Unit-3
Database Design
A database includes bulk information deposited in a framework, making it easier to locate and explore relevant information. A well-designed database contains accurate and up-to-date information, allowing and data to be fetched easily whenever needed.
In this article, we’ll discuss the importance of a good database design and how it can benefit your data endeavors. We’ll also go through some of the most common database design techniques. Lastly, we’ll cover basic steps and best practices to help you design a good database for your organization.
What is Database Design?
Database Design is defined as a collection of steps that help with designing, creating, implementing, and maintaining a business’s data management systems. The main purpose of designing a database is to produce physical and logical models of designs for the proposed database system.
What is a Good Database Design?
A good database design process is governed by specific rules. The first rule dictates that redundant data must be avoided; as it wastes space and increases the probability of faults and discrepancies within the database. The next rule is that the accuracy and comprehensiveness of information is extremely imperative. If the database contains erroneous information, any documents that fetch data from such a database will also include inaccurate information. Consequently, any decisions based on those documents will be misleading.
So, how can you ensure that your database design is good? A well-designed database is the one that:
ETL Your Enterprise Data Using MYSQL Connector
Move MySQL Data to a Destination of Your Choice Through a Codeless, Drag-and-Drop UI.
Importance of Database Design
Database design defines the database structure used for planning, storing, and managing information. Accuracy in data can only be accomplished if a database is designed to store only valuable and necessary information.
A well-designed database is imperative in guaranteeing information consistency, eliminating redundant data, efficiently executing queries, and improving the performance of the database. Meticulously designing a database saves you from wasting time and getting frustrated during the database development phase. A good database design also allows you to easily access and retrieve data whenever needed.
The reliability of data depends on the table structure; whereas creating primary and unique keys guarantees uniformity in the stored information. Data replication can be avoided by forming a table of probable values and using a key to denote the value. So, whenever the value changes, the alteration happens only once in the main table.
As the general performance of a database depends on its design, a good database design uses simple queries and faster implementation. It is easy to maintain and update; whereas fixing trivial interruptions in a poor database design may harm stored events, views, and utilities.
Database Development Life Cycle
There are various stages in database development. However, it is not necessary to follow each of the steps sequentially. The life cycle can be broadly divided into three steps: requirement analysis, database designing, and implementation.
1- Requirement Analysis
Requirement analysis requires two steps:
2- Database designing
The actual database designing takes into account two key models:
3- Implementation
The implementation stage of database development life cycle is concerned with:
Database Designing Techniques
The two most common techniques used to design a database include:
Implement Virtual Database
Implement Virtual Database Tools to Provide Business-Users the Accessibility and Flexibility They Requires to Analyze Data.
How to Design Database: Steps of Designing Database
Database designing generally starts with identifying the purpose of your database. The relevant data is then collected and organized into tables. Next, you specify the primary keys and analyze relationships between different tables. After refining the tables, the last step is to apply normalization rules for table standardization.
Let’s look at these steps of database design in detail:
The first step is to determine the purpose of your database. For example, if you are a small home-based business, you could be designing a customer database that maintains a list of consumer info to generate emails and reports.
At the end of this step, you’ll have a strong mission statement that you can refer to throughout the database design process. It’ll help you concentrate on your objectives when making important decisions.
The next step is to collect all kinds of information that you might want to store in the database. Begin with the current information. Mull over the questions you want your database to answer, and it’ll help you decide which data needs to be recorded.
Once you’ve amassed all the necessary data items, the next step is to divide them into main entities or subject areas. For example, if you are a retailer, some of your main entities could be products, customers, suppliers, and orders. Each entity will then become a separate table.
Here’s an example of how you can divide data into different entities:
Data is segregated into tables, such that every data item becomes a field and is shown as a column. For instance, a Customer table might include fields like name, address, e-mail address, and city.
After determining the preliminary set of columns for every table, you can refine them. For instance, customer name can be recorded as two distinct columns: first name and last name. Likewise, you can store the address in five distinct columns based on address, town, state, zip code, and region. This will make it convenient for you to filter information.
Streamline Cross-Database Analysis
Access the MariaDB Database and Create a Holistic View of Your Data Through Codeless Integration.
The next step to improve your database design is to select a primary key for every table. This primary key is a column or a set of column that’s used to distinctively pinpoint each row. For instance, in your customer table, the primary key could be customer ID. This will allow you to uniquely identify each row based on the customer ID.
More than one primary key can also exist, called a composite key, including multiple columns. For example, in your Order Details table, primary keys could be order ID and product ID. The composite key can be made using fields with similar or varying data types.
Similarly, if you wish to get an idea of your product sales, you can identify the product ID from the Products table and the order number or ID from the Orders table.
After dividing data into tables, information needs to be brought together in a meaningful manner. So, explore each table and determine how the data in one table is linked with the data in another table. If needed, you can add fields or form new tables to simplify the relationship based on the types of information.
Below is an example of different entity types and relation types.
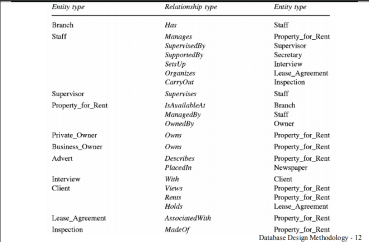
Fig 1 - Example of different entity types and relation types
In this step, you’ll create one-to-one, one-to-many, and/or many-to-many relationships between different table entries.
When only one item from a table is associated with an item from another table, it’s called a one-to-one (1:1) relationship. In a one-to-many (1:M) relationship, an item in one table is related to many items in the other table, such as one customer placing several orders. A many-to-many (M:N) relationship occurs if many items from one table are related to many items in other tables.
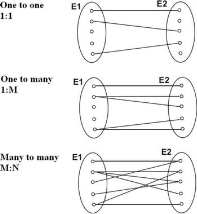
Fig 2 - Example
Now that you have all the required tables, fields, and relationships, the next step is to refine your database design by creating and populating your tables with mockup information. Experiment with the sample data by creating queries or adding new items. This will help you analyze your design for faults and you’ll be able to highlight possible errors. If needed, adjust your design to mitigate those problems.
The last step is to implement the normalization rules for your database design. It is a systematic approach that removes redundancy and unwanted characteristics, such as Insertion, Update, and Deletion irregularities.
This multi-step process stores data in a tabular form, eliminating redundant data from the relation tables.
Final Words
The database design process helps you simplify the design, development, execution, and maintenance of your corporate data management system.
A good database design can help save disk storage space by reducing data redundancy. Along with maintaining data precision and reliability, it allows you to access data in various ways. Moreover, a well-designed database is easier to use and maintain, making integration a breeze.
Key takeaway
A database includes bulk information deposited in a framework, making it easier to locate and explore relevant information. A well-designed database contains accurate and up-to-date information, allowing and data to be fetched easily whenever needed.
In this article, we’ll discuss the importance of a good database design and how it can benefit your data endeavors. We’ll also go through some of the most common database design techniques. Lastly, we’ll cover basic steps and best practices to help you design a good database for your organization.
Functional Dependency
Functional dependency (FD) is a set of constraints between two attributes in a relation. Functional dependency says that if two tuples have same values for attributes A1, A2,..., An, then those two tuples must have to have same values for attributes B1, B2, ..., Bn.
Functional dependency is represented by an arrow sign (→) that is, X→Y, where X functionally determines Y. The left-hand side attributes determine the values of attributes on the right-hand side.
Armstrong's Axioms
If F is a set of functional dependencies then the closure of F, denoted as F+, is the set of all functional dependencies logically implied by F. Armstrong's Axioms are a set of rules, that when applied repeatedly, generates a closure of functional dependencies.
Trivial Functional Dependency
Normalization
If a database design is not perfect, it may contain anomalies, which are like a bad dream for any database administrator. Managing a database with anomalies is next to impossible.
Normalization is a method to remove all these anomalies and bring the database to a consistent state.
First Normal Form
First Normal Form is defined in the definition of relations (tables) itself. This rule defines that all the attributes in a relation must have atomic domains. The values in an atomic domain are indivisible units.
Fig 3 – 1NF
We re-arrange the relation (table) as below, to convert it to First Normal Form.
Fig 4 - Re-arrange the relation 1NF
Each attribute must contain only a single value from its pre-defined domain.
Second Normal Form
Before we learn about the second normal form, we need to understand the following −
If we follow second normal form, then every non-prime attribute should be fully functionally dependent on prime key attribute. That is, if X →A holds, then there should not be any proper subset Y of X, for which Y → A also holds true.
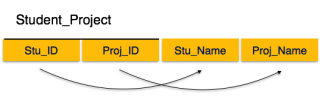
Fig 5 – 2 NF
We see here in Student_Project relation that the prime key attributes are Stu_ID and Proj_ID. According to the rule, non-key attributes, i.e. Stu_Name and Proj_Name must be dependent upon both and not on any of the prime key attribute individually. But we find that Stu_Name can be identified by Stu_ID and Proj_Name can be identified by Proj_ID independently. This is called partial dependency, which is not allowed in Second Normal Form.
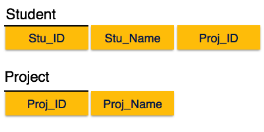
Fig 6 - Partial dependency
We broke the relation in two as depicted in the above picture. So there exists no partial dependency.
Third Normal Form
For a relation to be in Third Normal Form, it must be in Second Normal form and the following must satisfy −
- X is a superkey or,
- A is prime attribute.

Fig 7 – 3 NF
We find that in the above Student_detail relation, Stu_ID is the key and only prime key attribute. We find that City can be identified by Stu_ID as well as Zip itself. Neither Zip is a superkey nor is City a prime attribute. Additionally, Stu_ID→ Zip → City, so there existstransitive dependency.
To bring this relation into third normal form, we break the relation into two relations as follows −
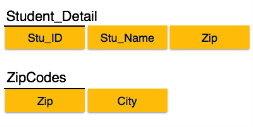
Boyce-Codd Normal Form
Boyce-Codd Normal Form (BCNF) is an extension of Third Normal Form on strict terms. BCNF states that −
In the above image, Stu_ID is the super-key in the relation Student_Detail and Zip is the super-key in the relation ZipCodes. So,
Stu_ID→Stu_Name, Zip
and
Zip → City
Which confirms that both the relations are in BCNF.
Key takeaway
Functional dependency (FD) is a set of constraints between two attributes in a relation. Functional dependency says that if two tuples have same values for attributes A1, A2,..., An, then those two tuples must have to have same values for attributes B1, B2, ..., Bn.
Functional dependency is represented by an arrow sign (→) that is, X→Y, where X functionally determines Y. The left-hand side attributes determine the values of attributes on the right-hand side.
What is Functional Dependency?
Functional Dependency (FD) is a constraint that determines the relation of one attribute to another attribute in a Database Management System (DBMS). Functional Dependency helps to maintain the quality of data in the database. It plays a vital role to find the difference between good and bad database design.
A functional dependency is denoted by an arrow "→". The functional dependency of X on Y is represented by X → Y. Let's understand Functional Dependency in DBMS with example.
Example:
Employee number | Employee Name | Salary | City |
1 | Dana | 50000 | San Francisco |
2 | Francis | 38000 | London |
3 | Andrew | 25000 | Tokyo |
In this example, if we know the value of Employee number, we can obtain Employee Name, city, salary, etc. By this, we can say that the city, Employee Name, and salary are functionally depended on Employee number.
Key terms
Here, are some key terms for Functional Dependency in Database:
Key Terms | Description |
Axiom | Axioms is a set of inference rules used to infer all the functional dependencies on a relational database. |
Decomposition | It is a rule that suggests if you have a table that appears to contain two entities which are determined by the same primary key then you should consider breaking them up into two different tables. |
Dependent | It is displayed on theright side of the functional dependency diagram. |
Determinant | It is displayed on the left side of the functional dependency Diagram. |
Union | It suggests that if two tables are separate, and the PK is the same, you should consider putting them. together |
Rules of Functional Dependencies
Below are the Three most important rules for Functional Dependency in Database:
Types of Functional Dependencies in DBMS
There are mainly four types of Functional Dependency in DBMS. Following are the types of Functional Dependencies in DBMS:
Multivalued Dependency in DBMS
Multivalued dependency occurs in the situation where there are multiple independent multivalued attributes in a single table. A multivalued dependency is a complete constraint between two sets of attributes in a relation. It requires that certain tuples be present in a relation. Consider the following Multivalued Dependency Example to understand.
Example:
Car_model | Maf_year | Color |
H001 | 2017 | Metallic |
H001 | 2017 | Green |
H005 | 2018 | Metallic |
H005 | 2018 | Blue |
H010 | 2015 | Metallic |
H033 | 2012 | Gray |
In this example, maf_year and color are independent of each other but dependent on car_model. In this example, these two columns are said to be multivalue dependent on car_model.
This dependence can be represented like this:
car_model ->maf_year
car_model-> colour
Trivial Functional Dependency in DBMS
The Trivial dependency is a set of attributes which are called a trivial if the set of attributes are included in that attribute.
So, X -> Y is a trivial functional dependency if Y is a subset of X. Let's understand with a Trivial Functional Dependency Example.
For example:
Emp_id | Emp_name |
AS555 | Harry |
AS811 | George |
AS999 | Kevin |
Consider this table of with two columns Emp_id and Emp_name.
{Emp_id, Emp_name} ->Emp_id is a trivial functional dependency as Emp_id is a subset of {Emp_id,Emp_name}.
Non Trivial Functional Dependency in DBMS
Functional dependency which also known as a nontrivial dependency occurs when A->B holds true where B is not a subset of A. In a relationship, if attribute B is not a subset of attribute A, then it is considered as a non-trivial dependency.
Company | CEO | Age |
Microsoft | Satya Nadella | 51 |
SundarPichai | 46 | |
Apple | Tim Cook | 57 |
Example:
(Company} -> {CEO} (if we know the Company, we knows the CEO name)
But CEO is not a subset of Company, and hence it's non-trivial functional dependency.
Transitive Dependency in DBMS
A Transitive Dependency is a type of functional dependency which happens when t is indirectly formed by two functional dependencies. Let's understand with the following Transitive Dependency Example.
Example:
Company | CEO | Age |
Microsoft | Satya Nadella | 51 |
SundarPichai | 46 | |
Alibaba | Jack Ma | 54 |
{Company} -> {CEO} (if we know the compay, we know its CEO's name)
{CEO } -> {Age} If we know the CEO, we know the Age
Therefore according to the rule of rule of transitive dependency:
{ Company} -> {Age} should hold, that makes sense because if we know the company name, we can know his age.
Note: You need to remember that transitive dependency can only occur in a relation of three or more attributes.
What is Normalization?
Normalization is a method of organizing the data in the database which helps you to avoid data redundancy, insertion, update& deletion anomaly. It is a process of analyzing the relation schemas based on their different functional dependencies and primary key.
Normalization is inherent to relational database theory. It may have the effect of duplicating the same data within the database which may result in the creation of additional tables.
Advantages of Functional Dependency
Summary
Key takeaway
Functional Dependency (FD) is a constraint that determines the relation of one attribute to another attribute in a Database Management System (DBMS). Functional Dependency helps to maintain the quality of data in the database. It plays a vital role to find the difference between good and bad database design.
A functional dependency is denoted by an arrow "→". The functional dependency of X on Y is represented by X → Y. Let's understand Functional Dependency in DBMS with example.
Closure of an Attribute: Closure of an Attribute can be defined as a set of attributes that can be functionally determined from it.
OR
Closure of a set F of FDs is the set F+ of all FDs that can be inferred from F
Closure of a set of attributes X concerning F is the set X+ of all attributes that are functionally determined by X
Pseudocode to find Closure of an Attribute?
Determine X+, the closure of X under functional dependency set F
X Closure : = will contain X itself;
Repeat the process as:
old X Closure : = X Closure;
for each functional dependency P → Q in FD set do
if X Closure is subset of P then X Closure := X Closure U Q ;
Repeat until ( X Closure = old X Closure);
Algorithm of Determining X+, the Closure of X under F
Input: A set F of FDs on a relation schema R, and a set of attributes X, which is a subset of R.
QUESTIONS ON CLOSURE SET OF ATTRIBUTE:
1) Given relational schema R( P Q R S T U V) having following attribute P Q R S T U and V, also there is a set of functional dependency denoted by FD = { P->Q, QR->ST, PTV->V }.
Determine Closure of (QR)+ and (PR)+
a) QR+ = QR (as the closure of an attribute or set of attributes contain same).
Now as per algorithm look into a set of FD that complete the left side of any FD contains either Q, R, or QR since in FD QR→ST has complete QR.
Hence QR+ = QRST
Again, trace the remaining two FD that any left part of FD contains any Q, R, S, T.
Since no complete left side of the remaining two FD{P->Q, PTV->V} contain Q, R, S, T.
Therefore QR+ = QRST (Answer)
Note: In FD PTV→V, T is in QRST but that cannot be entertained, as complete PTV should be a subset of QRST
b) PR + = PR (as the closure of an attribute or set of attributes contain same)
Now as per algorithm look into a set of FD, and check that complete left side of any FD contains either P, R, or PR. Since in FD P→Q, P is a subset of PR, Hence PR+ = PRQ
Again, trace the remaining two FD that any left part of FD contains any P, R, Q, Since, in FD QR → ST has its complete left part QR in PQR
Hence PR+ = PRQST
Again trace the remaining one FD { PTV->V } that its complete left belongs to PRQST. Since complete PTV is not in PRQST, hence we ignore it.
Therefore PR+ = PRQST ( Answer)
2. Given relational schema R( P Q R S T) having following attributes P Q R S and T, also there is a set of functional dependency denoted by FD = { P->QR, RS->T, Q->S, T-> P }.
Determine Closure of ( T )+
T + = T (as the closure of an attribute or set of attributes contain same) Now as per algorithm look into a set of FD that complete the left side of any FD contains T since, in FD T → P, T is in T, Hence T+ = TP Again trace the remaining three FD that any left part of FD contain any TP, Since in FD P → QR has its complete left part P in TP, Hence T+ = TPQR Again trace the remaining two FD { RS->T, Q->S } that any of its Complete left belongs to TPQR, Since in FD Q → S has its complete left part Q in TPQR, Hence T+ = TPQRS Again trace the remaining one FD { RS->T } that its complete left belongs to TPQRS, Since in FD RS → T has its complete left part RS in TPQRS Hence T+ = TPQRS ( no changes, as T, is already in TPQRS) Therefore T+ = TPQRS ( Answer).
Key takeaway
Closure of an Attribute: Closure of an Attribute can be defined as a set of attributes that can be functionally determined from it.
OR
Closure of a set F of FDs is the set F+ of all FDs that can be inferred from F
Closure of a set of attributes X concerning F is the set X+ of all attributes that are functionally determined by X
Normalization
Types of Normal Forms
There are the four types of normal forms:
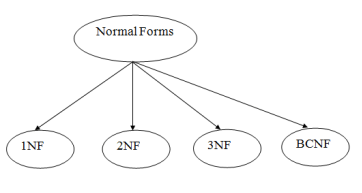
Fig 8 – Normal Forms
Normal Form | Description |
1NF | A relation is in 1NF if it contains an atomic value. |
2NF | A relation will be in 2NF if it is in 1NF and all non-key attributes are fully functional dependent on the primary key. |
3NF | A relation will be in 3NF if it is in 2NF and no transition dependency exists. |
4NF | A relation will be in 4NF if it is in Boyce Codd normal form and has no multi-valued dependency. |
5NF | A relation is in 5NF if it is in 4NF and not contains any join dependency and joining should be lossless. |
First Normal Form (1NF)
Example: Relation EMPLOYEE is not in 1NF because of multi-valued attribute EMP_PHONE.
EMPLOYEE table:
EMP_ID | EMP_NAME | EMP_PHONE | EMP_STATE |
14 | John | 7272826385, | UP |
20 | Harry | 8574783832 | Bihar |
12 | Sam | 7390372389, | Punjab |
The decomposition of the EMPLOYEE table into 1NF has been shown below:
EMP_ID | EMP_NAME | EMP_PHONE | EMP_STATE |
14 | John | 7272826385 | UP |
14 | John | 9064738238 | UP |
20 | Harry | 8574783832 | Bihar |
12 | Sam | 7390372389 | Punjab |
12 | Sam | 8589830302 | Punjab |
Second Normal Form (2NF)
Example: Let's assume, a school can store the data of teachers and the subjects they teach. In a school, a teacher can teach more than one subject.
TEACHER table
TEACHER_ID | SUBJECT | TEACHER_AGE |
25 | Chemistry | 30 |
25 | Biology | 30 |
47 | English | 35 |
83 | Math | 38 |
83 | Computer | 38 |
In the given table, non-prime attribute TEACHER_AGE is dependent on TEACHER_ID which is a proper subset of a candidate key. That's why it violates the rule for 2NF.
To convert the given table into 2NF, we decompose it into two tables:
TEACHER_DETAIL table:
TEACHER_ID | TEACHER_AGE |
25 | 30 |
47 | 35 |
83 | 38 |
TEACHER_SUBJECT table:
TEACHER_ID | SUBJECT |
25 | Chemistry |
25 | Biology |
47 | English |
83 | Math |
83 | Computer |
Third Normal Form (3NF)
A relation is in third normal form if it holds atleast one of the following conditions for every non-trivial function dependency X → Y.
Example:
EMPLOYEE_DETAIL table:
EMP_ID | EMP_NAME | EMP_ZIP | EMP_STATE | EMP_CITY |
222 | Harry | 201010 | UP | Noida |
333 | Stephan | 02228 | US | Boston |
444 | Lan | 60007 | US | Chicago |
555 | Katharine | 06389 | UK | Norwich |
666 | John | 462007 | MP | Bhopal |
Super key in the table above:
Candidate key: {EMP_ID}
Non-prime attributes: In the given table, all attributes except EMP_ID are non-prime.
Here, EMP_STATE & EMP_CITY dependent on EMP_ZIP and EMP_ZIP dependent on EMP_ID. The non-prime attributes (EMP_STATE, EMP_CITY) transitively dependent on super key(EMP_ID). It violates the rule of third normal form.
That's why we need to move the EMP_CITY and EMP_STATE to the new <EMPLOYEE_ZIP> table, with EMP_ZIP as a Primary key.
EMPLOYEE table:
EMP_ID | EMP_NAME | EMP_ZIP |
222 | Harry | 201010 |
333 | Stephan | 02228 |
444 | Lan | 60007 |
555 | Katharine | 06389 |
666 | John | 462007 |
EMPLOYEE_ZIP table:
EMP_ZIP | EMP_STATE | EMP_CITY |
201010 | UP | Noida |
02228 | US | Boston |
60007 | US | Chicago |
06389 | UK | Norwich |
462007 | MP | Bhopal |
Boyce Codd normal form (BCNF)
Example: Let's assume there is a company where employees work in more than one department.
EMPLOYEE table:
EMP_ID | EMP_COUNTRY | EMP_DEPT | DEPT_TYPE | EMP_DEPT_NO |
264 | India | Designing | D394 | 283 |
264 | India | Testing | D394 | 300 |
364 | UK | Stores | D283 | 232 |
364 | UK | Developing | D283 | 549 |
In the above table Functional dependencies are as follows:
Candidate key: {EMP-ID, EMP-DEPT}
The table is not in BCNF because neither EMP_DEPT nor EMP_ID alone are keys.
To convert the given table into BCNF, we decompose it into three tables:
EMP_COUNTRY table:
EMP_ID | EMP_COUNTRY |
264 | India |
264 | India |
EMP_DEPT table:
EMP_DEPT | DEPT_TYPE | EMP_DEPT_NO |
Designing | D394 | 283 |
Testing | D394 | 300 |
Stores | D283 | 232 |
Developing | D283 | 549 |
EMP_DEPT_MAPPING table:
EMP_ID | EMP_DEPT |
D394 | 283 |
D394 | 300 |
D283 | 232 |
D283 | 549 |
Functional dependencies:
Candidate keys:
For the first table: EMP_ID
For the second table: EMP_DEPT
For the third table: {EMP_ID, EMP_DEPT}
Now, this is in BCNF because left side part of both the functional dependencies is a key.
Fourth normal form (4NF)
Example
STUDENT
STU_ID | COURSE | HOBBY |
21 | Computer | Dancing |
21 | Math | Singing |
34 | Chemistry | Dancing |
74 | Biology | Cricket |
59 | Physics | Hockey |
The given STUDENT table is in 3NF, but the COURSE and HOBBY are two independent entity. Hence, there is no relationship between COURSE and HOBBY.
In the STUDENT relation, a student with STU_ID, 21 contains two courses, Computer and Math and two hobbies, Dancing and Singing. So there is a Multi-valued dependency on STU_ID, which leads to unnecessary repetition of data.
So to make the above table into 4NF, we can decompose it into two tables:
STUDENT_COURSE
STU_ID | COURSE |
21 | Computer |
21 | Math |
34 | Chemistry |
74 | Biology |
59 | Physics |
STUDENT_HOBBY
STU_ID | HOBBY |
21 | Dancing |
21 | Singing |
34 | Dancing |
74 | Cricket |
59 | Hockey |
Fifth normal form (5NF)
Example
SUBJECT | LECTURER | SEMESTER |
Computer | Anshika | Semester 1 |
Computer | John | Semester 1 |
Math | John | Semester 1 |
Math | Akash | Semester 2 |
Chemistry | Praveen | Semester 1 |
In the above table, John takes both Computer and Math class for Semester 1 but he doesn't take Math class for Semester 2. In this case, combination of all these fields required to identify a valid data.
Suppose we add a new Semester as Semester 3 but do not know about the subject and who will be taking that subject so we leave Lecturer and Subject as NULL. But all three columns together acts as a primary key, so we can't leave other two columns blank.
So to make the above table into 5NF, we can decompose it into three relations P1, P2 & P3:
P1
SEMESTER | SUBJECT |
Semester 1 | Computer |
Semester 1 | Math |
Semester 1 | Chemistry |
Semester 2 | Math |
P2
SUBJECT | LECTURER |
Computer | Anshika |
Computer | John |
Math | John |
Math | Akash |
Chemistry | Praveen |
P3
SEMSTER | LECTURER |
Semester 1 | Anshika |
Semester 1 | John |
Semester 1 | John |
Semester 2 | Akash |
Semester 1 | Praveen |
Key takeaway
Relational Decomposition
Types of Decomposition
Fig 9 - Decomposition
Lossless Decomposition
Example:
EMPLOYEE_DEPARTMENT table:
EMP_ID | EMP_NAME | EMP_AGE | EMP_CITY | DEPT_ID | DEPT_NAME |
22 | Denim | 28 | Mumbai | 827 | Sales |
33 | Alina | 25 | Delhi | 438 | Marketing |
46 | Stephan | 30 | Bangalore | 869 | Finance |
52 | Katherine | 36 | Mumbai | 575 | Production |
60 | Jack | 40 | Noida | 678 | Testing |
The above relation is decomposed into two relations EMPLOYEE and DEPARTMENT
EMPLOYEE table:
EMP_ID | EMP_NAME | EMP_AGE | EMP_CITY |
22 | Denim | 28 | Mumbai |
33 | Alina | 25 | Delhi |
46 | Stephan | 30 | Bangalore |
52 | Katherine | 36 | Mumbai |
60 | Jack | 40 | Noida |
DEPARTMENT table
DEPT_ID | EMP_ID | DEPT_NAME |
827 | 22 | Sales |
438 | 33 | Marketing |
869 | 46 | Finance |
575 | 52 | Production |
678 | 60 | Testing |
Now, when these two relations are joined on the common column "EMP_ID", then the resultant relation will look like:
Employee ⋈ Department
EMP_ID | EMP_NAME | EMP_AGE | EMP_CITY | DEPT_ID | DEPT_NAME |
22 | Denim | 28 | Mumbai | 827 | Sales |
33 | Alina | 25 | Delhi | 438 | Marketing |
46 | Stephan | 30 | Bangalore | 869 | Finance |
52 | Katherine | 36 | Mumbai | 575 | Production |
60 | Jack | 40 | Noida | 678 | Testing |
Hence, the decomposition is Lossless join decomposition.
Dependency Preserving
Key takeaway
Multivalued Dependency
Example: Suppose there is a bike manufacturer company which produces two colors(white and black) of each model every year.
BIKE_MODEL | MANUF_YEAR | COLOR |
M2011 | 2008 | White |
M2001 | 2008 | Black |
M3001 | 2013 | White |
M3001 | 2013 | Black |
M4006 | 2017 | White |
M4006 | 2017 | Black |
Here columns COLOR and MANUF_YEAR are dependent on BIKE_MODEL and independent of each other.
In this case, these two columns can be called as multivalued dependent on BIKE_MODEL. The representation of these dependencies is shown below:
This can be read as "BIKE_MODEL multidetermined MANUF_YEAR" and "BIKE_MODEL multidetermined COLOR".
Fourth normal form (4NF)
Example
STUDENT
STU_ID | COURSE | HOBBY |
21 | Computer | Dancing |
21 | Math | Singing |
34 | Chemistry | Dancing |
74 | Biology | Cricket |
59 | Physics | Hockey |
The given STUDENT table is in 3NF, but the COURSE and HOBBY are two independent entity. Hence, there is no relationship between COURSE and HOBBY.
In the STUDENT relation, a student with STU_ID, 21 contains two courses, Computer and Math and two hobbies, Dancing and Singing. So there is a Multi-valued dependency on STU_ID, which leads to unnecessary repetition of data.
So to make the above table into 4NF, we can decompose it into two tables:
STUDENT_COURSE
STU_ID | COURSE |
21 | Computer |
21 | Math |
34 | Chemistry |
74 | Biology |
59 | Physics |
STUDENT_HOBBY
STU_ID | HOBBY |
21 | Dancing |
21 | Singing |
34 | Dancing |
74 | Cricket |
59 | Hockey |
Key takeaway
Join Dependency
Fifth normal form (5NF)
Example
SUBJECT | LECTURER | SEMESTER |
Computer | Anshika | Semester 1 |
Computer | John | Semester 1 |
Math | John | Semester 1 |
Math | Akash | Semester 2 |
Chemistry | Praveen | Semester 1 |
In the above table, John takes both Computer and Math class for Semester 1 but he doesn't take Math class for Semester 2. In this case, combination of all these fields required to identify a valid data.
Suppose we add a new Semester as Semester 3 but do not know about the subject and who will be taking that subject so we leave Lecturer and Subject as NULL. But all three columns together acts as a primary key, so we can't leave other two columns blank.
So to make the above table into 5NF, we can decompose it into three relations P1, P2 & P3:
P1
SEMESTER | SUBJECT |
Semester 1 | Computer |
Semester 1 | Math |
Semester 1 | Chemistry |
Semester 2 | Math |
P2
SUBJECT | LECTURER |
Computer | Anshika |
Computer | John |
Math | John |
Math | Akash |
Chemistry | Praveen |
P3
SEMSTER | LECTURER |
Semester 1 | Anshika |
Semester 1 | John |
Semester 1 | John |
Semester 2 | Akash |
Semester 1 | Praveen |
Key takeaway
Reference Books
1. “Database Management Systems”, Raghu Ramakrishnan and Johannes Gehrke, 2002, 3rd Edition.
2. “Fundamentals of Database Systems”, RamezElmasri and ShamkantNavathe, Benjamin Cummings, 1999, 3rd Edition.
3. “Database System Concepts”, Abraham Silberschatz, Henry F. Korth and S.Sudarshan, Mc Graw Hill, 2002, 4th Edition.




