UNIT 1
Q1 Explain Database system architecture?
Answer 1
The ANSI/SPARC Architecture
A DBMS can be considered as a buffer between application programs, end users and a database designed to fulfill features of data independence. In 1975 the American National Standards Institute Standards Planning and Requirements Committee (ANSI-SPARC) proposed three-level architecture identified three levels of abstraction. These levels are sometimes referred to as schemas or views.
- The External or User Level:
- This level describes the user’s or application program’s view of the database. Several programs or users may share the same view.
- End-users operate on this tier and they know nothing about any existence of the database beyond this layer.
- At this layer, multiple views of the database can be provided by the application.
- At the external level, a database contains several schemas that sometimes called as subschema. The subschema is used to describe the different view of the database.
- An external schema is also known as view schema.
- All views are generated by applications that reside in the application tier.
- Each view schema describes the database part that a particular user group is interested and hides the remaining database from that user group.
- The view schema describes the end user interaction with database systems.
2. The Conceptual Level:
- This level describes the organization’s view of all the data in the database, the relationships between the data and the constraints applicable to the database. This level describes a logical view of the database i.e. a view locking implementation detail.
- The conceptual schema describes the design of a database at the conceptual level. Conceptual level is also known as logical level.
- The conceptual schema describes the structure of the whole database.
- The conceptual level describes what data are to be stored in the database and also describes what relationship exists among those data.
- In the conceptual level, internal details such as an implementation of the data structure are hidden.
- Programmers and database administrators work at this level.
3. The Internal or Physical Level:
- The internal level has an internal schema which describes the physical storage structure of the database.
- The internal schema is also known as a physical schema.
- It uses the physical data model.
- It is used to define that how the data will be stored in a block.
- This level describes the way in which data is stored and the way in which data may be accessed.
- At this tier, the database resides along with its query processing languages. We also have the relations that define the data and their constraints at this level.
- The physical level is used to describe complex low-level data structures in detail.
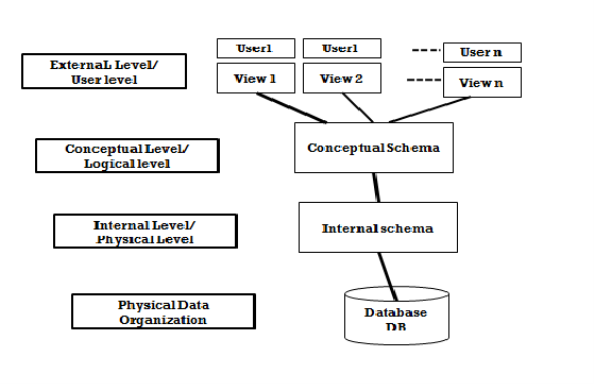
Figure: ANSI/SPARC Architecture of DBMS
Q2 What is data abstraction and data independence?
Answer 2
Data abstraction
- For the system to be usable, it must retrieve data efficiently. The need for efficiency has led designers to use complex data structures to represent data in the database.
- When the DBMS hides certain details of how data is stored and maintained, it provides what is called as the abstract view of data.
- This is to simplify user-interaction with the system.
- Complexity (of data and data structure) is hidden from users through several levels of abstraction.
- Data abstraction is used for following purposes:
- To provide abstract view of data.
- To hide complexity from user.
- To simplify user interaction with DBMS.
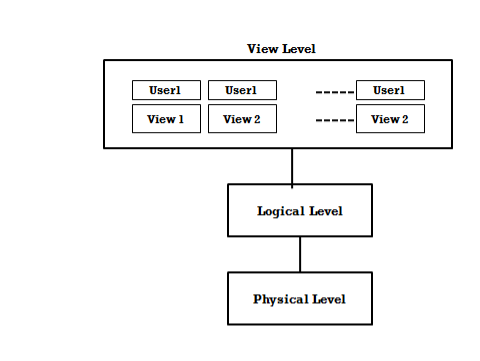
Levels of data abstraction
There are three levels of data abstraction.
- Physical level
- Logical level
- View level
- Physical level: It describes how a record (e.g., customer) is stored.
Features:
- Lowest level of abstraction.
- It describes how data are actually stored.
- It describes low-level complex data structures in detail.
- At this level, efficient algorithms to access data are defined.
2. Logical level: It describes what data stored in database, and the relationships among the data.
Features:
- It is next-higher level of abstraction. Here whole Database is divided into small simple structures.
- Users at this level need not be aware of the physical-level complexity used to implement the simple structures.
- Here the aim is ease of use.
- Generally, database administrators (DBAs) work at logical level of abstraction.
3. View level: Application programs hide details of data types. Views can also hide information (e.g., salary) for security purposes.
Features:
- It is the highest level of abstraction.
- It describes only a part of the whole Database for particular group of users.
- This view hides all complexity.
- It exists only to simplify user interaction with system.
- The system may provide many views for the whole system.
Data Independence:-
Definition -Data independence is the ability to modify a schema definition in one level without affecting a schema definition in a higher level is called data independence.
- Metadata itself follows a layered architecture, so that when we change data at one layer, it does not affect the data at another level.
- This data is independent but mapped to each other.
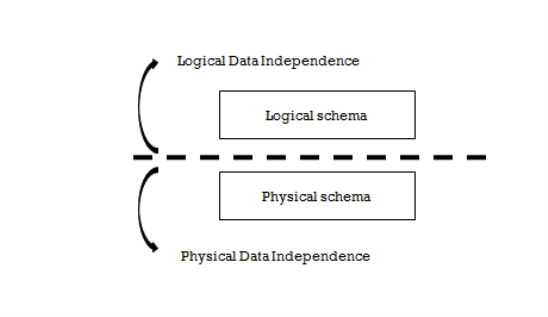
Figure: - Data Independence
There are two types of ‘data independence’:
- Physical data independence
- It is the ability to modify the physical scheme without causing application programs to be rewritten.
- Modifications at this level are usually to improve performance.
- All the schemas are logical, and the actual data is stored in bit format on the disk. Physical data independence is the power to change the physical data without impacting the schema or logical data.
- For example, in case we want to change or upgrade the storage system itself − suppose we want to replace hard-disks with SSD − it should not have any impact on the logical data or schemas.
2. Logical data independence
- It is the ability to modify the conceptual scheme without causing application programs to be rewritten.
- Logical data is data about database, that is, it stores information about how data is managed inside.
- It is usually done when logical structure of database is altered.
- Logical data independence is harder to achieve as the application programs are usually heavily dependent on the logical structure of the data.
- An analogy is made to abstract data types in programming languages.
- Logical data independence is a kind of mechanism, which liberalizes itself from actual data stored on the disk.
If we do some changes on table format, it should not change the data residing on the disk.
Q3 Explain database languages DDL and DML?
Answer 3
Database languages:-
We have Data Definition Languages (DDL) to specify database schemas and Data Manipulation Language (DML) to express database updates and queries.
In practice, these are not to separate languages but are part of a single database language, like SQL.
- Data Definition Languages (DDL) it is the language that is used to specify database schemas by a set of definitions contained in it.
- Data Manipulation Language (DML) it is a language for accessing and manipulating the data organized by the appropriate data model.
Data Definition Language
- DDL stands for Data Definition Language. It is used to define database structure or pattern.
- It is used to create schema, tables, indexes, constraints, etc. in the database.
- Using the DDL statements, you can create the skeleton of the database.
- Data definition language is used to store the information of metadata like the number of tables and schemas, their names, indexes, columns in each table, constraints, etc.
- Used by the DBA and database designers to specify the conceptual schema of a database.
- In many DBMSs, the DDL is also used to define internal and external schemas (views).
Tasks associated with DDL:-
- Create: It is used to create objects in the database.
- Alter: It is used to alter the structure of the database.
- Drop: It is used to delete objects from the database.
- Truncate: It is used to remove all records from a table.
- Rename: It is used to rename an object.
- Comment: It is used to comment on the data dictionary.
Features of DDL:-
- Used to specify a database schema as a set of definitions expressed in a DDL
- DDL statements are compiled, resulting in a set of tables stored in a special file called a data dictionary or data directory.
- The data directory contains metadata (data about data).
- The storage structure and access methods used by the database system are specified by a set of definitions in a special type of DDL called a data storage and definition language.
- Basic idea of DDL: To hide implementation details of the database schemes from the users.
Data Manipulation Language
DML is also known as query language.
- There are two types of DML
- Procedural DMLs
- Declarative DMLs (non-procedural DMLs)
- Procedural DMLs - This language requires user to specify what data is required and how to get those data.
2. Declarative DMLs (non-procedural DMLs) - This language requires user to specify what data is required without specifying how to get those data.
Tasks associated with DML:
- Select: It is used to retrieve data from a database.
- Insert: It is used to insert data into a table.
- Update: It is used to update existing data within a table.
- Delete: It is used to delete all records from a table.
- Merge: It performs UPSERT operation, i.e., insert or update operations.
- Call: It is used to call a structured query language or a Java subprogram.
- Explain Plan: It has the parameter of explaining data.
- Lock Table: It controls concurrency.
Features of DML:-
- A DML is a language which enables users to access and manipulate data.
- The goal is to provide efficient human interaction with the system.
- There are two types of DMLs.
- Procedural: Here user specifies what data is needed and how to get it.
- Non-procedural: Here user only specifies what data is needed.
- Easier for user.
- May not generate code as efficient as that produced by procedural languages.
Q4 Explain data models?
Answer 4
Data Models:-
- Data Model is the modeling of the data description, data semantics, and consistency constraints of the data. It provides the conceptual tools for describing the design of a database at each level of data abstraction. Therefore, there are following four data models used for understanding the structure of the database.
- A data model is collection of tools for describing
1. Data
2. Data Relationships
3. Data Semantics
4. Data Constraints
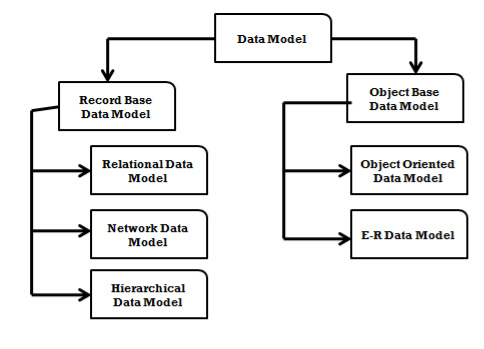
Figure: - Data Models
- Relational Data Model:
- This type of model designs the data in the form of rows and columns within a table.
- Thus, a relational model uses tables for representing data and in-between relationships.
- Tables are also called relations. This model was initially described by Edgar F. Codd, in 1969. The relational data model is the widely used model which is primarily used by commercial data processing applications.
- Network Data Model (Semi-structured Data Model):-
- This type of data model is different from the other three data models (explained above).
- The semi-structured data model allows the data specifications at places where the individual data items of the same type may have different attributes sets.
- The Extensible Markup Language, also known as XML, is widely used for representing the semi-structured data. Although XML was initially designed for including the markup information to the text document, it gains importance because of its application in the exchange of data.
3. Hierarchical Model:-
- In the hierarchical model, data are represented by collections of records.
- Relationships among data are represented by links. 3. In this model Tree data structure is used. There are two concepts associated with the hierarchical model – segment types and parent-child relationships. Segment type is similar to the record types in the network models.
- The information retrieved only by navigating from the root segment type to the nodes segment types.
- Thus you can access a segment type only via its parent segment type in the parent-child relationship.
- The operators provided for manipulating such structures include operators for traversing hierarchic paths up and down the trees.
4. Object-based Data Model:-
- An extension of the ER model with notions of functions, encapsulation, and object identity, as well.
- This model supports a rich type system that includes structured and collection types.
- Thus, in 1980s, various database systems following the object-oriented approach were developed. Here, the objects are nothing but the data carrying its properties.
5. Entity-Relationship Data Model:
- An ER model is the logical representation of data as objects and relationships among them.
- These objects are known as entities, and relationship is an association among these entities. This model was designed by Peter Chen and published in 1976 papers
- It was widely used in database designing. A set of attributes describe the entities. For example, student_name, student_id describes the 'student' entity.
- A set of the same type of entities is known as an 'Entity set', and the set of the same type of relationships is known as 'relationship set'.
Q5 Explain relational data models?
Answer 5
Relational Data Model:-
1. The relational model uses tables to represent the data and the relationships among those data.
2. Each table has multiple columns, and each column is identified by a unique name.
3. It is a low level model.
Name | Street | City | Number |
John | North | Brooklyn | 878 |
White | South | Queens | 654 |
Jacob | Wales | London | 900 |
Hobbs | North | Queens | 145 |
Shaw | SideHill | Bronx | 286 |
Number | Balance |
900 | 4423 |
654 | 1245 |
145 | 776456 |
286 | 987 |
878 | 10000 |
In this database, each row in the table represents a different customer. Relationships link rows from two tables on the basis of the key field, in this case – number.
Advantages of Relational Data Model
- Structural Independence – Relational database model has structural independence, i.e. changes made in the database structure do not affect the DBMS’s capability to access data.
- Simplicity – The relational model is the simplest model at the conceptual level. It allows the designer to concentrate on the logical view of the database, leaving the physical data storage details.
- Ease of designing, implementation, maintenance, and usage – Due to the inherent features of data independence and structural independence, and the relational model makes it easy to design, implement, maintain and use the databases.
- Adhoc query capability – One of the main reasons for the huge popularity of the relational database model is the presence of powerful, flexible and easy-to-use query capability. The query language of the relational database model Structure Query Language or SQL – is a fourth generation language (4GL). A 4GL concentrates on the ‘what’ and not on the ‘how’ of the problem. Selective output can be achieved by giving a simple query. The relational database translates the user queries into the code required to extract the desired information.
Disadvantages of Relational Data Model
- Hardware overheads – The RDBMS needs comparatively powerful hardware as it hides the implementation complexities and the physical data storage details from the users.
- Ease of design can result in bad design – As the relational database is an easy-to-design and use system, it can result in the development and implementation of poorly designed database management systems. As the size of the database increases, several problems may creep in – system shutdown, performance degradation and data corruption.
Q6 Explain database and its functions?
Answer 6
Data - Data is meaningful known raw facts that can be processed and stored as information.
Database - Database is a collection of interrelated and organized data
DBMS - Database Management System (DBMS) is a collection of interrelated data [usually called database] and a set of programs to access, update and manage those data [which form part of management system].
- It is a software package to facilitate creation and maintenance of computerized database. It is general purpose software that facilitates the following:
- Defining: Specifying data types and structures, and constraints for data to be stored.
- Constructing: Storing data in a storage medium.
- Manipulating: Involves querying, updating and generating reports.
- Sharing: Allowing multiple users and programs to access data simultaneously.
Primary goals of DBMS are:
- To provide a way to store and retrieve database information that is both convenient and efficient.
- To manage large and small bodies of information. It involves defining structures for storage of information and providing mechanism for manipulation of information.
- It should ensure safety of information stored, despite system crashes or attempts at unauthorized access.
- If data are to be shared among several users, then system should avoid possible anomalous results.
Example of DBMS applications
- Banking – For customer information, accounts, and loans, and banking transactions. [all transactions]
- Airlines – For reservation and schedule information. [reservations, schedules]
- Universities – For student information, course registrations, and grades. [registration, grades]
- Credit Card Transactions – For purchases on credit card and generation of monthly statements.
- Telecommunication – For keeping records of calls made, generating monthly bills, maintaining balances on prepaid calling cards, and storing information about communication networks.
- Finance – For storing information about holdings, sales, and purchases of financial instruments such as stocks and bonds.
- Sales – For customer, product, and purchase information. [customers, products, purchases]
- Manufacturing – For management of supply chain and for tracking production of items in factories, inventories of items in warehouses/stores, and orders for items. [production, inventory, orders, supply chain]
- Human Resources – For information about employees, salaries, payroll taxes and benefits, and generation of paychecks. [employee records, salaries, tax deductions]
Functions of a DBMS
The functions performed by a typical DBMS are the following:
- Data Definition - The DBMS provides functions to define the structure of the data in the application. These include defining and modifying the record structure, the type and size of fields and the various constraints/conditions to be satisfied by the data in each field.
- Data Manipulation - Once the data structure is defined, data needs to be inserted, modified or deleted. The functions which perform these operations are also part of the DBMS. These function can handle planned and unplanned data manipulation needs. Planned queries are those which form part of the application. Unplanned queries are ad-hoc queries which are performed on a need basis.
- Data Security & Integrity - The DBMS contains functions which handle the security and integrity of data in the application. These can be easily invoked by the application and hence the application programmer need not code these functions in his/her programs.
- Data Recovery & Concurrency - Recovery of data after a system failure and concurrent access of records by multiple users are also handled by the DBMS.
- Data Dictionary Maintenance - Maintaining the Data Dictionary which contains the data definition of the application is also one of the functions of a DBMS.
- Performance - Optimizing the performance of the queries is one of the important functions of a DBMS. Hence the DBMS has a set of programs forming the Query Optimizer which evaluates the different implementations of a query and chooses the best among them.
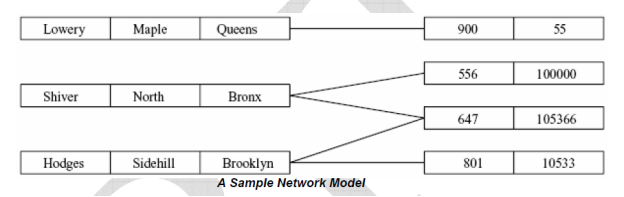
Q7 Explain network data model?
Answer 7
Network Data Model –
- In the network model, data are represented by collections of records.
2. Relationships among data are represented by links.
3. In this model Graph data structure is used.
4. A network model permits a record to have more than one parent
Advantages of Network Data Model
- Simplicity – The network data model is also conceptually simple and easy to design.
- Ability to handle more relationship types – The network model can handle the one-to-many and many-to-many relationships.
- Ease of data access – In the network database terminology, a relationship is a set. Each set comprises of two types of records – an owner record and a member record. In a network model an application can access an owner record and all the member records within a set.
- Data Integrity – In a network model, no member can exist without an owner. A user must therefore first define the owner record and then the member record. This ensures the data integrity.
- Data Independence – The network model draws a clear line of demarcation between the programs and the complex physical storage details. The application programs work independently of the data.Any changes made in the data characteristics do not affect the application program.
- Database standards – The standards devised by the DBTG (Database Task Group of CODASYL Committee) form the basis of the network model. These standards were further enhanced by ANSI/SPARC (American National Standards Institute/Standards Planning and Requirements Committee) in the 1970s. All the network database management systems adhere to these standards. These standards comprise of a DDL and a DML that augments the database administration and portability.
Disadvantages of Network Data Model
- System complexity – In a network model, data are accessed one record at a time. This makes it essential for the database designers, administrators, and programmers to be familiar with the internal data structures to gain access to the data. Therefore, a user-friendly database management system cannot be created using the network model.
- Lack of structural independence – Making structural modifications to the database is very difficult in the network database model as the data access method is navigational. Any changes made to the database structure require the application programs to be modified before they can access data. Though the network database model achieves data independence, it still fails to achieve structural independence.
Q8 Explain object oriented data model and its advantages?
Answer 8
Object Oriented Model –
- The object-oriented model is based on a collection of objects, like the E-R model.
- An object contains values stored in instance variables within the object.
- Unlike the record-oriented models, these values are themselves objects.
- Thus objects contain objects to an arbitrarily deep level of nesting.
- An object also contains bodies of code that operate on the object. These bodies of code are called methods.
- Objects that contain the same types of values and the same methods are grouped into classes.
- A class may be viewed as a type definition for objects.
- Analogy: the programming language concept of an abstract data type.
- The only way in which one object can access the data of another object is by invoking the method of that other object. This is called sending a message to the object.
- Internal parts of the object, the instance variables and method code, are not visible externally.
- Result is two levels of data abstraction.
- For example, consider an object representing a bank account.
- The object contains instance variables number and balance.
- The object contains a method pay-interest which adds interest to the balance.
- Under most data models, changing the interest rate entails changing code in application programs.
- In the object-oriented model, this only entails a change within the pay-interest method.]
- Unlike entities in the E-R model, each object has its own unique identity, independent of the values it contains:
- Two objects containing the same values are distinct.
- Distinction is maintained in physical level by assigning distinct object identifiers.
Advantages of Object Oriented Data Model
- Capability to handle large number of different data types – Traditional database models like hierarchical, network and relational database are limited in their capability to store the different types of data.
- For e.g., one cannot store pictures, voices and video in these databases. But the object-oriented database can store any type of data including text, numbers, pictures, voice and video.
- Combination of object-oriented programming and database technology – Perhaps the most significant characteristic of object-oriented database technology is that it combines object-oriented programming with database technology to provide an integrated application development system.
- Object-oriented features improve productivity – Inheritance allows one to develop solutions to complex problems incrementally by defining new objects in terms of previously defined objects.
- Polymorphism and dynamic binding allow one to define operations for one object and then to share the specification of the operation with other objects. These objects can further extend this operation to provide behaviors that are unique to those objects.
- Dynamic binding determines at runtime, which of these operations is actually executed, depending on the class of the object requested to perform the operation.
- Polymorphism and dynamic binding are powerful object-oriented features that allow one to compose objects to provide solutions without having to write code that is specific to each object. All of these capabilities come together to provide significant productivity advantages to database application developers.
- Data access – Object-oriented database represent relationships explicitly, supporting both navigational and associative access to information. As the complexity of interrelationships between information within the database increases, the greater the advantages of representing relationships explicitly.
- Another benefit of using explicit relationships is the improvement in data access performance over relational value-based relationships.
Disadvantages of Object Oriented Data Model
- Difficult to maintain – In the real world, the data model is not static. It changes as organizational information needs change and as missing information is identified. Consequently, the definition of objects must be changed periodically and existing databases migrated to conform to the new object definitions.
- Object-oriented databases are semantically rich introducing a number of challenges when changing object definitions and migrating databases. Object-oriented databases have a greater challenge handling schema migration because it is not sufficient to simply migrate the data representation to conform to the changes in class specifications. One must also update the behavioral code associated with each object.
- Not suited for all applications – Object-oriented database systems are not suited for all applications.
- If it is used in situations where it is not required, then it will result in performance degradation and high processing requirements.
- OODBMS is popular in area such as e-commerce, engineering product data management, and special purpose databases in securities and medicine. The strength of the object model is in applications where there is an underlying needed to manage complex relationships among data objects.
Q9 What are integrity constrains and types of integrity constraints.
Answer9
Integrity Constraints
- Integrity constraints are a set of rules. It is used to maintain the quality of information.
- Integrity constraints ensure that the data insertion, updating, and other processes have to be performed in such a way that data integrity is not affected.
- Thus, integrity constraint is used to guard against accidental damage to the database.
Constraints
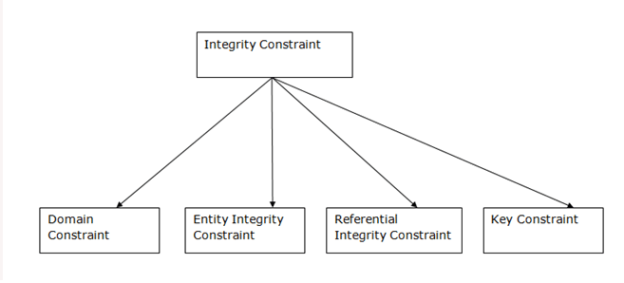
Every relation has some conditions that must hold for it to be a valid relation. These conditions are called Relational Integrity Constraints.
There are four main integrity constraints −
- Domain Constraints
- Entity Integrity Constraint
- Referential Integrity constraints
- Key constraints
1. Domain constraints
- Domain constraints can be defined as the definition of a valid set of values for an attribute.
- The data type of domain includes string, character, integer, time, date, currency, etc. The value of the attribute must be available in the corresponding domain.
- Attributes have specific values in real-world scenario. For example, age can only be a positive integer. The same constraints have been tried to employ on the attributes of a relation.
- Every attribute is bound to have a specific range of values. For example, age cannot be less than zero and telephone numbers cannot contain a digit outside 0-9.
Student_Id | Student_Name | Semester | Age |
2020 | Mark | 4 | 21 |
2021 | Roy | 5 | 22 |
2022 | Carl | 7 | 21 |
2023 | Billy | 3 | 23 |
2024 | Carry | 2 |
|

Not allowed because age is integer attribute
2. Entity integrity constraints
- The entity integrity constraint states that primary key value can't be null.
- This is because the primary key value is used to identify individual rows in relation and if the primary key has a null value, then we can't identify those rows.
- A table can contain a null value other than the primary key field.
Student_Id | Student_Name | Age |
2027 | Nortan | 19 |
2020 | Mark | 21 |
2025 | Hella | 20 |
| Bob | 22 |
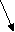
Not possible primary key can’t contain null values
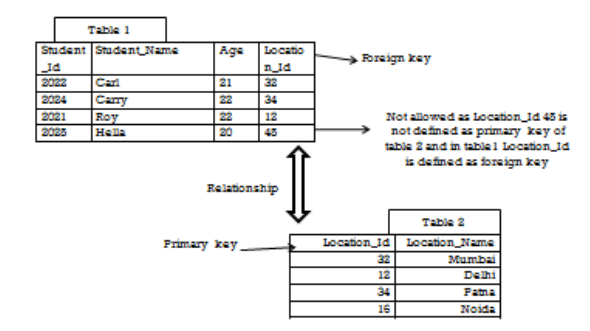
3. Referential Integrity Constraints
A referential integrity constraint is specified between two tables.
In the Referential integrity constraints, if a foreign key in Table 1 refers to the Primary Key of Table 2, then every value of the Foreign Key in Table 1 must be null or be available in Table 2.
Referential integrity constraints work on the concept of Foreign Keys. A foreign key is a key attribute of a relation that can be referred in other relation.
Referential integrity constraint states that if a relation refers to a key attribute of a different or same relation, then that key element must exist.
4. Key constraints
- Keys are the entity set that is used to identify an entity within its entity set uniquely.
- An entity set can have multiple keys, but out of which one key will be the primary key. A primary key can contain a unique and null value in the relational table.
- There must be at least one minimal subset of attributes in the relation, which can identify a tuple uniquely.
- This minimal subset of attributes is called key for that relation.
- If there are more than one such minimal subsets, these are called candidate keys.
- Key constraints force that –in a relation with a key attribute, no two tuples can have identical values for key attributes.
- A key attribute cannot have NULL values.
- Key constraints are also referred to as Entity Constraints.
Student_Id | Student_Name | Semester | Age |
2021 | Roy | 5 | 22 |
2022 | Carl | 7 | 21 |
2024 | Carry | 2 | 22 |
| Mona | 2 | 23 |

Not allowed all row must be unique
Q10 What are data manipulations operations?
Answer 10
Data Manipulation Operations
Data manipulation operations are performed on text based data types. Range manipulation operations may include but are not limited to – concatenation, trim, chop, search and replace, length. A minimum of four manipulations are performed on any text based data types.
Data Manipulation Commands in DBMS
- Select. Select statement retrieves the data from database according to the constraints specifies alongside. ...
- Insert. Insert statement is used to insert data into database tables.
- Update. The update command updates existing data within a table.
- Delete.
- Merge.
Data Manipulation
- Data manipulation refers to the process of adjusting data to make it organized and easier to read.
- Data manipulation language, or DML, is a programming language that adjusts data by inserting, deleting and modifying data in a database such as to cleanse or map the data.
- At the physical level, a customer, account, or employee record can be described as a block of consecutive storage locations (for example, words or bytes).
The language compiler hides this level of detail from programmers. Similarly, the database system hides many of the lowest-level storage details from database programmers.
- Database administrators, on the other hand, may be aware of certain details of the physical organization of the data.
- At the logical level, each such record is described by a type definition, as in the previous code segment, and the interrelationship of these record types is defined as well.
- Programmers using a programming language work at this level of abstraction. Similarly, database administrators usually work at this level of abstraction.
- Finally, at the view level, computer users see a set of application programs that hide details of the data types. Similarly, at the view level, several views of the database are defined, and database users see these views.
- In addition to hiding details of the logical level of the database, the views also provide a security mechanism to prevent users from accessing certain parts of the database.
- For example, tellers in a bank see only that part of the database that has information on customer accounts; they cannot access information about salaries of employees.




