UNIT 5
Case Study
What is Linux?
From smartphones to cars, supercomputers and home appliances, home desktops to enterprise servers, the Linux operating system is everywhere.
Linux has been around since the mid-1990s and has since reached a user-base that spans the globe. Linux is actually everywhere: It?s in your phones, your thermostats, in your cars, refrigerators, Roku devices, and televisions. It also runs most of the Internet, all of the world’s top 500 supercomputers, and the world’s stock exchanges.
But besides being the platform of choice to run desktops, servers, and embedded systems across the globe, Linux is one of the most reliable, secure and worry-free operating systems available.
Here is all the information you need to get up to speed on the Linux platform.
What is Linux?
Just like Windows, iOS, and Mac OS, Linux is an operating system. In fact, one of the most popular platforms on the planet, Android, is powered by the Linux operating system. An operating system is software that manages all of the hardware resources associated with your desktop or laptop. To put it simply, the operating system manages the communication between your software and your hardware. Without the operating system (OS), the software wouldn?t function.
The Linux operating system comprises several different pieces:
Why use Linux?
This is the one question that most people ask. Why bother learning a completely different computing environment, when the operating system that ships with most desktops, laptops, and servers works just fine?
To answer that question, I would pose another question. Does that operating system you?re currently using really work ?just fine?? Or, do you find yourself battling obstacles like viruses, malware, slow downs, crashes, costly repairs, and licensing fees?
If you struggle with the above, Linux might be the perfect platform for you. Linux has evolved into one of the most reliable computer ecosystems on the planet. Combine that reliability with zero cost of entry and you have the perfect solution for a desktop platform.
That’s right, zero cost of entry… as in free. You can install Linux on as many computers as you like without paying a cent for software or server licensing.
Let’s take a look at the cost of a Linux server in comparison to Windows Server 2016. The price of the Windows Server 2016 Standard edition is $882.00 USD (purchased directly from Microsoft). That doesn’t include Client Access License (CALs) and licenses for other software you may need to run (such as a database, a web server, mail server, etc.). For example, a single user CAL, for Windows Server 2016, costs $38.00. If you need to add 10 users, for example, that’s $388.00 more dollars for server software licensing. With the Linux server, it?s all free and easy to install. In fact, installing a full-blown web server (that includes a database server), is just a few clicks or commands away (take a look at ?Easy LAMP Server Installation? to get an idea how simple it can be).
If zero cost isn’t enough to win you over? what about having an operating system that will work, trouble free, for as long as you use it? I’ve used Linux for nearly 20 years (as both a desktop and server platform) and have not had any issues with ransomware, malware, or viruses. Linux is generally far less vulnerable to such attacks. As for server reboots, they’re only necessary if the kernel is updated. It is not out of the ordinary for a Linux server to go years without being rebooted. If you follow the regular recommended updates, stability and dependability are practically assured.
Open source:
Linux is also distributed under an open source license. Open source follows these key tenants:
These points are crucial to understanding the community that works together to create the Linux platform. Without a doubt, Linux is an operating system that is ?by the people, for the people?. These tenants are also a main factor in why many people choose Linux. It?s about freedom and freedom of use and freedom of choice.
What is a “distribution?”
Linux has a number of different versions to suit any type of user. From new users to hard-core users, you’ll find a “flavor” of Linux to match your needs. These versions are called distributions (or, in the short form, “distros”). Nearly every distribution of Linux can be downloaded for free, burned onto disk (or USB thumb drive), and installed (on as many machines as you like).
Popular Linux distributions include:
Each distribution has a different take on the desktop. Some opt for very modern user interfaces (such as GNOME and Elementary OS’s Pantheon), whereas others stick with a more traditional desktop environment (openSUSE uses KDE).
And don’t think the server has been left behind. For this arena, you can turn to:
Some of the above server distributions are free (such as Ubuntu Server and CentOS) and some have an associated price (such as Red Hat Enterprise Linux and SUSE Enterprise Linux). Those with an associated price also include support.
Which distribution is right for you?
Which distribution you use will depend on the answer to three simple questions:
If your computer skills are fairly basic, you’ll want to stick with a newbie-friendly distribution such as Linux Mint, Ubuntu (Figure 3), Elementary OS or Deepin. If your skill set extends into the above-average range, you could go with a distribution like Debian or Fedora. If, however, you’ve pretty much mastered the craft of computer and system administration, use a distribution like Gentoo. If you really want a challenge, you can build your very own Linux distribution, with the help of Linux From Scratch.
If you’re looking for a server-only distribution, you will also want to decide if you need a desktop interface, or if you want to do this via command-line only. The Ubuntu Server does not install a GUI interface. This means two things your server won’t be bogged down loading graphics and you’ll need to have a solid understanding of the Linux command line. However, you can install a GUI package on top of the Ubuntu Server with a single command like sudo apt-get install ubuntu-desktop. System administrators will also want to view a distribution with regards to features. Do you want a server-specific distribution that will offer you, out of the box, everything you need for your server? If so, CentOS might be the best choice. Or, do you want to take a desktop distribution and add the pieces as you need them? If so, Debian or Ubuntu Linux might serve you well.
Installing Linux:
For many people, the idea of installing an operating system might seem like a very daunting task. Believe it or not, Linux offers one of the easiest installations of all operating systems. In fact, most versions of Linux offer what is called a Live distribution ? which means you run the operating system from either a CD/DVD or USB flash drive without making any changes to your hard drive. You get the full functionality without having to commit to the installation. Once you’ve tried it out, and decided you wanted to use it, you simply double-click the “Install” icon and walk through the simple installation wizard.
Typically, the installation wizards walk you through the process with the following steps (We’ll illustrate the installation of Ubuntu Linux):
That’s it. Once the system has completed the installation, reboot and you’re ready to go. For a more in-depth guide to installing Linux, take a look at “How to Install and Try Linux the Absolutely Easiest and Safest Way” or download the Linux Foundation’s PDF guide for Linux installation.
Installing software on Linux:
Just as the operating system itself is easy to install, so too are applications. Most modern Linux distributions include what most would consider an app store. This is a centralized location where software can be searched and installed. Ubuntu Linux (and many other distributions) rely on GNOME Software, Elementary OS has the AppCenter, Deepin has the Deepin Software Center, openSUSE has their AppStore, and some distributions rely on Synaptic.
Regardless of the name, each of these tools do the same thing? a central place to search for and install Linux software. Of course, these pieces of software depend upon the presence of a GUI. For GUI-less servers, you will have to depend upon the command-line interface for installation.
Let’s look at two different tools to illustrate how easy even the command line installation can be. Our examples are for Debian-based distributions and Fedora-based distributions. The Debian-based distros will use the apt-get tool for installing software and Fedora-based distros will require the use of the yum tool. Both work very similarly. We’ll illustrate using the apt-get command. Let’s say you want to install the wget tool (which is a handy tool used to download files from the command line). To install this using apt-get, the command would like like this:
sudo apt-get install wget?
The sudo command is added because you need super user privileges in order to install software. Similarly, to install the same software on a Fedora-based distribution, you would first su to the super user (literally issue the command su and enter the root password), and issue this command:
yum install wget
That’s all there is to installing software on a Linux machine. It’s not nearly as challenging as you might think. Still in doubt? Recall the Easy Lamp Server Installation from earlier? With a single command:
sudo taskel
You can install a complete LAMP (Linux Apache MySQL PHP) server on either a server or desktop distribution. It really is that easy.
Linux Design Principles:
In its overall design, Linux resembles another non-microkernel UNIX implementation. It is a multi-user, multi-tasking system with complete UNIX-compatible tools. The Linux file system follows the traditional UNIX semantics, and the UNIX standard network model is implemented as a whole. The internal characteristics of Linux design have been influenced by the history of the development of this operating system.
Although Linux can run on a variety of platforms, at first it was developed exclusively on PC architecture. Most of the initial development was carried out by individual enthusiasts, not by large funded research facilities, so that from the start Linux tried to include as much functionality as possible with very limited funds. Currently, Linux can run well on multi-processor machines with very large main memory and disk space that is also very large, but still capable of operating in a useful amount of RAM smaller than 4 MB.
Linux Design Principles:
As a result of the development of PC technology, the Linux kernel is also becoming more complete in implementing UNIX functions. Fast and efficient are important design goals, but lately the concentration of Linux development has focused more on the third design goal, standardization. The POSIX standard consists of a collection of specifications from different aspects of operating system behavior. There are POSIX documents for ordinary operating system functions and for extensions such as processes for threads and real-time operations. Linux is designed to fit the relevant POSIX documents; there are at least two Linux distributions that have received POSIX official certification.
Because Linux provides a standard interface to programmers and users, Linux does not make many surprises to anyone who is familiar with UNIX. But the Linux programming interface refers to the UNIX SVR4 semantics rather than BSD behavior. A different collection of libraries is available to implement the BSD semantics in places where the two behaviors are very different.
There are many other standards in the UNIX world, but Linux’s full certification of other UNIX standards sometimes becomes slow because it is more often available at a certain price (not freely), and there is a price to pay if it involves certification of approval or compatibility of an operating system with most standards . Supporting broad applications is important for all operating systems so that the implementation of the standard is the main goal of developing Linux even though its implementation is not formally valid. In addition to the POSIX standard, Linux currently supports POSIX thread extensions and subsets of extensions for POSIX real-time process control.
Linux System Components:
The Linux system consists of three important code parts:
Kernel:
Although various modern operating systems have adopted a message-passing architecture for their internal kernel, Linux uses the historical UNIX model: the kernel was created as a single, monolithic binary. The main reason is to improve performance: Because all data structures and kernel code are stored in one address space, context switching is not needed when a process calls an operating system function or when a hardware interrupt is sent. Not only scheduling core and virtual memory code occupies this address space; all kernel code, including all device drivers, file systems, and network code, come in the same address space.
The Linux kernel forms the core of the Linux operating system. It provides all the functions needed to run the process, and is provided with system services to provide settings and protection for access to hardware resources. The kernel implements all the features needed to work as an operating system. However, if alone, the operating system provided by the Linux kernel is not at all similar to UNIX systems. It does not have many extra UNIX features, and the features provided are not always in the format expected by the UNIX application. The interface of the operating system that is visible to the running application is not maintained directly by the kernel. Instead, the application makes calls to the system library, which then invokes the operating system services that are needed.
System Library:
The system library provides many types of functions. At the easiest level, they allow applications to make requests to the kernel system services. Making a system call involves transferring controls from non-essential user mode to important kernel mode; the details of this transfer are different for each architecture. The library has the duty to collect system-call arguments and, if necessary, arrange those arguments in the special form needed to make system calls.
Libraries can also provide more complex versions of basic system calls. For example, the buffered file-handling functions of the C language are all implemented in the system library, which results in better control of file I / O than those provided by the basic kernel system call. The library also provides routines that have nothing to do with system calls, such as sorting algorithms, mathematical functions, and string manipulation routines. All functions needed to support the running of UNIX or POSIX applications are implemented in the system library.
System Utilities:
Linux systems contain many user-mode programs: system utilities and user utilities. The system utilities include all the programs needed to initialize the system, such as programs for configuring network devices or for loading kernel modules. Server programs that are running continuously are also included as system utilities; This kind of program manages user login requests, incoming network connections, and printer queues.
Not all standard utilities perform important system administration functions. The UNIX user environment contains a large number of standard utilities for doing daily work, such as making directory listings, moving and deleting files, or showing the contents of a file. More complex utilities can perform text-processing functions, such as compiling textual data or performing pattern-searches on text input. When combined, these utilities form the standard toolset expected by users on any UNIX system; even if it doesn’t perform any operating system functions, utilities are still an important part of a basic Linux system.
What is Process Scheduling?
Process Scheduling is an OS task that schedules processes of different states like ready, waiting, and running.
Process scheduling allows OS to allocate a time interval of CPU execution for each process. Another important reason for using a process scheduling system is that it keeps the CPU busy all the time. This allows you to get the minimum response time for programs.
Process Scheduling Queues:
Process Scheduling Queues help you to maintain a distinct queue for each and every process states and PCBs. All the process of the same execution state are placed in the same queue. Therefore, whenever the state of a process is modified, its PCB needs to be unlinked from its existing queue, which moves back to the new state queue.
Three types of operating system queues are:
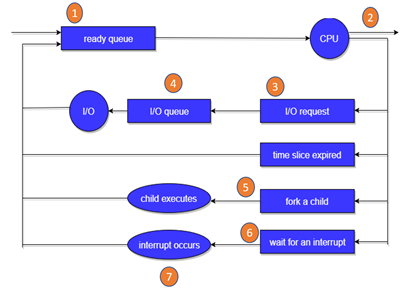
Fig 1 - Queue
In the above-given Diagram,
Two State Process Model:
Two-state process models are:
Running
In the Operating system, whenever a new process is built, it is entered into the system, which should be running.
Not Running
The process that are not running are kept in a queue, which is waiting for their turn to execute. Each entry in the queue is a point to a specific process.
Scheduling Objectives
Here, are important objectives of Process scheduling
Type of Process Schedulers
A scheduler is a type of system software that allows you to handle process scheduling.
There are mainly three types of Process Schedulers:
Long Term Scheduler:
Long term scheduler is also known as a job scheduler. This scheduler regulates the program and select process from the queue and loads them into memory for execution. It also regulates the degree of multi-programing.
However, the main goal of this type of scheduler is to offer a balanced mix of jobs, like Processor, I/O jobs., that allows managing multiprogramming.
Medium Term Scheduler:
Medium-term scheduling is an important part of swapping. It enables you to handle the swapped out-processes. In this scheduler, a running process can become suspended, which makes an I/O request.
A running process can become suspended if it makes an I/O request. A suspended processes can't make any progress towards completion. In order to remove the process from memory and make space for other processes, the suspended process should be moved to secondary storage.
Short Term Scheduler:
Short term scheduling is also known as CPU scheduler. The main goal of this scheduler is to boost the system performance according to set criteria. This helps you to select from a group of processes that are ready to execute and allocates CPU to one of them. The dispatcher gives control of the CPU to the process selected by the short term scheduler.
Difference between Schedulers
Long-Term Vs. Short Term Vs. Medium-Term
Long-Term | Short-Term | Medium-Term |
Long term is also known as a job scheduler | Short term is also known as CPU scheduler | Medium-term is also called swapping scheduler. |
It is either absent or minimal in a time-sharing system. | It is insignificant in the time-sharing order. | This scheduler is an element of Time-sharing systems. |
Speed is less compared to the short term scheduler. | Speed is the fastest compared to the short-term and medium-term scheduler. | It offers medium speed. |
Allow you to select processes from the loads and pool back into the memory | It only selects processes that is in a ready state of the execution. | It helps you to send process back to memory. |
Offers full control | Offers less control | Reduce the level of multiprogramming. |
What is Context switch?
It is a method to store/restore the state or of a CPU in PCB. So that process execution can be resumed from the same point at a later time. The context switching method is important for multitasking OS.
Summary:
What is CPU Scheduling?
CPU Scheduling is a process of determining which process will own CPU for execution while another process is on hold. The main task of CPU scheduling is to make sure that whenever the CPU remains idle, the OS at least select one of the processes available in the ready queue for execution. The selection process will be carried out by the CPU scheduler. It selects one of the processes in memory that are ready for execution.
Types of CPU Scheduling
Here are two kinds of Scheduling methods:
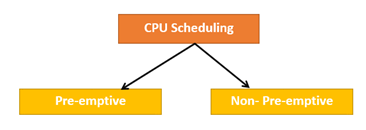
Fig 2 – CPU scheduling
Preemptive Scheduling:
In Preemptive Scheduling, the tasks are mostly assigned with their priorities. Sometimes it is important to run a task with a higher priority before another lower priority task, even if the lower priority task is still running. The lower priority task holds for some time and resumes when the higher priority task finishes its execution.
Non-Preemptive Scheduling:
In this type of scheduling method, the CPU has been allocated to a specific process. The process that keeps the CPU busy will release the CPU either by switching context or terminating. It is the only method that can be used for various hardware platforms. That's because it doesn't need special hardware (for example, a timer) like preemptive scheduling.
When scheduling is Preemptive or Non-Preemptive?
To determine if scheduling is preemptive or non-preemptive, consider these four parameters:
Only conditions 1 and 4 apply, the scheduling is called non- preemptive.
All other scheduling are preemptive-
Important CPU scheduling Terminologies:
CPU Scheduling Criteria
A CPU scheduling algorithm tries to maximize and minimize the following:
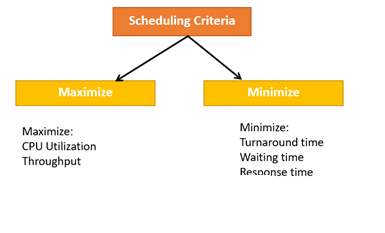
Fig 3 – Scheduling Criteria
Maximize-
CPU utilization: CPU utilization is the main task in which the operating system needs to make sure that CPU remains as busy as possible. It can range from 0 to 100 percent. However, for the RTOS, it can be range from 40 percent for low-level and 90 percent for the high-level system.
Throughput: The number of processes that finish their execution per unit time is known Throughput. So, when the CPU is busy executing the process, at that time, work is being done, and the work completed per unit time is called Throughput.
Minimize-
Waiting time: Waiting time is an amount that specific process needs to wait in the ready queue.
Response time: It is an amount to time in which the request was submitted until the first response is produced.
Turnaround Time: Turnaround time is an amount of time to execute a specific process. It is the calculation of the total time spent waiting to get into the memory, waiting in the queue and, executing on the CPU. The period between the time of process submission to the completion time is the turnaround time.
Interval Timer:
Timer interruption is a method that is closely related to preemption. When a certain process gets the CPU allocation, a timer may be set to a specified interval. Both timer interruption and preemption force a process to return the CPU before its CPU burst is complete.
Most of the multi-programmed operating system uses some form of a timer to prevent a process from tying up the system forever.
What is Dispatcher?
It is a module that provides control of the CPU to the process. The Dispatcher should be fast so that it can run on every context switch. Dispatch latency is the amount of time needed by the CPU scheduler to stop one process and start another.
Functions performed by Dispatcher:
Types of CPU scheduling Algorithm :
There are mainly six types of process scheduling algorithms
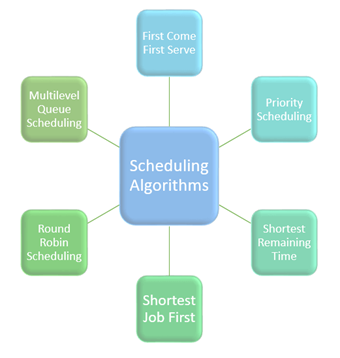
Fig 4 - Scheduling Algorithms
First Come First Serve:
First Come First Serve is the full form of FCFS. It is the easiest and most simple CPU scheduling algorithm. In this type of algorithm, the process which requests the CPU gets the CPU allocation first. This scheduling method can be managed with a FIFO queue.
As the process enters the ready queue, its PCB (Process Control Block) is linked with the tail of the queue. So, when CPU becomes free, it should be assigned to the process at the beginning of the queue.
Characteristics of FCFS method:
Shortest Remaining Time
The full form of SRT is Shortest remaining time. It is also known as SJF preemptive scheduling. In this method, the process will be allocated to the task, which is closest to its completion. This method prevents a newer ready state process from holding the completion of an older process.
Characteristics of SRT scheduling method:
Priority Based Scheduling
Priority scheduling is a method of scheduling processes based on priority. In this method, the scheduler selects the tasks to work as per the priority.
Priority scheduling also helps OS to involve priority assignments. The processes with higher priority should be carried out first, whereas jobs with equal priorities are carried out on a round-robin or FCFS basis. Priority can be decided based on memory requirements, time requirements, etc.
Round-Robin Scheduling
Round robin is the oldest, simplest scheduling algorithm. The name of this algorithm comes from the round-robin principle, where each person gets an equal share of something in turn. It is mostly used for scheduling algorithms in multitasking. This algorithm method helps for starvation free execution of processes.
Characteristics of Round-Robin Scheduling
Shortest Job First
SJF is a full form of (Shortest job first) is a scheduling algorithm in which the process with the shortest execution time should be selected for execution next. This scheduling method can be preemptive or non-preemptive. It significantly reduces the average waiting time for other processes awaiting execution.
Characteristics of SJF Scheduling
Multiple-Level Queues Scheduling
This algorithm separates the ready queue into various separate queues. In this method, processes are assigned to a queue based on a specific property of the process, like the process priority, size of the memory, etc.
However, this is not an independent scheduling OS algorithm as it needs to use other types of algorithms in order to schedule the jobs.
Characteristic of Multiple-Level Queues Scheduling:
The Purpose of a Scheduling algorithm
Here are the reasons for using a scheduling algorithm:
Summary:
Key takeaway-
What is Linux?
Just like Windows, iOS, and Mac OS, Linux is an operating system. In fact, one of the most popular platforms on the planet, Android, is powered by the Linux operating system. An operating system is software that manages all of the hardware resources associated with your desktop or laptop. To put it simply, the operating system manages the communication between your software and your hardware. Without the operating system (OS), the software wouldn?t function.
The Linux operating system comprises several different pieces:
What is Memory?
Computer memory can be defined as a collection of some data represented in the binary format. On the basis of various functions, memory can be classified into various categories. We will discuss each one of them later in detail.
A computer device that is capable to store any information or data temporally or permanently, is called storage device.
How Data is being stored in a computer system?
In order to understand memory management, we have to make everything clear about how data is being stored in a computer system.
Machine understands only binary language that is 0 or 1. Computer converts every data into binary language first and then stores it into the memory.
That means if we have a program line written as int α = 10 then the computer converts it into the binary language and then store it into the memory blocks.
The representation of inti = 10 is shown below.
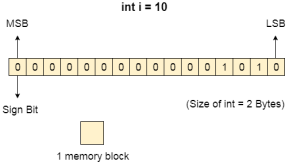
The binary representation of 10 is 1010. Here, we are considering 32 bit system therefore, the size of int is 2 bytes i.e. 16 bit. 1 memory block stores 1 bit. If we are using signed integer then the most significant bit in the memory array is always a signed bit.
Signed bit value 0 represents positive integer while 1 represents negative integer. Here, the range of values that can be stored using the memory array is -32768 to +32767.
well, we can enlarge this range by using unsigned int. in that case, the bit which is now storing the sign will also store the bit value and therefore the range will be 0 to 65,535.
Need for Multi programming:
However, The CPU can directly access the main memory, Registers and cache of the system. The program always executes in main memory. The size of main memory affects degree of Multi programming to most of the extant. If the size of the main memory is larger than CPU can load more processes in the main memory at the same time and therefore will increase degree of Multi programming as well as CPU utilization.
Therefore, we can state that the CPU utilization will be increased if the memory size gets increased.
File Systems:
File system is the part of the operating system which is responsible for file management. It provides a mechanism to store the data and access to the file contents including data and programs. Some Operating systems treats everything as a file for example Ubuntu.
The File system takes care of the following issues
We have seen various data structures in which the file can be stored. The task of the file system is to maintain an optimal file structure.
Whenever a file gets deleted from the hard disk, there is a free space created in the disk. There can be many such spaces which need to be recovered in order to reallocate them to other files.
The major concern about the file is deciding where to store the files on the hard disk.
A File may or may not be stored within only one block. It can be stored in the non contiguous blocks on the disk. We need to keep track of all the blocks on which the part of the files reside.
File System Structure:
File System provide efficient access to the disk by allowing data to be stored, located and retrieved in a convenient way. A file System must be able to store the file, locate the file and retrieve the file.
Most of the Operating Systems use layering approach for every task including file systems. Every layer of the file system is responsible for some activities.
The image shown below, elaborates how the file system is divided in different layers, and also the functionality of each layer.
Fig 5 - File system is divided in different layers
Operating System Input Output I/O
The three main jobs of a computer are Input, Output, and Processing. In most of the cases, the most important job is Input / Output, and the processing is simply incidental. For an example, when we browse a web page or edit any file, our immediate attention is to read or enter some information, not for computing an answer. The fundamental role of the operating system in computer Input / Output is to manage and organize I/O operations and all I/O devices.
The various devices that are connected to the computer need to be controlled and it is a key concern of operating-system designers. This is as I/O devices vary so widely in their functionality and speed (for example a mouse, a hard disk and a CD-ROM), varied methods are required for controlling them. These methods form the I/O sub-system of the kernel of OS that separates the rest of the kernel from the complications of managing I/O devices.
I/O Hardware
Computers operate many huge kinds of devices. General categories of storage devices are like disks, tapes, transmission devices (like network interface cards, modems) and human interface devices (like screen, keyboard, etc.).
A device which communicates with the operating system of a computer by transferring signals over cable or even through the air. The Peripheral devices that communicate with the machine through a connection point also called ports- (one example is a serial port). Whenever devices use a set of wires or cables, that connecting cables are called a "bus". Simply, a bus is a collection of wires and a firmly defined protocol that describes a set of messages that can be sent on the wires.
An I/O port usually contains four different registers −
(1) control, (2) status, (3) data-in, and (4) data-out registers.
Key takeaway
What is Memory?
Computer memory can be defined as a collection of some data represented in the binary format. On the basis of various functions, memory can be classified into various categories. We will discuss each one of them later in detail.
A computer device that is capable to store any information or data temporally or permanently, is called storage device.
What is Inter Process Communication?
Inter process communication (IPC) is used for exchanging data between multiple threads in one or more processes or programs. The Processes may be running on single or multiple computers connected by a network. The full form of IPC is Inter-process communication.
It is a set of programming interface which allow a programmer to coordinate activities among various program processes which can run concurrently in an operating system. This allows a specific program to handle many user requests at the same time.
Since every single user request may result in multiple processes running in the operating system, the process may require to communicate with each other. Each IPC protocol approach has its own advantage and limitation, so it is not unusual for a single program to use all of the IPC methods.
Approaches for Inter-Process Communication
Here, are few important methods for interprocess communication:
Fig 6 - ICP
Pipes
Pipe is widely used for communication between two related processes. This is a half-duplex method, so the first process communicates with the second process. However, in order to achieve a full-duplex, another pipe is needed.
Message Passing:
It is a mechanism for a process to communicate and synchronize. Using message passing, the process communicates with each other without resorting to shared variables.
IPC mechanism provides two operations:
Message Queues:
A message queue is a linked list of messages stored within the kernel. It is identified by a message queue identifier. This method offers communication between single or multiple processes with full-duplex capacity.
Direct Communication:
In this type of inter-process communication process, should name each other explicitly. In this method, a link is established between one pair of communicating processes, and between each pair, only one link exists.
Indirect Communication:
Indirect communication establishes like only when processes share a common mailbox each pair of processes sharing several communication links. A link can communicate with many processes. The link may be bi-directional or unidirectional.
Shared Memory:
Shared memory is a memory shared between two or more processes that are established using shared memory between all the processes. This type of memory requires to protected from each other by synchronizing access across all the processes.
FIFO:
Communication between two unrelated processes. It is a full-duplex method, which means that the first process can communicate with the second process, and the opposite can also happen.
Why IPC?
Here, are the reasons for using the interprocess communication protocol for information sharing:
Terms Used in IPC
The following are a few important terms used in IPC:
Semaphores: A semaphore is a signaling mechanism technique. This OS method either allows or disallows access to the resource, which depends on how it is set up.
Signals: It is a method to communicate between multiple processes by way of signaling. The source process will send a signal which is recognized by number, and the destination process will handle it.
What is Like FIFOS and Unlike FIFOS
Like FIFOS | Unlike FIFOS |
It follows FIFO method | Method to pull specific urgent messages before they reach the front |
FIFO exists independently of both sending and receiving processes. | Always ready, so don't need to open or close. |
Allows data transfer among unrelated processes. | Not have any synchronization problems between open & close. |
Summary:
Key takeaway-
Inter process communication (IPC) is used for exchanging data between multiple threads in one or more processes or programs. The Processes may be running on single or multiple computers connected by a network. The full form of IPC is Inter-process communication.
It is a set of programming interface which allow a programmer to coordinate activities among various program processes which can run concurrently in an operating system. This allows a specific program to handle many user requests at the same time.
Since every single user request may result in multiple processes running in the operating system, the process may require to communicate with each other. Each IPC protocol approach has its own advantage and limitation, so it is not unusual for a single program to use all of the IPC methods.
Network Structure
There are basically two types of networks: local-area networks (LAN) and wide-area networks (WAN). The main difference between the two is the way in which they are geographically distributed. Local-area networks are composed of processors distributed over small areas (such as a single building? or a number of adjacent buildings), whereas wide-area networks are composed of a number of autonomous processors distributed over a large area (such as the United States). These differences imply major variations in the speed and reliability of the communications network, and they are reflected in the distributed operating-system design.
Local-Area Networks
Local-area networks emerged in the early 1970s as a substitute for large mainframe computer systems. For many enterprises, it is more economical to have a number of small computers, each with its own self-contained applications, than to have a single large system. Because each small computer is likely to need a full complement of peripheral devices (such as disks and printers), and because some form of data sharing is likely to occur in a single enterprise, it was a natural step to connect these small systems into a network.
LANs, as mentioned, are usually designed to cover a small geographical area (such as a single building or a few adjacent buildings) and are generally used in an office environment. All the sites in such systems are close to one another, so the communication links tend to have a higher speed and lower error rate than do their counterparts in wide-area networks.
High-quality (expensive) cables are needed to attain this higher speed and reliability. It is also possible to use the cable exclusively for data network traffic. Over longer distances, the cost of using high-quality cable is enormous, and the exclusive use of the cable tends to be prohibitive.
The most common links in a local-area network are twisted-pair and fiberoptic cabling. The most common configurations are multiaccess bus, ring, and star networks. Communication speeds range from 1 megabit per second, for networks such as AppleTalk, infrared, and the new Bluetooth local radio network, to 1 gigabit per second for gigabit Ethernet.
Ten megabits per second is most common and is the speed of lOBaseT Ethernet. 100BaseT Ethernet requires a higher-quality cable but runs at 100 megabits per second and is becoming common. Also growing is the use of optical-fiber-based FDDI networking.
The FDDI network is token-based and runs at over 100 megabits per second. A typical LAN may consist of a number of different computers (from mainframes to laptops or PDAs), various shared peripheral devices (such as laser printers and magnetic-tape drives), and one or more gateways (specialized processors) that provide access to other networks (Figure 16.2).
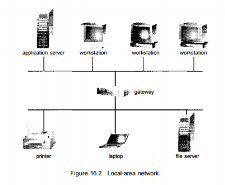
Fig 7 – Local area network
An Ethernet scheme is commonly vised to construct LANs. An Ethernet network has no central controller, because it is a multiaccess bus, so new hosts can be added easily to the network. The Ethernet protocol is defined by the IEEE 802.3 standard.
Wide-Area Networks
Wide-area networks emerged in the late 1960s, mainly as an academic research project to provide efficient communication among sites, allowing hardware and software to be shared conveniently and economically by a wide community of visers. The first WAN to be designed and developed was the Arpanet. Begun in 1968, the Arpanet has grown from a four-site experimental network to a worldwide network of networks, the Internet, comprising millions of computer systems. Because the sites in a WAN are physically distributed over a large geographical area, the communication links are, by default, relatively slow and unreliable.
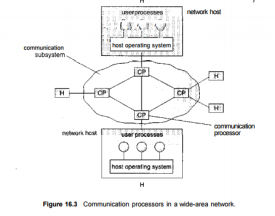
Fig 8 – Communication processors in a WAN
Typical links are telephone lines, leased (dedicated data) lines, microwave links, and satellite channels. These commvmication links are controlled by special communication processors (Figure 16.3), which are responsible for defining the interface through which the sites communicate over the network, as well as for transferring information among the various sites. For example, the Internet WAN provides the ability for hosts at geographj ically separated sites to communicate with one another.
The host computers ] typically differ from one another in type, speed, word length, operating system, i and so on. Hosts are generally on LANs, which are, in turn, connected to J the Internet via regional networks. The regional networks, such as NSFnet \ in the northeast United States, are interlinked with routers (Section 16.5.2) • to form the worldwide network. Connections between networks frequently j use a telephone-system service called Tl, which provides a transfer rate of 1.544 megabits per second over a leased line. For sites requiring faster Internet access, Tls are collected into multiple-Tl units that work in parallel to provide more throughput. For instance, a T3 is composed of 28 Tl connections and 5 has a transfer rate of 45 megabits per second. The routers control the path *
Each message takes through the net. This routing may be either dynamic, to : increase communication efficiency, or static, to reduce security risks or to allow
Communication charges to be computed.
Other WANs use standard telephone lines as their primary means of communication. Modems are devices that accept digital data from the computer side and convert it to the analog signals that the telephone system uses. A modem at the destination site converts the analog signal back to digital form, and the destination receives the data.
The UNIX news network, UUCP, allows systems to communicate with each other at predetermined times, via modems, to exchange messages. The messages are then routed to other nearby systems and in this way either are propagated to all hosts on the network (public messages) or are transferred to their destination (private messages). WANs are generally slower than LANs; their transmission rates range from 1,200 bits per second to over 1 megabit per second. UUCP has been superseded by PPP, the point-to-point protocol. PPP functions over modem connections, allowing home computers to be fully connected to the Internet.
Operating System – Security:
Security refers to providing a protection system to computer system resources such as CPU, memory, disk, software programs and most importantly data/information stored in the computer system. If a computer program is run by an unauthorized user, then he/she may cause severe damage to computer or data stored in it. So a computer system must be protected against unauthorized access, malicious access to system memory, viruses, worms etc. We're going to discuss following topics in this chapter.
Authentication
Authentication refers to identifying each user of the system and associating the executing programs with those users. It is the responsibility of the Operating System to create a protection system which ensures that a user who is running a particular program is authentic. Operating Systems generally identifies/authenticates users using following three ways −
One Time passwords:
One-time passwords provide additional security along with normal authentication. In One-Time Password system, a unique password is required every time user tries to login into the system. Once a one-time password is used, then it cannot be used again. One-time password are implemented in various ways.
Program Threats
Operating system's processes and kernel do the designated task as instructed. If a user program made these process do malicious tasks, then it is known as Program Threats. One of the common example of program threat is a program installed in a computer which can store and send user credentials via network to some hacker. Following is the list of some well-known program threats.
System Threats:
System threats refers to misuse of system services and network connections to put user in trouble. System threats can be used to launch program threats on a complete network called as program attack. System threats creates such an environment that operating system resources/ user files are misused. Following is the list of some well-known system threats.
Computer Security Classifications
As per the U.S. Department of Defense Trusted Computer System's Evaluation Criteria there are four security classifications in computer systems: A, B, C, and D. This is widely used specifications to determine and model the security of systems and of security solutions. Following is the brief description of each classification.
S.N. | Classification Type & Description
|
| Type A: Highest Level. Uses formal design specifications and verification techniques. Grants a high degree of assurance of process security. |
| Type B: Provides mandatory protection system. Have all the properties of a class C2 system. Attaches a sensitivity label to each object. It is of three types.
|
| Type C: Provides protection and user accountability using audit capabilities. It is of two types.
|
| Type D: Lowest level. Minimum protection. MS-DOS, Window 3.1 fall in this category.
|
Key takeaway-
There are basically two types of networks: local-area networks (LAN) and wide-area networks (WAN). The main difference between the two is the way in which they are geographically distributed. Local-area networks are composed of processors distributed over small areas (such as a single building? or a number of adjacent buildings), whereas wide-area networks are composed of a number of autonomous processors distributed over a large area (such as the United States). These differences imply major variations in the speed and reliability of the communications network, and they are reflected in the distributed operating-system design.
Introduction
Are you wondering about the Windows 7 operating system? Perhaps you are trying to decide if you want to upgrade from XP or Vista. Maybe you are thinking about buying a new computer and want to learn more about Windows 7 first. With these questions in mind, we explored Windows 7 and would like to share what we found with you.
In this lesson, we will compare Windows 7 with previous Vista and XP operating systems. In addition, we will discuss performance improvements and review the major features.
What is Windows 7?
Windows 7 is an operating system that Microsoft has produced for use on personal computers. It is the follow-up to the Windows Vista Operating System, which was released in 2006. An operating system allows your computer to manage software and perform essential tasks. It is also a Graphical User Interface (GUI) that allows you to visually interact with your computer’s functions in a logical, fun, and easy way.
For example, in Windows 7 you can view two windows side by side by using the Aero Snap feature. This feature automatically sizes—or snaps—two windows to fit together on the screen, allowing you the convenience of viewing them next to each other.
How is Windows 7 different from Vista or XP?
Based on customer feedback, Microsoft is promoting that it has simplified the PC experience by making many functions easier to use, such as better previewing on the Task Bar, instant searching for files or media, and easy sharing via HomeGroup networking. It also claims improved performance by supporting 64-bit processing, which is increasingly the standard in desktop PCs. In addition, Windows 7 is designed to sleep and resume faster, use less memory, and recognize USB devices faster. There are also new possibilities with media streaming and touch-screen capabilities.
The above are improvements for both Vista and XP users. If you are already a Vista user, the improvements to Windows 7 will be more subtle. Vista users are likely already familiar with features like the Aero visual functions, Start Menu organization, and Search. However, if you are currently using XP, then you may require a bit of an adjustment period.
Improvements for both Vista and XP usersChanges and improvements from Windows XP only
Will Windows 7 improve my computer's performance?
As previously mentioned, Microsoft is promoting that Windows 7 is designed to:
This is promising news, because slow wait time appeared to be one of the chief complaints regarding Windows Vista. Windows 7 also saves time by not booting up various devices during Start Up unless they are currently being used. In other words, if you are not using a Bluetooth device when you start the computer Windows 7 will not waste time by running that program in the background; it will wait until you have plugged it in.
However, performance tests of Windows 7 indicate that actual improvements vary and depend greatly on the conditions of your specific computer and the programs you are running. We will go into more detail regarding your computer's ability to run Windows 7 in future lessons.
What can you do in Windows 7?
Aero
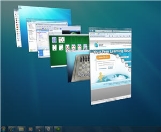
Aero is an interface that makes your visual interactions with the desktop fun and easy.
The taskbar is now more convenient to use, with larger views and easier access.
As soon as you start typing in the Search bar of the Start Menu, you will instantly see a list of relevant options grouped by categories with highlighted keywords and text. This allows you to easily scan for the documents, music, pictures, and emails you are looking for.
Libraries
Libraries allow you to organize your files in one place so they are easy to search and access.
Windows 7 has four default Libraries for documents, music, pictures, and videos; however, you can customize and create you own Libraries based on your needs.
You can select or download gadgets such as a slide show, calendar, or weather update to add to your desktop. The live updates of some gadgets like weather, stocks, and feed headlines are quite convenient.
Additional things you can do in Windows 7
Conclusion
By now, you should have a better idea of what Windows 7 is all about. Now you can start considering if upgrading to Windows 7 will be a good choice for you. In making this decision, you may want to compare your desires with what your current computer is capable of.
While Microsoft is promoting that Windows 7 can be used on older computers, this does not mean that all of the features will be available or work the same as they will on a new computer. For example, we have found that some of the Aero features, like Peek and 3D, do not work on one of our older, 32-bit computers.
In addition, upgrading to Windows 7 from XP is more complicated than upgrading from Vista. In the next lesson, we will review the cost and requirements for running Windows 7 which are important factors in making a decision.
Key takeaway-
Are you wondering about the Windows 7 operating system? Perhaps you are trying to decide if you want to upgrade from XP or Vista. Maybe you are thinking about buying a new computer and want to learn more about Windows 7 first. With these questions in mind, we explored Windows 7 and would like to share what we found with you.
In this lesson, we will compare Windows 7 with previous Vista and XP operating systems. In addition, we will discuss performance improvements and review the major features.
What is the context switching in the operating system?
The Context switching is a technique or method used by the operating system to switch a process from one state to another to execute its function using CPUs in the system. When switching perform in the system, it stores the old running process's status in the form of registers and assigns the CPU to a new process to execute its tasks. While a new process is running in the system, the previous process must wait in a ready queue. The execution of the old process starts at that point where another process stopped it. It defines the characteristics of a multitasking operating system in which multiple processes shared the same CPU to perform multiple tasks without the need for additional processors in the system.
The need for Context switching:
A context switching helps to share a single CPU across all processes to complete its execution and store the system's tasks status. When the process reloads in the system, the execution of the process starts at the same point where there is conflicting.
Following are the reasons that describe the need for context switching in the Operating system.
Example of Context Switching
Suppose that multiple processes are stored in a Process Control Block (PCB). One process is running state to execute its task with the use of CPUs. As the process is running, another process arrives in the ready queue, which has a high priority of completing its task using CPU. Here we used context switching that switches the current process with the new process requiring the CPU to finish its tasks. While switching the process, a context switch saves the status of the old process in registers. When the process reloads into the CPU, it starts the execution of the process when the new process stops the old process. If we do not save the state of the process, we have to start its execution at the initial level. In this way, context switching helps the operating system to switch between the processes, store or reload the process when it requires executing its tasks.
Context switching triggers
Following are the three types of context switching triggers as follows.
Interrupts: A CPU requests for the data to read from a disk, and if there are any interrupts, the context switching automatic switches a part of the hardware that requires less time to handle the interrupts.
Multitasking: A context switching is the characteristic of multitasking that allows the process to be switched from the CPU so that another process can be run. When switching the process, the old state is saved to resume the process's execution at the same point in the system.
Kernel/User Switch: It is used in the operating systems when switching between the user mode, and the kernel/user mode is performed.
What is the PCB?
A PCB (Process Control Block) is a data structure used in the operating system to store all data related information to the process. For example, when a process is created in the operating system, updated information of the process, switching information of the process, terminated process in the PCB.
Steps for Context Switching
There are several steps involves in context switching of the processes. The following diagram represents the context switching of two processes, P1 to P2, when an interrupt, I/O needs, or priority-based process occurs in the ready queue of PCB.
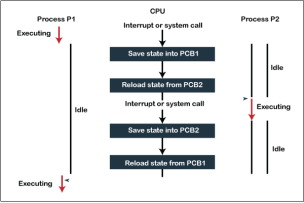
Fig 9 – Context switching
As we can see in the diagram, initially, the P1 process is running on the CPU to execute its task, and at the same time, another process, P2, is in the ready state. If an error or interruption has occurred or the process requires input/output, the P1 process switches its state from running to the waiting state. Before changing the state of the process P1, context switching saves the context of the process P1 in the form of registers and the program counter to the PCB1. After that, it loads the state of the P2 process from the ready state of the PCB2 to the running state.
The following steps are taken when switching Process P1 to Process 2:
Similarly, process P2 is switched off from the CPU so that the process P1 can resume execution. P1 process is reloaded from PCB1 to the running state to resume its task at the same point. Otherwise, the information is lost, and when the process is executed again, it starts execution at the initial level.
Operating System - File System
File:
A file is a named collection of related information that is recorded on secondary storage such as magnetic disks, magnetic tapes and optical disks. In general, a file is a sequence of bits, bytes, lines or records whose meaning is defined by the files creator and user.
File Structure:
A File Structure should be according to a required format that the operating system can understand.
File Type:
File type refers to the ability of the operating system to distinguish different types of file such as text files source files and binary files etc. Many operating systems support many types of files. Operating system like MS-DOS and UNIX have the following types of files −
Ordinary files
Directory files
Special files
These files are of two types −
File Access Mechanisms
File access mechanism refers to the manner in which the records of a file may be accessed. There are several ways to access files −
Sequential access
A sequential access is that in which the records are accessed in some sequence, i.e., the information in the file is processed in order, one record after the other. This access method is the most primitive one. Example: Compilers usually access files in this fashion.
Direct/Random access
Indexed sequential access
Space Allocation
Files are allocated disk spaces by operating system. Operating systems deploy following three main ways to allocate disk space to files.
Contiguous Allocation
Linked Allocation
Indexed Allocation
Network operating System (RTOS)
An operating system (OS) is basically a collection of software that manages computer hardware resources and provides common services for computer programs. Operating system is a crucial component of the system software in a computer system.
Network Operating System is one of the important type of operating system.
Network Operating System runs on a server and gives the server the capability to manage data, users, groups, security, applications, and other networking functions. The basic purpose of the network operating system is to allow shared file and printer access among multiple computers in a network, typically a local area network (LAN), a private network or to other networks.
Some examples of network operating systems include Microsoft Windows Server 2003, Microsoft Windows Server 2008, UNIX, Linux, Mac OS X, Novell NetWare, and BSD.
Advantages
Disadvantages
Application Programming Interface (API)
An Application Programming Interface (API) contains software building tools, subroutine definitions as well as communication protocols that facilitate interaction between systems. An API may be for a database system, operating system, computer hardware or a web-based system.
An Application Programming Interface makes it simpler to use certain technologies to build applications for the programmers. API can include specifications for data structures, variables, routines, object classes, remote calls etc.
A diagram that shows the API in the system is as follows −
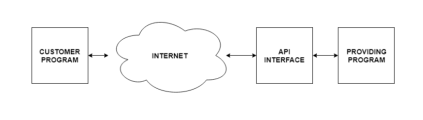
Fig 10 – API in the system
Uses of Application Programming Interfaces
API’s are useful in many scenarios. Some of these are given in detail as follows −
Operating Systems
The interface between an operating system and an application is specified with an API. For example- Posix has API’s that can convert an application written for one POSIX Operating System to one that can be used on another POSIX operating system.
Libraries and Frameworks
Often API’s are related to software libraries. The API describes the behaviour of the system while the libraries actually implement that behaviour. A single API can have multiple libraries as it can have many different implementations. Sometimes, an API can be linked to a software framework as well. A framework is based on many libraries that implement different API’s whose behaviour is built into the framework.
Web APIs
The application programming interfaces for web servers or web browsers are known as web API’s. These web API’s can be server side or client side.
Server side web APIs have an interface that contains endpoints which lead to request-response message systems that are written in JSON or XML. Most of this is achieved using a HTTP web server. Client side web API’s are used to extend the functionality of a web browser. Earlier they were in the form of plug-in browser extensions but now JavaScript bindings are used.
Remote APIs
The remote application programming interfaces allow the programmers to manipulate remote resources. Most remote API’s are required to maintain object abstraction in object oriented programming. This can be done by executing a method call locally which then invokes the corresponding method call on a remote object and gets the result locally as a return value.
Release policies for API:
The policies for releasing API’s are private, partner and public. Details about these are given as follows −
Private release policies:
The application programming interfaces released under this policy are for private internal use by the company.
Partner release policies:
The application programming interfaces released under this policy can be used by the company and its specific business partners. This means that the companies can control the quality of the API, by monitoring the apps which have access to it.
Public release policies:
The application programming interfaces released under public release policies are freely available to the public. Some examples of this are Microsoft Windows API, Apple’s Cocoa and Carbon API’s etc.
Key takeaway-
What is the context switching in the operating system?
The Context switching is a technique or method used by the operating system to switch a process from one state to another to execute its function using CPUs in the system. When switching perform in the system, it stores the old running process's status in the form of registers and assigns the CPU to a new process to execute its tasks. While a new process is running in the system, the previous process must wait in a ready queue. The execution of the old process starts at that point where another process stopped it. It defines the characteristics of a multitasking operating system in which multiple processes shared the same CPU to perform multiple tasks without the need for additional processors in the system.
Text Books:
1. Operating System Concepts - Abraham Silberschatz, Peter B. Galvin & Grege Gagne (Wiley)
2. Operating Systems - A Concept Based approach - Dhananjay M Dhamdhere (TMGH).
Reference Books:
1. Unix Concepts and Applications – Sumtabha Das (TMGH).
2) Operating System : Concepts and Design - Milan Milenkovic ( TMGH)
3) Operating System with case studies in Unix, Netware and Windows NT - Achyut S. Godbole (TMGH).




