UNIT 3
- Explain Hashing and types of Hashing?
Answer 1
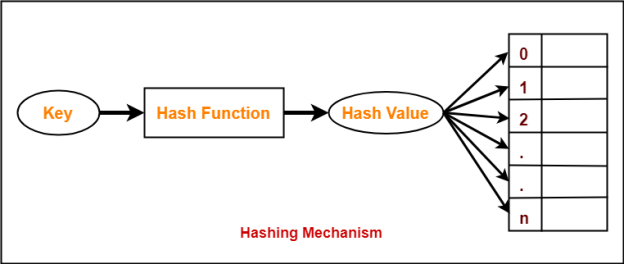
Hashing
- For a huge database structure, it can be almost next to impossible to search all the index values through all its level and then reach the destination data block to retrieve the desired data.
- Hashing is an effective technique to calculate the direct location of a data record on the disk without using index structure.
- Hashing uses hash functions with search keys as parameters to generate the address of a data record.
Hash Organization
- Bucket − A hash file stores data in bucket format. Bucket is considered a unit of storage. A bucket typically stores one complete disk block, which in turn can store one or more records.
- Hash Function − A hash function, h, is a mapping function that maps all the set of search-keys K to the address where actual records are placed. It is a function from search keys to bucket addresses.
Static Hashing:-
- In static hashing, when a search-key value is provided, the hash function always computes the same address.
- A bucket is a unit of storage containing one or more records (a bucket is typically a disk block).
- In a hash file organization we obtain the bucket of a record directly from its search-key value using a hash function.
- Hash function h is a function from the set of all search-key values K to the set of all bucket addresses B.
- Hash function is used to locate records for access, insertion as well as deletion.
- Records with different search-key values may be mapped to the same bucket; thus entire bucket has to be searched sequentially to locate a record.
- For example, if mod-4 hash function is used, then it shall generate only 5 values. The output address shall always be same for that function. The number of buckets provided remains unchanged at all times.
Dynamic Hashing:-
- The problem with static hashing is that it does not expand or shrink dynamically as the size of the database grows or shrinks.
- Hash function, in dynamic hashing, is made to produce a large number of values and only a few are used initially.
- Good for database that grows and shrinks in size
- Dynamic hashing provides a mechanism in which data buckets are added and removed dynamically and on-demand.
- Dynamic hashing is also known as extended hashing.
- Allows the hash function to be modified dynamically.
- Hash function generates values over a large range — typically b-bit integers, with b = 32.
- At any time use only a prefix of the hash function to index into a table of bucket addresses.
- Let the length of the prefix be i bits, 0 i 32.
- Bucket address table size = 2i. Initially i = 0
- Value of i grows and shrinks as the size of the database grows and shrinks.
- Thus, actual number of buckets is < 2i .
- The number of buckets also changes dynamically due to coalescing and splitting of buckets.
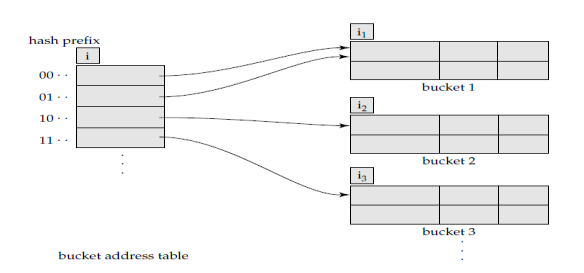
Figure: General extended Hash structure
2. Explain types of Indexing?
Answer 2
Indexing:-
- Indexing is a data structure technique to retrieve records from the database file based on some attribute on which the indexing has been done.
- Indexing in database is similar to index in books.
- A database index is a data structure that improves the speed of data retrieval operations on a database table at the cost of additional writes and storage space to maintain data structure.


 Example:-
Example:-



 Where are books by Rolan ?
Where are books by Rolan ?



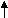 Where is foundation?
Where is foundation?
Types of indexing
Primary indexing
- Dense and sparse indices
- Multilevel indices
- Index update
Secondary indices
Clustering indices
Primary Index:-
- A primary index is specified on the ordering key field of an ordered file of records.
- All files are ordered sequentially on some search key.
- Such files with a primary index on the search key are called index- sequential files.
- They represent one of the oldest index schemes used in database systems.
Dense and sparse indices:-
- An index record or index entry consists of a search key value and pointers to one or more records with that value as their search–key value.
- The pointer to a record consists of the identifier of a disk block and an offset within the disk block to identify the record within the block.
- There are two types of ordered indices that we can use:1)Dense index. 2) Sparse Index
Dense Index:-
- A record appears for every search key value in the file.
- In a dense primary index the index record contains the search key and a pointer to the first data record with that search key value.
- The rest of the records with the same search key value would be stored sequentially after the first record.
A-217 | Alpha | 750 |
|
A-101 | Charlie | 500 |
|
A-156 | Charlie | 600 |
|
A-873 | Bravo | 250 |
|
A-321 | Bootcamp | 150 |
|
A-401 | Bootcamp | 300 |
|
A-501 | Bootcamp | 100 |
|
A-176 | Redlight | 850 |
|
A-508 | Park Jin | 540 |
|





|
Charlie |
|
|
|
|




Sparse Index:-
- An index record appears for only some of the search key values.
- As in true in dense indices, each index record contains a search key value and a pointer to the first data record with that search key value.
- To locate a record we find the index entry with the largest search key value that is less than or equal to the search key value for which we are looking.
Alpha |
|
|

A-217 | Alpha | 700 |
|
A-101 | Charlie | 500 |
|
A-156 | Charlie | 600 |
|
A-873 | Bravo | 250 |
|
A-321 | Bootcamp | 750 |
|
A-401 | Bootcamp | 300 |
|
A-501 | Bootcamp | 700 |
|
A-176 | Redlight | 850 |
|
A-508 | Park Jin | 540 |
|







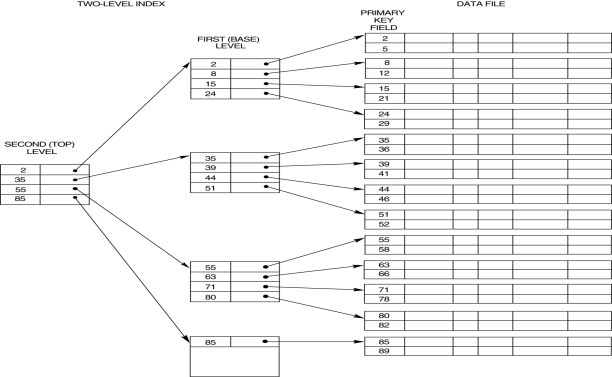
Multilevel index -
- Because a single-level index is an ordered file, we can create a primary index to the index itself; in this case, the original index file is called the first-level index and the index to the index is called the second-level index.
- We can repeat the process, creating a third, fourth, ..., top level until all entries of the top level fit in one disk block
- A multi-level index can be created for any type of first-level index (primary, secondary, clustering)
Secondary indices
- Secondary indices must be dense, with an index entry for every search key value and a pointer to every record in the file.
- A primary index may be sparse, storing only some of the search key values.
- If a secondary stores only some of the search key values, records with intermediate search key values may be anywhere in then file and in general we cannot find them without searching the entire file.
A-217 | Alpha | 700 |
|
A-101 | Charlie | 500 |
|
A-156 | Charlie | 600 |
|
A-873 | Bravo | 250 |
|
A-321 | Bootcamp | 700 |
|
A-401 | Bootcamp | 300 |
|
A-501 | Bootcamp | 700 |
|
A-176 | Redlight | 850 |
|
A-508 | Park Jin | 540 |
|





|

|
500 |
|
700 |
|
|
|



|


|
|
|


|
|
|
|
Clustering Indexes:-
- If records of a file are physically ordered on a non-key field which does not have a distinct value for each record that field is called the clustering field
- We can create a different type of index called a clustering index.
- A clustering index is also an ordered file with two fields the first field is of the same type as the clustering field of the data file and the second field is a block pointer.
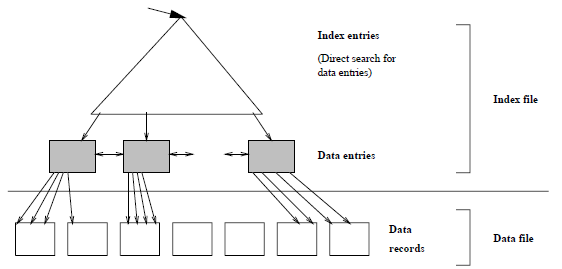
Figure: - Clustering indexing
3. What are b tree and B+ tree? What is difference between them?
Answer 3
B –Tree:-
- A search tree is a special type of tree that is used to guide the search for a record, given the value of one of the record’s field.
- B-Tree is a commonly used index structure.
- Non-Sequential ‘balanced’, hence it is also known as balanced tree.
- Adapts well to insertions and deletions.
- Consists of blocks holding at most ‘n’ keys and ‘n+1’ pointers.
B+ Tree
- A B+ tree is a balanced binary search tree that follows a multi-level index format.
- The leaf nodes of a B+ tree denote actual data pointers. B+ tree ensures that all leaf nodes remain at the same height, thus balanced. Additionally, the leaf nodes are linked using a link list; therefore, a B+ tree can support random access as well as sequential access.
- In a B+ Tree Data pointers are stored only at leaf nodes of the tree; hence the structure of leaf nodes differs from the structure of internal nodes.
- The leaf nodes have an entry for every value of the search field, along with a data pointer to the record.
Structure of B+ Tree
Every leaf node is at equal distance from the root node. A B+ tree is of the order n where n is fixed for every B+ tree.
P1 | K1 | P2 |
|
|
| p(n-1) | K(n-1) | P(n) |
A | B | C | |||
|
|
|
| ||



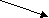
Keys<A Keys>C
A<=keys<=B B<=Keys<=C
Internal nodes −
- Internal (non-leaf) nodes contain at least ⌈n/2⌉ pointers, except the root node.
- At most, an internal node can contain n pointers.
Leaf nodes −
- Leaf nodes contain at least ⌈n/2⌉ record pointers and ⌈n/2⌉ key values.
- At most, a leaf node can contain n record pointers and n key values.
- Every leaf node contains one block pointer P to point to next leaf node and forms a linked list.
Difference between B-tree and B+-tree:
- B - tree:
• Data pointers may be stored in internal nodes
• Every value of the search field appears once -- at some level in the tree
- B+ tree
• Data pointers stored only in leaf nodes
• Internal nodes contain only keys and tree pointers
• Can pack more pointers in internal nodes
• Improved search time due to fewer levels in the tree
• No wasted space due to “null” tree pointers in leaf nodes
• B+-tree can have less levels (or higher capacity of search values) than the corresponding B-tree.
4. Explain insertion in B+ tree?
ANSWER 4
B+ Tree Insertion
Algorithm
- B+ trees are filled from bottom and each entry is done at the leaf node.
- If a leaf node overflows −
- Split node into two parts.
- Partition at i = ⌊(m+1)/2⌋.
- First i entries are stored in one node.
- Rest of the entries (i+1 onwards) are moved to a new node.
- ith key is duplicated at the parent of the leaf.
- If a non-leaf node overflows -
- Split node into two parts.
- Partition the node at i = ⌈(m+1)/2⌉.
- Entries up to i are kept in one node.
- Rest of the entries are moved to a new node.
Procedure:-
- Starting at the root, search to a leaf node.
- If the key value is in the leaf node you have a duplicate, then “Stop”.
- If there is room in node, put the new value there, “Stop”.
- If there is not room, allocate a new leaf node.
- Redistribute the keys in a manner that half keys go into old node and half go into new node. If there is odd number of keys put the extra key in old node. Order the keys so that the smaller ones go into old node and larger ones go into new node. All the keys in the old node will be smaller than any key in the new node.
- Duplicate the smallest key in the new node into the parent Non-Leaf node.
- If there is no parent node create a new node, adjust the pointers and “Stop”. If there is room in the parent node, adjust the pointers, “Stop”.
- If the parent node is full, allocate a new non-leaf node.
- Redistribute the keys that were in old non-leaf node plus the new key into the 2 non-leaf nodes, except the middle-valued key. Move the middle-valued key up the tree into the parent node. If there is an odd number of keys to be redistributed into two nodes put the extra one on the old (left) non-leaf node.
- Go to step 7.
- Check that the tree is still balanced.
5. Explain deletion in B+ tree?
ANSWER 5
B+ Tree Deletion
Algorithm:-
- B+ tree entries are deleted at the leaf nodes.
- The target entry is searched and deleted.
- If it is an internal node, delete and replace with the entry from the left position.
- After deletion, underflow is tested,
- If underflow occurs, distribute the entries from the nodes left to it.
- If distribution is not possible from left, then
- Distribute from the nodes right to it.
- If distribution is not possible from left or from right, then
- Merge the node with left and right to it.
Procedure:-
- While insertion causes a B+ tree to grow, it is expected deletion causes B+ tree to shrink
- A node item with the key is deleted by shifting all items ‘s’ with a key greater than ‘k’ one position to left (within the node boundaries) and by decreasing the count variable in the node header by one.
- Each node item is deleted decreases the number of records variable of the tree header by one.
- When a tree node is deleted, space reclamation is not performed, so the number of nodes variable of the tree header is not altered.
Four characteristic situations; - There are four characteristic techniques applied when deleting a key in a B+ tree.
- Key in a leaf with more than ‘m’ keys.
- Key in a node that is not a leaf.
- Key in a node with exactly in keys, where a neighbor node has more than ‘m’ keys (redistribution).
- Key in a node with exactly ‘m’ keys, where no one neighbor node has ‘m’ keys (merging).
Complexity of operation in B+ trees:-
- The number of operations needed for a worst case insertion or deletion is proportional to log(n/2) (K).
- Where n = the maximum number of pointers in a node.
- K = the number of search key values
- The cost of insertion and deletion operations is proportional to the height of the B+ tree and is therefore low.
- It is the speed of operation on B+ tree that makes them a frequently used index structure in database implementation.
6. What are fixed length and variable length record?
Answer 6
Page format
Fixed Length Records-
- If all records on the page are guaranteed to be of same length, record slots are uniform and can be arranged consecutively within a page.
- At any instant, some slots are occupied by records, and others are unoccupied. When a record is inserted into page, we must locate an empty slot and place record there.
Variable Length Record-
- If records are of variable length, then we cannot divide the page into a fixed collection of slots.
- The problem is that when a new record is to be inserted, we have to find an empty slot of just the right length, if we use a slot that is too big, we waste space, and obviously we cannot use a slot that is too smaller than the record length.
- Therefore, when a record is inserted we must allocate just the right amount of space for it, and when a record is deleted , we must move records to fill the hole created by the deletion in order to ensure that all free spaces on the page is contiguous. Thus the ability to move records on a page becomes very important.
Record Formats-
Fixed Length records-
- In a fixed length record, each field has a fixed length (that is, the value in this field is of same length in all records) and the number of fields are also fixed.
- The fields of such a record can be stored consecutively and given the address of record the address of a particular field can be calculated using information about the lengths of preceding fields which is available in the system catalog.
F1 | F2 | F3 | F4 | F5 |

 |--L1 --|--L2----|---L3--|---L4---|----L5---| F1=Field 1
|--L1 --|--L2----|---L3--|---L4---|----L5---| F1=Field 1
Base address (B) Address=B+L1+L2 L1=length of field 1
Variable Length Record:-
- In the relational model, every record in a relation contains the same number of fields.
- If the number of fields is fixed a record of variable length only because some of its fields are of variable length.
- One possible organization is to store fields consecutively separated by delimiters( which are special characters that do not appear in the data itself).
- This organization requires a scan of the record in order to locate a desired field.
F1 | $ | F2 | $ | F3 | $ | F4 | $ | F5 | $ |
Fields delimited by special symbol $
7. Explain dynamic hashing?
Answer 7
Dynamic Hashing:-
- The problem with static hashing is that it does not expand or shrink dynamically as the size of the database grows or shrinks.
- Hash function, in dynamic hashing, is made to produce a large number of values and only a few are used initially.
- Good for database that grows and shrinks in size
- Dynamic hashing provides a mechanism in which data buckets are added and removed dynamically and on-demand.
- Dynamic hashing is also known as extended hashing.
- Allows the hash function to be modified dynamically.
- Hash function generates values over a large range — typically b-bit integers, with b = 32.
- At any time use only a prefix of the hash function to index into a table of bucket addresses.
- Let the length of the prefix be i bits, 0 i 32.
- Bucket address table size = 2i. Initially i = 0
- Value of i grows and shrinks as the size of the database grows and shrinks.
- Thus, actual number of buckets is < 2i .
- The number of buckets also changes dynamically due to coalescing and splitting of buckets.
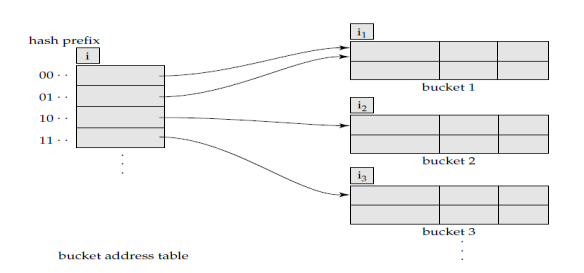
Figure: General extended Hash structure
8. Write algorithm and example for insertion in B+ trees?
Answer 8
B+ tree operations – insert
- Insert and delete are efficient but a bit complicated. Because nodes may overflow or underflow
- _ Ignoring node overflow and underflow
– Insert data record with search-key k
- _ Find leaf node where k would appear
- _ If search-key k found
– Add data record to file, create indirect block if there isn't one
– Add record pointer to indirect block
- _ If search-key k not found
– Add data record to file
– Insert (k, data pointer) in leaf node
- _ Such that all search keys in leaf node remain in order.
• When a leaf node is split during insertion, unlike the procedure for B-trees, a copy of the key of
- The middle key is promoted. Both middle keys are kept in the leaf nodes, since they contain the
- Actual records that are stored in the tree.
• The key promoted from a leaf node is inserted into the tree structure which consists of only the interior nodes.
• The insertion of the promoted node into the tree is performed in the same way as insertion into a B-tree.
- Four cases
- Simple case: There is space in leaf node
- Leaf node overflow
- Internal node overflow
- New root
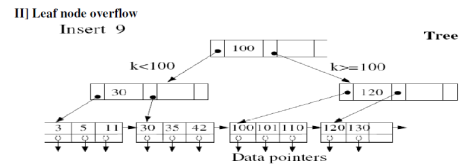
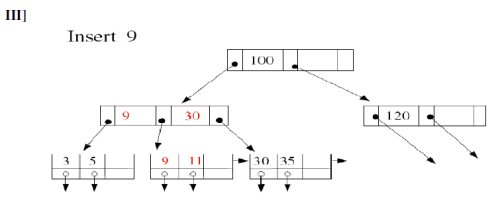
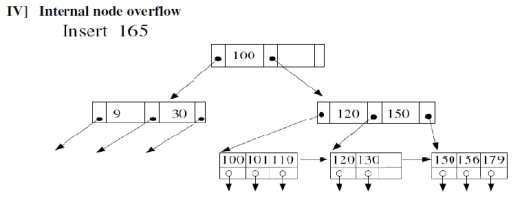
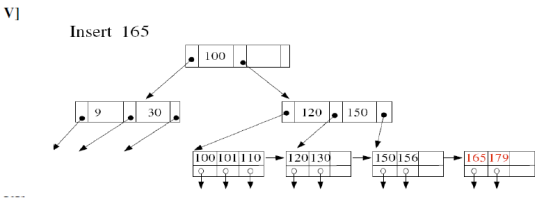
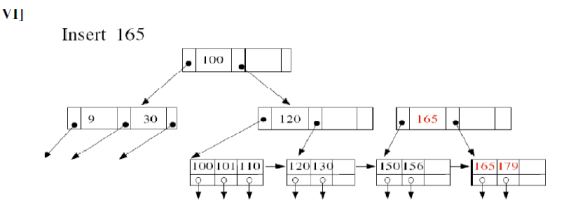
9. Write Algorithm with example for deletion in B+ trees?
Answer 9
B+ tree operations – delete
- Ignoring node overflow and underflow
– Delete data record with search-key k
- _ Find leaf node with search-key k
- _ Find data record pointer, delete data record from file
- _ Remove (k, record pointer) entry from leaf node if there is no indirect block associated with that entry
– Or if indirect block becomes empty as a result of the deletion
- Simple case:-
– Deletion does not cause underflow at leaf
- Underflow case – Key redistribution:-
– Redistribute keys
- _ Borrow one key from adjacent node
- _ Redistribute evenly between adjacent nodes
– Update parent nodes
– Parent node may underflow
_ Recursively apply deletion procedure up the tree
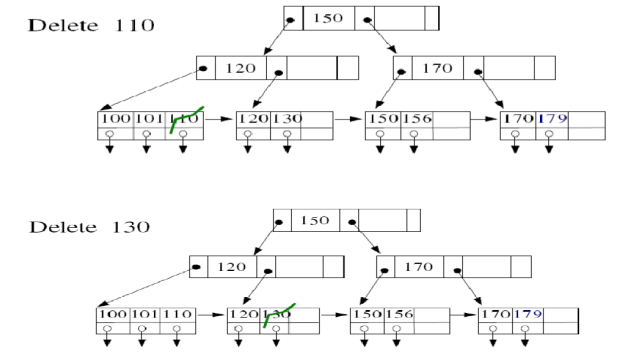
10. What is static hashing?
Answer 10
Static Hashing:-
- In static hashing, when a search-key value is provided, the hash function always computes the same address.
- A bucket is a unit of storage containing one or more records (a bucket is typically a disk block).
- In a hash file organization we obtain the bucket of a record directly from its search-key value using a hash function.
- Hash function h is a function from the set of all search-key values K to the set of all bucket addresses B.
- Hash function is used to locate records for access, insertion as well as deletion.
- Records with different search-key values may be mapped to the same bucket; thus entire bucket has to be searched sequentially to locate a record.
- For example, if mod-4 hash function is used, then it shall generate only 5 values. The output address shall always be same for that function. The number of buckets provided remains unchanged at all times.
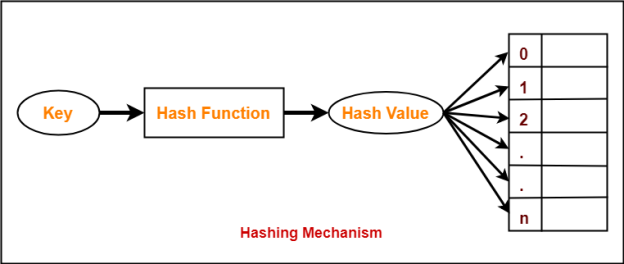
Operation
- Insertion − When a record is required to be entered using static hash, the hash function h computes the bucket address for search key K, where the record will be stored.
- Bucket address = h(K)
- Search − When a record needs to be retrieved, the same hash function can be used to retrieve the address of the bucket where the data is stored.
- Delete − This is simply a search followed by a deletion operation.
Bucket Overflow:-
The condition of bucket-overflow is known as collision. This is a fatal state for any static hash function. In this case, overflow chaining can be used.
- Overflow Chaining − When buckets are full, a new bucket is allocated for the same hash result and is linked after the previous one. This mechanism is called Closed Hashing.
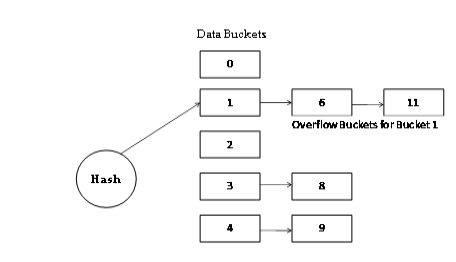
Figure: - Bucket Overflow
Linear Probing − When a hash function generates an address at which data is already stored, the next free bucket is allocated to it. This mechanism is called Open Hashing.
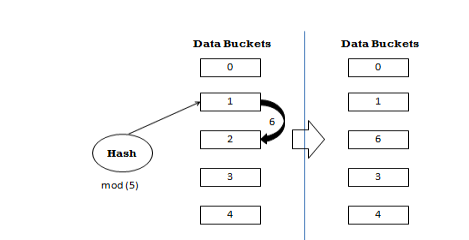
Figure: - Open Hashing




