UNIT 2
Q1 Explain relational algebra operations?
Answer1
Relational algebra
Relational Algebra works on the whole table at once, so we do not have to use loops etc to iterate over all the rows (tuples) of data one by one. All we have to do is specify the table name from which we need the data, and in a single line of command, relational algebra will traverse the entire given table to fetch data for you.
The primary operations that we can perform using relational algebra are:
- Select
- Project
- Union
- Set Different
- Cartesian product
- Rename
1. Select Operation (σ)
This is used to fetch rows (tuples) from table (relation) which satisfies a given condition.
Syntax: σp(r)
Where, σ represents the Select Predicate, r is the name of relation (table name in which you want to look for data), and p is the prepositional logic, where we specify the conditions that must be satisfied by the data. In prepositional logic, one can use unary and binary operators like =, <, > etc, to specify the conditions.
Let's take an example of the Student table we specified above in the Introduction of relational algebra, and fetch data for students with age more than 17.
σage > 17 (Student)
This will fetch the tuples (rows) from table Student, for which age will be greater than 17.
You can also use, and, or etc operators, to specify two conditions, for example,
σage > 17 and gender = 'Male' (Student)
This will return tuples (rows) from table Student with information of male students, of age more than 17.(Consider the Student table has an attribute Gender too.)
2. Project Operation (∏)
Project operation is used to project only a certain set of attributes of a relation. In simple words, If you want to see only the names all of the students in the Student table, then you can use Project Operation.
It will only project or show the columns or attributes asked for, and will also remove duplicate data from the columns.
Syntax: ∏A1, A2...(r)
Where A1, A2 etc are attribute names(column names).
For example,
∏Name, Age(Student)
Above statement will show us only the Name and Age columns for all the rows of data in Student table.
3. Union Operation (∪)
This operation is used to fetch data from two relations (tables) or temporary relation (result of another operation).
For this operation to work, the relations (tables) specified should have same number of attributes (columns) and same attribute domain. Also the duplicate tuples are automatically eliminated from the result.
Syntax: A ∪ B
Where A and B are relations.
For example, if we have two tables RegularClass and ExtraClass, both have a column student to save name of student, then,
∏Student(RegularClass) ∪ ∏Student(ExtraClass)
Above operation will give us name of Students who are attending both regular classes and extra classes, eliminating repetition
- RUS means, a union operation on R and S that will produce another table which will have all the rows of R and S except the duplicates.
- There are 2 Sally in R and S, so, just take 1 from them.
R S
First | Last | Age |
Bill | Smith | 22 |
Sally | Green | 28 |
Mary | Keen | 23 |
Tony | Jones | 32 |
First | Last | Age |
Forest | Gump | 36 |
Sally | Green | 28 |
Don | Marco | 27 |
R U S
First | Last | Age |
Bill | Smith | 22 |
Sally | Green | 28 |
Mary | Keen | 23 |
Tony | Jones | 32 |
Forest | Gump | 36 |
Don | Marco | 27 |
4. Set Difference (-)
This operation is used to find data present in one relation and not present in the second relation. This operation is also applicable on two relations, just like Union operation.
Syntax: A - B
Where A and B are relations.
For example, if we want to find name of students who attend the regular class but not the extra class, then, we can use the below operation:
∏Student(RegularClass) - ∏Student(ExtraClass)
R-S
First | Last | Age |
Bill | Smith | 22 |
Mary | Keen | 23 |
Tony | Jones | 32 |
- R-S means, a difference operation on R and S that will produce another table which will have all the rows which is in R but not in S.
- As Sally is in R and in S, so, she has been omitted.
5. Cartesian product (X)
This is used to combine data from two different relations (tables) into one and fetch data from the combined relation.
Syntax: A X B
For example, if we want to find the information for Regular Class and Extra Class which are conducted during morning, then, we can use the following operation:
σtime = 'morning' (RegularClass X ExtraClass)
For the above query to work, both RegularClass and ExtraClass should have the attribute time.
R S
First | Last | Age |
Bill | Smith | 22 |
Mary | Keen | 23 |
Tony | Jones | 32 |
Dinner |
Dessert |
Steak | Ice-cream |
Lobster | Cake |
R X S
First | Last | Age | Dinner | Dessert |
Bill | Smith | 22 | Steak | Ice-cream |
Bill | Smith | 22 | Lobster | Cake |
Mary | Keen | 23 | Steak | Ice-cream |
Mary | Keen | 23 | Lobster | Cake |
Tony | Jones | 32 | Steak | Ice-cream |
Tony | Jones | 32 | Lobster | Cake |
6. Rename Operation (ρ)
This operation is used to rename the output relation for any query operation which returns result like Select, Project etc. Or to simply rename a relation (table)
Syntax: ρ(RelationNew, RelationOld)
Q2 Explain what is commercial database?
Answer2
Open source and Commercial DBMS
Open source databases store vital information in software which the organization can control. An open source database allows users to create a system based on their unique requirements and business needs. It is free and can also be shared. The source code can be modified to match any user preference.
Open source databases address the need to analyze data from a growing number of new applications at lower cost. The deluge of social media and the Internet of Things (IoT) has ushered an age of massive data that needs to be collected and analyzed. The data only has value if an enterprise can analyze it to find useful patterns or real-time insights. But the data contains vast amounts of information that can overload a traditional database. The flexibility and cost-effectiveness of open source database software has revolutionized database management systems.
The most common open source databases include:
- Key-value databases — Store key and value data in memory for speedy lookup.
- Document databases — Store document information.
- Wide-column store databases — Similar to key-value with a large number of columns. They are well suited for analyzing huge data sets.
MYSQL
- MySQL is the most popular Open Source Relational SQL Database Management System.
- MySQL is one of the best RDBMS being used for developing various web-based software applications.
- MySQL is developed, marketed and supported by MySQL AB, which is a Swedish company
- MySQL is an open-source relational database management system that works on many platforms. It provides multi-user access to support many storage engines and is backed by Oracle.
6 ORACLE
Oracle Database allows you to quickly and safely store and retrieve data. Here are the integration benefits of the Oracle Database:
- Oracle Database is cross-platform. It can run on various hardware across operating systems including Windows Server, Unix, and various distributions of GNU/Linux.
- Oracle Database has its networking stack that allows application from a different platform to communicate with the Oracle Database smoothly. For example, applications running on Windows can connect to the Oracle Database running on Unix.
- ACID-compliant – Oracle is ACID-compliant Database that helps maintain data integrity and reliability.
- Commitment to open technologies – Oracle is one of the first Database that supported GNU/Linux in the late 1990s before GNU/Linux become a commerce product. It has been supporting this open platform since then.
DB2
- DB2 is a database product from IBM. It is a Relational Database Management System (RDBMS). DB2 is designed to store, analyze and retrieve the data efficiently. DB2 product is extended with the support of Object-Oriented features and non-relational structures with XML.
- This operational database is designed to deliver high performance, actionable insights, data availability and reliability, and it is supported across Linux, Unix and Windows operating systems.
Q3 Explain sql and its operations?
Answer 3
Structured Query Language (SQL)
SQL is the core of a relational database which is used for accessing and managing the database. By using SQL, you can add, update or delete rows of data, retrieve subsets of information, modify databases and perform many actions. The different subsets of SQL are as follows:
- DDL (Data Definition Language) – It allows you to perform various operations on the database such as CREATE, ALTER and DELETE objects.
- DML (Data Manipulation Language) – It allows you to access and manipulate data. It helps you to insert, update, delete and retrieve data from the database.
- DCL (Data Control Language) – It allows you to control access to the database. Example – Grant or Revoke access permissions.
- TCL (Transaction Control Language) – It allows you to deal with the transaction of the database. Example – Commit, Rollback, Savepoint, Set Transaction.
DDl (Data Definition Language)
DDL is short name of Data Definition Language, which deals with database schemas and descriptions, of how the data should reside in the database. DDL statements are used to build and modify the structure of your tables and other objects in the database. When you execute a DDL statement, it takes effect immediately
- CREATE - to create a database and its objects like (table, index, views, store procedure, function, and triggers)
- ALTER - alters the structure of the existing database
- DROP - delete objects from the database
- TRUNCATE - remove all records from a table, including all spaces allocated for the records are removed
- COMMENT - add comments to the data dictionary
- RENAME - rename an object
1. CREATE
The create table statement does exactly that:
CREATE TABLE[Table Name]
(Col_name1 Datatype(size ( )[NULL/NOTNULL] ,
Col_name2 Datatype(size ( )[NULL/NOTNULL],
.
.
Col_nameN Datatype(size ( )[NULL/NOTNULL]
)
The data types that will use most frequently are character strings, which might be called VARCHAR or CHAR for variable or fixed length strings; numeric types such as NUMBER or INTEGER, which will usually specify a precision; and DATE or related types. Data type syntax is variable from system to system; the only way to be sure is to consult the documentation for your own software.
Example :-
CREATE TABLE Users
(user_id int NOTNULL ,
Name varchar(50) NOTNULL,
Dob date NOTNULL,
Age int NOTNULL
);
2. Alter
To add a new column to the existing table,
Alter table Add New Column
ALTER TABLE [Table_Name]
ADD [New_Column_Name] Data_Type (Length) NULL | NOT NULL
3. Drop to delete columns or table
Drop Table [table name];
To delete column ALTER TABLE [Table_Name] DROP COLUMN [Column_Name]
Example:- ALTER TABLE [users] DROP COLUMN [age]
Will delete the column age and its contents from table users
4. Truncate The Truncate Table statement removes all rows from the specified table, but the table structure, constraints, columns, indexes will remain the same.
TRUNCATE TABLE Database_Name.Schema_Name.Table_Name
5. Rename
In SQL, there is a stored procedure called SP_RENAME to rename Table name. In this example, we will rename the Customer table using this sp.
Rename table Name is: SP_RENAME '[Old Table Name]', '[New Table Name]';
DML(Data Manipulation Language)
DML is short name of Data Manipulation Language which deals with data manipulation and includes most common SQL statements such SELECT, INSERT, UPDATE, DELETE, etc., and it is used to store, modify, retrieve, delete and update data in a database.
- SELECT - retrieve data from a database
- INSERT - insert data into a table
- UPDATE - updates existing data within a table
- DELETE - Delete all records from a database table
- MERGE - UPSERT operation (insert or update)
- CALL - call a PL/SQL or Java subprogram
- EXPLAIN PLAN - interpretation of the data access path
- LOCK TABLE - concurrency Control
- Select:- this statement selects rows and table
Select* fromTable_name
Selects the every value from table
- Insert:- The insert statement is used, obviously, to add new rows to a table.
INSERT INTO <table name>
VALUES (<value 1>, ... <value n>);
You will need a separate INSERT statement for every row.
- Update:-The update statement is used to change values that are already in a table.
UPDATE <table name>
SET <attribute> = <expression>
WHERE <condition>;
The update expression can be a constant, any computed value, or even the result of a SELECT statement that returns a single row and a single column
- Delete:- statement does just that, for rows in a table.
DELETE FROM <table name>
WHERE <condition>;
- Commit:-f you are using a large multi-user system, you may need to make your DML changes visible to the rest of the users of the database. Although this might be done automatically when you log out, you could also just type:
COMMIT;
- Rollback:- If you’ve messed up your changes in this type of system, and want to restore your private copy of the database to the way it was before you started (this only works if you haven’t already typed COMMIT), just type:
ROLLBACK;
Q4 What is dependency preservations
Answer 4
Data dependency
Dependencies in DBMS is a relation between two or more attributes. It has the following types in DBMS −
- Functional Dependency
- Fully-Functional Dependency
- Transitive Dependency
- Multivalued Dependency
- Partial Dependency
Let us start with Functional Dependency −
Functional Dependency
If the information stored in a table can uniquely determine another information in the same table, then it is called Functional Dependency. Consider it as an association between two attributes of the same relation.
Fully-functionally Dependency
An attribute is fully functional dependent on another attribute, if it is Functionally Dependent on that attribute and not on any of its proper subset.
A functional dependency”X →Y” is said to be full FD if and only if removal of attributes from ‘X’ makes “X→Y” invalid
For example, an attribute Q is fully functional dependent on another attribute P, if it is Functionally Dependent on P and not on any of the proper subset of P.
Eg:- consider relation R(ABCD)
FD={AB→C, B→D}
Sol-AB+={ABCD}
B+={BD}
Transitive Dependency
If there is a relation among non-key attributes then it is called transitive dependency.
Another possible condition where table not have a transitive dependency-
Table has 2 attribute only
All the attribute are part of the primary key
When an indirect relationship causes functional dependency it is called Transitive Dependency.
If P -> Q and Q -> R is true, then P-> R is a transitive dependency.
Eg:- consider relation R(ABC)
FD={A→BC, B→D}
Sol-A+={ABC}
B+={BC}
Multivalued Dependency
When existence of one or more rows in a table implies one or more other rows in the same table, then the Multi-valued dependencies occur.
If a table has attributes P, Q and R, then Q and R are multi-valued facts of P.
Instead, they require that other tuples of a certain form be present in the relation.
Let R be a relation schema, and let α is a subset of R and β is a subset of R.
The multivalued dependency
α ->> β
Partial Dependency
Partial Dependency occurs when a nonprime attribute is functionally dependent on part of a candidate key.
All non-key attributes should totally depend on key attribute else it is leading to partial dependency
Relation R(ABCD)
FD={AB C, B D}
FD={AB}
Key attribute={AB
Non key attribute={CD}}
Q5 What is normal form and the types of normal forms
Answer 5
Normal forms
- The data in the database can be considered to be in one of a number of ‘normal forms’.
- Basically the normal form of the data indicates how much redundancy is in that data. The normal forms have a strict ordering.
a) 1NF
b) 2NF
c) 3NF
d) BCNF
First Normal Form (1NF)
- We say a relation is in 1NF if all values stored in the relation are single valued and atomic.
- 1NF places restrictions on the structure of relations. Values must be simple.
- 1NF disallows repeating values, set of values, relations within relations, nested relations.
- 1NF deals with the ‘shape’ of the record.
- To remove the repeating group, either:
- Flatten the table and extend the key, or
- Decompose the relation leading to 1NF.
Second Normal Form (2NF):
- Second normal form (2NF) is based on the concept of full functional dependency.
- A relation schema R is in 2NF if it is in 1NF, and every nonprime attribute is fully functionally dependent on each candidate key of R.
- General Def. Of 2NF – A relation schema R is in 2NF if every nonprime attribute A in R is not partially dependent on any key of R.
- A relation is 2NF will not have any partial dependencies.
- If a relation schema is not in 2NF, it can be “second normalized” or “2NF normalized” into a number of 2NF relations in which nonprime attributes are associated only with the part of the primary key on which they are fully functionally dependent.
Third Normal Form (3NF)
1) Third normal form (3NF) is based on the concept of transitive dependency.
2) A relation schema R is in 3NF if it is in 2NF and no nonprime attribute of R is transitively dependent on the primary key.
3) General Def. Of 3NF – A relation schema R is in third normal form (3NF) if, whenever a nontrivial functional dependency X_A holds in R, either
- X is a super key of R, or
- A is a prime attribute of R.
Boyce-CODD Normal Form (BCNF)
- General Def. Of BCNF – A relation schema R is in BCNF if whenever a nontrivial functional dependency X_ A holds in R, then X is a super key of R.
- A relation schema R is in BCNF if it is in 3NF and every determinant is a candidate key of R.
- Boyce-Codd normal form (BCNF) was proposed as a simpler form of 3NF, but it was found to be stricter than 3NF. That is, every relation in BCNF is also in 3NF; however, a relation in 3NF is not necessarily in BCNF.
Q6 Explain briefly on oracle database?
Answer 6
ORACLE
Oracle Database allows you to quickly and safely store and retrieve data. Here are the integration benefits of the Oracle Database:
- Oracle Database is cross-platform. It can run on various hardware across operating systems including Windows Server, Unix, and various distributions of GNU/Linux.
- Oracle Database has its networking stack that allows application from a different platform to communicate with the Oracle Database smoothly. For example, applications running on Windows can connect to the Oracle Database running on Unix.
- ACID-compliant – Oracle is ACID-compliant Database that helps maintain data integrity and reliability.
- Commitment to open technologies – Oracle is one of the first Database that supported GNU/Linux in the late 1990s before GNU/Linux become a commerce product. It has been supporting this open platform since then.
Features of ORACLE Database
- Logical data structure – Oracle uses the logical data structure to store data so that you can interact with the database without knowing where the data is stored physically.
- Partitioning – is a high-performance feature that allows you to divide a large table into different pieces and store each piece across storage devices.
- Memory caching – the memory caching architecture allows you to scale up a very large database that still can perform at a high speed.
- Data Dictionary is a set of internal tables and views that supports administer Oracle Database more effectively.
- Backup and recovery – ensure the integrity of the data in case of system failure. Oracle includes a powerful tool called Recovery Manager (RMAN) – allows DBA to perform cold, hot, and incremental database backups and point-in-time recoveries.
- Clustering – Oracle Real Application Clusters (RAC) – Oracle enables high availability that enables the system is up and running without interruption of services in case one or more server in a cluster fails.
Oracle Database Editions
Oracle provides three main editions of Oracle Databases as follows:
- Enterprise Edition (EE) is the common and expensive edition of the Oracle Database. It has the following characteristics:
- No maximum number of CPUs
- No limits on memory or database size
- Include premium features that are not available in other editions.
- Standard Edition (SE) is a limited edition of the Enterprise Edition that has the following characteristics:
- Limited to four or fewer CPUs
- No limit on memory or database size
- Include many features, but no as many as EE
- Expression Edition (XE) is a free-to-use version of the Oracle Database that available on both Windows and GNU/Linux platforms. These are the features of Oracle Database XE 18c:
- Limited to 2 CPUs
- Can use the maximum of 2GB of RAM, and has 12GB of user data.
- Very limited features
Q7 Explain joins and types of joins operation?
Answer 7
JOIN Operation
- The sequence of Cartesian product followed by select is used quite commonly to identify and select related tuples from two relations, a special operation, called JOIN. It is denoted by a”|><| “
- This operation is very important for any relational database with more than a single relation, because it allows us to process relationships among relations.
- The general form of a join operation on two relations R(A1, A2, . . ., An) and S(B1, B2, . . ., Bm) is:
R <join condition>S
Where R and S can be any relations that result from general relational algebra expressions
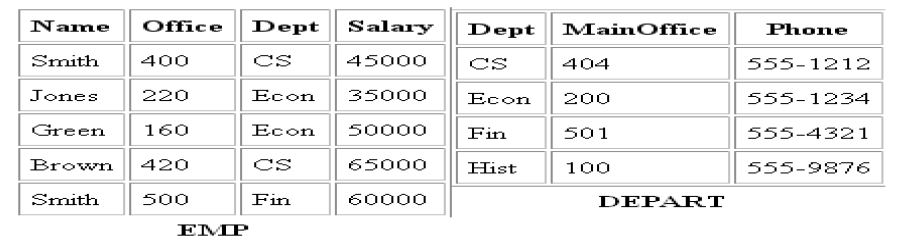
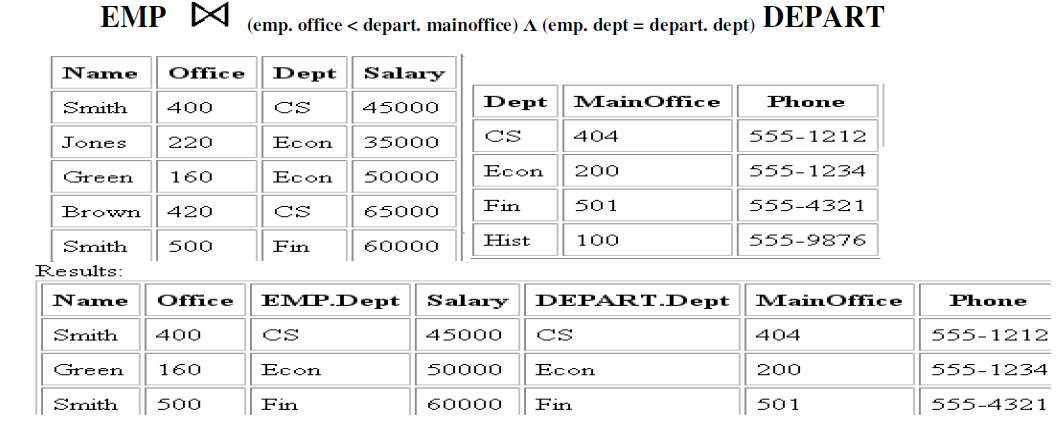
EQUIJOIN Operation
- The most common use of join involves join conditions with equality comparisons only. Such a join, where the only comparison operator used is =, is called an EQUIJOIN. In the result of an EQUIJOIN we always have one or more pairs of attributes (whose names need not be identical) that have identical values in every tuple.
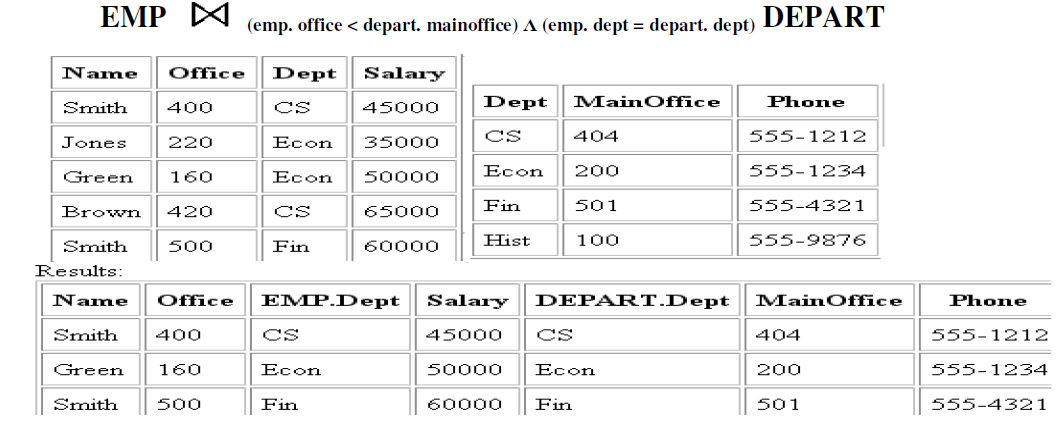
Figure Equi Join
NATURAL JOIN Operation
- Because one of each pair of attributes with identical values is superfluous, a new operation called natural join—denoted by *—was created to get rid of the second (superfluous) attribute in an EQUIJOIN condition.
- The standard definition of natural join requires that the two join attributes, or each pair of corresponding join attributes, have the same name in both relations. If this is not the case, a renaming operation is applied first.
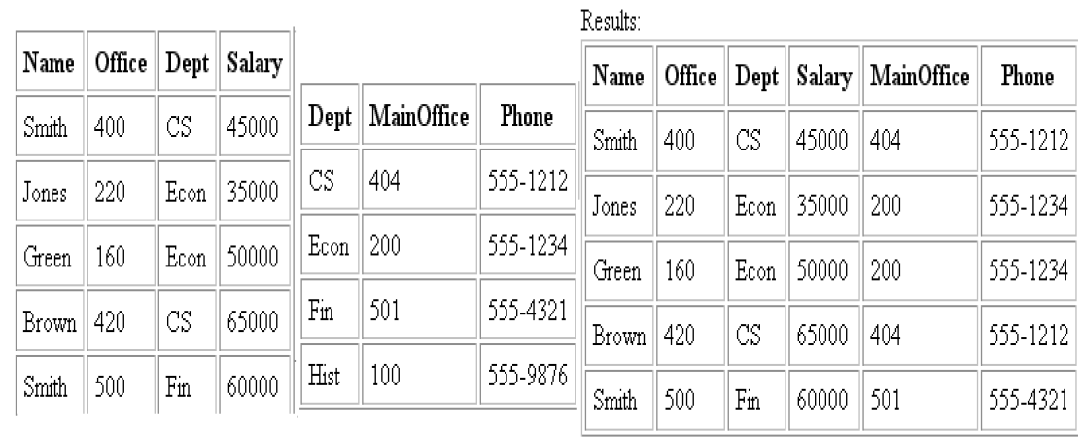
Figure Natural join
The OUTER JOIN Operation
- In NATURAL JOIN tuples without a matching (or related) tuple are eliminated from the join result. Tuples with null in the join attributes are also eliminated. This amounts to loss of information.
- A set of operations, called outer joins, can be used when we want to keep all the tuples in R, or all those in S, or all those in both relations in the result of the join, regardless of whether or not they have matching tuples in the other relation.
- The left outer join operation keeps every tuple in the first or left relation R in R S; if no matching tuple is found in S, then the attributes of S in the join result are filled or “padded” with null values.
- A similar operation, right outer join, keeps every tuple in the second or right relation S in the result of R S.
- A third operation, full outer join, denoted by keeps all tuples in both the left and the right relations when no matching tuples are found, padding them with null values as needed.
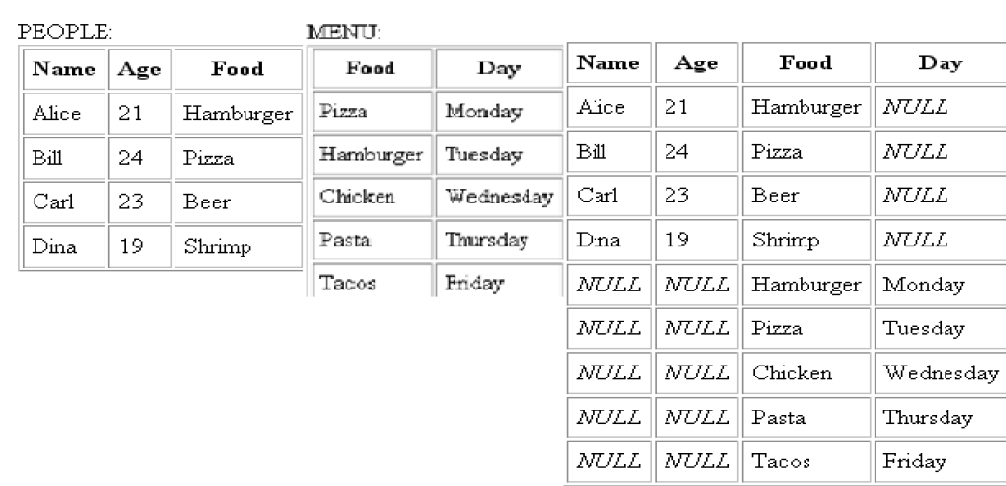
Figure Full outer join
Q8 Explain what is relational database designs?
Answer 8
Relational Database Design
- A relational database organizes data in tables (or relations). A table is made up of rows and columns. A row is also called a record (or tuple). A column is also called a field (or attribute).
- A database table is similar to a spreadsheet. However, the relationships that can be created among the tables enable a relational database to efficiently store huge amount of data, and effectively retrieve selected data.
A language called SQL (Structured Query Language) was developed to work with relational databases.
Database Design Objectives
A well-designed database shall:
- Eliminate Data Redundancy: the same piece of data shall not be stored in more than one place. This is because duplicate data not only waste storage spaces but also easily lead to inconsistencies.
- Ensure Data Integrity and Accuracy:
Relational database design process
Database design is more art than science, as you have to make many decisions. Databases are usually customized to suit a particular application. No two customized applications are alike, and hence, no two database are alike. Guidelines (usually in terms of what not to do instead of what to do) are provided in making these design decision, but the choices ultimately rest on the you - the designer.
Step 1: Define the Purpose of the Database (Requirement Analysis)
Gather the requirements and define the objective of your database,
Drafting out the sample input forms, queries and reports, often helps.
Step 2: Gather Data, Organize in tables and Specify the Primary Keys
Once you have decided on the purpose of the database, gather the data that are needed to be stored in the database. Divide the data into subject-based tables.
Primary Key
- In the relational model, a table cannot contain duplicate rows, because that would create ambiguities in retrieval. To ensure uniqueness, each table should have a column (or a set of columns), called primary key that uniquely identifies every records of the table. For example, a unique number customerID can be used as the primary key for.
- Most RDBMSs build an index on the primary key to facilitate fast search and retrieval.
- The primary key is also used to reference other tables (to be elaborated later).
You have to decide which column(s) is to be used for primary key. The decision may not be straight forward but the primary key shall have these properties:
- The values of primary key shall be unique (i.e., no duplicate value). For example, customerName may not be appropriate to be used as the primary key for the Customers table, as there could be two customers with the same name.
- The primary key shall always have a value. In other words, it shall not contain NULL.
Step 3: Create Relationships among Tables
A database consisting of independent and unrelated tables serves little purpose (you may consider to use a spreadsheet instead). The power of relational database lies in the relationship that can be defined between tables. The most crucial aspect in designing a relational database is to identify the relationships among tables. The types of relationship include:
- One-to-many
- Many-to-many
- One-to-one
One-to-Many
In a "class roster" database, a teacher may teach zero or more classes, while a class is taught by one (and only one) teacher. In a "company" database, a manager manages zero or more employees, while an employee is managed by one (and only one) manager. In a "product sales" database, a customer may place many orders; while an order is placed by one particular customer. This kind of relationship is known as one-to-many.
Many-to-Many
In a "product sales" database, a customer's order may contain one or more products; and a product can appear in many orders. In a "bookstore" database, a book is written by one or more authors; while an author may write zero or more books. This kind of relationship is known as many-to-many.
One-to-One
In a "product sales" database, a product may have optional supplementary information such as image, more Description and comment. Keeping them inside the Products table results in many empty spaces (in those records without these optional data). Furthermore, these large data may degrade the performance of the database.
Some databases limit the number of columns that can be created inside a table. You could use a one-to-one relationship to split the data into two tables. One-to-one relationship is also useful for storing certain sensitive data in a secure table, while the non-sensitive ones in the main table.
Step 4: Refine & Normalize the Design
For example,
- Adding more columns,
- Create a new table for optional data using one-to-one relationship,
- Split a large table into two smaller tables,
Q9 Explain briefly MYSQL database and its features?
Answer 9
MYSQL
- MySQL is the most popular Open Source Relational SQL Database Management System.
- MySQL is one of the best RDBMS being used for developing various web-based software applications.
- MySQL is developed, marketed and supported by MySQL AB, which is a Swedish company
- MySQL is an open-source relational database management system that works on many platforms. It provides multi-user access to support many storage engines and is backed by Oracle.
Features of MYSQl
- Ease of Management – The software very easily gets downloaded and also uses an event scheduler to schedule the tasks automatically.
- Robust Transactional Support – Holds the ACID (Atomicity, Consistency, Isolation, and Durability) property, and also allows distributed multi-version support.
- Comprehensive Application Development – MySQL has plug-in libraries to embed the database into any application. It also supports stored procedures, triggers, functions, views and many more for application development.
- High Performance – Provides fast load utilities with distinct memory caches and table index partitioning.
- Low Total Cost Of Ownership – This reduces licensing costs and hardware expenditures.
- Open Source & 24 * 7 Support – This RDBMS can be used on any platform and offers 24*7 support for open source and enterprise edition.
- Secure Data Protection – MySQL supports powerful mechanisms to ensure that only authorized users have access to the databases.
- High Availability – MySQL can run high-speed master/slave replication configurations and it offers cluster servers.
- Scalability & Flexibility – With MySQL you can run deeply embedded applications and create data warehouses holding a humongous amount of data.
Data Types supported in MYSQl
- Numeric – This data type includes integers of various sizes, floating point (real) of various precisions and formatted numbers.
- Character-string – These data types either have a fixed, or a varying number of characters. This data type also has a variable-length string called CHARACTER LARGE OBJECT (CLOB) which is used to specify columns that have large text values.
- Bit-string – These data types are either of a fixed length or varying length of bits. There is also a variable-length bit string data type called BINARY LARGE OBJECT (BLOB), which is available to specify columns that have large binary values, such as images.
- Boolean – This data type has TRUE or FALSE values. Since SQL, has NULL values, a three-valued logic is used, which is UNKNOWN.
- Date & Time – The DATE data type has: YEAR, MONTH, and DAY in the form YYYY-MM-DD. Similarly, the TIME data type has the components HOUR, MINUTE, and SECOND in the form HH:MM: SS. These formats can change based on the requirement.
- Timestamp & Interval – The TIMESTAMP data type includes a minimum of six positions, for decimal fractions of seconds and an optional WITH TIME ZONE qualifier in addition to the DATE and TIME fields. The INTERVAL data type mentions a relative value that can be used to increment or decrement an absolute value of a date, time, or timestamp.
Q10 What is tuple and domain relational calculus?
Answer 10
Tuple and domain relational calculus,
1. Tuple Relational Calculus (TRC)
Tuple relational calculus is used for selecting those tuples that satisfy the given condition.
Table: Student
First name | Last name | Age |
Ajeet | Singh | 30 |
Chaitanya | Singh | 31 |
Rajeev | Bhatia | 27 |
Carl | Pratap | 28 |
Lets write relational calculus queries.
Query to display the last name of those students where age is greater than 30
{ t.Last_Name | Student(t) AND t.age > 30 }
In the above query you can see two parts separated by | symbol. The second part is where we define the condition and in the first part we specify the fields which we want to display for the selected tuples.
The result of the above query would be:
Last name |
Singh |
Query to display all the details of students where Last name is ‘Singh’{ t | Student(t) AND t.Last_Name = 'Singh' }
Output:
First name | Last name | Age |
Ajeet | Singh | 30 |
Chaitanya | Singh | 31 |
2. Domain Relational Calculus (DRC)
In domain relational calculus the records are filtered based on the domains.
Again we take the same table to understand how DRC works.
Table: Student
First name | Lastr name | Age |
Ajeet | Singh | 30 |
Chaitanya | Singh | 31 |
Rajeev | Bhatia | 27 |
Carl | Pratap | 28 |
Query to find the first name and age of students where student age is greater than 27
{< First_Name, Age > | ∈ Student ∧ Age > 27}
The symbols used for logical operators are: ∧ for AND, ∨ for OR and ┓ for NOT.
Output:
First name | Age |
Ajeet | 30 |
Chaitanya | 31 |
Carl | 28 |




