a path expression like Bib.paper.address doesn't add up , and therefore the system may issue a warning to the user, instead of just return an empty result. A more subtle hint are often given for a path expression like Bib.book.*.lastname: here the system may warn the user that * can only be sure to author.
4. Optimization
McHugh and Widom describe a standard query optimizer for Lorel. Queries are translated into query execution plans, which use a rich set of physical operators, and these successively are optimized.
Other researchers have considered schema-based query optimizations (a quite semantic optimization). Assume the query condition Bib.*.last = 130. Without schema information, a question processor has got to traverse the whole data to look for the attribute last. Now assume that the data's structure is described by the DTD in Fig. Only a Bib.(paper|book).page path can cause a final attribute. This offers a useful hint to the query processor: don't follow, say, author links.
Such an optimization is named query pruning and may be achieved by a process almost like that of constructing the product automaton of two automata; it's been shown to yield a guaranteed “optimal" query. But query pruning has only been described for single path queries and a restricted quite schemas (graph schemas): DTD's are richer, and that they may interact in subtle ways with more complex queries.
Some researchers have addressed query optimization from a theoretical angle. Abiteboul and Vianu consider path equations. for instance , considering a database of assemblies and parts, the equation part.(subpart)*.description = catalog.partdescription says that each one descriptions are often reached directly through the catalog. Then the query part. (subpart)*.description.section.paragraph are often replaced with the simpler catalog.partdescription.section.paragraph.
In general, we've a group of path equations E and would really like to make a decision whether two given path expressions p1; p2 are equal. The authors in have shown the surprising result that this problem is decidable, and moreover shown that its complexity is tractable under certain restrictions. The authors show that containment and equivalence conjunctive queries with regular path expressions decidable, and, moreover, for a restricted case, the complexity is NP. Both results are still at a theoretical level and haven't yet been applied during a practical framework.
5. Distributed Evaluation
XML links extend and generalize HTML anchors: an XML document may contain links to things residing in other XML documents. Links may cross server and organization boundaries, similarly to HTML anchors. This poses serious challenges to query evaluation. A naive solution is in fact to down-load all interlinked XML documents during a centralized site, and evaluated the query locally. This is often impractical in most cases. A more sensible approach is to start out evaluating the query at the basis site, then ship the query to the remote site whenever a link is reached.
A problem arises if the remote site isn't responding, or if it doesn't accept an equivalent query language. Assuming it does return some result, we proceed with the query evaluation at the basis site until we reach another link, and so on. An improvement would be to anticipate all possible query shipping’s and bundle them into one TCP connection. That work shows that single path expressions are often evaluated with only two connections between the basis site and every one the opposite sites, while more complex queries can still be evaluated with a hard and fast number of connections, but that number may depend upon the query.
Those techniques are described within the general framework of semistructured data, and don't consider any schema information. Against this XML data will possibly be described by DTD's, which may make pretty clear which data fragments reside on which websites. This information must be utilized in order to evaluate queries efficiently on distributed XML data.
6. Efficient Storage
Current research prototypes using semistructured data store the info as a graph. The schema is thus stored with every data item. This is often an unnecessarily conservative approach. When a DTD is given, XML data are often stored more efficiently. A method is to store it in an object-oriented database, using a one-to-one mapping between the weather within the DTD and therefore the classes within the object-oriented database: each element within the XML data becomes an object. Some SGML objects are stored in textual form, thus increasing the granularity of the storage. When that object is fetched, it must be parsed.
We will model XML data as a labelled graph during which nodes associated with abstract objects (e.g. OIDs) and edges are labelled with element tags 4. In many cases, the graph may be a tree (XML-tree). Then it's a distinguished node called the root. Each leaf of G is labelled with one string value.
Considering a mixed content of an element, string values are often also in non-leaf nodes. XML data are often queried by a mixture of value search and structure search. the previous includes matching document names, element names/values, and attribute names/values. The latter is typically specified by regular path expressions and is completed by examining ancestor-descendent relationship in XML-tree. the most role of indexing XML data is to support both these searches. the path to a string value is that the sequence of tags from the root to the string value node. In XQL, e.g., the occurrence of attributes during a path is restricted to the path end.
Attributes are often used in regular path expressions. Regular path expressions of most query languages over XML data are supported syntax of XPath, extended with special operators and predicates. For our purposes, we'll suppose regular path expressions, or path expressions, e, over formulas in F, the set of Boolean combinations of predicates over the domain PCDATA. The predicates include at least”=”. Then e: = | label | ∗ | e/e | e//e | (e|e) | [f], where label may be a tag, ∗ denotes any tag, e/e is concatenation, e//e is concatenation with any path in between, and (e|e) is alternation.
Brackets [ ] enclose a Boolean expression that is a predicate for a given step during a given path. We don't consider e ∗, i.e. the Kleene closure. A path expression consists of a series of steps. Each step represents movement through a XML document during a particular direction.
A possible predicate eliminates nodes that fail to satisfy a given condition. The results of each step may be a list of nodes that is a starting point for subsequent step. Each e expresses a query over XML data. the solution of a query may be a list of nodes gained by evaluation of the last step in e.
Example 1.
The example of the DTD and therefore the valid XML document is in Figure. the path titles/book/author denotes a query for obtaining all book authors from the document.
<!DOCTYE title[
<!ELEMENT title(book*)>
<!ELEMENT book(#PCDATA|author)*>
<!ELEMENT author(#PCDATA)>
]>
Fig. 5.9(I) a) The example of DTD.
<? Xml version=”1.0”>
<titles>
<book>AMLBOOK<author>Frank</author></book>
<book>TREEBOOK<author>Tony</author></book>
<book>BOOK<author>Frank</author></book>
</titles>
b) The example of valid XML document
One of the first samples of original evaluation strategies of queries over XML data is Lore’s cost-based optimizer. It uses three evaluation strategies: top-down for exploiting path expressions, bottom-up for exploiting value predicates, and a hybrid strategy. Obviously, the simple approach to traversing hierarchies of XML data leads often to exhaustive search of the tree.
To support these strategies, four kinds of index structures are proposed: value index and text index to go looking objects with a specific value, link index and path index for providing fast access to parents of an object and every one objects reachable via a given labelled path.
Most of indexing schemes keep record of existing paths within the database summarizing path information. Two pioneering approaches for indexing semistructured data for path expressions are DataGuide and 1-index. DataGuides were introduced in [GW97] as a concise and accurate summary of a semis tructured data instance. Let p1, p2, . . . e all paths occurring during a XML document D.
The DataGuide for D is that the trie structure for p1, p2, . . .. In other words, the DataGuide may be a tree, whith one node for every distinct path, and an edge labelled l between any two nodes of the form p and p.l, where p may be a path and l may be a label. The worst-case number of nodes within the DataGuide is exponential within the size of the original tree for D. Authors of observe that for irregular and deeply nested D the DataGuide grows out of proportions. They propose a data structure called a reversed DataGuide, which is simply the trie structure for the reverse paths.
The 1 -index of is additionally a graph, which encodes all paths within the XML graph. It improves over DataGuides within the amount of memory necessary for the graph representation. 1-indices take less memory than DataGuides. Another improvement within the size of the index graph is gained by A(k)-index.
The key observation exploited by the A(k)-indices is that not all structure is interesting, i.e. the indices are only approximate for paths longer than k. Above approaches are applicable for queries specified by one path expression. Authors of introduce a more general structure, called template index (T-index). It makes it possible to affect more paths during a query and with path classes, which are specified by so called path templates.
To speed up the processing regular path expression queries, it's important to be able quickly determine ancestor-descendant relationship between any pair of nodes within the XML-graph. One possibility the way to make out is to use an entire k-ary tree with many virtual nodes. Unfortunately, the number of nodes of a tree is getting large with increasing its arity. Consequently, some numbering schemes are used for this purpose. Forinstance, Dietz’s approach is predicated on the proposition: for two given nodes x and y of a XML tree, T, x is an ancestor of y if x occurs before y within the preorder traversal of T and after y within the postorder traversal.
Then, each node is provided by a pair of preorder and post order numbers. This system is clearly appropriate for constant XML data. Authors of extend this approach to get more flexible numb erring schema. In their system KISS, they propose a complex data structure supported classical B-trees and arrays. They show that associated algorithms can process queries with regular path expressions by up to an order of magnitude faster than conventional approaches.
Reference Book
Reference link




