Unit - 2
The Buffer Cache
The kernel allocates space to the buffer cache when the device initializes. The buffer cache comprises two regions/arts. One is the buffer header for the data/files that will be read from the disk.
Data in the buffer cache fits the logical blocks of the file system's disk block. In memory," the buffer cache is a representation of the disk blocks." This mapping is temporary because at some later time, the kernel will choose to load data from some other files into the cache.
There will never be a scenario where the buffer contains two entries for the same file on disk as this may lead to inconsistency. In the buffer, there is just a single copy of a file.
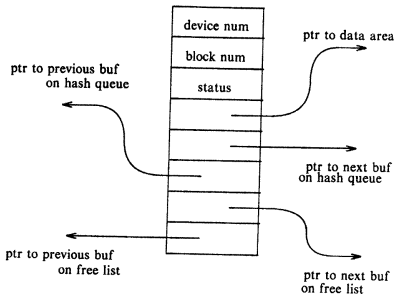
The buffer header provides metadata information such as the number of the unit and the list of block numbers on which the data is kept by this buffer. This stores the logical number of the device and not the number of the physical device. The buffer header also includes the pointer to the buffer data list (i.e. the data area pointer) .
The buffer header also includes the buffer's state. The buffer's state may be:
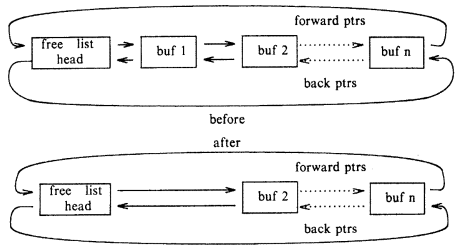
The least recently used data is cached by the kernel into the buffer pool. Once the back of the buffer pool is fixed to a device disk, this block cannot be used by any other data file. A free list of buffers is maintained by the kernel as well. A doubly circular list of buffers is the free list.
It eliminates a node from the free list if the kernel needs to assign some buffer, usually from the beginning of the list, but it can also be taken from the center of the list. This free node is inserted at the end of the free list when the kernel frees a node from the buffer list.
It scans the buffer pool for a certain device number-block number combination when the kernel needs to access the disk (which is maintained in the buffer header).
As a function of the system number-block number mix, the whole buffer pool is arranged as queues hashed. The figure below describes the buffers on their hash queues.
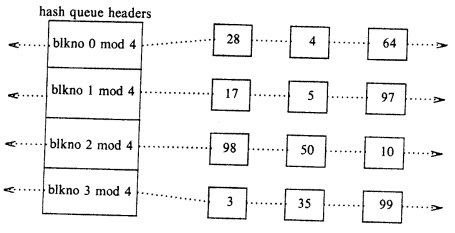
The key thing to remember here is that no two nodes in the buffer pool will hold the data of same disk block i.e. same file.
The file subsystem's high-level kernel algorithm invokes the buffer pool algorithm to handle the buffer cache. In getblk, the kernel can adopt five standard scenarios to allocate a buffer for a disk block.
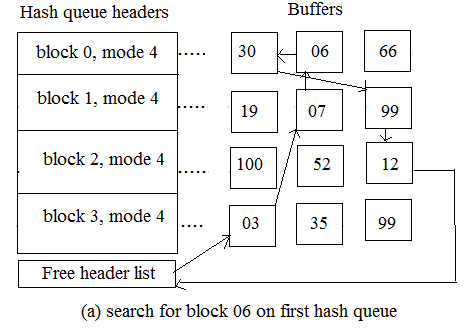
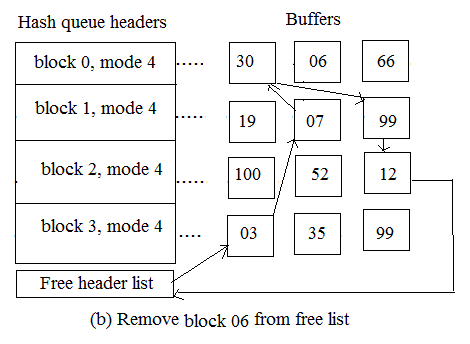
2.3.1 The kernel finds the block on its hash queue, and its buffer is free
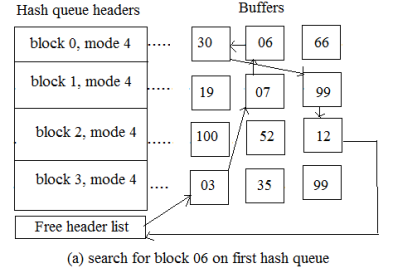
The above figure shows the first case in which the kernel checks for block 6 in the hash queue labelled 'blkno 0 mod 4.' The kernel excludes it from the free list by locating the buffer, and adds blocks 7 and 30 adjacent to the free list.
2.3.2 The kernel cannot find the block on the hash queue, therefore it allocates a buffer from the free list
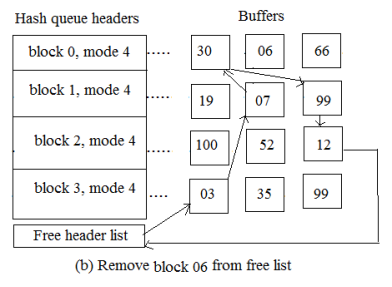
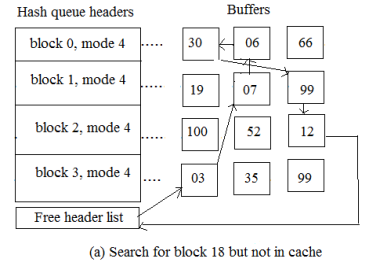
The second situation in the getblk algorithm is the kernel looking for a hash queue that could contain the block, but it wasn't there, so the block can't be on another hash queue so it can't "hash" elsewhere, it's not in the buffer cache. So, instead, the kernel eliminates the first buffer from the free list; that buffer was assigned to another disk block and is on a hash queue as well. The kernel tags the buffer busy, extracts it from the hash queue where it currently resides, reassigns the system and block number of the buffer header to that of the disk block for which the process is looking, and puts the buffer on the right hash queue if the buffer has not been ready for delayed writing.
2.3.3 The kernel is unable to locate the block in the hash queue and notices a buffer on the free list that has been labelled "delayed write." by trying to assign a buffer from the free list (as in scenario 2). The kernel must write the "delayed write" buffer to the disk and allocate another buffer.
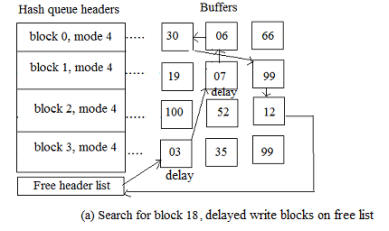
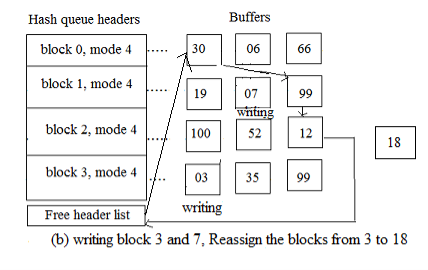
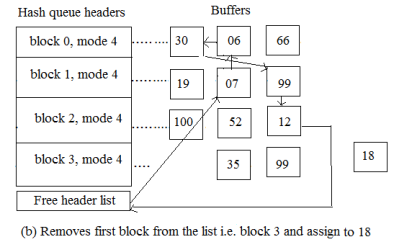
in Figure, the kernel cannot find block 18, but when it attempts to allocate the first two buffers (one at a time) on the free list, it finds them marked for delayed write. The kernel removes them from the free list, starts write operations to disk for the blocks, and allocates the third buffer on the free list, block 4. It reassigns the buffer's device and block number fields appropriately and places the buffer, now marked block 18, on its new hash queue.
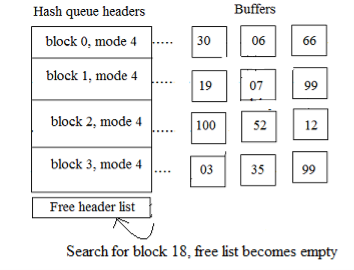
2.3.4 The kernel is unable to locate the hash queue stack, and the free list of buffers is empty
In below example the kernel, operating on process A, is unable to find the disk block in its hash queue, so it tries to allocate a new free list buffer, as in the second example. There are no buffers on the free list, however, so process A goes to sleep before another process performs an algorithm split, releasing a buffer. When the kernel schedules process A, the block has to look for the hash queue again. A buffer cannot be allocated automatically from the free list because it is likely that many processes have been waiting for a free buffer and that a newly released buffer has been allocated by one of them to the target block requested by process A.
2.3.5 On a hash queue, the kernel finds the block, but its buffer is currently busy
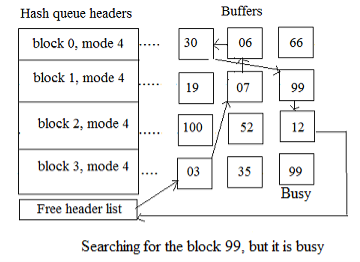
If process A wants to read a disk block and assigns a buffer as in scenario 2, it will sleep white, waiting to finish the I/O transmission from the disk. Suppose the kernel schedules a second process as process A sleeps, B, which attempts to access the disk block whose buffer was just locked by process A. The locked block on the hash queue would be identified by Process B (going through scenario 5). Although the use of a locked buffer is illegal and the allocation of a second buffer for a disk block is illegal, process B labels the "in demand" buffer and then rests and waits for process A to release the buffer.
The allocation of the buffer algorithm has been protected until now; it should be easy to grasp the procedures for reading and writing disk blocks. To read a disk block, a process uses the getblk algorithm to check in the buffer cache for it first. If it is accessible in the cache, instead of manually reading the block from the disk, the kernel will return it automatically. The kernel calls the disk drive to 'schedule' a read request if it is not present in the cache and goes to sleep awaiting the event that the I/O completes. The disk driver notifies the hardware of the disk controller that it requires data to be read, and the disk controller then transmits the data to the buffer.
Finally, when the I/O is complete, the disk controller interrupts the machine, and the disk interrupt handler awakens the sleeping process; the output of the disk block is now in the buffer. The modules that demanded the unique block now have the information; they unlock it so that other processes can use it when they no longer require the buffer.
2.4.1 Algorithm for reading the block (bread)
2.4.2 Algorithm for writing the block
2.5.1 Advantages
You give the machine instruction, which you can also name instruction, and save it, which allows you easier access to the program.
2.5.2 Disadvantages
References:
1. “Unix Concepts and Administration”, Sumitabha Das, TMGH, 3rd Edition.
2. “Unix Shell Programming”, YeshvantKanetkar, BPB Publications.
3. “Unix Utilities”, Tare, MGM.
4. “Advanced Programming in the UNIX Environment”, Stevens and Rego, Pearson Education, 2nd Edition.




