UNIT 1
Overview of Operating Systems
An operating system is a construct that allows the user application programs to interact with the system hardware. Operating system by itself does not provide any function but it provides an atmosphere in which different applications and programs can do useful work.
The operating system can be observed from the point of view of the user or the system. This is known as the user view and the system view respectively. More details about these are given as follows −
Fig1 – Process state
User View:
The user view depends on the system interface that is used by the users. The different types of user view experiences can be explained as follows −
There are some devices that contain very less or no user view because there is no interaction with the users. Examples are embedded computers in home devices, automobiles etc.
System View:
According to the computer system, the operating system is the bridge between applications and hardware. It is most intimate with the hardware and is used to control it as required.
The different types of system view for operating system can be explained as follows:
Key takeaway
An operating system is a construct that allows the user application programs to interact with the system hardware. Operating system by itself does not provide any function but it provides an atmosphere in which different applications and programs can do useful work.
The operating system can be observed from the point of view of the user or the system. This is known as the user view and the system view respectively. More details about these are given as follows −
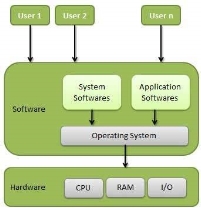
An Operating System (OS) is an interface between a computer user and computer hardware. An operating system is a software which performs all the basic tasks like file management, memory management, process management, handling input and output, and controlling peripheral devices such as disk drives and printers.
Some popular Operating Systems include Linux Operating System, Windows Operating System, VMS, OS/400, AIX, z/OS, etc.
Definition
An operating system is a program that acts as an interface between the user and the computer hardware and controls the execution of all kinds of programs.
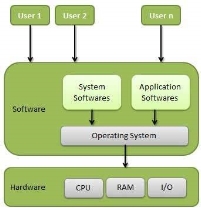
Fig 2 – Operating system
Following are some of important functions of an operating System-
Memory Management:
Memory management refers to management of Primary Memory or Main Memory. Main memory is a large array of words or bytes where each word or byte has its own address.
Main memory provides a fast storage that can be accessed directly by the CPU. For a program to be executed, it must in the main memory. An Operating System does the following activities for memory management −
Processor Management:
In multiprogramming environment, the OS decides which process gets the processor when and for how much time. This function is called process scheduling. An Operating System does the following activities for processor management −
Device Management:
An Operating System manages device communication via their respective drivers. It does the following activities for device management −
File Management:
A file system is normally organized into directories for easy navigation and usage. These directories may contain files and other directions.
An Operating System does the following activities for file management −
Other Important Activities
Following are some of the important activities that an Operating System performs −
Operating System - Properties
Batch processing:
Batch processing is a technique in which an Operating System collects the programs and data together in a batch before processing starts. An operating system does the following activities related to batch processing −
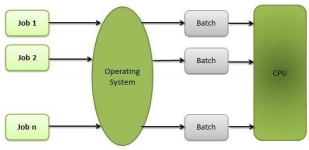
Fig 3 - Batch processing
Advantages:
Disadvantages:
Multitasking:
Multitasking is when multiple jobs are executed by the CPU simultaneously by switching between them. Switches occur so frequently that the users may interact with each program while it is running. An OS does the following activities related to multitasking −
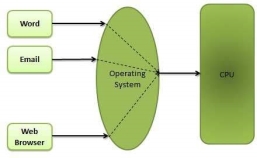
Fig 4 - Multitasking
Multiprogramming:
Sharing the processor, when two or more programs reside in memory at the same time, is referred as multiprogramming. Multiprogramming assumes a single shared processor. Multiprogramming increases CPU utilization by organizing jobs so that the CPU always has one to execute.
The following figure shows the memory layout for a multiprogramming system.

Fig 5 - Multiprogramming system
An OS does the following activities related to multiprogramming.
Advantages:
Disadvantages:
Interactivity:
Interactivity refers to the ability of users to interact with a computer system. An Operating system does the following activities related to interactivity −
The response time of the OS needs to be short, since the user submits and waits for the result.
Real Time System:
Real-time systems are usually dedicated, embedded systems. An operating system does the following activities related to real-time system activity.
Distributed Environment :
A distributed environment refers to multiple independent CPUs or processors in a computer system. An operating system does the following activities related to distributed environment.
Spooling:
Spooling is an acronym for simultaneous peripheral operations on line. Spooling refers to putting data of various I/O jobs in a buffer. This buffer is a special area in memory or hard disk which is accessible to I/O devices.
An operating system does the following activities related to distributed environment −
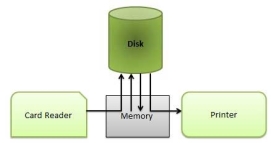
Fig 6 – Spooling
Advantages
Key takeaway-
An Operating System (OS) is an interface between a computer user and computer hardware. An operating system is a software which performs all the basic tasks like file management, memory management, process management, handling input and output, and controlling peripheral devices such as disk drives and printers.
Some popular Operating Systems include Linux Operating System, Windows Operating System, VMS, OS/400, AIX, z/OS, etc.
Definition
An operating system is a program that acts as an interface between the user and the computer hardware and controls the execution of all kinds of programs.
Following are some of important functions of an operating System-
As already mentioned, in addition to the hardware, a computer also needs a set of programs—an operating system—to control the devices. This page will discuss the following:
When you can recognize the typical parts of each operating system’s user interface, you will mostly be able to use both Windows and Linux as well as e.g. Mac OS.
The role of operating system in the computer:
An operating system (OS) is a set of programs which ensures the interoperability of the hardware and software in your computer. The operating system enables, among other things,
What happens when you turn on your computer or smartphone?
– The computer checks the functionality of its components and any devices connected to it, and starts to look for the OS on a hard drive or other memory media.
– If the OS is found, the computer starts to load it into the RAM (Random Access Memory).
– When the OS has loaded, the computer waits for commands from you.
Different operating systems-
Over the years, several different operating systems have been developed for different purposes. The most typical operating systems in ordinary computers are Windows, Linux and Mac OS.
Windows
The name of the Windows OS comes from the fact that programs are run in “windows”: each program has its own window, and you can have several programs open at the same time. Windows is the most popular OS for home computers, and there are several versions of it. The newest version is Windows 10.
Linux and Unix
Linux is an open-source OS, which means that its program code is freely available to software developers. This is why thousands of programmers around the world have developed Linux, and it is considered the most tested OS in the world. Linux has been very much influenced by the commercial Unix OS.
In addition to servers, Linux is widely used in home computers, since there are a great number of free programs for it (for text and image processing, spreadsheets, publishing, etc.). Over the years, many different versions of Linux have become available for distribution, most of which are free for the user (such as Ubuntu, Fedora and Mint, to name a few).
Mac OS X
Apple’s Mac computers have their own operating system, OS X. Most of the programs that are available for PCs are also available for Macs running under OS X, but these two types of computers cannot use the exact same programs: for example, you cannot install the Mac version of the Microsoft Office suite on a Windows computer. You can install other operating systems on Mac computers, but the OS X is only available for computers made by Apple. Apple’s lighter portable devices (iPads, iPhones) use a light version of the same operating system, called iOS.
Mac computers are popular because OS X is considered fast, easy to learn and very stable and Apple’s devices are considered well-designed—though rather expensive.
Android
Android is an operating system designed for phones and other mobile devices. Android is not available for desktop computers, but in mobile devices it is extremely popular: more than a half of all mobile devices in the world run on Android.
User interfaces
A user interface (UI) refers to the part of an operating system, program, or device that allows a user to enter and receive information. A text-based user interface (see the image to the left) displays text, and its commands are usually typed on a command line using a keyboard. With a graphical user interface (see the right-hand image), the functions are carried out by clicking or moving buttons, icons and menus by means of a pointing device.
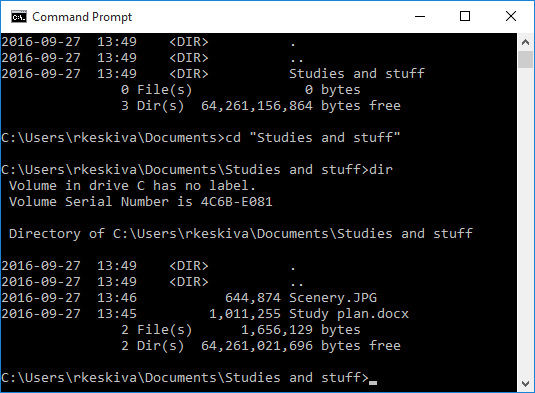

The images contain the same information: a directory listing of a computer. You can often carry out the same tasks regardless of which kind of UI you are using.
Text user interface (TUI)
Modern graphical user interfaces have evolved from text-based UIs. Some operating systems can still be used with a text-based user interface. In this case, the commands are entered as text (e.g., “cat story.txt”).
To display the text-based Command Prompt in Windows, open the Start menu and type cmd. Press Enter on the keyboard to launch the command prompt in a separate window. With the command prompt, you can type your commands from the keyboard instead of using the mouse.
Graphical user interface
In most operating systems, the primary user interface is graphical, i.e. instead of typing the commands you manipulate various graphical objects (such as icons) with a pointing device. The underlying principle of different graphical user interfaces (GUIs) is largely the same, so by knowing how to use a Windows UI, you will most likely know how to use Linux or some other GUI.
Most GUIs have the following basic components:
Key takeaway-
There are different kinds of operating systems: such as Windows, Linux and Mac OS
Efficiency:
The efficient use of disk space depends heavily on the disk allocation and directory algorithms in use. For instance, UNIX inodes are preallocated on a volume. Even an "empty" disk has a percentage of its space lost to inodes. However, by preallocating the inodes and. spreading them across the volume, we improve the file system's performance. This improved performance results from the UNIX allocation and free-space algorithms, which try to keep a file's data blocks near that file's inode block to reduce seek time. As another example, let's reconsider the clustering scheme discussed in Section 11.4, which aids in file-seek and file-transfer performance at the cost of internal fragmentation.
To reduce this fragmentation, BSD UNIX varies the cluster size as a file grows. Large clusters are used where they can be filled, and small clusters are used for small files and the last cluster of a file. This system is described in Appendix A. The types of data normally kept in a file's directory (or inode) entry also require consideration. Commonly, a 'last write date" is recorded to supply information to the user and, to determine whether the file needs to be backed up. Some systems also keep a "last access date," so that a user can determine when the file was last read.
The result of keeping this information is that, whenever the file is read, a field in the directory structure must be written to. That means the block must be read into memory, a section changed, and the block written back out to disk, because operations on disks occur only in block (or cluster) chunks. So any time a file is opened for reading, its directory entry must be read and written as well. This requirement can be inefficient for frequently accessed files, so we must weigh its benefit against its performance cost when designing a file system. Generally, every data item associated with a file needs to be considered for its effect on efficiency and performance.
As an example, consider how efficiency is affected by the size of the pointers used to access data. Most systems use either 16- or 32-bit pointers throughout the operating system. These pointer sizes limit the length of a file to either 2 16 (64 KB) or 232 bytes (4 GB). Some systems implement 64-bit pointers to increase this limit to 264 bytes, which is a very large number indeed. However, 64-bit pointers take more space to store and in turn make the allocation and free-space-management methods (linked lists, indexes, and so on) use more disk space. One of the difficulties in choosing a pointer size, or indeed any fixed allocation size within an operating system, is planning for the effects of changing technology. Consider that the IBM PC XT had a 10-MB hard drive and an MS-DOS file system that could support only 32 MB. (Each FAT entry was 12 bits, pointing to an 8-KB cluster.)
As disk capacities increased, larger disks had to be split into 32-MB partitions, because the file system could not track blocks beyond 32 MB. As hard disks with capacities of over 100 MB became common, most disk controllers include local memory to form an on-board cache that is large enough to store entire tracks at a time. Once a seek is performed, the track is read into the disk cache starting at the sector under the disk head (reducing latency time).
The disk controller then transfers any sector requests to the operating system. Once blocks make it from the disk controller into main memory, the operating system may cache the blocks there. Some systems maintain a separate section of main memory for a buffer cache, where blocks are kept under the assumption that they will be used again shortly. Other systems cache file data using a page cache.
The page cache uses virtual memory techniques to cache file data as pages rather than as file-system-oriented blocks. Caching file data using virtual addresses is far more efficient than caching through physical disk blocks, as accesses interface with virtual memory rather than the file system. Several systems—including Solaris, Linux, and Windows NT, 2000, and XP—use page caching to cache both process pages and file data. This is known as unified virtual memory. Some versions of UNIX and Linux provide a unified buffer cache. To illustrate the benefits of the unified buffer cache, consider the two alternatives for opening and accessing a file. One approach is to use memory mapping (Section 9.7); the second is to use the standard system calls readO and write 0 . Without a unified buffer cache, we have a situation similar to Figure 11.11.
Here, the read() and write () system calls go through the buffer cache. The memory-mapping call, however, requires using two caches—the page cache and the buffer cache. A memory mapping proceeds by reading in disk blocks from the file system and storing them in the buffer cache. Because the virtual memory system does not interface with the buffer cache, the contents of the file in the buffer cache must be copied into the page cache. This situation is known as double caching and requires caching file-system data twice. Not only does it waste memory but it also wastes significant CPU and I/O cycles due to the extra data movement within, system memory.
In add ition, inconsistencies between the two caches can result in corrupt files. In contrast, when a unifiedthe disk data structures and algorithms in MS-DOS had to be modified to allow larger file systems. (Each FAT entry was expanded to 16 bits and later to 32 bits.) The initial file-system decisions were made for efficiency reasons; however, with the advent of MS-DOS version 4, millions of computer users were inconvenienced when they had to switch to the new, larger file system. Sun's ZFS file system uses 128-bit pointers, which theoretically should never need to be extended. (The minimum mass of a device capable of storing 2'2S bytes using atomic-level storage would be about 272 trillion kilograms.) As another example, consider the evolution of Sun's Solaris operating system.
Originally, many data structures were of fixed length, allocated at system startup. These structures included the process table and the open-file table. When the process table became full, no more processes could be created. When the file table became full, no more files could be opened. The system would fail to provide services to users. Table sizes could be increased only by recompiling the kernel and rebooting the system. Since the release of Solaris 2, almost all kernel structures have been allocated dynamically, eliminating these artificial limits on system performance. Of course, the algorithms that manipulate these tables are more complicated, and the operating system is a little slower because it must dynamically allocate and deallocate table entries; but that price is the usual one for more general, functionality.
Performance:
Even after the basic file-system algorithms have been selected, we can still improve performance in several ways. As will be discussed in Chapter 13, most disk controllers include local memory to form an on-board cache that is large enough to store entire tracks at a time. Once a seek is performed, the track is read into the disk cache starting at the sector under the disk head (reducing latency time). The disk controller then transfers any sector requests to the operating system. Once blocks make it from the disk controller into main memory, the operating system may cache the blocks there. Some systems maintain a separate section of main memory for a buffer cache, where blocks are kept under the assumption that they will be used again shortly. Other systems cache file data using a page cache.
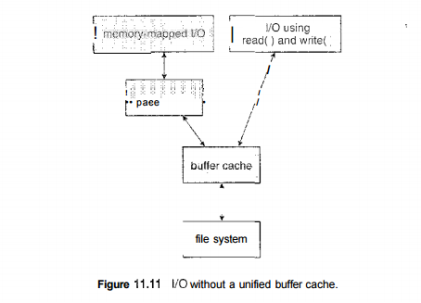
Fig 7 – I/O without a unified buffer cache.
The page cache uses virtual memory techniques to cache file data as pages rather than as file-system-oriented blocks. Caching file data using virtual addresses is far more efficient than caching through physical disk blocks, as accesses interface with virtual memory rather than the file system. Several systems—including Solaris, Linux, and Windows NT, 2000, and XP—use page caching to cache both process pages and file data. This is known as unified virtual memory. Some versions of UNIX and Linux provide a unified buffer cache.
To illustrate the benefits of the unified buffer cache, consider the two alternatives for opening and accessing a file. One approach is to use memory mapping (Section 9.7); the second is to use the standard system calls readO and write 0 .
Without a unified buffer cache, we have a situation similar to Figure 11.11. Here, the read() and write () system calls go through the buffer cache. The memory-mapping call, however, requires using two caches—the page cache and the buffer cache. A memory mapping proceeds by reading in disk blocks from the file system and storing them in the buffer cache. Because the virtual memory system does not interface with the buffer cache, the contents of the file in the buffer cache must be copied into the page cache.
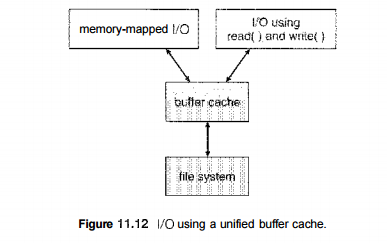
Fig 8 – I/O using a unified buffer cache
This situation is known as double caching and requires caching file-system data twice. Not only does it waste memory but it also wastes significant CPU and I/O cycles due to the extra data movement within, system memory. In add ition, inconsistencies between the two caches can result in corrupt files. In contrast, when a unified buffer cache is provided, both memory mapping and the read () and write () system calls use the same page cache. This has the benefit of avoiding double caching, and it allows the virtual memory system to manage file-system data. The unified buffer cache is shown in Figure 11.12. Regardless of whether we are caching disk blocks or pages (or both), LEU (Section 9.4.4) seems a reasonable general-purpose algorithm for block or page replacement. However, the evolution of the Solaris page-caching algorithms reveals the difficulty in choosing an algorithm. Solaris allows processes and the page cache to share unused in Emory.
Versions earlier than Solaris 2.5.1 made no distinction between allocating pages to a process and allocating them to the page cache. As a result, a system performing many I/O operations used most of the available memory for caching pages. Because of the high rates of I/O, the page scanner (Section 9.10.2) reclaimed pages from processes— rather than from the page cache—when free memory ran low. Solaris 2.6 and Solaris 7 optionally implemented priority paging, in which the page scanner gives priority to process pages over the page cache. Solaris 8 applied a fixed limit to process pages and the file-system page cache, preventing either from forcing the other out of memory. Solaris 9 and 10 again changed the algorithms to maximize memory use and minimize thrashing. This real-world example shows the complexities of performance optimizing and caching.
There are other issvies that can affect the performance of I/O such as whether writes to the file system occur synchronously or asynchronously. Synchronous writes occur in the order in which the disk subsystem receives them, and the writes are not buffered. Thus, the calling routine must wait for the data to reach the disk drive before it can proceed. Asynchronous writes are done the majority of the time. In an asynchronous write, the data are stored in the cache, and control returns to the caller. Metadata writes, among others, can be synchronous.
Operating systems frequently include a flag in the open system call to allow a process to request that writes be performed synchronously. For example, databases use this feature for atomic transactions, to assure that data reach stable storage in the required order. Some systems optimize their page cache by using different replacement algorithms, depending on the access type of the file.
A file being read or written sequentially should not have its pages replaced in LRU order, because the most 11.7 Recovery 435 recently used page will be used last, or perhaps never again. Instead, sequential access can be optimized by techniques known as free-behind and read-ahead. Free-behind removes a page from the buffer as soon as the next page is requested. The previous pages are not likely to be used again and waste buffer space. With read-ahead, a requested page and several subsequent pages are read and cached. These pages are likely to be requested after the current page is processed.
Retrieving these data from the disk in one transfer and caching them saves a considerable amount of time. One might think a track cache on the controller eliminates the need for read-ahead on a multiprogrammed system. However, because of the high latency and overhead involved in making many small transfers from the track cache to main memory, performing a read-ahead remains beneficial. The page cache, the file system, and the disk drivers have some interesting interactions. When data are written to a disk file, the pages are buffered in the cache, and the disk driver sorts its output queue according to disk address. These two actions allow the disk driver to minimize disk-head seeks and to write data at times optimized for disk rotation.
Unless synchronous writes are required, a process writing to disk simply writes into the cache, and the system asynchronously writes the data to disk when convenient. The user process sees very fast writes. When data are read from a disk file, the block I/O system does some read-ahead; however, writes are much more nearly asynchronous than are reads. Thus, output to the disk through the file system is often faster than is input for large transfers, counter to intuition.
Operating System – Services-
An Operating System provides services to both the users and to the programs.
Following are a few common services provided by an operating system −
a) Program execution.
b) I/O operations.
c) File System manipulation.
d) Communication.
e) Error Detection.
f) Resource Allocation.
g) Protection.
Program execution
Operating systems handle many kinds of activities from user programs to system programs like printer spooler, name servers, file server, etc. Each of these activities is encapsulated as a process.
A process includes the complete execution context (code to execute, data to manipulate, registers, OS resources in use). Following are the major activities of an operating system with respect to program management −
I/O Operation:
An I/O subsystem comprises of I/O devices and their corresponding driver software. Drivers hide the peculiarities of specific hardware devices from the users.
An Operating System manages the communication between user and device drivers.
File system manipulation:
A file represents a collection of related information. Computers can store files on the disk (secondary storage), for long-term storage purpose. Examples of storage media include magnetic tape, magnetic disk and optical disk drives like CD, DVD. Each of these media has its own properties like speed, capacity, data transfer rate and data access methods.
A file system is normally organized into directories for easy navigation and usage. These directories may contain files and other directions. Following are the major activities of an operating system with respect to file management −
Communication:
In case of distributed systems which are a collection of processors that do not share memory, peripheral devices, or a clock, the operating system manages communications between all the processes. Multiple processes communicate with one another through communication lines in the network.
The OS handles routing and connection strategies, and the problems of contention and security. Following are the major activities of an operating system with respect to communication −
Error handling:
Errors can occur anytime and anywhere. An error may occur in CPU, in I/O devices or in the memory hardware. Following are the major activities of an operating system with respect to error handling −
Resource Management:
In case of multi-user or multi-tasking environment, resources such as main memory, CPU cycles and files storage are to be allocated to each user or job. Following are the major activities of an operating system with respect to resource management −
Protection:
Considering a computer system having multiple users and concurrent execution of multiple processes, the various processes must be protected from each other's activities.
Protection refers to a mechanism or a way to control the access of programs, processes, or users to the resources defined by a computer system. Following are the major activities of an operating system with respect to protection −
Key takeaway-
The efficient use of disk space depends heavily on the disk allocation and directory algorithms in use. For instance, UNIX inodes are preallocated on a volume. Even an "empty" disk has a percentage of its space lost to inodes. However, by preallocating the inodes and. spreading them across the volume, we improve the file system's performance. This improved performance results from the UNIX allocation and free-space algorithms, which try to keep a file's data blocks near that file's inode block to reduce seek time. As another example, let's reconsider the clustering scheme discussed in Section 11.4, which aids in file-seek and file-transfer performance at the cost of internal fragmentation.
To reduce this fragmentation, BSD UNIX varies the cluster size as a file grows. Large clusters are used where they can be filled, and small clusters are used for small files and the last cluster of a file. This system is described in Appendix A. The types of data normally kept in a file's directory (or inode) entry also require consideration. Commonly, a 'last write date" is recorded to supply information to the user and, to determine whether the file needs to be backed up. Some systems also keep a "last access date," so that a user can determine when the file was last read.
Operating systems are there from the very first computer generation and they keep evolving with time. In this chapter, we will discuss some of the important types of operating systems which are most commonly used.
Batch operating system:
The users of a batch operating system do not interact with the computer directly. Each user prepares his job on an off-line device like punch cards and submits it to the computer operator. To speed up processing, jobs with similar needs are batched together and run as a group. The programmers leave their programs with the operator and the operator then sorts the programs with similar requirements into batches.
The problems with Batch Systems are as follows −
Time-sharing operating systems:
Time-sharing is a technique which enables many people, located at various terminals, to use a particular computer system at the same time. Time-sharing or multitasking is a logical extension of multiprogramming. Processor's time which is shared among multiple users simultaneously is termed as time-sharing.
The main difference between multiprogrammed Batch Systems and Time-Sharing Systems is that in case of multiprogrammed batch systems, the objective is to maximize processor use, whereas in Time-Sharing Systems, the objective is to minimize response time.
Multiple jobs are executed by the CPU by switching between them, but the switches occur so frequently. Thus, the user can receive an immediate response. For example, in a transaction processing, the processor executes each user program in a short burst or quantum of computation. That is, if n users are present, then each user can get a time quantum. When the user submits the command, the response time is in few seconds at most.
The operating system uses CPU scheduling and multiprogramming to provide each user with a small portion of a time. Computer systems that were designed primarily as batch systems have been modified to time-sharing systems.
Advantages of Timesharing operating systems are as follows −
Disadvantages of Time-sharing operating systems are as follows −
Distributed operating System:
Distributed systems use multiple central processors to serve multiple real-time applications and multiple users. Data processing jobs are distributed among the processors accordingly.
The processors communicate with one another through various communication lines (such as high-speed buses or telephone lines). These are referred as loosely coupled systems or distributed systems. Processors in a distributed system may vary in size and function. These processors are referred as sites, nodes, computers, and so on.
The advantages of distributed systems are as follows −
Network operating System:
A Network Operating System runs on a server and provides the server the capability to manage data, users, groups, security, applications, and other networking functions. The primary purpose of the network operating system is to allow shared file and printer access among multiple computers in a network, typically a local area network (LAN), a private network or to other networks.
Examples of network operating systems include Microsoft Windows Server 2003, Microsoft Windows Server 2008, UNIX, Linux, Mac OS X, Novell NetWare, and BSD.
The advantages of network operating systems are as follows −
The disadvantages of network operating systems are as follows −
Real Time operating System:
A real-time system is defined as a data processing system in which the time interval required to process and respond to inputs is so small that it controls the environment. The time taken by the system to respond to an input and display of required updated information is termed as the response time. So in this method, the response time is very less as compared to online processing.
Real-time systems are used when there are rigid time requirements on the operation of a processor or the flow of data and real-time systems can be used as a control device in a dedicated application. A real-time operating system must have well-defined, fixed time constraints, otherwise the system will fail. For example, Scientific experiments, medical imaging systems, industrial control systems, weapon systems, robots, air traffic control systems, etc.
There are two types of real-time operating systems-
Hard real-time systems:
Hard real-time systems guarantee that critical tasks complete on time. In hard real-time systems, secondary storage is limited or missing and the data is stored in ROM. In these systems, virtual memory is almost never found.
Soft real-time systems:
Soft real-time systems are less restrictive. A critical real-time task gets priority over other tasks and retains the priority until it completes. Soft real-time systems have limited utility than hard real-time systems. For example, multimedia, virtual reality, Advanced Scientific Projects like undersea exploration and planetary rovers, etc.
Batch processing-
Batch processing is a technique in which an Operating System collects the programs and data together in a batch before processing starts. An operating system does the following activities related to batch processing −
Fig 9 – Batch processing
Advantages
Disadvantages
Multitasking:
Multitasking is when multiple jobs are executed by the CPU simultaneously by switching between them. Switches occur so frequently that the users may interact with each program while it is running. An OS does the following activities related to multitasking −
Fig 10 - Multitasking
Multiprogramming:
Sharing the processor, when two or more programs reside in memory at the same time, is referred as multiprogramming. Multiprogramming assumes a single shared processor. Multiprogramming increases CPU utilization by organizing jobs so that the CPU always has one to execute.
The following figure shows the memory layout for a multiprogramming system.

Fig 11 - Multiprogramming
An OS does the following activities related to multiprogramming.
Advantages:
Disadvantages:
Interactivity-
Interactivity refers to the ability of users to interact with a computer system. An Operating system does the following activities related to interactivity −
The response time of the OS needs to be short, since the user submits and waits for the result.
Real Time System
Real-time systems are usually dedicated, embedded systems. An operating system does the following activities related to real-time system activity.
Distributed Environment
A distributed environment refers to multiple independent CPUs or processors in a computer system. An operating system does the following activities related to distributed environment −
Spooling
Spooling is an acronym for simultaneous peripheral operations on line. Spooling refers to putting data of various I/O jobs in a buffer. This buffer is a special area in memory or hard disk which is accessible to I/O devices.
An operating system does the following activities related to distributed environment −
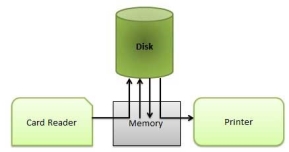
Fig 12 – Spooling
Advantages
Key takeaway-
Batch operating system:
The users of a batch operating system do not interact with the computer directly. Each user prepares his job on an off-line device like punch cards and submits it to the computer operator. To speed up processing, jobs with similar needs are batched together and run as a group. The programmers leave their programs with the operator and the operator then sorts the programs with similar requirements into batches.
The problems with Batch Systems are as follows −
An operating system is a construct that allows the user application programs to interact with the system hardware. Operating system by itself does not provide any function but it provides an atmosphere in which different applications and programs can do useful work.
The major operations of the operating system are process management, memory management, device management and file management. These are given in detail as follows:
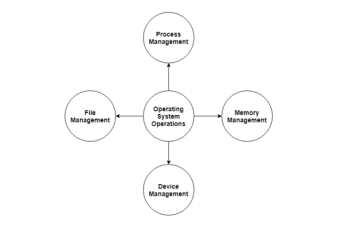
Fig 13 – Operating system operations
Process Management:
The operating system is responsible for managing the processes i.e assigning the processor to a process at a time. This is known as process scheduling. The different algorithms used for process scheduling are FCFS (first come first served), SJF (shortest job first), priority scheduling, round robin scheduling etc.
There are many scheduling queues that are used to handle processes in process management. When the processes enter the system, they are put into the job queue. The processes that are ready to execute in the main memory are kept in the ready queue. The processes that are waiting for the I/O device are kept in the device queue.
Memory Management:
Memory management plays an important part in operating system. It deals with memory and the moving of processes from disk to primary memory for execution and back again.
The activities performed by the operating system for memory management are −
Device Management:
There are many I/O devices handled by the operating system such as mouse, keyboard, disk drive etc. There are different device drivers that can be connected to the operating system to handle a specific device. The device controller is an interface between the device and the device driver. The user applications can access all the I/O devices using the device drivers, which are device specific codes.
File Management:
Files are used to provide a uniform view of data storage by the operating system. All the files are mapped onto physical devices that are usually non-volatile so data is safe in the case of system failure.
The files can be accessed by the system in two ways i.e. sequential access and direct access −
The information in a file is processed in order using sequential access. The files records are accessed on after another. Most of the file systems such as editors, compilers etc. use sequential access.
In direct access or relative access, the files can be accessed in random for read and write operations. The direct access model is based on the disk model of a file, since it allows random accesses.
Key takeaway-
An operating system is a construct that allows the user application programs to interact with the system hardware. Operating system by itself does not provide any function but it provides an atmosphere in which different applications and programs can do useful work.
The major operations of the operating system are process management, memory management, device management and file management. These are given in detail as follows:
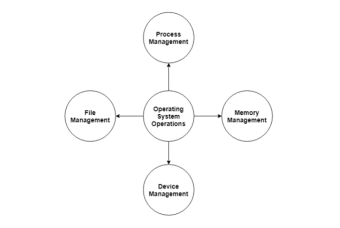
The entire operating system works in the kernel space in the monolithic system. This increases the size of the kernel as well as the operating system. This is different than the microkernel system where the minimum software that is required to correctly implement an operating system is kept in the kernel.
A diagram that demonstrates the architecture of a monolithic system is as follows −
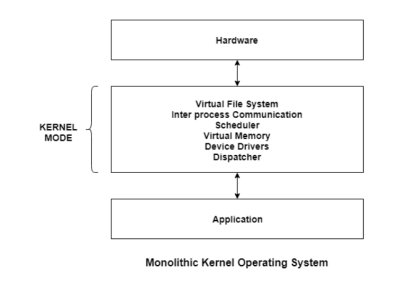
Fig 14 – Monolithic kernel operating system
The kernel provides various services such as memory management, file management, process scheduling etc. using function calls. This makes the execution of the operating system quite fast as the services are implemented under the same address space.
Differences Between Microkernel and Monolithic Kernel-
Some of the differences between microkernel and monolithic kernel are given as follows −
Advantages of Monolithic Kernel-
Some of the advantages of monolithic kernel are −
Disadvantages of Monolithic Kernel-
Some of the disadvantages of monolithic kernel are −
Key takeaway-
The entire operating system works in the kernel space in the monolithic system. This increases the size of the kernel as well as the operating system. This is different than the microkernel system where the minimum software that is required to correctly implement an operating system is kept in the kernel.
A diagram that demonstrates the architecture of a monolithic system is as follows −
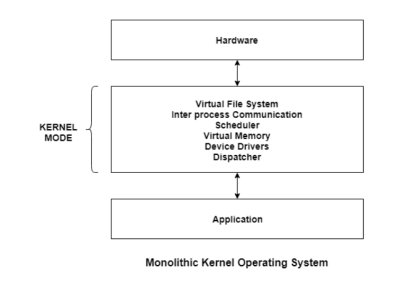
The kernel provides various services such as memory management, file management, process scheduling etc. using function calls. This makes the execution of the operating system quite fast as the services are implemented under the same address space.
A virtual machine (VM) is a virtual environment that functions as a virtual computer system with its own CPU, memory, network interface, and storage, created on a physical hardware system (located off- or on-premises). Software called a hypervisor separates the machine’s resources from the hardware and provisions them appropriately so they can be used by the VM.
The physical machines, equipped with a hypervisor such as Kernel-based Virtual Machine (KVM), is called the host machine, host computer, host operating system, or simply host. The many VMs that use its resources are guest machines, guest computers, guest operating systems, or simply guests. The hypervisor treats compute resources—like CPU, memory, and storage—as a pool of resources that can easily be relocated between existing guests or to new virtual machines.
VMs are isolated from the rest of the system, and multiple VMs can exist on a single piece of hardware, like a server. They can be moved between host servers depending on demand or to use resources more efficiently.
VMs allow multiple different operating systems to run simultaneously on a single computer—like a Linux® distro on a MacOS laptop. Each operating system runs in the same way an operating system or application normally would on the host hardware, so the end user experience emulated within the VM is nearly identical to a real-time operating system experience running on a physical machine.
How do VMs work?
Virtualization technology allows you to share a system with many virtual environments. The hypervisor manages the hardware and separates the physical resources from the virtual environments. Resources are partitioned as needed from the physical environment to the VMs.
When the VM is running and a user or program issues an instruction that requires additional resources from the physical environment, the hypervisor schedules the request to the physical system’s resources so that the virtual machine’s operating system and applications can access the shared pool of physical resources.
Types of hypervisors-
There are 2 different types of hypervisors that can be used for virtualization.
Type 1:
A type 1 hypervisor is on bare metal. VM resources are scheduled directly to the hardware by the hypervisor. KVM is an example of a type 1 hypervisor. KVM was merged into the Linux kernel in 2007, so if you’re using a modern version of Linux, you already have access to KVM.
Type 2:
A type 2 hypervisor is hosted. VM resources are scheduled against a host operating system, which is then executed against the hardware. VMware Workstation and Oracle VirtualBox are examples of type 2 hypervisors.
Why use a VM?
Server consolidation is a top reason to use VMs. Most operating system and application deployments only use a small amount of the physical resources available when deployed to bare metal. By virtualizing your servers, you can place many virtual servers onto each physical server to improve hardware utilization.
This keeps you from needing to purchase additional physical resources, like hard drives or hard disks, as well as reducing the need for power, space, and cooling in the datacenter. VMs provide additional disaster recovery options by enabling failover and redundancy that could previously only be achieved through additional hardware.
A VM provides an environment that is isolated from the rest of a system, so whatever is running inside a VM won’t interfere with anything else running on the host hardware.
Because VMs are isolated, they are a good option for testing new applications or setting up a production environment. You can also run a single purpose VM to support a specific process.
Key takeaway
A virtual machine (VM) is a virtual environment that functions as a virtual computer system with its own CPU, memory, network interface, and storage, created on a physical hardware system (located off- or on-premises). Software called a hypervisor separates the machine’s resources from the hardware and provisions them appropriately so they can be used by the VM.
The physical machines, equipped with a hypervisor such as Kernel-based Virtual Machine (KVM), is called the host machine, host computer, host operating system, or simply host. The many VMs that use its resources are guest machines, guest computers, guest operating systems, or simply guests. The hypervisor treats compute resources—like CPU, memory, and storage—as a pool of resources that can easily be relocated between existing guests or to new virtual machines.
What is Kernel?
A kernel is an important part of an OS that manages system resources. It also acts as a bridge between the software and hardware of the computer. It is one of the first program which is loaded on start-up after the bootloader. The Kernel is also responsible for offering secure access to the machine's hardware for various programs. It also decides when and how long a certain application uses specific hardware.
What is Microkernel?
Microkernel is a software or code which contains the required minimum amount of functions, data, and features to implement an operating system. It provides a minimal number of mechanisms, which is good enough to run the most basic functions of an operating system. It allows other parts of the operating system to be implemented as it does not impose a lot of policies.
Microkernels and their user environments are usually implemented in the C++ or C programming languages with a little bit of assembly. However, other implementation languages are possible with some high-level coding.
What is a Monolithic Kernel?
Monolithic Kernel runs all the basic system services like process management, Memory management, I/O communication, and interrupt handling, file system, etc in kernel space.
In this type of Kernel approach, the entire operating system runs as a single program in kernel mode. The operating system is written as a collection of procedures that are linked together into a large executable binary program.
Microkernel Architecture:
A Microkernel is the most important part for correct implementation of an operating system. You can see in the below-given diagram, that Microkernel fulfills basic operations like memory, process scheduling mechanisms, and inter-process communication.
Fig 15 - Microkernel Based Operating System
Microkernel is the only software executing at the privileged level. The other important functionalities of the OS are removed from the kernel-mode and run in the user mode. These functionalities may be device drivers, application, file servers, interprocess communication, etc.
Components of Microkernel:
A microkernel comprises only the core functionalities of the system. A component is included in the Microkernel only if putting it outside would interrupt the functionality of the system. All other non-essential components should be put in the user mode.
The minimum functionalities required in the Microkernel are:
Difference between Microkernel and Monolithic Kernel
Parameters | Monolithic kernel | MicroKernel |
Basic | It is a large process running in a single address space | It can be broken down into separate processes called servers. |
Code | In order to write a monolithic kernel, less code is required. | In order to write a microkernel, more code is required |
Security | If a service crashes, the whole system collapses in a monolithic kernel. | If a service crashes, it never affects the working of a microkernel. |
Communication | It is a single static binary file | Servers communicate through IPC. |
Example | Linux, BSDs, Microsoft Windows (95,98, Me), Solaris, OS-9, AIX, DOS, XTS-400, etc. | L4Linux, QNX, SymbianK42, Mac OS X, Integrity, etc. |
Advantages of Microkernel :
Here, are the pros/benefits of using Microkernel
Disadvantage of Microkernel :
Here, are drawback/cons of using Microkernel:
Summary:
a) A kernel is an important part of an OS that manages system resources.
b) A microkernel is a software or code which contains the required minimum amount of functions, data, and features to implement an operating system.
c) In Monolithic Kernel approach, the entire operating system runs as a single program in kernel mode.
d) A Microkernel is the most important part for correct implementation of an operating system.
e) A microkernel comprises only the core functionalities of the system.
f) A monolithic kernel is a large process running in a single address space, whereas Microkernel can be broken down into separate processes called servers.
g) Microkernel architecture is small and isolated therefore it can function better.
h) Providing services in a microkernel system are expensive compared to the normal monolithic system.
Key takeaway-
What is Kernel?
A kernel is an important part of an OS that manages system resources. It also acts as a bridge between the software and hardware of the computer. It is one of the first program which is loaded on start-up after the bootloader. The Kernel is also responsible for offering secure access to the machine's hardware for various programs. It also decides when and how long a certain application uses specific hardware.
Text Books:
1. Operating System Concepts - Abraham Silberschatz, Peter B. Galvin & Grege Gagne (Wiley) .
2. Operating Systems - A Concept Based approach - Dhananjay M Dhamdhere (TMGH).
Reference Books:
1. Unix Concepts and Applications – Sumtabha Das (TMGH).
2) Operating System : Concepts and Design - Milan Milenkovic ( TMGH)
3) Operating System with case studies in Unix, Netware and Windows NT - Achyut S. Godbole (TMGH).




