UNIT 4
File systems and I/O systems
File:
A file is a named collection of related information that is recorded on secondary storage such as magnetic disks, magnetic tapes and optical disks. In general, a file is a sequence of bits, bytes, lines or records whose meaning is defined by the files creator and user.
File Structure:
A File Structure should be according to a required format that the operating system can understand.
a) A file has a certain defined structure according to its type.
b) A text file is a sequence of characters organized into lines.
c) A source file is a sequence of procedures and functions.
d) An object file is a sequence of bytes organized into blocks that are understandable by the machine.
e) When operating system defines different file structures, it also contains the code to support these file structure. Unix, MS-DOS support minimum number of file structure.
File Type:
File type refers to the ability of the operating system to distinguish different types of file such as text files source files and binary files etc. Many operating systems support many types of files. Operating system like MS-DOS and UNIX have the following types of files −
Ordinary files:
a) These are the files that contain user information.
b) These may have text, databases or executable program.
c) The user can apply various operations on such files like add, modify, delete or even remove the entire file.
Directory files:
a) These files contain list of file names and other information related to these files.
Special files:
a) These files are also known as device files.
b) These files represent physical device like disks, terminals, printers, networks, tape drive etc.
These files are of two types −
a) Character special files − data is handled character by character as in case of terminals or printers.
b) Block special files − data is handled in blocks as in the case of disks and tapes.
File Access Mechanisms:
File access mechanism refers to the manner in which the records of a file may be accessed. There are several ways to access files −
a) Sequential access.
b) Direct/Random access.
c) Indexed sequential access.
Sequential access:
A sequential access is that in which the records are accessed in some sequence, i.e., the information in the file is processed in order, one record after the other. This access method is the most primitive one. Example: Compilers usually access files in this fashion.
Direct/Random access:
a) Random access file organization provides, accessing the records directly.
b) Each record has its own address on the file with by the help of which it can be directly accessed for reading or writing.
c) The records need not be in any sequence within the file and they need not be in adjacent locations on the storage medium.
Indexed sequential access:
a) This mechanism is built up on base of sequential access.
b) An index is created for each file which contains pointers to various blocks.
c) Index is searched sequentially and its pointer is used to access the file directly.
Space Allocation
Files are allocated disk spaces by operating system. Operating systems deploy following three main ways to allocate disk space to files.
a) Contiguous Allocation.
b) Linked Allocation.
c) Indexed Allocation.
Contiguous Allocation
a) Each file occupies a contiguous address space on disk.
b) Assigned disk address is in linear order.
c) Easy to implement.
d) External fragmentation is a major issue with this type of allocation technique.
Linked Allocation
a) Each file carries a list of links to disk blocks.
b) Directory contains link / pointer to first block of a file.
c) No external fragmentation
d) Effectively used in sequential access file.
e) Inefficient in case of direct access file.
Indexed Allocation
a) Provides solutions to problems of contiguous and linked allocation.
b) A index block is created having all pointers to files.
c) Each file has its own index block which stores the addresses of disk space occupied by the file.
d) Directory contains the addresses of index blocks of files.
Key takeaway-
File:
A file is a named collection of related information that is recorded on secondary storage such as magnetic disks, magnetic tapes and optical disks. In general, a file is a sequence of bits, bytes, lines or records whose meaning is defined by the files creator and user.
What is a File?
A file can be defined as a data structure which stores the sequence of records. Files are stored in a file system, which may exist on a disk or in the main memory. Files can be simple (plain text) or complex (specially-formatted).
The collection of files is known as Directory. The collection of directories at the different levels, is known as File System.

Fig 1 – File system
Attributes of the File-
1. Name:
Every file carries a name by which the file is recognized in the file system. One directory cannot have two files with the same name.
2. Identifier:
Along with the name, Each File has its own extension which identifies the type of the file. For example, a text file has the extension .txt, A video file can have the extension .mp4.
3. Type:
In a File System, the Files are classified in different types such as video files, audio files, text files, executable files, etc.
4. Location:
In the File System, there are several locations on which, the files can be stored. Each file carries its location as its attribute.
5. Size:
The Size of the File is one of its most important attribute. By size of the file, we mean the number of bytes acquired by the file in the memory.
6. Protection:
The Admin of the computer may want the different protections for the different files. Therefore each file carries its own set of permissions to the different group of Users.
7. Time and Date:
Every file carries a time stamp which contains the time and date on which the file is last modified.
Operations-
There are various operations which can be implemented on a file. We will see all of them in detail.
1. Create:
Creation of the file is the most important operation on the file. Different types of files are created by different methods for example text editors are used to create a text file, word processors are used to create a word file and Image editors are used to create the image files.
2. Write:
Writing the file is different from creating the file. The OS maintains a write pointer for every file which points to the position in the file from which, the data needs to be written.
3. Read:
Every file is opened in three different modes : Read, Write and append. A Read pointer is maintained by the OS, pointing to the position up to which, the data has been read.
4. Re-position:
Re-positioning is simply moving the file pointers forward or backward depending upon the user's requirement. It is also called as seeking.
5. Delete:
Deleting the file will not only delete all the data stored inside the file, It also deletes all the attributes of the file. The space which is allocated to the file will now become available and can be allocated to the other files.
6. Truncate:
Truncating is simply deleting the file except deleting attributes. The file is not completely deleted although the information stored inside the file get replaced.
Key takeaway-
Operations:
There are various operations which can be implemented on a file. We will see all of them in detail.
1. Create:
Creation of the file is the most important operation on the file. Different types of files are created by different methods for example text editors are used to create a text file, word processors are used to create a word file and Image editors are used to create the image files.
2. Write:
Writing the file is different from creating the file. The OS maintains a write pointer for every file which points to the position in the file from which, the data needs to be written.
3. Read:
Every file is opened in three different modes : Read, Write and append. A Read pointer is maintained by the OS, pointing to the position up to which, the data has been read.
4. Re-position:
Re-positioning is simply moving the file pointers forward or backward depending upon the user's requirement. It is also called as seeking.
5. Delete:
Deleting the file will not only delete all the data stored inside the file, It also deletes all the attributes of the file. The space which is allocated to the file will now become available and can be allocated to the other files.
6. Truncate:
Truncating is simply deleting the file except deleting attributes. The file is not completely deleted although the information stored inside the file get replaced.
What is File System?
A file is a collection of correlated information which is recorded on secondary or non-volatile storage like magnetic disks, optical disks, and tapes. It is a method of data collection that is used as a medium for giving input and receiving output from that program.
In general, a file is a sequence of bits, bytes, or records whose meaning is defined by the file creator and user. Every File has a logical location where they are located for storage and retrieval.
Objective of File management System
Here are the main objectives of the file management system:
a) It provides I/O support for a variety of storage device types.
b) Minimizes the chances of lost or destroyed data
c) Helps OS to standardized I/O interface routines for user processes.
d) It provides I/O support for multiple users in a multiuser systems environment.
Properties of a File System
Here, are important properties of a file system:
a) Files are stored on disk or other storage and do not disappear when a user logs off.
b) Files have names and are associated with access permission that permits controlled sharing.
c) Files could be arranged or more complex structures to reflect the relationship between them.
File structure:
A File Structure needs to be predefined format in such a way that an operating system understands . It has an exclusively defined structure, which is based on its type.
Three types of files structure in OS:
a) A text file: It is a series of characters that is organized in lines.
b) An object file: It is a series of bytes that is organized into blocks.
c) A source file: It is a series of functions and processes.
File Attributes
A file has a name and data. Moreover, it also stores meta information like file creation date and time, current size, last modified date, etc. All this information is called the attributes of a file system.
Here, are some important File attributes used in OS:
a) Name: It is the only information stored in a human-readable form.
b) Identifier: Every file is identified by a unique tag number within a file system known as an identifier.
c) Location: Points to file location on device.
d) Type: This attribute is required for systems that support various types of files.
e) Size. Attribute used to display the current file size.
f) Protection. This attribute assigns and controls the access rights of reading, writing, and executing the file.
g) Time, date and security: It is used for protection, security, and also used for monitoring.
File Type:
It refers to the ability of the operating system to differentiate various types of files like text files, binary, and source files. However, Operating systems like MS_DOS and UNIX has the following type of files:
Character Special File:
It is a hardware file that reads or writes data character by character, like mouse, printer, and more.
Ordinary files:
a) These types of files stores user information.
b) It may be text, executable programs, and databases.
c) It allows the user to perform operations like add, delete, and modify.
Directory Files:
a) Directory contains files and other related information about those files. Its basically a folder to hold and organize multiple files.
Special Files:
a) These files are also called device files. It represents physical devices like printers, disks, networks, flash drive, etc.
Functions of File:
a) Create file, find space on disk, and make an entry in the directory.
b) Write to file, requires positioning within the file
c) Read from file involves positioning within the file
d) Delete directory entry, regain disk space.
e) Reposition: move read/write position.
Commonly used terms in File systems-
Field:
This element stores a single value, which can be static or variable length.
DATABASE:
Collection of related data is called a database. Relationships among elements of data are explicit.
FILES:
Files is the collection of similar record which is treated as a single entity.
RECORD:
A Record type is a complex data type that allows the programmer to create a new data type with the desired column structure. Its groups one or more columns to form a new data type. These columns will have their own names and data type.
File Access Methods
File access is a process that determines the way that files are accessed and read into memory. Generally, a single access method is always supported by operating systems. Though there are some operating system which also supports multiple access methods.
Three file access methods are:
a) Sequential access
b) Direct random access
c) Index sequential access
Sequential Access:
In this type of file access method, records are accessed in a certain pre-defined sequence. In the sequential access method, information stored in the file is also processed one by one. Most compilers access files using this access method.
Random Access:
The random access method is also called direct random access. This method allow accessing the record directly. Each record has its own address on which can be directly accessed for reading and writing.
Sequential Access:
This type of accessing method is based on simple sequential access. In this access method, an index is built for every file, with a direct pointer to different memory blocks. In this method, the Index is searched sequentially, and its pointer can access the file directly. Multiple levels of indexing can be used to offer greater efficiency in access. It also reduces the time needed to access a single record.
Space Allocation:
In the Operating system, files are always allocated disk spaces.
Three types of space allocation methods are:
a) Linked Allocation
b) Indexed Allocation
c) Contiguous Allocation
Contiguous Allocation
In this method,
a) Every file users a contiguous address space on memory.
b) Here, the OS assigns disk address is in linear order.
c) In the contiguous allocation method, external fragmentation is the biggest issue.
Linked Allocation
In this method,
a) Every file includes a list of links.
b) The directory contains a link or pointer in the first block of a file.
c) With this method, there is no external fragmentation
d) This File allocation method is used for sequential access files.
e) This method is not ideal for a direct access file.
Indexed Allocation-
In this method,
File Directories
A single directory may or may not contain multiple files. It can also have sub-directories inside the main directory. Information about files is maintained by Directories. In Windows OS, it is called folders.

Fig 2 - Single Level Directory
Following is the information which is maintained in a directory:
File types- name, extension
File Type | Usual extension | Function |
Executable | exe, com, bin or none | Ready-to-run machine- language program |
Object | obj, o | Complied, machine language, not linked |
Source code | c. p, pas, 177, asm, | Source code in various languages |
Batch | bat, sh | Series of commands to be executed |
Text | txt, doc | textual data documents |
Word processor | doc,docs, tex, rrf, etc. | Various word-processor formats |
Library | lib, h | Libraries of routines. |
Archive | arc, zip, tar | Related files grouped into one file, sometimes compressed. |
Summary:
- Linked Allocation
- Indexed Allocation
- Contiguous Allocation
Key takeaway-
What is File System?
A file is a collection of correlated information which is recorded on secondary or non-volatile storage like magnetic disks, optical disks, and tapes. It is a method of data collection that is used as a medium for giving input and receiving output from that program.
In general, a file is a sequence of bits, bytes, or records whose meaning is defined by the file creator and user. Every File has a logical location where they are located for storage and retrieval.
I/O Hardware
One of the important jobs of an Operating System is to manage various I/O devices including mouse, keyboards, touch pad, disk drives, display adapters, USB devices, Bit-mapped screen, LED, Analog-to-digital converter, On/off switch, network connections, audio I/O, printers etc.
An I/O system is required to take an application I/O request and send it to the physical device, then take whatever response comes back from the device and send it to the application. I/O devices can be divided into two categories −
Device Controllers:
Device drivers are software modules that can be plugged into an OS to handle a particular device. Operating System takes help from device drivers to handle all I/O devices.
The Device Controller works like an interface between a device and a device driver. I/O units (Keyboard, mouse, printer, etc.) typically consist of a mechanical component and an electronic component where electronic component is called the device controller.
There is always a device controller and a device driver for each device to communicate with the Operating Systems. A device controller may be able to handle multiple devices. As an interface its main task is to convert serial bit stream to block of bytes, perform error correction as necessary.
Any device connected to the computer is connected by a plug and socket, and the socket is connected to a device controller. Following is a model for connecting the CPU, memory, controllers, and I/O devices where CPU and device controllers all use a common bus for communication.
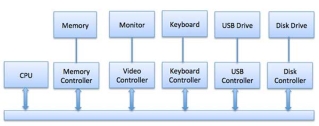
Fig 3 – Communication bus
Synchronous vs asynchronous I/O:
Communication to I/O Devices:
The CPU must have a way to pass information to and from an I/O device. There are three approaches available to communicate with the CPU and Device.
Special Instruction I/O:
This uses CPU instructions that are specifically made for controlling I/O devices. These instructions typically allow data to be sent to an I/O device or read from an I/O device.
Memory-mapped I/O:
When using memory-mapped I/O, the same address space is shared by memory and I/O devices. The device is connected directly to certain main memory locations so that I/O device can transfer block of data to/from memory without going through CPU.
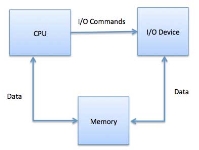
Fig 4 – I/O commands
While using memory mapped IO, OS allocates buffer in memory and informs I/O device to use that buffer to send data to the CPU. I/O device operates asynchronously with CPU, interrupts CPU when finished.
The advantage to this method is that every instruction which can access memory can be used to manipulate an I/O device. Memory mapped IO is used for most high-speed I/O devices like disks, communication interfaces.
Direct Memory Access (DMA):
Slow devices like keyboards will generate an interrupt to the main CPU after each byte is transferred. If a fast device such as a disk generated an interrupt for each byte, the operating system would spend most of its time handling these interrupts. So a typical computer uses direct memory access (DMA) hardware to reduce this overhead.
Direct Memory Access (DMA) means CPU grants I/O module authority to read from or write to memory without involvement. DMA module itself controls exchange of data between main memory and the I/O device. CPU is only involved at the beginning and end of the transfer and interrupted only after entire block has been transferred.
Direct Memory Access needs a special hardware called DMA controller (DMAC) that manages the data transfers and arbitrates access to the system bus. The controllers are programmed with source and destination pointers (where to read/write the data), counters to track the number of transferred bytes, and settings, which includes I/O and memory types, interrupts and states for the CPU cycles.
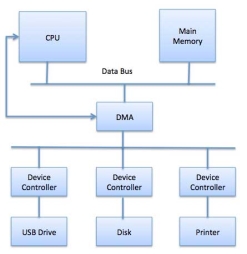
Fig 5 – Data bus
The operating system uses the DMA hardware as follows −
Step | Description |
1 | Device driver is instructed to transfer disk data to a buffer address X. |
2 | Device driver then instruct disk controller to transfer data to buffer. |
3 | Disk controller starts DMA transfer. |
4 | Disk controller sends each byte to DMA controller. |
5 | DMA controller transfers bytes to buffer, increases the memory address, decreases the counter C until C becomes zero. |
6 | When C becomes zero, DMA interrupts CPU to signal transfer completion. |
Polling vs Interrupts I/O
A computer must have a way of detecting the arrival of any type of input. There are two ways that this can happen, known as polling and interrupts. Both of these techniques allow the processor to deal with events that can happen at any time and that are not related to the process it is currently running.
Polling I/O
Polling is the simplest way for an I/O device to communicate with the processor. The process of periodically checking status of the device to see if it is time for the next I/O operation, is called polling. The I/O device simply puts the information in a Status register, and the processor must come and get the information.
Most of the time, devices will not require attention and when one does it will have to wait until it is next interrogated by the polling program. This is an inefficient method and much of the processors time is wasted on unnecessary polls.
Compare this method to a teacher continually asking every student in a class, one after another, if they need help. Obviously the more efficient method would be for a student to inform the teacher whenever they require assistance.
Interrupts I/O
An alternative scheme for dealing with I/O is the interrupt-driven method. An interrupt is a signal to the microprocessor from a device that requires attention.
A device controller puts an interrupt signal on the bus when it needs CPU’s attention when CPU receives an interrupt, It saves its current state and invokes the appropriate interrupt handler using the interrupt vector (addresses of OS routines to handle various events). When the interrupting device has been dealt with, the CPU continues with its original task as if it had never been interrupted.
Key takeaway
I/O Interface:
There is need of surface whenever any CPU wants to communicate with I/O devices. The interface is used to interpret address which is generated by CPU. Thus, surface is used to communicate to I/O devices i.e. to share information between CPU and I/O devices interface is used which is called as I/O Interface.
Various applications of I/O Interface:
Application of I/O is that we can say interface have access to open any file without any kind of information about file i.e., even basic information of file is unknown. It also has feature that it can be used to also add new devices to computer system even it does not cause any kind of interrupt to operating system. It can also used to abstract differences in I/O devices by identifying general kinds. The access to each of general kind is through standardized set of function which is called as interface.
Each type of operating system has its own category for interface of device-drivers. The device which is given may ship with multiple device-drivers-for instance, drivers for Windows, Linux, AIX and Mac OS, devices may is varied by dimensions which is as illustrated in the following table :
S.No. | Basis | Alteration | Example |
1. | Mode of Data-transfer | character or block | Terminal disk |
2. | Method of Accessing data | sequential or random | Modem, CD-ROM |
3. | Transfer schedule | synchronous or asynchronous | Tape, keyboard |
4. | Sharing methods | dedicated or sharable | Tape, keyboard |
5. | Speed of device | latency, seek time, transfer rate, delay between operations |
|
6. | I/O Interface | read only, write only, read-write | CD-ROM graphics controller disk |
A character stream or block both transfers data in form of bytes. The difference between both of them is that character-stream transfers bytes in linear way i.e., one after another whereas block transfers whole byte in single unit.
To transfer data in fixed order determined by device, we use sequential device whereas user to instruct device to seek to any of data storage locations, random-access device is used.
Data transfers with predictable response times is performed by synchronous device, in coordination with others aspects of system. An irregular or unpredictable response times not coordinated with other computer events is exhibits by an asynchronous device.
Several processes or threads can be used concurrently by sharable device; whereas dedicated device cannot.
The speed of device has range set which is of few bytes per second to few giga-bytes per second.
Different devices perform different operations, some supports both input and output, but others supports only one data transfer direction either input or output.
Key takeaway-
I/O Interface:
There is need of surface whenever any CPU wants to communicate with I/O devices. The interface is used to interpret address which is generated by CPU. Thus, surface is used to communicate to I/O devices i.e. to share information between CPU and I/O devices interface is used which is called as I/O Interface.
The kernel provides many services related to I/O. Several services such as scheduling, caching, spooling, device reservation, and error handling – are provided by the kernel, s I/O subsystem built on the hardware and device-driver infrastructure. The I/O subsystem is also responsible for protecting itself from the errant processes and malicious users.
To schedule a set of I/O request means to determine a good order in which to execute them. The order in which application issues the system call are the best choice. Scheduling can improve the overall performance of the system, can share device access permission fairly to all the processes, reduce the average waiting time, response time, turnaround time for I/O to complete.
OS developers implement scheduling by maintaining a wait queue of the request for each device. When an application issue a blocking I/O system call, The request is placed in the queue for that device. The I/O scheduler rearrange the order to improve the efficiency of the system.
2. Buffering –
A buffer is a memory area that stores data being transferred between two devices or between a device and an application. Buffering is done for three reasons.
Q. After the system call returns, what happens if the application of the buffer changes the content of the buffer?
Ans. With copy semantic, the version of the data written to the disk is guaranteed to be the version at the time of the application system call.
3. Caching –
A cache is a region of fast memory that holds a copy of data. Access to the cached copy is much easier than the original file. For instance, the instruction of the currently running process is stored on the disk, cached in physical memory, and copied again in the CPU’s secondary and primary cache.
The main difference between a buffer and a cache is that a buffer may hold only the existing copy of a data item, while cache, by definition, holds a copy on faster storage of an item that resides elsewhere.
4. Spooling and Device Reservation –
A spool is a buffer that holds the output of a device, such as a printer that cannot accept interleaved data streams. Although a printer can serve only one job at a time, several applications may wish to print their output concurrently, without having their output mixes together.
The OS solves this problem by preventing all output continuing to the printer. The output of all applications is spooled in a separate disk file. When an application finishes printing then the spooling system queues the corresponding spool file for output to the printer.
5. Error Handling –
An Os that uses protected memory can guard against many kinds of hardware and application errors, so that a complete system failure is not the usual result of each minor mechanical glitch, Devices, and I/O transfers can fail in many ways, either for transient reasons, as when a network becomes overloaded or for permanent reasons, as when a disk controller becomes defective.
6. I/O Protection –
Errors and the issue of protection are closely related. A user process may attempt to issue illegal I/O instructions to disrupt the normal function of a system. We can use the various mechanisms to ensure that such disruption cannot take place in the system.
To prevent illegal I/O access, we define all I/O instructions to be privileged instructions. The user cannot issue I/O instruction directly.
Key takeaway-
The kernel provides many services related to I/O. Several services such as scheduling, caching, spooling, device reservation, and error handling – are provided by the kernel, s I/O subsystem built on the hardware and device-driver infrastructure. The I/O subsystem is also responsible for protecting itself from the errant processes and malicious users.
We know that there is handshaking between device driver and device controller but here question is that how operating system connects application request or we can say I/O request to set of network wires or to specific disk sector or we can say to hardware -operations.
To understand concept let us consider example which is as follows.
Example –
We are reading file from disk. The application we request for will refers to data by file name. Within disk, file system maps from file name through file-system directories to obtain space allocation for file. In MS-DOS, name of file maps to number that indicates as entry in file-access table, and that entry to table tells us that which disk blocks are allocated to file. In UNIX, name maps to inode number, and inode number contains information about space-allocation. But here question arises that how connection is made from file name to disk controller?
The method that is used by MS-DOS, is relatively simple operating system. The first part of MS-DOS file name, is preceding with colon, is string that identifies that there is specific hardware device.
The UNIX uses different method from MS-DOS. It represents device names in regular file-system name space. Unlike MS-DOS file name, which has colon separator, but UNIX path name has no clear separation of device portion. In fact, no part of path name is name of device. Unix has mount table that associates with prefixes of path names with specific hardware device names.
Modern operating systems gain significant flexibility from multiple stages of lookup tables in path between request and physical device stages controller. There is general mechanisms is which is used to pass request between application and drivers. Thus, without recompiling kernel, we can introduce new devices and drivers into computer. In fact, some operating system have the ability to load device drivers on demand. At the time of booting, system firstly probes hardware buses to determine what devices are present. It is then loaded to necessary drivers, accordingly I/O request.
The typical life cycle of blocking read request, is shown in the following figure. From figure, we can suggest that I/O operation requires many steps that together consume large number of CPU cycles.
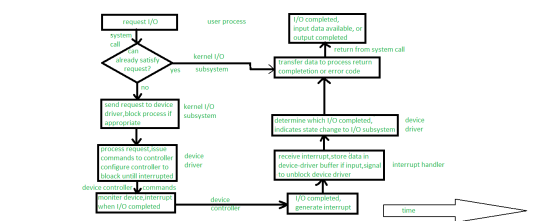
Figure 6 – The life cycle of I/O request
Whenever, any I/O request comes, process issues blocking read() system call to previously opened file descriptor of file. Basically, role of system-call code is to check parameters for correctness in kernel. If data we put in form of input is already available in buffer cache, data is going to returned to process, and in that case I/O request is completed.
If the data is not available in buffer cache then physical I/O must be performed. The process is removes from run queue and is placed on wait queue for device, and I/O request is scheduled. After scheduling, I/O subsystem sends request to device driver via subroutine call or in-kernel message but it depends upon operating system by which mode request will send.
After receiving the request, device driver have to receive data and it will receive data by allocating kernel buffer space and after receiving data it will schedules I/O. After all this, command will be given to device controller by writing into device-control registers.
Now, device controller operates device hardware. Actually, data transfer is done by device hardware.
After data transfer, driver may poll for status and data, or it may have set up DMA transfer into kernel memory. The transfer is managed by DMA controller. At last when transfers complete, it will generates interrupt.
The interrupt is sending to correct interrupt handler through interrupt-vector table. It stores any necessary data, signals device driver, and returns from interrupt.
When, device driver receives signal. This signal determines that I/O request has completed and also determines request’s status, signals kernel I/O subsystem that request has been completed. After transferring data or return codes to address space kernel moves process from wait queue back to ready queue.
When process moves to ready queue it means process is unblocked. When the process is assigned to CPU, it means process resumes execution at completion of system call.
Key takeaway
We know that there is handshaking between device driver and device controller but here question is that how operating system connects application request or we can say I/O request to set of network wires or to specific disk sector or we can say to hardware -operations.
Text Books:
1. Operating System Concepts - Abraham Silberschatz, Peter B. Galvin & Grege Gagne (Wiley)
2. Operating Systems - A Concept Based approach - Dhananjay M Dhamdhere (TMGH).
Reference Books:
1. Unix Concepts and Applications – Sumtabha Das (TMGH).
2) Operating System : Concepts and Design - Milan Milenkovic ( TMGH)
3) Operating System with case studies in Unix, Netware and Windows NT - Achyut S. Godbole (TMGH).




