UNIT 2
Processes, Threads and Synchronization
What is a Program?
A program is an executable file which contains a certain set of instructions written to complete the specific job on your computer. For example, Google browser chrome.exe is an executable file which stores a set of instructions written in it which allow you to view web pages.
Programs are never stored on the primary memory in your computer. Instead, they are stored on a disk or secondary memory on your PC or laptop. They are read from the primary memory and executed by the kernel.
What is a Process?
A process is an execution of any specific program. It is considered an active entity that actions the purpose of the application. Multiple processes may be related to the same program.
For example, If you are double click on your Google Chrome browser icon on your PC or laptop, you start a process which will run the Google Chrome program. When you open another instance of Chrome, you are essentially creating a two process.
Fig 1 - Process
KEY DIFFERENCE:
Features of Program:
Features of Process:
Program vs Process.
Some significant difference between program and process are given below:
Parameter | Process | Program |
Definition | An executing part of a program is called a process. | A program is a group of ordered operations to achieve a programming goal. |
Nature | The process is an instance of the program being executing. | The nature of the program is passive, so it's unlikely to do to anything until it gets executed. |
Resource management | The resource requirement is quite high in case of a process. | The program only needs memory for storage. |
Overheads | Processes have considerable overhead. | No significant overhead cost. |
Lifespan | The process has a shorter and very limited lifespan as it gets terminated after the completion of the task. | A program has a longer lifespan as it is stored in the memory until it is not manually deleted. |
Creation | New processes require duplication of the parent process. | No such duplication is needed. |
Required Process | Process holds resources like CPU, memory address, disk, I/O, etc. | The program is stored on disk in some file and does not require any other resources. |
Entity type | A process is a dynamic or active entity. | A program is a passive or static entity. |
Contain | A process contains many resources like a memory address, disk, printer, etc. | A program needs memory space on disk to store all instructions. |
Key takeaway:
What is a Program?
A program is an executable file which contains a certain set of instructions written to complete the specific job on your computer. For example, Google browser chrome.exe is an executable file which stores a set of instructions written in it which allow you to view web pages.
Programs are never stored on the primary memory in your computer. Instead, they are stored on a disk or secondary memory on your PC or laptop. They are read from the primary memory and executed by the kernel.
To implement the process model, the operating system maintains a table with one entry per process. This table is called as process table.
The entry contains the information about the process state, its program counter, stack pointer, memory allocation, the status of its open files, its accounting and the scheduling information, and everything else about the process that must be saved when the process is switched from running state to ready state or blocked state, so that it can be restarted later as if it had never been stopped.
The table given below shows some of the important fields in a typical system.
Process Management | Memory Management | File Management |
Registers | Pointer to text segment | Root directory |
Program counter | Pointer to data segment | Working directory |
Program status word | Pointer to stack segment | File descriptors |
Stack pointer |
| User Identity |
Process state |
| Group Identity |
Priority |
|
|
Scheduling parameters |
|
|
Process Identity |
|
|
Parent process |
|
|
Process group |
|
|
Signals |
|
|
Time when process started |
|
|
Central Processing Unit time used |
|
|
Central Processing Unit time of Children |
|
|
Time of next alarm |
|
|
The fields in the column one relate to process management, the fields in the column two related to the memory management, and the fields in the column three related to the file management.
Key takeaway:
To implement the process model, the operating system maintains a table with one entry per process. This table is called as process table.
The entry contains the information about the process state, its program counter, stack pointer, memory allocation, the status of its open files, its accounting and the scheduling information, and everything else about the process that must be saved when the process is switched from running state to ready state or blocked state, so that it can be restarted later as if it had never been stopped.
Threads in Operating System:
There is a way of thread execution inside the process of any operating system. Apart from this, there can be more than one thread inside a process. Thread is often referred to as a lightweight process.
The process can be split down into so many threads. For example, in a browser, many tabs can be viewed as threads. MS Word uses many threads - formatting text from one thread, processing input from another thread, etc.
Types of Threads:
In the operating system, there are two types of threads.
User-level thread
The operating system does not recognize the user-level thread. User threads can be easily implemented and it is implemented by the user. If a user performs a user-level thread blocking operation, the whole process is blocked. The kernel level thread does not know nothing about the user level thread. The kernel-level thread manages user-level threads as if they are single-threaded processes? Examples: Java thread, POSIX threads, etc.
Advantages of User-level threads:
Disadvantages of User-level threads:
Kernel level thread.
The kernel thread recognizes the operating system. There are a thread control block and process control block in the system for each thread and process in the kernel-level thread. The kernel-level thread is implemented by the operating system. The kernel knows about all the threads and manages them. The kernel-level thread offers a system call to create and manage the threads from user-space. The implementation of kernel threads is difficult than the user thread. Context switch time is longer in the kernel thread. If a kernel thread performs a blocking operation, the Banky thread execution can continue. Example: Window Solaris.
Advantages of Kernel-level threads:
Disadvantages of Kernel-level threads:
Components of Threads:
Any thread has the following components.
Benefits of Threads-
What is Process Synchronization?
Process Synchronization is the task of coordinating the execution of processes in a way that no two processes can have access to the same shared data and resources.
It is specially needed in a multi-process system when multiple processes are running together, and more than one processes try to gain access to the same shared resource or data at the same time.
This can lead to the inconsistency of shared data. So the change made by one process not necessarily reflected when other processes accessed the same shared data. To avoid this type of inconsistency of data, the processes need to be synchronized with each other.
How Process Synchronization Works?
For Example, process A changing the data in a memory location while another process B is trying to read the data from the same memory location. There is a high probability that data read by the second process will be erroneous.
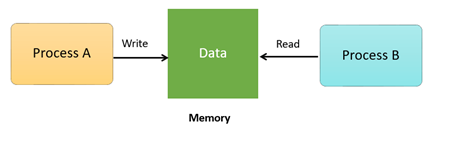
Fig 2 - Memory
Sections of a Program:
Here, are four essential elements of the critical section:
What is Critical Section Problem?
A critical section is a segment of code which can be accessed by a signal process at a specific point of time. The section consists of shared data resources that required to be accessed by other processes.
In the critical section, only a single process can be executed. Other processes, waiting to execute their critical section, need to wait until the current process completes its execution.
Rules for Critical Section:
The critical section need to must enforce all three rules:
Solutions To The Critical Section:
In Process Synchronization, critical section plays the main role so that the problem must be solved.
Here are some widely used methods to solve the critical section problem.
Peterson Solution-
Peterson's solution is widely used solution to critical section problems. This algorithm was developed by a computer scientist Peterson that's why it is named as a Peterson's solution.
In this solution, when a process is executing in a critical state, then the other process only executes the rest of the code, and the opposite can happen. This method also helps to make sure that only a single process runs in the critical section at a specific time.
Example -

PROCESS Pi
FLAG[i] = true
while( (turn != i) AND (CS is !free) ){ wait;
}
CRITICAL SECTION FLAG[i] = false
turn = j; //choose another process to go to CS.
Synchronization Hardware
Some times the problems of the Critical Section are also resolved by hardware. Some operating system offers a lock functionality where a Process acquires a lock when entering the Critical section and releases the lock after leaving it.
So when another process is trying to enter the critical section, it will not be able to enter as it is locked. It can only do so if it is free by acquiring the lock itself.
Mutex Locks
Synchronization hardware not simple method to implement for everyone, so strict software method known as Mutex Locks was also introduced.
In this approach, in the entry section of code, a LOCK is obtained over the critical resources used inside the critical section. In the exit section that lock is released.
Semaphore Solution:
Semaphore is simply a variable that is non-negative and shared between threads. It is another algorithm or solution to the critical section problem. It is a signaling mechanism and a thread that is waiting on a semaphore, which can be signaled by another thread.
It uses two atomic operations, 1)wait, and 2) signal for the process synchronization.
Example
WAIT ( S ):
while ( S <= 0 );
S = S - 1;
SIGNAL ( S ):
S = S + 1;
Summary:
Key takeaway:
There is a way of thread execution inside the process of any operating system. Apart from this, there can be more than one thread inside a process. Thread is often referred to as a lightweight process.
The process can be split down into so many threads. For example, in a browser, many tabs can be viewed as threads. MS Word uses many threads - formatting text from one thread, processing input from another thread, etc.
Race conditions, Critical Sections and Semaphores are an key part of Operating systems. Details about these are given as follows −
Race Condition:
A race condition is a situation that may occur inside a critical section. This happens when the result of multiple thread execution in critical section differs according to the order in which the threads execute.
Race conditions in critical sections can be avoided if the critical section is treated as an atomic instruction. Also, proper thread synchronization using locks or atomic variables can prevent race conditions.
Critical Section:
The critical section in a code segment where the shared variables can be accessed. Atomic action is required in a critical section i.e. only one process can execute in its critical section at a time. All the other processes have to wait to execute in their critical sections.
The critical section is given as follows:
do{
Entry Section
Critical Section
Exit Section
Remainder Section
} while (TRUE);
In the above diagram, the entry sections handles the entry into the critical section. It acquires the resources needed for execution by the process. The exit section handles the exit from the critical section. It releases the resources and also informs the other processes that critical section is free.
The critical section problem needs a solution to synchronise the different processes. The solution to the critical section problem must satisfy the following conditions −
Mutual exclusion implies that only one process can be inside the critical section at any time. If any other processes require the critical section, they must wait until it is free.
Progress means that if a process is not using the critical section, then it should not stop any other process from accessing it. In other words, any process can enter a critical section if it is free.
Bounded waiting means that each process must have a limited waiting time. Itt should not wait endlessly to access the critical section.
Semaphore-
A semaphore is a signalling mechanism and a thread that is waiting on a semaphore can be signalled by another thread. This is different than a mutex as the mutex can be signalled only by the thread that called the wait function.
A semaphore uses two atomic operations, wait and signal for process synchronization.
The wait operation decrements the value of its argument S, if it is positive. If S is negative or zero, then no operation is performed.
wait(S){
while (S<=0);
S--;
}
The signal operation increments the value of its argument S.
signal(S){
S++;
}
Key takeaway-
Race Condition:
A race condition is a situation that may occur inside a critical section. This happens when the result of multiple thread execution in critical section differs according to the order in which the threads execute.
Race conditions in critical sections can be avoided if the critical section is treated as an atomic instruction. Also, proper thread synchronization using locks or atomic variables can prevent race conditions.
Introduction:
When two or more process cooperates with each other, their order of execution must be preserved otherwise there can be conflicts in their execution and inappropriate outputs can be produced.
A cooperative process is the one which can affect the execution of other process or can be affected by the execution of other process. Such processes need to be synchronized so that their order of execution can be guaranteed.
The procedure involved in preserving the appropriate order of execution of cooperative processes is known as Process Synchronization. There are various synchronization mechanisms that are used to synchronize the processes.
Race Condition
A Race Condition typically occurs when two or more threads try to read, write and possibly make the decisions based on the memory that they are accessing concurrently.
Critical Section
The regions of a program that try to access shared resources and may cause race conditions are called critical section. To avoid race condition among the processes, we need to assure that only one process at a time can execute within the critical section.
The Critical Section Problem
Critical Section is the part of a program which tries to access shared resources. That resource may be any resource in a computer like a memory location, Data structure, CPU or any IO device.
The critical section cannot be executed by more than one process at the same time; operating system faces the difficulties in allowing and disallowing the processes from entering the critical section.
The critical section problem is used to design a set of protocols which can ensure that the Race condition among the processes will never arise.
In order to synchronize the cooperative processes, our main task is to solve the critical section problem. We need to provide a solution in such a way that the following conditions can be satisfied.
Requirements of Synchronization mechanisms:
Primary-
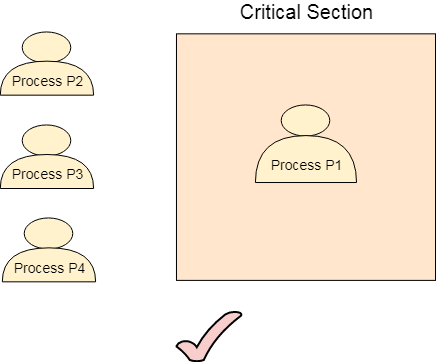
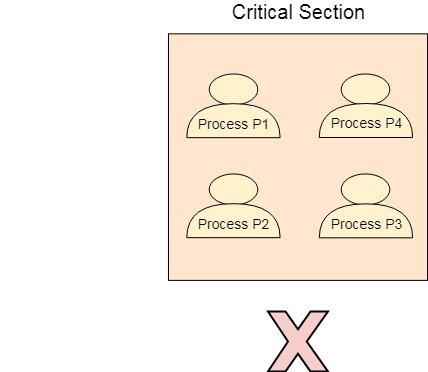
Our solution must provide mutual exclusion. By Mutual Exclusion, we mean that if one process is executing inside critical section then the other process must not enter in the critical section.
Fig 3 – Critical Section
2. Progress:
Progress means that if one process doesn't need to execute into critical section then it should not stop other processes to get into the critical section.
Secondary-
We should be able to predict the waiting time for every process to get into the critical section. The process must not be endlessly waiting for getting into the critical section.
2. Architectural Neutrality:
Our mechanism must be architectural natural. It means that if our solution is working fine on one architecture then it should also run on the other ones as well.
Classical problems of Synchronization with Semaphore Solution
In this article, we will see number of classical problems of synchronization as examples of a large class of concurrency-control problems. In our solutions to the problems, we use semaphorers for synchronization, since that is the traditional way to present such solutions. However, actual implementations of these solutions could use mutex locks in place of binary semaphores.
These problems are used for testing nearly every newly proposed synchronization scheme. The following problems of synchronization are considered as classical problems:
1. Bounded-buffer (or Producer-Consumer) Problem,
2. Dining-Philosophers Problem,
3. Readers and Writers Problem,
4. Sleeping Barber Problem.
These are summarized, for detailed explanation; you can view the linked articles for each.
Bounded Buffer problem is also called producer consumer problem. This problem is generalized in terms of the Producer-Consumer problem. Solution to this problem is, creating two counting semaphores “full” and “empty” to keep track of the current number of full and empty buffers respectively. Producers produce a product and consumers consume the product, but both use of one of the containers each time.
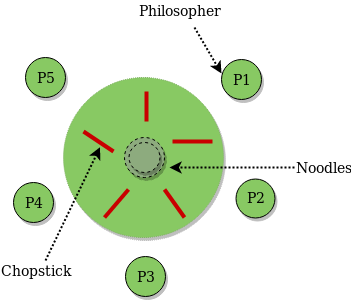
2. Dining Philosophers Problem:
The Dining Philosopher Problem states that K philosophers seated around a circular table with one chopstick between each pair of philosophers. There is one chopstick between each philosopher. A philosopher may eat if he can pickup the two chopsticks adjacent to him. One chopstick may be picked up by any one of its adjacent followers but not both. This problem involves the allocation of limited resources to a group of processes in a deadlock-free and starvation-free manner.
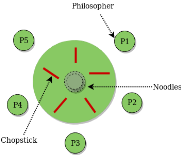
Fig 4 - Philosopher
3. Readers and writers problem:
Suppose that a database is to be shared among several concurrent processes. Some of these processes may want only to read the database, whereas others may want to update (that is, to read and write) the database. We distinguish between these two types of processes by referring to the former as readers and to the latter as writers. Precisely in OS we call this situation as the readers-writers problem. Problem parameters:
a) One set of data is shared among a number of processes.
b) Once a writer is ready, it performs its write. Only one writer may write at a time.
c) If a process is writing, no other process can read it.
d) If at least one reader is reading, no other process can write.
e) Readers may not write and only read.
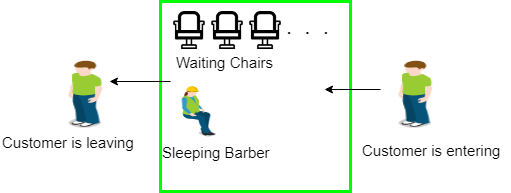
4. Sleeping Barber Problem:
Barber shop with one barber, one barber chair and N chairs to wait in. When no customers the barber goes to sleep in barber chair and must be woken when a customer comes in. When barber is cutting hair new customers take empty seats to wait, or leave if no vacancy.
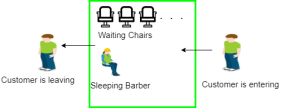
Fig 5 – Sleeping barber
Key takeaway-
Introduction
When two or more process cooperates with each other, their order of execution must be preserved otherwise there can be conflicts in their execution and inappropriate outputs can be produced.
A cooperative process is the one which can affect the execution of other process or can be affected by the execution of other process. Such processes need to be synchronized so that their order of execution can be guaranteed.
The procedure involved in preserving the appropriate order of execution of cooperative processes is known as Process Synchronization. There are various synchronization mechanisms that are used to synchronize the processes.
Monitors and semaphores are used for process synchronization and allow processes to access the shared resources using mutual exclusion. However, monitors and semaphores contain many differences. Details about both of these are given as follows −
Monitors:
Monitors are a synchronization construct that were created to overcome the problems caused by semaphores such as timing errors.
Monitors are abstract data types and contain shared data variables and procedures. The shared data variables cannot be directly accessed by a process and procedures are required to allow a single process to access the shared data variables at a time.
This is demonstrated as follows:
monitor monitorName
{
data variables;
Procedure P1(....)
{
}
Procedure P2(....)
{
}
Procedure Pn(....)
{
}
Initialization Code(....)
{
}
}
Only one process can be active in a monitor at a time. Other processes that need to access the shared variables in a monitor have to line up in a queue and are only provided access when the previous process release the shared variables.
Semaphores:
A semaphore is a signalling mechanism and a thread that is waiting on a semaphore can be signalled by another thread. This is different than a mutex as the mutex can be signalled only by the thread that called the wait function.
A semaphore uses two atomic operations, wait and signal for process synchronization.
The wait operation decrements the value of its argument S, if it is positive. If S is negative or zero, then no operation is performed.
wait(S)
{
while (S<=0);
S--;
}
The signal operation increments the value of its argument S.
signal(S)
{
S++;
}
There are mainly two types of semaphores i.e. counting semaphores and binary semaphores.
Counting Semaphores are integer value semaphores and have an unrestricted value domain. These semaphores are used to coordinate the resource access, where the semaphore count is the number of available resources.
The binary semaphores are like counting semaphores but their value is restricted to 0 and 1. The wait operation only works when the semaphore is 1 and the signal operation succeeds when semaphore is 0.
Key takeaway
Monitors:
Monitors are a synchronization construct that were created to overcome the problems caused by semaphores such as timing errors.
Monitors are abstract data types and contain shared data variables and procedures. The shared data variables cannot be directly accessed by a process and procedures are required to allow a single process to access the shared data variables at a time.
Process Scheduling
Definition:
The process scheduling is the activity of the process manager that handles the removal of the running process from the CPU and the selection of another process on the basis of a particular strategy.
Process scheduling is an essential part of a Multiprogramming operating systems. Such operating systems allow more than one process to be loaded into the executable memory at a time and the loaded process shares the CPU using time multiplexing.
Process Scheduling Queues
The OS maintains all PCBs in Process Scheduling Queues. The OS maintains a separate queue for each of the process states and PCBs of all processes in the same execution state are placed in the same queue. When the state of a process is changed, its PCB is unlinked from its current queue and moved to its new state queue.
The Operating System maintains the following important process scheduling queues −
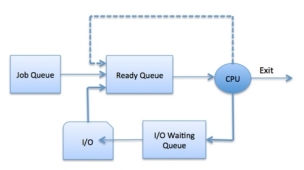
Fig 6 – Process state
The OS can use different policies to manage each queue (FIFO, Round Robin, Priority, etc.). The OS scheduler determines how to move processes between the ready and run queues which can only have one entry per processor core on the system; in the above diagram, it has been merged with the CPU.
Two-State Process Model:
Two-state process model refers to running and non-running states which are described below −
S.N. | State & Description: |
| Running: When a new process is created, it enters into the system as in the running state. |
| Not Running: Processes that are not running are kept in queue, waiting for their turn to execute. Each entry in the queue is a pointer to a particular process. Queue is implemented by using linked list. Use of dispatcher is as follows. When a process is interrupted, that process is transferred in the waiting queue. If the process has completed or aborted, the process is discarded. In either case, the dispatcher then selects a process from the queue to execute. |
Schedulers:
Schedulers are special system software which handle process scheduling in various ways. Their main task is to select the jobs to be submitted into the system and to decide which process to run. Schedulers are of three types −
Long Term Scheduler:
It is also called a job scheduler. A long-term scheduler determines which programs are admitted to the system for processing. It selects processes from the queue and loads them into memory for execution. Process loads into the memory for CPU scheduling.
The primary objective of the job scheduler is to provide a balanced mix of jobs, such as I/O bound and processor bound. It also controls the degree of multiprogramming. If the degree of multiprogramming is stable, then the average rate of process creation must be equal to the average departure rate of processes leaving the system.
On some systems, the long-term scheduler may not be available or minimal. Time-sharing operating systems have no long term scheduler. When a process changes the state from new to ready, then there is use of long-term scheduler.
Short Term Scheduler:
It is also called as CPU scheduler. Its main objective is to increase system performance in accordance with the chosen set of criteria. It is the change of ready state to running state of the process. CPU scheduler selects a process among the processes that are ready to execute and allocates CPU to one of them.
Short-term schedulers, also known as dispatchers, make the decision of which process to execute next. Short-term schedulers are faster than long-term schedulers.
Medium Term Scheduler:
Medium-term scheduling is a part of swapping. It removes the processes from the memory. It reduces the degree of multiprogramming. The medium-term scheduler is in-charge of handling the swapped out-processes.
A running process may become suspended if it makes an I/O request. A suspended processes cannot make any progress towards completion. In this condition, to remove the process from memory and make space for other processes, the suspended process is moved to the secondary storage. This process is called swapping, and the process is said to be swapped out or rolled out. Swapping may be necessary to improve the process mix.
Comparison among Scheduler
S.N. | Long-Term Scheduler | Short-Term Scheduler | Medium-Term Scheduler |
1 | It is a job scheduler. | It is a CPU scheduler. | It is a process swapping scheduler. |
2 | Speed is lesser than short term scheduler. | Speed is fastest among other two. | Speed is in between both short and long term scheduler. |
3 | It controls the degree of multiprogramming. | It provides lesser control over degree of multiprogramming. | It reduces the degree of multiprogramming. |
4 | It is almost absent or minimal in time sharing system. | It is also minimal in time sharing system. | It is a part of Time sharing systems. |
5 | It selects processes from pool and loads them into memory for execution. | It selects those processes which are ready to execute. | It can re-introduce the process into memory and execution can be continued. |
Context Switch:
A context switch is the mechanism to store and restore the state or context of a CPU in Process Control block so that a process execution can be resumed from the same point at a later time. Using this technique, a context switcher enables multiple processes to share a single CPU. Context switching is an essential part of a multitasking operating system features.
When the scheduler switches the CPU from executing one process to execute another, the state from the current running process is stored into the process control block. After this, the state for the process to run next is loaded from its own PCB and used to set the PC, registers, etc. At that point, the second process can start executing.
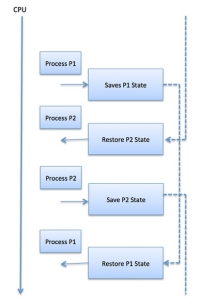
Fig 7 – Context switch
Context switches are computationally intensive since register and memory state must be saved and restored. To avoid the amount of context switching time, some hardware systems employ two or more sets of processor registers. When the process is switched, the following information is stored for later use.
Operating System Scheduling algorithms:
A Process Scheduler schedules different processes to be assigned to the CPU based on particular scheduling algorithms. There are six popular process scheduling algorithms which we are going to discuss in this chapter −
These algorithms are either non-preemptive or preemptive. Non-preemptive algorithms are designed so that once a process enters the running state, it cannot be preempted until it completes its allotted time, whereas the preemptive scheduling is based on priority where a scheduler may preempt a low priority running process anytime when a high priority process enters into a ready state.
First Come First Serve (FCFS):
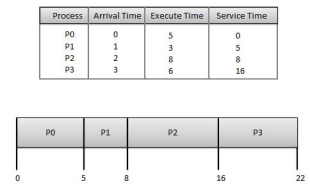
Fig 8 - FCFS
Wait time of each process is as follows −
Process | Wait Time : Service Time - Arrival Time |
P0 | 0 - 0 = 0 |
P1 | 5 - 1 = 4 |
P2 | 8 - 2 = 6 |
P3 | 16 - 3 = 13 |
Average Wait Time: (0+4+6+13) / 4 = 5.75
Shortest Job Next (SJN):
Given: Table of processes, and their Arrival time, Execution time.
Process | Arrival Time | Execution Time | Service Time |
P0 | 0 | 5 | 0 |
P1 | 1 | 3 | 5 |
P2 | 2 | 8 | 14 |
P3 | 3 | 6 | 8 |
 Waiting time of each process is as follows −
Waiting time of each process is as follows −
Process | Waiting Time |
P0 | 0 - 0 = 0 |
P1 | 5 - 1 = 4 |
P2 | 14 - 2 = 12 |
P3 | 8 - 3 = 5 |
Average Wait Time: (0 + 4 + 12 + 5)/4 = 21 / 4 = 5.25
Priority Based Scheduling:
Given:Table of processes, and their Arrival time, Execution time, and priority. Here we are considering 1 is the lowest priority.
Process | Arrival Time | Execution Time | Priority | Service Time |
P0 | 0 | 5 | 1 | 0 |
P1 | 1 | 3 | 2 | 11 |
P2 | 2 | 8 | 1 | 14 |
P3 | 3 | 6 | 3 | 5 |

Waiting time of each process is as follows −
Process | Waiting Time |
P0 | 0 - 0 = 0 |
P1 | 11 - 1 = 10 |
P2 | 14 - 2 = 12 |
P3 | 5 - 3 = 2 |
Average Wait Time: (0 + 10 + 12 + 2)/4 = 24 / 4 = 6
Shortest Remaining Time:
Round Robin Scheduling:
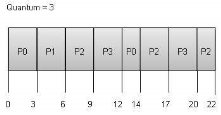
Fig 9 - Quantum
Wait time of each process is as follows −
Process | Wait Time : Service Time - Arrival Time. |
P0 | (0 - 0) + (12 - 3) = 9 |
P1 | (3 - 1) = 2 |
P2 | (6 - 2) + (14 - 9) + (20 - 17) = 12 |
P3 | (9 - 3) + (17 - 12) = 11 |
Average Wait Time: (9+2+12+11) / 4 = 8.5
Multiple-Level Queues Scheduling:
Multiple-level queues are not an independent scheduling algorithm. They make use of other existing algorithms to group and schedule jobs with common characteristics.
For example, CPU-bound jobs can be scheduled in one queue and all I/O-bound jobs in another queue. The Process Scheduler then alternately selects jobs from each queue and assigns them to the CPU based on the algorithm assigned to the queue.
Key takeaway:
The process scheduling is the activity of the process manager that handles the removal of the running process from the CPU and the selection of another process on the basis of a particular strategy.
Process scheduling is an essential part of a Multiprogramming operating systems. Such operating systems allow more than one process to be loaded into the executable memory at a time and the loaded process shares the CPU using time multiplexing.
What is Preemptive Scheduling?
Preemptive Scheduling is a scheduling method where the tasks are mostly assigned with their priorities. Sometimes it is important to run a task with a higher priority before another lower priority task, even if the lower priority task is still running.
At that time, the lower priority task holds for some time and resumes when the higher priority task finishes its execution.
What is Non- Preemptive Scheduling?
In this type of scheduling method, the CPU has been allocated to a specific process. The process that keeps the CPU busy will release the CPU either by switching context or terminating.
It is the only method that can be used for various hardware platforms. That's because it doesn't need specialized hardware (for example, a timer) like preemptive Scheduling.
Non-Preemptive Scheduling occurs when a process voluntarily enters the wait state or terminates.
Difference Between Preemptive and Non-Preemptive Scheduling in OS
Here, are Preemptive and Non-Preemptive Scheduling in OS
Preemptive Scheduling | Non-preemptive Scheduling |
A processor can be preempted to execute the different processes in the middle of any current process execution. | Once the processor starts its execution, it must finish it before executing the other. It can't be paused in the middle. |
CPU utilization is more efficient compared to Non-Preemptive Scheduling. | CPU utilization is less efficient compared to preemptive Scheduling. |
Waiting and response time of preemptive Scheduling is less. | Waiting and response time of the non-preemptive Scheduling method is higher. |
Preemptive Scheduling is prioritized. The highest priority process is a process that is currently utilized. | When any process enters the state of running, the state of that process is never deleted from the scheduler until it finishes its job. |
Preemptive Scheduling is flexible. | Non-preemptive Scheduling is rigid. |
Examples: - Shortest Remaining Time First, Round Robin, etc. | Examples: First Come First Serve, Shortest Job First, Priority Scheduling, etc. |
Preemptive Scheduling algorithm can be pre-empted that is the process can be Scheduled | In non-preemptive scheduling process cannot be Scheduled |
In this process, the CPU is allocated to the processes for a specific time period. | In this process, CPU is allocated to the process until it terminates or switches to the waiting state. |
Preemptive algorithm has the overhead of switching the process from the ready state to the running state and vice-versa. | Non-preemptive Scheduling has no such overhead of switching the process from running into the ready state. |
Advantages of Preemptive Scheduling:
Here, are pros/benefits of Preemptive Scheduling method:
Advantages of Non-preemptive Scheduling:
Here, are pros/benefits of Non-preemptive Scheduling method:
Disadvantages of Preemptive Scheduling:
Here, are cons/drawback of Preemptive Scheduling method:
Disadvantages of Non-Preemptive Scheduling:
Here, are cons/drawback of Non-Preemptive Scheduling method:
Example of Non-Preemptive Scheduling :
In non-preemptive SJF scheduling, once the CPU cycle is allocated to process, the process holds it till it reaches a waiting state or terminated.
Consider the following five processes each having its own unique burst time and arrival time.
Process Queue | Burst time | Arrival time |
P1 | 6 | 2 |
P2 | 2 | 5 |
P3 | 8 | 1 |
P4 | 3 | 0 |
P5 | 4 | 4 |
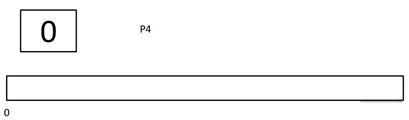
Step 0) At time=0, P4 arrives and starts execution.
Step 1) At time= 1, Process P3 arrives. But, P4 still needs 2 execution units to complete. It will continue execution.
Step 2) At time =2, process P1 arrives and is added to the waiting queue. P4 will continue execution.
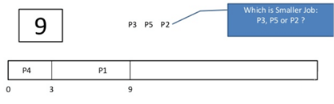
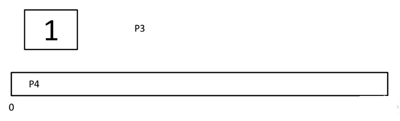
Step 3) At time = 3, process P4 will finish its execution. The burst time of P3 and P1 is compared. Process P1 is executed because its burst time is less compared to P3.
Step 4) At time = 4, process P5 arrives and is added to the waiting queue. P1 will continue execution.

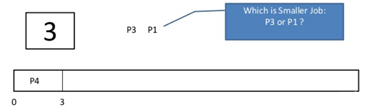
Step 5) At time = 5, process P2 arrives and is added to the waiting queue. P1 will continue execution.

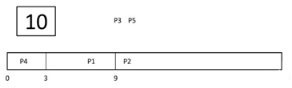
Step 6) At time = 9, process P1 will finish its execution. The burst time of P3, P5, and P2 is compared. Process P2 is executed because its burst time is the lowest.
Step 7) At time=10, P2 is executing, and P3 and P5 are in the waiting queue.
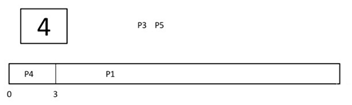
Step 8) At time = 11, process P2 will finish its execution. The burst time of P3 and P5 is compared. Process P5 is executed because its burst time is lower.
Step 9) At time = 15, process P5 will finish its execution.
Step 10) At time = 23, process P3 will finish its execution.

Step 11) Let's calculate the average waiting time for above example.
Wait time
P4= 0-0=0
P1= 3-2=1
P2= 9-5=4
P5= 11-4=7
P3= 15-1=14
Average Waiting Time= 0+1+4+7+14/5 = 26/5 = 5.2
Example of Pre-emptive Scheduling:
Consider this following three processes in Round-robin
Process Queue | Burst time |
P1 | 4 |
P2 | 3 |
P3 | 5 |
Step 1) The execution begins with process P1, which has burst time 4. Here, every process executes for 2 seconds. P2 and P3 are still in the waiting queue.
Step 2) At time =2, P1 is added to the end of the Queue and P2 starts executing
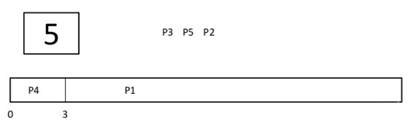
Step 3) At time=4 , P2 is preempted and add at the end of the queue. P3 starts executing.
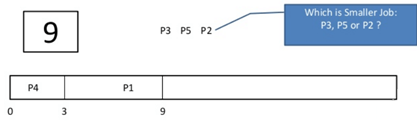
Step 4) At time=6 , P3 is preempted and add at the end of the queue. P1 starts executing.
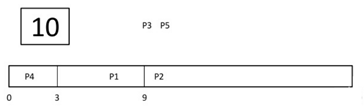
Step 5) At time=8 , P1 has a burst time of 4. It has completed execution. P2 starts execution
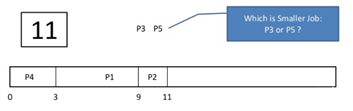
Step 6) P2 has a burst time of 3. It has already executed for 2 interval. At time=9, P2 completes execution. Then, P3 starts execution till it completes.
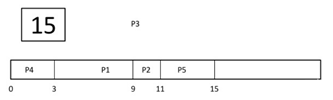
Step 7) Let's calculate the average waiting time for above example.
Wait time
P1= 0+ 4= 4
P2= 2+4= 6
P3= 4+3= 7
KEY DIFFERENCES:
Key takeaway:
What is Preemptive Scheduling?
Preemptive Scheduling is a scheduling method where the tasks are mostly assigned with their priorities. Sometimes it is important to run a task with a higher priority before another lower priority task, even if the lower priority task is still running.
At that time, the lower priority task holds for some time and resumes when the higher priority task finishes its execution.
What is Non- Preemptive Scheduling?
In this type of scheduling method, the CPU has been allocated to a specific process. The process that keeps the CPU busy will release the CPU either by switching context or terminating.
It is the only method that can be used for various hardware platforms. That's because it doesn't need specialized hardware (for example, a timer) like preemptive Scheduling.
Non-Preemptive Scheduling occurs when a process voluntarily enters the wait state or terminates.
What is Process Scheduling?
Process Scheduling is an OS task that schedules processes of different states like ready, waiting, and running.
Process scheduling allows OS to allocate a time interval of CPU execution for each process. Another important reason for using a process scheduling system is that it keeps the CPU busy all the time. This allows you to get the minimum response time for programs.
Process Scheduling Queues.
Process Scheduling Queues help you to maintain a distinct queue for each and every process states and PCBs. All the process of the same execution state are placed in the same queue. Therefore, whenever the state of a process is modified, its PCB needs to be unlinked from its existing queue, which moves back to the new state queue.
Three types of operating system queues are:
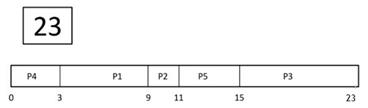
Fig 10 – Process state
In the above-given Diagram,
Two State Process Model
Two-state process models are:
Running
In the Operating system, whenever a new process is built, it is entered into the system, which should be running.
Not Running
The process that are not running are kept in a queue, which is waiting for their turn to execute. Each entry in the queue is a point to a specific process.
Scheduling Objectives:
Here, are important objectives of Process scheduling
Type of Process Schedulers:
A scheduler is a type of system software that allows you to handle process scheduling.
There are mainly three types of Process Schedulers:
Long Term Scheduler:
Long term scheduler is also known as a job scheduler. This scheduler regulates the program and select process from the queue and loads them into memory for execution. It also regulates the degree of multi-programing.
However, the main goal of this type of scheduler is to offer a balanced mix of jobs, like Processor, I/O jobs., that allows managing multiprogramming.
Medium Term Scheduler:
Medium-term scheduling is an important part of swapping. It enables you to handle the swapped out-processes. In this scheduler, a running process can become suspended, which makes an I/O request.
A running process can become suspended if it makes an I/O request. A suspended processes can't make any progress towards completion. In order to remove the process from memory and make space for other processes, the suspended process should be moved to secondary storage.
Short Term Scheduler:
Short term scheduling is also known as CPU scheduler. The main goal of this scheduler is to boost the system performance according to set criteria. This helps you to select from a group of processes that are ready to execute and allocates CPU to one of them. The dispatcher gives control of the CPU to the process selected by the short term scheduler.
Difference between Schedulers
Long-Term Vs. Short Term Vs. Medium-Term
Long-Term | Short-Term | Medium-Term |
Long term is also known as a Job scheduler . | Short term is also known as CPU scheduler . | Medium-term is also called Swapping scheduler. |
It is either absent or minimal in a time-sharing system. | It is insignificant in the time-sharing order. | This scheduler is an element of Time-sharing systems. |
Speed is less compared to the short term scheduler. | Speed is the fastest compared to the short-term and medium-term scheduler. | It offers medium speed. |
Allow you to select processes from the loads and pool back into the memory . | It only selects processes that is in a ready state of the execution. | It helps you to send process back to memory. |
Offers full control . | Offers less control . | Reduce the level of multiprogramming. |
What is Context switch?
It is a method to store/restore the state or of a CPU in PCB. So that process execution can be resumed from the same point at a later time. The context switching method is important for multitasking OS.
Summary:
Key takeaway-
Process Scheduling is an OS task that schedules processes of different states like ready, waiting, and running.
Process scheduling allows OS to allocate a time interval of CPU execution for each process. Another important reason for using a process scheduling system is that it keeps the CPU busy all the time. This allows you to get the minimum response time for programs.
Text Books:
1. Operating System Concepts - Abraham Silberschatz, Peter B. Galvin & Grege Gagne (Wiley)
2. Operating Systems - A Concept Based approach - Dhananjay M Dhamdhere (TMGH).
Reference Books:
1. Unix Concepts and Applications – Sumtabha Das (TMGH).
2) Operating System : Concepts and Design - Milan Milenkovic ( TMGH)
3) Operating System with case studies in Unix, Netware and Windows NT - Achyut S. Godbole (TMGH).




