Unit – 1
Introduction
Q1) What do you mean by speech production and modelling?
Ans: Speech production and modelling
The nature of speech coding systems is heavily influenced by how the human auditory system functions. Understanding how sounds are heard allows resources in the coding system to be distributed more efficiently, resulting in cost savings. Many speech coding requirements are tailored to take advantage of the properties of the human auditory system.
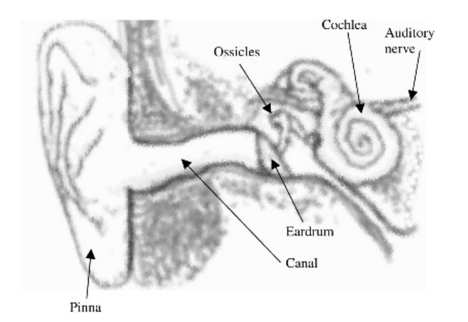
Fig 1: Diagram of the human auditory system
Figure depicts a simplified diagram of the human auditory system. The pinna (or ear informally) is the surface that surrounds the canal through which sound travels. The canal directs sound waves into the eardrum, a membrane that serves as an acoustic-to-mechanical transducer.
The sound waves are then converted into mechanical vibrations and transmitted to the cochlea through the ossicles, a collection of bones. The presence of the ossicles increases sound propagation by lowering the amount of reflection, which is achieved using the impedance matching principle.
The cochlea is a fluid-filled rigid snail-shaped organ. Mechanical oscillations impinge on the ossicles cause the basilar membrane, an internal membrane, to vibrate at different frequencies. A bank of filters can be used to model the activity of the basilar membrane, which is defined by a series of frequency responses at various points along the membrane. Inner hair cells detect movement along the basilar membrane and cause neural processes that are transmitted to the brain through the auditory nerve.
Depending on the frequencies of the incoming sound waves, various points along the basilar membrane respond differently. As a result, sounds of various frequencies excite hair cells at various locations along the membrane. The frequency specificity is maintained by the neurons that touch the hair cells and transmit the excitation to higher auditory centers.
The human auditory system acts very much like a frequency analyzer as a result of this arrangement, and system characterization in the frequency domain is much easier.
Q2) What is the general structure of speech coders?
Ans: General structure of speech coders
The generic block diagrams of a speech encoder and decoder are shown in Figure. The encoder processes and analyzes the input speech to derive a set of parameters that describe the frame. With the binary indices sent as the compressed bit-stream, these parameters are encoded or quantized.
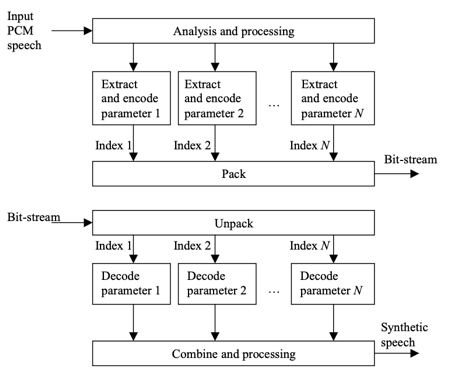
Fig 2: General structure of a speech coder. Top: Encoder. Bottom: Decoder
The indices are packed together to form the bit-stream; that is, they are arranged in a predetermined order and transmitted to the decoder, as we can see.
The speech decoder decodes the bitstream and sends the recovered binary indices to the corresponding parameter decoder to obtain quantized parameters. To create synthetic expressions, these decoded parameters are combined and processed.
The functionality and features of the various processing, analysis, and quantization blocks are determined by the algorithm designer. Their choices can influence the speech coder's success and characteristics.
Q3) Define classification of speech coding technique ?
Ans: Classification of speech coding techniques – parametric
Parametric coders and Waveform approximating coders are the two most common types of speech coders.
Parametric coders use a number of model parameters to model the speech signal. The encoder quantizes the extracted parameters before sending them to the decoder. The decoder synthesizes speech based on the model defined.
The speech production model ignores quantization noise and does not attempt to maintain waveform consistency between synthesized and original speech signals. The estimation of model parameters may be an open loop method that receives no input from the quantization or speech synthesis.
Only the features used in the speech development model, such as the spectral envelope, pitch, and energy contour, are preserved by these coders. With improved quantization of model parameters, the speech quality of parametric coders does not converge towards the transparent quality of the original speech.
Because of the limitations of the speech development model used, this is the case. Furthermore, they do not maintain waveform similarity, and measuring the signal to noise ratio (SNR) is meaningless because the SNR sometimes becomes negative when expressed in dB (due to the lack of phase alignment between the input and output waveforms).
The SNR has no bearing on the content of synthesized expression, which should be judged subjectively (or perceptually).
Q4) Illustrate requirements of speech codecs?
Ans: Speech quality and bit rate are two variables that are in direct dispute. Lowering the speech coder's bit rate, i.e. using higher signal compression, results in some output degradation (simple parametric vocoders). The quality standards for systems that link to the Public Switched Telephone Network (PSTN) and related systems are stringent, and they must adhere to the restrictions and guidelines placed by relevant regulatory bodies, such as the International Telecommunication Union (ITU).
Such systems necessitate the use of high-quality (toll-quality) coding. Closed systems, such as private commercial networks and military systems, can, on the other hand, jeopardize efficiency in order to reduce capacity requirements.
While absolute quality is frequently defined, it is frequently jeopardized when other variables are given a higher overall ranking. In a mobile radio system, for example, the overall average output is often the determining factor. This average quality takes both good and poor transmission conditions into account.
Q5) Define Coding delays?
Ans: A speech transmission system's coding delay is a factor that is directly linked to the consistency requirements. Coding delays can be algorithmic (buffering speech for analysis), computational (processing the stored speech samples), or transmission - related.
Only the first two are related to the speech coding subsystem, though the coding scheme is often designed so that transmission can begin before the algorithm has finished processing all of the information in the analysis frame; for example, in the pan-European digital mobile radio system, the encoder transmits the spectral parameters as soon as they are visible.
Low delay is important for PSTN applications if the major problem of echo is to be minimized. Echo cancellation is used in mobile device applications and satellite communication systems because significant propagation delays already occur. However, if coders with long delays are implemented on the PSTN, where there is very little delay, additional echo cancellers will be needed. The strictly subjective frustration factor is the other issue with encoder/decoder delay.
As compared to a regular 64 kb/s PCM method, most low-rate algorithms introduce a significant coding delay. For example, the GSM system's initial upper limit for a back-to-back configuration was 65 milliseconds, while the 16 kbps G.728 specification had a maximum of 5 milliseconds with a target of 2 milliseconds.
Q6) Define Robustness?
Ans: The speech source coding rate normally consumes just a fraction of the total channel capacity for many applications, with the remaining capacity being used for forward error correction (FEC) and signaling. A coding scheme's built-in tolerance to channel errors is critical for an acceptable average overall efficiency, i.e. communication quality, on mobile connections, which suffer greatly from both random and burst errors.
Built-in robustness allows for less FEC to be used and more source coding capability to be usable, resulting in improved speech quality. This trade-off between speech quality and robustness is always a difficult one to strike, and it is a condition that must be taken into account right from the start of the speech coding algorithm design.
Other applications that use less extreme networks, such as fiber-optic connections, have less issues with channel errors, and robustness can be overlooked in favor of higher clean channel speech efficiency. This is a significant distinction between wireless mobile systems and fixed link systems. Coders can have to work in noisy background conditions in addition to channel noise.
Q7) Define Waveform?
Ans : The error between the synthesized and original speech waveforms is minimized by waveform coders. Early waveform coders including compressed Pulse Code Modulation (PCM) and Adaptive Differential Pulse Code Modulation (ADPCM) send a quantized value for each speech sample.
ADPCM, on the other hand, uses an adaptive pole zero predictor and quantizes the error signal with a variable phase scale adaptive quantizer. Backward adaptive ADPCM predictor coefficients and quantizer phase size are modified at the sampling rate.
The vocal tract model and long term prediction are specifically used to model the associations present in the speech signal in recent waveform-approximating coders based on time domain analysis by synthesis, such as Code Excited Linear Prediction (CELP). CELP coders buffer the speech signal and conduct block-based analysis before transmitting the prediction filter coefficients and an excitation vector index. They often use perceptual weighting, which hides the quantization noise range behind the signal stage.
Q8) Define Hybrid Coding?
Ans: Regardless of the widely varying character of the speech signal, i.e. voiced, unvoiced, mixed, transitions, etc., almost all current speech coders use the same coding principle. ADPCM (Adaptive Differential Pulse Code Modulation), CELP (Code Excited Linear Prediction), and Improved Multi Band Excitation are some examples (IMBE).
The perceived quality of these coders degrades more for some speech segments when the bit rate is decreased, while remaining adequate for others. This demonstrates that the assumed coding theory is insufficient for all forms of expression. Hybrid coders, which combine different coding concepts to encode different types of speech segments, have been implemented to solve this issue.
A hybrid coder can choose from a number of different coding modes. As a result, they're also known as multimode coders. A hybrid coder is an adaptive coder that can adjust the coding technique or mode based on the source, choosing the best mode for the speech signal's local character. By adjusting the modes and bit rate, as well as modifying the relative bit allocation of the source and channel coding, a coder may adjust to network load or channel error output.
Q9) What are the stages of speech production?
Ans: Humans produce speech on a daily basis. People are social creatures and are always talking to one another. Whether it is through social media, live conversation, texting, chat, or otherwise, we are always producing some form of speech. We produce this speech without thought.
That is, without the thought of how we produce it. Of course, we think about what we are going to say and how to say it so that the other people will listen but we don’t think about what it is made of and how our mind and body actually product speech.
Stage 1 – Conceptualization
The first one is called the Conceptualization Stage. This is when a speaker spontaneously thinks of what he or she is going to say. It is an immediate reaction to external stimuli and is often based on prior knowledge of the particular subject. No premeditation goes into these words and they are all formulated based upon the speaker’s knowledge and experience at hand. It is spontaneous speech. Examples of this can range from answering questions to the immediate verbiage produced as a result of stubbing your toe.
Stage 2 – Formulation
The second stage is called the Formulation Stage. This is when the speaker thinks of the particular words that are going to express their thoughts. It occurs almost simultaneously with the conceptualization stage. However, this time the speaker thinks about the response before responding. The speaker is formulating his or her words and deciding how best to reply to the external stimuli. Where conceptualization is more of an instant and immediate response, formulation is a little delayed.
Stage 3 – Articulation
The third stage is the Articulation Stage. This is when the speaker physically says what he or she has thought of saying. This is a prepared speech or planned wordage. In addition, the words may have been rehearsed such as when someone practices a presentation or rehearses a lie.
It involves the training of physical actions of several motor speech organs such as the lungs, larynx, tongue, lips, and other vocal apparatuses. Of course, the first two stages also involve these organs, however, the articulation stage uses these organs multiple times for the same word patterns.
Stage 4 – Self-Monitoring
The fourth stage is called the Self-Monitoring Stage. This is when the speaker reflects on what he or she has said and makes an effort to correct any errors in his or her speech. Oftentimes this is done in a rebuttal or last words argument.
In addition, it could also be done during a conversation when the speaker realizes that he or she slipped up. This is the action of reflecting on what you said and making sure that what you said is what you meant.
Q10) What are the systems involved in speech production?
Ans: The Systems Involved in Speech Production
In order to spot signs of deceit, the CVSA uses speech analysis. To understand the science of CVSA technology, law enforcement practitioners must first understand how these technologies operate.
There are four major body systems involved in human speech development. Physical manifestations of speech are controlled by the respiratory, laryngeal, and articulatory systems, which are all regulated by the nervous system on both conscious and unconscious levels.
The Respiratory System and Airflow
The respiratory system is responsible for the movement of air in and out of the body, including the absorption of oxygen and the exhalation of carbon dioxide, at its most basic level. Speech processing will be difficult without air supply into the respiratory system. The lungs and diaphragm are two important components of the respiratory system. The lungs remove the air used to generate voice, while the diaphragm contractions dictate the vocal sound's power—which is why actors and singers are continually reminded to project from their diaphragm.
The Laryngeal System and Phonation
The larynx is the most important structure in the laryngeal system, and it is protected by the hyoid bone and cartilage in the region. The larynx is responsible for phonation, or the development of sound, among other things. Phonation is influenced by the laryngeal system's musculature, which includes the vocalis muscle, extrinsic muscles, and supplementary muscles. The nature of the sound waves created when a person speaks is influenced by the movements of these muscles.
Zooming in on the Articulatory System
When a person speaks, the articulatory system is in control of the nuances of speech sounds. The dimensions and anatomical features of the mouth-nostril area, which include the cavities, muscles, bones, and teeth, enable humans to create complex speech sounds. The synchronized gestures of these features are referred to as articulation.
The vocal tract is made up of the cavities of the articulatory system. The vocal tract is divided into three cavities:
● The nasal cavity, which is the space between the top of the skull and the upper jaw.
● The oral cavity, which is the space between the upper jaw and the lower jaw.
● The pharyngeal cavity, which is the space in the back of the throat.
In addition to these cavities, the articulatory system's structures, known collectively as the articulators, are critical for speech development. The fixed articulators and the movable articulators are two types of these structures.
The fixed articulators, as their name implies, are anatomical structures that are fixed in place, such as the incisors, hard palate, and alveolar ridge. Although sound waves communicate with these structures, the physical qualities of the sound waves that are actually generated are unaffected.
The movable articulators, on the other hand, are versatile and can alter in ways that affect the physical properties of sound waves. Lips, tongue, pharynx, soft palate, and mandible are some of the movable articulators. Finally, as air passes through the cavities of the vocal tract, the interactions between these structures and the fixed articulators form the distinct qualities of the sound waves that manifest as human expression. CVSA technology can then capture these sound waves in visual form.
The Role of the Nervous System
The respiratory, laryngeal, and articulatory systems all work together to make complex speech sounds, and the nervous system is in charge of managing their activities. The central nervous system, which regulates conscious processes, is in control of certain aspects. You can actively shift your lips to make various vowel and consonant sounds, for example.
The autonomic nervous system, which regulates unconscious body functions including heartbeat and digestion, is also active at the same time. Physiological tremor, which refers to muscle oscillations associated with the respiratory, laryngeal, and articulatory systems, is also affected.
Putting It All Together: What CVSA Technology Detects
The sound waves generated by a person taking a CVSA exam are captured by the technology. The waves are depicted visually in an easy-to-read map that can then be evaluated for stress-related changes. The physical manifestations of the complex interactions of air movement through the respiratory, laryngeal, and articulatory systems are the final waves produced. When a person's physiological tremor changes the basic properties of sound waves, it's a sign that he or she is stressed.
CVSA technology works as a truth testing tool because it can detect deception-related changes in a person's speech sound waves. It is focused on the physiology of human communication. CVSA has already shown its efficacy in the field, and as more law enforcement practitioners become aware of the research behind this innovation, it can only gain in popularity.




