Multicores
In many of the previous modules, we have looked et different ways of exploiting ILP. ILP is parallelism at the machine -instruction level, through which the processor can re-order, pipeline instructions, use predication, do aggressive branch prediction, etc. ILP had enabled rapid increases in processor speeds for two decades or so. During this period, the transistor densities doubled every 18 months (Moore’s Law) and the frequencies increased making the pipelines deeper and deeper. The trend that happened. But deeply pipelined circuits had to do deal with the heat generated, due to the rise in temperatures. The design of such complicated processors was difficult and there was also diminishing returns with increasing frequencies. All these made it difficult to make single-core clock frequencies even higher. The power densities increased so rapidly that they had to be somehow contained within limits.
Additionally, from the application point of view also, many new applications are multithreaded. Single-core superscalar processors cannot fully exploit TLP. So, the general trend in computer architecture is to shift towards more parallelism. There has been a paradigm shift from complicated single core architectures to simpler multicore architectures. This is parallelism on a coarser scale – explicitly exploiting TLP.
Multi-core processors take advantage of a fundamental relationship between power and frequency. By incorporating multiple cores, each core is able to run at a lower frequency, dividing among them the power normally given to a single core. The result is a big performance increase over a single-core processor. The following illustration in Figures shows this key advantage.
|
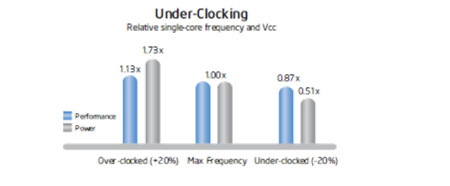
Fig 1 – Under clocking
As shown in Figure 37.3, increasing the clock frequency by 20 percent to a single core delivers a 13 percent performance gain, but requires 73 percent greater power. Conversely, decreasing clock frequency by 20 percent reduces power usage by 49 percent, but results in just a 13 percent performance loss.
|
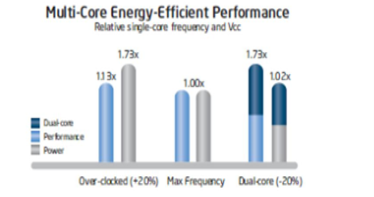
Fig 2 – Multi core energy efficient performance
A second core is added to the under-clocked example above. This results in a dual-core processor that at 20 percent reduced clock frequency, effectively delivers 73 percent more performance while using approximately the same power as a single-core processor at maximum frequency. This is shown in Figure 37.4.
A multicore processor is a special kind of a multiprocessor, where all processors are on the same chip. Multicore processors fall under the category of MIMD – different cores execute different threads (Multiple Instructions), operating on different parts of memory (Multiple Data). Multicore is a shared memory multiprocessor, since all cores share the same memory. Therefore, all the issues that we have discussed with MIMD style of shared memory architectures hold good for these processors too.
Multicore architectures can be homogeneous or heterogeneous. Homogeneous processors are those that have identical cores on the chip. Heterogeneous processors have different types of cores on the chip. The software technologists will need to understand the architecture to get appropriate performance gains. With dual core & multicore processors ruling the entire computer industry, some of the architectural issues would be different than the traditional issues . For example, the new performance mantra would be performance per watt.
We shall discuss different multicore architectures as case studies. The following architectures will be discussed:
• Intel
• Sun’s Niagara
• IBM’s Cell BE
Of these, this module will deal with the salient features of the Intel’s multicore architectures.
Intel’s Multicore Architectures: Like all other partners in the computer industry, Intel also acknowledged that it had hit a “thermal wall” in 2004 and disbanded one of its most advanced design groups and said it would abandon two advanced chip development projects. Now, Intel is embarked on a course already adopted by some of its major rivals: obtaining more computing power by stamping multiple processors on a single chip rather than straining to increase the speed of a single processor. The evolution of the Intel processors from 1978 to the introduction of multicore processors.
The following are the salient features of the Intel’s multicore architectures:
- Hyper-threading
- Turbo boost technology
- Improved cache latency with smart L3 cache
- New Platform Architecture
- Quick Path Interconnect (QPI)
- Intelligent Power Technology
- Higher Data-Throughput via PCI Express 2.0 and DDR3 Memory Interface
- Improved Virtualization Performance
- Remote Management of Networked Systems with Intel Active Management Technology
- Other improvements – Increase in window size, better branch prediction, more instructions and accelerators, etc.
We shall discuss each one of them in detail.
Optimized Multithreaded Performance through Hyper-Threading: Intel introduced Hyper-Threading Technology on its processors in 2002. Hyper -threading exposes a single physical processing core as two logical cores to allow them to share resources between execution threads and therefore increase the system efficiency, as shown in Figure 37.6. Because of the lack of OSs that could clearly differentiate between logical and physical processing cores, Intel removed this feature when it introduced multicore CPUs. With the release of OSs such as Windows Vista and Windows 7, which are fully aware of the differences between logical and physical core, Intel brought back the hyper-threading feature in the Core i7 family of processors. Hyper-threading allows simultaneous execution of two execution threads on the same physical CPU core. With four cores, there are eight threads of execution. Hyper-threading technology benefits from larger caches and increased memory bandwidth of the Core i7 processors, delivering greater throughput and responsiveness for multithreaded applications.
CPU Performance Boost via Intel Turbo Boost Technology: The applications that are run on multicore processors can be single threaded or multi -threaded. In order to provide a performance boost for lightly threaded applications and to also optimize the processor power consumption, Intel introduced a new feature called Intel Turbo Boost. Intel Turbo Boost features offer processing performance gains for all applications regardless of the number of execution threads created. It automatically allows active processor cores to run faster than the base operating frequency when certain conditions are met. This mode is activated when the OS requests the highest processor performance state. The maximum frequency of the specific processing core on the Core i7 processor is dependent on the number of active cores, and the amount of time the processor spends in the Turbo Boost state depends on the workload and operating environment.
Operating frequencies of the processing cores in the quad-core Core i7 processor change to offer the best performance for a specific workload type. In an idle state, all four cores operate at their base clock frequency. If an application that creates four discrete execution threads is initiated, then all four processing cores start operating at the quad-core turbo frequency. If the application creates only two execution threads, then two idle cores are put in a low-power state and their power is diverted to the two active cores to allow them to run at an even higher clock frequency. Similar behaviour would apply in the case where the applications generate only a single execution thread.
For example, the Intel Core i7-820QM quad-core processor has a base clock frequency of 1.73 GHz. If the application is using only one CPU core, Turbo Boost technology automatically increases the clock frequency of the active CPU core on the Intel Core i7-820QM processor from 1.73 GHz to up to 3.06 GHz and places the other three cores in an idle state, thereby providing optimal performance for all application types. This is shown in the table below.
|
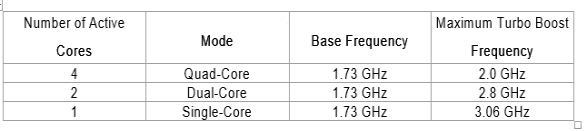
The duration of time that the processor spends in a specific Turbo Boost state depends on how soon it reaches thermal, power, and current thresholds. With adequate power supply and heat dissipation solutions, a Core i7 processor can be made to operate in the Turbo Boost state for an extended duration of time. In some cases, the users can manually control the number of active processor cores through the controller’s BIOS to fine tune the operation of the Turbo Boost feature for optimizing performance for specific application types.
Improved Cache Latency with Smart L3 Cache: All of us are aware of the fact that the cache is a block of high-speed memory for temporary data storage located on the same silicon die as the CPU. If a single processing core, in a multicore CPU, requires specific data while executing an instruction set, it first searches for the data in its local caches (L1 and L2). If the data is not available, also known as a cache-miss, it then accesses the larger L3 cache. In an exclusive L3 cache, if that attempt is unsuccessful, then the core performs cache snooping – searches the local caches of other cores – to check whether they have data that it needs. If this attempt also results in a cache-miss, it then accesses the slower system RAM for that information. The latency of reading and writing from the cache is much lower than that from the system RAM, therefore a smarter and larger cache greatly helps in improving processor performance.
The Core i7 family of processors features an inclusive s hared L3 cache that can be up to 12 MB in size. Figure 37.8 shows the different types of caches and their layout for the Core i7-820QM quad-core processor. It features four cores, where each core has 32 kilobytes for instructions and 32 kilobytes for data of L1 cache, 256 kilobytes per core of L2 cache, along with 8 megabytes of shared L3 cache. The L3 cache is shared across all cores and its inclusive nature helps increase performance and reduces latency by reducing cache snooping traffic to the processor cores. An inclusive shared L3 cache guarantees that if there is a cache-miss, then the data is outside the processor and not available in the local caches of other cores, which eliminates unnecessary cache snooping. This feature provides improvement for the overall performance of the processor and is beneficial for a variety of applications including test, measurement, and control.
New Platform Architecture: As shown in Figure 37.9, the previous Intel micro-architectures for a single processor system included three discrete components – a CPU, a Graphics and Memory Controller Hub (GMCH), also known as the Northbridge and an I/O Controller Hub (ICH), also known as the Southbridge. The GMCH and ICH combined together are referred to as the chipset. In the older Penryn architecture, the front-side bus (FSB) was the interface for exchanging data between the CPU and the northbridge. If the CPU had to read or write data into system memory or over the PCI Express bus, then the data had to traverse over the external FSB. In the new Nehalem micro-architecture, Intel moved the memory controller and PCI Express controller from the northbridge onto the CPU die, reducing the number of external data buses that the data had to traverse. These changes help increase data-throughput and reduce the latency for memory and PCI Express data transactions. These improvements make the Core i7 family of processors ideal for test and measurement applications such as high-speed design validation and high-speed data record and playback.
Higher – Performance Multiprocessor Systems with Quick Path Interconnect (QPI): Not only was the memory controller moved to the CPU for Nehalem processors, Intel also introduced a distributed shared memory architecture using Intel QuickPath Interconnect (QPI). QPI is the new point-to-point interconnect for connecting a CPU to either a chipset or another CPU. It provides up to 25.6 GB/s of total bidirectional data throughput per link. Intel’s decision to move the memory controller in the CPU and introduce the new QPI data bus has had an impact for single-processor systems. However, this impact is much more significant for multiprocessor systems. Figure 37.10 illustrates the typical block diagrams of multiprocessor systems based on the previous generation and the Nehalem microarchitecture.
Each CPU has access to local memory but they also can access memory that is local to other CPUs via QPI transactions. For example, one Core i7 processor can access the memory region local to another processor through QPI either with one direct hop or through multiple hops. QPI is a high-speed, point-to-point interconnect. Figure 37.11 illustrates this. It provides high bandwidth and low latency, which delivers the interconnect performance needed to unleash the new microarchitecture and deliver the Reliability, Availability, and Serviceability (RAS) features expected in enterprise applications. RAS requirements are met through advanced features which include: CRC error detection, link-level retry for error recovery, hot-plug support, clock fail-over, and link self-healing. Detection of clock failure & automatic readjustment of the width & clock being transmitted on a predetermined dataline increases availability.
It supports simultaneous movement of data between various components. Support for several features such as lane/polarity reversal, data recovery and deskew circuits, and waveform equalization that ease the design of the high-speed link, are provided. The Intel® QuickPath Interconnect includes a cache coherency protocol to keep the distributed memory and caching structures coherent during system operation. It supports both low-latency source snooping and a scalable home snoop behaviour. The coherency protocol provides for direct cache-to-cache transfers for optimal latency.
The QPI supports a layered architecture as shown in Figure 37.12. The Physical layer consists of the actual wires, as well as circuitry and logic to support ancillary features required in the transmission and receipt of the 1s and 0s – unit of transfer is 20-bits, called a Phit (for Physical unit). • The Link layer is responsible for reliable transmission and flow control – unit of transfer is an 80-bit Flit (for Flow control unit). The Routing layer provides the framework for directing packets through the fabric. The Transport layer is an architecturally defined layer (not implemented in the initial products) providing advanced routing capability for reliable end-to-end transmission. The Protocol layer is the high-level set of rules for exchanging packets of data between devices. A packet is comprised of an integral number of Flits.
Intelligent Power Technology: Intel’s multicore processors provide intelligent power gates that allow the idling processor cores to near zero power, thus reducing the power consumption. Power consumption is reduced to 10 watts compared to 16 to 50 watts earlier. There is support provided for automated low power states to put the processor and memory in the lowest power state allowable in a workload.
Higher Data-Throughput via PCI Express 2.0 and DDR3 Memory Interface: To support the need of modern applications to move data at a faster rate, the Core i7 processors offer increased throughput for the external databus and its memory channels. The new processors feature the PCI Express 2.0 databus, which doubles the data throughput from PCI Express 1.0 while maintaining full hardware and software compatibility with PCI Express 1.0. A x16 PCI Express 2.0 link has a maximum throughput of 8 GB/s/direction. To allow data from the PCI Express 2.0 databus to be stored in system RAM, the Core i7 processors feature multiple DDR3 1333 MHz memory channels. A system with two channels of DDR3 1333 MHz RAM had a theoretical memory bandwidth of 21.3 GB/s. This throughput matches well with the theoretical maximum throughput of a x16 PCI Express 2.0 link.
Improved Virtualization Performance: Virtualization is a technology that enables running multiple OSs side-by-side on the same processing hardware. In the test, measurement, and control space, engineers and scientists have used this technology to consolidate discrete computing nodes into a single system. With the Nehalem mircoarchitecture, Intel has added new features such as hardware-assisted page-table management and directed I/O in the Core i7 processors and its chipsets that allow software to further improve their performance in virtualized environments.
Remote Management of Networked Systems with Intel Active Management Technology (AMT): AMT provides system administrators the ability to remotely monitor, maintain, and update systems. Intel AMT is part of the Intel Management Engine, which is built into the chipset of a Nehalem-based system. This feature allows administrators to boot systems from a remote media, track hardware and software assets, and perform remote troubleshooting and recovery. Engineers can use this feature for managing deployed automated test or control systems that need high uptime. Test, measurement, and control applications are able to use AMT to perform remote data collection and monitor application status. When an application or system failure occurs, AMT enables the user to remotely diagnose the problem and access debug screens. This allows for the problem to be resolved sooner and no longer requires interaction with the actual system. When software updates are required, AMT allows for these to be done remotely, ensuring that the system is updated as quickly as possible since downtime can be very costly. AMT is able to provide many remote management benefits for PXI systems.
Other Improvements: Apart from the features discussed above, there are also other improvements brought in. They are listed below:
- Greater Parallelism
Increase amount of code that can be executed out-of-order by increasing the size of the window and scheduler
- Efficient algorithm
Improved performance of synchronization primitives
Faster handling of branch mis-prediction
Improved hardware prefetch & better Load-Store scheduling
- Enhanced Branch Prediction
New Second-Level Branch Target Buffer (BTB)
New Renamed Return Stack Buffer (RSB)
New Application Targeted Accelerators and Intel SSE4 (Streaming SIMD extensions-4)
- Enable XML parsing/accelerators
To summarize, we have dealt in detail the salient features of intel’s multicore architectures in this module. The following features were discussed:
- Hyper-threading
- Turbo boost technology
- Improved cache latency with smart L3 cache
- New Platform Architecture
- Quick Path Interconnect (QPI)
- Intelligent Power Technology
- Higher Data-Throughput via PCI Express 2.0 and DDR3 Memory Interface
- Improved Virtualization Performance
- Remote Management of Networked Systems with Intel Active Management Technology
- Other improvements
Most computer systems are single processor systems i.e they only have one processor. However, multiprocessor or parallel systems are increasing in importance nowadays. These systems have multiple processors working in parallel that share the computer clock, memory, bus, peripheral devices etc. An image demonstrating the multiprocessor architecture is −
|
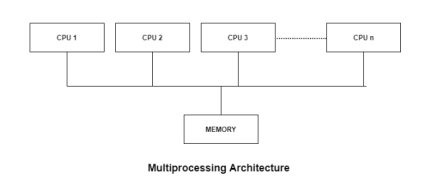
Fig 3 – Multiprocessing architecture
There are mainly two types of multiprocessors i.e. symmetric and asymmetric multiprocessors. Details about them are as follows –
Symmetric Multiprocessors
In these types of systems, each processor contains a similar copy of the operating system and they all communicate with each other. All the processors are in a peer to peer relationship i.e. no master - slave relationship exists between them.
An example of the symmetric multiprocessing system is the Encore version of Unix for the Multimax Computer.
Asymmetric Multiprocessors
In asymmetric systems, each processor is given a predefined task. There is a master processor that gives instruction to all the other processors. Asymmetric multiprocessor system contains a master slave relationship.
Asymmetric multiprocessor was the only type of multiprocessor available before symmetric multiprocessors were created. Now also, this is the cheaper option.
Advantages of Multiprocessor Systems
There are multiple advantages to multiprocessor systems. Some of these are −
More reliable Systems
In a multiprocessor system, even if one processor fails, the system will not halt. This ability to continue working despite hardware failure is known as graceful degradation. For example: If there are 5 processors in a multiprocessor system and one of them fails, then also 4 processors are still working. So the system only becomes slower and does not ground to a halt.
Enhanced Throughput
If multiple processors are working in tandem, then the throughput of the system increases i.e. number of processes getting executed per unit of time increase. If there are N processors then the throughput increases by an amount just under N.
More Economic Systems
Multiprocessor systems are cheaper than single processor systems in the long run because they share the data storage, peripheral devices, power supplies etc. If there are multiple processes that share data, it is better to schedule them on multiprocessor systems with shared data than have different computer systems with multiple copies of the data.
Disadvantages of Multiprocessor Systems
There are some disadvantages as well to multiprocessor systems. Some of these are:
Increased Expense
Even though multiprocessor systems are cheaper in the long run than using multiple computer systems, still they are quite expensive. It is much cheaper to buy a simple single processor system than a multiprocessor system.
Complicated Operating System Required
There are multiple processors in a multiprocessor system that share peripherals, memory etc. So, it is much more complicated to schedule processes and impart resources to processes. than in single processor systems. Hence, a more complex and complicated operating system is required in multiprocessor systems.
Large Main Memory Required
All the processors in the multiprocessor system share the memory. So a much larger pool of memory is required as compared to single processor systems.
Clusters
Cluster is a set of loosely or tightly connected computers working together as a unified computing resource that can create the illusion of being one machine. Computer clusters have each node set to perform the same task, controlled and produced by software.
The components of a clusters are usually connected to each other using fast area networks, with each node running its own instance of an operating system. In most circumstances, all the nodes uses same hardware and the same operating system, although in some setups different hardware or different operating system can be used.
|
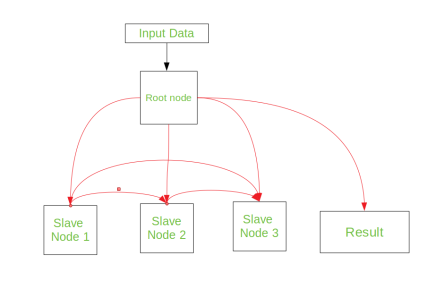
Fig 4 – Master/Slave
Types of Clusters –
Computer Clusters are arranged together in such a way so as to support different purpose from general purpose business needs such as web-service support, to computation intensive scientific calculation. Basically there are three types of Clusters, they are:
- Load-Balancing Cluster – A cluster requires an effective capability for balancing the load among available computers. In this, cluster nodes share computational workload so as to enhance the overall performance. For example- a high-performance cluster used for scientific calculation would balance load from different algorithms from the web-server cluster, which may just use a round-robin method by assigning each new request to a different node. This type of cluster is used on farms of Web servers (web farm).
- Fail-Over Clusters – The function of switching applications and data resources over from a failed system to an alternative system in the cluster is referred to as fail-over. These types are used to cluster database of critical mission, mail, file and application servers
- High-Availability Clusters – These are also known as “HA clusters”. They offer a high probability that all the resources will be in service. If a failure does occur, such as a system goes down or a disk volume is lost, then the queries in progress are lost. Any lost query, if retried, will be serviced by different computer in the cluster. This type of cluster is widely used in web, email, news or FTP servers.
Benefits –
- Absolute scalability – It is possible to create a large cluster that beats the power of even the largest standalone machines. A cluster can have dozens of multiprocessor machines.
- Additional scalability – A cluster is configured in such a way that it is possible to add new systems to the cluster in small increment. Clusters have the ability to add systems horizontally. This means that more computers may be added to the clusters to improve its performance, redundancy and fault tolerance (the ability for a system to continue working with a malfunctioning of node).
- High availability – As we know that each node in a cluster is a standalone computer, the failure of one node does not mean loss of service. A single node can be taken down for maintenance, while the rest of the clusters takes on the load of that individual node.
- Preferable price/performance – Clusters are usually set up to improve performance and availability over single computers, while typically being much more cost effective than single computers of comparable speed or availability.
Key takeaways
- In many of the previous modules, we have looked et different ways of exploiting ILP. ILP is parallelism at the machine -instruction level, through which the processor can re-order, pipeline instructions, use predication, do aggressive branch prediction, etc. ILP had enabled rapid increases in processor speeds for two decades or so. During this period, the transistor densities doubled every 18 months (Moore’s Law) and the frequencies increased making the pipelines deeper and deeper. Figure 37.1 shows the trend that happened. But deeply pipelined circuits had to do deal with the heat generated, due to the rise in temperatures. The design of such complicated processors was difficult and there was also diminishing returns with increasing frequencies. All these made it difficult to make single-core clock frequencies even higher. The power densities increased so rapidly that they had to be somehow contained within limits. Figure 37.2 shows the increase in power densities.
POWER WALL
|
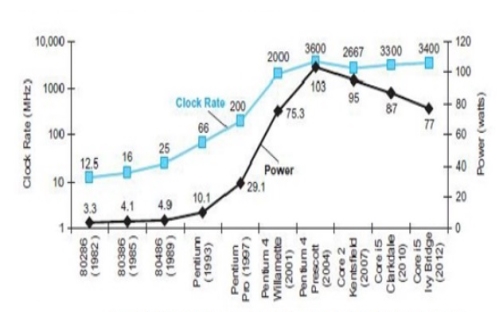
Fig 5 – Power Wall
The dominant technology for integrated circuits is called CMOS (complementary metal oxide semiconductor). For CMOS, the primary source of energy consumption is so-called dynamic energy— that is, energy that is consumed when transistors switch states from 0 to 1 and vice versa. The dynamic energy depends on the capacitive loading of each transistor and the voltage applied.
Key takeaways
- The dominant technology for integrated circuits is called CMOS (complementary metal oxide semiconductor). For CMOS, the primary source of energy consumption is so-called dynamic energy— that is, energy that is consumed when transistors switch states from 0 to 1 and vice versa. The dynamic energy depends on the capacitive loading of each transistor and the voltage applied.
- A type of architecture that is based on a single computing unit. All operations (additions, multiplications, etc) are done sequentially on the unit.
Multiprocessor:
- A type of architecture that is based on multiple computing units. Some of the operations (not all, mind you) are done in parallel and the results are joined afterwards.
There are many types of classifications for multiprocessor architectures, the most commonly known would be the Flynn Taxonomy.
MIPS (originally an acronym for Microprocessor without Interlocked Pipeline Stages) is a reduced instruction set computer (RISC) instruction set architecture (ISA) developed by MIPS Technologies.
The power limit has forced a dramatic change in the design of microprocessors. Since 2002, the rate has slowed from a factor of 1.5 per year to a factor of 1.2 per year. Rather than continuing to decrease the response time of a single program running on the single processor, as of 2006 all desktop and server companies are shipping microprocessors with multiple processors per chip, where the benefit is oft en more on throughput than on response time. To reduce confusion between the words processor and microprocessor, companies refer to processors as “cores,” and such microprocessors are generically called multicore microprocessors.
Hence, a “quadcore” microprocessor is a chip that contains four processors or four cores. In the past, programmers could rely on innovations in hardware, architecture, and compilers to double performance of their programs every 18 months without having to change a line of code. Today, for programmers to get significant improvement in response time, they need to rewrite their programs to take advantage of multiple processors. Moreover, to get the historic benefit of running faster on new microprocessors, programmers will have to continue to improve performance of their code as the number of cores increases.
Key takeaways
- A type of architecture that is based on multiple computing units. Some of the operations (not all, mind you) are done in parallel and the results are joined afterwards.
- There are many types of classifications for multiprocessor architectures, the most commonly known would be the Flynn Taxonomy.
- MIPS (originally an acronym for Microprocessor without Interlocked Pipeline Stages) is a reduced instruction set computer (RISC) instruction set architecture (ISA) developed by MIPS Technologies.
Suppose, Moni have to attend an invitation. Moni’s another two friend Diya and Hena are also invited. There are conditions that all three friends have to go there separately and all of them have to be present at door to get into the hall. Now Moni is coming by car, Diya by bus and Hena is coming by foot. Now, how fast Moni and Diya can reach there it doesn’t matter, they have to wait for Hena. So to speed up the overall process, we need to concentrate on the performance of Hena other than Moni or Diya.
This is actually happening in Amdahl’s Law. It relates the improvement of the system’s performance with the parts that didn’t perform well, like we need to take care of the performance of that parts of the systems. This law often used in parallel computing to predict the theoretical speedup when using multiple processors.
Amdahl’s Law can be expressed in mathematically as follows −
SpeedupMAX = 1/((1-p)+(p/s)) SpeedupMAX = maximum performance gain s = performance gain factor of p after implement the enhancements. p = the part which performance needs to be improved. Let’s take an example, if the part that can be improved is 30% of the overall system and its performance can be doubled for a system, then − SpeedupMAX = 1/((1-0.30)+(0.30/2)) = 1.18 Now, in another example, if the part that can be improved is 70% of the overall system and its performance can be doubled for a system, then − SpeedupMAX= 1/((1-0.70)+(0.70/2)) = 1.54 |
So, we can see, if 1-p can’t be improved, the overall performance of the system cannot be improved so much. So, if 1-p is 1/2, then speed cannot go beyond that, no matter how many processors are used.
Multicore programming is most commonly used in signal processing and plant-control systems. In signal processing, one can have a concurrent system that processes multiple frames in parallel. the controller and the plant can execute as two separate tasks, in plant-control systems.
Multicore programming helps to split the system into multiple parallel tasks, which run simultaneously, speeding up the overall execution time.
Key takeaways
- Suppose, Moni have to attend an invitation. Moni’s another two friend Diya and Hena are also invited. There are conditions that all three friends have to go there separately and all of them have to be present at door to get into the hall. Now Moni is coming by car, Diya by bus and Hena is coming by foot. Now, how fast Moni and Diya can reach there it doesn’t matter, they have to wait for Hena. So to speed up the overall process, we need to concentrate on the performance of Hena other than Moni or Diya.
- This is actually happening in Amdahl’s Law. It relates the improvement of the system’s performance with the parts that didn’t perform well, like we need to take care of the performance of that parts of the systems. This law often used in parallel computing to predict the theoretical speedup when using multiple processors.
Parallel processing has been developed as an effective technology in modern computers to meet the demand for higher performance, lower cost and accurate results in real-life applications. Concurrent events are common in today’s computers due to the practice of multiprogramming, multiprocessing, or multicomputing.
Modern computers have powerful and extensive software packages. To analyse the development of the performance of computers, first we have to understand the basic development of hardware and software.
- Computer Development Milestones − There is two major stages of development of computer - mechanical or electromechanical parts. Modern computers evolved after the introduction of electronic components. High mobility electrons in electronic computers replaced the operational parts in mechanical computers. For information transmission, electric signal which travels almost at the speed of a light replaced mechanical gears or levers.
- Elements of Modern computers − A modern computer system consists of computer hardware, instruction sets, application programs, system software and user interface.
|
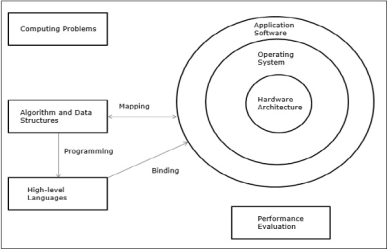
Fig 6 – Performance Evaluation
The computing problems are categorized as numerical computing, logical reasoning, and transaction processing. Some complex problems may need the combination of all the three processing modes.
- Evolution of Computer Architecture − In last four decades, computer architecture has gone through revolutionary changes. We started with Von Neumann architecture and now we have multicomputers and multiprocessors.
- Performance of a computer system − Performance of a computer system depends both on machine capability and program behaviour. Machine capability can be improved with better hardware technology, advanced architectural features and efficient resource management. Program behaviour is unpredictable as it is dependent on application and run-time conditions
Multiprocessors and Multicomputers
In this section, we will discuss two types of parallel computers −
- Multiprocessors
- Multicomputers
Three most common shared memory multiprocessors models are −
In this model, all the processors share the physical memory uniformly. All the processors have equal access time to all the memory words. Each processor may have a private cache memory. Same rule is followed for peripheral devices.
When all the processors have equal access to all the peripheral devices, the system is called a symmetric multiprocessor. When only one or a few processors can access the peripheral devices, the system is called an asymmetric multiprocessor.
|
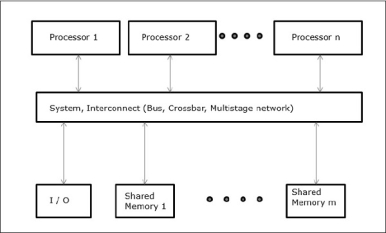
Fig 7 - Non-uniform Memory Access (NUMA)
In NUMA multiprocessor model, the access time varies with the location of the memory word. Here, the shared memory is physically distributed among all the processors, called local memories. The collection of all local memories forms a global address space which can be accessed by all the processors.
|
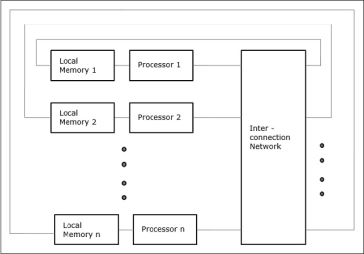
Fig 8 - Cache Only Memory Architecture (COMA)
The COMA model is a special case of the NUMA model. Here, all the distributed main memories are converted to cache memories.
|
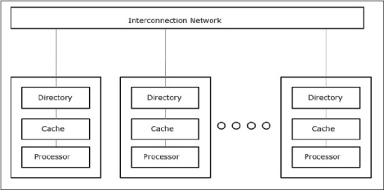
Fig 9 – Interconnection Network
- Distributed - Memory Multicomputers − A distributed memory multicomputer system consists of multiple computers, known as nodes, inter-connected by message passing network. Each node acts as an autonomous computer having a processor, a local memory and sometimes I/O devices. In this case, all local memories are private and are accessible only to the local processors. This is why, the traditional machines are called no-remote-memory-access (NORMA) machines.
|
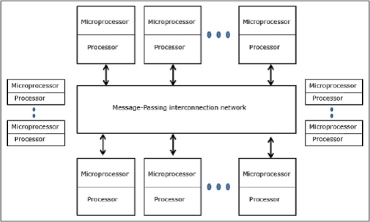
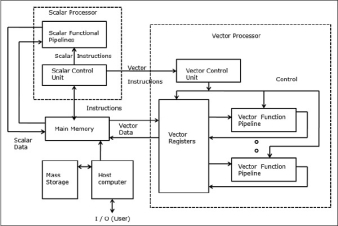
Fig 10 - Multivector and SIMD Computers
In this section, we will discuss supercomputers and parallel processors for vector processing and data parallelism.
In a vector computer, a vector processor is attached to the scalar processor as an optional feature. The host computer first loads program and data to the main memory. Then the scalar control unit decodes all the instructions. If the decoded instructions are scalar operations or program operations, the scalar processor executes those operations using scalar functional pipelines.
On the other hand, if the decoded instructions are vector operations then the instructions will be sent to vector control unit.
|
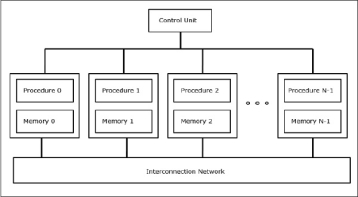
In SIMD computers, ‘N’ number of processors are connected to a control unit and all the processors have their individual memory units. All the processors are connected by an interconnection network.
|
The ideal model gives a suitable framework for developing parallel algorithms without considering the physical constraints or implementation details.
The models can be enforced to obtain theoretical performance bounds on parallel computers or to evaluate VLSI complexity on chip area and operational time before the chip is fabricated.
Parallel Random-Access Machines
Sheperdson and Sturgis (1963) modelled the conventional Uniprocessor computers as random-access-machines (RAM). Fortune and Wyllie (1978) developed a parallel random-access-machine (PRAM) model for modeling an idealized parallel computer with zero memory access overhead and synchronization.
|
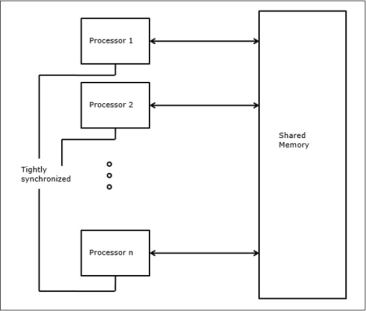
Fig 13 – Processor and memory
An N-processor PRAM has a shared memory unit. This shared memory can be centralized or distributed among the processors. These processors operate on a synchronized read-memory, write-memory and compute cycle. So, these models specify how concurrent read and write operations are handled.
Following are the possible memory update operations −
- Exclusive read (ER) − In this method, in each cycle only one processor is allowed to read from any memory location.
- Exclusive write (EW) − In this method, at least one processor is allowed to write into a memory location at a time.
- Concurrent read (CR) − It allows multiple processors to read the same information from the same memory location in the same cycle.
- Concurrent write (CW) − It allows simultaneous write operations to the same memory location. To avoid write conflict some policies are set up.
Parallel computers use VLSI chips to fabricate processor arrays, memory arrays and large-scale switching networks.
Nowadays, VLSI technologies are 2-dimensional. The size of a VLSI chip is proportional to the amount of storage (memory) space available in that chip.
We can calculate the space complexity of an algorithm by the chip area (A) of the VLSI chip implementation of that algorithm. If T is the time (latency) needed to execute the algorithm, then A.T gives an upper bound on the total number of bits processed through the chip (or I/O). For certain computing, there exists a lower bound, f(s), such that
A.T2 >= O (f(s))
Where A=chip area and T=time
Architectural Development Tracks
The evolution of parallel computers I spread along the following tracks −
- Multiple Processor Tracks
- Multiprocessor track
- Multicomputer track
- Multiple data track
- Vector track
- SIMD track
- Multiple threads track
- Multithreaded track
- Dataflow track
In multiple processor track, it is assumed that different threads execute concurrently on different processors and communicate through shared memory (multiprocessor track) or message passing (multicomputer track) system.
In multiple data track, it is assumed that the same code is executed on the massive amount of data. It is done by executing same instructions on a sequence of data elements (vector track) or through the execution of same sequence of instructions on a similar set of data (SIMD track).
In multiple threads track, it is assumed that the interleaved execution of various threads on the same processor to hide synchronization delays among threads executing on different processors. Thread interleaving can be coarse (multithreaded track) or fine (dataflow track).
Key takeaways
- Parallel processing has been developed as an effective technology in modern computers to meet the demand for higher performance, lower cost and accurate results in real-life applications. Concurrent events are common in today’s computers due to the practice of multiprogramming, multiprocessing, or multicomputing.
- Modern computers have powerful and extensive software packages. To analyze the development of the performance of computers, first we have to understand the basic development of hardware and software.
- Diminishing returns of ILP
- Programs have only so much instruction-level parallelism.
- It's very expensive to extract the last bit of ILP.
- We are limited by various bottlenecks like fetch bandwidth, memory hierarchy, etc. that are hard to parallelize in a single-threaded system.
- Peak performance increases linearly with more processors. If a problem is nearly perfectly parallelizable, a parallel system with N processors can run the program N times faster. In the single-processor world, we're very happy if we can get 2 IPC. But with parallel computers, some programs can get N IPC where N is as large as you like, if you can afford N processors.
- Adding processors is easier. Rather than changing a single-processor through expensive re-design of the microarchitecture, we can simply add many of the same old processors together. We still have to design the logic to glue them together, but that is easier. We can generalize this to cluster computers that are connected by commodity communication technologies.
- Adding processors is cheap. I can buy a dual-processor Athlon MP 1500 with a motherboard for $390.00, vs. $439 for the top-of-the-line Athlon XP 2700. For parallelizable workloads, the cheaper dual-processor system will be significantly faster.
- But if the workload has a large serial component, the extra parallelism will not give us a linear speedup.
There are two main parallel software models, i.e., two ways the multiple processing elements (nodes) are represented to the programmer. They differ in how they communicate data and how they synchronize. Synchronization is essentially how processors communicate control flow among nodes.
- Message passing.
- Processors fork processes, typically one per node.
- Processes communicate only by passing messages.
- Message-passing code is inserted by the programmer or by high-level compiler optimizations. Some systems use message passing to implement parallel languages.
- Send a message to some specific process using a unique tag to name the message. send(pid, tag, message);
- receive (tag, message); Wait until a message with a given tag is received.
- Processes can synchronize by blocking on messages. The processor waits until a message arrives.
- Shared memory.
- Processors fork threads.
- Threads all share the same address space.
- Typically one thread per node.
- Threads are either explicitly programmed by the programmer or found through high-level analysis by the compiler.
- Threads communicate through the shared address space.
- Loads and stores.
- Cache contents are an issue.
- Threads synchronize by atomic memory operations, e.g. test-and-set.
- Processors fork threads.
Message Passing Multicomputers and Cluster Computers
This kind of architecture is a collection of computers (nodes) connected by a network. The processors may all be on the same motherboard, or each on different motherboards connected by some communication technology, or some of each.
- Computers are augmented with fast network interface
- send, receive, barrier
- user-level, memory mapped
- Computer is otherwise indistinguishable from a conventional PC or workstation.
- One approach is to network many workstations with a very fast network. This idea is called "cluster computers." Off-the-shelf APIs like MPI can be used over fast Ethernet or ATM, or other fast communication technology.
These systems have many processors but present a single, coherent address space to the threads.
- Several processors share one address space.
- Conceptually like a shared memory.
- Often implemented just like a message-passing multicomputer.
- E.g. Address space distributed over private memories.
- Communication is implicit.
- Read and write accesses to shared memory locations.
- Simply by doing a load instruction, one processor may communicate with another.
- Synchronization
- Via shared memory locations.
- E.g. spin waiting for non-zero.
- Or e.g. special synchronization instructions
Cache coherence is an issue with shared memory multiprocessors. Although the system conceptually uses a large shared memory, we know what is really going on behind the scenes: each processor has its own cache.
- With caches, action is required to prevent access to stale data.
- Some processor may read old data from its cache instead of new data from memory.
- Some processor may read old data from memory instead of new data in some other processor's cache.
- Solutions
- No caching of shared data.
- Cache coherence protocol.
- Keep track of copies
- Notify (update or invalidate) on writes
- Ignore the problem and leave it up to the programmer.
- Implementation eased by inclusive caches.
Granularity and Cost-Effectiveness of Parallel Computers
- Parallel computers built for:
- Capability - run problems that are too big or take too long to solve any other way. Absolute performance at any cost. Predicting the weather, simulating nuclear bombs, code-breaking, etc.
- Capacity - get throughput on lots of small problems. Transaction processing, web-serving, parameter searching.
- A parallel computer built from workstation size nodes will always have a lower performance/cost than a workstation.
- Sublinear speedup
- Economies of scale
- A parallel computer with less memory per node can have better performance/cost than a workstation
Moore's Law gives us billions of transistors on a die, but with relatively slow wires. How can we build a computer out of these components?
- Technology changes the cost and performance of computer elements in a non-uniform way.
- Logic and arithmetic is becoming plentiful and cheap.
- Wires are becoming slow and scarce.
- This changes the trade-offs between alternative architectures.
- Superscalar doesn't scale well.
- Global control and data lead aren't good when we have slow wires.
- So what will the architectures of the future look like?
A quote from Andy Glew, a noted microarchitect: "It seems to me that CPU groups fall back to explicit parallelism when they have run out of ideas for improving uniprocessor performance. If your workload has parallelism, great; even if it doesn't currently have parallelism, sometimes occasionally it is easy to write multithreaded code than single threaded code. But, if your workload doesn't have enough natural parallelism, it is far too easy to persuade yourself that software should be rewritten to expose more parallelism... because explicit parallelism is easy to microarchitect for."
- Build a multiprocessor on a single chip.
- Linear increase in peak performance.
- Advantage of fast communication between processors, relative to going off-chip.
- But memory bandwidth problem is multiplied; each processor will be making demands on the memory system.
- Exploiting CMPs. Where will the parallelism come from to keep all of these processors busy?
- ILP - limited to about 5.
- Outer-loop parallelism, e.g., domain decomposition. Requires big problems to get lots of parallelism.
- TLP (thread-level parallelism). Fine threads:
- Make communication and syncronization very fast (1 cycle)
- Break the problem into smaller pieces
- More parallelism
- Examples of CMPs:
- Cell. This processor developed by IBM has one Power Processor Element (PPE) and eight Synergistic Processing Elements (SPE) linked by a high-speed bus on chip. The PPE is a POWER-compatible processor that acts as a controller for the SPEs and performs the single-threaded component of the program. The SPEs are 128-bit SIMD RISC processors, i.e., RISC processors with vector instructions. Each SPE has its own local memory that can also be accessed by the PPE. Its peak computing power for single-precision floating point should far outrun other platforms such as Intel. However, it is hard to program.
- Niagara. This processor developed by Sun Microsystems has 4, 6, or 8 processor cores on a single chip. Each processor can run 4 independent threads. It's kind of like a supercomputer on a chip. Each core is simple compared with contemporary single-core CPUs. They are inorder, have small caches, and no branch prediction.
- Athlon 64 X2. This line of processors developed by AMD has two processor cores on a single chip. Each processor has a private cache. They are connected by a HyperTransport bus.
- POWER4 and POWER5 from IBM are dual core.
- Intel's Pentium D, Pentium 4 Extreme Edition, and Core Duo are dual-core processors.
- There are others.
- Main idea - put the processor and main memory onto a single chip.
- Much lower memory latency.
- Much higher memory bandwidth.
- But it's kind of weird.
- Graphics processors (GPUs) make use of this kind of idea.
- Adapt the processor to the application.
- Special functional units.
- Special wiring between functional units.
- Builds on FPGA technology (field programmable gate arrays).
- FPGAs are inefficient.
- A multiplier built from an FPGA is about 100x larger and 10x slower than a custom multiplier.
- Need to raise the granularity from the gate-level. Configure ALUs, or whole processors.
- Memory and communication are usually the bottleneck. Not addressed by configuring a lot of ALUs.
Key takeaways
- Diminishing returns of ILP
- Programs have only so much instruction-level parallelism.
- It's very expensive to extract the last bit of ILP.
- We are limited by various bottlenecks like fetch bandwidth, memory hierarchy, etc. that are hard to parallelize in a single-threaded system.
According to me, multithreaded architecture is actually a trend and reliable and easy to applicable solution for upcoming microprocessor design, so I studied four research papers on this topic just to familiarize myself with the technology involved in this subject.
In today’s world, there is a rapid progress of Very Large-Scale Integrated circuit (VLSI) technology that allows processors’ designers to assimilate more functions on a single chip, in future microprocessors will soon be able to issue more than 12 instructions per machine cycle.
Existing superscalar and Very Large Instruction Word (VLIW) microprocessors utilize multiple functional units in order to exploit instruction-level parallelism from a single thread of control flow. These kinds of microprocessors are depending on the compiler or the hardware of the system in order to excerpt instruction-level parallelism from programs and to then afterward schedule independent instructions on multiple functional units on each machine cycle. And when the issue rate of future microprocessors increases, however, the compiler or the hardware will have to extract some more instruction-level parallelism from programs by analysing a larger instruction buffer (for example -Reservation Station Entry).
It is very tough to extract enough parallelism with a single thread of control even for a small number of functional units.
Limitation of Single-threaded sequencing mechanism are as follow:
- In order to exploit instruction-level parallelism, independent instructions from different-different basic building-blocks in a single instruction stream needed to be examined and issued together.
- As the issue rate increases, a larger instruction buffer (for example -Reservation Station Entry) is needed to contain several basic building-blocks, which will be control dependency on different branch conditions, but their examination must be hit together.
- And Instruction-level analytical execution with branch prediction is also needed to move independent instructions across basic block boundaries. This problem is especially serious when a compiler attempts to pipeline a loop with many conditional branches.
- Here, the accuracy of systems is very low.
- Here, the speed of the system is quite low as compare to multithreaded architectures.
Features of Multithreaded Architecture are as follow:
- In its regular form, a multithreaded processor is made up of many numbers of thread processing elements that are connected to each other with a unidirectional ring which helps in performing the system in a better way.
- All the multiple thread processing elements have their own private level-one instruction cache, but they’ll share the level-one data cache and the level-two cache.
- In the multithreaded systems also some shared register files present that used for maintaining some global registers and a lock register.
- During run-time, the multiple thread processing elements, each has its own program counter and instruction execution path, which can then easily fetch and execute instructions from multiple program locations simultaneously.
- Each of the present thread processing element always has a private memory buffer to cache speculative stores and which is also used to support run-time data dependency checking.
- Fortunately, the compiler statically divides the control flow graph of a program into threads that coincide with a portion of the control flow graph. A thread performs a round of computation on a set of data that has no, or only a few, dependencies with other concurrent threads. The compiler will later determine the granularity (it’ll directly affect the performance) of the threads, which are hardly one or several iterations of a loop.
- The real execution of a program initiates from its entry thread. This entry thread can then transfers the systems’ processing to a successor thread on some another thread processing element. The successor thread can further transfer the systems’ processing to its own successor thread. This process will continue until all thread processing elements are busy with some appropriate tasks.
- When the multiple threads are executed on the multithreaded processor, the primeval thread in the sequential order is referred to as the head thread. And then all of the other threads which are derived from it are called successor threads. Once the head thread completes its computation, then further it will retire and release the thread processing element and then its (just) successor thread then becomes the new head thread. This completion and retirement of the threads must have to follow the original sequential execution order.
- In the multithreaded system (or model), a thread can transfer the systems’ processing one of its successor threads with or without control speculation. When the transfer of the systems’ processing from head to its successor thread without control speculation, the thread performing the fork operation must ensure that all of the control dependencies of the newly generated successor thread have been satisfied.
- If the transfer of the systems’ processing from the head to its successor thread with control speculation, however, it must be later on verifying all of the speculated control dependencies. If any of the speculated control dependencies are not true, the thread must have to issue a command to kill the successor thread and all of its subsequent threads.
- In general, the multithreaded architecture will use a thread pipelining execution model in order to enforce data dependencies between concurrent threads. Unlike the instruction pipelining mechanism in a superscalar processor, where instruction sequencing, data dependencies checking, and forwarding are performed by processor hardware automatically, the multithreaded architecture performs thread initiation and data forwarding through explicit thread management and communication instructions.
Key takeaways
- According to me, multithreaded architecture is actually a trend and reliable and easy to applicable solution for upcoming microprocessor design, so I studied four research papers on this topic just to familiarize myself with the technology involved in this subject.
- In today’s world, there is a rapid progress of Very Large Scale Integrated circuit (VLSI) technology that allows processors’ designers to assimilate more functions on a single chip, in future microprocessors will soon be able to issue more than 12 instructions per machine cycle.
Service Set Identifier (SSID)
Service Set Identifier (SSID) is the primary name associated with an 802.11 wireless local area network (WLAN) that includes home networks and public hotspots. Client devices use this name to identification and to join wireless networks. For example, while trying to connect to a wireless network at work or school named guest_network you see several others within range that are called something entirely different names. All the names you see are the SSIDs for those networks. On home Wi-Fi networks, a broadband router or broadband modem stores the SSID but administrators can change it. Routers broadcast this name to help wireless clients find the network.
The Service Set Identifier (SSID) is a case-sensitive text string that can be as long as 32 characters consisting of letters or numbers or a combination of both. Within these rules, the SSID can say anything. Router manufacturers set a default SSID for the Wi-Fi unit, such as TP_LINK, D_LINK, JIO_FI or just DEFAULT. Since the SSID can be changed, not all wireless networks have a standard name like that.
Uses of SSID by devices –
Wireless devices like phones, laptops etc scan the local area for networks broadcasting their SSIDs and presents a list of names. A user can join a new network connection by picking a name from the list. In addition to obtaining the network’s name, the Wi-Fi scan also determines whether each network has wireless security options enabled or not. In most cases, the device identifies a secured network with a lock symbol next to the SSID.
Most wireless devices keep track of the different networks a user joins as well as the connection preferences. Users can also set up a device to automatically join networks having certain SSIDs by saving that setting into their profiles. In other words, once connected, the device usually asks if you want to save the network and reconnect automatically in future.
Most wireless routers offer the option to disable SSID broadcasting to improve Wi-Fi network security as it basically requires the clients to know two passwords, the SSID and the network password. However, the effectiveness of this technique is limited since it’s fairly easy to get the SSID from the header of data packets flowing through the router. Connecting to networks with disabled SSID broadcast requires the user to manually create a profile with the name and other connection parameters.
Problem with SSIDs –
- If there is no wireless security options enabled on a network then anyone can connect to it by knowing only the SSID.
- Using a default SSID increases the chances that another nearby network will have the same name which can confuse wireless clients. When a Wi-Fi device discovers two networks with the same name, it will prefer and may try auto-connecting to the stronger radio signal, which might be the unwanted choice. In the worst case, a person might get dropped from their own home network and reconnected to a neighbor’s who does not have login protection enabled.
- The SSID chosen for a home network should contain only generic and sensible information. Some names (like HackMyWIFIIfYouCan) unnecessarily provoke thieves to target certain homes and networks over others.
- An SSID can contain publicly visible or offensive language or coded messages.
SIMD stands for 'Single Instruction and Multiple Data Stream'. It represents an organization that includes many processing units under the supervision of a common control unit.
All processors receive the same instruction from the control unit but operate on different items of data.
The shared memory unit must contain multiple modules so that it can communicate with all the processors simultaneously.
|
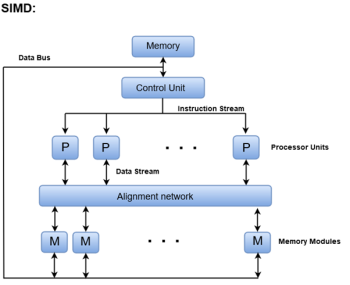
Fig 14 - SIMD
SIMD is mainly dedicated to array processing machines. However, vector processors can also be seen as a part of this group.
Parallel computing is a computing where the jobs are broken into discrete parts that can be executed concurrently. Each part is further broken down to a series of instructions. Instructions from each part execute simultaneously on different CPUs. Parallel systems deal with the simultaneous use of multiple computer resources that can include a single computer with multiple processors, a number of computers connected by a network to form a parallel processing cluster or a combination of both.
Parallel systems are more difficult to program than computers with a single processor because the architecture of parallel computers varies accordingly and the processes of multiple CPUs must be coordinated and synchronized.
The crux of parallel processing are CPUs. Based on the number of instruction and data streams that can be processed simultaneously, computing systems are classified into four major categories:
|
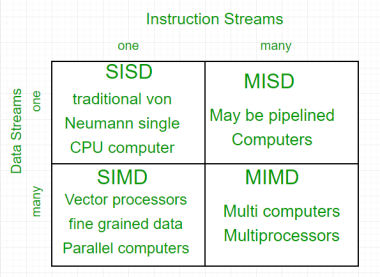
Fig 15 – Instruction Streams
Flynn’s classification –
- Single-instruction, single-data (SISD) systems –
An SISD computing system is a uniprocessor machine which is capable of executing a single instruction, operating on a single data stream. In SISD, machine instructions are processed in a sequential manner and computers adopting this model are popularly called sequential computers. Most conventional computers have SISD architecture. All the instructions and data to be processed have to be stored in primary memory.
|
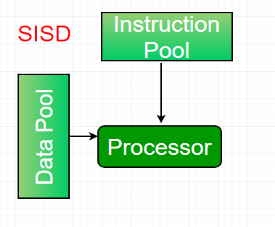
Fig 16 - SISD
The speed of the processing element in the SISD model is limited(dependent) by the rate at which the computer can transfer information internally. Dominant representative SISD systems are IBM PC, workstations.
2. Single-instruction, multiple-data (SIMD) systems –
An SIMD system is a multiprocessor machine capable of executing the same instruction on all the CPUs but operating on different data streams. Machines based on an SIMD model are well suited to scientific computing since they involve lots of vector and matrix operations. So that the information can be passed to all the processing elements (PEs) organized data elements of vectors can be divided into multiple sets (N-sets for N PE systems) and each PE can process one data set.
|
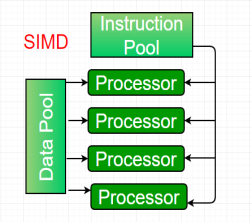
FIG 17 - SIMD
Dominant representative SIMD systems is Cray’s vector processing machine.
3. Multiple-instruction, single-data (MISD) systems –
An MISD computing system is a multiprocessor machine capable of executing different instructions on different PEs but all of them operating on the same dataset.
|
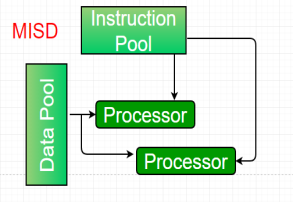
Fig 18 - MISD
Example Z = sin(x)+cos(x)+tan(x)
The system performs different operations on the same data set. Machines built using the MISD model are not useful in most of the application, a few machines are built, but none of them are available commercially.
4. Multiple-instruction, multiple-data (MIMD) systems –
An MIMD system is a multiprocessor machine which is capable of executing multiple instructions on multiple data sets. Each PE in the MIMD model has separate instruction and data streams; therefore machines built using this model are capable to any kind of application. Unlike SIMD and MISD machines, PEs in MIMD machines work asynchronously.
|
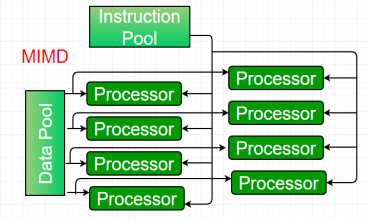
Fig 19 - MIMD
MIMD machines are broadly categorized into shared-memory MIMD and distributed-memory MIMD based on the way PEs are coupled to the main memory.
In the shared memory MIMD model (tightly coupled multiprocessor systems), all the PEs are connected to a single global memory and they all have access to it. The communication between PEs in this model takes place through the shared memory, modification of the data stored in the global memory by one PE is visible to all other PEs. Dominant representative shared memory MIMD systems are Silicon Graphics machines and Sun/IBM’s SMP (Symmetric Multi-Processing).
In Distributed memory MIMD machines (loosely coupled multiprocessor systems) all PEs have a local memory. The communication between PEs in this model takes place through the interconnection network (the inter process communication channel, or IPC). The network connecting PEs can be configured to tree, mesh or in accordance with the requirement.
The shared-memory MIMD architecture is easier to program but is less tolerant to failures and harder to extend with respect to the distributed memory MIMD model. Failures in a shared-memory MIMD affect the entire system, whereas this is not the case of the distributed model, in which each of the PEs can be easily isolated. Moreover, shared memory MIMD architectures are less likely to scale because the addition of more PEs leads to memory contention. This is a situation that does not happen in the case of distributed memory, in which each PE has its own memory. As a result of practical outcomes and user’s requirement, distributed memory MIMD architecture is superior to the other existing models.
Vector processor classification
According to from where the operands are retrieved in a vector processor, pipe lined vector computers are classified into two architectural configurations:
- Memory to memory architecture –
In memory-to-memory architecture, source operands, intermediate and final results are retrieved (read) directly from the main memory. For memory to memory vector instructions, the information of the base address, the offset, the increment, and the vector length must be specified in order to enable streams of data transfers between the main memory and pipelines. The processors like TI-ASC, CDC STAR-100, and Cyber-205 have vector instructions in memory-to-memory formats. The main points about memory-to-memory architecture are:
- There is no limitation of size
- Speed is comparatively slow in this architecture
- Register to register architecture –
In register-to-register architecture, operands and results are retrieved indirectly from the main memory through the use of large number of vector registers or scalar registers. The processors like Cray-1 and the Fujitsu VP-200 use vector instructions in register-to-register formats. The main points about register-to-register architecture are:
- Register to register architecture has limited size.
- Speed is very high as compared to the memory to memory architecture.
- The hardware cost is high in this architecture.
A block diagram of a modern multiple pipeline vector computer is shown below:
|
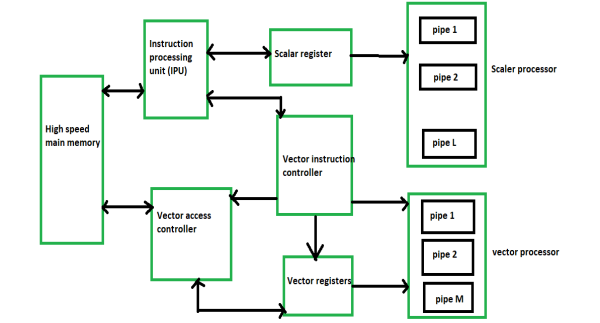
Fig 20 - A typical pipe lined vector processor.
Key takeaways
- Service Set Identifier (SSID) is the primary name associated with an 802.11 wireless local area network (WLAN) that includes home networks and public hotspots. Client devices use this name to identification and to join wireless networks. For example, while trying to connect to a wireless network at work or school named guest network you see several others within range that are called something entirely different names. All the names you see are the SSIDs for those networks. On home Wi-Fi networks, a broadband router or broadband modem stores the SSID but administrators can change it. Routers broadcast this name to help wireless clients find the network.
Reference
1. William Stallings: Computer Organization & Architecture, 7th Edition, PHI, 2006.
2. Vincent P. Heuring & Harry F. Jordan: Computer Systems Design and Architecture, 2 nd Edition, Pearson Education, 2004.




