UNIT 4
Devices, Images, Multi-Media
Device detection is a technique for identifying devices accessing online content. Knowledge of visiting devices is an important asset for all businesses who want to maximize revenues from their websites and online services. It powers various aspects of web optimization, user experience, targeted advertising and device-aware web analytics tools.
Based on entries within the device database, an answer like DeviceAtlas can report on the characteristics of visiting devices with an API, and this is used for any purpose which needs device awareness. Read on to higher understand how it works, what it’s used for, and the way it’s deployed.
Device detection works by analyzing User-Agent (UA) strings, and, in some cases, other HTTP headers. The detection mechanism searches for patterns within the User-Agent to match with a tool entry within the device database in real time. High speed API calls can return the acceptable values for any device characteristic stored within the database.
For example, the API used to return the device’s OS. This information used for any purpose where knowledge of the OS is required, like to optimize website content, or to serve targeted ads.
Mobile Detection
Before talking about detection of mobile devices and services on the server, we'd like to travel back a small amount and consider an old friend: the HyperText Transfer Protocol, also referred to as HTTP. Knowing a bit about its internals will help us determine what we will do in terms of mobile web development.
A. HTTP
HTTP may be a protocol defined in 1991 for document transportation over TCP/ IP networks. It’s two main versions: 1.0 and 1.1. This same protocol is that the one that we'd like to use from the server side in mobile web development.
The last sentence isn’t strictly true if we consider WAP 1.1, where the device communicates with the WAP gateway and therefore the WAP gateway is that the one connecting to our server via HTTP. An identical approach is used in proxied browsers, like Opera Mini and Bolt. However, from the server’s point of view the requests coming in will always be HTTP requests.

Figure 4.1(I) When the user is accessing our website via a proxied browser or a transcoder, we will not receive the request directly from the user’s mobile device.
1. The request
An HTTP request involves a client sending a request to a server using its IP address. That request features a header and an optional body. The body is usually sent once we do a POST request. The foremost common request type may be a GET, requesting a document or a file from the server.
The server responds with a response status code, a header, and an optional body. The body is that the requested file. Why are we taking this two-minute networking class? Because it illustrates many of the techniques we'll use in server-side detection.
2. The request header
The request header has many attributes defined by the browser and sent to the server. A number of the attributes that we'll find useful are listed below.
Table 4.1(II) Most common HTTP request headers
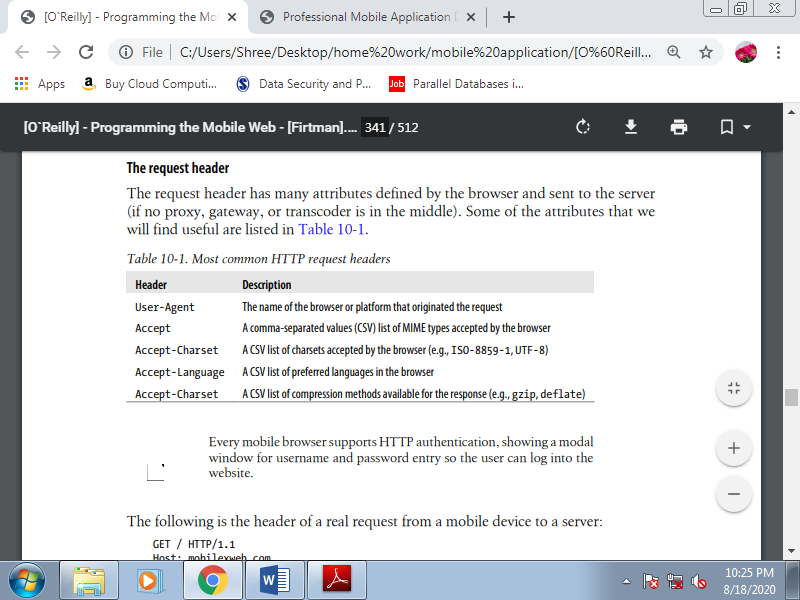
The following is the header of a real request from a mobile device to a server:
GET / HTTP/1.1
Host: mobilexweb.com
Accept: application/vnd.wap.wmlscriptc, text/vnd.wap.wml,
Application/vnd.wap.xhtml+xml, application/xhtml+xml, text/html, multipart/mixed, */*
Accept-Charset: ISO-8859-1, US-ASCII, UTF-8; Q=0.8, ISO-10646-UCS-2; Q=0.6
Accept-Language: en
DRM-Version: 2.0
Cookie2: $Version="1"
Accept-Encoding: gzip, deflate
User-Agent: Nokia5300/2.0 (03.50) Profile/MIDP-2.0 Configuration/CLDC-1.1
x-wap-profile: "http://nds1.nds.nokia.com/uaprof/N5300r100.xml"
3. The user agent
The user-agent string identifies the browser. It’s had a complex history, with the result that today there are browsers that identify themselves as six different browsers at an equivalent time within the same string. This somewhat complicates browser detection.
In the beginning of the web era developers often searched for a specific string within the User-Agent header to see what content to deliver, many browsers, starting with Microsoft Internet Explorer, started employing a hack that today has resulted in user agent hell.
The hack was for Internet Explorer to identify itself as Mozilla. After this first identification, it clarified that it had been not actually Mozilla, but rather a compatible browser (IE). Microsoft also added other information to the user-agent string, just as the OS and details on the plug-ins and languages supported. The top result was a really complex user agent syntax with no standards.
In the mobile world, things is even worse. Some browsers use the IE hack and identify themselves as Mozilla, others identify themselves with the right browser name, and still others send the device brand and model number within the User-Agent header.
Even an equivalent device may provide a special user-agent string depending on the OS version or the firmware used. This makes device detection using this string a bit complex.
The following is a list of some mobile user-agent strings provided by a Nokia N95, a Nokia 3510, a Motorola v3, a BlackBerry, an iPhone 3.0, a Windows Mobile device, and a Japanese phone from the carrier Au:
• Mozilla/5.0 (SymbianOS/9.2; U; Series60/3.1 NokiaN95/20.0.015 Profile/
MIDP-2.0 Configuration/CLDC-1.1 ) AppleWebKit/413 (KHTML, like Gecko)
Safari/413
• Nokia3510i/1.0 (05.30) Profile/MIDP-1.0 Configuration/CLDC-1.0
• MOT-V3i/08.B4.34R MIB/2.2.1 Profile/MIDP-2.0 Configuration/CLDC-1.1
• BlackBerry8100/4.2.0 Profile/MIDP-2.0 Configuration/CLDC-1.1 VendorID/125
• Mozilla/5.0 (iPhone; U; CPU like Mac OS X; en) AppleWebKit/420+ (KHTML, like
Gecko) Version/3.0 Mobile/1A538a Safari/419.3
• Mozilla/4.0 (compatible; MSIE 4.01; Windows CE; PPC; 240×320)
• UP.Browser/3.04-TS14 UP.Link/3.4.4
There's no standard for this string. So, the initial approach is to look for a few term for instance , “iPhone” or “Symbian” to try to see which device or platform a request has originated from.
4. What we can identify
Identification is beneficial for context definition. We’d like to recollect that the user may be a mobile user, and for these users the context is extremely important. We would like to get all the data we will that context, so we will provide the foremost useful experience possible.
The mobile browser doesn’t send information about:
• The International Mobile Equipment Identity (IMEI) or serial number to spot the device uniquely
• The sort of network used (WiFi, 3G, GPRS, EDGE, CDMA)
• The carrier (operator) providing service to the device
• The country of the user
• If the user is roaming
• The phone number of the user
• The device’s brand and model number (not directly)
Some of this information are inferred, but the other identification data won't be available. That's why we cannot identify users automatically without a login, as in desktop web applications.
Here’s what we will glean from the device headers:
• The carrier and country, from the IP address of the request (if it's using a 2G or 3G network).
• The country (and maybe city or maybe location), from the IP address of the request (if it's using a WiFi network).
• The brand and model number, inferred from the User-Agent header.
• The language during which the OS is defined.
• What markups and document types are accepted, if the header isn't defined as */*.
5. The User Agent Profile
The UAProf (User Agent Profile) may be a voluntary standard defined by the Open Mobile Alliance (formerly WAP Forum). It takes the form of an XML file defining the abilities of the device, including its screen size, download features, and markup support.
The XML is defined by the manufacturer or the carrier, and a link to the XML is defined during a header (typically x-wap-profile).
x-wap-profile: http://nds1.nds.nokia.com/uaprof/N5300r100.xml
This URL will are defined when the browser was created, which can are several years before. If the URL remains working, we should always get XML just like the following extract:
<prf:ImageCapable>Yes</prf:ImageCapable>
<prf:Keyboard>Qwerty</prf:Keyboard>
<prf:Model>BlackBerry 8100</prf:Model>
<prf:NumberOfSoftKeys>0</prf:NumberOfSoftKeys>
<prf:PointingResolution>Character</prf:PointingResolution>
<prf:PixelAspectRatio>1x1</prf:PixelAspectRatio>
<prf:ScreenSize>240x260</prf:ScreenSize>
<prf:ScreenSizeChar>26x18</prf:ScreenSizeChar>
UAProf files have many problems. First, we'd like to download the XML for every request, process it, and either extract the properties we would like or make a local copy on our server. Second, the community has found many bugs and problems during this official information.
Some devices don’t define a UAProf file, and that they don’t define an equivalent properties. Also, UAProf doesn't have the right granularity of information; for instance, you'll read that Flash is supported, but no information is there about which version.
B. Detecting the Context
We’ve already seen how the network protocol works, and what information is provided and not provided during a mobile browser request. Now let’s get some data and knowledge from the context.
1. How to read a header
The specifics depend upon the language, but all server-side platforms offer how to read the request’s header. Some languages use an equivalent header because the parameter (for example, Accept-Charset), et al. Use a bigger version with the syntax HTTP_X, where X is that the header name altogether uppercase and with the - replaced by (for example, HTTP_ACCEPT_CHARSET).
In Java Servlets or JSP, we read a header using:
Request.getHeader("header_key")
In ASP 3, we use this:
Request.ServerVariables("header_key_large")
And in PHP:
$_SERVER["header_key_large"]
In ASP.NET with C# or Visual Basic, we have a Headers collection and public members for most of the common headers:
// This is the C# version
Request.Headers["header_key"]
' This is the VB version
Request.Headers("header_key")
2. How to read the IP address
The IP address from which the request originated are often read with the subsequent code:
// In Java
String address = req.getRemoteAddr();
// In PHP
$address = $_SERVER["REMOTE_ADDR"];
// In C#
String address = Request.UserHostAddress;
What we will do with the IP address? If we would like to define the user’s carrier and country immediately , we'd like to get an updated list of the IP ranges assigned to every carrier. The carriers distribute this information to their partners, and it also can be found in forums and communities or through commercial services.
3. Opera Mini
There are some browsers on the market, and that we got to take care of differences within the headers in such browsers. Even on a well-known device, like a BlackBerry or a Nokia N97, if Opera Mini is in use the requests we receive on our servers will come from the Opera Mini proxy and not from the device itself.
So, the client IP address are going to be Opera’s server address, and therefore the user-agent string are going to be the proxy’s one. On any device, the Opera Mini 5 user-agent string seems like this:
Opera/9.80 (J2ME/MIDP; Opera Mini/5.0.16823/1126; U; en) Presto/2.2.0
Fortunately, Opera Mini offers the first IP address and therefore the original user-agent string, alongside other information.
Table 4.1(III) Opera Mini additional HTTP headers

4. Mobile detection
If you simply want to understand whether the user is browsing from a desktop or a mobile device, the quickest thanks to determine is to see for a few different well-known strings (iPhone, iPod, Nokia, etc.) inside the User-Agent header. Supported their presence or absence, you'll make an educated guess about whether or not the user is on a mobile device.
Andy Moore has developed a really simple but powerful PHP script for detecting mobile user agents and browsers.
C. Transcoders
With WAP 1.1, operator gateways were required to precompile WML and make it lighter and more easily useable by devices with limited memory/CPU resources. Gateways were also relied upon to manage cookies on behalf of the devices and for integration with the operator’s backend.
With WAP 2 pre-compilation was not needed, but other aspects of gateways were and still are today, to some extent. During a lot of various contexts, the presence of a WAP gateway is useful to developers and content providers. Around 2002, some companies started selling tools to “mobilize” web page .
That is, users could A URL into a field, and therefore the transcoder/content reformatter would chop it up into pages that would be viewed by mobile devices.
Around 2006, some quite genetic mutation happened: transcoder vendors realized that transcoders might be deployed in proxy mode and therefore the whole Web might be transcoded behind the backs of the users and content providers, no matter the presence of a mobile-optimized experience for any given site. This dangerous move posed a significant threat to the mobile ecosystem.
1. What is a transcoder?
Defining transcoders requires a bit of care. Not only has the term “transcoders” been utilized in other industries, but there also are other terms within the mobile world that identify mobile-web transcoders and what they do: notably, content transformation and content adaptation.
Content transformation is essentially a synonym for “transcoding,” but content adaptation also can ask development techniques that, while they bear some similarities to transcoding, are more traditional approaches to the creation of mobile websites.
When you say “transcoders” to mobile web developers, they’ll possibly consider the proxies (from companies like Novarra, InfoGin, Openwave, and ByteMobile) that network operators (Vodafone, Verizon, Sprint, etc.) install in their networks to intercept desktop sites on their way to mobile devices and “reformat” them. By “reformatting,” that mean one or more of the following:
• Splitting a page into several smaller pages (which are supposedly more manageable for mobile devices)
• Replacing the initial graphics with images of lower size (and lower quality)
• Adding an operator navigation bar on every page
• Injecting advertising from unknown sources
• Disabling mechanisms to detect successful download of applications, Java ME MIDlets, and other downloadable content
A less obvious effect of transcoders is that they often intercept and modify HTTP requests, removing the UAProf and/or the original user-agent string
2. Why are transcoders a problem?
If you're a content provider otherwise you build mobile websites, transcoders will cause you to furious. As soon as an operator deploys a transcoder, you'll notice that you simply are unable to recognize devices using that operator’s network and its transcoder.
If you've got invested time and money in installing a framework to recognize mobile devices, all of your work are going to be lost: all you'll see are browser requests hitting your server. But that’s not all.
Your branding is extremely likely to be disrupted, then is your business model if, for instance , you're not ready to bill your customers directly, or if the ad banners you were injecting into your pages get discarded. These are things that have happened in practice and driven people mad.
The icing on the cake was when operators started injecting their own advertising into other people’s content, trying to monetize other people’s efforts. It's no surprise that this has caused huge uproar amongst transcoder “victims.”
3. Parties involved in the transcoding problem
There are two main culprits behind the mess caused by transcoders: operators and transcoder vendors. Transcoder vendors are guilty of telling operators, “Look, we've this fantastic technology which will bring the whole Web to all or any of your users. A lot of fantastic content you don’t need to buy . Isn’t this great? And who cares if people that have invested millions in creating mobile sites complain…We are the longer term, after all!”
This was deeply irresponsible, but in fact a part of the blame goes to the operators who actually believed this story, decided to deploy transcoders, and were flooded by a wave of complaints and thrown into disrepute. Of course, I had a role in making mobile developers specialize in the matter intimately , but there have been thousands of irritated developers who backed me instantly once I blogged about the issue.
4. What was the response from carriers after receiving complaints?
Officially, the carriers were silent. After all, these are huge organizations, and getting anyone to face up and talk on behalf of their employees is just not realistic. Behind the scenes, I got a lot of support from people working for operators ( Vodafone Global, Germany, and UK).
5. Operator whitelists
Some operators offer whitelists where you'll explicitly opt your site out of transcoding. Whitelists aren't the way to go, though. Accepting whitelists means accepting the law of the jungle.
If we were to comply with whitelisting our sites with each and each operator around the planet, we might effectively be giving operators a right they are doing not have. The network and HTTP must be an equivalent for everybody, or this is able to represent a large step back for the entire mobile industry.
6. Making content transformation a standard
Transcoding is stealing. How does one standardize stealing? there's just one answer: you don’t. Stealing is against the law and must remain that way. Of course, transcoding vendors try to convince the W3C to make “quasi-standards” that allow transcoding in some instances, which in real deployments will naturally translate into “whenever the heck we would like .” the matter here is that the corporations who sit at the W3C table call the shots in their own interests.
7. Transcoder detection
There is an ongoing battle between transcoder vendors and therefore the remainder of the mobile ecosystem. There are ways to recognize a transcoder, by checking certain headers. Again, the Manifesto has more information. The matter is that the business model of transcoder vendors is in direct conflict with the business model of content owners.
For this reason, transcoders are progressively making it harder for others to detect them, by removing those hints from HTTP requests. Each day may come when developers will got to maintain a list of IP ranges to spot transcoders and treat requests coming from them specially.
8. What to do after detection
Assuming you've got detected a transcoder, adopting the Cache-Control: no-trans form header and using mobile-specific MIME types and DTDs is your best bet to stop your content from being touched. Serving your content from a hostname with a pattern like m.*, wap.*, or *.mobi will usually also help. I say “help” because this is often not a guarantee. Your content remains at the mercy of the operators’ transcoder policies, and no-one will follow them on your behalf if they decide to not respect your directives.
D. Device Libraries
Just watching the HTTP headers and therefore the UAProf won't give us enough useful information about the mobile devices that are accessing our websites. This is often where device libraries come to our help.
Device libraries are offline databases that take a user-agent string and return to us dozens of properties about the detected device, from screen size, to Java ME compatibility, to Ajax support and video codec compatibility.
1. WURFL
Wireless Universal Resource File (known as WURFL) may be a community-based, open source device capabilities repository created and maintained by the developer Luca Passani, a fellow member of the Forum Nokia Champion program and author of the preceding section on transcoders.
The library is out there within the sort of an XML file. While updates to WURFL data happen a day on the WURFL DB, a publicly available “snapshot” of the DB is produced and published about once per month on the WURFL website.
The sources of data include official technical information published by manufacturers, UAProf files, and data collected by the community after testing on real devices. Today, the WURFL database contains thousands of devices, with information on subversions, operating systems, firmware and hardware variations, and many attributes that we will query for everyone.
Architecture.
WURFL groups the devices into a hierarchy of devices and attributes. Some devices are like other devices from an equivalent series, possibly with some new features, so there's a fallback mechanism in WURFL allowing a tool to increase the features of another one. An equivalent applies for various models within the same brand or maybe different brands with an equivalent OS.
Also, there's a feature called “actual device root” that manages multiple subversions of an equivalent device, therefore the information isn't duplicated in two records; the subversion are going to be supported the most record with any added or different abilities noted.
The WURFL database features a root fallback device called “generic device” that's matched when the device, the brand, and therefore the series can’t be determined.
Patch file.
What do you have to do if you would like to form changes to the WURFL XML, whether to identify new devices or bugs that you’ve found or to feature new private or public capabilities to be queried? Changing the first WURFL XML would be impractical, because you'd have problems within the future once you wanted to download updates from the site.
That’s why a patch file is included within the WURFL architecture. A patch is sort of a miniWURFL. The WURFL API will merge the patch information with the knowledge within the WURFL database when the service starts.
WURFL is meant to be used on mobile websites; that's why this library doesn't detect desktop browsers, or if they're detected misidentifies them as some fallback mobile. If users may access your mobile website from their desktops and you would like to be ready to detect that using WURFL, you'll download a web patch which will detect desktop web browsers like Firefox and Internet Explorer. You’ll got to merge this patch with the most XML.
Capabilities.
Every ability, property, or attribute is named a capability within the WURFL world. Capabilities are organized into groups. Each capability for every device has an optional string value . That value are often converted to a Boolean, a number, a string, or an empty string.
Table 4.1(IV) Most useful WURFL capability groups
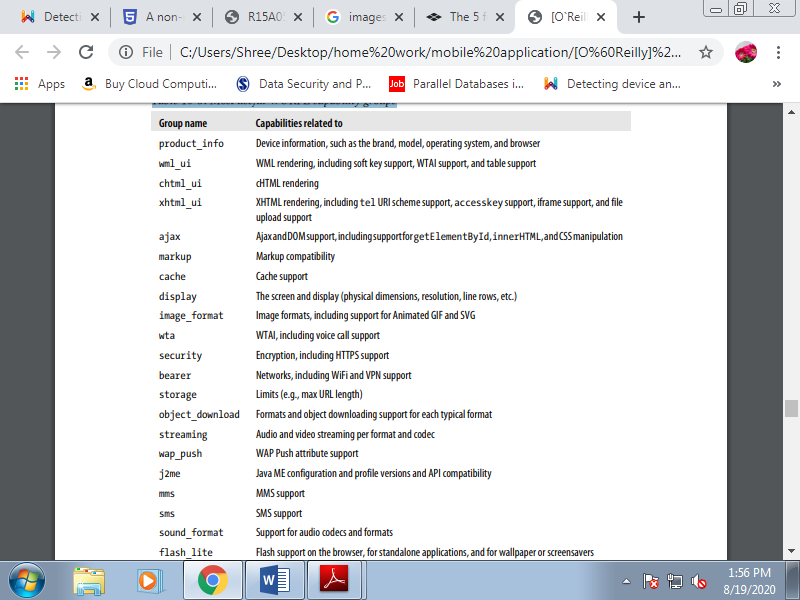
The information that the XML provides is basically complete. If you would like to browse all the capabilities, you'll browse the XML with any reader or use the tools that go along with the Java API. You'll check the primary device definition, because the generic device and fallback for all devices.
If any property isn't defined within the generic device, there'll be no fallback value to use if the device doesn't define it. Table shows the foremost important capabilities we will query, supported the compatibility problems outlined within the preceding chapters. Remember that there are dozens of other properties that you simply can query; take a look at the library so you’ll have a thought of all the chances .
Table 4.1(V) Most useful WURFL capabilities
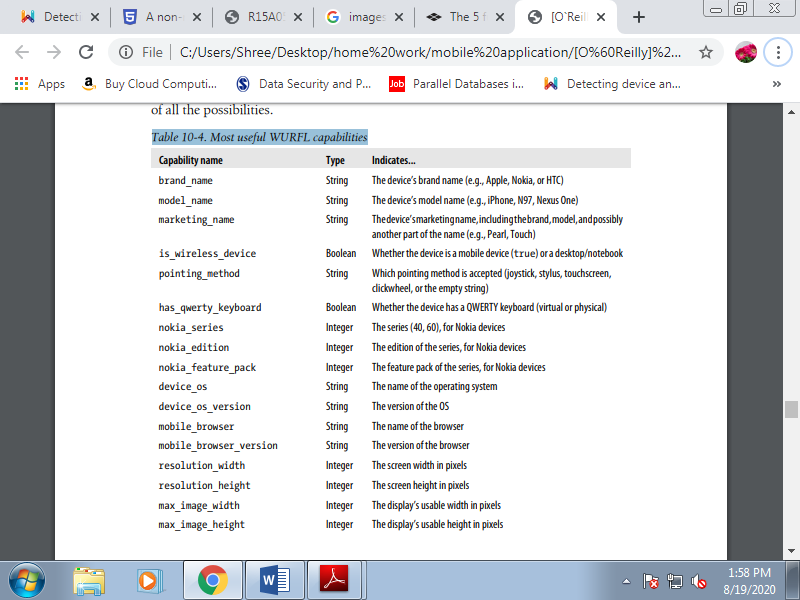
2. WURFL usage
You can use WURFL by browsing the file as you'd the other XML file and matching user-agent strings, but the wheel has already been invented, and on an equivalent website where you'll download the XML you'll find APIs for the foremost common server platforms: Java, PHP, and .NET.
Generally speaking you should use the new APIs available on the web site, except for compatibility purposes you'll still find old APIs to download. These APIs allow us to use WURFL during a few lines, with many advantages:
• Automatic device detection using the header information
• Two-step user agent analysis (optimized and clever user-agent searching inside the XML)
• Detection of transcoders and proxies, and matching of the right user agent and device information
• Merging of the static XML provided by WURFL with patches (the web patch or your own), providing an easy and unique thanks to query capabilities
• Caching of the XML parsing for the simplest performance on every request
PHP API installation
To use WURFL in PHP, you should download the PHP API and extract the contents of the GZIP file. The package contains documentation, examples, resources, unit tests, and a WURFL folder where the API resides.
To make it work, follow these steps:
1. Copy the WURFL folder in your web server root folder.
2. Copy the resources or examples/resources folder into your web server root folder.
3. Download the latest wurfl-<version>.zip file from the website and copy it to the new resources folder.
4. Create a cache folder inside the resources folder another place and verify that it PHP scripts have write permissions for this folder.
5. Edit the resources/wurfl-config.xml file and check that the <main-file> tag matches the name of the ZIP file containing the main XML repository. It can be a decompressed XML file.
6. Edit the resources/wurfl-config.xml file, go to the persistence node, and check that the <params> tag matches the name of the cache folder, as in <params>dir=cache</params>. The path needs to be relative to the config XML folder.
Once WURFL is installed, we will create our first PHP script that uses the repository. Using version 1.0 of the API, the code will be:
<?php
Require_once('WURFL/WURFLManagerProvider.php');
$configFile='resources/wurfl-config.xml';
$wurflManager=WURFL_WURFLManagerProvider::getWURFLManager($configFile);
$device=$wurflManager->getDeviceForHttpRequest($_SERVER);
?>
Using the PHP API
The PHP API is an object-oriented API. Once you've got the WURFLManager object, no matter whether you're using version 1.0 or 1.1 of the API, you'll use it.
A typical usage is getting a tool object using the manager’s methods:
• getDeviceForHttpRequest($_SERVER)
• getDeviceForUserAgent($user_agent)
• getDevice($deviceId)
If you would like to access the capabilities of the present device accessing your website, the primary option is that the best one. If you would like to get properties for other devices, you'll use the user_agent method or the deviceId method. Every device in WURFL has an ID that we will store in our databases for statistics or logs. We will then search for its capabilities later, after the mobile request.
You can also get all the possible groups and capabilities using getListOfGroups() and getCapabilitiesNameForGroup(groupId), both methods of the manager. Once you've got the device object, you'll get all properties with the getAllCapabili ties() method or query for one particular feature with getCapability($capability Name).
WURFL-related products
A lot of related tools, utilities, and frameworks are available at http://wurfl.sourceforge.net. These include:
• Device Thumbnails (a repository of device images for thumbnails on websites)
• Image Server (a Java servlet for dynamic conversion, scaling, and delivery of images to mobile devices)
• Tera-WURFL (a PHP and MySQL implementation of the WURFL repository)
• GAIA Image Transcoder
• PHP Image Rendering Library (works with an old version of the PHP API)
• Apache Mobile Filter
3. DeviceAtlas
In February 2008, the dotMobi company, which owns the .mobi top-level domain, launched its own device database that's similar in some ways to WURFL. Consistent with dotMobi, this is often not only the foremost important but also the most accurate device database on the market. The most features are:
• Monthly, weekly, daily, or constant updates to the database, counting on your license
• a knowledge explorer to browse the database from the online
• JSON format support
• APIs for PHP, Java, .NET, Python, and Ruby
• Apache server module (with the enterprise license)
At the time of this writing, the essential license costs $99 per server per year and includes monthly updates but excludes the likelihood to merge private data and other options available in higher license options.
A. Common approaches to device detection
Device detection are often accomplished server-side, before content is delivered to the client, or client-side, after content and related files are loaded to the device itself. Both approaches have advantages and drawbacks, which are described during this topic.
Smartphone browsers generally have better client-side detection capabilities than cheaper feature phones, and this provides Web developers more flexibility to use design techniques like the responsive design approach. Feature phone browsers are designed to supply speed, performance and bandwidth optimization, but may lack advance features required for a few design approaches.
B. Client-side detection
Client-side detection employs JavaScript to detect the sort of browser, also as using DOM objects and properties like screen.width, screen.pixelDepth, navigator.userAgent, and navigator.cookieEnabled. Using CSS, it's now also possible to implement 'progressive enhancement’, which may be a design strategy to enable any browser to access the essential content of a web page, while serving the entire feature set of the page to those browsers that support advanced technologies.
Media queries are another common strategy for adapting content to a tool, supported media type and device width or display size. For more information on media query techniques, see Creating a Mobile-First Responsive Web Design and Mobifying Your HTML5 Site on HTML5 Rocks.
C. Problems with client-side detection
1. Loading delay
Using JavaScript to switch URLs in <img> tags are result in additional delays before images show. This is because the common practice of adding the scripts at the bottom of the <body> of the page means the whole page must load before the scripts can run and therefore before the images are requested by the browser. Other patterns may not be affected.
The techniques described for CSS images in my article perform about as well as server-side techniques.
2. You do the work
Server-side detection could become completely transparent – see below.
Client-side detection, however, will always require quite little bit of developer intervention – and hence be harder to take care of.
D. Advantages of client-side detection
The main advantage of client-side detection is that the ability to react promptly to exact client conditions like size, orientation, and accurately assess support for specific elements and APIs. Capability detection is developed and executed purely on the client, using CSS and JavaScript.
There’s no requirement for web servers to supply device detection or serve alternative content, and installation and maintenance of a tool database isn't required.
Client-side detection can provide a useful fallback and may implement run-time tweaks in response to behavior like changes in device orientation. On more advanced devices, client-side Ajax and CSS are often wont to download additional content and enhancements without having to refresh a whole page.
E. Disadvantages of client-side detection
When incorrectly implemented, client-side detection cause a tool to request content that's unsupported. During this case, a user are going to be notified that the browser isn't capable of rendering the content only after time and bandwidth are wasted delivering it.
Because JavaScript and CSS execute locally, a whole page may need to be downloaded before scripts can process and manipulate the Document Object Model DOM. Additionally, JavaScript and media queries aren't supported on some older devices, and there could also be a delay between page load and execution of client-side adaptation.
Server-side detection of devices and capabilities is typically performed by analyzing HTTP request headers received from the client (also called the user agent). In most cases, only the User-Agent string is required, but sometimes a mixture of quite one header is required.
For more information about specific server-side detection techniques, see:
Server-Side Detection: History, Benefits and How-To
A Non-Responsive Approach to putting together Cross-Device Webapps.
A. The History Of Sever-Side Device Detection
First-generation mobile devices had no DOM and small or no CSS, JavaScript or ability to reflow content. In fact, the phone browsers of the first 2000s were so limited that the utmost HTML sizes that a lot of of them handled was well under 10 KB; many didn’t support images, and so on. Pages that didn’t cater to a device’s particular capabilities would often cause the browser or maybe the whole phone to crash.
During this very limited environment, server-side device detection was the only way to safely publish mobile web page , because each device had restrictions and bugs that had to be worked around. Thus, from the very earliest days of the mobile Web, device detection was an important a part of any developer’s toolkit.
With device detection, the HTTP headers that browsers send as a part of every request they create are examined and are usually sufficient to uniquely identify the browser or model and, its properties. The foremost important HTTP header used for this purpose is that the user-agent header.
The designers of the HTTP protocol anticipated the necessity to serve content to user agents with different capabilities and specifically found out the user-agent header as a way to do this; namely, RFC 1945 (HTTP 1.0) and RFC 2616 (HTTP 1.1). Device-detection solutions use various pattern-matching techniques to map these headers to data stores of devices and properties.
With the arrival of smartphones, a couple of things have changed, and lots of the device limitations described above are overcome. This has allowed developers to require shortcuts and make full-fledged websites that partially adapt themselves to mobile devices, using client-side adaptation.
This has sparked the thought that client-side adaptation could ultimately make device detection unnecessary. The concept of a “one-size-fits-all” website is extremely romantic and seductive, because of the potential of JavaScript to form the device-fragmentation problem disappear.
The prospect of not having to take a position during a device-detection framework makes client-side adaptation appealing to CFOs also. However, we strongly believe that reality isn't quite that easy.
B. The Importance Of Device Detection
Creating mobile websites with a pure client-side approach, including techniques like progressive enhancement and responsive Web design (RWD), often takes one only thus far. Admittedly, this could be far enough for companies that want to minimize the value of development, but is it what every company really wants? From our long experience within the mobile space, we all know one thing for sure: companies want control over the user experience.
No two business models are alike, and slightly different requirements could affect the way an internet site and its content are managed by its stakeholders. That’s where client-side solutions often come short.
We will look more deeply at the most issue, one that engineers and project managers alike will recognize: regardless of how clever they're , usually “one-size-fits-all” approaches cannot really address the wants of a large brand’s Web offering.
1. Catering To Devices and Business Requirements
The first point to notice is that not all devices support modern HTML5 and JavaScript features equally, so a number of the issues from the first days of the mobile Web still exist. Client-side feature detection can help work around this issue, but many browsers still return false positives for such tests.
The other problem is that a website might look okay to a user on a high-end device with great bandwidth, but within the process of making it, several bridges are burned and really little room has been left for the adjustments, backtracking and corrections caused by the company’s always-evolving business model. The maintenance of responsive internet sites is difficult.
As an analogy, an engineer who deals with responsive Web design is sort of a funambulist, up within the air, on an extended wire, with a pole in their hands for balance, standing on one leg, with a pile of dishes on their head. They could have performed well thus far, but there's little else that one can reasonably ask them to do at now .
Device-detection engineers are during a luckier situation. All of them features a lot more freedom to deliver the final result to the varied target platforms, be it desktop, mobile or tablet. They're also better positioned to deal with unexpected events and changes in requirements. Extending the analogy, device-detection engineers have chosen alternative ways to reach their destinations.
One person is driving, another is on a train, yet one more is biking, and a fourth is on a helicopter. The one with the car decided to prevent at a motel for the night and rest a touch. The one within the helicopter was asked to bring the CEO to Vegas for a few of days. No big deal; those changes were unexpected, but things remains in check.
No analogy is ideal , but this one is pretty close. Device detection might sound to cost significantly quite responsive design, but device detection is what gives a company control. When the business model changes, device detection enables a corporation to shuffle quite few things around and still avoid panic mode. a method to seem at it's that device detection is one application of the favored divide-and-conquer strategy. On the other hand, RWD could be very limiting.
While many designers embrace the flexible nature of the online, with device detection, you'll fine-tune the experience to precisely match the wants of the user and therefore the device they're using. This is often the most argument for device detection it enables you to deliver a little contained experience to feature phones, an upscale JavaScript-enhanced solution to smartphones and a lean-back experience to TVs, all from an equivalent URL.
In my opinion, no other technique has this expressive range today. This is often the reason why Facebook, Google, eBay, Yahoo, Netflix and lots of other major Internet brands use device detection. I’ve written about how Facebook and Google deliver their mobile Web experiences over on mobiForge.
2. Speed and Efficiency
Device detection has some key attributes in addition to flexibility and control:
- Rendering speed. Because device-detection solutions can prepare just the proper package of HTML and resources on the server, the browser is left to do much less add rendering the page. This will make a big difference to the end-user experience and evidently is a component of the reason why Twitter recently abandoned its client-side rendering approach in favor of a server-side model.
- Efficiency. Device-detection solutions allow the developer to send only the content required to the requesting browser, making the method as efficient as possible. Remember that even if you've got a 3G or Wi-Fi connection, the effective bandwidth available to the user might be greatly but it should be; ask anyone who has used airport Wi-Fi or congested cellular data on their mobile device. This will make the difference between a page that loads during a few seconds and one that never finishes loading, causing the user to abandon the web site in frustration.
- Choice of programming language. You can implement the difference logic in whatever programing language you would like, rather than being limited to only JavaScript.
3. Fine-Tuning Content to Device Capabilities
Another area where device detection has a plus is in fine-tuning media formats and other resources delivered to the device in question. A good device-detection system is in a position to tell you of the exact media types supported by the given device, from simple image formats like PNG, JPEG and SVG to more advanced media formats involving video codecs and bit rates.
4. Server-Side vs. Client-Side Detection
Many client-side JavaScript libraries have recently been released that enable developers to work out certain properties of the browser with an easy JavaScript API. The simplest known of those libraries is undoubtedly Modernizr. These feature tests are often including “polyfills” that replace missing browser capabilities with JavaScript substitutes.
These clients-side feature-detection libraries are very useful and are often combined with server-side techniques to offer the simplest of both worlds, but there are limitations and differences in approach that limit their usefulness:
• They detect only browser features and can't determine the physical nature of the underlying device. In many cases, browser features are all that's required, but if, for instance, you would like to provide a deep link to an app download for a specific Android OS version, a feature detection library cannot tell you what you would like to understand.
• The browser features are available only after the DOM has loaded and therefore the tests have run, by which time it's too late to form major changes to the page’s content. For this reason, client-side detection is usually wont to tweak visual layouts, instead of make substantive changes to content and interactions. That said, the features determined via client-side detection are often stored during a cookie and used on subsequent pages to form more substantive changes.
• While some browser properties are often queried via JavaScript, many browsers still return false positives surely tests, and causing incorrect decisions to be made.
• Some properties aren't available in the least via Javascript; for instance , whether a tool may be a phone, tablet or desktop, its model name, vendor name and maximum HTML size, whether it supports click-to-call, and so on.
While server-side detection does impose some load on the server, it's typically negligible compared to the value of serving the page and its resources. Locally deployed server-side solutions can typically manage well in more than tens of thousands of recognitions per second, and much higher for Apache and NGINX module variants that are supported C++.
Cloud-based solutions make a question over the network for every new device they see, but they cache the resulting information for a configurable period afterward to reduce latency and network overhead.
The main disadvantages of server-side detection are the following:
• The device databases that they utilize got to be updated frequently. Vendors usually make this as easy as possible by providing sample cron scripts to download daily updates.
• Device databases might get out of date or contain bad information causing wrong data to be delivered to specific range of devices.
• Device-detection solutions are typically commercial products that has got to be licensed.
• Not all solutions allow personalization of the information stored for every device.
C. Time for a Practical Example
Having covered all of that, it’s time for a practical example. Let’s say that a company wishes to supply optimized user experience for a spread of devices: desktop, tablets and mobile devices. Let’s also say that the company splits mobile devices into two categories: smartphone and legacy devices.
This categorization is dictated by the company’s business model, which needs optimal placement of advertising banners on the various platforms. This breakdown of “views” supported the kind of HTTP client is usually mentioned as “segmentation.” during this example, we've four segments: desktop, tablets, smartphones and legacy mobile devices.
Some notes:
• The green boxes below represent the advertising banners. Obviously, the corporate expects them to be positioned differently for every segment. Ads are typically delivered by different ad networks (say, Google AdSense for the web and for tablets, and a mobile-specific ad network for mobile).
• In addition to banners, the content and content distribution will vary wildly. Not all desktop web page is equally relevant for mobile, so a less cluttered navigation model would make more sense.
• We want certain content to be available within the sort of a carousel (i.e. slideshow) for tablets, but not other devices.
• Mobile should be broken down in smartphone and legacy devices.
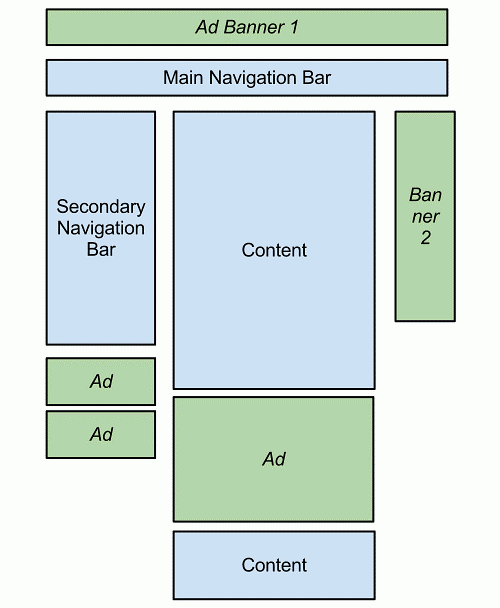
Figure 4.3(I) Structure of a desktop website.
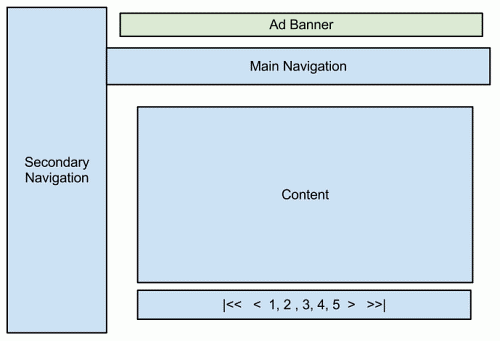
Figure 4.3(II) Structure tablet site.
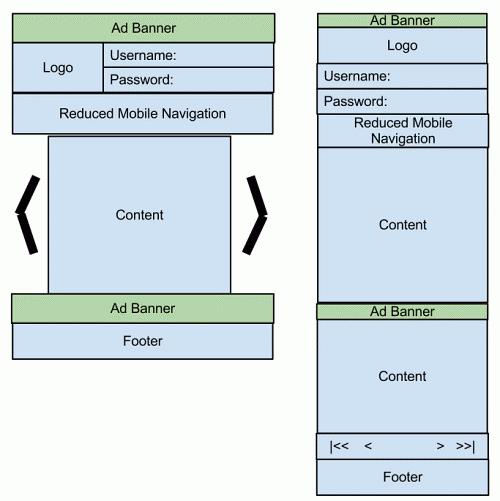
Figure 4.3(III) On the left: Structure Smartphone site. On the right: Structure legacy device site.
We will show how the segmentation above are often achieved through device detection. A note about the most device-detection frameworks out there first.
D. Server-Side Detection Frameworks
Device-detection frameworks are essentially built around two components: a database of device information and an API that lets one associate an HTTP request or other device ID to the list of its properties. The most device-detection frameworks out there are WURFL by ScientiaMobile and DeviceAtlas by dotMobi. Another player during this area is DetectRight.
The code snippets below ask the WURFL and DeviceAtlas APIs and show a rough outline of how an application might be made to route HTTP requests in several directions to support each segment.
The two frameworks are available either as a standalone self-hosted option or within the cloud. The pseudo-code below is inspired by the frameworks’ respective cloud APIs and will be easily adaptable by PHP programmers also as programmers on other platforms.
For the sake of simplicity, let’s define a smartphone as any device whose screen is wider than 320 pixels. This probably doesn't quite cut it for you. Engineers can use any capability or combination of capabilities to define smartphones during a way that creates sense for the given company’s business model.
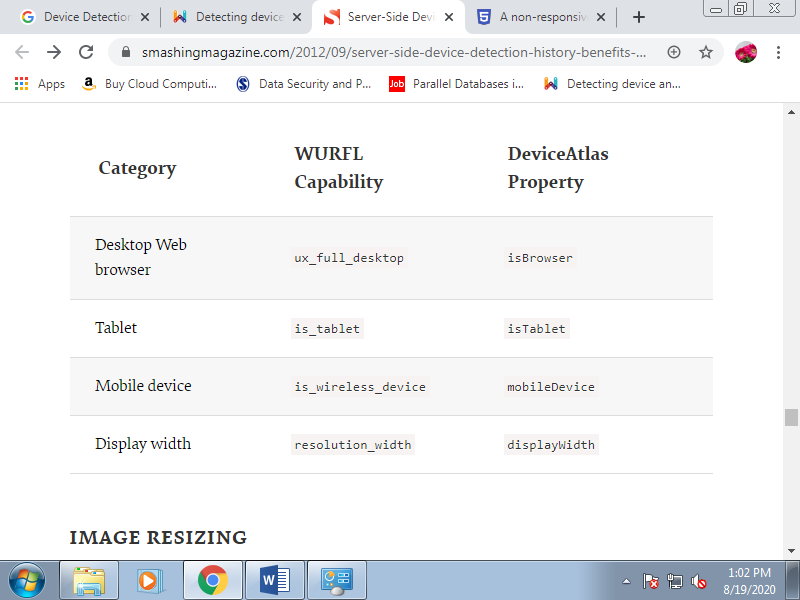
The following table lists the capabilities involved within the example above. Each device-detection solution comes with many capabilities which will be wont to adapt a company’s Web offering to the foremost specific requirements. For instance , Adobe Flash support, video and audio codecs, OS and OS version, browser and browser version are all dimensions of the issues which may be relevant to supporting an organization’s business model.
1. Image Resizing
One aspect that we didn't touch on in our example but that certainly represents one among the most use cases of device detection is image resizing. Serving a large picture on a daily website is ok, but there are multiple reasons why sending an equivalent picture to a mobile user isn't OK: mobile devices have much smaller screens, more limited bandwidth and more limited computation power.
By providing a lower resolution and/or a smaller size of the image, the mobile UX is formed acceptable. There are two approaches to image resizing:
• Each published image are often created in multiple versions, with device detection wont to serve a pointer to the foremost appropriate version for that device or browser.
• Software libraries like JAI, ImageMagick and GD are often wont to resize images on the fly, supported the properties of the requesting HTTP client.
An interesting article on .net magazine, “Getting Started With RESS,” shows an example of server-side enhanced RWD i.e. how an internet site built with RWD can still enjoy image resizing and server-side detection. This system is usually mentioned as RESS.
2. Single-Url Entry Points
Segmenting your content could lead on to the mapping of various segments into different URLs. This in itself isn't good because users might exchange links across devices, leading to URLs that time to the incorrect experience. It doesn’t got to be that way, though.
Proper design of your application makes it possible to have common URL entry points for all segments. All you would like to do is dispatch your request internally. This is often easily achievable with just about any development language and framework around.
E. Criticism of Device Detection
Recently, we've observed a particular level of criticism of device detection and have found it odd. After all, device detection is an option for those that want extra control, not a legal obligation of any kind. Much of this criticism are often traced back to the abstract ideal of a unified Web. Ideals are nice, but end users don’t care about ideals nearly the maximum amount as they care a few decent experience.
In fact, if we called end-users by their other name, i.e. consumers, the sentence above would make even more immediate sense to everyone. How can anyone be surprised that companies care about controlling the UX delivered to their consumers, by whatever means they choose?
Interestingly, one doesn’t have to go any longer than this website to listen to vocal critics of server-side detection (or UA-sniffing, as they disparagingly call it). Interestingly, Opera adopted WURFL (a popular open-source device-detection framework) to customize its content and services for mobile users.
Additionally, the Opera Mini browser sends extra HTTP headers with device information to certain partners to enable better server-side fine-tuning of the user experience (X-OperaMini-Width/Height). Permanently measure, the device original’s user-agent header is additionally preserved within the X-OperaMini-Phone-Ua header. In short, ideals are one thing, on the other hand there's the truth of the devices that people have in their hands.
F. Advantages of server-side detection
The main advantages of server-side detection are that it saves client resources and doesn't believe the power of the client to adapt the content that it receives. As soon because the client makes a request, server-side applications learn the identity of the device and what it can do. This makes it possible to serve only media and content that's most appropriate for that specific device.
For instance , if a mobile device is old and features a small screen, it'll not be served a page section displaying HD video.
Server-side detection enables optimization of assets like CSS files, CSS image sprites, scripts, and so on. It are often extremely efficient when combined with device or ‘group-based’ caching on the server. For an example of a group-detection script, see WordPress Mobile Pack's device group detection script.
G. Disadvantages of server-side detection
Databases for server-side detection require frequent updating, aren't always accurate, and don't answer user settings or personalization. Employing a tool database requires implementing a server-side API and maintaining it. (The simplest solution is to use a brief script containing only very basic information, like the one shown in WordPress Mobile Pack’s lite-detection php script.)
H. Best of both worlds
Server-side and client-side detection techniques are often used together to enable the developer to only serve content that's supported by a device, while allowing the browser to regulate style and layout in response to the present context.
I. WURFL Functionality
The sample code below is from the WURFL repository file (WURFL.xml), which contains groups and capabilities for a device:
<device user_agent="Nokia3650" actual_device_root="true" fall_back="nokia_generic_series60" id="nokia_3650_ver1"><br/>
<group id="image_format"><br/>
<capability name="bmp" value="true"/><br/>
<capability name="colors" value="4096"/><br/>
</group><br/>
</device>
This is the configuration file which is queried for device information. So, if a new device is introduced into the market, we'd like to feature the knowledge during this file.
The functionality of WURFL are often explained in two steps :
1. Device detection : When a request from a tool comes in, the WURFL repository file is queried for the USER_AGENT value. This is often a singular value for every device.
2. Return capability Value : Once the USER_AGENT is obtained, the repository is queried again and corresponding groups and capabilities are obtained. Then the markup is made for the requesting device that corresponds to the potential values. If the capabilities aren't found within the id for USER_AGENT, the capabilities are obtained following the inheritance using the id from the FALL_BACK value. The inheritance chain continues till the capability values are available for markup.
J. Including WURFL
WURFL are often included in various formats like PHP, JSP and .NET. The example below shows how we include a WURFL repository to a JSP page.
A WURFL enabled page must include two files:
• /WEB-INF/tld/wall.tld: This tag library descriptor page is included at the highest of the page.
• /WEB-INF/tld/c.tld: This page is included just above the body tag
The example below demonstrates how WURFL works and shows how a WURFL enabled JSP page hosted within the web server might like look:
<%@ taglib uri="/WEB-INF/tld/wall.tld" prefix="wall" %>
<wall:document>
<wall:xmlpidtd />
<%@ taglib uri="/WEB-INF/tld/c.tld" prefix="c" %>
<wall:load_capabilities />
<wall:body>
<wall:body>
<wall:block>
<c:choose>
<c:when test="${capabilities.resolution_width >= 700}">
<iframe frameborder="0" scrolling="no" src="pageA.html" ></iframe>
</c:when>
<c:otherwise>
<iframe frameborder="0" scrolling="no" src="pageB.html"></iframe>
</c:otherwise>
</c:choose>
</wall:block>
</wall:body>
</wall:document>
In this example, if the page is requested by a web browser whose resolution width is quite 700, the primary a part of the condition are going to be executed and pageA.html would seem on the iframe. Otherwise, pageB.html would seem.
Similarly, we will make use of capabilities to question the device properties and supply markups, display styles, images, and and also manipulate content supported device type.
K. Who is Using WURFL?
Currently, a large number of companies are using WURFL for development of mobile websites. These include companies who are large and medium content providers, but the foremost popular usage of WURFL is in companies that are small content providers. A number of the foremost popular companies that make use of WURFL are Vodafone, Mobile Galleries, and Pepsi UK.
The 5 fundamental methods of connected device interaction
To explore the sector of connected devices means the exploration of latest technology and ways of understanding the globe around you. Over the last several decades we've understood the first way to interact with software is thru a screen, which is now changing. As voice and bot interactions are starting to gain traction they open up new ways during which we will experience the world around us.
A sensors and devices become more connected, they provide richer ways we engage each single device. As we investigated the space of connected devices we've found 5 fundamental methods during which we interact with connected devices. Each of those 5 methods have implications for both the technology and business model of a specific connected device.
The way during which a user interacts with a tool may mean the intelligence of the device must be local or conversely it can fully live in the cloud, only being called upon when explicitly needed.
This framework provides a summary of the various interaction methods, also as samples of why each method can have an impression on the connected device itself. Companies can use this framework to brainstorm the various ways during which their device may act or function.
1. The user interacts with the device (through a middle layer)
The most prominent use case with connected devices on the market today. Users interact with connected devices employing a screen based system, like an application. Companies got to keep in mind that new technology is now allowing users to interact with their devices in new ways, like voice, or through other 3rd party application with chat, bots, and other UI.Companies got to consider the simplest interactions methods that reduce the foremost friction when defining how users will interact with a tool.
2. The device interacts with the user
One of the large advantages of connected devices are their ability to speak to users. This will be used, for instance , to precise a requirement from the system or provide the user with a status of a system component. This is often great for being proactive, and may go thus far on ask questions or provide a direction on the choice.
3. The user physically interacts with a device
Potentially the foremost ignored aspect of connected devices, companies producing these must not ever forget that in many cases, devices can still be physically interacted with, and this may influence the software layer. For commercial devices physical interaction could also be a totally secondary aspect, except for many consumer devices, a physical interaction is common.
4. The device understands surrounding context
One of the foremost unique situations for a connected device is its ability to tug in data from other sources. These other pieces of knowledge are often tter inform the device on what it should do or how it can be smarter. This enables for automation of functions over user set automations, like an alarm that turns on a light-weight.
Devices can now begin to know the context during which they're in. Is it dark or light? Cold or Hot? Is it raining? Is there only one person or many. This information are often utilized in an almost limitless set of the way.
5. The device talks to a company (interacts with a backend or cloud system)
With each new connected device comes a proliferation of knowledge which will be harvested and used on anything from product improvements to providing other devices with context and triggering actions. This sort of communication also has the most important implications on business models and privacy. Devices which will ask a backend, or company, open up a bigger service offering layer that companies can begin to monetize.
With this, users also are exposing their data and can be weary of privacy concerns. Companies should see this sort of interaction as a key opportunity for his or her devices, but even be careful on what they collect from users, what they are doing with it, and therefore the privacy behind it.
It’s often said that an image is worth thousand words. This is often true within the mobile web, too. However, we'd like to find a balance with reference to the amount of images during a document. Every image adds to the network traffic, number of requests, and load time. For now, we are talking about the img tag. This tag should be used only for:
• a company logo
• a piece of writing or product photo
• A map
Don’t use the image tag for:
• Buttons
• Icons for links or menus
• Backgrounds
• Visual separators
• Titles
This doesn’t mean that we won’t use images for any of these purposes we just won’t use the image tag. The image tag is semantically correct for images that the user understands as images in their title , not for visual aids. An arrow icon for a link isn’t considered as a picture for a traditional user. It's just a button, or a link. We'll follow an equivalent rule.
Serving audio and video content to mobile devices is extremely important for several portals and content providers. Unfortunately, there are so many formats and distribution methods and therefore the landscape is changing so fast that it’s difficult to supply up-to-date information during this book. We will provide multimedia content in three formats:
• Downloadable content
• On-demand streaming content
• Live streaming content
For downloadable content, there are many formats and codecs that we will use. Not all devices support all of them, so we should always check the documentation for our target devices or use WURFL properties to see for support on the fly.
Video and audio files come with two technologies: a container format and one or more codecs inside. The foremost compatible container formats for mobile devices are 3GP and 3GP2, created by the 3GPP organization. They're very almost like the MPEG-4 (MP4) format, such a big amount of devices support both.
There also are devices with support for MPEG, Flash Video, AVI, Real Audio, Real Video, MOV, and Windows Media Audio/Video containers. Most devices support the H.263 and H.264 codecs. Within the audio world, the foremost standard formats today are MP3 and MIDI, but some devices also support MP4, Real Audio, WAV, AAC, and other audio formats.
A. Delivering Multimedia Content
If we would like to deliver multimedia content, we'd like to first check out the Accept header or WURFL properties to determine whether the device supports the format we’re using. If so, we will use the delivery methods defined earlier. Counting on the device’s capabilities, it's going to download the whole file before playing it or it's going to attempt to play it while downloading using HTTP streaming techniques.
For the simplest HTTP streaming technique, we'd like the server to support partial downloads. The direct download technique works in almost every compatible phone: Symbian, iPhone, Android, Nokia Series 40, etc.
B. Embedding Audio and Video
Not all devices support embedded multimedia in sites. On some devices, the display and CPU constraints make this feature impossible.
1. Flash Video
Flash Lite3.0 and Flash Player for mobile devices support Flash Video format (FLV). For the compatible devices, like Symbian devices from 3rd edition FP1, you'll embed any Flash content, although it's better if you compile your SWFs for Flash Player 8. In fact, the YouTube desktop version works well on Flash Lite 3 enabled devices.
2. Object embedding
You can use an object tag to include a video in a web page:
<object data="video.mp4" type="video/mp4" />
Safari will show an image with a play button. When the user presses play, the video will open in a full-screen QuickTime Player window instead of being embedded in the browser.
An alternative is the embed tag, preferred for iOS 1 and 2.X:
<embed src="poster.jpg" href="video.m4v" type="video/x-m4v" />
The object tag also works on Symbian devices.
3. HTML 5
Although at the time of this writing they're only compatible with some mobile browsers, like Safari on iOS 3.0 and later, the audio and video tags defined in HTML 5 also can be wont to embed multimedia content. The behavior is similar to using the thing tag. The video element supports the usage of a source child tag that permits us to define different media files in several codecs and bit rates for best compatibility. The traditional syntax is:
<video src="url"
Poster="some_optional_picture.png"
Controls="true"
Width="320"
Height="240" />
Safari supports the formats 3GP, MOV, and MPEG-4, and the H.264 and AAC-LC codecs.
4. Reference movies for iPhone
Safari on iOS also supports “reference movies,” created with QuickTime Pro or an identical tool. A reference movie provides a listing of movie URLs with different bit rates, so QuickTime can select the right one for the device. In embed or video tag, we point to the present new file.
C. Streaming
Streaming audio or video may be a difficult solution if we would like to be compatible with all devices. Different platforms support different streaming technologies. Some devices, including Symbian, Windows Mobile, and BlackBerry devices, support the important Time Streaming Protocol (RTSP).
When a link with this protocol is employed , the default media player as Real Player, Windows Media, etc. is opened. The content are often a file to be streamed (a prerecorded audio or video file) or a live event (radio or television program , sports event, etc.).
We should expect more Flash streaming services for mobile devices when the complete Flash Player is out there for mobile devices. Today, Flash Lite 3.0 devices should work with Adobe Flash Media Server or the Red5 open source alternative. For general audio and video streaming there also are other streaming solutions, just like the commercial Helix Media Delivery Platform and QuickTime Streaming Server. Apple also maintains an open source alternative called Darwin Streaming Server.
A streaming server uses TCP or UDP but generally doesn't use HTTP. Some proxies may have problems redirecting the server’s TCP or UDP packages, so HTTP has some advantages. However, it also has more overhead than TCP or UDP and it's not prepared for live streaming events. Some mobile devices that use HTTP need to download the whole file before playing it. Other devices will start playing the file while downloading it.
1. HTTP Live Streaming
Apple has created a new way to deliver live streaming using HTTP, called HTTP Live Streaming, which it's presented to the IETF as a proposed Internet standard. It's supported by iOS 3.0 and allows the transmission of live events using an equivalent HTTP protocol we all know .
In fact, this is often the only streaming solution that works on the iPhone. Implementing HTTP Live Streaming requires some changes on the online server end. The simplified explanation of the protocol is that on the server, the live stream is buffered in little packages sent to the client. It’s like transmitting a live radio show by sending a series of 10-second MP3s.
HTTP Live Streaming supports the H.264 codec for video and AAC or MP3 for live audio streaming, also as a bandwidth switcher for various qualities. However, the simplest feature is that it passes any firewall or proxy because it's HTTP-based.
A. Testing and Debugging
Emulators and simulators are very useful and supply an easy, fast, and fairly accurate testing solution. If it doesn’t add the emulator, it probably won't work on the important device, and if it works within the emulator, it probably will work on the important device.
There are some problems with this testing approach, though. For one thing, there are many differences between real devices, and many bugs. Furthermore, there are several platforms without emulation. That’s why real device testing is mandatory. But how can we get access to multiple real devices? Here are a couple of suggestions:
• Acquire as many friends as you will (with different devices, if possible).
• Buy or rent devices. Some vendors offer promotions for purchasing or renting devices for developers and their partners.
• Use a testing house company. This is an expensive solution and not recommended for mobile web developers; we'd like to be as close as possible to the devices.
• Create a beta tester program, for receiving feedback.
• Use a remote lab.
1. Remote Labs
“Any sufficiently advanced technology is indistinguishable from magic,” said sci-fi writer Arthur C. Clarke in 1961. A remote lab may be a web service that permits us to use a true device remotely without being physically within the same place. It’s an easy but very powerful solution that provides us access to thousands of real devices, connected to real networks everywhere the world, with one click. You’ll consider it as a remote desktop for mobile phones. There are three sorts of remote lab solutions for mobile devices:
• Software-based solutions, employing a resident application on the device that captures the screen, sends it to the server, and emulates keyboard input or touches on the screen.
• Hardware-based solutions, using some technology to attach the server to the hardware components of the device (screen, touchscreen, keypad, lights, audio, etc.).
• Mixed solutions, having some hardware connection, some software additions, and perhaps a video camera for screen recording.
Remote Device Access
Forum Nokia offers a free remote lab solution for Symbian and Maemo devices called Remote Device Access (RDA). You'll need Java Runtime 5.0 or newer, because RDA may be a WebStart Java application. At the present , usage is restricted to eight hours per day. The most features are:
• Complete usage of the device
• 3G and WiFi connection support
• Application installation
• Device rebooting
• Changing screen orientation
• Browser and widget WRT support
• Reservation of devices for future usage
• Usage of devices with SIM cards connected in Europe
• Saving screenshot images
• Incoming calls and SMS available
At the time of this writing, there are quite 50 devices available. There’s no audio or accelerometer support, and counting on your network bandwidth you'll select the video quality you would like.
Samsung Lab.Dev
Samsung also offers a free remote lab web service, using an equivalent solution provider as Nokia’s RDA, called Lab.Dev. It includes some Windows Mobile devices. Counting on your membership with Samsung you'll have access to more duplicated devices for testing purposes.
Lab.Dev has an equivalent features as RDA, so you'll test web applications and widgets using this solution. The devices don’t have SIM cards, though, so you'll only test WiFi connections (not 3G).
DeviceAnywhere
DeviceAnywhere is that the leader and pioneer in remote lab solutions for mobile testing. It offers a hardware solution that permits any device (low-end, mid-end, or smartphone, from any vendor) to plug into the architecture.
2. Server-Side Debugging
To debug server-side detection, adaptation, or content delivery scripts, we will use some HTTP tools before turning to real devices.
When you’ve installed this plug-in, you'll find a new submenu within the Tools menu of Firefox using the name of the present user agent. The plug-in changes the user-agent string that Firefox uses for creating HTTP requests to the server. It comes with some user agents preinstalled, like iPhone 3.0, and you'll add as many others as you would like using the Edit User Agent option.
You can then browse to any website and see how the server manages the user agent and which content it serves. Remember to go back to the default user agent after finishing the debug session, otherwise you may encounter problems in your browser.
When using real devices, it'll be useful while debugging to store in some log all the request and response headers from the server-side code, so you'll see the info the device is sending and receiving.
DeviceAnywhere includes an answer for this purpose for all devices, otherwise you can use any emulator that supports HTTP sniffing, just like the Nokia and BlackBerry emulators. If you work with the ASP.NET platform on the server, you'll activate the remote tracing mechanism and you'll see every header and response from your mobile devices.
3. Markup Debugging
There is no automatic way to debug XHTML. This is often a manual operation on every emulator, device, or remote device you'll access. Safari on iOS features a console window that we will check for markup errors, but before doing this it's an honest practice to validate the code using one among the web tools available for mobile markup.
W3C mobileOK Checker
The W3C offers a mobile markup checker that you simply can use for free of charge at http://validator .w3.org/mobile. You'll upload a file, copy and paste the code, or use a URL if you have already got your mobile site on your server.
This markup checker is predicated on best practices published within the Mobile Web Best Practices standard defined at http://www.w3.org/TR/mobile-bp. It doesn’t guarantee that your code will work perfectly on all mobile devices if it passes; it's just intended to assist you discover possible problems in your code and areas that don’t conform to best practices. The checker validates:
Ready.mobi
The dotMobi team has created a free validator that has the W3C mobileOK Checker tests and a few others, plus some emulators and detailed error reports with suggestions. The validator is out there at http://www.ready.mobi. You'll use it for one document by providing a URL or copying and pasting the code, or to report on a whole site, including site-wide testing.
As an advanced feature, you'll specify the user agent that we would like the checker to use, and a list of accepted MIME types.
After analyzing your document, ready.mobi will assign you a score on a scale of 1 (very bad) to five (excellent). It'll also report on the dimensions of your document and resources and therefore the estimated time and download costs for the user.
Firefox plug-ins
There is a plug-in for Firefox which will allow this browser to support the XHTML MP MIME type. You’ll download the plug-in from http:// xhtmlmp.mozdev.org.
4. Client-Side Debugging
JavaScript debugging is one among the foremost painful activities in mobile web development. Every browser features a different JavaScript engine, and sometimes code that works on one device doesn’t work on another. Typical desktop JavaScript techniques should be used first to debug logic problems in our code.
This includes using the developer tools from Chrome, Safari, or Internet Explorer, or the classic Firebug for Firefox. But simply because everything works during a desktop browser doesn’t mean that it'll add a mobile browser. Rich Internet Application techniques are the worst problem areas.
Browser-based solutions
Some mobile browsers offer developer tools for JavaScript debugging or console logging features.
Safari on iOS Debug Console
Safari includes a debugging console that we will activate (both in simulators and on real devices) by getting to Settings→Safari→Developer→Debug Console. With the debug console activated, you'll find a new 60-pixel-high toolbar below the highest toolbar of the browser.
Clicking this toolbar opens a full-screen Console window, as shown in Figure, where you'll see advice, warnings, errors, and console output, which you'll filter into HTML, JavaScript, and CSS categories. For better detail reading, use landscape orientation.
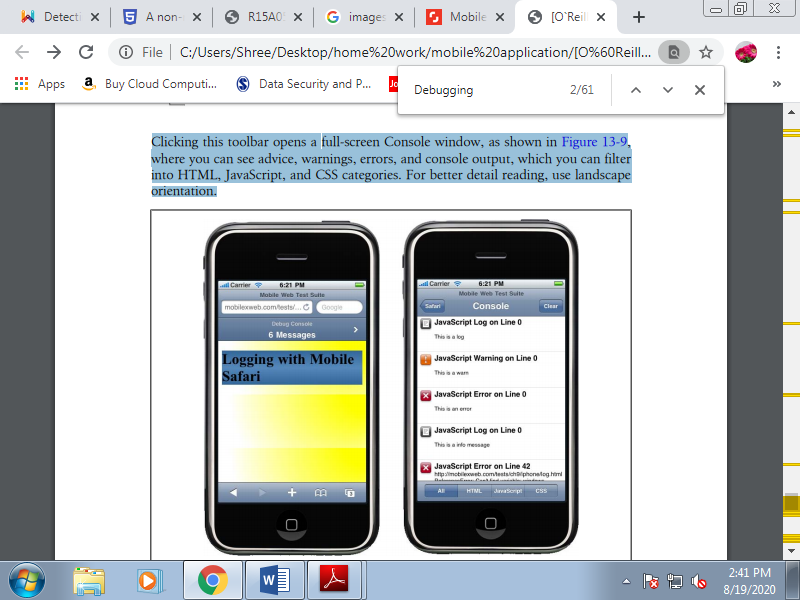
Figure 4.7(I) once you activate the debug console you'll see the console toolbar (left), which you'll click on to access a details list (right).
From JavaScript, you'll send messages to the console using the log, warn, error, and info methods of the console global object available within the iPhone browser. All of those methods receive a string. The difference between them is that the icon won’t to show the text. For example:
Console.log("This text will appear on the Console");
Opera Dragonfly
From Opera Mobile 9.5, we will debug mobile web applications using the remote debugging tool Dragonfly. To use this tool you'll need Opera 9.5 or afterward you’re desktop. You’ll open Dragonfly by getting to Tools→Advanced→Developer Tools and checking the Remote Debug option. When you’re done, enter opera:debug in your Opera Mobile browser and specify your desktop IP address . You’ll then have access to an equivalent debugging features (DOM, CSS, and JavaScript) that you simply would if you were debugging an area desktop file.
Android Debug Bridge.
Android doesn’t have as nice a console output as Safari on iOS, but we will still read the console errors and even use an equivalent console object using the Android Debug Bridge (adb). Adb may be a command-line application available within the tools folder of your SDK.
BlackBerry web development tools
BlackBerry offers two plug-ins which will be wont to develop and also to debug, profile, and package web applications. Both provide JavaScript debugging with breakpoints, Ajax requests visibility, and time-to-load reporting for web page .
Widget debuggers.
The BONDI SDK for widgets offers a remote debugging feature which will be used from the Google Chrome Developer Tools. WRT plug-ins for Aptana Studio and Visual Studio also support debugging over the emulator (remember that it's not the important engine). The LG SDK and therefore the BlackBerry web development tools have great debugging tools for widgets, too.
JavaScript solutions
There are some scripts that job as a sort of debugger, including DOM and CSS inspectors and a few that job for JavaScript debugging, too. The mobile compatibility for these tools is complicated, though, due to the shortage of space on the screen to point out all the knowledge.
There also are some Ajax-based solutions which will work better, allowing you to look at the debug results and panes from a desktop. Creating an easy log console is straightforward, using a floating div or another visual element to point out messages sent by a console.log call.
For example:
If (console==undefined) {
Var console = new Object();
Console.log = function(text) {
If (document.getElementById("console")==undefined) {
Document.getElementsByTagName("body")[0].innerHTML = "<div id='console'></div>";
}
Document.getElementById("console").innerHTML += "<p>" + text + "</p>";
}
}
With some CSS to the console and console p selectors, you'll see a console. With some scripts, you'll also create an object browser and a console JavaScript execution engine using eval.
B. Performance Optimization
Performance is that the key to mobile web success. People want high-performance websites. We hate to attend on our desktops, and therefore the situation is way worse on mobile devices, with their constrained resources. I could write an entire book about mobile web performance, except for now i will be able to just attempt to distill some best practices and share some hacks that you simply can easily apply to enhance your website’s performance.
Performance has recently become a hot topic within the desktop web world. Generally mobile web developers should follow an equivalent practices, but there are some new ones to stay in mind also , and a few desktop web best practices which will not work on these devices.
Mobile browsers aren’t an equivalent as desktop web browsers, and not all mobile browsers are created equal. Specifically, the number of resources which will be downloaded in parallel and therefore the cache functionality differ. Nevertheless, it's better to approach mobile performance optimization from here than from the bottom .
1. Measurement
The first thing we'd like to do is to measure. If we cannot measure, we cannot optimize. However, measuring mobile websites isn't easy. Typical desktop measurement and profiling tools don’t work for mobile devices, and HTTP sniffers are difficult to implement for mobile browsers.
Advanced memory and process profiling for JavaScript remains more of a dream than a reality. However, Yahoo! has created an easy JavaScript profiler called the Yahoo! UI Profiler work on any A-grade browser (Symbian, iPhone, Android), and you'll always use new Date().get Milliseconds() to get the time differences between two moments in your JavaScript code.
If you're using an emulator or a true device with WiFi capabilities, you'll use any HTTP sniffer proxy, configuring the emulator and your device together with your desktop IP address and port because the proxy for navigation. There are dozens of tools for doing this, but the one i prefer best is named the Charles Web Debugging Proxy.
2. Best Practices
Here are some global best practices you should always have in mind:
• Keep it simple.
• Reduce the HTTP requests to the minimum possible.
• Implement Ajax requests if you'll , and if the device supports them.
• Make the cache your friend.
Reducing requests
There are many tips for reducing network requests:
• Use just one CSS and JavaScript external link per page.
• If the script and/or CSS is only for one document, don’t use external code; instead, embed it within the page.
• Use inline images whenever you'll .
• Use CSS Sprites.
• Reduce the utilization of images for effects, titles, and text. Attempt to meet all of those needs using only CSS.
• Use multipart documents when compatible.
• Download only the initially required code and resources then , after the onload event, download all the remainder on Ajax devices (lazy loading).
Compressing
Compression may be a necessity, and there are different techniques you'll use for it:
• Minimize your XHTML files, removing spaces, comments, and non-useful tags.
• Minimize your CSS files, removing spaces and comments.
• Minimize your JavaScript files, removing spaces and comments and obfuscating the code.
• Use HTTP 1.1 compression for delivering static and dynamic text-based files
(XHTML, JavaScript, CSS, XML, JSON).
• Use a cookie-free domain (or alias domain) for static content files
HTTP compression
HTTP 1.1 added compression (using GZIP and deflate) as an optional possibility when delivering a file to the client. Using this feature is strongly recommended for text-based files on most mobile devices, because it'll reduce the traffic between the server and therefore the client by up to 80%. It'll add some overhead on the client, but it’s well worthwhile .
Network traffic are going to be one among our worst problems if the user isn't connected to a WiFi network. Even with 3G connections, the network can have latency problems.
JavaScript performance
Again, keep your code simple. Here are another specific tips for mobile JavaScript coding:
• Don’t use try/catch expressions for expensive code.
• Avoid using eval, even in situations where you would possibly not believe it getting used, like when employing a string in setTimeout rather than a function.
• Avoid using with.
• Minimize the usage of worldwide variables.
• Minimize the amount of changes within the DOM, and make the changes within the same operation. Many browsers repaint the entire screen on each change.
• Implement a timeout for Ajax calls.
• Compress your code.
A common situation within the mobile web world is content delivery. Java applications, widgets, music, video, wallpapers, and the other content are often delivered to compatible devices, but this needs a bit of explanation and expertise.
A. Defining MIME Types
MIME types, many of which are listed within the Appendix, are a key element for content delivery. Many mobile browsers don’t care about the file extension; they decide whether or to not accept the content supported the MIME type delivered by the server. Remember that the MIME type travels with the HTTP header response.
1. Static definition
The simplest way to define the proper MIME types is to statically define them on your web server. If you're working with a shared hosting service, the control panels often allow you to define document MIME types. If you manage your own server, you'll set them up with the subsequent instructions.
Apache
In Apache, the only way is to open the mime.types file located within the conf folder of the Apache root. In your favorite text editor, you'll add one row per MIME type to be configured. You'll find many MIME type declarations. The primary thing to do is to seem for the subsequent line and change the MIME type to the right one for mobile XHTML documents:
Text/html html htm
As you'll see, each line contains a MIME type followed by a series of spaces or tabs and an area separated list of file extensions.
Internet Information Server
Configuring MIME types in Microsoft IIS can be done via the UI. To configure the MIME types in IIS 6.0 on Windows XP or Windows Server 2003:
1. Go to IIS Manager.
2. Right-click the whole server, a website, or a folder and select Properties.
3. On the HTTP Headers tab, click MIME Types.
4. Click New, type the file extension and MIME type, and press OK to finish.
In IIS 7.0 for Windows Vista/7 and Windows 2008 Server:
1. Go to IIS Manager.
2. Navigate to the level you want to manage.
3. In Features View, double-click on MIME Types.
4. In the Actions pane, click Add.
5. Type the file extension and MIME type and press OK to finish.
In IIS 7.0, it is also possible to define static MIME type declarations in the web.config file in your ASP.NET folder. The syntax is:
<configuration>
<system.webServer>
<staticContent>
<mimeMap fileExtension=".mp4" mimeType="video/mp4" />
<mimeMap fileExtension=".vcf" mimeType="text/x-vcard" />
</staticContent>
</system.webServer>
</configuration>
2. Dynamic definition
The other possible way to declare MIME types is to use dynamic header declarations in your server script code. In PHP, you must define the MIME type before the other output using the header function:
Header('Content-Type: application/xhtml+xml');
If you're delivering downloadable content (not markup), sort of a video, you must also define a filename. If not, when the file is saved it'll have a .php extension and it'll not work.
To define the name of the file we use the Content-disposition header, as shown within the following sample:
$path = '/videos/video.mp4';
Header('Content-Type: video/mp4');
Header('Content-disposition: attachment; filename=video.mp4');
// We serve the file from our local filesystem
Header("Content-Length: " . Filesize($path) );
Readfile($path);
ASP.NET has a Response.ContentType property that we can define:
// This is C# code
Response.ContentType = "application/xhtml+xml";
The filename should also be defined if it is downloadable content, using
Response.AddHeader.
In a Java servlet or JSP, you should define the headers using the setContentType method of the response object:
Response.setContentType("application/xhtml+xml");
B. File Delivery
To deliver a file, there are three models:
• Direct linking
• Delayed linking
• OMA Download
You can use any of those three methods to deliver the files, either using the physical file (video, audio, game, etc.) directly or via a script (PHP, ASPX, etc.). If you employ a script to deliver a file, you'll log, secure, and even charge for each download. If the file is out there directly through the online server, anyone with the URL can download the file.
1. Direct linking
Direct linking is that the easiest method to deliver content. a direct link is simply a link to the file, a link to a script which will deliver the file, or a link to a script which will redirect the user to the file. For example:
<a href="game.jad">Download This Game</a>
<a href="download.php?id=22222">Download This Game</a>
The download.php script can save the download to the database, check permissions, then deliver the content using the suitable MIME type, writing the file to the response output or redirecting the browser to the file:
<?php
If ($everything_ok) {
Header('Location: game.jad');
} else {
Header('Location: download_error.php');
}
2. Delayed linking
Delayed linking is a technique utilized in download sites for desktop browsers. It allows us to point out a landing page before the download starts. This landing page also will be the document the user will see after the download has finished or, if the browser supports background downloading, while it's downloading.
The technique involves linking to an XHTML document which will show the user some information and can use a refresh metatag to redirect the user to the direct link in X seconds.
So, the download page will redirect to:
<a href="download.html">Download This Game</a>
And download.html will contain code like the following:
<!DOCTYPE html PUBLIC "-//WAPFORUM//DTD XHTML Mobile 1.0//EN"
"http://www.wapforum.org/DTD/xhtml-mobile10.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
<meta http-equiv="refresh" content="5;game.jad" />
<title>Download File</title>
</head>
<body>
<h1>Your game is being downloaded</h1>
<p>If the file is not downloaded in 5 seconds,
<a href="game.jad">click here</a>
<h2>Brought to you by "Your favourite ad here"</h2>
<p>Trouble downloading this game? <a href="sms:611">Send us an SMS</a>
<a href="tel:611">Call Us</a></p>
<a href="/">More Downloads</a>
</body>
</html>
3. OMA Download
OMA Download a standard defined in 2004 by the Open Mobile Alliance to permit us more control over the delivery of media objects. It also has support for Digital Rights Management (DRM) in two versions, OMA DRM 1.0 and OMA DRM 2.0. The specification was used because the basis for the Java ME MIDlet OTA installation method that we'll see later during this chapter, therefore the two are very similar.
OMA Download adds two phases to the download process: before download and after download. The before download process involves an outline file downloaded using HTTP before the real file is downloaded.
This description file is an XML file containing meta information for the OS and instructions for doing the download. This process gives the user a chance to check information about the content (name, compatibility, size) before accepting it.
The after download process involves an HTTP request posted to your web server from the OS, confirming the ultimate status of the download. This enables you to verify that the file has been correctly downloaded and installed.
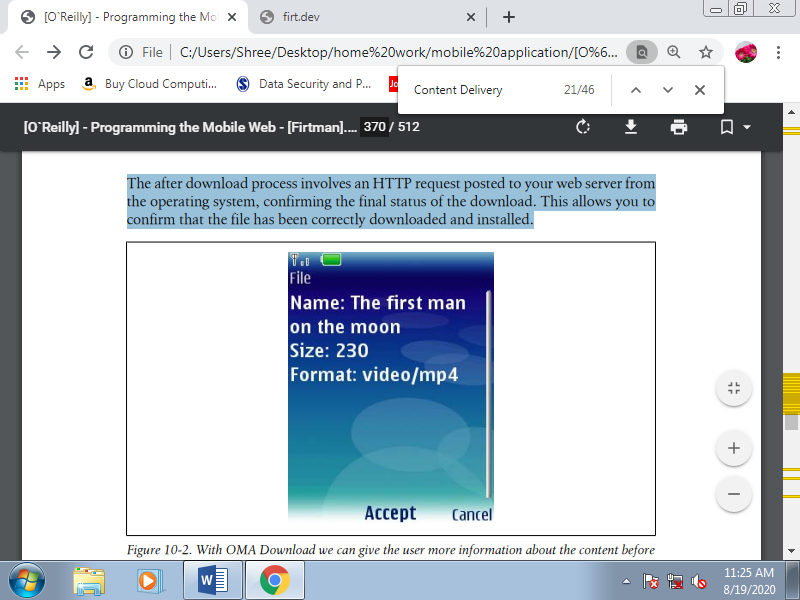
Figure 4.8(I) With OMA Download we can give the user more information about the content before she downloads it.
OMA DRM supports the ability to define the proper to play, display, or execute a media object or a file a limited number of times. DRM should be managed with care, and you would like to check compatibility with the devices you’re targeting before using it.
Download descriptor
The descriptor is an XML-based file that should be served using the MIME type application/vnd.oma.dd+xml.
Here’s a simple example of this file:
<?xml version="1.0"?>
<media xmlns="http://www.openmobilealliance.org/xmlns/dd">
<name>The first man on the moon</type>
<type>video/mp4</type>
<objectURI>http://mobilexweb.com/video.mp4</objectURI>
<size>230</size>
<installNotifyURI>http://mobilexweb.com/download/notify.php?id=3333
</installNotifyURI>
</media>
These are the standard attributes: name, the user-readable name of the content file; type, the MIME sort of the file; objectURI, absolutely the URL of the file; size, the file size expressed in KB; and installNotifyURI, the URL which will receive the after-download status.
Additional properties also are available, like nextURL (the URL of a web site to go to after the download has finished), description (a short description of the media file), vendor (the organization providing the file), and iconURI (an optional icon to be shown with the file information).
Post-download status report.
If you define the installNotifyURI within the download descriptor, you'll receive a POST request thereto URL when the download finishes. This URL will receive because the POST body an integer code with a standing message.
The important thing is that this request doesn't are available the traditional URL-encoded way, so you can’t use the standard $_FORM or Request.Form. To read the status code, you’ll got to read the request body during a low-level format.
Table 4.8(II) OMA Download status codes

To read the OMA Download response from a PHP script, you can use the following sample code:
<?php
// We get the post body from the input
$post = file_get_contents('php://input');
// We get the first three characters without spaces
$status = substr(trim($post), 0, 3);
If ($status==900) {
// Download OK, save information to the database
} else {
}
?>
If you're delivering premium content that the user has purchased , if the download fails you must deliver an equivalent content without forcing the user to pay again. Even though the download has succeeded, many carriers insist that the content be made available freed from charge for twenty-four hours. Some new application stores also allow the users to download the premium content again although they modify their mobile devices.
Table 4.8(III) OMA Download compatibility table
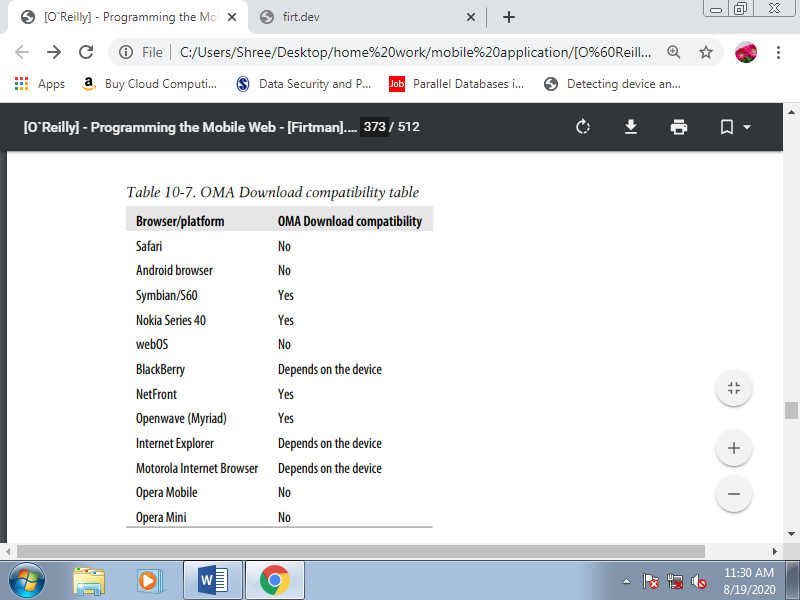
D. Application and Games Delivery
In the beginning, the mobile content delivery world centered on ringtones and wallpapers. To deliver this type of content, we should always believe what we've seen before: if we deliver the right MIME type, the file are going to be saved by the mobile . For current devices, ringtones are generally MIDI or MP3 files, while there are other audio formats suitable for low-end and older devices. A wallpaper are often a JPG, an animated GIF, or maybe a Flash Lite file for compatible devices.
The next content that appeared on the market was games, followed by applications (the difference is n
• If you're creating a game or application store
• If you're developing a mobile website for a current application
• If you've got a richer version of your mobile website available as a widget or application
• If you're providing a shortcut for your website embedded as an application ot technical). Applications delivery are often useful:
The formats that you simply can deliver from a web site are:
• Java ME (formerly J2ME)
• Flash Lite
• Symbian native applications
• Widgets
• Android applications
• Windows Mobile applications
• BlackBerry applications
We cannot deliver iOS native applications for iPhone, iPad, or iPod on to users, because the App Store is that the unique public way to install and deliver applications for this OS. However, we will link to the App Store native application with the app we would like the user to shop for or download onscreen.
There are similar restrictions on delivering webOS applications. For widgets and Android, Symbian, and Windows Mobile applications, we just got to use the proper MIME type when delivering the file. No special mechanism is employed .
E. Java ME
Java ME was the well-liked language for games and applications for years. Its usage is declining, but it's still the foremost widespread platform within the world. It's compatible with Nokia, non-Android Motorola, LG, Samsung, Sony Ericsson, BlackBerry, and lots of other devices. A Java ME project is shipped as a JAR (Java ARchive) file, which is simply a zip file containing the application. It must be delivered using the MIME type application/java-archive.
Many phones accept this file type directly, although the simplest (and 100% compatible) way of delivering Java ME games or apps is to first deliver a JAD (Java Application Descriptor) file. The JAD file is simply a document served with the MIME type text/vnd.sun.j2me.app-descriptor that contains metadata about the application, almost like OMA Download’s download descriptor files.
So, the device first downloads the JAD file and shows the knowledge to the user (name of the application, size, format, etc.). If the user accepts, the JAR file is then downloaded and installed. The Java ME developer usually generates the JAD file, and that we receive it in its final state. However, because it may be a document , we will generate it ourselves or change it employing a server-side script.
At the time of this writing, there are two major versions of the Java ME platform for mobile devices: MIDP 1.0 and MIDP 2.0. If we’re providing an equivalent application or game in both versions (e.g., basic and advanced versions), we should always first check the device’s compatibility with Java ME then deliver the right JAD and JAR files. WURFL has properties to see if MIDP 1 or MIDP 2 is available.
1. Serving JAD files
Let’s analyze a part of the MIDP 1.0 version of the JAD file sent to the device when a user tries to download Opera Mini 3:
MIDlet-Version: 3.1
MIDlet-1: Opera Mini 3, /i.png, Browser
MIDlet-Data-Size: 10240
MIDlet-Description: Opera Mini
MIDlet-Icon: /i.png
MIDlet-Info-URL: http://mini.opera.com/
MIDlet-Install-Notify: http://mini.opera.com/n/13045Bviprdome_en
MIDlet-Jar-Size: 58800
MIDlet-Jar-URL: opera-mini-3.1.13045-basic-en.jar
MIDlet-Name: Opera Mini 3
MIDlet-Vendor: Opera Software ASA
Content-Folder: Applications
MicroEdition-Configuration: CLDC-1.0
MicroEdition-Profile: MIDP-1.0
The emphasized parts of the code are those that we'd like to worry about when delivering Java ME applications.
MIDlet-Jar-URL defines the relative or absolute URL of the JAR file. We will insert the JAR file directly here, or, if we would like to secure and log the download, we will use a URL to a dynamic script including a URL parameter included within the JAD generation.
MIDlet-Install-Notify is that the same because the installNotifyURI parameter in OMA Download. It's an optional parameter that defines a URL which will receive by POST an equivalent codes as in OMA Download (from 900 to 906), as seen in Table 10-6.
Starting with MIDP 2.0, the standard added new codes that we will receive within the MIDletInstall-Notify URL. The added status codes are shown in Table 10-8.
Table 4.8(IV) Additional MIDP 2 status codes

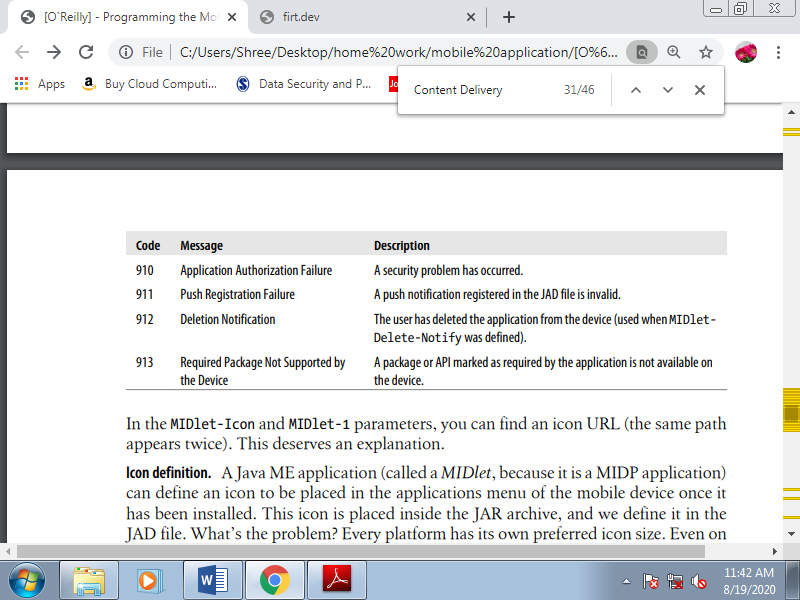
In the MIDlet-Icon and MIDlet-1 parameters, you can find an icon URL (the same path appears twice). This deserves an explanation.
Icon definition
A Java ME application (called a MIDlet, because it's a MIDP application) can define an icon to be placed within the applications menu of the mobile device once it's been installed. This icon is placed inside the JAR archive, and that we define it within the JAD file. What’s the problem? Every platform has its own preferred icon size.
Even on different devices supported an equivalent OS, the icon size can change. Additionally , the developer wants the user to have the simplest possible experience, and a broken, small, or pixelated icon creates a bad user experience.
There are two solutions:
• The Java developer creates n packages for every device or group of devices.
• The Java developer creates one or more packages with all the possible icon sizes inside the JAR then we, because the web developers, use a device library to dynamically define within the JAD which icon is that the best for the present device.
2. Custom properties
Java ME allows us to define custom properties within the JAD file as string values. Each property can then be read by the Java ME application when it’s executed. A custom property is simply a key: value line within the JAD file. This system must be coordinated with the Java ME developer. These values can't be changed by the user and are fixed with the application until it's deleted or updated.
This can be useful for providing any of the following:
• A download ID for future identification
• User agent or device information that the server knows but Java ME doesn't
• A username or user ID for transactions
• Key codes for nonstandard keys that the server knows but Java ME doesn't
• IP or server addresses
• Other useful or dynamic parameters.
3. Java ME for BlackBerry
Newer BlackBerry devices accept an equivalent JAD and JAR files that we’ve been examining. However, the foremost compatible way to serve Java ME files on these devices is to use BlackBerry’s own format for JAR files: COD files. BlackBerry uses an equivalent JAD files, with two new mandatory attributes: RIM-COD-URL and RIM-COD-Size. The COD file must be served as application/vnd.rim.cod, and it's generated employing a free tool from RIM that converts a JAR into a COD file.
F. Flash Lite Content
Flash Lite movies, games, or applications are just SWF files. The problem with this format is that a SWF file isn't “an installed application”; it's managed like all other document on the device, as a enter the filesystem. For Flash Lite content to be installed as an application, it should be contained in another format, such as:
Nokia Flash Lite (NFL)
Nokia provides a packager for Flash Lite for Series 40 devices.
Symbian SIS
There are many Flash packagers for Symbian which will embed Flash content during a Symbian native format.
Widget for Symbian
For compatible devices, you'll embed a Flash application during a widget.
Capuchin
The Capuchin Project is an API compatible with Sony Ericsson devices that permits the usage of a SWF file inside a Java ME application.
The NFL format is simply a zip file with a .nfl extension, served as application/ vnd.nokia.flashlite-archive, with a minimum of three files inside: a SWF, an icon file, and a descriptor.inf document . The contents of the document look something like this:
FL-Version: 1.0
FL-Icon: image.png
FL-Name: Super Game
FL-Root: supergame.swf
G. IPhone Applications
If you've got your own application that has already been accepted for distribution via
The App Store, or if you would like to supply users with a link to shop for or download an application, game, ebook, music file, movie, or TV show, you'll use a special iTunes link which will open iTunes or the App Store automatically, displaying the specified content.
You'll create one among these links using the web service iTunes Link Maker. You'll select which country’s App Store to seem for the content in, then look for the content you would like to link.
First, let’s define what we mean during this article once we say “native app” and “mobile web app”.
A. What is a Native App?
A native app is an app for a particular mobile device (smartphone, tablet, etc.) They’re installed directly onto the device. Users typically acquire these apps through a web store or marketplace like The App Store or Android Apps on Google Play.
Examples of native apps are Camera+ for iOS devices and KeePassDroid for Android devices.
B. What is a Mobile Web App?
Mobile web apps are referring to Internet-enabled apps that have specific functionality for mobile devices. They’re accessed through the mobile device’s browser (i.e. on the iPhone, this is often Safari by default) and that they don’t got to be downloaded and installed on the device.
Comparison of Native App vs. Mobile Web AppLet’s do a fast rundown and evaluate native apps versus mobile web apps under these factors:
- User interface
- Development
- Capabilities
- Monetization
- Method of delivery
- Versioning of the app
- Strengths
- Weaknesses
1. User Interface
Some companies prefer to develop both a native app and a mobile web app. Here’s a side-by-side check out Facebook’s native app and mobile web app:
2. Development
NATIVE APPS | MOBILE WEB APPS |
Each mobile application development platform (e.g. IOS, Android) needs its own development process | Runs in the mobile device’s web browser and each have its own features and quirks |
Each mobile application development platform has its own native programming language: Java (Android), Objective-C (iOS), and Visual C++ (Windows Mobile), etc. | Mobile web apps are written in HTML5, CSS3, JavaScript and server-side languages or web application frameworks of the developer’s choice for example PHP, Rails, Python |
Standardized software development kits (SDKs), development tools and common user interface elements such as buttons, text input fields, etc. are provided by the manufacturer of the platform | There are no standard software development kits (SDKs) that developers are need to use to create a mobile web app |
There are many tools and frameworks to help in developing apps for deployment on multiple mobile OS platforms and web browsers (e.g. PhoneGap, Sencha Touch 2,Appcelerator Titanium, etc.) | |
3. Capabilities
NATIVE APPS | MOBILE WEB APPS |
Can interface with the device’s native features, information and hardware like (camera, accelerometer, etc.) | Mobile web apps access a limited amount of the device’s native features and information orientation, geolocation, media, etc. |
4. Monetization
NATIVE APPS | MOBILE WEB APPS |
Mobile-specific ad platforms like AdMob (though there can be restrictions set by the mobile device’s manufacturer) | Mobile web apps can monetize through site advertisement and subscription fees |
Developers have the ability to charge a download price and app stores will handle the payment process | Charging users to use the mobile web app need you to set up your own paywall or subscription-based system |
5. Method of Delivery
NATIVE APPS | MOBILE WEB APPS |
Downloaded in a mobile device | Accessed with help of a mobile device’s web browser |
Installed and runs as a standalone application web browser not required | No need to install new software |
Users need to manually download and install app updates | Updates are made to the web server without any user intervention |
There are stores and marketplaces to help users search your app | Since there is no app store for the Mobile Web then difficult for users to find your app |
6. Versioning of the App
NATIVE APPS | MOBILE WEB APPS |
Some users may choose to ignore an update, resulting in different users running different versions of the app | All users are on the same version |
7. Strengths
NATIVE APPS | MOBILE WEB APPS |
Perform faster than mobile web apps | Having a common code base across all platforms |
App stores and marketplaces which help to users find native apps | Users don’t have to go to a store or marketplace, download and install the app |
App store approval processes help to assure users of the quality and safety of the app | Released in any form and time as there isn’t an app store that has to approve the app |
Tools, support and standard development best practices provided by device manufacturers supports speed up development | If you already have a web app, you can retrofit it with a responsive web design |
8. Weaknesses
NATIVE APPS | MOBILE WEB APPS |
Are more expensive to develop, if you’re supporting many mobile devices | Mobile web apps can’t access all of the device’s features |
Supports different platforms needs to maintain multiple code bases and can result in more costs in development, maintenance, pushing out updates, etc. | Supports multiple mobile web browsers result in higher costs in development and maintenance, etc. |
Users work on different versions and can make your app harder to maintain and provide support | Users work on different mobile browsers and make your app difficult to maintain and provide support |
App store approval processes take a time to the launch of the app or prevent the release of the app | For users, it is difficult to find a mobile web app because of the lack of a centralized app store (though listings do exist such as Apple’s |
Reference Text Book
1. Jeff McWherter, Scott Gowell, Professional Mobile Application Development, John Wiley & Sons, Ref: www.it-ebooks.org
2. Maximiliano Firtman, Programming the mobile Web, Oreilly, 2nd Edition, 2013, ISBN: 978-1-449-33497-0
Reference link
1. Https://www.webfx.com/blog/web-design/native-app-vs-mobile-web-app-comparison/
2. Https://webplatform.github.io/docs/concepts/Detecting_device_and_browser/




