Unit-5
Transaction Processing and Concurrency Control
A transaction can be defined as a group of tasks. A single task is the minimum processing unit which cannot be divided further.
Let’s take an example of a simple transaction. Suppose a bank employee transfers Rs 500 from A's account to B's account. This very simple and small transaction involves several low-level tasks.
A’s Account
Open_Account(A)
Old_Balance = A.balance
New_Balance = Old_Balance - 500
A.balance = New_Balance
Close_Account(A)
B’s Account
Open_Account(B)
Old_Balance = B.balance
New_Balance = Old_Balance + 500
B.balance = New_Balance
Close_Account(B)
ACID Properties
A transaction is a very small unit of a program and it may contain several lowlevel tasks. A transaction in a database system must maintain Atomicity, Consistency, Isolation, and Durability − commonly known as ACID properties − in order to ensure accuracy, completeness, and data integrity.
Serializability
When multiple transactions are being executed by the operating system in a multiprogramming environment, there are possibilities that instructions of one transactions are interleaved with some other transaction.
In a multi-transaction environment, serial schedules are considered as a benchmark. The execution sequence of an instruction in a transaction cannot be changed, but two transactions can have their instructions executed in a random fashion. This execution does no harm if two transactions are mutually independent and working on different segments of data; but in case these two transactions are working on the same data, then the results may vary. This ever-varying result may bring the database to an inconsistent state.
To resolve this problem, we allow parallel execution of a transaction schedule, if its transactions are either serializable or have some equivalence relation among them.
Equivalence Schedules
An equivalence schedule can be of the following types −
Result Equivalence
If two schedules produce the same result after execution, they are said to be result equivalent. They may yield the same result for some value and different results for another set of values. That's why this equivalence is not generally considered significant.
View Equivalence
Two schedules would be view equivalence if the transactions in both the schedules perform similar actions in a similar manner.
For example −
Conflict Equivalence
Two schedules would be conflicting if they have the following properties −
Two schedules having multiple transactions with conflicting operations are said to be conflict equivalent if and only if −
Note− View equivalent schedules are view serializable and conflict equivalent schedules are conflict serializable. All conflict serializable schedules are view serializable too.
States of Transactions
A transaction in a database can be in one of the following states −
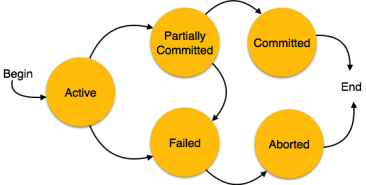
Fig 1 - States of Transactions
- Re-start the transaction
- Kill the transaction
Key takeaway
A transaction can be defined as a group of tasks. A single task is the minimum processing unit which cannot be divided further.
Let’s take an example of a simple transaction. Suppose a bank employee transfers Rs 500 from A's account to B's account. This very simple and small transaction involves several low-level tasks.
DBMS is the management of data that should remain integrated when any changes are done in it. It is because if the integrity of the data is affected, whole data will get disturbed and corrupted. Therefore, to maintain the integrity of the data, there are four properties described in the database management system, which are known as the ACID properties. The ACID properties are meant for the transaction that goes through a different group of tasks, and there we come to see the role of the ACID properties.
In this section, we will learn and understand about the ACID properties. We will learn what these properties stand for and what does each property is used for. We will also understand the ACID properties with the help of some examples.
ACID Properties
The expansion of the term ACID defines for:
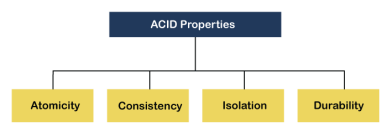
Fig 2 - ACID Properties
1) Atomicity: The term atomicity defines that the data remains atomic. It means if any operation is performed on the data, either it should be performed or executed completely or should not be executed at all. It further means that the operation should not break in between or execute partially. In the case of executing operations on the transaction, the operation should be completely executed and not partially.
Example: If Remo has account A having $30 in his account from which he wishes to send $10 to Sheero's account, which is B. In account B, a sum of $ 100 is already present. When $10 will be transferred to account B, the sum will become $110. Now, there will be two operations that will take place. One is the amount of $10 that Remo wants to transfer will be debited from his account A, and the same amount will get credited to account B, i.e., into Sheero's account. Now, what happens - the first operation of debit executes successfully, but the credit operation, however, fails. Thus, in Remo's account A, the value becomes $20, and to that of Sheero's account, it remains $100 as it was previously present.
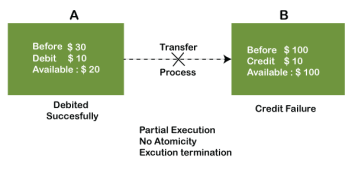
In the above diagram, it can be seen that after crediting $10, the amount is still $100 in account B. So, it is not an atomic transaction.
The below image shows that both debit and credit operations are done successfully. Thus the transaction is atomic.
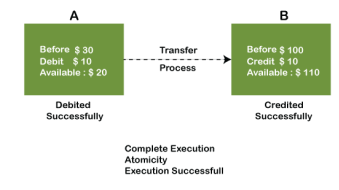
Thus, when the amount loses atomicity, then in the bank systems, this becomes a huge issue, and so the atomicity is the main focus in the bank systems.
2) Consistency: The word consistency means that the value should remain preserved always. In DBMS, the integrity of the data should be maintained, which means if a change in the database is made, it should remain preserved always. In the case of transactions, the integrity of the data is very essential so that the database remains consistent before and after the transaction. The data should always be correct.
Example:
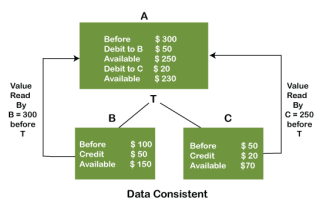
In the above figure, there are three accounts, A, B, and C, where A is making a transaction T one by one to both B & C. There are two operations that take place, i.e., Debit and Credit. Account A firstly debits $50 to account B, and the amount in account A is read $300 by B before the transaction. After the successful transaction T, the available amount in B becomes $150. Now, A debits $20 to account C, and that time, the value read by C is $250 (that is correct as a debit of $50 has been successfully done to B). The debit and credit operation from account A to C has been done successfully. We can see that the transaction is done successfully, and the value is also read correctly. Thus, the data is consistent. In case the value read by B and C is $300, which means that data is inconsistent because when the debit operation executes, it will not be consistent.
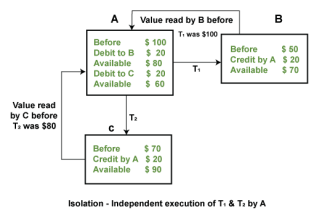
4) Isolation: The term 'isolation' means separation. In DBMS, Isolation is the property of a database where no data should affect the other one and may occur concurrently. In short, the operation on one database should begin when the operation on the first database gets complete. It means if two operations are being performed on two different databases, they may not affect the value of one another. In the case of transactions, when two or more transactions occur simultaneously, the consistency should remain maintained. Any changes that occur in any particular transaction will not be seen by other transactions until the change is not committed in the memory.
Example: If two operations are concurrently running on two different accounts, then the value of both accounts should not get affected. The value should remain persistent. As you can see in the below diagram, account A is making T1 and T2 transactions to account B and C, but both are executing independently without affecting each other. It is known as Isolation.
4) Durability: Durability ensures the permanency of something. In DBMS, the term durability ensures that the data after the successful execution of the operation becomes permanent in the database. The durability of the data should be so perfect that even if the system fails or leads to a crash, the database still survives. However, if gets lost, it becomes the responsibility of the recovery manager for ensuring the durability of the database. For committing the values, the COMMIT command must be used every time we make changes.
Therefore, the ACID property of DBMS plays a vital role in maintaining the consistency and availability of data in the database.
Thus, it was a precise introduction of ACID properties in DBMS. We have discussed these properties in the transaction section also.
Key takeaway
DBMS is the management of data that should remain integrated when any changes are done in it. It is because if the integrity of the data is affected, whole data will get disturbed and corrupted. Therefore, to maintain the integrity of the data, there are four properties described in the database management system, which are known as the ACID properties. The ACID properties are meant for the transaction that goes through a different group of tasks, and there we come to see the role of the ACID properties.
In a database, the transaction can be in one of the following states -
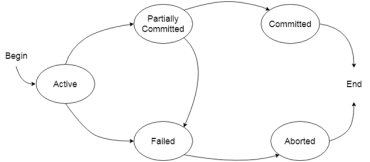
Fig 3 - Transaction states
Active state
Partially committed
Committed
A transaction is said to be in a committed state if it executes all its operations successfully. In this state, all the effects are now permanently saved on the database system.
Failed state
Aborted
- Re-start the transaction
- Kill the transaction
Key takeaway
The transaction has the four properties. These are used to maintain consistency in a database, before and after the transaction.
Property of Transaction
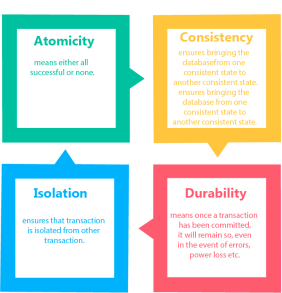
Fig 4 - Property of Transaction
Atomicity
Atomicity involves the following two operations:
Abort: If a transaction aborts then all the changes made are not visible.
Commit: If a transaction commits then all the changes made are visible.
Example: Let's assume that following transaction T consisting of T1 and T2. A consists of Rs 600 and B consists of Rs 300. Transfer Rs 100 from account A to account B.
T1 | T2 |
Read(A) | Read(B) |
After completion of the transaction, A consists of Rs 500 and B consists of Rs 400.
If the transaction T fails after the completion of transaction T1 but before completion of transaction T2, then the amount will be deducted from A but not added to B. This shows the inconsistent database state. In order to ensure correctness of database state, the transaction must be executed in entirety.
Consistency
For example: The total amount must be maintained before or after the transaction.
Therefore, the database is consistent. In the case when T1 is completed but T2 fails, then inconsistency will occur.
Isolation
Durability
Key takeaway
The transaction has the four properties. These are used to maintain consistency in a database, before and after the transaction.
Property of Transaction
What is serializability?
1. Conflict Serializability
The following rules are important in Conflict Serializability,
1. If two transactions are both read operation, then they are not in conflict.
2. If one transaction wants to perform a read operation and other transaction wants to perform a write operation, then they are in conflict and cannot be swapped.
3. If both the transactions are for write operation, then they are in conflict, but can be allowed to take place in any order, because the transactions do not read the value updated by each other.
2. View Serializability
Example : Let us assume two transactions T1 and T2 that are being serialized to create two different schedules SH1 and SH2, where T1 and T2 want to access the same data item. Now there can be three scenarios
1. If in SH1, T1 reads the initial value of data item, then in SH2 , T1 should read the initial value of that same data item.
2. If in SH2, T1 writes a value in the data item which is read by T2, then in SH2, T1 should write the value in the data item before T2 reads it.
3. If in SH1, T1 performs the final write operation on that data item, then in SH2, T1 should perform the final write operation on that data item.
If a concurrent schedule is view equivalent to a serial schedule of same transaction then it is said to be View serializable.
Testing of Serializability
Serialization Graph is used to test the Serializability of a schedule.
Assume a schedule S. For S, we construct a graph known as precedence graph. This graph has a pair G = (V, E), where V consists a set of vertices, and E consists a set of edges. The set of vertices is used to contain all the transactions participating in the schedule. The set of edges is used to contain all edges Ti ->Tj for which one of the three conditions holds:
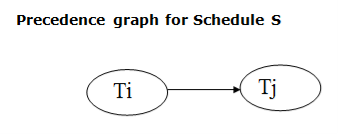
Fig 5 – Precedence Graph
For example:
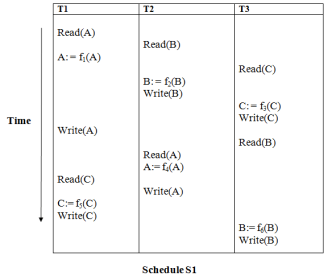
Explanation:
Read(A): In T1, no subsequent writes to A, so no new edges
Read(B): In T2, no subsequent writes to B, so no new edges
Read(C): In T3, no subsequent writes to C, so no new edges
Write(B): B is subsequently read by T3, so add edge T2 → T3
Write(C): C is subsequently read by T1, so add edge T3 → T1
Write(A): A is subsequently read by T2, so add edge T1 → T2
Write(A): In T2, no subsequent reads to A, so no new edges
Write(C): In T1, no subsequent reads to C, so no new edges
Write(B): In T3, no subsequent reads to B, so no new edges
Precedence graph for schedule S1:
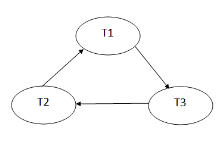
Fig 6 – Precedence graph
The precedence graph for schedule S1 contains a cycle that's why Schedule S1 is non-serializable.
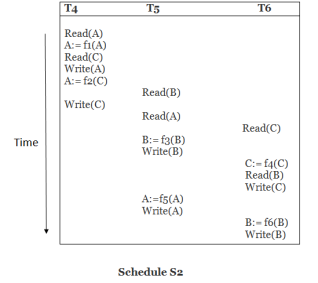
Explanation:
Read(A): In T4,no subsequent writes to A, so no new edges
Read(C): In T4, no subsequent writes to C, so no new edges
Write(A): A is subsequently read by T5, so add edge T4 → T5
Read(B): In T5,no subsequent writes to B, so no new edges
Write(C): C is subsequently read by T6, so add edge T4 → T6
Write(B): A is subsequently read by T6, so add edge T5 → T6
Write(C): In T6, no subsequent reads to C, so no new edges
Write(A): In T5, no subsequent reads to A, so no new edges
Write(B): In T6, no subsequent reads to B, so no new edges
Precedence graph for schedule S2:
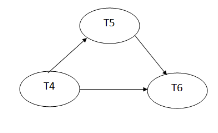
Fig 7 - Precedence graph
The precedence graph for schedule S2 contains no cycle that's why ScheduleS2 is serializable.
Key takeaway
DBMS Concurrency Control
Concurrency Control is the management procedure that is required for controlling concurrent execution of the operations that take place on a database.
But before knowing about concurrency control, we should know about concurrent execution.
Concurrent Execution in DBMS
Problems with Concurrent Execution
In a database transaction, the two main operations are READ and WRITE operations. So, there is a need to manage these two operations in the concurrent execution of the transactions as if these operations are not performed in an interleaved manner, and the data may become inconsistent. So, the following problems occur with the Concurrent Execution of the operations:
Problem 1: Lost Update Problems (W - W Conflict)
The problem occurs when two different database transactions perform the read/write operations on the same database items in an interleaved manner (i.e., concurrent execution) that makes the values of the items incorrect hence making the database inconsistent.
For example:
Consider the below diagram where two transactions TX and TY, are performed on the same account A where the balance of account A is $300.
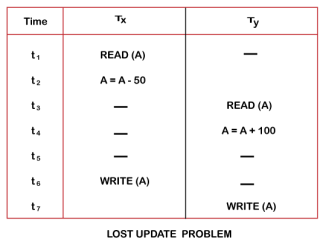
Hence data becomes incorrect, and database sets to inconsistent.
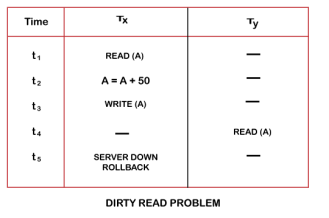
Dirty Read Problems (W-R Conflict)
The dirty read problem occurs when one transaction updates an item of the database, and somehow the transaction fails, and before the data gets rollback, the updated database item is accessed by another transaction. There comes the Read-Write Conflict between both transactions.
For example:
Consider two transactions TX and TY in the below diagram performing read/write operations on account A where the available balance in account A is $300:
Unrepeatable Read Problem (W-R Conflict)
Also known as Inconsistent Retrievals Problem that occurs when in a transaction, two different values are read for the same database item.
For example:
Consider two transactions, TX and TY, performing the read/write operations on account A, having an available balance = $300. The diagram is shown below:
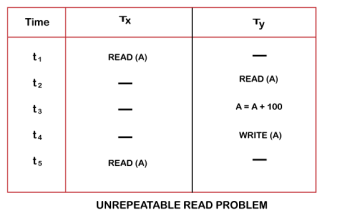
Thus, in order to maintain consistency in the database and avoid such problems that take place in concurrent execution, management is needed, and that is where the concept of Concurrency Control comes into role.
Concurrency Control
Concurrency Control is the working concept that is required for controlling and managing the concurrent execution of database operations and thus avoiding the inconsistencies in the database. Thus, for maintaining the concurrency of the database, we have the concurrency control protocols.
Concurrency Control Protocols
The concurrency control protocols ensure the atomicity, consistency, isolation, durability and serializability of the concurrent execution of the database transactions. Therefore, these protocols are categorized as:
Lock-Based Protocol
In this type of protocol, any transaction cannot read or write data until it acquires an appropriate lock on it. There are two types of lock:
1. Shared lock:
2. Exclusive lock:
There are four types of lock protocols available:
1. Simplistic lock protocol
It is the simplest way of locking the data while transaction. Simplistic lock-based protocols allow all the transactions to get the lock on the data before insert or delete or update on it. It will unlock the data item after completing the transaction.
2. Pre-claiming Lock Protocol
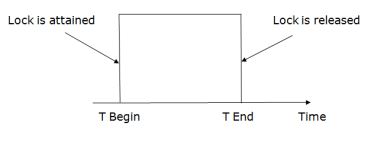
Fig 8 – Pre-claiming lock protocol
3. Two-phase locking (2PL)
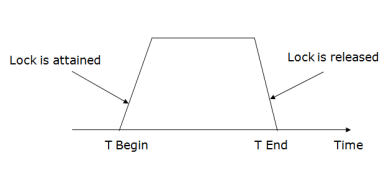
Fig 9 - Two-phase locking protocol
There are two phases of 2PL:
Growing phase: In the growing phase, a new lock on the data item may be acquired by the transaction, but none can be released.
Shrinking phase: In the shrinking phase, existing lock held by the transaction may be released, but no new locks can be acquired.
In the below example, if lock conversion is allowed then the following phase can happen:
Example:
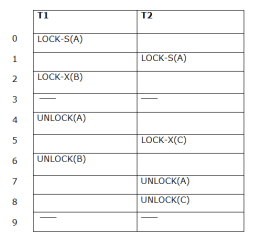
The following way shows how unlocking and locking work with 2-PL.
Transaction T1:
Transaction T2:
4. Strict Two-phase locking (Strict-2PL)
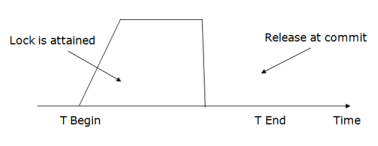
Fig 10 - Strict-2PL
It does not have cascading abort as 2PL does.
Timestamp Ordering Protocol
Basic Timestamp ordering protocol works as follows:
1. Check the following condition whenever a transaction Ti issues a Read (X) operation:
2. Check the following condition whenever a transaction Ti issues a Write(X) operation:
Where,
TS(TI) denotes the timestamp of the transaction Ti.
R_TS(X) denotes the Read time-stamp of data-item X.
W_TS(X) denotes the Write time-stamp of data-item X.
Advantages and Disadvantages of TO protocol:
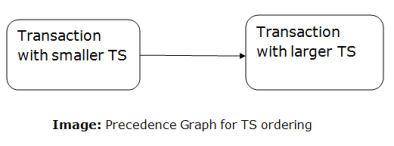
Fig 11 – Precedence graph for TS ordering
Validation Based Protocol
Validation phase is also known as optimistic concurrency control technique. In the validation based protocol, the transaction is executed in the following three phases:
Here each phase has the following different timestamps:
Start(Ti): It contains the time when Ti started its execution.
Validation (Ti): It contains the time when Ti finishes its read phase and starts its validation phase.
Finish(Ti): It contains the time when Ti finishes its write phase.
Key takeaway
Concurrency Control is the management procedure that is required for controlling concurrent execution of the operations that take place on a database.
But before knowing about concurrency control, we should know about concurrent execution.
Granularity: It is the size of data item allowed to lock.
Multiple Granularity:
For example: Consider a tree which has four levels of nodes.
- Database
- Area
- File
- Record
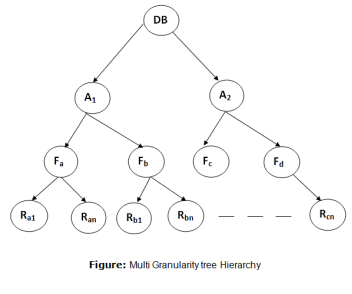
Fig 12 – Multi granularity tree hierarchy
In this example, the highest level shows the entire database. The levels below are file, record, and fields.
There are three additional lock modes with multiple granularity:
Intention Mode Lock
Intention-shared (IS): It contains explicit locking at a lower level of the tree but only with shared locks.
Intention-Exclusive (IX): It contains explicit locking at a lower level with exclusive or shared locks.
Shared & Intention-Exclusive (SIX): In this lock, the node is locked in shared mode, and some node is locked in exclusive mode by the same transaction.
Compatibility Matrix with Intention Lock Modes: The below table describes the compatibility matrix for these lock modes:
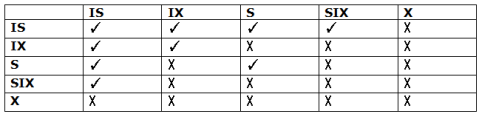
Fig 13 - Compatibility matrix for these lock modes
It uses the intention lock modes to ensure serializability. It requires that if a transaction attempts to lock a node, then that node must follow these protocols:
Observe that in multiple-granularity, the locks are acquired in top-down order, and locks must be released in bottom-up order.
Key takeaway
Granularity: It is the size of data item allowed to lock.
Multiple Granularity:
A deadlock is a condition where two or more transactions are waiting indefinitely for one another to give up locks. Deadlock is said to be one of the most feared complications in DBMS as no task ever gets finished and is in waiting state forever.
For example: In the student table, transaction T1 holds a lock on some rows and needs to update some rows in the grade table. Simultaneously, transaction T2 holds locks on some rows in the grade table and needs to update the rows in the Student table held by Transaction T1.
Now, the main problem arises. Now Transaction T1 is waiting for T2 to release its lock and similarly, transaction T2 is waiting for T1 to release its lock. All activities come to a halt state and remain at a standstill. It will remain in a standstill until the DBMS detects the deadlock and aborts one of the transactions.
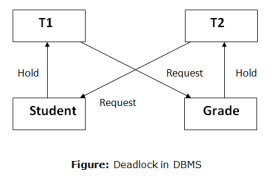
Fig 14 – Deadlock in DBMS
Deadlock Avoidance
Deadlock Detection
In a database, when a transaction waits indefinitely to obtain a lock, then the DBMS should detect whether the transaction is involved in a deadlock or not. The lock manager maintains a Wait for the graph to detect the deadlock cycle in the database.
Wait for Graph
The wait for a graph for the above scenario is shown below:
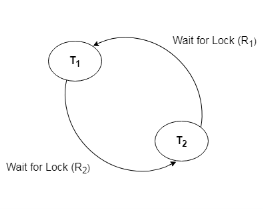
Fig 15 - Wait for a graph
Deadlock Prevention
Wait-Die scheme
In this scheme, if a transaction requests for a resource which is already held with a conflicting lock by another transaction then the DBMS simply checks the timestamp of both transactions. It allows the older transaction to wait until the resource is available for execution.
Let's assume there are two transactions Ti and Tj and let TS(T) is a timestamp of any transaction T. If T2 holds a lock by some other transaction and T1 is requesting for resources held by T2 then the following actions are performed by DBMS:
Wound wait scheme
Key takeaway
A deadlock is a condition where two or more transactions are waiting indefinitely for one another to give up locks. Deadlock is said to be one of the most feared complications in DBMS as no task ever gets finished and is in waiting state forever.
Reference Books
1. “Database Management Systems”, Raghu Ramakrishnan and Johannes Gehrke, 2002, 3rd Edition.
2. “Fundamentals of Database Systems”, RamezElmasri and ShamkantNavathe, Benjamin Cummings, 1999, 3rd Edition.
3. “Database System Concepts”, Abraham Silberschatz, Henry F. Korth and S.Sudarshan, Mc Graw Hill, 2002, 4th Edition.




