|
|
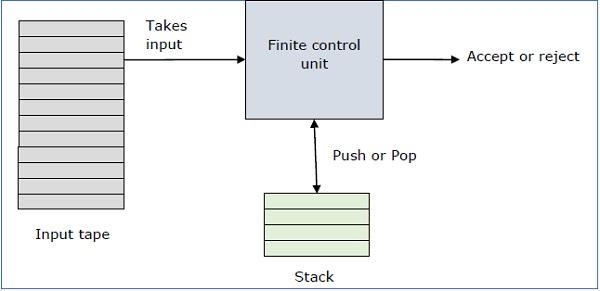
● process the entire string,
● end in a final state
● end with an empty stack.
|
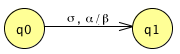
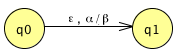
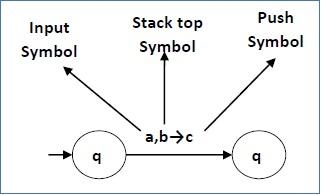
● the top of the stack must match α
● if we make the transition, pop α and push β
A PDA is non-deterministic. There are several forms on non-determinism in the description:● Δ is a relation
● there are ε-transitions in terms of the input
● there are ε-transitions in terms of the stack contents
The true PDA ε-transition, in the sense of being equivalent to the NFA ε-transition is this:
|
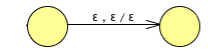
{x ∈ {a,b,c}* : x = wcwR for w ∈ {a,b}*}
|
|
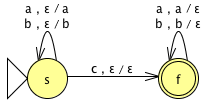
{x ∈ {a,b}* : x = wwR for w ∈ {a,b}*} |
| |||
This PDA is identical to the previous |
| |||

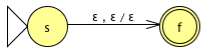
|




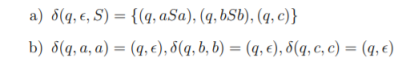
|
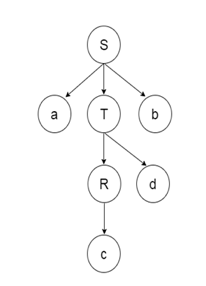
- The parsing begins with the start symbol in the top-down parsing and transforms it into the input symbol.
- A top-down parsing technique that builds the parse tree from the top and reads the input from left to right is recursive descent.
|
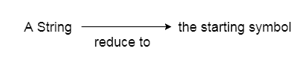
- Bottom-up parsing is also known as parsing for shift-reduce.
- Bottom-up parsing is used to build an input string parsing tree.
- Shift reduction parsing is a mechanism by which a string is reduced to the beginning symbol of a grammar.- The grammar of operator precedence is a kind of shift reduction system of parsing.
References:2. Theory of Computer Science (Automata, Languages and Computation), 2e by K. L. P. Mishra and N. Chandrasekharan, PHI
3. Michael Sipser, Introduction to the Theory of Computation, PWS Publishing.



