Unit - 4
Sampling distributions
Sampling distribution of a statistic is the theoretical probability distribution of the statistic which is easy to understand and is used in inferential or inductive statistics. A statistic is a random variable since its value depends on observed sample values which will differ from sample to sample. Whereas its particular value depends on a given set of sample values. Thus determination of sampling distribution of a statistic is essentially a mathematical problem.
Statistical methods are used to study a process by analyzing the data, discrete or continuous, recorded as either numerical value or a descriptive representation to improve the “quality” of the process. Thus statistician is mainly concerned with the analysis of data about the characteristics of persons or objects or observations.
Population-
The population is the collection or group of observations under study.
The total number of observations in a population is known as population size and it is denoted by N.
Types of population-
- Finite population – the population contains finite numbers of observations is known as finite population
- Infinite population- it contains infinite number of observations.
- Real population- the population which comprises the items which are all present physically is known as real population.
- Hypothetical population- if the population consists the items which are not physically present but their existence can be imagined, is known as hypothetical population.
Sample –
To get the information from all the elements of a large population may be time consuming and difficult. And also if the elements of population are destroyed under investigation then getting the information from all the units is not make a sense. For example, to test the blood, doctors take very small amount of blood. Or to test the quality of certain sweet we take a small piece of sweet. In such situations, a small part of population is selected from the population which is called a sample
Complete survey-
When each and every element of the population is investigated or studied for the characteristics under study then we call it complete survey or census.
Sample Survey-
When only a part or a small number of elements of population are investigated or studied for the characteristics under study then we call it sample survey or sample enumeration Simple Random Sampling or Random Sampling
The simplest and most common method of sampling is simple random sampling. In simple random sampling, the sample is drawn in such a way that each element or unit of the population has an equal and independent chance of being included in the sample. If a sample is drawn by this method then it is known as a simple random sample or random sample
Simple Random Sampling without Replacement (SRSWOR)
In simple random sampling, if the elements or units are selected or drawn one by one in such a way that an element or unit drawn at a time is not replaced back to the population before the subsequent draws is called SRSWOR.
Suppose we draw a sample from a population, the size of sample is n and the size of population is N, then total number of possible sample is 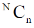
Simple Random Sampling with Replacement (SRSWR)
In simple random sampling, if the elements or units are selected or drawn one by one in such a way that a unit drawn at a time is replaced back to the population before the subsequent draw is called SRSWR.
Suppose we draw a sample from a population, the size of sample is n and the size of population is N, then total number of possible sample is 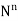 .
.
Parameter-
A parameter is a function of population values which is used to represent the certain characteristic of the population. For example, population mean, population variance, population coefficient of variation, population correlation coefficient, etc. are all parameters. Population parameter mean usually denoted by μ and population variance denoted by 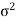
Sample mean and sample variance-
Let 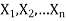 be a random sample of size n taken from a population whose pmf or pdf function f(x,
be a random sample of size n taken from a population whose pmf or pdf function f(x, 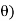
Then the sample mean is defined by-
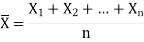
And sample variance-
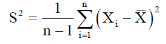
Statistic-
Any quantity which does not contain any unknown parameter and calculated from sample values is known as statistic.
Suppose 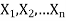 is a random sample of size n taken from a population with mean μ and variance
is a random sample of size n taken from a population with mean μ and variance 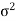 then the sample mean-
then the sample mean-
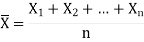
Is a statistic.
Estimator and estimate-
If a statistic is used to estimate an unknown population parameter then it is known as estimator and the value of the estimator based on observed value of the sample is known as estimate of parameter.
Hypothesis-
A hypothesis is a statement or a claim or an assumption about the value of a population parameter.
Similarly, in case of two or more populations a hypothesis is comparative statement or a claim or an assumption about the values of population parameters.
For example-
If a customer of a car wants to test whether the claim of car of a certain brand gives the average of 30km/hr is true or false.
Simple and composite hypotheses-
If a hypothesis specifies only one value or exact value of the population parameter then it is known as simple hypothesis. And if a hypothesis specifies not just one value but a range of values that the population parameter may assume is called a composite hypothesis.
Null and alternative hypothesis
The hypothesis which is to be tested as called the null hypothesis.
The hypothesis which complements to the null hypothesis is called alternative hypothesis.
In the example of car, the claim is  and its complement is
and its complement is 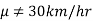 .
.
The null and alternative hypothesis can be formulated as-

And
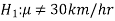
Example: A company has replaced its original technology of producing electric bulbs with CFL technology. The company manager wants to compare the average life of bulbs manufactured by original technology and new technology CFL. Write appropriate null and alternate hypotheses
Sol.
Let the average life of original and CFL technology bulbs are denoted by  and
and  .
.
The null and alternative hypotheses will be-


Here the alternate hypothesis is two-tailed so that the test will also be two-tailed.
If the manager is interested just to know whether the average life of CFL is greater than the original technology bulbs then the null and alternative hypotheses will be-
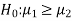
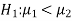
Here the alternative hypothesis is left tailed so that the corresponding test will also be left tailed.
Critical region-
Let  be a random sample drawn from a population having unknown population parameter
be a random sample drawn from a population having unknown population parameter  .
.
The collection of all possible values of 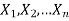 is called sample space and a particular value represent a point in that space.
is called sample space and a particular value represent a point in that space.
In order to test a hypothesis, the entire sample space is partitioned into two disjoint sub-spaces, say, 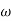 and S –
and S – 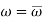 . If calculated value of the test statistic lies in , then we reject the null hypothesis and if it lies in
. If calculated value of the test statistic lies in , then we reject the null hypothesis and if it lies in 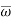 then we do not reject the null hypothesis. The region is called a “rejection region or critical region” and the region
then we do not reject the null hypothesis. The region is called a “rejection region or critical region” and the region 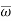 is called a “non-rejection region”.
is called a “non-rejection region”.
Therefore, we can say that
“A region in the sample space in which if the calculated value of the test statistic lies, we reject the null hypothesis then it is called critical region or rejection region.”
The region of rejection is called critical region.
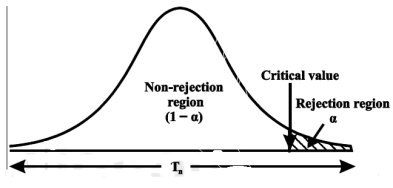
The critical region lies in one or two tails on the probability curve of sampling distribution of the test statistic it depends on the alternative hypothesis.
Therefore there are three cases-
CASE-1: if the alternative hypothesis is right sided such as 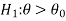 then the entire critical region of size
then the entire critical region of size 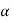 lies on right tail of the probability curve.
lies on right tail of the probability curve.
CASE-2: if the alternative hypothesis is left sided such as 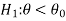 then the entire critical region of size
then the entire critical region of size 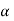 lies on left tail of the probability curve.
lies on left tail of the probability curve.
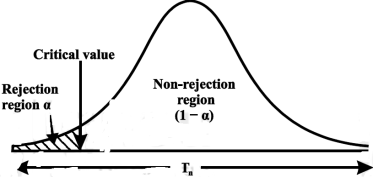
CASE-3: if the alternative hypothesis is two sided such as 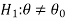 then the entire critical region of size
then the entire critical region of size  lies on both tail of the probability curve
lies on both tail of the probability curve
Type-1 and Type-2 error-
Type-1 error-
The decision relating to rejection of null hypo. When it is true is called type-1 error.
The probability of type-1 error is called size of the test, it is denoted by  and defined as-
and defined as-

Note-
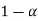 is the probability of correct decision.
is the probability of correct decision.
Type-2 error-
The decision relating to non-rejection of null hypo. When it is false is called type-1 error.
It is denoted by 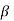 and defined as-
and defined as-
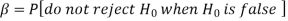
Decision |
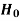 | 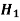 |
Reject  | Type-1 error | Correct decision |
Do not reject  | Correct decision | Type-2 error |
One tailed and two tailed tests-
A test of testing the null hypothesis is said to be two-tailed test if the alternative hypothesis is two-tailed whereas if the alternative hypothesis is one-tailed then a test of testing the null hypothesis is said to be one-tailed test.
For example, if our null and alternative hypothesis are-
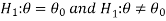
Then the test for testing the null hypothesis is two-tailed test because the
Alternative hypothesis is two-tailed.
If the null and alternative hypotheses are-
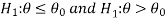
Then the test for testing the null hypothesis is right-tailed test because the alternative hypothesis is right-tailed.
Similarly, if the null and alternative hypotheses are-
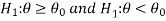
Then the test for testing the null hypothesis is left-tailed test because the alternative hypothesis is left-tailed
Procedure for testing a hypothesis-
Step-1: first we set up null hypothesis  and alternative hypothesis
and alternative hypothesis  .
.
Step-2: after setting the null and alternative hypothesis, we establish a
Criteria for rejection or non-rejection of null hypothesis, that is,
Decide the level of significance ( ), at which we want to test our
), at which we want to test our
Hypothesis. Generally, it is taken as 5% or 1% (α = 0.05 or 0.01).
Step-3: The third step is to choose an appropriate test statistic under H0 for testing the null hypothesis as given below
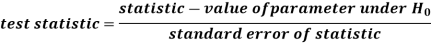
Now after doing this, specify the sampling distribution of the test statistic preferably in the standard form like Z (standard normal),  , t, F or any other well-known in literature
, t, F or any other well-known in literature
Step-4: Calculate the value of the test statistic described in Step III on the basis of observed sample observations.
Step-5: Obtain the critical (or cut-off) value(s) in the sampling distribution of the test statistic and construct rejection (critical) region of size 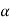 .
.
Generally, critical values for various levels of significance are putted in the form of a table for various standard sampling distributions of test statistic such as Z-table, 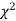 -table, t-table, etc
-table, t-table, etc
Step-6: After that, compare the calculated value of test statistic obtained from Step IV, with the critical value(s) obtained in Step V and locates the position of the calculated test statistic, that is, it lies in rejection region or non-rejection region.
Step-7: in testing the hypothesis we have to reach at a conclusion, it is performed as below-
First- If calculated value of test statistic lies in rejection region at 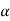 level of significance then we reject null hypothesis. It means that the sample data provide us sufficient evidence against the null hypothesis and there is a significant difference between hypothesized value and observed value of the parameter
level of significance then we reject null hypothesis. It means that the sample data provide us sufficient evidence against the null hypothesis and there is a significant difference between hypothesized value and observed value of the parameter
Second- If calculated value of test statistic lies in non-rejection region at  level of significance then we do not reject null hypothesis. Its means that the sample data fails to provide us sufficient evidence against the null hypothesis and the difference between hypothesized value and observed value of the parameter due to fluctuation of sample
level of significance then we do not reject null hypothesis. Its means that the sample data fails to provide us sufficient evidence against the null hypothesis and the difference between hypothesized value and observed value of the parameter due to fluctuation of sample
Procedure of testing of hypothesis for large samples-
The sample size more than 30 is considered as large sample size. So that for large samples, we follow the following procedure to test the hypothesis.
Step-1: first we set up the null and alternative hypothesis.
Step-2: After setting the null and alternative hypotheses, we have to choose level of significance. Generally, it is taken as 5% or 1% (α = 0.05 or 0.01). And accordingly rejection and non-rejection regions will be decided.
Step-3: Third step is to determine an appropriate test statistic, say, Z in case of large samples. Suppose Tn is the sample statistic such as sample
Mean, sample proportion, sample variance, etc. for the parameter 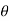 then for testing the null hypothesis, test statistic is given by
then for testing the null hypothesis, test statistic is given by

Step-4: The test statistic Z will assumed to be approximately normally distributed with mean 0 and variance 1 as
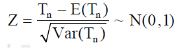
By putting the values in above formula, we calculate test statistic Z.
Suppose z be the calculated value of Z statistic
Step-5: After that, we obtain the critical (cut-off or tabulated) value(s) in the sampling distribution of the test statistic Z corresponding to  assumed in Step II. We construct rejection (critical) region of size α in the probability curve of the sampling distribution of test statistic Z.
assumed in Step II. We construct rejection (critical) region of size α in the probability curve of the sampling distribution of test statistic Z.
Step-6: Take the decision about the null hypothesis based on the calculated and critical values of test statistic obtained in Step IV and Step V.
Since critical value depends upon the nature of the test that it is one tailed test or two-tailed test so following cases arise-
Case-1 one-tailed test- when
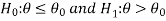 (right-tailed test)
(right-tailed test)
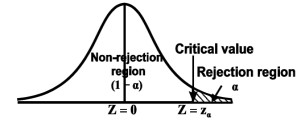
In this case, the rejection (critical) region falls under the right tail of the probability curve of the sampling distribution of test statistic Z.
Suppose  is the critical value at
is the critical value at 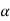 level of significance so entire region greater than or equal to
level of significance so entire region greater than or equal to 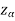 is the rejection region and less than
is the rejection region and less than
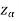 is the non-rejection region
is the non-rejection region
If z (calculated value ) ≥ 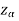 (tabulated value), that means the calculated value of test statistic Z lies in the rejection region, then we reject the null hypothesis H0 at
(tabulated value), that means the calculated value of test statistic Z lies in the rejection region, then we reject the null hypothesis H0 at  level of significance. Therefore, we conclude that sample data provides us sufficient evidence against the null hypothesis and there is a significant difference between hypothesized or specified value and observed value of the parameter.
level of significance. Therefore, we conclude that sample data provides us sufficient evidence against the null hypothesis and there is a significant difference between hypothesized or specified value and observed value of the parameter.
If z <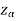 that means the calculated value of test statistic Z lies in non rejection region, then we do not reject the null hypothesis H0 at
that means the calculated value of test statistic Z lies in non rejection region, then we do not reject the null hypothesis H0 at 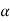 level of significance. Therefore, we conclude that the sample data fails to provide us sufficient evidence against the null hypothesis and the difference between hypothesized value and observed value of the parameter due to fluctuation of sample.
level of significance. Therefore, we conclude that the sample data fails to provide us sufficient evidence against the null hypothesis and the difference between hypothesized value and observed value of the parameter due to fluctuation of sample.
So the population parameter 
Case-2: when
 (left-tailed test)
(left-tailed test)

The rejection (critical) region falls under the left tail of the probability curve of the sampling distribution of test statistic Z.
Suppose -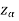 is the critical value at
is the critical value at  level of significance then entire region less than or equal to -
level of significance then entire region less than or equal to - is the rejection region and greater than -
is the rejection region and greater than -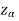 is the non-rejection region
is the non-rejection region
If z ≤-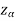 , that means the calculated value of test statistic Z lies in the rejection region, then we reject the null hypothesis H0 at
, that means the calculated value of test statistic Z lies in the rejection region, then we reject the null hypothesis H0 at 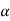 level of significance.
level of significance.
If z >-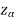 , that means the calculated value of test statistic Z lies in the non-rejection region, then we do not reject the null hypothesis H0 at
, that means the calculated value of test statistic Z lies in the non-rejection region, then we do not reject the null hypothesis H0 at  level of significance.
level of significance.
In case of two tailed test-

In this case, the rejection region falls under both tails of the probability curve of sampling distribution of the test statistic Z. Half the area (α) i.e. α/2 will lies under left tail and other half under the right tail. Suppose 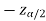 and
and 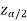 are the two critical values at the left-tailed and right-tailed respectively. Therefore, entire region less than or equal to
are the two critical values at the left-tailed and right-tailed respectively. Therefore, entire region less than or equal to 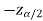 and greater than or equal to
and greater than or equal to 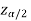 are the rejection regions and between -
are the rejection regions and between -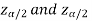 is the non-rejection region.
is the non-rejection region.
If Z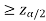 that means the calculated value of test statistic Z lies in the rejection region, then we reject the null hypothesis H0 at
that means the calculated value of test statistic Z lies in the rejection region, then we reject the null hypothesis H0 at  level of significance.
level of significance.
If 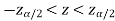 that means the calculated value of test statistic Z lies in the non-rejection region, then we do not reject the null hypothesis H0 at
that means the calculated value of test statistic Z lies in the non-rejection region, then we do not reject the null hypothesis H0 at 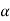 level of significance.
level of significance.
Testing of hypothesis for population mean using Z-Test
For testing the null hypothesis, the test statistic Z is given as-
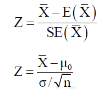
The sampling distribution of the test statistics depends upon variance 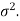
So that there are two cases-
Case-1: when  is known -
is known -
The test statistic follows the normal distribution with mean 0 and variance unity when the sample size is the large as the population under study is normal or non-normal. If the sample size is small then test statistic Z follows the normal distribution only when population under study is normal. Thus,
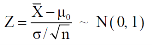
Case-2: when  is unknown –
is unknown –
We estimate the value of 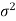 by using the value of sample variance
by using the value of sample variance
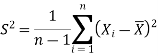
Then the test statistic becomes-
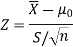
After that, we calculate the value of test statistic as may be the case ( is known or unknown) and compare it with the critical value at prefixed level of significance α.
is known or unknown) and compare it with the critical value at prefixed level of significance α.
Example: A company of pens claims that a certain pen manufactured by him has a mean writing-life at least 460 A-4 size pages. A purchasing agent selects a sample of 100 pens and put them on the test. The mean writing-life of the sample found 453 A-4 size pages with standard deviation 25 A-4 size pages. Should the purchasing agent reject the manufacturer’s claim at 1% level of significance?
Sol.
It is given that-
Specified value of population mean = 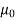 = 460,
= 460,
Sample size = 100
Sample mean = 453
Sample standard deviation = S = 25
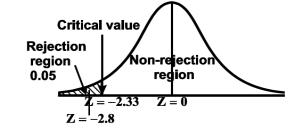
The null and alternative hypothesis will be-

Also the alternative hypothesis left-tailed so that the test is left tailed test.
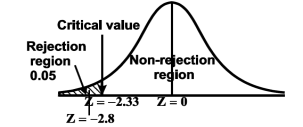
Here, we want to test the hypothesis regarding population mean when population SD is unknown. So we should used t-test for if writing-life of pen follows normal distribution. But it is not the case. Since sample size is n = 100 (n > 30) large so we go for Z-test. The test statistic of Z-test is given by
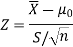

We get the critical value of left tailed Z test at 1% level of significance is 
Since calculated value of test statistic Z (= ‒2.8) is less than the critical value
(= −2.33), that means calculated value of test statistic Z lies in rejection region so we reject the null hypothesis. Since the null hypothesis is the claim so we reject the manufacturer’s claim at 1% level of significance.
Example: A big company uses thousands of CFL lights every year. The brand that the company has been using in the past has average life of 1200 hours. A new brand is offered to the company at a price lower than they are paying for the old brand. Consequently, a sample of 100 CFL light of new brand is tested which yields an average life of 1220 hours with standard deviation 90 hours. Should the company accept the new brand at 5% level of significance?
Sol.
Here we have-

The company may accept the new CFL light when average life of
CFL light is greater than 1200 hours. So the company wants to test that the new brand CFL light has an average life greater than 1200 hours. So our claim is  > 1200 and its complement is
> 1200 and its complement is  ≤ 1200. Since complement contains the equality sign so we can take the complement as the null hypothesis and the claim as the alternative hypothesis. Thus,
≤ 1200. Since complement contains the equality sign so we can take the complement as the null hypothesis and the claim as the alternative hypothesis. Thus,
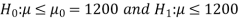
Since the alternative hypothesis is right-tailed so the test is right-tailed test.
Here, we want to test the hypothesis regarding population mean when population SD is unknown, so we should use t-test if the distribution of life of bulbs known to be normal. But it is not the case. Since the sample size is large (n > 30) so we can go for Z-test instead of t-test.
Therefore, test statistic is given by
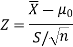

The critical values for right-tailed test at 5% level of significance is
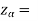 1.645
1.645
Since calculated value of test statistic Z (= 2.22) is greater than critical value (= 1.645), that means it lies in rejection region so we reject the null hypothesis and support the alternative hypothesis i.e. we support our claim at 5% level of significance
Thus, we conclude that sample does not provide us sufficient evidence against the claim so we may assume that the company accepts the new brand of bulbs
Example: A manufacturer of electric bulbs claims that a certain pen manufactured by him has a mean life of at least 460 days. A purchasing officer selects a sample of 100 bulbs and put them on the test. The mean life of the sample found 453 days with a standard deviation of 25 days. Should the purchasing officer reject the manufacturer’s claim at a 1% level of significance?
Sol.
Here the population mean = 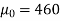
Sample size = n = 100
Sample mean = 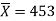
Sample standard deviation = S = 25
The null and alternative hypotheses will be-
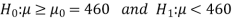
Here alternative hypothesis is left tailed so that the test is left tailed test-
Here population standard deviation is unknown so that we should use a t-test if the life of the bulbs follows a normal distribution.
But it is not the case. Here sample size is 100 which is large.
Note- a sample size of more than 30 is considered a large sample.
So here we use Z-test-


The critical value of Z statistic at a 1% level of significance is = -2.33
Since the calculated value of the test statistic is less than the critical value that means the test statistic lies in the rejection region.
Therefore we reject the null hypothesis.
So that we reject the manufacturer’s claim at a 1% level of significance.
Level of significance-
The probability of type-1 error is called level of significance of a test. It is also called the size of the test or size of the critical region. Denoted by  .
.
Basically it is prefixed as 5% or 1% level of significance.
If the calculated value of the test statistics lies in the critical region then we reject the null hypothesis.
The level of significance relates to the trueness of the conclusion. If null hypothesis do not reject at level 5% then a person will be sure “concluding about the null hypothesis” is true with 95% assurance but even it may false with 5% chance.
Confidence limits-
Let  be a random sample of size n drawn from a population having pdf (pmf)
be a random sample of size n drawn from a population having pdf (pmf) 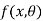 .
.
Let 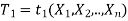 and
and 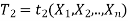 (here
(here  be two statistic such that the probability that the random interval [
be two statistic such that the probability that the random interval [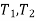 ] including the true value of population parameter
] including the true value of population parameter 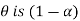 , that is-
, that is-
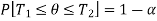
Here  does not depends on
does not depends on  .
.
Then the random interval [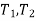 ] is called as (1 –
] is called as (1 – 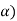 100 % confidence interval for unknown population parameter
100 % confidence interval for unknown population parameter 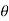 and (1 –
and (1 –  is known as confidence coefficient.
is known as confidence coefficient.
The length of interval can be defined as-
Length = Upper confidence – Lower confidence limit
Key takeaways:
- The population is the collection or group of observations under study.
- The total number of observations in a population is known as population size and it is denoted by N.
- A parameter is a function of population values which is used to represent the certain characteristic of the population.
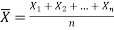
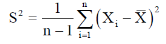
- A hypothesis is a statement or a claim or an assumption about the value of a population parameter.
- A region in the sample space in which if the calculated value of the test statistic lies, we reject the null hypothesis then it is called critical region or rejection region
- Type-1 error-
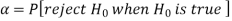
9. Type-2 error-
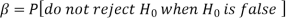
10. 
Whenever n is large, the sampling distribution of X is approximately (nearly) normal with mean μ and variance 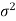 /n regardless of the form of the population distribution.
/n regardless of the form of the population distribution.
Theorem: If X is the mean of a sample of size n drawn from a population with mean μ and finite variance 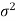 then the standardized sample mean
then the standardized sample mean

Is a random variable whose distribution function approaches that of the standard normal distribution N (Z; 0, 1) as n 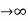
Normal Population (Small Sample)- Sampling distribution of X is normally distributed even for small samples of size n < 30 provided sampling is from normal population.
Testing of hypothesis for population mean using Z-Test
For testing the null hypothesis, the test statistic Z is given as-
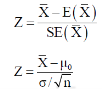
The sampling distribution of the test statistics depends upon variance 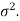
So that there are two cases-
Case-1: when 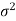 is known -
is known -
The test statistic follows the normal distribution with mean 0 and variance unity when the sample size is the large as the population under study is normal or non-normal. If the sample size is small then test statistic Z follows the normal distribution only when population under study is normal. Thus,
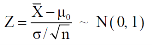
Case-2: when 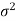 is unknown –
is unknown –
We estimate the value of 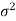 by using the value of sample variance
by using the value of sample variance

Then the test statistic becomes-
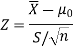
After that, we calculate the value of test statistic as may be the case (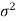 is known or unknown) and compare it with the critical value at prefixed level of significance α.
is known or unknown) and compare it with the critical value at prefixed level of significance α.
Example: A company of pens claims that a certain pen manufactured by him has a mean writing-life at least 460 A-4 size pages. A purchasing agent selects a sample of 100 pens and put them on the test. The mean writing-life of the sample found 453 A-4 size pages with standard deviation 25 A-4 size pages. Should the purchasing agent reject the manufacturer’s claim at 1% level of significance?
Sol.
It is given that-
Specified value of population mean =  = 460,
= 460,
Sample size = 100
Sample mean = 453
Sample standard deviation = S = 25
The null and alternative hypothesis will be-
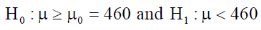
Also the alternative hypothesis left-tailed so that the test is left tailed test.
Here, we want to test the hypothesis regarding population mean when population SD is unknown. So we should used t-test for if writing-life of pen follows normal distribution. But it is not the case. Since sample size is n = 100 (n > 30) large so we go for Z-test. The test statistic of Z-test is given by
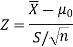
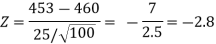
We get the critical value of left tailed Z test at 1% level of significance is 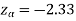
Since calculated value of test statistic Z (= ‒2.8) is less than the critical value
(= −2.33), that means calculated value of test statistic Z lies in rejection region so we reject the null hypothesis. Since the null hypothesis is the claim so we reject the manufacturer’s claim at 1% level of significance.
Example: A big company uses thousands of CFL lights every year. The brand that the company has been using in the past has average life of 1200 hours. A new brand is offered to the company at a price lower than they are paying for the old brand. Consequently, a sample of 100 CFL light of new brand is tested which yields an average life of 1220 hours with standard deviation 90 hours. Should the company accept the new brand at 5% level of significance?
Sol.
Here we have-
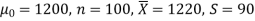
The company may accept the new CFL light when average life of
CFL light is greater than 1200 hours. So the company wants to test that the new brand CFL light has an average life greater than 1200 hours. So our claim is 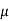 > 1200 and its complement is
> 1200 and its complement is 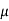 ≤ 1200. Since complement contains the equality sign so we can take the complement as the null hypothesis and the claim as the alternative hypothesis. Thus,
≤ 1200. Since complement contains the equality sign so we can take the complement as the null hypothesis and the claim as the alternative hypothesis. Thus,

Since the alternative hypothesis is right-tailed so the test is right-tailed test.
Here, we want to test the hypothesis regarding population mean when population SD is unknown, so we should use t-test if the distribution of life of bulbs known to be normal. But it is not the case. Since the sample size is large (n > 30) so we can go for Z-test instead of t-test.
Therefore, test statistic is given by
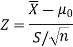

The critical values for right-tailed test at 5% level of significance is
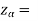 1.645
1.645
Since calculated value of test statistic Z (= 2.22) is greater than critical value (= 1.645), that means it lies in rejection region so we reject the null hypothesis and support the alternative hypothesis i.e. we support our claim at 5% level of significance
Thus, we conclude that sample does not provide us sufficient evidence against the claim so we may assume that the company accepts the new brand of bulbs
Significance test of difference between sample means
Given two independent examples 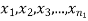 and
and  with means
with means 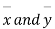 standard derivations
standard derivations 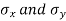 from a normal population with the same variance, we have to test the hypothesis that the population means
from a normal population with the same variance, we have to test the hypothesis that the population means 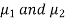 are same For this, we calculate
are same For this, we calculate
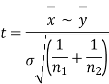
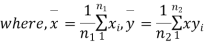
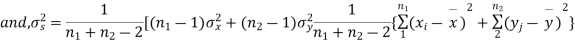
It can be shown that the variate t defined by (1) follows the t distribution with 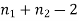 degrees of freedom.
degrees of freedom.
If the calculated value  the difference between the sample means is said to be significant at 5% level of significance.
the difference between the sample means is said to be significant at 5% level of significance.
If  , the difference is said to be significant at 1% level of significance.
, the difference is said to be significant at 1% level of significance.
If 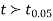 the data is said to be consistent with the hypothesis that
the data is said to be consistent with the hypothesis that 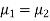 .
.
Cor. If the two samples are of same size and the data are paired, then t is defined by
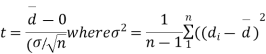
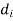 =difference of the ith member of the sample
=difference of the ith member of the sample
d=mean of the differences =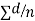 and the member of d.f.=n-1.
and the member of d.f.=n-1.
Example
Eleven students were given a test in statistics. They were given a month’s further tuition and the second test of equal difficulty was held at the end of this. Do the marks give evidence that the students have benefitted by extra coaching?
Boys | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
Marks I test | 23 | 20 | 19 | 21 | 18 | 20 | 18 | 17 | 23 | 16 | 19 |
Marks II test | 24 | 19 | 22 | 18 | 20 | 22 | 20 | 20 | 23 | 20 | 17 |
Sol. We compute the mean and the S.D. Of the difference between the marks of the two tests as under:
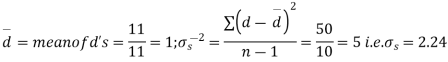
Assuming that the students have not been benefitted by extra coaching, it implies that the mean of the difference between the marks of the two tests is zero i.e.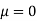
Then, 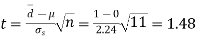 nearly and df v=11-1=10
nearly and df v=11-1=10
Students | 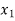 | 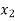 |  | 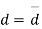 | 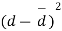 |
1 | 23 | 24 | 1 | 0 | 0 |
2 | 20 | 19 | -1 | -2 | 4 |
3 | 19 | 22 | 3 | 2 | 4 |
4 | 21 | 18 | -3 | -4 | 16 |
5 | 18 | 20 | 2 | 1 | 1 |
6 | 20 | 22 | 2 | 1 | 1 |
7 | 18 | 20 | 2 | 1 | 1 |
8 | 17 | 20 | 3 | 2 | 4 |
9 | 23 | 23 | - | -1 | 1 |
10 | 16 | 20 | 4 | 3 | 9 |
11 | 19 | 17 | -2 | -3 | 9 |
|
|
|  |
| 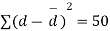 |
We find that 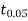 (for v=10) =2.228. As the calculated value of
(for v=10) =2.228. As the calculated value of 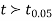 , the value of t is not significant at 5% level of significance i.e. the test provides no evidence that the students have benefitted by extra coaching.
, the value of t is not significant at 5% level of significance i.e. the test provides no evidence that the students have benefitted by extra coaching.
Example:
From a random sample of 10 pigs fed on diet A, the increase in weight in certain period were 10,6,16,17,13,12,8,14,15,9 lbs. For another random sample of 12 pigs fed on diet B, the increase in the same period were 7,13,22,15,12,14,18,8,21,23,10,17 lbs. Test whether diets A and B differ significantly as regards their effect on increases in weight?
Sol. We calculate the means and standard derivations of the samples as follows
| Diet A |
|
| Diet B |
|
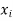 | 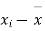 | 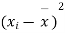 | 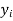 | 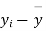 | 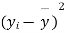 |
10 | -2 | 4 | 7 | -8 | 64 |
6 | -6 | 36 | 13 | -2 | 4 |
16 | 4 | 16 | 22 | 7 | 49 |
17 | 5 | 25 | 15 | 0 | 0 |
13 | 1 | 1 | 12 | -3 | 9 |
12 | 0 | 0 | 14 | -1 | 1 |
8 | -4 | 16 | 18 | 3 | 9 |
14 | 2 | 4 | 8 | -7 | 49 |
15 | 3 | 9 | 21 | 6 | 36 |
9 | -3 | 9 | 23 | 8 | 64 |
|
|
| 10 | -5 | 25 |
|
|
| 17 | 2 | 4 |
|
|
|
|
|
|
120 |
|
| 180 | 0 | 314 |

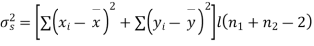
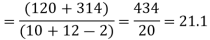
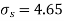
Assuming that the samples do not differ in weight so far as the two diets are concerned i.e. 
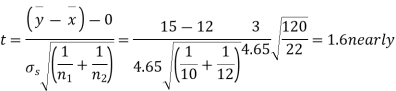
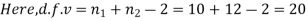
For v=20, we find 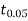 =2.09
=2.09
The calculated value of 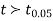
Hence the difference between the samples means is not significant i.e. thew two diets do not differ significantly as regards their effects on increase in weight.
Testing of hypothesis for difference of two population means using Z-Test-
Let there be two populations, say, population-I and population-II under study.
Also let 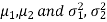 denote the means and variances of population-I and population-II respectively where both
denote the means and variances of population-I and population-II respectively where both  are unknown but
are unknown but 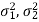 may be known or unknown. We will consider all possible cases here. For testing the hypothesis about the difference of two population means, we draw a random sample of large size n1 from population-I and a random sample of large size n2 from population-II. Let
may be known or unknown. We will consider all possible cases here. For testing the hypothesis about the difference of two population means, we draw a random sample of large size n1 from population-I and a random sample of large size n2 from population-II. Let 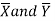 be the means of the samples selected from population-I and II respectively.
be the means of the samples selected from population-I and II respectively.
These two populations may or may not be normal but according to the central limit theorem, the sampling distribution of difference of two large sample means asymptotically normally distributed with mean 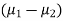 and variance
and variance 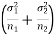

And
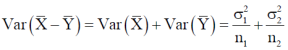
We know that the standard error = 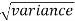
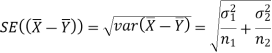
Here, we want to test the hypothesis about the difference of two population means so we can take the null hypothesis as
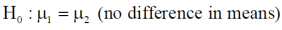
Or
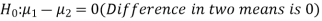
And the alternative hypothesis is-
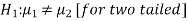
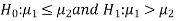
Or
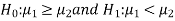
The test statistic Z is given by-

Or
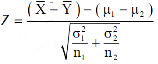
Since under null hypothesis we assume that 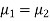 , therefore , we get-
, therefore , we get-
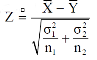
Now, the sampling distribution of the test statistic depends upon  that both are known or unknown. Therefore, four cases arise-
that both are known or unknown. Therefore, four cases arise-
Case-1: When 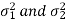 are known and
are known and 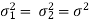
In this case, the test statistic follows normal distribution with mean
0 and variance unity when the sample sizes are large as both the populations under study are normal or non-normal. But when sample sizes are small then test statistic Z follows normal distribution only when populations under study are normal, that is,

Case-2: When  are known and
are known and 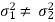
In this case, the test statistic also follows the normal distribution as described in case I, that is,
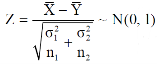
Case-3: When 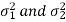 are unknown and
are unknown and 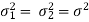
In this case, σ2 is estimated by value of pooled sample variance 
Where,

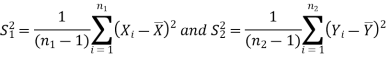
And test statistic follows t-distribution with (n1 + n2 − 2) degrees of freedom as the sample sizes are large or small provided populations under study follow normal distribution.
But when the populations are under study are not normal and sample sizes n1 and n2are large (> 30) then by central limit theorem, test statistic approximately normally distributed with mean
0 and variance unity, that is,
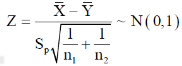
Case-4: When 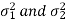 are unknown and
are unknown and 
In this case, 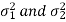 are estimated by the values of the sample variances
are estimated by the values of the sample variances 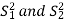 respectively and the exact distribution of test statistic is difficult to derive. But when sample sizes n1 and n2 are large (> 30) then central limit theorem, the test statistic approximately normally distributed with mean 0 and variance unity,
respectively and the exact distribution of test statistic is difficult to derive. But when sample sizes n1 and n2 are large (> 30) then central limit theorem, the test statistic approximately normally distributed with mean 0 and variance unity,
That is,

After that, we calculate the value of test statistic and compare it with the critical value at prefixed level of significance α.
Example: A college conducts both face to face and distance mode classes for a particular course indented both to be identical. A sample of 50 students of face to face mode yields examination results mean and SD respectively as-

And other sample of 100 distance-mode students yields mean and SD of their examination results in the same course respectively as:
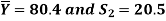
Are both educational methods statistically equal at 5% level?
Sol. Here we have-
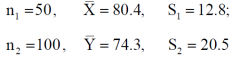
Here we wish to test that both educational methods are statistically equal. If 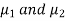 denote the average marks of face to face and distance mode students respectively then our claim is
denote the average marks of face to face and distance mode students respectively then our claim is 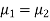 and its complement is
and its complement is 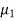 ≠
≠  . Since the claim contains the equality sign so we can take the claim as the null hypothesis and complement as the alternative hypothesis. Thus,
. Since the claim contains the equality sign so we can take the claim as the null hypothesis and complement as the alternative hypothesis. Thus,
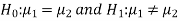
Since the alternative hypothesis is two-tailed so the test is two-tailed test.
We want to test the null hypothesis regarding two population means when standard deviations of both populations are unknown. So we should go for t-test if population of difference is known to be normal. But it is not the case.
Since sample sizes are large (n1, and n2 > 30) so we go for Z-test.
For testing the null hypothesis, the test statistic Z is given by

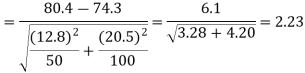
The critical (tabulated) values for two-tailed test at 5% level of significance are-

Since calculated value of Z ( = 2.23) is greater than the critical values
(= ±1.96), that means it lies in rejection region so we
Reject the null hypothesis i.e. we reject the claim at 5% level of significance
Key takeaways-
- Significance test of difference between sample means
3. Testing of hypothesis for difference of two population means using Z-Test-
General procedure of t-test for testing hypothesis-
Let X1, X2,…, Xn be a random sample of small size n (< 30) selected from a normal population, having parameter of interest, say,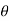
Which is actually unknown but its hypothetical value- then
Step-1: First of all, we setup null and alternative hypotheses
Step-2: After setting the null and alternative hypotheses our next step is to decide a criteria for rejection or non-rejection of null hypothesis i.e. decide the level of significance  at which we want to test our null hypothesis. We generally take
at which we want to test our null hypothesis. We generally take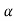 = 5 % or 1%.
= 5 % or 1%.
Step-3: The third step is to determine an appropriate test statistic, say, t for testing the null hypothesis. Suppose Tn is the sample statistic (may be sample mean, sample correlation coefficient, etc. depending upon 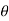 ) for the parameter
) for the parameter 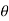 then test-statistic t is given by
then test-statistic t is given by
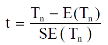
Step-4: As we know, t-test is based on t-distribution and t-distribution is described with the help of its degrees of freedom, therefore, test statistic t follows t-distribution with specified degrees of freedom as the case may be.
By putting the values of Tn, E(Tn) and SE(Tn) in above formula, we calculate the value of test statistic t. Let t-cal be the calculated value of test statistic t after putting these values.
Step-5: After that, we obtain the critical (cut-off or tabulated) value(s) in the sampling distribution of the test statistic t corresponding to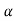 assumed in Step II. The critical values for t-test are corresponding to different level of significance (α). After that, we construct rejection (critical) region of size
assumed in Step II. The critical values for t-test are corresponding to different level of significance (α). After that, we construct rejection (critical) region of size 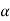 in the probability curve of the sampling distribution of test statistic t.
in the probability curve of the sampling distribution of test statistic t.
Step-6: Take the decision about the null hypothesis based on calculated and critical value(s) of test statistic obtained in Step IV and Step V respectively.
Critical values depend upon the nature of test.
The following cases arises-
In case of one tailed test-
Case-1: 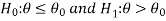 [Right-tailed test]
[Right-tailed test]
In this case, the rejection (critical) region falls under the right tail of the probability curve of the sampling distribution of test statistic t.
Suppose 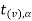 is the critical value at
is the critical value at  level of significance then entire region greater than or equal to
level of significance then entire region greater than or equal to 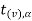 is the rejection region and less than
is the rejection region and less than 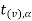 is the non-rejection region.
is the non-rejection region.
If 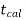 ≥
≥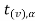 that means calculated value of test statistic t lies in the rejection (critical) region, then we reject the null hypothesis
that means calculated value of test statistic t lies in the rejection (critical) region, then we reject the null hypothesis 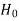 at
at 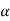 level of significance.
level of significance.
If 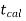 <
< that means calculated value of test statistic t lies in non rejection region, then we do not reject the null hypothesis
that means calculated value of test statistic t lies in non rejection region, then we do not reject the null hypothesis 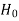 at
at 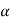 level of significance.
level of significance.
Case-2:  [Left-tailed test]
[Left-tailed test]
In this case, the rejection (critical) region falls under the left tail of the probability curve of the sampling distribution of test statistic t.
Suppose -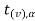 is the critical value at
is the critical value at 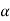 level of significance then entire region less than or equal to -
level of significance then entire region less than or equal to -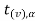 is the rejection region and greater than -
is the rejection region and greater than -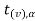 is the non-rejection region.
is the non-rejection region.
If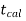 ≤ −
≤ −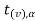 that means calculated value of test statistic t lies in the rejection (critical) region, then we reject the null hypothesis
that means calculated value of test statistic t lies in the rejection (critical) region, then we reject the null hypothesis 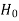 at
at 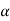 level of significance.
level of significance.
If 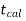 > −
> −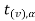 , that means calculated value of test statistic t lies in the non-rejection region, then we do not reject the null hypothesis
, that means calculated value of test statistic t lies in the non-rejection region, then we do not reject the null hypothesis 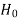 at
at 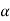 level of significance.
level of significance.
In case of two tailed test-
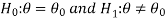
In this case, the rejection region falls under both tails of the probability curve of sampling distribution of the test statistic t. Half the area (α) i.e. α/2 will lies under left tail and other half under the right tail. Suppose - , and
, and 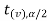 are the two critical values at the left- tailed and right-tailed respectively. Therefore, entire region less than or equal to -
are the two critical values at the left- tailed and right-tailed respectively. Therefore, entire region less than or equal to - and greater than or equal to
and greater than or equal to 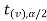 are the rejection regions and between -
are the rejection regions and between -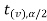 and
and 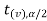 is the non rejection region.
is the non rejection region.
If 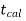 ≥
≥ 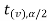 or
or 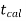 ≤ -
≤ - , that means calculated value of test statistic t lies in the rejection(critical) region, then we reject the null hypothesis
, that means calculated value of test statistic t lies in the rejection(critical) region, then we reject the null hypothesis  at
at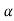 level of significance.
level of significance.
And if -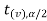 <
< 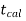 <
<  , that means calculated value of test statistic t lies in the non-rejection region, then we do not reject the null hypothesis
, that means calculated value of test statistic t lies in the non-rejection region, then we do not reject the null hypothesis 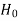 at
at 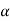 level of significance.
level of significance.
Testing of hypothesis for population mean using t-Test
There are the following assumptions of the t-test-
- Sample observations are random and independent.
- Population variance
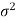 is unknown
is unknown - The characteristic under study follows normal distribution.
For testing the null hypothesis, the test statistic t is given by-
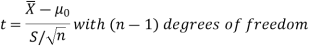
Example: A tube manufacturer claims that the average life of a particular category
Of his tube is 18000 km when used under normal driving conditions. A random sample of 16 tube was tested. The mean and SD of life of the tube in the sample were 20000 km and 6000 km respectively.
Assuming that the life of the tube is normally distributed, test the claim of the manufacturer at 1% level of significance using appropriate test.
Sol.
Here we have-

We want to test that manufacturer’s claim is true that the average life (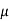 ) of tube is 18000 km. So claim is μ = 18000 and its complement is μ ≠ 18000. Since the claim contains the equality sign so we can take the claim as the null hypothesis and complement as the alternative hypothesis. Thus,
) of tube is 18000 km. So claim is μ = 18000 and its complement is μ ≠ 18000. Since the claim contains the equality sign so we can take the claim as the null hypothesis and complement as the alternative hypothesis. Thus,
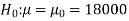

Here, population SD is unknown and population under study is given to be normal.
So here can use t-test-
For testing the null hypothesis, the test statistic t is given by-

The critical value of test statistic t for two-tailed test corresponding (n-1) = 15 df at 1% level of significance are 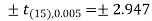
Since calculated value of test statistic t (= 1.33) is less than the critical (tabulated) value (= 2.947) and greater that critical value (= − 2.947), that means calculated value of test statistic lies in non-rejection region, so we do not reject the null hypothesis. We conclude that sample fails to provide sufficient evidence against the claim so we may assume that manufacturer’s claim is true.
F-test-
Assumption of F-test-
The assumptions for F-test for testing the variances of two populations are:
- The samples must be normally distributed.
- The samples must be independent.
Let 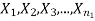 be random sample of size
be random sample of size 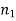 taken froma normal population with
taken froma normal population with  and variance
and variance  be a random sample of size
be a random sample of size  from another normal population with mean
from another normal population with mean  and
and 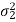 .
.
Here, we want to test the hypothesis about the two population variances so we can take our alternative null and hypotheses as-
For two tailed test-

For one tailed test-
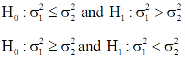
We use test statistic F for testing the null hypothesis-


And
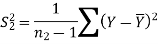
In case of one-tailed test-
Case-1: 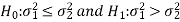 (right-tailed test)
(right-tailed test)
In this case, the rejection (critical) region falls at the right side of the probability curve of the sampling distribution of test statistic F. Suppose 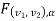 is the critical value of test statistic F with (
is the critical value of test statistic F with (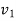 =
=  – 1,
– 1,  =
= 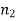 – 1) df at
– 1) df at 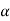 level of significance so entire region greater than or equal
level of significance so entire region greater than or equal 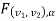 to is the rejection (critical) region and less than
to is the rejection (critical) region and less than 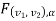 is the non-rejection region.
is the non-rejection region.

If 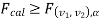 that means calculated value of test statistic lies in rejection (critical) region, then we reject the null hypothesis H0 at
that means calculated value of test statistic lies in rejection (critical) region, then we reject the null hypothesis H0 at level of significance. Therefore, we conclude that samples data provide us sufficient evidence against the null hypothesis and there is a significant difference between population variances
level of significance. Therefore, we conclude that samples data provide us sufficient evidence against the null hypothesis and there is a significant difference between population variances
If 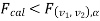 , that means calculated value of test statistic lies in non-rejection region, then we do not reject the null hypothesis H0 at
, that means calculated value of test statistic lies in non-rejection region, then we do not reject the null hypothesis H0 at 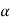 level of significance. Therefore, we conclude that the samples data fail to provide us sufficient evidence against the null hypothesis and the difference between population variances due to fluctuation of sample.
level of significance. Therefore, we conclude that the samples data fail to provide us sufficient evidence against the null hypothesis and the difference between population variances due to fluctuation of sample.
Case-2:  (left-tailed test)
(left-tailed test)

In this case, the rejection (critical) region falls at the left side of the probability curve of the sampling distribution of test statistic F. Suppose 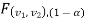 is the critical value at
is the critical value at level of significance then entire region less than or equal to
level of significance then entire region less than or equal to 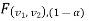 is the rejection(critical) region and greater than
is the rejection(critical) region and greater than 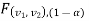 is the non-rejection region.
is the non-rejection region.
If 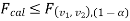 that means calculated value of test statistic lies in rejection (critical) region, then we reject the null hypothesis H0 at
that means calculated value of test statistic lies in rejection (critical) region, then we reject the null hypothesis H0 at 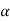 level of significance.
level of significance.
If 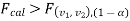 that means calculated value of test statistic lies in non-rejection region, then we do not reject the null hypothesis H0 at
that means calculated value of test statistic lies in non-rejection region, then we do not reject the null hypothesis H0 at 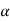 level of significance.
level of significance.
In case of two-tailed test-
When 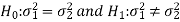
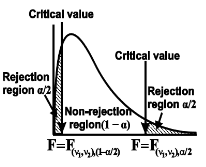
In this case, the rejection (critical) region falls at both sides of the probability curve of the sampling distribution of test statistic F and half the area(α) i.e. α/2 of rejection (critical) region lies at left tail and other half on the right tail
Suppose 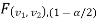 and
and  are the two critical values at the left-tailed and right-tailed respectively on pre-fixed
are the two critical values at the left-tailed and right-tailed respectively on pre-fixed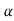 level of significance. Therefore, entire region less than or equal to
level of significance. Therefore, entire region less than or equal to 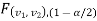 and greater than or equal to
and greater than or equal to 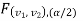 are the rejection (critical) regions and between
are the rejection (critical) regions and between 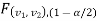 and
and  is the non-rejection region
is the non-rejection region
If  or
or  that means calculated value of test statistic lies in rejection(critical) region, then we reject the null hypothesis H0 at α level of significance.
that means calculated value of test statistic lies in rejection(critical) region, then we reject the null hypothesis H0 at α level of significance.
If 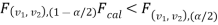 that means calculated value of test statistic F lies in non-rejection region, then we do not reject the null hypothesis H0 at α level of significance.
that means calculated value of test statistic F lies in non-rejection region, then we do not reject the null hypothesis H0 at α level of significance.
Example: Two sources of raw materials are under consideration by a bulb manufacturing company. Both sources seem to have similar characteristics but the company is not sure about their respective uniformity. A sample of 12 lots from source A yields a variance of 125 and a sample of 10 lots from source B yields a variance of 112. Is it likely that the variance of source A significantly differs to the variance of source B at significance level α = 0.01?
Sol.

The null and alternative hypothesis will be-
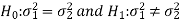
Since the alternative hypothesis is two-tailed so the test is two-tailed test.
Here, we want to test the hypothesis about two population variances and sample sizes 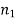 = 12(< 30) and
= 12(< 30) and 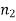 = 10 (< 30) are small. Also populations under study are normal and both samples are independent.
= 10 (< 30) are small. Also populations under study are normal and both samples are independent.
So we can go for F-test for two population variances.
Test statistic is-
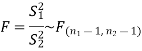
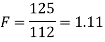
The critical (tabulated) value of test statistic F for two-tailed test corresponding 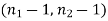 = (11, 9) df at 5% level of significance are
= (11, 9) df at 5% level of significance are 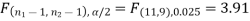 and
and
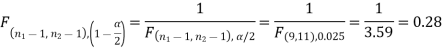
Since calculated value of test statistic (= 1.11) is less than the critical value (= 3.91) and greater than the critical value (= 0.28), that means calculated value of test statistic lies in non-rejection region, so we do not reject the null hypothesis and reject the alternative hypothesis. We conclude that samples provide us sufficient evidence against the claim so we may assume that the variances of source A and B is differ.
Chi-Square test
The chi-square test works under the following circumstances-
1. When the given data is normally distributed.
2. Sample observations are random and independent.
When a fair coin is tossed 80 times we expect from the theoretical considerations that heads will appear 40 times and tail 40 times. But this never happens in practice that is the results obtained in an experiment do not agree exactly with the theoretical results. The magnitude of discrepancy between observations and theory is given by the quantity 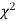 (pronounced as chi-squares). If
(pronounced as chi-squares). If 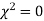 the observed and theoretical frequencies completely agree. As the value of
the observed and theoretical frequencies completely agree. As the value of 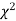 increases, the discrepancy between the observed and theoretical frequencies increases.
increases, the discrepancy between the observed and theoretical frequencies increases.
(1) Definition. If 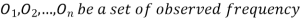 and
and 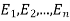 be the corresponding set of expected (theoretical) frequencies, then
be the corresponding set of expected (theoretical) frequencies, then 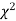 is defined by the relation
is defined by the relation

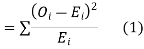
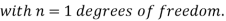
(2) Chi-square distribution
If 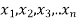 be n independent normal variates with mean zero and s.d. Unity, then it can be shown that
be n independent normal variates with mean zero and s.d. Unity, then it can be shown that 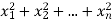 is a random variate having
is a random variate having 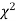 distribution with ndf.
distribution with ndf.
The equation of the 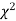 curve is
curve is
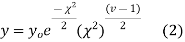
(3) Properties of 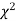 distribution
distribution
- If v = 1, the
 curve (2) reduces to
curve (2) reduces to 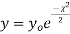 which is the exponential distribution.
which is the exponential distribution. - If
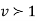 this curve is tangential to x – axis at the origin and is positively skewed as the mean is at v and mode at v-2.
this curve is tangential to x – axis at the origin and is positively skewed as the mean is at v and mode at v-2. - The probability P that the value of
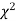 from a random sample will exceed
from a random sample will exceed 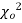 is given by
is given by
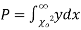
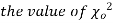 have been tabulated for various values of P and for values of v from 1 to 30. (Table V Appendix 2)
have been tabulated for various values of P and for values of v from 1 to 30. (Table V Appendix 2)
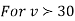 ,the
,the curve approximates to the normal curve and we should refer to normal distribution tables for significant values of
curve approximates to the normal curve and we should refer to normal distribution tables for significant values of 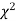 .
.
IV. Since the equation of 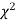 the curve does not involve any parameters of the population, this distribution does not dependent on the form of the population.
the curve does not involve any parameters of the population, this distribution does not dependent on the form of the population.
V. Mean = 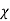 and variance =
and variance = 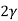
Goodness of fit
The values of 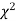 is used to test whether the deviations of the observed frequencies from the expected frequencies are significant or not. It is also used to test how well a set of observations fit given distribution
is used to test whether the deviations of the observed frequencies from the expected frequencies are significant or not. It is also used to test how well a set of observations fit given distribution 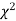 therefore provides a test of goodness of fit and may be used to examine the validity of some hypothesis about an observed frequency distribution. As a test of goodness of fit, it can be used to study the correspondence between theory and fact.
therefore provides a test of goodness of fit and may be used to examine the validity of some hypothesis about an observed frequency distribution. As a test of goodness of fit, it can be used to study the correspondence between theory and fact.
This is a nonparametric distribution-free test since in this we make no assumptions about the distribution of the parent population.
Procedure to test significance and goodness of fit
(i) Set up a null hypothesis and calculate
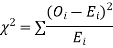
(ii) Find the df and read the corresponding values of 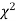 at a prescribed significance level from table V.
at a prescribed significance level from table V.
(iii) From 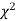 table, we can also find the probability P corresponding to the calculated values of
table, we can also find the probability P corresponding to the calculated values of 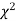 for the given d.f.
for the given d.f.
(iv) If P<0.05, the observed value of  is significant at a 5% level of significance
is significant at a 5% level of significance
If P<0.01 the value is significant at the 1% level.
If P>0.05, it is good faith and the value is not significant.
Example. A set of five similar coins is tossed 320 times and the result is
Number of heads | 0 | 1 | 2 | 3 | 4 | 5 |
Frequency | 6 | 27 | 72 | 112 | 71 | 32 |
Solution. For v = 5, we have 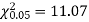
P, probability of getting a head=1/2;q, probability of getting a tail=1/2.
Hence the theoretical frequencies of getting 0,1,2,3,4,5 heads are the successive terms of the binomial expansion 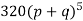

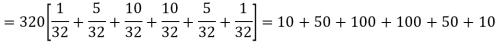
Thus the theoretical frequencies are 10, 50, 100, 100, 50, 10.
Hence, 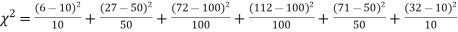
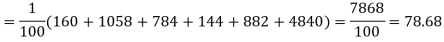
Since the calculated value of  is much greater than
is much greater than  the hypothesis that the data follow the binomial law is rejected.
the hypothesis that the data follow the binomial law is rejected.
Example. Fit a Poisson distribution to the following data and test for its goodness of fit at a level of significance 0.05.
X | 0 | 1 | 2 | 3 | 4 |
F | 419 | 352 | 154 | 56 | 19 |
Solution. Mean m =
Hence, the theoretical frequency is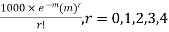
X | 0 | 1 | 2 | 3 | 4 | Total |
F | 404.9 (406.2) | 366 | 165.4 | 49.8 | 11..3 (12.6) | 997.4 |
Hence, 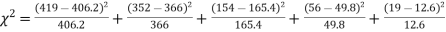
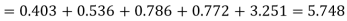
Since the mean of the theoretical distribution has been estimated from the given data and the totals have been made to agree, there are two constraints so that the number of degrees of freedom v = 5- 2=3
For v = 3, we have 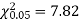
Since the calculated value of 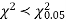 the agreement between the fact and theory is good and hence the Poisson distribution can be fitted to the data.
the agreement between the fact and theory is good and hence the Poisson distribution can be fitted to the data.
Example. In experiments of pea breeding, the following frequencies of seeds were obtained
Round and yellow | Wrinkled and yellow | Round and green | Wrinkled and green | Total |
316 | 101 | 108 | 32 | 556 |
Theory predicts that the frequencies should be in proportions 9:3:3:1. Examine the correspondence between theory and experiment.
Solution. The corresponding frequencies are
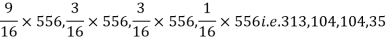
Hence, 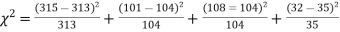
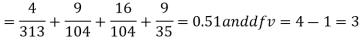
For v = 3, we have 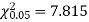
Since the calculated value of 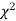 is much less than
is much less than 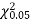 there is a very high degree of agreement between theory and experiment.
there is a very high degree of agreement between theory and experiment.
Key takeaways-
- For testing the null hypothesis, the test statistic t is given by-

2. We use test statistic F for testing the null hypothesis-

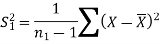
And

3.
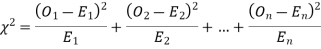

Correlation
So far we have confined our attention to the analysis of observations on a single variable. There are however, many phenomenon where the changes in one variable are related to the changes in the other variable. For instance the yield of a crop varies with the amount of rainfall, the price of a commodity increases with the reduction in its supply and so on. Such a data connecting two variables is called bivariate population.
To obtain a measure of relationship between the two variables, we plot their corresponding values on the graph taking one of the variable along the x axis and the other along the y axis. (Figure 25.6).
Let the origin be shifted to 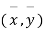 , where
, where  re the means of X’s and y's that the new coordinates are given by
re the means of X’s and y's that the new coordinates are given by
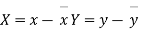
Now the points (X,Y) are so distributed over the four quadrants of XY plane that the product XY is positive in the first and third quadrant but negative in the second and fourth quadrants. The algebraic sum of the products can be taken as describing the trend of the dots in all the quadrants.
(i) If 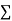 XY is positive, the trend of the dots is through the first and third quadrants.
XY is positive, the trend of the dots is through the first and third quadrants.
(ii) If 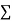 XY is negative the trend of two dots is in the second and fourth quadrants and
XY is negative the trend of two dots is in the second and fourth quadrants and
(iii) If 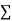 XY is zero, the points indicate no trend i.e. the points are evenly distributed over the quadrants.
XY is zero, the points indicate no trend i.e. the points are evenly distributed over the quadrants.
The  XY or better still
XY or better still  XY i.e. the average of n products may be taken as a measure of correlation. If we put X and Y in their units, i.e.
XY i.e. the average of n products may be taken as a measure of correlation. If we put X and Y in their units, i.e.  taking, as the unit for x and
taking, as the unit for x and  for y, then
for y, then

Is the measure of correlation.
Coefficient of correlation
The numerical measure of correlation is called the coefficient of correlation and is defined by the relation

Where, X = deviation from the mean =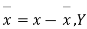 = devaluation from the mean
= devaluation from the mean 
 = Standard deviation of x series,
= Standard deviation of x series, 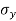 = standard deviation of y series and n = number of the values of the two variables
= standard deviation of y series and n = number of the values of the two variables
Methods of calculation
(a) Direct method. Substituting the value of 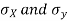 in the above formula we get
in the above formula we get
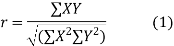
Another form of the formula (1) which is quite handy for calculation is
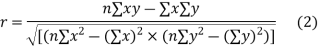
(b) Step deviation method. The direct method becomes very lengthy and tedious if the means of the two series are not integers. In such cases, use is made of assumed means. If  are step deviations from the assumed means, then
are step deviations from the assumed means, then

(c) Coefficient of correlation for grouped data. When x and y series are both given as frequency distributions these can be represented by a two way table known as the correlation table. The coefficient of correlation for such a bivariate frequency distribution is calculated by the formula
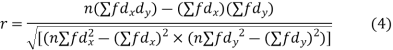
Where 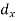 = derivation of the central values from the assumed mean of x series
= derivation of the central values from the assumed mean of x series
 derivation of the central values from the assumed mean of y series
derivation of the central values from the assumed mean of y series
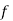 is the frequency corresponding to the pair (x, y)
is the frequency corresponding to the pair (x, y)
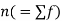 is the total number of frequency.
is the total number of frequency.
Example. Psychological test of the intelligence and of Engineering ability were applied to 10 students. Here is a record of ungrouped data showing intelligence ratio (I.R) and Engineering ratio (E.R). Calculate the coefficient of correlation.
Student | A | B | C | D | E | F | G | H | I | J |
I.R. | 105 | 104 | 102 | 101 | 100 | 99 | 98 | 96 | 93 | 92 |
E.R. | 101 | 103 | 100 | 98 | 95 | 96 | 104 | 92 | 97 | 94 |
Solution. We construct the following table
Student | Intelligence ratio x 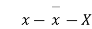 | Engineering ratio y y  |  | 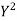 | XY |
A | 105 6 | 101 3 | 36 | 9 | 18 |
B | 104 5 | 103 5 | 25 | 25 | 25 |
C | 102 3 | 100 2 | 9 | 4 | 6 |
D | 101 2 | 98 0 | 4 | 0 | 0 |
E | 100 1 | 95 -3 | 1 | 9 | -3 |
F | 99 0 | 96 - 2 | 0 | 4 | 0 |
G | 98 -1 | 104 6 | 1 | 36 | -6 |
H | 96 -3 | 92 -6 | 9 | 36 | 18 |
I | 93 -6 | 97 -1 | 36 | 1 | 6 |
J | 92 -7 | 94 -4 | 49 | 16 | 28 |
Total | 990 0 | 980 0 | 170 | 140 | 92 |
From this table, mean of x, i.e. 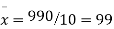 and mean of y, i.e.
and mean of y, i.e. 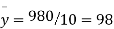

Substituting these value in the formula (1)p.744 we have

Example. The correlation table given below shows that the ages of husband and wife of 53 married couples living together on the census night of 1991. Calculate the coefficient of correlation between the age of the husband and that of the wife.
Age of husband | Age of wife | Total | ||||||
15-25 | 25-35 | 35-45 | 45-55 | 55-65 | 65-75 | |||
15-25 | 1 | 1 | - | - | - | - | 2 | |
25-35 | 2 | 12 | 1 | - | - | - | 15 | |
35-45 | - | 4 | 10 | 1 | - | - | 15 | |
45-55 | - | - | 3 | 6 | 1 | - | 10 | |
55-65 | - | - | - | 2 | 4 | 2 | 8 | |
65-75 | - | - | - | - | 1 | 2 | 3 | |
Total | 3 | 17 | 14 | 9 | 6 | 4 | 53 | |
Solution.
Age of husband | Age of wife x series | Suppose 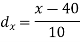  | |||||||||||
15-25 | 25-35 | 35-45 | 45-55 | 55-65 | 65-75 |
Total f | |||||||
Years | Midpoint x | 20 | 30 | 40 | 50 | 60 | 70 | ||||||
Age group | Midpoint y |
|
| -20 | -10 | 0 | 10 | 20 | 30 | 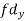 |  | 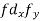 | |
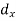 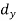 | -2 | -1 | 0 | 1 | 2 | 3 | |||||||
15-25 | 20 | -20 | -2 | 4 1 | 2 1 |
|
|
|
| 2 | -4 | 8 | 6 |
25-35 | 30 | -10 | -1 | 4 2 | 12 12 | 0 1 |
|
|
| 15 | -15 | 15 | 16 |
35-45 | 40 | 0 | 0 |
| 0 4 | 0 10 | 0 1 |
|
| 15 | 0 | 0 | 0 |
45-55 | 50 |
|
|
|
| 0 3 | 6 6 | 2 1 |
| 10 | 10 | 10 | 8 |
55-65 | 60 |
|
|
|
|
| 4 2 | 16 4 | 12 2 | 8 | 16 | 32 | 32 |
65-75 | 70 |
|
|
|
|
|
| 6 1 | 18 2 | 3 | 9 | 27 | 24 |
Total f | 3 | 17 | 14 | 9 | 6 | 4 | 53 = n | 16 | 92 | 86 | |||
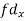 | -6 | -17 | 0 | 9 | 12 | 12 | 10 | Thick figures in small sqs. For 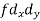 Check: 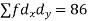 From both sides | |||||
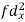 | 12 | 17 | 0 | 9 | 24 | 36 | 98 | ||||||
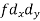 | 8 | 14 | 0 | 10 | 24 | 30 | 86 | ||||||
With the help of the above correlation table, we have


Lines of Regression
It frequently happens that the dots of the scatter diagram generally tends to cluster along a well- defined direction which suggests a linear relationship between the variables x and y. Such a line of best fit for the given distribution of dots is called the line of regression (figure 25.6). In fact there are two such lines, one giving the best possible mean values of y for each specified value pf x and the other giving the best possible mean values of x for given value of y. The former is known as the line of regression of y on x and the latter as the line of regression of x on y.
Consider first the line of regression of y on x. Let the straight line satisfying the general trend of n dots in a scatter diagram be
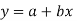 (1)
(1)
We have to determine the constant a and b so that (1) gives for each value of x, the best estimate for the average value of y in accordance with the principle of least squares therefore, the normal equation for a and b are
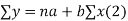
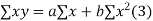
 i.e.
i.e. 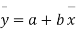
This shows that  i.e. the mean of x and y lie on (1).
i.e. the mean of x and y lie on (1).
Shifting the origin to 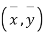 (3) takes the form of
(3) takes the form of
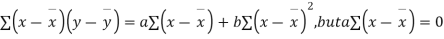
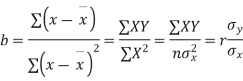
Cor. The correlation coefficient r is the geometric mean between the two regression coefficients
For 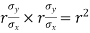
Example. The two regression equations of the variable x and y are x = 19.13 and y = 11.64 – 0.50 x. Find (i) mean of x’s (ii) mean of y’s and (iii) the correlation coefficient between x and y.
Solution. Since the mean of x’s and the mean of y’s lie on the two regression lines, we have
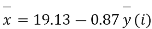

Multiplying (ii) by 0.87 and subtracting from (i) we have
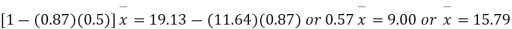

Regression coefficient of y and x is -0.50 and that of x and y is -0.87.
Now since the coefficient of correlation is the geometric mean between the two regression coefficients.

[-ve sign is taken since both the regression coefficients are –ve]
Example. If 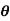 is the angle between the two regression lines show that
is the angle between the two regression lines show that
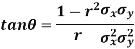
Explain the significance when 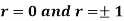 .
.
Solution. The equations to the line of regression of y on x and x on y are
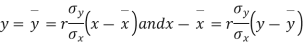
Their slopes are 
Thus, 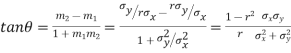
When r = 0,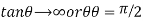 i.e. when the variable are independent, the two lines of regression are perpendicular to each other.
i.e. when the variable are independent, the two lines of regression are perpendicular to each other.
When 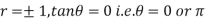 . Thus the line of regression coincide i.e. there is perfect correlationbetween the two variables.
. Thus the line of regression coincide i.e. there is perfect correlationbetween the two variables.
Example. While calculating correlation coefficient between two variables x and y from 25 pairs of observations, the following results were obtained : n = 25,  Later it was discovered at the time of checking that the pairs of values x -8,6 and y = 12, 8 were copied down as x = 6,8 and y = 14,6. Obtain the correct value of correlation coefficients.
Later it was discovered at the time of checking that the pairs of values x -8,6 and y = 12, 8 were copied down as x = 6,8 and y = 14,6. Obtain the correct value of correlation coefficients.
Solution. To get the correct results, we subtract the incorrect values and add the corresponding correct values.
The correct results would be
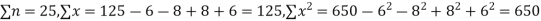
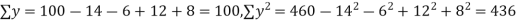
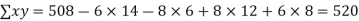
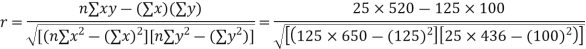

RANK CORRELATION
A group of n individuals may be arranged in order to merit with respect to some characteristics. The same group would give different orders for different characteristics. Considering the orders corresponding to two characteristics A and B, the correction between these n pairs of rank is called the rank correlation in the characteristics A and B for that group of individuals.
Let 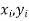 be the ranks of the ith individuals in A and B respectively. Assuming that no two individuals are bracketed equal in either case, each of the variables taking the values 1,2,3,…,n we have
be the ranks of the ith individuals in A and B respectively. Assuming that no two individuals are bracketed equal in either case, each of the variables taking the values 1,2,3,…,n we have

If X, Y be the deviations of x, y from their means, then
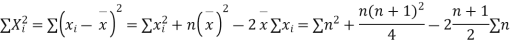

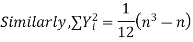
Now let, 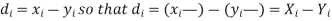
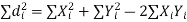
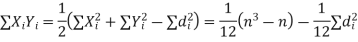
Hence the correlation coefficient between these variables is
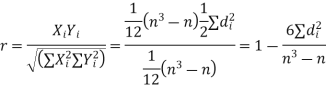
This is called the rank correlation coefficient and is denoted by 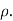
Example. Ten participants in a contest are ranked by two judges as follows:
x | 1 | 6 | 5 | 10 | 3 | 2 | 4 | 9 | 7 | 8 |
y | 6 | 4 | 9 | 8 | 1 | 2 | 3 | 10 | 5 | 7 |
Calculate the rank correlation coefficient 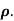
Solution. If 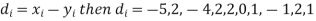

Hence, 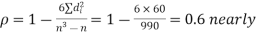
Example. Three judges A,B,C give the following ranks. Find which pair of judges has common approach
A | 1 | 6 | 5 | 10 | 3 | 2 | 4 | 9 | 7 | 8 |
B | 3 | 5 | 8 | 4 | 7 | 10 | 2 | 1 | 6 | 9 |
C | 6 | 4 | 9 | 8 | 1 | 2 | 3 | 10 | 5 | 7 |
Solution. Here n = 10
A (=x) | Ranks by B(=y) | C (=z) | 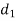 x-y | 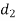 y - z | 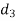 z-x | 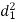
|  | 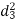 |
1 | 3 | 6 | -2 | -3 | 5 | 4 | 9 | 25 |
6 | 5 | 4 | 1 | 1 | -2 | 1 | 1 | 4 |
5 | 8 | 9 | -3 | -1 | 4 | 9 | 1 | 16 |
10 | 4 | 8 | 6 | -4 | -2 | 36 | 16 | 4 |
3 | 7 | 1 | -4 | 6 | -2 | 16 | 36 | 4 |
2 | 10 | 2 | -8 | 8 | 0 | 64 | 64 | 0 |
4 | 2 | 3 | 2 | -1 | -1 | 4 | 1 | 1 |
9 | 1 | 10 | 8 | -9 | 1 | 64 | 81 | 1 |
7 | 6 | 5 | 1 | 1 | -2 | 1 | 1 | 4 |
8 | 9 | 7 | -1 | 2 | -1 | 1 | 4 | 1 |
Total |
|
| 0 | 0 | 0 | 200 | 214 | 60 |

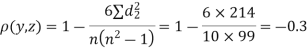
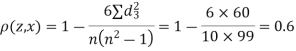
Since  is maximum, the pair of judge A and C have the nearest common approach.
is maximum, the pair of judge A and C have the nearest common approach.
Key takeaways-
Coefficient of correlation

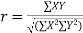
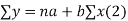
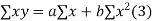
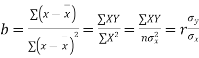

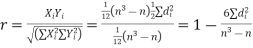
Let 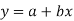 (1)
(1)
Be the straight line to be fitted to the given data points

Let 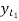 be the theoretical value for
be the theoretical value for 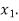
Then, 
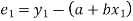

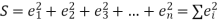
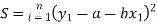
For S to be minimum

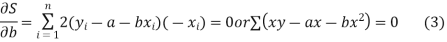
On simplification equation (2) and (3) becomes
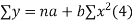
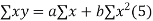
The equation (3) and (4) are known as Normal equations.
On solving ( 3) and (4) we get the values of a and b
(b)To fit the parabola
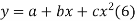
The normal equations are 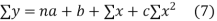

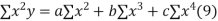
On solving three normal equations we get the values of a,b and c.
Example. Find the best values of a and b so that y = a + bx fits the data given in the table
x | 0 | 1 | 2 | 3 | 4 |
y | 1.0 | 2.9 | 4.8 | 6.7 | 8.6 |
Solution.
y = a + bx
x | y | Xy | 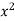 |
0 | 1.0 | 0 | 0 |
1 | 2.9 | 2.0 | 1 |
2 | 4.8 | 9.6 | 4 |
3 | 6.7 | 20.1 | 9 |
4 | 8.6 | 13.4 | 16 |
 |  |  |  |
Normal equations,  y= na+ b
y= na+ b x (2)
x (2)
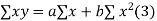
On putting the values of 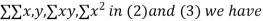
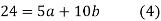
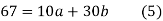
On solving (4) and (5) we get,
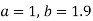
On substituting the values of a and b in (1) we get
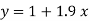
Example. By the method of least squares, find the straight line that best fits the following data:
x | 1 | 2 | 3 | 4 | 5 |
y | 14 | 27 | 40 | 55 | 68 |
Solution. Let the equation of the straight line best fit be y = a + bx. (1)
x | y | x y | 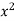 |
1 | 14 | 14 | 1 |
2 | 27 | 54 | 4 |
3 | 40 | 120 | 9 |
4 | 55 | 220 | 16 |
5 | 68 | 340 | 25 |
 | 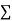 | 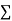 | 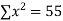 |
Normal equations are 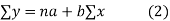

On putting the values of  x,
x,  y,
y,  xy and
xy and  in (2) and (3) we have
in (2) and (3) we have
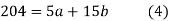
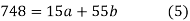
On solving equations (4) and (5) we get
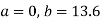
On substituting the values of (a) and (b) in (1) we get,
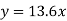
Example. Find the least squares approximation of second degree for the discrete data
x | 2 | -1 | 0 | 1 | 2 |
y | 15 | 1 | 1 | 3 | 19 |
Solution. Let the equation of second degree polynomial be 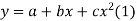
x | y | Xy |  | 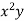 |  | 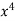 |
-2 | 15 | -30 | 4 | 60 | -8 | 16 |
-1 | 1 | -1 | 1 | 1 | -1 | 1 |
0 | 1 | 0 | 0 | 0 | 0 | 0 |
1 | 3 | 3 | 1 | 3 | 1 | 1 |
2 | 19 | 38 | 4 | 76 | 8 | 16 |
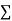 | 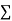 | 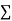 |  |  | 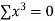 | 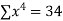 |
Normal equations are 

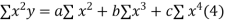
On putting the values of  x,
x, 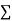 y,
y, xy,
xy,
 have
have
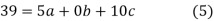

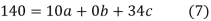
On solving (5),(6),(7), we get, 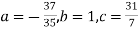
The required polynomial of second degree is
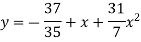
Second degree parabolas and more general curves
Change of scale
If the data is of equal interval in large numbers then we change the scale as 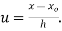
Example. Fit a second degree parabola to the following data by least square method:
x | 1929 | 1930 | 1931 | 1932 | 1933 | 1934 | 1935 | 1936 | 1937 |
y | 352 | 356 | 357 | 358 | 360 | 361 | 365 | 360 | 359 |
Solution. Taking 
Taking 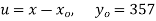
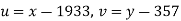
The equation 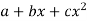 is transformed to
is transformed to 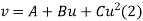
x | 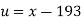 | y | 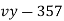 | Uv | 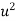 | 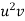 | 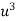 | 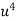 |
1929 | -4 | 352 | -5 | 20 | 16 | -80 | -64 | 256 |
1930 | -3 | 360 | -1 | 3 | 9 | -9 | -27 | 81 |
1931 | -2 | 357 | 0 | 0 | 4 | 0 | -8 | 16 |
1932 | -1 | 358 | 1 | -1 | 1 | 1 | -1 | 1 |
1933 | 0 | 360 | 3 | 0 | 0 | 0 | 0 | 0 |
1934 | 1 | 361 | 4 | 4 | 1 | 4 | 1 | 1 |
1935 | 2 | 361 | 4 | 8 | 4 | 16 | 8 | 16 |
1936 | 3 | 360 | 3 | 9 | 9 | 27 | 27 | 81 |
1937 | 4 | 350 | 2 | 8 | 16 | 32 | 64 | 256 |
Total |  |
|  |  | 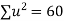 |  |  |  |
Normal equations are
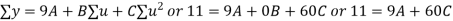
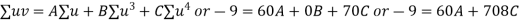
On solving these equations we get 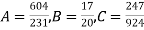

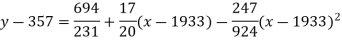


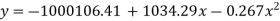
Example. Fit a second degree parabola to the following data.
x=1.0 | 1.5 | 2.0 | 2.5 | 3.0 | 3.5 | 4.0 |
y=1.1 | 1.3 | 1.6 | 2.0 | 2.7 | 3.4 | 4.1 |
Solution. We shift the origin to (2.5, 0) antique 0.5 as the new unit. This amounts to changing the variable x to X, by the relation X = 2x – 5.
Let the parabola of fit be y = a + bX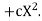 The values of
The values of 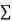 X etc. Are calculated as below:
X etc. Are calculated as below:
x | X | y | Xy | 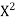 | 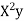 |  | 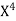 |
1.0 | -3 | 1.1 | -3.3 | 9 | 9.9 | -27 | 81 |
1.5 | -2 | 1.3 | -2.6 | 4 | 5.2 | -5 | 16 |
2.0 | -1 | 1.6 | -1.6 | 1 | 1.6 | -1 | 1 |
2.5 | 0 | 2.0 | 0.0 | 0 | 0.0 | 0 | 0 |
3.0 | 1 | 2.7 | 2.7 | 1 | 2.7 | 1 | 1 |
3.5 | 2 | 3.4 | 6.8 | 4 | 13.6 | 8 | 16 |
4.0 | 3 | 4.1 | 12.3 | 9 | 36.9 | 27 | 81 |
Total | 0 | 16.2 | 14.3 | 28 | 69.9 | 0 | 196 |
The normal equations are
7a + 28c =16.2; 28b =14.3; 28a +196c=69.9
Solving these as simultaneous equations we get

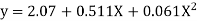
Replacing X bye 2x – 5 in the above equation we get
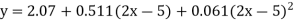
Which simplifies to y =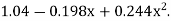 This is the required parabola of the best fit
This is the required parabola of the best fit
Key takeaways-
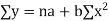

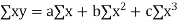

References:
1. E. Kreyszig, “Advanced Engineering Mathematics”, John Wiley & Sons, 2006.
2. P. G. Hoel, S. C. Port and C. J. Stone, “Introduction to Probability Theory”, Universal Book Stall, 2003.
3. S. Ross, “A First Course in Probability”, Pearson Education India, 2002.
4. W. Feller, “An Introduction to Probability Theory and its Applications”, Vol. 1, Wiley, 1968.
5. N.P. Bali and M. Goyal, “A text book of Engineering Mathematics”, Laxmi Publications, 2010.
6. B.S. Grewal, “Higher Engineering Mathematics”, Khanna Publishers, 2000.
7. T. Veerarajan, “Engineering Mathematics”, Tata McGraw-Hill, New Delhi, 2010.
8. BV ramana mathematics.




