Unit-3
Design Methodology
The aim of the object-oriented approach is to capture information systems' structure and behavior into small modules that incorporate both data and processes. Object Oriented Design (OODmain )'s goal is to enhance the efficiency and effectiveness of the research and design of the system by making it more accessible.
OO models are used in the research process to fill the void between the problem and the solution. It performs well in situations where there is continuous design, adaptation, and maintenance of systems. This describes the objects in the problem domain, categorizing them in terms of knowledge and behavior.
In the following ways, the OO model is beneficial:
● It enables, at low cost, improvements in the system.
● It facilitates the reuse of pieces.
● This simplifies the issue of combining parts in order to configure a large device.
● The architecture of distributed systems is simpler.
Advantages
The object-oriented approach offers the opportunity to decrease some of the major systems-related costs, such as maintenance and programming code creation. Some of the advantages of the object-oriented approach are here:
● Reduced Maintenance: The primary purpose of object-oriented growth is to ensure that the device can have a longer life while having much lower maintenance costs. The behaviors can be reused and adapted into new behaviors since most of the processes inside the system are encapsulated.
● Real-World Modeling: The object-oriented system aims to model the natural world more thoroughly than conventional techniques do. Objects are grouped into object classes, and actions are correlated with objects. The model is based, rather than on data and processing, on objects.
● Improved Reliability and Flexibility: Object-oriented systems promise to be much more stable than conventional systems, largely because existing artefacts can "built'' new behaviors. Since it is possible to dynamically call and access objects, new objects can be generated at any time. New objects may inherit the characteristics of data from one or several other objects. Behaviors can be inherited from super - classes, and new behaviors can be implemented without disrupting the roles of existing structures.
● High Code Reusability: When a new object is created, the data attributes and characteristics of the class it was spawned from will be automatically inherited. The new object would also inherit all super classes in which it participates from the data and behaviors. When a user introduces a new form of widget, "wigitty" is the new object, while the device has new behaviors that are described.
Disadvantages
When contemplating the use of an object-oriented system, there are many major misconceptions that must be addressed:
● For complex, interactive environments, object-oriented development is ideally suited, as demonstrated by its widespread adoption in CAD/CAM and engineering design systems. Wide-scale object-oriented corporate systems are still unproven, and the object-oriented approach does not support many bread-and-butter information system implementations (i.e. payroll, accounting).
● Object-oriented Development is not a technology: While many proponents are religious in their favor of object-oriented systems, note that all "HOOPLA" focuses on the problem-solving object-oriented approach, and not on any particular technology.
● Object-oriented Development is not yet completely accepted by major vendors: Some market respectability has been gained through object-oriented growth, and suppliers have gone from catering to a' lunatic fringe' to a respected market.
Key takeaway:
● The aim of the object-oriented approach is to capture information systems' structure and behavior into small modules that incorporate both data and processes.
● OO models are used in the research process to fill the void between the problem and the solution.
Analysis is a process of discovering what the system will do rather than how it will do it. In the analysis process the complex problem statement is broken into easy and manageable elements and relationships to develop the solution. Analysis is the first step in software development. It has basically two parts i.e. static analysis and dynamic analysis model.
Static analysis model can be depicted by class diagram, class diagram shows the classes composing the system and relationship between the classes can be shown. Dynamic analysis models can be depicted by communication diagrams.
There are two inputs to the analysis process first is the business requirement and second is the system requirement. These inputs are converted to a model of the objects which have attributes and their relationships processed by the proposed system. The objects lie within the system as well as at system boundaries which can be accessed by the available interfaces. The object identified by the system can
be physical objects or conceptual objects.
Analysis needs to be done before implementation because understanding the problem is more important than jumping directly to design and implementation. understanding is not complete with only business requirement model as it models the use case as per the business view or it cannot be completely understood by system requirement model as it model use case as per system view. Both the business requirement model and system requirement model must be done before design for complete understanding of the problem statement.
Key takeaway:
● Analysis is a process of discovering what the system will do rather than how it will do it.
● Analysis needs to be done before implementation because understanding the problem is more important than jumping directly to design and implementation.
● Analysis is the first step in software development.
It is the next step in software development. Once the problem statement is analyzed, the developer must approach the system design. In this development phase the decision about system architecture is devised for the problem statement and the solution is developed by organizing the system into subsystems, assigning subsystems to hardware and software. Major policy decisions are taken in this phase.
System design is a software development process in which the architecture of a system is devised. The decision about the design of modules and components of the system is taken. It deals with the interface and data required for the system to satisfy the system requirement. Overall structure and architectural style of the system is devised by the developer. System design focuses on how to solve the problem.
This process is divided into 2 parts, logical design and physical design.
Logical Design: it models the very easy and simple representation of the system. It shows the abstract representation of the system using graphical notations showing the input, output and data flow. It can be shown with the help of DFD and ER diagrams.
Physical Design: Physical design deals with how the input is given to the system, how it is processed and how the output is supposed to be displayed by the system. It does not refer to the actual hardware or physical design of the system. It is non tangible design of the system.
In system design the developer takes major and critical decisions about the structure, organization and architectural style of the system. following are few decisions taken during system design.
1) System performance estimation
2) Making a reuse plan
3) Dividing the system into subsystems
4) Concurrency identification
5) Subsystem allocation to hardware
6) Estimating Hardware Resource Requirements
7) Task allocation to the processor
8) Making Hardware- software trade-off
9) Data store Management
10) Global resource management
11) Selecting a global control strategy
12) Handling boundary conditions
13) Setting trade off priorities
14) Choose an architectural style
System Performance estimation
For a new system an approximate performance estimate must be calculated. A rough estimate of the system performance should be calculated using common sense such as the maximum response time of the system, number of transactions processed by the system, the storage requirement of the system etc. it is estimated to check the feasibility of the system not to achieve high accuracy of the system.
Making a reuse plan
Reuse is one of the benefits of object oriented design and modeling. Reusing is always better than creating new things and using them. Reusable things include models, libraries, framework and patterns.
The logic in one model can be used and applied to many different problems.
i) Library based reuse
These are the programming subroutines which are prewritten, readily available to use which act as template for the programmers to use during programming. Libraries help the programmer save time and simplify the work by using the pre written codes rather than investing time to write them.
A good library is a collection of carefully organized classes which shows many qualities like coherence, completeness, consistency, efficiency, extensibility and generosity. Reusing classes from many resources creates problem. Hence limiting the reuse. Some problems arising due to reuse can be related to validation of arguments either collectively or Individually.
● The problem like error handling may arise due to different error handling techniques in different sources.
● Different class libraries may use different control paradigms like event driven paradigm or procedure driven paradigm, using them together creates problems.
● Garbage collection is one of the problems created due to library based reuse, because different libraries have their own technique of garbage collection. Like in java it is done automatically whereas in C++ its applications responsibility to de allocate memory.
● Name collision is also a problem aroused due reuse because some classes from different libraries may have the same name in public identifiers.
ii) Framework based reuse
A framework can be defined as a skeletal structure of a program on which a complete application can be built. It is an abstraction in which common code providing generic functionalities can be used and reused by the user code. It is a special case of software libraries in which reusable abstractions of code are wrapped in application programming interfaces (API). Frameworks contain housekeeping and utility codes facilitating user application on specific domains.
There are many different types of framework available like
● Resource Description framework
● Internet business framework
● Sender Policy Framework
● Zachman framework
● .Net framework etc
Microsoft .net framework is a framework for windows OS, it includes many libraries and supports several programming languages.
iii) Pattern based reuse
Pattern is a proven solution to general software development problems. There are different design patterns for different phases of the software life cycle. Design patterns provide a general solution to problems in object oriented programming. The patterns are not always specific to specific problems. They are generally reused in different problems. There are different types of the pattern like structural pattern, creational pattern and behavioral pattern.
Dividing the system into subsystems
A system can be divided into subsystem and subsystem and a subsystem can be further divided into smaller subsystems of its own. Dividing the system into smaller chunks makes the system more manageable. A subsystem can be described as a collection of different elements like classes, association, operations, events and constraints which are interrelated. The relationship between 2 Subsystems can be client-server or peer-to-peer relationship.
A system can be divided into layers and partitions. The system when divided in terms of layers can be divided into horizontal layers. This is a layered approach where each subsystem is built upon each other.
Partitioning divides the system vertically in weak subsystems and each subsystem in the partitioned architectural model collaborates with the peer subsystem at the same level of abstraction. Layered architectural style differs in level of abstraction for each layer is different.
Subsystem can be identified by the following steps
• start with the analysis model
• go through the separation of design concerns
• check functionally related classes and interfaces
• identify class’s interfaces and subsystems with many dependencies
• search for large-grained components
• search for reusable components
• get the interfaces
• identify software products that need to be wrapped up as a subsystem
• check legacy systems which need to be wrapped up as a subsystem
• look for service subsystems
• identify for software products that need to be wrapped up as a subsystem.
Concurrency identification
Concurrency improves efficiency of the system. In a system design not all objects are concurrent. We need to identify the objects which are actively concurrent in implementation during system design and to identify objects which are mutually exclusive.
For real time and concurrent applications, we can identify object concurrency by doing following activities
● Search for inherent concurrency: if two objects can receive events at the same time without interacting with each other, we can say that both the objects are inherently concurrent. Inherently concurrent subsystems should not be implemented as separate units.
● Concurrent task: objects in the system can be dependent on each other. Observing the state diagram of each object and the events they exchange to other objects help to define objects with a single thread of model or multiple thread of model.
● Draw overall structure of the software architecture. Organize the application into a subsystem and take decisions about subsystem structure and interface. if it is a distributed application, decide about how to structure and organize the distributed subsystem in configurable components and define the communication interface between the subsystems.
● Make decisions about the characteristics of the object whether they are active or passive objects. Organize the system into concurrent tasks for each subsystem by using task structuring criteria and define the task interfaces.
● Design class interface. identify the passive classes(information hiding classes) and design their parameters and operations. Build class hierarchies using inheritance.
● Build a detailed software design which can address the issues concerning task synchronization, design of concurrent task and communication
Subsystem allocation to hardware
When a system is divided into subsystems, each concurrent subsystem must be allocated to a hardware unit. A hardware unit can be a general purpose processor or a specialized functional unit. For allocating subsystems to hardware the system designer needs to do following activities
● Calculate the approximate performance needs and the resources required to achieve the performance.
● Select proper hardware or software implementation for the subsystem
● To improve performance, allocate software subsystem to processor and minimize the inter process communication
● Connect the physical units to implement the subsystem. Check the connection between the nodes and communication protocol
● A deployment diagram shows the physical distribution of the system, look for the interface implied by the diagram.
Estimating Hardware Resource Requirements
Use of multiple processors or many hardware units for the implementation of the system increases the performance of the system. The total no of functional hardware units and processors depends on the no. of computations and the speed of the hardware. Therefore, the system designer must estimate the processing power of the processor and the time required to process the transaction, as well as no of
transaction processed per unit of time.
Making Hardware- software trade-off
The hardware –software trade off generally focuses on selecting which subsystem to implement as hardware or to implement on software. Usually taking decisions to implement the subsystem in hardware has 2 major advantages, first the cost of hardware is now a day’s decreasing as the technology advances. Second, dedicated hardware always gives high performance.
Task allocation to the processor
There are many tasks in a system belonging to many subsystems. These tasks may be independent or they may be concurrent. Allocate concurrent tasks to the independent processors or processes to increase the performance.
There are certain reasons for assigning tasks to processors which are
mentioned as below
Reason 1: there can be few tasks that need to be carried out at specific or specialized locations so that they can avail the benefit of being executed on dedicated software
Reason 2: due to communication limits few tasks are allocated on the processor. The processes which are allocated on some hardware may get short of available bandwidth between them due to excess data flow or delayed response time.
Reason 3: the no of computation carried out by any single processor is limited so multiple processors are used to carry out the task. Even independent subsystems can be allocated to different processors to increase the performance.
Data store Management
There are many different types of data storage available depending upon the type, complexity and volume of the data to be stored. The system designer decides which type of data storage to choose for storing and managing the data. Data can be stored in files, data structures or data bases or in combinations of any of the data storage. Depending upon the complexity of the data, the access time, type of access and portability of data the system designer should select the data storage , it can be flat
files or relational databases or object databases.
While selecting the data storage the system admin needs to take following points into consideration
● Cost: system needs database to store the data so the cost of the system increases which also requires licensed purchasing.
● Life cycle cost also needs to taken into consideration as it requires the cost for purchase, development and maintenance
● System designers need to think about the current amount of data and increase in data in near future, how to handle and store the data.
● Designer also need to consider the data storage extensibility and portability
● As data increases and technology advances the system designer should think on the distributing data , concurrent access to the data and recovery of the data after failure of the machine etc
Files can be the cheapest mode of data storage where we can access the file sequentially or randomly. This mode of storage is easy, cheap and simple but the data in the file system may behave abruptly when transferred to another system because different systems may have different file systems.
The data like historical data, high volume data, simple structured data, read only data are the most suitable type of data to be stored in files.
Another type of storage can be database management systems. There many different types of database such as relational database, object oriented database, object relational database, networked and hierarchical database. Databases are easy to port. The data which needs to be stored for longer time, the data which needs to be prevented from unauthorized access and exist in large volume, the data which needs to be accessed by multiple users in restricted form are the most suitable form of data to get stored in databases.
Global resource management
The system designer is supposed to identify the global resources and make decisions on how to control the access to them. The global resource can be physical systems, peripheral devices, logical names and shared data.
Physical system consists of processors , tape drives ,etc which can control access to themselves by having set a protocol for accessing them.
Peripheral devices such as keyboard, monitor, mouse etc
Logical name such as object ids, class names, file names etc
Shared data is data in databases which needs to be accessed in restriction.
Logical names and databases must have access control in a shared environment to prevent conflict. One strategy is to have a guardian object which controls access to all resources and prevents conflict. All requests to access the resources must pass through the guardian object only. This will prevent unauthorized access to the shared resource and prevent conflict to access them. Second strategy can be to divide the resources logically and provide one guardian object to each logically partitioned unit.
Selecting a global control strategy
The system consists of two different flows of control in software systems such as internal control and external control. Internal control refers to control flow within the process that exists only in the implementation whereas the external control refers to flow of externally visible events among the object of the system. There are different types of external control flow like procedure driven control, event- driven control and concurrent system control.
Handling boundary conditions
The system designer designs the system to work smooth and steady but the designer must consider the boundary conditions. There may be certain issues associated with the initialization, termination and failure of the system.
Initialization boundary condition: it includes initialization of the constants, parameters, global variables, guardian object and classes etc. At system initialization these must be initialized as per their hierarchy of initialization. Failure of initialization may lead to prolonged delays and halting of the system.
Termination boundary condition: on termination every object must release the allocated space and also inform other objects about its termination state.
Failure: it is an unexpected termination of the system due to any of the reasons like exhausting resources, system fault due to user errors, errors, bugs , breakdown from external system. In this scenario system designers must provide ways to recover and read error logs to find the cause of failure.
Setting trade off priorities
The system designer must set some trade off not only for the software but also for the process of developing it.
The designer can use extra memory or increase the memory to increase the performance and to make the system faster. Such design tradeoff have major impact on the design of the system. Setting trade off priorities is the best vague.
Choose an architectural style
The standard definition as per ANSI/IEEE standard 1471-2000 is “fundamental organization of a system, embodied in its components, their relationships to each other and the environment, and the principles governing its design and evolution”
The system architecture completely describes the structure of the system, highlighting the high level decision about how the system is composed of, what are the components of the system, how they are communicating with each other and the key properties of the components.
There are many system architectural styles that exist in the system which are suitable to some type of systems.
These prototypical architectural styles are
● Batch transformation
● Continuous transformation
● Interactive interface
● Dynamic simulation
● Real time system
● Transaction manager
Key takeaway :
● System design is a software development process in which the architecture of a system is devised.
● System design focuses on how to solve the problem.
● In system design the developer takes major and critical decisions about the structure, organization and architectural style of the system.
● Reuse is one of the benefits of object oriented design and modeling.
● A system can be divided into subsystem and subsystem and a subsystem can be further divided into smaller subsystems of its own.
● Concurrency improves efficiency of the system. In a system design not all objects are concurrent.
● The global resource can be physical systems, peripheral devices, logical names and shared data.
We have an entity, dynamic, and functional model after study, but the object model is the key structure on which the design is designed. Examination of the object model may not display operations. In the object model, the designer must translate the behavior and behaviors of the dynamic model and the functional model processes into operations attached to classes. Each diagram of a state describes an object's life history. A transformation is a modification of the object's state and maps the object into an operation.
With each event obtained by an entity, we may associate an action. The operation performed by a transformation depends on both the occurrence and the object's condition in the state diagram. The algorithm that implements an operation therefore depends on the state of the object. If more than one state of an object can receive the same occurrence, then the code implementing the algorithm must have a state-dependent case statement. An event that an object sends may represent an action on another object.
Events frequently occur in pairs, with an action being initiated by the first event and the outcome returned by the second event when the action is completed. In this case, if the events are on a single thread, the event pair can be mapped into an operation that performs the action and returns power. In the functional model, an event or behavior triggered by a transition in a state diagram can extend into an entire dfd. The process network within the dfd represents the body of an operation.
Intermediate values in action are the flows in the diagram. The designer transforms the diagram's graphic structure into the algorithm's linear sequence of steps. Sub operations represent the mechanism in the dfd. Some, but not necessarily all, of these may be operations on the original target object or other objects To artefacts.
Determine a sub-target operation's object as follows:
● If a method derives a value from the input flow, then the goal is the input flow.
● The method has the same type of input flow or output flow, and the goal is the input output flow.
● The method constructs the value of the output from multiple input flows, so the operation is a class operation on the output class.
● The data store or actor is the target whether a process has input or output to the data store or actor.
Key takeaway:
● A transformation is a modification of the object's state and maps the object into an operation.
● The operation performed by a transformation depends on both the occurrence and the object's condition in the state diagram.
Two key stages, namely, system design and object design, include object-oriented design.
System design
The complete architecture of the desired system is planned at this stage. The framework is conceived as a set of subsystems that interact and, in turn, consists of a hierarchy of objects that interact, grouped into groups. According to both the system analysis model and the proposed system architecture, system design is completed. Here, instead of the processes in the system, the focus is on the objects comprising the system.
Object design
A design model is developed in this stage based on both the models developed in the process of system analysis and the architecture built in the phase of system design. The required classes are all established. The designer decides if −
● There are new classes to be built from scratch,
● It is possible to use some existing classes in their original form, or
● The new classes should be inherited from the classes that exist.
The relations between the classes identified are formed and the class hierarchies are identified. In addition, the developer designs the classes and their associations' internal information, i.e., the data structure for each attribute and the operations algorithms.
Key takeaway :
● According to both the system analysis model and the proposed system architecture, system design is completed.
● A design model is developed in this stage based on both the models developed in the process of system analysis and the architecture built in the phase of system design.
For each operation obtained from the DFD, an algorithm is designed. The DFD only specifies operations, what operation does whereas an algorithm specifies how it is to be done. The data store or an actor here is treated as a target of the process.
The object designer must do the following tasks to design an algorithm for the operation
● Select a suitable algorithm.
There are many criteria depending on which the algorithm can be selected. The criteria can be computational complexity, ease of implementation and flexibility. Computational complexity: calculate the computational complexity of the algorithms and choose the algorithm with lesser computational complexity, e.g. merge sort can be chosen over bubble sort as the complexity of merge sort is less as compared to the bubble sort.
Ease of implementation: if the operation is non critical then it can be implemented in a simple algorithm that can result in improved efficiency.
Flexibility: Most of the algorithms are expected to be extended in future. So the object designer must design the algorithm with flexibility to extend or to have a change in future without affecting the efficiency of the algorithm.
● Select a suitable data structure
While designing an algorithm data structure is required. We need to choose suitable data structures for the algorithm like trees, graphs, linked list, stack, array, strings etc. Choosing the appropriate data structure increases the efficiency of the algorithm. Therefore, the object designer must choose suitable data structure for the algorithm.
● Add new classes and operation if needed
While implementing an algorithm, it may generate an intermediate result. To store the intermediate result, the object designer plans to add new classes. Any complex operation may sometimes break into small sub operations for simplicity. The object designer must have the provision to add new classes and operations as per the need.
● Assign responsibility to the class
The object designer must assign the operations to the appropriate classes. But there are some operations which appear in many classes and create complexity when many objects are involved. To simplify the task and to assign the operation to the correct class following steps are followed.
If there are two objects, one which performs the action and another on which the action is performed then associate the operation with the target of the operation. If the object gets modified by the operation and another object remains unaffected then assign the operation to the modified object.
If the class and associations form the star like network of the object, then associate the operation with the central class.
Key takeaway :
● For each operation obtained from the DFD, an algorithm is designed.
● The DFD only specifies operations, what operation does whereas an algorithm specifies how it is to be done.
● There are many criteria depending on which the algorithm can be selected.
Only logical information about a system is captured by the analysis model, the object model has to add additional information and more details to support access to the information. The object designer has to maintain balance between the efficiency of the system and clarity of the system.
The object designer can do the design optimization as mentioned below.
- Add redundant associations to increase the convenience and to decrease the access cost
- Reorganizing the computations to increase the efficiency Some times during execution there may exist some paths where chances of execution on this path are very rare or less. The designer can avoid this by rearranging the computation at an early stage. By optimizing the algorithm, the efficiency can be increased.
- Save the derived attributes to avoid re computation of complicated expressions The derived data is that data which can be derived from other data. It is sometimes redundant and cached to avoid re computation of the data again.
The designer needs to implement the state diagram from the dynamic model. There are following ways in which the designer can implement the state diagram
- Use location within the program to hold state
The location of control in the program shows state of the program. We can say that the control of the program branches to other location depending upon the event occurred. The state diagram can be converted into codes by following the below guidelines
o Find the main path within the diagram that will execute normally on the events.
o Find state along the path which can be converted to sequence of statements in the
program.
o Find the other paths that branch from the main path. This can become the conditional statement the programming code
o Find the backward paths that branches out of the main path and travel back to it. This becomes the looping construct in the code.
o Remaining states and conditions if any becomes exceptional conditions which can be handled through exceptional handling mechanism in programming code. This approach fails if there is a lack of modularity in the diagram.
2. State diagram implementation
3. Using concurrent tasks
We must formulate a strategy for implementing all associations in the object model during the object design stage. We can either select a global strategy for universally implementing all associations, or a specific technique for each association.
- Analyzing Association Traversal
Inherently, relations are bidirectional. Their implementation will be simplified if the association in your application is crossed in one direction. The specifications on your application may change, you may need to add a fresh procedure later that needs to cross the association in the reverse direction. Use bidirectional associations for prototype work so that we can incorporate fresh actions and expand/modify. In the case of optimization work, refine those associations.
2. One-way association
● It can be implemented as a pointer if an association is only crossed in one direction.
● If the multiplicity is "many," it is implemented as a pointer set.
● If the number is ordered, use a list instead of a set.
● As a dictionary object, a qualified association with multiplicity one is implemented (A dictionary is a collection of value pairs mapping selector values into target values.
● Professional association with multiplicity is rare for many (it is implemented as a dictionary set of objects).
3. Two way association
Many connections, but not usually with equal frequency, are traversed in both directions. Three approaches to their implementation exist:
Implement only in one direction as an attribute and perform a search when a backward traversal is required. This method is useful only if there is a significant disparity in crossing frequency and it is important to reduce both the cost of storage and the cost of updating.
4. Link attributes
Its introduction depends on multiplicity.
● If a relation attribute is a one-one relationship, it is stored in any of the classes concerned.
● The relation attribute can be stored as attributes of several objects if it is a multi-one association, since each many objects appears only once in the association.
● If it is a multi-association, any entity may not be associated with the relation attribute; association is enforced as a separate class in which each instance is one link and its attributes.
Key takeaway :
● We can either select a global strategy for universally implementing all associations, or a specific technique for each association.
● Use bidirectional associations for prototype work so that we can incorporate fresh actions and expand/modify.
● In the case of optimization work, refine those associations.
Programs consist of discrete physical units that can be modified, compiled, imported, or otherwise tampered with. There are different degrees of packaging in object oriented languages. In any large project, it is necessary to carefully partition an implementation into packages in order to allow various individuals to Act on a programme cooperatively.
The following problems include packaging:
I. Hiding internal information from outside view :
One design purpose is to treat Đlasses as "black boxes" with a public external interface, but whose internal information are shielded from view. Hiding internal data allows a class to be modified without asking any customers in the class to alter the code. Additions and modifications to the class are surrounded by "fire walls͟" that influence the effects of the class.
Any alteration so that improvements can be recognised clearly. Trade off between practises of hiding information and optimization. We are interested in hiding data during study.
The less factors an operation is aware of, the less likely any changes will affect it. The less activities that are aware of a class's data, the easier it is to change the class if necessary.
To restrict the spectrum of awareness of any operation, the following design principles help:
● Allocate the duty of conducting operations to each class and include information that applies to it.
● Calling an attribute access operation belonging to an entity of another class Prevent traversing connections that are not related to the current class. At as high a level of abstraction as possible, describe interfaces.
● By defining abstract interface classes, that is, classes that mediate between the system and the raw external objects, hide external objects at the system boundary.
● Avoid applying a method to the outcome of another method unless the output class is already the caller's method provider. Consider writing a process to merge the two operations instead.
II. Coherence of entities
Coherence of entities is one significant design theory. An organisation is cohesive, such as a class, an operation, or a module, if it is structured on a clear plan and all its components match together against a common purpose. It shouldn't be a set of parts that are unrelated. A technique should do one thing well. A single technique should not involve both strategy and execution.
Policy includes decision-making, the processing of global knowledge, contact with the outside world and the interpretation of special cases. Policy approaches include feedback statements, conditionals and access to data stores.
It does not have complicated algorithms, but calls different algorithms instead
Methods of implementation. Without making any choices, assumptions, defaults or exceptions, an implementation method performs exactly one activity. All data is given in the form of arguments (list is long). Separating strategy and execution increases reusability. Therefore, methods of implementation do not have any reliance on context. So they are likely to be reusable, they are clear and consist of a rewritten policy process in an application.
Decisions at the high level and demands for approaches at the low level. Too many roles a class does not fulfil.
III. Constructing physical module
We divided the object model into modules during the research and device design stages.
● The initial organisation may not be sufficient for final system implementation packaging, Added new classes to the current module or layer or separate module.
It is important to describe modules so that interfaces are minimal and well defined. It is possible to use object model communication as a reference for partitioning modules. There should be groups in the same module that are closely related by associations. Classes that are loosely linked should be divided into different modules. In a module, classes can represent similar kinds of items in the application or be components of the same composite object.
Inside a module, try to encapsulate tight coupling. Coupling is determined by the number of different events that move through a given association. The number represents the number, not the frequency, of the various ways the relation is used.
Key takeaway :
● Programs consist of discrete physical units that can be modified, compiled, imported.
● In any large project, it is necessary to carefully partition an implementation into packages in order to allow various individuals to Act on a programme cooperatively.
● A policy is to make context-dependent decisions.
● There are different degrees of packaging in object oriented languages.
There are many object oriented analysis and design methodologies. Few methodologies which were accepted as real object oriented analysis and design methodologies are listed below
1) Object Oriented Design with Applications (OODA) by Booch
2) Object Oriented Analysis and Object Oriented Design by Coad & Yourdon
3) Object Oriented Analysis and Design (OOAD) by Martin & Odell
4) Object Modeling Technique (OMT) by Rumbaugh
5) Object Oriented Systems Analysis (OOSA) by Shlaer & Mellor
6) Designing Object Oriented Software (DOOS) by Wirfs-Brock
Object Oriented Design with Applications(OODA) by Booch
This Booch methodology was developed in 1994.In this type of methodology Booch have given few specifications of general properties of well-structured complex systems. All the systems which support the OODAnalysis methodology must have these specifications. Problem domain is modelled in two aspects, one is the logical structure of the system and another is the physical structure of the system. Both static
and dynamic semantics are modelled in this type of methodology.
Object oriented analysis and object oriented design by Coad and Yourdon
It was developed in 1991 by Coad and Yourdon. The methodology is dependent on many general principles for handling the complex system. In the analysis phase the problem is divided into 5 layers which shows class, object, relationship, inheritance , messages etc. these 5 layers are then matched to four components like problem domain, data management, task management and human interaction domain during the design phase. Various graphical notations are available for showing the behavior of the object and functional structure.
Object Oriented Analysis and Design (OOAD) by Martin & Odell
This methodology mostly focuses on describing the behavior of the object. It uses the benefit of set theory and logic. Many methods are available for specifying objects and their relationship to describe the dynamic behavior of the object.
Object Modeling Technique (OMT) by Rumbaugh
James Rumbaugh led a team at research labs of General Electric to develop the Object Modeling Technique (OMT) in 1991. This methodology has analysis, design and implementation phases for a system using object oriented techniques. In this methodology the static, dynamic and functional view of the system is captured.
These views are modeled using object model, dynamic model and functional model. This methodology is very fast and a good approach to identify the objects of the system.
Object Oriented Systems Analysis (OOSA) by Shlaer & Mellor
This methodology was developed by shlaer and Mellor in 1992. This methodology includes object oriented analysis and helps in solving few problems in structured analysis approach. The main focus of this methodology is to analyse the static specification of the objects. All the techniques specified in this methodology are used to model the static, dynamic and functional specification of the objects.
Designing Object Oriented Software (DOOS) by Wirfs-Brock
Wirfs and Brock developed the Responsibility Driven Design(RDD) methodology in 1990. This methodology mainly focuses on the analysis phase of the SDLC. Object oriented concepts like abstraction and encapsulation are used to solve the real world complexity of the problem. This methodology treats the problem domain as a set of collaborating objects. The system is developed in two stages.
In first stage objects, their responsibilities and the collaborations to fulfil the responsibilities are identified.
In the second phase two graphical techniques are used. One technique is to show classes and class structures and the other is to show classes, subsystems and their relationships.
Key takeaway :
● OOAD by Booch, in this type of methodology Booch has given few specifications of general properties of well-structured complex systems.
● In OMT, methodology, the static, dynamic and functional view of the system is captured.
● OOSA methodology includes object oriented analysis and helps in solving few problems in a structured analysis approach.
● In 1983, JSD was invented by Michael Jackson.
● JSD's basic concept is that it focuses on the system's representation of the real world, i.e. its main emphasis is to chart real-world progress rather than determine the functions performed by the system.
● JSD is an action-related technique.
● In OOSD, the principal entities are:
- Modeling Stage- The Entity Behavior and Entity Structure are part of this stage.
- Network Stage-Initial step of model, Feature Step, and Step of Device Timing.
- Stage of implementation-Step of implementation.
● We focus on state vector and data stream interaction in the initial model stage.
● A data stream is an unbounded queue in which the read operator extracts the next record from the queue if there are no records while the read operation process waits until the record is available, while the next record is put in the written operation data stream in the read operation process.
● Entity action: acts are performed in time by entities. The behaviour is atomic, and can not be further broken down.
● Entity Structure: Phase partially sequences the order of action in relation to time
● The function stage is made up of pseudo code for the performance of state-generated action. In this stage, a complete system specification is needed by the developer.
● The System Timing Phase refers to the system performance constraints.
|
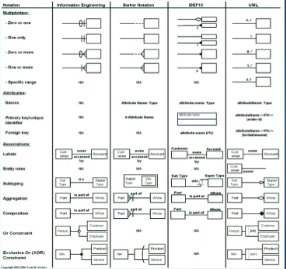
Fig : information modeling notation
Key takeaway :
● The aim of this method of design is to build software that can be maintained.
● Created by Michael A. Jackson, this design approach takes into account the fact that the system design is an extension of the design of the software.
References:
- “Object Oriented Modeling and Design”, Rambaugh, Premerlani, Eddy, Lorenson, PHI.
2. “Practical Object Oriented Design with UML”, Mark Priestley.
3. “Object Oriented Analysis and Design”, Kahate, TMH.




