Unit - 5
Coding & Software Testing
Software development is a process of analysing, writing and maintaining a large pool of instructions written in a programming language. The source code is written and saved by the programmers and regularly updated if occur with any anomalies.
1. Selecting a language: to develop a software the programming language is selected as there has been a large no. of languages available.
2. Coding guidelines & writing code: The code is written according to a stack of rules called syntax for the selected programming language.
After the coding is done, it is tested to check whether it is working to give the desired output or not. The process of checking the code is called testing.
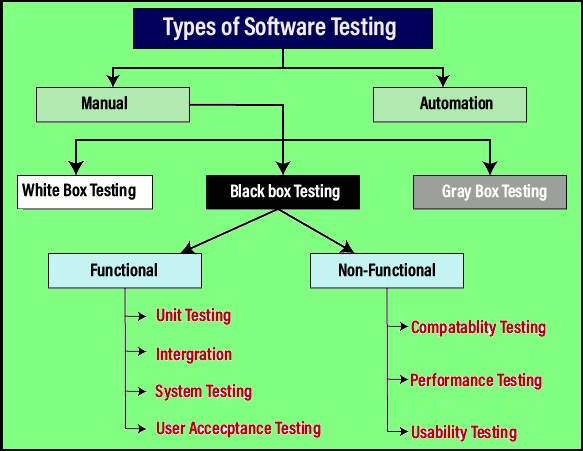
Testing process
Software testing is an essential part of software development process, which is used to identify the correctness, completeness and quality of developed software. The objective is to detect errors in the software as errors keeps software from producing outputs as per user requirement. Software is considered as incomplete, inconsistent, or incorrect if errors are present in it.
IEEE defines testing as “process of exercising or evaluating a system or system component by manual or automated means to verify that it satisfies specified requirements or to identify differences between expected and actual results.”
Software testing is closely associated with the terms verification and validation.
Verification is the process of evaluating a system or component to determine whether the products of a given development phase satisfy the conditions imposed at the start of that phase
Validation is the process of evaluating a system or component during or at the end of development process to determine whether it satisfies the specified requirements
Testing= Verification+ Validation

There are several Software testing tools available in market some are free or open to use and others are for premium users i.e. paying customers. Users can select the tools on the basis of their requirement of testing.
The software testing tools are categorized below into the following:
IEEE defines test case as “a set of input values, execution preconditions, expected results and execution post conditions, developed for a particular objective or test condition, such as to exercise a particular program path or to verify compliance with a specific requirement”. Generally, a test case contains particulars, such as test case identifier, testcase name, its objective, test conditions/setup, input data requirements, steps, and expected results.
(a) Test Case Generation
The process of generating test cases helps in locating problems in the requirements or design of software. To generate a test case, initially a criterion that evaluates a set of test cases is specified. Then, a set of test cases that satisfy the specified criterion is generated. There are two methods used to generate test cases, which are given below:
• Code based test case generation: also known as structure based testused to analyse the entire software code to generate test cases but not concerned with
User requirements. Unit testing uses this test cases.
• Specification based test case generation:
It deals with external view of software to generate test cases & is used for integration testing and system testing to assure software is performing the required task.
Different levels of Testing are summarized below in figure given below.
It is a type of software testing which is used to verify the functionality of the software application, whether the function is working according to the requirement specification
Black-box testing
It is also known by “behavioural testing” which focuses on the functional requirements of the software, and, is performed at later stages of testing process unlike white box which takes place at early stage. Black-box testing aims at functional requirements for a program to derive sets of input conditions whichshould be tested. Black box is not an alternative to white-box, rather, it is a complementary approach to find out a different class of errors other than white-box testing.
Black-box testing is emphasizing on different set of errors which falls under following categories:
a) Incorrect or missing functions
b) Interface errors
c) Errors in data structures or external data base access
d) Behaviour or performance errors
e) Initialization and terminationerrors.
The input is divided into higher and lower end values. If these values pass the test, it is assumed that all values in between may pass too.
b. Equivalence class testing
The input is divided into similar classes. If one element of a class passes the test, it is assumed that all the class is passed.
c. Decision table testing
Decision table technique is one of the widely used case design techniques for black box testing. This is a systematic approach where various input combinations and their respective system behaviourare captured in a tabular form. That’s why it is also known as a cause-effect table. This technique is used to pick the test cases in a systematic manner; it saves the testing time and gives good coverage to the testing area of the software application. Decision table technique is appropriate for the functions that have a logical relationship between two and more than two inputs.
Structural testing is done to by coders or developers as it is a way to test the structure of the code and requires knowledge of coding.
This testing consider single input conditions and do not explore combinations of input circumstances. The steps are as followed:
Step-1 Causes & effects in the specifications are identified. A cause is a distinct input condition or an equivalence class of input conditions. An effect is an output condition or a system transformation
Step -2 semantic content of the specification is analysed and transformed into a Boolean graph linking the causes & effects
Step-3 Constraints are imposed
Step-4 graph – limited entry decision table. Each column in the table represent a test case.
Step -5 columns in the decision table are converted into test cases.
b. Basis Path testing
Basis path testing is a white-box testing technique was proposed by Tom McCabe. This testing method enables the test case designer to derive a logical complexitymeasure of a procedural design and further use this measure as a template for defining a basis set of execution paths. Test cases derived to exercise the basis set are guaranteed to execute every statement in the program at least one time during testing.
Flow Graph Notation
To understand basis path method, a simple notation for the representation of control flow, called a flow graph (or program graph) must be explained. The flow graph depicts logical control flow with the help of symbols.
To demonstrate the use of a flow graph, we consider the procedural design representation inFigure below where a flowchart is used to depict program control structure.
Cyclomatic Complexity Measures: Control flow graphs
Cyclomatic complexity is used to measure logical complexity of a program. When used in basis path testing method, the value computed for Cyclomatic complexity defines the number of independent paths in the program to give upper bound for the number of tests that must be executed at least once.
An independent path is any path through the program that introduces at least one new set of processing statements or a new condition. When stated in terms of a flowgraph, an independent path must move along at least one edge that has not been traversed before the path is defined. For example, a set of independent paths (B) for the flow graph (A) illustrated in Figures below.
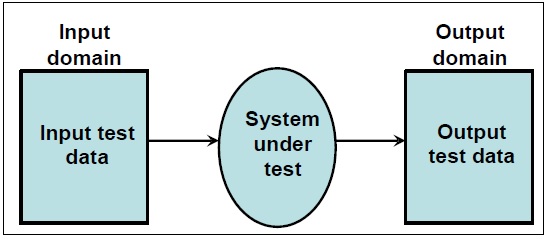
path 1: 1-11
path 2: 1-2-3-4-5-10-1-11
path 3: 1-2-3-6-8-9-10-1-11
path 4: 1-2-3-6-7-9-10-1-11
Note that each new path introduces a new edge. The pathis not considered to be an independent path because it is simply a combination of already specified paths and does not traverse any new edges.
1-2-3-4-5-10-1-2-3-6-8-9-10-1-11
Cyclomatic complexity has its basis in graph theory and is an extremely useful software metric. Complexity is computed in one of three ways:
1. The number of regions of the flow graph correspond to the Cyclomatic complexity.
2. Cyclomatic complexity, V(G), for a flow graph, G, is defined as
V(G) = E + N where E is the number of flow graph edges, N is the number of flow graph
nodes.
3. Cyclomatic complexity, V (G), for a flow graph, G, is also defined as
V (G) = P + 1,
where P is the number of predicate nodes contained in the flow graph G.
The Cyclomatic complexity can be computed using given equations:
1. The flow graph has four regions.
2. V(G) = 11 edges - 9 nodes + 2 = 4.
3. V(G) = 3 predicate nodes + 1 = 4.
Therefore, the Cyclomatic complexity of the flow graph is 4.V (G) provides us with an upper bound for the number of independent paths that form the basis set and, by implication, an upper bound on the number of tests that must be designed and executed to guarantee coverage of all program statements.
Unit testing, Integration and system testing
Unit testing implements all white box testing techniques as it is done over the code of software.
This testing technique emphasis to cover all the data variables included in the program. It tests where the variables were declared and defined and where they were used or changed.
The purpose of the control-flow testing to set up test cases which covers all statements and branch conditions. The branch conditions are tested for both being true and false, so that all statements can be covered
This technique is a white box testing method to test Boolean values. This technique deals with possibility of two or more outcomes from Control flow statements. By using control flow graph or chart every true or false scenario is checked and covered by it.
Integration Testing
Integration testing is about integrating all the unit modules and test them for their efficacy. After unit testing of individual modules integration testing takes place.
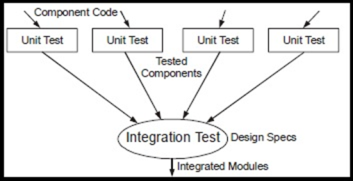
Types of Integration Testing:
Top-down testing
In top-down testing approach, testing of higher level modules with lower level modules is done till successful completion of all modules. This testing yields highdesign flaws which can be rectified early as critical modules are tested first.
Bottom to up testing
The bottom to up testing approach lower level modules are tested with higher level modules until testing is successfully completed for all the modules. Top level modules are tested at end, so it can turn in to a fault.
Acceptance Testing
When the software is ready to hand over to the customer it has to go through last phase of testing where it is tested for user-interaction and response. This is important because even if the software matches all user requirements and if user does not like the way it appears or works, it may be rejected.
Alpha testing
The team of developer themselves perform alpha testing by using the system as if it is being used in work environment. They try to find out how user would react to some action in software and how the system should respond to inputs.
Beta testing
After the software is tested internally, it is handed over to the users to use it under their production environment only for testing purpose. This is not as yet the delivered product. Developers expect that users at this stage will bring minute problems, which were skipped to attend.

Mutation testing
Mutation testing is a white box approach where a mutant is inserted into the program to test existing test case can detect the invader or error or not. The mutantis created by making modification or alteration in original code. This testing is done to check the ability of test cases to do testing.
Whenever a software product is updated with new code, feature or functionality, it is tested thoroughly to detect if there is any negative impact of the added code. This is known as regression testing.
Testing standards
Software Reliability means Operational reliability. It is described as the ability of a system or component to perform its required functions under static conditions for a specific period.it can also be described as the probability that a software system fulfils its assigned task in a given environment for a predefined number of input cases, assuming that the hardware and the input are free of error.
Software Reliability is a composite attribute composed of following features:
Reliability metrics are used to quantitatively express the reliability of the software product. The option of which parameter is to be used depends upon the type of system to which it applies & the requirements of the application domain.
The current methods of software reliability measurement can be divided into four categories:
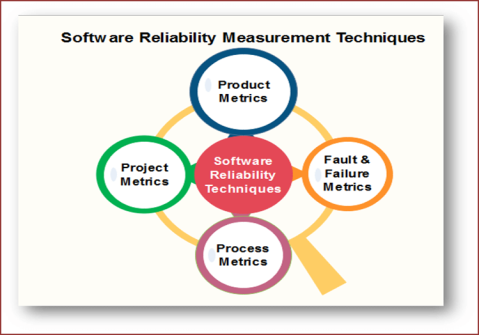
1. Product Metrics
Product metrics are characteristics of the product such as size, complexity, design features, performance, efficiency, reliability, portability etc.
Software size is considered as measurement of complexity, development effort, and reliability. It is calculated in terms of Lines of Code (LOC), or LOC in thousands (KLOC). It is used to determine of the functional complexity of the program and is independent of the programming language.
Function point (fp)is a method used to determine the functionality of proposed software development based on the count of inputs, outputs, master files, inquires, and interfaces.
Quality metrics depicts the quality at different levelsof software development. An important quality metric is Defect Removal Efficiency (DRE).
2. Project Management Metrics
Project metrics are explained as different project characteristics and its execution such as: Number of software developers, Staffing pattern over the life-cycle of the software, Cost and schedule, Productivity
3. Process Metrics
Process metrics are defined as efficacy and quality of the processes that produce the software product.Examples are:
4. Fault and Failure Metrics
A fault is a defect in a software which appears on execution under some particular condition. These metrics determine whether the software is failure-free or not. Software testing is done to find faults or feedback of users are collected and analyzed to rectify the fault.
3. Reliability Metrics
Reliability metrics are used to express reliability of a software product. Some reliability metrics:




