Unit - 5
Web Applications Service Protocols
The Hypertext Transfer Protocol (HTTP) is a protocol for distributed, shared, hyper-media information systems at the application level. Since 1990, this has been the basis for data exchange on the World Wide Web (i.e. the Internet). HTTP is a generic and stateless protocol that can also be used to use extensions of its request methods, error codes, and headers for other purposes.
Basically, HTTP is a networking protocol based on TCP/IP that is used on the World Wide Web to provide data (HTML files, image files, query results, etc.). TCP 80 is the default port, but other ports can also be used. It provides computers with a consistent way to communicate with each other.
The HTTP specification defines how client request information will be created and sent to the server, and how servers will respond to these requests.
Architecture :
The following diagram illustrates a web application's very simple architecture and shows where HTTP sits:
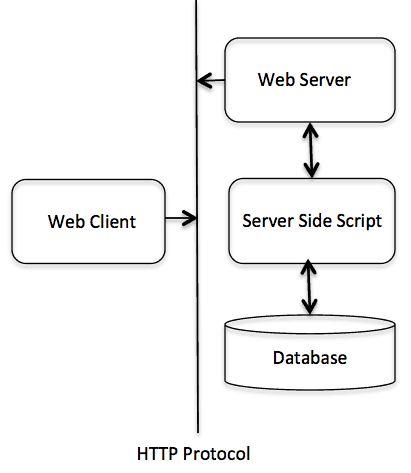
Fig 1: HTTP architecture
The HTTP protocol is a client/server-based request/response protocol in which web servers, robots, search engines, etc. behave like HTTP clients, and the Web server acts as a server.
Client : The HTTP client sends a request to the server in the form of a request process, URI and protocol version, followed by a MIME-like message over a TCP/IP link containing request modifiers, client information, and potential body material.
Server : The HTTP server responds with a status line, including the protocol version of the request and a success or error code, followed by a MIME-like message containing server information, entity meta information, and possible entity-body text.
Key takeaway :
● HTTP is a networking protocol based on TCP/IP that is used on the World Wide Web to provide data.
● The HTTP protocol is a client/server-based request/response protocol in which web servers, robots, search engines, etc.
● HTTP is a generic and stateless protocol that can also be used to use extensions of its request methods, error codes, and headers for other purposes.
It is possible to group the documents into three broad categories: static, dynamic, and active. The category is based on the time at which it decides the substance of the text.
Static documents
Static documents are documents with defined content that are produced and stored on a server. Only a copy of the document can be accessed by the customer. In other words, when the file is created, the contents of the file are decided, not when it's used.
Of course, it is possible to change the content on the server, but the user is unable to change it. A copy of the document is submitted when a customer accesses the document. The user may then view the document using a browser programme.
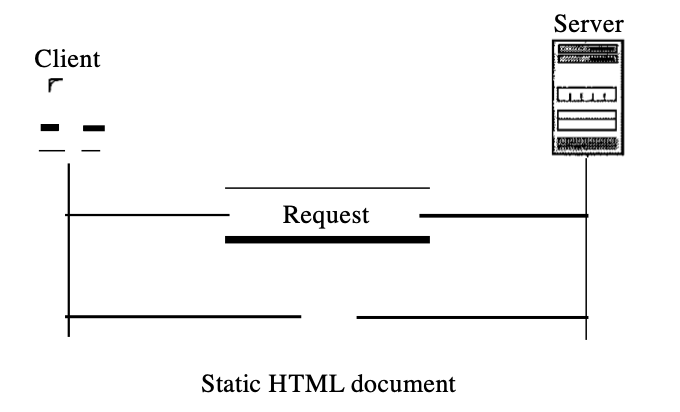
Fig 2: static document
Dynamic documents
Whenever a browser requests a document, the Web server produces a dynamic document. When a request arrives, an application programme or a script that generates a complex document is run by the Web server. The server returns the software or script output to the browser that requested the document as a response. Because each request produces a new document, the contents of a dynamic document can differ from one request to another.
Retrieving the time and date from a server is a very simple example of a dynamic text. Time and date are kinds of dynamic details in that they shift from moment to moment. The client may ask the server to run a programme such as the UNIX date programme and return the programme result to the client.
● Common Gateway Interface (CGI)
A technology that generates and manages dynamic documents is the Common Gateway Interface (CGI). CGI is a collection of standards that describe how a dynamic document is written, how the software enters data, and how the product of the output is used.
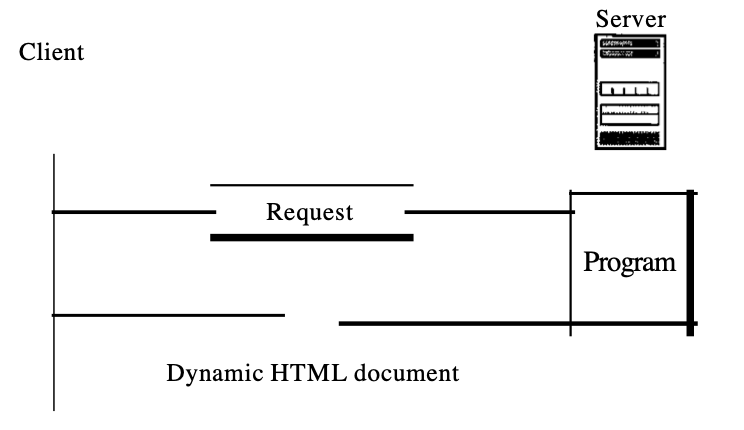
Fig 3: dynamic documents using CGI
● Scripting Technologies for Dynamic Documents
The issue with CGI technology is that if part of the dynamic document to be generated is set and does not shift from request to request, it results in inefficiency. For example, assume that a list of spare parts, availability, and prices for a particular car brand needs to be retrieved.
The name, definition, and picture of the components are fixed, although the availability and prices differ from time to time. If we are using CGI, any time a request is created, the programme must construct an entire document. The solution is to use HTML to construct a file containing the fixed part of the document and to embed a script, a source code, which can be executed by the server to provide a variable section of availability and price.
The development of complex documents using scripts has included a few technologies. Hypertext Preprocessor (pHP), which uses Perl lan-guage, is among the most common; Java Server Pages (JSP), which uses the Java scripting language; Active Server Pages (ASP), a Microsoft product that uses the Visual Basic scripting language; and ColdFusion, which embeds queries from the SQL database throughout the HTML document.
Active documents
We need a programme or a script to be executed on the client site for several applications. Active records are called these. Suppose, for instance, we want to run a programme that produces on-screen animated graphics or a programme that communicates with the user. It is certainly important to run the software on the client site where the animation or interaction occurs. The server sends a copy of the document or a script when a browser requests an active document. The text is then executed at the location of the client (browser).
● Java Applets
Using Java applets is one way to build an active document. Java is a combination of a high-level programming language, a run-time environment, and a class library that allows an active document (an applet) to be written by a programmer and run by a browser. It may also be a programme that is stand-alone and does not use a browser.
An applet is a programme on the server that is written in Java. It is compiled and is ready for running. The text is in the format of a byte-code (binary). An instance of this applet is created and run by the client process (browser).

Fig 4: active documents using java applets
The browser can execute a Java applet in two ways. The first method allows the browser to request the Java applet programme directly from the URL and to obtain the applet in binary form. The second method allows the browser to retrieve and run an HTML file that has the applet's address embedded as a tag.
● Java Script
For active documents, the concept of scripts in dynamic documents may also be used. If the active part of the document is small, it can be written in a scripting language and can be interpreted and executed simultaneously by the client. The script is not in binary form, but in source code (text). In this case, the scripting technology used is commonly JavaScript. JavaScript, which bears a slight resemblance to Java, is a scripting language designed for this purpose at a very high level.
Key takeaway :
● Static documents are documents with defined content that are produced and stored on a server.
● Dynamic documents are often referred to as dynamic documents from the server site.
● Client-site dynamic documents are often referred to as active documents.
The HTTP transaction between the client and the server is shown in the figure. While HTTP uses TCP services, HTTP itself is a protocol that is stateless. By sending a request message, the client initialises the transaction. By sending an answer, the server responds.
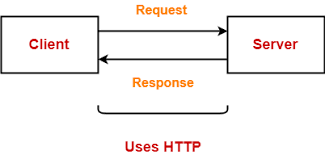
Fig 5: HTTP transaction
The request formats and the response messages are identical. A request message is made up of a line of request, a header, and often a body. A answer message is made up of a line of status, a header, and often a body.
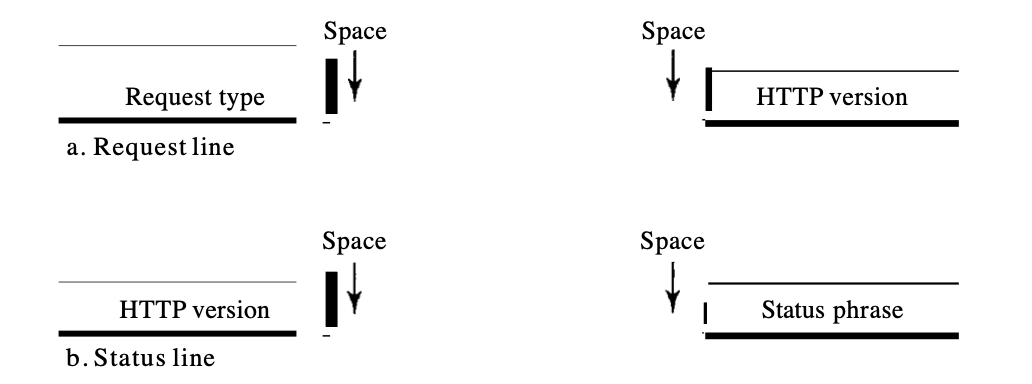
Fig 6: request and response
Request : The request message, consisting of a request line, headers, and often a body, is sent by the client.
Response : The reply message is sent to the client by the server, which consists of a status line, headers, and often a body.
● Request and Status Lines : The first line in the request message is called the request line; the first line is called the status line in the answer message. As seen, there is one common field.
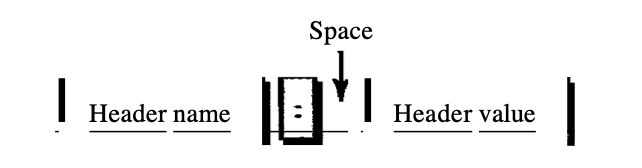
Fig 7: request and status line
Version: The most current version of HTTP is 1.1.
Status code : This field is used in the reply message format. The area of the status code is close to those of the protocols FTP and SMTP. It's made up of three digits. Although codes in the range of 100 are only informative, codes in the range of 200 indicate a good request.
Status phrase : In the reaction message, his field is used. In text form, it describes the status code.
● Request type : In the request message, this field is used. Several request types are specified in version 1.1 of HTTP. As specified, the request form is categorised into methods.
Method | Action |
GET | Requests a document from the server |
HEAD | Requests information about a document but not the document itself |
POST | Sends some information from the client to the serve. |
PUT | Sends a document from the server to the client. |
TRACE | Echoes the incoming request |
CONNECT | Reserved |
OPTION | Inquires about available options. |
Key takeaway :
● A request message is made up of a line of request, a header, and often a body.
● The reply message is sent to the client by the server, which consists of a status line, headers, and often a body.
Between the client and the server, the header shares additional details. The client may, for example, request that the document be submitted in a specific format, or the server can submit additional document information. One or more header lines may be composed of the header. There is a header name, a colon, a space, and a header value on each header line.
One of the four groups belongs to a header line: general header, request header, response header, and entity header. Only general, request, and entity headers can be found in a request message. On the other hand, a response message may only contain general, response, and entity headers.
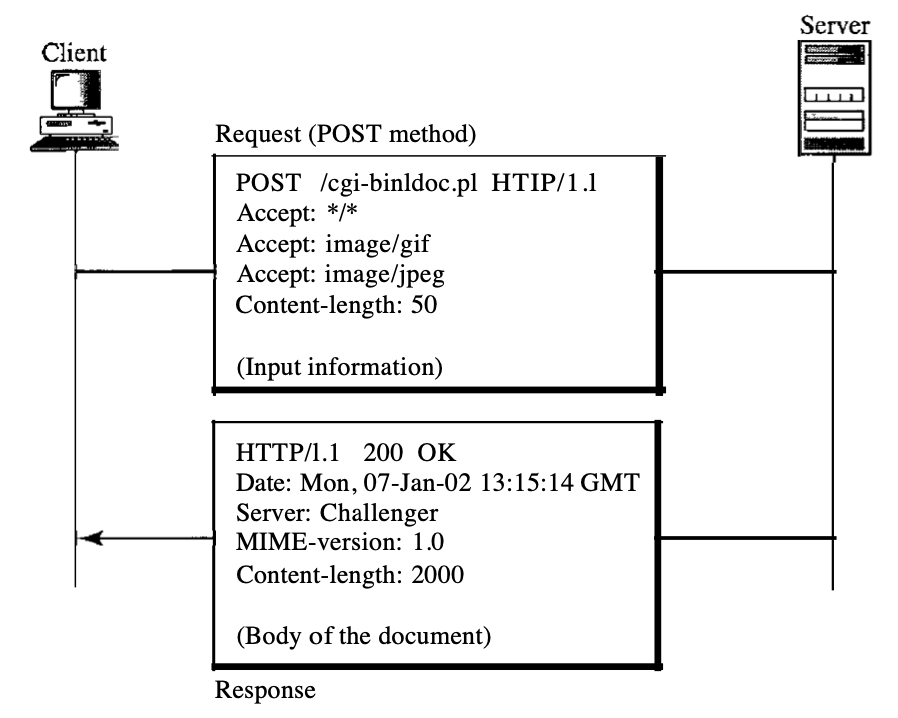
Fig 8: header format
● General header : The general header contains general message information and may be present in both a request and a response.
Header | Description |
Cache - control | Specifies information about caching |
Connection | Shows whether the connections should be closed or not |
Data | Shows the current date |
MIME - version | Shows the MIME - version used |
Upgrade | Specifies the preferred communication protocol |
● Request header : Only a request message may contain a request header. It defines the configuration of the client and the desired document format of the client.
Header | Description |
Accept | Shows the medium format the client can accept |
Accept-charset | Shows the character set the client can handle |
Accept-encoding | Shows the encoding scheme the client can handle |
Accept-language | Shows the language the client can accept |
Authorization | Shows what permission the client has |
From | Shows the e-mail address of the user |
Host | Shows the host and port number of the server |
● Response header : Only in a response message will the response header be present. It defines the server's configuration and relevant request information.
Header | Description |
Accept - range | Shows if server accept the range requested by client |
Age | Shows the age of the document |
Public | Shows the supported list of methods |
Retry - after | Specifies the date after which the server is available |
Server | Shows the server name and version number |
● Entity header : The header of an organisation contains details about the body of the text. Although it is mostly present in response messages, this kind of header is also used by some request messages, such as POST or PUT methods, that contain a body.
Header | Description |
Allow | Lists valid methods that can be used with a URL |
Content-encoding | Specifies the encoding scheme |
Content-language | Specifies the language |
Content-length | Shows the length of the document |
Etag | Gives an entity tag |
Expires | Gives the date and time when content may changes |
Location | Specifies the location of the created or moved document |
● Body : In a request or reaction message, the body may be present. It normally includes the document that is to be submitted or received.
Example
The client wants to submit data to the server in this case. We're using the POST process. The request line shows the (POST), URL, and HTTP versions of the process (1.1). Four lines of headers are open. The request body contains the information for input. The answer message includes a line of status and four header lines. The document produced, which is a CGI document, is included as an entity.
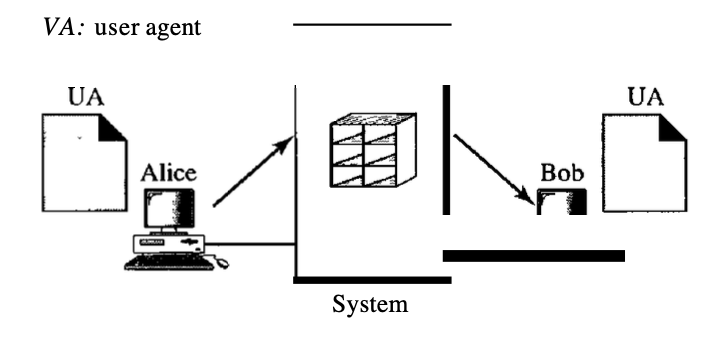
Fig 9: example
Key takeaway :
● There is a header name, a colon, a space, and a header value on each header line.
● Between the client and the server, the header shares additional details.
Prior to version 1.1, HTTP defined a non-persistent link, while version 1.1 defaults to a persistent connection.
Non - persistent
In a non-persistent connection, for each request/response, one TCP connection is made. The steps in this strategy are described below:
1. A TCP link is opened by the client and a request is submitted.
2. The server sends the answer and the connection closes.
3. The client reads the data until an end-of-file marker is encountered; the link is then closed.
In this technique, the connection must be opened and closed N times for N different images in different files. The non-persistent strategy imposes high overhead on the server because each time a connection is opened, the server needs N different buffers and requires a slow start procedure.
Persistent
By design, HTTP Version 1.1 defines a persistent link. On a persistent connection, after sending a response, the server leaves the connection open for more requests. At the request of a client, the server will close the connection or if a time-out has been reached. With each answer, the sender generally sends the length of the data. There are some times, however, where the sender does not know the data length. When a text is dynamically or actively developed, this is the case.
In these instances, after submitting the data, the server tells the client that the length is not known and closes the connection so that the client knows that the end of the data has been reached.
Key takeaway :
● By design, HTTP Version 1.1 defines a persistent link.
● In a non-persistent connection, for each request/response, one TCP connection is made.
HTTP supports servers with proxies. A proxy server is a system that holds copies of recent request responses. A request to the proxy server is submitted by the HTTP client. Its cache is reviewed by the proxy server. The proxy server sends the request to the corresponding server if the response is not stored in the cache. For future requests from other clients, incoming responses are sent to the proxy server and processed.
The proxy server reduces the load, reduces traffic and increases latency on the original server. However, the client must be configured to access the proxy instead of the target server in order to use the proxy server.
Electronic Mail is one of the most popular Internet services (e-mail). The success of this application software was possibly never conceived by the programmers of the Internet.
The messages sent by electronic mail were short at the beginning of the Internet era and consisted only of text; they let people exchange fast memos. Electronic mail is much more complicated today. It enables text, audio, and video to be included in a post. It also facilitates the sending of one message to one or more recipients.
The general e-mail system architecture comprises three main components: the user agent, the message transfer agent, and the message access agent.
Architecture
We propose four scenarios to illustrate the architecture of e-mail.
First scenario :
In the first case, users (or application programmes) on the same device are the sender and the e-mail recipient; they are directly connected to a common system. For every user where the received messages are kept, the administrator has generated one mailbox. A mailbox, a special file with authorization limits, is part of a local hard drive.
Only the mailbox owner has access to it. Alice runs a user agent (VA) programme to prepare the message and store it in Bob's mailbox when Alice, a user, needs to send a message to Bob, another user. The message has the mail-box addresses of the sender and receiver (names of files).
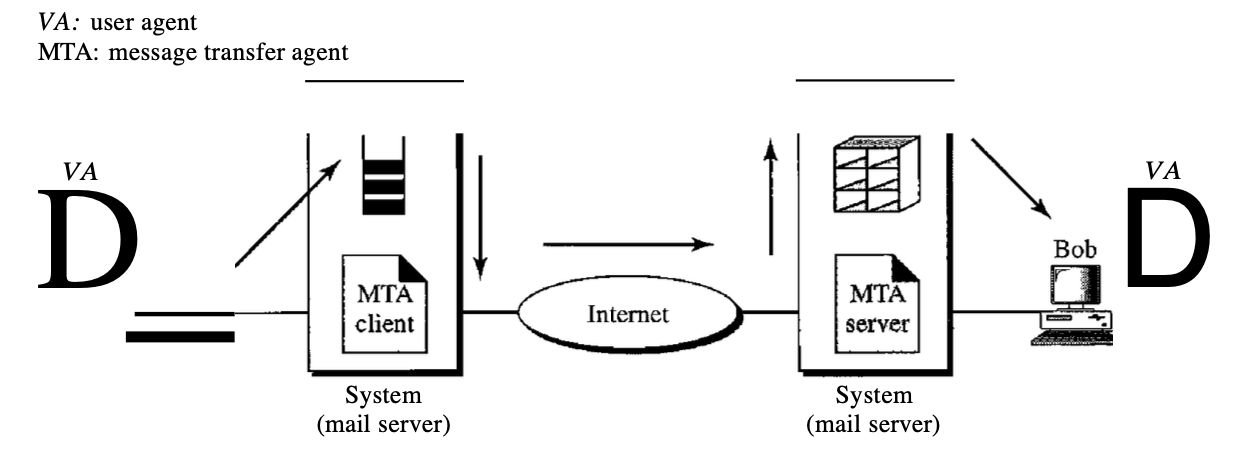
Fig 10: first scenario in electronic mail
At his convenience, using a user agent, Bob can retrieve and read the contents of his mailbox.
The authors the memo and inserts it in Bob's mailbox when Alice wants to send a memo to Bob. He notices Alice's memo when Bob opens his inbox, and reads it.
Second scenario :
In the second scenario, users (or application programmes) on two separate systems are the sender and the recipient of the e-mail. The message has to be transmitted over the Internet. We need user agents (VAs) and agents for message transfer here (MTAs).
To deliver her message to the device at her own place, Alice needs to use a user agent programme. The framework at her site (sometimes referred to as the mail server) uses a queue to store messages waiting to be sent. In order to retrieve messages saved in the system's mailbox at his location, Bob also requires a user agent application. The post, however, needs to be sent from Alice's site to Bob's site through the Internet.
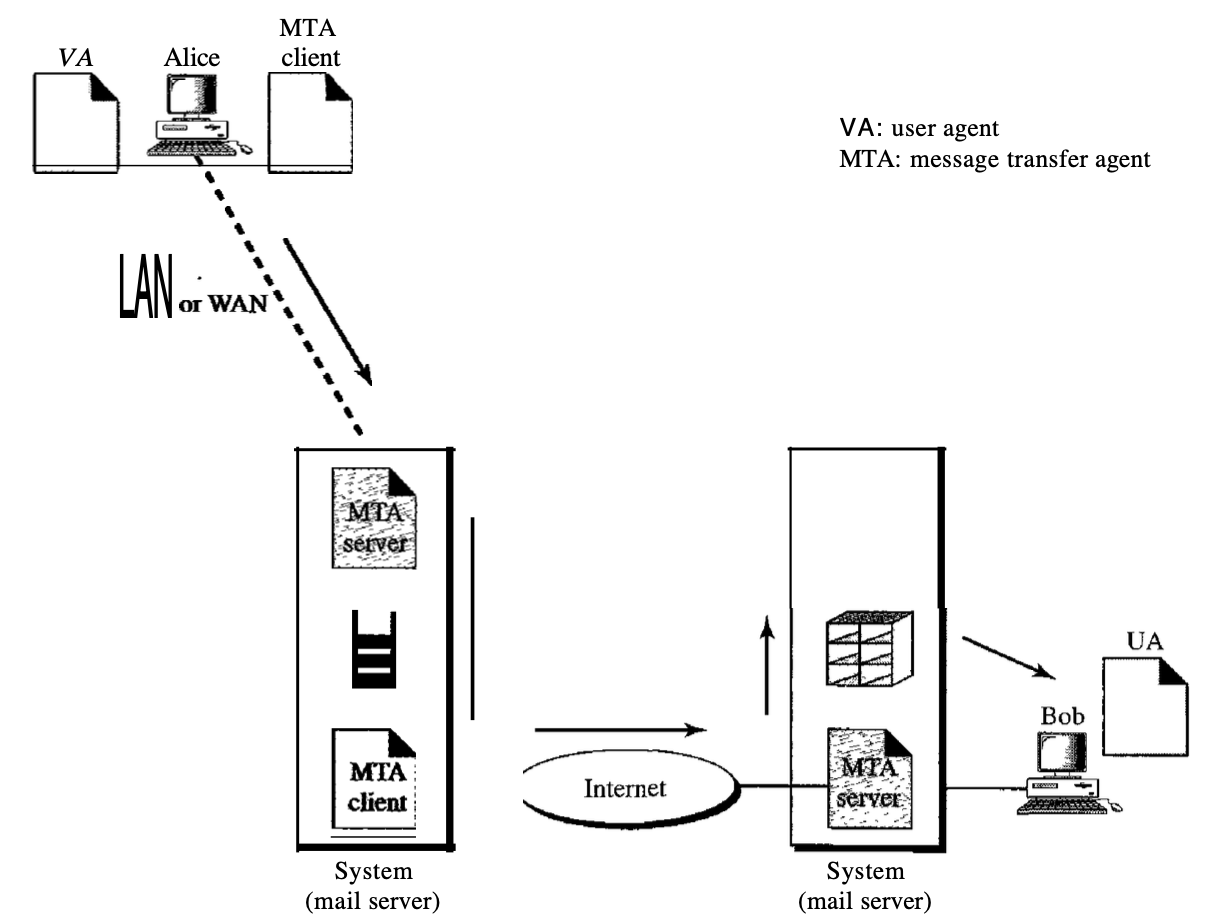
Fig 11: second scenario
Third scenario :
Bob, as in the second scenario, is directly linked to his system in the third scenario. However, Alice is isolated from her system. Either Alice is connected to the device through a point-to-point WAN, such as a dial-up modem, a DSL, or a cable modem; or, in a company that uses a single mail server to handle e-mails, it is connected to a LAN; all users have to send their messages to that mail server.
To prepare their post, Alice still needs a user agent. Then via the LAN or WAN, she needs to send the message. A pair of message transfer agents will do this (client and server). She calls the user agent if Alice has a message to send, which, in turn, calls the MTA client. The MTA client creates a connection that is running all the time with the MTA server on the device.
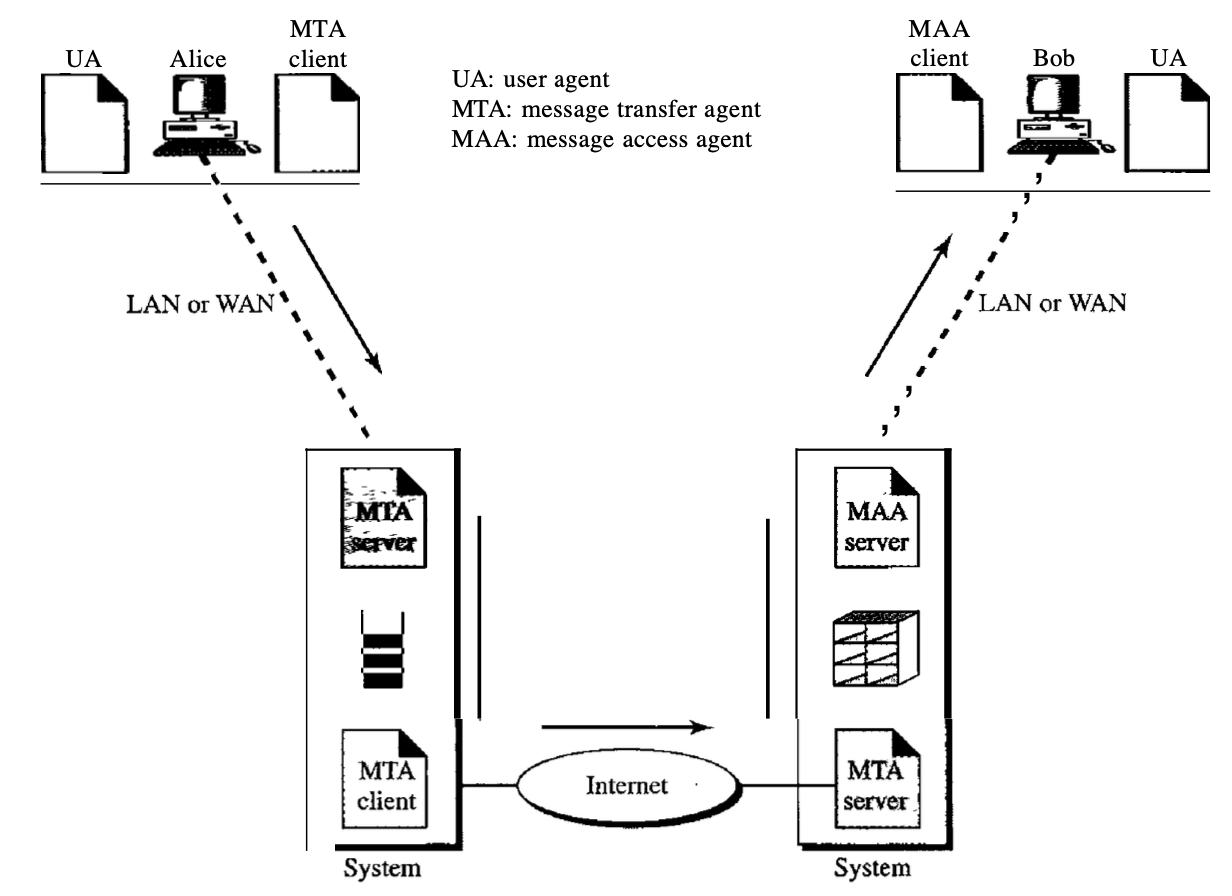
Fig 12: third scenario
Fourth scenario :
Bob is also linked to his mail server by a WAN or a LAN in the fourth and most popular scenario. Bob has to retrieve it after the message has hit Bob's mail server. We need another set of client/server agents here, which we call agents for message access (MAAs). To retrieve his messages, Bob uses an MAA client. The client sends a request to the MAA server, which is running all the time, and asks for messages to be transferred.
Here, there are two major points. Second, it's not possible for Bob to bypass the mail server and directly use the MTA server. Bob will need to run the MTA server all the time to use the MTA server directly, so he doesn't know when a message is coming. This means that if he is linked to his machine via a LAN, Bob must keep his computer on all the time. He must keep the link up all the time if he is linked via a-WAN. Today, none of these situations is feasible.
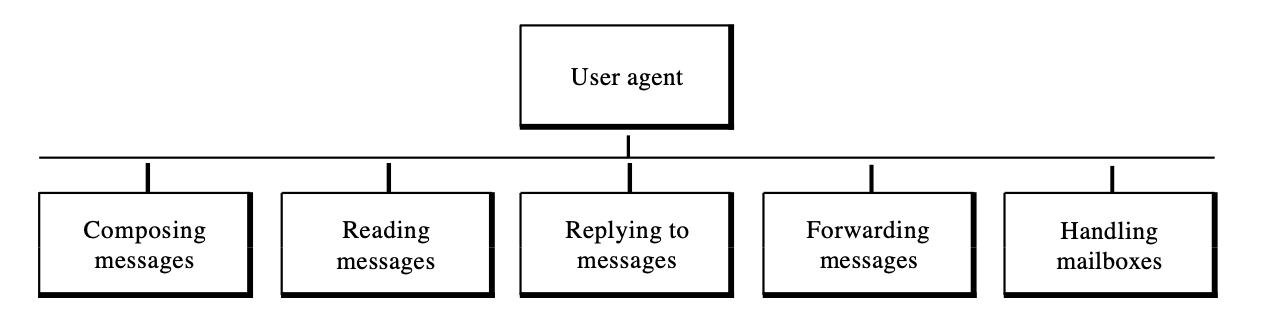
Fig 13: fourth scenario
Key takeaway :
● We need only two user agents when the sender and the recipient of an e-mail are on the same device, in the 1st scenario.
● We require two VAs and a pair of MTAs when the sender and recipient of an e-mail are on separate systems (client and server), in the second scenario.
● We need two VAs and two pairs of MTAs when the sender is linked via a LAN or a WAN to the mail server (clIent and server), in third scenario.
The user agent is the first part of an electronic mail system (VA). This provides the customer with a service to simplify the process of sending and receiving a message.

Fig 15: user agent services
Services provided by user agent
A software package (programme) that composes, reads, listens to, and for- wards messages is a user agent. It manages mailboxes as well.
● Composing messages :
A user agent supports the user in writing the e-mail message to be sent. A template on the screen to be filled in by the user is given by most user agents. Some even have a built-in editor that from a sophisticated word processor can do spell checking, grammar checking, and other tasks planned. Of course, a user can natively use his or her preferred text editor or word processor to build and import the message into the user agent template, or cut and paste it.
● Reading messages :
The second task of the user agent is to read the mes-sages that come in. It first checks the mail in the incoming mailbox when a user invokes a user agent. A one-line description of any mail received is shown by most user agents. The following fields are found in each e-mail.
1. Field, Anumberfield.
2. A flag field that displays the mail status, such as new, read but not replied to, or read and responded to.
3. The message size.
4. Of the sender.
5. Optional field for the subject.
● Replying to messages :
A user can use the user agent to respond to a message after reading a message. Typically, a user agent allows the user to respond to the original sender or to reply to all the message recipients. The original message (for fast reference) and the new message may be included in the reply message.
● Forwarding message :
Replying is defined as submitting a message to the copy sender or receiver. Forwarding is defined as sending the message to a third party. A user agent enables the recipient to forward the message to a third party, with or without additional comments.
● Handling mailboxes :
Two mailboxes are usually generated by a user agent: an inbox and an outbox. Every box is a special format file that can be managed by the user agent. The inbox holds all the e-mails received until the user deletes them. The outbox keeps all the e-mails sent until they are removed by the user. Most user agents are also able to create personalised mailboxes.
Types of user agents
Two kinds of user agents exist: command-driven and GUI-based.
● Command - driven
The command-driven user agents belong to electronic mail's early days. They're still present on servers as the underlying user agents. In order to perform its mission, a command-driven user agent usually accepts a one-character command from the keyboard.
Mail, Pine, and Elm are some examples of command-driven user agents.
● GUI - based
User agents on modems are GUI-based. They provide components of graphical-user interfaces (GUI) that allow the user to use both the keyboard and the mouse to interact with the applications. They have graphical components that make the services easy to navigate, including icons, menu bars, and windows. Eudora, Microsoft's Outlook, and Netscape are some examples of GUI oriented user agents.
Eudora, Outlook, and Netscape are several examples of GUI-based user agents.
Key takeaway :
● The user agent is the first part of an electronic mail system (VA).
● A software package (programme) that composes, reads, listens to, and for- wards messages is a user agent.
● A user agent supports the user in writing the e-mail message to be sent.
A mail handling system must use an addressing system of unique addresses to send mail. The address consists of two components on the internet: a local component and a domain name, separated by a @ sign.

Fig 16: e-mail address
Local part
The local component specifies the name of a special file, called the user mailbox, in which the message access agent stores all the mail that a user receives for retrieval.
Domain name
The domain name is the second part of the address. Usually, an entity chooses one or more hosts to receive and distribute e-mails ; hosts are often referred to as mail servers or exchangers. Each mail exchanger's assigned domain name either comes from the DNS database or is a logical name (for example, the name of the organization).
Key takeaway :
● The address consists of two components on the internet: a local component and a domain name, separated by a @ sign.
● The local component specifies the name of a special file, called the user mailbox.
● The domain name is the second part of the address.
An electronic communication device capable of identifying and responding to delays in e-mail delivery. Through using other methods to transmit the information intended for distribution by e-mail, the device may adjust to delays. The mechanism can convey the information to the recipient once the recipient's e-mail system receives the delayed electronic mail message.
In this respect, when the receiver intends to be away from his or her e-mail system, the recipient will make arrangements to receive information in the e-mail message. In addition, or alternatively, when the recipient receives an indication of a delayed electronic mail message, the recipient can opt to initiate out-of-band contact with the sender.
Via message transfer agents, the actual mail transfer is completed. A system has to have a client MTA to send mail, and a system must have a server MTA to receive mail. The formal protocol specifying the Internet MTA client and server is known as the Simple Mail Transfer Protocol (SMTP). In the most common case, as stated before, two pairs of MTA client/server programmes are used (fourth scenario).
SMTP clearly determines how you must send commands and answers back and forth. For deployment, each network is free to select a software package.
In order to transfer messages between an MTA client and an MTA server, SMTP uses commands and responses.

Fig 17: commands and response
A two-character (carriage return and line feed) end-of-line token terminates each command or reply.
● Commands : Commands are sent to the server from the client. It consists of a keyword accompanied by arguments of zero or more. SMTP describes fourteen commands. The first five are compulsory; these five commands must be supported by any implementation. The next three are used and highly recommended regularly. Rarely are the last six included.
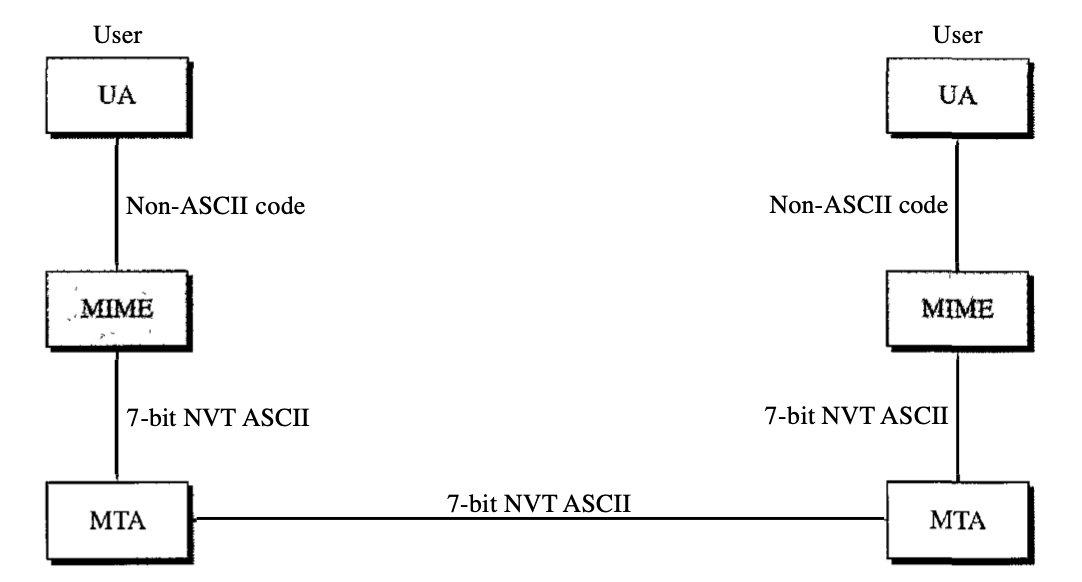
Fig 18: commands formats
Listed the commands below :
Keyword | Arguments |
HELO | Sender’s host name |
MAIL FROM | Sender of the message |
DATA | Body of the mail |
RSET |
|
VRFY | Name of the recipient to be verified |
TURN |
|
HELP | Command name |
SEND FROM | Intended recipients of the message |
● Response : Responses are sent to the client from the server. A reply is a three one - Digit code that may be accompanied by additional textual details.
Code | Description |
Positive Completion Reply | |
211 | System status or help reply |
214 | Help message |
220 | Service ready |
221 | Service closing transmission channel |
250 | Request command completed |
251 | User not local; message will be forwarded |
Positive Intermediate Reply | |
354 | Start mail input |
Transient Negative Completion Reply | |
421 | Service not available |
450 | Mailbox not available |
451 | Command aborted: local error |
452 | Command aborted: insufficient storage |
Key takeaway :
● The formal protocol specifying the Internet MTA client and server is known as the Simple Mail Transfer Protocol (SMTP).
● In order to transfer messages between an MTA client and an MTA server, SMTP uses commands and responses.
● two pairs of MTA client/server programmes are used.
– In three steps, the process of moving a mail message takes place:
● SMTP mail transfer connection establishment,
● Perform the transfer of mail,
● SMTP of mail transfer connection termination.
– To send mail, the user generates mail through the user agent (UA) that Postal mail looks quite similar.
Three steps :
When you have one or more email messages to deliver to that server, an SMTP sender may attempt to set up a TCP link with the target host. During link setup, the following sequence happens:
● The sender opens the receiver's TCP connection.
● The receiver identifies itself as '220 Service Ready' once the connection is formed.
● With the HELO signal, the sender identifies itself.
● "The recipient acknowledges the identification of the sender with "250 'Fine".
● If the destination mail service is not available, the destination host returns a reply in Phase 2 to "421 Service Not Available" and the procedure is terminated.
2. Mail transfer
● The SMTP sender can send one or more messages to the SMTP receiver once the link has been formed.
● The transfer of a message requires three conceptual stages:
2. The recipients of this message are marked by one or more RCPT commands.
3. A DATA command transfers the text of the message.
3. Connection termination
In the following manner, the SMTP sender closes the connection:
2. The sender begins the TCP closing operation for a TCP link.
3. After sending a reply to the QUIT command, the receiver initiates its TCP closure.
Key takeaway :
● The SMTP sender can send one or more messages to the SMTP receiver once the link has been formed.
● When you have one or more email messages to deliver to that server, an SMTP sender may attempt to set up a TCP link.
Electronic mail has a structure that is basic. However, its simplicity comes at a price. Only the NVT 7-bit ASCII format will send messages. It has, in other words, certain restrictions. It cannot, for example, be used in languages that do not support 7-bit ASCII characters (such as French, German, Hebrew, Russian, Chinese, and Japanese). Also, it can not be used to send video or audio data or binary files.
Multipurpose Internet Mail Extensions (MIME) is a supplementary protocol that enables e-mail sending of non-ASCII data. MIME converts non-ASCII data to NVT ASCII data on the sender site and delivers it to the MTA client to be transmitted over the Internet. The receiving side of the message is translated back to the original results.
We can see MIME as a collection of software features that convert non-ASCII data (bit stream) to ASCII data and vice versa.

Fig 19: MIME
In order to specify transformation parameters, MIME specifies five headers that can be applied to the original e-mail header section:
MIME-version 1.1
2. Content - type : The type of data used in the message's body is specified by this header. A slash distinguishes the content type and the content subtype. The header can contain other parameters, depending on the subtype.
content - Type :<type/subtype; parameter>
3. Content - Transfer - Encoding : The methods used to encode messages in Os and Is for transport are specified by this header:
Content -Transfer-Encoding<type>
There are 5 types of content encoding methods :
Type | Description |
7 - bit | NVT ASCII characters and short lines |
8 - bit | Non - ASCII characters and short lines |
Binary | Non - ASCII characters with unlimited-length lines |
Base - 64 | 6-bit blocks of data encoded into 8-bit ASCII character |
Quoted-printable | Non - ASCII characters encoded as an equals sign followed by an ASCII code |
4. Content - Id : In a multiple-message setting, this header identifies the entire message uniquely.
Content-Id: Id =<content-id>
5. Content - Description : Whether the body is an image, audio, or video is specified in this header.
Content-Description : <description>
Key takeaway :
● Multipurpose Internet Mail Extensions (MIME) is a supplementary protocol that enables e-mail sending of non-ASCII data.
● MIME converts non-ASCII data to NVT ASCII data on the sender site and delivers it to the MTA client to be transmitted over the Internet.
Post Office Protocol, version 3 (POP3) is simple and feature-limited. The POP3 client software is installed on the receiving machine; the POP3 server software is installed on the mail server.
If the user wants to download e-mails from the mailbox on the mail server, mail access begins with the client. On TCP port 110, the client opens a connection to the server. In order to reach the mailbox, it then sends the user name and password. The user will then, one by one, list and retrieve the mail messages.
There are two modes for POP3: the delete mode and the hold mode. In the delete mode, after each retrieval, the mail is removed from the mailbox. In keep mode, after retrieval, the mail stays in the mailbox. When the user is operating on their permanent device, the delete mode is usually used and after reading or replying, the received mail can be saved and sorted. Normally, the keep mode is used when the user accesses her mail away from her main computer (e.g., a laptop). For later retrieval and organisation, the mail is read but kept in the system.
In some aspects, POP3 is deficient. It does not allow the user to arrange his mail on the server; it is impossible for the user to have multiple folders on the server. (The user will build directories on their own computer, of course.)

Fig 20: command and response of POP3
Advantages of POP3
● As they are already saved on our PC, it provides easy and simple access to the emails.
● The size of the email that we receive or send has no limit.
● When all emails are saved on the local computer, it takes less server storage space.
● The maximum size of a mailbox is available, but the size of the hard disc is limited.
● It is a straightforward protocol, so it is one of the most common protocols used today.
● Configuring and using it is simple.
Disadvantages of POP3
● By default, if the emails are downloaded from the server, all the emails are deleted from the server. Mails will also not be accessed from other computers unless they are programmed to leave a mail copy on the server.
● It can be tough to move the mail folder from the local computer to another machine.
● As all of the attachments are placed on your local computer, if the virus scanner does not scan them, there is a high chance of a virus attack. Virus attacks can destroy your machine.
● There could also be corruption in the email folder that is downloaded from the mail server.
● Mails are saved on a local server, so the email folder can be accessed by someone who is sitting on your machine.
Key takeaway :
● Post Office Protocol, version 3 is simple and feature-limited.
● The POP3 client software is installed on the receiving machine; the POP3 server software is installed on the mail server.
● In order to reach the mailbox, it then sends the user name and password.
References:
2. Internetworking with TCP/IP by Douglas Comer
3. Computer Networking: A Top-Down Approach by Jim Kurose




