Unit - 1
Introduction to RDBMS
Database
The database is a set of interrelated data used to efficiently retrieve, insert and remove data. It is also used in the form of a table, schema, views, and reports to organise the data, etc.
You can conveniently retrieve, attach, and delete information using the database.
Database management system (DBMS)
A DBMS is a programme that enables database creation, specification and manipulation, allowing users to easily store, process and analyse information.
DBMS provides one with an interface or a tool to conduct different operations, such as building databases, storing data in them, updating data, creating database tables, and much more.
The DBMS also provides databases with privacy and security. In the case of multiple users, it also ensures data consistency.
Some Example of DBMS:
● MySql
● Oracle
● SQL Server
● IBM DB2
Characteristics of DBMS
● Data stored into tables
● Reduced redundancy
● Query language
● Data consistency
● Security
● DBMS support transactions
● Support multiple user and concurrent access
Advantages of DBMS
● Controls database redundancy: It can control data redundancy because it stores all the data in one single database file and that recorded data is placed in the database.
● Data sharing: In DBMS, the authorized users of an organization can share the data among multiple users.
● Easily Maintenance: It can be easily maintainable due to the centralized nature of the database system.
● Reduce time: It reduces development time and maintenance need.
● Backup: It provides backup and recovery subsystems which create automatic backup of data from hardware and software failures and restores the data if required.
● multiple user interface: It provides different types of user interfaces like graphical user interfaces, application program interfaces
Disadvantages of DBMS
● Cost of Hardware and Software: It requires a high speed of data processor and large memory size to run DBMS software.
● Size: It occupies a large space of disks and large memory to run them efficiently.
● Complexity: Database system creates additional complexity and requirements.
● Higher impact of failure: Failure is highly impacted the database because in most of the organization, all the data stored in a single database and if the database is damaged due to electric failure or database corruption then the data may be lost forever.
Key takeaway:
- You can conveniently retrieve, attach, and delete information using the database.
- The DBMS provides databases with privacy and security.
- In the case of multiple users, it also ensures data consistency.
Relational Database Management System stands for Relational Database Management System.
RDBMS underpins all modern database management systems, including SQL, MS SQL Server, IBM DB2, ORACLE, My-SQL, and Microsoft Access.
It's termed Relational Database Management System (RDBMS) since it's based on E.F. Codd's relational paradigm.
The fact that the values of each table are related to each other is the cornerstone of relational DBMS. It is capable of handling enormous amounts of data and easily simulating queries.
Working of RDBMS
In RDBMS, data is represented as tuples (rows).
The most prevalent database is a relational database. It has many tables, each with its own primary key.
Data in RDBMS may be accessible quickly thanks to a collection of well-organized tables.
Characteristics
● In a database file, data must be saved in tabular form, that is, in the form of rows and columns.
● Each table row is referred to as a record/tuple. The cardinality of the table is the collection of such records.
● Each table column is referred to as an attribute/field. The arity of the table is a collection of similar columns.
● The DB table cannot have duplicate records. By employing a candidate key, data duplication is eliminated. The Candidate Key is a set of properties that must be present for each record to be uniquely identified.
● Foreign keys are used to link tables together.
● Database tables also support NULL values, which means that if the values of any of the table's elements are not filled or missing, the value becomes a NULL value, which is not the same as zero.
Advantages
● Simple to manage: Each table can be manipulated independently of the others.
● It is more secure since it has numerous levels of security. Access to shared data might be restricted.
● Flexible: Data may be updated in one place rather than having to change many files. Databases may be simply expanded to accommodate additional records, increasing scalability. It also makes it easier to use SQL queries.
● Users: RDBMS can store many users in a client-side architecture.
● Large amounts of data can be stored and retrieved more easily.
● Fault Tolerance: Database replication allows for simultaneous access and aids in system recovery in the event of calamities such as power outages or unexpected shutdowns.
Disadvantages
● High Cost and Extensive Hardware and Software Support: These systems demand significant investment and setup.
● Scalability: As more data is added, more servers, as well as more power and memory, are necessary.
● Complexity: Large amounts of data complicate understanding of relationships and may reduce performance.
● Structured Limits: A relational database system's fields or columns are encased inside various limits, which might lead to data loss.
Difference between DBMS and RDBMS
Although both DBMS and RDBMS are used to store information in physical databases, they have some significant differences.
The following are the primary distinctions between DBMS and RDBMS:
DBMS | RDBMS |
Data is saved as a file in DBMS applications. | Data is stored in a tabular format in RDBMS applications. |
Data is typically stored in DBMS in either a hierarchical or navigational format. | Tables in RDBMS have a primary key identifier, and data values are kept in the form of tables. |
The DBMS does not support normalisation. | RDBMS supports normalisation. |
When it comes to data manipulation, the DBMS provides no protection. | The integrity constraint is defined by RDBMS for the ACID (Atomicity, Consistency, Isolation, and Durability) attribute. |
Because DBMS stores data on a file system, there will be no relationship between the tables. | Data values are saved in the form of tables in RDBMS, hence a relationship between these data values will also be stored as a table. |
The DBMS must provide certain standard techniques for accessing the data. | To access the stored information, the RDBMS system supports a tabular data structure and a relationship between them. |
Distributed databases are not supported by DBMS. | Distributed databases are supported by RDBMS. |
DBMSs are designed for tiny businesses that deal with little amounts of data. It only allows for one user. | RDBMS was created to deal with enormous amounts of data. It can accommodate numerous users. |
File systems, XML, and other DBMS are examples. | Mysql, Postgre, SQL Server, Oracle, and other RDBMS are examples. |
Key takeaway
RDBMS underpins all modern database management systems, including SQL, MS SQL Server, IBM DB2, ORACLE, My-SQL, and Microsoft Access.
The modelling of the data description, data semantics, and consistency constraints of the data is the Data Model. It offers conceptual resources at each level of data abstraction to explain the architecture of a database.
Object Relational Model
The object-oriented database derivation is the integrity of object-oriented
Programming language systems and consistent systems. The power of object-oriented databases comes from the cyclical treatment of both consistent data, as found in databases, and transient data, as found in executing programs.

Fig 1: Object - oriented model
Object-oriented databases use small, recyclable separated of software called objects. The objects themselves are stored in the object-oriented database. Each object contains of two elements:
1. Piece of data (e.g., sound, video, text, or graphics).
2. Instructions, or software programs called methods, for what to do with the data.
There are two types of ORM:-
a. Object-Oriented Data Model (OODM)
b. Object-Relational Data Model (ORDM)
These models are used to handle objects:
1) To provide support for complex objects.
2) To provide user extensibility for data types, operators and access methods.
3) There should be mechanism to support:
a) Abstract data type.
b) Data of type ‘procedure’.
c) Rules.
Network Model:
- Network model uses two different data structures:
a) A record type is used to represent an entity set.
b) A set type is used to represent a directed relationship between two record types.
- This is the Hierarchical model's extension. Data is arranged more like a graph in this model, and is allowed to have more than one parent node.
- Data is more linked in this database model as more relationships are formed in this database model. Also, as the data is more linked, it is also simpler and quicker to access the information. To map many-to-many data relationships, this database model was used.
- This was the most commonly used database architecture prior to the advent of the Relational Model.
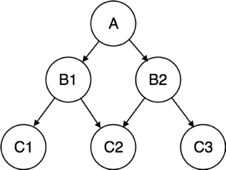
Fig 2: Network model
Hierarchical Model
- This model of the database organises information into a tree-like structure with a single root to which all the other information is connected. The hierarchy begins from the root data and extends to the parent nodes like a tree, adding child nodes.
- A child node can only have a single parent node in this model.
- A Hierarchical model uses tree structure to represent relationships among entities.
- This model represents many real-world relationships effectively, such as a book index, recipes, etc.
- Data is structured into a tree-like structure in the hierarchical model with a one-to-many relationship between two different data forms.
For instance, one department can have many classes, many professors and many students of course.

Fig 3: Hierarchical model
Relational Model
● Relational model uses a collection of tables to represent both data and the relationships among those data.
● This model is useful for constructing a database that can then be converted into relational model tables.
● Data is arranged in two-dimensional tables in this model and the relationship is preserved by storing a common field.
● In the relational model, the basic structure of data is tables. In the rows of that table, all information relating to a specific category is stored.
Therefore, in the relational model, tables are also known as relations.
Sample relational database
- Teacher Table
Teacher_id | Teacher_name | Teacher_Subject |
1001 | Pritisha | C++ |
1002 | Akon | DBMS |
1003 | Rahul | SE |
1004 | Raj | Data structure |
- Department Table
Dept_id | Dept_name |
A101 | CSE |
B102 | Electronics |
C103 | Civil |
D104 | Mechanical |
- Teaches in table
Teacher_id | Dept_id |
1001 | A101 |
1002 | B102 |
1003 | C103 |
1004 | D104 |
Physical data model
A Physical Data Model specifies how the data model is implemented in a database. It provides database abstraction and assists in schema generation. This is due to the abundance of meta-data that a Physical Data Model provides. By recreating database column keys, constraints, indexes, triggers, and other RDBMS characteristics, the physical data model aids in visualising database structure.

Fig 4: Physical data model
Characteristics
● The physical data model covers the data requirements for a specific project or application, albeit it may be combined with different physical data models depending on the scope of the project.
● The Data Model contains relationships between tables that address relationship cardinality and nullability.
● Designed for a specific version of a database management system, project location, data storage, or technology.
● Columns should be assigned precise datatypes, lengths, and default values.
● Views, indexes, access profiles, and authorizations, among other things, are defined.
Advantages
● The primary purpose of a developing data model is to ensure that the functional team's data items are appropriately represented.
● The data model should be sufficiently detailed to be employed in the construction of the physical database.
● Table relationships, primary and foreign keys, and stored procedures can all be defined using the data model's metadata.
● Data modelling aids internal and cross-organizational communication.
● In the ETL process, a data model is useful for documenting data mappings.
● Assist in identifying appropriate data sources for the model.
Disadvantages
● To create a data model, one must first understand the physical features of the data.
● This navigational system results in the construction and management of complicated applications. As a result, it necessitates biographical knowledge.
● Even minor changes in structure necessitate changes to the entire application.
● In DBMS, there is no standard data manipulation language.
Key takeaway:
Relational model uses a collection of tables to represent both data and the relationships among those data.
A Hierarchical model uses tree structure to represent relationships among entities.
Physical Data Model explains how the system will be built using a certain database management system. DBAs and developers are usually the ones who construct this model. The goal is to get the database up and running.
Relation
A relational database stores everything in the form of relations. Tables are used to hold data in the RDBMS database. A table is a collection of connected data items that stores data in rows and columns. Each table represents a real-world entity, such as a person, a location, or an event, for which data is gathered. The logical perspective of the database is the orderly collection of data into a relational table.
Properties of a Relation:
● Each relation in the database is identified by a distinct name.
● There are no duplicate tuples in this relationship.
● A relation's tuples are not in any particular sequence.
● A relation's properties are all atomic, meaning that each cell holds precisely one value.
Employee table
ID | Name | Age | Salary |
1 | Rohani | 34 | 13000 |
2 | Alex | 28 | 15000 |
3 | Stuart | 20 | 18000 |
4 | Vimal | 42 | 19020 |
Attribute
A column in a table is a vertical item that holds all information linked with a certain field. For example, in the preceding table, the column "name" provides all information on a student's name.
Attribute Properties:
● Each attribute of a relation must have a name.
● The attributes are allowed to have null values.
● If no other value is supplied for an attribute, default values might be specified and are automatically inserted.
● The main key is a set of attributes that uniquely identify each tuple in a relation.
Example
Name |
Rohani |
Alex |
Stuart |
Vimal |
Domain
For each attribute, all possible values are listed. This differs slightly from the attribute's data type. For example, a field's data type could be integer number, indicating that it can only accept whole integers. There may, however, be extra constraints, such as the number must be between 1 and 10. As a result, the domain would be this range of whole numbers.
Tuple
A table row is also known as a record or row. It offers detailed information about each table entry. In the table, it is a horizontal entity. The table above, for example, has five records.
A tuples properties include:
● In all of their entries, no two tuples are identical to each other.
● The relation's tuples all have the same format and number of entries.
● The tuple's order is unimportant. They are distinguished by their content rather than by their location.
Example
ID | Name | Age | Salary |
1 | Rohani | 34 | 13000 |
Entities
The mastery of a single distinct thing in the real world. A single person, a single product, or a single business are examples of entities.
A Database Administrator (DBA) is the person or entity in charge of the database management system's control, maintenance, coordination, and operation. The primary role is to manage, secure, and maintain the database system.
They are in charge of approving database access, managing database capacity, planning, installation, and monitoring uses, as well as procuring and gathering software and hardware resources as needed. Configuration, database design, migration, security, troubleshooting, backup, and data recovery are all roles they play. Database administration is a critical job for any company or organisation that uses one or more databases. They are the database system's overall commander.
The primary role of Database administrator is as follows −
● Database design
● Performance issues
● Database accessibility
● Capacity issues
● Data replication
● Table Maintenance
Types of Database Administrator (DBA):
- Administrative DBA – Their role is to keep the server up and running. They're worried about data backups, security, troubleshooting, replication, and migration, among other things.
- Data Warehouse DBA – Previously assigned roles, but now responsible for combining data from multiple sources into a data warehouse. Prior to loading, they also construct warehouses with cleaning and cleanses data.
- Development DBA – They create and construct queries, store procedures, and other tools to satisfy the demands of a company or organisation. At programmer, they are on par.
- OLAP DBA – They create multi-dimensional cubes for use in decision support or OLAP systems.
- Architect – They are in charge of defining schemas and creating tables. They work to create a structure that fulfils the needs of the organisation. Developers and development DBAs use the design to create and implement real-world applications.
- Application DBA – They are responsible for all application component requirements that interface with databases, as well as operations such as application installation and coordination, application updates, database cloning, data load process management, and so on.
Responsibilities of DBA
The following are DBA's responsibilities:
- Makes the final decision on the database's content.
- The storage structure and access strategy are planned.
- Provides assistance to users.
- The security and integrity checks are defined here.
- Backup and recovery solutions for interpreters.
- Monitoring and reacting to changes in the needs.
Importance of Database Administrator (DBA):
- Database Administrators administer and control three levels of databases: internal, conceptual, and external levels of database management system architecture, and define the database's world view in consultation with a large user community. The exterior perspective of different users and programmes is then provided.
- Database administrators guarantee that the database's integrity and security are protected from unauthorised users. It gives database users authorization and keeps track of each and every user's profile.
- The database administrator is also responsible for ensuring that the database is safe and secure, with no risk of data loss.
Skills required for DBA
The following are the skills needed to be a successful DBA:
- Creating a database.
- Understanding of the Structured Query Language (SQL).
- Understand the concept of distributed architecture.
- Understanding of several operating servers.
- Relational Database Management System Concept (RDBMS).
- Prepared to meet obstacles and solve problems promptly.
Key takeaway
A Database Administrator (DBA) is the person or entity in charge of the database management system's control, maintenance, coordination, and operation. The primary role is to manage, secure, and maintain the database system.
The primary data model is the Relational Data Model, which is commonly used for data storage and processing around the world. This model is simple and has all the features and functionality needed to process data with efficiency in storage.
The relational model can be interpreted as a table with rows and columns. Each row is called a tuple. There's a name or attribute for each table in the column.
Structure
A relational database is made up of several tables.
- Each table is given its own name.
- There are several rows in each table.
- Each row is a collection of data that are, by definition, related to one another in some way; these values correspond to the table's attributes or columns.
- Each table attribute has a set of authorized values for that attribute; this set of permitted values is the attribute's domain.
Basic concept:
- Table: Relationships are saved in the format of tables in a relational data model. The relationship between entities is stored in this format. A table includes rows and columns, where rows represent information, and attributes are represented by columns.
- Tuple: A tuple is called a single row of a table, which contains a single record for that relationship.
Attributes and Domains
- Domain: It includes a set of atomic values that can be adopted by an attribute.
- Attribute: In a specific table, it includes the name of a column. Every Ai attribute must have a domain, a domain (Ai)
Relations
- Relational instance: The relational example is represented in the relational database structure by a finite set of tuples. There are no duplicate tuples for relation instances.
- Relational schema: The name of the relationship and the name of all columns or attributes are used in a relational schema.
- Relational key: Each row has one or more attributes in the relational key. It can uniquely identify the row in the association.
Example: STUDENT Relation
NAME | ROLL_NO | PHONE_NO | ADDRESS | AGE |
Ram | 14795 | 7305758992 | Noida | 24 |
Shyam | 12839 | 9026288936 | Delhi | 35 |
Laxman | 33289 | 8583287182 | Gurugram | 20 |
Mahesh | 27857 | 7086819134 | Ghaziabad | 27 |
Ganesh | 17282 | 9028 9i3988 | Delhi | 40 |
- In the given table, NAME, ROLL_NO, PHONE_NO, ADDRESS, and AGE are the attributes.
- The instance of schema STUDENT has 5 tuples.
- t3 = <Laxman, 33289, 8583287182, Gurugram, 20>
Key takeaway
The primary data model is the Relational Data Model, which is commonly used for data storage and processing around the world. This model is simple and has all the features and functionality needed to process data with efficiency in storage.
Relational Algebra is procedural query language. It takes Relation as input and generates relation as output. Relational algebra mainly provides theoretical foundation for relational databases and SQL.
Basic Operations which can be performed using relational algebra are:
1. Projection
2. Selection
3. Join
4. Union
5. Set Difference
6. Intersection
7. Cartesian product
8. Rename
Consider following relation R (A, B, C)
A | B | C |
1 | 1 | 1 |
2 | 3 | 1 |
4 | 1 | 3 |
2 | 3 | 4 |
5 | 4 | 5 |
- Projection (π):
This operation is used to select particular columns from the relation.
Π(AB) R:
It will select A and B column from the relation R. It produces the output like:
A | B |
1 | 1 |
2 | 3 |
4 | 1 |
5 | 4 |
Project operation automatically removes duplicates from the resultant set.
2. Selection (σ):
This operation is used to select particular tuples from the relation.
σ(C<4) R:
It will select the tuples which have a value of c less than 4.
But select operation is used to only select the required tuples from the relation. To display those tuples on screen, select operation must be combined with project operation.
Π (σ (C<4) R) will produce the result like:
A | B | C |
1 | 1 | 1 |
2 | 3 | 1 |
4 | 1 | 3 |
3. Join
A Cartesian product followed by a selection criterion is basically a joint process.
Operation of join, denoted by ⋈
The JOIN operation often allows tuples from different relationships to join different tuples
Types of JOIN:
Various forms of join operation are:
Inner Joins:
- Theta join
- EQUI join
- Natural join
Outer join:
- Left Outer Join
- Right Outer Join
- Full Outer Join
4. Union
Union operation in relational algebra is the same as union operation in set theory, only the restriction is that both relations must have the same set of attributes for a union of two relationships.
Syntax: table_name1 ∪ table_name2
For instance, if we have two tables with RegularClass and ExtraClass, both have a student column to save the student name, then,
∏Student(RegularClass) ∪ ∏Student(ExtraClass)
The above operation will send us the names of students who attend both normal and extra classes, reducing repetition.
5. Set difference
Set Difference in relational algebra is the same operation of set difference as in set theory, with the limitation that the same set of attributes can have both relationships.
Syntax: A - B
Where the A and B relationships.
For instance, if we want to find the names of students who attend the regular class, but not the extra class, then we can use the following procedure:
∏Student(RegularClass) - ∏Student(ExtraClass)
6. Intersection
The symbol ∩ is the definition of an intersection.
A ∩ B
Defines a relationship consisting of a set of all the tuples in both A and B. A and B must be union-compatible, however.
7. Cartesian product
This is used to merge information into one from two separate relationships(tables) and to fetch information from the merged relationship.
Syntax: A X B
For example, if we want to find the morning Regular Class and Extra Class data, then we can use the following operation:
σtime = 'morning' (RegularClass X ExtraClass)
Both RegularClass and ExtraClass should have the attribute time for the above query to operate.
8. Rename
Rename is a unified operation that is used to rename relationship attributes.
ρ (a/b)R renames the 'b' component of the partnership to 'a'.
Syntax: ρ(RelationNew, RelationOld)
Key takeaway:
- Relational Algebra is procedural query language.
- It takes Relation as input and generates relation as output.
- Data stored in a database can be retrieved using a query.
References:
- Database system concept- Korth Silberschatz.
- SQL-PL/SQL by Ivan Bayross BPB Publications.
- Structure query language-By Osborne
- Learning MySQL by O’reilly




