Unit - 2
Software Project Planning
Software project planning is a work that must be completed before software development can begin. It's there to help with software development, but it doesn't entail any specific action that has anything to do with software production; rather, it's a collection of many procedures that help with software production.
Once a project is determined to be feasible, computer code project managers develop the project. Even before any development activity begins, project design is conducted and finalized. Following are the steps involved in project planning:
Estimating the project's later characteristics:
- Project size - What are the potential drawbacks in terms of the effort and time required to build the product?
- Cost - What percentage of the project's worth is it costing to develop?
- Duration - How long will it take for you to want complete development?
- Effort - What percentage of effort is required?
The accuracy of such estimations will determine the effectiveness of the next designing tasks.
- Alternative resources and a planning force
- Plans for worker organization and staffing
- Identifying risks, analyzing them, and devising strategies to mitigate them.
- Various arrangements such as a quality assurance plan, configuration, management arrangement, and so on.
Order of precedence for project planning activities
A project manager's many project-related estimates have already been mentioned. The figure below depicts the sequence in which critical project development activities are carried out. The first action is size estimate, which can be easily identified. Alternative estimations, such as the estimation of effort, cost, resource, and project length, are furthermore significant parts of project development.
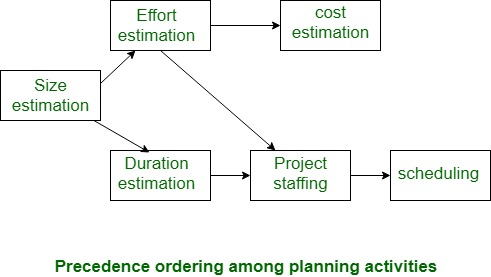
Fig 1: Precedence ordering among planning activities
Sliding Window Planning
Because adherence to incorrect time and resource estimates results in schedule slippage, project planning requires extreme caution and attention. Client dissatisfaction and a negative impact on team morale will result from schedule delays. It may potentially result in project failure.
Project design, on the other hand, can be a tough task. Creating accurate blueprints, particularly for huge structures, is quite difficult. Because the correct parameters, the scope of the project, project personnel, and other factors may change over the course of the project, this is a part of the problem. To overcome this disadvantage, most project managers approach project design in stages.
Managers are protected from making large commitments too early by designing a project in stages. Window design is the term for this technique of staggered design. Beginning with an initial set up, the project is planned more precisely in consecutive development stages using the window technique.
At the start of a project, project managers receive only a smattering of information on the project's important aspects. As the project goes through different phases, its data base improves step by step. After each section is completed, the project managers will set up each subsequent section more precisely and with increasing levels of confidence.
Key takeaway
Software project planning is a work that must be completed before software development can begin. It's there to help with software development, but it doesn't entail any specific action that has anything to do with software production; rather, it's a collection of many procedures that help with software production.
Estimating software size is an important component of Software Project Management. It aids the project manager in estimating the amount of effort and time required to complete the project. Project size estimation employs a variety of methods. Here are a few examples:
- Lines of Code
- Number of entities in ER diagram
- Total number of processes in detailed data flow diagram
- Function points
- Lines of Code (LOC):
LOC stands for Lines of Code and refers to the total amount of lines of source code in a project. The following are the LOC units:
- KLOC- Thousand lines of code
- NLOC- Non comment lines of code
- KDSI- Thousands of delivered source instruction
The size is calculated by comparing it to similar systems that already exist. Experts use it to estimate the size of individual software components and then sum them up to acquire the total size.
Estimating LOC by analysing the problem specification is difficult. Only after the entire code has been written can a precise LOC be calculated. Because project planning must be finished before development work can commence, this statistic is of limited help to project managers.
Two source files with the same number of lines may not need the same amount of effort. It would take longer to construct a file with intricate logic than one with simple logic. Based on LOC, accurate assessment may be impossible.
LOC stands for "length of time it takes to fix an issue." This figure will vary significantly from one programmer to the next. A more experienced programmer can write the same logic in fewer lines than a novice coder.
Advantages
- It is widely recognised and is found in many models, including COCOMO.
- Estimation is more in line with the developer's viewpoint.
- It's easy to use.
Disadvantages
- The number of lines in various programming languages varies.
- This approach has no official industry standard.
- In the early stages of a project, it is difficult to predict the magnitude using this method.
2. Number of entities in ER diagram
The ER model shows the project in a static state. It describes the entities as well as their connections. The number of entities in an ER model can be used to estimate the project's size. The number of entities is determined by the project's size. Because additional entities required more classes/structures, more coding was required.
Advantages
- Size estimation can be done early in the planning process.
- The number of entities is unaffected by the programming language.
Disadvantages
- There are no set rules. Some organisations make larger contributions to projects than others.
- It, like FPA, is underutilised in cost estimation models. As a result, it needs to be transformed to LOC.
3. Total number of processes in detailed data flow diagram
The functional view of software is represented by the Data Flow Diagram (DFD). The model represents the primary software processes/functions as well as the data flow between them. The number of functions in DFD is used to determine programme size. Existing processes of a comparable type are examined and used to determine the process's size. The final estimated size is the sum of the projected sizes of each step.
Advantages
- It doesn't matter what programming language you use.
- Each large process can be broken down into smaller ones. This will improve estimation precision.
Disadvantages
- It takes more time and effort to research similar procedures in order to determine magnitude.
- The building of DFD does not necessitate the completion of all software projects.
4. Function Point Analysis
The number and type of functions offered by the software are used to determine FPC in this method (function point count). The following are the steps in function point analysis:
- Count the number of functions of each proposed type.
- Compute the Unadjusted Function Points(UFP).
- Find Total Degree of Influence(TDI).
- Compute Value Adjustment Factor(VAF).
- Find the Function Point Count(FPC).
Count the number of functions of each proposed type:
Determine the number of functions in each of the following categories:
- External Inputs: Data entering the system's functions.
- External outputs: These are functions that deal with data leaving the system.
- External Inquiries: They cause data to be retrieved from the system but do not change it.
- Internal Files: Logical files kept on the system's hard drive. There are no log files included in this package.
- External interface Files: These are logical files that our system uses to interact with other apps.
Compute the Unadjusted Function Points(UFP):
Based on their complexity, classify each of the five function types as simple, average, or difficult. Find the weighted sum by multiplying the count of each function type by its weighting factor. The following are the weighting factors for each kind based on their complexity:
Function type | Simple | Average | Complex |
External Inputs | 3 | 4 | 6 |
External Output | 4 | 5 | 7 |
External Inquiries | 3 | 4 | 6 |
Internal Logical Files | 7 | 10 | 15 |
External Interface Files | 5 | 7 | 10 |
Find Total Degree of Influence:
Find the degree of effect of each of the '14 general features' of a system. The TDI is calculated by adding all 14 degrees of influence. The TDI scale runs from 0 to 70. Data Communications, Distributed Data Processing, Performance, Heavily Used Configuration, Transaction Rate, On-Line Data Entry, End-user Efficiency, Online Update, Complex Processing Reusability, Installation Ease, Operational Easability, Multiple Sites, and Facilitate Change are the 14 general characteristics.
Each of the aforementioned traits is rated on a scale of 0 to 5.
Compute Value Adjustment Factor(VAF):
To compute VAF, use the formula below
VAF = (TDI * 0.01) + 0.65
Find the Function Point Count:
To compute FPC , use the formula below
FPC = UFP * VAF
Advantages:
- It's simple to employ in the early stages of project development.
- It doesn't matter what programming language you use.
- Even if the projects employ different technology, it can be used to compare them (database, language etc).
Disadvantages:
- It is not suitable for real-time or embedded systems.
- Because many cost estimating models, such as COCOMO, employ LOC, FPC must be translated to LOC.
For all projects, accurate cost estimates are important. It would be difficult to prepare a business plan, set up comprehensive budgets, forecast resource needs or manage project costs without a cost estimate.
Estimating project costs scares a lot of people. They don't know how much it's going to cost, but they know whatever value they offer, their boss will keep them.
The Project Cost Engineer uses either one or a combination of the following instruments and techniques in the cost estimation process:
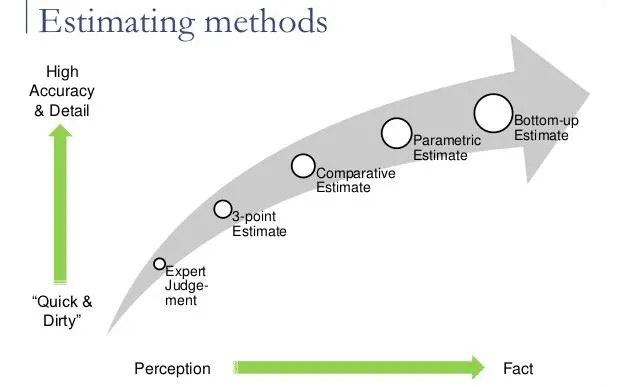
Fig 2: Cost estimation technique
- EXPERT JUDGEMENT
To estimate the cost of the project, expert judgement uses the expertise and knowledge of experts. The particular factors related to the project can be taken into account in this technique. It can also be biased, however.
- ANALOGOUS ESTIMATING
The values such as scope, expense, budget and length or measurements of scale such as size, weight and complexity from a previous, equivalent project are used in an analogous cost estimate as the basis for calculating the same parameter or measurement for a current project.
This methodology relies on the actual cost of previous, related projects when calculating costs as the basis for estimating the cost of the current project.
- PARAMETRIC ESTIMATING
In order to build a cost estimate, parametric estimation uses statistical modelling. To calculate an estimate for various parameters such as cost and length, it utilizes historical data from key cost drivers. Square footage, for instance, is used in some building projects.
- BOTTOM-UP ESTIMATING
In order to calculate an overall cost estimate for the project, bottom-up estimating uses the estimates of individual job packages that are then summarized or 'rolled up'. In general, this type of calculation is more comprehensive than other approaches since it looks at costs from a more granular perspective.
- THREE - POINT ESTIMATING
By using three estimates, the three-point estimation approach defines a spectrum of operation costs.
- Best case (B)
- Most likely (M)
- Worst case (W)
One of the main benefits of using the project cost estimation approach is that, compared to other project cost estimation methods, it gives you far more reliable and balanced estimates. The formula for three is used - estimation is :
Formula: E = (B + 4M + W) /6
- PROJECT MANAGEMENT ESTIMATING SOFTWARE
Software forecasting project management includes software cost estimating programs, spreadsheets, modelling applications, and tools for statistical software. This form of programme is particularly useful for looking at alternatives to cost estimation.
- Decision-Making Method
Unanimity, majority, plurality, division of points, and dictatorship are some decision techniques. All must insist on unanimity; there is a common consensus. Normally, a majority or plurality is decided by a vote. For a majority, more than half the participants must agree on the decision.
Key takeaway
For all projects, accurate cost estimates are important.
One of the most significant processes of project management is calculating costs.
You can use it for many reasons, such as when negotiating for a project, if a company needs to know the cost of quoting the correct price.
The Constructive Cost Model (COCOMO) is an empirical estimation model i.e., the model uses a theoretically derived formula to predict cost related factors. This model was created by “Barry Boehm”. The COCOMO model consists of three models:
● The Basic COCOMO model: - It computes the effort & related cost applied on the software development process as a function of program size expressed in terms of estimated lines of code (LOC or KLOC).
● The Intermediate COCOMO model: - It computes the software development effort as a function of – a) Program size, and b) A set of cost drivers that includes subjective assessments of product, hardware, personnel, and project attributes.
● The Advanced COCOMO model: - It incorporates all the characteristics of the intermediate version along with an assessment of cost driver’s impact on each step of software engineering process.
The COCOMO models are defined for three classes of software projects, stated as follows:
● Organic projects: - These are relatively small and simple software projects which require small team structure having good application experience. The project requirements are not rigid.
● Semi-detached projects: - These are medium size projects with a mix of rigid and less than rigid requirements level.
● Embedded projects: - These are large projects that have a very rigid requirements level. Here the hardware, software and operational constraints are of prime importance.
Basic COCOMO Model
The effort equation is as follows: -
E = a * (KLOC) b
D = c * (E) d
Where E effort applied by per person per month, D = development time in consecutive months, KLOC estimated thousands of lines of code delivered for the project. The coefficients a, b, and the coefficients c, d are given in the Table below
Software Project | a | B | c | d |
Organic | 2.4 | 1.05 | 2.5 | 0.38 |
Semidetached | 3.0 | 1.12 | 2.5 | 0.35 |
Embedded | 3.6 | 1.20 | 2.5 | 0.32 |
Intermediate COCOMO Model
The effort equation is as follows: -
E = a * (KLOC) b * EAF
Where E = efforts applied by per person per month, KLOC = estimated thousands of lines of code delivered for the project, and t he coefficients a and exponent b are given in the Table below. EAF is Effort Adjustment Factor whose typical ranges from 0.9 to 1.4 and the value of EAF can be determined by the tables published by “Barry Boehm” for four major categories – product attributes, hardware attributes, personal attributes and project attributes.
Software Project | A | b |
Organic | 3.2 | 1.05 |
Semidetached | 3.0 | 1.12 |
Embedded | 2.8 | 1.20 |
Key takeaway
The Constructive Cost Model (COCOMO) is an empirical estimation model i.e., the model uses a theoretically derived formula to predict cost related factors. This model was created by “Barry Boehm”.
The Lawrence Putnam model estimates how much time and effort it would take to complete a software project of a given scale. To estimate project effort, schedule, and defect rate, Putnam uses a so-called The Norden / Rayleigh Curve, as shown in fig:
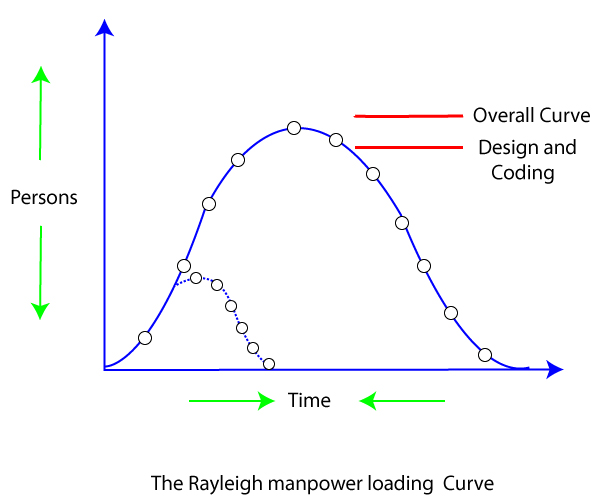
Fig 3: The Rayleigh manpower curve
Putnam found that the Rayleigh distribution was accompanied by software staffing profiles. Putnam derived the program equation from his observation of efficiency levels:
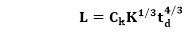
The various term of above equation:
- K- L is the product estimate in KLOC, and K is the cumulative effort spent (in PM) in product growth.
- td - The period of device and integration testing is described by td. As a result, td can be thought of as the time taken to manufacture the product.
- Ck - Is the state of technology constant and represents requirements that obstruct the program's development.
- Typical values of Ck = 2 for poor development environment
Putnam suggested that the Rayleigh curve could be used to determine how much a project's staff develops. To carry out planning and specification tasks, only a small number of engineers are needed at the start of a project. The number of engineers required grows as the project progresses and more extensive work is required. The number of project employees decreases after implementation and unit testing.
Key takeaway
The Lawrence Putnam model estimates how much time and effort it would take to complete a software project of a given scale.
Risk Identification
Risk identification is a systematic attempt to specify threats to the project plan (estimates, schedule, resource loading, etc.). By identifying known and predictable risks, the project manager takes a first step toward avoiding them when possible and controlling them when necessary.
One method for identifying risks is to create a risk item checklist. The checklist can be used for risk identification and focuses on some subset of known and predictable risks in the following generic categories:
- Product size—risks associated with the overall size of the software to be built or modified.
- Business impact—risks associated with constraints imposed by management or the marketplace.
- Customer characteristics—risks associated with the sophistication of the customer and the developer's ability to communicate with the customer promptly.
- Process definition—risks associated with the degree to which the software process has been defined and is followed by the development organization.
- Development environment—risks associated with the availability and quality of the tools to be used to build the product.
- Technology to be built—risks associated with the complexity of the system to be built and the "newness" of the technology that is packaged by the system.
- Staff size and experience—risks associated with the overall technical and project experience of the software engineers who will do the work.
Key takeaway
Risk identification is a systematic attempt to specify threats to the project plan.
One method for identifying risks is to create a risk item checklist.
Risk Projection
Risk projection, also called risk estimation, attempts to rate each risk in two ways—the likelihood or probability that the risk is real and the consequences of the problems associated with the risk, should it occur. The project planner, along with other managers and technical staff, performs four risk projection activities:
- Establish a scale that reflects the perceived likelihood of a risk,
- Delineate the consequences of the risk,
- Estimate the impact of the risk on the project and the product, and
- Note the overall accuracy of the risk projection so that there will be no misunderstandings.
Risk prediction seeks two ways to score each risk -
- a possibility that the danger is true.
- The result, should it occur, of the problems associated with the risk.
Four risk projection measures are undertaken by the project planner, manager, and technical personnel.
These measures are intended to consider risks in a way that contributes to prioritization.
The software team will assign limited resources to prioritize hazards where they will have the most effect.
Risk impacts on risk components:
- Negligible
- Critical
- Marginal
- Catastrophic
Factors affecting impacts of risk:
- Nature
- Scope
- Timing
Key takeaway
The effect of risk on the project and the product is calculated.
The risk table is used for calculation.
RMMM
The software project plan may include a risk management approach or organize the risk management measures into a separate Risk Reduction, Tracking, and Management Plan. As part of risk analysis, the RMMM plan documents all work done and is used as part of the overall project plan by the project manager.
A structured RMMM document is not established by such software teams. Instead, using a risk information sheet, each risk is personally reported. In most cases, using a database system, the RIS is retained, so that development and entry of information, priority orders, searches, and other analysis can be done easily.
Risk reduction and monitoring measures begin once RMMM has been recorded and the project has begun. Risk reduction is an operation for problem avoidance, as we have already discussed. Danger monitoring is a project tracking operation with three main goals:
- Assessing whether expected risks occur;
- Ensuring that the risk aversion measures identified for the risk are properly implemented; and
- To gather the information that can be used for the prediction of potential risks.
Key takeaway
The process of developing options and actions to maximize prospects and mitigate risks to project goals is risk reduction planning.
The RMMM plan documents all work done and is used as part of the overall project plan by the project manager.
Project scheduling
In a project, project scheduling refers to a road map of all activities that must be completed in a specific order and within the time slots assigned to each task. Project managers typically define multiple tasks and project milestones and organize them according to a variety of parameters. They look for tasks that are in the critical route of the plan and must be completed in a specified order (due to task interdependency) and within the time allotted. Tasks that are not on the critical path are less likely to have an impact on the project's overall timetable.
For scheduling a project, it is necessary to -
- Determine all of the functionalities that are required to finish the project.
- Break down large tasks into smaller tasks.
- Determine the degree of interdependence between various activities.
- Determine the most likely size for the amount of time it will take to accomplish the tasks.
- Assign resources to various activities.
- Plan the start and end dates for various events.
- Determine the most important path. The set of actions that determine the project's duration is a significant way.
Identifying all of the functions required to finish the project is the first step in arranging a software plan. A strong understanding of the project's complexities and development process aids the supervisor in efficiently identifying the project's vital role. The large functions are then split down into a series of valid little activities that are assigned to different engineers. The structure of the job breakdown After the project manager has broken down the purpose and constructed the work breakdown structure, formalism assists the manager in systematically breaking down the function; he must uncover the dependencies among the tasks. The order in which the various events are carried out is determined by the dependencies among the various activities.
If the outcomes of one action A are required by another activity B, activity A must be scheduled after activity B. Function dependencies, in general, describe a partial ordering among functions, i.e., each service may precede a subset of other functions, but other functions may not have any precedence ordering defined between them (called concurrent function). The pattern of an activity network defines the dependencies between the activities.
Following the processing of the activity network representation, resources are given to each activity. A Gantt chart is commonly used to allocate resources. Following the completion of resource allocation, a PERT chart is created. The PERT chart is a handy tool for monitoring and controlling programmes. The project plan must breakdown the project functions into a series of activities in order to schedule tasks. It is necessary to specify the time frame in which each action should be completed.
A milestone is the point at which an action comes to a finish. By auditing the timely completion of milestones, the project manager keeps track on the project's function. If he examines that the milestones start getting delayed, then he has to handle the activities carefully so that the complete deadline can still be met.
Advantages of Project Scheduling
Project schedules have a number of advantages in our project management:
- Simply put, it guarantees that everyone is on the same page in terms of task completion, dependencies, and deadlines.
- It aids in the early detection of difficulties and concerns such as a lack of or unavailability of resources.
- It also aids in the identification of relationships and the monitoring of the process.
- It allows for efficient budgeting and risk mitigation.
Key takeaway
Project scheduling refers to a road map of all activities that must be completed in a specific order and within the time slots assigned to each task. Project managers typically define multiple tasks and project milestones and organize them according to a variety of parameters.
Project Tracking
Project tracking is a project management technique for keeping track of how tasks in a project are progressing. You can compare actual progress to projected progress and uncover concerns that may prevent the project from staying on schedule and under budget by tracking it.
By evaluating project variance and tracking milestones, project managers and stakeholders may see what work has been completed, the resources that were needed to complete those tasks, and produce an earned value analysis.
Project Tracking Software and Management Tools
To generate project plans, execute reports, and employ timesheets, project tracking software is commonly used. The project management software efficiently manages time and activities while also assisting you in staying on budget. It also shows how many project phases have been accomplished so far, as well as how many project tasks are still outstanding.
Project management software is a low-cost, time-saving, and effective option. Project tracking guarantees that the relevant tasks are accomplished in the best possible manner at the right time. You can also use project tracking software to efficiently manage all of your projects.
The design of software is an iterative process by which specifications are converted into a "blueprint" for software construction. That is, at a high level of abstraction the architecture is expressed, a level that can be clearly traced to the basic purpose of the system and more comprehensive details, functional and behavioural specifications.
Subsequent refinement contributes to design representations at far lower levels of abstraction as design iterations occur. These can still be traced to specifications, but more subtle is the relation.
The design phase of software development is concerned with converting customer needs as defined in SRS documents into a format that can be implemented using a programming language.
The software design process can be broken down into three layers of design phases:
- Interface Design
- Architectural Design
- Detailed Design
Interface Design
The interaction between a system and its surroundings is specified by interface design. This phase proceeds at a high level of abstraction with respect to the system's inner workings, i.e., the internals of the system are totally ignored during interface design, and the system is viewed as a black box. The dialogue between the target system and the users, devices, and other systems with which it interacts is the centre of attention. The people, other systems, and gadgets collectively known as agents should be identified in the design problem statement created during the problem analysis process.
The following details should be included in the interface design:
- Agent messages or precise descriptions of events in the environment to which the system must respond.
- Detailed explanation of the system's required events or messages.
- Data specifications, as well as the forms of data entering and exiting the system.
- Order and timing links between entering events or messages and outgoing events or outputs are specified.
Architectural Design:
The specification of the primary components of a system, their duties, attributes, interfaces, and the relationships and interactions between them is known as architectural design. The overall framework of the system is chosen in architectural design, but the inside details of major components are overlooked.
Architectural design issues include:
- The systems are broken down into their major components.
- Components are assigned functional duties.
- Interfaces between components
- Scaling and performance properties of components, resource consumption properties, and dependability properties, to name a few.
- Interaction and communication between components.
Important aspects that were overlooked during the interface design are included in the architectural design. The internals of the primary components are not designed until the very end of the design process.
Detailed Design
Design is the specification of all key system components' internal aspects, including their attributes, relationships, processing, and, in some cases, algorithms and data structures.
The detailed design may contain the following:
- Major system components are broken down into programme units.
- Units are assigned functional duties.
- Interfaces for users.
- State changes and unit states
- Interaction of data and control between units.
- Data packaging and implementation, as well as programme scope and visibility concerns.
- Data structures and algorithms
Key takeaway:
- Design provides you with software representations which can be tested for consistency.
- Design is the position where excellence of software engineering is promoted.
A specific region provided by design principles for the evaluation of specific design characteristics. There are three different sorts of principles, which are described below:
- Division of problems
These concepts are based on the division of a large problem into smaller sections. Different programmes developed each individual component. Every single component can be customised.
- This makes the system more self-sufficient.
- This idea reduces the scale of the problem and makes repair or maintenance simple and straightforward.
- This results in a design hierarchy.
It is vital to achieve effective coordination between these little bits of problems in order to solve a large problem.
2. Abstraction
It is the process of obtaining information about software components from outside sources.
3. Top down and bottom up design planning
This method divides a large problem into two smaller portions called modules, which are then solved one at a time so that no one module affects the others. There are two approaches we can take. The top down method works from the highest level to the lowest. The bottom up approach, on the other hand, works in the other direction, from the lowest to the highest level.
Top down design planning -
When a system's planning begins with the goal that the system wishes to achieve, this is known as top down design planning. When we notice that the desired work is difficult to complete, we divide it into portions, which we call subtasks. These subtasks have the following qualities:
- Size of problem will be small
- Reduce the level of difficulty
- Easy to achieve
If a task is complex, we can break it down into low-difficulty, easily accomplished subtasks. Thus, the splitting of diverse jobs into subtasks is done in order to make them simple and easy to utilise or solve. Many sorts of modules are built on this method, however it is only useful in cases when the aim is explicitly stated.
Advantages
- This approach to programme development is similar to how humans solve problems. In this technique, we first determine the goal and then take steps to achieve the objectives.
- At every stage, the coder became aware of the goal.
- It lowers the level of perplexity.
- It provides a correct procedure for solving this problem swiftly and easily.
Bottom-up design planning -
This method is used to determine the system's overall goal. It began on the lowest level and progressed to the highest level. Individual modules are merged in this technique so that a large module, which is the system's goal, can be produced.
For this strategy to succeed, it must start with a good idea. We can't decide what operations to assist at this time until we have a better notion of what the higher-level operation needs are.
Throughout the history of software engineering, design principles have evolved. Each principle provides a basis for the software designer from which more advanced methods of design can be implemented. Below is a brief description of essential principles in software design that encompass both conventional and object-oriented software creation.
1. Abstraction
When you consider every problem to be a modular solution, several levels of
Abstraction may be posed. At the highest level of abstraction, using the language of the problem setting, a solution is described in general terms. A more detailed explanation of the solution is provided at lower levels of abstraction. Finally, the solution is described in a way that can be explicitly applied at the lowest level of abstraction.
A procedural abstraction relates to a set of instructions that have a particular and restricted purpose. These functions are indicated by the name of a procedural abstraction, but precise specifics are suppressed. A data abstraction is a set of named data representing a data object.
2. Architecture
The architecture of the software alludes to "the general layout of the software and
The ways in which the context provides a structure with logical integrity”.
Architecture is, in its simplest form, the arrangement or organisation of software components (modules), the way in which these components communicate, and the data structure used by the components.
A collection of properties is defined by Shaw and Garlan as part of an architectural design:
Structural Properties This part of the description of architectural architecture describes the Device components (e.g., modules, objects, filters) and the way these components are packaged and communicate with each other.
Extra Functional Properties The definition of architectural design should discuss how the build architecture achieves requirements for performance, power, reliability, protection, adaptability, and other device characteristics.
Families of related system Repeatable patterns can be used in architectural design. In the configuration of families of identical structures, these are frequently encountered. The architecture should, in turn, have the capacity to reuse architectural building blocks.
3. Design Patterns
A pattern is a so-called insight nugget that transmits the essence of a known in a certain context, in the midst of conflicting problems, solutions to a recurrent problem. Stated
A design pattern defines a design framework that addresses a specific design problem within a particular context and in the midst of "forces" that may influence the way the pattern is implemented and used.
Each design pattern is intended to provide a definition that helps a designer to decide
- If the pattern applies to the current job is
- If they can reuse the pattern (hence, saving design time)
- If the model may serve as a guide to creating a pattern that is similar, but functionally or structurally different.
4. Separation of Concerns
Separation of concerns is a principle of design which implies that if it is subdivided into pieces that can each be solved and/or optimized separately, any complex problem can be addressed more easily.
If the perceived complexity of p1 is greater than the perceived complexity of p2, for two problems, p1 and p2, it follows that the effort needed to solve p1 is greater than the effort required to solve p2. This outcome, as a general case, is intuitively evident. It takes more time for a complex problem to be solved. It also follows that when two issues are combined, the perceived complexity is always greater than the amount of the perceived complexity when each is taken separately.
This leads to a divide-and-conquer strategy; when you break it into manageable bits, it is easier to solve a complicated problem. With respect to device modularity, this has significant consequences.
5. Modularity
The most common manifestation of separation of worries is modularity.
Software is split into separately named and addressable components that are combined to fulfil problem requirements, also called modules.
Modularity is the single attribute of software that enables a programme to be intellectually manageable," it has been stated." The number of paths of management, reference period, number of variables, and overall complexity will make comprehension almost impossible. You should split the design into several modules in almost all situations, aiming to make comprehension simpler and, as a result, reduce the cost of creating the programme.
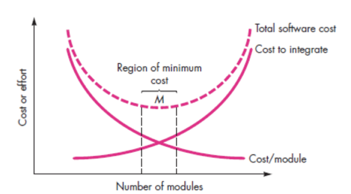
Fig 4: Modularity
6. Information Hiding
The theory of hiding information implies that modules are "Characterized by design decisions that hide from everyone else." In other words, modules should be defined and configured so that information stored within a module (algorithms and data) is inaccessible to other modules that do not require such information.
Hiding means that it is possible to achieve successful modularity by specifying a series of independent modules that interact with each other only with the information required to achieve software functionality.
Abstraction helps describe the groups that make up the software that are procedural (or informational). Hiding defines and enforces access restrictions within a module and any local data structure used by the module for both procedural information.
Key takeaway:
● Hiding information implies that modules are "Characterized by design decisions that hide from everyone else.
● Perhaps the most significant intellectual method built to help software design is knowledge hiding.
● Provides the fundamental inspiration for languages of the abstract data form (ADT)
7. Functional Independence
The idea of functional independence is a direct outgrowth Separation of interests, modularity, and the principles of hiding knowledge and abstraction.
The creation of modules with "single minded" features and an "aversion" to undue contact with other modules achieves functional independence. In other words, you can design software such that each module addresses a particular subset of requirements and, when viewed from other sections of the programme structure, has a simple interface.
Two qualitative measures are used to determine independence: cohesion and coupling
A single task is carried out by a cohesive module, requiring little contact with other modules in other parts of a programme. Simply put, a coherent module can do only one thing (ideally).
Although you should always aim for high cohesion (i.e. single-mindedness), making a software component perform several functions is also important and advisable.
In a software structure, coupling is an indication of interconnection between modules. Coupling relies on the complexity of the interface between modules, the point at which a module entry or reference is made, and what data moves through the interface.
Key takeaway:
● The idea of functional independence is a direct outgrowth Separation of interests, modularity, and the principles of hiding knowledge and abstraction.
● Coupling relies on the complexity of the interface between modules
8. Refinement
Stepwise refinement is a technique for top-down design. The creation of a software is
By successively refining procedural information levels. A hierarchy is defined by stepwise decomposing a macroscopic function statement (a procedural abstraction) until programming language statements are reached.
In reality, refinement is a process of elaboration that starts with a function statement (or knowledge description) that is described at a high level of abstraction. As design advances, sophistication allows you to uncover low-level information.
Key takeaway:
● Stepwise refinement is a technique for top-down design.
● refinement is a process of elaboration that starts with a function statement or knowledge description at a high level of abstraction.
9. Aspects
A collection of "concerns" is discovered as the review of requirements occurs. These “Include requirements, use cases, features, data structures, quality of service problems, variants, boundaries of intellectual property, collaborations, trends and contracts".
Ideally, a model of requirements should be designed in a way that allows you to separate each problem (requirement) so that it can be independently considered. However, in fact, some of these problems span the entire structure and can not be easily compartmentalized.
10. Refactoring
For several agile processes, a significant design task is the refactoring of a Technique of reorganization that simplifies a component's design (or code) without modifying its purpose or behaviour. "Refactoring is the process of modifying a software system in such a way that it does not change the code [design]’s behaviour, but improves its internal structure."
The current design is checked for duplication, unused design components, ineffective or redundant algorithms, improperly designed or inadequate data structures, or some other design flaw that can be changed to create a better design when software is refactored. The effect would be software that is easier to integrate, easier to evaluate, and easier to manage.
11. Object-Oriented Design Concept
In modern software engineering, the object-oriented (OO) paradigm is commonly used. Concepts of OO architecture, such as classes and artefacts, inheritance, Messages, and, among others, polymorphism.
12. Design Classes
You can identify a collection of design classes as the design model evolves,
By providing design specifics that will allow the classes to be implemented, and implementing a software infrastructure that supports the business solution, they refine the study classes.
Key takeaway:
- By supplying design information, a set of design classes refined the research class.
- You can identify a collection of design classes as the design model evolves.
Heuristic evaluations are used to uncover any issues with user interface design. On the basis of numerous years of expertise teaching and consulting about usability engineering, usability consultant Jakob Nielsen developed this method.
In the subject of human-computer interaction, heuristic evaluations are one of the most informal approaches of usability examination. Many different usability design heuristics exist; they are not mutually exclusive and cover many of the same areas of user interface design.
Usability concerns are frequently classified—often on a numeric scale—according to their expected influence on user performance or acceptance.
Heuristic evaluation is frequently carried out in the context of use cases (typical user tasks) to provide feedback to developers on the extent to which the interface is likely to be consistent with the demands and preferences of the intended users.
Heuristic evaluation's simplicity is advantageous in the early phases of design. This form of usability assessment does not necessitate user testing, which can be time consuming due to the need for users, a testing location, and payment for their time. Heuristic evaluation requires only one expert, minimising the evaluation's complexity and time spent. The majority of heuristic evaluations can be completed in a few days.
The amount of time required depends on the size of the artefact, its complexity, the review's aim, the type of the usability concerns that occur during the review, and the reviewers' competency. Prior to user testing, heuristic evaluation will lessen the number and severity of design flaws detected by users. Although heuristic evaluation can quickly identify many key usability issues, one common critique is that the conclusions are heavily impacted by the professional reviewer's knowledge (s). This "one-sided" evaluation consistently produces different results than software performance testing, with each sort of testing revealing a unique set of issues.
Advantages:
- Many latent usability issues are revealed.
- It aids in the evaluation of the overall user experience.
- Usability testing and heuristic evaluation can be combined.
- More users can be engaged with better heuristics evaluation.
- It is less expensive and quicker than full-fledged usability testing.
Limitations:
- Even professionals have difficulty solving some situations.
- Experts to undertake the Heuristics Evaluation become scarce.
- We will require a small number of experienced assessors to make usability testing more manageable.
- Design flaws will have an impact on user engagement with the product.
- Only a few specialists' competence is required for heuristics testing.
NIELSEN'S HEURISTICS
The heuristics of Jakob Nielsen are arguably the most widely utilised usability heuristics for user interface design. Nielsen created the heuristics in 1990 while working with Rolf Molich. Nielsen published the final set of heuristics that are being used today in 1994.
Visibility of system status:
The system should always keep users up to date on what's going on by providing suitable feedback in a timely manner.
Match between system and the real world:
Instead of using system-oriented jargon, the system should speak the user's language, using words, ideas, and concepts that are recognisable to the user. Follow real-world norms to present data in a logical and natural sequence.
User control and freedom:
Users frequently select system functions by accident, necessitating the presence of a clearly defined "emergency escape" that allows them to quit the unwanted state without having to go through a lengthy discussion. Undo and redo are encouraged.
Consistency and standards:
Users should not have to guess what different words, situations, or actions signify. Observe the platform's conventions.
Error prevention:
A thorough design that prevents a problem from developing in the first place is even better than effective error messages. Either eliminate or check for error-prone circumstances and provide users with a confirmation option before committing to an action.
Recognition rather than recall:
Make objects, actions, and options visible to reduce the user's memory load. The user should not have to recall facts from one dialogue segment to the next. When possible, instructions for using the system should be visible or easily accessible.
Flexibility and efficiency of use:
Unseen by the beginner user, accelerators can sometimes speed up the interaction for the expert user, allowing the system to cater to both inexperienced and experienced users. Allow users to customise their routine actions.
Aesthetic and minimalist design:
Information that is irrelevant or only occasionally required should not be included in dialogues. Every additional piece of information in a conversation competes with the important pieces of information, lowering their relative exposure.
A specification of software requirements (SRS) is a document that explains what the software is supposed to do and how it is expected to work. It also describes the functionality needed by the product to fulfill the needs of all stakeholders (business, users).
A standard SRS consists of -
- A purpose - Initially, the main objective is to clarify and illustrate why this document is important and what the intention of the document is.
- An overall description - The product summary is explained here. It's simply a rundown or an overall product analysis.
- Scope of this document - This outline and demonstrates the overall work and primary goal of the paper and what value it can bring to the consumer. It also provides a summary of the cost of construction and the necessary time.
When embedded in hardware, or when linked to other software, the best SRS documents describe how the software can communicate.
Why we use SRS document -
For your entire project, a software specification is the foundation. It sets the structure that will be followed by any team involved in development.
It is used to provide multiple teams with essential information - creation, quality assurance, operations, and maintenance. This keeps it on the same page for everybody.
The use of the SRS helps ensure fulfilment of specifications. And it can also help you make decisions about the lifecycle of your product, such as when to remove a feature.
Writing an SRS can also reduce time and costs for overall production. The use of an SRS especially benefits embedded development teams.
Key takeaway:
- SRS is a document that explains what the software is supposed to do and how it is expected to work.
- For your entire project, a software specification is the foundation.
- The use of the SRS helps ensure fulfilment of specifications.
Data Design Elements
Like other things in software engineering, data design (sometimes referred to as data architecture) generates a data and/or knowledge model that is Described at a high abstract level. This data model is then refined into more and more implementation-specific representations that the computer-based system can process.
A significant part of software design has always been the structure of data. For the development of high-quality applications, the design of data structures and the associated algorithms needed to manipulate them is important at the software component level. At the application stage, the transformation into a database of a data model is central to the achievement of a system's business objectives.
The compilation of information collected in various databases and reorganized into a "data warehouse" at the business level allows data mining or exploration of knowledge that can have an impact on the performance of the organization itself.
Key takeaway
- A significant part of software design has always been the structure of data.
- This data model is then refined into more and more implementation
- Specific representations that the computer-based system can process.
Architectural Design
Architectural design is a method for defining the subsystems that make up a system and the sub-system control and communication structure. A summary of the software architecture is the result of this design process. Architectural design is an early stage of the process of system design. It reflects the interaction between processes of specification and design and is often conducted in parallel with other activities of specification.
At two levels of abstraction, software architectures can be designed:
- The design of individual programmes is concerned with small architecture. At this stage, we are concerned with the manner in which an individual programme is broken down into elements.
- In large architecture is concerned with the architecture of complex business systems, and other elements of systems, programmes, and programmes. These enterprise systems are spread over numerous computers that can be owned and operated by various businesses.
- Design Decisions
Architectural design is a creative activity, so the process varies according to the type of structure being built. A number of common decisions, however, cover all design processes and these decisions influence the system's non-functional features:
● Is there an application architecture that can be used generically?
● To organise the method, what approach will be used?
● How will the scheme be broken down into modules?
● What technique for regulation should be used?
● How is the architectural plan going to be assessed?
● How should the design be documented?
● How's the system going to be distributed?
● What are suitable architectural styles?
Similar architectures also have structures in the same domain that represent domain concepts. Application product lines with variations that meet unique customer specifications are designed around core architecture. A system's architecture can be built around one of several architectural patterns/styles, which capture an architecture's essence and can be instantiated in various ways.
The basic architectural style should rely upon the requirements of the non-functional system:
- Performance: Localize essential tasks and minimise experiences. Using components that are wide rather than fine-grain.
- Security: Using a layered system with vital resources in the inner layers.
- Safety: In a limited number of subsystems, localise safety-critical functions.
- Availability: Redundant elements and fault tolerance mechanisms are included.
- Maintainability: Using replaceable, fine-grain parts.
2. Views, Patterns
Only one view or viewpoint of the structure is shown by each architectural model. It could explain how a system is decomposed into modules, how the run-time processes communicate, or how system components are spread around a network in various ways. You typically need to present several views of the software architecture for both design and documentation.
View model of software architecture:
- A logical view that shows the main abstractions as objects or object classes in the method.
- A process view that explains how the system is composed of interacting processes at run-time.
- A development viewpoint, which explains how the programme is broken down for development.
- A physical view that illustrates the hardware of the device and how software components are spread through system processors.
Patterns
Patterns are a form of information representation, sharing and reuse. A stylized definition of a successful design method that has been tried and tested in various environments is an architectural pattern. Patterns should include data on when they are and when they are not helpful. Using tabular and graphical representations, patterns can be described.
3. Application Architectures
In order to satisfy an organisational need, application systems are developed. As organisations have a lot in common, their application systems often tend to have a common architecture that represents the specifications for the application. An architecture for a type of software system that can be configured and modified to build a system that meets particular specifications is a generic application architecture.
It is possible to use application architectures as:
- An architectural design starting point.
- Checklist for design.
- Way to coordinate the development team's work.
- Means of testing elements for reuse.
- Vocabulary to talk about forms of application.
Examples of application types:
Data processing applications
Data oriented applications that process data in batches during processing without explicit user interaction.
Transaction processing applications
Data-centric applications that process user requests in a system database and update details
Event processing systems
Applications where device behaviour depends on the understanding of events from the environment of the scheme
Language processing systems
Applications in which the intentions of the users are defined in a formal language which the system processes and interprets
Key takeaway:
- Architectural design is a creative activity, so the process varies according to the type of structure being built.
- A system's architecture can be built around one of several architectural patterns/styles, which capture an architecture's essence and can be instantiated in various ways.
- Architectural design is an early stage of the process of system design.
- A summary of the software architecture is the result of this design process.
Interface Design
- The interface review is done once. It is important to define in detail all the tasks needed by the end user and the interface design activity begins.
- Like all other software engineering design processes, interface design is an iterative process.
- Step in the design of the user interface happens multiple times. Each data produced in the previous step is elaborated and refined.
- However, so many models of user interface design have been suggested, all of which propose a combination of the following steps:
- Analysis, description of interface objects and action using knowledge generated during interface analysis (operation).
- Defines events that trigger a change in the state of the user interface.
- Show each state of the interface, as it will actually look at the end-user.
- Indicate how the user interprets the state of the systems through the interface from the information given.
Applying interface design steps -
Defining the interface artefacts and the acts that are applied to them are the most significant steps in interface design
- Cases of usage are parsed to satisfy this.
- That is, a description is written of a use case.
- To construct a list of objects and actions, nouns (objects) and verbs (actions) are separated.
- Once the objects and behaviour are iteratively described and elaborated, their forms are categorized.
Interface design issue -
- Response time
- Help facilities
- Error handling
- Menu and command labeling
- Application accessibility
- internationalization
Key takeaways
Like other software engineering design processes, interface design is an iterative process.
The interface review is done once.
Each data produced in the previous step is elaborated and refined.
Procedural Design
The goal of procedural design is to convert structural components into a software procedural description.
After the data and programme structures have been developed, i.e. after architectural design, this process occurs. Different approaches to represent procedural details include:
Graphical Design Notation:
The flowchart is the most extensively used notation. Flowchart notation includes the following symbols:
- Processing steps are indicated by boxes.
- A diamond represents a logical condition.
- Arrows to represent control flow.
- A Sequence will be shown by two boxes connected by a control line.
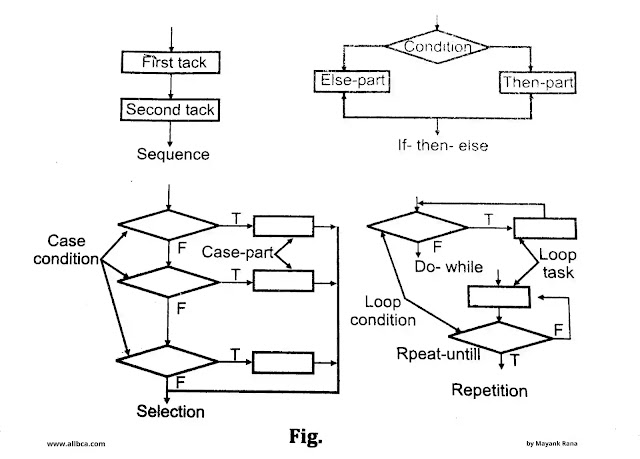
Tabular Design Notation:
- Actions and conditions are translated into a tabular form using decision tables.
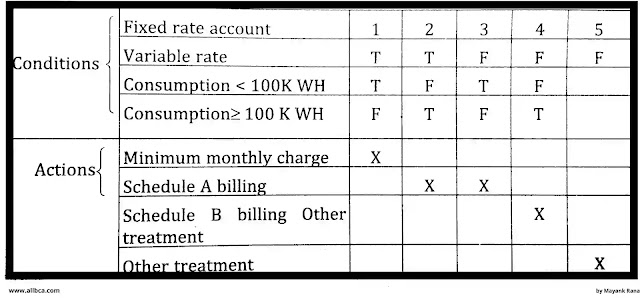
- A list of all conditions can be found in the upper left-hard section. The actions that are feasible based on the conditions are listed in the lower left-hand area. The right-hand portions comprise a matrix that shows condition combinations and the actions that will be taken in response to each combination.
Program Design Language:
It is a way for defining and documenting software processes and procedures. It's similar to pseudocode, but unlike pseudocode, it's written in plain language with no terms that hint a programming language or library.
References:
- Roger S Pressman, Bruce R Maxim, “Software Engineering: A Practitioner’s Approach”, Kindle Edition, 2014.
- Ian Sommerville,” Software engineering”, Addison Wesley Longman, 2014.
- James Rumbaugh. Micheal Blaha “Object oriented Modeling and Design with UML”, 2004.
- Ali Behforooz, Hudson, “Software Engineering Fundamentals”, Oxford, 2009.
- Charles Ritcher, “Designing Flexible Object Oriented systems with UML”, TechMedia, 2008.
- Https://www.allbca.com/2020/04/procedural-design-in-software-engineering.html
- Https://www.tutorialspoint.com/software_engineering/se_overview_qa4.htm




