Unit-4
Data Storage and Indexes
Relative data and information is stored collectively in file formats. A file is a sequence of records stored in binary format. A disk drive is formatted into several blocks that can store records. File records are mapped onto those disk blocks.
File Organization
File Organization defines how file records are mapped onto disk blocks. We have four types of File Organization to organize file records −
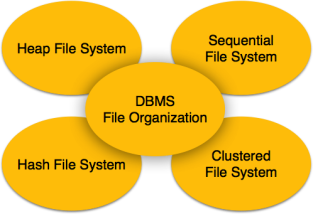
Fig 1 – DBMS file organisation
Heap File Organization
When a file is created using Heap File Organization, the Operating System allocates memory area to that file without any further accounting details. File records can be placed anywhere in that memory area. It is the responsibility of the software to manage the records. Heap File does not support any ordering, sequencing, or indexing on its own.
Sequential File Organization
Every file record contains a data field (attribute) to uniquely identify that record. In sequential file organization, records are placed in the file in some sequential order based on the unique key field or search key. Practically, it is not possible to store all the records sequentially in physical form.
Hash File Organization
Hash File Organization uses Hash function computation on some fields of the records. The output of the hash function determines the location of disk block where the records are to be placed.
Clustered File Organization
Clustered file organization is not considered good for large databases. In this mechanism, related records from one or more relations are kept in the same disk block, that is, the ordering of records is not based on primary key or search key.
File Operations
Operations on database files can be broadly classified into two categories −
Update operations change the data values by insertion, deletion, or update. Retrieval operations, on the other hand, do not alter the data but retrieve them after optional conditional filtering. In both types of operations, selection plays a significant role. Other than creation and deletion of a file, there could be several operations, which can be done on files.
- removes all the locks (if in shared mode),
- saves the data (if altered) to the secondary storage media, and
- releases all the buffers and file handlers associated with the file.
The organization of data inside a file plays a major role here. The process to locate the file pointer to a desired record inside a file various based on whether the records are arranged sequentially or clustered.
Key takeaway
Relative data and information is stored collectively in file formats. A file is a sequence of records stored in binary format. A disk drive is formatted into several blocks that can store records. File records are mapped onto those disk blocks.
File Organization
File Organization defines how file records are mapped onto disk blocks. We have four types of File Organization to organize file records.
Indexing in DBMS
Index structure:
Indexes can be created using some database columns.
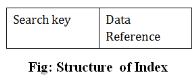
Fig 2 – Structure of Index
Indexing Methods
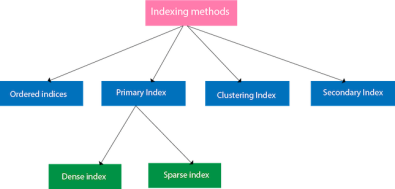
Fig 3 – Indexing Methods
Ordered indices
The indices are usually sorted to make searching faster. The indices which are sorted are known as ordered indices.
Example: Suppose we have an employee table with thousands of record and each of which is 10 bytes long. If their IDs start with 1, 2, 3....and so on and we have to search student with ID-543.
Primary Index
Dense index
Fig 4 – Dense Index
Sparse index
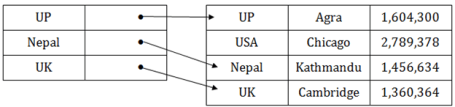
Fig 5 – Sparse Index
Clustering Index
Example: suppose a company contains several employees in each department. Suppose we use a clustering index, where all employees which belong to the same Dept_ID are considered within a single cluster, and index pointers point to the cluster as a whole. Here Dept_Id is a non-unique key.
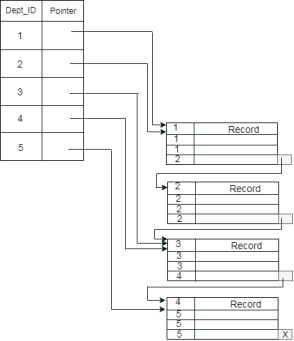
The previous schema is little confusing because one disk block is shared by records which belong to the different cluster. If we use separate disk block for separate clusters, then it is called better technique.
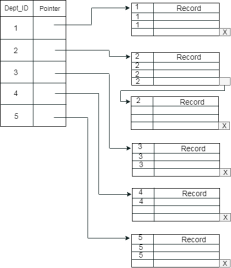
Secondary Index
In the sparse indexing, as the size of the table grows, the size of mapping also grows. These mappings are usually kept in the primary memory so that address fetch should be faster. Then the secondary memory searches the actual data based on the address got from mapping. If the mapping size grows then fetching the address itself becomes slower. In this case, the sparse index will not be efficient. To overcome this problem, secondary indexing is introduced.
In secondary indexing, to reduce the size of mapping, another level of indexing is introduced. In this method, the huge range for the columns is selected initially so that the mapping size of the first level becomes small. Then each range is further divided into smaller ranges. The mapping of the first level is stored in the primary memory, so that address fetch is faster. The mapping of the second level and actual data are stored in the secondary memory (hard disk).
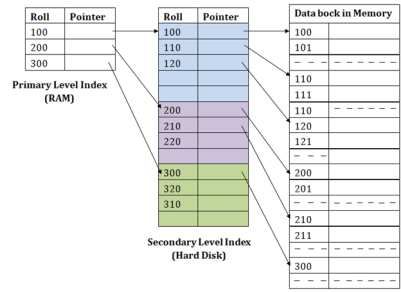
Fig 6 – Secondary Index
For example:
Key takeaway
Hashing
In a huge database structure, it is very inefficient to search all the index values and reach the desired data. Hashing technique is used to calculate the direct location of a data record on the disk without using index structure.
In this technique, data is stored at the data blocks whose address is generated by using the hashing function. The memory location where these records are stored is known as data bucket or data blocks.
In this, a hash function can choose any of the column value to generate the address. Most of the time, the hash function uses the primary key to generate the address of the data block. A hash function is a simple mathematical function to any complex mathematical function. We can even consider the primary key itself as the address of the data block. That means each row whose address will be the same as a primary key stored in the data block.
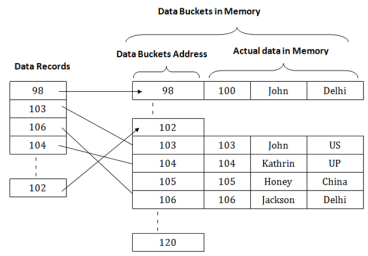
Fig 7 – Data buckets in memory
The above diagram shows data block addresses same as primary key value. This hash function can also be a simple mathematical function like exponential, mod, cos, sin, etc. Suppose we have mod (5) hash function to determine the address of the data block. In this case, it applies mod (5) hash function on the primary keys and generates 3, 3, 1, 4 and 2 respectively, and records are stored in those data block addresses.

Types of Hashing:
Fig 8 - Hashing
Static Hashing
In static hashing, the resultant data bucket address will always be the same. That means if we generate an address for EMP_ID =103 using the hash function mod (5) then it will always result in same bucket address 3. Here, there will be no change in the bucket address.
Hence in this static hashing, the number of data buckets in memory remains constant throughout. In this example, we will have five data buckets in the memory used to store the data.
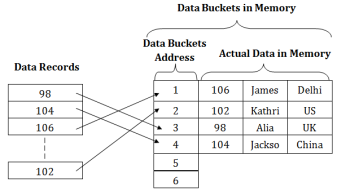
Fig 9 – Static hashing
Operations of Static Hashing
When a record needs to be searched, then the same hash function retrieves the address of the bucket where the data is stored.
When a new record is inserted into the table, then we will generate an address for a new record based on the hash key and record is stored in that location.
To delete a record, we will first fetch the record which is supposed to be deleted. Then we will delete the records for that address in memory.
To update a record, we will first search it using a hash function, and then the data record is updated.
If we want to insert some new record into the file but the address of a data bucket generated by the hash function is not empty, or data already exists in that address. This situation in the static hashing is known as bucket overflow. This is a critical situation in this method.
To overcome this situation, there are various methods. Some commonly used methods are as follows:
1. Open Hashing
When a hash function generates an address at which data is already stored, then the next bucket will be allocated to it. This mechanism is called as Linear Probing.
For example: suppose R3 is a new address which needs to be inserted, the hash function generates address as 112 for R3. But the generated address is already full. So the system searches next available data bucket, 113 and assigns R3 to it.
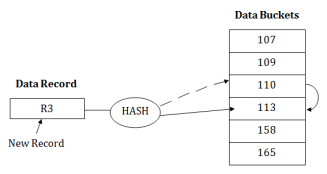
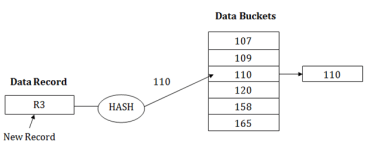
2. Close Hashing
When buckets are full, then a new data bucket is allocated for the same hash result and is linked after the previous one. This mechanism is known as Overflow chaining.
For example: Suppose R3 is a new address which needs to be inserted into the table, the hash function generates address as 110 for it. But this bucket is full to store the new data. In this case, a new bucket is inserted at the end of 110 buckets and is linked to it.
Dynamic Hashing
How to search a key
How to insert a new record
For example:
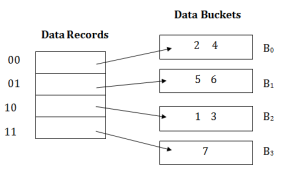
Consider the following grouping of keys into buckets, depending on the prefix of their hash address:
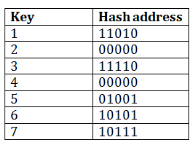
The last two bits of 2 and 4 are 00. So it will go into bucket B0. The last two bits of 5 and 6 are 01, so it will go into bucket B1. The last two bits of 1 and 3 are 10, so it will go into bucket B2. The last two bits of 7 are 11, so it will go into B3.
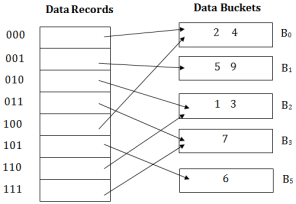
Insert key 9 with hash address 10001 into the above structure:
Advantages of dynamic hashing
Disadvantages of dynamic hashing
Key takeaway
In a huge database structure, it is very inefficient to search all the index values and reach the desired data. Hashing technique is used to calculate the direct location of a data record on the disk without using index structure.
In this technique, data is stored at the data blocks whose address is generated by using the hashing function. The memory location where these records are stored is known as data bucket or data blocks.
In this, a hash function can choose any of the column value to generate the address. Most of the time, the hash function uses the primary key to generate the address of the data block. A hash function is a simple mathematical function to any complex mathematical function. We can even consider the primary key itself as the address of the data block. That means each row whose address will be the same as a primary key stored in the data block.
We know that data is stored in the form of records. Every record has a key field, which helps it to be recognized uniquely.
Indexing is a data structure technique to efficiently retrieve records from the database files based on some attributes on which the indexing has been done. Indexing in database systems is similar to what we see in books.
Indexing is defined based on its indexing attributes. Indexing can be of the following types −
Ordered Indexing is of two types −
Dense Index
In dense index, there is an index record for every search key value in the database. This makes searching faster but requires more space to store index records itself. Index records contain search key value and a pointer to the actual record on the disk.
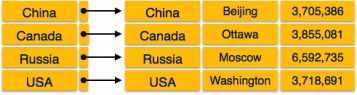
Fig 10 – Dense Index
Sparse Index
In sparse index, index records are not created for every search key. An index record here contains a search key and an actual pointer to the data on the disk. To search a record, we first proceed by index record and reach at the actual location of the data. If the data we are looking for is not where we directly reach by following the index, then the system starts sequential search until the desired data is found.
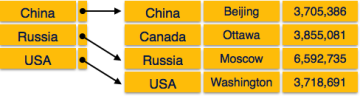
Fig 11 – sparse index
Multilevel Index
Index records comprise search-key values and data pointers. Multilevel index is stored on the disk along with the actual database files. As the size of the database grows, so does the size of the indices. There is an immense need to keep the index records in the main memory so as to speed up the search operations. If single-level index is used, then a large size index cannot be kept in memory which leads to multiple disk accesses.
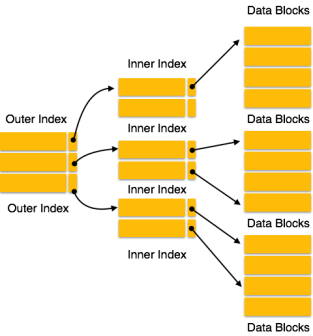
Fig 12 – Multilevel Index
Multi-level Index helps in breaking down the index into several smaller indices in order to make the outermost level so small that it can be saved in a single disk block, which can easily be accommodated anywhere in the main memory.
B+ Tree
A B+ tree is a balanced binary search tree that follows a multi-level index format. The leaf nodes of a B+ tree denote actual data pointers. B+ tree ensures that all leaf nodes remain at the same height, thus balanced. Additionally, the leaf nodes are linked using a link list; therefore, a B+ tree can support random access as well as sequential access.
Structure of B+ Tree
Every leaf node is at equal distance from the root node. A B+ tree is of the order n where n is fixed for every B+ tree.
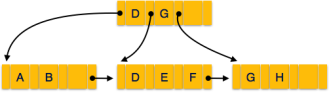
Fig 13 – B+ Tree
Internal nodes−
Leaf nodes−
B+ Tree Insertion
- Split node into two parts.
- Partition at i = ⌊(m+1)/2⌋.
- First i entries are stored in one node.
- Rest of the entries (i+1 onwards) are moved to a new node.
- ith key is duplicated at the parent of the leaf.
- Split node into two parts.
- Partition the node at i = ⌈(m+1)/2⌉.
- Entries up to i are kept in one node.
- Rest of the entries are moved to a new node.
B+ Tree Deletion
- If it is an internal node, delete and replace with the entry from the left position.
- If underflow occurs, distribute the entries from the nodes left to it.
- Distribute from the nodes right to it.
- Merge the node with left and right to it.
Key takeaway
We know that data is stored in the form of records. Every record has a key field, which helps it to be recognized uniquely.
Indexing is a data structure technique to efficiently retrieve records from the database files based on some attributes on which the indexing has been done. Indexing in database systems is similar to what we see in books.
To handle above situation, multiple key accesses are introduced. Here, we use combination of two or more columns which are frequently queried to get index. In the above example, both DEPT_ID and SALARY are clubbed into one index and are stored in the files. Now what happens when we fire above query? It filters both DEPT_ID = 20 and SALARY = 5000 at a shot and returns the result.
This type of indexing works well when all the columns used in the index are involved in the query. In above example we have index on (DEPT_ID, SALARY) and both the columns are used in the query. Hence it resulted quickly. But what will happen when any one of the column is used in the query? This index will not be used to fetch the record. Hence query becomes slower.
Imagine another case where we have queried like below. Here both the columns are used differently- we have queried to find the salary less than 5000, not equal to 5000. What will happen in this case?
SELECT * FROM EMPLOYEE WHERE DEPT_ID = 20 and SALARY < 5000;
This query will use the index and will fetch the result quickly. Reason is it has to find the address of the record in the file where DEPT_ID = 20 and SALARY = 5000 and then it has to return all the records which are stored previous to this address. Hence the query becomes simple and faster.
Imagine another case for the same example, where DEPT_ID <20 but SALARY = 5000 is used to fetch the record. What will happen in this case?
SELECT * FROM EMPLOYEE WHERE DEPT_ID < 40 and SALARY = 5000;
This query will not use the index. Why? The order of the columns in the index is (DEPT_ID, SALARY). The multiple key indexes work as below.
The condition (DEPT_ID1, SALARY1) < (DEPT_ID2, SALARY2) is used only if
DEPT_ID1 < DEPT_ID2
OR
DEPT_ID1 = DEPT_ID2 AND SALARY1 <SALARY2
In this example, we are checking for second condition, where we have DEPT_ID <40. But SALARY < 5000 should have been used for the index to be used. But it is not the case in the query. That means, it should have only one condition DEPT_ID <40 or both conditions like DEPT_ID = 20 AND SALARY<5000 to use the index. This method of ordering in index is called lexicographic ordering.
Have a look at below index file to understand these examples. We can see that, records are first grouped based on DEPT_ID and then on SALARY. If we have to select DEPT_ID <40 alone, then all the records less than DEPT_ID =40 address have to selected which easy and quick. We get all records in a sequence here. DEPT_ID1 <DEPT_ID2 condition holds well here.
If DEPT_ID =20 but SALARY < 5000 condition is used, pointer will go to DEPT_ID = 20 Section in the file and then fetch all the records less than 5000. The index is used in the query making it faster. Here, second conditions for lexicographic works.
What if we have to search DEPT_ID <40 and SALARY = 5000, it is same as traversing the whole table. We will not be able to find all requested records at one place.
Similarly, if only one column in the index is used, say SALARY = 5000, then also searching is a full table scan. Below diagram clearly shows SALARY = 5000 is scattered in the memory file and have to traverse whole file to get the result. Hence it is not efficient.
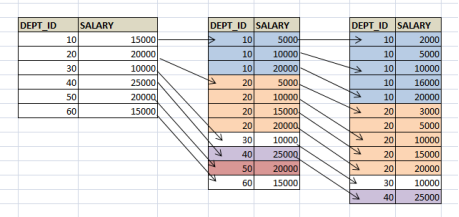
In order to create a multiple key index
Advantages of Multiple Key Accesses
Disadvantages of Multiple Key Accesses
Key takeaway
To handle above situation, multiple key accesses are introduced. Here, we use combination of two or more columns which are frequently queried to get index. In the above example, both DEPT_ID and SALARY are clubbed into one index and are stored in the files. Now what happens when we fire above query? It filters both DEPT_ID = 20 and SALARY = 5000 at a shot and returns the result.
This type of indexing works well when all the columns used in the index are involved in the query. In above example we have index on (DEPT_ID, SALARY) and both the columns are used in the query. Hence it resulted quickly. But what will happen when any one of the column is used in the query? This index will not be used to fetch the record. Hence query becomes slower.
Reference Books
1. “Database Management Systems”, Raghu Ramakrishnan and Johannes Gehrke, 2002, 3rd Edition.
2. “Fundamentals of Database Systems”, RamezElmasri and ShamkantNavathe, Benjamin Cummings, 1999, 3rd Edition.
3. “Database System Concepts”, Abraham Silberschatz, Henry F. Korth and S.Sudarshan, Mc Graw Hill, 2002, 4th Edition.




