UNIT- 7
AWK
The awk utility, which takes its name from the initials of its authors (Alfred V, Aho, Peter J Weinberger and Brian W Kernighan), is a powerful programming language disguised as a utility. Its behavior is to some extent like sed. It reads the input file, line by line, and performs an action on a part of pr on the entire line. Unlike sed, however, it does not print the line unless specifically told to print it.
Awk is one of the most powerful tools in unix used for processing the rows and columns in a file. Awk has built in string functions and associative arrays. Awk supports most of the operators, conditional blocks and loops available in c language.
Syntax:
awk BEGIN {Start_action} {action}
END {stop_action} filename
Here the actions in the being block are performed before processing the file the rest of actions are performed while processing the file.
Examples:
awk {print $ 1} input_file
Here $1 has a meaning $1, $2, $3..... represents the first, second third columns.... in a row respectively this awk command will print the first column in each row as shown below
_rw_r_r_ _
_rw_r_ _r_ _
Awk introduction and printing operation: Awk is a programming which allows easy manipulation of structured data and the generation of formatted reports. Awk stands for the names of its authors "Aho weinbergen and Kernighan.”
The Awk is mostly used for pattern scanning and processing. It searches one or more files to see if they contain lines that matches with the specified patterns and then perform associated actions.
Some of the key features of awk are
1. Awk views a text file as records and fields
2. Like common programming language, awk has variables, conditional loops.
3. Awk has arithmetic and string operators.
4 Awk can generate formatted reports.
The awk utility, which takes its name from the initials of its authors (Alfred V, Aho, Peter J Weinberger and Brian W Kernighan), is a powerful programming language disguised as a utility. Its behavior is to some extent like sed. It reads the input file, line by line, and performs an action on a part of pr on the entire line. Unlike sed, however, it does not print the line unless specifically told to print it. "awk" is a utility that's useful for processing text files. The utility considers each file as a set of records, which by default are the lines in the file. "awk" enables you to create a condition and action pair, and for each record that matches the condition, the action will fire. The awk concept is presented in Figure
|
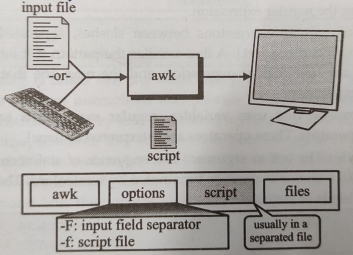
There are only two UNIX options for the awk utility. The -F option specifies the input field separator. The - f option names the script file. When the script is contained in the command line, it should be quoted to protect it from the shell. Multiple input files can be specified. If no file is given, the input is assumed to come from the keyboard. To provide input from the keyboard and one or more files, the keyboard is designated by a dash (-).
Record: A record is a collection of data items arranged for processing by a program. Multiple records are contained in a file or data set. The organization of data in the record is usually prescribed by the programming language that defines the record's organization and/or by the application that processes it. Typically, records can be of fixed-length or be of variable length with the length information contained within the record.
In other words, a record also called struct or compound data that is a basic data structure. A record is a collection of fields, possibly of different data types, typically in fixed number and sequence. The fields of records may also be called elements. The awk language divides its input into records and fields. Records are separated by a character called the record separator. By default, the record separator is the newline character, defining a record to be a single line of text.
The pattern argument is one of the following:
1. One of the awk keywords BEGIN or END. The BEGIN pattern matches only once before the first line of the file. The END pattern matches only once, after the last line of the file
2 A regular expression between slashes (eg//^name:/). A line satisfies this pattern if it matches the regular expression.
3. A pair of regular expressions between slashes, separated by a comma [e.g. |^name:|,|^end headerl]. A line satisfies the pattern if it lies between a line that matches the first regular expression, and the next line that satisfies the second regular expression.
4. An expression that uses variables, regular expressions and relational and/or logical operators. These operators are interpreted as usual.
Action of awk: The action argument is a sequence of statements that resemble CH statements. All statements must be terminated by semicolons. The following table lists the different kinds of statements.
S no | Statement | Description |
1 | If (pattern) statement else Statement | Typical if then else statement for Decisions |
2 | While (pattern) statement | Typical while statement for iteration. |
3 | For (Expression; pattern expression) statement. | Typical for statement for iteration.
|
4 | For (eliminate in array) statement | Typical for each statement for iteration through an array of items. |
5 | Break | Break statement to discontinue iteration continue statement skips current iteration, proceeds to the next iteration |
6 | Variable = Expression. | Variable assignment. |
7 | Print [List of expression] [<Expression]. | Print the list of expressions.
|
8 | Print f format [List of expressions][>Expression] | Provides formatted output the format is specified by a string. Variables can be placed inside of the format string that is replaced by the value of their corresponding expression. This is how the printf library function works in the C programing language and is similar to the formate function in scheme. |
9 | Next | Skip the remeding patterns on the current line of input |
10 | Exit | Skip the rest of the current line. |
11 | List of statement | Curly braces provide for nested statements. |
The awk utility is called like any other utility. In addition to input data, awk also requires one or more instructions that provide editing instructions. When there are only a few instructions, they may be entered at the command line from the keyboard. Most of the time, however, they are placed in a file known as an awk script (program). Each instruction in an awk script contains a pattern and an action. If the script is short and easily fits on one line, it can be coded directly in the command line. When coded on the command line, the script is enclosed in quotes. The format for the command line script is:
$ awk 'pattern { action }' input-file
For longer scripts, or for scripts that are going to be executed repeatedly over time, a separate script file is preferred. To create the script we use a text editor, such as vi or emacs. Once the script has been created, we execute it using the file option (-Ė), which tells awk that the script is in a file. The following example shows how to execute an awk script:
$ awk -f scriptFile.awk input-file
There are two different types of variables in awk system variables and user-defined variables.
1. System Variables: There are more than twelve system variables used by awk. Their names and function are defined by awk. Four of them are totally controlled by awk. The others have standard defaults that can be changed through a script. The system variables are defined in Table.
Variable | Function | Default |
FS | Input field separator | Space or tab |
RS | Input record separator | Newline |
OFS | Output field separator | Space or tab |
ORS | Output record separator | Newline |
NF | Number of nonempty fields in current record |
|
NR | Number of records read from all files |
|
FNR | File number of records read-record number in current file |
|
FILENAME | Name of the current file |
|
ARGC | Number of command-line arguments |
|
ARGV | Command-line argument array |
|
RLENGTH | Length of string matched by a built-in string function |
|
RSTART | Start of string matched by a built-in string function |
|
Awk Built in Variables: FS - Input field separator variable: We have seen the fields are separated by a space character. By default Awk assumes that fields in a file are separated by space characters. If the fields in the file are separated by any other character, we can use the FS variable to tell about the delimiter. $ awk 'BEGIN {FS="/"} {print $2}'emp.dat Or $ awk -F"/" '{print $2} emp.dat 12 09 02 04 12 08
OFS - Output field separator variable: By default whenever we printed the fields using the print statement the fields are displayed with space character as delimiter. We can change this default behavior using the OFS variable as: $ awk 'BEGIN {OFS=":"} {print $4,$5}’ input_file Name:Position Gupta:BM Agrawal:Director Krishna:Manager Saxena:Accounting Singh:Director Sen:Executive
Print $4, $5 and print $4 $5 will not work the same way. The first one displays the output with space as delimiter. The second one displays the output without any delimiter. NF - Number of fields variable: The NF can be used to know the number of fields in line. To display the number of columns in each row, we can use the command below. $ awk 'END {print NF)}' emp.dat 6 NR - Number of records variable: The NR can be used to know the line number or count of lines in a file. $ awk 'END {print NR}" input_file 7
2. User-Defined Variables: We can define any number of user-defined variables within an awk script. They can be numbers, strings, or arrays. Variable names start with a letter and can be followed by any sequence of letters, digits, and underscores. They do not need to be declared; they simply come into existence the first time they are referenced. All variables are initially created as strings and initialized to a null string (“”).
|
All awk scripts are divided into three parts : begin, body and end.
Pattern {Actions} Body Pattern {Actions}
Initialization Processing (BEGIN): The initialization processing is done only once, before awk starts reading the file. It is identified by the keyword, BEGIN, and the instructions are enclosed in a set of braces. The beginning instructions are used to initialize variables, create report headings, and perform other processing that must be completed before the file processing starts. Body Processing: The body is a loop that processes the data in a file. The body star when awk reads the first record or line from the file. It then processes the data through the body instructions, applying them as appropriate. When the end of the body instructions is reached, awk repeats the process by reading the next record or line and processing it against the body instructions. In this way, the awk utility processes each record or line in the file, one after the other, through the instructions in the body. This means that if a file contains 50 records, the body will normally be executed 50 times once for each record. On the other hand, if there are no records in the file, the body will not be executed at all. One final point: Unlike other utilities, awk does not write or print a record unless there is an explicit instruction to do so in the file. End Processing (END): The end processing is executed after all input data have been read. At this time information accumulated during the processing can be analyzed and printed or other end activities can be conducted. The basic syntax of AWK: Syntax : awk 'BEGIN {start action} {action} END {stop action}’ filename Here the actions in the begin block are performed before processing the file and the actions in the end block are performed after processing the file. The rest of the actions are performed while processing the file. Examples Create a file emp.dat with the following data. EmpNo Name Position Salary Dept. DOB 2004 Gupta BM 12000 Sales 12/12/52 2006 Agrawal Director 18000 Marketing 26/09/45 1001 Krishna Manager 8000 Marketing 15/02/77 4008 Saxena Accounting 6000 Sales 18/04/82 2000 Singh Director 20000 Production 01/12/46 1020 Sen Executive 6000 Personnel 10/08/80
$ awk 'BEGIN {sum=0} (sum=sum+$6} END {print sum}' emp.dat This will prints the sum of the value in the 6th column In the Begin block the variable sum is assigned with value 0. In the next block the value of 6th column is added to the sum variable. This addition of the 6th column to the sum variable repeats for every row it processed. When all the rows are processed the sum variable will hold the sum of the values in the 6th column. This value is printed in the End block.
|

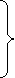

1. Awk reads the input files one line at a time. 2. For each line, it matches with given pattern in the given order, if matches performs the corresponding action. 3. If no pattern matches, no action will be performed. 4. In the above syntax, either search pattern on action are optional, but not both. 5. If the search pattern is not given then awk performs the given actions for each line of the input. 6. If the action is not given, print all that lines that matches with the given patterns which is the default action. 7. Empty braces without any action does nothing. It went perform default printing 8. operations. Each statement in action should be delimited by semicolon (). To understand the working process of an awk let's consider an example. We use a small file of four records, each with three numbers. We then run a simple script that adds the three numbers and prints them followed by their sum. $ cat total.awk BEGIN {print "Print Totals"} {total = $1 + $2 + $3} {print $1 "+" $2 "+" $3 " = total} END (print "End Totals") $ cat total.dat 22 78 44 66 31 70 52 30 44 88 31 66 $ awk-f total.awk total.dat Print Totals 22+78 +44 = 144 66 + 31 + 70 = 167 52 + 30 + 44 = 126 88 +31 +66 = 185 End Totals 1. The begin instruction is executed once. It prints "Print Totals". 2. The body instruction is executed four times, once for each record.
3. After the last record is processed, end processing prints an end of script message and the script ends.
|
The awk utility supports four expressions: regular, arithmetic, relational and logical.
1. Regular Expressions: The awk regular expressions (regexp) are those defined in egrep. In addition to the expression, awk requires one of two operators: Match or not match (: When using a regular expression, remember that it must be enclosed in /slashes/. The match and not match operators are:
Operator Explanation
~ Regular expression must match text
!~ Regular expression must not match text.
Example:
$0 ~/^A. *B$/ #Record must begin with A and end with 'B'
$3 !~/^ / # Third field must not start with a space
$4 !~ /bird/ # Fourth field must not contain "bird
2. Arithmetic Expressions: An arithmetic expression is the result of an arithmetic operation. When the expression is arithmetic, it matches the record when the value is nonzero, either plus or minus, it does not match the record when it is zero (false)
Table lists the operators used by awk in arithmetic expressions.
Operator | Example | Explanation |
*/%* | a^2 | Variable a is raised to power 2 (a2). |
++ | ++a a++ | Adds 1 to a. |
-- | --a a-- | Subtracts 1 from a. |
+- | a+b, a-b | Adds or subtracts two values. |
+ | +a | Unary plus: Value is unchanged. |
- | -a | Unary minus: Value is complemented. |
= | a=0 | a is assigned the value 0. |
*= | x*=y | The equivalent of x - x* y; x is assigned the product of x*y. |
/= | x/=y | The equivalent of x =x/ y; x is assigned the quotient of x/y. |
%= | x%=y | The equivalent of x = x % y where "%' is the modulo operator; x is assigned the modulus of x / y. |
+= | x+=5 | The equivalent of x = x + 5; x is assigned the sum of x and 5. |
-= | x-=5 | The equivalent of x = x - 5; x is assigned the difference (x - 5). |
In the following example, two fields in a record are algebraically compared. If the result is nonzero, the line is printed.
$3-$4 (print)
3. Relational Expressions: Relational expressions compare two values and determine if the first is less than, equal to, or greater than the second. When the two values are numeric, and algebraic comparison is used; when they are strings string comparison is used. If a string is compared to a number, the number is converted to a string and a string compare-is used. However, we can force a string to be numeric by adding 0 to it we can force a numeric to be a string by appending a null string ("") to it. The relational expressions are listed in table. Operator
Operator | Explanation |
< | Less than |
<= | Less than or equal |
== | Equal |
!= | Not Equal |
> | Greater than |
>= | Greater than or equal |
$ cat sales
1 clothing 3141
1 computers 4567
1 textbooks 8753
2 clothing 3141
2 computers 25161
2 supplies 3141
$ awk '$2 == "computers" {print}' sales
1 computers 4567
2 computers 25161
4. Logical Expressions : A logical expression uses logical operators to combine two or more expressions Table.
Operator | Explanation |
!expr | Not expression |
expr1 && expr2 | Expression 1 and Expression 2 |
expr1 || expr2 | Expression 1 or Expression 2 |
The result of a logical and expression is true if and only if both expressions are true; it is false if either of the expressions is false. The result of a logical or expression is true if either of the expressions is true; it is false if and only if both expressions are false. The not operator complements the expression: If the expression is true, not makes it false; if it is false, not makes it true.
$ awk '$2 == "computers" && $3 >10000 (print)' sales
2 computers 25161
There are three output actions in awk. The first is the simple print action. The second is the C formatted print statement printf. The third is sprintf. 1. Print: Print writes the specified data to the standard output file. Each print action writes a separate line. When multiple fields or variables are being written, they must be separated with commas. If no data are specified, the entire record (line) is printed. In the below example, we use the whole line format. As each line is processed, it is copied to standard output. Because the entire line is being printed, the input line field separator (tab) is used, which aligns each field into columns. $ awk '{print}' sales2 1 clothing 3141 1 computers 9161 1 software 3141 1 supplies 2131 1 textbooks 21312 1 sporting 0 2 clothing 3252 2 computers 12321 2 software 3252 2 supplies 2242 2 textbooks 22452 2 sporting 2345 3 clothing 3363 3 computers 13431 3 software 3363 3 supplies 2353 3 textbooks 23553 3 sporting 4554 $ awk '{print $1, $2, $3)’ sales2 | head -5 1 clothing 3141 1 computers 9161 1 software 3141 1 supplies 2131 1 textbooks 21312 When we print fields, if we want columns, we need to change the output field separator to a tab. The output is separated into columns. Again, we print only the first five lines. $ awk 'BEGIN { OFS = " \t "}; {print $1, $2, $3)’ sales2 | head -5 1 clothing 3141 1 computers 9161 1 software 3141 1 supplies 2131 1 textbooks 21312
2. Formatted Printiprintf): The awk utility also contains the C formatted print statement, printf. Each printf action consists of a format string enclosed in double quotes, and a list of zero or more values to be printed. The data formatting is described by a field specification, which begins with a percent sign and ends with a format code that defines the data type. Anything that is not a field specification is text that is to be printed. $awk '{printf("%2d %-12s $%9.2f\n", $1, $2, $3)}’ sales | head -5 1 clothing $ 3141.00 1 computers $ 9161.00 1 software $ 3141.00 1 supplies $ 2131.00 1 textbooks $ 21312.00
3. String Print (sprintf): There is one more print command in awk : string print (sprintf). This command uses the formatted print concept to combine two or more fields into one string that can be used as a variable. As a simple demonstration, in below example, we combine the fields in the first record of our bookstore into one string and then print its length and contents. $ cat sprint.awk NR == 1{ str= sprintf("%2d %-12s $%9.2f\n", $1, $2, $3) len = length(str) print len "” str } $ awk -f sprintf.awk sales2 27 1 clothing $ 3141.00
|
References:
- Sumitabha Das: UNIX – Concepts and Applications, 4th Edition, Tata McGraw Hill, 2006.
- Behrouz A. Forouzan and Richard F. Gilberg: UNIX and Shell Programming, Cengage Learning, 2005.
- M.G. Venkateshmurthy: UNIX & Shell Programming, Pearson Education, 2005.




