Unit - 1
Amino Acids, Peptides and Proteins
Introduction
Proteins, whose name comes from the Greek word proteios, which means "first," are a type of organic compound found in and essential to all living cells. Proteins hold together, protect, and structure the body of a multicellular organism in the form of skin, hair, callus, cartilage, muscles, tendons, and ligaments. They catalyse, regulate, and protect the body chemistry in the forms of enzymes, hormones, antibodies, and globulins. They influence the transport of oxygen and other substances within an organism as haemoglobin, myoglobin, and various lipoproteins.
Proteins are widely regarded as beneficial and are an essential component of all animals' diets. If humans do not consume enough suitable protein, they can become seriously ill; the disease kwashiorkor is an extreme form of protein deficiency. Antibiotics and vaccines based on protein help to fight disease, and we warm and protect our bodies with clothing and shoes that are frequently made of protein (e.g., wool, silk and leather).
Protein toxins and venoms are less well known for their lethal properties. Botulinum toxin A, produced by Clostridium botulinum, is the most potent poison ever discovered. A teaspoon of this toxin would be enough to kill a fifth of the world's population, according to toxicology studies. Tetanus and diphtheria microorganisms produce toxins that are nearly as poisonous. The venoms of many snakes, as well as ricin, a toxic protein found in castor beans, would be included on a list of highly toxic proteins or peptides.
Despite their diverse physiological functions and physical properties— Proteins are sufficiently similar in molecular structure to be treated as a single chemical family, despite the fact that silk is a flexible fibre, horn is a tough rigid solid, and pepsin is a water-soluble crystal. Proteins are fundamentally different from carbohydrates and lipids in terms of composition. Lipids are mostly made up of hydrocarbons, which account for 75 to 85 percent of their mass. Carbohydrates are roughly half-oxygen and, like lipids, usually contain less than 5% nitrogen (often none at all). Proteins and peptides, on the other hand, contain 15 to 25% nitrogen and roughly the same amount of oxygen. The size difference between proteins and peptides is significant. Peptides, with molecular weights less than 10,000, are small proteins.
Natural α-Amino Acids
When proteins are hydrolyzed in aqueous acid or base, small molecules known as -aminocarboxylic acids are produced. The most common of these components have been isolated, and they are listed in the table below. Because they are not synthesised by human metabolic processes, the amino acids with green names are essential diet components. Protein is the best source of these nutrients, but not all proteins are created equal. Peanuts, for example, have a higher protein content by weight than fish or eggs, but peanut protein contains only a third of the essential amino acids found in the other two sources. Each amino acid is given a one or three letter abbreviation for reasons that will become clear when discussing the structures of proteins and peptides.
Natural α-Amino Acids
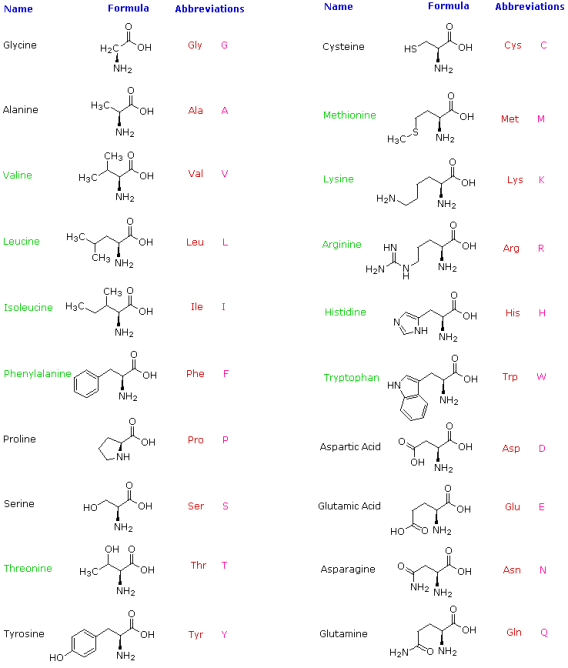
There are a few things to keep in mind about these amino acids. They are all 1o-amines with the exception of proline, and they are all chiral with the exception of glycine. When written as a Fischer projection formula, the configurations of the chiral amino acids are the same, as shown in the diagram on the right, and this was dubbed the L-configuration by Fischer. The remaining structural component that varies from one amino acid to the next is the R-substituent, which in proline is a three-carbon chain that connects the nitrogen to the alpha-carbon in a five-membered ring. With the exception of cysteine, all of these natural chiral amino acids have an S-configuration according to the Cahn-Ingold-Prelog notation.
The R-substituent in the first seven compounds in the left column is a hydrocarbon. The last three amino acids in the left column have hydroxyl functional groups, while the first two in the right column have thiol and sulphide functional groups, respectively. Histidine and tryptophan have less basic nitrogen heterocyclic rings as substituents than lysine and arginine, which have basic amine functions in their side chains. Finally, carboxylic acid side-chains are substituents on aspartic and glutamic acid, and the last two compounds in the right column are their corresponding amides.
The amino acid formulas above are simple covalent bond representations based on prior knowledge of mono-functional analogues. In reality, the formulas are incorrect. A comparison of the physical properties listed in the following table demonstrates this. The four compounds in the table are all of similar size and have moderate to excellent water solubility. Simple carboxylic acids make up the first two, while an amino alcohol makes up the third. Each of the three compounds is soluble in organic solvents (such as ether) and has a low melting point. The carboxylic acids have pKa values around 4.5, while the amine's conjugate acid has a pKa of 10. The last entry is alanine, a simple amino acid. It has a high melting point (with decomposition), is insoluble in organic solvents, and is a million times weaker as an acid than regular carboxylic acids.
Physical Properties of Selected Acids and Amines | ||||||
Compound
| Formula | Mol.Wt. | Solubility
| Solubility | Melting | PKa
|
Isobutyric acid | (CH3)2CHCO2H
| 88 | 20g/100mL
| Complete
| -47 ºC
| 5.0 |
Lactic acid | CH3CH(OH)CO2H
| 90 | Complete
| Complete
| 53 ºC
| 3.9 |
Amino-2-butanol | CH3CH(NH2)CH(OH)CH3
| 89 | Complete | Complete
| 9 ºC
| 10.0
|
Lanine | CH3CH(NH2)CO2H
| 89 | 18g/100mL
| Complete
| Ca. 300 ºC
| 9.8 |
All of these differences point to a proton transfer from the acidic carboxyl function to the basic amino group forming an internal salt. The resulting ammonium carboxylate structure, also known as a zwitterion, is also supported by alanine's spectroscopic properties.
CH3CH(NH2)CO2H  CH3CH(NH3)(+)CO2(–)
CH3CH(NH3)(+)CO2(–)
The alanine zwitterion has a high melting point, is insoluble in nonpolar solvents, and has the acid strength of a 1o-ammonium ion, as expected given its ionic character. A Jmol representation of a L-amino acid is shown to the right. By pressing the appropriate button beneath the display, the model will change to its zwitterionic state. A few specific amino acids can be seen in their preferred neutral zwitterionic form as well. It's worth noting that the amine function closest to the carboxyl group in lysine is more basic than the alpha-amine. As a result, the positively charged ammonium moiety at the chain terminus attracts the negatively charged carboxylate, forming a coiled conformation.
Because amino acids, peptides, and proteins contain both acidic and basic functional groups, the predominant molecular species present in an aqueous solution is determined by its pH. The Henderson - Hasselbalch Equation, written below, is used to determine the nature of the molecular and ionic species present in aqueous solutions at various pHs. The pKa here denotes the acidity of a particular conjugate acid function (HA). The concentrations of HA and A (-) must be equal when the pH of the solution equals pKa (log 1 = 0).
Henderson-Hasselbalch equation: 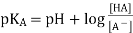
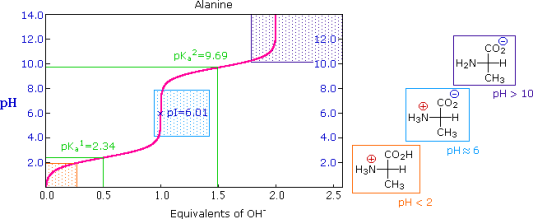
This relationship is demonstrated by the titration curve for alanine, which is shown below. Because both the carboxylate and amine functions of alanine are protonated at pH levels below 2, the alanine molecule has a net positive charge. The amine exists as a neutral base and the carboxyl as its conjugate base at pH greater than 10, giving the alanine molecule a net negative charge. The zwitterion concentration rises at intermediate pHs, and the negatively and positively charged molecular species are present in equal concentrations at the isoelectric point (pI). This is true for all simple (difunctional) amino acids. The pKa's of the acidic functions range from 1.8 to 2.4 for -CO2H and 8.8 to 9.7 for -NH3(+) starting from a fully protonated state. Isoelectric points range between 5.5 and 6.2. The neutralisation of these acids by added base, as well as the change in pH during the titration, are depicted in titration curves.
The University of Virginia in Charlottesville has a useful site where you can look at titration curves for a variety of other amino acids. (To learn more about this person, click on his or her name.)
Electrophoresis, a technique for observing the movement of solute molecules in an electric field, can be used to show the distribution of charged species in a sample. An ionic buffer solution is incorporated in a solid matrix layer made of paper or a crosslinked gelatine-like substance for such experiments. As shown in the diagram, a small amount of the amino acid, peptide, or protein sample is placed near the centre of the matrix strip, and an electric potential is applied at the strip's ends. The solute molecules will remain where they are inserted due to the solid structure of the matrix, which prevents them from diffusing unless the electrostatic potential acts on them. In this example, four different amino acids are investigated at the same time in a pH 6.00 buffered medium. To see the result of this experiment, click on the illustration. Note that the colors in the display are only a convenient reference, since these amino acids are colorless.
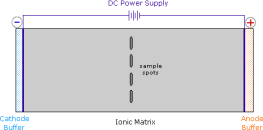
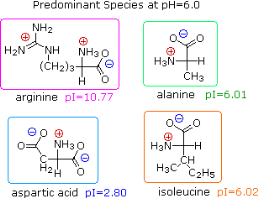
Alanine and isoleucine exist as neutral zwitterionic molecules at pH 6.00 and are unaffected by the electric field. The amino acid arginine is a basic one. In the pH 6.00 matrix, both base functions exist as "onium" conjugate acids. As a result, the arginine solute molecules have an excess positive charge and move toward the cathode. At pH 6.00, aspartic acid's two carboxyl functions are both ionised, and the negatively charged solute molecules move toward the anode in the electric field. All of these species' structures are displayed to the right of the display.
It should be obvious that the pH of the matrix buffer has a significant impact on the outcome of this experiment. If we repeated the electrophoresis of these compounds at a pH of 3.80, the aspartic acid would stay put, while the other amino acids would move toward the cathode. Arginine would move twice as fast as alanine and isoleucine, ignoring differences in molecular size and shape, because its solute molecules would have a double positive charge on average.
The titration curves of simple amino acids have two inflection points, one for the strongly acidic carboxyl group (pKa1 = 1.8 to 2.4) and the other for the less acidic ammonium function (pKa2 = 8.8 to 9.7), as previously mentioned. The pKa2 of the 2o-amino acid proline is 10.6, indicating that 2o-amines are more basic.
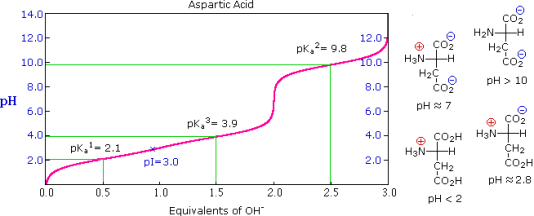
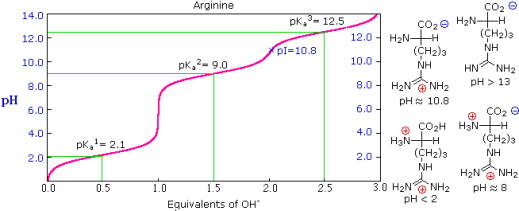
The side chains of some amino acids have additional acidic or basic functions. In the table to the right, you'll find a list of these compounds. The extra function's acidity or basicity is represented by a third pKa in the table's fourth column. These amino acids' pIs (last column) are frequently very different from those of the simpler members. As can be seen in the titration curves of arginine and aspartic acid shown below, such compounds have three inflection points in their titration curves. There are four possible charged species for each of these compounds, one of which has no overall charge. The formulas for these species, as well as the pH at which each is expected to predominate, are written to the right of the titration curves. The very high pH required to remove the last acidic proton from arginine reflects the exceptionally high basicity of the guanidine moiety at the end of the side chain.
PKa Values of Polyfunctional Amino Acids | ||||
Amino Acid | α-CO2H | α-NH3 | Side Chain | PI |
Arginine | 2.1 | 9.0 | 12.5 | 10.8 |
Aspartic Acid | 2.1 | 9.8 | 3.9 | 3.0 |
Cysteine | 1.7 | 10.4 | 8.3 | 5.0 |
Glutamic Acid | 2.2 | 9.7 | 4.3 | 3.2 |
Histidine | 1.8 | 9.2 | 6.0 | 7.6 |
Lysine | 2.2 | 9.0 | 10.5 | 9.8 |
Tyrosine | 2.2 | 9.1 | 10.1 | 5.7 |
The Isoelectric Point
The isoelectric point, pI, is the pH of an aqueous solution of an amino acid (or peptide) at which the molecules have no net charge on average, as defined above. In other words, the negatively charged groups balance out the positively charged groups perfectly. The pI of simple amino acids like alanine is calculated by adding the pKas of the carboxyl (2.34) and ammonium (9.69) groups. Thus, the experimentally determined pI for alanine is calculated as (2.34 + 9.69)/2 = 6.02. The pI is the average of the pKas of the two most similar acids if additional acidic or basic groups are present as side-chain functions. We define two classes of acids to aid in determining similarity. The first group consists of acids that are protonated to be neutral (e.g., CO2H & SH). Acids that are positively charged in their protonated state (e.g. -NH3+) fall into the second category. The alpha-carboxyl function (pKa = 2.1) and the side-chain carboxyl function (pKa = 3.9) are similar acids in aspartic acid, so pI = (2.1 + 3.9)/2 = 3.0. For arginine, the similar acids are the guanidinium species on the side-chain (pKa = 12.5) and the alpha-ammonium function (pKa = 9.0), so the calculated pI = (12.5 + 9.0)/2 = 10.75.
Other Natural Amino Acids
The twenty alpha-amino acids listed above are the primary components of proteins, with the genetic code governing their incorporation. There are a variety of other naturally occurring amino acids, and the structures of a few of them are shown below. Some are simply functionalized derivatives of a previously described compound, such as hydroxylysine and hydroxyproline. Only collagen, a common structural protein, contains these two amino acids. Higher homologs of their namesakes, homoserine and homocysteine. Beta-amino alanine's group has moved to the end of the three-carbon chain. It's a part of pantothenic acid, HOCH2C(CH3)2CH(OH)CONHCH2CH2CH2CO2H, a vitamin B complex member and essential nutrient. Acetyl coenzyme A is a pyrophosphorylated pantothenic acid amide derivative. GABA, a neurotransmitter inhibitor and antihypertensive agent, is a gamma-amino homolog.
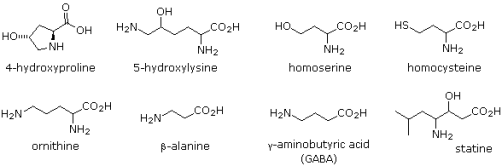
Microorganisms produce a variety of unusual amino acids, including D-enantiomers of some common acids. Ornithine, a component of the antibiotic bacitracin A, and statin, a pentapeptide that inhibits the action of the digestive enzyme pepsin, are two examples.
Reactions of α-Amino Acids
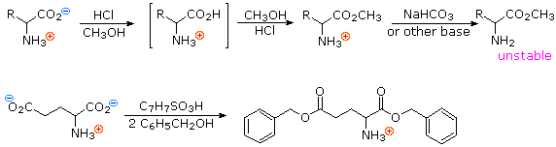
1. Carboxylic Acid Esterification
If the pH is set to an appropriate level, amino acids go through the majority of the chemical reactions that are characteristic of each function. As shown in the two equations below, carboxylic acid esterification is usually carried out under acidic conditions. Amine functions are converted to their ammonium salts under these conditions, but carboxylic acids are not dissociated. The first equation is a typical methanol Fischer esterification. A stable ammonium salt is the first product. Due to acylation of the amine by the ester function, the amino ester formed by neutralisation of this salt is unstable.
The second reaction uses p-toluenesulfonic acid as an acid catalyst to benzylate aspartic acid's two carboxylic acid functions. Zwitterionic species are no longer possible once the carboxyl function is esterified, and the product behaves like any other 1o-amine.
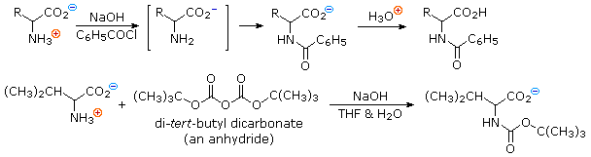
2. Amine Acylation
To convert an amino acids amine function into an amide, the pH of the solution must be raised to 10 or higher, allowing for the presence of free amine nucleophiles in the reaction system. At such a high pH, carboxylic acids are all converted to carboxylate anions, and amine acylation reactions are unaffected. The two reactions that follow are examples. The acylating reagent in the first is an acid chloride. Because water and the hydroxide anion are also present as competing nucleophiles, this is a good example of nitrogen's superior nucleophilicity in acylation reactions. In the Heinsberg test, amines were found to have a similar selectivity. For the acylation in the second reaction, an anhydride-like reagent is used. The ease with which the t-butylcarbonyl (t-BOC) group can be removed later makes this a particularly useful procedure in peptide synthesis. Because amides are only weakly basic (pKa -1), the amino acid derivatives produced are not zwitterionic and can be converted to a variety of carboxylic acid derivatives.
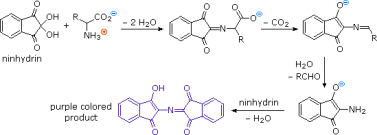
3. The Ninhydrin Reaction
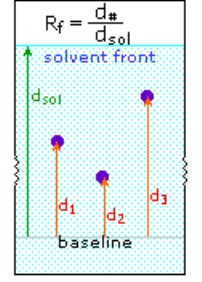
Except for proline, common alpha-amino acids undergo a unique reaction with the triketohydrindene hydrate known as ninhydrin in addition to these common amine-carboxylic acid reactions. A purple coloured imino derivative is one of the products of this unusual reaction (shown on the left below), which serves as a useful colour test for these amino acids, which are mostly colourless. The ninhydrin test is frequently used to visualise amino acids in paper chromatography. Samples of amino acids or mixtures of amino acids are applied along a line near the bottom of a rectangular sheet of paper, as shown in the diagram on the right (the baseline). The paper's bottom edge is immersed in an aqueous buffer, which slowly climbs toward the top edge. The compounds in each sample are carried along at a rate that is characteristic of their functionality, size, and interaction with the cellulose matrix of the paper as the solvent front passes through the sample spots. Some compounds move quickly up the paper, while others move very slowly. The retardation (or retention) factor Rf is defined as the ratio of the distance a compound moves from the baseline to the distance the solvent front moves from the baseline. Under ideal conditions, different amino acids have different Rfs. The three sample compounds (1, 2 & 3) in the example on the right have Rf values of 0.54, 0.36, and 0.78, respectively.
Paper Chromatography
4. Oxidative Coupling
Iodine, a mild oxidant, reacts selectively with the side groups of certain amino acids. The phenolic ring in tyrosine, as well as the heterocyclic rings in tryptophan and histidine, all yield electrophilic iodination products. In addition, iodine oxidises the sulphur groups in cysteine and methionine. The number of such residues in peptides has been determined using quantitative iodine consumption measurements. At pH less than 8, the basic functions of lysine and arginine are onium cations, which are unreactive.
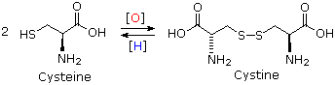
Cysteine is a thiol that, like most thiols, oxidises to a disulfide that is sometimes listed as a separate amino acid under the name cystine. Many peptides and proteins contain disulfide bonds of this type. Two disulfide links, for example, hold the two peptide chains that make up insulin together. Keratin, a fibrous protein found in our hair, contains an unusually high proportion of cysteine. Disulfide bonds are first broken and then created after the hair is reshaped in the procedure known as "permanent waving." The sulphur atom in methionine is oxidised to a sulfoxide after treatment with dilute aqueous iodine.
Cysteine-Cystine Interconversion
1.2.1 Amino acids:
Proteins are made up of amino acids, which are organic compounds that combine to form proteins. The building blocks of life are amino acids and proteins.
Amino acids are left over after proteins are digested or broken down. Amino acids are used by the human body to make proteins that aid in the following functions:
• Break down food
• Grow
• Repair body tissue
• Perform many other body functions
Amino acids can also be used as a source of energy by the body.
Amino acids are classified into three groups:
• Essential amino acids
• Nonessential amino acids
• Conditional amino acids
ESSENTIAL AMINO ACIDS
• Essential amino acids cannot be made by the body. As a result, they must come from food.
• The 9 essential amino acids are: histidine, isoleucine, leucine, lysine, methionine, phenylalanine, threonine, tryptophan, and valine.
NONESSENTIAL AMINO ACIDS
The term "non-essential" refers to the fact that our bodies can make an amino acid even if we don't get it from food. Alanine, arginine, asparagine, aspartic acid, cysteine, glutamic acid, glutamine, glycine, proline, serine, and tyrosine are non-essential amino acids.
CONDITIONAL AMINO ACIDS
• Conditional amino acids are usually not essential, except in times of illness and stress.
• Arginine, cysteine, glutamine, tyrosine, glycine, ornithine, proline, and serine are all conditional amino acids.
• You don't have to eat essential and non-essential amino acids at every meal, but it's important to get a good balance of them throughout the day. A diet consisting solely of plant foods will not suffice, but we no longer have to worry about combining proteins (such as beans and rice) in a single meal. Instead, we assess the overall adequacy of the diet throughout the day.
1.2.2 Building blocks of proteins
Proteins are critical for life on Earth to continue to function properly. The vast majority of chemical reactions in the cell are catalysed by proteins. They provide many of a cell's structural elements and aid in the fusion of cells into tissues. To allow movement, some proteins act as contractile elements. Others are in charge of transporting vital materials from the cell's exterior ("extracellular") to its interior ("intracellular"). Proteins protect animals from disease in the form of antibodies, and interferon mounts an intracellular attack against viruses that have eluded destruction by antibodies and other immune system defences. Many hormones are proteins. Last but certainly not least, proteins control the activity of genes (“gene expression”).
The incredible diversity of known proteins, which differ significantly in size, shape, and charge, reflects this wide range of critical functions. Scientists realised by the end of the nineteenth century that, while there are many different types of proteins in nature, all proteins hydrolyze to a class of simpler compounds called amino acids, which are the building blocks of proteins. Glycine is the most basic amino acid, named after its sweet taste (glyco, "sugar"). It was isolated from the protein gelatine in 1820 and was one of the first amino acids to be identified. Scientists working on elucidating the relationship between proteins and genes agreed in the mid-1950s that 20 amino acids (known as standard or common amino acids) should be considered the essential building blocks of all proteins. Threonine, the last of these to be discovered, was discovered in 1935.
1.2.3 Chirality
Except for glycine, all amino acids are chiral molecules. That is, they exist in two optically active asymmetric forms (referred to as enantiomers) that are mirror images of one another. (This property is analogous to the spatial relationship between the left and right hands.) One enantiomer is labelled D, while the other is labelled L. It's worth noting that the L-configuration is almost always found in amino acids found in proteins. This is due to the fact that enzymes involved in protein synthesis have evolved to only use the L-enantiomers. The prefix L is usually omitted to reflect this near universality. D-amino acids are found in microorganisms, particularly in bacteria's cell walls and in a number of antibiotics. The ribosome, on the other hand, does not produce these.
1.2.4 Acid-base properties
The presence of both a basic and an acidic group at the -carbon is another important feature of free amino acids. Amino acids, for example, are amphoteric compounds because they can act as both an acid and a base. The pKa of the basic amino group is usually between 9 and 10, while the pKa of the acidic -carboxyl group is usually around 2. (a very low value for carboxyls). The pH value at which the protonated group's concentration equals that of the unprotonated group is known as the group's pKa. At physiological pH (around 7–7.4), free amino acids mostly exist as dipolar ions, or "zwitterions" (German for "hybrid ions"; a zwitterion has an equal number of positively and negatively charged groups). Any free amino acid, as well as any protein, will exist in the form of a zwitterion at a specific pH. When exposed to changes in pH, all amino acids and proteins pass through a state in which the number of positive and negative charges on the molecule is equal. The isoelectric point (or isoelectric pH) is the pH at which this occurs, and it is denoted as pI. All amino acids and proteins are predominantly in their isoelectric form when dissolved in water. In other words, there is a pH (isoelectric point) at which the molecule has a net zero charge (equal number of positive and negative charges), but no pH at which the molecule has an absolute zero charge (complete absence of positive and negative charges). Amino acids and proteins, in other words, are always in the form of ions and carry charged groups. This fact is critical when studying the biochemistry of amino acids and proteins in depth.
1.2.5 Standard amino acids
The polarity (that is, the distribution of electric charge) of the R group is one of the most useful ways to classify the standard (or common) amino acids (e.g., side chain).
Group I: Nonpolar amino acids
Glycine, alanine, valine, leucine, isoleucine, proline, phenylalanine, methionine, and tryptophan are all members of Group I amino acids. These amino acids have either aliphatic or aromatic groups in their R groups. This makes them hydrophobic (afraid of water). Globular proteins fold into a three-dimensional shape in aqueous solutions to bury these hydrophobic side chains in the protein interior. Group I amino acids have the following chemical structures:
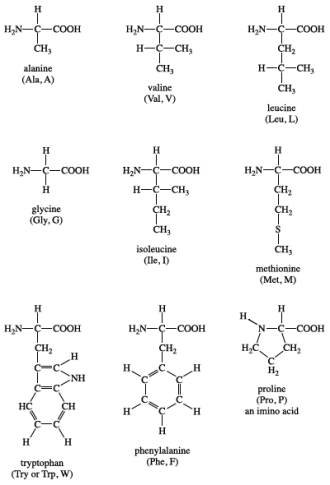
Isoleucine is a chiral isomer of leucine that contains two carbon atoms. Proline is the only amino acid in the standard amino acid family that lacks both free -amino and free -carboxyl groups. Instead, the nitrogen atom of proline is linked to two carbon atoms, forming a cyclic structure in its side chain. (In strict terms, this means that proline is a -imino acid rather than an amino acid.) Phenylalanine is made up of a phenyl group attached to alanine, as the name suggests. Methionine is one of the two sulfur-containing amino acids. Methionine is almost always the initiating amino acid in protein biosynthesis (translation), so it plays a crucial role. Methionine also serves as a source of methyl groups for metabolism. An indole ring is attached to the alanyl side chain in tryptophan.
Group II: Polar, uncharged amino acids
Serine, cysteine, threonine, tyrosine, asparagine, and glutamine are all members of Group II amino acids. This group's side chains have a wide range of functional groups. Most, however, have at least one atom with electron pairs available for hydrogen bonding to water and other molecules (nitrogen, oxygen, or sulphur). Group II amino acids have the following chemical structures:
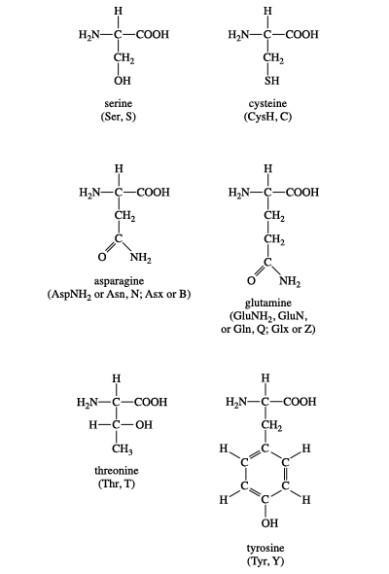
Serine and threonine are two amino acids that contain aliphatic hydroxyl groups (an oxygen atom bonded to a hydrogen atom, represented as OH). Tyrosine is a phenol derivative because it has a hydroxyl group in the aromatic ring. The hydroxyl groups in these three amino acids are phosphorylated, which is a common type of posttranslational modification (see Nonstandard amino acids). Cysteine, like methionine, has a sulphur atom. However, unlike methionine's sulphur atom, cysteine's sulphur atom is chemically reactive (see Cysteine oxidation below). Both asparagine and glutamine, which were first isolated from asparagus, have amide R groups. The amino group (NH2) can act as a hydrogen bond donor, while the carbonyl group can act as a hydrogen bond acceptor.
Group III: Acidic amino acids
Aspartic acid and glutamic acid are the two amino acids in this group. Each one has a carboxylic acid on its side chain, which makes it acidic (proton-donating). All three functional groups on these amino acids will ionise in an aqueous solution at physiological pH, resulting in an overall charge of 1. Aspartate and glutamate are the ionic forms of the amino acids. Group III amino acids have the following chemical structures:
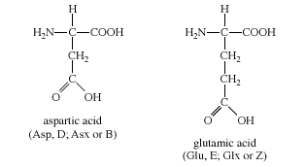
Aspartate and glutamate side chains can form ionic bonds (also known as "salt bridges") and act as hydrogen bond acceptors. Metal-binding sites containing aspartate or glutamate side chains, or both, are found in many proteins that bind metal ions for structural or functional reasons. The amino acid metabolism is dominated by free glutamate and glutamine. In the central nervous system, glutamate is the most abundant excitatory neurotransmitter.
Group IV: Basic amino acids
Arginine, histidine, and lysine are the three amino acids that make up this group. Each side chain is fundamental (i.e., can accept a proton). At physiological pH, both lysine and arginine have an overall charge of +1. The guanidino group in the side chain of arginine is the most fundamental of all R groups (a fact reflected in its pKa value of 12.5). Ionic bonds form between the side chains of arginine and lysine, just as they do with aspartate and glutamate. Group IV amino acids have the following chemical structures:
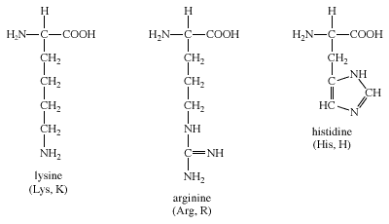
Histidine's imidazole side chain allows it to work in both acid and base catalysis at physiological pH levels. This is a chemical property that none of the other standard amino acids have. As a result, histidine is a common amino acid found in the active sites of protein enzymes.
The majority of amino acids in Groups II, III, and IV are hydrophilic (meaning they like to be near water). As a result, they are frequently found in aqueous solutions clustered on the surface of globular proteins.
1.2.6 Amino acid reactions
Amino acids can undergo a variety of chemical reactions thanks to their various chemical functionalities (carboxyls, amino, and R groups). However, because of their impact on protein structure, two reactions (peptide bond and cysteine oxidation) are particularly important.
• Peptide bond
Amino acids can be linked by a condensation reaction in which an OH is lost from one amino acids carboxyl group and a hydrogen is lost from another's amino group, forming a molecule of water and leaving the two amino acids linked via an amide—called a peptide bond in this case. Emil Fischer, a German chemist, proposed the linking of amino acids at the turn of the twentieth century. Because the carboxyl and amino groups of individual amino acids have reacted to form the peptide bond, they are no longer able to act as acids or bases when they are combined to form proteins. As a result, the overall ionisation characteristics of the individual R groups of the component amino acids determine the acid-base properties of proteins.
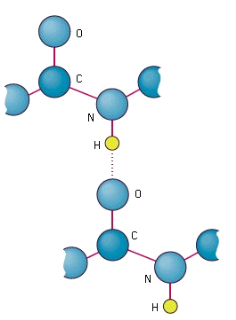
Peptide bond
The linking of atoms in a peptide bond.
A peptide is a collection of amino acids linked together by a series of peptide bonds. Individual amino acids are referred to as amino acid residues after they've been incorporated into a peptide. Oligopeptides are small polymers of amino acids with fewer than 50 amino acids, whereas polypeptides have more than 50. As a result, a protein molecule is a polypeptide chain made up of numerous amino acid residues linked together by peptide bonds. Proteins can range in length from a few dozen to thousands of amino acids, and each one contains different proportions of the 20 standard amino acids.
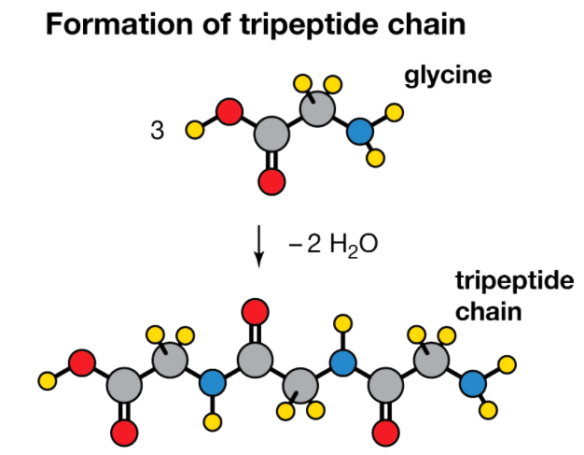
Condensation reaction
Three molecules of the amino acid glycine are condensed to form a tripeptide chain, with two molecules of water being removed (H2O).
• Cysteine oxidation
Cysteine's thiol (sulfur-containing) group is extremely reactive. This group's most common reaction is a reversible oxidation that produces a disulfide. The oxidation of two cysteine molecules produces cystine, a molecule with a disulfide bond. A disulfide bridge is formed when two cysteine residues in a protein form such a bond. Disulfide bridges are a common way for many proteins to be stabilised in nature. Extracellular proteins that are secreted from cells frequently contain disulfide bridges. The endoplasmic reticulum, an organelle in eukaryotic organisms, is where disulfide bridges are formed.
The sulfhydryl groups of cysteine are rapidly oxidised to form cystine in extracellular fluids (such as blood). There is a defect in cystinuria, a genetic disorder that causes excessive cystine excretion in the urine. Because cystine is the least soluble of the amino acids, crystallisation of excreted cystine causes calculi (also known as "stones") to form in the kidney, ureter, or urinary bladder. Intense pain, infection, and blood in the urine are all possible side effects of kidney stones. The use of D-penicillamine as a medical intervention is common. Penicillamine works by forming a 50-fold more water-soluble complex with cystine than cystine alone. In summary, a protein's shape and biological function, as well as its physical and chemical properties, are determined by its amino acid sequence. Proteins are polymers of 20 different kinds of amino acids, which gives them their functional diversity. The hormone insulin, for example, is a "simple" protein with 51 amino acids. With 20 amino acids to choose from at each of these 51 positions, a total of 2051, or roughly 1066, different proteins could theoretically be created.
• Other functions
Amino acids are the building blocks for a wide range of complex nitrogen-containing molecules. The nitrogenous base components of nucleotides and nucleic acids (DNA and RNA) are prominent among these. Cofactors derived from complex amino acids, such as heme and chlorophyll, are also present. Heme is an iron-containing organic group that is required for the biological activity of proteins like haemoglobin, which transports oxygen, and cytochrome c, which transports electrons. Photosynthesis requires the pigment chlorophyll.
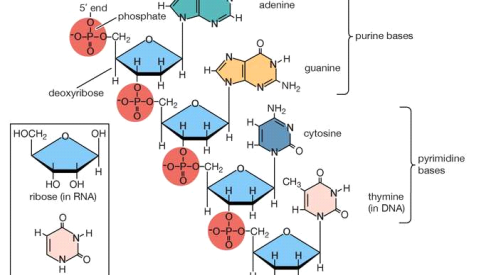
Polynucleotide chain of deoxyribonucleic acid (DNA)
Deoxyribonucleic acid polynucleotide chain portion (DNA). The corresponding pentose sugar and pyrimidine base in ribonucleic acid are shown in the inset (RNA).
Chemical messengers include several -amino acids (or their derivatives). Neurotransmitters include -aminobutyric acid (GABA; a glutamic acid derivative), serotonin and melatonin (tryptophan derivatives), and histamine (histidine derivative). Hormones include thyroxine (a tyrosine derivative produced in the thyroid gland of animals) and indole acetic acid (a tryptophan derivative found in plants).
Several amino acids, both standard and nonstandard, are frequently used as metabolic intermediates. The amino acids arginine, citrulline, and ornithine, which are all part of the urea cycle, are good examples of this. The main mechanism for removing nitrogenous waste is the synthesis of urea.
1.2.7 Nonstandard amino acids
Nonstandard amino acids are those that have been chemically modified after being incorporated into a protein (a process known as "posttranslational modification"), as well as those that occur naturally in living organisms but are not found in proteins. -carboxyglutamic acid, a calcium-binding amino acid residue found in the blood-clotting protein prothrombin, is one of these modified amino acids (as well as in other proteins that bind calcium as part of their biological function). Collagen is the most abundant protein in vertebrates in terms of mass. 4-hydroxyproline and 5-hydroxylysine are modified forms of proline and lysine that make up a significant portion of collagen's amino acids.
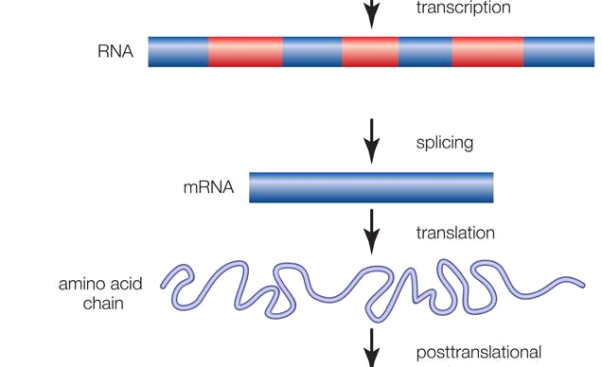
Gene; intron and exon
Promoter regions and alternating regions of introns (noncoding sequences) and exons make up genes (coding sequences). The transcription of a gene from DNA into RNA, the removal of introns and splicing together of exons, the translation of the spliced RNA sequences into a chain of amino acids, and the posttranslational modification of the protein molecule are all steps in the production of a functional protein.
The reversible addition of a phosphate molecule to the hydroxyl portion of the R groups of serine, threonine, and tyrosine is arguably the most important posttranslational modification of amino acids in eukaryotic organisms (including humans). This process is known as phosphorylation, and it is used to control the activity of proteins in the cell's day-to-day operations. Serine is the most commonly phosphorylated amino acid in proteins, followed by threonine and tyrosine.
Glycoproteins are proteins that have carbohydrates (sugars) covalently attached to them. Glycoproteins are widely distributed in nature and perform the same range of functions as unmodified proteins. Sugar groups are attached to amino acids in glycoproteins by either oxygen (O-linked sugars) or nitrogen atoms (N-linked sugars) in the amino acid residues. The oxygen atoms in serine, threonine, hydroxylysine, or hydroxylproline residues attach O-linked sugars to proteins. The nitrogen atom in asparagine is used to attach N-linked sugars to proteins.
Last but not least, there's selenocysteine. Despite the fact that it is only found in a few proteins, there is a good scientific reason to call it the 21st amino acid because it is introduced during protein biosynthesis rather than created through a posttranslational modification. Selenocysteine is derived from the amino acid serine (in a convoluted manner), and it contains selenium instead of cysteine's sulphur.
1.2.8 Synthesis of α-Amino Acids
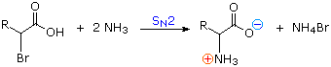
1) The following equation illustrates a simple method for preparing alpha-aminocarboxylic acids by amination of alpha-bromocarboxylic acids. Bromoacids, on the other hand, are easily made from carboxylic acids by reacting them with Br2 + PCl3. Although this direct method produced mediocre results when used to make simple amines from alkyl halides, it is more effective when used to make amino acids because the nitrogen atom in the product has a lower nucleophilicity. However, for amino acid synthesis, more complex procedures with high yields of pure compounds are frequently used.
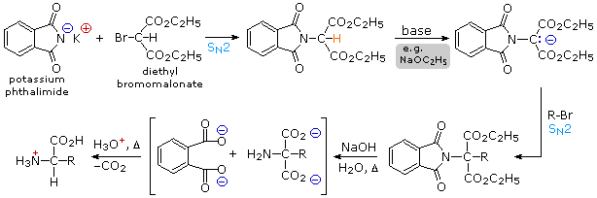
2) The proclivity of amines to undergo multiple substitutions is removed by modifying the nitrogen as a phthalimide salt, resulting in a single clean substitution reaction of 1o- and many 2o-alkylhalides. As shown in the upper equation of the following scheme, this procedure, known as the Gabriel synthesis, can be used to aminate bromomalonic esters. This intermediate can be converted to an ambident anion and alkylated because the phthalimide substituted malonic ester has an acidic hydrogen (coloured orange) that is activated by the two ester groups. Finally, acidification and thermal decarboxylation of the phthalimide moiety and esters, followed by base catalysed hydrolysis of the phthalimide moiety and esters, yields an amino acid and phthalic acid (not shown).
3) The Strecker synthesis assembles an alpha-amino acid from ammonia (the amine precursor), cyanide (the carboxyl precursor), and an aldehyde in an elegant manner. This reaction is essentially an imino analogue of cyanohydrin formation (shown below). The resulting alpha-amino nitrile can then be hydrolyzed to an amino acid using acid or base catalysis.

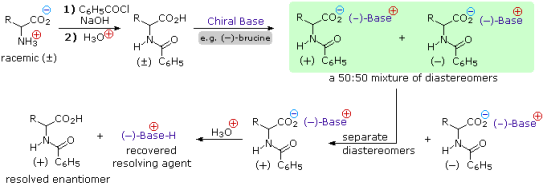
4) Resolution Racemic amino acid products are produced by the three synthetic procedures described above, as well as many others that can be imagined. It is necessary to resolve these racemic mixtures if pure L or D enantiomers are desired. Diastereomeric salt formation with a pure chiral acid or base is a common method of resolving racemates. The following diagram depicts this for a generic amino acid. Keep an eye out for charge symbols, which are shown in coloured circles, and optical rotation signs, which are shown in parenthesis. The carboxylic acid function contributes to the formation of diastereomeric salts in the initial display. To remove the basic character of the amino group, the racemic amino acid is first converted to a benzamide derivative. The carboxylic acid is then combined with an optically pure amine, such as brucine, to form an ammonium salt (a relative of strychnine). Because it is not a critical factor in the logical progression of steps, the structure of this amine is not shown. An equimolar mixture of diastereomeric salts is formed when the amino acid moiety is racemic and the base is a single enantiomer (laevorotatory in this case) (drawn in the green shaded box). Diastereomers can be separated using crystallisation, chromatography, or other physical methods, allowing one of the isomers to be isolated for further treatment; in this case, the (+) :(-) diastereomer. Finally, the salt is broken down with acid, yielding the resolved (+)-amino acid derivative and the resolving agent (the optically active amine). Of course, the (-)-enantiomer of the amino acid could be obtained using the same procedure.
The basic character of the amine function could also be used to achieve resolution because amino acids are amphoteric. To use tartaric acid as the resolving agent, we'd need an enantiomerically pure chiral acid. This alternate resolution strategy can be seen by clicking on the diagram above. It's worth noting that the carboxylic acid function is esterified first in order to avoid competing with the resolving acid.
Enzymatic discrimination in the hydrolysis of amides can also be used to resolve amino acid derivatives. An aminoacylase enzyme from pig kidneys, for example, cleaves the amide derivative of a natural L-amino acid much more quickly than the D-enantiomer. The L-enantiomer (whatever its rotation) will be rapidly converted to its free zwitterionic form if the racemic mixture of amides shown in the green shaded box above is treated with this enzyme, whereas the D-enantiomer will remain largely unchanged. The diastereomeric species in this case are transition states, not isolable intermediates. Kinetic resolution is the separation of enantiomers based on very different reaction rates.
1.3.1 IONIC COMPOUNDS
A transfer of electrons usually occurs when an element composed of atoms that readily lose electrons (a metal) reacts with an element composed of atoms that readily gain electrons (a nonmetal), resulting in ions. The electrostatic attractions (ionic bonds) between the ions of opposite charge present in the compound stabilise the compound formed by this transfer. When each sodium atom in a sample of sodium metal (group 1) gives up one electron to form a sodium cation, Na+, and each chlorine atom in a sample of chlorine gas (group 17) accepts one electron to form a chloride anion, Cl, the resulting compound, NaCl, is made up of sodium ions and chloride ions in the ratio of one Na+ ion to each Cl ion. Similarly, each calcium atom (group 2) can give up two electrons and transfer one to each of two chlorine atoms to form CaCl2, which is made up of Ca2+ and Cl ions in a one-to-two ratio.
An ionic compound is one that contains ions and is held together by ionic bonds. Many of the ionic compounds can be identified using the periodic table: The compound is usually ionic when a metal is combined with one or more nonmetals. For most of the compounds encountered in an introductory chemistry course, this guideline works well for predicting ionic compound formation. However, this isn't always the case (for example, aluminium chloride, AlCl3, is not ionic).
Because of their properties, ionic compounds are easily identifiable. Ionic compounds are solids that melt at high temperatures and boil at temperatures even higher. Sodium chloride, for example, melts at 801°C and boils at 1413°C. (By comparison, the molecular compound water melts at 0 degrees Celsius and boils at 100 degrees Celsius.) Because its ions are unable to flow in solid form, an ionic compound is not electrically conductive (“electricity” is the flow of charged particles). However, when molten, it can conduct electricity because its ions can freely move through the liquid. (Figure).

Figure. When molten, sodium chloride melts at 801°C and conducts electricity.
The total number of positive charges of the cations equals the total number of negative charges of the anions in every ionic compound. Ionic compounds, despite containing both positive and negative ions, are electrically neutral in general. This observation can be used to help us write the formula for an ionic compound. An ionic compound's formula must have an ion ratio that equalises the number of positive and negative charges.
Example
Predicting the Formula of an Ionic Compound
The gemstone sapphire (Figure) is primarily an aluminium and oxygen compound with aluminium cations (Al3+) and oxygen anions (O2). What is the chemical formula for this substance?

Figure. Although pure aluminium oxide is colorless, trace amounts of iron and titanium give blue sapphire its characteristic color.
Solution
The ionic compound must have the same number of positive and negative charges to be electrically neutral. We'd get six positive charges from two aluminium ions with a charge of 3+ each, and six negative charges from three oxide ions with a charge of 2. Al2O3 would be the formula.
1.3.2 Ionic Compound Properties
Melting Points
Ionic crystal lattices are extremely strong due to the numerous simultaneous attractions between cations and anions that occur. In order to break all of the ionic bonds in an ionic compound, large amounts of energy must be added during the melting process. The melting point of sodium chloride, for example, is around 800°C.
Shattering
Ionic compounds are hard but brittle in general. What is the reason for this? To force one layer of ions to shift relative to its neighbour, a large amount of mechanical force is required, such as striking a crystal with a hammer. When this happens, however, it brings ions with the same charge together (see Figure below). The crystal shatters due to the repulsive forces between like-charged ions. Because of the regular arrangement of the ions, when an ionic crystal breaks, it tends to do so along smooth planes.
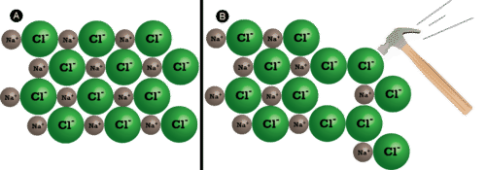
(A) The sodium chloride crystal is shown in two dimensions. (B) When struck by a hammer, the negatively-charged chloride ions are forced near each other and the repulsive force causes the crystal to shatter.
Conductivity
The electrical conductivity of ionic compounds is another distinguishing feature. Three experiments are shown below, in which two electrodes connected to a light bulb are placed in beakers with three different substances.
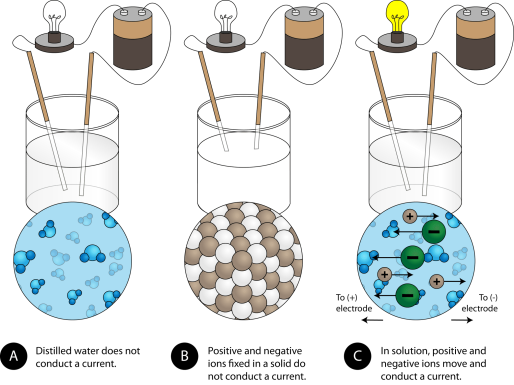
(A) Distilled water is not an electrical conductor. (B) A solid ionic compound, on the other hand, does not conduct. (C) An ionic compound in water conducts electricity well.
Because water is a molecular compound, it does not conduct a current in the first beaker. Solid sodium chloride in the second beaker also does not conduct a current. The solid crystal lattice, despite being ionic and thus composed of charged particles, prevents the ions from moving between the electrodes. For the circuit to be complete and the light bulb to turn on, mobile charged particles are required. The NaCl has been dissolved in the distilled water in the third beaker. The crystal lattice has now been broken apart, allowing the positive and negative ions to move freely. The movement of cations to one electrode and anions to the other allows electricity to flow (see Figure below). When an ionic compound is melted, the ions become free to conduct a current. When melted or dissolved in water, ionic compounds produce an electric current.
1.3.3 Chemical Reaction:
Chemical reactions play an important role in biology at all levels. A reaction, in its most basic form, necessitates reactants and products. The atoms or molecules that are involved in the change are known as reactants, and the changed atoms or molecules are known as products. Enzymes act as catalysts in most biological reactions, speeding up the process. When reactants are combined to form a product with different chemical properties than the original reactants, this is known as a chemical reaction. An energy change and a change in the electron configuration around the original atoms are always involved. A chemical reaction occurs when electrons redistribute their orbitals to include two or more atomic nuclei, as in a covalent bond, or donate or accept electrons, as in an ionic bond. During chemical reactions, two types of bonds form: covalent and ionic.
Ionic bonds are formed when an atom's outermost, or valence, electrons are given or received in association with another atom. Because the electrons are now orbiting the receiving atom rather than their original atom, the receiving atom's number of protons and electrons is now imbalanced, and it becomes a negatively charged ion. The donating atom has a proton-electron imbalance as well, and as a result of losing a negatively charged electron while maintaining the same number of protons, it becomes a positively charged ion. The properties of the resulting molecule differ from those of the original atoms. It's important to remember that the resulting ionic compounds have partial charges due to the unequal electron distribution around the reacting atoms. This significance is discussed in more depth in Specialized Cell Structure and Function, but it explains why water can dissolve any substance with a partial charge. The joining of a sodium atom that donates an electron to a chlorine atom that accepts the electron to form sodium chloride, also known as table salt, is an example of an ionic bond.
When two or more atoms share their electrons, they form covalent bonds. Instead of being donated or accepted, the electrons incorporate their orbitals to form an electron cloud around all of the participating atoms. When electrons are evenly distributed among all reacting nuclei, the resulting molecule has no partial charge, as when carbon covalently bonds with itself. However, in some cases, such as polar covalent bonds, the electrons are not evenly distributed, resulting in partial charges.
Many bonds, in reality, are a hybrid of ionic and covalent bonds, with characteristics of both types. Atoms with polar covalent bonds share their electrons unevenly (covalent characteristic) and give one end of the molecule a slight positive (+) charge and the other end a slight negative (-) charge. Because the oxygen atom has more protons acting as electron magnets, the electrons spend more time around it, making water a polar covalent molecule. Because the electrons spend more time orbiting around the oxygen atom due to this unequal sharing of electrons, the oxygen end of the molecule has a slight negative charge, while the hydrogen end has a partial positive charge. There is a partial positive and partial negative end to the molecule as a whole. As a result, water molecules tend to align themselves so that one molecule's positive end aligns with another's negative end (opposites attract).
The electrons are drawn away from the sending atom and accepted by the receiving atom in the ionic model. The covalent model depicts electrons being shared equally among all atoms, whereas the polar covalent model depicts unequal electron sharing.
The driving force behind any chemical reaction is always a move toward greater atom stability. Atoms react to lower their energy and increase their entropy in order to increase stability (randomness or lack of organization). This means they strive for a stable number of electrons in their outermost orbital in chemical terms. The stable number indicates that the outermost energy level is either fully charged or fully discharged. This is referred to as the v by chemists because it frequently takes eight valence electrons to achieve stability. Atoms donate/accept electrons (ionic) or share them to achieve this electron configuration (covalent). Because they contain the element carbon and are covalently bonded, biomolecules are classified as organic.
1.4.1 Zwitterion Definition
“A zwitterion is a molecule that has both positive and negative regions of charge.” Amino acids exist in the solid state as zwitterions, which are dipolar ions. The pH range in which the information is required must be specified when discussing whether a substance is zwitterionic or not (because a sufficiently alkaline solution will change the zwitterion to an anion, and a sufficiently acid solution will change it to a cation).
Some key Characteristics of Zwitterion are;
• Ampholytes, which contain both acid and base groups in their molecules, can be used to make them.
• The charged atoms in this type of ion are usually held together by one or more covalent bonds.
• On the atoms of zwitterionic compounds, there are stable, separated unit electrical charges.
• Quaternary ammonium cations are present in these compounds.
Let us further understand the topic by looking at an example of Zwitterion.
1.4.2 Zwitterion Structure
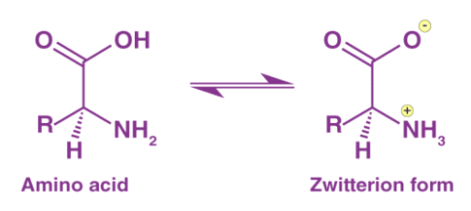
Amino Acids
Zwitterions are most commonly found in amino acids. They are made up of a positive charge ammonium or amino group and a negative charge carboxyl group. An amino acid's zwitterion form is as follows:
Aside from amino acids, any compound with acid and base centres can be converted to a Zwitterion form. Tricine, bicine, solid sulfamic acid, and alkaloids like psilocybin are some more examples.
1.4.3 Isoelectric Point
• Another important feature of a Zwitterion is that it has an isoelectric point (pI, pH(I), IEP).
• This point is the pH value at which the charge in molecules is neutral.
• The pH of a molecule's surrounding environment has a significant impact on its net charge.
• As a result of the increase or decrease in the number of protons, molecules can become more charged (positively or negatively).
• When it comes to amino acids, the amino group is a powerful proton acceptor, while the carboxyl group is a powerful proton donor.
• Furthermore, the pI value influences the solubility of a molecule at a given pH.
1.4.4 Calculation of pH Value
The pH value at the isoelectric point can be calculated from the equilibrium constants (acid and base) of the Zwitterion. It is represented by the formula;
PI=pKa1+pKa22
Where,
• pI = isoelectric point,
• Ka1 = the equilibrium constant of the acid.
• Ka2 = the equilibrium constant of the base.
1.4.5 Applications of Zwitterions
• Zwitterions are widely used in the separation of protein molecules using the SDS PAGE (sodium dodecyl sulfate-polyacrylamide gel electrophoresis) method, which is one of the most widely used molecular biology techniques.
• They also have significant potential for use in a variety of medical and biological fields.
• Medical implants, drug delivery, blood contacted sensor, separation membrane, and antifouling coatings for biomedical implants that help prevent microbial adhesion and biofilm formation are just a few of the applications.
• Zwitterionic polymers are used in the marine industry to prevent subaquatic organisms from growing on boats and piers.
1.5.1 pKa Definition
PKa is the negative base-10 logarithm of the acid dissociation constant (Ka) of a solution.
pKa = -log10Ka
The lower the pKa value, the stronger the acid. Acetic acid, for example, has a pKa of 4.8, while lactic acid has a pKa of 3.8. Lactic acid is a stronger acid than acetic acid, as evidenced by the pKa values.
Because it uses small decimal numbers to describe acid dissociation, pKa is used. Ka values can provide the same type of information, but they are typically extremely small numbers written in scientific notation that are difficult to comprehend for most people.
1.5.2 pKa Values:
It's useful to be able to compare the Bronsted-Lowry acidities of various compounds. If protons are passed from a more acidic site to a less acidic site, the site that binds the proton more tightly will keep the proton, while the site that binds the proton less tightly will lose the proton. We can predict which direction a proton will be transferred if we know which sites bind protons more tightly.

A parameter that has been determined experimentally tells us how tightly protons are bound to different compounds. The term "experimental" conjures up images of "untested" or "unreliable" in the minds of students, but in this case, it simply means that someone has done the work to determine how tightly the proton is bound. In this context, experimental means "based on physical evidence."
"The pKa" is the name given to this experimental parameter. The pKa is a measure of how tightly a Bronsted acid holds a proton. A pKa value can be as low as -3 or as high as -5. It could be a higher, positive number like 30 or 50. A Bronsted acid's pKa indicates how easily it gives up its proton. The higher the pKa of a Bronsted acid, the more tightly the proton is held and the more difficult it is to release the proton.

Figure. The pKa scale as an index of proton availability.
• Low pKa means a proton is not held tightly.
• pKa can sometimes be so low that it is a negative number!
• High pKa means a proton is held tightly.
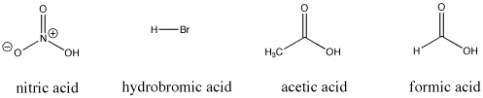
Figure. Some Bronsted acidic compounds; all of these compounds are relatively easy to supply protons.
Nitric acid and hydrochloric acid, for example, both readily give up their protons. The pKa of nitric acid in water is -1.3, while hydrobromic acid has a pKa of -9.0. Acetic acid (found in vinegar) and formic acid (the irritant found in ant and bee stings) will both release protons, but they will do so more tightly. The pKas of these two proteins are 4.76 and 3.77, respectively. Water has a pKa of 15.7, which means it doesn't give up a proton easily. Methane has a pKa of about 50, which indicates that it is not really an acid.

Figure. A few less acidic compounds Water is only mildly acidic, whereas methane is not at all acidic.
A Bronsted acid's "strength" is measured by its pKa. A proton, H+, is a strong Lewis acid that attracts electron pairs so well that it is almost always associated with an electron donor. A strong Bronsted acid is a substance that readily gives up its proton.
A weak Bronsted acid is one that has a harder time giving up its proton. To take it a step further, a compound from which removing a proton is extremely difficult is not considered an acid at all.
When a compound loses a proton, it keeps the electron pair it shared with the proton previously. It takes on the form of a conjugate base. Another way to look at it is that a strong Bronsted acid easily gives up a proton, resulting in a weak Bronsted base. The Bronsted base has a difficult time bonding to the proton. It has a hard time giving up its electron pair to a proton. It only does so in a shaky way.
Similarly, if a compound loses a proton and transforms into a strong base, the base will readily accept the proton back. The strong base effectively competes for the proton so well that the compound remains protonated. Rather than ionising and becoming the strong conjugate base, the compound remains a Bronsted acid. It's a Bronsted acid that's not very strong.
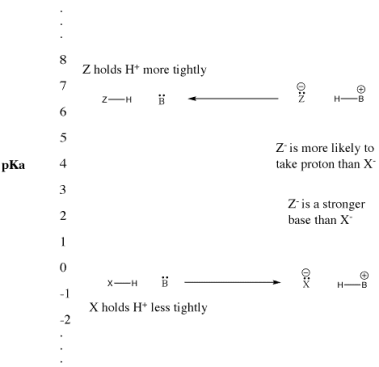
Figure. The pKa scale and its effect on conjugate bases.
• "Strong" Bronsted acids ionize easily to provide H+.
• This term is usually used to describe common acids such as sulfuric acid and hydrobromic acid.
• "Weak" Bronsted acids do not ionize as easily.
• This term is often used to describe common acids such as acetic acid and hydrofluoric acid.
The terms "strong" and "weak" are, however, subjective. We've seen pKa values ranging from -5 to 50. What is a weak acid if it has a pKa of 4? What is a strong acid if it has a pKa of 25? Is this a very weak acid? It's unquestionably a better proton source than something with a pKa of 35. Is that a VERY, VERY, VERY, VERY In a pKa unit, how many "verys" are there?
This concept holds true when a base pick up a proton to form a conjugate acid. The strength with which the base can remove protons from other acids is proportional to how tightly the conjugate acid holds a proton. The stronger something's conjugate is as a proton sponge, the weaker it is as a source of protons.
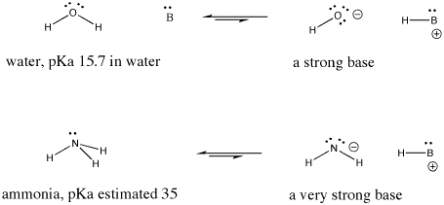
Figure. Examples of a strong base and an even stronger one.
• The terms "strong acid" and "weak acid" can be used relatively, rather than absolutely.
• The same is true for "strong base" and "weak base".
• Sometimes, whether something is called "strong" or "weak" depends on what else it is being compared to.
1.5.3 pKa and Buffer Capacity
In addition to determining the acid's strength, pKa can be used to select buffers. Because of the relationship between pKa and pH, this is possible:
Where the square brackets indicate the concentrations of the acid and its conjugate base, pH = pKa + log10([A-]/[AH])
The following is a rewrite of the equation:
[A-]/[AH] = Ka/[H+]
When half of the acid has dissociated, the pKa and pH are equal. When the pKa and pH values are close, a species' buffering capacity, or ability to maintain the pH of a solution, is at its peak. When choosing a buffer, the one with a pKa value close to the chemical solution's target pH is the best option.
Key Takeaways:
- The pKa value is one method used to indicate the strength of an acid.
- PKa is the negative log of the acid dissociation constant or Ka value.
- A lower pKa value indicates a stronger acid. That is, the lower value indicates the acid more fully dissociates in water.
1.6.1 Electrophoresis
Proteins' positively and negatively charged side chains cause them to behave like amino acids in an electrical field, migrating to the cathode (negative terminal) at low pH and to the anode (positive terminal) at high pH during electrophoresis (positive terminal). For many proteins, the isoelectric point, or the pH at which the protein molecule does not migrate, is in the range of pH 5 to 7. Proteins rich in lysine and arginine, such as lysozyme, cytochrome c, histone, and others, have isoelectric points in the pH range of 8 to 10. Pepsin's isoelectric point is close to 1, despite the fact that it contains very few basic amino acids.
Number of amino acids per protein molecule | ||||||||
Amino acid | Protein* | |||||||
Cyto | Hb Alpha | Hb Beta | RNase | Lys | Chgen | Fdox | ||
*Cyto = human cytochrome c; Hb alpha = human hemoglobin A, alpha-chain; Hb beta = human hemoglobin A, beta-chain; RNase = bovine ribonuclease; Lys = chicken lysozyme; Chgen = bovine chymotrypsinogen; Fdox = spinach ferredoxin. | ||||||||
**The values recorded for aspartic acid and glutamic acid include asparagine and glutamine, respectively. | ||||||||
Lysine | 18 | 11 | 11 | 10 | 6 | 14 | 4 | |
Histidine | 3 | 10 | 9 | 4 | 1 | 2 | 1 | |
Arginine | 2 | 3 | 3 | 4 | 11 | 4 | 1 | |
Aspartic acid** | 8 | 12 | 13 | 15 | 21 | 23 | 13 | |
Threonine | 7 | 9 | 7 | 10 | 7 | 23 | 8 | |
Serine | 2 | 11 | 5 | 15 | 10 | 28 | 7 | |
Glutamic acid** | 10 | 5 | 11 | 12 | 5 | 15 | 13 | |
Proline | 4 | 7 | 7 | 4 | 2 | 9 | 4 | |
Glycine | 13 | 7 | 13 | 3 | 12 | 23 | 6 | |
Alanine | 6 | 21 | 15 | 12 | 12 | 22 | 9 | |
Half-cystine | 2 | 1 | 2 | 8 | 8 | 10 | 5 | |
Valine | 3 | 13 | 18 | 9 | 6 | 23 | 7 | |
Methionine | 3 | 2 | 1 | 4 | 2 | 2 | 0 | |
Isoleucine | 8 | 0 | 0 | 3 | 6 | 10 | 4 | |
Leucine | 6 | 18 | 18 | 2 | 8 | 19 | 8 | |
Tyrosine | 5 | 3 | 3 | 6 | 3 | 4 | 4 | |
Phenylalanine | 3 | 7 | 8 | 3 | 3 | 6 | 2 | |
Tryptophan | 1 | 1 | 2 | 0 | 6 | 8 | 1 | |
Total | 104 | 141 | 146 | 124 | 129 | 245 | 97 | |

Two-dimensional gel electrophoresis
Proteins are separated by charge and size in two-dimensional gel electrophoresis. Isoelectric focusing (IEF), sodium dodecyl sulphate (SDS), polyacrylamide gel electrophoresis (PAGE), and immobilised pH gradient (IPG-Dalt) SDS-PAGE are all methods that are commonly used.
The original method of determining electrophoretic migration, free-boundary electrophoresis, has been largely replaced by zone electrophoresis, in which the protein is placed in either a starch, agar, or polyacrylamide gel or a porous medium such as paper or cellulose acetate. Visually, haemoglobin and other coloured proteins can be followed as they migrate. Following electrophoresis, colourless proteins are stained with a suitable dye to make them visible.
1.6.2 The Isoelectric Point
The isoelectric point, pI, is the pH of an aqueous solution of an amino acid (or peptide) at which the molecules on average have no net charge. In other words, the positively charged groups are exactly balanced by the negatively charged groups. For simple amino acids such as alanine, the pI is an average of the pKa's of the carboxyl (2.34) and ammonium (9.69) groups. Thus, the pI for alanine is calculated to be: (2.34 + 9.69)/2 = 6.02, the experimentally determined value. If additional acidic or basic groups are present as side-chain functions, the pI is the average of the pKa's of the two most similar acids. To assist in determining similarity we define two classes of acids. The first consists of acids that are neutral in their protonated form (e.g., CO2H & SH). The second includes acids that are positively charged in their protonated state (e.g. -NH3+). In the case of aspartic acid, the similar acids are the alpha-carboxyl function (pKa = 2.1) and the side-chain carboxyl function (pKa = 3.9), so pI = (2.1 + 3.9)/2 = 3.0. For arginine, the similar acids are the guanidinium species on the side-chain (pKa = 12.5) and the alpha-ammonium function (pKa = 9.0), so the calculated pI = (12.5 + 9.0)/2 = 10.75
1.6.3 Isoelectric Point Separations of Peptides and Proteins.
The separation of biomolecules, particularly proteins, in the presence of an electric field (e.g., electrophoresis) has spawned a slew of methodologies for reducing sample complexity and probing the physiochemical properties of these biomolecules. Electrophoretic methods are used to investigate proteins and peptides, which are possibly the most studied class of molecules. Electrophoresis on agarose and polyacrylamide gels, two-dimensional gel electrophoresis (2DE), capillary electrophoresis, isotachophoresis, and other methods are among them.
Isoelectric focusing (IEF) is an electrophoretic technique that separates ampholytic components, or molecules that act as weak acids and bases, according to their isoelectric points. In IEF, ampholytes travel according to their charge in the presence of a pH gradient, under the influence of an electric field, until the molecule's net charge is zero (e.g., isoelectric point, pI). When it comes to peptides and proteins, the separation is determined by the amino acid composition and exposed charged residues that act as weak acids and bases (Figure). The migration of ampholytic species will follow basic electrophoresis principles; however, in the presence of a pH gradient, mobility will change, with migration slowing at values close to the pI value. Ampholytes as simple as amino acids can create a pH gradient and act as an isoelectric buffer.
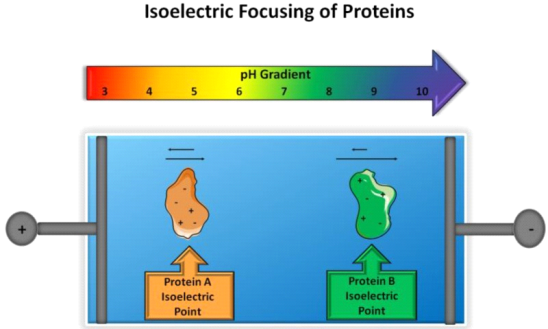
The isoelectric focusing principle. In the presence of a pH gradient and an electric field, two proteins with different isoelectric points will migrate until the net charge of one protein is zero, at which point migration will stop.
The most common chemical components used to create pH gradients are carrier ampholytes. Pentaethylenehexamine and acrylic acid were used to create the chemistry of carrier ampholytes at first. Vesterberg used a second-generation approach in carrier ampholyte synthesis, in which a heterogeneous mixture of amines was reacted with acrylic acid and a complex product produced thousands of molecules with varying pI values but very small changes in pI values across a pH range. As a result, an ideal carrier ampholyte mixture is created, consisting of a large number of components with similar pI values and a linear pH gradient. In terms of gels, carrier ampholytes can be embedded in acrylamide gels and separated using the slab/flatbed method. The history and specifics of carrier ampholyte synthesis have already been discussed.
The generation of immobilised pH gradients in 1982 [8] was a major achievement that was an extension of the synthesis of carrier ampholytes. Bjellqvist et al. Used acrylamide as a backbone, adding amino and carboxyl groups via radical-mediated reactions, allowing for branching and crosslinking with different pKa carrier ampholytes. The end result is a pH gradient that acts as a buffer and is immobile in an electric field. PH values range from 1 to 13, and linear and nonlinear forms can be synthesised. The length of the IEF setup used has an impact on the required resolution. This significant advancement paved the way for a variety of isoelectric focusing applications in the separation of biological molecules, particularly peptides and proteins. A series of factors in the experiment, including the diffusion coefficient, conductivity, and electric current density, determine the resolving power of IEF (pI). The slope and charge curve near the focusing point are two gradient properties. These properties and connections have been thoroughly examined.
IEF can be done in many different ways, including preparative, analytical, and microscale. IEF has proven to be useful as a preparative method on a larger scale because of its ability to separate large amounts of samples with high resolution and high recovery yields. This separation method is particularly advantageous because it can concentrate large amounts of samples while also removing common interfering agents or unwanted analytes. In addition, as described below, IEF can be performed in capillaries, microfluidic channels, and multi-compartment electrolyzers (MCE). In general, IEF is a very powerful technique that allows fractionation of samples in any format, resulting in reduced sample complexity and more in-depth analysis.
1.7.1 Peptides:
Peptide, any organic compound with molecules that are structurally similar to proteins but smaller. Many hormones, antibiotics, and other compounds that participate in the metabolic functions of living organisms are classified as peptides. Peptide molecules are made up of two or more amino acids linked together by the carboxyl group of one amino acid and the amino group of the next. A peptide bond is the chemical bond that exists between the carbon and nitrogen atoms of each amide group. Partial or complete hydrolysis of the compound can break some or all of the peptide bonds that connect the consecutive triplets of atoms in the chain regarded as the molecule's backbone. This reaction, which produces smaller peptides and then individual amino acids, is commonly used in peptide and protein composition and structure research.
A prefix indicates the number of amino-acid molecules present in a peptide: a dipeptide has two amino acids, an octapeptide has eight, an oligopeptide has a few, and a polypeptide has many. The distinction between a polypeptide and a protein is hazy and largely academic; some authorities have set a molecular weight limit of 10,000 for polypeptides (that of a peptide composed of about 100 amino acids).
1.7.2 Types & Classes of Peptides
These are categorized into several classes, based on their production type.
- Milk Peptides: Casein is a milk protein that is broken down by the digestive system. They're also made up of proteinases produced by lactobacilli during milk fermentation.
- Peptones: Peptones are formed when animal milk or meat is proteolyzed. Vitamins, fats, metals, and some salts can all be used to make it. Peptones are useful in nutrient media for growing fungi and bacteria.
- Ribosomal Peptides: These are created by mRNA translation (the process by which cellular ribosomes turn mRNA into proteins). They are frequently subjected to proteolysis in order to reach their mature form. Antibiotic peptides are produced by some organisms, such as microcins (small bacteria). However, post-translational modifications such as hydroxylation, phosphorylation, sulfonation, and glycosylation occur in these peptides.
- Non-ribosomal Peptides: Instead of the ribosome, non-ribosomal peptides are made up of enzymes that are specific to each peptide. The most common non-ribosomal peptide is glutathione. The structures of these peptides are extremely complex, and they are frequently cyclic.
- Peptide Fragments: The fragments of proteins that are used to quantify or identify the source of protein are referred to as Peptide fragments.
1.7.3 Classification of Peptides:
As previously stated, oligopeptides and polypeptides are distinguished by whether the peptide is made up of less than four or more than four amino acids. Natural peptides are made up of different amino acids, but homopeptides can be made artificially (triglycine, polyphenylalanine etc.).
1.7.4 Classification of AMPs:
The diversity of natural AMPs causes difficulty in their classification. AMPs are classified based on (1) source, (2) activity, (3) structural characteristics, and (4) amino acid-rich species (Figure).
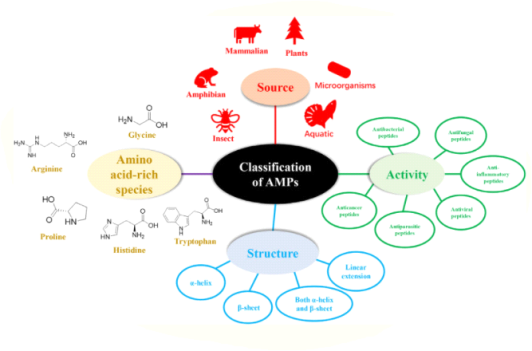
Classification of antimicrobial peptides
1.7.5 Classification of AMPs Based on Sources
According to statistical data in APD3, the sources of AMPs are mammals (human host defence peptides account for a large proportion), amphibians, microorganisms, and insects. The AMPs discovered in oceans have also gotten a lot of attention.
• Mammalian Antimicrobial Peptides
Humans, sheep, cattle, and other vertebrates all have antimicrobial peptides. Cathelicidins and defensins are the two most common AMP families. Defensins are classified as -, -, or -defensins, depending on where the disulfide bonds are located (Reddy et al., 2004). HDPs (human host defence peptides) can protect humans from microbial infections, but they have different expressions at different stages of life. Cathelicidin LL-37, a well-known AMP derived from the human body, is commonly found in the skin of new born infants, whereas human beta-defensin 2 (hBD-2) is frequently expressed in the elderly rather than the young (Gschwandtner et al., 2014). HDPs can be found in the skin, eyes, ears, mouth, respiratory tract, lung, intestine, and urethra, among other places. Furthermore, AMPs in human breast milk play an important role in breastfeeding by lowering the morbidity and mortality of breast-fed infants (Field, 2005). Casein201 (peptide derived from -Casein 201–220 aa), which has been identified in colostrum, is found in preterm and term human colostrums at different levels (Zhang et al., 2017). Dairy is a significant source of AMPs, which are produced by the enzymatic hydrolysis of milk. Several AMPs have been discovered in -lactalbumin, -lactoglobulin, lactoferrin, and casein fractions, with lactoferricin B (LfcinB) being the most well-known (Sibel Akaln, 2014). Furthermore, it will be interesting to see if AMPs derived from dairy products can be used to preserve dairy products.
HDPs, such as cathelicidins and defensins, affect immune regulation, apoptosis, and wound healing in addition to antimicrobial activity (Wang, 2014).
• Amphibian-Derived Antimicrobial Peptides
Amphibian antimicrobial peptides are important in protecting amphibians from pathogens that have caused a global decline in amphibian populations (Rollins-Smith, 2009). The most well-known amphibian AMP is magainin, which is found in the skin secretions of frogs from the genera Xenopus, Silurana, Hymenochirus, and Pseudhymenochirus, all of which belong to the Pipidae family (Conlon and Mechkarska, 2014). Cancrin, whose amino acid sequence is GSAQPYKQLHKVVNWDPYG, has also been identified as the first AMP discovered in the sea amphibian Rana cancrivora (Lu et al., 2008). This indicates a larger source of amphibian AMPs.
• Insect-Derived Antimicrobial Peptides
Antimicrobial peptides are primarily synthesised in insects' fat bodies and blood cells, which is one of the primary reasons for their high adaptability to survival (Vilcinskas, 2013). Cecropin is the most well-known family of insect AMPs, and it's found in guppy silkworm, bees, and Drosophila. Cecropin A has been shown to have anti-inflammatory and anti-cancer properties. The number of AMPs varies significantly between species; for example, the invasive harlequin ladybird (Harmonia axyridis) and black soldier fly (Hermetia illucens) have up to 50 AMPs, whereas the pea aphid (Acyrthosiphon pisum) has none. Jellein, a peptide derived from bee royal jelly, has antibacterial and antifungal properties, and its lauric acid-conjugated form inhibits the parasite Leishmania major.
• Microorganisms-Derived Antimicrobial Peptides
Antimicrobial peptides can be extracted from bacteria and fungi, and some well-known peptides include nisin and gramicidin from Lactococcus lactis, Bacillus subtilis, and Bacillus brevis, among others (Cao et al., 2018). Biological expression has received increased attention as a result of the high cost of chemical synthesis of AMPs. Expression systems have been used in Pichia pastoris, Saccharomyces cerevisiae, and bacteria such as Escherichia coli, B. Subtilis, and plants, but it should be noted that AMPs are difficult to produce in E. Coli due to toxicity, proteolytic degradation, and purification, which is required to take advantage of fusion.
Furthermore, a variety of AMPs have been extracted and isolated from plant stems, seeds, and leaves, and they are divided into several groups, including thionins, defensins, and snakins. More marine-derived AMPs have been reported to have contributed to people's increasing value for marine resources. Several of the reported marine AMPs have shown promising results in vivo, for example, As-CATH4 has an immunity-stimulating effect in vivo and can enhance the anti-infective capability of drugs used in combination with it. Myticusin-beta is an immune-related AMP produced by Mytilus coruscus that could be used instead of antibiotics. Furthermore, GE33, also known as pardaxin, is a marine AMP, and a vaccine based on it has been shown to improve antitumor immunity in mice.
1.7.6 Classification Based on Activity
According to the ADP3 database's statistics, AMP activity can be divided into 18 categories. Antibacterial, antiviral, antifungal, antiparasitic, anti-human immunodeficiency virus (HIV), and anti-tumor peptides are the different types of antibacterial, antiviral, antifungal, antiparasitic, anti-human immunodeficiency virus (HIV), and anti-tumor peptides (Figure).
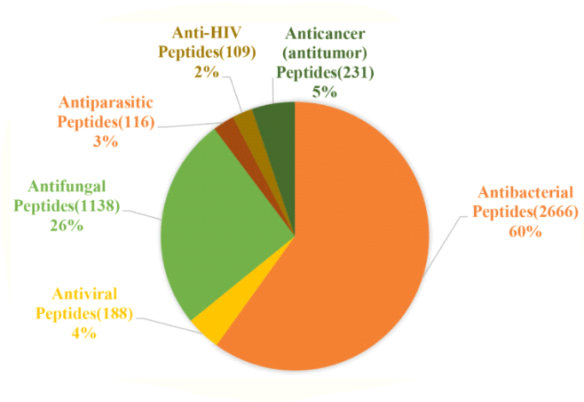
Antimicrobial peptides' main functions in statistics. Antibacterial peptides account for approximately 60% of all peptides, followed by antifungal peptides (26%), and antiviral, antiparasitic, anticancer, and anti-HIV peptides (2–5%). (The figure is drawn based on data in APD3).
• Antibacterial Peptides
Antibacterial peptides make up a significant portion of AMPs and have a broad inhibitory effect on pathogenic bacteria such as VRE, Acinetobacter baumannii, and MRSA in clinical medicine, S. Aureus, Listeria monocytogenes, E. Coli in food, and Salmonella, Vibrio parahaemolyticus in aquatic products. Many natural and synthetic AMPs, such as nisin, cecropins, and defensins, have shown good Gram-positive and Gram-negative bacteria inhibition activity. Recent research has found that the AMPs P5 (YIRKIRRFFKKLKKILKK-NH2) and P9 (SYERKINRHFKTLKKNLKKK-NH2), which are based on Aristicluthys nobilia interferon-I, inhibit MRSA and have a low cytotoxicity.
• Antifungal Peptides (AFPs)
Antifungal peptides are a type of AMP that targets fungal infections that are resistant to drugs. Many AFPs have demonstrated excellent antifungal activity against common pathogenic fungi in clinical medicine, such as Aspergillus and Candida albicans, yeast, filamentous fungi (e.g., Aspergillus flavus), and mould in food and agriculture. Apart from brevinin, ranatuerin, and cecropins, many synthetic peptides have antifungal properties. AurH1, derived from aurein 1.2, for example, can effectively treat C. Albicans infection, which has a lethal rate of up to 40%. Aflatoxin is a carcinogen produced by Aflatoxin. Flavus, on the other hand, is harmful to the human body. Many AFPs can stop A. Flavus from growing. An AFP with the sequence FPSHTGMSVPPP, for example, can stop A. Flavus MD3 from growing. In fresh maize seeds, a mixture of 37 antifungal peptides isolated from Lactobacillus plantarum TE10 can reduce A. Flavus spore formation. Furthermore, two chemically synthesised radish AMPs inhibit different yeast species, including Zygosaccharomyces bailii and Zygosaccharomyces rouxii.
• Antiviral Peptides (AVPs)
Viruses endanger human life and cost the animal husbandry industry a lot of money. COVID-19, the most recent outbreak, has resulted in significant loss of life and property. Furthermore, long-term threats to human life include the foot-and-mouth disease virus, avian influenza virus (AIV), and HIV. As a result, solving these issues is critical, and antiviral peptides offer new options. Antiviral peptides kill viruses by (1) inhibiting virus attachment and cell membrane fusion, (2) destroying the virus envelope, or (3) inhibiting virus replication (Jung et al., 2019) (Figure). According to a recent study, AMP Epi-1 mediates virus particle inactivation and has good inhibitory activity against the foot-and-mouth disease virus (Huang et al., 2018). Furthermore, the pathogen of infectious bronchitis is infectious bronchitis virus (IBV), and inoculation of swine intestinal AMP (SIAMP)–IBV mixed solution significantly reduced the mortality of chicken embryos compared to the IBV infection group, demonstrating SIAMP's good inhibitory activity on IBV (Sun et al., 2010). Anti-HIV peptides belong to the anti-viral peptide’s family. Defensins (including - and -defensins, which have different mechanisms), LL-37, gramicidin D, caerin 1, maximin 3, magainin 2, dermaseptin-S1, dermaseptin-S4, siamycin-I, siamycin-II, and RP 71955 are examples of these peptides, and the antiviral peptide Fuzeon (enfuvirtide) has been commercialised as an (Ashkenazi et al., 2011).
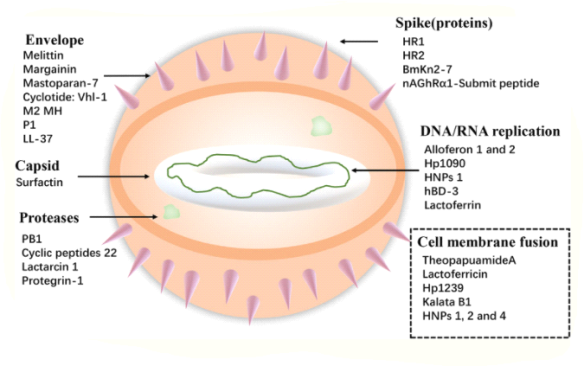
Examples of specific targets for Antiviral peptides.
The antiviral peptides against the coronavirus will be discussed in greater depth due to the global spread of the COVID-19. Coronaviruses (CoVs) are enveloped viruses with a positive-sense single-stranded RNA genome and helical symmetry that belong to the Coronaviridae family (Franks and Galvin, 2014). CoVs, such as the SARS-CoV and the Middle East respiratory syndrome coronavirus (MERS-CoV) (Mustafa et al., 2018), as well as the recent COVID-19 outbreak, have posed serious threats to human life and property. The viral particle is made up of the spike glycoprotein (S), the envelope (E), the membrane (M), and the nucleocapsid (N). CoVs can cause life-threatening respiratory diseases (N). It's worth noting that their infectivity is contingent on the presence of viral spike (S) protein. Fusion inhibitor peptides bind to the S protein and prevent infection by interfering with folding. In addition, the SARS-CoV S protein's S2 domain contains HR1 and HR2 heptad repeat sequences. HR2 (SLTQINTTLLDLTYEMLSLQQVVVKALNESYIDLKEL) and its lipid-binding peptide are very similar, if not identical, to the near-membrane portion of S protein ferredoxin, which prevents it from folding into post-fusion fusion-catalyzing domains (FDs). The lipopeptide EK1C4, which is derived from EK1 (SLDQINVTFLDLEYEMKKLEEAIKKLEESYIDLKEL), is the most effective fusion inhibitor against COVID-19 S protein-mediated membrane fusion, according to recent research. Timorin has potential therapeutic applications against MERS-CoV, according to homology modelling and protein-peptide docking. K12 and K29, two AMPs derived from SARS-non-structural CoV's protein nsp10, can inhibit SARS-CoV replication (Ke et al., 2012). Furthermore, in the presence of SARS-CoV, animals treated with rhesus theta-defensin 1 (RTD-1) have a significant reduction in mortality, whereas the peptide alone causes airway inflammation, suggesting that RTD-1's mechanism of action is immunomodulatory. In general, AMPs against coronavirus can be divided into three categories: peptides derived from the spike protein's HR1, HR2, and RBD subunits, peptides derived from other AMPs, and peptides derived from non-structural protein. Furthermore, according to molecular docking analysis, peptides were used to disrupt the interaction between COVID-19 and ACE2 (angiotensin-converting enzyme 2) in order to prevent COVID-19 from entering cells (Souza et al., 2020). Finally, clinical trials for this therapy are lacking, and the primary method of animal testing is intranasal administration. This serves as a reminder that nasal drug delivery (NDD) could be used to treat AMPs as anti-coronavirus drugs. Furthermore, the antiviral database AVPdb2 contains a large number of antiviral peptides.
COVID-19 information. (A) C-F13-nCoV Wuhan strain 02, CHPC 2020.00002; NPRC 2020.00002, National Pathogen Resource Collection Center, Source: (National Institute for Viral Disease Control and Prevention under Chinese Center for Disease Control and Prevention). (B) The structure of a novel coronavirus spike receptor-binding domain in complex with the ACE2 receptor.
• Antiparasitic Peptides
Parasitic protozoa can infect humans and animals via a number of routes, including animal-to-human or person-to-person contact, water, soil, and food. The need for new treatments has grown as parasite drug resistance has increased. Antiparasitic peptides kill parasites that cause diseases like malaria and leishmaniasis, while AMPs like cathelicidin and temporins-SHd have high parasite inhibition activity. Epi-1, a marine synthetic AMP, has been shown to effectively inhibit Trichomonas vaginalis by destroying its membrane. Jellein, a peptide derived from bee royal jelly, as well as the 4-amino acid AMP KDEL (lysine, aspartic acid, glutamic acid, and leucine), have both shown to have a significant effect on the Leishmania parasite. It should be noted, however, that their mechanisms are not identical. Antiparasitic activity of cyanobacterial peptides differs from that of higher-eukaryote AMPs because it is dependent on specific protein targets. Even though they belong to the same family or genus, these target parasites can be distinguished accurately.
• Anticancer Peptides (ACPs)
The ACPs exhibit anticancer mechanisms by (1) recruiting immune cells (such as dendritic cells) to kill tumour cells, (2) inducing cancer cell necrosis or apoptosis, (3) inhibiting tumour nutrition and preventing metastasis, and (4) activating certain regulatory functional proteins to interfere with tumour cell gene transcription and translation. In vitro, tritrpticin and its analogues cause significant toxicity in Jurkat cells, whereas indolicidin and puroindoline A can also function as ACPs (Arias et al., 2020). It's worth noting that both net charge and hydrophobicity are important factors in optimising ACP anticancer activity, and they can both constrain and influence one another. For better anticancer activity, achieving a balance between net charge and hydrophobicity is critical.
Anti-inflammatory, anti-diabetic, spermicidal, and other peptides have been discovered in addition to the peptide mentioned above, but they are not the same as antimicrobial peptides. Simply put, anti-inflammatory peptides reduce the production of inflammatory mediators and cytokines (nitric oxide, interleukin-6, and interleukin-1), and some of them also block inflammatory signals such as the NF-B, MAPK, and JAK-STAT pathways (Meram and Wu, 2017; Gao et al., 2020). Anti-diabetic peptides work by activating glucagon-like peptide-1 (GLP-1) receptors or modulating the G protein-coupled receptor kinase (GRK 2/3). However, classifying these peptides as AMPs is inaccurate, and bioactive peptides may be more convincing.
1.7.7 Classification of AMPs Based on Amino Acid-Rich Species
• Proline-Rich Peptides (PrAMPs)
The amino acid proline is a non-polar amino acid. PrAMPs differ from other AMPs in that they enter the bacterial cytoplasm via the inner membrane transporter SbmA rather than killing bacteria by destroying membranes. PrAMPs enter the cytoplasm and bind to ribosomes, blocking aminoacyl-tRNA binding to the peptidyltransferase centre or trapping decoding release factors on the ribosome during translation termination, interfering with protein synthesis (Seefeldt et al., 2015). Tur1A, for example, a Tursiops truncatus orthologous AMP of bovine PrAMP Bac7, interferes with the transition from the initial to the extension phase of protein synthesis by binding to ribosomes. Furthermore, while different PrAMPs have little in common in terms of sequence, they all have short motifs containing repeating proline and arginine (Arg) residues (e.g., -PPXR- in Bac5 and -PRPX- in Bac7). Although PrAMPs are primarily effective against Gram-positive bacteria, pPR-AMP1, a proline-rich AMP isolated from the crab Scylla paramamosain, has antimicrobial activity against both Gram-positive and Gram-negative bacteria. Furthermore, studies have revealed that PrAMPs have immunostimulatory properties.
• Tryptophan- and Arginine-Rich Antimicrobial Peptides
Tryptophan (Trp), a non-polar amino acid, has a notable effect on the lipid bilayer's interface region, whereas Arg, a basic amino acid, confers peptide charge and hydrogen bond interactions, both of which are necessary when combining with the bacterial membrane's abundant anionic component. Trp residues appear to act as natural aromatic activators of Arg-rich AMPs via ion-pair interactions, resulting in improved peptide-membrane interactions. In addition to the well-known AMPs indolicidin and triptrpticin, which are both high in Arg and Trp residues. Octa 2 (RRWWRWWR) is a Trp and Arg-rich AMP that inhibits Gram-negative E. Coli and Pseudomonas aeruginosa, as well as Gram-positive S. Aureus. Short Trp- and Arg-rich AMPs based on bovine and murine lactoferricin have also demonstrated strong antibacterial activity.
• Histidine-Rich Peptides
Histidine is a common basic amino acid, and AMPs that are high in histidine have good membrane permeation activity. HV2 is a histidine-rich AMP based on the RR(XH)2XDPGX(YH)2RR–NH2RR(XH)2XDPGX(YH)2RR–NH2 (where X represents I, W, V, and F). This peptide causes cell membrane rupture and death by increasing the permeability of bacterial cell membranes. Furthermore, HV2 inhibits bacterial movement in a concentration-dependent manner and has a potent anti-inflammatory effect by inhibiting tumour necrosis factor (TNF-) production. By replacing the Arg residues in Octa 2 with histidine, an AMP with therapeutic potential has been developed. By inserting four histidine sequences in leucine and alanine, L4H4, which is based on the linear cationic amphiphilic peptide magainin, also shows good antibacterial activity and cell penetration properties.
• Glycine-Rich Antimicrobial Peptides
In biology, the R group of glycine is classified as a non-polar amino acid. Attacins and diptericins are examples of glycine-rich AMPs found in nature. These peptides contain 14 to 22 percent glycine residues, which have a significant impact on the peptide chain's tertiary structure. Traditional AMPs activate phagocyte-mediated microbicidal mechanisms, but a glycine-rich AMP derived from salmonid cathelicidins activates phagocyte-mediated microbicidal mechanisms. Furthermore, against clinical Gram-negative bacteria, the glycine-rich central–symmetrical GG3 is an ideal commercial drug candidate (Wang et al., 2015).
• Classification Based on Antimicrobial Peptide Structures
Linear -helical peptides, -sheet peptides, linear extension structure, and both -helix and -sheet peptides are the four types of antimicrobial peptides that can be classified based on their structures. Furthermore, cyclic peptides and AMPs with increasingly complex topologies are being developed (including lasso peptides and thioether bridged structures).
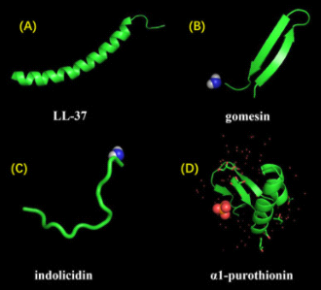
AMPs come in a variety of shapes and sizes. (A) The -helical conformation of LL-37 is typical. (B) Gomesin is a -sheet peptide with a disulfide bond that stabilises it. (C) Indolicidin is an AMP that has a linear extension structure rather than a well-defined three-dimensional structure. (D) The alpha-helix and beta-sheet conformations of 1-purothionin are shown, with arrows indicating the direction of extension.
Key takeaway:
- A peptide is a polymer made up of amino acid subunits linked together. A peptide molecule can function biologically on its own or as a component of a larger molecule. Proteins are essentially very long peptides that are frequently made up of multiple peptide subunits.
- Peptides perform important functions and may be an underutilised drug class. The issue is that they can't be taken orally because stomach acids degrade them before they reach the bloodstream.
1.8.1 Introduction to Peptide Structure Determination.
Structure of a Protein:
The amino acid sequence is the primary (1°) structure.
Secondary (2°): substructures or folds that occur frequently.
Tertiary (3°): all atoms in a single polypeptide chain are arranged in three dimensions.
1. Determine the presence of amino acids and their relative ratios.
2. Break the peptide or protein down into smaller peptide fragments and figure out their sequences.
3. Determine the sequences of the peptide or protein using a different method. Align the peptide fragment sequences from the two methods. Quaternary (4°): the overall organisation of a functional protein's non-covalently linked subunits.
1.8.2 Primary Protein Structure
Natural proteins differ from each other primarily due to differences in their side chains. It's partly a matter of composition. In wool, for example, cysteine makes up 11% of the side chains, whereas silk has no cysteine at all. However, the sequence in which the different side chains occur accounts for a much larger portion of the differences between different proteins. This is particularly true for globular proteins such as enzymes. The primary structure of a polypeptide is defined as the sequence of side chains along the backbone of peptide bonds.
The 20 different amino acids allow for the creation of a wide range of primary structures. Consider how many tripeptides similar to the one shown in Eq. 1 on the polypeptide chains page can be made from the 20 amino acids. The first amino acid in the chain in this example is glycine, but it could just as well be proline or any of the other 20 amino acids. As a result, there are 20 options for first place in the chain. Similarly, there are 20 options for the second position in the chain, for a total of 20 x 20 = 400 combinations. We can choose from 20 amino acids for the third position in the chain for each of these 400 structures, giving us a total of 400 20 = 203 = 8000 possible structures for the tripeptide.
When considering that most proteins contain at least 50 amino acid residues, a general formula for the number of primary structures for a polypeptide containing n amino acid units is 20n. [2050 = (2 10)50 = 250 1050 = 1015 1050 = 1065] [2050 = (2 10)50 = 250] [2050 = (2 10)50 = 250] [2050 = (2 10)50 = 250] [2050 = (2 10) Starting with the —NH3+ end of the polymer, primary structure is traditionally specified by writing the three-letter abbreviations for each amino acid. In some cases, the abbreviation sequence is even reduced to a single letter. For instance, consider the following structure which reading from the -NH3+ end is alanine, glycine, glycine would be specified as
Ala-Gly-Gly or AGG
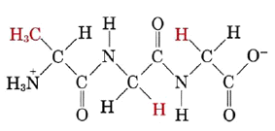
Both three letter and single letter abbreviations are shown in Figure:
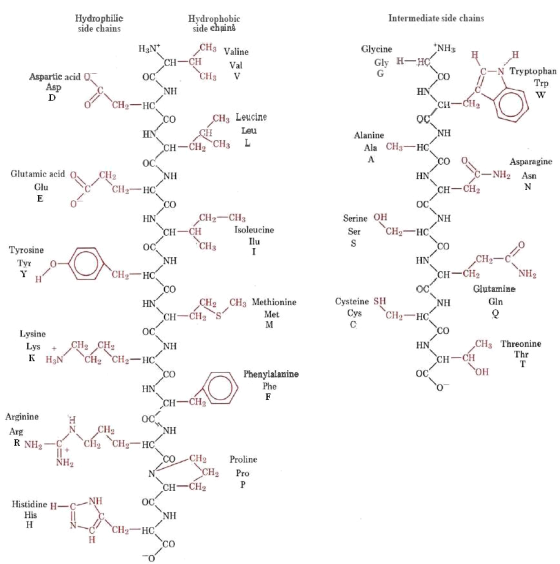
Figure: At pH 7, the structures of the 20 most common amino acid side chains in proteins. There is also a three-letter and single-letter abbreviation for each.
The determination of a protein's primary structure is a difficult and time-consuming task. It's also a big one: the amino acid sequence determines the protein's three-dimensional shape and, ultimately, its biological function. As a result, much effort has gone into developing methods for elucidating primary structure.
Insulin's amino acid sequence was the first to be determined. Frederick Sanger, a British biochemist, was awarded the Nobel Prize for this groundbreaking work, which was completed in 1953 after a ten-year effort (born 1918). The primary structure, he discovered, was
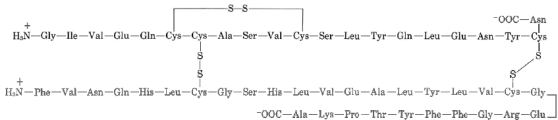
It's worth noting that this structure has two chains, one with 21 side chains and the other with 30. Disulfide (—S—S—) bridges connect these two chains in two places, each connecting two cysteine residues in different chains.
A known mass of pure sample is first boiled in acid or base until it is completely hydrolyzed to individual amino acids in order to determine the primary structure of a protein. After that, the amino acid mixture is chromatographically separated, and the exact amount of each amino acid is determined. In this way, one can calculate that there are 6 mol leucine for every 3 mol serine in the insulin molecule. Breaking down the protein into smaller fragments is the next step. The protein is selectively hydrolyzed by enzymes called proteases, such as trypsin or chymotrypsin, after disulfide bridges are broken by oxidation. In a good case, you'll end up with several fragments, each with 10 or 20 amino acid residues. After that, they can be separated and analysed separately.
The sequence of amino acids in one of these polypeptide fragments is usually determined using Edman degradation, which is named after Pehr Edman, C6H5N = C = S, which specifically targets the polypeptide chain's —NH3+ end. This reaction takes place in very basic conditions. The terminal amino acid is then separated by the addition of acid, and it can be identified. This process can be repeated because the rest of the polypeptide chain is intact, allowing each amino acid in the sequence to be attacked, removed, and identified. By snipping off amino acids one at a time, the complete sequence for the fragment is eventually discovered. This entire process can be automated and thus greatly accelerated. After the fragments have been sequenced, it's just a matter of putting them in the right order. Different fragmentation patterns can be used to determine the sequence for the whole protein because different proteases hydrolyze peptide bonds at different places in the amino acid sequence. For example, the end of a trypsin digest fragment will be in the middle of a chymotrypsin digest fragment. This makes it possible to sequence unknown protein sequences in a relatively short amount of time.
In today's world, Edman degradation isn't the only way to sequence proteins. Using a technique known as tandem mass spectrometry, mass spectrometry can sequence polypeptides of 20 to 30 amino acids in length. In this method, a polypeptide is ionised by passing it through a single mass spectrometer. After that, the charged peptide enters a collision chamber, where it fragments at different peptide bonds. A second mass spectrometer is used to measure the fragments that result. The resultant spectrum can determine the peptide sequence by differences in mass of the fragments.
Many protein sequences are now determined indirectly, through the genetic code, thanks to the development of DNA sequencing methods and the success of the Human Genome Project. When a protein's DNA sequence is known, it can be used to deduce the protein's sequence. Similarly, a known protein sequence can be used to figure out which gene codes for that protein. As a result, there are a variety of approaches to determining protein sequences, all of which complement one another.
As methods for determining primary structure have improved, a large number of proteins have been sequenced, allowing for some fascinating comparisons. Cytochrome c, an electron carrier found in all organisms that use oxygen for respiration, is a particularly intriguing example. When cytochrome c samples from different organisms are compared, the amino acid sequence is found to be different in each case. Furthermore, the greater the difference in protein sequences between two species, the further apart their macroscopic features are. When cytochrome c from horses and yeast are compared, 45 out of 104 residues are different. Between chicken and duck, there are only two substitutions, and cytochrome c in pigs, cows, and sheep is identical. The magnitudes of these changes match biological taxonomy based on macroscopically visible differences quite well. Cytochrome c can be used to track biological evolution from unicellular organisms to today's diverse species, as well as to estimate when branching in the family tree of life took place. As a result, molecular methods are a useful tool for evolutionary biologists.
1.9.1 Peptide Synthesis - Methods and Reagents
Peptide synthesis is the process of creating peptides from multiple amino acids linked by peptide bonds in organic chemistry. Protein biosynthesis, on the other hand, is the biological process of producing long peptides (proteins).
Although the concept of linking amino acids to form chains has been around for over a century, it took another 50 years to find solutions to problems that arose.
The solid-phase peptide synthesis was pioneered by Robert Bruce Merrifield (Order our Merrifield Resin ABIN1536402)1. It is possible to make peptides with a length of up to 50 amino acids using SPPS. The technology allows for the synthesis of natural peptides that are difficult to express in bacteria, as well as the incorporation of unnatural amino acids and the creation of unique peptides to optimise a desired biological response or other outcome.
Synthetic peptides are now used in a variety of applications, including the development of epitope-specific antibodies against pathogenic proteins, the study of protein functions, and the identification and characterization of proteins, thanks to the invention of peptide synthesis. Synthetic peptides make it possible to study important cell signalling enzymes such as kinases and proteases, as well as enzyme-substrate interactions. Finally, in mass spectrometry (MS)-based applications, synthetic peptides are used as standards and reagents.
1.9.2 Solid-Phase Peptide Synthesis SPPS
The C-terminus of the first amino acid is coupled to an activated solid support, usually chemically unreactive polystyrol, to begin the SPPS. The resin serves as a C-terminal protecting group, allowing the immobilised protein to be retained during filtration while liquid-phase reagents and synthesis by-products are flushed away.
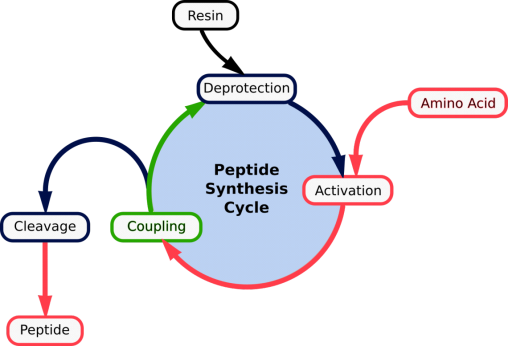
Figure. Repetitive cycles of (1) deprotection; (2) aa activation; (3) coupling | mature peptide detachment
SPPS works on the principle of repeated cycles of deprotection-wash-coupling-wash. A single N-protected amino acid unit is coupled to the free N-terminal amine of a solid-phase attached peptide (see below). After that, the unit is deprotected, revealing a new N-terminal amine to which another amino acid can be added.
1.9.3 Applications of synthetic peptides
Synthetic peptides have been used in a variety of applications since their invention in the 1950s and 1960s, including the development of epitope-specific antibodies against pathogenic proteins, the study of protein functions, and the identification and characterization of proteins. Synthetic peptides are also used to investigate enzyme-substrate interactions in key enzyme classes like kinases and proteases, which are critical in cell signalling.
In cell biology, homologous synthetic peptide sets are frequently used to investigate receptor binding or the substrate recognition specificity of newly discovered enzymes. Synthetic peptides can be made to look like naturally occurring peptides and can be used to treat cancer and other serious illnesses. Finally, in mass spectrometry (MS)-based applications, synthetic peptides are used as standards and reagents. Synthetic peptides are crucial in the discovery, characterization, and quantification of proteins using mass spectrometry, especially those that serve as early biomarkers for diseases.
1.9.4 Process of synthesizing peptides
The carboxyl group of the incoming amino acid is usually coupled to the N-terminus of the growing peptide chain during peptide synthesis. Protein biosynthesis, in which the N-terminus of the incoming amino acid is linked to the C-terminus of the protein chain, is the polar opposite of C-to-N synthesis (N-to-C). The addition of amino acids to the growing peptide chain occurs in a precise, step-wise, and cyclic manner due to the complex nature of in vitro protein synthesis. While the various methods of peptide synthesis differ in some important ways, they all use the same step-by-step method of adding amino acids to the growing peptide chain one at a time.
• Peptide deprotection
Because amino acids contain multiple reactive groups, peptide synthesis must be done carefully to avoid side reactions that reduce the length of the peptide chain and cause branching. Chemical groups that bind to the reactive groups of amino acids and block or protect the functional group from nonspecific reaction have been developed to facilitate peptide formation with minimal side reactions.
Prior to synthesis, purified individual amino acids are reacted with these protecting groups, and then specific protecting groups are removed from the newly added amino acid (a step called deprotection) just after coupling to allow the next incoming amino acid to bind to the growing peptide chain in the proper orientation. All remaining protecting groups are removed from the nascent peptides after peptide synthesis is completed. Depending on the method of peptide synthesis, three types of protecting groups are commonly used, as described below.
Because they are relatively easy to remove to allow peptide bond formation, the amino acid N-termini are protected by groups known as "temporary" protecting groups. The N-terminal protecting groups tert-butoxycarbonyl (Boc) and 9-fluorenylmethoxycarbonyl (Fmoc) are the most common, and each has unique properties that influence their use. Boc must be removed from the newly added amino acid with a moderately strong acid such as trifluoracetic acid (TFA), whereas Fmoc is a base-labile protecting group that can be removed with a mild base such as piperidine.
Boc chemistry was first described in the 1950s and requires acidic conditions for deprotection, whereas Fmoc is cleaved under mild, basic conditions and was not discovered for another twenty years (3,4,5,6). Fmoc chemistry is more commonly used in commercial settings because of the higher quality and yield, whereas Boc chemistry is preferred for complex peptide synthesis or when non-natural peptides or analogues that are base-sensitive are required.
The use of a C-terminal protecting group is dependent on the type of peptide synthesis used; while liquid-phase peptide synthesis requires protection of the C-terminus of the first amino acid (C-terminal amino acid), solid-phase peptide synthesis does not, because the only C-terminal amino acid that requires protection is protected by a solid support (resin) (see Protein Synthesis Strategies).
Because amino acid side chains contain a wide range of functional groups, they are a hotspot for side chain reactivity during peptide synthesis. As a result, a variety of protecting groups are required, though they are most commonly based on the benzyl (Bzl) or tert-butyl (tBu) groups. Depending on the peptide sequence and the type of N-terminal protection used, the specific protecting groups used during peptide synthesis vary (see next paragraph). Side chain protecting groups are referred to as permanent protecting groups because they can withstand multiple chemical treatments during the synthesis phase and are only removed after the synthesis is complete during treatment with strong acids.
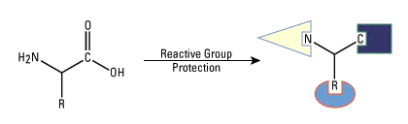
Amino acid functional group protection. The N-termini and amino acid side chains are "protected" with chemical groups prior to peptide synthesis to prevent nonspecific reactions. To facilitate peptide extension in the correct orientation, the C-terminus of the C-terminal amino acid of the peptide is also protected.
Because multiple protecting groups are commonly used in peptide synthesis, it is clear that these groups must be compatible in order for different protecting groups to be deprotected without affecting other protecting groups. As a result, protecting schemes are created to match protecting groups so that the deprotection of one group does not affect the binding of the others. Because N-terminal deprotection occurs continuously during peptide synthesis, different types of side chain protecting groups (Bzl or tBu) have been matched to Boc or Fmoc, respectively, for optimised deprotection. Each of the synthesis and cleavage steps, as described in the table and later sections of this page, are also included in these protecting schemes.
Protecting Scheme | Deprotection | Coupling | Cleavage | Wash |
Boc/Bzl | TFA | Coupling | HF, HBr, TFMSA | DMF |
Fmoc/tBut | Piperidine | TFA |
Common protecting scheme-specific solvents.
When protecting groups are removed, especially under acidic conditions, cationic species are formed, which can alkylate the functional groups on the peptide chain. As a result, during the deprotection step, scavengers such as water, anisol, or thiol derivatives can be added in excess to react with any of these free reactive species.
• Amino acid coupling
Synthetic peptide coupling necessitates the use of carbodiimides such as dicyclohexylcarbodiimide (DCC) or diisopropylcarbodiimide to activate the C-terminal carboxylic acid on the incoming amino acid (DIC). These coupling reagents react with the carboxyl group to form a highly reactive O-acylisourea intermediate, which is quickly displaced by nucleophilic attack from the deprotected primary amino group on the growing peptide chain, forming the nascent peptide bond.
Racemization of the amino acid can occur when carbodiimides form a reactive intermediate. As a result, reagents that react with the O-acylisourea intermediate, such as 1-hydroxybenzotriazole (HOBt), are frequently added, resulting in a less reactive intermediate that reduces the risk of racemization. Other coupling agents, such as benzotriazol-1-yl-oxy-tris(dimethylamino)phosphonium hexafluorophosphate (BOP) and 2-(1H-benzotriazol-1-yl)-1,1,3,3-tetramethyluronium hexafluorophosphate (HBTU), which both require activating bases to mediate amino acid coupling, have also been investigated due to side reactions caused by car.
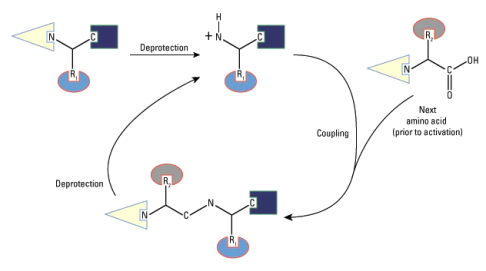
Diagram of peptide synthesis
The C-terminal amino acid of the peptide to be synthesised is first deprotected from the N-terminal protecting group. Following the removal of the unbound protecting groups, a coupling agent (e.g., DCC; not shown) activates the next amino acid at the C-terminal end, facilitating peptide bond formation between the deprotected N-terminus of the first amino acid and the activated C-terminus of the incoming amino acid. The growing peptide's new N-terminus is then deprotected and coupled to the next amino acid. The deprotection and coupling cycle is repeated until the full-length peptide is obtained.
• Peptide cleavage
All remaining protecting groups in the nascent peptide must be removed after successive cycles of amino acid deprotection and coupling. Acidolysis is used to cleave these groups, and the chemical used for cleavage depends on the protection scheme used; strong acids like hydrogen fluoride (HF), hydrogen bromide (HBr), or trifluoromethane sulfonic acid (TFMSA) are used to cleave Boc and Bzl groups, while TFA is used to cleave Fmoc and tBut groups. Cleavage removes the N-terminal protecting group of the last amino acid added, the C-terminal protecting group (either chemical or resin) of the first amino acid, and any side-chain protecting groups when done correctly. Scavengers, like deprotectors, are included in this step to react to free protecting groups. Because cleavage is so important in peptide synthesis, it should be optimised to avoid acid-catalyzed side reactions.
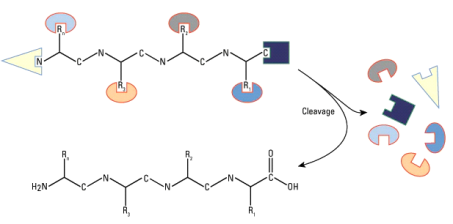
Diagram of peptide cleavage after synthesis
After peptide synthesis, strong acid treatment is used to remove the remaining N-terminal protecting groups, all side-chain protecting groups, and the C-terminal protecting group or solid support.
1.9.5 Peptide synthesis strategies
Liquid-phase peptide synthesis was the first method used by scientists when they learned how to make peptides in vitro, and it is still widely used for large-scale synthesis. However, because the product must be manually removed from the reaction solution after each step, this method is slow and labor-intensive. This method also necessitates the addition of a chemical group to protect the first amino acids C-terminus. However, because the product is purified after each step-in liquid-phase synthesis, side reactions are easily detected. Convergent synthesis, in which separate peptides are synthesised and then linked together to form larger peptides, is also an option.
Solid-phase peptide synthesis, on the other hand, is by far the most common method of peptide synthesis today. The C-terminus of the first amino acid is coupled to an activated solid support, such as polystyrene or polyacrylamide, instead of being protected by a chemical group. This method serves two purposes: the resin serves as a C-terminal protecting group, and it also serves as a quick way to separate the growing peptide product from the various reaction mixtures during synthesis. Peptide synthesisers, like many other biological manufacturing processes, have been developed for automation and high-throughput peptide production.
Peptide Synthesis: Protecting groups
• Protein synthesis is important for a variety of reasons, including confirming the structure of natural proteins (for medical research, for example) and investigating how the amino acid sequence controls protein structure and function.
• However, forming amides from amino acids is not as simple as mixing them together.
• A mixture of alanine, A, and glycine, G, for example, would yield a mixture of amides: A-G, G-A, A-A, and G-G, plus higher polypeptides)
• It is necessary to use protecting groups to control the coupling reaction.
• A specific amide bond can be formed by protecting the amine group of one component and the carboxylic acid group of the other.
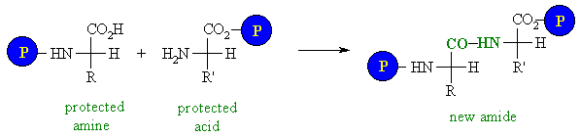
As a result, the required sequence is: protect the amino group in the N-terminal amino acid and the carboxyl group in the C-terminal amino acid; and couple the two amino acids by forming a new amide bond.
The new peptide's termini should be deprotected (as and if required)
Polypeptides can be grown one amino acid residue at a time by repeating the process, or by building pieces and then joining them together.
Amine protecting groups
1. benzoyloxycarbonyl groups (abbreviation = Z or Cbz in older literature)
Protection

Deprotection
2. tert-butoxycarbonyl groups (abbreviation = Boc)
Protection

Deprotection
Carboxyl protecting groups
1. simple esters esp. methyl, and ethyl
Protection
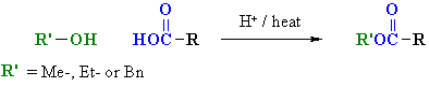
Deprotection
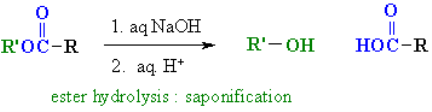
2. benzyl esters (abbreviation = Bn)
Deprotection

1.10.1 The Strategy of Peptide Bond Synthesis- N-Protection and C-Activation.
Proteins, Proteios, which means first in Greek, is a class of organic compounds found in and essential to every living cell. Proteins hold a multicellular organism's body together, protect it, and give it structure in the form of skin, hair, callus, cartilage, muscles, tendons, and ligaments. They catalyse, regulate, and protect body chemistry in the form of enzymes, hormones, antibodies, and globulins. They affect the transport of oxygen and other substances within an organism in the form of haemoglobin, myoglobin, and various lipoproteins.
1.11.1 Introduction
More than half a century ago, Nobel Laureate Bruce Merrifield introduced the concept of solid-phase organic synthesis (SPOS), which involves performing a chemical transformation on an insoluble solid-support. SPOS has found widespread use in many aspects of modern organic synthesis since this seminal report, proving to be especially useful in the rapid construction of complex biological molecules and diverse libraries of small organic compounds. Because SPOS has many advantages over traditional solution-phase synthesis, such as product isolation via filtration, the ability to use large amounts of reagents, the ability to drive reactions to completion, and the ease of handling, many aspects of SPOS have been automated.
The fact that the resin must be washed between procedures to remove excess reagents and by-products, resulting in large amounts of contaminated organic solvent waste, is a major issue with SPOS. The reprotoxic polar aprotic solvents dimethylformamide (DMF), dimethylacetamide (DMA), and N-methyl pyrrolidone are some of the most commonly used solvents for this (NMP). These are all classified as Substances of Very High Concern (SVHC) under REACH (Registration, Evaluation, Authorization, and Restriction of Chemicals), implying that their use will be restricted in the near future. Dichloromethane and diethyl ether are two other commonly used solvents for SPOS, both of which are widely regarded as highly problematic solvents that should be replaced as soon as possible in the context of green chemistry.
Furthermore, solvent use has been found to account for a large portion of the waste generated by a typical batch chemical operation in the pharmaceutical and fine chemical industries. Constable et al. Previously reported that the solvent accounts for 80–90% of the waste mass generated by typical batch chemical operations. More recently, the American Chemical Society Green Chemistry Institute Pharmaceutical Roundtable (ACS-GCIPR) estimated that solvent will account for 56 percent of the mass required to produce 1 kg of an active pharmaceutical ingredient (API). As a result, the overall toxicity profile of a given process is frequently defined by the solvent, which means that substituting a solvent with more desirable health, safety, or environmental characteristics will often result in the greatest reduction in environmental impact.
When compared to traditional solution-phase chemistry, however, this is not as simple in SPOS because the use of an insoluble solid-support places additional considerations on the solvent. Most notably, adequate solid-support solvation, also known as swelling, is often regarded as the most important prerequisite for SPOS. Due to poor mass transfer between the bulk solution-phase and the solid-support, insufficient swelling will result in poor active site accessibility and reduced reaction rates.
For the reasons stated above, there has been a lot of interest in more sustainable approaches to SPOS in recent years, particularly in the field of solid-phase peptide synthesis (SPPS), which is the most common application of SPOS. This review will look at recent approaches to greener SPOS/SPPS that focus on the use of alternative reaction media like water, greener organic solvents, and compressed carbon dioxide, as well as some interesting approaches that have used a combination of green principles along the way. Because it is beyond the scope of this review, sustainable approaches to peptide synthesis using solution-phase methods as well as solventless methods, such as ball milling, have been omitted.
1.11.2 Water
In recent years, the use of water as a reaction solvent in synthetic chemistry has gotten a lot of attention. It is a highly desirable alternative to conventional organic solvents because it is inexpensive, safe, and environmentally friendly. As a result, much of the early work on developing greener SPOS has focused on its implementation; however, there are a number of obstacles to overcome, particularly for SPPS. The peptide is typically assembled from the C-terminus to the N-terminus using an iterative method that involves coupling suitably N-protected amino acids and then deprotecting them. The most commonly used protecting groups for this process are the t-butyloxycarbonyl (Boc) and 9-fluorenylmethoxycarbonyl (Fmoc) groups for solution- and solid-phase peptide synthesis, respectively, both of which have very low water solubility. Furthermore, adequate water solvation of the solid-support is a critical consideration. For the reasons stated above, the use of water in SPPS has remained an unsolved problem for many years.
• Hydrophilic protecting groups
The use of water-soluble N-protecting groups and coupling agents was one of the first approaches to this. Various examples of solution-phase peptide chemistry have been described in the literature, but it was not until the work of Kawasaki and co-workers in 2001 that the entire process of SPPS in water was realised. This was made possible in part by the development of polyethylene glycol (PEG)-based resins, which are more easily swollen by a wider range of solvents due to their amphiphilic nature. The 2-(phenyl(methyl)sulfonio) ethoxycarbonyl (Pms) group 1 was created as a water-soluble N-protecting group that can be easily removed using a 5 percent sodium bicarbonate solution. The water soluble 1-ethyl-3-(3′-dimethylaminopropyl)-carbodiimide hydrochloride (WSCD) and N-hydroxy-5-norbornene-2,3-dicarboximide (HONB) coupling reagents were used on a PEG-grafted Rink amide resin to produce the endogenous opioid peptide Leu-enkephalinamide (H-Tyr-Gly-G Notably, a non-ionic surfactant (0.2 percent Triton X) was required for the coupling and washing procedures in order to adequately enhance the resin's swelling in water. Furthermore, the method for preparing Pms-amino acids did not work for Met or Cys, but this was addressed in a subsequent communication.

Kawasaki and colleagues discovered water-soluble protective groups.
Due to the onium salt present, the Pms protecting group was found to be rather unstable. As a result, Kawasaki and colleagues went on to develop additional SPPS-protecting groups in water. The 2-ethanesulfonylethoxycarbonyl (Esc) 2 group was discovered to be moderately base labile and moderately polar, resulting in good solubility in aqueous and organic solutions and a 71 percent isolated yield of the test peptide Leu-enkephalinamide. However, the lack of aromatic functionality, excluding aromatic amino acids, made it unsuitable for automated SPPS at the time because they are not detectable by optical absorbance spectroscopy. This led to the creation of the 2-(4-sulfophenylsulfonyl)ethoxycarbonyl (Sps) 3 group, which was discovered to have high base lability and water solubility and was used to produce the Leu-enkephalinamide peptide in a 61 percent yield. While these were very promising results for SPPS in water, none of the conditions listed produced more Leu-enkephalinamide in an isolated yield than Fmoc-protected amino acids in organic solvents.
• Fmoc- and Boc-protected nanoparticles
Due to the desire to avoid waste, reduce energy consumption, and minimise derivatization in synthetic procedures, the additional steps associated with the synthesis of hydrophilic protecting groups are not favourable in the context of green chemistry. For these reasons, Hojo and colleagues looked for a way to make SPPS in water using Fmoc- and Boc-protecting groups, which are widely used in peptide synthesis and are commercially available, but are only sparingly soluble in water, as previously mentioned. Hojo and colleagues used zirconium oxide beads and PEG in a ball mill to make aqueous dispersions of Fmoc-protected amino acids with nanoparticles between 250 and 500 nm in diameter, in the hopes that the increased surface area of the nanoparticles would improve their homogeneous mixing with the SPPS resin in water.
The prepared water-dispersible nanoparticles were then used to make Leu-enkephalinamide, which yielded 67 percent of the target pentapeptide. Importantly, unprocessed Fmoc-amino acids and unprocessed Fmoc-amino acids in the presence of PEG failed to produce significant amounts of the target peptide. In addition, using a non-ionic surfactant (0.5 percent Trition-X) for the nanoparticle preparation and deprotection steps resulted in a much higher 79 percent yield of Leu-enkephalinamide. It's also worth noting that Hojo and colleagues showed that dispersed nanoparticles can be easily removed from aqueous waste streams using filtration or ultracentrifugation. Hojo and co-workers went on to demonstrate the use of similar water-dispersible Boc-nanoparticles in subsequent publications, as well as the use of efficient microwave heating to reduce coupling times from 1 h to 3 min.
1.11.3 Enzymatic synthesis
Flitsch and colleagues were the first to report the use of enzymes, specifically proteases, for the construction of peptides on solid supports. The use of these enzymes poses a significant challenge because, in water, the equilibrium between amide bond formation and hydrolysis favours hydrolysis. Traditionally, organic co-solvents or highly concentrated solutions were used to overcome this. Flitsch and co-workers discovered that by attaching the amino component to a solid support, in this case PEGA, a copolymer of PEG and polyacrylamide (PA), the equilibrium can be forced to favour amide bond formation (Fig). When a racemic acyl donor was used, only the L, L-diastereomer was observed, indicating that enzymes are highly enantioselective.

On a solid support, thermolysin catalysed peptide synthesis.
This was initially limited to the synthesis of simple dipeptides, with good yields only possible with hydrophobic amino acids. The use of a hydrophobic protecting group to protect the polar or charged side chains allowed a much wider range of amino acids to be tolerated. When attempting to construct larger peptides, this method's limitations become apparent. Chemical deprotections of the Fmoc-protected amino acid were required using piperidine in DMF (20 percent v/v) in an iterative process similar to conventional SPPS. Furthermore, beyond tetraleucine, hydrolysis of the peptide began to compete with synthesis in the preparation of polyleucine peptides, resulting in a mixture of products.
1.11.4 Microwave assisted synthesis
In order to use commercially available Boc- or Fmoc-protected amino acids in aqueous reactions, complex synthetic methods have typically been required. Galanis et al. Recently described a relatively straightforward method for coupling Boc-protected amino acids to PEG-based resins in water, involving water soluble coupling reagents and microwave irradiation. Galanis et al. Used 1N HCl(aq) for the deprotection steps, which is important because Boc-protecting groups are easily removed under acidic conditions. This is the first example of SPPS that uses water for both coupling and deprotection steps, with only a small amount of methanol used for resin washing. The developed methodology was then used to synthesise Leu-enkephalin (H-Tyr-Gly-Gly-Phe-Leu-OH), which yielded a crude purity of 67 percent. However, using a surfactant (0.5 percent Trition-X100) for both the coupling and deprotection steps, which is known to improve the swelling properties of PEG-based resins in water, resulted in a much-improved 81 percent crude purity for the microwave assisted synthesis of Leu-enkephalin.
1.11.5 N-carboxyanhydrides
N-carboxyanhydrides (NCAs), also known as Leuchs' anhydrides 4, are a fascinating class of compounds in which the amino group is protected while the carboxylate is activated at the same time. Unlike traditional approaches to peptide synthesis, this results in a simplified reaction scheme and a highly atom-efficient peptide bond synthesis. De Marco et al. Were the first to report the use of NCAs in the solid-supported synthesis of peptides. The NCA derivatives were first made in almost quantitative yields by using a solvent-free, microwave-assisted synthesis to treat the relevant amino acid with triphosgene. The NCAs were then used to make the opioid tetrapeptide endomorphin-1 5 (H-Tyr-Pro-Trp-Phe-NH2) on a PEG-based resin in an aqueous borate buffer (pH 10.2). Despite the fact that the target peptide was only obtained in a moderate yield and purity, the method is highly desirable because it uses a small amount of bulk chemicals, has excellent atom economy, and is free of organic solvents.
SPPS of endomorphin-1 using NCAs in an aqueous media
1.11.6 Alternative organic solvents
While water is frequently considered a desirable solvent for synthetic chemistry due to the advantages listed above, using water does not always imply a benign or "green" process. Contamination of aqueous waste streams with organic compounds or metal catalysts can be a significant financial or environmental burden to clean up or dispose of, depending on the circumstances. As a result, there has been a recent trend toward using organic solvents for SPOS that have better health, safety, or environmental properties than conventional organic solvents.
Acosta et al. Were the first to report on this method, which looked into using acetonitrile instead of DMF in SPPS couplings. While acetonitrile is not commonly thought of as a green solvent, when compared to DMF, it is a less problematic dipolar aprotic solvent. Because of its lower viscosity and boiling point, Acosta et al. Argue that it is a more user-friendly solvent. While acetonitrile was unable to adequately swell PS-based resins, it was able to do so with PEG-based resins. The suitability of acetonitrile for SPPS in the preparation of the test peptides Leu-enkephalinamide and acyl carrier protein (ACP 65-74) (H-Val-Gln-Ala-Ala-Ile-Asp-Tyr-Ile-Asn-Gly-NH2) on PEG-based resins in excellent crude purity was then demonstrated by Acosta et al. [30]. Albericio and coworkers' subsequent reports have continued along the same theme of using less problematic alternatives to DMF for SPPS couplings, with the use of acetonitrile, THF, 2-MeTHF, and CPME being explored in greater detail. Importantly, the solution-phase synthesis of Z-Phg-Pro-NH2 revealed that each of these solvents suppressed racemisation as well as, if not better than, DMF. When the coupling reagents are carefully considered, acetonitrile and THF were found to be fairly good solvents in the synthesis of the Aib-enkephalin pentapeptide (H-Tyr-Aib-Aib-Phe-Leu-NH2) on PEG-based resins, producing the missed coupling product des-Aib (H-Tyr-Aib-Phe-Leu-NH2) in minimal quantities (Using the aforementioned test sequence, 2-MeTHF and CPME performed significantly worse on PEG-resins. They were however, found to suitably swell PS-resins and excellent results were obtained for 2-MeTHF, with only 3.0% of the des-Aib sequence observed.
While these are all promising results for replacing DMF with SPPS, they all have one major flaw: they all require piperidine in DMF (20% v/v) for the deprotection steps and DMF/CH2Cl2 for the resin washing. This has since been addressed by Jad et al., who used a combination of 2-MeTHF, EtOAc, and IPA to investigate a variety of coupling and washing protocols. Finally, the aggregation-prone Aib-ACP decapeptide (H-Val-Gln-Aib-Aib-Ile-Asp-Tyr-Ile-Asn-Gly-NH2) was produced in 87.1 percent crude purity using 2-MeTHF for both coupling and deprotection, as well as 2-MeTHF and EtOAc for washing the resin between steps. A significant improvement over the equivalent synthesis using DMF, which yielded 70.0 percent crude purity for the target peptide. Jad et al. Recently looked into the use of various green solvents for the Fmoc-deprotection step, finding that -valerolactone performs similarly to DMF on both PS and PEG-based resins.
The use of cyclic carbonates for SPPS by Lawrenson et al has recently contributed to the field of alternative organic solvents for SPOS. Because they are non-toxic, biodegradable, and produce no NOx or SOx when incinerated, cyclic carbonates have been touted as a promising replacement for traditional polar aprotic solvents. They can also be made through a 100 percent atom-efficient reaction between epoxides and carbon dioxide, which is receiving a lot of attention as a way to valorize waste carbon dioxide. Lawrenson et al. Showed that propylene carbonate was an appropriate solvent for both coupling and deprotection steps in solution-phase control reactions, as well as coupling without epimerisation. The inflammatory mediator bradykinin (H-Arg-Pro-Pro-Gly-Phe-Ser-Pro-Phe-Arg-OH) was then synthesised in 77 percent crude purity using a DMF-free synthesis, with a reference sample synthesised in DMF in 79 percent crude purity.
SPOS methodology has not been limited to the use of more favourable organic solvents. Coats et al. Previously investigated the use of a variety of unusual solvents for Lawesson's reagent-based solid-phase thionation of amides. Due to inefficient heating and stirring, high temperatures were required to drive the reactions to completion when performed in parallel, necessitating the use of a solvent with a high boiling point and low vapour pressure. Benzyl benzoate was identified as a potentially suitable replacement for toluene or CH2Cl2 in this transformation during an initial screening. The target thioamides 7 were produced in good to excellent conversions at 100°C after only 8 hours of thionation of PS-supported aryl and alkyl-derivatives of phenylalanine 6 with Lawesson's reagent 8 and benzyl benzoate as the reaction solvent.
Thionation of PS-supported phenylalanine in benzyl benzoate with Lawesson's reagent.
Lawrenson et al. Recently published a study on the ability of a variety of emerging green solvents to swell common SPOS resins in an effort to promote the use of greener solvents for SPOS. A total of nine PS-, PEG-, PS-PEG-, and polyamide-based resins were investigated in this study, and their swelling was determined for a set of 25 green solvents using Santini et al general's swelling method. With the exception of SpheriTide polyamide resin, eight of the nine resins investigated had a suitable green solvent that could adequately swell the resin. A study of the solid-supported multicomponent Ugi reaction was used to confirm the experimental findings. 2-MeTHF was found to adequately swell PS-based resins, yielding Ugi product 14 isolated yields nearly ten times higher than MeOH, which is unable to swell PS to a satisfactory level. The results obtained when a solid support that can swell in both solvents (PEG) is used are comparable to those obtained in solution-phase control reactions.
Solid-phase Ugi reaction upon PS- and PEG-based resins in MeOH and 2-MeTHF.
1.11.7 Supercritical carbon dioxide
Supercritical carbon dioxide (scCO2) is an unusual reaction medium that has gotten a lot of attention in the field of green chemistry in recent years. It is a highly desirable solvent because it is non-toxic, non-flammable, and chemically inert to a wide range of substances. It can also be easily removed by depressurization. Furthermore, because the critical point is low (74 bar, 31°C), the energy required to generate scCO2 is low. However, the use of compressed carbon dioxide in SPOS is relatively unexplored; for example, Stobrawe et al. [41] investigated the use of compressed carbon dioxide in the solid-supported hydroformylation reaction.
As previously stated, poor mass transfer between the solid and liquid phases causes sluggish reaction kinetics in solid-supported reactions; this is even more of an issue in triphasic reactions (g/l/s). The use of scCO2 was hoped to help overcome these constraints, resulting in efficient synthesis of the target hydroformylation products on a PS support. However, initial condition screening revealed that using scCO2 as the only reaction solvent produced the target product in only 10% yield over 24 hours. This was thought to be due to the resin's poor swelling properties in scCO2, so small amounts of an organic co-solvent, in this case toluene, were added and found to greatly improve the catalytic activity, yielding the target hydroformylation products in >98% of cases.
The solid-supported hydroformylation products could then be used to make more complex derivatives on the solid-support, as demonstrated by Stobrawe et alHantzsch's pyridine synthesis. In the multicomponent coupling with acetoacetonate 17 and methyl 3-aminocrotonate 18, the solid-supported aldehydes 15/16 were used without further purification. The intermediates 19 and 20 were then aromatised and cleaved from the solid-support, yielding the isomeric pyridines 21 and 22 in a 99 percent yield and a 1.4:1 ratio.
Catalytic hydroformylation in scCO2 upon PS-resin and subsequent Hantzsch pyridine synthesis
In compressed carbon dioxide, Stobrawe et al. Investigated the solid-supported Pauson-Khand reaction (PKR). The PKR between polystyrene-supported 1-pentyn-5-ol 23, CO (20 bar), and norbornene 24a or norbornadiene 24b in THF at 120°C produced the target products 25a/25b in good to moderate yields after cleavage by TFA under conventional conditions. Both 25a and 25b were formed in significantly improved yields when performed in the presence of compressed carbon dioxide, resulting in a gas expanded liquid (GXL). These reactions were also successful when performed in parallel.
The use of scCO2 resulted in a decrease in yield, which can be explained by the fact that the increased mass-transfer to the resin is offset by a significant reduction in catalyst concentration.
Solid-supported Pauson-Khand reaction under conventional and GXL conditions.
1.12.1 Proteins:
Protein, all living organisms contain this highly complex substance. Proteins have a high nutritional value and play a direct role in the chemical processes that keep life going. Proteins were recognised as important by chemists in the early nineteenth century, including Swedish chemist Jöns Jacob Berzelius, who coined the term protein in 1838, a word derived from the Greek prteios, which means "first place." Proteins are species-specific, which means that proteins from one species differ from proteins from another. They are also organ-specific; for example, muscle proteins differ from brain and liver proteins within a single organism.
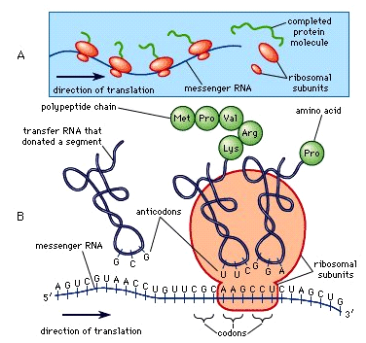
A protein molecule is much larger than a sugar or salt molecule, and it is made up of many amino acids linked together in long chains, much like beads on a string. Proteins contain about 20 different amino acids that occur naturally. Amino acid composition and sequence are similar in proteins with similar functions. Although it is not yet possible to deduce all of a protein's functions from its amino acid sequence, the properties of the amino acids that make up proteins have been linked to established correlations between structure and function.
Plants can synthesise all amino acids, whereas animals cannot, despite the fact that they are all required for life. Plants can grow in a medium that contains inorganic nutrients such as nitrogen, potassium, and other essential nutrients. During photosynthesis, they use carbon dioxide from the air to create organic compounds such as carbohydrates. Animals, on the other hand, must rely on outside sources for organic nutrients. Because most plants have a low protein content, animals that eat only plant material, such as ruminants (e.g., cows), require a large amount of plant material to meet their amino acid requirements. Protein is primarily obtained by nonruminant animals, including humans, from animals and their products, such as meat, milk, and eggs. Legume seeds are increasingly being used to make low-cost protein-rich foods (see human nutrition).
Animal organs typically have a much higher protein content than blood plasma. Muscles, for example, contain about 30% protein, while the liver contains 20% to 30% and red blood cells contain 30%. Hair, bones, and other organs and tissues with a low water content contain higher percentages of protein. In animals, the amount of free amino acids and peptides is much lower than the amount of protein; protein molecules are made in cells by stepwise alignment of amino acids and released into the body fluids only after synthesis is completed.
The high protein content of some organs does not imply that protein importance is proportional to their quantity in an organism or tissue; on the contrary, some of the most important proteins, such as enzymes and hormones, are found in minute quantities. Proteins' significance stems primarily from their function. So far, all enzymes discovered have been proteins. Enzymes are the catalysts for all metabolic reactions, allowing an organism to build up the chemical substances required for life—proteins, nucleic acids, carbohydrates, and lipids—convert them to other substances, and degrade them. It is impossible to live without enzymes. There are a number of protein hormones that play important regulatory roles. The respiratory protein haemoglobin serves as an oxygen carrier in the blood, transporting oxygen from the lungs to body organs and tissues in all vertebrates. The structure of the animal body is maintained and protected by a large group of structural proteins.
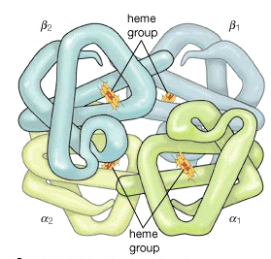
1.12.2 Structure:
• Primary Structure
The primary structure of a protein is the unique amino acid sequence in each polypeptide chain that makes up the protein. This is essentially a list of which amino acids appear in which order in a polypeptide chain, rather than a structure. However, because the final protein structure is determined by this sequence, it is referred to as the polypeptide chain's primary structure. Insulin, for example, is composed of two polypeptide chains, A and B.
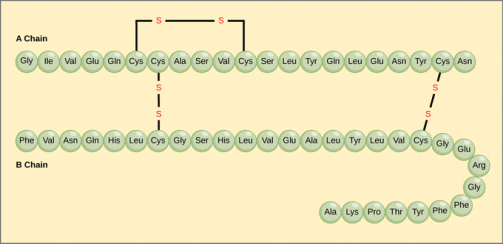
Primary structure: Insulin has a 21-amino-acid A chain and a 30-amino-acid B chain, with each sequence being unique to the insulin protein.
The unique sequence of amino acids in each peptide chain is ultimately determined by the gene, or DNA sequence. A change in the nucleotide sequence of the gene's coding region may result in the addition of a different amino acid to the growing polypeptide chain, resulting in a change in protein structure and function.
Hemoglobin is a protein that transports oxygen. It is made up of four polypeptide chains, two identical chains, and two identical chains. A single amino acid substitution in the haemoglobin chain causes the entire protein's structure to change in sickle cell anaemia. When glutamic acid is replaced by valine in the chain, the polypeptide folds into a slightly different shape, resulting in a haemoglobin protein that is dysfunctional. As a result, even a single amino acid substitution can result in significant changes. Under low-oxygen conditions, these dysfunctional haemoglobin proteins start associating with one another, forming long fibres made up of millions of aggregated haemoglobins that distort red blood cells into crescent or "sickle" shapes, clogging arteries. Breathlessness, dizziness, headaches, and abdominal pain are common symptoms of the disease.
Sickle cell disease Sickle cells are crescent shaped, while normal cells are disc-shaped.
• Secondary Structure
The secondary structure of a protein is whatever regular structures form as the polypeptide folds into its functional three-dimensional form due to interactions between neighbouring or nearby amino acids. H bonds form between local groups of amino acids in a region of the polypeptide chain, resulting in secondary structures. A single secondary structure rarely extends the length of a polypeptide chain. It usually only affects a portion of the chain. The -helix and -pleated sheet structures are the most common types of secondary structure, and they play an important structural role in most globular and fibrous proteins.
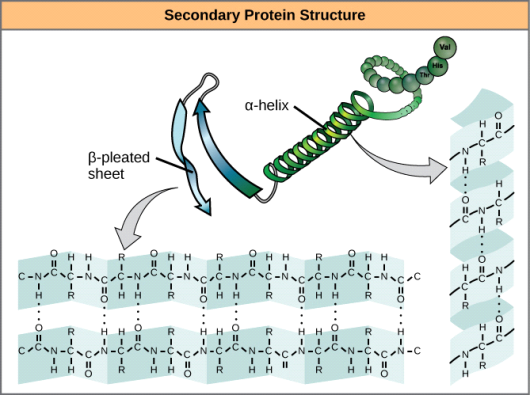
Secondary structure: The peptide backbone forms the -helix and -pleated sheet due to hydrogen bonding between carbonyl and amino groups. Certain amino acids are more likely to form a -helix, whereas others are more likely to form a -pleated sheet.
The hydrogen bond forms in the -helix chain between the oxygen atom in one amino acids polypeptide backbone carbonyl group and the hydrogen atom in the polypeptide backbone amino group of another amino acid four amino acids down the chain. This keeps the amino acid stretch in a right-handed coil. An alpha helix has 3.6 amino acid residues per helical turn. The polypeptide's R groups (side chains) protrude from the -helix chain and are not involved in the H bonds that keep the -helix structure together. Due to the non-linear nature of single C-C and C-N covalent bonds, stretches of amino acids in -pleated sheets are held in an almost fully extended conformation that "pleats" or zig-zags. -pleated sheets are never found on their own. Other -pleated sheets must be used to keep them in place. Because hydrogen bonds form between the oxygen atom in a polypeptide backbone carbonyl group of one -pleated sheet and the hydrogen atom in a polypeptide backbone amino group of another -pleated sheet, the stretches of amino acids in -pleated sheets are held in their pleated sheet structure. The -pleated sheets that hold each other together are aligned parallel or antiparallel. The R groups of amino acids in a -pleated sheet point out perpendicular to the hydrogen bonds that hold the sheets together, and they are not involved in maintaining the structure of the -pleated sheet.
• Tertiary Structure
After all of the secondary structure elements have folded together among themselves, the tertiary structure of a polypeptide chain is its overall three-dimensional shape. The complex three-dimensional tertiary structure of a protein is formed by interactions between polar, nonpolar, acidic, and basic R groups within the polypeptide chain. When protein folding occurs in the body's aqueous environment, nonpolar amino acids' hydrophobic R groups are mostly found inside the protein, while the hydrophilic R groups are mostly found on the outside. In the presence of oxygen, the only covalent bond formed during protein folding is disulfide linkages formed by cysteine side chains. The protein's final three-dimensional shape is determined by all of these weak and strong interactions. A protein's function is lost when it loses its three-dimensional shape.
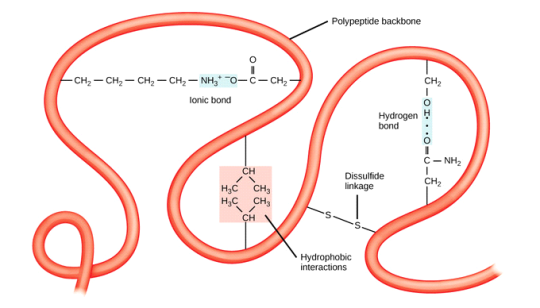
Tertiary structure: Hydrophobic interactions, ionic bonding, hydrogen bonding, and disulfide linkages all contribute to the tertiary structure of proteins.
• Quaternary Structure
The orientation and arrangement of a protein's subunits with respect to one another is known as its quaternary structure. As a result, quaternary structure is only relevant to multi-subunit proteins, or proteins made up of more than one polypeptide chain. A quaternary structure will not be found in proteins made from a single polypeptide.
Weak interactions between subunits help to stabilise the overall structure of proteins with more than one subunit. Enzymes are frequently involved in the bonding of subunits to form a fully functional protein.
Insulin, for example, is a globular, ball-shaped protein with both hydrogen and disulfide bonds that hold its two polypeptide chains together. Silk is a fibrous protein that is formed by hydrogen bonding between -pleated chains.
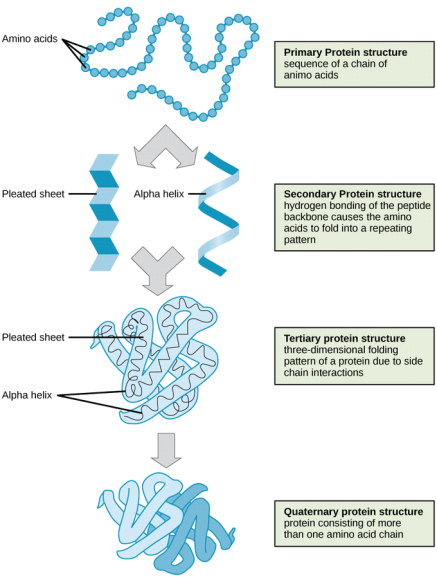
Four levels of protein structure: The four levels of protein structure can be observed in these illustrations.
Key takeaway:
Proteolytic enzymes can be found in a variety of places. Pepsin, trypsin, and chymotrypsin are the three main proteolytic enzymes produced naturally in your digestive system.
They are produced by your body to aid in the breakdown of dietary proteins such as meat, eggs, and fish into smaller fragments known as amino acids.
The inability of the body to digest and use certain protein building blocks (amino acids), namely lysine, arginine, and ornithine, causes lysinuric protein intolerance.
1.13.1 Denaturation:
What is Denaturation of Proteins?
Denaturation refers to the breakdown of a protein's tertiary structure, resulting in the formation of random polypeptide chains.
Protein denaturation is one of the phenomena that causes the protein's stability and structure to be disrupted. Because of the abundance of these biomolecules in living systems, protein chemistry has always been important. Protein is required for the structural and functional components of our bodies. Our bodies get this protein from foods such as pulses, cheese, milk, meat, nuts, and so on.
What causes Denaturation of Proteins?
These biomolecules are also necessary for our bodies to function properly. We've looked at different protein structures and discovered that each one has its own three-dimensional structure.
Denaturation of Proteins
The stability of protein and its structure depends on physical and chemical conditions.
• Temperature and pH have a significant impact on their stability.
• When the unique three-dimensional structure of a protein is exposed to changes, this is known as denaturation.
• The hydrogen bonds in proteins are disrupted by changes in temperature, pH, or other chemical activities. This causes the uncoiling of the helix structure and the unfolding of globular proteins.
• The chemistry of proteins is affected by the uncoiling of helix structures, and they lose their biological activity.
• Denaturation of proteins is the process of proteins losing their activity and uncoiling their helix structure as a result of physical or chemical changes.
• The secondary and tertiary structures of proteins are destroyed during denaturation, leaving only the primary structure.
• Covalent bonds are broken, and amino-acid chain interactions are disrupted. As a result, the proteins' biological activity is lost.
Process of Denaturation of Proteins
• The structure of secondary, tertiary, and quaternary proteins can be easily altered by a process known as denaturation. These modifications have the potential to be quite harmful.
• Denaturation can be caused by heat, acid or base exposure, or even violent physical action.
• Heat denatures the albumin protein in egg white, causing it to solidify into a semisolid mass. In the preparation of meringue, the violent physical action of an egg beater achieves nearly the same result.
• Heavy metal poisons, such as lead and cadmium, alter protein structure by binding to functional groups on the surface.
• Denaturation of proteins can be accomplished by introducing physical changes as well as chemicals.
• The majority of denaturation processes are irreversible, but it has been observed (in a few cases) that some denaturation processes can be reversed; this is referred to as protein renaturation.
• The coagulation of egg white when an egg is boiled is one of the most common examples of protein denaturation. Changes in temperature cause denaturation in this case.
• Curdling of milk is another example of protein denaturation, which occurs when lactic acid is produced by microbial action.
1.13.2 Renaturation
In molecular biology, renaturation refers to the restoration of a protein or nucleic acid (such as DNA) to its original state, especially after denaturation. As a result, this is the polar opposite of denaturation. Proteins or nucleic acids lose their native biomolecular structure during denaturation. A DNA molecule, for example, is denatured by heat. Heat denatures the DNA, separating it into two strands. Denaturation of proteins occurs when an external stress or compound, such as a strong acid or base, a concentrated inorganic salt, an organic solvent, radiation, or heat, is applied. Renaturation is the process of restoring a denatured nucleic acid or protein to its original state. For example, heat-denatured DNA can be restored to its original state by slowly cooling the two strands and reforming into a double-stranded helix. Although it is possible to restore a denatured protein after denaturation, it is not as common as it is with denatured nucleic acids. Following denaturation during PAGE or IEF protein identification, one way to restore a denatured protein to its original form is to remove the SDS and denaturing agents.
References:
1. Talwar, G.P. & Srivastava, M. Textbook of Biochemistry and Human Biology, 3rd Ed. PHI Learning.
2. Berg, J.M., Tymoczko, J.L. & Stryer, L. Biochemistry, W.H. Freeman, 2002.
3. Murray, R.K., Granner, D.K., Mayes, P.A. And Rodwell, V.W. (2009) Harper’s Illustrated Biochemistry. XXVIII edition. Lange Medical Books/ McGraw-Hill.
4. Berg, J.M., Tymoczko, J.L. And Stryer, L. (2006) Biochemistry, 6th Edition. W.H. Freeman and Co. (2002).
5. Wilson, K. & Walker, J. Practical Biochemistry. Cambridge University Press (2009).




