Unit - 3
Syntax Analysis
The parser or syntactic analyzer obtains from the lexical analyzer a string of tokens and verifies that the grammar will produce the string for the source language. In the software, it reports any syntax errors. It also recovers from frequently occurring errors so that its input can continue to be processed.
|
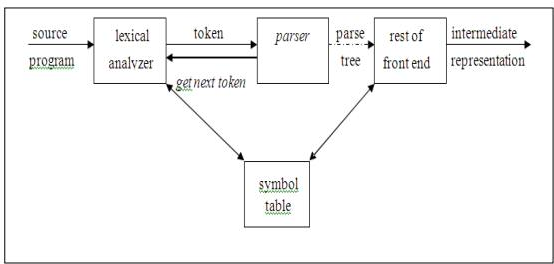
Fig 1: position of parser
- Based on the grammar, it tests the structure created by the tokens.
- This builds the tree of parse.
- It records mistakes.
- It carries out error recovery.
Issues :
The parser is unable to detect errors like:
● Re-declaration of Variable
● Initialization of variable before use
● For an operation, data type mismatch.
The above problems are discussed in the Semantic Analysis stage.
Syntax Error Handling :
At several different levels, programmes can contain errors. For instance:
● Lexical, such as misspelling, keyword, or operator of an identifier.
● Syntactics, such as unbalanced parentheses in an arithmetic expression.
● Semantic, such as being applied to an incompatible operand by an operator.
● Logical, such as a call which is infinitely recursive.
Functions of error handler :
● It should clearly and reliably report the existence of errors.
● It should recover quickly enough from each mistake to be able to detect subsequent errors.
● The processing of right programmes does not substantially slow down.
Error recovery strategies :
The various methods a parse uses to recover from a syntactic error are:
- Panic mode
- Phrase level
- Error productions
- Global correction
The above topic described below :
Panic mode recovery
The parser discards input symbols one at a time upon finding an error before a synchronising token is found. Typically, the synchronising tokens are delimiters, such as end or semicolon. It has the value of simplicity and doesn't go through an endless loop. This approach is very useful when several errors in the same statement are uncommon.
Phase level recovery
The parser performs local correction on the remaining input when finding an error, which allows it to proceed. Example: Insert the missing semicolon, or erase the alien semicolon, etc.
Error production
The parser is constructed with error outputs using augmented grammar. If the parser uses error generation, suitable error diagnostics can be created to show the erroneous constructs that the input recognises.
Global correction
Some algorithms can be used to find a parse tree for the y string because of the incorrect input string x and grammar G, such that the number of token insertions, deletions and changes is as limited as possible. In general, however, these methods are too expensive in terms of time and space.
Key takeaway :
● The parser or syntactic analyzer obtains from the lexical analyzer a string of tokens and verifies that the grammar will produce the string for the source language.
● It also recovers from frequently occurring errors so that its input can continue to be processed.
● The parser discards input symbols one at a time upon finding an error before a synchronising token is found.
● The parser is constructed with error outputs using augmented grammar.
To describe context-free languages, context-free grammar (CFGs) is used. A context-free grammar is a set of recursive rules that are used to produce string patterns. All regular languages and more can be described in context-free grammar, but not all possible languages can be described.
Grammars that are context-free can generate context-free languages. They do this by taking a set of variables that are recursively defined, in terms of each other, by a set of rules of production. Context-free grammars are named as such because, regardless of context, any of the production rules in the grammar can be implemented; it does not rely on any other symbols that may or may not be around a given symbol that has a rule applied to it.
A Context-Free Grammar consists of terminals, non-terminals, starting symbols and productions in a quadruple.
Terminals : The basic symbols from which strings are formed are these.
Non - terminal : The syntactic variables that denote a set of strings are these. These assist in helping to Defines the language that grammar generates.
Start symbol : The "Start-symbol" is denoted as one non-terminal in the grammar and the string set it denotes is the language defined by the grammar.
Production : The way terminals and non-terminals can be combined to form strings is specified. Each production consists of a non-terminal, followed by a string of non-terminals and terminals, followed by an arrow.
Follow these steps to create a string from a grammar that is context-free:
● Start the string by using the start symbol.
● By substituting the start symbol for the right side of the production, apply one of the production rules to the start symbol on the left-hand side.
● Repeat the process of selecting and replacing non-terminal symbols in the string with the right-hand side of the corresponding output until all non-terminals have been replaced with terminal symbols.
Formal definition :
A four-element tuple (V,Σ,R,S) can be described by context-free grammar, where
● V is a finite set of variables (which are non-terminal);
● Σ is a finite set (disjoint from V) of terminal symbols;
● R is a set of production rules where each production rule maps a variable to a string s∈(V∪Σ)∗;
● S (which is in V) which is a start symbol.
Key takeaway :
● A context-free grammar is a set of recursive rules that are used to produce string patterns.
● Grammars that are context-free can generate context-free languages.
● Context-free grammars are named as such because, regardless of context, any of the production rules in the grammar can be implemented.
Recursive or predictive parsing is known as top-down parsing.
The parsing begins with the start symbol in the top-down parsing and transforms it into the input symbol.
The top-down parser is the parser that, by expanding the non-terminals, generates a parse for the given input string with the aid of grammar productions, i.e. it begins from the start symbol and ends on the terminals.
Parse Tree The input string representation of acdb is as follows:
|
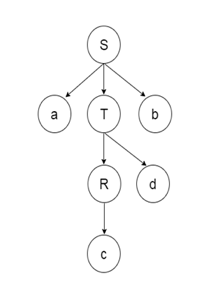
Fig 2: parse tree
There are 2 types of additional Top-down parser:
- Recursive descent parser, and
- Non-recursive descent parser.
It is also known as Brute force parser or the with backtracking parser. Basically, by using brute force and backtracking, it produces the parse tree.
A top-down parsing technique that builds the parse tree from the top and reads the input from left to right is recursive descent. For any terminal and non-terminal entity, it uses procedures.
The input is recursively parsed by this parsing technique to make a parse tree, which may or may not require back-tracking. But the related grammar (if not left-faced) does not prevent back-tracking. Predictive is considered a type of recursive-descent parsing that does not require any back-tracking.
As it uses context-free grammar that is recursive in nature, this parsing technique is called recursive.
Predictive parser
Predictive parser is a recursive descent parser, which has the capability to predict which production is to be used to replace the input string. The predictive parser does not suffer from backtracking.
To accomplish its tasks, the predictive parser uses a look-ahead pointer, which points to the next input symbols. To make the parser back-tracking free, the predictive parser puts some constraints on the grammar and accepts only a class of grammar known as LL(k) grammar.
Predictive parsing uses a stack and a parsing table to parse the input and generate a parse tree. Both the stack and the input contains an end symbol $ to denote that the stack is empty and the input is consumed. To take some decision on the input and stack element combination, the parser refers to the parsing table.
|
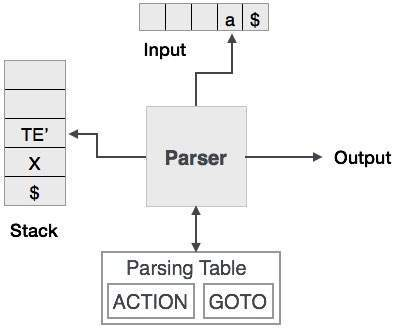
Fig 3: predictive parser
In recursive descent parsing, for a single instance of input, the parser can have more than one output to choose from, while in predictive parser, each stage has at most one production to choose from. There may be instances where the input string does not fit the production, making the parsing procedure fail.
Key takeaway :
● A top-down parsing technique that builds the parse tree from the top and reads the input from left to right is recursive descent.
● The input is recursively parsed by this parsing technique to make a parse tree, which may or may not require back-tracking.
● Predictive parser is a recursive descent parser, which has the capability to predict which production is to be used to replace the input string.
Bottom up parsing is also known as parsing for shift-reduce.
Bottom-up parsing is used to build an input string parsing tree.
The parsing begins with the input symbol in the bottom up parsing and builds the parse tree up to the start symbol by tracing the rightmost string derivations in reverse.
Parsing from the bottom up is known as multiple parsing. That are like the following:
- Shift-Reduce Parsing
- Operator Precedence Parsing
- Table Driven LR Parsing
- LR( 1 )
- SLR( 1 )
- CLR ( 1 )
- LALR( 1 )
Shift - reduce parsing:
● Shift reduction parsing is a mechanism by which a string is reduced to the beginning symbol of a grammar.
● Using a stack to hold the grammar and an input tape to hold the string, Shift reduces parsing.
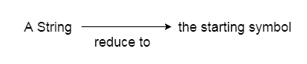
● The two acts are done by Shift Decrease Parsing: move and decrease. This is why it is considered that shift reduce parsing.
● The current symbol in the input string is moved into the stack for the shift operation.
● The symbols will be substituted by the non-terminals at each reduction. The mark is the right side of manufacturing and the left side of output is non-terminal.
Example:
Grammar:
- S → S+S
- S → S-S
- S → (S)
- S → a
Input string :
a1-(a2+a3)
Parsing table :
|
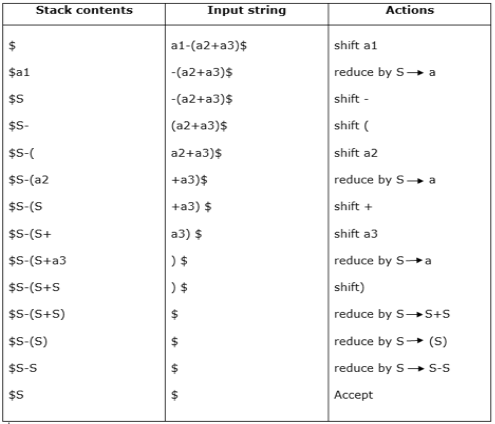
For bottom-up parsing, shift-reduce parsing uses two special steps. Such steps are referred to as shift-step and reduce-step.
Shift - step: The shift step refers to the progression to the next input symbol, which is called the shifted symbol, of the input pointer. Into the stack, this symbol is moved. The shifted symbol will be viewed as a single parse tree node.
Reduce - step: When a complete grammar rule (RHS) is found by the parser and substituted with (LHS), it is known as a reduction stage.This happens when a handle is located at the top of the stack. A POP function is performed on the stack that pops off the handle and substitutes it with a non-terminal LHS symbol to decrease.
Key takeaway :
● Bottom-up parsing is used to build an input string parsing tree.
● Parsing from the bottom up is known as multiple parsing.
● Shift reduction parsing is a mechanism by which a string is reduced to the beginning symbol of a grammar.
The grammar of operator precedence is a kind of shift reduction system of parsing. It is applied to a small grammar class of operators.
A grammar, if it has two properties, is said to be operator precedence grammar:
● There's no R.H.S. of any production.
● There are no two adjoining non-terminals.
Operator precedence can only be defined between the terminals of the grammar. A non-terminal is overlooked.
The three operator precedence relations exist:
● a ⋗ b suggests that the precedence of terminal "a" is greater than terminal "b"
● a ⋖ b means the lower precedence of terminal "a" than terminal "b"
● a ≐ b indicates that all terminals "a" and "b" have the same precedence.
Precedence table:
|
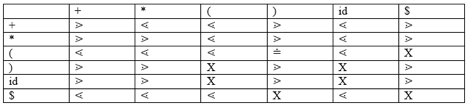
Parsing Action
● Add the $ symbol at both ends of the specified input string.
● Now search the right-left input string until the ⁇ is encountered.
● Scan to the left over all of the equal precedence until much of the first left is met.
● A handle is anything between most of the left and most of the right.
● $ on $ means the parsing succeeds.
Example - Grammar:
- E → E+T/T
- T → T*F/F
- F → id
Given string:
- w = id + id * id
For it, let us take a parse tree as follows:
|
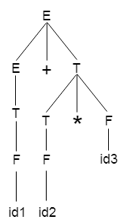
Fig 4: example
We can design the following operator precedence table on the basis of the tree above:
|
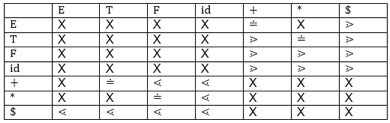
Let us now process the string with the assistance of the precedence table above:
|
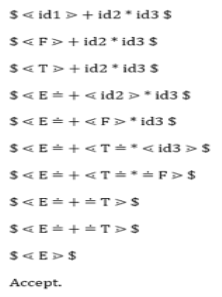
Key takeaway :
● The grammar of operator precedence is a kind of shift reduction system of parsing.
● It is applied to a small grammar class of operators.
● In the LR parser, “ L” means left to right scanning of any input .
● One form of bottom up parsing is LR parsing. It is used to evaluate a broad grammar class.
● R" stands for the construction of a proper reverse derivation.
● "K" is the number of look-ahead input symbols used to make a number of parsing decisions.
LR parsing is divided into four parts: parsing for LR (0), parsing for SLR, parsing for CLR and parsing for LALR.
|
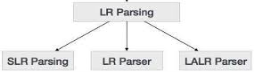
Fig 5: types of LR parser
LR algorithm :
The stack, input, output and parsing table are required by the LR algorithm. The input, output and stack are the same in all modes of LR parsing, but the parsing table is different.
|
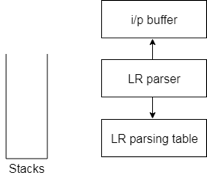
Fig 6: diagram of LR parser
● The input buffer is used to denote the end of the input and includes the string followed by the $ symbol to be parsed.
● To contain a series of grammar symbols with $ at the bottom of the stack, a stack is used.
● A two dimensional array is a parsing table. It comprises two parts: Action part and Go To part.
Except for the decreased data, the SLR parser is similar to the LR(0) parser. Reduced outputs are written only in the FOLLOW of the variable whose output is reduced.
Construction of SLR parsing table:-
- Constructing C = { I0, I1, ....... In}, a list of LR(0) object sets for G '.
- State I is made out of Ii. The parsing acts are calculated as follows for State I
● If [A ->? A. .a? ] is set to 'move j' in Ii and GOTO(Ii, a) = Ij, then set ACTION[i, a]. A must-be terminal here.
● If [A ->? .] is in Ii and then ACTION[i, a] is set to "reduce A ->??" In FOLLOW(A) for all a '; here A may not be S'.
● Is [S -> S.] in Ii, then 'accept' is set to action[i,$].
3. For all nonterminals A, the goto transitions for state I are constructed using the rule:
if GOTO( Ii , A ) = Ij then GOTO [i, A] = j.
4. An mistake is made in all entries not specified by Rules 2 and 3.
If we have several entries in the parsing table, then it is said that a dispute is
Consider the grammar E -> T+E | T
T ->id
Augmented grammar - E’ -> E
E -> T+E | T
T -> id
With one distinction, LALR parsers are the same as CLR parsers. If two states differ only in the lookahead in the CLR parser, then we combine those states in the LALR parser. If the parsing table does not clash, the grammar is still LALR after minimization.
Example
consider the grammar S ->AA
A -> aA | b
Augmented grammar - S’ -> S
S ->AA
A -> aA | b
Key takeaway :
● In the LR parser, “ L” means left to right scanning of any input .
● LR parsing is divided into four parts: parsing for LR (0), parsing for SLR, parsing for CLR and parsing for LALR.
● Except for the decreased data, the SLR parser is similar to the LR(0) parser.
● With one distinction, LALR parsers are the same as CLR parsers.
References :
- “Compilers - Principles, Techniques and Tools”, A.V. Aho, R. Shethi and J.D.Ullman, Pearson Education
2. “Compiler Construction”, Barret, Bates, Couch, Galgotia.
3. “Compiler Construction”, Dhamdere, Mc-Millan.
4. “Unix Programming”, Pepkin Pike.




