UNIT 6
File systems and I/O systems
A file is a collection of correlated information which is recorded on secondary or non-volatile storage like magnetic disks, optical disks, and tapes. It is a method of data collection that is used as a medium for giving input and receiving output from that program.
In general, a file is a sequence of bits, bytes, or records whose meaning is defined by the file creator and user. Every File has a logical location where they are located for storage and retrieval.
Objective of File Management System
Here are the main objectives of the file management system:
- It provides I/O support for a variety of storage device types.
- Minimizes the chances of lost or destroyed data
- Helps OS to standardized I/O interface routines for user processes.
- It provides I/O support for multiple users in a multiuser systems environment.
Here, are important properties of a file system:
- Files are stored on disk or other storage and do not disappear when a user logs off.
- Files have names and are associated with access permission that permits controlled sharing.
- Files could be arranged or more complex structures to reflect the relationship between them.
A File Structure needs to be predefined format in such a way that an operating system understands. It has an exclusively defined structure, which is based on its type.
Three types of files structure in OS:
- A text file: It is a series of characters that is organized in lines.
- An object file: It is a series of bytes that is organized into blocks.
- A source file: It is a series of functions and processes.
A file has a name and data. Moreover, it also stores meta information like file creation date and time, current size, last modified date, etc. All this information is called the attributes of a file system.
Here, are some important File attributes used in OS:
- Name: It is the only information stored in a human-readable form.
- Identifier: Every file is identified by a unique tag number within a file system known as an identifier.
- Location: Points to file location on device.
- Type: This attribute is required for systems that support various types of files.
- Size. Attribute used to display the current file size.
- Protection. This attribute assigns and controls the access rights of reading, writing, and executing the file.
- Time, date and security: It is used for protection, security, and also used for monitoring
It refers to the ability of the operating system to differentiate various types of files like text files, binary, and source files. However, Operating systems like MS_DOS and UNIX has the following type of files:
It is a hardware file that reads or writes data character by character, like mouse, printer, and more.
- These types of files stores user information.
- It may be text, executable programs, and databases.
- It allows the user to perform operations like add, delete, and modify.
- Directory contains files and other related information about those files. Its basically a folder to hold and organize multiple files.
- These files are also called device files. It represents physical devices like printers, disks, networks, flash drive, etc.
- Create file, find space on disk, and make an entry in the directory.
- Write to file, requires positioning within the file
- Read from file involves positioning within the file
- Delete directory entry, regain disk space.
- Reposition: move read/write position.
Commonly used terms in File systems
This element stores a single value, which can be static or variable length.
Collection of related data is called a database. Relationships among elements of data are explicit.
Files is the collection of similar record which is treated as a single entity.
A Record type is a complex data type that allows the programmer to create a new data type with the desired column structure. Its groups one or more columns to form a new data type. These columns will have their own names and data type.
File access is a process that determines the way that files are accessed and read into memory. Generally, a single access method is always supported by operating systems. Though there are some operating system which also supports multiple access methods.
Three file access methods are:
- Sequential access
- Direct random access
- Index sequential access
In this type of file access method, records are accessed in a certain pre-defined sequence. In the sequential access method, information stored in the file is also processed one by one. Most compilers access files using this access method.
The random access method is also called direct random access. This method allows accessing the record directly. Each record has its own address on which can be directly accessed for reading and writing.
This type of accessing method is based on simple sequential access. In this access method, an index is built for every file, with a direct pointer to different memory blocks. In this method, the Index is searched sequentially, and its pointer can access the file directly. Multiple levels of indexing can be used to offer greater efficiency in access. It also reduces the time needed to access a single record.
In the Operating system, files are always allocated disk spaces.
Three types of space allocation methods are:
- Linked Allocation
- Indexed Allocation
- Contiguous Allocation
In this method,
- Every file user a contiguous address space on memory.
- Here, the OS assigns disk address is in linear order.
- In the contiguous allocation method, external fragmentation is the biggest issue.
In this method,
- Every file includes a list of links.
- The directory contains a link or pointer in the first block of a file.
- With this method, there is no external fragmentation
- This File allocation method is used for sequential access files.
- This method is not ideal for a direct access file.
In this method,
- Directory comprises the addresses of index blocks of the specific files.
- An index block is created, having all the pointers for specific files.
- All files should have individual index blocks to store the addresses for disk space.
A single directory may or may not contain multiple files. It can also have sub-directories inside the main directory. Information about files is maintained by Directories. In Windows OS, it is called folders.
|
Fig 1 - Single Level Directory
Following is the information which is maintained in a directory:
- Name The name which is displayed to the user.
- Type: Type of the directory.
- Position: Current next-read/write pointers.
- Location: Location on the device where the file header is stored.
- Size: Number of bytes, block, and words in the file.
- Protection: Access control on read/write/execute/delete.
- Usage: Time of creation, access, modification
File Type | Usual extension | Function |
Executable | exe, com, bin or none | ready-to-run machine- language program |
Object | obj, o | complied, machine language, not linked |
Source code | c. p, pas, 177, asm, a | source code in various languages |
Batch | bat, sh | Series of commands to be executed |
Text | txt, doc | textual data documents |
Word processor | doc,docs, tex, rrf, etc. | various word-processor formats |
Library | lib, h | libraries of routines |
Archive | arc, zip, tar | related files grouped into one file, sometimes compressed. |
|
|
|
- A file is a collection of correlated information which is recorded on secondary or non-volatile storage like magnetic disks, optical disks, and tapes.
- It provides I/O support for a variety of storage device types.
- Files are stored on disk or other storage and do not disappear when a user logs off.
- A File Structure needs to be predefined format in such a way that an operating system understands it.
- File type refers to the ability of the operating system to differentiate different types of files like text files, binary, and source files.
- Create find space on disk and make an entry in the directory.
- Indexed Sequential Access method is based on simple sequential access
- In Sequential Access method records are accessed in a certain pre-defined sequence
- The random access method is also called direct random access
- Three types of space allocation methods are:
- Linked Allocation
- Indexed Allocation
- Contiguous Allocation
- Information about files is maintained by Directories
Key takeaway
A file is a collection of correlated information which is recorded on secondary or non-volatile storage like magnetic disks, optical disks, and tapes. It is a method of data collection that is used as a medium for giving input and receiving output from that program.
In general, a file is a sequence of bits, bytes, or records whose meaning is defined by the file creator and user. Every File has a logical location where they are located for storage and retrieval.
There are various operations which can be implemented on a file. We will see all of them in detail.
1. Create
Creation of the file is the most important operation on the file. Different types of files are created by different methods for example text editors are used to create a text file, word processors are used to create a word file and Image editors are used to create the image files.
2. Write
Writing the file is different from creating the file. The OS maintains a write pointer for every file which points to the position in the file from which, the data needs to be written.
3. Read
Every file is opened in three different modes: Read, Write and append. A Read pointer is maintained by the OS, pointing to the position up to which, the data has been read.
4. Re-position
Re-positioning is simply moving the file pointers forward or backward depending upon the user's requirement. It is also called as seeking.
5. Delete
Deleting the file will not only delete all the data stored inside the file, It also deletes all the attributes of the file. The space which is allocated to the file will now become available and can be allocated to the other files.
6. Truncate
Truncating is simply deleting the file except deleting attributes. The file is not completely deleted although the information stored inside the file gets replaced.
Key takeaway
There are various operations which can be implemented on a file.
Create
Write
Read
Re-position
Delete
Truncate
Let's look at various ways to access files stored in secondary memory.
|
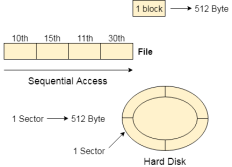
Fig 2 – Sequential access
Most of the operating systems access the file sequentially. In other words, we can say that most of the files need to be accessed sequentially by the operating system.
In sequential access, the OS read the file word by word. A pointer is maintained which initially points to the base address of the file. If the user wants to read first word of the file then the pointer provides that word to the user and increases its value by 1 word. This process continues till the end of the file.
Modern word systems do provide the concept of direct access and indexed access but the most used method is sequential access due to the fact that most of the files such as text files, audio files, video files, etc need to be sequentially accessed.
The Direct Access is mostly required in the case of database systems. In most of the cases, we need filtered information from the database. The sequential access can be very slow and inefficient in such cases.
Suppose every block of the storage stores 4 records and we know that the record we needed is stored in 10th block. In that case, the sequential access will not be implemented because it will traverse all the blocks in order to access the needed record.
Direct access will give the required result despite of the fact that the operating system has to perform some complex tasks such as determining the desired block number. However, that is generally implemented in database applications.
|
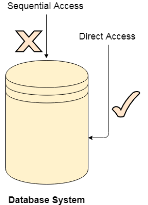
Fig 3 – Database system
If a file can be sorted on any of the filed, then an index can be assigned to a group of certain records. However, A particular record can be accessed by its index. The index is nothing but the address of a record in the file.
In index accessing, searching in a large database became very quick and easy but we need to have some extra space in the memory to store the index value.
Key takeaway
In sequential access, the OS read the file word by word. A pointer is maintained which initially points to the base address of the file. If the user wants to read first word of the file then the pointer provides that word to the user and increases its value by 1 word. This process continues till the end of the file.
Modern word systems do provide the concept of direct access and indexed access but the most used method is sequential access due to the fact that most of the files such as text files, audio files, video files, etc need to be sequentially accessed.
Operating System - I/O Hardware
One of the important jobs of an Operating System is to manage various I/O devices including mouse, keyboards, touch pad, disk drives, display adapters, USB devices, Bit-mapped screen, LED, Analog-to-digital converter, On/off switch, network connections, audio I/O, printers etc.
An I/O system is required to take an application I/O request and send it to the physical device, then take whatever response comes back from the device and send it to the application. I/O devices can be divided into two categories −
- Block devices − A block device is one with which the driver communicates by sending entire blocks of data. For example, Hard disks, USB cameras, Disk-On-Key etc.
- Character devices − A character device is one with which the driver communicates by sending and receiving single characters (bytes, octets). For example, serial ports, parallel ports, sounds cards etc
Device drivers are software modules that can be plugged into an OS to handle a particular device. Operating System takes help from device drivers to handle all I/O devices.
The Device Controller works like an interface between a device and a device driver. I/O units (Keyboard, mouse, printer, etc.) typically consist of a mechanical component and an electronic component where electronic component is called the device controller.
There is always a device controller and a device driver for each device to communicate with the Operating Systems. A device controller may be able to handle multiple devices. As an interface its main task is to convert serial bit stream to block of bytes, perform error correction as necessary.
Any device connected to the computer is connected by a plug and socket, and the socket is connected to a device controller. Following is a model for connecting the CPU, memory, controllers, and I/O devices where CPU and device controllers all use a common bus for communication.
|
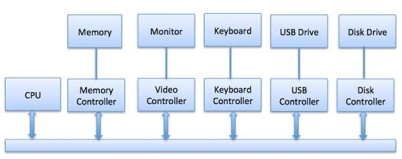
Fig 4 – communication devices
Synchronous vs asynchronous I/O
- Synchronous I/O − In this scheme CPU execution waits while I/O proceeds
- Asynchronous I/O − I/O proceeds concurrently with CPU execution
The CPU must have a way to pass information to and from an I/O device. There are three approaches available to communicate with the CPU and Device.
- Special Instruction I/O
- Memory-mapped I/O
- Direct memory access (DMA)
This uses CPU instructions that are specifically made for controlling I/O devices. These instructions typically allow data to be sent to an I/O device or read from an I/O device.
When using memory-mapped I/O, the same address space is shared by memory and I/O devices. The device is connected directly to certain main memory locations so that I/O device can transfer block of data to/from memory without going through CPU.
|
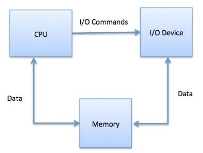
Fig 5 – I/O commands
While using memory mapped IO, OS allocates buffer in memory and informs I/O device to use that buffer to send data to the CPU. I/O device operates asynchronously with CPU, interrupts CPU when finished.
The advantage to this method is that every instruction which can access memory can be used to manipulate an I/O device. Memory mapped IO is used for most high-speed I/O devices like disks, communication interfaces.
Slow devices like keyboards will generate an interrupt to the main CPU after each byte is transferred. If a fast device such as a disk generated an interrupt for each byte, the operating system would spend most of its time handling these interrupts. So a typical computer uses direct memory access (DMA) hardware to reduce this overhead.
Direct Memory Access (DMA) means CPU grants I/O module authority to read from or write to memory without involvement. DMA module itself controls exchange of data between main memory and the I/O device. CPU is only involved at the beginning and end of the transfer and interrupted only after entire block has been transferred.
Direct Memory Access needs a special hardware called DMA controller (DMAC) that manages the data transfers and arbitrates access to the system bus. The controllers are programmed with source and destination pointers (where to read/write the data), counters to track the number of transferred bytes, and settings, which includes I/O and memory types, interrupts and states for the CPU cycles.
|
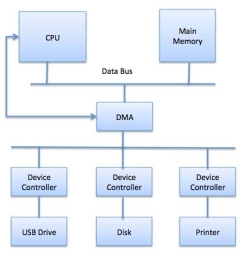
Fig 6 - DMA
The operating system uses the DMA hardware as follows −
Step | Description |
1 | Device driver is instructed to transfer disk data to a buffer address X. |
2 | Device driver then instruct disk controller to transfer data to buffer. |
3 | Disk controller starts DMA transfer. |
4 | Disk controller sends each byte to DMA controller. |
5 | DMA controller transfers bytes to buffer, increases the memory address, decreases the counter C until C becomes zero. |
6 | When C becomes zero, DMA interrupts CPU to signal transfer completion. |
A computer must have a way of detecting the arrival of any type of input. There are two ways that this can happen, known as polling and interrupts. Both of these techniques allow the processor to deal with events that can happen at any time and that are not related to the process it is currently running.
Polling is the simplest way for an I/O device to communicate with the processor. The process of periodically checking status of the device to see if it is time for the next I/O operation, is called polling. The I/O device simply puts the information in a Status register, and the processor must come and get the information.
Most of the time, devices will not require attention and when one does it will have to wait until it is next interrogated by the polling program. This is an inefficient method and much of the processors time is wasted on unnecessary polls.
Compare this method to a teacher continually asking every student in a class, one after another, if they need help. Obviously the more efficient method would be for a student to inform the teacher whenever they require assistance.
An alternative scheme for dealing with I/O is the interrupt-driven method. An interrupt is a signal to the microprocessor from a device that requires attention.
A device controller puts an interrupt signal on the bus when it needs CPU’s attention when CPU receives an interrupt, It saves its current state and invokes the appropriate interrupt handler using the interrupt vector (addresses of OS routines to handle various events). When the interrupting device has been dealt with, the CPU continues with its original task as if it had never been interrupted.
Operating System - I/O Software’s
I/O software is often organized in the following layers −
- User Level Libraries − This provides simple interface to the user program to perform input and output. For example, studio is a library provided by C and C++ programming languages.
- Kernel Level Modules − This provides device driver to interact with the device controller and device independent I/O modules used by the device drivers.
- Hardware − This layer includes actual hardware and hardware controller which interact with the device drivers and makes hardware alive.
A key concept in the design of I/O software is that it should be device independent where it should be possible to write programs that can access any I/O device without having to specify the device in advance. For example, a program that reads a file as input should be able to read a file on a floppy disk, on a hard disk, or on a CD-ROM, without having to modify the program for each different device.
|
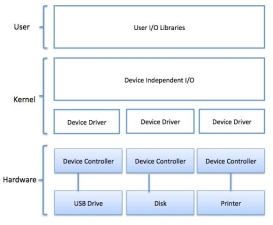
Fig 7 – I/O software’s
Device drivers are software modules that can be plugged into an OS to handle a particular device. Operating System takes help from device drivers to handle all I/O devices. Device drivers encapsulate device-dependent code and implement a standard interface in such a way that code contains device-specific register reads/writes. Device driver, is generally written by the device's manufacturer and delivered along with the device on a CD-ROM.
A device driver performs the following jobs −
- To accept request from the device independent software above to it.
- Interact with the device controller to take and give I/O and perform required error handling
- Making sure that the request is executed successfully
How a device driver handles a request is as follows: Suppose a request comes to read a block N. If the driver is idle at the time a request arrives, it starts carrying out the request immediately. Otherwise, if the driver is already busy with some other request, it places the new request in the queue of pending requests.
An interrupt handler, also known as an interrupt service routine or ISR, is a piece of software or more specifically a call back function in an operating system or more specifically in a device driver, whose execution is triggered by the reception of an interrupt.
When the interrupt happens, the interrupt procedure does whatever it has to in order to handle the interrupt, updates data structures and wakes up process that was waiting for an interrupt to happen.
The interrupt mechanism accepts an address ─ a number that selects a specific interrupt handling routine/function from a small set. In most architectures, this address is an offset stored in a table called the interrupt vector table. This vector contains the memory addresses of specialized interrupt handlers.
Device-Independent I/O Software
The basic function of the device-independent software is to perform the I/O functions that are common to all devices and to provide a uniform interface to the user-level software. Though it is difficult to write completely device independent software but we can write some modules which are common among all the devices. Following is a list of functions of device-independent I/O Software −
- Uniform interfacing for device drivers
- Device naming - Mnemonic names mapped to Major and Minor device numbers
- Device protection
- Providing a device-independent block size
- Buffering because data coming off a device cannot be stored in final destination.
- Storage allocation on block devices
- Allocation and releasing dedicated devices
- Error Reporting
These are the libraries which provide richer and simplified interface to access the functionality of the kernel or ultimately interactive with the device drivers. Most of the user-level I/O software consists of library procedures with some exception like spooling system which is a way of dealing with dedicated I/O devices in a multiprogramming system.
I/O Libraries (e.g., studio) are in user-space to provide an interface to the OS resident device-independent I/O SW. For example putchar(), getchar(), printf() and scanf() are example of user level I/O library studio available in C programming.
Kernel I/O Subsystem is responsible to provide many services related to I/O. Following are some of the services provided.
- Scheduling − Kernel schedules a set of I/O requests to determine a good order in which to execute them. When an application issues a blocking I/O system call, the request is placed on the queue for that device. The Kernel I/O scheduler rearranges the order of the queue to improve the overall system efficiency and the average response time experienced by the applications.
- Buffering − Kernel I/O Subsystem maintains a memory area known as buffer that stores data while they are transferred between two devices or between a device with an application operation. Buffering is done to cope with a speed mismatch between the producer and consumer of a data stream or to adapt between devices that have different data transfer sizes.
- Caching − Kernel maintains cache memory which is region of fast memory that holds copies of data. Access to the cached copy is more efficient than access to the original.
- Spooling and Device Reservation − A spool is a buffer that holds output for a device, such as a printer, that cannot accept interleaved data streams. The spooling system copies the queued spool files to the printer one at a time. In some operating systems, spooling is managed by a system daemon process. In other operating systems, it is handled by an in kernel thread.
- Error Handling − An operating system that uses protected memory can guard against many kinds of hardware and application errors.
Key takeaway
One of the important jobs of an Operating System is to manage various I/O devices including mouse, keyboards, touch pad, disk drives, display adapters, USB devices, Bit-mapped screen, LED, Analog-to-digital converter, On/off switch, network connections, audio I/O, printers etc.
File system is the part of the operating system which is responsible for file management. It provides a mechanism to store the data and access to the file contents including data and programs. Some Operating systems treats everything as a file for example Ubuntu.
The File system takes care of the following issues
- File Structure
We have seen various data structures in which the file can be stored. The task of the file system is to maintain an optimal file structure.
- Recovering Free space
Whenever a file gets deleted from the hard disk, there is a free space created in the disk. There can be many such spaces which need to be recovered in order to reallocate them to other files.
- disk space assignment to the files
The major concern about the file is deciding where to store the files on the hard disk. There are various disks scheduling algorithm which will be covered later in this tutorial.
- tracking data location
A File may or may not be stored within only one block. It can be stored in the non-contiguous blocks on the disk. We need to keep track of all the blocks on which the part of the files resides.
File System provide efficient access to the disk by allowing data to be stored, located and retrieved in a convenient way. A file System must be able to store the file, locate the file and retrieve the file.
Most of the Operating Systems use layering approach for every task including file systems. Every layer of the file system is responsible for some activities.
The image shown below, elaborates how the file system is divided in different layers, and also the functionality of each layer.
|
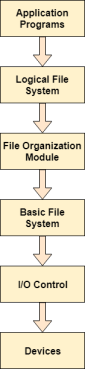
Fig 8 – File system layers
- When an application program asks for a file, the first request is directed to the logical file system. The logical file system contains the Meta data of the file and directory structure. If the application program doesn't have the required permissions of the file then this layer will throw an error. Logical file systems also verify the path to the file.
- Generally, files are divided into various logical blocks. Files are to be stored in the hard disk and to be retrieved from the hard disk. Hard disk is divided into various tracks and sectors. Therefore, in order to store and retrieve the files, the logical blocks need to be mapped to physical blocks. This mapping is done by File organization module. It is also responsible for free space management.
- Once File organization module decided which physical block the application program needs, it passes this information to basic file system. The basic file system is responsible for issuing the commands to I/O control in order to fetch those blocks.
- I/O controls contain the codes by using which it can access hard disk. These codes are known as device drivers. I/O controls are also responsible for handling interrupts.
Key takeaway
File system is the part of the operating system which is responsible for file management. It provides a mechanism to store the data and access to the file contents including data and programs. Some Operating systems treats everything as a file for example Ubuntu.
References:
1. Operating Systems –A Concept Based approach –Dhananjay M Dhamdhere (TMGH).3rdedition.
2. Operating System Concepts –Abraham Silberschatz, Peter B. Galvin &Grege Gagne(Wiley)
3. UNIX Concepts and Applications –Sumitabha Das(TMGH).
4. Operating System: Concepts and Design –Milan Milenkovic (TMGH)
5. Operating System with case studies in Unix, Netware and Windows NT –Achyut S. Godbole (TMGH).




