UNIT 3
Introduction to Data base and Data warehouse
Meaning of DBMS
DBMS stands for Database Management System. We can break it like this DBMS = Database + Management System. Database is a collection of data and Management System is a set of programs to store and retrieve those data.
Based on this we can define DBMS like DBMS is a collection of inter-related data and set of programs to store & access those data in an easy and effective manner.
The main aim of a DBMS is to supply a way to store up and retrieve database information that is both convenient and efficient. By data, we mean known facts that can be recorded and that have embedded meaning.
A database management system (DBMS) refers to the technology for creating and managing databases. DBMS is a software tool to organize (create, retrieve, update, and manage) data in a database.
Knowledge refers to the useful use of information. As you know, that information can be transported, stored, and shared without any problems and difficulties, but the same cannot be said about knowledge. Knowledge necessarily involves personal experience and practice.
Database systems are meant to handle an extensive collection of information. Management of data involves both defining structures for storage of information and providing mechanisms that can do the manipulation of those stored information. Moreover, the database system must ensure the safety of the information stored, despite system crashes or attempts at unauthorized access.
- To develop software applications In less time.
- Data independence and efficient use of data.
- For uniform data administration.
- For data integrity and security.
- For concurrent access to data, and data recovery from crashes.
- To use user-friendly declarative query language.
Need for using DBMS
Database systems are basically developed for large amount of data. When dealing with huge amount of data, there are two things that require optimization: Storage of data and retrieval of data.
Storage: According to the principles of database systems, the data is stored in such a way that it acquires lot less space as the redundant data (duplicate data) has been removed before storage. Let’s take a layman example to understand this:
In a banking system, suppose a customer is having two accounts, one is saving account and another is salary account. Let’s say bank stores saving account data at one place (these places are called tables we will learn them later) and salary account data at another place, in that case if the customer information such as customer name, address etc. are stored at both places then this is just a wastage of storage (redundancy/ duplication of data), to organize the data in a better way the information should be stored at one place and both the accounts should be linked to that information somehow. The same thing we achieve in DBMS.
Fast Retrieval of data: Along with storing the data in an optimized and systematic manner, it is also important that we retrieve the data quickly when needed. Database systems ensure that the data is retrieved as quickly as possible.
The main purpose of database systems is to manage the data. Consider a university that keeps the data of students, teachers, courses, books etc. To manage this data we need to store this data somewhere where we can add new data, delete unused data, update outdated data, retrieve data, to perform these operations on data we need a Database management system that allows us to store the data in such a way so that all these operations can be performed on the data efficiently.
Concepts of tables
A database is a collection of related data. Each of these data is grouped into different related groups. Each of these groups is stored in the physical memory like disks in the form of bits. But when a user wants to see some specific data, if he is given in the form of bits, he will not understand what it is. Also, in the memory records are scattered in different data blocks and it will not be in any order. But user would always like to see a meaningful and formatted data. Hence the user is given a logical view of the data stored in the database. This is achieved by displaying the records in the form of a table with rows and columns. Each column in the table forms the related set of information of an object. Object can be anything in the real world –either living or non-living. For example, if we consider Pen as an object, we can create a table for it with columns like its name, type, pen color, ink color, orientation, weight, ease of use etc. Basically column contains the specification or details about the object with which a table is created. Rows of the table contain the value for these entire columns. Each row will have specific values related to single object. For example, a pen (Reynolds, Ballpoint, Blue, blue, linear, .5, Yes) will be specific to one type of pen. There can be multiple types of pen, and each specification of them forms different rows.
|
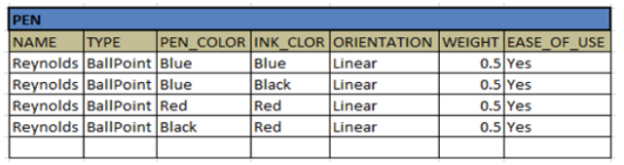
The Record
A record is a group of data saved in a table. It is a set of fields, like an employee’s job record as shown below.
Employee ID | Last Name | First Name | Position | Department | Hire Date |
00108 | Kumar | Jay | Assistant Manager | Human Resources | November 16, 2020 |
00109 | Patel | Anant | Supervisor | Financial Services | May 1, 2019 |
A record in a database is an object that can have one or more values. Groups of records are then saved in a table; the table determines the data that each record may have. Various tables hold various records in a database.
A new record produces a new row in the table that’s why records are oftentimes labeled as rows. Separate fields are referred to as columns because they are identical for every record in the table. Record and row can be utilized mutually, but nearly all database management systems utilize row for error messages and queries.
Records provide a practical way to save and pull out data from the database. Each record can have diverse types of data, and thus a single row could have several kinds of information. Records can be easily created, altered and erased without affecting other data in the database. An ideal database design should have a primary key for the table. A primary key is a unique field in each record in a database. In an employee’s job record sample above, the Employee ID is the primary key.
A group of records can be called a file, data set or table.
Concepts of attributes in DBMS
when dealing with Database Management Systems (RDBMS). In RDBMS, a table organizes data in rows and columns. The columns are known as attributes whereas the rows are known as records.
|
Example: A school maintains the data of students in a table named “student”. Suppose the data they store in table is student id, student name & student age. To do this they have had three columns in the table:
Student id, student age, student name. The table looks like this:
Student id | Student age | Student name |
101 | 12 | Jay |
102 | 13 | Akshay |
103 | 12 | Sana |
Here student id, student age and student name are the attributes.
Keys
Key plays an important role in relational database; it is used for identifying unique rows from table. It also establishes relationship among tables.
Primary Key – A primary is a column or set of columns in a table that uniquely identifies tuples (rows) in that table.
Super Key – A super key is a set of one of more columns (attributes) to uniquely identify rows in a table.
Candidate Key – A super key with no redundant attribute is known as candidate key
Alternate Key – Out of all candidate keys, only one gets selected as primary key, remaining keys are known as alternate or secondary keys.
Composite Key – A key that consists of more than one attribute to uniquely identify rows (also known as records & tuples) in a table is called composite key.
Foreign Key – Foreign keys are the columns of a table that points to the primary key of another table. They act as a cross-reference between tables.
Concepts of integrity constraints in DBMS
Constraints enforce limits to the data or type of data that can be inserted/updated/deleted from a table. The whole purpose of constraints is to maintain the data integrity during an update/delete/insert into a table. In this tutorial we will learn several types of constraints that can be created in DBMS.
- Integrity constraints are a set of rules. It is used to maintain the quality of information.
- Integrity constraints ensure that the data insertion, updating, and other processes have to be performed in such a way that data integrity is not affected.
- Thus, integrity constraint is used to guard against accidental damage to the database.
|
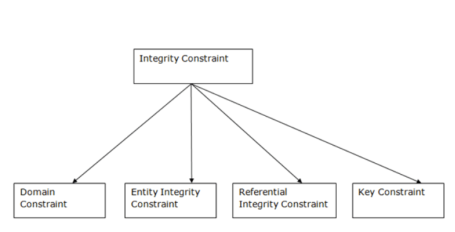
Types of constraints
- NOT NULL
- UNIQUE
- DEFAULT
- CHECK
- Key Constraints – PRIMARY KEY, FOREIGN KEY
- Domain constraints
- Mapping constraints
NOT NULL:
NOT NULL constraint makes sure that a column does not hold NULL value. When we don’t provide value for a particular column while inserting a record into a table, it takes NULL value by default. By specifying NULL constraint, we can be sure that a particular column(s) cannot have NULL values.
UNIQUE:
UNIQUE Constraint enforces a column or set of columns to have unique values. If a column has a unique constraint, it means that particular column cannot have duplicate values in a table.
DEFAULT:
The DEFAULT constraint provides a default value to a column when there is no value provided while inserting a record into a table.
CHECK:
This constraint is used for specifying range of values for a particular column of a table. When this constraint is being set on a column, it ensures that the specified column must have the value falling in the specified range.
Types of Integrity Constraint
1. Domain constraints
- Domain constraints can be defined as the definition of a valid set of values for an attribute.
- The data type of domain includes string, character, integer, time, date, currency, etc. The value of the attribute must be available in the corresponding domain.
2. Entity integrity constraints
- The entity integrity constraint states that primary key value can't be null.
- This is because the primary key value is used to identify individual rows in relation and if the primary key has a null value, then we can't identify those rows.
- A table can contain a null value other than the primary key field.
3. Referential Integrity Constraints
- A referential integrity constraint is specified between two tables.
4. Key constraints
- Keys are the entity set that is used to identify an entity within its entity set uniquely.
- An entity set can have multiple keys, but out of which one key will be the primary key. A primary key can contain a unique and null value in the relational table.
Schema architecture
The three-schema architecture is as follows:
|
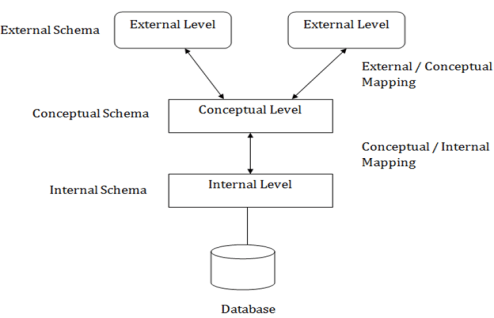
In the above diagram:
- It shows the DBMS architecture.
- Mapping is used to transform the request and response between various database levels of architecture.
- Mapping is not good for small DBMS because it takes more time.
- In External / Conceptual mapping, it is necessary to transform the request from external level to conceptual schema.
- In Conceptual / Internal mapping, DBMS transform the request from the conceptual to internal level.
1. Internal Level
- The internal level has an internal schema which describes the physical storage structure of the database.
- The internal schema is also known as a physical schema.
- It uses the physical data model. It is used to define that how the data will be stored in a block.
- The physical level is used to describe complex low-level data structures in detail.
2. Conceptual Level
- The conceptual schema describes the design of a database at the conceptual level. Conceptual level is also known as logical level.
- The conceptual schema describes the structure of the whole database.
- The conceptual level describes what data are to be stored in the database and also describes what relationship exists among those data.
- In the conceptual level, internal details such as an implementation of the data structure are hidden.
- Programmers and database administrators work at this level.
3. External Level
- At the external level, a database contains several schemas that sometimes called as subschema. The subschema is used to describe the different view of the database.
- An external schema is also known as view schema.
- Each view schema describes the database part that a particular user group is interested and hides the remaining database from that user group.
- The view schema describes the end user interaction with database systems.
Advantages of Three-schema Architecture
Following are the advantages of three schema architecture:
- This architecture makes the database abstract. It is used to hide the details of how data is physically stored in a computer system, which makes it easier to use for a user.
- This architecture allows each user to access the same database with a different customized view of data.
- This architecture enables a database admin to change the storage structure of the database without affecting the user currently on the system.
Data independence
A database system normally contains a lot of data in addition to users’ data. For example, it stores data about data, known as metadata, to locate and retrieve data easily. It is rather difficult to modify or update a set of metadata once it is stored in the database. But as a DBMS expands, it needs to change over time to satisfy the requirements of the users. If the entire data is dependent, it would become a tedious and highly complex job.
|
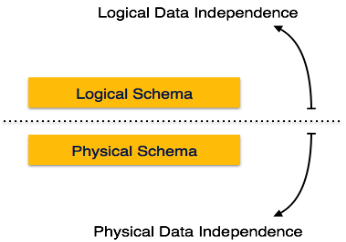
Metadata itself follows a layered architecture, so that when we change data at one layer, it does not affect the data at another level. This data is independent but mapped to each other.
Logical Data Independence
Logical data is data about database, that is, it stores information about how data is managed inside. For example, a table (relation) stored in the database and all its constraints, applied on that relation.
Logical data independence is a kind of mechanism, which liberalizes itself from actual data stored on the disk. If we do some changes on table format, it should not change the data residing on the disk.
Physical Data Independence
All the schemas are logical, and the actual data is stored in bit format on the disk. Physical data independence is the power to change the physical data without impacting the schema or logical data.
For example, in case we want to change or upgrade the storage system itself − suppose we want to replace hard-disks with SSD − it should not have any impact on the logical data or schemas.
Key Takeaways:
- DBMS is a collection of inter-related data and set of programs to store & access those data in an easy and effective manner.
- A record in a database is an object that can have one or more values.
- Key plays an important role in relational database; it is used for identifying unique rows from table. It also establishes relationship among tables.
Concepts of Data warehousing
A Data Warehousing (DW) is process for collecting and managing data from varied sources to provide meaningful business insights. A Data warehouse is typically used to connect and analyze business data from heterogeneous sources. The data warehouse is the core of the BI system which is built for data analysis and reporting.
It is a blend of technologies and components which aids the strategic use of data. It is electronic storage of a large amount of information by a business which is designed for query and analysis instead of transaction processing. It is a process of transforming data into information and making it available to users in a timely manner to make a difference.
The decision support database (Data Warehouse) is maintained separately from the organization's operational database. However, the data warehouse is not a product but an environment. It is an architectural construct of an information system which provides users with current and historical decision support information which is difficult to access or present in the traditional operational data store.
A 3NF-designed database for an inventory system many have tables related to each other. For example, a report on current inventory information can include more than 12 joined conditions. This can quickly slow down the response time of the query and report. A data warehouse provides a new design which can help to reduce the response time and helps to enhance the performance of queries for reports and analytics.
Data warehouse system is also known by the following name:
- Decision Support System (DSS)
- Executive Information System
- Management Information System
- Business Intelligence Solution
- Analytic Application
- Data Warehouse
A Data Warehouse works as a central repository where information arrives from one or more data sources. Data flows into a data warehouse from the transactional system and other relational databases.
Data may be:
- Structured
- Semi-structured
- Unstructured data
The data is processed, transformed, and ingested so that users can access the processed data in the Data Warehouse through Business Intelligence tools, SQL clients, and spreadsheets. A data warehouse merges information coming from different sources into one comprehensive database.
By merging all of this information in one place, an organization can analyze its customers more holistically. This helps to ensure that it has considered all the information available. Data warehousing makes data mining possible. Data mining is looking for patterns in the data that may lead to higher sales and profits.
Importance of data warehouse for an organization
A data warehouse is a database of an organization’s multiple databases. The elaborate further, a data warehouse is a consolidation of data based on different subject matters over a period of time pulled together from different internal and external sources and departments within an organization for the purpose of analysis, discovery, reporting, and, finally, decision-making. The role and importance of data warehousing has increased rapidly with technological advancements, and as more and more enterprises focus on operating on the basis of insights derived from data-driven business strategies that favor an integrated, holistic approach to data. In some ways, a data warehouse enables decision-makers to arrive at a single version of truth that informs the business objectives and every activity undertaken by every department in service of those objectives.
As we careen towards an intensely competitive world with sky-high expectations of customers from their products and services, thanks to massive leaps in the field of technological innovations, businesses are facing heat to not just make the right and lucrative financial decisions, but to make them in record time. This can be made possible only when the right kind of data warehouse is implemented. While every organisation may have different goals and needs from their warehouse, generally speaking, data warehouses provide the following benefits to enterprises.
Speeds up response time
Since data warehouses pull different data sets from different sources on a variety of subjects and then standardize it into a single set that can then be distributed across departments, decision-makers are able to take strategic, fact-based decisions that are compatible with each other at a much faster pace, instead of each department taking a siloed approach to data and sometimes working at cross purposes. Another major way in which data helps businesses is by allowing them to regroup and redesign business processes and operations, if after analysis they find that their cross-purposes with the business strategy, which can often be the case when departments are using different, unrelated, or outdated data sets to base their decisions on.
Faster and more flexible reporting
While on the one hand data warehousing makes it possible to collect, consolidate and create reports in real time, on the other, it creates a repository of historical information on all the variables that affect profitability. This faster and flexible data reporting mechanism makes it possible for organisation’s to routinely undertake comparative and competitive analysis to gauge the efficacy of the services being provided by them, level of customer satisfaction, slow-moving products or non-performant assets, areas for improvement, find errors before they can cost the company a major loss in terms of money or reputation, identify market trends, and introduce product lines that are in line with emerging customer needs and far ahead of the competition. All these in turn improve the bottom line of the enterprise.
Reduced costs
When the process of collection, analysis and consolidation of data is simplified, and the subsequent data set is made easily accessible to all, it can result in significant savings for the company due to reduced operational and IT costs. Automating the process with the help of data warehousing tools reduces the organisation’s dependency on staff dedicated to reporting and maintaining the IT infrastructure, especially when the data warehouse is cloud-based, not on-premise. Another way it reduces costs is by helping the management to make the decision to drop non-performing products without wasting too much time.
Characteristics of Data warehouse
Data warehouse can be controlled when the user has a shared way of explaining the trends that are introduced as specific subject.
|
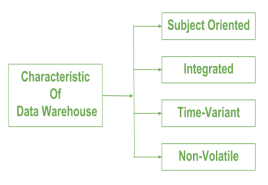
- Subject-oriented –
A data warehouse is always a subject oriented as it delivers information about a theme instead of organization’s current operations. It can be achieved on specific theme. That means the data warehousing process is proposed to handle with a specific theme which is more defined. These themes can be sales, distributions, marketing etc.
A data warehouse never put emphasis only current operations. Instead, it focuses on demonstrating and analysis of data to make various decision. It also delivers an easy and precise demonstration around particular theme by eliminating data which is not required to make the decisions. - Integrated –
It is somewhere same as subject orientation which is made in a reliable format. Integration means founding a shared entity to scale the all similar data from the different databases. The data also required to be resided into various data warehouse in shared and generally granted manner.
A data warehouse is built by integrating data from various sources of data such that a mainframe and a relational database. In addition, it must have reliable naming conventions, format and codes. Integration of data warehouse benefits in effective analysis of data. Reliability in naming conventions, column scaling, encoding structure etc. should be confirmed. Integration of data warehouse handles various subject related warehouse. - Time-Variant –
In this data is maintained via different intervals of time such as weekly, monthly, or annually etc. It founds various time limit which are structured between the large datasets and are held in online transaction process (OLTP). The time limits for data warehouse is wide-ranged than that of operational systems. The data resided in data warehouse is predictable with a specific interval of time and delivers information from the historical perspective. It comprises elements of time explicitly or implicitly. Another feature of time-variance is that once data is stored in the data warehouse then it cannot be modified, alter, or updated. - Non-Volatile –
As the name defines the data resided in data warehouse is permanent. It also means that data is not erased or deleted when new data is inserted. It includes the mammoth quantity of data that is inserted into modification between the selected quantity on logical business. It evaluates the analysis within the technologies of warehouse.
In this, data is read-only and refreshed at particular intervals. This is beneficial in analysing historical data and in comprehension the functionality. It does not need transaction process, recapture and concurrency control mechanism. Functionalities such as delete, update, and insert that are done in an operational application are lost in data warehouse environment. Two types of data operations done in the data warehouse are:- Data Loading
- Data Access
Functions of Data Warehouse:
It works as a repository and the data here hold by an organization that ensures the facilities to backup data functions. It reduces the cost of the storage system and even the backup data at the organizational level.
It stores facts about the tables that have high granular transaction levels that monitor to define the data warehousing techniques. Functions involved are:
- Data consolidations
- Data cleaning
- Data integration
- Data Extraction
- Data Cleaning
- Data Transformation
- Data Loading
Data Warehouse Architecture
Data Warehouse Architecture is complex as it’s an information system that contains historical and commutative data from multiple sources. There are 3 approaches for constructing Data Warehouse layers: Single Tier, Two tier and Three tier. This 3 tier architecture of Data Warehouse is explained as below.
Single-tier architecture
The objective of a single layer is to minimize the amount of data stored. This goal is to remove data redundancy. This architecture is not frequently used in practice.
Two-tier architecture
Two-layer architecture is one of the Data Warehouse layers which separates physically available sources and data warehouse. This architecture is not expandable and also not supporting a large number of end-users. It also has connectivity problems because of network limitations.
Three-Tier Data Warehouse Architecture
This is the most widely used Architecture of Data Warehouse.
It consists of the Top, Middle and Bottom Tier.
- Bottom Tier: The database of the Datawarehouse servers as the bottom tier. It is usually a relational database system. Data is cleansed, transformed, and loaded into this layer using back-end tools.
- Middle Tier: The middle tier in Data warehouse is an OLAP server which is implemented using either ROLAP or MOLAP model. For a user, this application tier presents an abstracted view of the database. This layer also acts as a mediator between the end-user and the database.
- Top-Tier: The top tier is a front-end client layer. Top tier is the tools and API that you connect and get data out from the data warehouse. It could be Query tools, reporting tools, managed query tools, Analysis tools and Data mining tools.
Business use of data warehouse
Organizations have a common goal – to make better business decisions. A data warehouse, once implemented into your business intelligence framework, can benefit your company in numerous ways. A data warehouse:
1. Delivers enhanced business intelligence
By having access to information from various sources from a single platform, decision makers will no longer need to rely on limited data or their instinct. Additionally, data warehouses can effortlessly be applied to a business’s processes, for instance, market segmentation, sales, risk, inventory, and financial management.
2. Saves times
A data warehouse standardizes, preserves, and stores data from distinct sources, aiding the consolidation and integration of all the data. Since critical data is available to all users, it allows them to make informed decisions on key aspects. In addition, executives can query the data themselves with little to no IT support, saving more time and money.
3. Enhances data quality and consistency
A data warehouse converts data from multiple sources into a consistent format. Since the data from across the organization is standardized, each department will produce results that are consistent. This will lead to more accurate data, which will become the basis for solid decisions.
4. Generates a high Return on Investment (ROI)
Companies experience higher revenues and cost savings than those that haven’t invested in a data warehouse.
5. Provides competitive advantage
Data warehouses help get a holistic view of their current standing and evaluate opportunities and risks, thus providing companies with a competitive advantage.
6. Improves the decision-making process
Data warehousing provides better insights to decision makers by maintaining a cohesive database of current and historical data. By transforming data into purposeful information, decision makers can perform more functional, precise, and reliable analysis and create more useful reports with ease.
7. Enables organizations to forecast with confidence
Data professionals can analyze business data to make market forecasts, identify potential KPIs, and gauge predicated results, allowing key personnel to plan accordingly.
8. Streamlines the flow of information
Data warehousing facilitates the flow of information through a network connecting all related or non-related parties.
In business intelligence, data warehouses serve as the backbone of data storage. Business intelligence relies on complex queries and comparing multiple sets of data to inform everything from everyday decisions to organization-wide shifts in focus.
To facilitate this, business intelligence is comprised of three overarching activities: data wrangling, data storage, and data analysis. Data wrangling is usually facilitated by extract, transform, load (ETL) technologies, which we’ll explain in detail below, and data analysis is done using business intelligence tools.
The glue holding this process together is data warehouses, which serve as the facilitator of data storage using OLAP. They integrate, summarize, and transform data, making it easier to analyze.
Even though data warehouses serve as the backbone of data storage, they’re not the only technology involved in data storage. Many companies go through a data storagehierarchy before reaching the point where they absolutely need a data warehouse.
Standard Reports and queries
A querying and reporting tool helps you run regular reports, create organized listings, and perform cross-tabular reporting and querying. Here are some querying and reporting tools to familiarize yourself with.
The Role of SQL
SQL is the official database query language used to access and update the data contained within a relational database management system, or DBMS.
The roots of SQL go back to IBM and its research labs during the early days of relational database technology. IBM and Oracle were among the first to adopt SQL as the language used to access their relational products (other DBMSs used different languages that their respective vendors invented).
The significance of SQL for querying and reporting (and for data warehousing) is that the language has represented a mostly standard way to access multiple RDBMS products.
Each DBMS product has a slightly different SQL dialect. Although the basic syntax is the same, especially for the most commonly used commands, all SQL dialects are slightly different. In the early 1990s, despite these syntactical differences, several different efforts provided a common gateway to SQL RDBMS products.
The most successful was Microsoft Open Database Connectivity (ODBC). The phrase ODBC-compliant became important to DBMS applications in the early and mid-1990s. A similar standard for the Java community also emerged in the late-1990s — Java Database Connectivity (JDBC). Virtually all major database manufacturers today have accessibility through both of these standard connectivity interfaces.
Technical query tools
The use of SQL as the basis for most querying and reporting tools was both good and bad for data warehousing. On the positive side, many more product-to-product matchups are possible in data warehousing environments, enabling tools to be provided both by RDBMS vendors and other third-party vendors.
On the negative side, though, SQL is a relatively complex language after you get past the basics. A series of query tools primarily allow users to type in and edit SQL queries. These tools aren’t really designed for end users, though it’s amazing how often they are deployed in end-user organizations.
User query tools
Most end-user querying and reporting tools provide visually oriented, painting, environments that enable users to design screens for report layouts, the data columns desired for the report, or the rows of data that they want to select (only salespeople who have met their quota, for example).
Using all this “painted” information, most tools have increasingly taken a smart query generation approach. Instead of generating a single, overly complex SQL statement that could get you an A in database class but draw a disgusted shake of the head from someone who has done this stuff in the real world, a sequence of SQL statements (usually taking advantage of temporary tables for intermediate results) is generated.
This sequence, in effect, decomposes the query into a more efficient series of steps.
Reporting tools
When end users want more complex user interaction or sophisticated formats, a tool with more reporting features is leveraged. You can find a separation between pure query tools and pure reporting tools. The query tool provides data access, filtering, and simple formatting. If you’re distributing reports across your enterprise or need to generate form-safe presentation, you use a reporting tool.
Like with query tools, reporting tools provide an environment that enables you to create sophisticated layouts that focus on formatting the data retrieved by the database query.
Key Takeaways:
- A Data warehouse is typically used to connect and analyze business data from heterogeneous sources. The data warehouse is the core of the BI system which is built for data analysis and reporting.
- Another major way in which data helps businesses is by allowing them to regroup and redesign business processes and operations
- A data warehouse, once implemented into your business intelligence framework, can benefit your company in numerous ways.
The scope and the techniques used
Given databases of sufficient size and quality, data mining technology can generate new business opportunities by providing these capabilities:
- Automated prediction of trends and behaviors: Data mining automates the process of finding predictive information in large databases. Questions that traditionally required extensive hands-on analysis can now be answered directly from the data — quickly. A typical example of a predictive problem is targeted marketing. Data mining uses data on past promotional mailings to identify the targets most likely to maximize return on investment in future mailings. Other predictive problems include forecasting bankruptcy and other forms of default, and identifying segments of a population likely to respond similarly to given events.
- Automated discovery of previously unknown patterns: Data mining tools sweep through databases and identify previously hidden patterns in one step. An example of pattern discovery is the analysis of retail sales data to identify seemingly unrelated products that are often purchased together. Other pattern discovery problems include detecting fraudulent credit card transactions and identifying anomalous data that could represent data entry keying errors.
Data mining techniques can yield the benefits of automation on existing software and hardware platforms, and can be implemented on new systems as existing platforms are upgraded and new products developed.
Databases can be larger in both depth and breadth:
- More columns: Analysts must often limit the number of variables they examine when doing hands-on analysis due to time constraints. Yet variables that are discarded because they seem unimportant may carry information about unknown patterns. High performance data mining allows users to explore the full depth of a database, without preselecting a subset of variables.
- More rows: Larger samples yield lower estimation errors and variance, and allow users to make inferences about small but important segments of a population.
The most used techniques in data mining are:
- Artificial neural networks: Non-linear predictive models that learn through training and resemble biological neural networks in structure.
- Decision trees: Tree-shaped structures that represent sets of decisions. These decisions generate rules for the classification of a dataset. Specific decision tree methods include Classification and Regression Trees (CART) and Chi Square Automatic Interaction Detection (CHAID).
- Genetic algorithms: Optimization techniques that use process such as genetic combination, mutation, and natural selection in a design based on the concepts of evolution.
- Nearest neighbor method: A technique that classifies each record in a dataset based on a combination of the classes of the k record(s) most similar to it in a historical dataset (where k ³ 1). Sometimes called the k-nearest neighbor technique.
- Rule induction: The extraction of useful if-then rules from data based on statistical significance.
- Detection of anomalies: Identifying unusual values in a dataset.
- Dependency modeling: Discovering existing relationships within a dataset. This frequently involves regression analysis.
- Clustering: Identifying structures (clusters) in unstructured data.
- Classification: Generalizing the known structure and applying it to the data.
Many of these technologies have been in use for more than a decade in specialized analysis tools that work with relatively small volumes of data. These capabilities are now evolving to integrate directly with industry-standard data warehouse and OLAP platforms.
Banking Industry
In the banking industry, concentration is given to risk management and policy reversal as well analyzing consumer data, market trends, government regulations and reports, and more importantly financial decision making.
Most banks also use warehouses to manage the resources available on deck in an effective manner. Certain banking sectors utilize them for market research, performance analysis of each product, interchange and exchange rates, and to develop marketing programs.
Analysis of card holder’s transactions, spending patterns and merchant classification, all of which provide the bank with an opportunity to introduce special offers and lucrative deals based on cardholder activity. Apart from all these, there is also scope for co-branding.
Finance Industry
Similar to the applications seen in banking, mainly revolve around evaluation and trends of customer expenses which aids in maximizing the profits earned by their clients.
Consumer Goods Industry
They are used for prediction of consumer trends, inventory management, market and advertising research. In-depth analysis of sales and production is also carried out. Apart from these, information is exchanged business partners and clientele.
Government and Education
The federal government utilizes the warehouses for research in compliance, whereas the state government uses it for services related to human resources like recruitment, and accounting like payroll management.
The government uses data warehouses to maintain and analyze tax records, health policy records and their respective providers, and also their entire criminal law database is connected to the state’s data warehouse. Criminal activity is predicted from the patterns and trends, results of the analysis of historical data associated with past criminals.
Universities use warehouses for extracting of information used for the proposal of research grants, understanding their student demographics, and human resource management. The entire financial department of most universities depends on data warehouses, inclusive of the Financial Aid department.
Healthcare
One of the most important sector which utilizes data warehouses is the Healthcare sector. All of their financial, clinical, and employee records are fed to warehouses as it helps them to strategize and predict outcomes, track and analyze their service feedback, generate patient reports, share data with tie-in insurance companies, medical aid services, etc.
Hospitality Industry
A major proportion of this industry is dominated by hotel and restaurant services, car rental services, and holiday home services. They utilize warehouse services todesign and evaluate their advertising and promotion campaigns where they target customers based on their feedback and travel patterns.
Insurance
As the saying goes in the insurance services sector, “Insurance can never be bought, it can be only be sold”, the warehouses are primarily used to analyze data patterns and customer trends, apart from maintaining records of already existing participants. The design of tailor-made customer offers and promotions is also possible through warehouses.
Manufacturing and Distribution Industry
This industry is one of the most important sources of income for any state. A manufacturing organization has to take several make-or-buy decisions which can influence the future of the sector, which is why they utilize high-end OLAP tools as a part of data warehouses to predict market changes, analyze current business trends, detect warning conditions, view marketing developments, and ultimately take better decisions.
They also use them for product shipment records, records of product portfolios, identify profitable product lines, analyze previous data and customer feedback to evaluate the weaker product lines and eliminate them.
For the distributions, the supply chain management of products operates through data warehouses.
The Retailers
Retailers serve as middlemen between producers and consumers. It is important for them to maintain records of both the parties to ensure their existence in the market.
They use warehouses to track items, their advertising promotions, and the consumers buying trends. They also analyze sales to determine fast selling and slow selling product lines and determine their shelf space through a process of elimination.
Services Sector
Data warehouses find themselves to be of use in the service sector for maintenance of financial records, revenue patterns, customer profiling, resource management, and human resources.
Telephone Industry
The telephone industry operates over both offline and online data burdening them with a lot of historical data which has to be consolidated and integrated.
Apart from those operations, analysis of fixed assets, analysis of customer’s calling patterns for sales representatives to push advertising campaigns, and tracking of customer queries, all require the facilities of a data warehouse.
Transportation Industry
In the transportation industry, data warehouses record customer data enabling traders to experiment with target marketing where the marketing campaigns are designed by keeping customer requirements in mind.
The internal environment of the industry uses them to analyze customer feedback, performance, manage crews on board as well as analyze customer financial reports for pricing strategies.
Data Mining Applications
Financial Data Analysis
The financial data in banking and financial industry is generally reliable and of high quality which facilitates systematic data analysis and data mining. Some of the typical cases are as follows −
- Design and construction of data warehouses for multidimensional data analysis and data mining.
- Loan payment prediction and customer credit policy analysis.
- Classification and clustering of customers for targeted marketing.
- Detection of money laundering and other financial crimes.
Retail Industry
Data Mining has its great application in Retail Industry because it collects large amount of data from on sales, customer purchasing history, goods transportation, consumption and services. It is natural that the quantity of data collected will continue to expand rapidly because of the increasing ease, availability and popularity of the web.
Data mining in retail industry helps in identifying customer buying patterns and trends that lead to improved quality of customer service and good customer retention and satisfaction. Here is the list of examples of data mining in the retail industry −
- Design and Construction of data warehouses based on the benefits of data mining.
- Multidimensional analysis of sales, customers, products, time and region.
- Analysis of effectiveness of sales campaigns.
- Customer Retention.
- Product recommendation and cross-referencing of items.
Telecommunication Industry
Today the telecommunication industry is one of the most emerging industries providing various services such as fax, pager, cellular phone, internet messenger, images, e-mail, web data transmission, etc. Due to the development of new computer and communication technologies, the telecommunication industry is rapidly expanding. This is the reason why data mining is become very important to help and understand the business.
Data mining in telecommunication industry helps in identifying the telecommunication patterns, catch fraudulent activities, make better use of resource, and improve quality of service. Here is the list of examples for which data mining improves telecommunication services
- Multidimensional Analysis of Telecommunication data.
- Fraudulent pattern analysis.
- Identification of unusual patterns.
- Multidimensional association and sequential patterns analysis.
- Mobile Telecommunication services.
- Use of visualization tools in telecommunication data analysis.
Biological Data Analysis
In recent times, we have seen a tremendous growth in the field of biology such as genomics, proteomics, functional Genomics and biomedical research. Biological data mining is a very important part of Bioinformatics. Following are the aspects in which data mining contributes for biological data analysis −
- Semantic integration of heterogeneous, distributed genomic and proteomic databases.
- Alignment, indexing, similarity search and comparative analysis multiple nucleotide sequences.
- Discovery of structural patterns and analysis of genetic networks and protein pathways.
- Association and path analysis.
- Visualization tools in genetic data analysis.
Other Scientific Applications
The applications discussed above tend to handle relatively small and homogeneous data sets for which the statistical techniques are appropriate. Huge amount of data have been collected from scientific domains such as geosciences, astronomy, etc. A large amount of data sets is being generated because of the fast numerical simulations in various fields such as climate and ecosystem modeling, chemical engineering, fluid dynamics, etc. Following are the applications of data mining in the field of Scientific Applications −
- Data Warehouses and data preprocessing.
- Graph-based mining.
- Visualization and domain specific knowledge.
Intrusion Detection
Intrusion refers to any kind of action that threatens integrity, confidentiality, or the availability of network resources. In this world of connectivity, security has become the major issue. With increased usage of internet and availability of the tools and tricks for intruding and attacking network prompted intrusion detection to become a critical component of network administration. Here is the list of areas in which data mining technology may be applied for intrusion detection −
- Development of data mining algorithm for intrusion detection.
- Association and correlation analysis, aggregation to help select and build discriminating attributes.
- Analysis of Stream data.
- Distributed data mining.
- Visualization and query tools.
Key Takeaways:
- Data mining automates the process of finding predictive information in large databases.
- The government uses data warehouses to maintain and analyze tax records, health policy records and their respective providers, and also their entire criminal law database is connected to the state’s data warehouse
- Data mining in telecommunication industry helps in identifying the telecommunication patterns, catch fraudulent activities, make better use of resource, and improve quality of service.
- Data mining in retail industry helps in identifying customer buying patterns and trends that lead to improved quality of customer service and good customer retention and satisfaction.
Reference Books:
1. Electronic Commerce - Technologies & Applications.
Bharat, Bhaskar
2. Microsoft Office Professional 2013 Step by Step
By Beth Melton, Mark Dodge, Echo Swinford, Andrew Couch




