Unit - 3
Internal Representation of Files
In UNIX operating systems, an inode is a data structure containing substantial information relating to files within a file system. In UNIX, when a file system is created, a fixed number of inodes is often created. Approximately 1% of the cumulative storage space of the file system is usually assigned to the inode table.
The words inode and inumber are also shared by citizens. The words are identical and apply to one another, but the same topics are not related to. Inode refers to the structure of the data; the inumber is essentially the inode identifier number, thus the inode number, or inumber, name. The number is only one significant data object for a file.
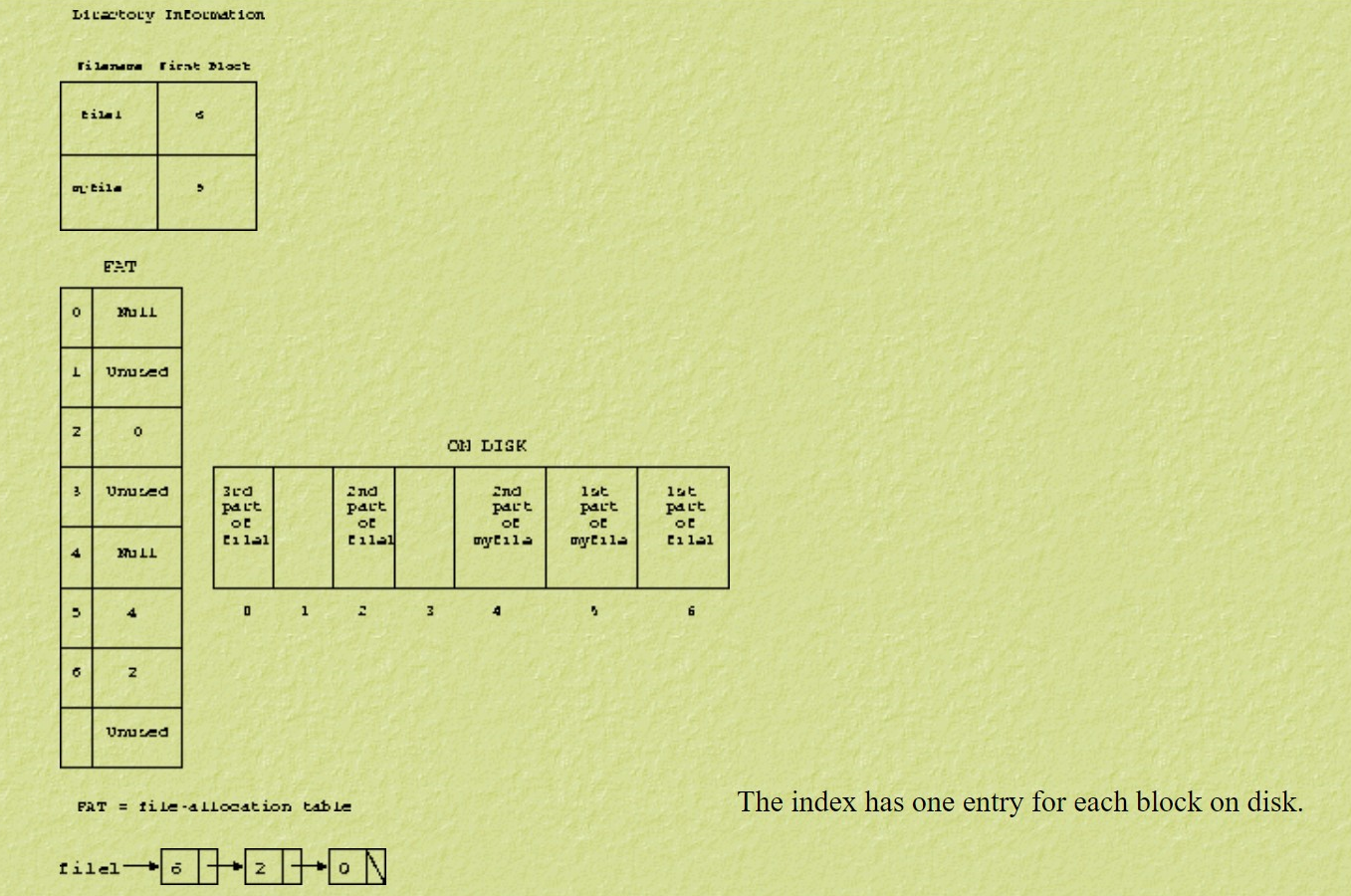
In UNIX, there is no linear disk storing of data in directories. The file size would not be flexible without massive fragmentation if it were to be stored sequentially. The inode will only need to store the starting address and size in the event of sequential storage. Instead, the disk block numbers on which the data is present are stored by the inode. But for such a technique, if a file has data over 1000 blocks, the number of 1000 blocks would need to be stored by the inode and the size of the inode would vary based on the file size.
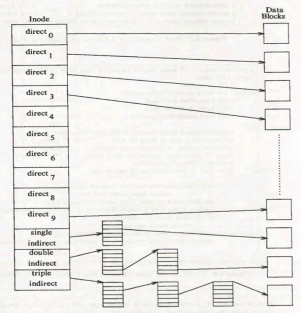
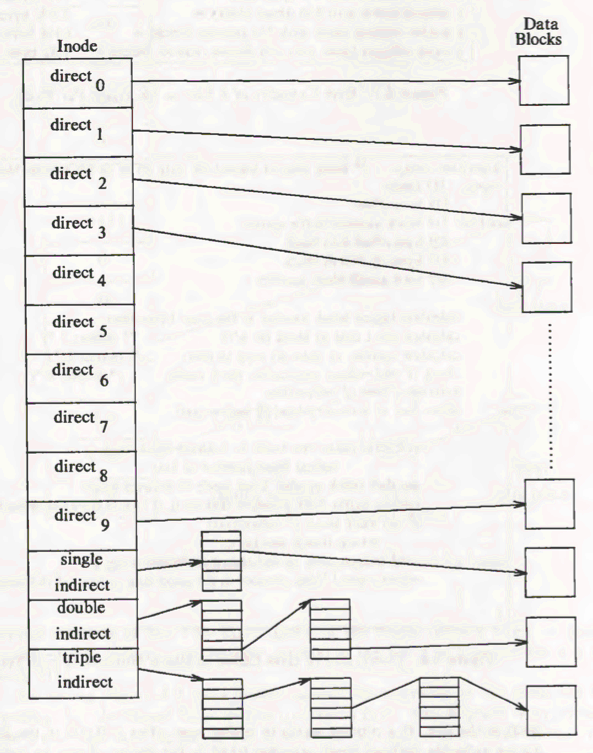
Indirect addressing is used to be able to provide a constant size and still enable big files. The inodes have a size 13 array and, while the number of elements in the array is independent of the storage technique, is used to store the block numbers. "direct addresses" are the first 10 members of the list, meaning they store the block numbers of individual records. "Single indirect" is the 11th member, who stores the block number of the block that has "direct addresses" The 12th member is "double indirect" and a "single indirect" block number number is stored. And it stores the block number of a "triple indirect" block, and the 13th member is "double indirect". You should widen this method to "quadruple" indirect addressing.
A directory is a file whose sole task is to store the names of the files and associated documents. The folders hold all files, whether common, unique, or directory files.
For the organisation of files and folders, Unix uses a hierarchical structure. This arrangement is often referred to as a tree directory. The tree has a single root node, a slash character (/), and it includes all the other directories below it.
3.3.1 Home Directory
Your home directory is called the directory you find yourself in as you first log in.
In your home directory and subdirectories that you will be building to manage your files, you will be doing most of your job.
You can use the following order at any time in your home directory –
~ The home directory is shown here. If you have to go to the home directory of some other person, use the following order –

You may use the following command to go into the last directory –

3.3.2 Pathnames - Absolute/Relative
In a hierarchy, directories are organized with root (/) at the end. Any file's location within the hierarchy is defined by its pathname.
Pathname elements are divided by a /. If defined in relation to the source, a pathname is absolute, so absolute pathnames always start with a /.
Any samples of absolute file names are given below.

It is also possible to connect a pathname to the existing working directory. Relative names never start with /. Any pathnames may look like this, relative to the home directory of user amrood,

To decide where you are at any time inside the filesystem hierarchy, enter the pwd command to print the new working directory –

3.3.3 Directories for Listing
You may use the following notation for listing the files in a directory −
 The following example lists all the files found in the directory /usr/local −
The following example lists all the files found in the directory /usr/local −

3.3.4 Directory formation
Now we can understand how directories should be built. Directories are generated using the following command −
 Here, the directory is the absolute or relative directory pathname that you want to build. For instance, the command −
Here, the directory is the absolute or relative directory pathname that you want to build. For instance, the command −

Creates a directory in the present directory, mydir. Another example is here −

This command generates the test-dir directory in the directory of /tmp. The mkdir command provides no output if the requested directory is generated successfully.
If you designate more than one directory on the command line, each of the directories is generated by mkdir. For instance, −

Build docs and pub files under the current directory.
3.3.5 Creating Directories for Parents
We can now understand how parent directories can be formed. Often the parent directory or directories might not exist when you try to construct a directory. In this case, as follows, mkdir issues an error code,
In such situations, the mkdir command may be defined as the -p alternative. It produces all the directories for you that are required. For instance −

The command above generates all of the parent folders needed.
3.3.6 Removal of Directories
You may uninstall directories using the rmdir command as follows –

Fast access to a file is by its path name, such as open, chdir (change directory), or device connection calls. Since the kernel deals for i-nodes rather than path names internally, it has to translate path names to i-nodes in order to access files. The namei algorithm parses the path name one component at a time, transforms each component into an i-node depending on its name and the searched directory, and eventually returns the i-node of the figure of the input path name.
A superblock is a log of a filesystem's features, including its height, the size of the block, the empty and filled blocks and their respective counts, the size and position of the inode tables, the map and use of the disk block, and the size of the block classes.
On the disk, the super block is preserved. The super block includes an array to cache the amount of free nodes in the file system to boost file system performance.
3.6.1 Algorithm for Inode Assignment to a New File
Procedure:
If the inode number list in the super block is not zero, the kernel assigns the next inode number, uses the iget algorithm to add the free inode to the newly allocated disk inode, copies the disk inode to the incore copy, initializes the inode field and returns the locked inode. A disk inode is modified to show that the inode is currently in use.
An area of non-zero file form reveals that the disk inode is reserved. The kernel has a strong inode in the simplest case, but there are race conditions that need further verification.
If the free inode super block list is empty, the kernel scans the disk and adds as many free inode numbers into the super block as possible. The kernel reads the inode list on the disk, block by block, and fills the inode number super block list to its maximum, bearing in mind the highest numbered inodes it finds.
It's the last one saved in super block, name that 'memorized' inode. The next time the kernel scans the disk for a free node, the recalled inode is used as its starting point, meaning that it does not spend time reading the disk block where there should be no free inodes.
After collecting the new set number of inodes, the inode assignment algorithm begins to begin. Whenever a disk inode is allocated by the kernel, the free inode count reported in a super block decreases.
Algorithm ialloc
/* allocate inode */
Input : file system
Output : locked inode
{
while (not done)
{
if (super block locked)
{
sleep (event super block become free);
continue;
/* while loop */
}
if (inode list in super block is empty)
{
lock super block;
get remembered inode for free inode search;
search disk for free inodes until super block full,
or no more free inodes (algorithms bread and brelse);
unlock super block;
wake up (event super block becomes free);
if (no free inodes found on disk)
return (no inode);
set remembered inode for next free inode search;
}
/* there are inodes in super block inode list */
get inode numbers in super block inode list;
get inode (algorithm iget);
if (inode not free after all)
/* !!! */
{
write inode to disk;
release inode (algorithm iput);
continue;
/* while loop */
}
/* inode is free */
initialize inode;
write inode to disk;
decrement file system free inode count;
return (inode);
}
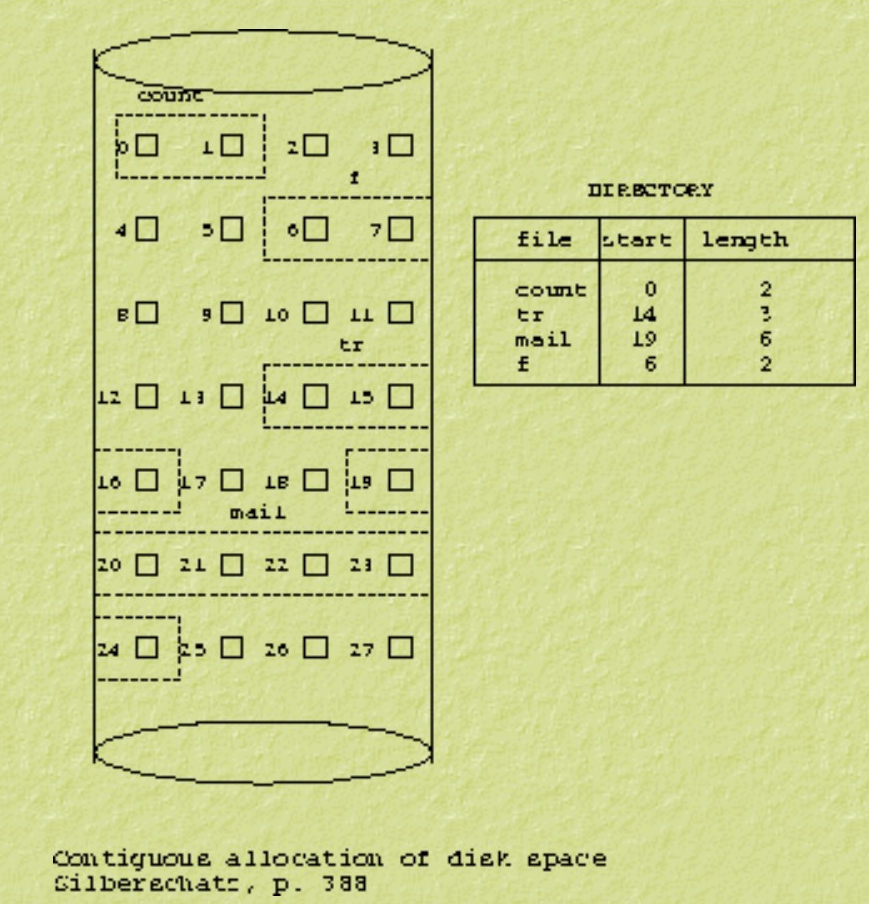
3.7.1 Contiguous allocation
Each file occupies a sequence of consecutive disk addresses.
Each entry in the directory includes:
Customary problem of dynamic storage allocation
If the file can be increased in size, either of them can

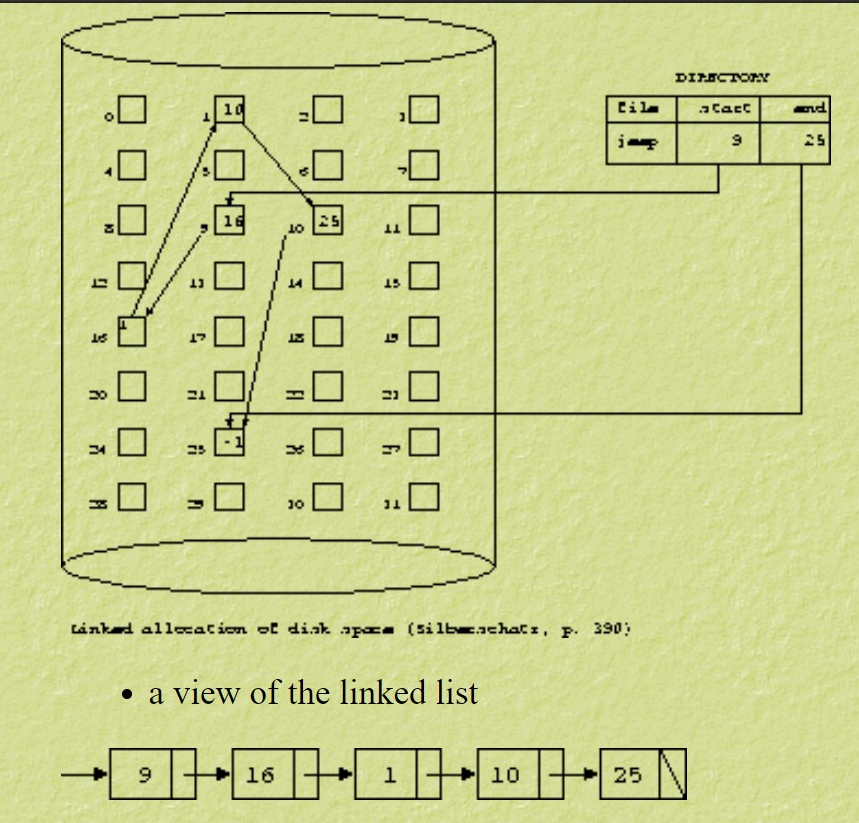
3.7.2 Linked allocation
The block address of the next block in the file is included in each data block.
Each entry in the directory includes:
3.7.3 Indexed allocation
Hold all pointers together in a table of indexes
3.7.3.1 all files in one index
- FAT may get very high and we can need to store FAT on disk to maximize access time.
- For e.g., 500 Mb of disk with 1 Kb block = 4 bytes * 500 K = 2 Mb of entry = 4 bytes
3.7.3.2 Separate index for each file
The index block gives data block pointers that can be distributed.
Direct access, direct access (computed offset)
There are three different types of files are given bellow
- Regular files
Data and executable programmes are stored in regular directories. The commands (ls) that you type at the prompt are known as executable programmes. The data can be anything, and there is no need for it to be stored in a certain format.
Standard files can be thought of as the UNIX tree's leaves.
3.8.2 Directories
Files that hold other files and sub-directories are referred to as directories. Directories are used to arrange data by grouping together files that are closely related. In the Windows operating system, files are similar to folders.
The directory file can only be written by the kernel. The kernel creates an entry when a file is attached to or removed from this directory.
A directory file may be thought of as a part of unix tree.
3.8.3 Special or Device files
The physical devices are represented by these files. Computer hardware, such as terminals and scanners, may often be referred to as files. Tape and disc drives, CD-ROM players, modems, network controllers, scanners, and some other piece of computer hardware can all be included in these system directories. Data is transmitted to the physical unit connected with a procedure as it writes to a specific register. Special files are not files in the traditional sense, but rather references to system drivers in the kernel. The same protection that applies to data also applies to physical devices.
3.9.1 OPEN
Whenever information is accessed in a file, we must first open the corresponding details.
The open() device call is used to open the open() file
Algorithm for opening a file:
3.9.2 READ
To read data from regular file we used read() system call is used
Algorithm for reading a file:

3.9.3 WRITE
To write the data to a regular file we used write() system call is used
Syntax of write system call
number=write(fd ,buffer, count)
Where…
fd ->is the file descriptor returned by open.
buffer -> buffer is the address of a data structure in the user process that will contain the data that process wants to write to file
count -> count is the number of bytes the user wants to write
Return value of system call write ()
The system call in turn returns an integer value.
- If successful the returned integer value is number is the number of bytes actually written to a file.
3.9.4 File and Record Locking
The initial Unix system that T & R built did not have this trait.
However, as database technology improves, System V applies this to functionality for UNIX.
File locking is the capacity granted to one method to lock files ,prevent all reading and writing partly in the same file from reading and writing or wholly by another method
In the other hand, record locking is the capacity granted to one approach to avoid reading and writing on relevant topics recorded by other processes in a file.
Uses fctl() for this form of file and record locking method () Device Call Calling System.
3.9.5 Adjusting the position of FILE I/O-LSEEK
Lseek()
A "current file offset." is associated with each open file. This is a nonnegative integer that measures the number of bytes from the beginning of the file. (Later in this section, we describe some exceptions to the "nonnegative" qualifier.) Read and write operations normally start at the current offset of the file and increase the offset by the number of bytes read or written. By default, when a file opens, this offset is initialized to 0, unless the O APPEND option is specified.
By calling lseek, an open file can be explicitly positioned.

The interpretation of the offset depends on the value of the argument from where it is.
If SEEK_SET is from there, the offset of the file is set to offset bytes from the beginning of the file.
If SEEK_CUR is from there, the offset of the file is set to its current value plus the offset. Positive or negative may be the offset.
If SEEK_END is where it comes from, the offset of the file is set to the file size plus the offset. Positive or negative may be the offset.
Since the new file offset is returned by a successful call to lseek, we can seek zero bytes from the current position to determine the current offset.

If the file descriptor refers to a pipe or FIFO, lseek returns -1 and sets errno to EPIPE. This method can also be used to determine if the referenced file is capable of searching.
With System V, the three symbolic constants, SEEK SET, SEEK CUR, and SEEK END, were introduced. Before System V, 0 (absolute), 1 (relative to current offset), or 2 (relative to current offset) were specified (relative to end of file). With these numbers hard-coded, a lot of software still exists.
Many commands line tools and text editors are provided by the UNIX operating system to create a text file. Under the GPL, you can use vi (emacs or joe), a terminal-based text editor for Unix. It is designed so that it is easy to use. In short, you can use any of the tools below:
3.10.1 Cat command
Use the cat command, followed by a redirection operator (>) and the name of the file you want to create, to create a new file. Press Enter, type the text and press CRTL+D to save the file once you're done.
We're creating a new file named file1.txt in the following example:
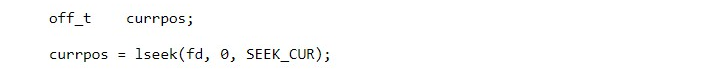

3.10.2 Echo or printf
To create a file called foo.txt, enter:
echo 'This is a test' > foo.txt
or
printf 'This is a test\n' > foo.txt
or
printf 'This is a test\n Another line' > foo.txt
3.10.3 Vi text editor
vi / vim is another text editor. To create a file called bar.txt, type:
To enter the new text, click I Type ESC+: +xx to save the file and exit vi (press ESC key, type: followed by x and [enter] key).
Special files can be generated using the mknod command.

Here, if the argument is p, a FIFO file called pipe is generated.
A block file is generated if the claim is 'b'. Here, it is important to define the major or minor unit numbers.
A character file is generated if the statement is 'c or u'. Here, it is important to define the major or minor unit numbers.
3.11.1 create special files like named pipes and device files
Special files are created by calling the device 'mknod'. A special file will be generated after the following sequence of steps is used.
For instance, the disk controller is the main device number for a disk, and the disk is the minor device.
Example from Unix: $ mknod <pipe name> p
On Unix, the cd command helps you to use the terminal program to change files.

3.12.1 Change Root
For the current operating process and its offspring, a chroot is an operation that alterations the apparent root directory. Files and commands outside the environmental directory tree cannot be reached by a program running in such an updated environment. This changed setting is referred to as the Chroot jail.
Changing root is commonly performed on systems where booting and/or logging in is no longer feasible to perform system maintenance. Examples that are popular are:
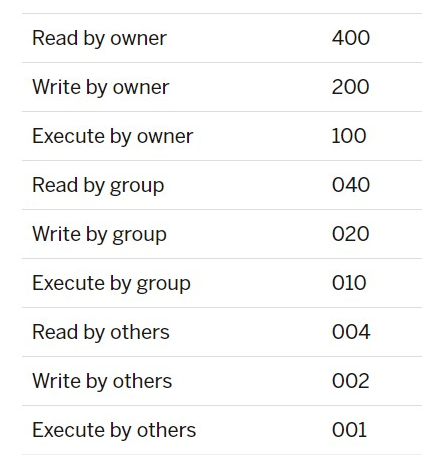
Using the chmod command to modify file and directory permissions (change mode). A file owner may modify user (u), community (g), or other (o) permissions by inserting (+) or subtracting (-) the read, write, and execute permissions.
There are two basic ways to modify file permissions using chmod: the symbolic method and the absolute form.
3.13.1 Symbolic method
The relative (or symbolic) method is the first and probably easiest way, allowing you to specify permissions with single letter abbreviations. This method uses the chmod command to consist of at least three parts from the following lists:
3.13.2 Absolute form
The other way to use the chmod command is to use an absolute form to designate a series of three numbers that describe all the access classes and categories together. Instead of being able to modify only specific attributes, you must define the full state of the permissions for the file.
The three numbers are given in the following order: consumer (or owner), party, etc. Each number is the sum of the read, write, and execute access: values specified.

Sum all the accesses you would like to authorize. For example, to give the owner of myfile (200+100=300) write and execute privileges and give all read privileges (400+040+004=444), you would type:
Chmod 744 Myfile
Other examples:
These functions return a file's information. No permissions are necessary for the file itself, but execute (search) permissions are required for all directories in the path leading to the file in the case of stat() and lstat().
Stat() notes the path-pointed file and fills in buf.
Lstat() is similar to stat(), except that the link itself is stat-ed if the route is a symbolic link, not the file to which it refers.
Fstat() is similar to stat(), except that the file descriptor files identify the file to be stat-ed.
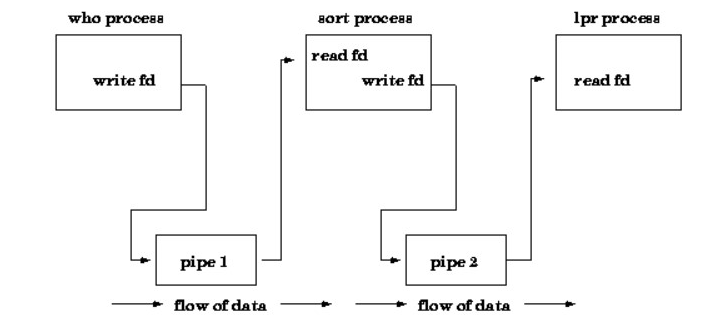
A Unix pipe supplies a one-way data flow.
If a Unix user issues a command, for example,
who | sort | lpr

It is possible to build a pipe directly in Unix using the pipe system call. It returns two file descriptors—fildes[0] and fildes[1], and both are open for reading and writing. A read from fildes[0] accesses first-in-first-out (FIFO) data written to fildes[1] and a read from fildes[1] accesses the data written to fildes[0] on a FIFO basis as well.
The first process is assumed to write to stdout while a pipe is used in a Unix command line and the second is assumed to read from stdin. In the first step, however, it is common practice to allocate the descriptor of the pipe write device to stdout and assign the descriptor of the pipe read device to stdin in the second process.
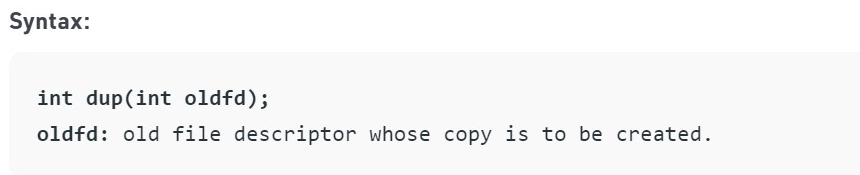
A copy of a file descriptor is generated with the dup () system call.

You need to install a file system before you can access files on a filesystem. Mounting a file system connects to a directory (mount point) the file system and makes it open to the system. For all times, the root (/) file system is installed. It is possible to link or disconnect some other file system from the root file system (/).
When you install a file system, and as long as the file system is installed, all data or folders in the underlying mount point directory are inaccessible. These files are not permanently impacted by the mounting process, and when the file system is unmounted, they become usable again. Usually, mount directories are bare, though, so you don't generally want to obscure existing data.
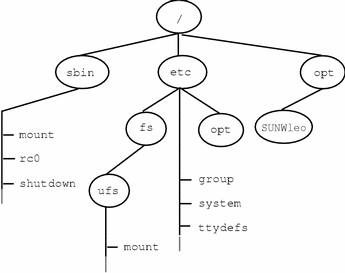
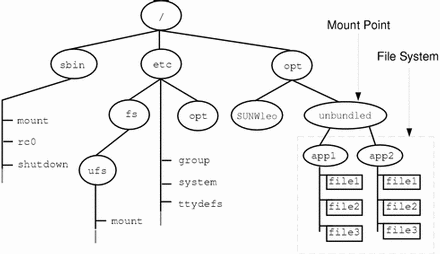
For example, the figure below shows a local file system, starting with a root (/) file system, sbin, etc, and opt-in subdirectories.
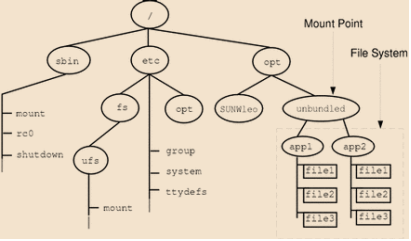
Now, say you wanted to access a local file system that contains a set of unbundled products from the /opt file system.
First, you need to create a directory to be used as a mount point, such as /opt/unbundled, for the file system that you want to mount. You can mount the file system once the mount point is generated (using the mount command), which makes all the files and directories in /opt/unbundled open, as seen in the following figure.
The /etc/mnttab (mount table) file is modified with a list of currently mounted file systems whenever you mount or unmount a file system. With a cat or more commands, you can show the contents of this file, but you can't modify it. Here is an example of the following file: /etc/mnttab
In UNIX, a link is a pointer to a file. Links in UNIX, like pointers in any programming language, are pointers that point to a file or directory. Link formation is a kind of shortcut for a file to be reached. In other places, links allow more than one file name to refer to the same file.
3.18.1 Hard Link
The same inode value as the original is allocated to each hard-linked file, so they reference the same physical file location. Even if the original or related files are transferred across the file system, hard links are more versatile and stay attached, while hard links are unable to cross multiple file systems.
The ls -l command displays all links with the number of links shown in the link column.
Links have actual file contents
Removing any link only decreases the number of links, but it does not affect other links.
Even if we change the original file's filename, then the hard links work properly as well.
To avoid recursive loops, we cannot create a hard link for a directory.

3.18.2 Soft Link
A soft link is similar to the file shortcut feature used in operating systems running Windows. There is a separate Inode value in each linked software file that points to the original file. Any changes to the data in either file are reflected in the other, as compared to hard links. Soft links can be connected across different file systems, although the soft linked file will not function properly if the original file is deleted or moved (called hanging link).
The command ls -l displays all the connections with the first column value of l? And the connection points to the original file.
The Soft Link contains the original file path and not the content of the file.
Deleting a soft link does not affect anything other than deleting the original file, the link becomes a "dangling" link pointing to an inexistent file.
You can link to a directory through a soft link.
Size of a soft link is equal to the name of the file for which the soft link is created. For example, if the file name is file1, the size of its soft link is 5 bytes, which is equal to the size of the original file name.
If we change the name of the original file then all the soft links for that file become dangling i.e. they are worthless now.
Link across file systems: You can only use symlinks/soft links if you would like to link files across file systems.
unlink() deletes a reputation from the filesystem. If that name was the last link to a file and no processes have the file open the file is deleted and therefore the space it had been using is formed available for reuse.
If the name was the last link to a file but any processes still have the file open the file will remain alive until the last file descriptor pertaining to it's closed.
If the name mentioned a symbolic link the link is removed. If the name mentioned a socket, fifo or device the name for its removed but processes which have the thing open may still use it.
Some file system abstractions are provided by Unix: files (map from inode to ordered byte sequence stored in disk blocks), directory entries (map from name to inode), inodes (file metadata and content pointer), and mount points (map from place in global filesystem namespace to filesystem on disk partition). These abstractions are represented in an object-oriented manner within the kernel (and within user-level file system implementations like NFS).
The organization of how data is stored and recovered is the responsibility of filesystems. One way or another, the filesystem can get corrupted over time and some parts of it may not be accessible. If such an inconsistency develops in your filesystem, it is recommended to check its integrity.
This can be done by means of a system utility called fsck (file system consistency check). During boot time, this check can be done automatically or run manually.
There are numerous situations in which you want to run FSCK. There are only a few references here:
You will need to make sure that the partition you are going to search is not installed in order to run fsck. For example, to repair the filesystem of sdb partition we should run the following command: # fsck /dev/sdb
References:
1. “Unix Concepts and Administration”, Sumitabha Das, TMGH, 3rd Edition.
2. “Unix Shell Programming”, YeshvantKanetkar, BPB Publications.
3. “Unix Utilities”, Tare, MGM.
4. “Advanced Programming in the UNIX Environment”, Stevens and Rego, Pearson Education, 2nd Edition.




