Unit - 4
Syntax Directed Translation and Run Time Environments
A Syntax Driven Description (SSD) is a context-free grammar generalisation in which each grammar symbol has an associated collection of attributes, divided into two subsets of that grammar symbol's synthesised and inherited attributes.
An attribute may represent a string, a number, a type, a position in the memory, or something. A semantic rule associated with the output used on that node determines the value of an attribute at a parse-tree node.
Types of Attributes : Attributes are grouped into two kinds:
1. Synthesized Attributes : These are the attributes that derive their values from their child nodes, i.e. the synthesised attribute value at the node is determined from the attribute values at the child nodes in the parse tree.
Example
E --> E1 + T { E.val = E1.val + T.val}
● Write the SDD using applicable semantic rules in the specified grammar for each production.
● The annotated parse tree is created and bottom-up attribute values are computed.
● The final output will be the value obtained at the root node.
Considering the above example:
S --> E
E --> E1 + T
E --> T
T --> T1 * F
T --> F
F --> digit
You can write the SDD for the above grammar as follows:
Production | Semantic Action |
S --> E | Print (E.val) |
E --> E1 + T | E.val = E1.val + T.val |
E --> T | E.val = T. val |
T --> T1 * F | T. val = T1.val * F. val |
T --> F | T. val = F. val |
F --> digit | F. val = digit.lexval |
For arithmetic expressions, let us consider the grammar. The Syntax Directed Description associates a synthesised attribute, called val, to each non-terminal. The semantic rule measures the value of the non-terminal attribute val on the left side of the non-terminal value on the right side of the attribute val.
2. Inherited Attributes : These are the attributes derived from their parent or sibling nodes by their values, i.e. the value of the inherited attributes is determined by the parent or sibling node value.
Example
A --> BCD { C.in = A.in, C.type = B.type }
● Using semantic behaviour, create the SDD.
● The annotated parse tree is created and the values of attributes are computed top-down.
Consider the grammar below
S --> T L
T --> int
T --> float
T --> double
L --> L1, id
L --> id
You can write the SDD for the above grammar as follows:
Production | Semantic Action |
S --> T L | L.in = T.type |
T --> int | T.type = int |
T --> float | T.type = float |
T --> double | T.type = double |
L --> L1, id | L1.in = L.in Enter_type(id.entry, L.in) |
L --> id | Entry _type(id.entry, L.in) |
Key takeaway :
● SSD is a context-free grammar generalisation in which each grammar symbol has an associated collection of attributes
● Attributes divided into two subsets of that grammar symbol's synthesised and inherited attributes.
● Synethesised are the attributes that derive their values from their child nodes,
● Inherited are the attributes derived from their parent or sibling nodes by their values
The abstract syntactic structure of source code written in a programming language is represented by a syntax tree. Rather than elements such as braces, semicolons that end sentences in some languages, it focuses on the laws.
It is also a hierarchy divided into many parts with the elements of programming statements. The tree nodes denote a construct that exists in the source code.
A form id + id * id will have the following tree of syntax:
|
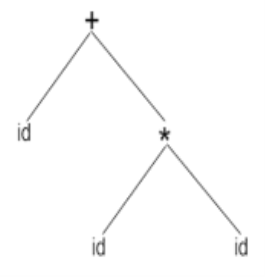
Fig 1: tree
It is possible to represent the Abstract Syntax Tree as :
|
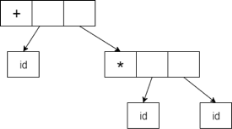
Fig 2: syntax tree
In a compiler, abstract syntax trees are significant data structures. It includes the least information that is redundant.
Key takeaway :
● Abstract syntax trees are more compact and can easily be used by a compiler than a parse tree.
● The syntax tree helps evaluate the compiler's accuracy.
● A parse forest is a collection of possible parse trees for a syntactically ambiguous word.
As a source code, a programme is merely a set of text (code, statements etc.) and it needs actions to be performed on the target computer to make it alive. To execute instructions, a programme requires memory resources. A programme includes names for processes, identifiers, etc. that enable the actual memory position to be mapped at runtime.
By runtime, we mean the execution of a programme. The runtime environment is the state of the target machine that can provide services to the processes running in the system, including software libraries, environment variables, and so on.
Procedure
A procedure description is a declaration associating a statement with an identifier. The identifier is the name of the procedure, and the sentence is the body of the procedure. For example, the following is the process description called readarray:
procedure readarray; var i : integer;
begin
for i : = 1 to 9 do read(a[i])
end;
The procedure is said to be named at that point where a procedure name occurs inside an executable sentence.
● Activation tree : The way control enters and leaves activations is depicted using an activation tree. In a tree with activation,
- Each node represents an activation of a procedure.
- The root represents the activation of the main program.
- The node for a is the parent of the node for b if and only if control flows from activation a to b.
- If and only if the lifetime of a begins before the lifetime of b, the node for an is to the left of the node for b.
● Control stack :
To keep track of live procedure activations, a control stack is used. The principle is to force the node into the control stack for an activation when the activation starts and to pop the node when the activation finishes. The contents of the control stack are aligned with the paths to the activation tree root. When node n is at the top of the control stack, nodes along the path from n to the root are present in the stack.
The Scope of a Declaration
A declaration is a syntactic construct that may be explicit in associating data with a n declaration, such as:
var i : integer ;
Or maybe they're tacit. For example, it is presumed that any variable name beginning with i denotes an integer. The scope of that assertion is called the portion of the programme to which a declaration refers.
Binding of Names
Even if each name is declared once in a program, different data objects at runtime may be denoted by the same name. "Data object" refers to a place of storage that contains values. The term environment refers to a feature that maps a storage location to a name. The term state refers to a function which maps the value kept there to a storage location. We assume that x is bound to s when an area associates storage position s with a name x. This relation is known as x binding.
|
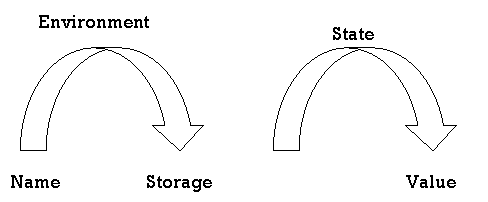
Fig 3: two stage mapping from names to values
Key takeaway :
● As a source code, a programme is merely a set of text and it needs actions to be performed on the target computer to make it alive.
● A programme includes names for processes, identifiers, etc. that enable the actual memory position to be mapped at runtime.
● A procedure description is a declaration associating a statement with an identifier.
● It runs in its own logical address space when the target programme is executed, where the value of each programme has a location.
● The logical address space is shared between the management and organisation of the compiler, operating system and target machine. The operating system is used to translate the logical address into a physical address that is typically distributed across the memory.
● Runtime storage comes into blocks, where the smallest unit of addressable memory is displayed using a byte. A machine word can be formed using four bytes. The multibyte object is stored in successive bytes and provides the address of the first byte.
|
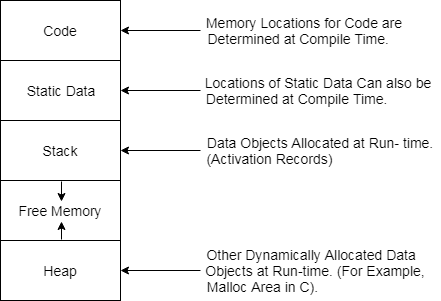
Fig 4: storage allocation
In each of the three data areas of the enterprise, there are essentially three storage-allocation methods used.
● At compile time, static allocation lays out storage for all data objects.
● Stack allocation handles as a stack the run-time storage,
● Heap allocation allocates and deallocates storage from a data area known as a heap, as required at runtime.
Static storage allocation :
● Names are attached to storage locations in static allocation.
● If the memory is created at the time of compilation, the memory is created in a static region and only once.
● The dynamic data structure is assisted by static allocation, meaning that memory is only generated at compile time and redistributed after programme completion.
● The downside of static storage allocation is that it is important to know the size and position of data objects at compile time.
● The constraint of the recursion method is another downside.
Stack storage allocation :
● Space is structured as a stack of static storage allocation.
● When activation begins, an activation record is placed into the stack and it pops when the activation finishes.
● The activation record includes the locals of each activation record so that they are connected to fresh storage. When the activation stops, the value for locals is deleted.
● It operates on the basis of last-in-first-out (LIFO) and the recursion mechanism is supported by this allocation.
Calling sequence :
In what is known as the calling sequence, which consists of code that allocates an activation record on the stack and enters data into its fields, named procedures are implemented. The return sequence is identical to the code to restore the machine state, so that after the call, the calling procedure will resume its execution. The code in the calling sequence is always split between the calling method (caller) and the calling procedure (callee).
Heap storage allocation :
● The most versatile allocation scheme is heap allocation.
● Depending on the requirement of the user, memory allocation and deallocation can be performed at any time and at any venue.
● Heap allocation is used to dynamically assign memory to the variables and then regain it when the variables are no longer used.
● The recursion mechanism is assisted by heap capacity allocation.
Key takeaway :
● If the memory is created at the time of compilation, the memory is created in a static region and only once, in static storage allocation.
● Space is structured as a stack of static storage allocation.
● The most versatile allocation scheme is heap allocation.
The medium of communication between procedures is known as passing parameters. The values of the variables from a calling procedure are passed by some process to the called procedure. Go first through some simple terminologies relating to the principles in a programme before going on.
r-value : An expression's value is called its r-value. The value stored in a single variable even, if it occurs on the right-hand side of the assignment operator, becomes an r-value. It is always possible to assign r-values to any other variable.
l-value : The memory location (address) at which an expression is stored is referred to as the l-value of that expression. It often appears on the left side of an operator's task.
Example
day = 1;
week = day * 7;
month = 1;
year = month * 12;
We understand from this example that constant values, such as 1, 7, 12, and variables such as day, week, month and year, all have r-values. As they also represent the memory location assigned to them, only variables have l-values.
7 = x + y;
As constant 7 does not represent any memory location, this is a l-value error.
Formal Parameter :
The formal parameters are called variables that take the data passed by the caller procedure. In the description of the call function, certain variables are declared.
Actual Parameter :
The actual parameters are called variables whose values or addresses are transferred to the calling process. These variables are defined as arguments in the function call.
Example
fun_one()
{
int actual_parameter = 16;
call fun_two(int actual_parameter);
}
fun_two(int formal_parameter)
{
print formal_parameter;
}
Depending on the parameter passing technique used, formal parameters hold the actual parameter information. It may be an address or a value.
Different ways of passing the parameters to the procedure
● Call by Value
The calling procedure passes the r-value of actual parameters in the pass by value mechanism, and the compiler puts that into the activation record of the called procedure. The formal parameters will then hold the values that the calling procedure passes. If the values held by the formal parameters are modified, the real parameters should not be influenced by this.
● Call by References
The formal and real parameters in the reference call refer to the same memory location. The l-value of the individual parameters is copied to the call function's activation record. The named function therefore has the address of the actual parameters. If there is no l-value(eg-i+3) for the actual parameters, it is evaluated at a new temporary location and the location address is transmitted. Any formal parameter changes are expressed in the actual parameters (because changes are made at the address).
● Call by Copy Restore
In copy call restore, the compiler copies the value to formal parameters when the procedure is called and copies the value back to real parameters when the control returns to the method called. The r-values are transferred, and the r-value of formals is copied to the l-value of actuals upon return.
● Call by Name
The actual parameters are substituted for formals in the call by name in all places where formals occur in the process. It is also referred to as lazy assessment since evaluation is only conducted on criteria when appropriate.
Key takeaway :
● The medium of communication between procedures is known as passing parameters.
● The formal parameters are called variables that take the data passed by the caller procedure.
● The actual parameters are called variables whose values or addresses are transferred to the calling process.
The Symbol Table is an essential data structure generated and maintained by the compiler to keep track of variable semantics, i.e. to store information about scope and binding information about names, information about instances of different entities, such as variable and function names, classes, objects, etc.
A table of symbols used for the following purposes:
● It is used to store the names of all individuals in one location in a standardised way.
● To check if a variable has been declared, it is used.
● It is used to evaluate a name's scope.
● It is used to enforce type checking by verifying the assignments and semantically correct expressions in the source code.
Symbol Table entries –
Every entry in the symbol table is associated with attributes that the compiler supports at various stages.
Items contained in Table Symbols:
● Variable names and constants
● Procedure and function names
● Literal constants and strings
● Compiler generated temporaries
● Labels in source languages
Details from the Symbol table used by the compiler:
● Data type and name
● Declaring procedures
● Offset in storage
● If structure or record then, pointer to structure table.
● For parameters, whether parameter passing by value or by reference
● Number and type of arguments passed to function
● Base Address
Operations of Symbol table –
The basic operations listed on the table of symbols include:
Operation | Functions |
insert | To insert a name into a table of symbols and return a pointer to its input.
|
lookup | To check for a name and return its input to the pointer
|
free | Removal of all entries and free symbol table storage.
|
allocate | To assign a new empty table of symbols. |
Implementation :
If the compiler is used to handle a small amount of data, the symbol table can be implemented in the unordered list.
In one of the following methods, a symbol table can be implemented:
● Linked list
● The linked list is used for this implementation. To each record, a connection field is added.
● Searching for names is performed in the order suggested by the link area of the link.
● To point to the first record of the symbol table, a pointer 'First' is retained.
● Insertion O(1) is fast, but search is slow on average for large tables-O(n)
● List
● An array is used in this technique to store names and associated information.
● A "available" pointer is kept at the end of all records stored and new names are inserted in order as they arrive.
● We start looking for a name from the beginning of the list till the pointer is available and if not found, we get the error "use of undeclared name"
● We need to ensure that it is not already present when adding a new name, otherwise there is an error, i.e. "Multiple defined name"
● Insertion O(1) is fast, but search is slow on average for large tables-O(n)
● The benefit is that a minimum amount of space is needed.
● Hash table
● Two tables are kept in the hashing system-a hash table and symbol table and is the most widely used method for implementing symbol tables.
● An array with an index range is a hash table: 0 to tablesize-1. These entries are pointers pointing to table symbol names.
● We use hash functions to look for a name that will result in any integer between 0 and tablesize-1.
● It is possible to insert and lookup very easily, O (1).
● The benefit is that it is possible to search rapidly and the downside is that it is difficult to implement hashing.
● Binary search tree
● Another solution is to use the binary search tree to enforce the symbol table, i.e. we add two relation fields, i.e. left and right kid.
● All the names are generated as root node children, which always follow the binary search tree property.
● On average, insertion and lookup are O(log2 n).
Key takeaway :
● It is used to store the names of all individuals in one location in a standardised way.
● Every entry in the symbol table is associated with attributes that the compiler supports at various stages.
● If the compiler is used to handle a small amount of data, the symbol table can be implemented in the unordered list.
The techniques necessary to enforce the dynamic allocation of storage rely primarily on how the storage is allocated. If deallocation is implicit, then it is the duty of the run-time support package to decide when a storage block is no longer required. If delocation is performed directly by the programmer, there is less a compiler has to do.
The methods needed to apply dynamic strategies for allocating storage rely on how the space is allocated. That is to say : implicitly or explicitly .
Explicit Allocation of Fixed - Sized Blocks
● Blocks of a fixed size include the simplest type of dynamic allocation.
● With little to no storage overhead, allocation and deallocation can be achieved easily.
● Suppose there are blocks to be drawn from a contiguous storage area. Using a portion of each block for a connection to the next block, initialization of the region is completed.
● The available pointer points to the first block. Allocation consists of removing a block from the list and deallocation consists of adding the block to the list.
Explicit Allocation of Variable - Sized Blocks
● Storage may become fragmented as blocks are allocated and translocated; that is, the heap can consist of free alternate blocks.
● The situation can occur if five blocks are allocated by a programme and the second and fourth are then de-allocated.
● If blocks are of fixed size, fragmentation is of no concern, but if they are of variable size, because, while the space is available, we could not assign a block larger than all of the free blocks.
● Some strategies for allocating variable-sized blocks include first fit, worst fit and best fit.
● |

Fig 5: free and used block
Implicit Deallocation
● Implicit allocation requires coordination between the user programme and the run-time package, because when a storage block is no longer used, the latter needs to know.
● By fixing the format of storage blocks, this cooperation is enforced.
- Reference counts :
● We keep track of the number of blocks which directly point to the current block. If this count ever drops to 0, because it can not be referred to, the block can be translocated.
● The block has been, in other words, garbage that can be gathered. Maintaining reference counts in time can be expensive.
II. Marketing techniques :
● An alternate method is to momentarily suspend user programme execution and use the frozen pointers to determine which blocks are in use.
|
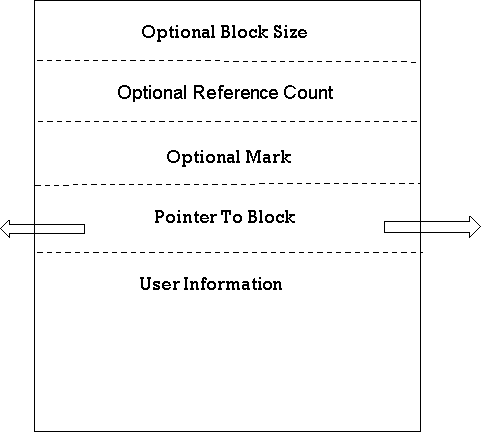
Fig 6: implicit deallocation
Key takeaway :
● The techniques necessary to enforce the dynamic allocation of storage rely primarily on how the storage is allocated.
● If delocation is performed directly by the programmer, there is less a compiler has to do.
● Blocks of a fixed size include the simplest type of dynamic allocation.
● Storage may become fragmented as blocks are allocated and translocated; that is, the heap can consist of free alternate blocks.
References :
- “Compiler Construction”, Dhamdere, Mc-Millan.
2. “Compilers - Principles, Techniques and Tools”, A.V. Aho, R. Shethi and J.D.Ullman, Pearson Education
3. “Compiler Construction”, Barret, Bates, Couch, Galgotia.
4. “Unix Programming”, Pepkin Pike.




