Unit - 2
Lexical Analysis
The first step in the compiler design is LEXICAL ANALYSIS. A Lexer takes the modified source code that is written in the form of sentences. In other words, it allows you to transform a sequence of characters into a sequence of tokens. This syntax is split into a series of tokens by the lexical analyzer. It eliminates any extra space or comment written in the source code.
Lexical analyzer programs are called lexical analyzers. A lexer includes a tokenizer or scanner. If the lexical analyzer detects that the token is invalid, an error is created. It reads character streams from the source code, checks for legal tokens, and when it needs the syntax analyzer, transfers the data to the syntax analyzer
Role of lexical analyzer
The following tasks are carried out by the Lexical Analyzer:
● Helps to classify tokens in the table of symbols
● Removes white spaces and the source program's comments
● Correlates with the source software error messages
● Helps you extend the macros if they are located in the source program
● Read the source program's input characters
Advantages of lexical analyzer
● Programs such as compilers that can use the parsed data from a programr's code to construct a compiled binary executable code use the lexical analyzer technique.
● Web browsers use it to format and view a web page with the assistance of JavaScript, HTML, CSS Script, CSS Script, and CSS Script parsed data.
● A separate lexical analyzer allows you to create a specialised and potentially more powerful processor for the assignment.
Disadvantages of lexical analyzer
● You need to spend considerable time reading and separating the source program in the form of tokens.
● In contrast to the PEG or EBNF law, certain regular expressions are very difficult to understand.
● It takes more time to build and debug the lexer and its token descriptions
● To generate the lexer tables and create the tokens, additional runtime overhead is required.
Key takeaway :
● The first step in the compiler design is LEXICAL ANALYSIS.
● Lexical analyzer programs are called lexical analyzers.
● It allows you to transform a sequence of characters into a sequence of tokens.
● One or more characters must be looked up past the next lexeme to guarantee that a suitable lexeme is found.
● A two-buffer framework is thus implemented to safely control large look aheads.
● Techniques for speeding up the lexical analyzer method have been introduced, such as the use of sentinels to mark the end of the buffer.
For the implementation of a lexical analyzer, there are three general approaches:
(i) To create the lexical analyzer from a regular expression-based specification by using a lexical-analyzer generator, such as the lex compiler. The generator offers routines for reading and buffering the input in this context.
(ii) Using the I/O facilities of that language to interpret the input by writing the lexical analyzer in a traditional systems-programming language.
(iii) Through writing the lexical analyzer and handling the reading of input directly in assembly language.
- Buffer Pair
Specialized buffering strategies have been developed to reduce the amount of overhead needed to process an input character due to a significant amount of time usage in moving characters.
The buffer pairs used to store the input data are shown in below Figure :
|
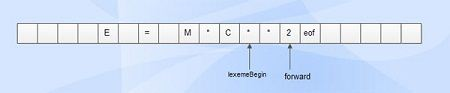
Fig 1: buffer pair
Scheme
● It consists of two buffers, each consisting of an N-character size that is alternatively reloaded.
● N-Number of characters, e.g., 4096, on one disc block.
● Using one device read instruction, N characters are read from the input file to the buffer.
● If the number of characters is less than N, an eof is inserted at the end.
Pointers
● LexemeBegin and forward are maintained by two pointers.
● The beginning of the lexeme leads to the beginning of the present lexeme, which has yet to be identified.
● Forward scans ahead before a match is found for a pattern.
● Once a lexeme is found, immediately after the lexeme that is just found, lexeme start is set to the character, and forward is set to the character at its right end.
● The existing lexeme is the character set that is between two pointers.
Disadvantages of the scheme
● Most of the time, this scheme works well, but the amount of looking ahead is reduced.
● In situations where the distance that the forward pointer must travel is more than the length of the buffer, this restricted lookahead can make it difficult to recognise tokens.
● Until the character follows the correct parenthesis, it cannot decide if DECLARE is a keyword or an array name.
2. Sentinels
● Time the forward pointer is shifted in the previous system, a check is performed to ensure that one half of the buffer has not moved off. If it is finished, then it is appropriate to reload the other half.
● Hence, with each advance of the forward pointer, the ends of the buffer halves need two checks.
Test 1: For the buffer end.
Test 2: Deciding which character is being read.
● By expanding each buffer half to carry a sentinel character at the end, the use of sentinel lowers the two checks to one.
● A sentinel is a unique character that cannot be used in the source software. (The character of eof is used as a sentinel).
● |
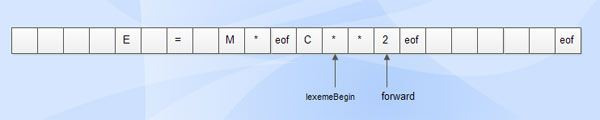
Fig 2: sentinels
Advantages
● It conducts only one test most of the time to see if a forward pointer points to an eof.
● This conducts further checks only when it hits the end of the buffer half or eof.
● The average number of tests per input character is very close to 1. since N input characters are encountered between eofs.
Key takeaway :
● Techniques for speeding up the lexical analyzer method have been introduced, such as the use of sentinels to mark the end of the buffer.
● A two-buffer framework is thus implemented to safely control large look aheads.
Token :
It is said that lexemes are a character sequence (alphanumeric) in a token. For each lexeme to be identified as a valid token, there are some predefined rules. These rules, by means of a pattern, are described by grammar rules. A pattern describes what a token can be, and by means of regular expressions, these patterns are described.
Keywords, constants, identifiers, sequences, numbers, operators and punctuation symbols can be used as tokens in the programming language.
Example : the variable declaration line in the C language
int num = 60 ;
contains the tokens: int (keyword) , num (identifiers) = (operator) , 60 (constant) and ; (symbol)
Specification of token :
Now let's explain how the following words are used in language theory.
- Alphabets : Any finite set of symbols
● {0,1} is a set of binary alphabets,
● {0,1,2,3,4,5,6,7,8,9,A,B,C,D,E,F} is a set of Hexadecimal alphabets,
● {a-z, A-Z} is a set of English language alphabets.
2. Strings : A string is called any finite sequence of alphabets.
3. Special Symbol : The following symbols are used in a standard high-level language:
Arithmetic Symbols | Addition(+), Subtraction(-), Multiplication(*), Division(/) |
Punctuation | Comma(,), Semicolon(;), Dot(.) |
Assignment | = |
Special Assignment | +=, -=, *=, /= |
Comparison | ==, !=. <. <=. >, >= |
Preprocessor | # |
4. Language : A language over any finite set of alphabets is known as a finite set of strings.
5. Longest Match Rule : When the lexical analyzer reads the source code, it checks the code letter by letter and concludes that a phrase is completed when it finds a white space, operator symbol, or special symbols.
6. Operation : The different language operations are:
● The Union is written in two languages, L and M as , L U M = {s | s is in L or s is in M}
● Two languages, L and M, are concatenated as, LM = {st | s is in L and t is in M}
● A Language L's Kleene Closure is written as , L* = Zero or more occurrence of language L .
7. Notations : If r and s are regular expressions that denote the L(r) and L(s) languages, then
● Union : L(r)UL(s)
● Concatenation : L(r)L(s)
● Kleene Closure : (L(r))*
8. Representing valid tokens of a language in regular expression : If x is an expression that is normal, then:
● x* implies the occurrence of x at zero or more.
● x+ implies one or more instances of x.
9. Finite automata : Finite Automata is a state machine that takes as input a string of symbols and changes its state accordingly.
If the input string is processed successfully and the automatic has reached its final state, it will be accepted.
The Finite Automata Mathematical Model consists of :
● Q - Finite set of state
● Σ - Finite set of input symbol
● q0 - One start state
● qf - set of final state
● δ - Transition function
The transition function (δ) maps the finite set of state (Q) to a finite set of input symbols (Σ), Q × Σ ➔ Q
Recognition of tokens
Reading input characters in the code and creating tokens is the key task of lexical analysis.
The Lexical Analyzer checks the program's entire source code. One by one, it recognises each token. Scanners are typically only implemented when requested by a parser to generate tokens. And here's how it works.
1) 'Get next token' is a command that is sent to the lexical analyzer from the parser.
2) The lexical analyzer scans the input until it identifies the next token upon obtaining this instruction.
3) It returns the Parser token.
|
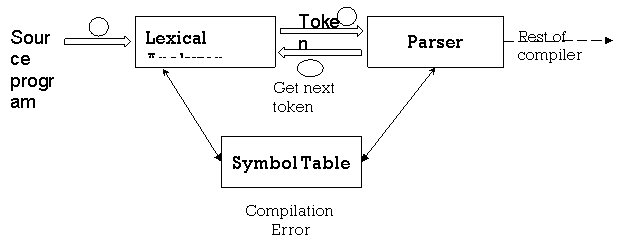
Fig 3: lexical analyzer
When generating these tokens, the Lexical Analyzer skips white spaces and comments. If there is an error, the Lexical Analyzer compares the error with the source file and the line number.
Key takeaway :
● It is said that lexemes are a character sequence (alphanumeric) in a token.
● A pattern describes what a token can be, and by means of regular expressions, these patterns are described.
● Reading input characters in the code and creating tokens is the key task of lexical analysis.
Finite Automata(FA) is the simplest pattern recognition machine. The finite automatic or finite state machine is an abstract machine with five components or tuples. It has a set of states and rules that switch from one state to another, but it depends on the input symbol that is added. It is essentially an abstract digital machine model.
Some important features of general automation are shown in the figure below.
|
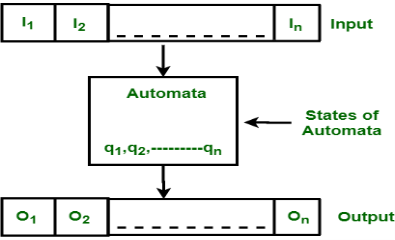
Fig 4: finite automata
The figure above shows the following automated features:
- Input
- Output
- State of Automata
- State relation
- Output relation
The following are Finite Automata:
● Q - Finite set of state
● Σ - Finite set of input symbol
● q0 - One start state
● qf - set of final state
● δ - Transition function
A formal computer specification is
{ Q, Σ, q, F, δ }
Finite automata model :
Input tape and finite control can be represented by Finite Automata.
● Input tape : It's a linear tape that has a certain number of cells. In each cell, each input symbol is positioned.
● Finite control : On receiving unique feedback from the input tape, the finite control determines the next condition. The tape reader reads the cells from left to right, one by one, and only one input symbol is read at a time.
|
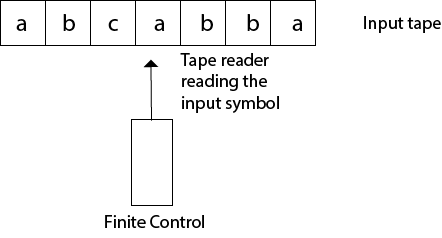
Fig 5: finite automata model
Types of automata
The FA is divided into two types:
- DFA (Deterministics finite automata)
In a DFA, the computer goes to only one state for a specific input character. For every input symbol, a transition function is specified for every state. Null (or ε) movement is also not permitted in DFA, i.e. DFA does not change state without any input characters.
DFA has five tuples {Q, ∑, q0, F, δ}
Q: set of all states
∑: finite set of input symbol where δ: Q x ∑ →Q
q0: initial state
F: final state
δ: Transition function
One important thing to remember is that, for a pattern, there can be several possible DFAs. As a rule, a DFA with a minimum number of states is favoured.
2. NFA (Non-deterministics finite automata)
NDFA applies to Finite Non-Deterministic Automata. It is used for a single input to pass through any number of states. NDFA embraces the NULL step, indicating that without reading the symbols, it can change the state.
Like the DFA, NDFA also has five states. NDFA, however, has distinct transformation features.
NDFA's transition role may be described as:
δ: Q x ∑ →2Q
Key takeaway :
● Finite Automata(FA) is the simplest pattern recognition machine.
● The finite automatic or finite state machine is an abstract machine with five components or tuples.
● In a DFA, the computer goes to only one state for a specific input character.
● NFA is used for a single input to pass through any number of states.
● Lexical Analyzer Generator introduces a tool called Lex, which enables a lexical analyzer to be described by defining regular expressions to define token patterns.
● The lex tool input is the lex language
● A program written in the lex language can compile and generate a C code named lex.yy.c through the lex compiler, i.e.
|
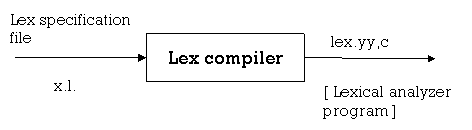
Fig 6: lex compiler
Now, as always, C code is compiled by the C compiler and produces a file called a.out, i.e.
|
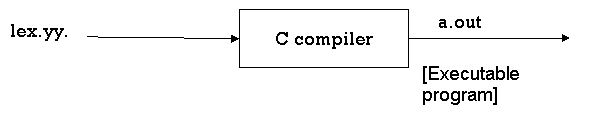
Fig 7: c compiler
The output of the C compiler is a working lexical analyser that can take an input character stream and generate a token stream, i.e.,
|
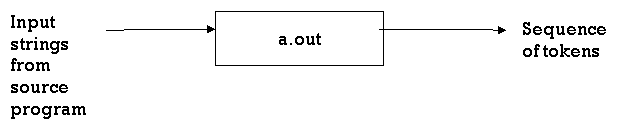
Fig 8: generator of lexical analyzer
● Lex is a lexical analyzer generating program. It is used to produce the YACC parser. A software that transforms an input stream into a sequence of tokens is the lexical analyzer. It reads the input stream and, by implementing the lexical analyzer in the C program, produces the source code as output.
|
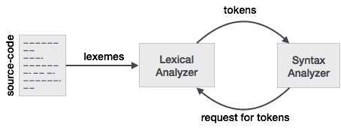
Fig 9: lexical analyzer generator
If a token is considered invalid by the lexical analyzer, it produces an error. The lexical analyzer works with the syntax analyzer in close collaboration. It reads character streams from the source code, checks for legal tokens, and, when necessary, passes the information to the syntax analyzer.
Structure of lex program
A Lex program has the following form
declarations
%%
transition rules
%%
auxiliary functions
Variable declarations, manifest constants (LT, LE, GT, GE) and standard definitions are included in the declaration section.
The basic type of rule for transition is : pattern{Action}
Where the pattern is a regular expression and action determines what action should be taken when it matches the pattern.
Second, the auxiliary function includes whatever extra features are used in the actions.
You can separately compile these functions and load them with the lexical analyzer.
LEX Program for Tokens
% {
ID, NUMBNER, RELOP, IF, THEN,
ELSE
% } || declaration of variables
delim [ space\t\n ]
ws [ delim ] +
letter [A - Z - a - z ]
digit [ 0 - 9 ]
id letter (letter / digit)
Number { digit } + ( \ . { digit } + ) ?
E [ +- ] ? {digit +} +)?
%%
*transition rule * |
{ ws } { No Action }
If { return (IF) ; }
{ id } { return (ID) ; Install - ID () ; }
1 { number } { return (number); Install-num (); }
“<” { return (RELOP, LT) }
“<=” { return (RELOP, LE) }
“=” { return (RELOP, EQ) }
%%
|* Auxiliary Section *|
install-ID ()
{
=
=
Y
install-num ()
{
=
=
}
Key takeaway :
● The lex tool input is the lex language.
● Lexical Analyzer Generator introduces a tool called Lex, which enables a lexical analyzer to be described by defining regular expressions to define token patterns.
● Lex is a lexical analyzer generating program.
● It is used to produce the YACC parser.
References :
1. “Compiler Construction”, Dhamdere, Mc-Millan.
2. “Compilers - Principles, Techniques and Tools”, A.V. Aho, R. Shethi and J.D.Ullman, Addison
Wesley Publishing Company.
3. “Compiler Construction”, Barret, Bates, Couch, Galgotia.
4. “Unix Programming”, Pepkin Pike.




