UNIT 2
Processes, Threads and Synchronization
A program is an executable file which contains a certain set of instructions written to complete the specific job on your computer. For example, Google browser chrome.exe is an executable file which stores a set of instructions written in it which allow you to view web pages.
Programs are never stored on the primary memory in your computer. Instead, they are stored on a disk or secondary memory on your PC or laptop. They are read from the primary memory and executed by the kernel.
A process is an execution of any specific program. It is considered an active entity that actions the purpose of the application. Multiple processes may be related to the same program.
For example, If you are double click on your Google Chrome browser icon on your PC or laptop, you start a process which will run the Google Chrome program. When you open another instance of Chrome, you are essentially creating a two process.
|
Fig 1 - Program
- Process is an executing part of a program whereas a program is a group of ordered operations to achieve a programming goal.
- The process has a shorter and minimal lifespan whereas program has a longer lifespan.
- Process contains many resources like a memory address, disk, printer while Program needs memory space on the disk to store all instructions.
- Process is a dynamic or active entity whereas Program is a passive or static entity.
- Process has considerable overhead whereas Program has no significant overhead cost.
- A program is a passive entity. It stores a group of instructions to be executed.
- Various processes may be related to the same program.
- A user may run multiple programs where the operating systems simplify its internal programmed activities like memory management.
- The program can't perform any action without a run. It needs to be executed to realize the steps mentioned in it.
- The operating system allocates main memory to store programs instructions.
- A process has a very limited lifespan
- They also generate one or more child processes, and they die like a human being.
- Like humans, even process has information like who is a parent when it is created, address space of allocated memory, security properties which includes ownership credentials and privileges.
- Processes are allocated system resources like file descriptors and network ports.
Some significant difference between program and process are given below:
Parameter | Process | Program |
Definition | An executing part of a program is called a process. | A program is a group of ordered operations to achieve a programming goal. |
Nature | The process is an instance of the program being executing. | The nature of the program is passive, so it's unlikely to do to anything until it gets executed. |
Resource management | The resource requirement is quite high in case of a process. | The program only needs memory for storage. |
Overheads | Processes have considerable overhead. | No significant overhead cost. |
Lifespan | The process has a shorter and very limited lifespan as it gets terminated after the completion of the task. | A program has a longer lifespan as it is stored in the memory until it is not manually deleted. |
Creation | New processes require duplication of the parent process. | No such duplication is needed. |
Required Process | Process holds resources like CPU, memory address, disk, I/O, etc. | The program is stored on disk in some file and does not require any other resources. |
Entity type | A process is a dynamic or active entity. | A program is a passive or static entity. |
Contain | A process contains many resources like a memory address, disk, printer, etc. | A program needs memory space on disk to store all instructions. |
Key takeaway
A program is an executable file which contains a certain set of instructions written to complete the specific job on your computer. For example, Google browser chrome.exe is an executable file which stores a set of instructions written in it which allow you to view web pages.
Programs are never stored on the primary memory in your computer. Instead, they are stored on a disk or secondary memory on your PC or laptop. They are read from the primary memory and executed by the kernel.
A process is an execution of any specific program. It is considered an active entity that actions the purpose of the application. Multiple processes may be related to the same program.
A process is basically a program in execution. The execution of a process must progress in a sequential fashion.
A process is defined as an entity which represents the basic unit of work to be implemented in the system.
To put it in simple terms, we write our computer programs in a text file and when we execute this program, it becomes a process which performs all the tasks mentioned in the program.
When a program is loaded into the memory and it becomes a process, it can be divided into four sections ─ stack, heap, text and data. The following image shows a simplified layout of a process inside main memory −
|
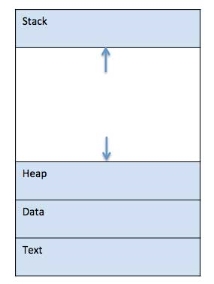
Fig 2 – Process inside main memory
S.N. | Component & Description |
1 | Stack The process Stack contains the temporary data such as method/function parameters, return address and local variables. |
2 | Heap This is dynamically allocated memory to a process during its run time. |
3 | Text This includes the current activity represented by the value of Program Counter and the contents of the processor's registers.
|
4 | Data This section contains the global and static variables. |
A program is a piece of code which may be a single line or millions of lines. A computer program is usually written by a computer programmer in a programming language. For example, here is a simple program written in C programming language −
#include <stdio.h>
int main() {
printf("Hello, World! \n");
return 0;
}
A computer program is a collection of instructions that performs a specific task when executed by a computer. When we compare a program with a process, we can conclude that a process is a dynamic instance of a computer program.
A part of a computer program that performs a well-defined task is known as an algorithm. A collection of computer programs, libraries and related data are referred to as a software.
When a process executes, it passes through different states. These stages may differ in different operating systems, and the names of these states are also not standardized.
In general, a process can have one of the following five states at a time.
S.N. | State & Description | |
1 | Start This is the initial state when a process is first started/created. | |
2 | Ready The process is waiting to be assigned to a processor. Ready processes are waiting to have the processor allocated to them by the operating system so that they can run. Process may come into this state after Start state or while running it by but interrupted by the scheduler to assign CPU to some other process. | |
3 | Running Once the process has been assigned to a processor by the OS scheduler, the process state is set to running and the processor executes its instructions. | |
4 | Waiting Process moves into the waiting state if it needs to wait for a resource, such as waiting for user input, or waiting for a file to become available. | |
5 | Terminated or Exit Once the process finishes its execution, or it is terminated by the operating system, it is moved to the terminated state where it waits to be removed from main memory.
|
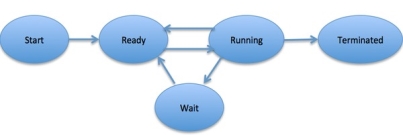
Fig 3 – Process state
A Process Control Block is a data structure maintained by the Operating System for every process. The PCB is identified by an integer process ID (PID). A PCB keeps all the information needed to keep track of a process as listed below in the table −
S.N. | Information & Description |
1 | Process State The current state of the process i.e., whether it is ready, running, waiting, or whatever. |
2 | Process privileges This is required to allow/disallow access to system resources. |
3 | Process ID Unique identification for each of the process in the operating system. |
4 | Pointer A pointer to parent process. |
5 | Program Counter Program Counter is a pointer to the address of the next instruction to be executed for this process. |
6 | CPU registers Various CPU registers where process need to be stored for execution for running state. |
7 | CPU Scheduling Information Process priority and other scheduling information which is required to schedule the process. |
8 | Memory management information This includes the information of page table, memory limits, Segment table depending on memory used by the operating system. |
9 | Accounting information This includes the amount of CPU used for process execution, time limits, execution ID etc. |
10 | IO status information This includes a list of I/O devices allocated to the process. |
The architecture of a PCB is completely dependent on Operating System and may contain different information in different operating systems. Here is a simplified diagram of a PCB –
|

Fig 4 - PCB
The PCB is maintained for a process throughout its lifetime, and is deleted once the process terminates.
Key takeaway
A process is basically a program in execution. The execution of a process must progress in a sequential fashion.
A process is defined as an entity which represents the basic unit of work to be implemented in the system.
To put it in simple terms, we write our computer programs in a text file and when we execute this program, it becomes a process which performs all the tasks mentioned in the program.
There is a way of thread execution inside the process of any operating system. Apart from this, there can be more than one thread inside a process. Thread is often referred to as a lightweight process.
The process can be split down into so many threads. For example, in a browser, many tabs can be viewed as threads. MS Word uses many threads - formatting text from one thread, processing input from another thread, etc.
In the operating system, there are two types of threads.
- Kernel level thread.
- User-level thread.
The operating system does not recognize the user-level thread. User threads can be easily implemented and it is implemented by the user. If a user performs a user-level thread blocking operation, the whole process is blocked. The kernel level thread does not know nothing about the user level thread. The kernel-level thread manages user-level threads as if they are single-threaded processes? Examples: Java thread, POSIX threads, etc.
Advantages of User-level threads
- The user threads can be easily implemented than the kernel thread.
- User-level threads can be applied to such types of operating systems that do not support threads at the kernel-level.
- It is faster and efficient.
- Context switch time is shorter than the kernel-level threads.
- It does not require modifications of the operating system.
- User-level threads representation is very simple. The register, PC, stack, and mini thread control blocks are stored in the address space of the user-level process.
- It is simple to create, switch, and synchronize threads without the intervention of the process.
Disadvantages of User-level threads
- User-level threads lack coordination between the thread and the kernel.
- If a thread causes a page fault, the entire process is blocked.
The kernel thread recognizes the operating system. There are a thread control block and process control block in the system for each thread and process in the kernel-level thread. The kernel-level thread is implemented by the operating system. The kernel knows about all the threads and manages them. The kernel-level thread offers a system call to create and manage the threads from user-space. The implementation of kernel threads is difficult than the user thread. Context switch time is longer in the kernel thread. If a kernel thread performs a blocking operation, the Banky thread execution can continue. Example: Window Solaris.
Advantages of Kernel-level threads
- The kernel-level thread is fully aware of all threads.
- The scheduler may decide to spend more CPU time in the process of threads being large numerical.
- The kernel-level thread is good for those applications that block the frequency.
Disadvantages of Kernel-level threads
- The kernel thread manages and schedules all threads.
- The implementation of kernel threads is difficult than the user thread.
- The kernel-level thread is slower than user-level threads.
Any thread has the following components.
- Program counter
- Register set
- Stack space
- Enhanced throughput of the system: When the process is split into many threads, and each thread is treated as a job, the number of jobs done in the unit time increases. That is why the throughput of the system also increases.
- Effective Utilization of Multiprocessor system: When you have more than one thread in one process, you can schedule more than one thread in more than one processor.
- Faster context switch: The context switching period between threads is less than the process context switching. The process context switch means more overhead for the CPU.
- Responsiveness: When the process is split into several threads, and when a thread completes its execution, that process can be responded to as soon as possible.
- Communication: Multiple-thread communication is simple because the threads share the same address space, while in process, we adopt just a few exclusive communication strategies for communication between two processes.
- Resource sharing: Resources can be shared between all threads within a process, such as code, data, and files. Note: The stack and register cannot be shared between threads. There are a stack and register for each thread.
Key takeaway
There is a way of thread execution inside the process of any operating system. Apart from this, there can be more than one thread inside a process. Thread is often referred to as a lightweight process.
The process can be split down into so many threads. For example, in a browser, many tabs can be viewed as threads. MS Word uses many threads - formatting text from one thread, processing input from another thread, etc.
What is Process Synchronization?
Process Synchronization is the task of coordinating the execution of processes in a way that no two processes can have access to the same shared data and resources.
It is specially needed in a multi-process system when multiple processes are running together, and more than one processes try to gain access to the same shared resource or data at the same time.
This can lead to the inconsistency of shared data. So the change made by one process not necessarily reflected when other processes accessed the same shared data. To avoid this type of inconsistency of data, the processes need to be synchronized with each other.
How Process Synchronization Works?
For Example, process A changing the data in a memory location while another process B is trying to read the data from the same memory location. There is a high probability that data read by the second process will be erroneous.
|
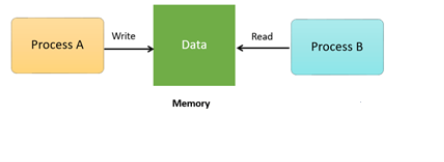
Fig 5 – Memory
Here, are four essential elements of the critical section:
- Entry Section: It is part of the process which decides the entry of a particular process.
- Critical Section: This part allows one process to enter and modify the shared variable.
- Exit Section: Exit section allows the other process that are waiting in the Entry Section, to enter into the Critical Sections. It also checks that a process that finished its execution should be removed through this Section.
- Remainder Section: All other parts of the Code, which is not in Critical, Entry, and Exit Section, are known as the Remainder Section.
Key takeaway
Process Synchronization is the task of coordinating the execution of processes in a way that no two processes can have access to the same shared data and resources.
It is specially needed in a multi-process system when multiple processes are running together, and more than one processes try to gain access to the same shared resource or data at the same time.
This can lead to the inconsistency of shared data. So the change made by one process not necessarily reflected when other processes accessed the same shared data. To avoid this type of inconsistency of data, the processes need to be synchronized with each other.
Race conditions, Critical Sections and Semaphores are a key part of Operating systems. Details about these are given as follows −
A race condition is a situation that may occur inside a critical section. This happens when the result of multiple thread execution in critical section differs according to the order in which the threads execute.
Race conditions in critical sections can be avoided if the critical section is treated as an atomic instruction. Also, proper thread synchronization using locks or atomic variables can prevent race conditions.
The critical section in a code segment where the shared variables can be accessed. Atomic action is required in a critical section i.e. only one process can execute in its critical section at a time. All the other processes have to wait to execute in their critical sections.
The critical section is given as follows:
do {
Entry Section
Critical Section
Exit Section
Remainder Section
} while (TRUE);
In the above diagram, the entry sections handle the entry into the critical section. It acquires the resources needed for execution by the process. The exit section handles the exit from the critical section. It releases the resources and also informs the other processes that critical section is free.
The critical section problem needs a solution to synchronise the different processes. The solution to the critical section problem must satisfy the following conditions −
- Mutual Exclusion
Mutual exclusion implies that only one process can be inside the critical section at any time. If any other processes require the critical section, they must wait until it is free.
- Progress
Progress means that if a process is not using the critical section, then it should not stop any other process from accessing it. In other words, any process can enter a critical section if it is free.
- Bounded Waitings
Bounded waiting means that each process must have a limited waiting time. It should not wait endlessly to access the critical section.
A semaphore is a signalling mechanism and a thread that is waiting on a semaphore can be signalled by another thread. This is different than a mutex as the mutex can be signalled only by the thread that called the wait function.
A semaphore uses two atomic operations, wait and signal for process synchronization.
The wait operation decrements the value of its argument S, if it is positive. If S is negative or zero, then no operation is performed.
wait(S){
while (S<=0);
S--;
}
The signal operation increments the value of its argument S.
signal(S){
S++;
}
Key takeaway
A race condition is a situation that may occur inside a critical section. This happens when the result of multiple thread execution in critical section differs according to the order in which the threads execute.
The critical section in a code segment where the shared variables can be accessed. Atomic action is required in a critical section i.e. only one process can execute in its critical section at a time. All the other processes have to wait to execute in their critical sections.
A semaphore is a signalling mechanism and a thread that is waiting on a semaphore can be signalled by another thread. This is different than a mutex as the mutex can be signalled only by the thread that called the wait function.
THE DINING PHILOSOPHERS PROBLEM
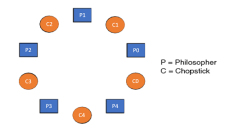
The dining philosopher's problem is the classical problem of synchronization which says that Five philosophers are sitting around a circular table and their job is to think and eat alternatively. A bowl of noodles is placed at the centre of the table along with five chopsticks for each of the philosophers. To eat a philosopher needs both their right and a left chopstick. A philosopher can only eat if both immediate left and right chopsticks of the philosopher is available. In case if both immediate left and right chopsticks of the philosopher are not available then the philosopher puts down their (either left or right) chopstick and starts thinking again.
The dining philosopher demonstrates a large class of concurrency control problems hence it's a classic synchronization problem.
|

Fig 6 - Five Philosophers sitting around the table
Dining Philosophers Problem- Let's understand the Dining Philosophers Problem with the below code, we have used fig 1 as a reference to make you understand the problem exactly. The five Philosophers are represented as P0, P1, P2, P3, and P4 and five chopsticks by C0, C1, C2, C3, and C4.
|
- Void Philosopher
- {
- while(1)
- {
- take_chopstick[i];
- take_chopstick[ (i+1) % 5] ;
- . .
- . EATING THE NOODLE
- .
- put_chopstick[i] );
- put_chopstick[ (i+1) % 5] ;
- .
- . THINKING
- }
- }
Let's discuss the above code:
Suppose Philosopher P0 wants to eat, it will enter in Philosopher () function, and execute take chopstick[i]; by doing this it holds C0 chopstick after that it execute take chopstick [ (i+1) % 5]; by doing this it holds C1 chopstick (since i =0, therefore (0 + 1) % 5 = 1)
Similarly suppose now Philosopher P1 wants to eat, it will enter in Philosopher () function, and execute take chopstick[i]; by doing this it holds C1 chopstick after that it execute take chopstick [ (i+1) % 5]; by doing this it holds C2 chopstick (since i =1, therefore (1 + 1) % 5 = 2)
But Practically Chopstick C1 is not available as it has already been taken by philosopher P0, hence the above code generates problems and produces race condition.
The solution of the Dining Philosophers Problem
We use a semaphore to represent a chopstick and this truly acts as a solution of the Dining Philosophers Problem. Wait and Signal operations will be used for the solution of the Dining Philosophers Problem, for picking a chopstick wait operation can be executed while for releasing a chopstick signal semaphore can be executed.
Semaphore: A semaphore is an integer variable in S, that apart from initialization is accessed by only two standard atomic operations - wait and signal, whose definitions are as follows:
- 1. wait( S )
- {
- while( S <= 0) ;
- S--;
- }
- 2. signal( S )
- {
- S++;
- }
From the above definitions of wait, it is clear that if the value of S <= 0 then it will enter into an infinite loop (because of the semicolon; after while loop). Whereas the job of the signal is to increment the value of S.
The structure of the chopstick is an array of a semaphore which is represented as shown below -
- semaphore C[5];
Initially, each element of the semaphore C0, C1, C2, C3, and C4 are initialized to 1 as the chopsticks are on the table and not picked up by any of the philosophers.
Let's modify the above code of the Dining Philosopher Problem by using semaphore operations wait and signal, the desired code looks like
- void Philosopher
- {
- while(1)
- {
- Wait( take_chopstickC[i] );
- Wait( take_chopstickC[(i+1) % 5] ) ;
- . .
- . EATING THE NOODLE
- .
- Signal( put_chopstickC[i] );
- Signal( put_chopstickC[ (i+1) % 5] ) ;
- .
- . THINKING
- }
- }
In the above code, first wait operation is performed on take_chopstickC[i] and take_chopstickC [ (i+1) % 5]. This shows philosopher i have picked up the chopsticks from its left and right. The eating function is performed after that.
On completion of eating by philosopher i the, signal operation is performed on take_chopstickC[i] and take_chopstickC [ (i+1) % 5]. This shows that the philosopher i have eaten and put down both the left and right chopsticks. Finally, the philosopher starts thinking again.
Let's understand how the above code is giving a solution to the dining philosopher problem?
Let value of i = 0(initial value), Suppose Philosopher P0 wants to eat, it will enter in Philosopher () function, and execute Wait(take_chopstickC[i] ); by doing this it holds C0 chopstick and reduces semaphore C0 to 0, after that it execute Wait( take_chopstickC[(i+1) % 5] ); by doing this it holds C1 chopstick( since i =0, therefore (0 + 1) % 5 = 1) and reduces semaphore C1 to 0
Similarly, suppose now Philosopher P1 wants to eat, it will enter in Philosopher() function, and execute Wait( take_chopstickC[i] ); by doing this it will try to hold C1 chopstick but will not be able to do that, since the value of semaphore C1 has already been set to 0 by philosopher P0, therefore it will enter into an infinite loop because of which philosopher P1 will not be able to pick chopstick C1 whereas if Philosopher P2 wants to eat, it will enter in Philosopher() function, and execute Wait( take_chopstickC[i] ); by doing this it holds C2 chopstick and reduces semaphore C2 to 0, after that, it executes Wait( take_chopstickC[(i+1) % 5] ); by doing this it holds C3 chopstick( since i =2, therefore (2 + 1) % 5 = 3) and reduces semaphore C3 to 0.
Hence the above code is providing a solution to the dining philosopher problem, A philosopher can only eat if both immediate left and right chopsticks of the philosopher are available else philosopher needs to wait. Also at one go two independent philosophers can eat simultaneously (i.e., philosopher P0 and P2, P1 and P3 & P2 and P4 can eat simultaneously as all are the independent processes and they are following the above constraint of dining philosopher problem)
The drawback of the above solution of the dining philosopher problem
From the above solution of the dining philosopher problem, we have proved that no two neighbouring philosophers can eat at the same point in time. The drawback of the above solution is that this solution can lead to a deadlock condition. This situation happens if all the philosophers pick their left chopstick at the same time, which leads to the condition of deadlock and none of the philosophers can eat.
To avoid deadlock, some of the solutions are as follows -
- Maximum number of philosophers on the table should not be more than four, in this case, chopstick C4 will be available for philosopher P3, so P3 will start eating and after the finish of his eating procedure, he will put down his both the chopstick C3 and C4, i.e. semaphore C3 and C4 will now be incremented to 1. Now philosopher P2 which was holding chopstick C2 will also have chopstick C3 available, hence similarly, he will put down his chopstick after eating and enable other philosophers to eat.
- A philosopher at an even position should pick the right chopstick and then the left chopstick while a philosopher at an odd position should pick the left chopstick and then the right chopstick.
- Only in case if both the chopsticks (left and right) are available at the same time, only then a philosopher should be allowed to pick their chopsticks
- All the four starting philosophers (P0, P1, P2, and P3) should pick the left chopstick and then the right chopstick, whereas the last philosopher P4 should pick the right chopstick and then the left chopstick. This will force P4 to hold his right chopstick first since the right chopstick of P4 is C0, which is already held by philosopher P0 and its value is set to 0, i.e C0 is already 0, because of which P4 will get trapped into an infinite loop and chopstick C4 remains vacant. Hence philosopher P3 has both left C3 and right C4 chopstick available, therefore it will start eating and will put down its both chopsticks once finishes and let others eat which removes the problem of deadlock.
The design of the problem was to illustrate the challenges of avoiding deadlock; a deadlock state of a system is a state in which no progress of system is possible. Consider a proposal where each philosopher is instructed to behave as follows:
- The philosopher is instructed to think till the left fork is available, when it is available, hold it.
- The philosopher is instructed to think till the right fork is available, when it is available, hold it.
- The philosopher is instructed to eat when both forks are available.
- then, put the right fork down first
- then, put the left fork down next
- repeat from the beginning.
The readers-writer’s problem is a classical problem of process synchronization; it relates to a data set such as a file that is shared between more than one process at a time. Among these various processes, some are Readers - which can only read the data set; they do not perform any updates, some are Writers - can both read and write in the data sets.
The readers-writer’s problem is used for managing synchronization among various reader and writer process so that there are no problems with the data sets, i.e. no inconsistency is generated.
Let's understand with an example - If two or more than two readers want to access the file at the same point in time there will be no problem. However, in other situations like when two writers or one reader and one writer wants to access the file at the same point of time, there may occur some problems, hence the task is to design the code in such a manner that if one reader is reading then no writer is allowed to update at the same point of time, similarly, if one writer is writing no reader is allowed to read the file at that point of time and if one writer is updating a file other writers should not be allowed to update the file at the same point of time. However, multiple readers can access the object at the same time.
Let us understand the possibility of reading and writing with the table given below:
TABLE 1
Case | Process 1 | Process 2 | Allowed / Not Allowed |
Case 1 | Writing | Writing | Not Allowed |
Case 2 | Reading | Writing | Not Allowed |
Case 3 | Writing | Reading | Not Allowed |
Case 4 | Reading | Reading | Allowed |
The solution of readers and writers can be implemented using binary semaphores.
We use two binary semaphores "write" and "mutex", where binary semaphore can be defined as:
Semaphore: A semaphore is an integer variable in S, that apart from initialization is accessed by only two standard atomic operations - wait and signal, whose definitions are as follows:
- 1. wait( S )
- {
- while( S <= 0) ;
- S--;
- }
- 2. signal( S )
- {
- S++;
- }
From the above definitions of wait, it is clear that if the value of S <= 0 then it will enter into an infinite loop (because of the semicolon; after while loop). Whereas the job of the signal is to increment the value of S.
The below code will provide the solution of the reader-writer problem, reader and writer process codes are given as follows -
The code of the reader process is given below -
- static int readcount = 0;
- wait (mutex);
- readcount ++; // on each entry of reader increment readcount
- if (readcount == 1)
- {
- wait (write);
- }
- signal(mutex);
- --READ THE FILE?
- wait(mutex);
- readcount --; // on every exit of reader decrement readcount
- if (readcount == 0)
- {
- signal (write);
- }
- signal(mutex);
In the above code of reader, mutex and write are semaphores that have an initial value of 1, whereas the readcount variable has an initial value as 0. Both mutex and write are common in reader and writer process code, semaphore mutex ensures mutual exclusion and semaphore write handles the writing mechanism.
The readcount variable denotes the number of readers accessing the file concurrently. The moment variable readcount becomes 1, wait operation is used to write semaphore which decreases the value by one. This means that a writer is not allowed how to access the file anymore. On completion of the read operation, readcount is decremented by one. When readcount becomes 0, the signal operation which is used to write permits a writer to access the file.
The code that defines the writer process is given below:
- wait(write);
- WRITE INTO THE FILE
- signal(wrt);
If a writer wishes to access the file, wait operation is performed on write semaphore, which decrements write to 0 and no other writer can access the file. On completion of the writing job by the writer who was accessing the file, the signal operation is performed on write.
Let's see the proof of each case mentioned in Table 1
CASE 1: WRITING - WRITING → NOT ALLOWED. That is when two or more than two processes are willing to write, then it is not allowed. Let us see that our code is working accordingly or not?
- Explanation:
- The initial value of semaphore write = 1
- Suppose two processes P0 and P1 wants to write, let P0 enter first the writer code, The moment P0 enters
- Wait (write); will decrease semaphore write by one, now write = 0
- And continue WRITE INTO THE FILE
- Now suppose P1 wants to write at the same time (will it be allowed?) let's see.
- P1 does Wait (write), since the write value is already 0, therefore from the definition of wait, it will go into an infinite loop (i.e. Trap), hence P1 can never write anything, till P0 is writing.
- Now suppose P0 has finished the task, it will
- signal(write); will increase semaphore write by 1, now write = 1
- if now P1 wants to write it since semaphore write > 0
- This proofs that, if one process is writing, no other process is allowed to write.
CASE 2: READING - WRITING → NOT ALLOWED. That is when one or more than one process is reading the file, then writing by another process is not allowed. Let us see that our code is working accordingly or not?
- Explanation:
- Initial value of semaphore mutex = 1 and variable readcount = 0
- Suppose two processes P0 and P1 are in a system, P0 wants to read while P1 wants to write, P0 enter first into the reader code, the moment P0 enters
- Wait (mutex); will decrease semaphore mutex by 1, now mutex = 0
- Increment readcount by 1, now readcount = 1, next
- if (readcount == 1)// evaluates to TRUE
- {
- wait (write); // decrement write by 1, i.e. write = 0(which
- clearly proves that if one or more than one
- reader is reading then no writer will be
- allowed.
- }
- signal(mutex); // will increase semaphore mutex by 1, now mutex = 1 i.e. other reader are allowed to enter.
- And reader continues to --READ THE FILE?
- Suppose now any writer wants to enter into its code then:
- As the first reader has executed wait (write); because of which write value is 0, therefore wait(writer); of the writer, code will go into an infinite loop and no writer will be allowed.
- This proofs that, if one process is reading, no other process is allowed to write.
- Now suppose P0 wants to stop the reading and wanted to exit then
- Following sequence of instructions will take place:
- wait(mutex); // decrease mutex by 1, i.e. mutex = 0
- readcount --; // readcount = 0, i.e. no one is currently reading
- if (readcount == 0) // evaluates TRUE
- {
- signal (write); // increase write by one, i.e. write = 1
- }
- signal(mutex);// increase mutex by one, i.e. mutex = 1
- Now if again any writer wants to write, it can do it now, since write > 0
CASE 3: WRITING -- READING → NOT ALLOWED. That is when if one process is writing into the file, then reading by another process is not allowed. Let us see that our code is working accordingly or not?
- Explanation:
- The initial value of semaphore write = 1
- Suppose two processes P0 and P1 are in a system, P0 wants to write while P1 wants to read, P0 enter first into the writer code, The moment P0 enters
- Wait (write); will decrease semaphore write by 1, now write = 0
- And continue WRITE INTO THE FILE
- Now suppose P1 wants to read the same time (will it be allowed?) let's see.
- P1 enters reader's code
- Initial value of semaphore mutex = 1 and variable readcount = 0
- Wait (mutex ); will decrease semaphore mutex by 1, now mutex = 0
- Increment readcount by 1, now readcount = 1, next
- if (readcount == 1)// evaluates to TRUE
- {
- wait (write); // since value of write is already 0, hence it
- will enter into an infinite loop and will not be
- allowed to proceed further (which clearly
- proves that if one writer is writing then no
- reader will be allowed.
- }
- The moment writer stops writing and willing to exit then
- This proofs that, if one process is writing, no other process is allowed to read.
- The moment writer stops writing and willing to exit then it will execute:
- signal( write); will increase semaphore write by 1, now write = 1
- if now P1 wants to read it can since semaphore write > 0
CASE 4: READING - READING → ALLOWED. That is when one process is reading the file, and other process or processes is willing to read, then they all are allowed i.e. reading - reading is not mutually exclusive. Let us see that our code is working accordingly or not?
- Explanation:
- Initial value of semaphore mutex = 1 and variable readcount = 0
- Suppose three processes P0, P1 and P2 are in a system, all the three processes P0, P1, and P2 want to read, let P0 enter first into the reader code, the moment P0 enters
- Wait (mutex ); will decrease semaphore mutex by 1, now mutex = 0
- Increment readcount by 1, now readcount = 1, next
- if (readcount == 1)// evaluates to TRUE
- {
- wait (write); // decrement write by 1, i.e. write = 0(which
- clearly proves that if one or more than one
- reader is reading then no writer will be
- allowed.
- }
- signal(mutex); // will increase semaphore mutex by 1, now mutex = 1 i.e. other reader are allowed to enter.
- And P0 continues to --READ THE FILE?
- →Now P1 wants to enter the reader code
- current value of semaphore mutex = 1 and variable readcount = 1
- let P1 enter into the reader code, the moment P1 enters
- Wait (mutex); will decrease semaphore mutex by 1, now mutex = 0
- Increment readcount by 1, now readcount = 2, next
- if (readcount == 1)// eval. to False, it will not enter if block
- signal(mutex); // will increase semaphore mutex by 1, now mutex = 1 i.e. other reader are allowed to enter.
- Now P0 and P1 continues to --READ THE FILE?
- →Now P2 wants to enter the reader code
- current value of semaphore mutex = 1 and variable readcount = 2
- let P2 enter into the reader code, The moment P2 enters
- Wait(mutex ); will decrease semaphore mutex by 1, now mutex = 0
- Increment readcount by 1, now readcount = 3, next
- if (readcount == 1)// eval. to False, it will not enter if block
- signal(mutex); // will increase semaphore mutex by 1, now mutex = 1 i.e. other reader are allowed to enter.
- Now P0, P1, and P2 continues to --READ THE FILE?
- Suppose now any writer wants to enter into its code then:
- As the first reader P0 has executed wait (write); because of which write value is 0, therefore wait(writer); of the writer, code will go into an infinite loop and no writer will be allowed.
- Now suppose P0 wants to come out of system (stop reading) then
- wait(mutex); //will decrease semaphore mutex by 1, now mutex = 0
- readcount --; // on every exit of reader decrement readcount by
- one i.e. readcount = 2
- if (readcount == 0)// eval. to FALSE it will not enter if block
- signal(mutex); // will increase semaphore mutex by 1, now mutex = 1 i.e. other reader are allowed to exit
- → Now suppose P1 wants to come out of system (stop reading) then
- wait(mutex); //will decrease semaphore mutex by 1, now mutex = 0
- readcount --; // on every exit of reader decrement readcount by
- one i.e. readcount = 1
- if (readcount == 0)// eval. to FALSE it will not enter if block
- signal(mutex); // will increase semaphore mutex by 1, now mutex = 1 i.e. other reader are allowed to exit
- →Now suppose P2 (last process) wants to come out of system (stop reading) then
- wait(mutex); //will decrease semaphore mutex by 1, now mutex = 0
- readcount --; // on every exit of reader decrement readcount by
- one i.e. readcount = 0
- if (readcount == 0)// eval. to TRUE it will enter into if block
- {
- signal (write); // will increment semaphore write by one, i.e.
- now write = 1, since P2 was the last process
- which was reading, since now it is going out,
- so by making write = 1 it is allowing the writer
- to write now.
- }
- signal(mutex); // will increase semaphore mutex by 1, now mutex = 1
Key takeaway
The dining philosopher's problem is the classical problem of synchronization which says that Five philosophers are sitting around a circular table and their job is to think and eat alternatively. A bowl of noodles is placed at the centre of the table along with five chopsticks for each of the philosophers. To eat a philosopher needs both their right and a left chopstick. A philosopher can only eat if both immediate left and right chopsticks of the philosopher is available. In case if both immediate left and right chopsticks of the philosopher are not available then the philosopher puts down their (either left or right) chopstick and starts thinking again.
The readers-writer’s problem is a classical problem of process synchronization; it relates to a data set such as a file that is shared between more than one process at a time. Among these various processes, some are Readers - which can only read the data set; they do not perform any updates, some are Writers - can both read and write in the data sets.
The readers-writer’s problem is used for managing synchronization among various reader and writer process so that there are no problems with the data sets, i.e. no inconsistency is generated.
Monitors and semaphores are used for process synchronization and allow processes to access the shared resources using mutual exclusion. However, monitors and semaphores contain many differences. Details about both of these are given as follows −
Monitors are a synchronization construct that were created to overcome the problems caused by semaphores such as timing errors.
Monitors are abstract data types and contain shared data variables and procedures. The shared data variables cannot be directly accessed by a process and procedures are required to allow a single process to access the shared data variables at a time.
This is demonstrated as follows:
monitor monitorName
{
data variables;
Procedure P1(....)
{
}
Procedure P2(....)
{
}
Procedure Pn(....)
{
}
Initialization Code(....)
{
}
}
Only one process can be active in a monitor at a time. Other processes that need to access the shared variables in a monitor have to line up in a queue and are only provided access when the previous process release the shared variables.
A semaphore is a signalling mechanism and a thread that is waiting on a semaphore can be signalled by another thread. This is different than a mutex as the mutex can be signalled only by the thread that called the wait function.
A semaphore uses two atomic operations, wait and signal for process synchronization.
The wait operation decrements the value of its argument S, if it is positive. If S is negative or zero, then no operation is performed.
wait(S)
{
while (S<=0);
S--;
}
The signal operation increments the value of its argument S.
signal(S)
{
S++;
}
There are mainly two types of semaphores i.e. counting semaphores and binary semaphores.
Counting Semaphores are integer value semaphores and have an unrestricted value domain. These semaphores are used to coordinate the resource access, where the semaphore count is the number of available resources.
The binary semaphores are like counting semaphores but their value is restricted to 0 and 1. The wait operation only works when the semaphore is 1 and the signal operation succeeds when semaphore is 0.
Key takeaway
Monitors are a synchronization construct that were created to overcome the problems caused by semaphores such as timing errors.
Monitors are abstract data types and contain shared data variables and procedures. The shared data variables cannot be directly accessed by a process and procedures are required to allow a single process to access the shared data variables at a time.
Reference:
1. Operating Systems –A Concept Based approach –Dhananjay M Dhamdhere (TMGH).3rdedition.
2. Operating System Concepts –Abraham Silberschatz, Peter B. Galvin &Grege Gagne(Wiley)
3. UNIX Concepts and Applications –Sumitabha Das(TMGH).
4. Operating System: Concepts and Design –Milan Milenkovic (TMGH)
5. Operating System with case studies in Unix, Netware and Windows NT –Achyut S. Godbole (TMGH).




