Unit-6
Recovery System
To find that where the problem has occurred, we generalize a failure into the following categories:
1. Transaction failure
The transaction failure occurs when it fails to execute or when it reaches a point from where it can't go any further. If a few transaction or process is hurt, then this is called as transaction failure.
Reasons for a transaction failure could be -
2. System Crash
Fail-stop assumption: In the system crash, non-volatile storage is assumed not to be corrupted.
3. Disk Failure
Key takeaway
To find that where the problem has occurred, we generalize a failure into the following categories:
A database system provides an ultimate view of the stored data. However, data in the form of bits, bytes get stored in different storage devices.
In this section, we will take an overview of various types of storage devices that are used for accessing and storing data.
Types of Data Storage
For storing the data, there are different types of storage options available. These storage types differ from one another as per the speed and accessibility. There are the following types of storage devices used for storing the data:
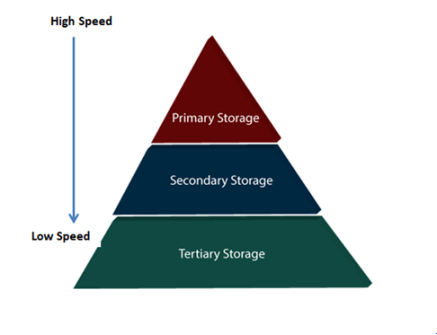
Fig 1 - Types of Data Storage
Primary Storage
It is the primary area that offers quick access to the stored data. We also know the primary storage as volatile storage. It is because this type of memory does not permanently store the data. As soon as the system leads to a power cut or a crash, the data also get lost. Main memory and cache are the types of primary storage.
Secondary Storage
Secondary storage is also called as Online storage. It is the storage area that allows the user to save and store data permanently. This type of memory does not lose the data due to any power failure or system crash. That's why we also call it non-volatile storage.
There are some commonly described secondary storage media which are available in almost every type of computer system:
Tertiary Storage
It is the storage type that is external from the computer system. It has the slowest speed. But it is capable of storing a large amount of data. It is also known as Offline storage. Tertiary storage is generally used for data backup. There are following tertiary storage devices available:
Storage Hierarchy
Besides the above, various other storage devices reside in the computer system. These storage media are organized on the basis of data accessing speed, cost per unit of data to buy the medium, and by medium's reliability. Thus, we can create a hierarchy of storage media on the basis of its cost and speed.
Thus, on arranging the above-described storage media in a hierarchy according to its speed and cost, we conclude the below-described image:
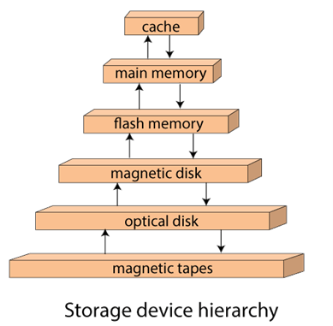
Fig 2 – Storage device hierarchy
In the image, the higher levels are expensive but fast. On moving down, the cost per bit is decreasing, and the access time is increasing. Also, the storage media from the main memory to up represents the volatile nature, and below the main memory, all are non-volatile devices.
Key takeaway
A database system provides an ultimate view of the stored data. However, data in the form of bits, bytes get stored in different storage devices.
In this section, we will take an overview of various types of storage devices that are used for accessing and storing data.
Stable-Storage Implementation :
To achieve such storage, we need to replicate the required information on multiple storage devices with independent failure modes. The writing of an update should be coordinate in such a way that it would not delete all the copies of the state and that, when we are recovering from a failure, we can force all the copies to a consistent and correct value, even if another failure occurs during the recovery. In these, we discuss how to meet these needs.
The disk write operation results to one of the following outcome:
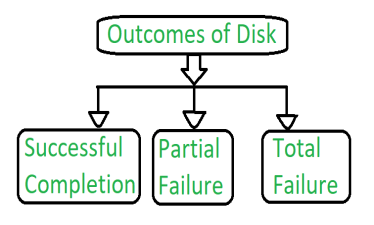
Figure 3 – Outcomes of Disk
The data will written correctly on disk.
In this case, failure is occurred in the middle of the data transfer, so that only some sectors were written with the new data, and the sector which is written during the failure may have been corrupted.
The failure occurred before the disk write started, so the previous data values on the disk remains intact.
During writing a block somehow if failure occurs, the system’s first work is to detect the failure and then invoke a recovery process to restore the consistent state. To do that, the system must contain two physical block for each logical block.
An output operation is executed as follows:
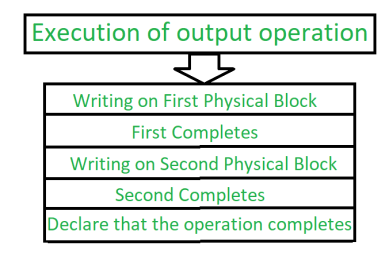
Figure 4 – Process of execution of output operation
During the recovery from a failure each of the physical block is examined. If both are the same and no detectable error exists, then no further action is necessary. If one block contains detectable errors then we replace its content with the value of the other block. If neither block contains the detectable error, but the block differ in content, then we replace the content of first block with the content of the second block.This procedure of the recovery give us an conclusion that either the write to stable content succeeds successfully or it results in no change.
This procedure will be extended if we want arbitrarily large number of copies of each block of the stable storage. With the usage of large number of copies, the chances of the failure reduces. Generally, it is usually reasonable to simulate stable storage with only two copies. The data present in the stable storage is safe unless a failure destroys all the copies. The data that is present in the stable storage is guaranteed to be safe unless a failure destroys all the copies.
Because waiting for disk writes to complete is time consuming, many storage arrays add NVRAM as a cache. Since the memory is no-volatile it can be trusted to store the data en route to the disks. In this way it is considered as a part of the stable storage. Writing to the stable storage is much faster than to disk, so performance is greatly improved.
Key takeaway
To achieve such storage, we need to replicate the required information on multiple storage devices with independent failure modes. The writing of an update should be coordinate in such a way that it would not delete all the copies of the state and that, when we are recovering from a failure, we can force all the copies to a consistent and correct value, even if another failure occurs during the recovery. In these, we discuss how to meet these needs.
Crash Recovery
DBMS is a highly complex system with hundreds of transactions being executed every second. The durability and robustness of a DBMS depends on its complex architecture and its underlying hardware and system software. If it fails or crashes amid transactions, it is expected that the system would follow some sort of algorithm or techniques to recover lost data.
Failure Classification
To see where the problem has occurred, we generalize a failure into various categories, as follows −
Transaction failure
A transaction has to abort when it fails to execute or when it reaches a point from where it can’t go any further. This is called transaction failure where only a few transactions or processes are hurt.
Reasons for a transaction failure could be −
System Crash
There are problems − external to the system − that may cause the system to stop abruptly and cause the system to crash. For example, interruptions in power supply may cause the failure of underlying hardware or software failure.
Examples may include operating system errors.
Disk Failure
In early days of technology evolution, it was a common problem where hard-disk drives or storage drives used to fail frequently.
Disk failures include formation of bad sectors, unreachability to the disk, disk head crash or any other failure, which destroys all or a part of disk storage.
Storage Structure
We have already described the storage system. In brief, the storage structure can be divided into two categories −
Recovery and Atomicity
When a system crashes, it may have several transactions being executed and various files opened for them to modify the data items. Transactions are made of various operations, which are atomic in nature. But according to ACID properties of DBMS, atomicity of transactions as a whole must be maintained, that is, either all the operations are executed or none.
When a DBMS recovers from a crash, it should maintain the following −
There are two types of techniques, which can help a DBMS in recovering as well as maintaining the atomicity of a transaction −
Log-based Recovery
Log is a sequence of records, which maintains the records of actions performed by a transaction. It is important that the logs are written prior to the actual modification and stored on a stable storage media, which is failsafe.
Log-based recovery works as follows −
<Tn, Start>
<Tn, X, V1, V2>
It reads Tn has changed the value of X, from V1 to V2.
<Tn, commit>
The database can be modified using two approaches −
Recovery with Concurrent Transactions
When more than one transaction are being executed in parallel, the logs are interleaved. At the time of recovery, it would become hard for the recovery system to backtrack all logs, and then start recovering. To ease this situation, most modern DBMS use the concept of 'checkpoints'.
Checkpoint
Keeping and maintaining logs in real time and in real environment may fill out all the memory space available in the system. As time passes, the log file may grow too big to be handled at all. Checkpoint is a mechanism where all the previous logs are removed from the system and stored permanently in a storage disk. Checkpoint declares a point before which the DBMS was in consistent state, and all the transactions were committed.
Recovery
When a system with concurrent transactions crashes and recovers, it behaves in the following manner −

Fig 5 - Recovery
All the transactions in the undo-list are then undone and their logs are removed. All the transactions in the redo-list and their previous logs are removed and then redone before saving their logs.
Key takeaway
DBMS is a highly complex system with hundreds of transactions being executed every second. The durability and robustness of a DBMS depends on its complex architecture and its underlying hardware and system software. If it fails or crashes amid transactions, it is expected that the system would follow some sort of algorithm or techniques to recover lost data.
Let's assume there is a transaction to modify the City of a student. The following logs are written for this transaction.
- <Tn, Start>
- <Tn, City, 'Noida', 'Bangalore' >
- <Tn, Commit>
There are two approaches to modify the database:
1. Deferred database modification:
2. Immediate database modification:
Recovery using Log records
When the system is crashed, then the system consults the log to find which transactions need to be undone and which need to be redone.
Key takeaway
Recovery using Checkpoint
In the following manner, a recovery system recovers the database from this failure:
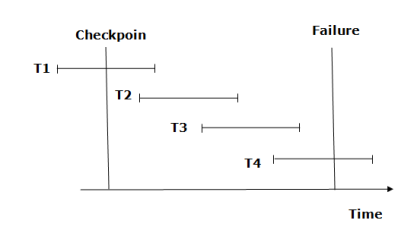
Fig 6 – Recovery using checkpoint
Key takeaway
This recovery scheme does not require the use of a log in a single-user environment. In a multiuser environment, a log may be needed for the concurrency control method. Shadow paging considers the database to be made up of a number of fixed-size disk pages (or disk blocks)—say, n—for recovery purposes. A directory with n entries is constructed, where the ith entry points to the ith database page on disk. The directory is kept in main memory if it is not too large, and all references—reads or writes—to database pages on disk go through it. When a transaction begins executing, the current directory—whose entries point to the most recent or current database pages on disk—is copied into a shadow directory. The shadow directory is then saved on disk while the current directory is used by the transaction.
During transaction execution, the shadow directory is never modified. When a write_itemoperation is performed, a new copy of the modified database page is created, but the old copy of that page is not overwritten. Instead, the new page is writ-ten elsewhere—on some previously unused disk block. The current directory entry is modified to point to the new disk block, whereas the shadow directory is not modified and continues to point to the old unmodified disk block. Figure 23.4 illustrates the concepts of shadow and current directories. For pages updated by the transaction, two versions are kept. The old version is referenced by the shadow directory and the new version by the current directory.
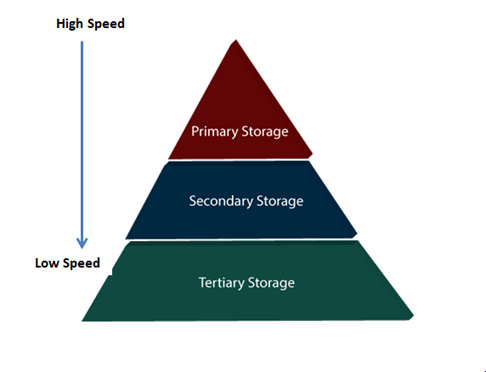
Fig 7 - Example
To recover from a failure during transaction execution, it is sufficient to free the modified database pages and to discard the current directory. The state of the data-base before transaction execution is available through the shadow directory, and that state is recovered by reinstating the shadow directory. The database thus is returned to its state prior to the transaction that was executing when the crash occurred, and any modified pages are discarded. Committing a transaction corresponds to discarding the previous shadow directory. Since recovery involves neither undoing nor redoing data items, this technique can be categorized as a NO-UNDO/NO-REDO technique for recovery.
In a multiuser environment with concurrent transactions, logs and checkpoints must be incorporated into the shadow paging technique. One disadvantage of shadow paging is that the updated database pages change location on disk. This makes it difficult to keep related database pages close together on disk without complex storage management strategies. Furthermore, if the directory is large, the overhead of writing shadow directories to disk as transactions commit is significant. A further complication is how to handle garbage collection when a transaction commits. The old pages referenced by the shadow directory that have been updated must be released and added to a list of free pages for future use. These pages are no longer needed after the transaction commits. Another issue is that the operation to migrate between cur-rent and shadow directories must be implemented as an atomic operation.
Key takeaway
This recovery scheme does not require the use of a log in a single-user environment. In a multiuser environment, a log may be needed for the concurrency control method. Shadow paging considers the database to be made up of a number of fixed-size disk pages (or disk blocks)—say, n—for recovery purposes. A directory with n entries is constructed, where the ith entry points to the ith database page on disk. The directory is kept in main memory if it is not too large, and all references—reads or writes—to database pages on disk go through it. When a transaction begins executing, the current directory—whose entries point to the most recent or current database pages on disk—is copied into a shadow directory. The shadow directory is then saved on disk while the current directory is used by the transaction.
In order to recuperate from database failure, database management systems resort to a number of recovery management techniques. In this chapter, we will study the different approaches for database recovery.
The typical strategies for database recovery are −
Recovery from Power Failure
Power failure causes loss of information in the non-persistent memory. When power is restored, the operating system and the database management system restart. Recovery manager initiates recovery from the transaction logs.
In case of immediate update mode, the recovery manager takes the following actions −
In case of deferred update mode, the recovery manager takes the following actions −
Recovery from Disk Failure
A disk failure or hard crash causes a total database loss. To recover from this hard crash, a new disk is prepared, then the operating system is restored, and finally the database is recovered using the database backup and transaction log. The recovery method is same for both immediate and deferred update modes.
The recovery manager takes the following actions −
Checkpointing
Checkpoint is a point of time at which a record is written onto the database from the buffers. As a consequence, in case of a system crash, the recovery manager does not have to redo the transactions that have been committed before checkpoint. Periodical checkpointing shortens the recovery process.
The two types of checkpointing techniques are −
Consistent Checkpointing
Consistent checkpointing creates a consistent image of the database at checkpoint. During recovery, only those transactions which are on the right side of the last checkpoint are undone or redone. The transactions to the left side of the last consistent checkpoint are already committed and needn’t be processed again. The actions taken for checkpointing are −
If in step 4, the transaction log is archived as well, then this checkpointing aids in recovery from disk failures and power failures, otherwise it aids recovery from only power failures.
Fuzzy Checkpointing
In fuzzy checkpointing, at the time of checkpoint, all the active transactions are written in the log. In case of power failure, the recovery manager processes only those transactions that were active during checkpoint and later. The transactions that have been committed before checkpoint are written to the disk and hence need not be redone.
Example of Checkpointing
Let us consider that in system the time of checkpointing is tcheck and the time of system crash is tfail. Let there be four transactions Ta, Tb, Tc and Td such that −
The situation is depicted in the following diagram −
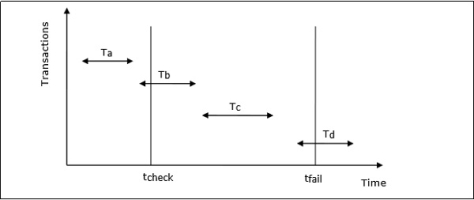
Fig 8 - Transaction
The actions that are taken by the recovery manager are −
Transaction Recovery Using UNDO / REDO
Transaction recovery is done to eliminate the adverse effects of faulty transactions rather than to recover from a failure. Faulty transactions include all transactions that have changed the database into undesired state and the transactions that have used values written by the faulty transactions.
Transaction recovery in these cases is a two-step process −
Steps for the UNDO operation are −
Steps for the REDO operation are −
Key takeaway
In order to recuperate from database failure, database management systems resort to a number of recovery management techniques. In this chapter, we will study the different approaches for database recovery.
The typical strategies for database recovery are −
Reference Books
1. “Database Management Systems”, Raghu Ramakrishnan and Johannes Gehrke, 2002, 3rd Edition.
2. “Fundamentals of Database Systems”, RamezElmasri and ShamkantNavathe, Benjamin Cummings, 1999, 3rd Edition.
3. “Database System Concepts”, Abraham Silberschatz, Henry F. Korth and S.Sudarshan, Mc Graw Hill, 2002, 4th Edition.




